[2026/03/16 ~ 22] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주에 선정된 10편의 논문들을 분석한 결과, 인공지능 연구가 단순한 성능 경쟁을 넘어 에이전트의 자율성, 학습 효율성, 그리고 아키텍처의 근본적 이해를 향해 나아가고 있음을 알 수 있습니다. 도출된 3가지 핵심 트렌드는 다음과 같습니다.
![]() 자율적 진화와 협업을 통한 '에이전트 시스템'의 고도화: 이번 주 논문들에서는 AI가 고정된 도구를 넘어 스스로 환경에 적응하고 협업하는 주도적 에이전트로 진화하는 흐름이 두드러집니다. APM 및 MetaClaw 연구는 에이전트가 통제된 비즈니스 프로세스 내에서 자율적으로 행동하거나, 실제 배포 환경에서 서비스 중단 없이 끊임없이 메타 학습을 통해 자신의 기술을 진화시키는 구조를 제안했습니다. 또한 분산 시스템으로서의 언어 모델 팀 논문은 여러 에이전트의 협업을 분산 컴퓨팅 이론에 접목하여 시스템의 견고함과 효율성을 설계하는 원칙을 제시했으며, 인지과학 기반 자율 학습 논문은 생물학적 메타 제어를 모방해 상황에 맞게 학습 모드를 전환하는 아키텍처를 선보였습니다. 이는 에이전트가 단순한 작업을 넘어 스스로 문제를 정의하고 상호 작용하며 지속해서 성장하는 생태계로 나아가고 있음을 시사합니다.
자율적 진화와 협업을 통한 '에이전트 시스템'의 고도화: 이번 주 논문들에서는 AI가 고정된 도구를 넘어 스스로 환경에 적응하고 협업하는 주도적 에이전트로 진화하는 흐름이 두드러집니다. APM 및 MetaClaw 연구는 에이전트가 통제된 비즈니스 프로세스 내에서 자율적으로 행동하거나, 실제 배포 환경에서 서비스 중단 없이 끊임없이 메타 학습을 통해 자신의 기술을 진화시키는 구조를 제안했습니다. 또한 분산 시스템으로서의 언어 모델 팀 논문은 여러 에이전트의 협업을 분산 컴퓨팅 이론에 접목하여 시스템의 견고함과 효율성을 설계하는 원칙을 제시했으며, 인지과학 기반 자율 학습 논문은 생물학적 메타 제어를 모방해 상황에 맞게 학습 모드를 전환하는 아키텍처를 선보였습니다. 이는 에이전트가 단순한 작업을 넘어 스스로 문제를 정의하고 상호 작용하며 지속해서 성장하는 생태계로 나아가고 있음을 시사합니다.
![]() 인간 데이터 의존성 탈피 및 새로운 강화학습(RL) 패러다임: 비용이 많이 드는 인간의 라벨링 데이터(SFT) 의존도를 낮추고, 합성 데이터와 혁신적인 강화학습 기법으로 모델의 고급 추론 능력을 끌어올리는 연구들도 돋보입니다. OpenSeeker는 1만 개 남짓한 고품질 합성 데이터만으로 강력한 오픈소스 검색 에이전트를 구축해 데이터 생성의 투명성을 증명했고, ICRL은 SFT 과정 없이 프롬프트 내 예시(In-Context)만으로 모델이 외부 도구 사용법을 깨우치게 하는 강화학습 기법을 도입했습니다. 나아가 AI는 과학적 안목을 학습할 수 있다 연구는 대규모 인용 데이터라는 집단 지성 피드백(RLCF)을 활용해 AI가 연구 가설의 잠재력까지 스스로 평가하도록 학습했습니다. 이는 데이터 병목 현상을 극복하는 동시에, 모델이 복잡하고 추상적인 가치 판단 영역까지 효율적으로 학습할 수 있음을 보여줍니다.
인간 데이터 의존성 탈피 및 새로운 강화학습(RL) 패러다임: 비용이 많이 드는 인간의 라벨링 데이터(SFT) 의존도를 낮추고, 합성 데이터와 혁신적인 강화학습 기법으로 모델의 고급 추론 능력을 끌어올리는 연구들도 돋보입니다. OpenSeeker는 1만 개 남짓한 고품질 합성 데이터만으로 강력한 오픈소스 검색 에이전트를 구축해 데이터 생성의 투명성을 증명했고, ICRL은 SFT 과정 없이 프롬프트 내 예시(In-Context)만으로 모델이 외부 도구 사용법을 깨우치게 하는 강화학습 기법을 도입했습니다. 나아가 AI는 과학적 안목을 학습할 수 있다 연구는 대규모 인용 데이터라는 집단 지성 피드백(RLCF)을 활용해 AI가 연구 가설의 잠재력까지 스스로 평가하도록 학습했습니다. 이는 데이터 병목 현상을 극복하는 동시에, 모델이 복잡하고 추상적인 가치 판단 영역까지 효율적으로 학습할 수 있음을 보여줍니다.
![]() 아키텍처의 내부 원리 규명 및 기초 최적화(Optimization): 대규모 모델의 효율적인 학습과 추론을 위해 내부 작동 원리를 파헤치고 수학적·구조적 기초 최적화를 다지는 연구도 중요한 축을 이룹니다. Mamba-3는 기존 트랜스포머의 비효율성을 극복하기 위해 상태 공간 모델(SSM) 원리와 다중 입력 다중 출력(MIMO) 구조를 결합하여 추론 효율과 성능의 파레토 프런티어를 새롭게 확장했습니다. 또한 스파이크, 스파스, 그리고 싱크 논문은 트랜스포머 내부에서 발생하는 '대규모 활성화'와 '어텐션 싱크' 현상의 인과관계를 프리-노름(pre-norm) 아키텍처 구조의 관점에서 체계적으로 규명했습니다. 여기에 딥러닝 학습의 핵심인 최적의 학습률 스케줄(Learning Rate Schedule) 형태를 과학적으로 탐색한 연구까지 더해져, 단순한 크기 확장을 넘어 모델의 근본적인 효율성과 안정성을 다지려는 학계의 실용적인 노력이 빛을 발하고 있습니다.
아키텍처의 내부 원리 규명 및 기초 최적화(Optimization): 대규모 모델의 효율적인 학습과 추론을 위해 내부 작동 원리를 파헤치고 수학적·구조적 기초 최적화를 다지는 연구도 중요한 축을 이룹니다. Mamba-3는 기존 트랜스포머의 비효율성을 극복하기 위해 상태 공간 모델(SSM) 원리와 다중 입력 다중 출력(MIMO) 구조를 결합하여 추론 효율과 성능의 파레토 프런티어를 새롭게 확장했습니다. 또한 스파이크, 스파스, 그리고 싱크 논문은 트랜스포머 내부에서 발생하는 '대규모 활성화'와 '어텐션 싱크' 현상의 인과관계를 프리-노름(pre-norm) 아키텍처 구조의 관점에서 체계적으로 규명했습니다. 여기에 딥러닝 학습의 핵심인 최적의 학습률 스케줄(Learning Rate Schedule) 형태를 과학적으로 탐색한 연구까지 더해져, 단순한 크기 확장을 넘어 모델의 근본적인 효율성과 안정성을 다지려는 학계의 실용적인 노력이 빛을 발하고 있습니다.
에이전틱 비즈니스 프로세스 관리: 연구 선언문 / Agentic Business Process Management: A Research Manifesto
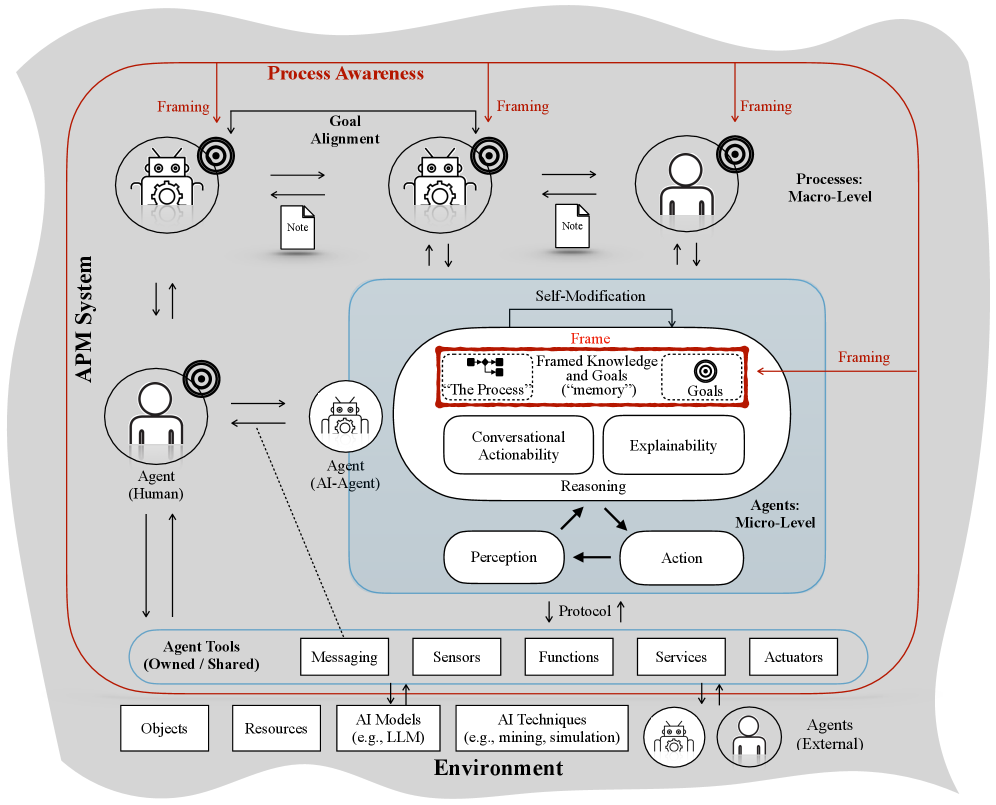
논문 소개
현대 조직의 운영 환경은 단순한 자동화를 넘어 자율적인 에이전트가 주도적으로 프로세스를 실행하고 관리하는 새로운 시대로 접어들고 있습니다. 기존의 비즈니스 프로세스 관리(Business Process Management, BPM)가 정해진 규칙에 따른 워크플로우 자동화에 집중했다면, 에이전틱 비즈니스 프로세스 관리(Agentic Business Process Management, APM)는 에이전트 중심의 추상화를 통해 시스템의 자율성과 프로세스 인식을 결합한 혁신적인 패러다임을 제시합니다. 이 체계에서 에이전트는 환경을 감지(Sensing)하고 목표에 부합하는 결정을 내리기 위해 추론(Reasoning)하며, 실제 환경에 영향을 미치는 행동(Acting)을 수행하는 연속적인 제어 루프(Control Loop)를 통해 독자적인 제어권을 행사합니다. APM 시스템은 인간 에이전트(Human Agents)뿐만 아니라 소프트웨어, 물리적 로봇, 그리고 대규모 언어 모델(Large Language Models, LLM) 기반의 인공지능 에이전트(AI Agents)가 상호작용하는 이종적인 환경을 포괄하며, 이를 통해 조직의 복잡한 요구사항을 유연하게 해결합니다. 특히 단순한 자율성을 넘어 시스템 차원의 프로세스 인식(Process Awareness)을 강조함으로써, 각 에이전트의 개별적인 활동이 조직의 운영 제약과 규격 및 전략적 목표에서 벗어나지 않도록 보장하는 사회-기술적 시스템(Socio-technical System)의 면모를 갖춥니다. 이를 구체화하기 위해 에이전트는 행동의 범위를 규정하는 프레이밍(Framing), 결정의 근거를 밝히는 설명 가능성(Explainability), 자연어 기반의 대화형 행동성(Conversational Actionability), 그리고 스스로 성능을 개선하는 자가 수정(Self-modification)이라는 네 가지 핵심 역량을 통해 지능적으로 작동합니다. 이러한 접근 방식은 정적인 프로세스 설계의 한계를 극복하고 맥락에 민감한(Context-sensitive) 의사결정을 가능하게 하여, 에이전트가 조직의 목표와 완벽하게 정렬(Alignment)된 상태에서 선제적이고 능동적인 역할을 수행하도록 돕습니다. 결과적으로 APM은 인공지능과 비즈니스 프로세스 관리, 그리고 다중 에이전트 시스템(Multi-Agent Systems) 간의 간극을 메우는 연구 로드맵으로서 미래 지향적인 지능형 조직 운영의 기술적 토대를 마련할 것입니다.
논문 초록(Abstract)
본 논문은 조직 내에서 프로세스를 실행하는 자율 에이전트(autonomous agents)를 관리하기 위한 비즈니스 프로세스 관리(BPM)의 확장인 에이전틱 비즈니스 프로세스 관리(Agentic Business Process Management, APM)의 개념적 토대를 명시하는 선언문을 제시합니다. 경영적 관점에서 APM은 프로세스 인지(process awareness)와 에이전트 중심 추상화(agent-oriented abstraction)의 실현을 통해 기존 비즈니스 프로세스의 관점으로부터의 패러다임 전환을 의미하며, 여기서 소프트웨어 및 인간 에이전트는 명시적인 프로세스 프레임 내에서 인지, 추론 및 행동하는 주요 기능적 엔티티(entities)로 작용합니다. 이러한 관점은 전통적인 자동화 중심의 BPM에서, 프로세스 인지를 통해 자율성이 제약되고 정렬(aligned)되며 운용화되는 시스템으로의 전환을 나타냅니다. 본 논문에서는 APM 시스템 구현에 필요한 핵심 추상화 및 아키텍처 요소를 도입하고, 이러한 APM 에이전트가 반드시 지원해야 하는 네 가지 핵심 역량인 프레임화된 자율성(framed autonomy), 설명 가능성(explainability), 대화형 행동 가능성(conversational actionability), 자기 수정(self-modification)에 대해 상세히 기술합니다. 이러한 역량들은 에이전트의 목표가 조직의 목표와 정렬되도록 공동으로 보장하며, 에이전트가 목표를 추구함에 있어 프레임 내에 있으면서도 주도적인 방식으로 행동하도록 합니다. 또한 이러한 역량의 실현 가능 범위를 논의하고, BPM, AI 및 멀티 에이전트 시스템(multi-agent systems) 분야의 추가적인 발전이 필요한 연구 과제들을 식별합니다. 결과적으로 본 선언문은 관련 학술 커뮤니티 간의 가교 역할을 하며 실무적인 APM 시스템 개발을 안내하는 로드맵으로 기능합니다.
This paper presents a manifesto that articulates the conceptual foundations of Agentic Business Process Management (APM), an extension of Business Process Management (BPM) for governing autonomous agents executing processes in organizations. From a management perspective, APM represents a paradigm shift from the traditional process view of the business process, driven by the realization of process awareness and an agent-oriented abstraction, where software and human agents act as primary functional entities that perceive, reason, and act within explicit process frames. This perspective marks a shift from traditional, automation-oriented BPM toward systems in which autonomy is constrained, aligned, and made operational through process awareness. We introduce the core abstractions and architectural elements required to realize APM systems and elaborate on four key capabilities that such APM agents must support: framed autonomy, explainability, conversational actionability, and self-modification. These capabilities jointly ensure that agents' goals are aligned with organizational goals and that agents behave in a framed yet proactive manner in pursuing those goals. We discuss the extent to which the capabilities can be realized and identify research challenges whose resolution requires further advances in BPM, AI, and multi-agent systems. The manifesto thus serves as a roadmap for bridging these communities and for guiding the development of APM systems in practice.
논문 링크
Mamba-3: 상태 공간 원리를 활용한 향상된 시퀀스 모델링 / Mamba-3: Improved Sequence Modeling using State Space Principles
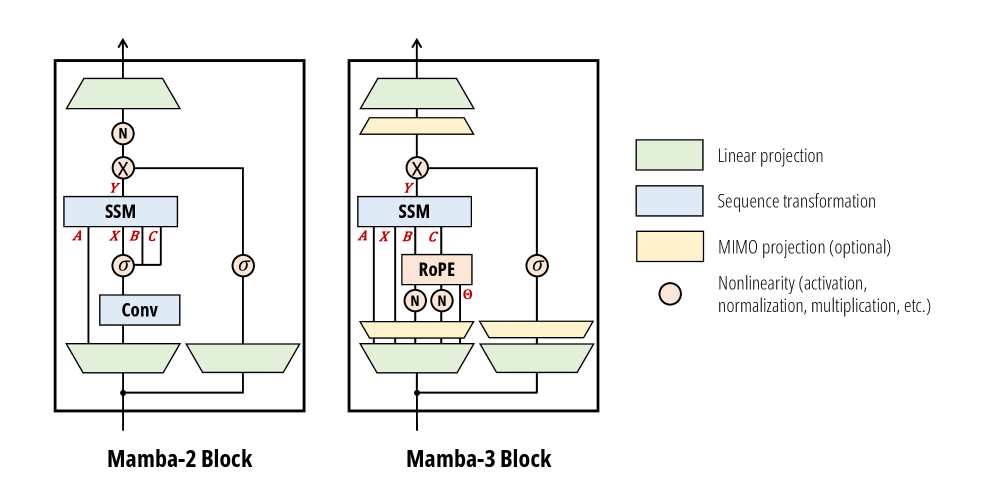
논문 소개
대규모 언어 모델(Large Language Models, LLMs)의 비약적인 발전 속에서 추론 단계의 계산 효율성은 모델의 실질적인 활용 가치를 결정짓는 핵심 지표로 부상하였습니다. 기존의 트랜스포머(Transformer) 아키텍처는 뛰어난 성능을 보장하지만, 시퀀스 길이에 따른 연산량의 제곱 급수적 증가와 선형적인 메모리 점유라는 구조적 한계로 인해 대규모 추론 환경에서 막대한 비용을 발생시킵니다. 이를 극복하기 위해 제안된 선형 복잡도 모델들은 연산 효율성을 얻는 대신 상태 추적(State Tracking) 능력이나 전반적인 모델 품질을 희생하는 경향이 있었으며, 이론적 효율성이 실제 하드웨어 가속으로 이어지지 못하는 문제도 안고 있었습니다. Mamba-3는 이러한 한계를 극복하고자 '추론 우선 관점(Inference-first perspective)'을 견지하며, 상태 공간 모델(State Space Model, SSM)의 원리에 기반한 세 가지 핵심 방법론적 혁신을 제안합니다.
첫째로, 시스템의 동역학을 보존하기 위해 지수-사다리꼴 이산화(Exponential-Trapezoidal Discretization) 기법을 도입하여 기존의 방식보다 훨씬 정교하고 표현력이 풍부한 순환 구조를 유도해냈습니다. 둘째로, 상태 업데이트 규칙에 복소수(Complex-valued) 체계를 적용함으로써 위상(Phase) 정보를 활용한 고도화된 상태 추적이 가능해졌으며, 이는 문맥 내 구조적 정보를 장기적으로 유지하는 데 결정적인 역할을 합니다. 마지막으로 도입된 다중 입력 다중 출력(Multi-Input, Multi-Output, MIMO) 정식은 디코딩 지연 시간을 늘리지 않으면서도 모델의 용량을 효과적으로 확장하여 성능을 극대화합니다. 특히 MIMO 구조는 기존의 단일 입력 단일 출력(Single-Input Single-Output, SISO) 알고리즘을 블랙박스로 활용할 수 있어 하드웨어 친화적인 구현이 가능하며, 연산 오버헤드를 최소화하면서도 복잡한 시퀀스 의존성을 모델링합니다.
1.5B 파라미터 규모의 실험에서 Mamba-3는 기존 최신 모델인 Gated DeltaNet 등을 상회하는 정확도를 기록하였으며, 이전 세대인 Mamba-2 대비 절반의 상태 크기(State Size)만으로도 동등한 수준의 퍼플렉서티(Perplexity)를 달성하는 성과를 거두었습니다. 결과적으로 Mamba-3는 검색(Retrieval)과 상태 추적 능력을 비약적으로 향상시켜 성능과 효율성 사이의 파레토 프런티어(Pareto Frontier)를 새롭게 확장하였으며, 긴 문맥 처리가 필수적인 차세대 지능형 시스템의 강력한 아키텍처적 토대를 마련하였습니다.
논문 초록(Abstract)
추론 시간 계산(inference-time compute)의 스케일링은 대규모 언어 모델(LLM) 성능의 중요한 동인으로 부상하였으며, 이에 따라 모델 품질과 더불어 추론 효율성이 모델 설계의 핵심 초점이 되었습니다. 현재의 트랜스포머(Transformer) 기반 모델은 강력한 모델 품질을 제공하지만, 이차 복잡도(quadratic)의 계산량과 선형(linear) 메모리 요구량으로 인해 추론 비용이 많이 듭니다. 이는 선형 계산량과 상수(constant) 메모리 요구량을 갖춘 서브-쿼드라틱(sub-quadratic) 모델의 개발을 촉진했습니다. 그러나 최근의 많은 선형 모델은 알고리즘 효율성을 위해 모델 품질과 성능을 희생하며, 상태 추적(state tracking)과 같은 태스크에서 실패하는 모습을 보입니다. 또한, 이들의 이론적으로 선형적인 추론은 실제 하드웨어상에서 여전히 비효율적입니다. 본 논문에서는 추론 우선적 관점에 따라, 선형 모델의 상태 공간 모델(SSM) 관점에서 영감을 얻은 세 가지 핵심 방법론적 개선 사항을 소개합니다. 본 연구는 (1) SSM 이산화(discretization)에서 도출된 더 표현력이 높은 재귀(recurrence), (2) 더 풍부한 상태 추적을 가능하게 하는 복소수 값(complex-valued) 상태 업데이트 규칙, 그리고 (3) 디코딩 지연 시간(decode latency)을 늘리지 않으면서 모델 성능을 향상시키는 다중 입력 다중 출력(MIMO) 공식을 결합했습니다. 구조적 개선과 함께 Mamba-3 모델은 검색(retrieval), 상태 추적 및 다운스트림 언어 모델링 태스크 전반에서 상당한 성능 향상을 달성했습니다. 1.5B 스케일에서 Mamba-3는 차순위 모델인 Gated DeltaNet과 비교해 평균 다운스트림 정확도를 0.6 퍼센트 포인트 향상시켰으며, Mamba-3의 MIMO 변체는 정확도를 1.2 포인트 추가로 향상시켜 총 1.8 포인트의 이득을 얻었습니다. 상태 크기 실험 전반에서 Mamba-3는 이전 모델 상태 크기의 절반만 사용하고도 Mamba-2와 대등한 퍼플렉시티(perplexity)를 달성했습니다. 본 평가 결과는 성능-효율 파레토 프런티어(Pareto frontier)를 확장하는 Mamba-3의 능력을 입증합니다.
Scaling inference-time compute has emerged as an important driver of LLM performance, making inference efficiency a central focus of model design alongside model quality. While the current Transformer-based models deliver strong model quality, their quadratic compute and linear memory make inference expensive. This has spurred the development of sub-quadratic models with reduced linear compute and constant memory requirements. However, many recent linear models trade off model quality and capability for algorithmic efficiency, failing on tasks such as state tracking. Moreover, their theoretically linear inference remains hardware-inefficient in practice. Guided by an inference-first perspective, we introduce three core methodological improvements inspired by the state space model (SSM) viewpoint of linear models. We combine: (1) a more expressive recurrence derived from SSM discretization, (2) a complex-valued state update rule that enables richer state tracking, and (3) a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency. Together with architectural refinements, our Mamba-3 model achieves significant gains across retrieval, state-tracking, and downstream language modeling tasks. At the 1.5B scale, Mamba-3 improves average downstream accuracy by 0.6 percentage points compared to the next best model (Gated DeltaNet), with Mamba-3's MIMO variant further improving accuracy by another 1.2 points for a total 1.8 point gain. Across state-size experiments, Mamba-3 achieves comparable perplexity to Mamba-2 despite using half of its predecessor's state size. Our evaluations demonstrate Mamba-3's ability to advance the performance-efficiency Pareto frontier.
논문 링크
더 읽어보기
OpenSeeker: 학습 데이터의 완전 오픈소스화를 통한 프런티어 검색 에이전트의 민주화 / OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data

논문 소개
정보의 폭발적인 증가로 인해 웹 환경에서 실시간으로 정확한 정보를 탐색하고 정제하는 능력은 현대적인 의사결정의 핵심이 되었으며, 이에 따라 대규모 언어 모델(Large Language Model, LLM) 에이전트에게 심층 검색(Deep Search) 역량은 필수적인 요소로 자리 잡았습니다. 그러나 고성능 검색 에이전트의 개발은 막대한 자본을 보유한 기업들이 구축한 ‘데이터 해자(Data Moat)’로 인해 폐쇄적인 영역으로 남아 있었으며, 이는 학계와 오픈소스 커뮤니티의 기술적 혁신을 저해하는 주요 원인이 되어왔습니다. OpenSeeker(오픈시커)는 이러한 데이터 격차를 해소하기 위해 모델 가중치는 물론, 고품질의 합성 데이터 생성 파이프라인 전체를 전면 공개하며 프론티어급 검색 에이전트의 대중화를 선언합니다.
본 연구의 핵심적인 방법론적 혁신은 팩트 기반의 확장 가능하고 제어 가능한 질의응답 합성(Fact-grounded Scalable Controllable QA Synthesis) 기술에 있으며, 이는 대규모 웹 아카이브의 구조를 역공학하여 인위적이지 않은 복잡한 추론 문제를 생성합니다. 구체적으로는 시드 페이지로부터 토폴로지 그래프 확장(Topological Graph Expansion)을 수행하여 정보 클러스터를 식별하고, 엔티티 난독화(Entity Obfuscation)를 적용함으로써 단순한 사실 나열을 고난도의 다단계 추론 퍼즐로 변환합니다. 또한 노이즈가 제거된 궤적 합성(Denoised Trajectory Synthesis) 기술을 도입하여, 에이전트가 방대한 웹 콘텐츠 속의 광고나 무의미한 스크립트 같은 노이즈를 뚫고 핵심적인 신호만을 파악하여 논리적인 행동을 생성하도록 유도합니다.
이 과정에서 사후 요약 메커니즘(Retrospective Summarization)을 활용해 교사 모델이 정제된 정보를 바탕으로 최적의 의사결정을 내리도록 학습 데이터를 구성함으로써 모델의 추론 효율성을 극대화했습니다. 실험 결과, OpenSeeker는 단 11,700개의 정교한 합성 샘플만을 활용한 지도 미세 조정(Supervised Fine-Tuning, SFT)만으로도 기존의 강력한 오픈소스 모델들을 압도하는 성능을 보여주었습니다. 특히 BrowseComp-ZH와 같은 주요 벤치마크에서는 방대한 추가 사전 학습과 인간 피드백 기반 강화학습(Reinforcement Learning from Human Feedback, RLHF)을 거친 산업계의 거대 모델들과 대등하거나 오히려 이를 능가하는 성과를 거두었습니다. 이러한 결과는 검색 에이전트의 지능을 고도화하는 데 있어 단순한 데이터의 양보다 질문의 복잡도와 추론 궤적의 밀도가 더욱 결정적인 역할을 한다는 점을 시사합니다. 결론적으로 OpenSeeker는 프론티어급 검색 지능의 ‘레시피’를 투명하게 공유함으로써, 연구자들이 거대 기업의 폐쇄적인 API에 의존하지 않고도 독자적인 혁신을 이어나갈 수 있는 협력적인 AI 생태계의 토대를 마련하였습니다.
논문 초록(Abstract)
심층 검색 능력은 최첨단 대규모 언어 모델(LLM) 에이전트에게 필수적인 역량이 되었지만, 투명하고 고품질인 학습 데이터의 부족으로 인해 고성능 검색 에이전트의 개발은 여전히 거대 IT 기업들에 의해 주도되고 있습니다. 이러한 지속적인 데이터 부족은 광범위한 연구 커뮤니티가 이 영역에서 개발하고 혁신하는 데 있어 근본적인 장애물이 되었습니다. 이러한 격차를 해소하기 위해, 우리는 두 가지 핵심 기술 혁신을 통해 최첨단 수준의 성능을 달성한 최초의 완전 오픈소스 검색 에이전트(즉, 모델 및 데이터)인 오픈시커(OpenSeeker)를 소개합니다. (1) 사실 기반의 확장 가능하고 제어 가능한 QA 합성: 위상적 확장(topological expansion) 및 엔티티 난독화(entity obfuscation)를 통해 웹 그래프를 역공학으로 분석하여 제어 가능한 범위와 복잡성을 가진 복잡한 멀티홉 추론(multi-hop reasoning) 과제를 생성합니다. (2) 노이즈가 제거된 궤적 합성(Denoised trajectory synthesis): 회고적 요약 메커니즘을 사용하여 궤적의 노이즈를 제거함으로써 교사 LLM이 고품질의 행동을 생성하도록 유도합니다. 실험 결과에 따르면, 단 11,700개의 합성 샘플만으로 학습된(단 한 번의 학습 과정) OpenSeeker는 BrowseComp, BrowseComp-ZH, xbench-DeepSearch, WideSearch를 포함한 여러 벤치마크에서 최첨단 성능(SOTA)을 달성했습니다. 특히, 단순 지도 미세조정(SFT)만으로 학습된 OpenSeeker는 두 번째로 우수한 완전 오픈소스 에이전트인 딥다이브(DeepDive)를 크게 능가했으며(예: BrowseComp에서 29.5% 대 15.3%), 광범위한 지속적 사전학습(continual pre-training), SFT 및 강화학습(RL)을 통해 학습된 퉁이 딥리서치(Tongyi DeepResearch)와 같은 산업계 경쟁 모델도 BrowseComp-ZH에서 앞질렀습니다(48.4% 대 46.7%). 우리는 최첨단 검색 에이전트 연구를 대중화하고 보다 투명하고 협력적인 생태계를 조성하기 위해 전체 학습 데이터셋과 모델 가중치를 완전히 오픈소스로 공개합니다.
Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent, high-quality training data. This persistent data scarcity has fundamentally hindered the progress of the broader research community in developing and innovating within this domain. To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA synthesis, which reverse-engineers the web graph via topological expansion and entity obfuscation to generate complex, multi-hop reasoning tasks with controllable coverage and complexity. (2) Denoised trajectory synthesis, which employs a retrospective summarization mechanism to denoise the trajectory, therefore promoting the teacher LLMs to generate high-quality actions. Experimental results demonstrate that OpenSeeker, trained (a single training run) on only 11.7k synthesized samples, achieves state-of-the-art performance across multiple benchmarks including BrowseComp, BrowseComp-ZH, xbench-DeepSearch, and WideSearch. Notably, trained with simple SFT, OpenSeeker significantly outperforms the second-best fully open-source agent DeepDive (e.g., 29.5% v.s. 15.3% on BrowseComp), and even surpasses industrial competitors such as Tongyi DeepResearch (trained via extensive continual pre-training, SFT, and RL) on BrowseComp-ZH (48.4% v.s. 46.7%). We fully open-source the complete training dataset and the model weights to democratize frontier search agent research and foster a more transparent, collaborative ecosystem.
논문 링크
더 읽어보기
대규모 언어 모델의 도구 사용을 위한 문맥 내 강화학습 / In-Context Reinforcement Learning for Tool Use in Large Language Models
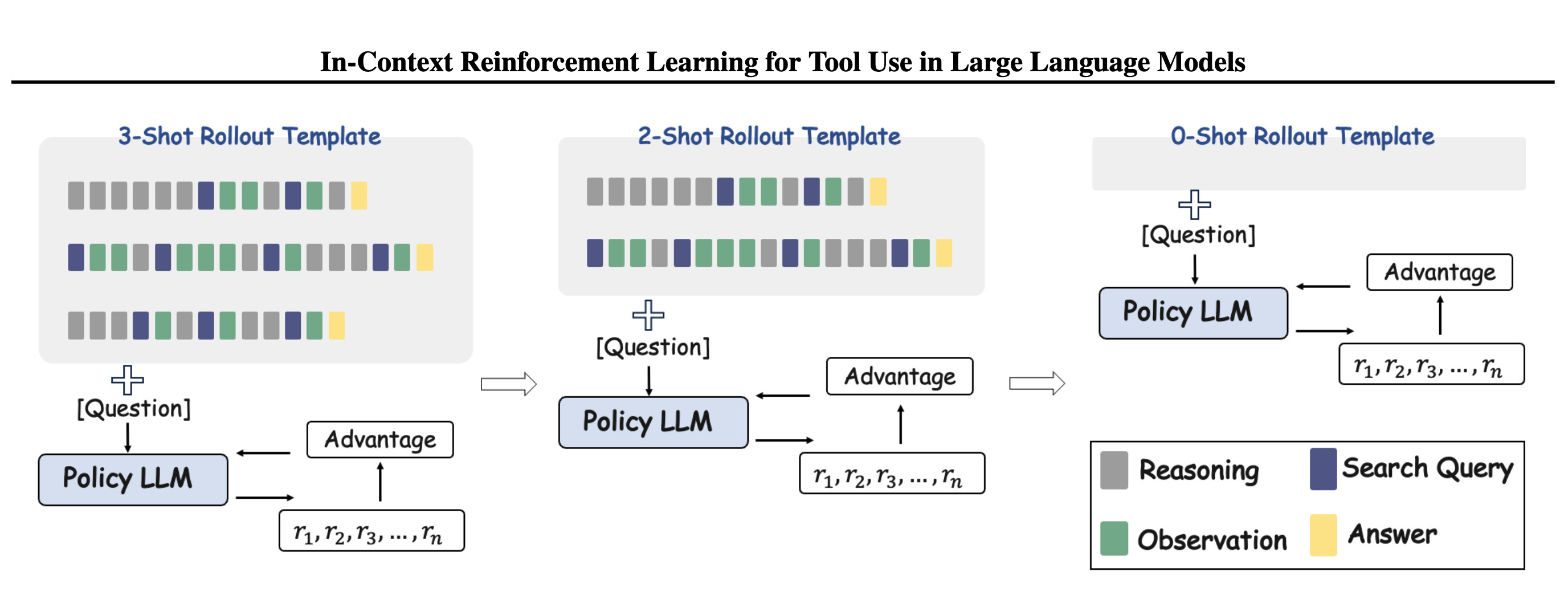
논문 소개
대규모 언어 모델(LLM)은 강력한 추론 능력을 보이지만, 복잡한 작업에서 내부 지식의 한계로 인해 성능이 제한되는 경우가 많습니다. 이러한 문제를 해결하기 위해, 수학 계산을 위한 파이썬 인터프리터나 사실 정보를 검색하는 검색 엔진과 같은 외부 도구를 모델에 추가하는 방법이 제안됩니다. 그러나 이러한 도구를 효과적으로 사용하는 것은 여전히 큰 도전 과제가 됩니다. 기존 방법은 일반적으로 감독된 파인튜닝(SFT)으로 시작하여 강화학습(RL)으로 진행되는 콜드 스타트 파이프라인에 의존합니다. 이러한 접근 방식은 SFT에 상당한 양의 레이블이 있는 데이터가 필요하며, 이는 주석을 달거나 합성하는 데 비용이 많이 듭니다. 본 연구에서는 SFT 필요성을 없애고 RL의 롤아웃 단계에서 퓨샷 프롬프트를 활용하는 강화학습 전용 프레임워크인 인-컨텍스트 강화학습(ICRL)을 제안합니다. ICRL은 롤아웃 프롬프트 내에 인-컨텍스트 예제를 도입하여 모델이 외부 도구를 호출하는 방법을 학습하도록 합니다. 훈련이 진행됨에 따라 인-컨텍스트 예제의 수는 점진적으로 줄어들며, 최종적으로는 제로샷 환경에서 모델이 독립적으로 도구를 호출하는 방법을 배우게 됩니다. 다양한 추론 및 도구 사용 벤치마크에서 광범위한 실험을 수행한 결과, ICRL은 최첨단 성능을 달성하여 전통적인 SFT 기반 파이프라인에 비해 확장 가능하고 데이터 효율적인 대안임을 입증하였습니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 강력한 추론 능력을 보이지만, 복잡한 작업에서의 성능은 종종 내부 지식의 한계에 의해 제약을 받습니다. 이러한 문제를 극복하기 위한 매력적인 접근 방식은 이 모델들을 외부 도구(예: 수학 계산을 위한 Python 해석기 또는 사실 정보를 검색하기 위한 검색 엔진)로 보강하는 것입니다. 그러나 모델이 이러한 도구를 효과적으로 사용하는 것을 가능하게 하는 것은 여전히 큰 도전 과제입니다. 기존 방법들은 일반적으로 감독 하에 파인튜닝(SFT)으로 시작하여 강화학습(RL)을 따르는 콜드 스타트 파이프라인에 의존합니다. 이러한 접근 방식은 SFT를 위해 상당량의 레이블이 지정된 데이터가 필요하며, 이는 주석을 달거나 합성하는 데 비용이 많이 듭니다. 본 연구에서는 RL 전용 프레임워크인 문맥 내 강화학습(ICRL)을 제안합니다. ICRL은 RL의 롤아웃 단계에서 퓨샷 프롬프트를 활용하여 SFT의 필요성을 없앱니다. 구체적으로, ICRL은 롤아웃 프롬프트 내에 문맥 내 예시를 도입하여 모델이 외부 도구를 호출하는 방법을 학습하도록 합니다. 또한, 훈련이 진행됨에 따라 문맥 내 예시의 수를 점차 줄여 나가며, 결국 모델이 독립적으로 도구를 호출하는 제로샷 설정에 도달하게 됩니다. 우리는 다양한 추론 및 도구 사용 벤치마크에 걸쳐 광범위한 실험을 수행하였습니다. 결과는 ICRL이 기존 SFT 기반 파이프라인에 대한 확장 가능하고 데이터 효율적인 대안으로서의 효과성을 입증하며, 최첨단 성능을 달성했음을 보여줍니다.
While large language models (LLMs) exhibit strong reasoning abilities, their performance on complex tasks is often constrained by the limitations of their internal knowledge. A compelling approach to overcome this challenge is to augment these models with external tools -- such as Python interpreters for mathematical computations or search engines for retrieving factual information. However, enabling models to use these tools effectively remains a significant challenge. Existing methods typically rely on cold-start pipelines that begin with supervised fine-tuning (SFT), followed by reinforcement learning (RL). These approaches often require substantial amounts of labeled data for SFT, which is expensive to annotate or synthesize. In this work, we propose In-Context Reinforcement Learning (ICRL), an RL-only framework that eliminates the need for SFT by leveraging few-shot prompting during the rollout stage of RL. Specifically, ICRL introduces in-context examples within the rollout prompts to teach the model how to invoke external tools. Furthermore, as training progresses, the number of in-context examples is gradually reduced, eventually reaching a zero-shot setting where the model learns to call tools independently. We conduct extensive experiments across a range of reasoning and tool-use benchmarks. Results show that ICRL achieves state-of-the-art performance, demonstrating its effectiveness as a scalable, data-efficient alternative to traditional SFT-based pipelines.
논문 링크
더 읽어보기
스파이크, 스파스, 그리고 싱크: 대규모 활성화와 어텐션 싱크의 해부학 / The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks
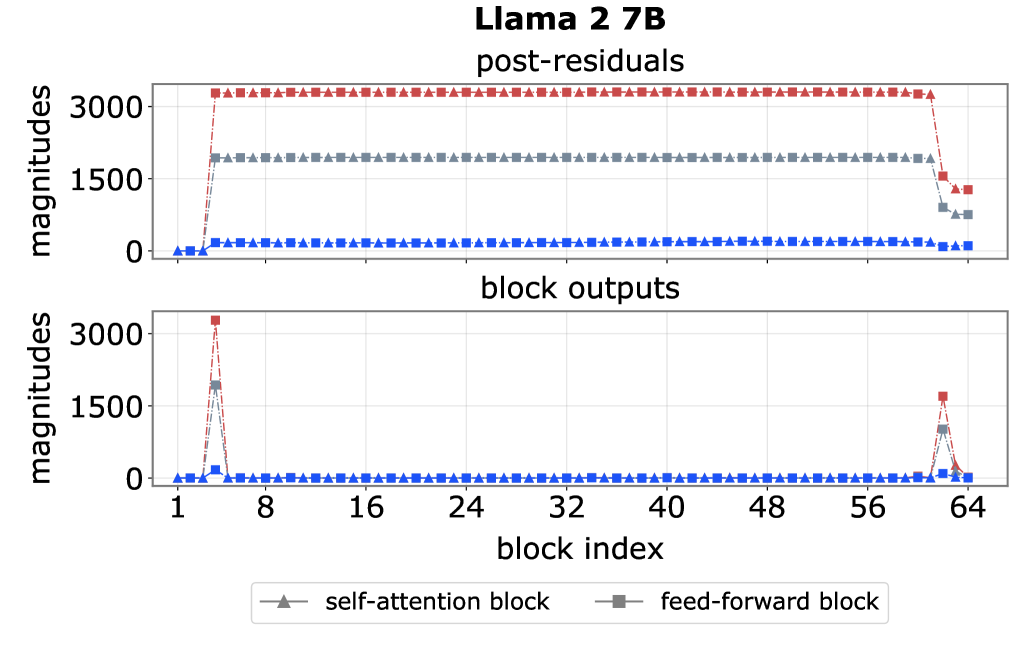
논문 소개
트랜스포머 언어 모델의 내부 작동 원리는 여전히 많은 연구자들에게 미지의 영역으로 남아 있으며, 본 연구는 이와 관련된 두 가지 중요한 현상인 대규모 활성화(massive activations)와 어텐션 싱크(attention sinks)를 탐구합니다. 대규모 활성화는 특정 토큰이 몇몇 채널에서 극단적인 이상치를 보이는 현상으로, 모델의 전반적인 성능과 효율성에 영향을 미칠 수 있습니다. 반면, 어텐션 싱크는 특정 토큰이 의미와 관계없이 과도한 주의를 끌어모으는 현상으로, 이는 모델의 주의 메커니즘에 중요한 영향을 미칩니다.
이 연구는 이러한 두 현상이 동시 발생하는 이유를 밝혀내기 위해 체계적인 실험을 수행하였으며, 그 결과를 통해 동시 발생이 단순한 우연이 아니라 현대 트랜스포머 아키텍처의 구조적 인공물이라는 점을 입증하였습니다. 특히, 대규모 활성화는 전역적 작용을 통해 모델의 숨겨진 표현을 안정적으로 유지하며, 어텐션 싱크는 국소적 작용을 통해 주의 출력을 조절하고 단기 의존성을 강화하는 역할을 합니다.
핵심 발견 중 하나는 사전 정규화(pre-norm) 구성이 이러한 동시 발생을 가능하게 하는 중요한 요소라는 것입니다. 연구팀은 이 구성을 제거함으로써 두 현상을 분리할 수 있음을 보여주었으며, 이는 아키텍처 설계에 대한 새로운 인사이트를 제공합니다. 더 나아가, 어텐션 싱크는 어텐션 공간의 차원과 훈련 중 맥락 길이 분포에 의해 주도됨을 밝혀내어, 이론적 설명을 넘어 기계적 원인을 규명하는 기초를 마련하였습니다.
이러한 연구 결과는 대규모 활성화와 어텐션 싱크 간의 인과 관계를 명확히 하고, 향후 모델 개선 및 최적화에 기여할 수 있는 중요한 기반을 제공합니다. 본 논문은 이러한 현상을 통합적으로 이해함으로써, 트랜스포머 아키텍처의 설계 및 실용화에 대한 새로운 방향성을 제시하고 있습니다.
논문 초록(Abstract)
우리는 트랜스포머 언어 모델에서 두 가지 반복적인 현상, 즉 극단적인 아웃라이어를 몇 개의 채널에서 나타내는 소수의 토큰으로 인한 대규모 활성화(massive activations)와 의미적 관련성과 관계없이 특정 토큰이 불균형적으로 많은 어텐션을 끌어당기는 어텐션 싱크(attention sinks)를 연구합니다. 이전 연구에서는 이러한 현상이 자주 동시에 발생하고 동일한 토큰이 관련되어 있다는 것을 관찰했지만, 그 기능적 역할과 인과 관계는 명확하지 않았습니다. 체계적인 실험을 통해 우리는 이러한 동시 발생이 현대 트랜스포머 설계의 주로 구조적 산물임을 보여주고, 두 현상이 관련 있지만 구별되는 기능을 수행한다는 것을 밝혀냈습니다. 대규모 활성화는 전역적으로 작용하며, 레이어를 넘나드는 거의 일정한 은닉 표현을 유도하여 모델의 암묵적 파라미터로 기능합니다. 어텐션 싱크는 국소적으로 작용하며, 헤드 간의 어텐션 출력을 조절하고 개별 헤드를 단기 의존성으로 편향시킵니다. 우리는 프리-노름(pre-norm) 구성이 동시 발생을 가능하게 하는 핵심 선택임을 확인하고, 이를 제거할 경우 두 현상이 분리된다는 것을 보여줍니다.
We study two recurring phenomena in Transformer language models: massive activations, in which a small number of tokens exhibit extreme outliers in a few channels, and attention sinks, in which certain tokens attract disproportionate attention mass regardless of semantic relevance. Prior work observes that these phenomena frequently co-occur and often involve the same tokens, but their functional roles and causal relationship remain unclear. Through systematic experiments, we show that the co-occurrence is largely an architectural artifact of modern Transformer design, and that the two phenomena serve related but distinct functions. Massive activations operate globally: they induce near-constant hidden representations that persist across layers, effectively functioning as implicit parameters of the model. Attention sinks operate locally: they modulate attention outputs across heads and bias individual heads toward short-range dependencies. We identify the pre-norm configuration as the key choice that enables the co-occurrence, and show that ablating it causes the two phenomena to decouple.
논문 링크
분산 시스템으로서의 언어 모델 팀 / Language Model Teams as Distributed Systems
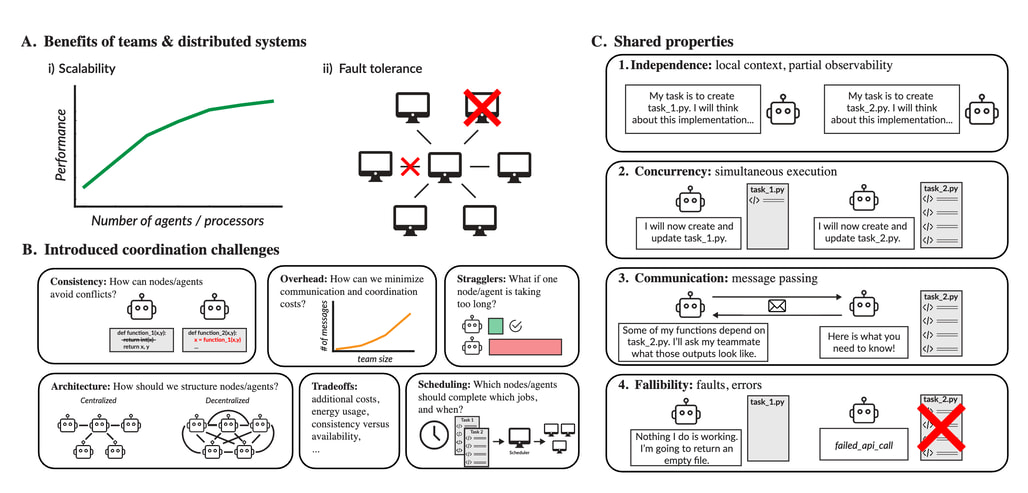
논문 소개
최근 대규모 언어 모델(Large Language Models, LLMs)의 비약적인 발전은 단일 모델이 가진 메모리와 컨텍스트 윈도우(Context Window)의 물리적 한계를 극복하기 위한 다중 에이전트 팀 구성에 대한 활발한 논의를 불러일으켰습니다. 인간의 협업 방식이 개별 역량의 합 이상의 성과를 내듯, 여러 언어 모델을 하나의 팀으로 오케스트레이션(Orchestration)하는 시도는 인공지능 성능 확장의 핵심적인 전략으로 자리 잡고 있습니다. 하지만 명확한 설계 원칙 없이 구성된 팀은 정보의 중복 출력이나 의사결정의 충돌, 그리고 서로의 오류를 강화하는 아첨(Sycophancy) 현상과 같은 심각한 비효율성을 초래할 위험이 큽니다.
이러한 문제를 해결하기 위해 본 연구는 수십 년간 검증된 분산 시스템(Distributed Systems) 이론을 대규모 언어 모델 팀의 설계와 평가를 위한 근본적인 토대로 제안합니다. 단일 프로세서에서 분산 아키텍처로 진화한 컴퓨팅의 역사와 마찬가지로, 언어 모델 에이전트들 역시 독립성(Independence), 통신(Communication), 동시성(Concurrency), 결함 가능성(Fallibility)이라는 분산 시스템의 핵심 속성을 공유하고 있음에 주목해야 합니다. 각 에이전트는 로컬 컨텍스트만을 유지하며 자연어 메시지를 통해 정보를 교환하고, 동시에 작업을 수행하면서도 환각(Hallucination)과 같은 개별적 결함에 노출되어 있다는 점에서 분산 노드와 구조적으로 대응됩니다.
이러한 관점의 전환은 암달의 법칙(Amdahl’s Law)과 같은 고전적인 확장 법칙을 인공지능 에이전트 팀에 적용하여, 작업의 병렬화 가능성에 따른 효율성 한계를 정밀하게 예측할 수 있게 합니다. 특히 중앙 집중형(Centralized)과 분산형(Decentralized) 아키텍처 사이의 트레이드오프(Tradeoffs) 분석을 통해, 지연 에이전트(Straggler)가 전체 성능에 미치는 영향이나 동적 작업 할당 시 발생하는 조정 비용 문제를 체계적으로 진단합니다. 수학 유틸리티 구현 및 데이터 분석과 같은 협업 코딩 과제를 통한 실증적 테스트 결과는 분산 컴퓨팅의 원리가 언어 모델 팀의 성능 병목 현상을 설명하는 데 매우 유효함을 입증하고 있습니다.
결론적으로 분산 시스템 이론에 기반한 접근법은 단순한 시행착오식 최적화를 넘어, 다중 에이전트 시스템이 대규모로 확장될 때 발생할 수 있는 자원 낭비를 방지하고 시스템의 견고함(Robustness)을 확보하는 원칙적인 가이드를 제공합니다. 이는 향후 이질적인 모델들로 구성된 팀의 시너지 창출이나 결함 허용(Fault Tolerance) 메커니즘 설계의 표준이 될 것이며, 궁극적으로 더욱 예측 가능하고 책임감 있는 인공지능 협업 생태계를 구축하는 데 기여할 것입니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 능력이 점차 향상됨에 따라, 최근 LLM 팀에 대한 관심이 높아지고 있습니다. 그러나 LLM 팀의 대규모 배포가 증가하고 있음에도 불구하고, 팀이 언제 도움이 되는지, 얼마나 많은 에이전트(agent)를 사용해야 하는지, 구조가 성능에 어떤 영향을 미치는지, 그리고 팀이 단일 에이전트보다 더 나은지 등의 핵심 질문을 해결하기 위한 원칙에 기반한 프레임워크가 부족한 실정입니다. 이러한 가능성들을 시행착오를 통해 설계하고 테스트하기보다, 본 논문은 LLM 팀을 구축하고 평가하기 위한 원칙적인 토대로서 분산 시스템(distributed systems)을 활용할 것을 제안합니다. 연구 결과, 분산 컴퓨팅(distributed computing) 분야에서 연구된 많은 근본적인 이점과 과제들이 LLM 팀에서도 동일하게 발생함을 확인했으며, 이는 두 연구 분야 간의 상호 교류를 통해 얻을 수 있는 풍부하고 실질적인 통찰력을 강조합니다.
Large language models (LLMs) are growing increasingly capable, prompting recent interest in LLM teams. Yet, despite increased deployment of LLM teams at scale, we lack a principled framework for addressing key questions such as when a team is helpful, how many agents to use, how structure impacts performance -- and whether a team is better than a single agent. Rather than designing and testing these possibilities through trial-and-error, we propose using distributed systems as a principled foundation for creating and evaluating LLM teams. We find that many of the fundamental advantages and challenges studied in distributed computing also arise in LLM teams, highlighting the rich practical insights that can come from the cross-talk of these two fields of study.
논문 링크
더 읽어보기
AI는 과학적 안목(Scientific Taste)을 학습할 수 있다 / AI Can Learn Scientific Taste
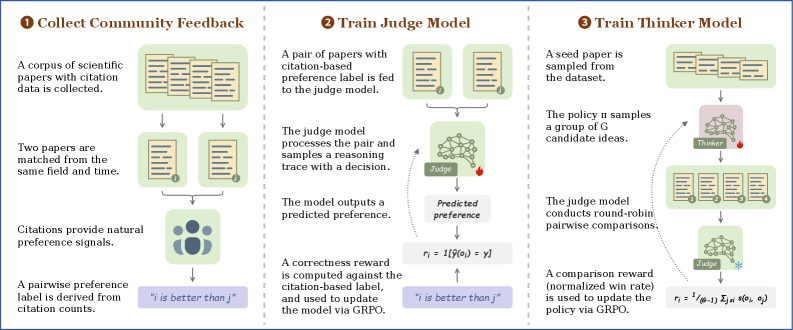
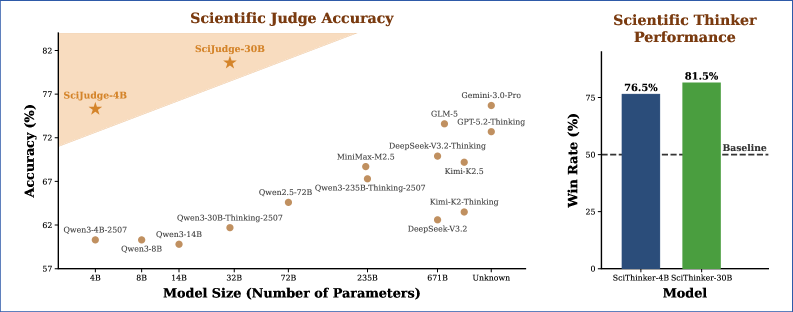
논문 소개
현대 인공지능 기술의 비약적인 발전은 코딩, 수학적 추론, 논리적 문제 해결과 같은 모델의 실행 능력(Executive Capability)을 전례 없는 수준으로 끌어올렸으나, 정작 "무엇을 연구할 것인가"라는 본질적인 질문에 답하는 능력은 여전히 미지의 영역으로 남아 있습니다. 위대한 과학자들은 수많은 가설 중에서 학문적 파급력이 높은 주제를 직관적으로 선별하는 독특한 안목을 지니고 있으며, 본 연구는 이를 '과학적 식견(Scientific Taste)'이라 명명하고 AI가 이를 학습할 수 있는 방법론을 탐구합니다. 과학적 식견은 단순한 지식의 축적을 넘어 미래의 학술적 가치를 예견하는 전략적 예지력(Foresight)을 의미하며, 저자들은 이를 정량화하기 위해 커뮤니티 피드백 기반 강화학습(Reinforcement Learning from Community Feedback, RLCF)이라는 혁신적인 훈련 패러다임을 도입합니다.
RLCF는 소수 검수자의 주관이 개입될 수 있는 기존의 인간 피드백 방식 대신, 수십 년간 과학계에서 검증된 대규모 인용 데이터를 공동체의 집단적 승인 신호로 활용하여 학습의 객관성을 확보합니다. 방법론의 핵심인 '사이언티픽 저지(Scientific Judge)'는 동일 분야 및 시기에 발표된 70만 쌍(700K pairs)의 논문을 대조 학습함으로써, 학문적 유행이나 분야별 인용 편향을 배제하고 연구의 본질적 가치를 판별하는 선호도 모델링(Preference Modeling)을 수행합니다. 이어지는 선호도 정렬(Preference Alignment) 단계에서는 사이언티픽 저지를 보상 모델(Reward Model)로 삼아, 높은 잠재력을 지닌 연구 가설을 스스로 제안하는 정책 모델인 '사이언티픽 씽커(Scientific Thinker)'를 고도화하여 과학적 가치의 문법을 내면화합니다.
엄격한 성능 검증 결과, 제안된 모델은 GPT-5.2 및 제미나이 3 프로(Gemini 3 Pro)와 같은 최첨단 거대 언어 모델들을 상대로 우월한 판단력을 입증했을 뿐만 아니라, 학습 데이터에 포함되지 않은 미래 시점의 논문과 미지의 학문 분야에서도 탁월한 일반화(Generalization) 성능을 보여주었습니다. 특히 실제 동료 심사(Peer-review) 결과와도 높은 상관관계를 보임으로써, AI가 단순히 통계적 패턴을 쫓는 것이 아니라 학계가 지향하는 보편적인 연구 가치를 성공적으로 파악했음을 증명했습니다. 이러한 결과는 AI가 연구 보조 도구를 넘어 인간 과학자와 대등한 수준에서 전략적 의사결정을 수행하는 파트너로 진화할 수 있다는 가능성을 시사하며, 궁극적으로 인간 수준의 AI 과학자(Human-level AI Scientist) 시대를 여는 결정적인 기술적 토대를 마련합니다.
논문 초록(Abstract)
위대한 과학자들은 우리가 과학적 취향(scientific taste)이라 부르는 요소와 밀접하게 연관된 강력한 판단력과 선견지명을 갖추고 있습니다. 본 논문에서 이 용어는 높은 잠재적 영향력을 가진 연구 아이디어를 판단하고 제안하는 능력을 의미합니다. 하지만 대부분의 관련 연구는 AI 과학자의 실행 능력을 향상시키는 데 초점을 맞추고 있으며, AI의 과학적 취향을 강화하는 연구는 여전히 충분히 탐구되지 않은 상태입니다. 본 연구에서는 대규모 커뮤니티 신호를 지도 신호(supervision)로 사용하는 학습 패러다임인 커뮤니티 피드백 기반 강화학습(Reinforcement Learning from Community Feedback, RLCF)을 제안하며, 과학적 취향 학습을 선호도 모델링 및 정렬(alignment) 문제로 정의합니다. 선호도 모델링을 위해, 아이디어를 판단할 수 있도록 분야와 시기가 일치하는 70만 개의 고인용 및 저인용 논문 쌍을 활용하여 사이언티픽 저지(Scientific Judge)를 학습시킵니다. 선호도 정렬을 위해, 사이언티픽 저지(Scientific Judge)를 보상 모델(reward model)로 사용하여 높은 잠재적 영향력을 가진 연구 아이디어를 제안하는 정책 모델인 사이언티픽 씽커(Scientific Thinker)를 학습시킵니다. 실험 결과, 사이언티픽 저지(Scientific Judge)는 GPT-5.2, 제미나이 3 프로(Gemini 3 Pro)와 같은 최첨단 대규모 언어 모델(SOTA LLM)을 능가하는 성능을 보였으며, 미래 연도 테스트, 학습되지 않은 분야, 그리고 동료 심사(peer-review) 선호도에 대해서도 우수한 일반화 능력을 입증했습니다. 나아가, 사이언티픽 씽커(Scientific Thinker)는 기존 베이스라인(baseline)보다 더 높은 잠재적 영향력을 가진 연구 아이디어를 제안합니다. 본 연구의 결과는 AI가 과학적 취향을 학습할 수 있음을 보여주며, 이는 인간 수준의 AI 과학자에 도달하기 위한 핵심적인 단계입니다.
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
논문 링크
더 읽어보기
AI 시스템이 학습하지 못하는 이유와 그 대응 방안: 인지과학에서 얻은 자율 학습에 관한 교훈 / Why AI systems don't learn and what to do about it: Lessons on autonomous learning from cognitive science
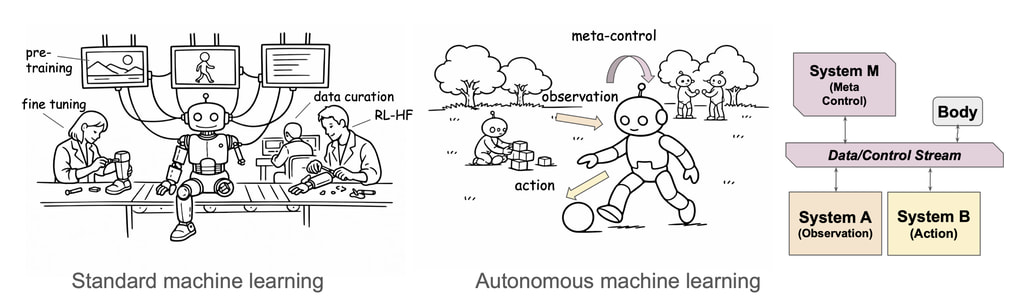
논문 소개
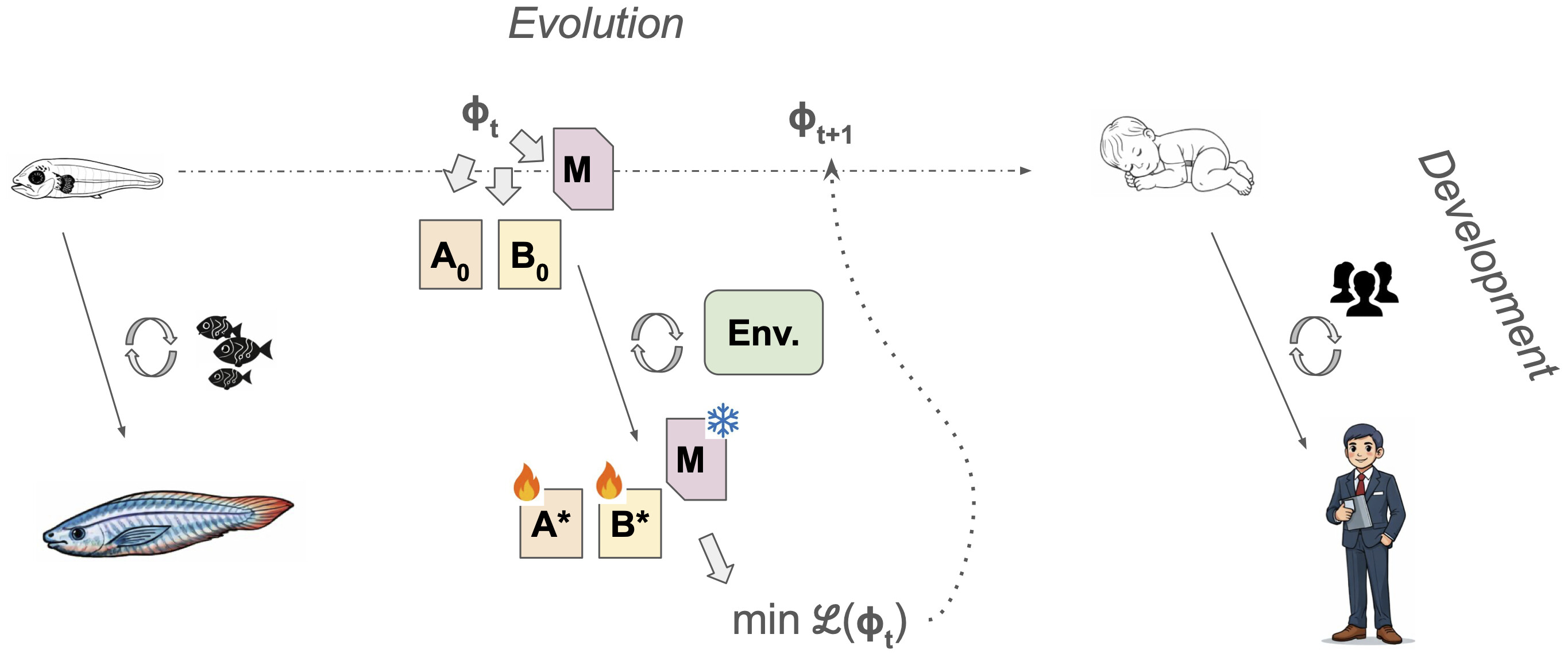
현대 인공지능은 방대한 데이터 학습을 통해 놀라운 발전을 이루었으나, 예측 불가능한 실제 환경에 적응하는 생물학적 유기체 수준의 자율 학습(Autonomous Learning)을 달성하는 데에는 여전히 한계를 보이고 있습니다. 인간이나 동물이 무엇을 언제 어떻게 학습할지 스스로 결정하는 것과 달리, 현재의 모델들은 정적인 데이터셋이나 명시적으로 정의된 보상 함수에 의존하는 구조적 제약에 갇혀 있기 때문입니다. 이러한 간극을 메우기 위해 인지 과학적 통찰을 바탕으로 관찰 기반 학습(Learning from Observation)과 능동적 행동 기반 학습(Learning from Active Behavior)을 유연하게 통합하는 새로운 아키텍처가 제안되었습니다.
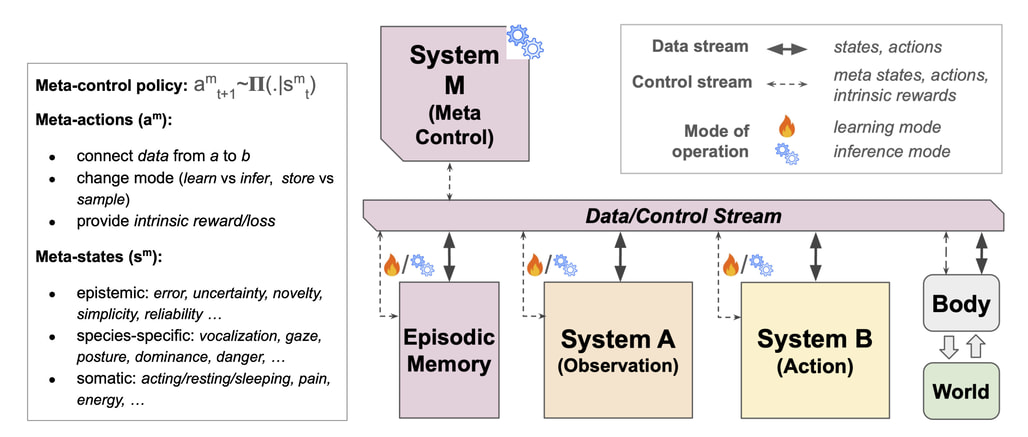
시스템 A(System A)는 환경으로부터 통계적 규칙성을 찾아내는 수동적 학습 모드로, 얼굴이나 목소리 같은 핵심 신호에 우선순위를 두는 선천적 감도(Innate Sensitivities, IS)를 통해 학습 효율을 극대화합니다. 반면 시스템 B(System B)는 행위자가 환경에 직접 개입하고 시행착오를 거치며 인과적 세계 모델(Causal World Model)을 구축함으로써, 단순한 패턴 복제를 넘어선 심층적인 학습 효과(Learning Effects, LE)를 창출합니다. 이 아키텍처의 중추인 시스템 M(System M)은 내부의 메타 상태(Meta-states)를 분석하여 현재 상황에 가장 적합한 학습 모드를 선택하고 전환하는 메타 제어(Meta-control) 역할을 수행합니다.
이 과정에서 불확실성(Uncertainty)이나 놀람(Surprise)과 같은 인식론적 신호는 모델 업데이트의 필요성을 알리는 트리거가 되며, 스트레스(Stress)나 수면(Sleep)과 같은 신체적 신호는 학습의 우선순위를 조절하고 오프라인 상태에서 기억을 공고히 하는 기능을 담당합니다. 이러한 인지적 구조의 도입은 AI가 환경에 수동적으로 반응하는 도구를 넘어, 스스로의 상태를 모니터링하고 전략을 최적화하는 능동적 행위자로 진화할 수 있는 토대를 마련합니다. 결과적으로 미래의 AI 연구는 단순히 파라미터 수를 늘리는 차원을 넘어, 생물학적 적응 기제를 모방한 지능적 아키텍처를 구축하는 방향으로 나아가야 합니다. 이러한 변화는 새로운 환경에서의 제로샷(Zero-shot) 추론 능력을 향상시킬 뿐만 아니라, 인간과 유사한 가치 체계를 형성할 수 있는 인공지능 정렬의 핵심적인 열쇠가 될 것입니다.
논문 초록(Abstract)
본 연구에서는 자율 학습(autonomous learning) 달성에 있어 현재 AI 모델이 가진 한계를 비판적으로 검토하고, 인간과 동물의 인지에서 영감을 받은 학습 아키텍처(learning architecture)를 제안합니다. 제안된 프레임워크는 관찰을 통한 학습(System A)과 능동적 행동을 통한 학습(System B)을 통합하는 동시에, 내부적으로 생성된 메타 제어 신호(System M)에 따라 이러한 학습 모드 사이를 유연하게 전환합니다. 또한, 진화적 및 발달적 시간 척도에 걸쳐 유기체가 실제 세계의 역동적인 환경에 적응하는 방식에서 영감을 얻어, 이러한 시스템이 어떻게 구축될 수 있는지에 대해 논의합니다.
We critically examine the limitations of current AI models in achieving autonomous learning and propose a learning architecture inspired by human and animal cognition. The proposed framework integrates learning from observation (System A) and learning from active behavior (System B) while flexibly switching between these learning modes as a function of internally generated meta-control signals (System M). We discuss how this could be built by taking inspiration on how organisms adapt to real-world, dynamic environments across evolutionary and developmental timescales.
논문 링크
MetaClaw: Just Talk - 실제 환경에서 메타 학습하며 진화하는 에이전트 / MetaClaw: Just Talk - An Agent That Meta-Learns and Evolves in the Wild
논문 소개
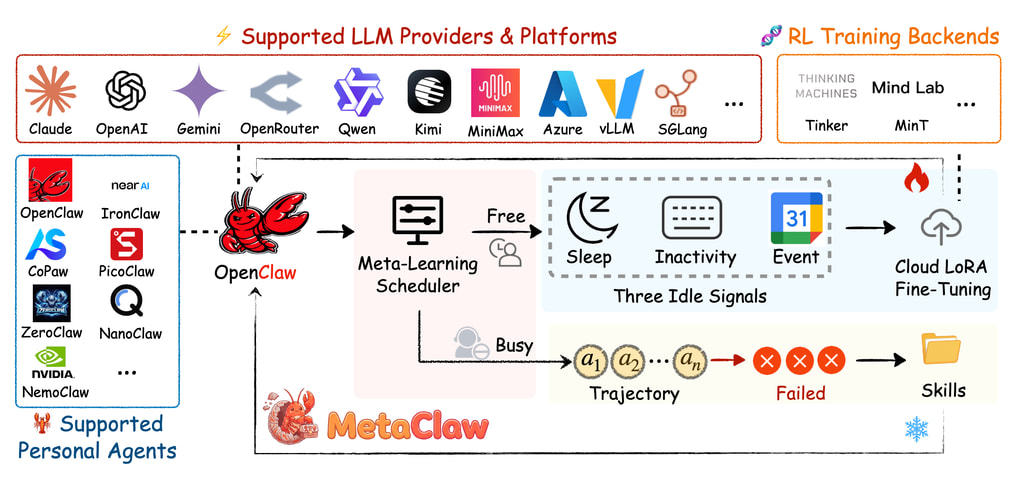
대규모 언어 모델(Large Language Model, LLM) 기반 에이전트가 복잡한 작업 수행에 널리 활용되고 있으나, 배포 이후 변화하는 사용자의 요구사항에 실시간으로 적응하지 못하는 정적인 한계가 상용화의 걸림돌이 되어 왔습니다. 특히 수십 개의 채널에서 다양한 워크로드가 발생하는 실제 운영 환경에서 에이전트의 역량을 업데이트하기 위해 서비스를 중단하거나 대규모 재학습을 수행해야 하는 문제는 시스템의 유연성을 저해하는 핵심 요소입니다. MetaClaw는 이러한 문제를 해결하기 위해 베이스 모델 정책과 재사용 가능한 행동 스킬 라이브러리를 동시에 진화시키는 지속적 메타 학습(Continual Meta-Learning) 프레임워크를 제안합니다.
이 시스템의 핵심인 스킬 기반 빠른 적응(Skill-driven fast adaptation) 메커니즘은 LLM 에볼버(LLM Evolver)를 통해 실패한 대화 궤적을 실시간으로 분석하고, 서비스 중단 없이 즉각적으로 새로운 실행 지침을 합성하여 에이전트의 행동을 교정합니다. 동시에 기회주의적 정책 최적화(Opportunistic policy optimization)를 통해 프로세스 보상 모델(Process Reward Model, PRM) 기반의 강화학습과 클라우드 LoRA(Low-Rank Adaptation, 저충격 적응) 파인튜닝을 수행함으로써 모델의 내부 파라미터를 정교하게 고도화합니다. 특히 기회주의적 메타 학습 스케줄러(Opportunistic Meta-Learning Scheduler, OMLS)는 시스템 유휴 시간과 사용자의 일정을 모니터링하여 최적의 시점에만 가중치 업데이트를 실행함으로써 사용자 경험의 연속성을 완벽하게 보장합니다.
데이터 오염을 방지하기 위해 도입된 버전 관리 메커니즘은 학습용 데이터와 평가용 데이터를 엄격히 분리하여 모델이 단순 암기를 넘어 뛰어난 일반화 능력을 갖추도록 유도하며, 프록시 기반의 확장형 아키텍처를 통해 로컬 자원의 제약 없이 상용 수준의 모델을 운용할 수 있도록 설계되었습니다. 정제된 정책이 더 나은 스킬 합성을 위한 데이터를 생성하고, 풍부해진 스킬이 다시 정책 최적화의 품질을 높이는 상호 보완적 선순환 구조는 에이전트의 자기 진화 성능을 극대화하는 핵심 동력입니다. 실험 결과, MetaClaw는 Kimi-K2.5 모델의 정확도를 기존 21.4%에서 40.6%로 두 배 가까이 향상시켰으며, 복합 견고성 측면에서도 18.3%의 유의미한 개선을 달성하며 실전 환경에서 스스로 진화하는 에이전트의 새로운 지평을 열었습니다.
논문 초록(Abstract)
대규모 언어 모델 (LLM) 에이전트는 복잡한 작업에 점점 더 많이 사용되고 있지만, 배포된 에이전트는 종종 정적인 상태로 남아 있어 사용자의 요구사항이 진화함에 따라 적응하지 못하는 경우가 많습니다. 이는 지속적인 서비스에 대한 필요성과 변화하는 작업 분포에 맞추어 능력을 업데이트해야 하는 필요성 사이에서 상충 관계를 발생시킵니다. 20개 이상의 채널에서 다양한 워크로드를 처리하는 오픈클로(OpenClaw)와 같은 플랫폼에서, 기존 방법들은 지식을 증류(distilling)하지 않은 채 가공되지 않은 트래젝토리(trajectory)를 단순히 저장하거나, 정적인 스킬 라이브러리를 유지하거나, 재학습을 위해 서비스 중단이 수반되는 다운타임(downtime)을 필요로 합니다. 본 논문에서는 기반 LLM 정책과 재사용 가능한 행동 스킬 라이브러리를 함께 진화시키는 지속적 메타 학습(continual meta-learning) 프레임워크인 메타클로(MetaClaw)를 제안합니다. 메타클로는 두 가지 상호 보완적인 메커니즘을 사용합니다. '스킬 기반 빠른 적응(Skill-driven fast adaptation)'은 LLM 이볼버(evolver)를 통해 실패 트래젝토리를 분석하여 새로운 스킬을 합성함으로써, 다운타임 없이 즉각적인 개선을 가능하게 합니다. '기회주의적 정책 최적화(Opportunistic policy optimization)'는 클라우드 LoRA 파인튜닝(fine-tuning)과 프로세스 보상 모델을 사용한 강화학습(RL-PRM)을 통해 그래디언트(gradient) 기반 업데이트를 수행합니다. 이는 시스템 비활성 상태와 캘린더 데이터를 모니터링하는 '기회주의적 메타 학습 스케줄러(OMLS)'에 의해 사용자 비활성 시간대(user-inactive windows)에 트리거됩니다. 이러한 메커니즘은 서로를 강화합니다. 즉, 정제된 정책은 스킬 합성을 위해 더 나은 트래젝토리를 생성하고, 더 풍부해진 스킬은 정책 최적화를 위해 더 고품질의 데이터를 제공합니다. 데이터 오염(data contamination)을 방지하기 위해 버전 관리 메커니즘이 서포트(support) 데이터와 쿼리(query) 데이터를 분리합니다. 프록시 기반 아키텍처를 바탕으로 구축된 메타클로는 로컬 GPU 없이도 상용 규모의 LLM으로 확장 가능합니다. MetaClaw-Bench 및 AutoResearchClaw에 대한 실험 결과, 스킬 기반 적응은 정확도를 상대적으로 최대 32%까지 향상시키는 것으로 나타났습니다. 전체 파이프라인은 Kimi-K2.5의 정확도를 21.4%에서 40.6%로 끌어올렸으며, 종합 강건성(composite robustness)을 18.3% 향상시켰습니다. 코드는 GitHub - aiming-lab/MetaClaw: 🦞 Just talk to your agent — it learns and EVOLVES 🧬. · GitHub 에서 확인할 수 있습니다.
Large language model (LLM) agents are increasingly used for complex tasks, yet deployed agents often remain static, failing to adapt as user needs evolve. This creates a tension between the need for continuous service and the necessity of updating capabilities to match shifting task distributions. On platforms like OpenClaw, which handle diverse workloads across 20+ channels, existing methods either store raw trajectories without distilling knowledge, maintain static skill libraries, or require disruptive downtime for retraining. We present MetaClaw, a continual meta-learning framework that jointly evolves a base LLM policy and a library of reusable behavioral skills. MetaClaw employs two complementary mechanisms. Skill-driven fast adaptation analyzes failure trajectories via an LLM evolver to synthesize new skills, enabling immediate improvement with zero downtime. Opportunistic policy optimization performs gradient-based updates via cloud LoRA fine-tuning and Reinforcement Learning with a Process Reward Model (RL-PRM). This is triggered during user-inactive windows by the Opportunistic Meta-Learning Scheduler (OMLS), which monitors system inactivity and calendar data. These mechanisms are mutually reinforcing: a refined policy generates better trajectories for skill synthesis, while richer skills provide higher-quality data for policy optimization. To prevent data contamination, a versioning mechanism separates support and query data. Built on a proxy-based architecture, MetaClaw scales to production-size LLMs without local GPUs. Experiments on MetaClaw-Bench and AutoResearchClaw show that skill-driven adaptation improves accuracy by up to 32% relative. The full pipeline advances Kimi-K2.5 accuracy from 21.4% to 40.6% and increases composite robustness by 18.3%. Code is available at GitHub - aiming-lab/MetaClaw: 🦞 Just talk to your agent — it learns and EVOLVES 🧬. · GitHub.
논문 링크
더 읽어보기
최적에 가까운 학습률 스케줄(Learning Rate Schedule)은 어떤 모습인가? / What do near-optimal learning rate schedules look like?
논문 소개
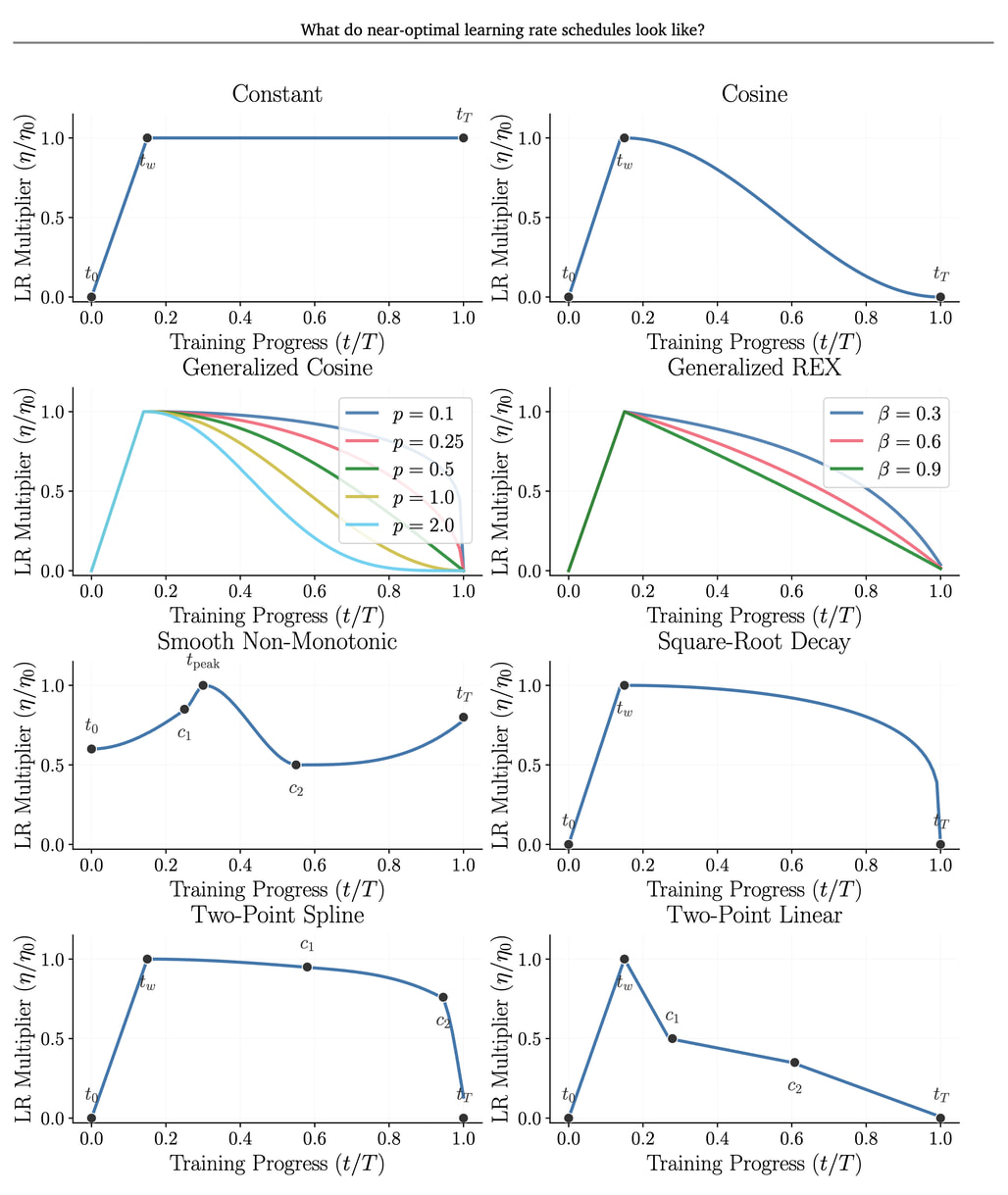
신경망 학습의 성패를 좌우하는 핵심 요소인 학습률 스케줄(Learning Rate Schedule)은 오랜 기간 연구되어 왔으나, 여전히 최적의 형태에 대한 학계의 명확한 합의가 부족한 상태입니다. 본 연구는 관행적으로 사용되는 스케줄링 방식에서 벗어나, 매개변수화된 스케줄 제품군 내에서 최상의 기하학적 형태를 도출하기 위한 체계적인 탐색 프레임워크를 제안합니다. 특히 스케줄의 '형태(Shape)'와 '기본 학습률(Base Learning Rate)'을 분리하여 분석함으로써, 단순히 학습률의 크기가 아닌 순수한 형태적 효용성을 공정하게 비교할 수 있는 혁신적인 방법론을 구축했습니다.
연구진은 선형 보간(Linear Interpolation) 및 거듭제곱 법칙(Power-law) 기반의 유연한 함수 클래스를 활용하여, 선형 회귀부터 이미지 분류(CIFAR-10)와 언어 모델링(Wikitext-103)에 이르는 광범위한 워크로드에서 최적에 가까운 스케줄을 탐색했습니다. 실험 결과, 학습 초기 단계의 안정성을 높이는 웜업(Warmup)과 수렴을 유도하는 감쇠(Decay)가 최적 스케줄의 견고한 공통 특징임을 재확인하는 동시에, 기존의 코사인 감쇠(Cosine Decay) 등이 모든 상황에서 최선은 아니라는 점을 입증했습니다.
또한 가중치 감쇠(Weight Decay)와 같은 정규화 하이퍼파라미터가 스케줄의 최적 형태에 미치는 강력한 상관관계를 규명하여, 하이퍼파라미터 간의 복합적인 상호작용을 깊이 있게 분석했습니다. 가중치 감쇠가 강할수록 학습 후반부에도 높은 학습률을 유지하거나 감쇠 시점을 늦추는 것이 유리하다는 통찰은 최적화 경로의 동역학(Dynamics)을 이해하는 데 중요한 단서를 제공합니다. 아울러 학습 예산(Training Budget)의 변화에 따라 스케줄이 단순히 시간 축을 늘리는 것이 아니라 비선형적으로 조정되어야 한다는 발견은 대규모 모델 학습을 위한 스케줄 설계에 실질적인 가이드라인을 제시합니다. 이러한 포괄적인 연구 결과는 딥러닝 최적화 과정에서 경험적 관습에 의존하던 기존 방식을 과학적 근거 기반의 접근법으로 전환하는 데 기여하며, 향후 더욱 복잡한 최적화 알고리즘 연구의 중요한 토대가 될 것으로 기대됩니다.
논문 초록(Abstract)
신경망 학습(neural network training)에서 아직 해결되지 않은 기본적인 질문은 '주어진 워크로드(workload)에 가장 적합한 학습률 스케줄 형태(learning rate schedule shape)는 무엇인가?'입니다. 학습률 스케줄의 선택은 학습 과정의 성패를 결정짓는 핵심 요소이지만, 특정 방식의 웜업(warmup)과 감쇠(decay)를 포함해야 한다는 점 외에는 어떤 형태가 좋은 스케줄인지에 대한 합의가 이루어지지 않았습니다. 이 질문에 답하기 위해, 본 연구에서는 매개변수화된 스케줄 제품군(parameterized schedule family) 내에서 최적의 형태를 찾기 위한 탐색 절차를 설계했습니다. 저희의 접근 방식은 스케줄 형태를 기본 학습률(base learning rate)로부터 분리하는데, 그렇지 않을 경우 기본 학습률이 스케줄 간 비교를 지배하게 되기 때문입니다. 저희는 세 가지 워크로드, 즉 선형 회귀(linear regression), CIFAR-10 이미지 분류(image classification), 그리고 Wikitext103 기반의 소규모 언어 모델링(language modeling)에서 다양한 스케줄 제품군에 탐색 절차를 적용했습니다. 실험을 통해 저희의 탐색 절차가 실제로 일반적으로 최적에 가까운 스케줄을 찾아낸다는 것을 보여주었습니다. 또한 웜업과 감쇠가 좋은 스케줄의 강건한 특징임을 확인했으며, 흔히 사용되는 스케줄 제품군이 이러한 워크로드에서 최적이 아님을 발견했습니다. 마지막으로 형태 탐색의 결과가 다른 최적화 하이퍼파라미터(hyperparameter)에 어떻게 의존하는지 조사하였으며, 가중치 감쇠(weight decay)가 최적의 스케줄 형태에 강력한 영향을 미칠 수 있음을 확인했습니다. 저희가 아는 바로는, 본 연구 결과는 현재까지 심층 신경망 학습(deep neural network training)을 위한 최적에 가까운 스케줄 형태에 관한 가장 포괄적인 연구 결과를 나타냅니다.
A basic unanswered question in neural network training is: what is the best learning rate schedule shape for a given workload? The choice of learning rate schedule is a key factor in the success or failure of the training process, but beyond having some kind of warmup and decay, there is no consensus on what makes a good schedule shape. To answer this question, we designed a search procedure to find the best shapes within a parameterized schedule family. Our approach factors out the schedule shape from the base learning rate, which otherwise would dominate cross-schedule comparisons. We applied our search procedure to a variety of schedule families on three workloads: linear regression, image classification on CIFAR-10, and small-scale language modeling on Wikitext103. We showed that our search procedure indeed generally found near-optimal schedules. We found that warmup and decay are robust features of good schedules, and that commonly used schedule families are not optimal on these workloads. Finally, we explored how the outputs of our shape search depend on other optimization hyperparameters, and found that weight decay can have a strong effect on the optimal schedule shape. To the best of our knowledge, our results represent the most comprehensive results on near-optimal schedule shapes for deep neural network training, to date.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()