안녕하세요. pytorch로 딥러닝을 공부하고 있는 학생입니다. 최근에 어떤 논문을 보게되었는데, 신기하게도 Cifar-10, MNIST를 두 개의 카테고리로 분류했습니다. 예를 들면, 아래와 같은 구문으로 분류하더군요. 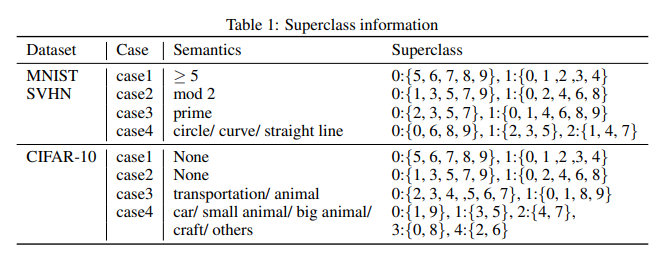
저도 저렇게 코드를 짜고 싶어서 여러모로 공부해봤는데도, 어느 부분에서 분류를 하는지 도저히 감이 잡히지가 않습니다. Cifar-100과 다르게 이미 분류된 클래스인 데이터 셋의 상위클래스를 만드려면 어느 부분에서 시작해야 하는지 여쭈어보고 싶습니다.
안녕하세요 @jjoon0928 님.
MNIST나 CIFAR-10 등과 같이 10개의 Class로 분류된 데이터셋을 2개(또는 5개)의 Class로 다시 분류하고 싶으신 것이 맞을까요?
그렇다면, Dataset class에서 label을 반환할 때 위 표의 Semantics와 같은 기준으로 다시 label을 변환하도록 하면 어떨까요?
예를들어, MNIST Dataset의 구현을 살펴보면, 대략
-
__init__()함수에서는 데이터를 가져온 뒤, -
_load_data()함수를 불러image와label을 반환하여 갖고 있다가 -
__get_item__()함수에서 각각 transform을 한 뒤 반환하고 있습니다.
이 과정에서 label을 처리하기 위한 target_transform() 함수를 사용하고 있으며, 이 함수는 MNIST Dataset을 선언할 때 지정하는 인자 중 하나이기도 합니다.
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], int(self.targets[index])
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.numpy(), mode="L")
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
아래 MNIST Dataset 문서에도 해당 인자에 대한 설명이 있습니다.
https://pytorch.org/vision/stable/generated/torchvision.datasets.MNIST.html#torchvision.datasets.MNIST
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
따라서, >=5, mod 2, prime 등의 Semantics에 따라 적절한 target_transform() 함수를 작성하여 Dataset 선언 시 제공하면 될 것 같습니다.
아래 Dataset 튜토리얼에도 해당 인자에 대한 설명이 있으니 참고하시면 좋을 것 같습니다.
https://tutorials.pytorch.kr/beginner/basics/data_tutorial.html
2개의 좋아요