안녕하세요. 지금까지 딥러닝을 가볍게 코드를 불러와서 사용하다가 이제 제가 직접 class를 선언하고 모델을 만들어 보려는 초심자입니다. 하나 여쭤볼게 있어서 커뮤니티에 글을 올리게 되었습니다.
pytorch를 이용해서 time series data에서 convolutional autoencoder를 사용하여 이상 탐지를 해보려고 합니다. 전체 모델 구성은 keras에 있는 tutorial code를 이용하여 pytorch로 변환하여 사용하려는데 아무래도 다른 package다 보니 변환이 쉽지 않아서 질문을 올리게 되었습니다.
timestamp,value
2014-04-01 00:00:00,18.3249185392
2014-04-01 00:05:00,21.970327182
2014-04-01 00:10:00,18.6248060317
2014-04-01 00:15:00,21.9536839759
2014-04-01 00:20:00,21.9091197303
2014-04-01 00:25:00,21.1752724156
2014-04-01 00:30:00,20.6376918483
2014-04-01 00:35:00,20.311228201
2014-04-01 00:40:00,21.4644061815
2014-04-01 00:45:00,19.1577580865
2014-04-01 00:50:00,19.8707248499
2014-04-01 00:55:00,20.4775598775
2014-04-01 01:00:00,19.6447619035
2014-04-01 01:05:00,19.7099458164
데이터는 다음과 같이 csv 파일로 구성이 되어있고 현재 저는 이 데이터를
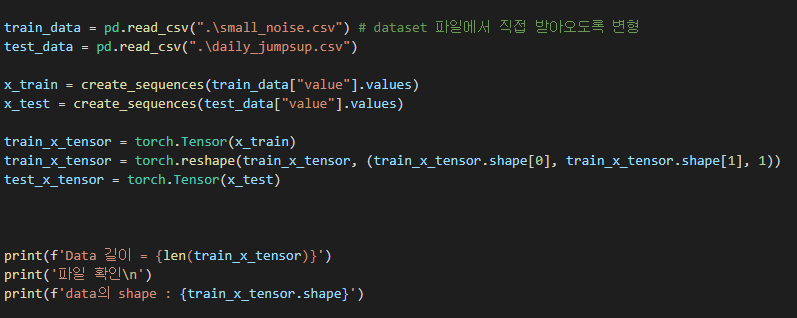
이와 같이 불러오려고 하고 있습니다.
그리고 모델 구성은 다음과 같이 코드를 짰습니다.
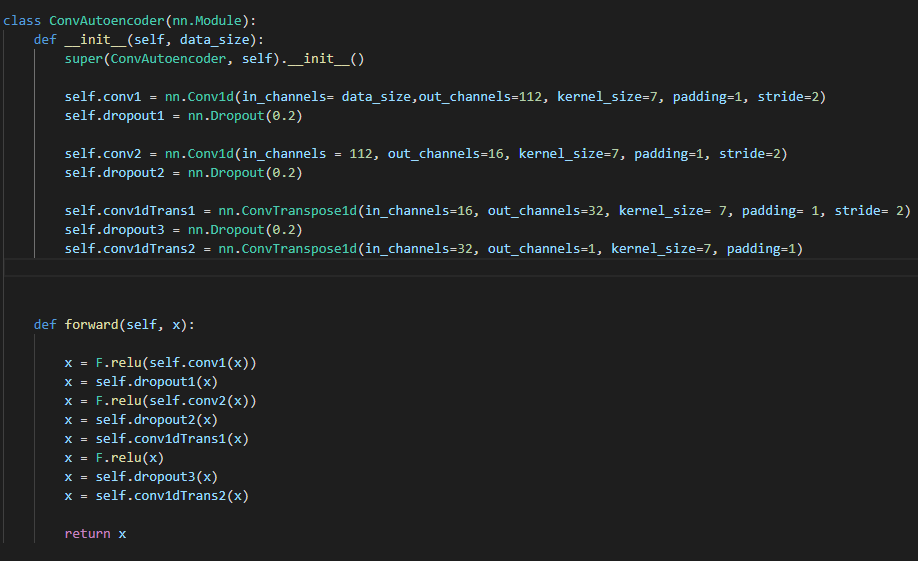
전체 데이터가 4032개인데 이것을 288개씩 하나의 묶음으로 모델에 input으로 넣으려고 합니다.
이 과정에서 제가 계속 막혀서 도움을 받고자 합니다.
질문
- 데이터를 불러올 때, 저렇게 csv 파일을 불러서 model에 input으로 넣으면 안되나요?
- model에서 in_channel, out_channel, stride, padding 과 같은 값은 어떻게 해야 하나요
- keras에서는 padding값을 "same"으로 넣었던데 pytorch에서는 어떤 값을 넣어야 "same"과 같은 역할을 하나요
keras의 코드는
에 있습니다.
pytorch를 이용하여 여러가지 만드려고 하는데 도움이 필요합니다. 이부분만 알게되면 좀더 많은 적용을 할 수 있을 것 같습니다.