loss 구한 다음
4, 5 loss.backward() → optimizer.step()
을 하게 되는데 이 때 4, 5번에서 loss.backward에서 모델의 Computational Graph와 Parameter 값을 어떻게 알고 backward를 진행할 수 있는것 인가요?
Parameter들 값은 optimizer 인스턴스를 생성할 때만 넣어주지 않나요?
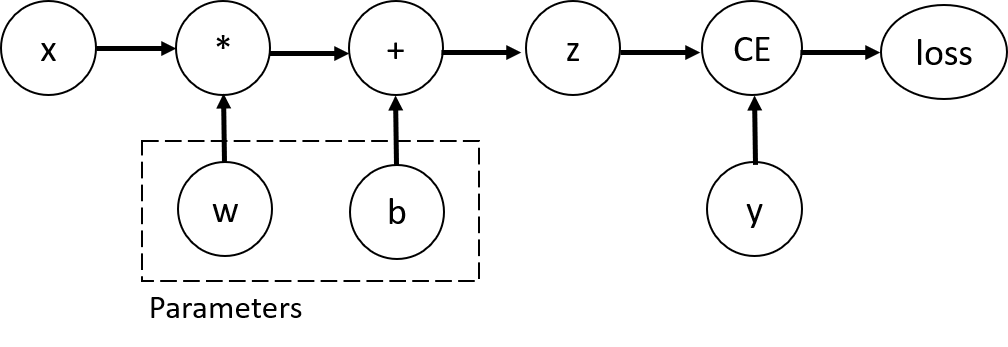
제가 이해하기로는, 모델에 어떤 값을 넣고 예측 값( \hat{y} )을 계산할 때, Tensor들 간의 연산을 하게 되고, 이 과정에서 동적으로 연산 그래프(Computational Graph)가 그려지는 것으로 알고 있습니다. 즉, 모델의 최종 연산 결과인 예측값을 기준으로, 연산 그래프를 따라올라가면 각각의 값들이 얼마만큼의 비중으로 기여(?)를 했는지 알 수 있습니다.
위 튜토리얼에 있는 예시를 보시면, \hat{y} = z = x * w + b 를 계산한 뒤에 정답 y 와 예측값 z 의 CrossEntropy로 loss를 구하게 되면, 이 때 아래와 같이 연산 그래프(Computational Graph)가 그려지게 됩니다.
이후, 말씀하셨던 4번째 단계의 loss.backward()가 호출될 때, 아래와 같은 과정들이 이뤄진다고 합니다. (아래 튜토리얼의 중간 부분에서 아래 내용을 확인하실 수 있습니다.)
순전파 단계에서, autograd는 다음 두 가지 작업을 동시에 수행합니다:
요청된 연산을 수행하여 결과 텐서를 계산하고,
DAG에 연산의 변화도 기능(gradient function) 를 유지(maintain)합니다.
역전파 단계는 DAG 뿌리(root)에서 .backward() 가 호출될 때 시작됩니다. autograd 는 이 때: