mlxcel 소개
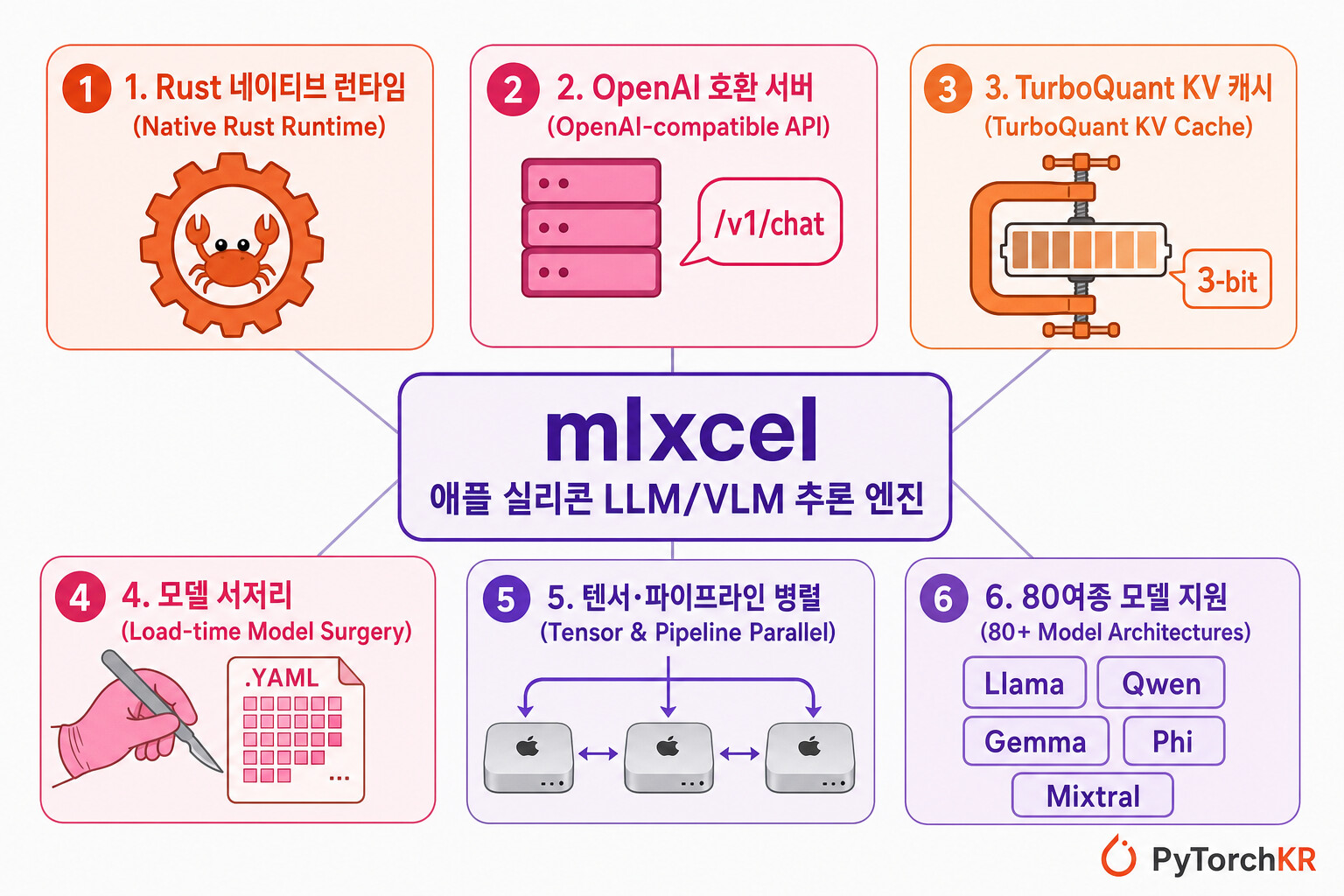
mlxcel은 애플 실리콘(Apple Silicon)에서 LLM과 VLM(시각-언어 모델)을 빠르게 실행하기 위해 래블업(lablup)이 공개한 추론 런타임 및 OpenAI 호환 서버입니다. CLI(mlxcel)와 서버(mlxcel-server) 모두 Rust로 구현되어 있고, 모델 실행은 애플의 머신러닝 프레임워크인 MLX의 C++ 바인딩을 직접 호출합니다. 그 결과 파이썬 런타임 없이 단일 네이티브 프로세스 안에서 모델 로딩, 스케줄링, 추론이 모두 완결됩니다. 리눅스/CUDA 환경도 보조 타깃으로 지원하지만, 일차적인 설계 대상은 맥북·맥 스튜디오로 대표되는 통합 메모리 기반의 애플 디바이스입니다.
mlxcel은 원래 구조적 모델 파인튜닝(fine-tuning) 작업에서 출발했지만, 지금은 로컬·소규모 클러스터 환경에서 LLM/VLM을 직접 서빙하는 범용 런타임으로 확장된 프로젝트입니다. 모델 커버리지는 파이썬 기반의 mlx-lm과 mlx-vlm을 추적하면서, 동일한 MLX 포맷 체크포인트를 그대로 사용할 수 있게 설계되어 있습니다. 2026년 5월 기준으로 80여종 이상의 텍스트 모델 아키텍처와 20여종 이상의 VLM을 지원하며, Llama, Qwen, Gemma, Phi, Mistral/Mixtral, DeepSeek, ExaOne, GLM, Mamba/RWKV/Jamba, Nemotron-H 등 트랜스포머·MoE·SSM·하이브리드 계열을 폭넓게 다룹니다.
mlxcel-server는 llama.cpp의 llama-server와 호환되는 다수의 플래그와 LLAMA_ARG_* 환경 변수를 받아들이도록 만들어져, 기존 llama.cpp 기반 스크립트를 큰 수정 없이 갈아끼울 수 있습니다. OpenAI 호환 HTTP API 서브셋(/v1/chat/completions, /v1/completions, /v1/responses)과 SSE 스트리밍을 지원하고, 연속 배치(continuous batching), 프롬프트 프리픽스 캐시(prompt-prefix caching), 자동 프리픽스 캐시, 투기적 디코딩(speculative decoding), KV 캐시 압축 등 실제 배포에서 필요한 서빙 기능을 단일 바이너리에 담아 제공합니다.
mlxcel의 주요 특징
mlxcel이 강조하는 차별점은 "파이썬 런타임을 떼어낸 단일 네이티브 서버 프로세스" 와 "MLX 백엔드 위에서의 서빙 기능 통합" 입니다. 단순한 추론 라이브러리가 아니라, 배포 산출물·OpenAI API 호환·런타임 제어를 한 묶음으로 본다는 점이 다른 MLX 기반 도구와 차이가 납니다. 공식 README의 Why mlxcel 섹션을 기준으로 정리하면 다음과 같습니다.
- 작은 런타임 표면: 모델 로딩·스케줄링·추론이 단일 네이티브 프로세스 안에서 끝납니다. 배포 시 파이썬 환경을 구성하거나 패키지 버전을 맞출 필요가 없고, 인터프리터 레이어를 거치지 않습니다.
- 단순한 배포 산출물:
mlxcel과mlxcel-server가 네이티브 실행 파일로 빌드되어 패키징·서비스 슈퍼바이저·업그레이드가 단순해집니다. 다만 플랫폼 런타임 라이브러리는 여전히 필요합니다 (애플 실리콘의 macOS 프레임워크, 리눅스의 CUDA/OpenBLAS/LAPACK 등). llama-server-스타일 운영:mlxcel-server는llama-server호환 플래그와LLAMA_ARG_*환경 변수를 받아들입니다. README는 이를 "호환 지향(compatibility-oriented)" 이라고 명시하며, 모든 llama.cpp 옵션이 동일하게 동작한다고는 보장하지 않습니다.- OpenAI 호환 HTTP API 서브셋:
/v1/chat/completions,/v1/completions,/v1/responses엔드포인트와 SSE 스트리밍을 제공합니다. - 실배포용 서빙 기능: 연속 배치, 프롬프트 프리픽스 캐시, 자동 프리픽스 캐시, 투기적 디코딩, KV 캐시 압축을 지원 모델/런타임 조합에서 사용할 수 있습니다.
- 차별화된 런타임 컨트롤: 기본 빌드에서 YAML 기반의 로드 타임 모델 서저리(load-time model surgery) 를 1급으로 노출합니다.
--surgery플래그 또는MLXCEL_SURGERY환경 변수로scale,add,prune,replace,interpolate등의 연산을 적용해, 재학습이나 변환된 체크포인트를 새로 쓰지 않고도 가중치 공간 변경을 재현 가능하게 수행할 수 있습니다. - 멀티 디바이스 및 분산 모드: 일부 모델 계열에 대해 텐서 병렬(Tensor Parallelism)과 파이프라인 병렬(Pipeline Parallelism)을 구현했고, 정적 설정 또는 mDNS 기반 발견(discovery)을 통해 거의 무설정에 가까운 파이프라인 시작을 지원합니다.
- 넓은 모델 패밀리 커버리지: Llama, Qwen, Gemma, Phi, Mistral/Mixtral, DeepSeek, Cohere, InternLM, GLM, ExaOne, OLMo, ERNIE, Hunyuan, Mamba/RWKV/Jamba, Nemotron, MiniMax, Step, Kimi 등과 다수의 VLM 패밀리를 위한 로더를 포함합니다.
mlxcel의 메모리 프리플라이트와 모델 서저리
로컬 환경에서 LLM을 돌릴 때 가장 자주 마주치는 사고는 "모델 + KV 캐시가 통합 메모리에 다 들어가지 않아서 OOM으로 죽는" 상황입니다. mlxcel은 이를 줄이기 위해 가중치·KV 캐시·런타임 헤드룸을 바이트 단위로 분해해 보여주는 mlxcel inspect 명령과, 같은 추정기를 사전 점검(preflight) 으로 실행하는 --estimate-memory 플래그를 제공합니다. 후자는 모델이 들어가지 않을 것으로 판단되면 실행을 중단하며, --force(별칭 --no-memory-check)로 강제 진행할 수 있습니다.
추가로 MLXCEL_MEMORY_LIMIT=NGB 환경 변수로 "가용 메모리" 의 상한을 인위적으로 낮춰, 메모리가 넉넉한 호스트에서도 프리플라이트가 의미 있게 동작하도록 만들 수 있습니다. 런타임 헤드룸 계수는 기본 1.20배 이며, MLXCEL_HEADROOM_FACTOR=<f> 로 조정할 수 있습니다. README는 src/execution/memory_estimate.rs 안에 보정용 레시피가 함께 들어 있다고 안내합니다.
로드 타임 모델 서저리는 mlxcel만의 색깔이 분명한 기능입니다. 변환된 새 체크포인트를 디스크에 쓰지 않고도 가중치를 수정한 상태로 로드 하기 때문에, 가중치 보간(interpolate)이나 일부 채널의 스케일링(scale), 모듈 교체(replace), 가지치기(prune) 같은 가중치 공간 실험을 빠르게 반복할 수 있습니다. 모든 명령은 YAML 파일로 기술해 --surgery에 넘기는 구조라, 같은 입력으로 항상 같은 출력을 얻는 재현 가능한 변형(reproducible weight-space change)이 보장됩니다.
mlxcel의 벤치마크 결과
mlxcel 0.0.28의 M5 Max 128GB 벤치마크 셋이 README에 정리되어 있습니다. 결과는 크게 짧은 프롬프트의 텍스트 프리필 가속 과 디코딩 단계의 동급 수준 처리량 두 갈래입니다. README는 절대치보다 비교 가능성을 강조하며, "모델 패밀리·양자화·프롬프트 모양·디코드 길이·하드웨어에 따라 결과가 달라지므로 자신의 하드웨어에서 다시 측정한 뒤 용량 계획에 사용하라" 고 명시합니다.
프리필 (Prefill, 첫 토큰 생성 직전까지의 프롬프트 처리)
짧은 프롬프트 프리필에서 mlxcel은 M5 Max 기준 mlx-lm 중앙값 대비 2.70x, M1 Ultra 기준 1.76x 로 측정되었습니다. VLM 프리필은 이미지 전처리·비전 인코더·프로젝터 작업이 포함될 수 있어 별도로 리포트됩니다.
| Mode | Baseline | M5 Max pairs | M5 Max median vs baseline | M1 Ultra pairs | M1 Ultra median vs baseline |
|---|---|---|---|---|---|
| Text | mlx-lm |
66 | 2.70x | 73 | 1.76x |
| VLM | mlx-vlm |
20 | 0.94x | 17 | 1.33x |
디코딩 (Decode, 정상 상태 토큰 생성)
디코딩은 동일 호스트의 mlx-lm / mlx-vlm 대비 거의 동급 수준을 유지합니다. M5 Max에서 텍스트 디코딩은 mlx-lm 대비 평균 98%, 중앙값 99%이며, VLM 디코딩은 평균 101%, 중앙값 100%입니다.
| Mode | Baseline | Pairs | Avg vs baseline | Median vs baseline | >=90% parity | >= baseline | Range |
|---|---|---|---|---|---|---|---|
| Text | mlx-lm |
66 | 98% | 99% | 62 / 66 (94%) | 27 / 66 (41%) | 72%-127% |
| VLM | mlx-vlm |
20 | 101% | 100% | 17 / 20 (85%) | 10 / 20 (50%) | 74%-123% |
대표 모델의 디코딩 처리량은 다음과 같습니다 (단위: tokens per second).
| Text model | M1 Ultra mlxcel | M5 Max mlxcel | M5 Max mlx-lm | mlxcel / mlx-lm |
|---|---|---|---|---|
| SmolLM-135M 4bit | 407 | 905 | 712 | 127% |
| Llama 3.1 8B 4bit | 107 | 117 | 117 | 99% |
| Qwen2.5 7B 4bit | 110 | 126 | 124 | 102% |
| Gemma 3 4B 4bit | 114 | 182 | 182 | 100% |
| Qwen3 MoE 30B 4bit | 71 | 156 | 147 | 106% |
| Mixtral 8x7B 4bit | 54 | 65 | 66 | 99% |
| GPT-OSS 120B 4bit | 59 | 114 | 110 | 103% |
| Solar Open 100B 4bit | 36 | 65 | 66 | 99% |
| VLM model | M1 Ultra mlxcel | M5 Max mlxcel | M5 Max mlx-vlm | mlxcel / mlx-vlm |
|---|---|---|---|---|
| LLaVA Interleave Qwen 0.5B bf16 | 270 | 344 | 345 | 100% |
| Qwen3.5 0.8B 4bit | 202 | 506 | 411 | 123% |
| Qwen3.5 35B-A3B 4bit | 71 | 151 | 129 | 117% |
| Gemma 4 E2B 4bit | 107 | 217 | 202 | 108% |
| Gemma 3n E2B 4bit | 72 | 151 | 125 | 121% |
전체 표는 docs/benchmark_results/benchmark-report.md 와 docs/benchmarks.md 에 방법론·예외 케이스와 함께 정리되어 있습니다. VLM 행은 비전 전처리·프로세서 구성·프롬프트 구성 방식이 모델 패밀리마다 달라서 텍스트와 분리해서 읽는 편이 좋습니다.
mlxcel 빠르게 시작하기
macOS(애플 실리콘) 환경에서는 Homebrew tap 하나로 CLI와 서버를 모두 설치할 수 있습니다. 설치 후 곧바로 MLX 포맷 체크포인트를 받아 생성·서빙까지 진행할 수 있습니다.
brew tap lablup/tap
brew install mlxcel
기본적인 동작 흐름은 다음과 같습니다. mlxcel inspect는 텐서를 로드하지 않고도 가중치/KV 캐시/런타임 헤드룸의 바이트 단위 내역을 출력해, 모델이 통합 메모리에 들어맞을지 미리 가늠할 수 있게 해 줍니다.
# MLX 포맷 체크포인트 다운로드
mlxcel download mlx-community/Qwen3.5-0.8B-4bit
# 메모리 사전 점검 (가중치 + 32K KV 캐시 기준)
mlxcel inspect -m models/Qwen3.5-0.8B-4bit --max-tokens 32768
# 1회성 생성
mlxcel generate \
-m models/Qwen3.5-0.8B-4bit \
-p "Hello, world!" -n 100
# 모델 + 32K KV 캐시가 들어가지 않으면 시작 자체를 거부
mlxcel generate \
-m models/Qwen3.5-0.8B-4bit \
-p "Hello, world!" -n 32768 \
--estimate-memory
# OpenAI 호환 서버 기동
mlxcel-server \
-m models/Qwen3.5-0.8B-4bit \
--port 8080
소스 빌드로 직접 만들고자 한다면, Rust 툴체인과 Xcode Command Line Tools, CMake 빌드 환경, Apple Metal 툴체인 컴포넌트가 사전에 필요합니다. 빌드 결과는 ./target/release/mlxcel 과 ./target/release/mlxcel-server 입니다.
xcodebuild -downloadComponent MetalToolchain # 처음 한 번만
git clone https://github.com/lablup/mlxcel.git
cd mlxcel
cargo build --release --features metal,accelerate
리눅스/CUDA 빌드는 cuda 피처를 켜고, CUDA 툴킷과 MLX가 사용하는 시스템 라이브러리를 함께 갖춰야 합니다. 상세 매트릭스는 docs/installation.md 의 사전 요구사항 표에서 확인할 수 있습니다.
GUI 환경을 선호한다면, 같은 조직(래블업)이 공개한 데스크톱 AI 플랫폼 AI:GO(Backend.AI Go) 를 채팅·모델 관리·멀티 모델 라우팅용 동반 UI로 연결해 사용할 수 있습니다. README는 이를 "Optional GUI" 로 명시하고 있어, mlxcel 자체는 HTTP 클라이언트로 곧장 사용해도 무방합니다.
라이선스
mlxcel은 Apache License 2.0으로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용·수정·배포할 수 있습니다. 단, 다른 프로젝트에 통합 또는 재배포 시에는 LICENSE 파일과 의존성 트리를 함께 확인하는 편이 안전합니다.
 mlxcel 공식 홈페이지 (Backend.AI 블로그)
mlxcel 공식 홈페이지 (Backend.AI 블로그)
 mlxcel 관련 문서 모음
mlxcel 관련 문서 모음
 mlxcel 프로젝트 GitHub 저장소
mlxcel 프로젝트 GitHub 저장소
 mlxcel과 함께 쓸 MLX 모델 모음
mlxcel과 함께 쓸 MLX 모델 모음
더 읽어보기
-
cider: Apple Silicon M5의 INT8 TensorOps로 LLM prefill 속도를 끌어올리는 MLX W8A8 추론 SDK
-
mlx-vlm: M5와 같은 Apple Silicon에 최적화된 MLX 기반 시각-언어 모델(VLM) 추론 및 파인튜닝 도구
-
turboquant-pytorch: Google의 TurboQuant를 PyTorch로 처음부터 직접 구현한 LLM KV 캐시 양자화 라이브러리
-
flash-moe: 순수 C와 Metal로 구현한, M3 Max 맥북 프로에서 397B 파라미터 MoE 모델을 실행하는 고성능 추론 엔진
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()