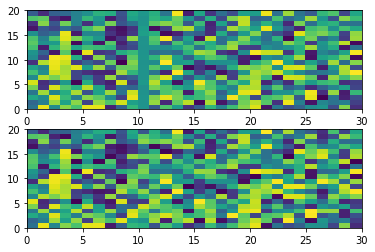
random으로 일단 해보는데 matplot으로 그래프를 보니 이상하게 나오더군요. tgt에 맞추어 나오려면 어떻게 해야 하는 걸까요? 아님 제가 잘못 이해하는 건지…
positional_encoding이나 tgt_mask등은 뺏습니다. 딱히 필요할 것 같지가 않아서요.
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(20, 30)
self.transformer = nn.Transformer(30, 5,dropout = 0)
def forward(self, src, tgt):
tgt_mask=self.transformer.generate_square_subsequent_mask(tgt.shape[1])
src = self.embedding(src)
src=src.permute(1,0,2)
tgt = tgt.permute(1,0,2)
out = self.transformer(src, tgt, tgt_mask=tgt_mask)
out = out.permute(1,0, 2)
return out
class Net(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(20, 30)
self.transformer = nn.Transformer(30, 5,dropout = 0)
def forward(self, src, tgt):
tgt_mask=self.transformer.generate_square_subsequent_mask(tgt.shape[1])
src = self.embedding(src)
src=src.permute(1,0,2)
tgt = tgt.permute(1,0,2)
out = self.transformer(src, tgt, tgt_mask=tgt_mask)
out = out.permute(1,0, 2)
return out
critic = nn.L1Loss()
model = Net()
optim = torch.optim.Adam(model.parameters())
src = torch.randint(1, 20, (10, 30))
tgt = torch.rand((10, 20, 30))
tgt_input = torch.cat((torch.zeros((10, 1, 30)), tgt[:, :-1, :]), 1)
model.train()
for _ in range(1500):
optim.zero_grad()
out=model(src, tgt_input)
loss=critic(out, tgt)
loss.backward()
optim.step()
fig, (ax0, ax1)=plt.subplots(2, 1)
ax0.pcolor(out[0].detach().numpy())
ax1.pcolor(tgt[0].detach().numpy())
plt.show()
설명해주실때… 코딩으로 보여주셨으면 합니다. ㅜㅜ. 제가 그냥 취미로 배우는거라… 전문가가 아니예요.
아 그리고 그래프는 이렇게 나옵니다.
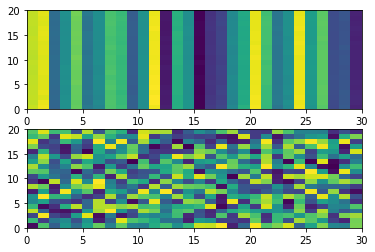
결과값이 선처럼 나오더라고요.