안녕하세요. “기초부터 시작하는 NLP: Sequence to Sequence 네트워크와 Attention을 이용한 번역” 튜토리얼을 공부하고 있습니다.
제가 이해되지 않는 부분이 있어서 글을 남깁니다 ㅠ
아래 Attention 디코더 구조에서 prev_hidden이 디코더 은닉 상태를 가리키고 input이 디코더 입력을 가리키는데, 어떻게 이 둘을 가지고 FC 레이어를 거쳐 attention weight를 구할 수 있는건지 모르겠습니다…
본래 Attention 구조는 디코더 은닉 상태와 인코더의 모든 은닉 상태와 결합하여 attention weight을 구하는 것 아닌가요?
여러 소중한 의견 주시면 감사하겠습니다!!
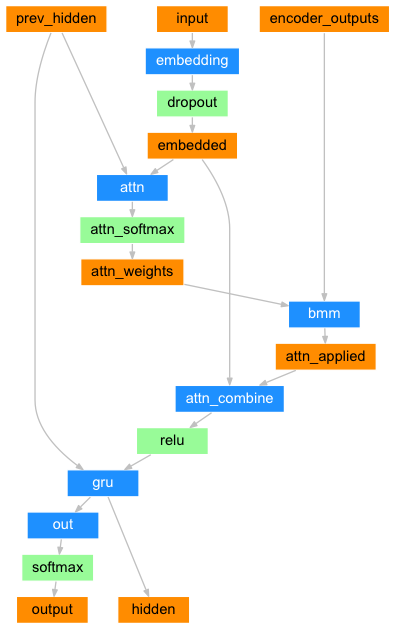
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)