소개
- MIT Han Lab에서 개발한 Streaming-LLM은 스트리밍 애플리케이션에서 대형 언어 모델(Large Language Models, LLM)을 효과적으로 배포하는 필요성에 대해 다룹니다.
- 특히, 여러번 주고 받는 대화 같은 긴 상호 작용이 예상되는 경우, 이러한 모델의 배포는 중요하지만, 메모리 소모와 효율성에서 문제가 야기될 수 있습니다.
- 이 논문에서 제안한 방법을 활용하여 효율성과 성능 중 어느 것도 희생하지 않으면서, 무한히 긴 길이의 입력에 대해서도 처리할 수 있는 LLM을 배포할 수 있습니다.
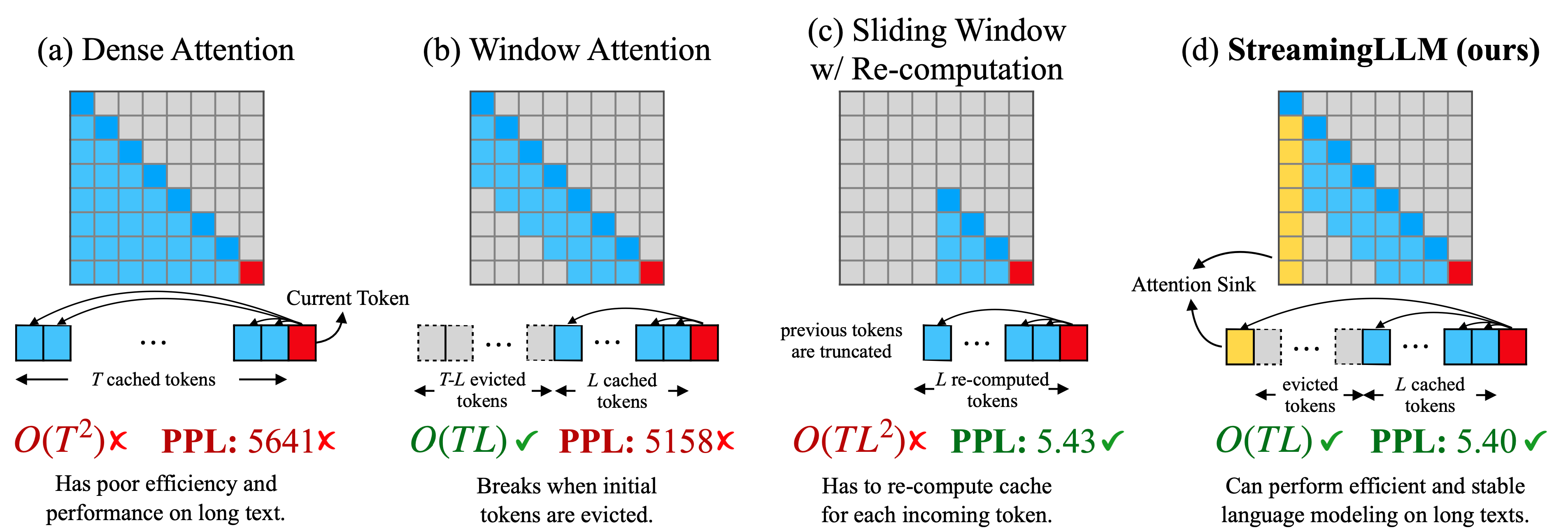
주요 내용
데모 영상
특징
- Streaming-LLM은 연속적인 스트리밍 데이터에 대한 효율적인 학습 및 추론을 위한 트랜스포머 기반의 언어 모델입니다.
- 이 모델은 기존의 트랜스포머 모델과 비교하여 메모리 사용량을 크게 줄이면서도 높은 성능을 유지합니다.
- Streaming-LLM은 다양한 NLP 작업에 적용될 수 있으며, 실시간 스트리밍 데이터 처리에 특히 유용합니다.
- Llama-2, MPT, Falcon, Pythia와 같은 모델에서 최대 4백만 토큰 이상의 입력을 안정적이고 효율적으로 처리할 수 있게 합니다. (최대 22.2배 속도 개선)
FAQ
-
Q. LLM의 "무한 길이 입력 작업(working on infinite-length inputs)"은 무슨 뜻인가요?
- LLM에서 무한히 긴 길이의 텍스트를 처리하는 것은 도전적입니다. 하지만, StreamingLLM은 최근의 토큰과 어텐션 싱크로 캐시 리셋 없이 이 문제를 해결합니다.
-
LLM의 컨텍스트 윈도우(context window) 길이가 확장되는 것인건가요?
- 아니요, 컨텍스트 윈도우는 변경되지 않습니다. 모델은 최신 토큰만 처리할 수 있습니다.
-
StreamingLLM에 긴 텍스트를 입력할 수 있나요?
- 긴 텍스트를 입력할 수 있지만, 모델은 최신 토큰만 인식합니다.
-
StreamingLLM의 이상적인 사용 사례는 무엇인가요?
- StreamingLLM은 스트리밍 애플리케이션에 최적화되어 있습니다.
-
StreamingLLM은 최근의 컨텍스트 확장 작업과 어떻게 관련되어 있나요?
- StreamingLLM은 최근의 컨텍스트 확장 방법과 직교하며 통합될 수 있습니다.