현재 Facebook의 SlowFast를 이용하고 있습니다.
4060ti(16GB) 2개를 이용해서 학습을 하고있는데, Ubuntu에서 NCCL을 통해서 병렬 계산은 성공 했습니다.
하지만 한쪽의 GPU(16GB) 이상의 용량이 넘어갈 시에 학습이 되질 않습니다.
즉 16+16 = 32GB가 아니라, 16GB이내에서 병렬 계산만 되고 있는것 같습니다.
어떻게 해야지 16+16=32GB를 쓸 수있나요?
찾아보니까 Distribute , DDP 등등이 있다고 들었습니다.
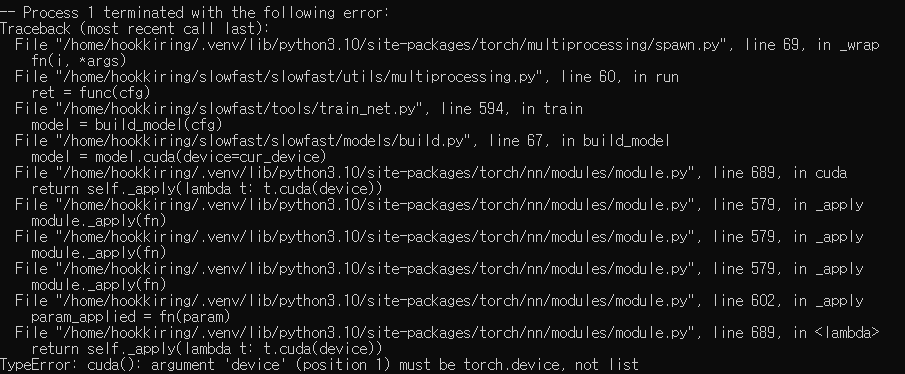
SlowFast 모델에도 gpu_id = None 이 되어있는 곳을 설정하면 바꿀 수 있는 것 같지만, gpu_id=[0,1]로 할경우 실행이 안되고 오류가 뜹니다.
(원래 코드) gpu_id=None
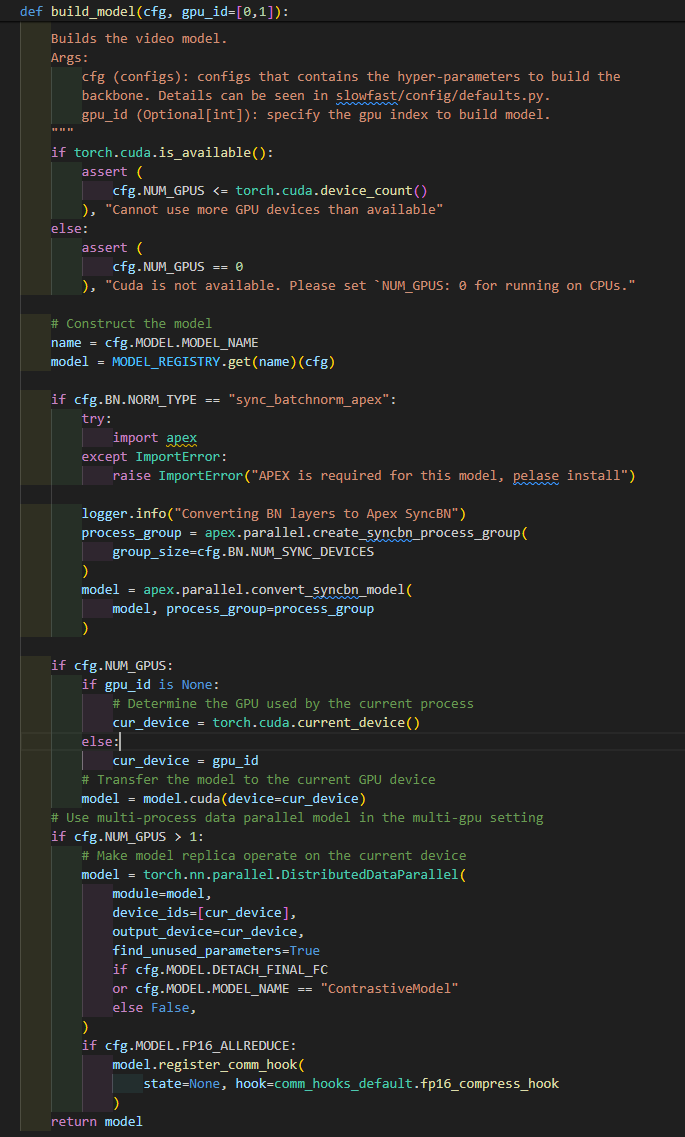
if cfg.NUM_GPUS:
if gpu_id is None:
# Determine the GPU used by the current process
cur_device = torch.cuda.current_device()
else:
cur_device = gpu_id
# Transfer the model to the current GPU device
model = model.cuda(device=cur_device)
# Use multi-process data parallel model in the multi-gpu setting
if cfg.NUM_GPUS > 1:
# Make model replica operate on the current device
model = torch.nn.parallel.DistributedDataParallel(
module=model,
device_ids=[cur_device],
output_device=cur_device,
find_unused_parameters=True
if cfg.MODEL.DETACH_FINAL_FC
or cfg.MODEL.MODEL_NAME == "ContrastiveModel"
else False,
)
if cfg.MODEL.FP16_ALLREDUCE:
model.register_comm_hook(
state=None, hook=comm_hooks_default.fp16_compress_hook
)
return model
이 코드를 봤을때 gpu_id 를 0,1 로 설정만 된다면, 16+16=32GB를 쓸 수 있을 것 같습니다만, 어떻게 해야하는지 잘 모르겠습니다. 도와주세요