- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

소개
이번 주 제공된 논문을 살펴보면, 트랜스포머(Transformer)와 강화학습(Reinforcement Learning)을 중심으로 한 인공지능 기술에 대한 논문들이 많이 보입니다. 또한, 다양한 분야의 문제를 해결하는 인공지능의 적용에 대한 논문들도 주목할 만 합니다.
'Transformers as SVMs', 'LLMs as Optimizers', 'Q-Transformer'와 같은 논문들은 트랜스포머를 중심으로 한 기술 트렌드를 보여줍니다. 이는 트랜스포머가 최근 딥러닝 분야에서 다양한 문제에 활용되면서 이에 대한 연구가 활발히 진행되고 있음을 반영하는 것으로 보입니다. 특히, 트랜스포머를 사용한 모델이 우수한 성능을 보여주고 있어, 이에 대한 이론적인 기초를 탄탄히 다지기 위한 연구들이 이어지고 있습니다.
또한, ‘Scaling RLHF with AI Feedback’, ‘GPT Solves Math Problems Without a Calculator’, ‘Multi-modality Instruction Tuning’ 등의 논문은 인공지능의 적용 분야를 확장시키는 방향으로 연구되고 있음을 보여줍니다. 강화학습, GPT의 수학문제 해결, 다양한 모달을 활용한 인공지능의 튜닝 방법 등 다양한 아이디어가 제시되고 있으며, 이는 인공지능 기술이 복잡한 문제를 해결하는 도구로서 점차 중요성이 강조되고 있음을 보여줍니다.
따라서 이 주의 논문 트렌드를 요약하자면, 트랜스포머와 강화학습을 중심으로 한 분야에서의 연구 활성화와, 인공지능의 적용 분야 확장에 초점이 맞춰져 있는 것으로 보입니다.
서포트 벡터 머신으로서의 트랜스포머 / Transformers as Support Vector Machines
논문 소개
- 트랜스포머에서 자기 주의의 최적화 기하학이 하드 마진 SVM 문제와 연관성이 있음을 발견하고, 조기 정지 없이 적용된 경사 하강이 자기 주의의 암묵적 규칙화와 수렴으로 이어짐을 발견하며, 이 연구는 언어 모델에 대한 이해를 심화시킬 수 있는 잠재력을 가지고 있습니다.
Finds that the optimization geometry of self-attention in transformers exhibits a connection to hard-margin svm problems; also finds that gradient descent applied without early-stopping leads to implicit regularization and convergence of self-attention; this work has the potential to deepen the understanding of language models.
논문 초록
- "Attention Is All You Need"에서 시작된 이래, 트랜스포머 아키텍처는 NLP의 혁신적인 발전을 이끌어 왔습니다. 트랜스포머 내의 주의 계층은 일련의 입력 토큰 X 를 허용하고, (K,Q) 가 학습 가능한 키-쿼리 매개변수인 소프트맥스 (XQK^\top X^\top) 로 계산된 쌍별 유사성을 통해 상호 작용하도록 합니다. 이 연구에서는 자기 주의의 최적화 기하학과 토큰 쌍의 외부 곱에 대한 선형 제약 조건을 사용하여 최적의 입력 토큰과 비최적 토큰을 분리하는 하드 마진 SVM 문제 사이의 형식적 동등성을 확립합니다. 이 형식주의를 사용하면 경사 하강으로 최적화된 1계층 트랜스포머의 암시적 편향을 특성화할 수 있습니다. (1) (K,Q) 로 매개변수화된 소실 정규화로 주의 계층을 최적화하면 결합된 매개변수 W=KQ^\ top 의 핵 표준을 최소화하는 SVM 솔루션으로 수렴하는 방향으로 귀결됩니다. 대신 W 로 직접 매개변수화하면 프로베니우스 노름 목표를 최소화할 수 있습니다. 우리는 이러한 수렴을 특성화하여 전역적 방향이 아닌 국지적으로 최적의 방향으로 발생할 수 있음을 강조합니다. (2) 이를 보완하여 적절한 기하학적 조건 하에서 경사 하강의 국부적/전체적 방향 수렴을 증명합니다. 중요한 것은 과도한 매개변수화가 SVM 문제의 실행 가능성을 보장하고 고정점이 없는 양성 최적화 환경을 보장함으로써 전역 수렴을 촉진한다는 것을 보여줍니다. (3) 우리의 이론은 주로 선형 예측 헤드에 적용되지만, 비선형 헤드를 사용하여 암시적 편향을 예측하는 보다 일반적인 SVM 동등성을 제안합니다. 우리의 연구 결과는 임의의 데이터셋에 적용 가능하며 실험을 통해 그 유효성을 검증합니다. 또한 몇 가지 미해결 문제와 연구 방향을 소개합니다. 이러한 연구 결과는 트랜스포머를 최적의 토큰을 분리하고 선택하는 SVM의 계층 구조로 해석하는 데 영감을 주었다고 생각합니다.
Since its inception in "Attention Is All You Need", transformer architecture has led to revolutionary advancements in NLP. The attention layer within the transformer admits a sequence of input tokens X and makes them interact through pairwise similarities computed as softmax (XQK^\top X^\top) , where (K,Q) are the trainable key-query parameters. In this work, we establish a formal equivalence between the optimization geometry of self-attention and a hard-margin SVM problem that separates optimal input tokens from non-optimal tokens using linear constraints on the outer-products of token pairs. This formalism allows us to characterize the implicit bias of 1-layer transformers optimized with gradient descent: (1) Optimizing the attention layer with vanishing regularization, parameterized by (K,Q), converges in direction to an SVM solution minimizing the nuclear norm of the combined parameter W=KQ^\top. Instead, directly parameterizing by W minimizes a Frobenius norm objective. We characterize this convergence, highlighting that it can occur toward locally-optimal directions rather than global ones. (2) Complementing this, we prove the local/global directional convergence of gradient descent under suitable geometric conditions. Importantly, we show that over-parameterization catalyzes global convergence by ensuring the feasibility of the SVM problem and by guaranteeing a benign optimization landscape devoid of stationary points. (3) While our theory applies primarily to linear prediction heads, we propose a more general SVM equivalence that predicts the implicit bias with nonlinear heads. Our findings are applicable to arbitrary datasets and their validity is verified via experiments. We also introduce several open problems and research directions. We believe these findings inspire the interpretation of transformers as a hierarchy of SVMs that separates and selects optimal tokens.
논문 링크
RLAIF: 인간 피드백을 통한 강화 학습을 AI 피드백으로 확장하기 / RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
논문 소개
- 인간과 AI 피드백의 효율성을 비교하여 RLAIF가 RLHF의 적합한 대안인지 테스트하고, 다양한 기술을 사용하여 AI 라벨을 생성하고 확장 연구를 수행하여 정렬된 선호도 생성을 위한 최적의 설정을 보고합니다. 주요 결과는 요약 작업에서 인간 평가자가 약 70%의 경우에서 기준선 SFT 모델보다 RLAIF와 RLHF 모두의 생성을 선호한다는 점입니다. rlhf
Tests whether rlaif is a suitable alternative to rlhf by comparing the efficacy of human vs. ai feedback; uses different techniques to generate ai labels and conduct scaling studies to report optimal settings for generating aligned preferences; the main finding is that on the task of summarization, human evaluators prefer generations from both rlaif and rlhf over a baseline sft model in ∼70% of cases.
논문 초록
- 인간 피드백으로부터의 강화 학습(RLHF)은 대규모 언어 모델(LLM)을 인간의 선호도에 맞추는 데 효과적이지만, 고품질의 인간 선호도 레이블을 수집하는 것이 주요 병목 현상입니다. 인간 대신 기성 LLM에 선호도 라벨을 붙이는 기술인 RLHF와 RLAIF(RL from AI Feedback)를 직접 비교한 결과, 두 기술이 비슷한 개선 효과를 가져온다는 것을 확인했습니다. 요약 작업에서 인간 평가자들은 약 70%의 사례에서 기본 감독 미세 조정 모델보다 RLAIF와 RLHF의 세대를 선호했습니다. 또한 RLAIF와 RLHF 요약에 대한 평가를 요청했을 때, 사람들은 두 가지를 동일한 비율로 선호했습니다. 이러한 결과는 RLAIF가 인간 수준의 성능을 낼 수 있으며, RLHF의 확장성 한계에 대한 잠재적인 해결책을 제공할 수 있음을 시사합니다.
Reinforcement learning from human feedback (RLHF) is effective at aligning large language models (LLMs) to human preferences, but gathering high quality human preference labels is a key bottleneck. We conduct a head-to-head comparison of RLHF vs. RL from AI Feedback (RLAIF) - a technique where preferences are labeled by an off-the-shelf LLM in lieu of humans, and we find that they result in similar improvements. On the task of summarization, human evaluators prefer generations from both RLAIF and RLHF over a baseline supervised fine-tuned model in ~70% of cases. Furthermore, when asked to rate RLAIF vs. RLHF summaries, humans prefer both at equal rates. These results suggest that RLAIF can yield human-level performance, offering a potential solution to the scalability limitations of RLHF.
논문 링크
더 읽어보기
https://twitter.com/omarsar0/status/1699102486928265530
계산기 없이도 수학 문제를 풀 수 있는 GPT / GPT Can Solve Mathematical Problems Without a Calculator
논문 소개
- 충분한 학습 데이터만 있으면 2b 언어 모델이 데이터 유출 없이 100% 정확도로 다단계 산술 연산을 수행할 수 있으며, 추가적인 다단계 산술 연산과 상세한 수학 문제가 포함된 데이터셋에서 GLM-10b로 미세 조정할 경우 5천 샘플 중국어 수학 문제 테스트 세트의 GPT-4와도 경쟁할 수 있음을 보여 줍니다. mathematical-reasoning wizardmath
Shows that with sufficient training data, a 2b language model can perform multi-digit arithmetic operations with 100% accuracy and without data leakage; it’s also competitive with gpt-4 on 5k samples chinese math problem test set when fine-tuned from glm-10b on a dataset containing additional multi-step arithmetic operations and detailed math problems.
논문 초록
- 이전 연구에서는 일반적으로 대규모 언어 모델은 계산기 도구를 사용하지 않고는 산술 연산, 특히 8자리 이상의 곱셈과 소수점 및 분수를 포함하는 연산을 정확하게 수행할 수 없다고 가정했습니다. 이 논문은 이러한 오해에 도전하는 것을 목표로 합니다. 충분한 학습 데이터만 있으면 20억 개의 파라미터로 구성된 언어 모델이 데이터 유출 없이 거의 100%의 정확도로 여러 자리 수 연산 작업을 정확하게 수행할 수 있으며, 이는 여러 자리 수 곱셈 정확도가 4.3%에 불과한 GPT-4를 훨씬 능가하는 수준입니다. 또한 다단계 산술 연산과 텍스트에 설명된 수학 문제가 추가된 데이터셋에서 GLM-10B를 미세 조정한 MathGLM이 5,000개 샘플의 중국어 수학 문제 테스트 세트에서 GPT-4와 유사한 성능을 달성했음을 입증합니다.
Previous studies have typically assumed that large language models are unable to accurately perform arithmetic operations, particularly multiplication of >8 digits, and operations involving decimals and fractions, without the use of calculator tools. This paper aims to challenge this misconception. With sufficient training data, a 2 billion-parameter language model can accurately perform multi-digit arithmetic operations with almost 100% accuracy without data leakage, significantly surpassing GPT-4 (whose multi-digit multiplication accuracy is only 4.3%). We also demonstrate that our MathGLM, fine-tuned from GLM-10B on a dataset with additional multi-step arithmetic operations and math problems described in text, achieves similar performance to GPT-4 on a 5,000-samples Chinese math problem test set.
논문 링크
더 읽어보기
https://twitter.com/_akhaliq/status/1699951105927512399
옵티마이저로서의 대규모 언어 모델 / Large Language Models as Optimizers
논문 소개
- 최적화 문제를 자연어로 기술하고, 정의된 문제와 이전에 찾은 솔루션을 기반으로 새로운 솔루션을 반복적으로 생성하도록 LLM에 지시하고, 각 최적화 단계에서 이전에 생성된 프롬프트의 궤적을 기반으로 테스트 정확도를 높이는 새로운 프롬프트를 생성하고, 최적화된 프롬프트는 GSM8K 및 빅벤치 하드에서 사람이 설계한 프롬프트보다 때로는 50% 이상 성능이 뛰어난 접근 방식입니다 optimizing
An approach where the optimization problem is described in natural language; an llm is then instructed to iteratively generate new solutions based on the defined problem and previously found solutions; at each optimization step, the goal is to generate new prompts that increase test accuracy based on the trajectory of previously generated prompts; the optimized prompts outperform human-designed prompts on gsm8k and big-bench hard, sometimes by over 50%
논문 초록
- 최적화는 어디에나 존재합니다. 미분 기반 알고리즘은 다양한 문제에 강력한 도구로 사용되어 왔지만, 그라데이션이 없기 때문에 많은 실제 애플리케이션에서 어려움을 겪고 있습니다. 이 연구에서는 최적화 작업을 자연어로 설명하는 대규모 언어 모델(LLM)을 최적화 도구로 활용하는 간단하고 효과적인 접근 방식인 OPRO(Optimization by PROmpting)를 제안합니다. 각 최적화 단계에서 LLM은 이전에 생성된 솔루션과 해당 값이 포함된 프롬프트에서 새로운 솔루션을 생성한 다음, 새로운 솔루션을 평가하여 다음 최적화 단계를 위한 프롬프트에 추가합니다. 먼저 선형 회귀와 여행하는 세일즈맨 문제에 대해 OPRO를 선보인 다음, 작업 정확도를 극대화하는 지침을 찾는 것이 목표인 프롬프트 최적화로 이동합니다. 다양한 LLM을 통해 OPRO로 최적화된 최상의 프롬프트가 사람이 직접 설계한 프롬프트보다 GSM8K에서는 최대 8%, 빅벤치 하드 작업에서는 최대 50%까지 성능이 뛰어나다는 것을 입증합니다.
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to prompt optimization where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks.
논문 링크
더 읽어보기
https://twitter.com/omarsar0/status/1700249035456598391
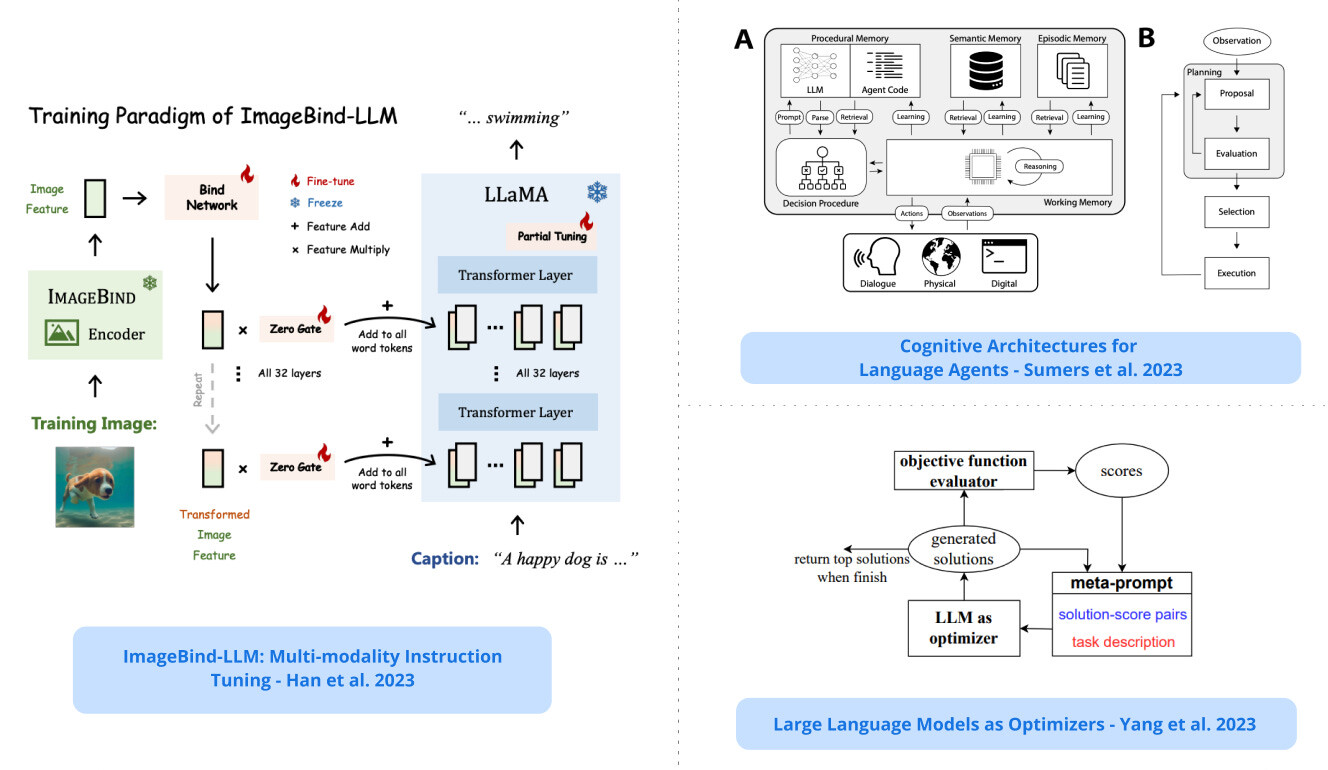
ImageBind-LLM: 멀티 모달리티 인스트럭션 튜닝 / ImageBind-LLM: Multi-modality Instruction Tuning
논문 소개
- 이미지바인드를 통한 llm의 멀티모달 인스트럭션 튜닝 방법인 imagebind-llm을 제시합니다. 이 모델은 높은 언어 생성 품질을 포함하여 오디오, 3D 포인트 클라우드, 비디오 등 다양한 모달리티의 인스트럭션에 응답할 수 있으며, 이는 학습 가능한 바인드 네트워크를 통해 이미지바인드의 비주얼 인코더를 llm에 정렬함으로써 달성됩니다. imagebind
Presents imagebind-llm, a multimodality instruction tuning method of llms via imagebind; this model can respond to instructions of diverse modalities such as audio, 3d point clouds, and video, including high language generation quality; this is achieved by aligning imagebind’s visual encoder with an llm via learnable bind network.
논문 초록
- 이미지바인드를 통한 대규모 언어 모델(LLM)의 멀티 모달리티 인스트럭션 튜닝 방법인 ImageBind-LLM을 소개합니다. 기존 연구들은 주로 언어와 이미지 인스트럭션 튜닝에 초점을 맞춘 반면, 이미지바인드-LLM은 이미지-텍스트 정렬 학습만으로 오디오, 3D 포인트 클라우드, 비디오, 임베딩 공간 연산 등 멀티 모달리티 조건에 대응할 수 있습니다. 학습 과정에서 학습 가능한 바인드 네트워크를 채택하여 LLaMA와 ImageBind의 이미지 인코더 사이의 임베딩 공간을 정렬합니다. 그런 다음 바인드 네트워크에 의해 변환된 이미지 특징을 LLaMA의 모든 레이어에 있는 단어 토큰에 추가하고, 주의가 필요 없는 제로 초기화 게이팅 메커니즘을 통해 시각적 지침을 점진적으로 주입합니다. 이미지 바인드의 공동 임베딩을 통해 간단한 이미지-텍스트 학습을 통해 모델이 뛰어난 멀티 모달리티 명령어 추종 기능을 발휘할 수 있습니다. 추론이 진행되는 동안 멀티 모달리티 입력은 해당 ImageBind 인코더에 공급되고, 추가적인 크로스 모달 임베딩 향상을 위해 제안된 시각 캐시 모델에 의해 처리됩니다. 학습이 필요 없는 캐시 모델은 ImageBind에서 추출한 300만 개의 이미지 피처에서 검색하여 학습-추론 모달리티 불일치를 효과적으로 완화합니다. 특히 이러한 접근 방식을 통해 ImageBind-LLM은 다양한 양식의 명령에 응답하고 상당한 언어 생성 품질을 보여줄 수 있습니다. 코드는 GitHub - OpenGVLab/LLaMA-Adapter: [ICLR 2024] Fine-tuning LLaMA to follow Instructions within 1 Hour and 1.2M Parameters 에서 공개됩니다.
We present ImageBind-LLM, a multi-modality instruction tuning method of large language models (LLMs) via ImageBind. Existing works mainly focus on language and image instruction tuning, different from which, our ImageBind-LLM can respond to multi-modality conditions, including audio, 3D point clouds, video, and their embedding-space arithmetic by only image-text alignment training. During training, we adopt a learnable bind network to align the embedding space between LLaMA and ImageBind's image encoder. Then, the image features transformed by the bind network are added to word tokens of all layers in LLaMA, which progressively injects visual instructions via an attention-free and zero-initialized gating mechanism. Aided by the joint embedding of ImageBind, the simple image-text training enables our model to exhibit superior multi-modality instruction-following capabilities. During inference, the multi-modality inputs are fed into the corresponding ImageBind encoders, and processed by a proposed visual cache model for further cross-modal embedding enhancement. The training-free cache model retrieves from three million image features extracted by ImageBind, which effectively mitigates the training-inference modality discrepancy. Notably, with our approach, ImageBind-LLM can respond to instructions of diverse modalities and demonstrate significant language generation quality. Code is released at GitHub - OpenGVLab/LLaMA-Adapter: [ICLR 2024] Fine-tuning LLaMA to follow Instructions within 1 Hour and 1.2M Parameters.
논문 링크
더 읽어보기
https://twitter.com/arankomatsuzaki/status/1699947731333345750
회로 효율을 통한 그로킹 설명 / Explaining grokking through circuit efficiency
논문 소개
- 신경망의 그로킹 행동을 설명하는 것을 목표로 하며, 특히 두 가지 새로운 행동을 예측하고 보여줍니다. 첫 번째는 모델이 임계값보다 작은 데이터셋에서 더 많이 학습될 때 완벽한 일반화에서 암기로 전환되는 언그로킹이고, 두 번째는 임계 데이터 세트 크기에서 무작위로 초기화된 네트워크를 학습할 때 네트워크가 그로킹과 유사한 전환을 보이는 세미그로킹입니다. grokking
Aims to explain grokking behavior in neural networks; specifically, it predicts and shows two novel behaviors: the first is ungrokking where a model goes from perfect generalization to memorization when trained further on a smaller dataset than the critical threshold; the second is semi-grokking where a network demonstrates grokking-like transition when training a randomly initialized network on the critical dataset size.
논문 초록
- 신경망 일반화에서 가장 놀라운 수수께끼 중 하나는 학습 정확도는 완벽하지만 일반화 능력이 떨어지는 네트워크가 추가 학습을 통해 완벽한 일반화로 전환되는 '그로킹(grokking)'입니다. 우리는 일반화 솔루션과 암기 솔루션이 있을 때 그루킹이 발생하며, 일반화 솔루션이 학습 속도는 느리지만 더 효율적이며 동일한 매개변수 규범을 가진 더 큰 로그를 생성한다고 제안합니다. 우리는 암기 회로는 학습 데이터 세트가 클수록 비효율적이지만 일반화 회로는 그렇지 않다는 가설을 세우고, 암기와 일반화가 똑같이 효율적인 임계 데이터 세트 크기가 있음을 시사합니다. 우리는 그로킹에 대한 네 가지 새로운 예측을 하고 이를 확인함으로써 우리의 설명을 뒷받침하는 중요한 증거를 제시했습니다. 가장 놀랍게도, 네트워크가 완벽한 테스트 정확도에서 낮은 테스트 정확도로 퇴보하는 언그루킹과 네트워크가 완벽한 테스트 정확도가 아닌 부분적인 일반화로 지연되는 세미그루킹이라는 두 가지 새롭고 놀라운 행동을 입증했습니다.
One of the most surprising puzzles in neural network generalisation is grokking: a network with perfect training accuracy but poor generalisation will, upon further training, transition to perfect generalisation. We propose that grokking occurs when the task admits a generalising solution and a memorising solution, where the generalising solution is slower to learn but more efficient, producing larger logits with the same parameter norm. We hypothesise that memorising circuits become more inefficient with larger training datasets while generalising circuits do not, suggesting there is a critical dataset size at which memorisation and generalisation are equally efficient. We make and confirm four novel predictions about grokking, providing significant evidence in favour of our explanation. Most strikingly, we demonstrate two novel and surprising behaviours: ungrokking, in which a network regresses from perfect to low test accuracy, and semi-grokking, in which a network shows delayed generalisation to partial rather than perfect test accuracy.
논문 링크
더 읽어보기
https://twitter.com/VikrantVarma_/status/1699823229307699305
AI 속임수: 사례, 위험 및 잠재적 해결책에 대한 조사 / AI Deception: A Survey of Examples, Risks, and Potential Solutions
논문 소개
- 인공지능 속임수의 경험적 사례에 대한 설문조사를 제공합니다. survey논문
Provides a survey of empirical examples of ai deception.
논문 초록
- 이 논문은 현재의 다양한 인공지능 시스템이 인간을 속이는 방법을 학습했다고 주장합니다. 우리는 속임수를 진실이 아닌 다른 결과를 추구하기 위해 잘못된 믿음을 체계적으로 유도하는 것으로 정의합니다. 먼저 AI 속임수의 경험적 사례를 조사하여 특정 경쟁 상황을 위해 구축된 특수 용도 AI 시스템(메타의 CICERO 포함)과 범용 AI 시스템(대규모 언어 모델 등)에 대해 논의합니다. 다음으로 사기, 선거 조작, AI 시스템에 대한 통제력 상실 등 AI 속임수로 인한 몇 가지 위험에 대해 자세히 설명합니다. 마지막으로, AI 속임수로 인한 문제에 대한 몇 가지 잠재적 해결책을 간략히 설명합니다. 첫째, 규제 프레임워크는 속임수를 사용할 수 있는 AI 시스템에 강력한 위험 평가 요건을 적용해야 하며, 둘째, 정책 입안자는 봇-오어-낫 법을 시행해야 하며, 마지막으로 정책 입안자는 AI 속임수를 탐지하고 AI 시스템을 덜 속일 수 있는 도구를 포함한 관련 연구에 우선적으로 자금을 지원해야 합니다. 정책 입안자, 연구자, 일반 대중은 AI 속임수로 인해 우리 사회의 공동 기반이 불안정해지는 것을 방지하기 위해 적극적으로 노력해야 합니다.
This paper argues that a range of current AI systems have learned how to deceive humans. We define deception as the systematic inducement of false beliefs in the pursuit of some outcome other than the truth. We first survey empirical examples of AI deception, discussing both special-use AI systems (including Meta's CICERO) built for specific competitive situations, and general-purpose AI systems (such as large language models). Next, we detail several risks from AI deception, such as fraud, election tampering, and losing control of AI systems. Finally, we outline several potential solutions to the problems posed by AI deception: first, regulatory frameworks should subject AI systems that are capable of deception to robust risk-assessment requirements; second, policymakers should implement bot-or-not laws; and finally, policymakers should prioritize the funding of relevant research, including tools to detect AI deception and to make AI systems less deceptive. Policymakers, researchers, and the broader public should work proactively to prevent AI deception from destabilizing the shared foundations of our society.
논문 링크
더 읽어보기
https://twitter.com/DanHendrycks/status/1699437800301752332
FLM-101B: 개방형 LLM과 10만 달러 예산으로 교육하는 방법 / FLM-101B: An Open LLM and How to Train It with $100K Budget
논문 소개
- 101개의 파라미터와 0.31TB의 토큰으로 10만 달러의 예산으로 학습할 수 있는 새로운 개방형 LLM인 FLM-101B의 경우, 저자들은 다양한 성장 전략을 분석하여 파라미터의 수를 작은 크기에서 큰 크기로 늘려가며 궁극적으로 비용을 50% 이상 절감하는 공격적인 전략을 사용합니다. 즉, 3개의 모델을 순차적으로 학습하고 각 모델은 더 작은 이전 모델(16b -> 51b -> 101b)의 지식을 상속하면서 경쟁력 있는 성능을 달성합니다.
A new open llm called flm-101b with 101b parameters and 0.31tb tokens which can be trained on a $100k budget; the authors analyze different growth strategies, growing the number of parameters from smaller sizes to large ones. they ultimately employ an aggressive strategy that reduces costs by >50%. in other words, three models are trained sequentially with each model inheriting knowledge from its smaller predecessor (16b -> 51b -> 101b) while achieving competitive performance.
논문 초록
- 대규모 언어 모델(LLM)은 자연어 처리 및 다중 모드 작업에서 괄목할 만한 성공을 거두었습니다. 이러한 성공에도 불구하고 대형 언어 모델 개발은 (i) 높은 계산 비용, (ii) 공정하고 객관적인 평가 수행의 어려움이라는 두 가지 주요 과제에 직면해 있습니다. LLM은 비용이 엄청나게 비싸기 때문에 소수의 주요 기업만이 교육을 받을 수 있으며, 이로 인해 연구와 응용 기회에 제약이 있습니다. 이는 비용 효율적인 LLM 교육의 중요성을 강조합니다. 이 논문에서는 LLM 교육 비용을 크게 절감할 수 있는 성장 전략을 활용합니다. 101억 개의 매개변수와 0.31TB의 토큰을 가진 LLM을 10만 달러의 예산으로 학습할 수 있음을 보여줍니다. 또한 지식 중심의 능력에 더 중점을 두는 기존 평가를 보완하기 위해 LLM의 IQ 평가를 위한 체계적인 평가 패러다임을 채택합니다. 심볼릭 매핑, 규칙 이해, 패턴 마이닝, 간섭 방지 등 지능의 중요한 측면에 대한 평가가 포함된 벤치마크를 도입합니다. 이러한 평가는 암기의 잠재적 영향을 최소화합니다. 실험 결과에 따르면 10만 달러의 예산으로 학습된 모델 FLM-101B는 특히 학습 데이터에서 볼 수 없는 컨텍스트가 있는 IQ 벤치마크 평가에서 강력하고 잘 알려진 모델(예: GPT-3 및 GLM-130B)과 비슷한 성능을 달성하는 것으로 나타났습니다. FLM-101B의 체크포인트는 CofeAI/FLM-101B · Hugging Face 에서 오픈소스로 공개됩니다.
Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks. Despite these successes, their development faces two main challenges: (i) high computational cost; and (ii) difficulty in conducting fair and objective evaluations. LLMs are prohibitively expensive, making it feasible for only a few major players to undertake their training, thereby constraining both research and application opportunities. This underscores the importance of cost-effective LLM training. In this paper, we utilize a growth strategy to significantly reduce LLM training cost. We demonstrate that an LLM with 101B parameters and 0.31TB tokens can be trained on a $100K budget. We also adopt a systematic evaluation paradigm for the IQ evaluation of LLMs, in complement to existing evaluations that focus more on knowledge-oriented abilities. We introduce our benchmark including evaluations on important aspects of intelligence including symbolic mapping, itrule understanding, pattern mining, and anti-interference. Such evaluations minimize the potential impact of memorization. Experimental results show that our model FLM-101B, trained with a budget of $100K, achieves comparable performance to powerful and well-known models, eg GPT-3 and GLM-130B, especially in the IQ benchmark evaluations with contexts unseen in training data. The checkpoint of FLM-101B will be open-sourced at CofeAI/FLM-101B · Hugging Face.
논문 링크
더 읽어보기
https://twitter.com/omarsar0/status/1700156132700963053
언어 에이전트를 위한 인지 아키텍처 / Cognitive Architectures for Language Agents
논문 소개
- 프로덕션 시스템과 인지 아키텍처에서 유사점을 도출하여 완전한 언어 에이전트를 이해하고 구축하기 위한 체계적인 프레임워크를 제안하고, 프레임워크에서 언어 에이전트의 인스턴스로서 언어 기반 추론, 근거, 학습 및 의사 결정을 위한 다양한 방법을 체계화합니다.
Proposes a systematic framework for understanding and building fully-fledged language agents drawing parallels from production systems and cognitive architectures; it systematizes diverse methods for llm-based reasoning, grounding, learning, and decision making as instantiations of language agents in the framework.
논문 초록
- 최근의 노력은 근거나 추론이 필요한 작업을 위해 외부 리소스(예: 인터넷) 또는 내부 제어 흐름(예: 프롬프트 체인)과 함께 대규모 언어 모델(LLM)을 통합하는 것입니다. 그러나 이러한 노력은 대부분 단편적인 것이었으며, 완전한 언어 에이전트를 구축하기 위한 체계적인 프레임워크가 부족했습니다. 이러한 문제를 해결하기 위해 우리는 심볼릭 인공지능에서 에이전트 설계의 풍부한 역사를 바탕으로 새로운 인지 언어 에이전트의 청사진을 개발합니다. 먼저 LLM이 프로덕션 시스템과 동일한 속성을 많이 가지고 있으며, 그 기반이나 추론을 개선하려는 최근의 노력은 프로덕션 시스템을 중심으로 구축된 인지 아키텍처의 발전을 반영하고 있음을 보여줍니다. 그런 다음 프레임워크에서 언어 에이전트의 인스턴스화로서 LLM 기반 추론, 근거, 학습 및 의사 결정을 위한 다양한 방법을 체계화하는 개념적 프레임워크인 언어 에이전트를 위한 인지 아키텍처(Cognitive Architectures for Language Agents, CoALA)를 제안합니다. 마지막으로, CoALA 프레임워크를 사용하여 부족한 부분을 강조하고 향후 더 뛰어난 언어 에이전트를 위한 실행 가능한 방향을 제안합니다.
Recent efforts have incorporated large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning. However, these efforts have largely been piecemeal, lacking a systematic framework for constructing a fully-fledged language agent. To address this challenge, we draw on the rich history of agent design in symbolic artificial intelligence to develop a blueprint for a new wave of cognitive language agents. We first show that LLMs have many of the same properties as production systems, and recent efforts to improve their grounding or reasoning mirror the development of cognitive architectures built around production systems. We then propose Cognitive Architectures for Language Agents (CoALA), a conceptual framework to systematize diverse methods for LLM-based reasoning, grounding, learning, and decision making as instantiations of language agents in the framework. Finally, we use the CoALA framework to highlight gaps and propose actionable directions toward more capable language agents in the future.
논문 링크
더 읽어보기
https://twitter.com/ShunyuYao12/status/1699396834983362690
Q-Transformer
논문 소개
- 인간의 데모와 자율적으로 수집한 데이터를 활용하여 대규모 오프라인 데이터셋에서 멀티태스크 정책을 학습하는 확장 가능한 RL 방법으로, 다양한 실제 로봇 조작 작업 세트에서 우수한 성능을 보여줍니다.
A scalable rl method for training multi-task policies from large offline datasets leveraging human demonstrations and autonomously collected data; shows good performance on a large diverse real-world robotic manipulation task suite.
논문 링크
https://q-transformer.github.io/
더 읽어보기
https://twitter.com/YevgenChebotar/status/1699909244743815677