[2024/11/11 ~ 11/17] 이번 주의 주요 ML 논문 (Top ML Papers of the Week)
PyTorchKR



-
이번 주에 선정된 논문들에서 뚜렷한 트렌드는 '모델 최적화 및 성능 향상'과 '강력한 인공지능 모델의 운영과 관찰 가능성 강화'라는 두 축으로 나뉩니다. 여러 논문들이 모델의 성능을 극대화하거나 모델의 안정성을 강화하는 방법을 탐구하고 있으며, 특히 대규모 언어 모델과 유사한 복잡한 시스템을 더욱 견고하고 효율적으로 운영하기 위한 접근법에 집중되고 있음을 알 수 있습니다.
-
첫 번째 트렌드는 모델 최적화 및 성능 향상입니다. 이 주제는 'Scaling Laws for Precision'과 같은 논문에서 잘 드러납니다. 모델의 성능을 더욱 높이기 위한 방법론을 연구하며, 최적의 모델 크기와 데이터의 관계에 대한 새로운 통찰을 제공합니다. 또한 'Mixture of Transformers' 논문은 서로 다른 트랜스포머 구성 요소들의 혼합을 통해 성능을 개선하려는 시도를 다루고 있습니다.
-
두 번째 트렌드는 '강력한 인공지능 모델의 운영과 관찰 가능성 강화'입니다. 특히 'A Taxonomy of AgentOps for Enabling Observability of Foundation Model-based Agents'는 대규모 모델의 내부 상태와 작동 방식을 더 잘 이해하고 모니터링하기 위한 다양한 방법론을 제안합니다. 이는 대규모 AI 시스템에서 발생할 수 있는 잠재적 오류를 신속히 탐지하고 문제를 해결하기 위해 필수적입니다. 또 다른 논문 'Mitigating LLM Jailbreaks with Few Examples'는 강력한 모델들이 예기치 않게 악용될 가능성을 줄이기 위한 방법에 초점을 맞추고 있습니다.
-
이와 같은 경향은 대규모 인공지능 시스템의 효율성과 안전성이 중요한 이슈로 떠오르고 있다는 것을 시사하며, 연구자들이 어떻게 하면 모델이 더욱 신뢰할 수 있고 투명하게 운영될 수 있을지를 고민하고 있음을 반영합니다. 이러한 연구는 AI 기술이 보다 널리 사용됨에 따라 그 중요성이 더욱 부각될 것입니다.
AI가 혁신에 미치는 영향 / Impacts of AI on Innovation
논문 소개
최고의 과학자들은 자신의 분야 지식을 활용하여 유망한 AI 제안의 우선순위를 정하는 반면, 다른 과학자들은 오탐을 테스트하는 데 상당한 자원을 낭비한다는 점, AI 소재 발견 기술을 구현하면 44% 더 많은 소재를 발견하고 39% 더 많은 특허를 출원하며 17% 제품 혁신을 이루는 등 생산성이 크게 향상된다는 점, 과학자의 82%가 창의력 저하와 기술 활용도 저하로 업무 만족도가 떨어졌다고 보고하는 등 이러한 이득에는 우려되는 상충관계가 있다는 점 등을 제시합니다.
Suggests that top scientists leverage their domain knowledge to prioritize promising AI suggestions, while others waste significant resources testing false positives; finds that implementing AI materials discovery technology leads to substantial increases in productivity, with 44% more materials discovered, 39% more patent filings, and 17% more product innovation; reports that these gains came with concerning tradeoffs, as 82% of scientists reported reduced job satisfaction due to decreased creativity and skill underutilization.
논문 초록(Abstract)
이 논문은 미국 대기업의 R&D 연구소에서 1,018명의 과학자에게 신소재 발견 기술을 무작위로 도입하여 인공지능이 혁신에 미치는 영향을 연구합니다. AI의 도움을 받은 연구원들은 44% 더 많은 물질을 발견하여 특허 출원이 39% 증가하고 다운스트림 제품 혁신이 17% 증가했습니다. 이러한 화합물은 더 새로운 화학 구조를 가지며 더 급진적인 발명으로 이어집니다. 그러나 이 기술은 생산성 분포에 따라 현저하게 다른 효과를 나타냈는데, 하위 3분의 1의 과학자들은 거의 혜택을 보지 못한 반면, 상위 연구자들의 연구 성과는 거의 두 배로 증가했습니다. 이러한 결과의 이면에 있는 메커니즘을 조사한 결과, AI가 '아이디어 생성' 작업의 57%를 자동화하여 연구원들이 모델에서 생성된 후보 물질을 평가하는 새로운 작업에 재할당하는 것으로 나타났습니다. 최고의 과학자들은 자신의 분야 지식을 활용하여 유망한 AI 제안의 우선순위를 정하는 반면, 다른 과학자들은 오탐을 테스트하는 데 상당한 리소스를 낭비합니다. 이러한 조사 결과를 종합하면, AI 증강 연구의 잠재력을 입증하고 혁신적인 프로세스에서 알고리즘과 전문성 간의 상호보완성을 강조합니다. 그러나 설문조사에 따르면 이러한 이득에는 대가가 따르는 것으로 나타났는데, 과학자의 82%가 업무 만족도 감소로 인해 창의성 및 기술 활용도 저하로 인해 업무에 대한 만족도가 떨어졌다고 답했습니다.
This paper studies the impact of artificial intelligence on innovation, exploiting the randomized introduction of a new materials discovery technology to 1,018 scientists in the R&D lab of a large U.S. firm. AI-assisted researchers discover 44% more materials, resulting in a 39% increase in patent filings and a 17% rise in downstream product innovation. These compounds possess more novel chemical structures and lead to more radical inventions. However, the technology has strikingly disparate effects across the productivity distribution: while the bottom third of scientists see little benefit, the output of top researchers nearly doubles. Investigating the mechanisms behind these results, I show that AI automates 57% of “idea-generation” tasks, reallocating researchers to the new task of evaluating model-produced candidate materials. Top scientists leverage their domain knowledge to prioritize promising AI suggestions, while others waste significant resources testing false positives. Together, these findings demonstrate the potential of AI-augmented research and highlight the complementarity between algorithms and expertise in the innovative process. Survey evidence reveals that these gains come at a cost, however, as 82% of scientists report reduced satisfaction with their work due to decreased creativity and skill underutilization.
논문 링크
https://aidantr.github.io/files/AI_innovation.pdf
더 읽어보기
https://x.com/omarsar0/status/1856424446720127024
정밀도를 위한 스케일링 법칙 / Scaling Laws for Precision
논문 소개
LLM에서 모델 성능이 훈련과 추론 정밀도에 의해 어떻게 영향을 받는지 예측하는 '정밀도 인식' 스케일링 법칙을 소개하며, 주요 연구 결과는 다음과 같습니다: 1) 모델이 더 많은 데이터로 훈련될수록 훈련 후 양자화가 더 해로워져 결국 추가적인 사전 훈련이 오히려 해롭다는 점, 2) 낮은 정밀도로 훈련하려면 성능을 유지하기 위해 모델 크기를 늘려야 한다는 점, 3) 모델 크기, 데이터, 정밀도를 함께 최적화할 때 컴퓨팅 최적 훈련 정밀도는 약 7~8비트이며 컴퓨팅과 무관하다는 점, 또한 모델 크기가 고정되면 컴퓨팅 최적 정밀도가 데이터에 따라 거의 로그적으로 증가한다는 점, 저자들은 최대 1까지 모델에서 예측을 검증한다는 점 등을 보고합니다.최대 26억 개의 토큰에 대해 7억 개의 파라미터를 훈련하여 매우 높은(16비트) 훈련 정밀도와 매우 낮은(4비트 미만) 훈련 정밀도 모두 최적이 아닐 수 있음을 보여줍니다.
Introduces "precision-aware" scaling laws that predict how model performance is affected by both training and inference precision in LLMs; key findings include: 1) post-training quantization becomes more harmful as models are trained on more data, eventually making additional pretraining actively detrimental, 2) training in lower precision requires increasing model size to maintain performance, and 3) when jointly optimizing model size, data, and precision, the compute-optimal training precision is around 7-8 bits and independent of compute; also reports that when the model size is fixed, compute-optimal precision increases approximately logarithmically with data; the authors validate their predictions on models up to 1.7B parameters trained on up to 26B tokens, showing that both very high (16-bit) and very low (sub 4-bit) training precisions may be suboptimal.
논문 초록(Abstract)
낮은 정밀도의 훈련과 추론은 언어 모델의 품질과 비용 모두에 영향을 미치지만, 현재의 스케일링 법칙은 이를 고려하지 않습니다. 이 연구에서는 훈련과 추론 모두를 위한 '정밀도 인식' 스케일링 법칙을 고안했습니다. 낮은 정밀도로 훈련하면 모델의 '유효 파라미터 수'가 줄어들어 낮은 정밀도 훈련과 훈련 후 정량화에서 발생하는 추가 손실을 예측할 수 있다고 제안합니다. 추론의 경우, 더 많은 데이터로 모델을 훈련할수록 훈련 후 양자화로 인한 성능 저하가 증가하여 결국 추가 사전 훈련 데이터가 오히려 해가 된다는 것을 발견했습니다. 훈련의 경우, 스케일링 법칙을 통해 서로 다른 정밀도로 서로 다른 부분의 모델 손실을 예측할 수 있으며, 더 큰 모델을 더 낮은 정밀도로 훈련하는 것이 계산 최적일 수 있음을 시사합니다. 학습 후 및 학습 전 정량화를 위한 스케일링 법칙을 통합하여 다양한 정밀도로 학습 및 추론의 성능 저하를 예측하는 단일 기능 형태에 도달합니다. 465개 이상의 사전 훈련 실행을 통해 최대 26억 개의 토큰에 대해 훈련된 최대 17억 개의 파라미터에 대한 모델 크기 예측을 검증합니다.
Low precision training and inference affect both the quality and cost of language models, but current scaling laws do not account for this. In this work, we devise "precision-aware" scaling laws for both training and inference. We propose that training in lower precision reduces the model's "effective parameter count," allowing us to predict the additional loss incurred from training in low precision and post-train quantization. For inference, we find that the degradation introduced by post-training quantization increases as models are trained on more data, eventually making additional pretraining data actively harmful. For training, our scaling laws allow us to predict the loss of a model with different parts in different precisions, and suggest that training larger models in lower precision may be compute optimal. We unify the scaling laws for post and pretraining quantization to arrive at a single functional form that predicts degradation from training and inference in varied precisions. We fit on over 465 pretraining runs and validate our predictions on model sizes up to 1.7B parameters trained on up to 26B tokens.
논문 링크
더 읽어보기
https://x.com/tanishqkumar07/status/1856045600355352753
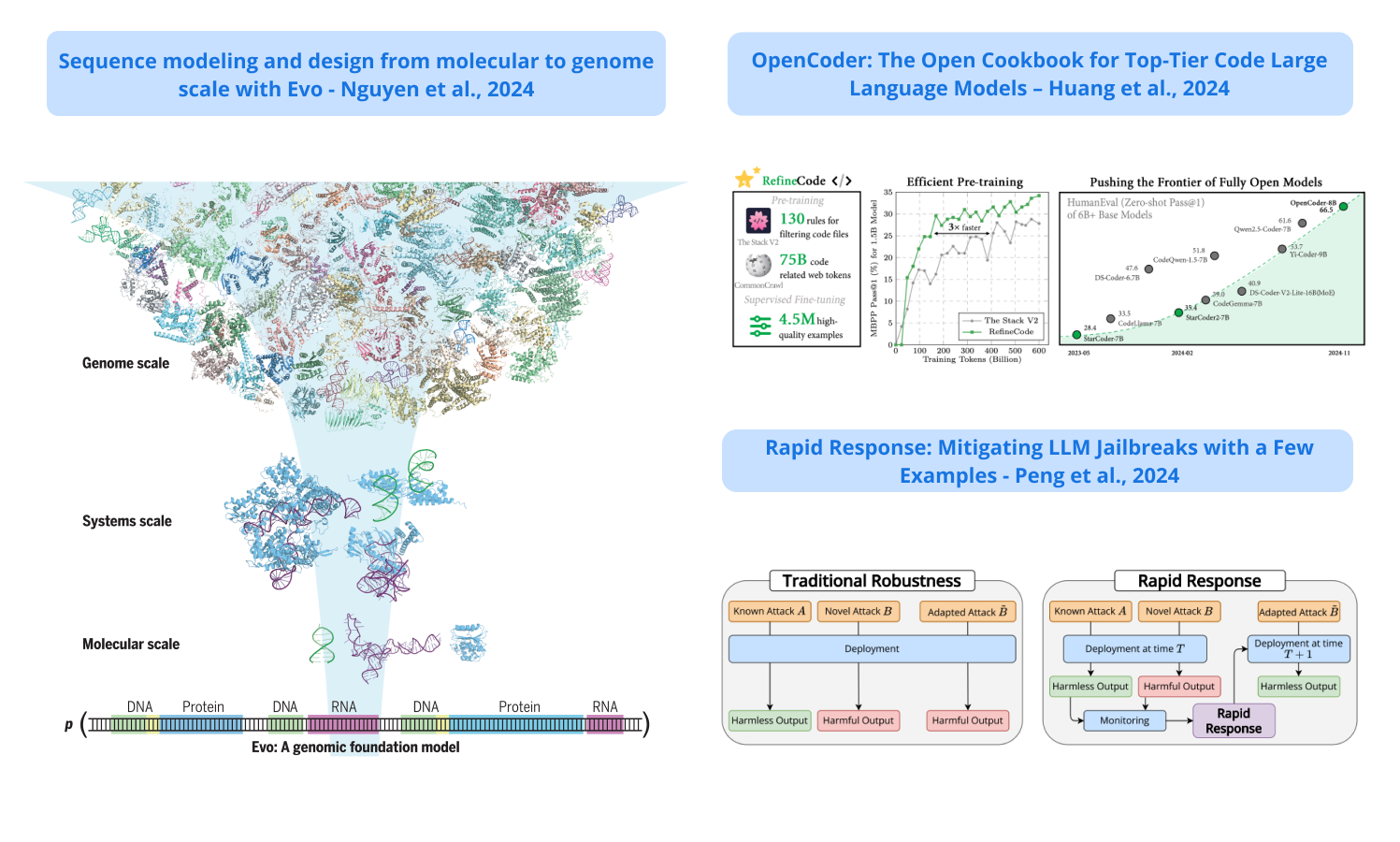
Evo
논문 소개
다양한 생물학적 규모에 걸쳐 DNA 염기서열을 이해하고 생성하도록 설계된 7B 파라미터 AI 모델; 270만 개의 원핵생물 및 파지 게놈을 학습한 이 모델은 단일 뉴클레오타이드 분해능을 유지하면서 최대 131킬로베이스 길이의 염기서열을 처리하여 분자 수준의 상호작용과 게놈 전체의 패턴을 모두 이해할 수 있습니다; Evo는 실험적으로 검증된 최초의 성공적인 AI 생성 CRISPR-Cas 복합체 및 트랜스포저블 시스템을 포함하여 기능성 DNA, RNA 및 단백질 시퀀스 예측 및 생성에 탁월한 성능을 발휘합니다.
A 7B parameter AI model designed to understand and generate DNA sequences across multiple biological scales; the model, trained on 2.7 million prokaryotic and phage genomes, can process sequences up to 131 kilobases long while maintaining single-nucleotide resolution, enabling it to understand both molecular-level interactions and genome-wide patterns; Evo demonstrates superior performance in predicting and generating functional DNA, RNA, and protein sequences, including the first successful AI-generated CRISPR-Cas complexes and transposable systems that have been experimentally validated.
논문 초록(Abstract)
게놈은 유기체의 기능을 조율하는 DNA, RNA, 단백질을 암호화하는 서열입니다. 수백만 개의 원핵생물 및 파지 게놈에 대해 훈련된 프론티어 아키텍처를 갖춘 긴 맥락 게놈 기반 모델인 Evo를 소개하고, 언어와 시각의 관찰을 보완하기 위해 DNA의 스케일링 법칙을 보고합니다. Evo는 DNA, RNA, 단백질 전반에 걸쳐 일반화되어 도메인별 언어 모델과 경쟁할 수 있는 제로 샷 기능 예측을 가능하게 하고, 언어 모델을 사용한 단백질-RNA 및 단백질-DNA 코드 디자인의 첫 번째 사례인 기능성 CRISPR-Cas 및 트랜스포손 시스템을 생성할 수 있습니다. 또한 Evo는 작은 돌연변이가 전체 유기체 적합성에 미치는 영향을 학습하고 그럴듯한 게놈 구조로 메가베이스 규모의 서열을 생성합니다. 이러한 예측 및 생성 기능은 분자에서 게놈 규모의 복잡성을 아우르며 생물학에 대한 이해와 제어를 발전시킵니다.
The genome is a sequence that encodes the DNA, RNA, and proteins that orchestrate an organism’s function. We present Evo, a long-context genomic foundation model with a frontier architecture trained on millions of prokaryotic and phage genomes, and report scaling laws on DNA to complement observations in language and vision. Evo generalizes across DNA, RNA, and proteins, enabling zero-shot function prediction competitive with domain-specific language models and the generation of functional CRISPR-Cas and transposon systems, representing the first examples of protein-RNA and protein-DNA codesign with a language model. Evo also learns how small mutations affect whole-organism fitness and generates megabase-scale sequences with plausible genomic architecture. These prediction and generation capabilities span molecular to genomic scales of complexity, advancing our understanding and control of biology.
논문 링크
https://www.science.org/doi/10.1126/science.ado9336
더 읽어보기
https://x.com/arcinstitute/status/1857138107038187945
OpenCoder: 최상위 코드 대규모 언어 모델을 위한 오픈 쿡북 / OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
논문 소개
코드 생성 및 이해에 특화된 완전 오픈 소스 LLM인 OpenCoder를 소개하며, 저자들은 고성능 코드 LLM을 구축하기 위한 몇 가지 중요한 요소를 파악합니다: (1) 중복 제거를 위해 코드에 최적화된 휴리스틱 규칙을 사용한 효과적인 데이터 정리, (2) 코드와 관련된 관련 텍스트 코퍼스 리콜, (3) 어닐링과 감독 미세 조정 단계 모두에서 고품질 합성; OpenCoder는 6B+ 파라미터 규모에서 이전의 완전 개방형 모델을 능가하며 모델 가중치뿐 아니라 전체 훈련 파이프라인, 데이터 세트 및 프로토콜도 공개하여 재현 가능한 연구를 가능하게 해줍니다.
Introduces OpenCoder, a fully open-source LLM specialized for code generation and understanding; the authors identify several critical factors for building high-performing code LLMs: (1) effective data cleaning with code-optimized heuristic rules for deduplication, (2) recall of relevant text corpus related to code, and (3) high-quality synthetic in both annealing and supervised fine-tuning stages; OpenCoder surpasses previous fully open models at the 6B+ parameter scale and releases not just the model weights but also the complete training pipeline, datasets, and protocols to enable reproducible research.
논문 초록(Abstract)
코드용 대규모 언어 모델(LLM)은 코드 생성, 추론 작업, 에이전트 시스템 등 다양한 영역에서 필수 불가결한 존재가 되었습니다. 오픈 액세스 코드 LLM은 점점 독점 모델의 성능 수준에 근접하고 있지만, 엄격한 과학적 조사에 적합한 고품질 코드 LLM, 특히 재현 가능한 데이터 처리 파이프라인과 투명한 훈련 프로토콜을 갖춘 코드 LLM은 여전히 제한적입니다. 이러한 희소성은 리소스 제약, 윤리적 고려 사항, 모델을 최신 상태로 유지하는 데 따른 경쟁 우위 등 다양한 문제 때문입니다. 이러한 격차를 해소하기 위해 주요 모델에 필적하는 성능을 달성할 뿐만 아니라 연구 커뮤니티를 위한 '오픈 쿡북' 역할을 하는 최상위 코드 LLM인 OpenCoder를 소개합니다. 이전과는 달리 모델 가중치와 추론 코드뿐만 아니라 재현 가능한 훈련 데이터, 완전한 데이터 처리 파이프라인, 엄격한 실험 제거 결과, 개방형 과학 연구를 위한 상세한 훈련 프로토콜까지 모두 공개합니다. 이 포괄적인 릴리스를 통해 (1) 데이터 정리를 위한 코드 최적화 휴리스틱 규칙과 데이터 중복 제거 방법, (2) 코드와 관련된 텍스트 코퍼스 리콜, (3) 어닐링 및 감독 미세 조정 단계의 고품질 합성 데이터 등 최상위 코드 LLM 구축을 위한 핵심 요소를 파악할 수 있습니다. 이러한 수준의 개방성을 제공함으로써 최고 수준의 코드 LLM의 모든 측면에 대한 접근성을 넓히고, 연구를 가속화하고 코드 AI의 재현 가능한 발전을 가능하게 하는 강력한 모델이자 개방형 기반으로서의 역할을 하는 OpenCoder를 목표로 하고 있습니다.
Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems. While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an "open cookbook" for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1857515355595526450
추상적 추론을 위한 시험 시간 훈련의 놀라운 효과 / The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
논문 소개
ARC 벤치마크를 사용하여 LLM의 추상적 추론 능력을 향상시키기 위해 추론 중에 모델 파라미터를 일시적으로 업데이트하는 테스트 시간 훈련(TTT)을 살펴보고, 세 가지 중요한 구성 요소를 식별합니다: 유사한 작업에 대한 초기 미세 조정, 보조 작업 형식 및 증강, 인스턴스별 훈련; TTT는 성능을 크게 개선하여 기본 미세 조정 모델에 비해 최대 6배의 정확도 향상; 8B LLM에 TTT를 적용할 경우 ARC의 공개 검증 세트에서 53%의 정확도를 달성하여 신경 접근법의 최신 기술을 25% 가까이 개선; 이 방법을 프로그램 생성 접근법과 결합하여 최신 공개 검증 정확도 61.9%로 인간의 평균 성능과 일치하며, 이 연구 결과는 명시적 기호 검색만이 LLM에서 추상적 추론을 개선하는 유일한 경로가 아니며, 짧은 예제에 대한 지속적인 훈련에 적용된 테스트 시간 훈련이 매우 효과적일 수 있음을 시사합니다.
Explores test-time training (TTT) - updating model parameters temporarily during inference - for improving an LLM's abstract reasoning capabilities using the ARC benchmark; identifies three crucial components: initial fine-tuning on similar tasks, auxiliary task format and augmentations, and per-instance training; TTT significantly improves performance, achieving up to 6x improvement in accuracy compared to base fine-tuned models; when applying TTT to an 8B LLM, they achieve 53% accuracy on ARC's public validation set, improving the state-of-the-art for neural approaches by nearly 25%; by ensembling their method with program generation approaches, they achieve state-of-the-art public validation accuracy of 61.9%, matching average human performance; the findings suggest that explicit symbolic search is not the only path to improved abstract reasoning in LLMs; test-time training applied to continued training on few-shot examples can be highly effective.
논문 초록(Abstract)
언어 모델은 학습 분포 내의 작업에서는 인상적인 성능을 보였지만 복잡한 추론이 필요한 새로운 문제에서는 종종 어려움을 겪습니다. 당사는 다음과 같이 조사합니다. 입력 데이터에서 파생된 손실을 사용해 추론하는 동안 일시적으로 모델 파라미터를 업데이트하는 테스트 시간 훈련(TTT)의 효과와 모델의 추론 능력 향상 메커니즘 추론 능력을 향상시키는 메커니즘으로 추상화 및 추론 코퍼스(ARC)를 벤치마크로 사용합니다. 체계적인 실험을 통해 성공적인 결과를 얻기 위한 세 가지 중요한 요소를 확인했습니다. TTT: (1) 유사한 작업에 대한 초기 미세 조정 (2) 보조 작업 형식 및 증강 (3) 인스턴스별 훈련. TTT는 ARC 작업의 성능을 크게 개선하여 다음과 같은 성과를 달성합니다. 미세 조정된 기본 모델에 비해 최대 6배의 정확도 향상; TTT를 적용하면 8B-파라미터 언어 모델에 적용하면 ARC의 공개 검증 세트에서 53%의 정확도를 달성합니다, 퍼블릭 및 순수 신경망 접근 방식에 대해 거의 25%의 정확도를 향상시켰습니다. 이로써 우리의 방법을 최신 프로그램 생성 접근 방식과 결합하여 SoTA 공개 검증 정확도는 61.9%로, 사람의 평균 점수와 일치합니다. 연구 결과는 다음과 같이 시사합니다. 명시적 기호 검색만이 신경망에서 추상적 추론을 개선할 수 있는 유일한 길은 아님을 시사합니다. 언어 모델에서 추상적 추론을 향상시키는 유일한 방법은 아니며, 짧은 예제에 대한 지속적인 훈련에 추가 테스트 시간을 적용하는 것 을 지속적으로 훈련하는 것도 매우 효과적일 수 있습니다.
Language models have shown impressive performance on tasks within their training distribution, but often struggle with novel problems requiring complex reasoning. We investigate the effectiveness of test-time training (TTT)—updating model parameters temporarily during inference using a loss derived from input data—as a mechanism for improving models’ reasoning capabilities, using the Abstraction and Reasoning Corpus (ARC) as a benchmark. Through systematic experimentation, we identify three crucial components for successful TTT: (1) initial finetuning on similar tasks (2) auxiliary task format and augmentations (3) per-instance training. TTT significantly improves performance on ARC tasks, achieving up to 6× improvement in accuracy compared to base fine-tuned models; applying TTT to a 8B-parameter language model, we achieve 53% accuracy on the ARC’s public validation set, improving the state-of-the-art by nearly 25% for public and purely neural approaches. By ensembling our method with recent program generation approaches, we get SoTA public validation accuracy of 61.9%, matching the average human score. Our findings suggest that explicit symbolic search is not the only path to improved abstract reasoning in neural language models; additional test-time applied to continued training on few-shot examples can also be extremely effective.
논문 링크
더 읽어보기
https://x.com/akyurekekin/status/1855680785715478546
파운데이션 모델 기반 에이전트의 통합 가시성을 위한 에이전트 운영 분류 체계 / A Taxonomy of AgentOps for Enabling Observability of Foundation Model based Agents
논문 소개
개발 및 프로덕션 수명 주기 전반에서 기본 모델 기반 자율 에이전트 시스템의 안정성을 보장하기 위해 포괄적인 통합 가시성 및 추적 기능의 필요성을 강조하면서 AgentOps 플랫폼과 도구를 분석합니다.
Analyzes AgentOps platforms and tools, highlighting the need for comprehensive observability and traceability features to ensure reliability in foundation model-based autonomous agent systems across their development and production lifecycle.
논문 초록(Abstract)
LLM의 품질이 지속적으로 향상됨에 따라 다양한 다운스트림 작업의 성장이 촉진되어 AI 자동화에 대한 수요가 증가하고 기초 모델(FM) 기반 자율 에이전트 개발에 대한 관심도 급증하고 있습니다. AI 에이전트 시스템이 더 복잡한 작업을 처리하고 발전함에 따라 에이전트 사용자, 에이전트 시스템 개발자 및 배포자, AI 모델 개발자 등 더 광범위한 이해관계자가 참여하게 됩니다. 또한 이러한 시스템은 AI 에이전트 워크플로, RAG 파이프라인, 프롬프트 관리, 에이전트 기능 및 통합 가시성 기능과 같은 여러 구성 요소를 통합합니다. 이 경우 이러한 에이전트로부터 신뢰할 수 있는 결과와 답변을 얻는 것이 여전히 어렵기 때문에 신뢰할 수 있는 실행 프로세스와 엔드투엔드 통합 가시성 솔루션이 필요합니다. 신뢰할 수 있는 AI 에이전트와 LLM 애플리케이션을 구축하려면 개발에서 프로덕션에 이르는 전체 수명 주기에서 통합 가시성과 추적성을 보장하는 에이전트옵스 플랫폼 설계로 전환하는 것이 필수적입니다. 이를 위해 저희는 신속한 검토를 수행하여 에이전트 에코시스템에서 관련 에이전트옵스 도구를 파악했습니다. 이 검토를 바탕으로 에이전트옵스의 필수 기능에 대한 개요를 제공하고 에이전트 프로덕션 수명 주기 전반에 걸쳐 통합 가시성 데이터/추적 가능한 아티팩트에 대한 포괄적인 개요를 제안합니다. 또한 현재 에이전트옵스 환경에 대한 체계적인 개요를 제공하며, 자율 에이전트 시스템의 안정성을 향상시키는 데 있어 통합 가시성/트레이스 가능성이 얼마나 중요한 역할을 하는지 강조합니다.
The ever-improving quality of LLMs has fueled the growth of a diverse range of downstream tasks, leading to an increased demand for AI automation and a burgeoning interest in developing foundation model (FM)-based autonomous agents. As AI agent systems tackle more complex tasks and evolve, they involve a wider range of stakeholders, including agent users, agentic system developers and deployers, and AI model developers. These systems also integrate multiple components such as AI agent workflows, RAG pipelines, prompt management, agent capabilities, and observability features. In this case, obtaining reliable outputs and answers from these agents remains challenging, necessitating a dependable execution process and end-to-end observability solutions. To build reliable AI agents and LLM applications, it is essential to shift towards designing AgentOps platforms that ensure observability and traceability across the entire development-to-production life-cycle. To this end, we conducted a rapid review and identified relevant AgentOps tools from the agentic ecosystem. Based on this review, we provide an overview of the essential features of AgentOps and propose a comprehensive overview of observability data/traceable artifacts across the agent production life-cycle. Our findings provide a systematic overview of the current AgentOps landscape, emphasizing the critical role of observability/traceability in enhancing the reliability of autonomous agent systems.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1857400667318702118
RAG를 위한 최적의 검색 및 검색을 향해 / Toward Optimal Search and Retrieval for RAG
논문 소개
QA 작업을 위한 RAG 파이프라인에서 검색이 성능에 미치는 영향을 조사하고, LLaMA 및 Mistral과 함께 BGE-base 및 ColBERT 검색기를 사용해 실험을 수행하여 더 많은 골드(관련성) 문서를 포함하면 QA 정확도가 향상된다는 사실을 발견하고, 리콜이 낮은 근사 근사 이웃 검색을 사용하면 속도와 메모리 효율을 개선하면서 성능에 최소한의 영향만 미친다는 사실을 발견합니다; 노이즈가 많거나 관련 없는 문서를 추가하면 성능이 지속적으로 저하되어 이전 연구 결과와 모순된다는 보고, 골드 문서의 검색 최적화가 RAG 성능에 매우 중요하며, 검색 정확도 수준을 낮춰 운영하는 것이 실제 애플리케이션에서 실행 가능한 접근 방식이 될 수 있다는 결론을 내립니다.
Examines how retrieval affects performance in RAG pipelines for QA tasks; conducts experiments using BGE-base and ColBERT retrievers with LLaMA and Mistral, finding that including more gold (relevant) documents improves QA accuracy; finds that using approximate nearest neighbor search with lower recall only minimally impacts performance while potentially improving speed and memory efficiency; reports that adding noisy or irrelevant documents consistently degrades performance, contradicting previous research claims; concludes that optimizing retrieval of gold documents is crucial for RAG performance, and that operating at lower search accuracy levels can be a viable approach for practical applications.
논문 초록(Abstract)
검색 증강 생성(RAG)은 대규모 언어 모델(LLM)과 관련된 메모리 관련 문제를 해결하기 위한 유망한 방법입니다. 검색기와 리더라는 두 개의 개별 시스템이 RAG 파이프라인을 구성하며, 각 시스템이 다운스트림 작업 성능에 미치는 영향은 잘 알려져 있지 않습니다. 여기서는 질문 답변(QA)과 같은 일반적인 작업을 위해 RAG 파이프라인에 리트리버를 최적화할 수 있는 방법을 이해하는 것을 목표로 작업합니다. 우리는 QA와 어트리뷰션된 QA에서 검색과 RAG 성능 간의 관계에 초점을 맞춘 실험을 수행하여 고성능 RAG 파이프라인을 개발하는 실무자에게 유용한 여러 가지 인사이트를 공개합니다. 예를 들어, 검색 정확도를 낮추면 검색 속도와 메모리 효율성은 잠재적으로 증가하지만 RAG 성능에 미치는 영향은 미미합니다.
Retrieval-augmented generation (RAG) is a promising method for addressing some of the memory-related challenges associated with Large Language Models (LLMs). Two separate systems form the RAG pipeline, the retriever and the reader, and the impact of each on downstream task performance is not well-understood. Here, we work towards the goal of understanding how retrievers can be optimized for RAG pipelines for common tasks such as Question Answering (QA). We conduct experiments focused on the relationship between retrieval and RAG performance on QA and attributed QA and unveil a number of insights useful to practitioners developing high-performance RAG pipelines. For example, lowering search accuracy has minor implications for RAG performance while potentially increasing retrieval speed and memory efficiency.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1856709865802252710
신속한 대응: 몇 가지 예시를 통해 LLM 탈옥 완화하기 / Rapid Response: Mitigating LLM Jailbreaks with a Few Examples
논문 소개
탈옥 공격으로부터 LLM을 방어하기 위한 새로운 접근 방식을 소개하며, 완벽한 공격자의 사전 견고성을 목표로 하기보다는 새로운 공격을 탐지한 후 신속하게 방어를 적용하는 데 중점을 두고, 입력 분류기를 미세 조정하는 가장 효과적인 방법인 새로운 벤치마크를 사용하여 각 공격 전략의 한 가지 예만 보고도 알려진 공격 유형은 240배 이상, 새로운 변형은 15배 이상 공격 성공률을 줄였으며 새로운 탈옥에 신속하게 대응하는 것이 기존의 정적 방어의 효과적인 대안이 될 수 있음을 입증합니다.
Introduces a new approach called for defending LLMs against jailbreak attacks, focusing on quickly adapting defenses after detecting new attacks rather than aiming for perfect adversarial upfront robustness; using a new benchmark, the most effective method, based on fine-tuning an input classifier, reduced attack success rates by over 240x for known attack types and 15x for novel variations after seeing just one example of each attack strategy; demonstrates that rapidly responding to new jailbreaks can be an effective alternative to traditional static defenses.
논문 초록(Abstract)
대규모 언어 모델(LLM)이 점점 더 강력해지면서 오용에 대한 안전성을 확보하는 것이 중요해지고 있습니다. 연구자들은 강력한 방어를 개발하는 데 주력해 왔지만, 아직 공격에 대한 완전한 무결성을 달성한 방법은 없습니다. 저희는 완벽한 공격 견고성을 추구하는 대신, 소수의 공격만 관찰한 후 전체 탈옥을 차단하는 신속한 대응 기술을 개발하는 대안을 제안합니다. 이 설정을 연구하기 위해 관찰된 몇 가지 사례에 적응한 후 다양한 탈옥 전략에 대한 방어의 견고성을 측정하는 벤치마크인 RapidResponseBench를 개발했습니다. 관찰된 사례와 유사한 탈옥을 자동으로 추가로 생성하는 탈옥 확산을 사용하는 5가지 신속 대응 방법을 평가합니다. 입력 분류기를 미세 조정하여 확산된 탈옥을 차단하는 가장 강력한 방법은 각 탈옥 전략의 예시를 하나만 관찰한 상태에서 탈옥의 배포 내 집합에서는 공격 성공률을 240배 이상, 배포 외 집합에서는 15배 이상 감소시켰습니다. 또한, 추가 연구에 따르면 확산 모델의 품질과 확산된 사례의 수가 이 방어의 효과에 중요한 역할을 하는 것으로 나타났습니다. 전반적으로, 이번 연구 결과는 새로운 탈옥에 신속하게 대응하여 LLM 오용을 제한할 수 있는 잠재력을 강조합니다.
As large language models (LLMs) grow more powerful, ensuring their safety against misuse becomes crucial. While researchers have focused on developing robust defenses, no method has yet achieved complete invulnerability to attacks. We propose an alternative approach: instead of seeking perfect adversarial robustness, we develop rapid response techniques to look to block whole classes of jailbreaks after observing only a handful of attacks. To study this setting, we develop RapidResponseBench, a benchmark that measures a defense's robustness against various jailbreak strategies after adapting to a few observed examples. We evaluate five rapid response methods, all of which use jailbreak proliferation, where we automatically generate additional jailbreaks similar to the examples observed. Our strongest method, which fine-tunes an input classifier to block proliferated jailbreaks, reduces attack success rate by a factor greater than 240 on an in-distribution set of jailbreaks and a factor greater than 15 on an out-of-distribution set, having observed just one example of each jailbreaking strategy. Moreover, further studies suggest that the quality of proliferation model and number of proliferated examples play an key role in the effectiveness of this defense. Overall, our results highlight the potential of responding rapidly to novel jailbreaks to limit LLM misuse.
논문 링크
더 읽어보기
https://x.com/AnthropicAI/status/1856752093945540673
혼합형 트랜스포머: 멀티 모달 파운데이션 모델을 위한 희소하고 확장 가능한 아키텍처 / Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
논문 소개
텍스트 및 이미지 처리에 컴퓨팅 리소스를 절반 정도만 사용하면서 기존 모델의 성능과 일치하는 새로운 스파스 멀티모달 트랜스포머 아키텍처인 MoT(혼합 트랜스포머)를 소개합니다. MoT는 55.8%의 FLOP만 사용하여 고밀도 기준선의 성능과 일치합니다.
Introduce Mixture-of-Transformers (MoT), a new sparse multi-modal transformer architecture that matches the performance of traditional models while using only about half the computational resources for text and image processing; MoT matches a dense baseline's performance using only 55.8% of the FLOPs.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 개발은 통합 프레임워크 내에서 텍스트, 이미지, 음성을 처리할 수 있는 멀티 모달 시스템으로 확장되었습니다. 이러한 모델을 훈련하려면 텍스트 전용 LLM에 비해 훨씬 더 큰 데이터 세트와 컴퓨팅 리소스가 필요합니다. 이러한 확장 문제를 해결하기 위해 유니티는 사전 훈련 계산 비용을 크게 줄여주는 희소 멀티모달 트랜스포머 아키텍처인 MoT(Mixture-of-Transformers)를 도입했습니다. MoT는 피드 포워드 네트워크, 주의 행렬, 레이어 정규화 등 모델의 비임베딩 파라미터를 모달별로 분리하여 전체 입력 시퀀스에 대한 글로벌 자체 주의로 모달별 처리를 가능하게 합니다. 여러 설정과 모델 규모에 걸쳐 MoT를 평가합니다. 카멜레온 7B 설정(자동 회귀적 텍스트 및 이미지 생성)에서 MoT는 55.8%의 FLOP만 사용하여 밀도가 높은 기준선의 성능과 일치합니다. 음성을 포함하도록 확장하면 MoT는 37.2%만 사용하여 고밀도 기준선에 필적하는 음성 성능에 도달합니다. 텍스트와 이미지가 서로 다른 목표로 훈련되는 수혈 설정에서 7B MoT 모델은 고밀도 기준선의 이미지 모달리티 성능과 1/3의 FLOP으로 일치하며 760M MoT 모델은 주요 이미지 생성 지표에서 1.4B 고밀도 기준선보다 성능이 뛰어납니다. 시스템 프로파일링은 월 클럭 시간의 47.2%에서 고밀도 기준 이미지 품질을, 월 클럭 시간의 75.6%에서 텍스트 품질을 달성하여 MoT의 실질적인 이점을 더욱 강조합니다(NVIDIA A100 GPU를 사용한 AWS p4de.24xlarge 인스턴스에서 측정).
The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework. Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs. MoT decouples non-embedding parameters of the model by modality -- including feed-forward networks, attention matrices, and layer normalization -- enabling modality-specific processing with global self-attention over the full input sequence. We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics. System profiling further highlights MoT's practical benefits, achieving dense baseline image quality in 47.2% of the wall-clock time and text quality in 75.6% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
논문 링크
HtmlRAG: RAG 시스템에서 검색된 지식을 모델링하는 데 일반 텍스트보다 HTML이 더 낫습니다 / HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
논문 소개
RAG 시스템을 구축하기 위한 형식으로 일반 텍스트 대신 HTML을 사용할 것을 제안하는 새로운 접근 방식, HTML 구조를 보존하면 일반적으로 제목, 표, 의미 태그와 같은 중요한 서식이 손실되는 일반 텍스트 변환에 비해 더 풍부한 의미 및 구조 정보를 제공한다는 핵심 발견, LLM 컨텍스트 창에 너무 긴 HTML 문서의 문제를 해결하기 위해 저자는 2단계 가지치기 방법을 개발했습니다: 먼저 불필요한 HTML 요소를 정리하고(길이를 94%까지 줄임), 임베딩 기반과 생성적 가지치기를 결합한 블록 트리 기반 가지치기 방식을 사용하여 중요한 정보를 유지하면서 콘텐츠를 더욱 줄임; 6개의 다른 QA 데이터 세트에서 실험한 결과 HtmlRAG가 기존의 일반 텍스트 기반 방법보다 성능이 우수하여 RAG 시스템에서 HTML 구조를 보존하는 이점을 검증했습니다.
A novel approach that proposes using HTML instead of plain text as the format for building RAG systems; the key finding is that preserving HTML structure provides richer semantic and structural information compared to plain text conversion, which typically loses important formatting like headings, tables, and semantic tags; to address the challenge of HTML documents being too long for LLM context windows, the authors develop a two-step pruning method: first cleaning unnecessary HTML elements (reducing length by 94%), then using a block-tree-based pruning approach that combines embedding-based and generative pruning to further reduce the content while maintaining important information; experiments across six different QA datasets demonstrate that HtmlRAG outperforms existing plain-text based methods, validating the advantages of preserving HTML structure in RAG systems.
논문 초록(Abstract)
검색 증강 세대(RAG)는 지식 능력을 향상시키고 LLM의 환각 문제를 완화하는 것으로 나타났습니다. 웹은 RAG 시스템에서 사용되는 외부 지식의 주요 소스이며, ChatGPT 및 Perplexity와 같은 많은 상용 시스템에서 웹 검색 엔진을 주요 검색 시스템으로 사용하고 있습니다. 일반적으로 이러한 RAG 시스템은 검색 결과를 검색하고, 결과의 HTML 소스를 다운로드한 다음, HTML 소스에서 일반 텍스트를 추출합니다. 일반 텍스트 문서 또는 청크는 LLM에 공급되어 생성을 보강합니다. 그러나 이 일반 텍스트 기반 RAG 프로세스에서는 제목과 표 구조 등 HTML 고유의 구조적 및 의미론적 정보가 대부분 손실됩니다. 이 문제를 완화하기 위해, 저희는 RAG에서 검색된 지식의 형식으로 일반 텍스트 대신 HTML을 사용하는 HtmlRAG를 제안합니다. 외부 문서에 있는 지식을 모델링하는 데는 일반 텍스트보다 HTML이 더 적합하며, 대부분의 LLM은 HTML을 이해하는 강력한 역량을 갖추고 있습니다. 하지만 HTML을 활용하는 데는 새로운 과제가 있습니다. HTML에는 태그, JavaScript, CSS 사양과 같은 추가 콘텐츠가 포함되어 있어 RAG 시스템에 추가 입력 토큰과 노이즈를 가져옵니다. 이 문제를 해결하기 위해 저희는 정보 손실을 최소화하면서 HTML을 단축하기 위한 HTML 정리, 압축, 가지치기 전략을 제안합니다. 구체적으로는 쓸모없는 HTML 블록을 잘라내고 관련 부분만 유지하는 2단계 블록 트리 기반 가지치기 방법을 설계합니다. 6개의 QA 데이터 세트에 대한 실험을 통해 RAG 시스템에서 HTML 사용의 우수성을 확인했습니다.
Retrieval-Augmented Generation (RAG) has been shown to improve knowledge capabilities and alleviate the hallucination problem of LLMs. The Web is a major source of external knowledge used in RAG systems, and many commercial systems such as ChatGPT and Perplexity have used Web search engines as their major retrieval systems. Typically, such RAG systems retrieve search results, download HTML sources of the results, and then extract plain texts from the HTML sources. Plain text documents or chunks are fed into the LLMs to augment the generation. However, much of the structural and semantic information inherent in HTML, such as headings and table structures, is lost during this plain-text-based RAG process. To alleviate this problem, we propose HtmlRAG, which uses HTML instead of plain text as the format of retrieved knowledge in RAG. We believe HTML is better than plain text in modeling knowledge in external documents, and most LLMs possess robust capacities to understand HTML. However, utilizing HTML presents new challenges. HTML contains additional content such as tags, JavaScript, and CSS specifications, which bring extra input tokens and noise to the RAG system. To address this issue, we propose HTML cleaning, compression, and pruning strategies, to shorten the HTML while minimizing the loss of information. Specifically, we design a two-step block-tree-based pruning method that prunes useless HTML blocks and keeps only the relevant part of the HTML. Experiments on six QA datasets confirm the superiority of using HTML in RAG systems.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1857870511302390013
원문
- 이 글은 GPT 모델로 정리한 것으로, 잘못된 부분이 있을 수 있으니 글 아래쪽의 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다.*

![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()