[2025/03/17 ~ 03/23] 이번 주의 주요 ML 논문 (Top ML Papers of the Week)
PyTorchKR



-
이번 주에 선정된 논문들은 주로 대규모 언어 모델(LLM)과 그에 관련된 강화 학습, 최적화, 그리고 메모리 시스템에 관한 연구가 두드러지게 나타났습니다. 특히, LLM의 체인 오브 생각(reasoning) 능력을 강화하기 위한 다양한 접근 방법과 효율적인 메모리 시스템, 그리고 스케일링 법칙에 대한 논의가 활발히 이루어졌습니다. 이러한 경향은 LLM이 다양한 분야에서의 문제 해결 능력을 향상시키기 위해 필요한 기술적 진보에 대한 관심이 집중되고 있음을 보여줍니다.
-
LLM의 성능을 극대화하기 위한 다양한 강화 학습 기법들이 이번 주 논문들에서 많이 다루어졌습니다. 예를 들어, "DAPO: An Open-Source LLM Reinforcement Learning System at Scale" 논문에서는 강화 학습을 통해 LLM의 체인 오브 생각 능력을 개선하고, 학습 효율성을 높이는 방법에 대해 논의하였습니다. 또한, "Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in LLMs"에서는 LLM의 보상 모델을 개선하여 더 나은 추론 능력을 제공하는 방법을 제안하였습니다. 이러한 연구들은 LLM의 학습 및 추론에서의 효율성을 극대화하는 방향으로 나아가고 있음을 알 수 있습니다.
-
또한, LLM의 메모리 시스템과 관련된 연구도 눈에 띄었습니다. "Agentic Memory for LLM Agents" 논문에서는 장기 메모리 시스템을 통해 복잡한 현실 세계의 과제를 해결하는 LLM 에이전트를 위한 새로운 메모리 시스템을 제안하였습니다. 이는 LLM이 정보를 더 효과적으로 저장하고 활용할 수 있도록 하여, 추론 능력을 향상시키는 데 기여할 수 있습니다. 이러한 연구들은 LLM이 더 복잡한 문제를 해결하고, 다양한 응용 분야에서 활용될 수 있도록 돕는 중요한 기술적 발전을 나타내고 있습니다.
딥시크 모델의 주요 혁신 기술에 대한 리뷰 / A Review of DeepSeek Models' Key Innovative Techniques
논문 소개
이 논문에서는 딥시크의 오픈소스 LLM인 DeepSeek-V3와 DeepSeek-R1의 최첨단 기술을 심층적으로 검토합니다. 이 모델들은 독점 모델에 비해 훨씬 낮은 리소스 요구 사항으로 최첨단 성능을 달성합니다. 주요 특징은 다음과 같습니다:
-
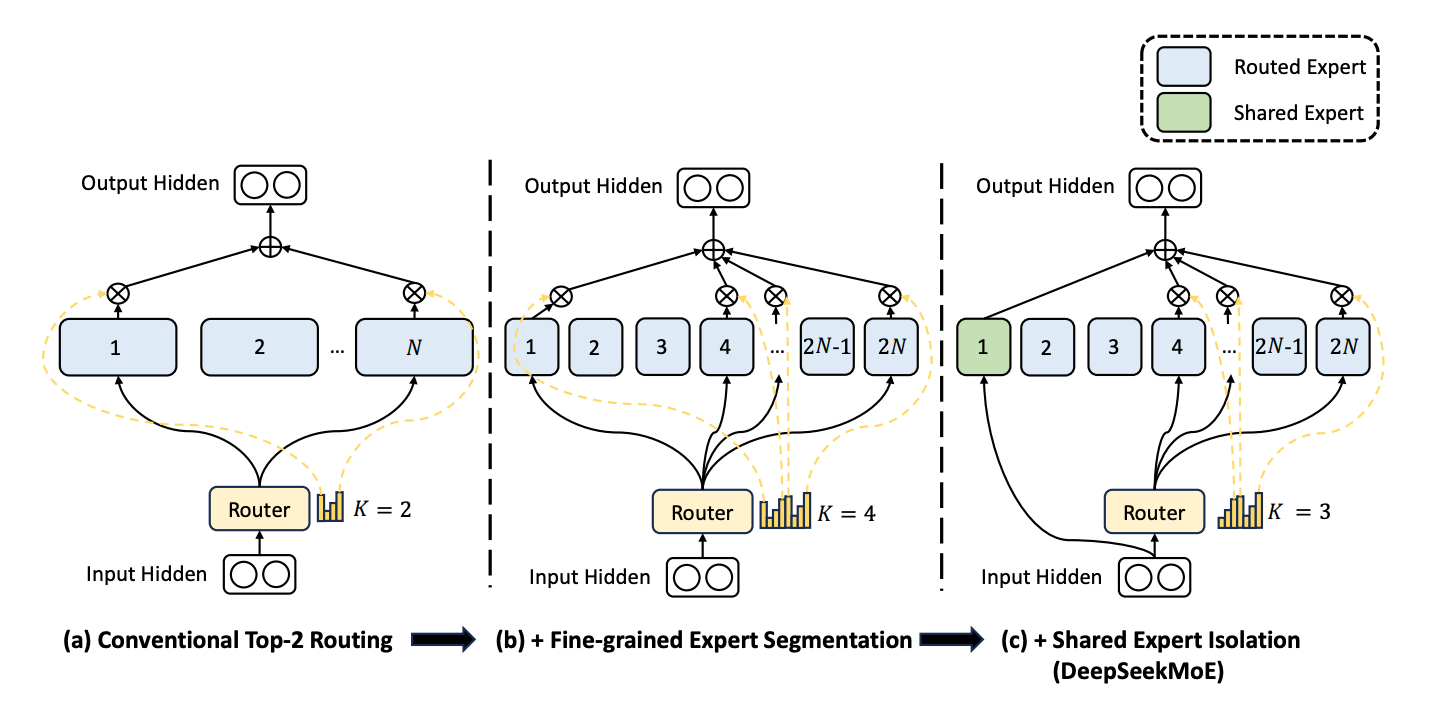
멀티 헤드 잠재 어텐션(MLA) - 키와 값을 잠재 벡터로 압축하여 효율적인 어텐션을 도입함으로써 성능 저하 없이 긴 컨텍스트 작업의 메모리 소비를 획기적으로 줄입니다. MLA는 로우랭크 압축과 분리된 회전 위치 임베딩을 사용하여 표준 멀티 헤드 어텐션보다 뛰어난 성능을 발휘합니다.
-
고급 전문가 혼합(MoE) - 세분화된 전문가 세분화와 전담 공유 전문가를 통합하여 조합의 유연성을 크게 향상시킵니다. 혁신적인 로드 밸런싱 전략으로 계산 효율성과 모델 성능을 더욱 최적화합니다.
-
멀티 토큰 예측(MTP) - 여러 개의 후속 토큰을 동시에 예측하여 학습 효율성을 높입니다. 효과적이지만 추가 학습 오버헤드가 발생하므로 추가적인 최적화가 필요합니다.
-
알고리즘-하드웨어 공동 설계 - 파이프라인 버블을 제거하도록 설계된 알고리즘인 듀얼파이프 스케줄링과 FP8 혼합 정밀도 학습과 같은 엔지니어링 발전을 통해 계산 효율성을 극대화하고 학습 리소스를 줄입니다.
-
GRPO(그룹 상대 정책 최적화) - PPO에서 값 함수 근사치를 제거하여 그룹화된 출력의 이점을 직접 추정하는 간소화된 RL 알고리즘을 제공하여 GPU 메모리 사용량을 대폭 줄입니다.
-
학습 후 강화 학습 - 감독된 미세 조정 없이 고급 추론을 학습하는 DeepSeek-R1-Zero에서 순수 RL의 기능을 보여줍니다. DeepSeek-R1은 반복적인 콜드 스타트 미세 조정, 거부 샘플링, RL 정렬을 통해 이 접근 방식을 더욱 개선하여 추론 품질과 언어 일관성을 향상시킵니다.
This paper provides an in-depth review of the cutting-edge techniques behind DeepSeek's open-source LLMs--DeepSeek-V3 and DeepSeek-R1. These models achieve state-of-the-art performance with significantly lower resource requirements compared to proprietary counterparts. Key highlights include:
- Multi-Head Latent Attention (MLA) - Introduces efficient attention by compressing keys and values into a latent vector, dramatically reducing memory consumption for long-context tasks without sacrificing performance. MLA employs low-rank compression and decoupled Rotary Position Embeddings, outperforming standard multi-head attention.
- Advanced Mixture of Experts (MoE) - Incorporates fine-grained expert segmentation and dedicated shared experts, significantly enhancing combinational flexibility. An innovative load-balancing strategy further optimizes computational efficiency and model performance.
- Multi-Token Prediction (MTP) - Enhances training efficiency by predicting multiple subsequent tokens simultaneously. Although effective, the additional training overhead warrants further optimization.
- Algorithm-Hardware Co-design - Presents engineering advancements like DualPipe scheduling, an algorithm designed to eliminate pipeline bubbles, and FP8 mixed-precision training, maximizing computational efficiency and reducing training resources.
- Group Relative Policy Optimization (GRPO) - Offers a streamlined RL algorithm eliminating value function approximation from PPO, directly estimating advantages from grouped outputs, drastically reducing GPU memory usage.
- Post-Training Reinforcement Learning - Demonstrates pure RL's capability in DeepSeek-R1-Zero, which learns advanced reasoning without supervised fine-tuning. DeepSeek-R1 further improves this approach via iterative cold-start fine-tuning, rejection sampling, and RL alignment to enhance reasoning quality and language consistency.
논문 초록(Abstract)
딥서치-V3와 딥서치-R1은 범용 작업 및 추론을 위한 선도적인 오픈소스 대규모 언어 모델(LLM)로, OpenAI와 Anthropic 같은 회사의 최신 폐쇄형 모델에 필적하는 성능을 달성하면서도 학습 비용은 일부에 불과합니다. DeepSeek의 성공 이면에 있는 주요 혁신 기술을 이해하는 것은 LLM 연구를 발전시키는 데 매우 중요합니다. 이 논문에서는 트랜스포머 아키텍처의 개선, 다중 헤드 잠재 어텐션 및 전문가 혼합, 다중 토큰 예측, 알고리즘, 프레임워크 및 하드웨어의 공동 설계, 그룹 상대 정책 최적화 알고리즘, 순수 강화 학습을 통한 사후 학습, 감독 미세 조정과 강화 학습을 번갈아 사용하는 반복 학습 등 이러한 모델의 놀라운 효과와 효율성을 이끄는 핵심 기술을 검토합니다. 또한 빠르게 발전하는 이 분야에서 몇 가지 미해결 질문을 파악하고 잠재적인 연구 기회를 강조합니다.
DeepSeek-V3 and DeepSeek-R1 are leading open-source Large Language Models (LLMs) for general-purpose tasks and reasoning, achieving performance comparable to state-of-the-art closed-source models from companies like OpenAI and Anthropic -- while requiring only a fraction of their training costs. Understanding the key innovative techniques behind DeepSeek's success is crucial for advancing LLM research. In this paper, we review the core techniques driving the remarkable effectiveness and efficiency of these models, including refinements to the transformer architecture, innovations such as Multi-Head Latent Attention and Mixture of Experts, Multi-Token Prediction, the co-design of algorithms, frameworks, and hardware, the Group Relative Policy Optimization algorithm, post-training with pure reinforcement learning and iterative training alternating between supervised fine-tuning and reinforcement learning. Additionally, we identify several open questions and highlight potential research opportunities in this rapidly advancing field.
논문 링크
대규모 언어 모델에서 향상된 추론을 위한 계층적 다단계 보상 모델에 대하여 / Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
논문 소개
세분화된 LLM 추론에서 보상 해킹과 오류 전파 문제를 해결하는 계층적 보상 모델(HRM)을 제안합니다. 또한 최소한의 계산 비용으로 라벨 다양성과 견고성을 강화하기 위해 계층적 노드 압축(HNC)을 도입하여 MCTS 기반 자동 데이터 주석을 보강합니다.
-
계층적 보상 대 단일 단계 보상 - 기존의 PRM(프로세스 보상 모델)은 단계별로 세분화된 보상을 할당하지만 이전의 실수에 대한 수정에 불이익을 줄 수 있습니다. 반면 HRM은 여러 단계를 연속적으로 평가하여 거친 단위의 일관성을 포착하고 이전 오류를 스스로 수정할 수 있도록 합니다. 따라서 보다 강력하고 신뢰할 수 있는 평가가 가능합니다.
-
"보상 해킹" 해결 - PRM은 종종 정책 모델을 인위적으로 단계별 보상을 극대화하는 근시안적인 전략으로 오도합니다. HRM의 다단계 피드백 프레임워크는 불완전하거나 일관성 없는 추론에 불이익을 주어 보상 해킹 행위를 완화합니다.
-
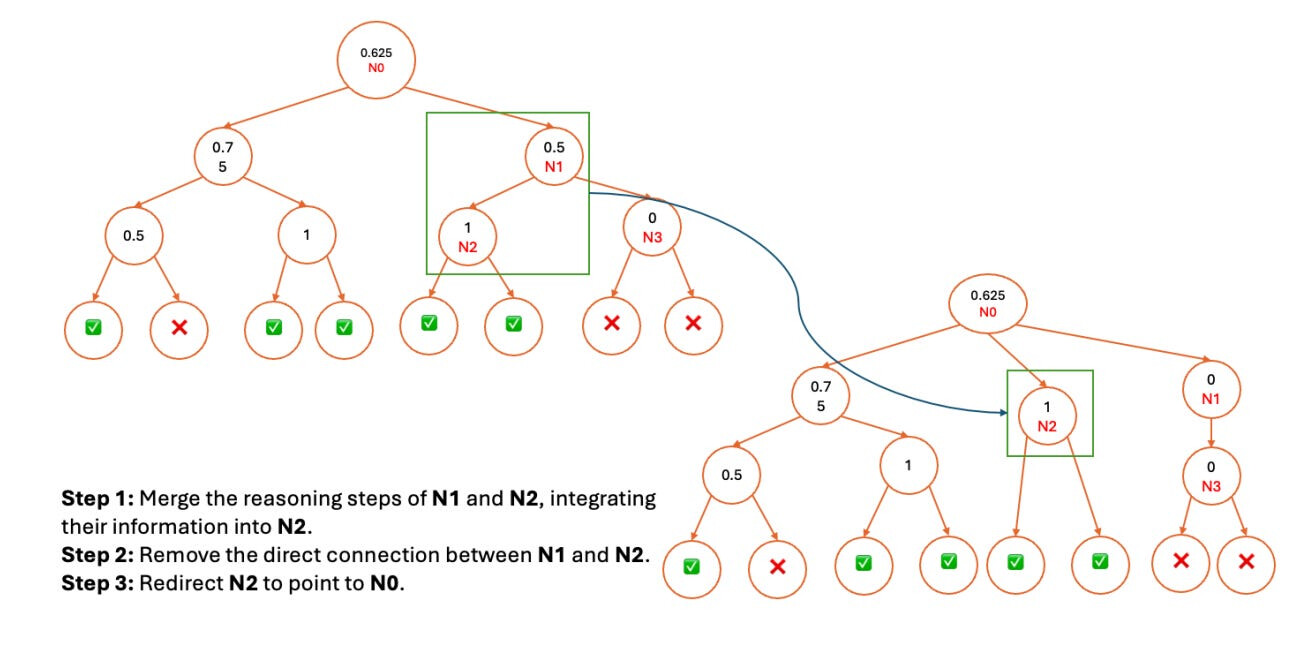
계층적 노드 압축(HNC) - 몬테카를로 트리 검색(MCTS)으로 단계별 주석을 생성하는 것은 계산 부담이 큽니다. HNC 방식은 검색 트리에서 인접한 노드를 병합하여 노이즈를 제어하면서도 추가 비용을 최소화하면서 데이터 세트를 확장합니다. 이렇게 더 다양한 학습 세트는 보상 모델의 견고성을 향상시킵니다.
-
강력한 일반화 - PRM800K 및 교차 도메인 작업(MATH500, GSM8K)에 대한 실험 결과, HRM은 특히 더 깊고 복잡한 사고 사슬에서 표준 결과 기반 또는 단계 기반 보상 모델보다 일관되게 우수한 성능을 보였습니다. HRM으로 미세 조정된 정책 모델은 더 높은 정확도와 더 안정적인 단계별 솔루션을 제공합니다.
It proposes a Hierarchical Reward Model (HRM) that addresses reward hacking and error propagation issues in fine-grained LLM reasoning. They also introduce Hierarchical Node Compression (HNC) to augment MCTS-based automatic data annotation, boosting label diversity and robustness at minimal computational cost.
- Hierarchical vs. single-step rewards - Traditional Process Reward Models (PRM) assign fine-grained rewards per step but can penalize corrections of earlier mistakes. By contrast, HRM assesses multiple consecutive steps, capturing coarse-grained coherence and enabling self-correction of earlier errors. This yields more robust and reliable evaluations.
- Solving "reward hacking" - PRM often misleads policy models into short-sighted strategies that artificially maximize step-level rewards. HRM's multi-step feedback framework penalizes incomplete or incoherent reasoning, mitigating reward hacking behaviors.
- Hierarchical Node Compression (HNC) - Generating step-by-step annotations with Monte Carlo Tree Search (MCTS) is computationally heavy. The HNC method merges adjacent nodes in the search tree, expanding the dataset with controlled noise yet minimal extra cost. This more diverse training set enhances the reward model's robustness.
- Stronger generalization - Experiments on PRM800K and cross-domain tasks (MATH500, GSM8K) show HRM consistently outperforms standard outcome-based or step-based reward models, particularly on deeper, more complex chains of thought. Policy models fine-tuned with HRM yield higher accuracy and more stable step-by-step solutions.
논문 초록(Abstract)
최근 연구에 따르면 대규모 언어 모델(LLM)은 감독된 미세 조정 또는 강화 학습을 통해 강력한 추론 능력을 달성할 수 있습니다. 그러나 핵심 접근 방식인 프로세스 보상 모델(PRM)은 보상 해킹으로 인해 최적의 중간 단계를 식별하는 데 있어 신뢰성이 떨어집니다. 이 논문에서는 새로운 보상 모델 접근 방식인 계층적 보상 모델(HRM)을 제안하는데, 이는 개별 및 연속 추론 단계를 세분화된 수준과 거친 수준에서 모두 평가합니다. HRM은 특히 이전 추론 단계가 틀렸을 때 추론의 일관성과 자기 성찰을 평가하는 데 더 효과적입니다. 또한 몬테카를로 트리 검색(MCTS)을 통한 PRM 학습 데이터 자동 생성의 비효율성을 해결하기 위해 트리 구조에서 노드 병합(연속된 두 추론 단계를 하나의 단계로 결합)을 기반으로 하는 가볍고 효과적인 데이터 증강 전략인 계층적 노드 압축(HNC)을 도입합니다. 이 접근 방식은 계산 오버헤드를 무시할 수 있는 수준으로 HRM에 대한 MCTS 결과를 다양화하여 노이즈를 도입함으로써 라벨의 견고성을 향상시킵니다. PRM800K 데이터 세트에 대한 경험적 결과는 HNC와 함께 HRM이 PRM에 비해 평가에서 우수한 안정성과 신뢰성을 달성한다는 것을 보여줍니다. 또한 MATH500과 GSM8K에 대한 교차 도메인 평가에서는 다양한 추론 작업에서 HRM의 우수한 일반화 및 견고성이 확인되었습니다. 모든 실험에 대한 코드는 https: //github.com/tengwang0318/hierarchial_reward_model 에서 공개될 예정입니다.
Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM's superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
논문 링크
더 읽어보기
https: //github.com/tengwang0318/hierarchial_reward_model
https://x.com/omarsar0/status/1902360668856315990
DAPO: 규모에 맞는 오픈소스 LLM 강화 학습 시스템 / DAPO: An Open-Source LLM Reinforcement Learning System at Scale
논문 소개
LLM의 연쇄 추론 기능을 강화하는 완전 오픈소스 대규모 RL 시스템인 DAPO를 소개합니다.
DAPO는 PPO 스타일 학습에서 클리핑 임계값("클립-하이퍼")을 높여 엔트로피 붕괴를 방지하고 정책이 더 다양한 토큰을 탐색할 수 있도록 지원합니다.
항상 맞거나 항상 틀린 샘플을 걸러냄으로써 DAPO는 유용한 그라데이션 신호가 있는 프롬프트에 학습을 집중하여 더 적은 업데이트 횟수로 수렴 속도를 높입니다.
샘플 수준에서 손실을 평균화하는 대신, DAPO는 토큰별로 정책 그라데이션을 적용하여 각 추론 단계를 중요하게 만듭니다. 이를 통해 고품질과 길이에 적합한 출력을 모두 보장합니다.
시스템은 지나치게 긴 답변을 가려주거나 부드럽게 불이익을 주어 무의미한 장황함이나 반복적인 텍스트를 방지합니다.
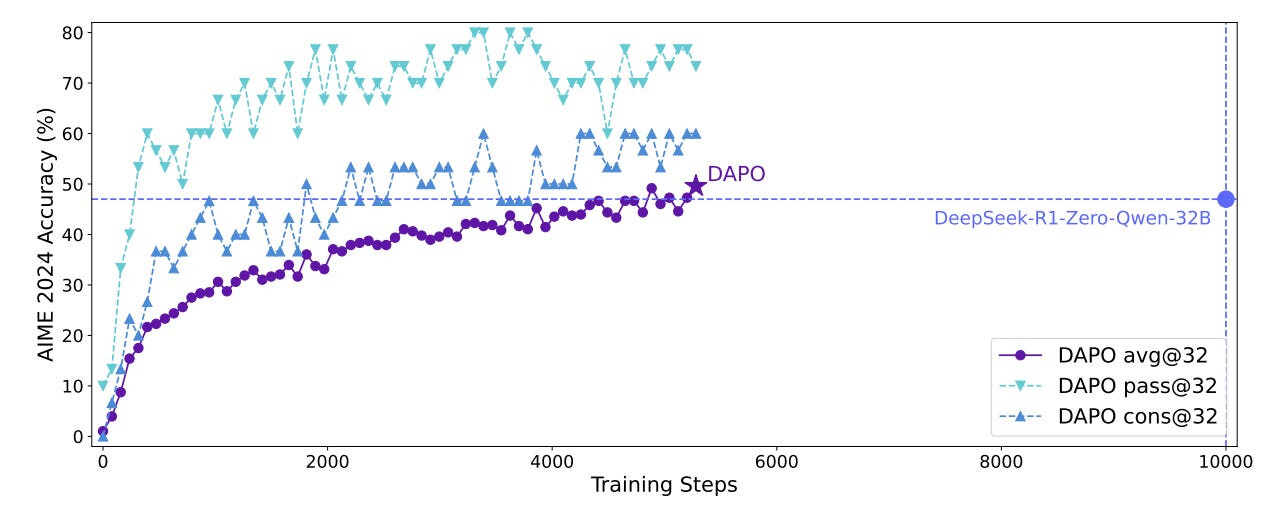
DAPO는 AIME 2024 테스트 세트에서 SOTA 수학 성능을 달성했습니다. 특히 Qwen2.5-32B 기반에서 학습된 DAPO는 50%의 정확도를 달성하여 더 적은 학습 시간으로 DeepSeek의 R1보다 뛰어난 성능을 보이며 대규모 오픈소스 재현성을 보여줍니다.
It introduces DAPO, a fully open-source, large-scale RL system that boosts the chain-of-thought reasoning capabilities of LLMs.
DAPO raises the upper clipping threshold ("Clip-Higher") in PPO-style training, preventing entropy collapse and helping the policy explore more diverse tokens.
By filtering out samples that are always correct or always wrong, DAPO focuses training on prompts with useful gradient signals, speeding up convergence in fewer updates.
Instead of averaging losses at the sample level, DAPO applies policy gradients per token, making each reasoning step matter. This ensures both high-quality and length-appropriate outputs.
The system masks or softly penalizes excessively long answers, preventing meaningless verbosity or repetitive text.
DAPO achieves SOTA math performance on the AIME 2024 test set. Specifically, DAPO trained from a Qwen2.5-32B base achieves 50% accuracy, outperforming DeepSeek's R1 with less training time, and showcasing open-source reproducibility at scale.
논문 초록(Abstract)
추론 스케일링은 복잡한 추론을 이끌어내는 핵심 기술인 강화 학습을 통해 전례 없는 추론 능력을 갖춘 LLM의 역량을 강화합니다. 그러나 최첨단 추론 LLM의 주요 기술적 세부 사항은 숨겨져 있어(예: OpenAI o1 블로그 및 DeepSeek R1 기술 보고서), 커뮤니티에서는 여전히 RL 학습 결과를 재현하는 데 어려움을 겪고 있습니다. 저희는 $\textbf{D}커플드 클립과 \textbf{D}동적 s\textbf{A}mpling \textbf{P}정책 \textbf{O}최적화(\textbf{DAPO}$) 알고리즘을 제안하고 Qwen2.5-32B 베이스 모델을 사용하여 AIME 2024에서 50점을 달성하는 최첨단 대규모 RL 시스템을 완전 오픈소스화했습니다. 학습 세부 사항을 공개하지 않는 기존 작업과 달리, 대규모 LLM RL을 성공으로 이끄는 알고리즘의 네 가지 핵심 기술을 소개합니다. 또한 신중하게 큐레이션 및 처리된 데이터 세트와 함께 verl 프레임워크에 구축된 학습 코드를 오픈소스로 공개합니다. 이러한 오픈소스 시스템의 구성 요소는 재현성을 향상시키고 대규모 LLM RL의 향후 연구를 지원합니다.
Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}ecoupled Clip and \textbf{D}ynamic s\textbf{A}mpling \textbf{P}olicy \textbf{O}ptimization (\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1902364950821257288
스킬의 최적 스케일링 연산: 지식 대 추론 / Compute Optimal Scaling of Skills: Knowledge vs Reasoning
논문 소개
위스콘신 대학과 Meta AI의 연구원들은 LLM에서 서로 다른 기술(지식 기반 QA와 코드 생성)이 어떻게 대조적인 최적의 확장 동작을 보이는지 조사합니다. 이들의 핵심 질문은 모델 크기와 데이터 볼륨 간의 컴퓨팅 최적 절충이 학습하는 스킬의 유형에 따라 달라질까요? 놀랍게도 대답은 '그렇다'로, 기술별로 '데이터 집약적'인 것과 '용량 집약적'인 선호도가 뚜렷하게 나타났습니다. 하이라이트:
-
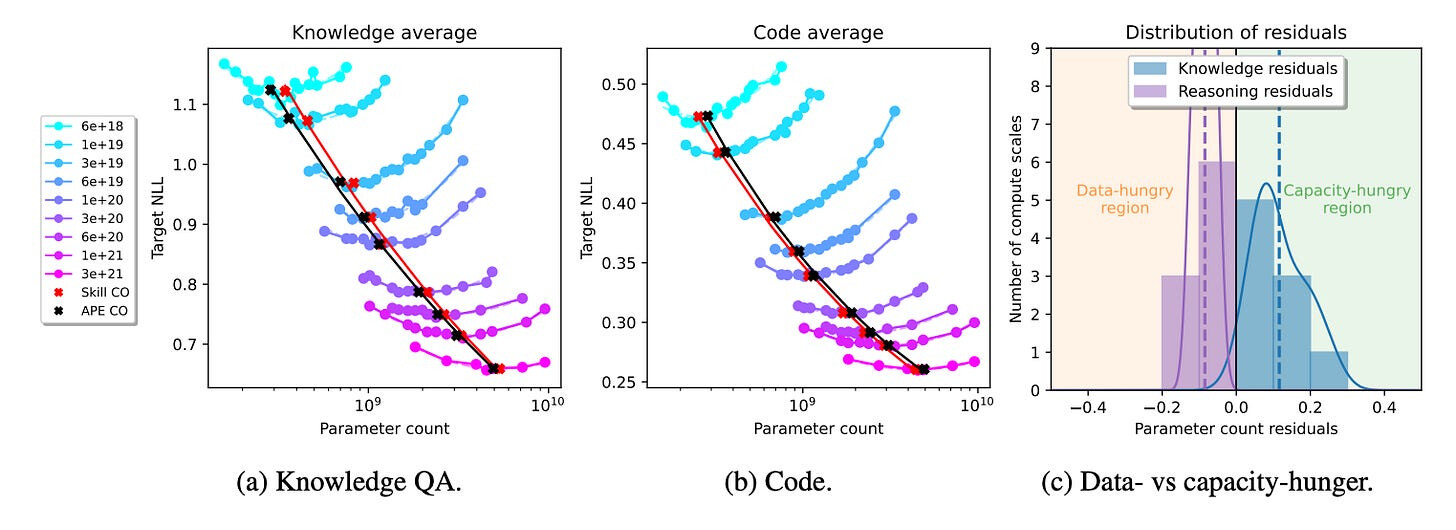
기술 의존적 확장 법칙 - 기존의 확장 법칙은 일반적인 검증 세트의 전체 손실을 최적화합니다. 그러나 이 논문에서는 지식 작업은 더 큰 모델(용량 집약적)을 선호하는 반면, 코드 작업은 더 많은 데이터 토큰(데이터 집약적)을 선호한다는 것을 보여줍니다.
-
데이터 균형을 맞춘 후에도 차이가 지속됨 - 사전 학습 조합을 조정(예: 코드 데이터 추가)하면 해당 스킬의 최적 비율을 바꿀 수 있지만 근본적인 차이는 여전히 남아 있습니다. 지식 기반 QA는 여전히 더 많은 매개변수가 필요한 경향이 있으며, 코드는 여전히 더 큰 데이터 예산의 이점을 누리고 있습니다.
-
검증 세트의 영향력 - 최종 스킬 조합을 반영하지 않는 검증 세트를 선택하면 낮은 컴퓨팅 규모에서는 컴퓨팅 최적 모델 크기가 30~50%까지 잘못 정렬될 수 있습니다. 더 높은 규모에서도 최적이 아닌 유효성 검사 세트는 최상의 파라미터 수를 10% 이상 왜곡합니다.
-
실용적인 시사점 - 모델 개발자는 실제 기술 조합을 나타내는 검증 세트를 선택하거나 설계해야 합니다. 궁극적인 목표가 지식 기반 QA에서 탁월한 역량을 발휘하는 것이라면, 더 많은 역량을 필요로 하는 전략이 필요할 수 있습니다. 코딩 작업이라면 데이터를 많이 사용하는 학습에 집중할 수 있습니다.
Researchers from the University of Wisconsin and Meta AI investigate how different skills (knowledge-based QA vs. code generation) exhibit contrasting optimal scaling behaviors in LLMs. Their key question: does the compute-optimal trade-off between model size and data volume depend on the type of skill being learned? Surprisingly, the answer is yes--they show distinct "data-hungry" vs. "capacity-hungry" preferences per skill. Highlights:
- Skill-dependent scaling laws - Traditional scaling laws optimize the overall loss on a generic validation set. However, this paper shows that knowledge tasks prefer bigger models (capacity-hungry), while code tasks prefer more data tokens (data-hungry).
- Differences persist even after balancing data - Tweaking the pretraining mix (e.g. adding more code data) can shift that skill's optimal ratio, but fundamental differences remain. Knowledge-based QA still tends to need more parameters, code still benefits from bigger data budgets.
- Huge impact of validation set - Choosing a validation set that doesn't reflect the final skill mix can lead to misaligned compute-optimal model sizes by 30%-50% at lower compute scales. Even at higher scales, suboptimal validation sets skew the best parameter count by over 10%.
- Practical takeaway - Model developers must pick or design validation sets that represent the real skill mix. If your ultimate goal is to excel at knowledge-based QA, you likely need a more capacity-hungry strategy. If it's coding tasks, you might focus on data-hungry training.
논문 초록(Abstract)
스케일링 법칙은 LLM 개발 파이프라인의 중요한 구성 요소로, 가장 유명한 것은 '계산 최적' 트레이드오프 파라미터 수와 데이터 세트 크기와 같은 학습 결정을 예측하는 방법이며, 최근에는 다른 중요한 결정 목록도 늘어나고 있습니다. 이 연구에서는 컴퓨팅 최적 스케일링 동작이 기술에 따라 달라질 수 있는지를 살펴봅니다. 특히, 지식 기반 QA 및 코드 생성과 같은 지식 및 추론 기반 기술을 살펴본 결과, 스케일링 법칙은 기술 의존적이라는 긍정적인 대답을 얻었습니다. 다음으로, 기술 의존적 스케일링이 사전 학습 데이터믹스의 인공물인지 이해하기 위해 다양한 데이터믹스를 광범위하게 제거한 결과, 데이터믹스 차이를 보정할 때도 지식과 코드가 스케일링 행동에 근본적인 차이를 보인다는 사실을 발견했습니다. 마지막으로 검증 세트를 사용한 표준 컴퓨팅 최적 스케일링과의 관계를 분석한 결과, 잘못 지정된 검증 세트는 기술 구성에 따라 컴퓨팅 최적 매개변수 수에 거의 50%까지 영향을 미칠 수 있다는 사실을 발견했습니다.
Scaling laws are a critical component of the LLM development pipeline, most famously as a way to forecast training decisions such as 'compute-optimally' trading-off parameter count and dataset size, alongside a more recent growing list of other crucial decisions. In this work, we ask whether compute-optimal scaling behaviour can be skill-dependent. In particular, we examine knowledge and reasoning-based skills such as knowledge-based QA and code generation, and we answer this question in the affirmative: scaling laws are skill-dependent. Next, to understand whether skill-dependent scaling is an artefact of the pretraining datamix, we conduct an extensive ablation of different datamixes and find that, also when correcting for datamix differences, knowledge and code exhibit fundamental differences in scaling behaviour. We conclude with an analysis of how our findings relate to standard compute-optimal scaling using a validation set, and find that a misspecified validation set can impact compute-optimal parameter count by nearly 50%, depending on its skill composition.
논문 링크
더 읽어보기
https://x.com/nick11roberts/status/1902875088438833291
생각하는 기계: LLM 기반 추론 전략에 관한 서베이 논문 / Thinking Machines: A Survey of LLM based Reasoning Strategies
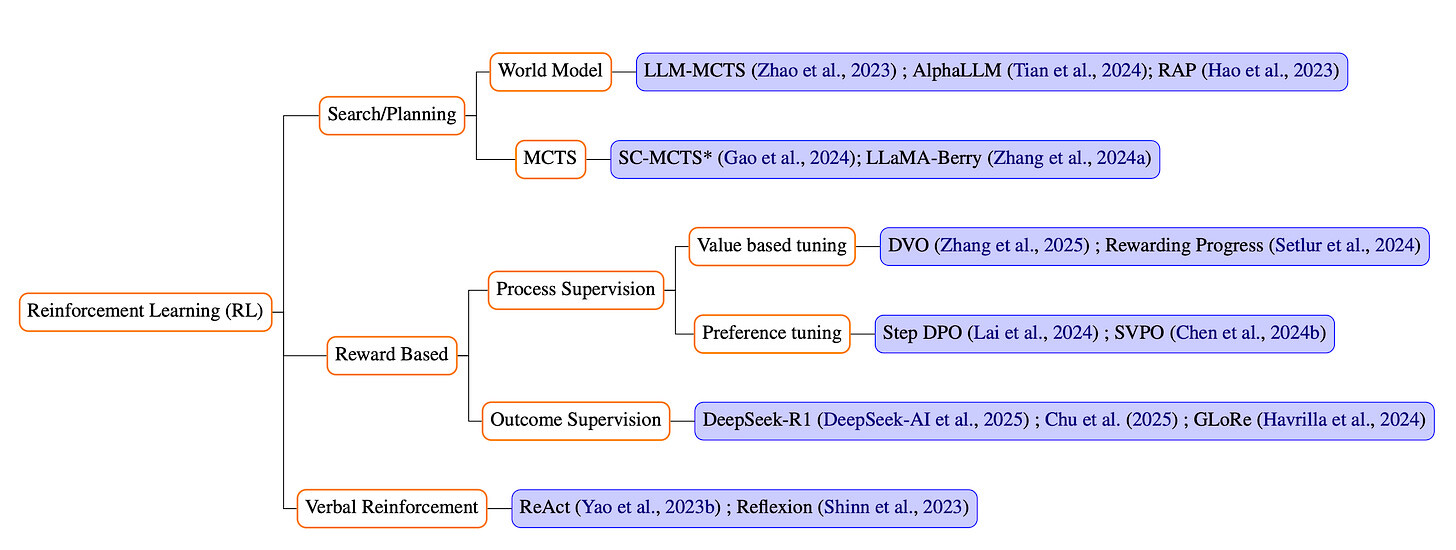
논문 소개
이 서베이 논문은 기존의 추론 기법에 대한 개요와 비교를 제공하고 추론이 내재된 언어 모델에 대한 체계적인 조사 결과를 제시합니다.
This survey provides an overview and comparison of existing reasoning techniques and presents a systematic survey of reasoning-imbued language models.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 언어 기반 작업에 매우 능숙합니다. 이들의 언어 능력은 미래 인공지능(AGI) 경쟁의 선두에 서게 했습니다. 그러나 자세히 살펴보면 Valmeekam 외(2024), Zecevic 외(2023), Wu 외(2024)는 언어 능력과 추론 능력 사이에 상당한 격차가 있음을 강조합니다. LLM과 비전 언어 모델(VLM)의 추론은 이러한 모델이 자신의 행동과 반응을 사고하고 재평가할 수 있게 함으로써 이 격차를 해소하는 것을 목표로 합니다. 추론은 복잡한 문제 해결을 위한 필수 역량이며 인공지능(AI)에 대한 신뢰를 구축하기 위한 필수 단계입니다. 이를 통해 의료, 은행, 법률, 국방, 보안 등과 같은 민감한 영역에 AI를 배포하는 데 적합합니다. 최근에는 OpenAI O1과 DeepSeek R1과 같은 강력한 추론 모델이 등장하면서 추론 부여가 LLM에서 중요한 연구 주제가 되었습니다. 이 논문에서는 기존 추론 기법에 대한 자세한 개요와 비교를 제공하고 추론 부여 언어 모델에 대한 체계적인 조사를 제시합니다. 또한 현재 당면한 과제를 연구하고 연구 결과를 제시합니다.
Large Language Models (LLMs) are highly proficient in language-based tasks. Their language capabilities have positioned them at the forefront of the future AGI (Artificial General Intelligence) race. However, on closer inspection, Valmeekam et al. (2024); Zecevic et al. (2023); Wu et al. (2024) highlight a significant gap between their language proficiency and reasoning abilities. Reasoning in LLMs and Vision Language Models (VLMs) aims to bridge this gap by enabling these models to think and re-evaluate their actions and responses. Reasoning is an essential capability for complex problem-solving and a necessary step toward establishing trust in Artificial Intelligence (AI). This will make AI suitable for deployment in sensitive domains, such as healthcare, banking, law, defense, security etc. In recent times, with the advent of powerful reasoning models like OpenAI O1 and DeepSeek R1, reasoning endowment has become a critical research topic in LLMs. In this paper, we provide a detailed overview and comparison of existing reasoning techniques and present a systematic survey of reasoning-imbued language models. We also study current challenges and present our findings.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1901645973681823962
지나친 생각은 그만: 대규모 언어 모델을 위한 효율적인 추론에 관한 서베이 논문 / Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
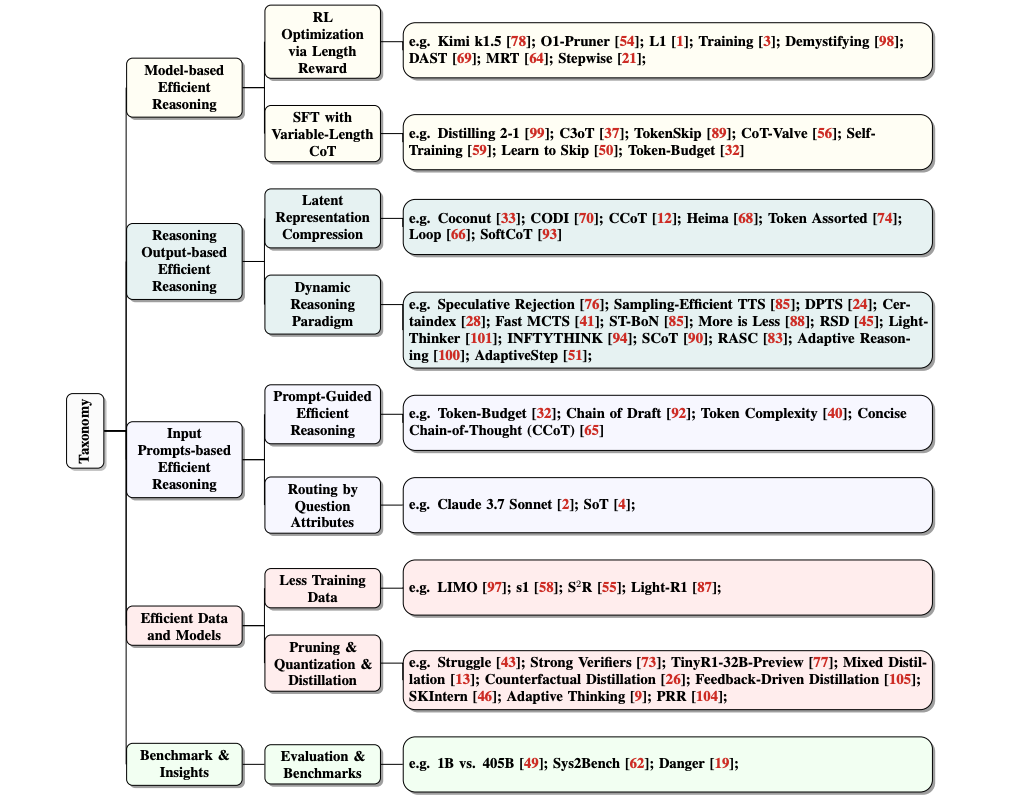
논문 소개
이 새로운 서베이 논문은 대규모 추론 모델(LRM)의 '오버씽킹 현상'을 해결하기 위한 기술을 조사하며, 기존 방법을 모델 기반 최적화, 출력 기반 추론 감소, 프롬프트 기반 효율성 향상으로 분류합니다. 이 서베이 논문은 OpenAI o1 및 DeepSeek-R1과 같은 모델에서 추론 능력과 계산 효율성의 균형을 맞추기 위한 지속적인 노력을 강조합니다.
This new survey investigates techniques to address the "overthinking phenomenon" in Large Reasoning Models (LRMs), categorizing existing methods into model-based optimizations, output-based reasoning reductions, and prompt-based efficiency enhancements. The survey highlights ongoing efforts to balance reasoning capability and computational efficiency in models like OpenAI o1 and DeepSeek-R1.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 복잡한 작업에서 놀라운 성능을 보여 왔습니다. 최근 OpenAI o1 및 DeepSeek-R1과 같은 대규모 추론 모델(LRM)의 발전은 수학 및 프로그래밍과 같은 시스템-2 추론 영역에서 감독 미세 조정(SFT) 및 강화 학습(RL) 기술을 활용하여 연쇄적 사고(CoT) 추론을 강화함으로써 성능을 더욱 향상시켰습니다. 그러나 CoT 추론 시퀀스가 길어지면 성능은 향상되지만, '오버씽킹 현상'으로 알려진 장황하고 중복된 출력으로 인해 상당한 계산 오버헤드가 발생하게 됩니다. 이 논문에서는 LLM에서 효율적인 추론을 달성하기 위한 현재 진행 상황을 체계적으로 조사하고 탐색하기 위한 최초의 구조화된 설문 조사를 제공합니다. 전반적으로 LLM의 고유한 메커니즘을 바탕으로 기존 연구를 (1) 전체 길이의 추론 모델을 보다 간결한 추론 모델로 최적화하거나 효율적인 추론 모델을 직접 학습하는 것을 고려하는 모델 기반 효율적 추론, (2) 추론 과정에서 추론 단계와 길이를 동적으로 줄이는 것을 목표로 하는 추론 출력 기반 효율적 추론, (3) 난이도나 길이 제어와 같은 입력 프롬프트 속성을 기반으로 추론 효율성을 높이려는 입력 프롬프트 기반 효율적 추론으로 분류하고, 각 방향의 주요 연구 결과를 살펴봅니다. 또한 추론 모델 학습을 위한 효율적인 데이터 활용을 소개하고, 소규모 언어 모델의 추론 능력을 살펴보고, 평가 방법과 벤치마킹에 대해 논의합니다.
Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1903109602826457531
A-MEM: LLM 에이전트를 위한 에이전트 메모리 / A-MEM: Agentic Memory for LLM Agents
논문 소개
럿거스 대학교와 앤트 그룹의 연구원들은 복잡한 실제 작업에서 장기 기억의 필요성을 해결하기 위해 LLM 에이전트를 위한 새로운 에이전트 메모리 시스템을 제안합니다. 주요 내용은 다음과 같습니다:
-
역동적이고 제텔카스텐에서 영감을 받은 디자인 - A-MEM은 텍스트 속성(키워드, 태그)과 임베딩이 포함된 포괄적인 메모리 메모를 자율적으로 생성한 다음 의미적 유사성을 기반으로 이를 상호 연결합니다. 이 접근 방식은 원자적 노트 작성과 유연한 연결이라는 Zettelkasten 방식에서 영감을 얻었지만, LLM 워크플로에 맞게 조정되어 보다 적응력 있고 확장 가능한 지식 관리를 가능하게 합니다.
-
자동 '메모리 진화' - 새로운 메모가 도착하면 시스템은 메모를 추가할 뿐만 아니라 태그와 문맥 설명을 다듬어 관련 이전 메모를 업데이트합니다. 이러한 지속적인 업데이트를 통해 시간이 지남에 따라 더 깊은 연관성을 포착할 수 있는 보다 일관성 있고 지속적으로 개선되는 메모리 네트워크를 구축할 수 있습니다.
-
우수한 멀티홉 추론 - 긴 대화형 데이터 세트에 대한 경험적 테스트 결과, 특히 여러 정보에 걸쳐 링크를 필요로 하는 복잡한 쿼리의 경우 A-MEM이 MemGPT나 MemoryBank 같은 정적 메모리 방식보다 일관되게 뛰어난 성능을 발휘하는 것으로 나타났습니다. 또한 상위 k개의 관련성 있는 메모리만 선택적으로 검색하여 정확도는 유지하면서 추론 비용을 낮춤으로써 토큰 사용량을 크게 줄여줍니다.
Researchers from Rutgers University and Ant Group propose a new agentic memory system for LLM agents, addressing the need for long-term memory in complex real-world tasks. Key highlights include:
- Dynamic & Zettelkasten-inspired design - A-MEM autonomously creates comprehensive memory notes--each with textual attributes (keywords, tags) and embeddings--then interlinks them based on semantic similarities. The approach is inspired by the Zettelkasten method of atomic note-taking and flexible linking, but adapted to LLM workflows, allowing more adaptive and extensible knowledge management.
- Automatic "memory evolution" - When a new memory arrives, the system not only adds it but updates relevant older memories by refining their tags and contextual descriptions. This continuous update enables a more coherent, ever-improving memory network capable of capturing deeper connections over time.
- Superior multi-hop reasoning - Empirical tests on long conversational datasets show that A-MEM consistently outperforms static-memory methods like MemGPT or MemoryBank, especially for complex queries requiring links across multiple pieces of information. It also reduces token usage significantly by selectively retrieving only top-k relevant memories, lowering inference costs without sacrificing accuracy.
논문 초록(Abstract)
대규모 언어 모델(LLM) 에이전트는 복잡한 실제 작업을 위해 외부 도구를 효과적으로 사용할 수 있지만, 과거 경험을 활용하기 위해서는 메모리 시스템이 필요합니다. 현재의 메모리 시스템은 기본적인 저장과 검색은 가능하지만 그래프 데이터베이스를 통합하려는 최근의 시도에도 불구하고 정교한 메모리 구성이 부족합니다. 또한 이러한 시스템의 고정된 연산과 구조는 다양한 작업에 대한 적응성을 제한합니다. 이 논문에서는 이러한 한계를 해결하기 위해 에이전트 방식으로 메모리를 동적으로 구성할 수 있는 LLM 에이전트를 위한 새로운 에이전트 메모리 시스템을 제안합니다. 제텔카스텐 방법의 기본 원리에 따라 동적 색인 및 연결을 통해 상호 연결된 지식 네트워크를 생성하도록 메모리 시스템을 설계했습니다. 새 메모가 추가되면 문맥 설명, 키워드, 태그 등 여러 구조화된 속성이 포함된 종합적인 메모를 생성합니다. 그런 다음, 시스템은 과거 메모를 분석해 관련성을 파악하고 의미 있는 유사성이 존재하는 곳에 링크를 설정합니다. 또한, 이 프로세스를 통해 새로운 기억이 통합되면 기존 기록 기억의 문맥적 표현과 속성을 업데이트하여 메모리 네트워크가 지속적으로 이해를 개선할 수 있도록 하는 메모리 진화를 가능하게 합니다. 이러한 접근 방식은 제텔카스텐의 구조화된 조직 원칙과 에이전트 중심 의사 결정의 유연성을 결합하여 보다 적응적이고 상황에 맞는 메모리 관리를 가능하게 합니다. 6가지 파운데이션 모델에 대한 경험적 실험 결과, 기존 SOTA 기준선 대비 탁월한 개선 효과가 나타났습니다. 성능 평가를 위한 소스 코드는 GitHub - WujiangXu/A-mem: The code for NeurIPS 2025 paper "A-Mem: Agentic Memory for LLM Agents" 에서 확인할 수 있으며, 에이전트 메모리 시스템의 소스 코드는 GitHub - agiresearch/A-mem: A-MEM: Agentic Memory for LLM Agents 에서 확인할 수 있습니다.
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems' fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code for evaluating performance is available at GitHub - WujiangXu/A-mem: The code for NeurIPS 2025 paper "A-Mem: Agentic Memory for LLM Agents", while the source code of agentic memory system is available at GitHub - agiresearch/A-mem: A-MEM: Agentic Memory for LLM Agents.
논문 링크
더 읽어보기
DeepMesh: 강화 학습을 통한 자동 회귀 아티스트 메시 생성 / DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
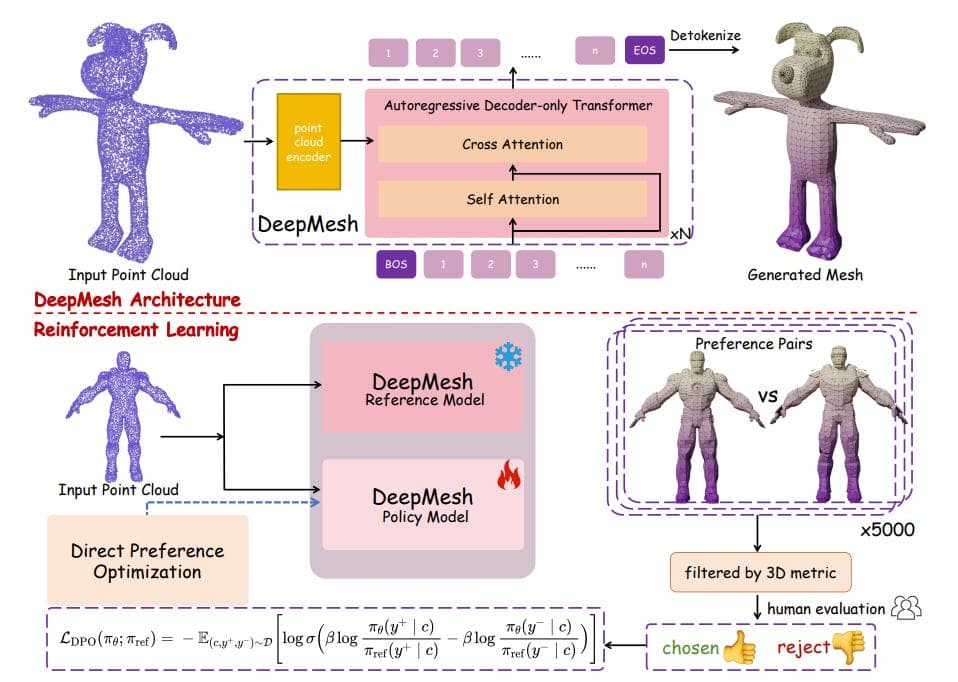
논문 소개
칭화대학교, 난양공과대학교, 성슈의 연구원들은 아티스트와 같은 토폴로지로 고품질 3D 메시를 생성하는 트랜스포머 기반 시스템인 DeepMesh를 제안합니다. 주요 아이디어는 다음과 같습니다:
-
효율적인 메시 토큰화 - 기하학적 디테일을 유지하면서 메시 시퀀스를 최대 72%까지 압축하는 새로운 알고리즘을 도입하여 대규모로 고해상도 메시를 생성할 수 있도록 합니다.
-
아티스트와 유사한 토폴로지 - 기존 접근 방식의 조밀하거나 불완전한 메시와 달리, 딥메시는 정교한 사전 학습 프로세스와 더 나은 데이터 큐레이션을 통해 심미적이고 편집하기 쉬운 구조화된 삼각형 레이아웃을 예측합니다.
-
사람의 피드백을 통한 강화 학습 - 직접 선호도 최적화(DPO)를 채택하여 메시 생성을 사람의 선호도에 맞게 조정합니다. 지오메트리 품질과 미학에 대한 사용자 레이블을 쌍으로 수집한 다음 모델을 미세 조정하여 더욱 매력적이고 완벽한 메시를 생성합니다.
-
확장 가능한 생성 - 딥메시는 대규모 메시(수만 개의 면)를 처리할 수 있으며 포인트 클라우드 및 이미지 기반 컨디셔닝을 모두 지원하여 기하학적 정확도와 사용자 평가에서 MeshAnythingv2 및 BPT와 같은 기준선보다 뛰어난 성능을 발휘합니다.
Researchers from Tsinghua University, Nanyang Technological University, and ShengShu propose DeepMesh, a transformer-based system that generates high-quality 3D meshes with artist-like topology. Key ideas include:
- Efficient mesh tokenization - They introduce a new algorithm that compresses mesh sequences by ~72% while preserving geometric detail, enabling higher-resolution mesh generation at scale.
- Artist-like topology - Unlike dense or incomplete meshes from existing approaches, DeepMesh predicts structured triangle layouts that are aesthetic and easy to edit, thanks to a refined pre-training process and better data curation.
- Reinforcement Learning with human feedback - The authors adopt Direct Preference Optimization (DPO) to align mesh generation with human preferences. They collect pairwise user labels on geometry quality and aesthetics, then fine-tune the model to produce more appealing, complete meshes.
- Scalable generation - DeepMesh can handle large meshes (tens of thousands of faces) and supports both point cloud- and image-based conditioning, outperforming baselines like MeshAnythingv2 and BPT in geometric accuracy and user ratings.
논문 초록(Abstract)
트라이앵글 메시는 3D 애플리케이션에서 효율적인 조작과 렌더링을 위해 중요한 역할을 합니다. 자동 회귀 방법은 이산 정점 토큰을 예측하여 구조화된 메시를 생성하지만, 제한된 면 수와 메시의 불완전성으로 인해 제약을 받는 경우가 많습니다. 이러한 문제를 해결하기 위해 유니티는 (1) 새로운 토큰화 알고리즘을 통합한 효율적인 사전 학습 전략과 데이터 큐레이션 및 처리 개선, (2) 강화 학습(RL)을 3D 메시 생성에 도입해 직접 선호도 최적화(DPO)를 통한 인간 선호도 정렬이라는 두 가지 핵심 혁신을 통해 메시 생성을 최적화하는 프레임워크인 DeepMesh를 제안합니다. 유니티는 사람의 평가와 3D 메트릭을 결합한 채점 기준을 설계하여 DPO를 위한 선호도 쌍을 수집함으로써 시각적 매력과 기하학적 정확성을 모두 보장합니다. 포인트 클라우드와 이미지를 기반으로 하는 DeepMesh는 복잡한 디테일과 정밀한 토폴로지를 갖춘 메시를 생성하여 정밀도와 품질 면에서 최첨단 방법보다 뛰어난 성능을 발휘합니다. 프로젝트 페이지: DeepMesh
Triangle meshes play a crucial role in 3D applications for efficient manipulation and rendering. While auto-regressive methods generate structured meshes by predicting discrete vertex tokens, they are often constrained by limited face counts and mesh incompleteness. To address these challenges, we propose DeepMesh, a framework that optimizes mesh generation through two key innovations: (1) an efficient pre-training strategy incorporating a novel tokenization algorithm, along with improvements in data curation and processing, and (2) the introduction of Reinforcement Learning (RL) into 3D mesh generation to achieve human preference alignment via Direct Preference Optimization (DPO). We design a scoring standard that combines human evaluation with 3D metrics to collect preference pairs for DPO, ensuring both visual appeal and geometric accuracy. Conditioned on point clouds and images, DeepMesh generates meshes with intricate details and precise topology, outperforming state-of-the-art methods in both precision and quality. Project page: DeepMesh
논문 링크
더 읽어보기
https://x.com/_akhaliq/status/1902713235079299255
딥러닝은 그렇게 신비롭거나 다르지 않습니다 / Deep Learning is Not So Mysterious or Different
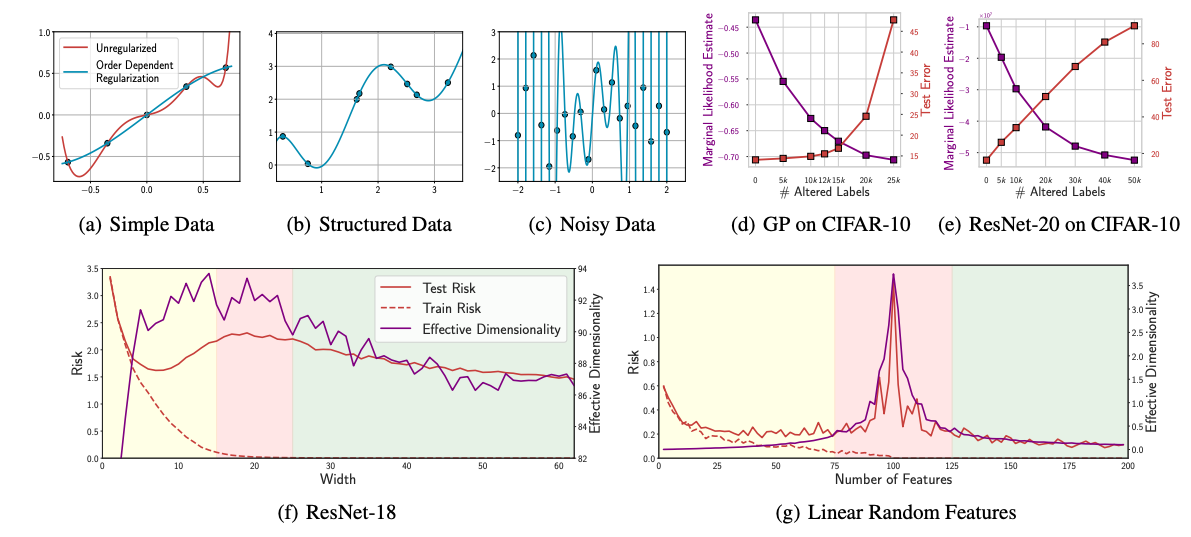
논문 소개
앤드류 고든 윌슨(뉴욕 대학교)은 양성 과적합, 이중 강하, 과모수화 성공과 같은 딥러닝 현상이 신경망에만 국한된 신비로운 현상도 아니고 배타적인 현상도 아니라고 주장합니다. 주요 요점은 다음과 같습니다:
-
양성 과적합 및 이중 하강 설명 - 이러한 현상은 간단한 선형 모델로도 재현할 수 있으며, 신경망의 전유물이라는 주장에 도전합니다. 저자는 차수 의존적 정규화를 특징으로 하는 고차 다항식으로 양성 과적합을 시연하며 유연한 모델이 잡음이 많은 데이터에 완벽하게 맞으면서도 구조화된 데이터가 있을 때 일반화할 수 있음을 강조합니다.
-
통합 원리로서의 소프트 귀납적 편향 - 이 논문은 기존의 하드 제약 대신 소프트 귀납적 편향을 옹호합니다. 과적합을 방지하기 위해 모델의 가설 공간을 제한하는 대신, 모델은 유연성을 유지하면서 관찰된 데이터와 일치하는 더 간단한 솔루션을 소프트하게 선호할 수 있습니다. 예를 들어 고차 항에 대한 페널티가 증가하는 다항식 회귀와 암시적 정규화 효과의 혜택을 받는 신경망 등이 있습니다.
-
확립된 프레임워크가 현상을 설명한다 - 윌슨은 PAC-Bayes와 계산 가능한 가설 경계와 같은 오랜 일반화 프레임워크가 이미 신경망의 수수께끼 같은 동작을 설명한다고 강조합니다. 저자는 딥러닝에 완전히 새로운 일반화 이론이 필요하다는 생각에 반대하며 기존 이론으로도 이러한 현상을 적절히 설명할 수 있다는 점을 강조합니다.
-
딥러닝의 독특한 측면 - 이 논문은 딥러닝이 독특하게 신비로운 것은 아니라고 주장하면서도 모드 연결성(서로 다른 네트워크 최소값의 놀라운 연결성), 표현 학습(적응 기저 함수), 다양한 작업에서 주목할 만한 보편성과 적응성과 같은 신경망의 진정으로 독특한 특성을 인정하고 있습니다.
-
실용적 및 이론적 시사점 - 저자는 신경망 예외주의에 대한 광범위한 믿음을 비판하며, 일반화 이론을 재창조하기보다는 기존의 일반화 이론을 기반으로 커뮤니티 간의 긴밀한 협업을 촉구합니다. 윌슨은 특히 규모에 따른 암묵적 편향과 표현 학습에 관한 딥 러닝의 진정한 미해결 질문을 확인하며 글을 마무리합니다.
Andrew Gordon Wilson (New York University) argues that deep learning phenomena such as benign overfitting, double descent, and the success of overparametrization are neither mysterious nor exclusive to neural networks. Major points include:
- Benign Overfitting & Double Descent Explained - These phenomena are reproducible with simple linear models, challenging their supposed exclusivity to neural networks. The author demonstrates benign overfitting with high-order polynomials featuring order-dependent regularization, emphasizing that flexible models can perfectly fit noisy data yet generalize well when structured data is present.
- Soft Inductive Biases as Unifying Principle - The paper advocates for soft inductive biases instead of traditional hard constraints. Rather than restricting a model's hypothesis space to prevent overfitting, a model can remain flexible, adopting a soft preference for simpler solutions consistent with observed data. Examples include polynomial regression with increasing penalties on higher-order terms and neural networks benefiting from implicit regularization effects.
- Established Frameworks Describe Phenomena - Wilson emphasizes that longstanding generalization frameworks like PAC-Bayes and countable hypothesis bounds already explain the supposedly puzzling behaviors of neural networks. The author argues against the notion that deep learning demands entirely new theories of generalization, highlighting how existing theories adequately address these phenomena.
- Unique Aspects of Deep Learning - While asserting deep learning is not uniquely mysterious, the paper acknowledges genuinely distinctive properties of neural networks, such as mode connectivity (the surprising connectedness of different network minima), representation learning (adaptive basis functions), and their notable universality and adaptability in diverse tasks.
- Practical and Theoretical Implications - The author critiques the widespread belief in neural network exceptionalism, urging closer collaboration between communities to build on established generalization theories rather than reinventing them. Wilson concludes by identifying genuine open questions in deep learning, particularly around scale-dependent implicit biases and representation learning.
논문 초록(Abstract)
심층 신경망은 일반화에 대한 기존의 관념을 무시함으로써 다른 모델 클래스와 다른 모습을 보이는 경우가 많습니다. 비정상적인 일반화 행동의 대표적인 예로는 양성 과적합, 이중 하강, 과매개변수화의 성공 등이 있습니다. 우리는 이러한 현상이 신경망에 고유하거나 특별히 신비로운 현상이 아니라고 주장합니다. 또한 이러한 일반화 동작은 직관적으로 이해할 수 있으며, PAC-Bayes 및 카운트 가능한 가설 경계와 같은 오랜 일반화 프레임워크를 사용하여 엄격하게 특성화할 수 있습니다. 이러한 현상을 설명하는 핵심 통합 원칙으로 소프트 귀납적 편향을 제시합니다. 과적합을 피하기 위해 가설 공간을 제한하는 대신 데이터와 일치하는 더 간단한 솔루션을 부드럽게 선호하면서 유연한 가설 공간을 수용하는 것입니다. 이 원칙은 많은 모델 클래스에서 인코딩할 수 있으므로 딥러닝은 다른 모델 클래스처럼 신비롭거나 다른 것처럼 보이지 않습니다. 그러나 표현 학습 능력, 모드 연결성과 같은 현상, 상대적 보편성 등 다른 측면에서는 딥러닝이 상대적으로 차별화된다는 점도 강조합니다.
Deep neural networks are often seen as different from other model classes by defying conventional notions of generalization. Popular examples of anomalous generalization behaviour include benign overfitting, double descent, and the success of overparametrization. We argue that these phenomena are not distinct to neural networks, or particularly mysterious. Moreover, this generalization behaviour can be intuitively understood, and rigorously characterized using long-standing generalization frameworks such as PAC-Bayes and countable hypothesis bounds. We present soft inductive biases as a key unifying principle in explaining these phenomena: rather than restricting the hypothesis space to avoid overfitting, embrace a flexible hypothesis space, with a soft preference for simpler solutions that are consistent with the data. This principle can be encoded in many model classes, and thus deep learning is not as mysterious or different from other model classes as it might seem. However, we also highlight how deep learning is relatively distinct in other ways, such as its ability for representation learning, phenomena such as mode connectivity, and its relative universality.
논문 링크
에이전트 워크플로우 성능의 예측 인자로서의 GNN / GNNs as Predictors of Agentic Workflow Performances
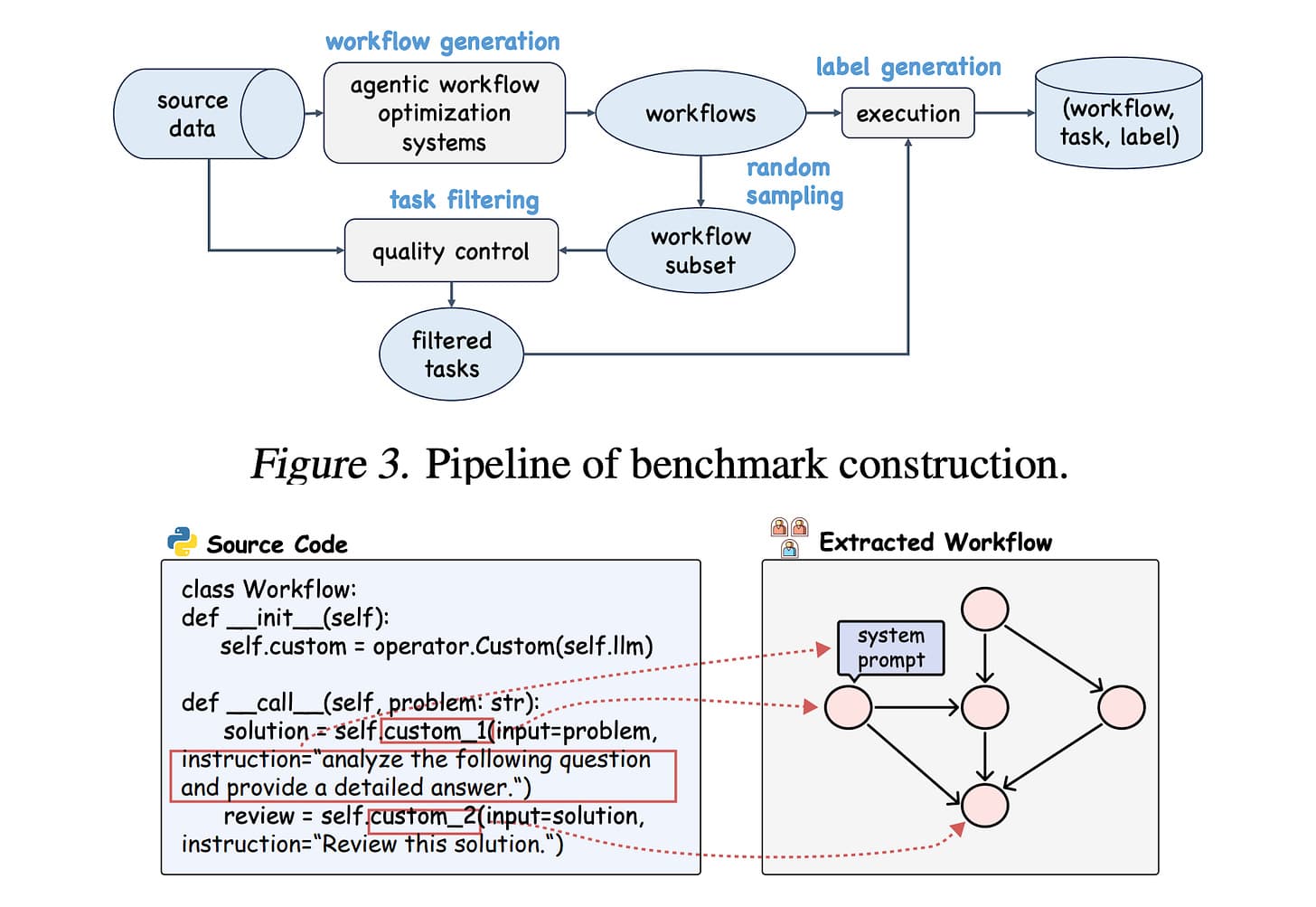
논문 소개
이 연구에서는 에이전트 워크플로우를 자동화하고 최적화하기 위한 GNN 기반 예측자를 평가하기 위한 대규모 벤치마크인 FLORA-Bench를 소개합니다. 그래프 신경망이 다중 에이전트 LLM 워크플로우의 성공을 효율적으로 예측하여 비용이 많이 드는 반복적인 모델 호출을 크게 줄일 수 있음을 보여줍니다.
This work introduces FLORA-Bench, a large-scale benchmark to evaluate GNN-based predictors for automating and optimizing agentic workflows. It shows that Graph Neural Networks can efficiently predict the success of multi-agent LLM workflows, significantly reducing costly repeated model calls.
논문 초록(Abstract)
LLM(대규모 언어 모델)에 의해 호출되는 에이전트 워크플로는 복잡한 작업을 처리하는 데 괄목할 만한 성공을 거두었습니다. 그러나 이러한 워크플로우를 최적화하는 것은 실제 애플리케이션에서 LLM의 광범위한 호출로 인해 비용이 많이 들고 비효율적입니다. 이 입장 논문에서는 이러한 격차를 메우기 위해 에이전트 워크플로를 계산 그래프로 공식화하고 평가를 위한 반복적인 LLM 호출을 피하면서 에이전트 워크플로 성능의 효율적인 예측자로서 그래프 신경망(GNN)을 옹호합니다. 이러한 입장을 경험적으로 뒷받침하기 위해 저희는 에이전트 워크플로우 성능 예측을 위한 GNN을 벤치마킹하기 위한 통합 플랫폼인 FLORA-Bench를 구축했습니다. 광범위한 실험을 통해 다음과 같은 결론에 도달했습니다: GNN은 간단하면서도 효과적인 예측 지표입니다. 이 결론은 GNN의 새로운 적용과 에이전트 워크플로우 최적화를 자동화하는 새로운 방향을 뒷받침합니다. 모든 코드, 모델 및 데이터는 GitHub - youngsoul0731/FLORA-Bench: [Arxiv 2025] Official code and datasets of paper: GNNs as Predictors of Agentic Workflow Performances 에서 확인할 수 있습니다.
Agentic workflows invoked by Large Language Models (LLMs) have achieved remarkable success in handling complex tasks. However, optimizing such workflows is costly and inefficient in real-world applications due to extensive invocations of LLMs. To fill this gap, this position paper formulates agentic workflows as computational graphs and advocates Graph Neural Networks (GNNs) as efficient predictors of agentic workflow performances, avoiding repeated LLM invocations for evaluation. To empirically ground this position, we construct FLORA-Bench, a unified platform for benchmarking GNNs for predicting agentic workflow performances. With extensive experiments, we arrive at the following conclusion: GNNs are simple yet effective predictors. This conclusion supports new applications of GNNs and a novel direction towards automating agentic workflow optimization. All codes, models, and data are available at GitHub - youngsoul0731/FLORA-Bench: [Arxiv 2025] Official code and datasets of paper: GNNs as Predictors of Agentic Workflow Performances.
논문 링크
더 읽어보기
원문
- 이 글은 GPT 모델로 정리한 것으로, 잘못된 부분이 있을 수 있으니 글 아래쪽의 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다.*

![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()