[2025/03/31 ~ 04/06] 이번 주의 주요 ML 논문 (Top ML Papers of the Week)
PyTorchKR



-
이번 주에 선정된 논문들을 살펴보면, 특히 대규모 언어 모델(LLM)과 관련된 연구가 두드러집니다. 많은 논문들이 LLM을 활용한 새로운 방법론이나, 이들의 응용에 대해 다루고 있으며, 특히 다중 모드와의 융합이나 효율성을 높이는 방법론에 초점을 맞추고 있습니다. 예를 들어, Command A와 같은 기업용 LLM, MedAgentSim의 의료 시뮬레이션, 그리고 Test-time Scaling을 통한 효율성 개선 등에 대한 연구가 포함되어 있습니다. 이는 LLM이 다양한 분야에서 효율적이고 실질적인 솔루션을 제공할 수 있는 가능성을 보여줍니다.
-
LLM을 중심으로 하는 연구가 주목받는 이유는 여러 가지가 있습니다. 첫째로, LLM은 다양한 분야에서의 문제 해결에 강력한 도구로 자리 잡고 있으며, 특히 자연어 처리, 정보 검색, 그리고 도메인 특화된 지식 응용에 있어 중요한 역할을 하고 있습니다. 이러한 모델들은 방대한 양의 데이터를 학습하여 복잡한 문제를 해결할 수 있는 잠재력을 가지고 있으며, 이는 연구자들이 계속해서 새로운 방법론을 개발하고 개선하는 원동력이 됩니다. 둘째로, LLM의 효율성을 높이고 비용을 줄이기 위한 다양한 접근법이 활발히 연구되고 있습니다. Test-time Scaling이나 효율적인 추론 알고리즘 개발은 이러한 노력의 일환으로, 모델의 실용성을 높이는 데 기여하고 있습니다.
-
또한, 이번 주 논문들에서는 LLM의 한계를 극복하거나 새로운 접근법을 제시하는 연구들이 많이 포함되어 있습니다. 예를 들어, Retrieval-Augmented Reasoning Model이나 Open Deep Search와 같은 연구는 기존의 LLM 모델이 지니고 있는 한계를 극복하고, 더 나은 성능을 발휘할 수 있는 기회를 제공합니다. 이러한 연구들은 LLM의 응용 가능성을 확장시키며, 다양한 분야와의 융합을 통해 새로운 가치를 창출할 수 있는 기반을 마련하고 있습니다.
PaperBench: 인공지능의 연구 복제 능력 평가하기 / PaperBench: Evaluating AI's Ability to Replicate AI Research

논문 소개
OpenAI는 AI 에이전트가 최첨단 머신러닝 연구 논문을 처음부터 복제할 수 있는지 테스트하기 위해 새로운 벤치마크인 PaperBench를 도입합니다.
-
엄격한 복제 챌린지 - PaperBench는 12개 연구 분야에 걸쳐 총 20개에 달하는 ICML 2024의 전체 ML 논문(총 20개)을 복제하는 에이전트를 평가합니다. 에이전트는 논문을 이해하고, 처음부터 코드베이스를 구축하고, 실험을 실행하여 결과를 일치시켜야 합니다. 각 논문에는 원저자와 공동 설계한 세분화된 루브릭(총 8,316개 과제)이 함께 제공됩니다.
-
LLM 심사위원을 통한 자동 채점 - 평가의 확장성을 위해 팀은 인간 전문가와 높은 일치도(F1 = 0.83)로 복제본에 점수를 매기는 루브릭 기반 심사위원(스캐폴딩이 있는 o3-mini)을 구축했습니다. 또한, 심사위원의 정확성을 평가하기 위한 벤치마크인 JudgeEval을 공개했습니다.
-
프론티어 모델 성능은 보통 수준 - 클로드 3.5 소네트가 21.0%로 가장 높은 점수를 받았고, 그다음으로 o1(13.2%), GPT-4o(4.1%)가 그 뒤를 이었습니다. 런타임이 길고 신속한 튜닝(반복 에이전트)을 사용하더라도 26.0%를 넘긴 모델은 없었습니다. 이와 대조적으로 ML PhD는 논문 3편 하위 집합에서 48시간 만에 41.4%를 기록해 장시간이 소요되는 에이전트 작업에서는 여전히 인간이 앞서고 있음을 보여주었습니다.
-
경량 평가를 위한 CodeDev 변형 - 간소화된 PaperBench Code-Dev 버전은 실행을 생략하고 코드 구조만 채점합니다. o1은 43.4%를 기록하여 런타임 문제를 제외하면 더 많은 가능성을 보여주었습니다.
-
실패 모드 및 인사이트 - 모델은 종종 "조기에 포기"하고, 전략적 계획이 부족하며, 반복에 실패했습니다. Claude는 기본 에이전트(보다 자유로운 형태)를 더 잘 수행한 반면, o1은 반복 에이전트(구조화된 프롬프트)의 이점을 활용했습니다. 이는 에이전트가 프롬프트와 스캐폴딩에 얼마나 민감한지를 잘 보여줍니다.
OpenAI introduces a new benchmark, PaperBench, to test whether AI agents can replicate cutting-edge machine learning research papers, from scratch.
- A rigorous replication challenge - PaperBench evaluates agents on reproducing entire ML papers from ICML 2024 (20 total, across 12 research areas). Agents must understand the paper, build the codebase from scratch, and run experiments to match results. Each paper comes with a fine-grained rubric (~8,316 tasks total) co-designed with the original authors.
- Automatic grading with LLM judges - To make evaluation scalable, the team built a rubric-based judge (o3-mini with scaffolding) that scores replications with high agreement (F1 = 0.83) against human experts. They also release JudgeEval, a benchmark for assessing judge accuracy.
- Frontier model performance is modest - Claude 3.5 Sonnet scored highest with 21.0%, followed by o1 (13.2%) and GPT-4o (4.1%). Even with longer runtimes and prompt tuning (IterativeAgent), no model surpassed a 26.0% score. By contrast, ML PhDs hit 41.4% on a 3-paper subset in 48 hours, showing humans still lead in long-horizon agentic tasks.
- CodeDev variant for lightweight evals - A simplified PaperBench Code-Dev version skips execution and just grades code structure. o1 scored 43.4% there, showing more promise when runtime issues are excluded.
- Failure modes and insights - Models often "gave up early," lacked strategic planning, and failed to iterate. Claude did better with BasicAgent (freer form), while o1 benefited from IterativeAgent (structured prompts). This highlights how sensitive agents are to prompting and scaffolding.
논문 초록(Abstract)
최첨단 AI 연구를 복제하는 AI 에이전트의 능력을 평가하는 벤치마크인 PaperBench를 소개합니다. 에이전트는 논문 기여도 이해, 코드베이스 개발, 성공적인 실험 실행 등 20개의 ICML 2024 스포트라이트 및 구두 논문을 처음부터 다시 복제해야 합니다. 객관적인 평가를 위해 각 복제 과제를 명확한 채점 기준과 함께 하위 과제로 계층적으로 세분화하는 루브릭을 개발합니다. PaperBench에는 총 8,316개의 개별 채점 가능한 작업이 포함되어 있습니다. 루브릭은 정확성과 현실감을 위해 각 ICML 논문의 저자와 공동 개발했습니다. 또한 확장 가능한 평가를 위해 루브릭을 기준으로 복제 시도를 자동으로 채점하는 LLM 기반 심사위원을 개발하고, 심사위원을 위한 별도의 벤치마크를 만들어 심사위원의 성과를 평가합니다. PaperBench에서 여러 프론티어 모델을 평가한 결과, 가장 성능이 우수한 테스트 에이전트인 오픈소스 스캐폴딩을 사용하는 Claude 3.5 Sonnet(New)이 평균 복제 점수 21.0%를 달성한 것으로 나타났습니다. 마지막으로, 최고의 머신러닝 박사들을 모집하여 PaperBench의 하위 집합을 시도한 결과, 모델이 아직 인간의 기준선을 능가하지 못한다는 사실을 발견했습니다. 저희는 향후 AI 에이전트의 AI 엔지니어링 역량을 이해하기 위한 연구를 촉진하기 위해 코드를 오픈소스로 공개합니다{GitHub - openai/frontier-evals: OpenAI Frontier Evals · GitHub}.
We introduce PaperBench, a benchmark evaluating the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate 20 ICML 2024 Spotlight and Oral papers from scratch, including understanding paper contributions, developing a codebase, and successfully executing experiments. For objective evaluation, we develop rubrics that hierarchically decompose each replication task into smaller sub-tasks with clear grading criteria. In total, PaperBench contains 8,316 individually gradable tasks. Rubrics are co-developed with the author(s) of each ICML paper for accuracy and realism. To enable scalable evaluation, we also develop an LLM-based judge to automatically grade replication attempts against rubrics, and assess our judge's performance by creating a separate benchmark for judges. We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0%. Finally, we recruit top ML PhDs to attempt a subset of PaperBench, finding that models do not yet outperform the human baseline. We \href{GitHub - openai/frontier-evals: OpenAI Frontier Evals · GitHub}{open-source our code} to facilitate future research in understanding the AI engineering capabilities of AI agents.
논문 링크
더 읽어보기
https://github.com/openai/preparedness
Command-A: 엔터프라이즈급 대규모 언어 모델 / Command A: An Enterprise-Ready Large Language Model
논문 소개
Cohere는 엔터프라이즈급 RAG, 에이전트, 코드 및 다국어 작업을 위해 구축된 111B 매개변수 오픈 가중치 LLM인 Command A를 발표했습니다. 주요 기여 사항은 다음과 같습니다:
- 도메인 숙달을 위한 모듈식 전문가 병합 - Command A는 모놀리식 사후 학습 대신 분산형 학습 파이프라인을 사용합니다. 특정 도메인(예: 수학, RAG, 다국어, 안전, 코드)에 대해 개별 전문가 모델을 미세 조정한 다음 효율적인 가중치 매개변수 수프 기법을 사용하여 하나의 모델로 병합합니다. 이렇게 하면 대부분의 전문가 성능이 평균 1.8% 정도만 떨어지면서 유지됩니다.
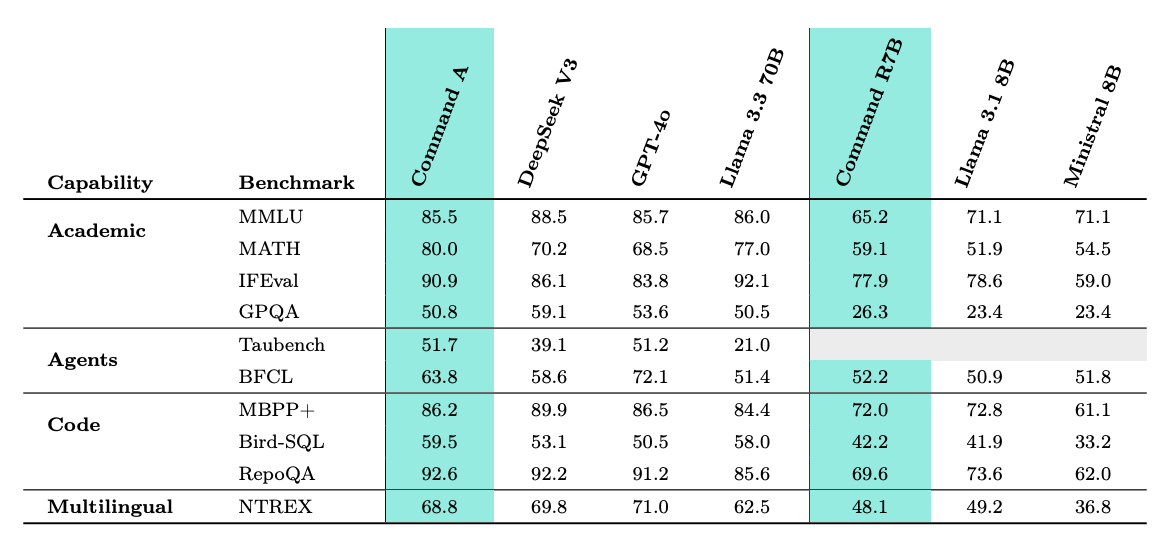
- 긴 컨텍스트 효율성을 위한 하이브리드 아키텍처 - Command A는 슬라이딩 윈도우와 전체 어텐션 레이어를 인터리빙하여 128k에서 LLaMA 3 70B의 ~33%에 불과한 획기적으로 낮은 KV 캐시 메모리 사용량으로 256k 컨텍스트 지원을 달성합니다. RULER에서 95.0%의 점수를 기록하여 대부분의 긴 컨텍스트 동급 제품보다 뛰어난 성능을 발휘합니다.
- 뛰어난 에이전트 기능 - RAG, 툴 사용, ReAct 스타일 에이전트를 위해 구축된 Command A는 TauBench 및 BFCL에서 GPT-4o와 Claude 3.5를 능가합니다. 도구 사용은 사람이 주석을 단 데이터와 합성 데이터를 혼합하여 학습한 다음 CoPG 및 SRPO(자체 개선 선호도 최적화)에 맞춰 조정됩니다.
- 동급 최고의 엔터프라이즈 평가 - 실제 생성 작업(예: 채팅 요약, FAQ 생성) 및 RAG 사용 사례(긴 직장 정책 문서)에서 Command A는 합격률 94.2%, 정확도 4.73, 무응답 QA 정확도 91%로 리더보드에서 1위를 차지했습니다.
- 다국어 우수성 - Command A는 방대한 데이터 큐레이션과 선호도 튜닝을 통해 23개 글로벌 언어로 학습되었습니다. 방언 정렬(ADI2)에서 1위, 평균 LPR(언어 일관성) 90.3%를 기록했으며 모든 언어에서 수동 아레나 스타일의 승률에서 LLaMA 3.3, GPT-4o, DeepSeek보다 뛰어난 성능을 발휘합니다.
- 인간 정렬을 위한 연마 - 최종 정렬은 오프라인 SRPO와 온라인 CoPG의 핑퐁 루프와 RLHF를 사용했습니다. 그 결과 코드에서 +17포인트, 추론에서 +10포인트의 인간 승률이 향상되었으며, Command A의 GPT-4o에 대한 승률이 동등한 수준(~50.4%)으로 올라갔습니다.
- 빠르고 효율적이며 개방적 - Command A는 강력한 성능에도 불구하고 단 2×A100 또는 H100으로 실행되며 초당 156개의 토큰을 생성해 GPT-4o 및 DeepSeek보다 더 빠릅니다. 모델 가중치는 허깅 페이스에서 공개(CC-BY-NC)됩니다.
Cohere announced Command A, a 111B parameter open-weights LLM built for enterprise-grade RAG, agents, code, and multilingual tasks. Key contributions:
- Modular expert merging for domain mastery - Instead of monolithic post-training, Command A uses a decentralized training pipeline. Separate expert models are fine-tuned for specific domains (e.g., math, RAG, multilingual, safety, code), then merged into one model using efficient weighted parameter soup techniques. This preserves most expert performance with just ~1.8% average drop.
- Hybrid architecture for long-context efficiency - Command A interleaves sliding window and full attention layers, achieving 256k context support with drastically lower KV cache memory usage--e.g., only ~33% of LLaMA 3 70B at 128k. It scores 95.0% on RULER, outperforming most long-context peers.
- Superb agentic capabilities - Built for RAG, tool use, and ReAct-style agents, Command A beats GPT-4o and Claude 3.5 on TauBench and BFCL. Tool use is trained via a blend of human-annotated and synthetic data, then aligned with CoPG and SRPO (self-improving preference optimization).
- Best-in-class enterprise evaluations - On real-world generative tasks (e.g., chat summarization, FAQ generation) and RAG use cases (long workplace policy documents), Command A tops the leaderboard with 94.2% pass rate, 4.73 correctness, and 91% unanswerable QA accuracy.
- Multilingual excellence - Command A is trained in 23 global languages with heavy data curation and preference tuning. It scores #1 in dialect alignment (ADI2), 90.3% average LPR (language consistency), and outperforms LLaMA 3.3, GPT-4o, and DeepSeek in manual Arena-style win rates across all languages.
- Polishing for human alignment - Final alignment used a ping-pong loop of offline SRPO and online CoPG with RLHF. This yielded +17pt human win rate gains on code, +10pt on reasoning, and lifted Command A's win rate over GPT-4o to parity (~50.4%).
- Fast, efficient, and open - Despite its power, Command A runs on just 2×A100s or H100s and generates 156 tokens/sec--faster than GPT-4o and DeepSeek. Model weights are released (CC-BY-NC) on Hugging Face.
논문 초록(Abstract)
이 보고서에서는 실제 엔터프라이즈 사용 사례에서 탁월한 성능을 발휘하도록 특별히 설계된 강력한 대규모 언어 모델인 Command A의 개발에 대해 설명합니다. Command A는 에이전트에 최적화된 다국어 지원 모델로, 23개 글로벌 비즈니스 언어를 지원하며, 효율성과 최고 성능의 균형을 맞춘 새로운 하이브리드 아키텍처를 갖추고 있습니다. 정교한 비즈니스 프로세스를 자동화하기 위한 기반 및 도구 사용과 함께 동급 최고의 검색-증강 생성(RAG) 기능을 제공합니다. 이러한 기능은 자체 개선 알고리즘과 모델 병합 기법을 포함한 분산형 학습 접근 방식을 통해 달성됩니다. 또한 Command A와 기능 및 아키텍처적 유사성을 공유하는 Command R7B에 대한 결과도 포함되어 있으며, 두 모델에 대한 가중치는 연구 목적으로 공개되었습니다. 이 기술 보고서에서는 자체 학습 파이프라인에 대해 자세히 설명하고, 기업 관련 작업과 공개 벤치마크 전반에 걸친 광범위한 모델 평가를 통해 뛰어난 성능과 효율성을 입증합니다.
In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
논문 링크
더 읽어보기
코드사이언티스트: 코드 기반 실험을 통한 엔드투엔드 반자동 과학적 발견 / CodeScientist: End-to-End Semi-Automated Scientific Discovery with Code-based Experimentation
논문 소개
AI2의 연구원들이 코드 기반 실험을 통해 과학적 가설을 자율적으로 생성하고 테스트하는 시스템인 CodeScientist를 출시합니다. 이 시스템은 사람의 개입을 최소화하면서 검증된 발견을 도출한 최초의 시스템 중 하나입니다. 핵심 아이디어는 다음과 같습니다:
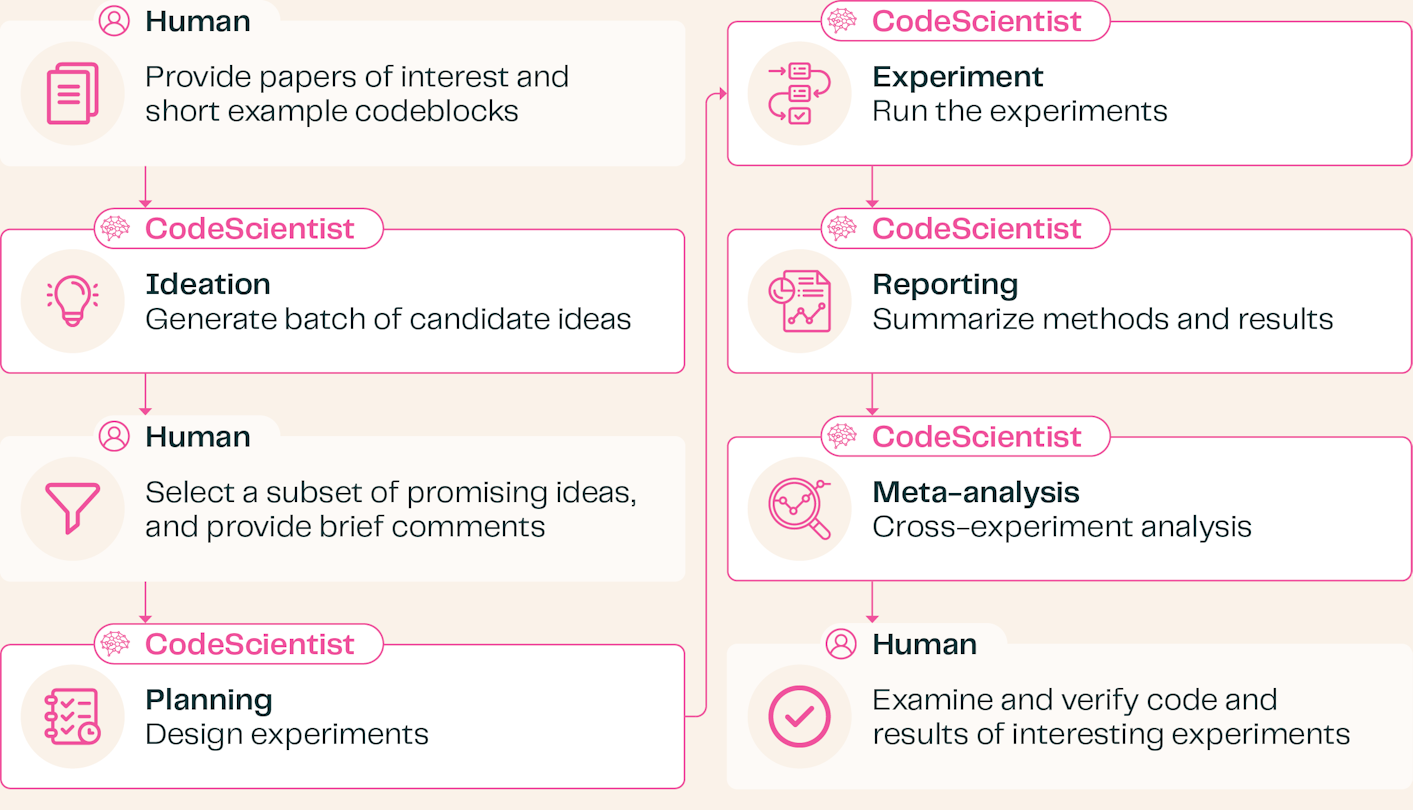
- 코드 우선 과학 에이전트 - CodeScientist는 연구 논문을 검토하고 검증된 Python 코드 블록(예: 분석, 시뮬레이션용)을 사용하여 실험을 조립합니다. 5단계 파이프라인을 따릅니다: 아이디어 -> 계획 -> 코드 실행 -> 보고 -> 메타 분석.
- 검증된 AI 발견 - 에이전트 및 가상 환경에 관한 50개의 AI 연구 논문 중에서 CodeScientist는 19개의 발견을 제안했습니다. 이 중 6건이 과학적으로 타당하고 참신한 것으로 평가되었습니다.
- 신뢰도 ≠ 정확도 - LLM이 자체 평가한 시뮬레이션의 신뢰도가 실제 정확도와 일치하지 않는 경우가 많았습니다.
- 간단한 상태 = 더 나은 예측 - 텍스트 상태보다 이진 상태를 사용하면 모델 신뢰도가 향상되었습니다.
- 그래프 메모리가 도움 - 그래프 구조의 메모리를 가진 에이전트가 과학 시뮬레이션 게임에서 기준선을 뛰어넘는 성능을 보였습니다.
- 사람이 안내하는 자율성 - 완전 자동화가 가능하지만, 간단한 피드백(예: 아이디어 순위 지정)을 통해 출력 품질을 크게 향상시킬 수 있습니다. 인간과 상호작용을 통해 아이디어 선택과 실험 디버깅을 개선할 수 있습니다.
- 여전히 남아있는 과제 - 성공에도 불구하고, 생성된 실험의 절반 이상이 과학적 결함이 아닌 코드 오류로 인해 실패합니다. 결과를 검증하기 위해서는 여전히 동료 검토가 필요하며, 현재의 시스템에는 방법론적 엄격함이 부족합니다.
Researchers at AI2 release CodeScientist, a system that autonomously generates and tests scientific hypotheses via code-based experimentation. It's among the first to produce validated discoveries with minimal human input. Key ideas:
- Code-first scientific agent - CodeScientist reviews research papers and assembles experiments using vetted Python code blocks (e.g., for analysis, simulation). It follows a five-step pipeline: Ideation -> Planning -> Code Execution -> Reporting -> Meta-Analysis.
- Validated AI discoveries - From 50 AI research papers on agents and virtual environments, CodeScientist proposed 19 findings. Of these, 6 were judged scientifically sound and novel.
- Confidence ≠ Accuracy - LLM self-assessed confidence in simulations often mismatched actual accuracy.
- Simpler state = better prediction - Using binary vs. text states improved model reliability.
- Graph memory helps - Agents with graph-structured memory outperformed baselines in a scientific simulation game.
- Human-guided autonomy - Full automation is possible, but brief human feedback (e.g., ranking ideas) significantly boosts output quality. Human-in-the-loop interaction improves idea selection and experiment debugging.
- Challenges remain - Despite successes, over half the generated experiments fail due to code errors , not scientific flaws. Peer review is still needed to verify results, and current systems lack deep methodological rigor.
논문 초록(Abstract)
소프트웨어 아티팩트(예: 개선된 머신러닝 알고리즘)의 자율적 과학적 발견(ASD)에 대한 관심이 급증하고 있지만, 현재의 ASD 시스템은 (1) 기존 코드베이스의 변형이나 유사하게 제한된 설계 공간을 주로 탐색하고 (2) 일반적으로 코드 평가가 제한된 컨퍼런스 스타일의 논문 리뷰를 사용하여 평가되는 대량의 연구 아티팩트(자동 생성된 논문 및 코드 등)를 생성한다는 두 가지 주요한 한계에 직면해 있습니다. 이 작업에서는 연구 논문과 도메인에서 공통적인 작업을 정의하는 코드 블록(예: 언어 모델 프롬프트)의 조합을 통해 공동으로 유전적 검색의 한 형태로 아이디어와 실험 구성의 틀을 짜는 새로운 ASD 시스템인 CodeScientist를 소개합니다. 이 패러다임을 사용하여 에이전트와 가상 환경의 영역에서 광범위하게 기계 생성 아이디어에 대한 수백 개의 자동화된 실험을 수행한 결과, 시스템은 19개의 발견을 반환했으며, 이 중 6개는 외부(컨퍼런스 스타일) 검토, 코드 검토, 복제 시도 등 이전 작업에서 일반적으로 수행되는 것 이상의 다면 평가를 거쳐 최소한의 건전성과 점진적으로 새로운 것으로 판정받았습니다. 또한 새로운 작업, 에이전트, 메트릭 및 데이터에 걸쳐 발견되어 벤치마크 최적화에서 더 광범위한 발견으로의 질적 전환을 시사합니다.
Despite the surge of interest in autonomous scientific discovery (ASD) of software artifacts (e.g., improved ML algorithms), current ASD systems face two key limitations: (1) they largely explore variants of existing codebases or similarly constrained design spaces, and (2) they produce large volumes of research artifacts (such as automatically generated papers and code) that are typically evaluated using conference-style paper review with limited evaluation of code. In this work we introduce CodeScientist, a novel ASD system that frames ideation and experiment construction as a form of genetic search jointly over combinations of research articles and codeblocks defining common actions in a domain (like prompting a language model). We use this paradigm to conduct hundreds of automated experiments on machine-generated ideas broadly in the domain of agents and virtual environments, with the system returning 19 discoveries, 6 of which were judged as being both at least minimally sound and incrementally novel after a multi-faceted evaluation beyond that typically conducted in prior work, including external (conference-style) review, code review, and replication attempts. Moreover, the discoveries span new tasks, agents, metrics, and data, suggesting a qualitative shift from benchmark optimization to broader discoveries.
논문 링크
더 읽어보기
https://github.com/allenai/codescientist
RARE: 검색 증강 추론 모델링 / RARE: Retrieval-Augmented Reasoning Modeling
논문 소개
암기가 아닌 추론에 초점을 맞춘 새로운 패러다임의 도메인별 LLM인 RARE를 소개합니다. 핵심 아이디어는 다음과 같습니다:
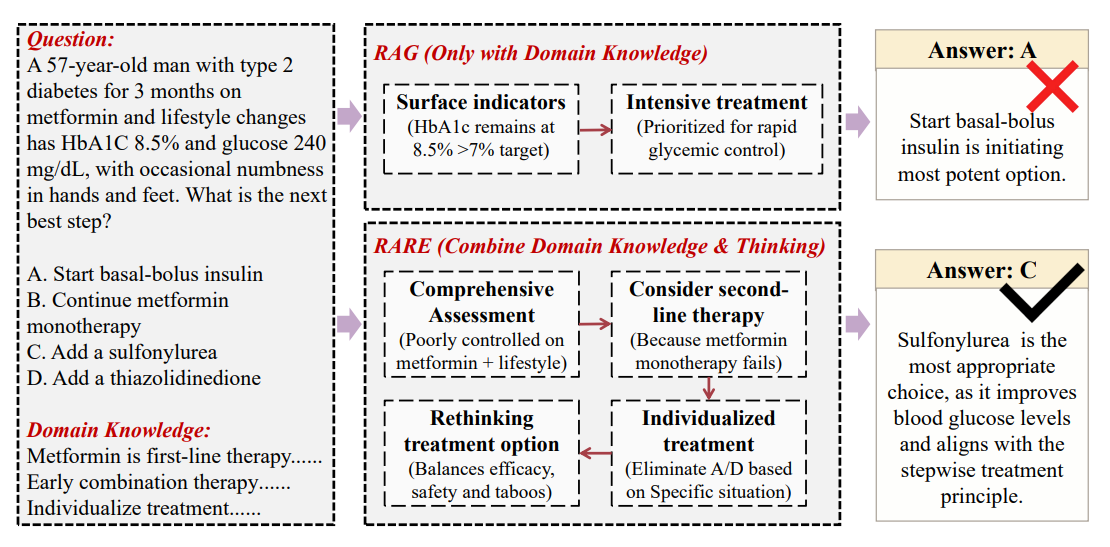
- 블룸의 분류법에서 영감을 얻은 RARE는 지식 암기('기억하기')에서 적용 및 평가('분석하기', '만들기')로 LLM 학습을 전환합니다. 도메인 지식(외부에서 검색)과 도메인 사고(학습 중 학습)를 분리하여 빠듯한 파라미터 예산 내에서 더 나은 성과를 낼 수 있도록 지원합니다.
- 오픈북 준비 학습 - RARE는 검색된 지식을 학습 프롬프트에 주입하여 모델이 암기된 사실 대신 추론 패턴을 학습할 수 있도록 합니다. 이 오픈북 방식의 추론 우선 설정은 특히 의학 분야에서 표준 SFT와 RAG 접근 방식을 모두 능가합니다.
- 소형 모델로 엄청난 정확도 향상 - 5개의 의료 QA 벤치마크에서 RARE로 학습된 Llama-3.1-8B 및 Qwen-2.5-7B는 최대 +20%의 정확도 향상(예: PubMedQA: 78.63% 대 GPT-4의 75.2%, CoVERT: 74.14% 대 GPT-4의 65.67%)으로 GPT-4 + RAG보다 뛰어난 성능을 발휘했습니다.
- **증류 + 적응형 검색을 통한 학습 - RARE는 강력한 교사(예: QwQ-32B)로부터 답변(및 추론 경로)을 증류하여 정답이 발견될 때까지 출력을 다듬습니다. 이를 통해 맥락에 맞는 사례 기반 사고를 가르치는 고품질 데이터 세트가 생성됩니다.
- 검색의 새로운 역할 - 추론에만 사용되는 표준 RAG와 달리, RARE는 학습 중에 검색을 사용해 추론을 형성합니다. 지식 통합(p(k|x, R(x)))과 추론(p(r|x, R(x), k))을 별도의 단계로 모델링하여 암기를 응용으로 대체합니다.
Introduces RARE, a new paradigm for training domain-specific LLMs that focuses on reasoning, not memorization. Key ideas:
- Inspired by Bloom 's Taxonomy - RARE shifts LLM training from memorizing knowledge ("Remember") to applying and evaluating it ("Analyze", "Create"). It separates domain knowledge (retrieved externally) from domain thinking (learned during training), enabling better performance under tight parameter budgets.
- Open-book prepared training - RARE injects retrieved knowledge into training prompts, letting models learn reasoning patterns instead of rote facts. This open-book, reasoning-first setup beats both standard SFT and RAG approaches, especially in medicine.
- Massive accuracy gains with small models - On five medical QA benchmarks, RARE-trained Llama-3.1-8B and Qwen-2.5-7B outperformed GPT-4 + RAG, with up to +20% accuracy boosts (e.g., PubMedQA: 78.63% vs. GPT-4's 75.2%, CoVERT: 74.14% vs. GPT-4's 65.67%).
- Training via distillation + adaptive retrie s - RARE distills answers (and reasoning paths) from a strong teacher (e.g., QwQ-32B), refining outputs until a correct answer is found. This creates a high-quality dataset that teaches contextualized, case-based thinking.
- New role for retrieval - Unlike standard RAG (used only at inference), RARE uses retrieval during training to shape reasoning. It models knowledge integration (p(k|x, R(x))) and reasoning (p(r|x, R(x), k)) as separate steps, replacing memorization with application.
논문 초록(Abstract)
도메인별 인텔리전스는 문제 해결을 위해 전문 지식과 정교한 추론을 요구하며, 제한된 매개변수 예산 하에서 지식 환각과 부적절한 추론 능력으로 어려움을 겪는 대규모 언어 모델(LLM)에 상당한 문제를 제기합니다. 교육 이론의 블룸 분류법에서 영감을 받아 지식 저장과 추론 최적화를 분리하는 새로운 패러다임인 검색 증강 추론 모델링(RARE)을 제안합니다. RARE는 도메인 지식을 검색 가능한 소스로 외부화하여 학습 중에 도메인별 추론 패턴을 내재화합니다. 특히 검색된 지식을 학습 프롬프트에 주입함으로써 RARE는 학습 목표를 암기식 암기에서 맥락화된 추론 적용으로 전환합니다. 이를 통해 모델은 매개변수 집약적인 암기를 우회하고 고차원적인 인지 프로세스의 개발에 우선순위를 둘 수 있습니다. 실험을 통해 경량 RARE 학습 모델(예: Llama-3.1-8B)이 검색 증강 GPT-4 및 Deepseek-R1 증류 모델을 능가하는 최첨단 성능을 달성할 수 있음을 입증했습니다. RARE는 유지 관리가 가능한 외부 지식 기반이 추론에 최적화된 소형 모델과 시너지를 발휘하여 보다 확장 가능한 도메인별 인텔리전스를 종합적으로 구동하는 패러다임의 전환을 구축합니다. 저장소: GitHub - OpenDCAI/RARE: Official implementation of RARE: Retrieval-Augmented Reasoning Modeling · GitHub
Domain-specific intelligence demands specialized knowledge and sophisticated reasoning for problem-solving, posing significant challenges for large language models (LLMs) that struggle with knowledge hallucination and inadequate reasoning capabilities under constrained parameter budgets. Inspired by Bloom's Taxonomy in educational theory, we propose Retrieval-Augmented Reasoning Modeling (RARE), a novel paradigm that decouples knowledge storage from reasoning optimization. RARE externalizes domain knowledge to retrievable sources and internalizes domain-specific reasoning patterns during training. Specifically, by injecting retrieved knowledge into training prompts, RARE transforms learning objectives from rote memorization to contextualized reasoning application. It enables models to bypass parameter-intensive memorization and prioritize the development of higher-order cognitive processes. Our experiments demonstrate that lightweight RARE-trained models (e.g., Llama-3.1-8B) could achieve state-of-the-art performance, surpassing retrieval-augmented GPT-4 and Deepseek-R1 distilled counterparts. RARE establishes a paradigm shift where maintainable external knowledge bases synergize with compact, reasoning-optimized models, collectively driving more scalable domain-specific intelligence. Repo: GitHub - OpenDCAI/RARE: Official implementation of RARE: Retrieval-Augmented Reasoning Modeling · GitHub
논문 링크
더 읽어보기
https://github.com/Open-DataFlow/RARE
LLM이 첫 번째 토큰에 주목하는 이유는 무엇인가요? / Why do LLMs attend to the first token?
논문 소개
이 새로운 논문은 LLM이 왜 첫 번째 토큰에 집착적으로 어텐션을 집중하는지, 즉 어텐션 싱크라고 알려진 현상에 대해 설명합니다. 이 이론은 딥 트랜스포머에서 표현 붕괴를 방지하는 데 유용한 트릭입니다.
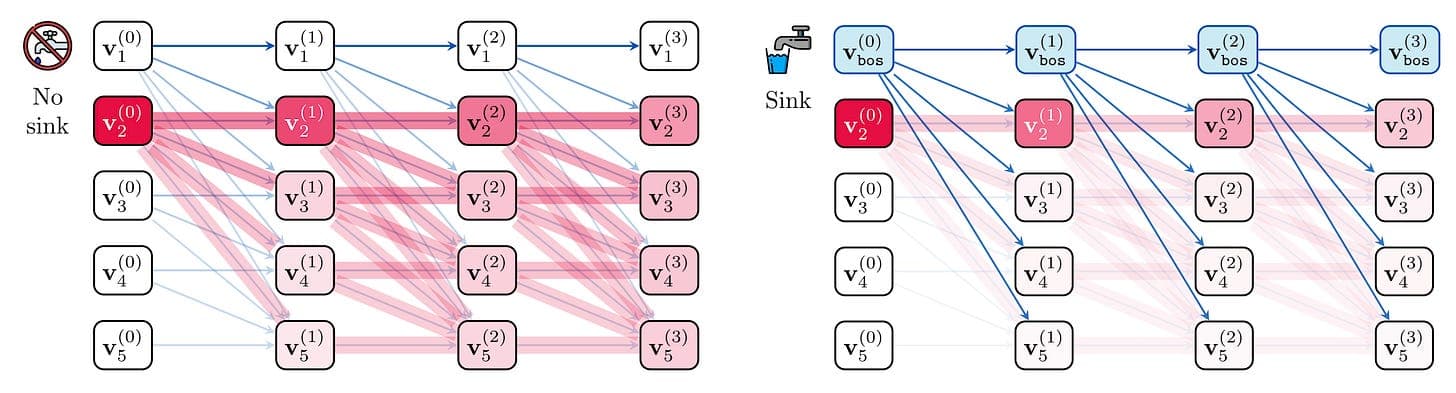
- 싱크 = 오버믹싱 쉴드 - 컨텍스트가 길고 레이어가 깊은 LLM은 정보를 과도하게 혼합하는 경향이 있어 모든 토큰에 대해 유사한 임베딩(즉, 순위 붕괴 또는 오버스쿼싱)을 유발합니다. 많은 헤드가 ⟨보스⟩ 토큰에 고정되는 어텐션 싱크는 토큰 상호 작용을 줄이고 레이어 간 표현 다양성을 보존하는 노옵(no-ops) 역할을 합니다.
- Gemma 및 LLaMa에 대한 날카로운 실험 - Gemma 7B의 섭동 테스트에 따르면 ⟨bos⟩는 모델을 통한 변화의 확산 속도를 상당히 늦추는 것으로 나타났습니다. 한편, LLaMa 3.1 모델에서는 어텐션 헤드의 80% 이상이 405B 변형에서 강한 싱크 현상을 보여 큰 모델일수록 더 강력한 싱크가 필요하다는 이론을 뒷받침합니다.
- 싱크가 자연스럽게 형성됨 - 특별한 사전 훈련 없이도 ⟨보스⟩ 토큰 자체 때문이 아니라 토큰의 위치 때문에 첫 번째 위치에 싱크가 형성되는 경향이 있습니다. 그러나 ⟨bos⟩가 학습 중에 고정되었다가 나중에 제거되면 성능이 저하되어 싱크 형성이 데이터에 따라 달라진다는 것을 보여줍니다.
- 이론적 근거 - 저자들은 싱크 발생을 자코비안 노멀 경계와 연결하여 싱크가 토큰 섭동에 대한 민감도를 감소시킨다는 것을 증명했습니다. 저자들의 수학은 더 깊은 모델과 더 긴 컨텍스트에는 더 강력한 싱크가 필요하다는 것을 보여줍니다.
- 계층적 역학 인사이트 - 일부 어텐션 헤드는 특별한 패턴(예: 아포스트로피)이 실제 계산을 트리거하지 않는 한 ⟨bos⟩를 '기본' 타깃으로 사용합니다. 이는 조건부 어텐션 메커니즘을 지원하는데, 다른 곳에서 필요하지 않는 한 ⟨bos⟩에 집중합니다.
This new paper explains why LLMs obsessively focus attention on the first token -- a phenomenon known as an attention sink. Their theory: it's a useful trick to prevent representational collapse in deep Transformers.
- Sinks = over-mixing shields - LLMs with long contexts and deep layers tend to over-mix information, causing similar embeddings for all tokens (i.e., rank collapse or over-squashing). Attention sinks--where many heads fixate on the ⟨bos⟩ token--act as no-ops that reduce token interaction and preserve representation diversity across layers.
- Sharp experiments on Gemma & LLaMa - Perturbation tests in Gemma 7B show ⟨bos⟩ significantly slows the spread of changes through the model. Meanwhile, in LLaMa 3.1 models, over 80% of attention heads show strong sink behavior in the 405B variant, supporting the theory that larger models need stronger sinks.
- Sinks emerge naturally - Even without special pretraining, sinks tend to form at the first position, not because of the ⟨bos⟩ token itself, but due to its location. However, if ⟨bos⟩ is fixed during training and later removed, performance collapses, showing that sink formation is data-dependent.
- Theoretical grounding - The authors connect sink emergence to Jacobian norm bounds, proving that sinks reduce sensitivity to token perturbations. Their math shows that deeper models and longer contexts require stronger sinks.
- Layerwise dynamics insight - Some attention heads use ⟨bos⟩ as a "default" target, unless a special pattern (e.g., apostrophe) triggers real computation. This supports a conditional attention mechanism--attend to ⟨bos⟩ unless needed elsewhere.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 시퀀스의 첫 번째 토큰에 집중하는 경향이 있어 소위 어텐션 싱크가 발생합니다. 많은 연구에서 이 현상을 자세히 연구하여 이를 활용하거나 완화하기 위한 다양한 방법을 제안했습니다. 어텐션 싱크는 정량화의 어려움, 보안 문제, 스트리밍 어텐션과 연관되어 있습니다. 그러나 많은 연구에서 이러한 현상이 발생하거나 발생하지 않는 조건을 제시했지만, 중요한 질문에 대한 답은 여전히 얕게 남아 있습니다: LLM은 왜 그러한 패턴을 학습하고 어떻게 활용될까요? 이 연구에서는 이러한 메커니즘이 LLM이 과도한 혼합을 피할 수 있는 방법을 제공한다는 것을 이론적, 경험적으로 증명하고, 이를 트랜스포머에서 정보가 전파되는 방식을 수학적으로 연구하는 기존 연구와 연결합니다. 저희는 실험을 통해 이론적 직관을 검증하고 컨텍스트 길이, 깊이, 데이터 패킹과 같은 선택 사항이 싱크 동작에 어떤 영향을 미치는지 보여줍니다. 이 연구가 어텐션 싱크가 LLM에서 유용한 이유에 대한 새로운 실용적 관점을 제시하여 학습 중에 형성되는 어텐션 패턴을 더 잘 이해할 수 있기를 바랍니다.
Large Language Models (LLMs) tend to attend heavily to the first token in the sequence -- creating a so-called attention sink. Many works have studied this phenomenon in detail, proposing various ways to either leverage or alleviate it. Attention sinks have been connected to quantisation difficulties, security issues, and streaming attention. Yet, while many works have provided conditions in which they occur or not, a critical question remains shallowly answered: Why do LLMs learn such patterns and how are they being used? In this work, we argue theoretically and empirically that this mechanism provides a method for LLMs to avoid over-mixing, connecting this to existing lines of work that study mathematically how information propagates in Transformers. We conduct experiments to validate our theoretical intuitions and show how choices such as context length, depth, and data packing influence the sink behaviour. We hope that this study provides a new practical perspective on why attention sinks are useful in LLMs, leading to a better understanding of the attention patterns that form during training.
논문 링크
더 읽어보기
사실적인 임상 상호작용을 위한 자체 진화형 멀티 에이전트 시뮬레이션 / Self-Evolving Multi-Agent Simulations for Realistic Clinical Interactions
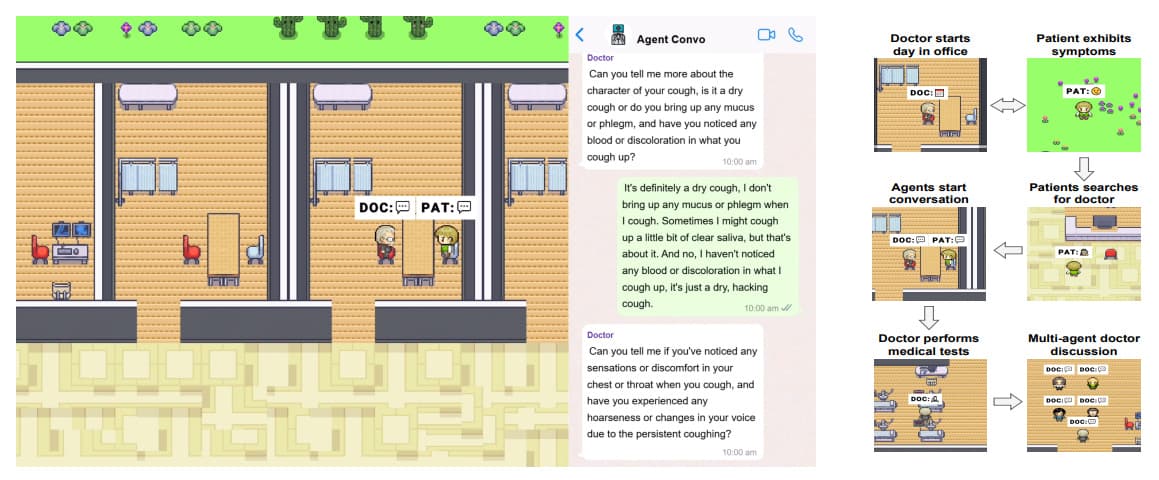
논문 소개
MedAgentSim은 완전 자동화된 오픈소스 병원 시뮬레이션으로, LLM 기반 에이전트가 동적 진단 환경에서 의사-환자 간 상호 작용을 시뮬레이션합니다. 이전의 정적 QA 벤치마크와 달리 MedAgentSim은 멀티턴 대화, 테스트 요청, 자기 개선 기능을 통해 실제 임상 워크플로를 모방합니다.
이 논문에 대해 자세히 알아보기:
- 활동적인 의사 에이전트 - MedAgentSim은 LLM 의사 에이전트가 멀티 턴 상담에 참여하고, 실험실 및 영상(예: 심전도, X-레이)을 요청하고, 진단을 반복적으로 개선하도록 요구하므로 미리 채워진 의료 QA 데이터세트보다 훨씬 더 현실적입니다.
- 메모리 + 반성을 통한 자체 개선 - 시스템은 성공적인 진단과 실패한 진단의 버퍼를 유지합니다. 검색된 과거 사례(kNN을 통해), 연쇄 추론, 앙상블을 사용해 시간이 지남에 따라 성능을 개선합니다. 오진은 메모리에 포함되기 전에 반사 단계를 트리거합니다.
- 완전 자율 또는 휴먼 인 더 루프 - 사용자가 선택적으로 의사 또는 환자 에이전트를 제어할 수 있습니다. 시뮬레이션 에셋은 2D 게임 엔진(Phaser)을 사용하여 구축되며, 에이전트는 가상 의료 도구를 탐색하고 대화하며 상호 작용할 수 있습니다.
- 벤치마크 전반에서 큰 성능 향상 - NEJM, MedQA, MIMIC-IV에서 MedAgentSim(LLaMA 3.3 포함)은 특히 의료 이미지 해석을 위해 LLaVA를 사용하는 비전 언어 작업에서 기본 설정보다 +6-37% 성능이 향상되었습니다.
- 편향 분석 및 공정성 초점 - 연구팀은 인지적 및 암묵적 편향 조건에서 진단 정확도를 연구했습니다. GPT-4o 및 LLaMA와 같은 모델은 Mixtral/Mistral보다 더 강력한 것으로 입증되어 편향 인식 평가의 중요성을 강조했습니다.
MedAgentSim is a fully automated, open-source hospital simulation where LLM-powered agents simulate doctor-patient interactions in dynamic diagnostic settings. Unlike previous static QA benchmarks, MedAgentSim mimics real-world clinical workflows with multi-turn dialogue, test requests, and self-improvement.
More about this paper:
- Active doctor agents - MedAgentSim requires LLM doctor agents to engage in multi-turn consultations, request labs and imaging (e.g., ECG, X-ray), and iteratively refine diagnoses, making it far more realistic than pre-filled medical QA datasets.
- Self-improvement via memory + reflection - The system maintains buffers of successful and failed diagnoses. It uses retrieved past cases (via kNN), chain-of-thought reasoning, and ensembling to improve performance over time. Misdiagnoses trigger a reflection phase before inclusion in memory.
- Fully autonomous or human-in-the-loop - Users can optionally take control of the doctor or patient agents. Simulation assets are built using a 2D game engine (Phaser), and the agents can navigate, converse, and interact with virtual medical tools.
- Big performance boost across benchmarks - On NEJM, MedQA, and MIMIC-IV, MedAgentSim (with LLaMA 3.3) outperforms baseline setups by +6-37%, especially in vision-language tasks using LLaVA for interpreting medical images.
- Bias analysis & fairness focus - The team studied diagnostic accuracy under cognitive and implicit bias conditions. Models like GPT-4o and LLaMA proved more robust than Mixtral/Mistral, highlighting the importance of bias-aware evaluation.
논문 초록(Abstract)
이 연구에서는 동적 진단 환경에서 LLM 성능을 평가하고 개선하기 위해 설계된 의사, 환자, 측정 에이전트가 포함된 오픈소스 시뮬레이션 임상 환경인 MedAgentSim을 소개합니다. 이전 접근 방식과 달리, 이 프레임워크에서는 의사 에이전트가 실제 진단 과정을 모방하기 위해 측정 에이전트에게 관련 의료 검사(예: 체온, 혈압, 심전도) 및 영상 결과(예: MRI, X-레이)를 요청하는 멀티턴 대화를 통해 환자와 적극적으로 소통하도록 요구합니다. 또한 모델이 진단 전략을 반복적으로 개선할 수 있는 자체 개선 메커니즘을 통합합니다. 다중 에이전트 토론, 연쇄 추론, 경험 기반 지식 검색을 통합하여 의사 에이전트가 더 많은 환자와 상호 작용하면서 점진적인 학습을 촉진함으로써 시뮬레이션 환경에서 LLM 성능을 향상시킵니다. 또한 상황에 맞는 동적 진단 상호 작용에 참여하는 LLM의 능력을 평가하기 위한 평가 벤치마크도 도입합니다. 메드에이전트심은 완전 자동화되어 있지만, 사용자 제어 모드도 지원하므로 의사 또는 환자 에이전트와 사람이 상호 작용할 수 있습니다. 다양한 시뮬레이션 진단 시나리오에 대한 종합적인 평가는 유니티의 접근 방식이 효과적임을 입증합니다. 코드, 시뮬레이션 도구, 벤치마크는 \href{https://medagentsim.netlify.app/}에서 확인할 수 있습니다.
In this work, we introduce MedAgentSim, an open-source simulated clinical environment with doctor, patient, and measurement agents designed to evaluate and enhance LLM performance in dynamic diagnostic settings. Unlike prior approaches, our framework requires doctor agents to actively engage with patients through multi-turn conversations, requesting relevant medical examinations (e.g., temperature, blood pressure, ECG) and imaging results (e.g., MRI, X-ray) from a measurement agent to mimic the real-world diagnostic process. Additionally, we incorporate self improvement mechanisms that allow models to iteratively refine their diagnostic strategies. We enhance LLM performance in our simulated setting by integrating multi-agent discussions, chain-of-thought reasoning, and experience-based knowledge retrieval, facilitating progressive learning as doctor agents interact with more patients. We also introduce an evaluation benchmark for assessing the LLM's ability to engage in dynamic, context-aware diagnostic interactions. While MedAgentSim is fully automated, it also supports a user-controlled mode, enabling human interaction with either the doctor or patient agent. Comprehensive evaluations in various simulated diagnostic scenarios demonstrate the effectiveness of our approach. Our code, simulation tool, and benchmark are available at \href{https://medagentsim.netlify.app/}.
논문 링크
더 읽어보기
https://github.com/MAXNORM8650/MedAgentSim
심층 검색을 열어보세요: 오픈소스 추론 에이전트를 통한 검색의 민주화 / Open Deep Search: Democratizing Search with Open-source Reasoning Agents
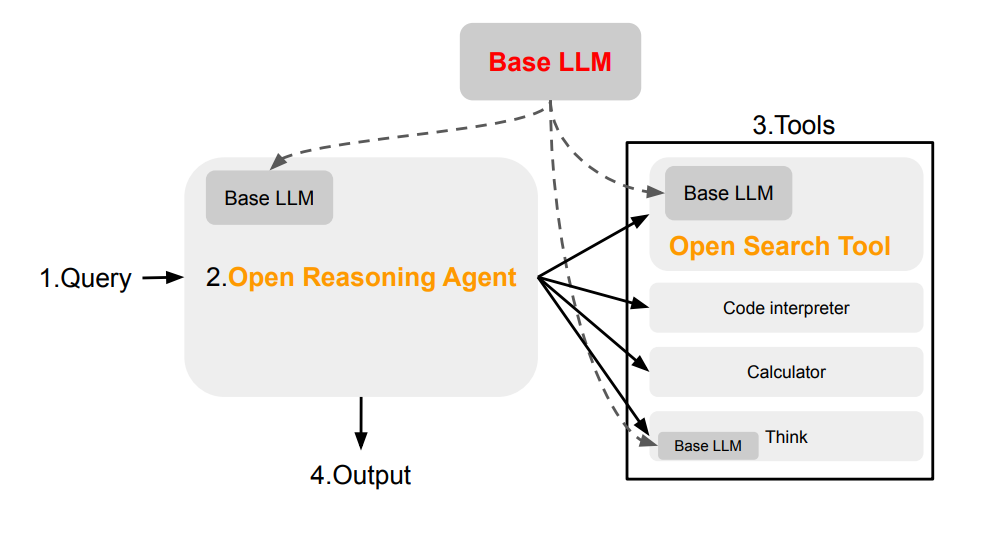
논문 소개
센티언트, UW, 프린스턴, UC 버클리의 연구원들이 GPT-4o Search Preview 및 Perplexity Sonar와 같은 최고의 독점 시스템에 필적하는 오픈소스 검색 AI 프레임워크인 Open Deep Search(ODS)를 소개합니다. 주요 인사이트는 다음과 같습니다:
- 두 가지 개방형 구성 요소: 검색 + 추론 - ODS는 (1) 쿼리 재구문, 스니펫 재순위 지정, 사이트별 로직을 사용해 고품질 웹 결과를 검색하고 정제하는 Open Search Tool과 (2) 쿼리에 응답하기 위해 도구 사용(검색, 계산기 등)을 조율하는 컨트롤러인 Open Reasoning Agent의 두 가지 모듈로 구성되어 있습니다. 두 가지 변형이 제공됩니다: ODS-v1(ReAct) 및 ODS-v2(CodeAct).
- SOTA 오픈소스 성능 - DeepSeek-R1을 기본 LLM으로 사용하는 ODS-v2는 SimpleQA에서 88.3%, FRAMES에서 75.3%의 점수를 기록하여 후자에서 GPT-4o Search Preview를 +9.7% 앞섰습니다. ODS는 쿼리당 검색 횟수를 조정하여 고정 쿼리 기준선보다 비용과 정확도의 균형을 더 효율적으로 맞춥니다(평균 3.39회, FRAMES 기준).
- 퍼플렉서티 소나보다 우수 - FRAMES와 SimpleQA 모두에서 ODS+DeepSeek-R1은 멀티홉 질문, 시간/날짜 계산, 이름 모호성을 포함하는 복잡한 추론 작업에서도 퍼플렉서티의 주력 검색 모델보다 뛰어난 성능을 발휘합니다.
- 코드 기반 에이전트로 추론 능력 향상 - ODS-v2는 CodeAct를 기반으로 구축되어 기호적 추론과 도구 호출을 수행하기 위해 Python 코드를 작성하고 실행할 수 있습니다. 그 결과 ODS-v1의 CoT 기반 ReAct에 비해 수치 정확도와 작업 유연성이 더욱 향상되었습니다.
Researchers from Sentient, UW, Princeton, and UC Berkeley introduce Open Deep Search (ODS), an open-source search AI framework that rivals top proprietary systems like GPT-4o Search Preview and Perplexity Sonar. Key insights:
- Two open components: search + reasoning - ODS has two modular parts: (1) Open Search Tool, which retrieves and refines high-quality web results using query rephrasing, snippet reranking, and site-specific logic; and (2) Open Reasoning Agent, a controller that orchestrates tool usage (search, calculator, etc.) to answer queries. Two variants are offered: ODS-v1 (ReAct) and ODS-v2 (CodeAct).
- SOTA open-source performance - With DeepSeek-R1 as the base LLM, ODS-v2 scores 88.3% on SimpleQA and 75.3% on FRAMES, beating GPT-4o Search Preview by +9.7% on the latter. ODS adapts the number of searches per query (avg. 3.39 on FRAMES), balancing cost and accuracy more efficiently than fixed-query baselines.
- Better than Perplexity Sonar - On both FRAMES and SimpleQA, ODS+DeepSeek-R1 outperforms Perplexity's flagship search models, even in complex reasoning tasks involving multi-hop questions, time/date calculations, and name disambiguation.
- Code-based agents enhance reasoning - ODS-v2 builds on CodeAct, allowing it to write and run Python code to perform symbolic reasoning and tool calls. This results in sharper numerical precision and task flexibility compared to CoT-based ReAct in ODS-v1.
논문 초록(Abstract)
퍼플렉시티의 소나 리서칭 프로, 오픈AI의 GPT-4o 서치 프리뷰와 같은 독점적인 검색 AI 솔루션과 오픈소스 솔루션 간의 격차를 줄이기 위해 오픈 딥서치(ODS)를 도입합니다. ODS에 도입된 주요 혁신은 웹 검색 도구를 현명하게 사용하여 쿼리에 답할 수 있는 추론 에이전트로 최신 오픈소스 LLM의 추론 기능을 보강하는 것입니다. 구체적으로 ODS는 사용자가 선택한 기본 LLM과 함께 작동하는 두 가지 구성 요소로 이루어져 있습니다: 오픈 검색 도구와 오픈 추론 에이전트입니다. 개방형 추론 에이전트는 주어진 작업을 해석하고 도구 호출을 포함하는 일련의 작업을 오케스트레이션하여 작업을 완료하며, 그 중 하나가 개방형 검색 도구입니다. 개방형 검색 도구는 독점적인 검색 도구보다 뛰어난 성능을 자랑하는 새로운 웹 검색 도구입니다. DeepSeek-R1과 같은 강력한 오픈소스 추론 LLM과 함께 ODS는 두 가지 벤치마크에서 기존의 최첨단 기준선과 거의 일치하고 때로는 이를 능가합니다: SimpleQA와 FRAMES. 예를 들어, FRAMES 평가 벤치마크에서 ODS는 최근 출시된 GPT-4o Search Preview의 기존 최고 기준선인 정확도를 9.7% 향상시켰습니다. ODS는 검색 및 추론 기능으로 모든 LLM을 원활하게 보강하기 위한 일반적인 프레임워크로, 예를 들어 SimpleQA에서 82.4%, FRAMES에서 30.1%를 달성하는 DeepSeek-R1은 SimpleQA에서 88.3%, FRAMES에서 75.3%의 최첨단 성능을 달성합니다.
We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity's Sonar Reasoning Pro and OpenAI's GPT-4o Search Preview, and their open-source counterparts. The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent. Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts. Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES. For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy. ODS is a general framework for seamlessly augmenting any LLMs -- for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES -- with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
논문 링크
더 읽어보기
https://github.com/sentient-agi/OpenDeepSearch
Z1: 코드를 통한 효율적인 테스트 시간 확장 / Z1: Efficient Test-time Scaling with Code
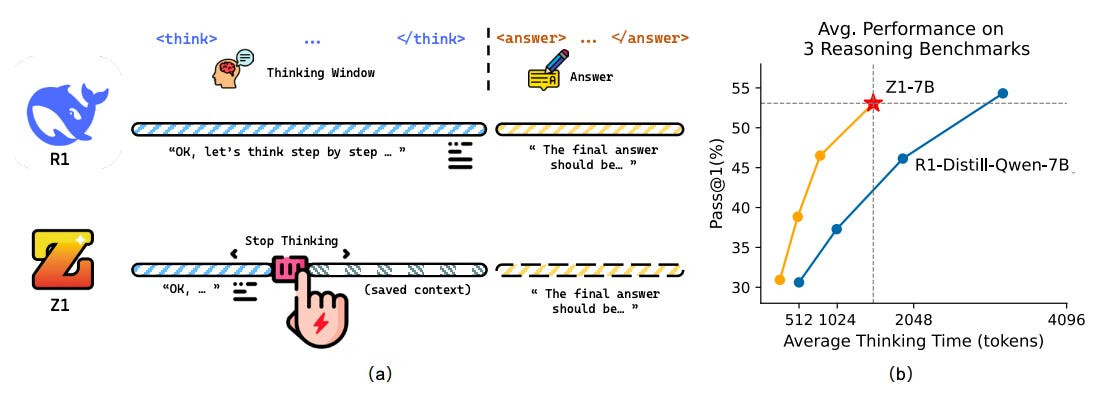
논문 소개
Z1은 테스트 시, 특히 추론 중에 LLM의 컴퓨팅 효율을 높이기 위한 새로운 방법입니다. 핵심 아이디어는 짧고 긴 코드 기반 추론 궤적으로 LLM을 훈련한 다음 추론 중에 추론 깊이를 동적으로 조정하는 것입니다. 주요 기여 사항은 다음과 같습니다:
- Z1-Code-Reasoning-107K 데이터 세트 - 간단하고 복잡한 코딩 문제에 대한 짧고 긴 추론 경로가 포함된 107K 샘플 데이터 세트를 구축합니다. 궤적은 QwQ-32B에서 추출되어 모델이 언제 사고를 멈춰야 하는지 학습할 수 있도록 짝을 이룹니다.
- 시프트된 사고 창 - 명시적인
<think>구분자를 없애는 새로운 시험 시간 전략. 대신, 모델은 문제 난이도에 따라 추론 토큰 예산을 조정합니다. 간단한 문제는 얕은 추론을 유도하고, 복잡한 문제는 한도가 제한되며(예: 최대 4096토큰), 힌트를 통해 모델이 답을 완성하도록 유도합니다. - 큰 효율성 향상 - 7B 규모 모델인 Z1-7B는 여러 추론 작업(MATH500, LiveCodeBench, GPQA Diamond)에서 R1-Distill-Qwen-7B와 일치하지만 추론 토큰의 30%만 사용합니다. 예를 들어, GPQA Diamond에서 Z1-7B는 절반 미만의 토큰을 사용하면서 47.5%를 달성했습니다.
- 코드 추론이 일반 작업으로 전이 - Z1은 코드 기반 CoT 데이터로만 학습되었음에도 불구하고 과학과 수학 같은 더 넓은 영역으로 잘 일반화되어 여러 벤치마크에서 다른 7B 추론 모델(예: OpenThinker-7B, s1.1-7B)보다 뛰어난 성능을 발휘합니다.
- **추론 데이터의 효과는 무엇인가요? ** - 추론 연구 결과, (1) 추론 궤적이 길수록 추론 품질이 향상되고, (2) 훈련 샘플 크기가 클수록 궤적 길이를 변경하지 않아도 평균 사고 시간과 정확도가 향상된다는 두 가지 핵심 데이터 세트 설계 레버리지가 밝혀졌습니다.
Z1 is a new method for making LLMs more compute-efficient at test time, especially during reasoning. The core idea is to train LLMs with short and long code-based reasoning trajectories, and then dynamically adjust reasoning depth during inference. Key contributions:
- Z1-Code-Reasoning-107K dataset - They construct a 107K-sample dataset with short and long reasoning paths for simple and complex coding problems. Trajectories are distilled from QwQ-32B and paired to help the model learn when to stop thinking.
- Shifted Thinking Window - A new test-time strategy that eliminates explicit
<think>delimiters. Instead, the model adapts reasoning token budget based on problem difficulty. Simple problems invoke shallow reasoning; complex ones get capped (e.g., 4096 tokens max), with hints nudging the model to finalize the answer.- Big efficiency gains - The 7B-scale model Z1-7B matches R1-Distill-Qwen-7B across multiple reasoning tasks (MATH500, LiveCodeBench, GPQA Diamond) but with ~30% of the reasoning tokens. For instance, on GPQA Diamond, Z1-7B achieves 47.5% while using less than half the tokens.
- Code reasoning transfers to general tasks - Despite being trained only on code-based CoT data, Z1 generalizes well to broader domains like science and math, outperforming other 7B reasoning models (e.g., OpenThinker-7B, s1.1-7B) across multiple benchmarks.
- What makes reasoning data effective? - Ablation studies reveal two key dataset design levers: (1) longer reasoning trajectories improve inference quality; (2) larger training sample sizes boost average thinking time and accuracy, even without altering trajectory length.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 테스트 시간 컴퓨팅 확장을 통해 복잡한 문제 해결 능력을 향상시킬 수 있지만, 여기에는 종종 더 긴 컨텍스트와 수많은 추론 토큰 비용이 수반됩니다. 이 백서에서는 코드 관련 추론 궤적에 대해 LLM을 훈련시켜 성능을 유지하면서 과도한 사고 토큰을 줄일 수 있는 효율적인 테스트 시간 확장 방법을 제안합니다. 먼저, 간단하고 복잡한 코딩 문제와 그 짧은 풀이 궤적 및 긴 풀이 궤적이 짝을 이루는 큐레이팅된 데이터 세트인 Z1-Code-Reasoning-107K를 생성합니다. 둘째, 문맥을 구분하는 태그(예: <생각>. . </생각>)를 제거하고 추론 토큰을 제한하여 과도한 사고 부담을 완화하는 새로운 시프트드 씽킹 윈도우를 제시합니다. 길고 짧은 궤적 데이터로 훈련되고 시프트드 씽킹 윈도우를 탑재한 모델인 Z1-7B는 문제의 복잡성에 따라 추론 수준을 조정하는 능력을 보여주며, 평균 사고 토큰의 약 30%로 R1-Distill-Qwen-7B 성능과 일치하는 다양한 추론 과제에서 효율적인 테스트 시간 확장을 보여줍니다. 특히 코드 궤적만으로 미세 조정된 Z1-7B는 더 광범위한 추론 과제에 대한 일반화를 보여줍니다(GPQA 다이아몬드에서 47.5%). 또한 효율적인 추론 도출에 대한 분석은 향후 연구를 위한 귀중한 인사이트를 제공합니다.
Large Language Models (LLMs) can achieve enhanced complex problem-solving through test-time computing scaling, yet this often entails longer contexts and numerous reasoning token costs. In this paper, we propose an efficient test-time scaling method that trains LLMs on code-related reasoning trajectories, facilitating their reduction of excess thinking tokens while maintaining performance. First, we create Z1-Code-Reasoning-107K, a curated dataset of simple and complex coding problems paired with their short and long solution trajectories. Second, we present a novel Shifted Thinking Window to mitigate overthinking overhead by removing context-delimiting tags (e.g., . . . ) and capping reasoning tokens. Trained with long and short trajectory data and equipped with Shifted Thinking Window, our model, Z1-7B, demonstrates the ability to adjust its reasoning level as the complexity of problems and exhibits efficient test-time scaling across different reasoning tasks that matches R1-Distill-Qwen-7B performance with about 30% of its average thinking tokens. Notably, fine-tuned with only code trajectories, Z1-7B demonstrates generalization to broader reasoning tasks (47.5% on GPQA Diamond). Our analysis of efficient reasoning elicitation also provides valuable insights for future research.
논문 링크
추론 경제 활용하기: 대규모 언어 모델을 위한 효율적인 추론에 대한 서베이 논문 / Harnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models
논문 소개
이 서베이는 심층 추론 성능과 계산 비용의 균형을 맞추는 방법을 분석하는 LLM의 추론 경제성에 초점을 맞춥니다. 학습 후 단계와 추론 단계 모두에서 비효율성, 행동 패턴, 잠재적 해결책을 검토합니다.
This survey focuses on reasoning economy in LLMs, analyzing how to balance deep reasoning performance with computational cost. It reviews inefficiencies, behavioral patterns, and potential solutions at both post-training and inference stages.
논문 초록(Abstract)
최근 대규모 언어 모델(LLM)의 발전으로 빠르고 직관적인 사고(시스템 1)에서 느리고 깊은 추론(시스템 2)으로 전환하면서 복잡한 추론 작업을 수행할 수 있는 능력이 크게 향상되었습니다. 시스템 2 추론은 작업 정확도를 향상시키지만, 느린 사고의 특성과 비효율적이거나 불필요한 추론 동작으로 인해 상당한 계산 비용이 발생하는 경우가 많습니다. 반대로 시스템 1 추론은 계산 효율은 높지만 최적의 성능을 발휘하지 못합니다. 따라서 성능(혜택)과 계산 비용(예산) 사이의 균형을 맞추는 것이 중요하며, 이는 추론 경제라는 개념을 낳게 되었습니다. 이 서베이 논문에서는 LLM의 학습 후 추론 단계와 시험 시간 추론 단계 모두에서 추론 경제성에 대한 포괄적인 분석을 제공하며, i) 추론 비효율의 원인, ii) 다양한 추론 패턴의 행동 분석, iii) 추론 경제성을 달성하기 위한 잠재적 솔루션을 포괄적으로 다룹니다. 실행 가능한 인사이트를 제공하고 미해결 과제를 강조함으로써 LLM의 추론 경제를 개선하기 위한 전략을 조명하여 이 진화하는 분야의 연구를 발전시키는 데 귀중한 자원이 되고자 합니다. 또한 빠르게 진화하는 이 분야의 발전 상황을 지속적으로 추적할 수 있는 공개 저장소를 제공합니다.
Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to perform complex reasoning tasks, transitioning from fast and intuitive thinking (System 1) to slow and deep reasoning (System 2). While System 2 reasoning improves task accuracy, it often incurs substantial computational costs due to its slow thinking nature and inefficient or unnecessary reasoning behaviors. In contrast, System 1 reasoning is computationally efficient but leads to suboptimal performance. Consequently, it is critical to balance the trade-off between performance (benefits) and computational costs (budgets), giving rise to the concept of reasoning economy. In this survey, we provide a comprehensive analysis of reasoning economy in both the post-training and test-time inference stages of LLMs, encompassing i) the cause of reasoning inefficiency, ii) behavior analysis of different reasoning patterns, and iii) potential solutions to achieve reasoning economy. By offering actionable insights and highlighting open challenges, we aim to shed light on strategies for improving the reasoning economy of LLMs, thereby serving as a valuable resource for advancing research in this evolving area. We also provide a public repository to continually track developments in this fast-evolving field.
논문 링크
더 읽어보기
인사이드 아웃: LLM의 숨겨진 사실 지식 / Inside-Out: Hidden Factual Knowledge in LLMs
논문 소개
이 연구에서는 LLM의 숨겨진 지식을 측정하는 프레임워크를 소개하며, 모델이 출력으로 표현하는 것보다 내부적으로 훨씬 더 많은 사실 정보를 최대 40% 더 많이 인코딩한다는 사실을 보여줍니다. 또한 일부 답변은 내부적으로 알려져 있지만 생성되지 않는 것으로 밝혀져 QA 작업의 테스트 시간 샘플링의 주요 한계를 강조합니다.
This study introduces a framework to measure hidden knowledge in LLMs, showing that models encode significantly more factual information internally than they express in outputs, up to 40% more. It also finds that some answers, although known internally, are never generated, highlighting key limits in test-time sampling for QA tasks.
논문 초록(Abstract)
이 연구는 대규모 언어 모델(LLM)이 출력에서 표현하는 것보다 파라미터에 더 많은 사실적 지식을 인코딩하는지 평가하는 프레임워크를 제시합니다. 몇몇 연구에서 이러한 가능성을 암시하고 있지만, 이 현상을 명확하게 정의하거나 입증한 연구는 없습니다. 먼저 지식에 대한 공식적인 정의를 제안하는데, 주어진 질문에 대해 정답과 오답 쌍 중 정답이 더 높은 순위를 차지하는 비율로 정량화합니다. 이는 개별 답안 후보의 점수를 매기는 데 사용된 정보, 즉 모델의 관찰 가능한 토큰 수준 확률 또는 중간 계산에 따라 외부 지식과 내부 지식을 발생시킵니다. 숨겨진 지식은 내부 지식이 외부 지식을 초과할 때 발생합니다. 그런 다음 이 프레임워크를 폐쇄형 QA 설정에서 널리 사용되는 세 가지 오픈 가중치 LLM에 적용한 사례 연구를 소개합니다. 연구 결과는 다음과 같습니다: (1) LLM은 일관되게 외부에 표현하는 것보다 내부에 더 많은 사실적 지식을 인코딩하며, 평균 40%의 상대적 격차를 보였습니다. (2) 놀랍게도 일부 지식은 너무 깊숙이 숨겨져 있어 모델이 내부적으로 완벽하게 답을 알고 있음에도 불구하고 1,000개의 답변을 대규모로 반복 샘플링해도 한 번도 생성하지 못하는 경우가 있습니다. 이는 LLM의 생성 기능에 근본적인 한계를 드러내며, (3) 비공개 QA에서 반복적인 답변 샘플링을 통해 테스트 시간 계산을 확장하는 데 실질적인 제약을 가합니다. 일부 답변은 실제로 샘플링되지 않기 때문에 상당한 성능 개선에 접근할 수 없지만, 샘플링이 이루어진다면 1순위를 보장할 수 있기 때문입니다.
This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at this possibility, none has clearly defined or demonstrated this phenomenon. We first propose a formal definition of knowledge, quantifying it for a given question as the fraction of correct-incorrect answer pairs where the correct one is ranked higher. This gives rise to external and internal knowledge, depending on the information used to score individual answer candidates: either the model's observable token-level probabilities or its intermediate computations. Hidden knowledge arises when internal knowledge exceeds external knowledge. We then present a case study, applying this framework to three popular open-weights LLMs in a closed-book QA setup. Our results indicate that: (1) LLMs consistently encode more factual knowledge internally than what they express externally, with an average relative gap of 40%. (2) Surprisingly, some knowledge is so deeply hidden that a model can internally know an answer perfectly, yet fail to generate it even once, despite large-scale repeated sampling of 1,000 answers. This reveals fundamental limitations in the generation capabilities of LLMs, which (3) put a practical constraint on scaling test-time compute via repeated answer sampling in closed-book QA: significant performance improvements remain inaccessible because some answers are practically never sampled, yet if they were, we would be guaranteed to rank them first.
논문 링크
더 읽어보기
원문
이 글은 GPT 모델로 정리한 것으로, 잘못된 부분이 있을 수 있으니 글 아래쪽의 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]() [2025/03/31 ~ 04/06] 이번 주의 주요 ML 논문 (Top ML Papers of the Week)
[2025/03/31 ~ 04/06] 이번 주의 주요 ML 논문 (Top ML Papers of the Week)