[2025/06/03 ~ 09] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



-
이번 주 선정된 논문들을 살펴보면, 인공지능 연구에서 특히 추론(reasoning) 능력과 관련된 연구들이 두드러지게 나타나고 있습니다. 여러 논문들이 복잡한 문제 해결과 추론 과정의 이해, 그리고 이를 향상시키기 위한 다양한 방법론을 제시하고 있는데, 이는 인공지능이 단순한 패턴 인식을 넘어 보다 정교한 사고와 판단 능력을 갖추는 방향으로 발전하고 있음을 보여줍니다. 특히, 추론 과정의 내부 구조와 한계에 대한 분석이 활발히 이루어지고 있으며, 이는 인공지능의 신뢰성과 설명 가능성을 높이기 위한 중요한 연구 흐름입니다.
-
두 번째로, 벡터 표현과 관련된 연구들이 강세를 보이고 있습니다. 텍스트 임베딩의 변환, 보안 문제, 그리고 벡터 데이터의 해석과 활용에 관한 연구들이 집중되고 있는데, 이는 자연어처리와 정보 검색, 데이터 보안 등 다양한 분야에서 벡터 기반 기술의 중요성이 커지고 있음을 반영합니다. 특히, 임베딩 공간의 구조를 이해하고 이를 활용하는 기술이 발전하면서, 인공지능의 응용 범위가 더욱 확장되고 있음을 알 수 있습니다.
-
마지막으로, 멀티모달 및 시간 시계열 데이터 처리와 관련된 연구들이 활발히 진행되고 있습니다. 예를 들어, 다변수 시계열 예측, 광범위한 도메인에서의 추론(reasoning) 환경 구축, 그리고 광범위한 센서 데이터와 이미지 데이터를 활용하는 연구들이 포함되어 있습니다. 이는 인공지능이 다양한 데이터 유형을 통합하여 복합적인 문제를 해결하는 능력을 갖추기 위한 노력이 지속되고 있음을 보여줍니다. 이러한 연구들은 인공지능의 실질적 적용 가능성을 높이고, 실세계 문제 해결에 더욱 적합한 모델 개발에 기여하고 있습니다.
사고의 환상: 문제 복잡성 관점에서 본 추론 모델의 강점과 한계 이해 / The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
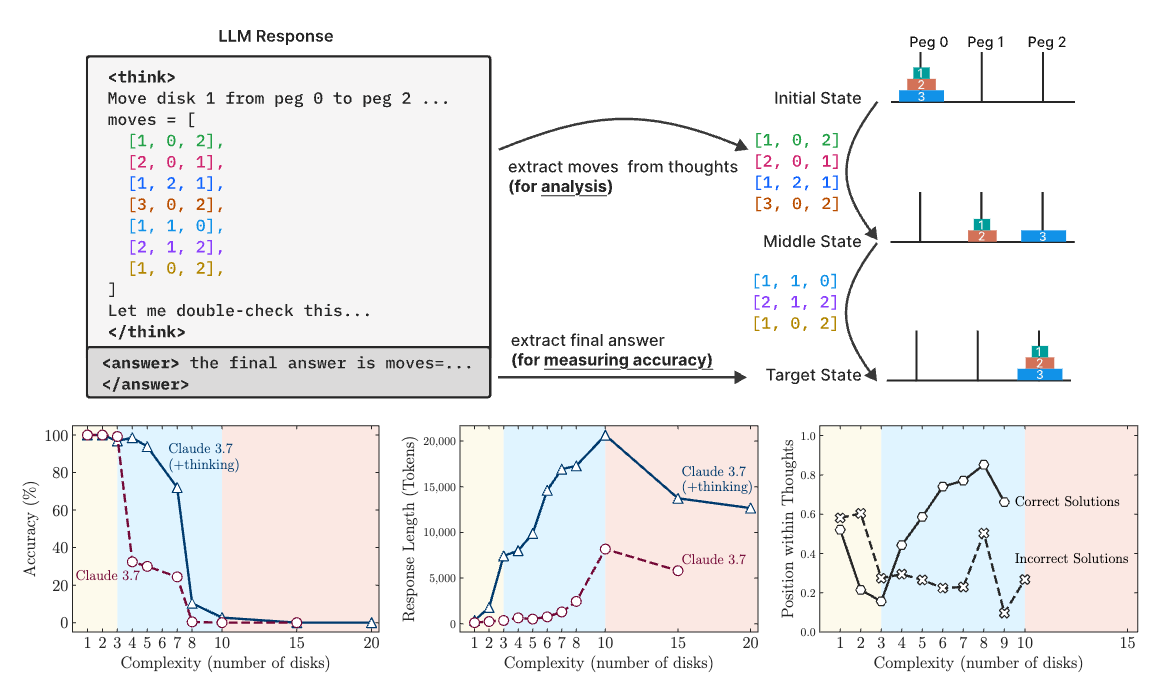
논문 소개
이 연구는 최신 대형 추론 모델(Large Reasoning Models, LRMs)의 성능과 한계를 문제 복잡성 관점에서 분석합니다. 실험을 통해 LRMs는 특정 복잡도를 넘어서면 정답 정확도가 급격히 저하되며, 문제 난이도에 따라 추론 능력이 비선형적으로 변화하는 현상을 발견했습니다. 또한, LRMs는 명시적 알고리즘을 활용하지 못하고 일관성 없는 추론을 수행하는 한계가 있으며, 복잡한 문제에서 기대하는 만큼의 사고 과정을 보여주지 못하는 것으로 나타났습니다. 이러한 결과는 LRMs의 추론 능력에 대한 이해를 높이고, 향후 모델 개선 방향에 중요한 시사점을 제공합니다.
논문 초록(Abstract)
최근 최첨단 언어 모델의 세대에서는 상세한 사고 과정(Reasoning 과정)을 생성한 후 답변을 제공하는 대형 사고 모델(Large Reasoning Models, LRMs)이 도입되고 있습니다. 이러한 모델들은 추론 벤치마크에서 향상된 성능을 보여주지만, 그 근본적인 능력, 확장성(스케일링) 특성, 그리고 한계에 대해서는 아직 충분히 이해되지 않고 있습니다. 현재의 평가 방식은 주로 확립된 수학 및 코딩 벤치마크에 초점을 맞추어 최종 답변의 정확성에 중점을 두고 있으며, 그러나 이러한 평가 패러다임은 데이터 오염 문제를 겪거나 사고 과정의 구조와 품질에 대한 통찰을 제공하지 못하는 한계가 있습니다. 본 연구에서는 조작이 가능한 퍼즐 환경을 활용하여 이러한 격차를 체계적으로 조사하였으며, 이 환경은 구성의 복잡성을 정밀하게 조절하면서도 일관된 논리 구조를 유지할 수 있게 합니다. 이 설정은 최종 답변뿐만 아니라 내부 사고 과정(Reasoning traces)도 분석할 수 있게 하여, LRMs이 어떻게 ‘생각’하는지에 대한 통찰을 제공합니다. 다양한 퍼즐에 대한 광범위한 실험을 통해, 최첨단 LRMs은 일정 수준의 복잡도를 넘어서면 정확도가 급격히 저하되는 현상을 확인하였으며, 또한 문제의 복잡도가 증가함에 따라 사고 노력(Reasoning effort)이 일정 지점까지는 증가하다가, 충분한 토큰 예산이 있음에도 불구하고 이후에는 감소하는 역설적인 확장 한계(스케일링 한계)를 보여줍니다. 동일한 추론 계산량(인퍼런스 컴퓨트) 하에서 LRMs과 표준 LLM(대형 언어 모델)을 비교한 결과, 세 가지 성능 구간을 확인하였습니다: (1) 낮은 복잡도의 작업에서는 표준 모델이 예상외로 LRMs보다 우수하며, (2) 중간 복잡도에서는 LRMs의 사고 과정이 유리하게 작용하며, (3) 높은 복잡도에서는 양 모델 모두 완전한 성능 붕괴를 경험합니다. 또한, LRMs은 정확한 계산(정확한 알고리즘 사용)에 한계가 있으며, 명시적 알고리즘을 활용하지 못하거나 퍼즐 간 일관성 없는 사고 과정을 보인다는 점도 발견하였습니다. 더 나아가 사고 과정의 패턴과 모델의 계산 행동을 심도 있게 분석하여, 이들의 강점과 한계를 조명하고, 궁극적으로 이들의 진정한 사고 능력에 대한 중요한 질문을 제기합니다.
Recent generations of frontier language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scal- ing properties, and limitations remain insufficiently understood. Current evaluations primarily fo- cus on established mathematical and coding benchmarks, emphasizing final answer accuracy. How- ever, this evaluation paradigm often suffers from data contamination and does not provide insights into the reasoning traces’ structure and quality. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of composi- tional complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs “think”. Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counter- intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget. By comparing LRMs with their standard LLM counterparts under equivalent inference compute, we identify three performance regimes: (1) low- complexity tasks where standard models surprisingly outperform LRMs, (2) medium-complexity tasks where additional thinking in LRMs demonstrates advantage, and (3) high-complexity tasks where both models experience complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across puzzles. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models’ computational behavior, shedding light on their strengths, limitations, and ultimately raising crucial questions about their true reasoning capabilities.
논문 링크
더 읽어보기
임베딩의 보편적 기하학 활용법 / Harnessing the Universal Geometry of Embeddings
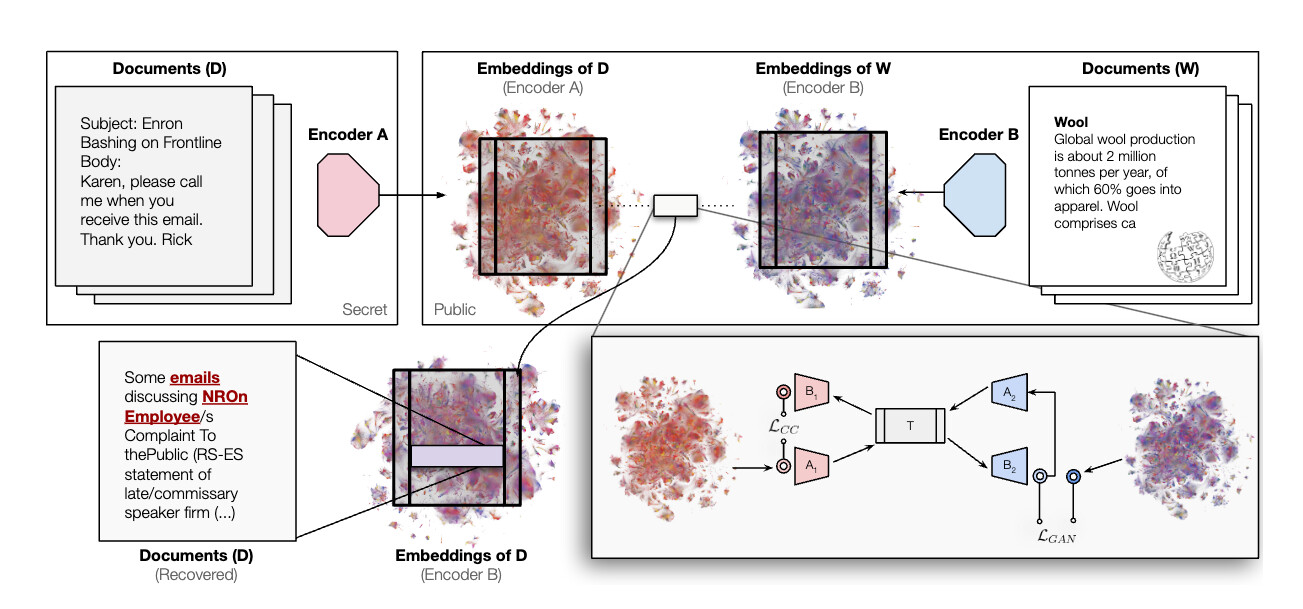
논문 소개
텍스트 임베딩을 서로 다른 벡터 공간 간에 대응 데이터나 인코더, 사전 정의된 매칭 없이 변환하는 최초의 무감독 학습 방법을 제안합니다. 이 방법은 모든 임베딩을 보편적 잠재 표현(universal latent representation)으로 변환하며, 이는 플라톤적 표현 가설(Platonic Representation Hypothesis)에 기반한 보편적 의미 구조를 활용합니다. 다양한 모델 구조, 파라미터 수, 학습 데이터셋 간에도 높은 코사인 유사도를 유지하는 변환 성능을 보입니다. 이러한 임베딩 공간 변환 능력은 벡터 데이터베이스의 보안에 중대한 영향을 미치며, 공격자가 임베딩 벡터만으로도 문서의 민감 정보를 추출할 수 있음을 시사합니다.
논문 초록(Abstract)
본 논문에서는 쌍(pair) 데이터, 인코더, 또는 사전 정의된 매칭 집합 없이 텍스트 임베딩을 한 벡터 공간에서 다른 벡터 공간으로 변환하는 최초의 방법을 제안합니다. 본 비지도 학습 방식은 모든 임베딩을 보편적 잠재 표현(universal latent representation), 즉 플라톤적 표현 가설(Platonic Representation Hypothesis)이 추정하는 보편적 의미 구조로부터 상호 변환할 수 있습니다. 제안하는 변환은 서로 다른 아키텍처, 파라미터 수, 학습 데이터셋을 가진 모델 쌍 간에 높은 코사인 유사도를 달성합니다. 알려지지 않은 임베딩을 기하학적 구조를 유지한 채 다른 공간으로 변환할 수 있는 능력은 벡터 데이터베이스의 보안에 중대한 영향을 미칩니다. 임베딩 벡터만 접근 가능한 공격자는 기저 문서에 대한 민감한 정보를 추출할 수 있으며, 이는 분류 및 속성 추론에 충분합니다.
We introduce the first method for translating text embeddings from one vector space to another without any paired data, encoders, or predefined sets of matches. Our unsupervised approach translates any embedding to and from a universal latent representation (i.e., a universal semantic structure conjectured by the Platonic Representation Hypothesis). Our translations achieve high cosine similarity across model pairs with different architectures, parameter counts, and training datasets. The ability to translate unknown embeddings into a different space while preserving their geometry has serious implications for the security of vector databases. An adversary with access only to embedding vectors can extract sensitive information about the underlying documents, sufficient for classification and attribute inference.
논문 링크
LLM 추론에서 부정적 강화의 놀라운 효과 / The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning
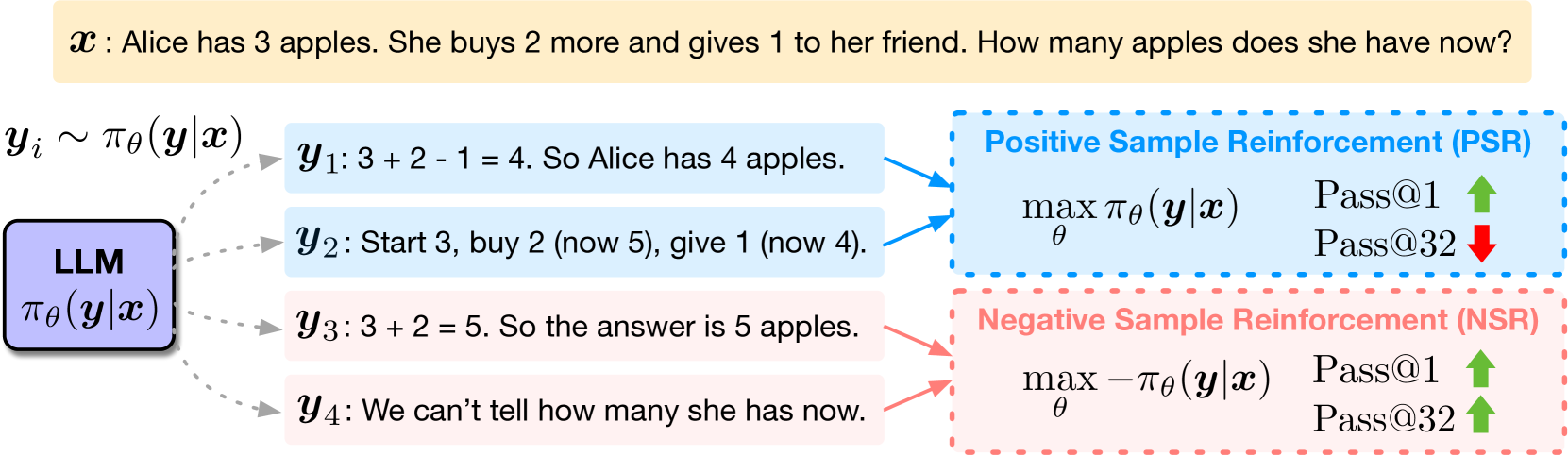
논문 소개
이 연구는 강화학습(Reinforcement Learning with Verifiable Rewards, RLVR)을 이용한 언어모델(LLM)의 수학적 추론 능력 향상에 대해 조사합니다. 특히, 올바른 답변을 강화하는 것(Positive Sample Reinforcement, PSR)보다 잘못된 답변을 페널티하는 것(Negative Sample Reinforcement, NSR)이 성능 향상에 더 효과적일 수 있음을 발견하였으며, 이는 모델이 기존 지식을 정제하는 데 기여합니다. 실험 결과, 오직 잘못된 답변에 대한 페널티만으로도 모델 성능이 크게 향상되며, 이는 기존 강화학습 기법보다 경쟁력이 있음을 보여줍니다. 이러한 통찰을 바탕으로, NSR을 강조하는 새로운 강화학습 목표를 제안하여 다양한 수학 문제 해결 성능을 지속적으로 개선할 수 있음을 확인하였습니다.
논문 초록(Abstract)
확인된 보상(Verifiable Rewards)을 활용한 강화학습(RLVR)은 추론 과제에서 출현하는 장기 사고의 연쇄(CoT)를 유도하는 언어 모델(LM) 학습에 유망한 접근법입니다. 감독 학습과 달리, 이는 정책 기울기(Policy Gradient)를 통해 정답 샘플과 오답 샘플 모두를 이용하여 모델을 업데이트합니다. 그 메커니즘을 보다 잘 이해하기 위해, 우리는 학습 신호를 정답 반응을 강화하는 것과 오답을 벌하는 것으로 분해하였으며, 각각 양성 샘플 강화(PSR, Positive Sample Reinforcement)와 음성 샘플 강화(NSR, Negative Sample Reinforcement)라고 부릅니다. 우리는 Qwen2.5-Math-7B와 Qwen3-4B를 수학 추론 데이터셋에 대해 학습시켰으며, 놀라운 결과를 발견하였습니다. 바로, 오답 샘플만을 사용하여 학습하는 것—즉, 정답 반응을 강화하지 않는 것—이 매우 효과적일 수 있다는 점입니다. 이는 전체 Pass@k 범위(최대 k=256)에서 일관되게 기본 모델의 성능을 향상시키며, 종종 PPO(Proximal Policy Optimization)와 GRPO(Generalized Reinforcement Policy Optimization)를 능가하거나 일치하는 성과를 보입니다. 반면, 정답 반응만을 강화하는 경우 Pass@$1$에서는 성능이 향상되지만, 높은 $k$에서는 다양성 감소로 인해 성능이 저하됩니다. 이러한 추론 확장(inference-scaling) 경향은 오답에 대한 벌이 성능 향상에 더 크게 기여할 수 있음을 시사합니다. 그라디언트 분석을 통해, NSR은 오답 생성 억제와 함께, 모델의 사전 신념에 따라 확률 질량을 다른 그럴듯한 후보로 재분배하는 방식으로 작동함을 보여줍니다. 이는 모델의 기존 지식을 정제하는 역할을 하며, 전혀 새로운 행동을 도입하는 것이 아닙니다. 이러한 통찰을 바탕으로, 우리는 NSR의 가중치를 높이는 간단한 RL 목표 변형을 제안하며, 이를 통해 MATH, AIME 2025, AMC23에서 전반적인 Pass@k 성능이 지속적으로 향상됨을 확인하였습니다. 저희 코드 역시 이 https URL에서 확인하실 수 있습니다.
Reinforcement learning with verifiable rewards (RLVR) is a promising approach for training language models (LMs) on reasoning tasks that elicit emergent long chains of thought (CoTs). Unlike supervised learning, it updates the model using both correct and incorrect samples via policy gradients. To better understand its mechanism, we decompose the learning signal into reinforcing correct responses and penalizing incorrect ones, referred to as Positive and Negative Sample Reinforcement (PSR and NSR), respectively. We train Qwen2.5-Math-7B and Qwen3-4B on a mathematical reasoning dataset and uncover a surprising result: training with only negative samples -- without reinforcing correct responses -- can be highly effective: it consistently improves performance over the base model across the entire Pass@k spectrum (k up to 256), often matching or surpassing PPO and GRPO. In contrast, reinforcing only correct responses improves Pass@1 but degrades performance at higher k, due to reduced diversity. These inference-scaling trends highlight that solely penalizing incorrect responses may contribute more to performance than previously recognized. Through gradient analysis, we show that NSR works by suppressing incorrect generations and redistributing probability mass toward other plausible candidates, guided by the model's prior beliefs. It refines the model's existing knowledge rather than introducing entirely new behaviors. Building on this insight, we propose a simple variant of the RL objective that upweights NSR, and show that it consistently improves overall Pass@k performance on MATH, AIME 2025, and AMC23. Our code is available at GitHub - TianHongZXY/RLVR-Decomposed: [NeurIPS 2025] Implementation for the paper "The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning".
논문 링크
더 읽어보기
https://github.com/TianHongZXY/RLVR-Decomposed
추론 훈련장: 검증 가능한 보상을 갖춘 강화학습용 사고 환경 / REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards

논문 소개
Reasoning Gym (RG)는 대수학, 기하학, 논리학, 게임 등 다양한 분야에서 100개 이상의 데이터 생성기 및 검증기를 제공하여 검증 가능한 보상을 기반으로 한 강화 학습(강화학습)을 지원하기 위해 설계된 라이브러리입니다. RG의 주요 혁신은 절차적 데이터 생성을 통해 거의 무제한적이고 조정 가능한 복잡성을 구현하는 데 있으며, 이는 고정된 추론 데이터셋의 한계를 극복합니다. 이 접근 방식은 다양한 난이도 수준에서 지속적인 평가를 가능하게 하여 추론 모델의 훈련 및 평가를 향상시킵니다. 실험 결과는 RG가 추론 능력 평가와 강화 학습 성능 개선 모두에서 효과적임을 확인했습니다.
논문 초록(Abstract)
우리는 검증 가능한 보상이 포함된 강화 학습용 추론 환경 라이브러리인 Reasoning Gym (RG)를 소개합니다. RG는 대수학, 산수, 계산, 인지, 기하학, 그래프 이론, 논리 및 다양한 일반 게임을 포함한 여러 도메인에 걸쳐 100개 이상의 데이터 생성기와 검증기를 제공합니다. 이 라이브러리의 핵심 혁신은 대부분의 기존 추론 데이터셋이 고정된 반면, 조절 가능한 복잡성을 갖춘 사실상 무한한 학습 데이터를 생성할 수 있다는 점입니다. 이 절차적 생성 방식을 통해 다양한 난이도 수준에서 지속적인 평가가 가능하며, 실험 결과는 RG가 추론 모델의 평가와 강화 학습 모두에 효과적임을 보여줍니다.
We introduce Reasoning Gym (RG), a library of reasoning environments for reinforcement learning with verifiable rewards. It provides over 100 data generators and verifiers spanning multiple domains including algebra, arithmetic, computation, cognition, geometry, graph theory, logic, and various common games. Its key innovation is the ability to generate virtually infinite training data with adjustable complexity, unlike most previous reasoning datasets, which are typically fixed. This procedural generation approach allows for continuous evaluation across varying difficulty levels. Our experimental results demonstrate the efficacy of RG in both evaluating and reinforcement learning of reasoning models.
논문 링크
저확률 토큰이 RL 학습에서 과도하게 지배하지 않도록 하는 방법 / Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
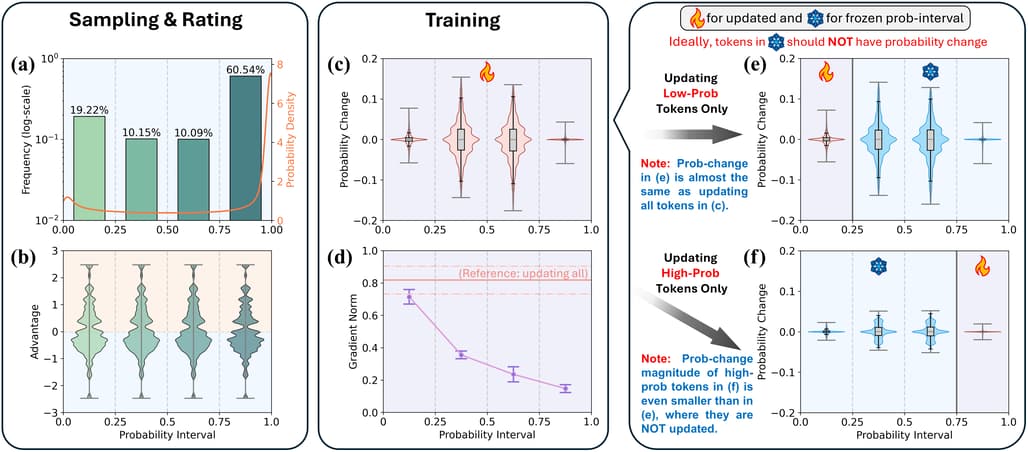
논문 소개
강화 학습(RL)은 대규모 언어 모델(LLMs)의 추론 능력을 향상시키는 데 널리 사용되며, 그룹 상대 정책 최적화(GRPO)와 같은 기술이 눈에 띄는 성과를 보여주고 있습니다. 그러나 낮은 확률의 토큰은 큰 기울기 크기로 인해 모델 업데이트에 과도한 영향을 미칠 수 있으며, 이는 성능에 중요한 높은 확률의 토큰 학습을 억제합니다. 이를 해결하기 위해 저자들은 두 가지 방법을 제안합니다: Advantage Reweighting과 Low-Probability Token Isolation(Lopti). 이 방법은 저확률 토큰의 영향을 줄이고 더 균형 잡힌 기울기 업데이트를 촉진합니다. 이러한 접근 방식은 RL 훈련 효율성과 모델 성능을 크게 향상시키며, 추론 작업에서 최대 46.2%의 성능 개선을 보여줍니다.
논문 초록(Abstract)
강화 학습(RL)은 대형 언어 모델(LLM)의 추론 능력 향상에 있어 핵심적인 역할을 담당하고 있으며, 최근에는 Group Relative Policy Optimization(GRPO)와 같은 혁신적인 방법들이 뛰어난 성과를 보여주고 있습니다. 본 연구에서는 RL 학습 과정에서 중요한 문제이지만 충분히 탐구되지 않은 이슈를 확인하였는데, 바로 낮은 확률 토큰이 큰 기울기 크기 때문에 모델 업데이트에 불균형적으로 영향을 미치는 현상입니다. 이러한 현상은 높은 확률 토큰의 학습을 방해하는데, 이들 토큰의 기울기는 LLM의 성능에 필수적이지만 상당히 억제되고 있기 때문입니다. 이를 완화하기 위해, 저희는 두 가지 새로운 방법인 Advantage Reweighting과 Low-Probability Token Isolation( Lopti)를 제안하며, 이들은 낮은 확률 토큰의 기울기를 효과적으로 약화시키면서 높은 확률 토큰에 의한 파라미터 업데이트를 강조합니다. 이러한 접근법은 확률이 다양한 토큰들 간의 균형 잡힌 업데이트를 촉진하여 RL 학습의 효율성을 높입니다. 실험 결과, 제안한 방법들이 GRPO로 학습된 LLM의 성능을 크게 향상시켜, K&K 논리 퍼즐 추론 과제에서 최대 46.2%의 성능 향상을 달성하였음을 보여줍니다. 저희 구현체는 GitHub - zhyang2226/AR-Lopti: [AI4MATH@ICML2025] Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs 에서 확인하실 수 있습니다.
Reinforcement learning (RL) has become a cornerstone for enhancing the reasoning capabilities of large language models (LLMs), with recent innovations such as Group Relative Policy Optimization (GRPO) demonstrating exceptional effectiveness. In this study, we identify a critical yet underexplored issue in RL training: low-probability tokens disproportionately influence model updates due to their large gradient magnitudes. This dominance hinders the effective learning of high-probability tokens, whose gradients are essential for LLMs' performance but are substantially suppressed. To mitigate this interference, we propose two novel methods: Advantage Reweighting and Low-Probability Token Isolation (Lopti), both of which effectively attenuate gradients from low-probability tokens while emphasizing parameter updates driven by high-probability tokens. Our approaches promote balanced updates across tokens with varying probabilities, thereby enhancing the efficiency of RL training. Experimental results demonstrate that they substantially improve the performance of GRPO-trained LLMs, achieving up to a 46.2% improvement in K&K Logic Puzzle reasoning tasks. Our implementation is available at GitHub - zhyang2226/AR-Lopti: [AI4MATH@ICML2025] Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs.
논문 링크
더 읽어보기
https://github.com/zhyang2226/AR-Lopti
고급 수학 문제 해결을 위한 실행 가능한 함수적 추상화: 생성 프로그램 추론 및 자동 생성 방법 / Executable Functional Abstractions: Inferring Generative Programs for Advanced Math Problems
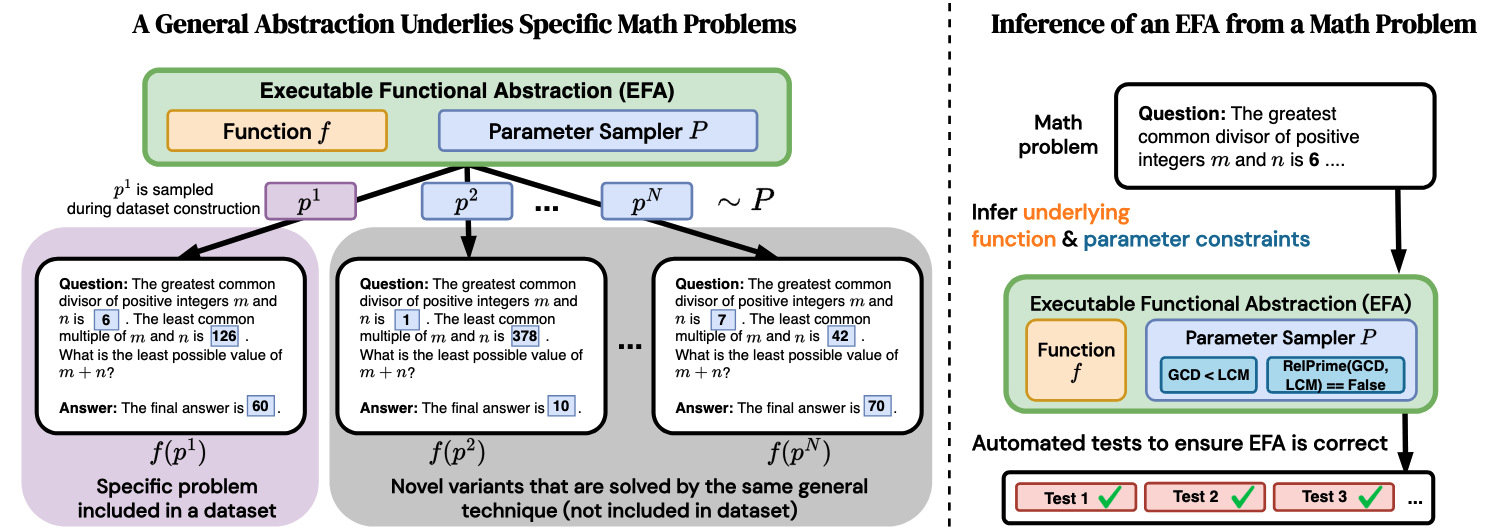
논문 소개
이 연구는 고급 수학 문제에 대한 실행 가능 함수적 추상화(Executable Functional Abstractions, EFA)를 자동으로 생성하는 방법을 제시합니다. EFA는 문제의 일반화된 규칙과 속성을 반영하는 프로그램으로, 이를 통해 문제 생성 및 난이도 조절, 데이터 생성 등의 다양한 응용이 가능합니다. 저자들은 대형 언어 모델(LLM)을 활용하여 초기 수학 문제와 해답을 바탕으로 EFA 후보를 생성하는 EFAGen 시스템을 개발하였으며, 이를 통해 다양한 경쟁 수준의 수학 문제에 대해 신뢰성 있는 EFA를 추론할 수 있음을 보여줍니다. 또한, EFA의 유효성을 검증하는 단위 테스트와 이를 활용한 학습 방법을 제안하여, 문제 난이도 조절 및 데이터 생성 등 후속 작업에 활용할 수 있음을 입증하였습니다.
논문 초록(Abstract)
과학자들은 종종 특정 문제 사례로부터 추상적인 절차를 유추하고, 이러한 추상화를 활용하여 새롭고 관련된 문제 사례를 생성합니다. 예를 들어, 시스템의 형식적 규칙과 특성을 인코딩하는 프로그램들은 강화학습(Procedural Environments)이나 물리학 시뮬레이션 엔진과 같은 다양한 분야에서 유용하게 활용되어 왔습니다. 이러한 프로그램들은 매개변수화(예를 들어, 격자 세계(Gridworld) 구성이나 초기 물리적 조건)에 따라 서로 다른 출력을 실행하는 함수로 볼 수 있습니다. 본 연구에서는 수학 문제에 대한 이러한 프로그램을 지칭하기 위해 ‘실행 가능한 함수적 추상화(Executable Functional Abstraction, EFA)’라는 용어를 도입합니다. EFA와 유사한 구조는 수학적 추론에 유용하며, 문제 생성기(problem generator)로서 모델의 스트레스 테스트를 수행하는 데 활용되어 왔습니다. 그러나 기존 연구는 초등학교 수준의 수학(단순 규칙이 프로그램으로 쉽게 인코딩 가능한 수준)의 추상화에 국한되어 있었으며, 고급 수학 문제에 대한 EFA를 생성하는 작업은 지금까지 인간의 공학적 개입이 필요했습니다. 본 연구에서는 고급 수학 문제에 대한 EFA의 자동 생성 방안을 탐구합니다. 우리는 EFA의 자동 구성을 프로그램 합성(program synthesis) 문제로 정형화하고, EFAGen이라는 시스템을 개발하였습니다. EFAGen은 시드 수학 문제와 그 단계별 해결 과정을 조건으로 하여, 시드 문제의 일반화된 문제 및 해답 범위에 충실한 후보 EFA 프로그램을 생성합니다. 또한, 유효한 EFA가 갖추어야 할 성질들을 실행 가능한 단위 테스트(executable unit tests)로 정형화하고, 이러한 테스트를 검증 가능한 보상으로 활용하여 LLM(대형 언어 모델)이 더 뛰어난 EFA 작성자가 되도록 학습시킬 수 있는 방법을 제시합니다. 실험 결과, EFAGen이 생성한 EFA는 시드 문제에 충실하며, 학습 가능한 문제 변형을 만들어내고, 다양한 경쟁 수준의 수학 문제 출처에서도 적절한 EFA를 추론할 수 있음을 보여줍니다. 마지막으로, 모델이 작성한 EFA의 후속 활용 예로서, 학습자가 해결하기 더 어렵거나 쉬운 문제 변형을 찾거나, 데이터 생성 등에 활용할 수 있음을 보여줍니다.
Scientists often infer abstract procedures from specific instances of problems and use the abstractions to generate new, related instances. For example, programs encoding the formal rules and properties of a system have been useful in fields ranging from RL (procedural environments) to physics (simulation engines). These programs can be seen as functions which execute to different outputs based on their parameterizations (e.g., gridworld configuration or initial physical conditions). We introduce the term EFA (Executable Functional Abstraction) to denote such programs for math problems. EFA-like constructs have been shown to be useful for math reasoning as problem generators for stress-testing models. However, prior work has been limited to abstractions for grade-school math (whose simple rules are easy to encode in programs), while generating EFAs for advanced math has thus far required human engineering. We explore the automatic construction of EFAs for advanced math problems. We operationalize the task of automatically constructing EFAs as a program synthesis task, and develop EFAGen, which conditions an LLM on a seed math problem and its step-by-step solution to generate candidate EFA programs that are faithful to the generalized problem and solution class underlying the seed problem. Furthermore, we formalize properties any valid EFA must possess in terms of executable unit tests, and show how the tests can be used as verifiable rewards to train LLMs to become better writers of EFAs. We demonstrate that EFAs constructed by EFAGen behave rationally by remaining faithful to seed problems, produce learnable problem variations, and that EFAGen can infer EFAs across multiple diverse sources of competition-level math problems. Finally, we show downstream uses of model-written EFAs e.g. finding problem variations that are harder or easier for a learner to solve, as well as data generation.
논문 링크
더 읽어보기
ReasonIR-8B: 추론 과제에 특화된 검색기 학습 방법 및 성능 향상 / ReasonIR: Training Retrievers for Reasoning Tasks
논문 소개
ReasonIR-8B는 일반적인 추론 작업에 특화된 최초의 검색기(리트리버)로, 기존의 검색기들이 추론 작업에서 제한된 성과를 보인 이유는 짧고 직설적인 사실 기반 쿼리와 문서에만 초점을 맞췄기 때문입니다. 이를 해결하기 위해, 합성 데이터 생성 파이프라인을 개발하여 각 문서에 도전적이고 관련성 높은 쿼리와 유사하지만 도움이 되지 않는 하드 네거티브를 생성하였으며, 이를 기존 공개 데이터와 혼합하여 학습시켰습니다. 그 결과, ReasonIR-8B는 BRIGHT 벤치마크에서 reranker 없이 29.9 nDCG@10, reranker와 함께 36.9 nDCG@10의 최고 성과를 달성하였으며, RAG( Retrieval-Augmented Generation) 작업에서 MMLU와 GPQA 성능을 각각 6.4%, 22.6% 향상시켰습니다. 또한, 테스트 시 더 길고 풍부한 쿼리와 결합할 때 성능이 지속적으로 향상되며, 오픈소스로 공개된 코드와 데이터는 향후 대형 언어모델(LLM) 확장에 유용하게 활용될 수 있습니다.
논문 초록(Abstract)
본 논문에서는 일반 추론(Reasoning) 작업에 특화되어 처음으로 훈련된 검색기(retriever)인 ReasonIR-8B를 소개합니다. 기존의 검색기들은 추론 작업에서 제한된 성과를 보여왔는데, 이는 부분적으로 기존의 학습 데이터셋이 문서와 직결된 짧은 사실적 쿼리(factual queries)에 초점을 맞추고 있기 때문입니다. 저희는 각 문서에 대해 도전적이고 관련성 높은 쿼리와 함께, 그와 관련은 있으나 궁극적으로 도움이 되지 않는 어려운 부정 예제(hard negative)를 생성하는 합성 데이터 생성 파이프라인(synthetic data generation pipeline)을 개발하였습니다. 이 파이프라인은 합성 데이터와 기존 공개 데이터(public data)를 혼합하여 학습함으로써, ReasonIR-8B는 널리 사용되는 추론 중심 정보 검색(Information Retrieval, IR) 벤치마크인 BRIGHT에서 reranker 없이 29.9 nDCG@10, reranker와 함께 36.9 nDCG@10의 새로운 최첨단 성과를 달성하였습니다. 또한, RAG( Retrieval-Augmented Generation) 작업에 적용했을 때, ReasonIR-8B는 폐쇄형(Closed-book) 기준선과 비교하여 MMLU와 GPQA 성능을 각각 6.4%, 22.6% 향상시키며, 다른 검색기 및 검색 엔진보다 뛰어난 성능을 보여줍니다. 더불어, ReasonIR-8B는 테스트 시 계산량(compute)을 보다 효율적으로 활용하는데, BRIGHT 데이터셋에서 더 길고 정보가 풍부한 재작성된 쿼리(rewritten queries)를 사용할수록 성능이 지속적으로 향상되며, LLM reranker와 결합했을 때도 다른 검색기보다 우수한 성능을 유지합니다. 저희의 학습 방법은 일반적이며, 향후 대형 언어모델(LLMs)에 쉽게 확장할 수 있도록 설계되었으며, 이를 위해 관련 코드, 데이터, 모델을 오픈소스로 공개합니다.
We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.
논문 링크
스펙트럼 연산자 신경망(Sonnet)을 활용한 다변수 시계열 예측 / Sonnet: Spectral Operator Neural Network for Multivariable Time Series Forecasting
논문 소개
Spectral Operator Neural Network (Sonnet)은 다변량 시계열 예측에서 exogenous 변수의 정보를 효과적으로 통합하여 예측 정확도를 향상시키는 새로운 아키텍처입니다. 이 모델은 학습 가능한 웨이브릿 변환과 Koopman 연산자를 활용한 스펙트럼 분석을 적용하며, 변수 간 의존성을 모델링하기 위해 스펙트럼 코히어런스 기반의 Multivariable Coherence Attention (MVCA)를 사용합니다. 실험 결과, Sonnet은 47개 예측 작업 중 34개에서 최고 성능을 기록했고, 특히 MVCA는 기존의 단순 attention보다 평균 MAE를 10.7% 낮추는 효과를 보였습니다. 이를 통해 Sonnet이 복잡한 변수 관계를 효과적으로 포착하는 강력한 시계열 예측 모델임을 입증합니다.
논문 초록(Abstract)
다변량 시계열 예측 방법은 외생 변수(exogenous variables)의 정보를 통합할 수 있어 예측 정확도를 크게 향상시킬 수 있습니다. 트랜스포머(Transformer) 아키텍처는 장기적 시퀀스 종속성을 포착하는 능력 덕분에 다양한 시계열 예측 모델에 널리 적용되고 있습니다. 그러나 트랜스포머를 단순히 적용하는 것만으로는 변수 간의 복잡한 관계를 효과적으로 모델링하는 데 한계가 있습니다. 이를 극복하기 위해, 저희는 새로운 아키텍처인 스펙트럼 연산자 신경망(Spectral Operator Neural Network, Sonnet)을 제안합니다. Sonnet은 학습 가능한 웨이블릿 변환(wavelet transformation)을 입력 데이터에 적용하고, 쿠프만(Koopman) 연산자를 이용한 스펙트럼 분석(spectral analysis)을 통합합니다. 이 모델의 예측 성능은 스펙트럼 일관성(spectral coherence)을 활용하는 다변량 일관성 주의(Multivariable Coherence Attention, MVCA)라는 연산에 의존하는데, 이는 변수 간 의존 관계를 보다 정밀하게 모델링하는 역할을 합니다. 실증 분석 결과, Sonnet은 47개 예측 과제 중 34개에서 최고의 성능을 기록하였으며, 가장 경쟁력 있는 기준 모델과 비교했을 때 평균 평균절대오차(Mean Absolute Error, MAE)가 1.1% 감소하는 성과를 보였습니다(과제별로 차별적 성과). 또한, MVCA를 기존 딥러닝 모델에서 사용하는 단순한 주의(attention) 대신 적용할 경우, 그 결함을 보완하여 가장 어려운 예측 과제들에서 평균 MAE를 10.7% 줄이는 데 기여함을 보여줍니다.
Multivariable time series forecasting methods can integrate information from exogenous variables, leading to significant prediction accuracy gains. Transformer architecture has been widely applied in various time series forecasting models due to its ability to capture long-range sequential dependencies. However, a na"ive application of transformers often struggles to effectively model complex relationships among variables over time. To mitigate against this, we propose a novel architecture, namely the Spectral Operator Neural Network (Sonnet). Sonnet applies learnable wavelet transformations to the input and incorporates spectral analysis using the Koopman operator. Its predictive skill relies on the Multivariable Coherence Attention (MVCA), an operation that leverages spectral coherence to model variable dependencies. Our empirical analysis shows that Sonnet yields the best performance on 34 out of 47 forecasting tasks with an average mean absolute error (MAE) reduction of 1.1\% against the most competitive baseline (different per task). We further show that MVCA -- when put in place of the na"ive attention used in various deep learning models -- can remedy its deficiencies, reducing MAE by 10.7\% on average in the most challenging forecasting tasks.
논문 링크
언어 모델의 스테가노그래피 잠재력: 메시지 은닉과 정보 은폐 능력 연구 / The Steganographic Potentials of Language Models
논문 소개
대형 언어 모델(LLMs)이 평문 내에 메시지를 은닉하는 스테가노그래피(은닉 기술) 능력을 갖추고 있어, 이를 통한 비정상적 AI 행위 감지와 방해가 어려워지고, LLM의 추론 신뢰성에 영향을 미칠 수 있음을 지적한다. 연구는 강화학습(RL)을 통해 미세 조정된 LLM이 은밀한 인코딩 방식 개발, 지시 시 스테가노그래피 수행, 그리고 은닉된 추론이 가능할 만한 현실적 시나리오에서의 활용 능력을 탐구한다. 실험 결과, 현재 모델은 보안성과 용량 측면에서 기초적인 스테가노그래피 능력을 보이나, 명확한 알고리즘적 지침이 주어질 때 은닉 능력이 크게 향상됨을 보여준다. 이러한 연구는 LLM의 은닉 능력에 대한 이해와 대응 방안을 모색하는 데 중요한 시사점을 제공한다.
논문 초록(Abstract)
이 논문 초록은 대형 언어 모델(LLMs)이 평문 내에 메시지를 숨기는 스테가노그래피(steganography) 능력을 갖추고 있다는 점이, 정렬되지 않은 인공지능 에이전트의 탐지와 방해를 어렵게 만들고, LLMs의 추론 신뢰성에 영향을 미칠 수 있음을 지적합니다. 본 연구에서는 강화 학습(RL)을 통해 미세 조정된 LLMs의 스테가노그래피 능력을 탐구하였으며, 구체적으로 다음 세 가지를 목표로 하였습니다: (1) 은밀한 인코딩 방식을 개발하는 것, (2) 프롬프트(질문 또는 명령)에 따라 스테가노그래피를 수행하는 것, 그리고 (3) 숨겨진 추론이 가능하지만 명시적으로 요청되지 않은 현실적인 시나리오에서 스테가노그래피를 활용하는 것. 이러한 시나리오에서는 LLM이 자신의 추론을 숨기려는 의도와 함께, 스테가노그래피 수행 능력도 함께 감지할 수 있었습니다. 본 연구의 미세 조정 실험과 비미세 조정(behavioral non fine-tuning) 평가 결과는, 현재 모델들이 보안성과 용량 측면에서 기초적인 스테가노그래피 능력을 갖추고 있음을 보여주었으며, 명확한 알고리즘적 지침이 이들의 정보 은닉 능력을 현저히 향상시킨다는 점을 확인하였습니다.
The potential for large language models (LLMs) to hide messages within plain text (steganography) poses a challenge to detection and thwarting of unaligned AI agents, and undermines faithfulness of LLMs reasoning. We explore the steganographic capabilities of LLMs fine-tuned via reinforcement learning (RL) to: (1) develop covert encoding schemes, (2) engage in steganography when prompted, and (3) utilize steganography in realistic scenarios where hidden reasoning is likely, but not prompted. In these scenarios, we detect the intention of LLMs to hide their reasoning as well as their steganography performance. Our findings in the fine-tuning experiments as well as in behavioral non fine-tuning evaluations reveal that while current models exhibit rudimentary steganographic abilities in terms of security and capacity, explicit algorithmic guidance markedly enhances their capacity for information concealment.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()