[2025/06/16 ~ 22] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주 선정된 논문들을 살펴보면, 대형 언어 모델의 적응성과 확장성, 그리고 효율성 개선에 관한 연구가 중심을 이루고 있습니다. 특히, 자연어 기반의 즉각적 적응과 강화학습을 접목한 사전학습 방법 등은 LLM을 다양한 과제에 빠르게 적용할 수 있는 가능성을 보여주며, 이는 모델 활용의 민주화와 비용 절감에 기여할 것으로 기대됩니다. 또한, 훈련 없이도 테스트 시 계산을 확장하는 새로운 프롬프트 기법은 복잡한 추론 문제 해결에 있어 실용적인 대안을 제시합니다.
한편, 대형 모델의 무거운 연산과 메모리 요구를 해결하기 위한 양자화, 효율적 추론 기법, 클러스터 및 인스턴스 수준의 서비스 최적화 연구도 활발히 이루어지고 있습니다. 이는 실제 산업 현장에서 LLM을 안정적이고 경제적으로 운영하기 위한 필수적인 기술로, 다양한 하드웨어 환경과 작업 부하에 대응할 수 있는 전략 마련에 중요한 밑거름이 될 것입니다.
마지막으로, 모델의 기억 능력과 추론 메커니즘에 대한 이론적 이해를 높이고, AI 에이전트의 동적 추론에서 발생하는 비용 문제를 분석하는 연구들이 포함되어, LLM의 내재적 한계 극복과 지속 가능한 AI 시스템 구축에 대한 관심이 높아지고 있음을 알 수 있습니다. 이러한 연구들은 앞으로 LLM의 성능과 효율성 간 균형을 맞추는 데 중요한 방향성을 제시할 것으로 보입니다.
Text-to-LoRA: 즉시 트랜스포머 적응 기술 / Text-to-LoRA: Instant Transformer Adaption
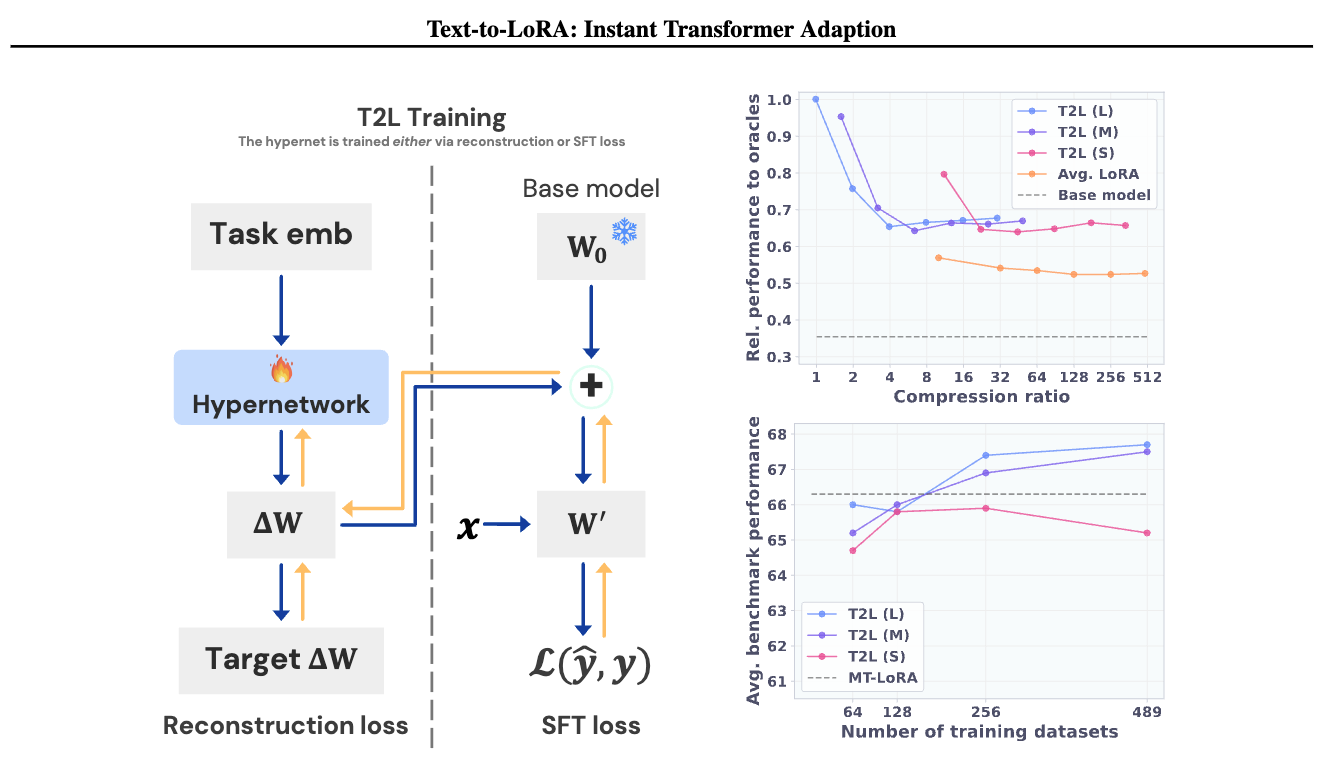
논문 소개
Text-to-LoRA (T2L)은 자연어 설명만으로 대형 언어 모델(LLM)을 즉시 적응시킬 수 있는 하이퍼네트워크(hypernetwork)입니다. 기존의 파인튜닝(fine-tuning) 방식이 고비용과 긴 훈련 시간, 하이퍼파라미터 민감성 문제를 갖는 데 반해, T2L은 단일 순전파(forward pass)만으로 LoRA(저랭크 적응) 어댑터를 생성하여 효율적인 적응을 가능하게 합니다. 9개의 사전 훈련된 LoRA 어댑터를 기반으로 학습된 T2L은 해당 작업별 어댑터와 동등한 성능을 보이며, 수백 개의 LoRA 인스턴스를 압축하고 완전히 새로운 작업에도 제로샷(zero-shot) 일반화가 가능합니다. 이 방법은 적은 연산 자원으로도 파운데이션 모델의 전문화(specialization)를 민주화하는 중요한 진전을 제시합니다.
논문 초록(Abstract)
파운데이션 모델은 빠른 콘텐츠 생성에 일반적인 도구를 제공하지만, 종종 특정 작업에 맞춘 적응이 필요합니다. 전통적으로 이러한 과정은 데이터셋의 신중한 선별과 기본 모델의 반복적인 파인튜닝을 포함합니다. 파인튜닝 기법은 파운데이션 모델을 다양한 새로운 응용에 적응시킬 수 있게 하지만, 비용이 많이 들고 학습 시간이 길며 하이퍼파라미터 선택에 매우 민감하다는 단점이 있습니다. 이러한 한계를 극복하기 위해, 본 논문에서는 자연어로 된 목표 작업 설명만으로 대형 언어 모델(LLM)을 즉시 적응시킬 수 있는 Text-to-LoRA(T2L) 모델을 제안합니다. T2L은 단일의 저비용 순전파(forward pass)로 LoRA를 생성하도록 학습된 하이퍼네트워크입니다. GSM8K, Arc 등 9개의 사전 학습된 LoRA 어댑터 세트로 T2L을 학습한 후, 즉석에서 재구성된 LoRA 인스턴스가 해당 테스트셋에서 작업별 어댑터와 동등한 성능을 보임을 확인하였습니다. 더 나아가 T2L은 수백 개의 LoRA 인스턴스를 압축할 수 있으며, 전혀 본 적 없는 작업에도 제로샷(zero-shot) 일반화가 가능합니다. 본 접근법은 파운데이션 모델의 특화 과정을 민주화하는 중요한 진전을 제공하며, 최소한의 연산 자원으로 언어 기반 적응을 가능하게 합니다. 본 코드 저장소는 GitHub - SakanaAI/text-to-lora: Hypernetworks that adapt LLMs for specific benchmark tasks using only textual task description as the input 에서 확인하실 수 있습니다.
While Foundation Models provide a general tool for rapid content creation, they regularly require task-specific adaptation. Traditionally, this exercise involves careful curation of datasets and repeated fine-tuning of the underlying model. Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyperparameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting large language models (LLMs) on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass. After training T2L on a suite of 9 pre-trained LoRA adapters (GSM8K, Arc, etc.), we show that the ad-hoc reconstructed LoRA instances match the performance of task-specific adapters across the corresponding test sets. Furthermore, T2L can compress hundreds of LoRA instances and zero-shot generalize to entirely unseen tasks. This approach provides a significant step towards democratizing the specialization of foundation models and enables language-based adaptation with minimal compute requirements. Our code is available at GitHub - SakanaAI/text-to-lora: Hypernetworks that adapt LLMs for specific benchmark tasks using only textual task description as the input
논문 링크
더 읽어보기
https://github.com/SakanaAI/text-to-lora
강화 학습 기반 사전 학습 (Reinforcement Pre-Training) / Reinforcement Pre-Training
논문 소개
Reinforcement Pre-Training (RPT)은 대규모 언어 모델과 강화학습(RL)을 통합하는 새로운 확장 패러다임을 제시합니다. 다음 토큰 예측을 강화학습 기반의 추론 과제로 재구성하여, 주어진 문맥에서 올바른 토큰을 예측할 때 검증 가능한 보상을 받도록 설계하였습니다. 이를 통해 도메인 특화된 주석 데이터 없이도 방대한 텍스트 데이터를 활용한 일반 목적의 강화학습이 가능하며, 다음 토큰 예측 정확도를 크게 향상시킵니다. 또한, RPT는 이후 강화학습 미세조정을 위한 강력한 사전학습 기반을 제공하며, 학습량 증가에 따른 성능 향상도 꾸준히 관찰됩니다.
논문 초록(Abstract)
본 연구에서는 대규모 언어 모델과 강화학습(RL)을 위한 새로운 확장 패러다임으로서 강화 사전학습(Reinforcement Pre-Training, RPT)을 제안합니다. 구체적으로, 다음 토큰 예측을 강화학습을 통해 학습되는 추론 과제로 재구성하여, 주어진 문맥에 대해 올바른 다음 토큰을 예측할 경우 검증 가능한 보상을 받도록 합니다. RPT는 도메인별 주석 답변에 의존하지 않고 방대한 텍스트 데이터를 일반 목적의 강화학습에 활용할 수 있는 확장 가능한 방법을 제공합니다. 다음 토큰 추론 능력을 강화함으로써 RPT는 다음 토큰 예측의 언어 모델링 정확도를 크게 향상시킵니다. 더불어, RPT는 추가적인 강화 미세조정을 위한 강력한 사전학습 기반을 제공합니다. 확장 곡선(scaling curves)은 학습 연산량 증가가 다음 토큰 예측 정확도를 지속적으로 향상시킨다는 것을 보여줍니다. 이러한 결과는 RPT가 언어 모델 사전학습을 발전시키기 위한 효과적이고 유망한 확장 패러다임임을 입증합니다.
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a reasoning task trained using RL, where it receives verifiable rewards for correctly predicting the next token for a given context. RPT offers a scalable method to leverage vast amounts of text data for general-purpose RL, rather than relying on domain-specific annotated answers. By incentivizing the capability of next-token reasoning, RPT significantly improves the language modeling accuracy of predicting the next tokens. Moreover, RPT provides a strong pre-trained foundation for further reinforcement fine-tuning. The scaling curves show that increased training compute consistently improves the next-token prediction accuracy. The results position RPT as an effective and promising scaling paradigm to advance language model pre-training.
논문 링크
학습 없이 테스트 시 계산 확장하는 사고의 연쇄 방법론 / Chain of Methodologies: Scaling Test Time Computation without Training
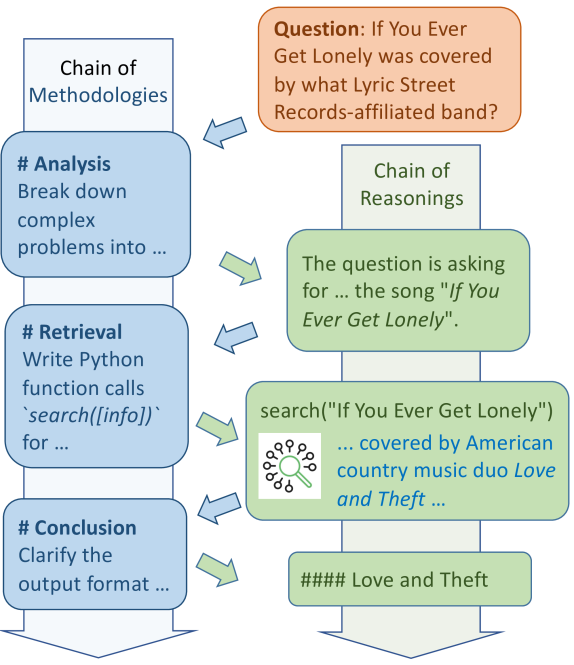
논문 소개
대형 언어 모델(LLM)은 복잡한 추론 과제에서 훈련 데이터에 부족한 심층적 통찰력으로 인해 한계를 보인다. Chain of Methodologies(CoM)는 인간의 방법론적 통찰을 통합하여 체계적인 사고를 촉진하는 혁신적인 프롬프트 기법으로, 명시적 미세조정 없이도 고급 LLM의 메타인지 능력을 활용한다. 실험 결과 CoM은 경쟁 기법들을 능가하며, 훈련 없이도 복잡한 추론 문제를 효과적으로 해결할 수 있음을 입증하였다. 이를 통해 인간 수준의 추론에 한걸음 다가가는 가능성을 보여준다.
논문 초록(Abstract)
대형 언어 모델(LLM)은 일반적으로 공개된 문서에 포함되지 않은 심층적인 통찰이 학습 데이터에 부족하여 복잡한 추론 과제 수행에 어려움을 겪습니다. 본 논문에서는 인간의 방법론적 통찰을 통합하여 구조화된 사고를 향상시키는 혁신적이고 직관적인 프롬프트 프레임워크인 Chain of Methodologies(CoM)를 제안합니다. CoM은 고급 LLM의 메타인지 능력을 활용하여 명시적인 미세조정 없이도 사용자 정의 방법론을 통해 체계적인 추론을 활성화함으로써 LLM이 확장된 추론을 요구하는 복잡한 과제를 해결할 수 있도록 합니다. 실험 결과 CoM은 경쟁력 있는 기준선들을 능가하였으며, 학습이 필요 없는 프롬프트 기법이 복잡한 추론 과제에 대한 강력한 해결책이 될 수 있음을 보여주고, 인간과 유사한 방법론적 통찰을 통해 인간 수준의 추론에 한 걸음 다가설 수 있음을 입증하였습니다.
Large Language Models (LLMs) often struggle with complex reasoning tasks due to insufficient in-depth insights in their training data, which are typically absent in publicly available documents. This paper introduces the Chain of Methodologies (CoM), an innovative and intuitive prompting framework that enhances structured thinking by integrating human methodological insights, enabling LLMs to tackle complex tasks with extended reasoning. CoM leverages the metacognitive abilities of advanced LLMs, activating systematic reasoning throught user-defined methodologies without explicit fine-tuning. Experiments show that CoM surpasses competitive baselines, demonstrating the potential of training-free prompting methods as robust solutions for complex reasoning tasks and bridging the gap toward human-level reasoning through human-like methodological insights.
논문 링크
양자화 인지 학습을 위한 확장 법칙 / Scaling Law for Quantization-Aware Training
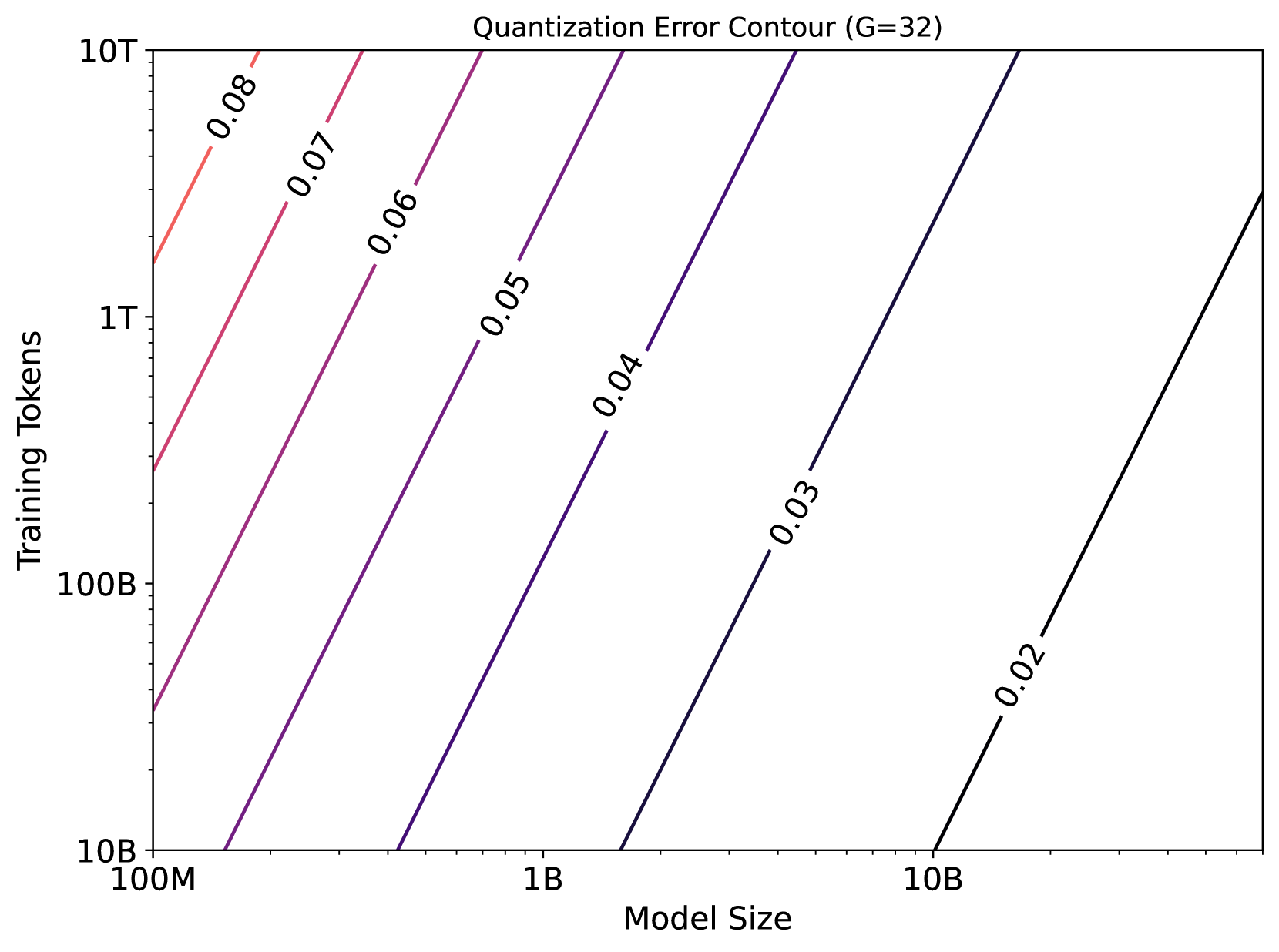
논문 소개
대규모 언어 모델(LLM)의 효율적 배포를 위해 정량화 인지 학습(QAT)이 활용되나, 특히 4비트 정밀도(W4A4)에서의 스케일링 특성은 명확하지 않았습니다. 본 연구는 모델 크기, 학습 데이터 양, 정량화 그룹 크기를 변수로 하는 통합 스케일링 법칙을 제안하여, 정량화 오차가 모델 크기 증가 시 감소하지만 학습 토큰 수와 정량화 세분화가 거칠어질수록 증가함을 실험적으로 입증하였습니다. W4A4 정량화 오차를 가중치와 활성화(activation) 오차로 분해한 결과, 두 요소가 서로 다른 민감도를 보이며 특히 FC2 층의 활성화 오차가 주요 병목임을 확인하였습니다. 혼합 정밀도 정량화를 적용하여 이 병목을 완화하고, 학습 데이터가 많아질수록 가중치 정량화 오차의 중요성도 커진다는 점을 밝혀 QAT 최적화 방향에 중요한 시사점을 제공하였습니다.
논문 초록(Abstract)
대형 언어 모델(LLM)은 상당한 계산 및 메모리 자원을 요구하여 배포에 어려움을 초래합니다. 양자화 인지 학습(QAT)은 모델 정밀도를 낮추면서도 성능을 유지함으로써 이러한 문제를 해결합니다. 그러나 특히 4비트 정밀도(W4A4)에서 QAT의 스케일링 특성은 아직 명확히 이해되지 않았습니다. 기존 QAT 스케일링 법칙들은 학습 토큰 수와 양자화 세분화와 같은 핵심 요소를 종종 무시하여 적용 범위가 제한적입니다. 본 논문은 모델 크기, 학습 데이터 양, 양자화 그룹 크기를 변수로 하는 양자화 오차의 통합 스케일링 법칙을 제안합니다. 268회의 QAT 실험을 통해 양자화 오차는 모델 크기가 커질수록 감소하지만, 학습 토큰 수가 많아지고 양자화 세분화가 거칠어질수록 증가함을 보였습니다. W4A4 양자화 오차의 원인을 규명하기 위해 이를 가중치와 활성화 성분으로 분해하였으며, 두 성분 모두 W4A4 양자화 오차의 전반적인 경향을 따르지만 민감도는 다릅니다. 특히, 가중치 양자화 오차는 학습 토큰 수 증가에 따라 더 빠르게 증가합니다. 추가 분석 결과, FC2 층의 활성화 양자화 오차가 이상치에 의해 발생하며, 이는 W4A4 QAT 양자화 오차의 주요 병목임을 확인하였습니다. 이 병목을 해결하기 위해 혼합 정밀도 양자화를 적용함으로써 가중치와 활성화 양자화 오차가 유사한 수준으로 수렴할 수 있음을 입증하였습니다. 또한 학습 데이터가 많아질수록 가중치 양자화 오차가 결국 활성화 양자화 오차를 초과함을 보여, 이러한 상황에서는 가중치 양자화 오차 감소도 중요함을 시사합니다. 본 연구 결과는 QAT 연구 및 개발의 향상을 위한 핵심적인 통찰을 제공합니다.
Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
논문 링크
대규모 언어 모델(LLM)의 효율적 추론 서비스 서베이 / Taming the Titans: A Survey of Efficient LLM Inference Serving
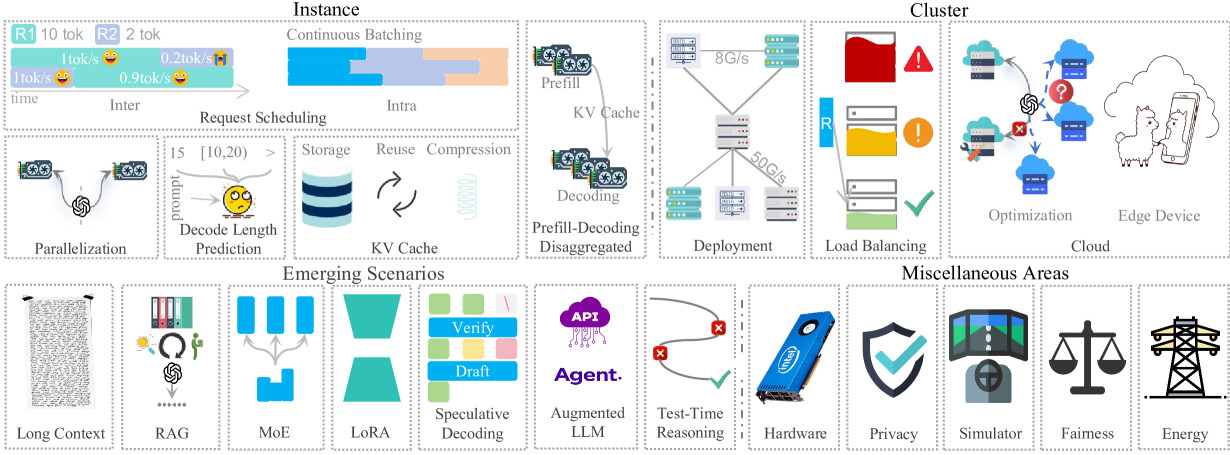
논문 소개
대규모 언어 모델(LLM)의 추론 서비스는 방대한 파라미터 수와 주의(attention) 메커니즘의 높은 연산 요구로 인해 낮은 지연 시간과 높은 처리량 달성에 어려움이 있습니다. 본 논문은 인스턴스 수준의 모델 배치, 요청 스케줄링, 디코딩 길이 예측 등 기본 기법부터 GPU 클러스터 배치, 다중 인스턴스 부하 분산, 클라우드 서비스 솔루션 등 클러스터 수준 전략까지 폭넓게 다룹니다. 또한 특정 작업 및 모듈 중심의 신흥 시나리오와 기타 중요하지만 상대적으로 덜 주목받는 분야도 함께 검토합니다. 마지막으로 LLM 추론 서비스의 발전을 위한 향후 연구 방향을 제시합니다.
논문 초록(Abstract)
생성형 AI를 위한 대형 언어 모델(LLM)은 놀라운 발전을 이루어내어 다양한 분야와 응용에서 널리 채택되는 정교하고 다재다능한 도구로 진화하였습니다. 그러나 방대한 파라미터 수로 인한 상당한 메모리 부담과 어텐션 메커니즘의 높은 연산 요구는 LLM 추론 서비스에서 낮은 지연 시간과 높은 처리량을 달성하는 데 큰 도전 과제를 제기합니다. 최근 획기적인 연구에 힘입어 이 분야의 발전이 크게 가속화되었습니다. 본 논문은 이러한 방법들을 포괄적으로 서베이하며, 기본적인 인스턴스 수준 접근법, 심층적인 클러스터 수준 전략, 신흥 시나리오 방향, 그리고 기타 중요하지만 다양한 영역을 다룹니다. 인스턴스 수준에서는 모델 배치, 요청 스케줄링, 디코딩 길이 예측, 저장소 관리, 그리고 분산화 패러다임을 검토합니다. 클러스터 수준에서는 GPU 클러스터 배포, 다중 인스턴스 부하 분산, 클라우드 서비스 솔루션을 탐구합니다. 신흥 시나리오에 대해서는 특정 작업, 모듈, 보조 방법을 중심으로 논의를 구성합니다. 전체적인 개요를 위해 몇 가지 틈새지만 중요한 영역도 강조합니다. 마지막으로, LLM 추론 서비스 분야의 추가 발전을 위한 잠재적 연구 방향을 제시합니다.
Large Language Models (LLMs) for Generative AI have achieved remarkable progress, evolving into sophisticated and versatile tools widely adopted across various domains and applications. However, the substantial memory overhead caused by their vast number of parameters, combined with the high computational demands of the attention mechanism, poses significant challenges in achieving low latency and high throughput for LLM inference services. Recent advancements, driven by groundbreaking research, have significantly accelerated progress in this field. This paper provides a comprehensive survey of these methods, covering fundamental instance-level approaches, in-depth cluster-level strategies, emerging scenario directions, and other miscellaneous but important areas. At the instance level, we review model placement, request scheduling, decoding length prediction, storage management, and the disaggregation paradigm. At the cluster level, we explore GPU cluster deployment, multi-instance load balancing, and cloud service solutions. For emerging scenarios, we organize the discussion around specific tasks, modules, and auxiliary methods. To ensure a holistic overview, we also highlight several niche yet critical areas. Finally, we outline potential research directions to further advance the field of LLM inference serving.
논문 링크
언어 모델은 얼마나 많은 정보를 암기하는가? / How much do language models memorize?

논문 소개
본 연구에서는 모델이 특정 데이터 포인트에 대해 얼마나 많은 정보를 알고 있는지를 추정하는 새로운 방법을 제안하고, 이를 통해 현대 언어 모델의 용량을 측정하였습니다. 기존 연구들이 암기(memorization)와 일반화(generalization)를 구분하는 데 어려움을 겪었던 반면, 본 연구는 암기를 의도치 않은 암기(unintended memorization)와 일반화로 명확히 분리하였습니다. 일반화를 완전히 제거했을 때 모델의 총 암기량을 계산할 수 있으며, 이를 통해 GPT 계열 모델의 용량이 파라미터당 약 3.6 비트임을 추정하였습니다. 또한, 다양한 크기의 데이터셋으로 학습한 수백 개의 트랜스포머 언어 모델 실험을 통해 모델 용량과 데이터 크기 간의 스케일링 법칙을 도출하고, 암기와 일반화 간의 관계를 분석하였습니다.
논문 초록(Abstract)
본 논문에서는 모델이 특정 데이터포인트에 대해 얼마나 “알고 있는지”를 추정하는 새로운 방법을 제안하고, 이를 활용하여 현대 언어 모델의 용량을 측정합니다. 기존의 언어 모델 암기 연구들은 암기와 일반화를 명확히 구분하는 데 어려움을 겪어왔습니다. 본 연구에서는 암기를 두 가지 구성 요소로 공식적으로 분리합니다: \textit{비의도적 암기}는 모델이 특정 데이터셋에 대해 보유한 정보이며, \textit{일반화}는 모델이 실제 데이터 생성 과정에 대해 보유한 정보입니다. 일반화를 완전히 제거할 경우, 총 암기를 계산할 수 있으며, 이는 모델 용량의 추정치를 제공합니다. 본 연구의 측정 결과에 따르면 GPT 스타일 모델은 파라미터당 약 3.6비트의 용량을 갖는 것으로 추정됩니다. 우리는 점차 크기가 증가하는 데이터셋으로 언어 모델을 학습시키고, 모델이 용량 한계에 도달할 때까지 암기하는 현상을 관찰하였으며, 이 시점에서 “grokking” 현상이 시작되어 모델이 일반화를 시작함에 따라 비의도적 암기가 감소함을 확인하였습니다. 또한, 50만에서 15억 파라미터에 이르는 수백 개의 트랜스포머 언어 모델을 학습시키고, 모델 용량과 데이터 크기 및 멤버십 추론(membership inference) 간의 관계를 나타내는 일련의 스케일링 법칙을 도출하였습니다.
We propose a new method for estimating how much a model
knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which pointgrokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from 500K to 1.5B parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
논문 링크
EfficientLLM: 대규모 언어 모델의 효율성 평가와 최적화 연구 / EfficientLLM: Efficiency in Large Language Models
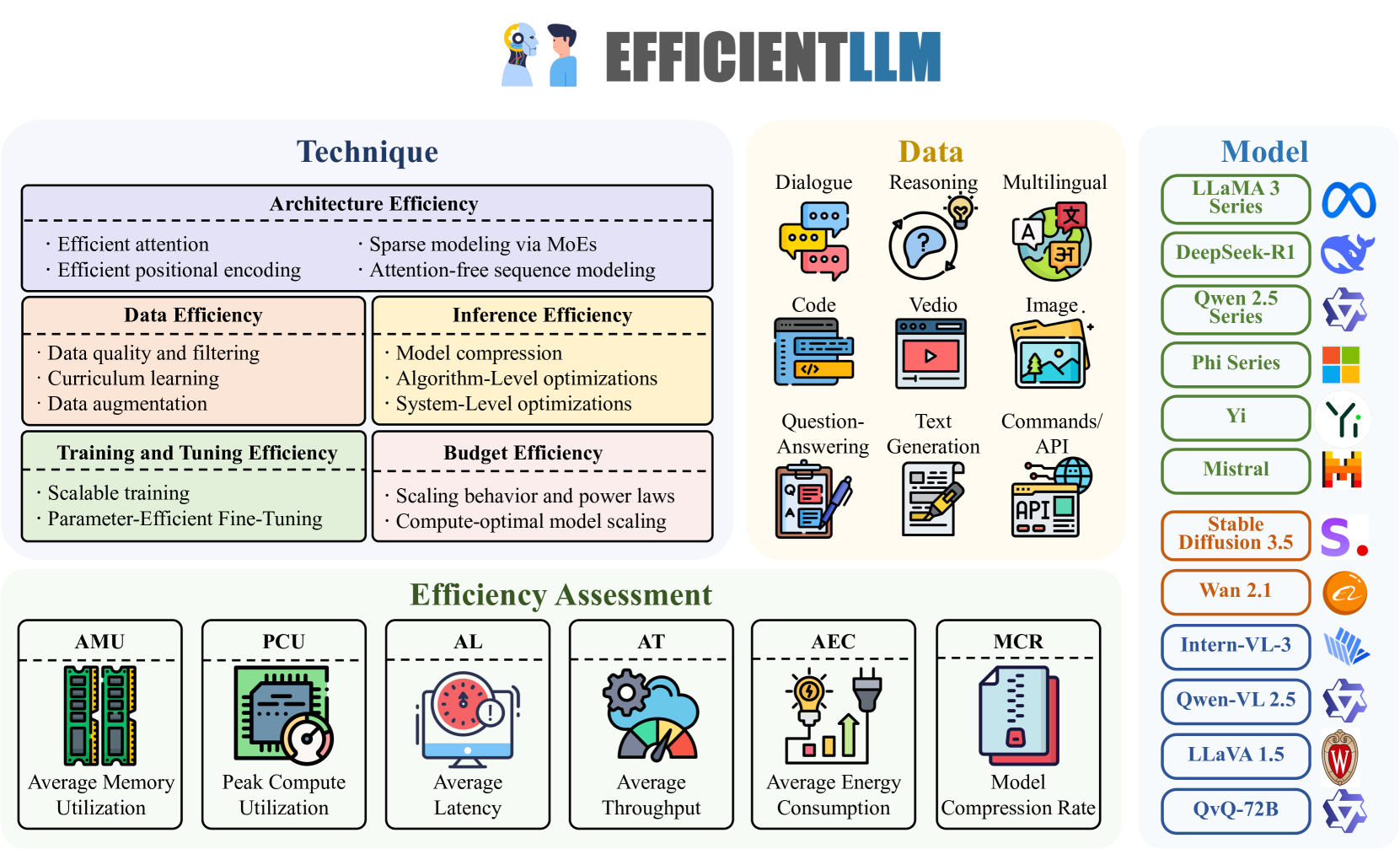
논문 소개
EfficientLLM은 대규모 언어 모델(LLM)의 효율성을 체계적으로 평가하기 위한 최초의 종합적 벤치마크이자 실증 연구를 제시합니다. 48xGH200, 8xH200 GPU 클러스터에서 아키텍처 사전학습(효율적 어텐션, 희소 MoE), 파인튜닝(LoRA 계열 기법), 추론(양자화) 등 세 가지 축을 중심으로 100여 개 모델-기법 조합을 평가하며, 메모리, 연산, 지연시간, 처리량, 에너지, 압축률 등 6가지 세분화된 지표를 도입하였습니다. 연구 결과, 효율성은 명확한 트레이드오프가 존재하며, 최적의 기법은 작업 유형과 모델 규모에 따라 달라지고, 일부 기법은 대규모 비전 및 비전-언어 모델에도 효과적으로 일반화됨을 확인하였습니다. 이를 통해 차세대 기초 모델의 효율성과 성능 간 균형을 모색하는 연구자와 엔지니어에게 중요한 지침을 제공합니다.
논문 초록(Abstract)
대형 언어 모델(LLM)은 상당한 발전을 이끌었으나, 증가하는 파라미터 수와 컨텍스트 윈도우 크기로 인해 계산, 에너지, 비용 측면에서 과도한 부담이 발생합니다. 본 논문에서는 EfficientLLM을 제안하며, 이는 LLM의 효율성 기법을 대규모로 평가한 최초의 종합적 실증 연구이자 벤치마크입니다. 48대의 GH200과 8대의 H200 GPU로 구성된 프로덕션급 클러스터에서 수행된 본 연구는 세 가지 핵심 축을 체계적으로 탐구합니다: (1) 아키텍처 사전학습(효율적 어텐션 변형: MQA, GQA, MLA, NSA; 희소 Mixture-of-Experts(MoE)), (2) 파인튜닝(파라미터 효율적 방법: LoRA, RSLoRA, DoRA), (3) 추론(양자화 기법: int4, float16). 하드웨어 포화도, 지연-처리량 균형, 탄소 비용을 포착하기 위해 메모리 활용도, 계산 활용도, 지연 시간, 처리량, 에너지 소비, 압축률 등 6개의 세분화된 지표를 정의하였습니다. 0.5B에서 72B 파라미터 범위의 100여 개 모델-기법 조합을 평가한 결과, 세 가지 주요 인사이트를 도출하였습니다: (i) 효율성은 정량화 가능한 트레이드오프를 수반하며, 단일 기법이 모든 상황에 최적이 아니며 예를 들어 MoE는 FLOPs를 줄이고 정확도를 향상시키나 VRAM을 40% 증가시키고, int4 양자화는 메모리와 에너지를 최대 3.9배 절감하나 정확도는 3-5% 하락합니다. (ii) 최적 기법은 작업과 규모에 따라 다르며, MQA는 제한된 디바이스에서 메모리-지연 균형에 최적이고, MLA는 품질이 중요한 작업에서 최저 perplexity를 달성하며, RSLoRA는 14B 파라미터 이상에서만 LoRA를 능가하는 효율성을 보입니다. (iii) 기법들은 모달리티를 넘어 일반화되며, 대형 비전 모델(Stable Diffusion 3.5, Wan 2.1)과 비전-언어 모델(Qwen2.5-VL) 평가 확장을 통해 효과적인 전이 가능성을 확인하였습니다. 데이터셋, 평가 파이프라인, 리더보드를 오픈소스로 공개함으로써 EfficientLLM은 차세대 파운데이션 모델의 효율성-성능 간 균형을 모색하는 연구자와 엔지니어에게 필수적인 지침을 제공합니다.
Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
논문 링크
생성형 에이전트 기반 모델링을 통한 대규모 다중접속 온라인 게임 경제 시뮬레이션 강화 / Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling

논문 소개
MMO 경제 연구에서 에이전트 기반 모델링(Agent-Based Modeling, ABM)은 게임 내 경제 분석에 효과적인 도구로 발전해왔으나, 기존 에이전트들은 신뢰성, 사회성, 해석 가능성 측면에서 한계를 보였습니다. 본 연구는 대규모 언어 모델(Large Language Models, LLMs)을 활용하여 인간과 유사한 의사결정과 적응력을 갖춘 생성형 에이전트를 설계하였습니다. 이러한 에이전트는 역할 수행(role-playing), 인지, 기억, 추론 능력을 갖추어 기존 문제를 해결하며, 시뮬레이션 결과 시장 규칙에 따른 역할 전문화와 가격 변동과 같은 자발적 현상을 유도함을 확인하였습니다. 이를 통해 MMO 경제 시뮬레이션의 현실성과 복잡성을 크게 향상시킬 수 있음을 보여줍니다.
논문 초록(Abstract)
대규모 다중접속 온라인 게임(MMO) 경제 연구 분야에서 에이전트 기반 모델링(Agent-Based Modeling, ABM)은 게임 경제 분석을 위한 강력한 도구로 부상하였으며, 초기의 규칙 기반 에이전트에서 강화학습을 적용한 의사결정 에이전트로 발전해왔습니다. 그럼에도 불구하고, 기존 연구들은 에이전트 간 인간과 유사한 경제 활동을 모방하는 데 있어 에이전트의 신뢰성, 사회성, 해석 가능성 측면에서 상당한 어려움을 겪고 있습니다. 본 연구에서는 MMO 경제 시뮬레이션에 대형 언어 모델(LLM)을 활용하는 새로운 접근법을 도입하는 예비적 시도를 수행합니다. LLM의 역할 수행 능력, 생성 능력, 추론 능력을 활용하여 인간과 유사한 의사결정 및 적응력을 갖춘 LLM 기반 에이전트를 설계하였습니다. 이 에이전트들은 역할 수행, 지각, 기억, 추론 능력을 갖추어 앞서 언급한 문제들을 효과적으로 해결합니다. 게임 내 경제 활동에 초점을 맞춘 시뮬레이션 실험 결과, LLM 기반 에이전트가 역할 전문화 및 시장 규칙에 따른 가격 변동과 같은 창발 현상을 촉진할 수 있음을 확인하였습니다.
Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
논문 링크
동적 추론의 비용: AI 에이전트와 테스트 시 확장성에 대한 AI 인프라 관점의 해명 / The Cost of Dynamic Reasoning: Demystifying AI Agents and Test-Time Scaling from an AI Infrastructure Perspective
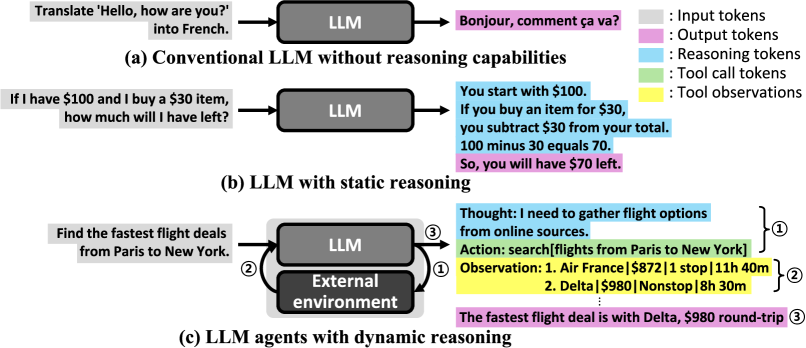
논문 소개
대형 언어 모델(LLM) 기반 AI 에이전트는 외부 도구와 협력하는 동적 추론(dynamic reasoning)을 통해 다단계 적응형 작업 수행이 가능해졌습니다. 이러한 에이전트는 작업 범용성과 유연성을 높이나, 시스템 비용, 효율성, 지속 가능성 측면에서 큰 부담을 초래합니다. 본 연구는 다양한 에이전트 설계와 테스트 시 확장 전략에 따른 자원 사용량, 지연 시간, 에너지 소비 및 데이터센터 전력 요구량을 종합적으로 분석하였으며, 정확도와 비용 간의 상충관계에 영향을 미치는 설계 요소들을 규명하였습니다. 결과적으로, 계산량 증가에 따른 정확도 향상은 점차 둔화되고 지연 시간 변동성은 커지며, 인프라 비용은 지속 불가능한 수준에 이르러 효율적인 추론 방식을 모색하는 설계 패러다임 전환이 필요함을 제안합니다.
논문 초록(Abstract)
최근 LLM(대형 언어 모델) 기반 AI 에이전트는 외부 도구와 협력하는 적응적 다단계 프로세스인 동적 추론(dynamic reasoning)을 활용하여 뛰어난 다재다능성을 보여주고 있습니다. 정적인 단일 턴 추론에서 벗어나 에이전트 기반의 다중 턴 워크플로우로 전환됨에 따라 작업 일반화와 행동 유연성이 확대되었으나, 시스템 수준의 비용, 효율성 및 지속 가능성에 대한 심각한 우려도 함께 제기되고 있습니다. 본 논문은 다양한 에이전트 설계 및 테스트 시 확장 전략 전반에 걸쳐 AI 에이전트의 자원 사용량, 지연(latency) 특성, 에너지 소비 및 데이터센터 전체 전력 소비 요구를 정량적으로 분석한 최초의 종합적인 시스템 수준 연구를 제시합니다. 또한, few-shot prompting(소수 예시 프롬프트), 반성 깊이(reflection depth), 병렬 추론(parallel reasoning)과 같은 AI 에이전트 설계 선택이 정확도-비용 간의 상충관계에 미치는 영향을 상세히 규명합니다. 연구 결과, 에이전트는 연산량 증가에 따라 정확도가 향상되지만, 급격한 수익 체감, 지연 시간 변동성 확대, 그리고 지속 불가능한 인프라 비용 문제에 직면함을 확인하였습니다. 대표적인 에이전트를 대상으로 한 정밀 평가를 통해 AI 에이전트 워크플로우가 초래하는 막대한 계산 요구를 부각시키며, 임박한 지속 가능성 위기를 경고합니다. 본 연구 결과는 실제 제약 조건 하에서 성능과 배포 가능성의 균형을 맞추는 연산 효율적 추론(compute-efficient reasoning)을 지향하는 에이전트 설계 패러다임의 전환을 촉구합니다.
Large-language-model (LLM)-based AI agents have recently showcased impressive versatility by employing dynamic reasoning, an adaptive, multi-step process that coordinates with external tools. This shift from static, single-turn inference to agentic, multi-turn workflows broadens task generalization and behavioral flexibility, but it also introduces serious concerns about system-level cost, efficiency, and sustainability. This paper presents the first comprehensive system-level analysis of AI agents, quantifying their resource usage, latency behavior, energy consumption, and datacenter-wide power consumption demands across diverse agent designs and test-time scaling strategies. We further characterize how AI agent design choices, such as few-shot prompting, reflection depth, and parallel reasoning, impact accuracy-cost tradeoffs. Our findings reveal that while agents improve accuracy with increased compute, they suffer from rapidly diminishing returns, widening latency variance, and unsustainable infrastructure costs. Through detailed evaluation of representative agents, we highlight the profound computational demands introduced by AI agent workflows, uncovering a looming sustainability crisis. These results call for a paradigm shift in agent design toward compute-efficient reasoning, balancing performance with deployability under real-world constraints.
논문 링크
중첩(superposition)에 의한 추론: 연속 사고의 연쇄에 대한 이론적 관점 / Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
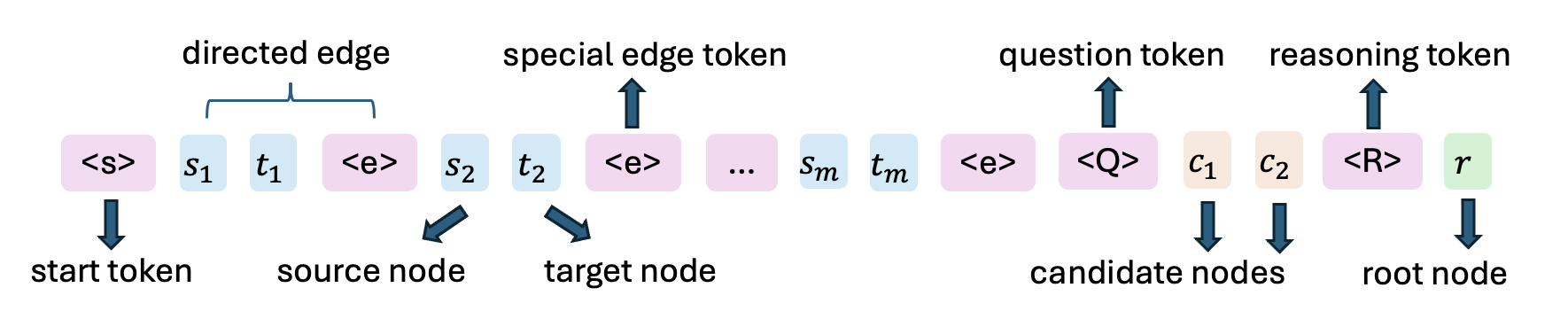
논문 소개
본 연구는 연속형 사고 연쇄(chain of continuous thought)를 활용한 대형 언어 모델(LLM)의 추론 능력에 대한 이론적 근거를 제시합니다. 특히, 두 층짜리 트랜스포머(transformer)가 그래프 지름(D)만큼의 연속적 사고 단계를 통해 방향 그래프 도달 문제(directed graph reachability)를 효율적으로 해결할 수 있음을 증명하였습니다. 이는 이산적 사고 연쇄(discrete CoTs)를 사용하는 기존 방법이 정점 수(n)의 제곱에 비례하는 단계가 필요한 것과 대조적입니다. 또한, 연속적 사고 벡터가 다중 탐색 경로를 동시에 인코딩하는 중첩 상태(superposition state)로 작동하여 병렬적 탐색이 가능하며, 실험 결과도 이론적 분석과 일치함을 확인하였습니다.
논문 초록(Abstract)
대형 언어 모델(LLM)은 사고의 연쇄(CoT) 기법을 통해 질문에 답하기 전에 ‘사고 토큰(thinking tokens)’을 생성하는 등, 어려운 추론 문제를 포함한 다양한 응용 분야에서 뛰어난 성능을 보여주고 있습니다. 기존 이론 연구들은 이산 토큰을 사용하는 CoT가 LLM의 능력을 향상시킨다는 점을 증명한 반면, 연속형 CoT가 방향 그래프 도달 가능성(directed graph reachability)과 같은 여러 추론 과제에서 이산형 CoT보다 우수한 이유에 대한 이론적 이해는 부족한 상태입니다. 방향 그래프 도달 가능성 문제는 많은 실제 도메인 응용을 포함하는 기본적인 그래프 추론 문제입니다. 본 논문에서는 두 층의 트랜스포머(transformer)가 그래프의 지름 $D$에 해당하는 D 단계의 연속형 CoT를 통해 방향 그래프 도달 가능성 문제를 해결할 수 있음을 증명합니다. 반면, 이산형 CoT를 사용하는 상수 깊이 트랜스포머의 최선 결과는 정점 수 $n$에 대해 O(n^2) 단계의 디코딩을 필요로 하며, 여기서 $D < n$입니다. 본 연구의 구성에서 각 연속형 사고 벡터는 여러 탐색 전선(search frontiers)을 동시에 인코딩하는 중첩 상태(superposition state)로서, 병렬 너비 우선 탐색(BFS)을 수행합니다. 반면, 이산형 CoT는 중첩 상태에서 샘플링된 단일 경로를 선택해야 하므로 순차적 탐색이 이루어져 훨씬 더 많은 단계가 필요하고 국소 해에 갇힐 위험이 있습니다. 또한, 본 논문에서는 학습 동역학(training dynamics)을 통해 얻은 경험적 해와 이론적 구성이 잘 일치함을 검증하는 광범위한 실험을 수행하였습니다. 특히, 명시적인 감독 없이도 연속형 CoT 학습 과정에서 여러 탐색 전선을 중첩 상태로 인코딩하는 현상이 자연스럽게 나타난다는 점이 주목할 만합니다.
Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens'' before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with D steps of continuous CoTs can solve the directed graph reachability problem, where D is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires O(n^2) decoding steps where n is the number of vertices (D<n). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()