[2025/06/30 ~ 7/6] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주 선정된 논문들을 살펴보면, 첫째로 확산(diffusion) 기반 언어 모델과 생성 모델에 대한 연구가 두드러집니다. Mercury, Block Diffusion 논문에서 보듯이, 기존의 자기회귀 언어 모델과 달리 확산 모델을 활용해 병렬 생성과 속도 향상을 추구하며, 고품질의 텍스트 및 코드 생성에 성공한 사례들이 소개되고 있습니다. 확산 모델은 병렬 처리와 생성 제어 측면에서 장점을 가지면서도, 길이 가변성 문제와 효율성 개선을 위한 다양한 기법들이 제안되고 있어, 자연어 처리 분야에서 새로운 패러다임으로 자리잡아 가고 있음을 알 수 있습니다.
다음으로, 멀티모달 통합 모델과 비전-언어-행동(Vision-Language-Action, VLA) 모델에 관한 연구가 활발히 진행되고 있습니다. Show-o2, UniVLA, WorldVLA, 그리고 Scene-R1 논문들은 텍스트, 이미지, 비디오, 3D 장면 이해 및 로봇 행동 제어를 하나의 통합된 프레임워크 내에서 다루려는 시도를 보여줍니다. 특히, 3D 장면 추론이나 로봇 조작과 같은 복잡한 태스크에 대해 다중 모달리티를 자연스럽게 융합하고, 강화학습과 자기회귀 모델링을 결합하여 실제 환경에서의 적용 가능성을 높이고자 하는 경향이 뚜렷합니다. 이는 인공지능이 단일 모달리티를 넘어 실세계 문제 해결에 한걸음 더 나아가고 있음을 의미합니다.
마지막으로, 강화학습과 자기회귀 모델을 결합한 로봇 제어 및 행동 학습 분야의 연구가 주목받고 있습니다. Steering Your Diffusion Policy with Latent Space Reinforcement Learning 논문에서는 행동 복제(behavior cloning)로 학습된 정책을 강화학습을 통해 효율적으로 개선하는 방법을 제안하며, 실제 로봇 환경에서의 적응력을 높이고자 합니다. 또한, VLA 모델의 후처리(post-training) 전략을 인간의 운동 학습과 비교하여 체계적으로 분석하는 연구도 포함되어, 로봇 및 자율 시스템의 실용적 적용과 지속적인 성능 향상을 위한 연구가 활발히 이루어지고 있음을 알 수 있습니다. 이러한 경향은 인공지능이 단순한 인지 능력을 넘어 실제 행동과 상호작용 능력까지 통합적으로 발전하고 있음을 보여줍니다.
Mercury: 디퓨전 기반의 초고속 언어 모델 / Mercury: Ultra-Fast Language Models Based on Diffusion
논문 소개
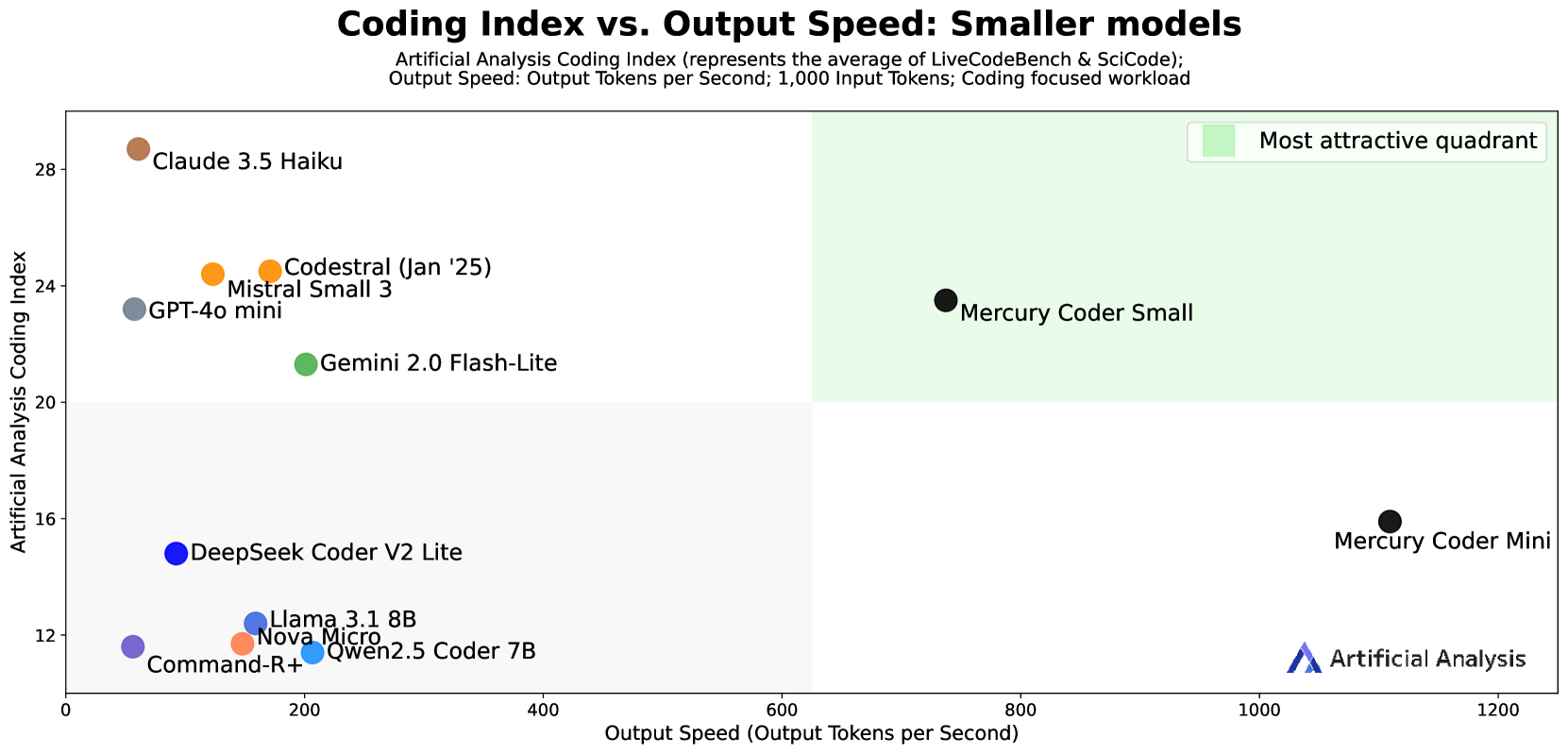
Mercury는 확산(diffusion) 기반의 차세대 대규모 언어 모델(LLM)로, 트랜스포머(Transformer) 구조를 활용해 다중 토큰을 병렬 예측하도록 설계되었습니다. Mercury Coder는 코딩 특화 모델로, Mini와 Small 두 가지 크기로 제공되며, NVIDIA H100 GPU에서 각각 초당 1109토큰과 737토큰의 처리 속도를 기록하며 속도와 품질 면에서 최첨단 성능을 달성했습니다. 독립 평가와 실제 개발자 검증을 통해 다양한 프로그래밍 언어 및 사용 사례에서 우수한 성능을 입증했으며, 현재 Copilot Arena에서 품질 2위이자 가장 빠른 모델로 평가받고 있습니다. 또한, 공개 API와 무료 체험 공간도 함께 제공되어 실사용 접근성을 높였습니다.
논문 초록(Abstract)
저희는 diffusion 기반의 차세대 상업용 대규모 언어 모델(LLM)인 Mercury를 소개합니다. 이 모델들은 트랜스포머(transformer) 아키텍처로 파라미터화되어 있으며, 다중 토큰을 병렬로 예측하도록 학습되었습니다. 본 보고서에서는 코딩 애플리케이션을 위해 설계된 최초의 diffusion LLM 세트인 Mercury Coder에 대해 자세히 설명합니다. 현재 Mercury Coder는 Mini와 Small 두 가지 크기로 제공됩니다. 이 모델들은 속도와 품질의 최적 경계(speed-quality frontier)에서 새로운 최첨단 성능을 기록합니다. Artificial Analysis에서 독립적으로 수행한 평가에 따르면, Mercury Coder Mini와 Mercury Coder Small은 각각 NVIDIA H100 GPU에서 초당 1109 토큰과 737 토큰의 최첨단 처리량을 달성하며, 속도 최적화 모델 대비 평균 최대 10배 빠른 속도를 보이면서도 유사한 품질을 유지합니다. 또한, 여러 언어와 다양한 사용 사례를 아우르는 코드 벤치마크에서의 추가 결과와 Copilot Arena에서 개발자들이 직접 검증한 실제 성능을 논의합니다. 해당 모델은 현재 품질 부문에서 2위를 차지하며 전체 모델 중 가장 빠른 속도를 기록하고 있습니다. 저희는 https://platform.inceptionlabs.ai/ 에서 공개 API를, https://chat.inceptionlabs.ai 에서 무료 플레이그라운드를 제공합니다.
We present Mercury, a new generation of commercial-scale large language models (LLMs) based on diffusion. These models are parameterized via the Transformer architecture and trained to predict multiple tokens in parallel. In this report, we detail Mercury Coder, our first set of diffusion LLMs designed for coding applications. Currently, Mercury Coder comes in two sizes: Mini and Small. These models set a new state-of-the-art on the speed-quality frontier. Based on independent evaluations conducted by Artificial Analysis, Mercury Coder Mini and Mercury Coder Small achieve state-of-the-art throughputs of 1109 tokens/sec and 737 tokens/sec, respectively, on NVIDIA H100 GPUs and outperform speed-optimized frontier models by up to 10x on average while maintaining comparable quality. We discuss additional results on a variety of code benchmarks spanning multiple languages and use-cases as well as real-world validation by developers on Copilot Arena, where the model currently ranks second on quality and is the fastest model overall. We also release a public API at https://platform.inceptionlabs.ai/ and free playground at https://chat.inceptionlabs.ai
논문 링크
더 읽어보기
https://platform.inceptionlabs.ai/
https://platform.inceptionlabs.ai/
https://chat.inceptionlabs.ai
블록 디퓨전: 자기회귀 및 디퓨전 언어 모델 간의 보간 방법 / Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models

논문 소개
Block diffusion 언어 모델은 기존의 자기회귀(autoregressive) 모델과 확산(diffusion) 모델의 장점을 결합하여, 병렬 생성(parallelized generation)과 제어 가능성(controllability)을 유지하면서도 유연한 길이의 문장 생성이 가능합니다. 이 모델은 KV 캐싱과 병렬 토큰 샘플링을 통해 추론 효율성을 크게 향상시키며, 효과적인 학습을 위해 그래디언트 분산 추정기와 데이터 기반 노이즈 스케줄링을 도입하여 분산을 최소화합니다. 그 결과, 기존 확산 모델 대비 언어 모델링 벤치마크에서 최첨단 성능을 달성하고 임의 길이의 시퀀스 생성을 지원합니다. 연구 결과와 코드, 모델 가중치는 공개되어 있어 재현과 확장이 용이합니다.
논문 초록(Abstract)
확산 언어 모델(diffusion language model)은 병렬화된 생성과 제어 가능성 측면에서 자기회귀 모델(autoregressive model)에 비해 고유한 장점을 제공하지만, 우도(likelihood) 모델링에서는 뒤처지며 고정 길이 생성에 제한이 있습니다. 본 연구에서는 이산적 노이즈 제거 확산(discrete denoising diffusion)과 자기회귀 모델 간의 중간 지점에 위치하는 블록 확산 언어 모델(block diffusion language model) 계열을 제안합니다. 블록 확산은 유연한 길이 생성과 KV 캐싱 및 병렬 토큰 샘플링을 통한 추론 효율성 향상을 지원함으로써 두 접근법의 주요 한계를 극복합니다. 우리는 효율적인 학습 알고리즘, 그래디언트 분산 추정기, 그리고 분산을 최소화하기 위한 데이터 기반 노이즈 스케줄을 포함하는 효과적인 블록 확산 모델 구축 방법론을 제안합니다. 블록 확산은 언어 모델링 벤치마크에서 확산 모델 중 새로운 최첨단(state-of-the-art) 성능을 달성하며 임의 길이 시퀀스 생성을 가능하게 합니다. 본 연구의 코드, 모델 가중치, 그리고 블로그 포스트는 프로젝트 페이지(Block Diffusion)에서 제공됩니다.
Diffusion language models offer unique benefits over autoregressive models due to their potential for parallelized generation and controllability, yet they lag in likelihood modeling and are limited to fixed-length generation. In this work, we introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. Block diffusion overcomes key limitations of both approaches by supporting flexible-length generation and improving inference efficiency with KV caching and parallel token sampling. We propose a recipe for building effective block diffusion models that includes an efficient training algorithm, estimators of gradient variance, and data-driven noise schedules to minimize the variance. Block diffusion sets a new state-of-the-art performance among diffusion models on language modeling benchmarks and enables generation of arbitrary-length sequences. We provide the code, along with the model weights and blog post on the project page: Block Diffusion
논문 링크
더 읽어보기
https://github.com/kuleshov-group/bd3lms
정규화 없이 구현한 트랜스포머: 동적 탄젠트 함수 기반 접근법 / Transformers without Normalization
논문 소개
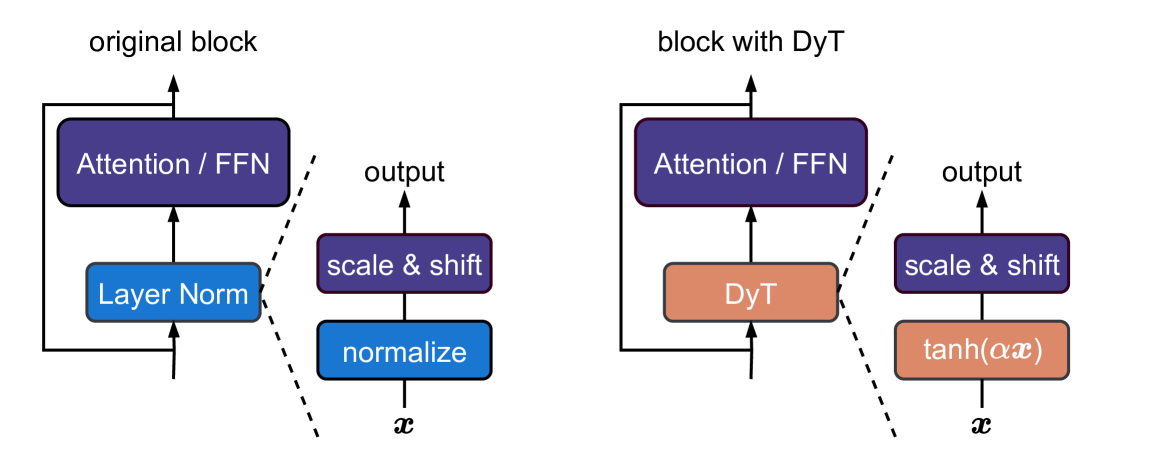
본 연구에서는 Transformer 모델에서 필수로 여겨지던 정규화(normalization) 층 없이도 동등하거나 더 우수한 성능을 달성할 수 있음을 보였습니다. 이를 위해 정규화 층을 대체하는 간단한 원소별 연산인 Dynamic Tanh(DyT)를 제안하였으며, DyT는 Transformer의 레이어 정규화가 종종 생성하는 S자형(tanh 유사) 입력-출력 매핑에서 영감을 받았습니다. DyT를 적용한 Transformer는 하이퍼파라미터 조정 없이도 다양한 작업(인식, 생성, 지도학습, 자기지도학습, 컴퓨터 비전, 언어 모델링)에서 기존 정규화 기반 모델과 동등하거나 우수한 성능을 보였습니다. 이 결과는 현대 신경망에서 정규화 층이 반드시 필요하다는 기존 통념에 도전하며, 정규화의 역할에 대한 새로운 통찰을 제공합니다.
논문 초록(Abstract)
정규화 층은 현대 신경망에서 매우 널리 사용되며 오랫동안 필수적인 요소로 여겨져 왔습니다. 본 연구는 정규화 없이도 트랜스포머가 놀라울 정도로 간단한 기법을 통해 동일하거나 더 나은 성능을 달성할 수 있음을 보여줍니다. 우리는 트랜스포머의 정규화 층을 대체할 수 있는 원소별 연산인 Dynamic Tanh(DyT), 즉 $DyT(x) = \tanh(\alpha x)$를 제안합니다. DyT는 트랜스포머의 레이어 정규화가 종종 tanh와 유사한 $S$자 형태의 입력-출력 매핑을 생성한다는 관찰에서 영감을 받았습니다. DyT를 도입함으로써, 정규화가 없는 트랜스포머는 대부분의 경우 하이퍼파라미터 튜닝 없이도 정규화된 모델과 동등하거나 더 우수한 성능을 보일 수 있습니다. 우리는 인식에서 생성, 지도학습에서 자기지도학습, 컴퓨터 비전에서 언어 모델에 이르기까지 다양한 환경에서 DyT를 적용한 트랜스포머의 효과를 검증하였습니다. 이러한 결과는 정규화 층이 현대 신경망에서 반드시 필요하다는 기존의 통념에 도전하며, 심층 신경망에서 정규화 층의 역할에 대한 새로운 통찰을 제공합니다.
Normalization layers are ubiquitous in modern neural networks and have long been considered essential. This work demonstrates that Transformers without normalization can achieve the same or better performance using a remarkably simple technique. We introduce Dynamic Tanh (DyT), an element-wise operation $DyT(x) = \tanh(\alpha x)$, as a drop-in replacement for normalization layers in Transformers. DyT is inspired by the observation that layer normalization in Transformers often produces tanh-like, S-shaped input-output mappings. By incorporating DyT, Transformers without normalization can match or exceed the performance of their normalized counterparts, mostly without hyperparameter tuning. We validate the effectiveness of Transformers with DyT across diverse settings, ranging from recognition to generation, supervised to self-supervised learning, and computer vision to language models. These findings challenge the conventional understanding that normalization layers are indispensable in modern neural networks, and offer new insights into their role in deep networks.
논문 링크
더 읽어보기
트랜스포머는 그래프 신경망이다 / Transformers are Graph Neural Networks
논문 소개
트랜스포머(Transformer) 아키텍처는 자연어 처리에서 시작되었으나, 그래프 신경망(Graph Neural Networks, GNNs)과 밀접한 관련이 있음을 밝힙니다. 트랜스포머는 토큰 간 완전 연결 그래프에서 메시지 전달(message passing) 방식의 GNN으로 해석할 수 있으며, 자기 주의 메커니즘(self-attention)은 토큰 간 상대적 중요도를 포착하고 위치 인코딩(positional encoding)은 순서나 구조 정보를 제공합니다. 따라서 트랜스포머는 사전 정의된 그래프에 구애받지 않고 입력 요소 간 관계를 학습하는 표현력 있는 집합 처리 네트워크입니다. 또한, 트랜스포머는 희소 메시지 전달보다 현대 하드웨어에서 훨씬 효율적인 밀집 행렬 연산(dense matrix operations)을 사용하여 구현되므로, 하드웨어 측면에서 우위를 점하고 있다고 평가됩니다.
논문 초록(Abstract)
우리는 자연어 처리 분야를 위해 처음 도입된 트랜스포머 아키텍처와 그래프 표현 학습을 위한 그래프 신경망(GNN) 간의 연관성을 확립합니다. 트랜스포머가 토큰들의 완전 연결 그래프에서 작동하는 메시지 전달 GNN으로 볼 수 있음을 보여주며, 여기서 셀프-어텐션 메커니즘은 모든 토큰 간의 상대적 중요도를 포착하고, 위치 인코딩은 순차적 순서나 구조에 대한 단서를 제공합니다. 따라서 트랜스포머는 사전 정의된 그래프에 제한받지 않고 입력 요소 간의 관계를 학습하는 표현력이 풍부한 집합 처리 네트워크입니다. GNN과의 이러한 수학적 연관성에도 불구하고, 트랜스포머는 희소 메시지 전달보다 현대 하드웨어에서 훨씬 효율적인 밀집 행렬 연산을 통해 구현됩니다. 이는 트랜스포머가 현재 하드웨어 복권을 당첨한 GNN이라는 관점을 제시합니다.
We establish connections between the Transformer architecture, originally introduced for natural language processing, and Graph Neural Networks (GNNs) for representation learning on graphs. We show how Transformers can be viewed as message passing GNNs operating on fully connected graphs of tokens, where the self-attention mechanism capture the relative importance of all tokens w.r.t. each-other, and positional encodings provide hints about sequential ordering or structure. Thus, Transformers are expressive set processing networks that learn relationships among input elements without being constrained by apriori graphs. Despite this mathematical connection to GNNs, Transformers are implemented via dense matrix operations that are significantly more efficient on modern hardware than sparse message passing. This leads to the perspective that Transformers are GNNs currently winning the hardware lottery.
논문 링크
더 읽어보기
Show-o2: 향상된 네이티브 통합 멀티모달 모델 / Show-o2: Improved Native Unified Multimodal Models
논문 소개
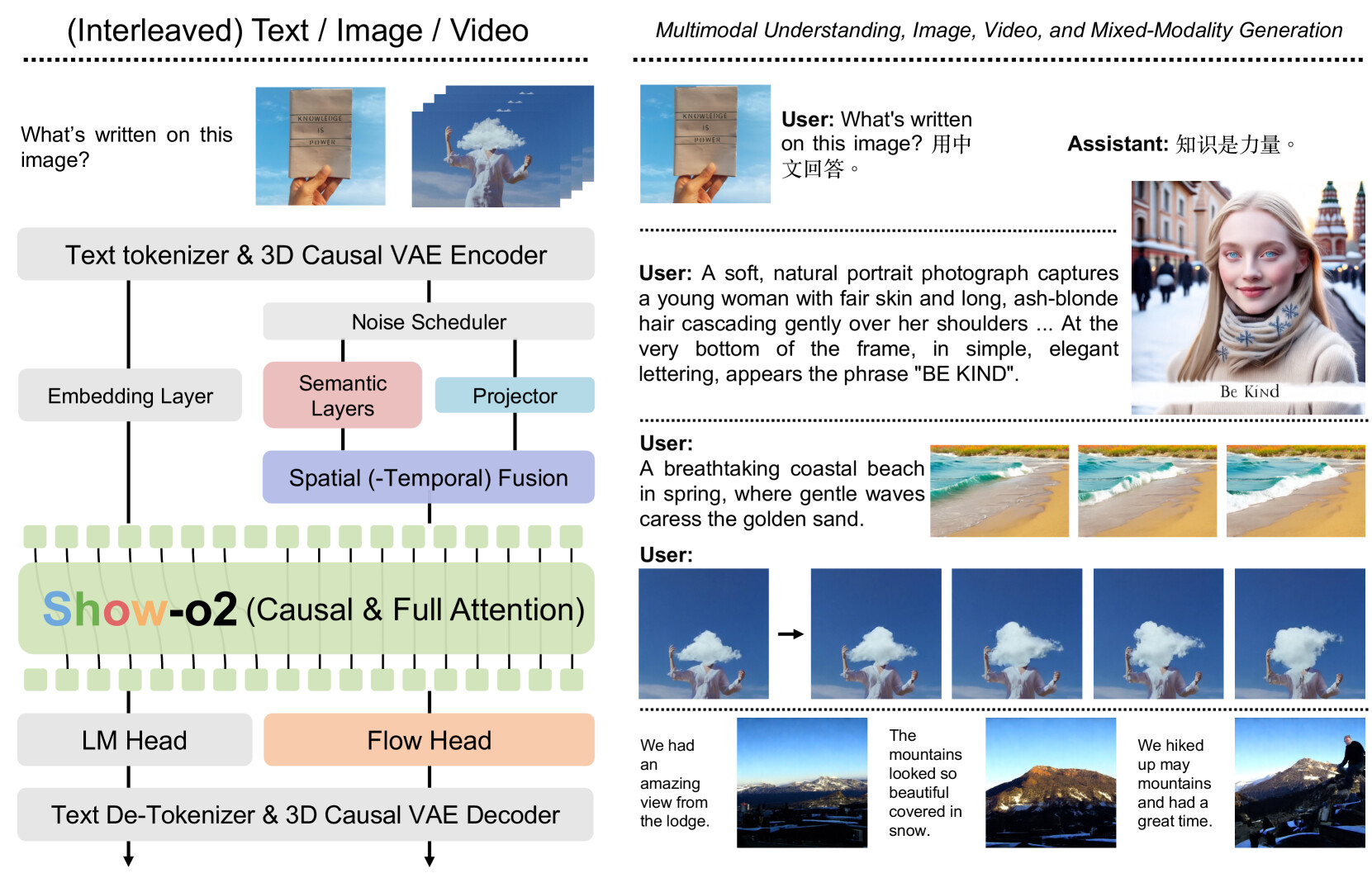
Show-o2는 자기회귀 모델링(autoregressive modeling)과 플로우 매칭(flow matching)을 활용하여 이미지와 비디오를 아우르는 통합 시각 표현을 생성하는 3D 인과적 변분 오토인코더(variational autoencoder) 기반의 멀티모달 모델입니다. 공간 및 시공간 융합(dual-path spatial-temporal fusion) 구조를 통해 다양한 시각 데이터에 확장 가능하며, 언어 모델의 언어 헤드와 플로우 헤드에 각각 자기회귀 모델링과 플로우 매칭을 적용하여 텍스트 예측과 이미지/비디오 생성을 동시에 수행합니다. 두 단계의 학습 과정으로 대규모 모델 학습을 효과적으로 지원하며, 텍스트, 이미지, 비디오 등 다양한 멀티모달 이해 및 생성 작업에서 우수한 성능을 보입니다. 코드와 모델은 공개되어 있어 연구 및 응용에 활용할 수 있습니다.
논문 초록(Abstract)
본 논문에서는 자기회귀 모델링(autoregressive modeling)과 플로우 매칭(flow matching)을 활용한 향상된 네이티브 통합 멀티모달 모델인 Show-o2를 제안합니다. 3D 인과적 변분 오토인코더(3D causal variational autoencoder) 공간을 기반으로, 공간 및 시공간 융합의 이중 경로를 통해 통합된 시각 표현을 구축하여 이미지와 비디오 모달리티 전반에 걸친 확장성을 확보함과 동시에 효과적인 멀티모달 이해 및 생성을 가능하게 합니다. 언어 모델을 기반으로, 자기회귀 모델링과 플로우 매칭이 각각 언어 헤드와 플로우 헤드에 네이티브 방식으로 적용되어 텍스트 토큰 예측과 이미지/비디오 생성을 지원합니다. 두 단계로 구성된 학습 레시피를 설계하여 효과적인 학습과 대형 모델로의 확장을 도모하였습니다. 결과적으로 Show-o2 모델은 텍스트, 이미지, 비디오 등 다양한 모달리티에 걸친 폭넓은 멀티모달 이해 및 생성 과제를 유연하게 처리함을 입증하였습니다. 코드와 모델은 GitHub - showlab/Show-o: [ICLR & NeurIPS 2025] Repository for Show-o series, One Single Transformer to Unify Multimodal Understanding and Generation. 에서 공개됩니다.
This paper presents improved native unified multimodal models, \emph{i.e.,} Show-o2, that leverage autoregressive modeling and flow matching. Built upon a 3D causal variational autoencoder space, unified visual representations are constructed through a dual-path of spatial (-temporal) fusion, enabling scalability across image and video modalities while ensuring effective multimodal understanding and generation. Based on a language model, autoregressive modeling and flow matching are natively applied to the language head and flow head, respectively, to facilitate text token prediction and image/video generation. A two-stage training recipe is designed to effectively learn and scale to larger models. The resulting Show-o2 models demonstrate versatility in handling a wide range of multimodal understanding and generation tasks across diverse modalities, including text, images, and videos. Code and models are released at GitHub - showlab/Show-o: [ICLR & NeurIPS 2025] Repository for Show-o series, One Single Transformer to Unify Multimodal Understanding and Generation..
논문 링크
더 읽어보기
https://github.com/showlab/Show-o
Scene-R1: 3D 주석 없이 비디오 기반 대형 언어 모델을 활용한 3D 장면 추론 / Scene-R1: Video-Grounded Large Language Models for 3D Scene Reasoning without 3D Annotations
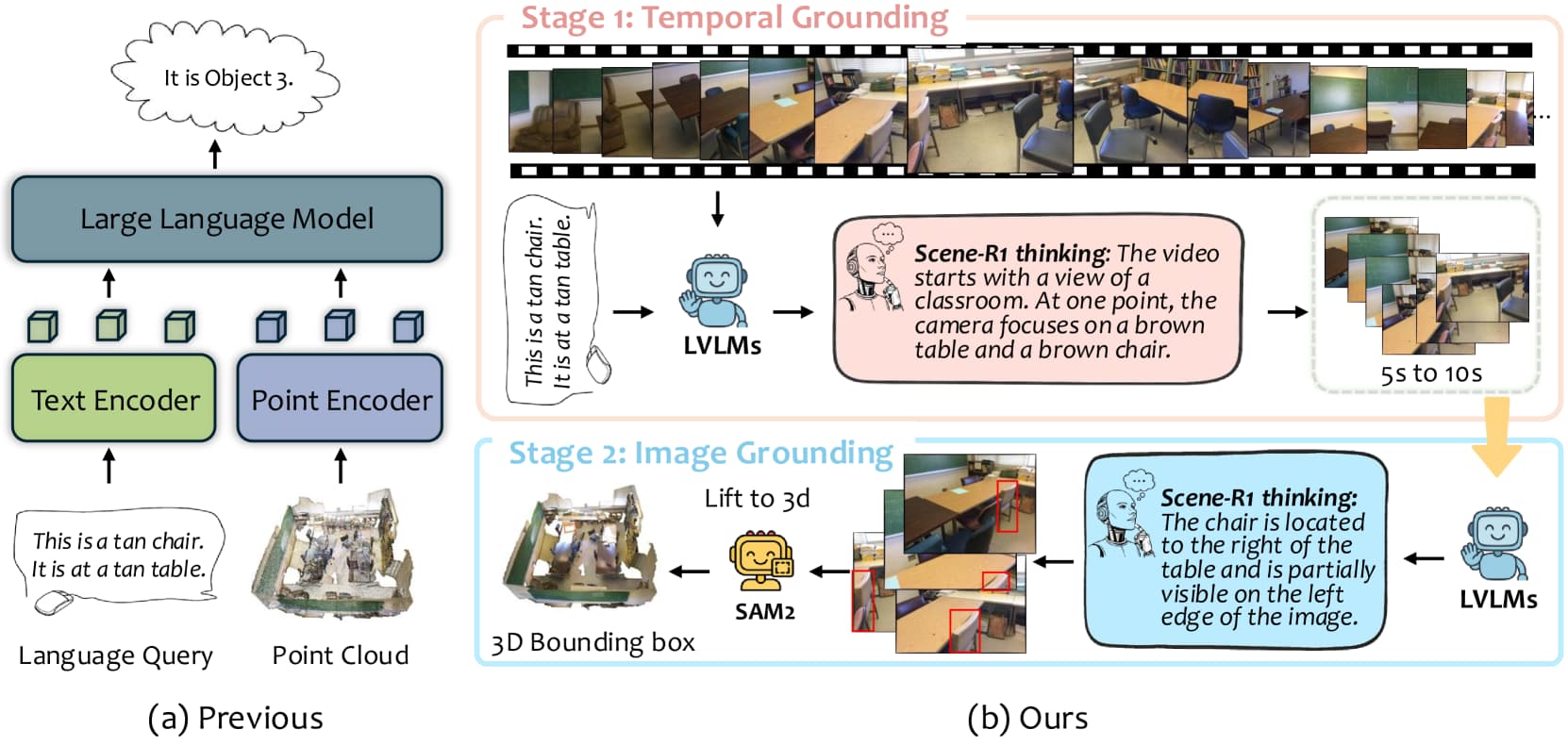
논문 소개
Scene-R1은 3D 주석 없이도 3D 장면 추론을 가능하게 하는 비디오 기반 대형 언어 모델 프레임워크입니다. 강화학습 기반 추론과 두 단계의 그라운딩(시간적 및 이미지 기반)을 결합하여, 비디오에서 쿼리와 관련된 부분을 선택하고 2D 바운딩 박스를 예측한 후, SAM2를 활용해 픽셀 단위 마스크를 생성하여 3D로 투영합니다. 이를 통해 기존의 3D 검출기 의존도를 없애면서도 정밀한 기하학적 및 재질 정보를 포착할 수 있습니다. Scene-R1은 2D 박스나 텍스트 라벨만으로 학습 가능하며, 여러 데이터셋에서 기존 오픈 보캐뷸러리(open-vocabulary) 모델을 능가하고 투명한 단계별 추론 과정을 제공합니다.
논문 초록(Abstract)
현재 대형 언어 모델(LLM)을 활용하여 3D 세계를 이해하는 연구가 활발히 진행되고 있습니다. 그러나 기존의 3D 인지 LLM은 블랙박스처럼 동작하여, 결정 과정은 공개하지 않고 단지 바운딩 박스나 텍스트 답변만 출력하며, 여전히 사전 학습된 3D 탐지기에 의존하여 객체 제안을 받습니다. 본 논문에서는 강화학습 기반 추론과 2단계 그라운딩 파이프라인을 결합하여 점 단위 3D 인스턴스 감독 없이 3D 장면을 추론하는 비디오 기반 프레임워크 Scene-R1을 제안합니다. 시간적 그라운딩 단계에서는 비디오를 명시적으로 추론하여 개방형 질의에 가장 관련 있는 비디오 스니펫을 선택합니다. 이후 이미지 그라운딩 단계에서는 이미지를 분석하여 2D 바운딩 박스를 예측합니다. 그 다음, SAM2를 이용해 RGB 프레임에서 픽셀 단위 정확한 마스크를 추적하고 이를 3D로 투영함으로써 3D 탐지기 기반 제안의 필요성을 제거하고 정밀한 기하학 및 재질 정보를 포착합니다. Scene-R1은 또한 3D 시각 질문 응답(Visual Question Answering) 작업에 적응하여 비디오에서 자유 형식 질문에 직접 답변할 수 있습니다. 학습 파이프라인은 밀집 3D 점 단위 레이블 없이 작업 수준의 2D 박스 또는 텍스트 라벨만 필요로 합니다. Scene-R1은 여러 데이터셋에서 기존의 오픈 보캐뷸러리 베이스라인을 능가하며, 투명하고 단계별 추론 근거를 제공합니다. 이러한 결과는 강화학습 기반 추론과 RGB-D 비디오만으로도 신뢰할 수 있는 3D 장면 이해를 위한 실용적이고 주석 효율적인 방법임을 보여줍니다.
Currently, utilizing large language models to understand the 3D world is becoming popular. Yet existing 3D-aware LLMs act as black boxes: they output bounding boxes or textual answers without revealing how those decisions are made, and they still rely on pre-trained 3D detectors to supply object proposals. We introduce Scene-R1, a video-grounded framework that learns to reason about 3D scenes without any point-wise 3D instance supervision by pairing reinforcement-learning-driven reasoning with a two-stage grounding pipeline. In the temporal grounding stage, we explicitly reason about the video and select the video snippets most relevant to an open-ended query. In the subsequent image grounding stage, we analyze the image and predict the 2D bounding box. After that, we track the object using SAM2 to produce pixel-accurate masks in RGB frames, and project them back into 3D, thereby eliminating the need for 3D detector-based proposals while capturing fine geometry and material cues. Scene-R1 can also adapt to the 3D visual question answering task to answer free-form questions directly from video. Our training pipeline only needs task-level 2D boxes or textual labels without dense 3D point-wise labels. Scene-R1 surpasses existing open-vocabulary baselines on multiple datasets, while delivering transparent, step-by-step rationales. These results show that reinforcement-learning-based reasoning combined with RGB-D video alone offers a practical, annotation-efficient route to trustworthy 3D scene understanding.
논문 링크
VLA 모델 사후 학습과 인간 운동 학습의 유사성: 진전, 과제 및 동향 / Parallels Between VLA Model Post-Training and Human Motor Learning: Progress, Challenges, and Trends
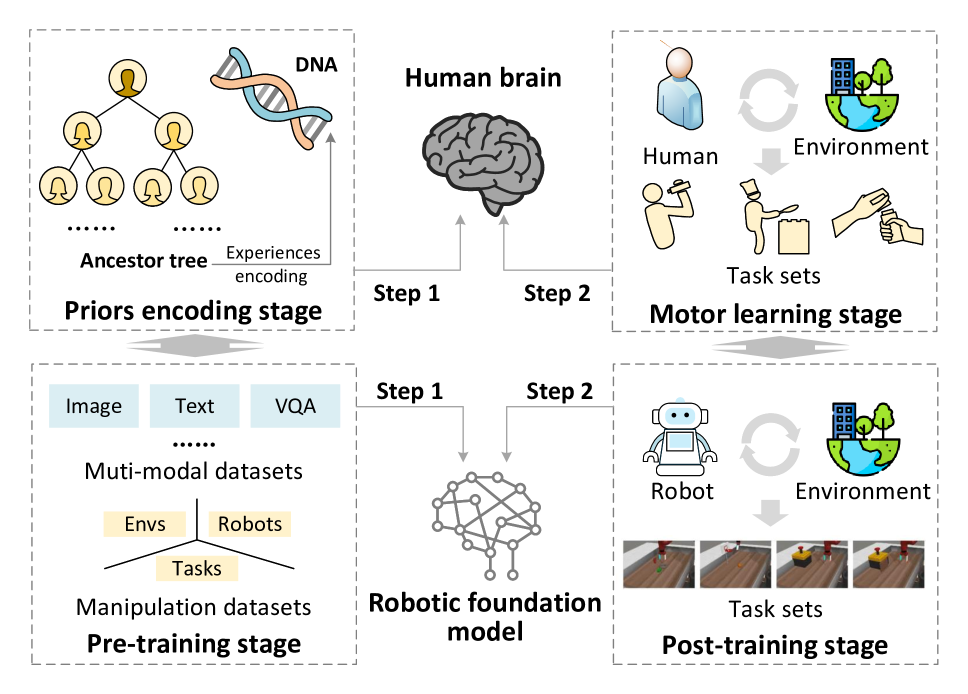
논문 소개
Vision-language-action (VLA) 모델은 로봇 조작을 위한 행동 생성 모듈을 통합하여 시각-언어 모델(VLM)의 인지 및 명령 이해 능력을 확장합니다. 그러나 고정밀 작업에서는 추가 적응(post-training)이 필요하며, 이는 인간의 운동 학습과 유사한 환경 인식, 신체 인지, 과제 이해의 세 가지 차원에서 접근됩니다. 본 연구는 이러한 차원에 따른 VLA 모델의 사후 학습 전략을 체계적으로 분류하고, 다중 구성 요소 통합 방식을 포함한 개념적 틀을 제시합니다. 이를 통해 VLA 모델의 발전 방향과 주요 도전 과제를 명확히 하여 후속 연구에 실질적인 통찰을 제공합니다.
논문 초록(Abstract)
비전-언어-행동(Vision-language-action, VLA) 모델은 로봇 조작을 위한 행동 생성 모듈을 통합하여 비전-언어 모델(Vision-language model, VLM)을 확장한 모델입니다. VLM이 시각 인지와 명령 이해에서 갖는 강점을 활용하여, VLA 모델은 다양한 조작 작업에 걸쳐 유망한 일반화 능력을 보입니다. 그러나 높은 정밀도와 정확도를 요구하는 응용 분야에서는 추가 적응 없이는 성능 격차가 드러납니다. 여러 분야에서의 증거는 기초 모델을 하위 응용에 맞추기 위한 사후 학습(post-training)의 중요성을 강조하며, 이에 따라 VLA 모델의 사후 학습에 관한 광범위한 연구가 진행되고 있습니다. VLA 모델 사후 학습은 인간의 운동 기술 습득 과정과 유사하게, 주어진 작업에 대해 환경과 상호작용하는 구현체(embodiment)의 능력을 향상시키는 과제를 해결하는 것을 목표로 합니다. 이에 본 논문은 인간 운동 학습 관점에서 환경, 구현체, 작업의 세 가지 차원을 중심으로 VLA 모델 사후 학습 전략을 검토합니다. 인간 학습 메커니즘에 부합하는 체계적 분류법을 제시하며, (1) 환경 인지 향상, (2) 구현체 인식 개선, (3) 작업 이해 심화, (4) 다중 구성 요소 통합의 네 가지 범주로 구분합니다. 마지막으로, 사후 학습 VLA 모델의 주요 도전 과제와 동향을 규명하여 향후 연구를 안내할 개념적 프레임워크를 구축합니다. 본 연구는 인간 운동 학습 관점에서 현재 VLA 모델 사후 학습 방법에 대한 포괄적 개요와 VLA 모델 개발을 위한 실질적 통찰을 제공합니다. (프로젝트 웹사이트: GitHub - AoqunJin/Awesome-VLA-Post-Training: A collection of vision-language-action model post-training methods.)
Vision-language-action (VLA) models extend vision-language models (VLM) by integrating action generation modules for robotic manipulation. Leveraging strengths of VLM in vision perception and instruction understanding, VLA models exhibit promising generalization across diverse manipulation tasks. However, applications demanding high precision and accuracy reveal performance gaps without further adaptation. Evidence from multiple domains highlights the critical role of post-training to align foundational models with downstream applications, spurring extensive research on post-training VLA models. VLA model post-training aims to address the challenge of improving an embodiment's ability to interact with the environment for the given tasks, analogous to the process of humans motor skills acquisition. Accordingly, this paper reviews post-training strategies for VLA models through the lens of human motor learning, focusing on three dimensions: environments, embodiments, and tasks. A structured taxonomy is introduced aligned with human learning mechanisms: (1) enhancing environmental perception, (2) improving embodiment awareness, (3) deepening task comprehension, and (4) multi-component integration. Finally, key challenges and trends in post-training VLA models are identified, establishing a conceptual framework to guide future research. This work delivers both a comprehensive overview of current VLA model post-training methods from a human motor learning perspective and practical insights for VLA model development. (Project website: GitHub - AoqunJin/Awesome-VLA-Post-Training: A collection of vision-language-action model post-training methods.)
논문 링크
더 읽어보기
https://github.com/AoqunJin/Awesome-VLA-Post-Training
통합 비전-언어-행동 모델 / Unified Vision-Language-Action Model
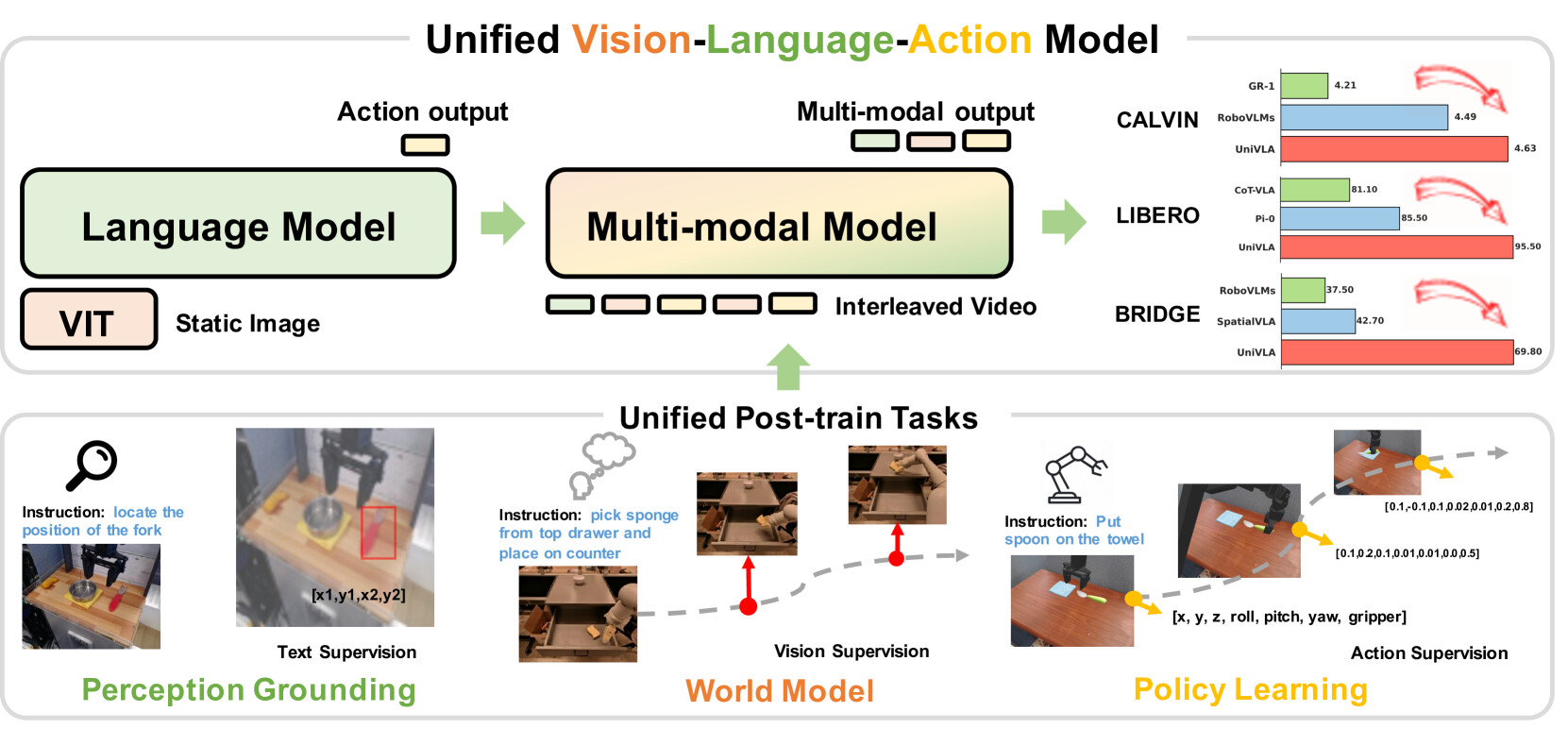
논문 소개
Unified Vision-Language-Action 모델인 UniVLA는 시각, 언어, 행동 신호를 이산 토큰 시퀀스로 자기회귀적(autoregressive)으로 모델링하여 멀티모달 학습을 통합적으로 수행합니다. 대규모 비디오 데이터를 활용해 세계 모델링(world modeling)을 도입함으로써 시각 관찰에 내재된 인과적(causal) 동역학을 효과적으로 학습하고, 이를 통해 장기 과제(long-horizon tasks)에 강한 정책 학습으로 전이할 수 있습니다. 다양한 시뮬레이션 벤치마크(CALVIN, LIBERO, Simplenv-Bridge)에서 기존 방법을 크게 능가하는 성능을 보였으며, 실제 조작 작업과 자율주행 분야에도 폭넓게 적용 가능함을 입증하였습니다.
논문 초록(Abstract)
비전-언어-행동 모델(Vision-language-action models, VLA)은 로봇 조작 분야 발전 가능성으로 인해 큰 주목을 받고 있습니다. 그러나 기존 접근법들은 주로 비전-언어 모델(Vision-language models, VLM)의 일반적인 이해 능력에 의존하여 행동 신호를 생성하는 데 집중하였으며, 시각 관찰에 내재된 풍부한 시간적 및 인과적 구조를 간과하는 경향이 있었습니다. 본 논문에서는 UniVLA라는 통합적이고 본질적인 멀티모달 VLA 모델을 제안합니다. UniVLA는 비전, 언어, 행동 신호를 이산 토큰 시퀀스로 자기회귀적(autoregressive)으로 모델링합니다. 이러한 정식화는 특히 대규모 비디오 데이터로부터 유연한 멀티모달 과제 학습을 가능하게 합니다. 사후 학습(post-training) 과정에서 세계 모델링(world modeling)을 도입함으로써 UniVLA는 비디오로부터 인과적 역학을 포착하여, 특히 장기 과제(long-horizon tasks)에 대해 하위 정책 학습(downstream policy learning)으로의 효과적인 전이를 촉진합니다. 본 접근법은 CALVIN, LIBERO, Simplenv-Bridge 등 여러 널리 사용되는 시뮬레이션 벤치마크에서 새로운 최첨단(state-of-the-art) 성과를 달성하며, 기존 방법들을 크게 능가합니다. 예를 들어, UniVLA는 LIBERO 벤치마크에서 평균 성공률 95.5%를 기록하여 pi0-FAST의 85.5%를 뛰어넘었습니다. 또한, 실제 환경의 ALOHA 조작 및 자율주행 분야에서도 광범위한 적용 가능성을 입증하였습니다.
Vision-language-action models (VLAs) have garnered significant attention for their potential in advancing robotic manipulation. However, previous approaches predominantly rely on the general comprehension capabilities of vision-language models (VLMs) to generate action signals, often overlooking the rich temporal and causal structure embedded in visual observations. In this paper, we present UniVLA, a unified and native multimodal VLA model that autoregressively models vision, language, and action signals as discrete token sequences. This formulation enables flexible multimodal tasks learning, particularly from large-scale video data. By incorporating world modeling during post-training, UniVLA captures causal dynamics from videos, facilitating effective transfer to downstream policy learning--especially for long-horizon tasks. Our approach sets new state-of-the-art results across several widely used simulation benchmarks, including CALVIN, LIBERO, and Simplenv-Bridge, significantly surpassing previous methods. For example, UniVLA achieves 95.5% average success rate on LIBERO benchmark, surpassing pi0-FAST's 85.5%. We further demonstrate its broad applicability on real-world ALOHA manipulation and autonomous driving.
논문 링크
WorldVLA: 자기회귀적 행동 월드 모델을 향하여 / WorldVLA: Towards Autoregressive Action World Model
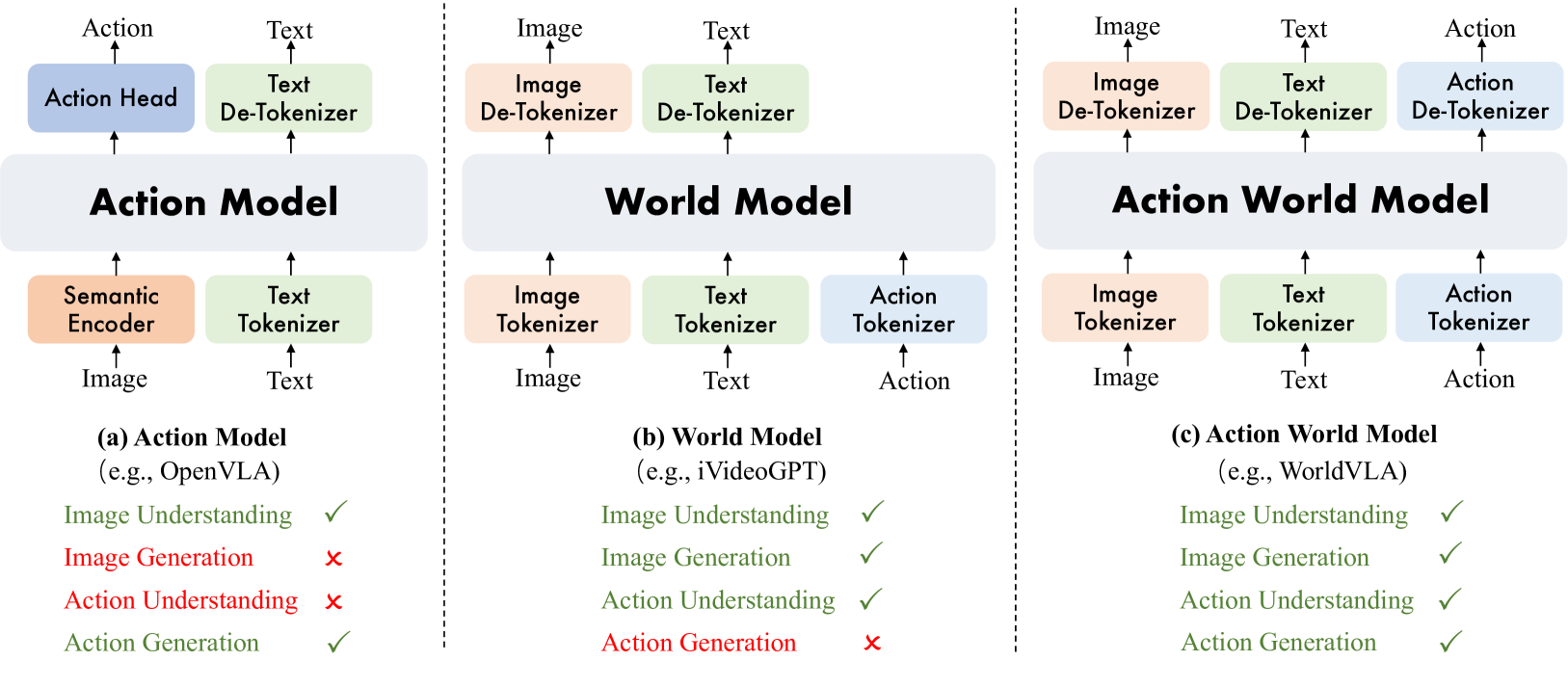
논문 소개
WorldVLA는 행동(action)과 이미지 이해 및 생성을 통합한 자기회귀(autoregressive) 행동 세계 모델(world model)입니다. 이 모델은 Vision-Language-Action(VLA) 모델과 세계 모델을 하나의 프레임워크로 결합하여, 환경의 물리 법칙을 학습하고 이를 통해 미래 이미지를 예측하며 행동 생성을 향상시킵니다. 행동 모델은 이미지 관찰을 바탕으로 다음 행동을 생성하여 시각적 이해를 돕고, 이는 다시 세계 모델의 시각적 생성 성능을 개선하는 상호 보완적 관계를 형성합니다. 또한, 행동 모델의 자기회귀적 행동 시퀀스 생성 시 발생하는 성능 저하 문제를 해결하기 위해, 이전 행동을 선택적으로 마스킹하는(attention mask) 전략을 제안하여 행동 청크 생성(task)에서 성능 향상을 달성하였습니다.
논문 초록(Abstract)
본 논문에서는 행동과 이미지의 이해 및 생성을 통합하는 자기회귀적 행동 세계 모델인 WorldVLA를 제안합니다. WorldVLA는 Vision-Language-Action(VLA) 모델과 세계 모델을 하나의 통합된 프레임워크로 결합합니다. 세계 모델은 행동과 이미지 이해를 모두 활용하여 미래 이미지를 예측하며, 환경의 근본적인 물리 법칙을 학습하여 행동 생성 성능을 향상시키는 것을 목표로 합니다. 한편, 행동 모델은 이미지 관찰을 기반으로 다음 행동을 생성하여 시각적 이해를 지원하고, 이는 다시 세계 모델의 시각적 생성에 도움을 줍니다. 우리는 WorldVLA가 단독 행동 모델 및 세계 모델보다 우수한 성능을 보이며, 세계 모델과 행동 모델 간의 상호 향상을 입증함을 보여줍니다. 또한, 자기회귀 방식으로 행동 시퀀스를 생성할 때 행동 모델의 성능이 저하되는 현상을 발견하였는데, 이는 행동 예측에 대한 모델의 일반화 능력 제한으로 인해 초기 행동에서 발생한 오류가 이후 행동으로 전파되기 때문입니다. 이를 해결하기 위해 현재 행동 생성 시 이전 행동을 선택적으로 마스킹하는 어텐션 마스크 전략을 제안하며, 이는 행동 청크 생성 과제에서 유의미한 성능 향상을 나타냅니다.
We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
논문 링크
더 읽어보기
https://github.com/alibaba-damo-academy/WorldVLA
잠재 공간 강화학습을 통한 확산 정책 제어 / Steering Your Diffusion Policy with Latent Space Reinforcement Learning
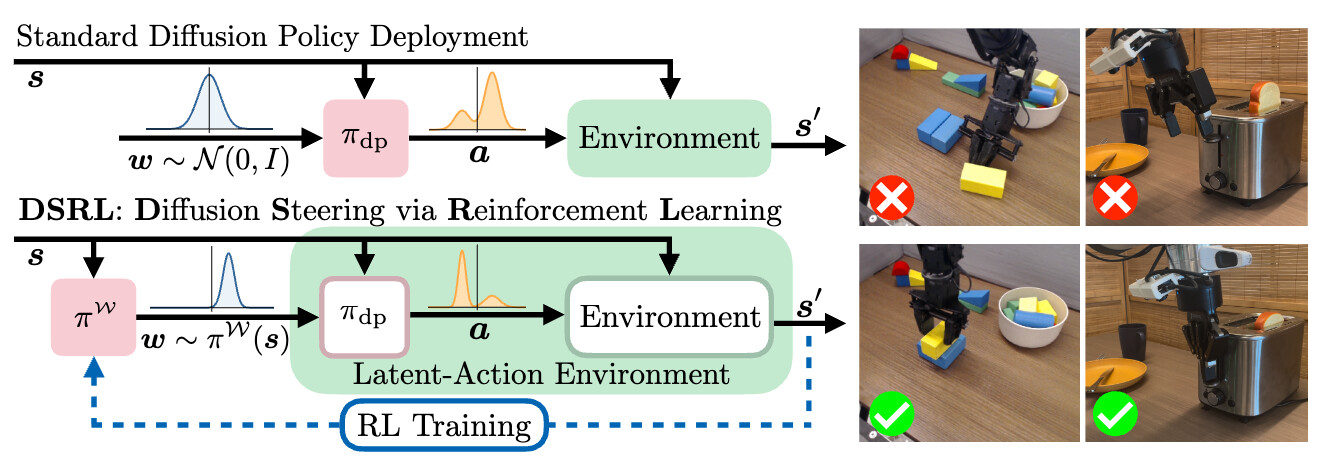
논문 소개
인간 시연으로 학습한 로봇 제어 정책은 실제 환경에서 우수한 성과를 보이나, 초기 성능이 낮은 새로운 환경에서는 추가 시연 데이터 수집이 필요해 비용과 시간이 많이 듭니다. 강화학습(RL)은 자율적인 온라인 정책 개선을 가능하게 하지만, 많은 샘플을 요구하는 단점이 있습니다. 본 연구에서는 확산 정책(diffusion policy)의 잠재 노이즈 공간(latent-noise space)에서 RL을 수행하는 확산 조향(diffusion steering) 기법인 DSRL을 제안하여, BC 기반 정책을 빠르고 효율적으로 자율 개선할 수 있음을 보였습니다. DSRL은 샘플 효율성이 높고, 정책의 내부 가중치 수정 없이 블랙박스 접근만으로 실세계에서 효과적인 정책 개선을 가능하게 합니다.
논문 초록(Abstract)
인간 시연으로부터 학습된 로봇 제어 정책은 다양한 실제 응용 분야에서 뛰어난 성과를 거두고 있습니다. 그러나 초기 성능이 만족스럽지 않은 경우, 특히 새로운 오픈월드 환경에서 흔히 발생하는 상황에서는, 이러한 행동 복제(Behavioral Cloning, BC) 학습 정책이 행동을 개선하기 위해 추가적인 인간 시연 수집이 필요하며, 이는 비용과 시간이 많이 소요되는 과정입니다. 반면, 강화학습(Reinforcement Learning, RL)은 자율적인 온라인 정책 개선을 가능하게 할 잠재력을 지니고 있으나, 일반적으로 많은 샘플을 필요로 하여 이 목표를 달성하는 데 어려움을 겪습니다. 본 연구에서는 효율적인 실제 환경 RL을 통해 BC 학습 정책의 빠른 자율 적응을 가능하게 하는 방향으로 나아갑니다. 특히 최첨단 BC 방법론인 diffusion 정책에 주목하여, 잠재 노이즈 공간에서 RL을 수행함으로써 BC 정책을 적응시키는 diffusion steering via reinforcement learning(DSRL)을 제안합니다. 우리는 DSRL이 매우 샘플 효율적이며, BC 정책에 대해 블랙박스 접근만으로도 가능하고, 실제 환경에서 효과적인 자율 정책 개선을 가능하게 함을 보였습니다. 더불어, DSRL은 diffusion 정책의 파인튜닝과 관련된 여러 문제를 회피하여, 기본 정책의 가중치를 전혀 수정할 필요가 없습니다. 시뮬레이션 벤치마크, 실제 로봇 작업, 그리고 사전 학습된 범용 정책 적응 실험을 통해 DSRL의 샘플 효율성과 실제 정책 개선에서의 우수한 성능을 입증하였습니다.
Robotic control policies learned from human demonstrations have achieved impressive results in many real-world applications. However, in scenarios where initial performance is not satisfactory, as is often the case in novel open-world settings, such behavioral cloning (BC)-learned policies typically require collecting additional human demonstrations to further improve their behavior -- an expensive and time-consuming process. In contrast, reinforcement learning (RL) holds the promise of enabling autonomous online policy improvement, but often falls short of achieving this due to the large number of samples it typically requires. In this work we take steps towards enabling fast autonomous adaptation of BC-trained policies via efficient real-world RL. Focusing in particular on diffusion policies -- a state-of-the-art BC methodology -- we propose diffusion steering via reinforcement learning (DSRL): adapting the BC policy by running RL over its latent-noise space. We show that DSRL is highly sample efficient, requires only black-box access to the BC policy, and enables effective real-world autonomous policy improvement. Furthermore, DSRL avoids many of the challenges associated with finetuning diffusion policies, obviating the need to modify the weights of the base policy at all. We demonstrate DSRL on simulated benchmarks, real-world robotic tasks, and for adapting pretrained generalist policies, illustrating its sample efficiency and effective performance at real-world policy improvement.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()