[2025/08/25 ~ 31] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 이번 주 선정된 논문들을 살펴보면 먼저, 멀티모달(Multimodal) 접근법의 증가는 여러 논문에서 다양한 입력 형태(예: 이미지, 텍스트, 오디오)를 통합하여 처리하는 방법론이 강조되고 있음을 보여줍니다. 예를 들어, M3-Agent와 같은 논문은 시각적 및 청각적 입력을 동시에 처리하고 이를 통해 장기 기억을 구축하는 방법을 제안하고 있습니다. 이러한 접근은 인간의 사고 방식과 유사한 방식으로 정보를 처리하고 이해하는 데 중요한 역할을 하고 있습니다.
이번 주 선정된 논문들을 살펴보면 먼저, 멀티모달(Multimodal) 접근법의 증가는 여러 논문에서 다양한 입력 형태(예: 이미지, 텍스트, 오디오)를 통합하여 처리하는 방법론이 강조되고 있음을 보여줍니다. 예를 들어, M3-Agent와 같은 논문은 시각적 및 청각적 입력을 동시에 처리하고 이를 통해 장기 기억을 구축하는 방법을 제안하고 있습니다. 이러한 접근은 인간의 사고 방식과 유사한 방식으로 정보를 처리하고 이해하는 데 중요한 역할을 하고 있습니다.
![]() 두 번째 트렌드인 강화 학습 기반의 새로운 학습 패러다임은 기존의 정적이고 수동적인 학습 방식에서 벗어나, 동적이고 지속적인 학습을 가능하게 하는 방법론이 주목받고 있음을 나타냅니다. Memento와 같은 논문은 메모리 기반의 온라인 강화 학습을 통해 LLM 에이전트가 지속적으로 적응할 수 있는 방법을 제시하고 있습니다. 이는 에이전트가 환경의 피드백에 따라 스스로 학습하고 개선할 수 있도록 하여, 더 효율적이고 유연한 시스템을 구축하는 데 기여하고 있습니다.
두 번째 트렌드인 강화 학습 기반의 새로운 학습 패러다임은 기존의 정적이고 수동적인 학습 방식에서 벗어나, 동적이고 지속적인 학습을 가능하게 하는 방법론이 주목받고 있음을 나타냅니다. Memento와 같은 논문은 메모리 기반의 온라인 강화 학습을 통해 LLM 에이전트가 지속적으로 적응할 수 있는 방법을 제시하고 있습니다. 이는 에이전트가 환경의 피드백에 따라 스스로 학습하고 개선할 수 있도록 하여, 더 효율적이고 유연한 시스템을 구축하는 데 기여하고 있습니다.
![]() 마지막으로, 시간적 추론의 중요성은 TimeMaster와 Time-R1과 같은 논문에서 강조되고 있습니다. 이들 연구는 시간에 대한 이해와 예측 능력을 강화하기 위한 새로운 방법론을 제안하고 있으며, 이는 복잡한 시간적 패턴을 다루는 데 있어 필수적입니다. 이러한 연구들은 AI 시스템이 과거의 사건을 이해하고 미래를 예측하는 데 있어 더 나은 성능을 발휘할 수 있도록 하는 방향으로 나아가고 있음을 보여줍니다.
마지막으로, 시간적 추론의 중요성은 TimeMaster와 Time-R1과 같은 논문에서 강조되고 있습니다. 이들 연구는 시간에 대한 이해와 예측 능력을 강화하기 위한 새로운 방법론을 제안하고 있으며, 이는 복잡한 시간적 패턴을 다루는 데 있어 필수적입니다. 이러한 연구들은 AI 시스템이 과거의 사건을 이해하고 미래를 예측하는 데 있어 더 나은 성능을 발휘할 수 있도록 하는 방향으로 나아가고 있음을 보여줍니다.
메타 CLIP 2: 전 세계 스케일링 레시피 / Meta CLIP 2: A Worldwide Scaling Recipe
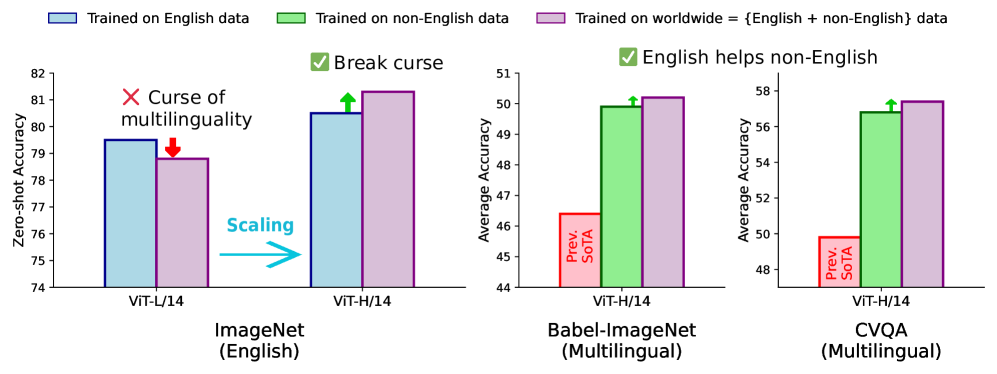
논문 소개
CLIP(대조적 언어-이미지 사전 학습) 모델은 제로샷 분류 및 검색을 지원하는 인기 있는 기초 모델로, 영어 데이터에서 성공적으로 훈련되었으나 전 세계 웹 데이터에서의 훈련 확장은 여전히 도전 과제로 남아 있습니다. 이를 해결하기 위해 Meta CLIP 2를 제안하며, 이는 전 세계 웹 규모의 이미지-텍스트 쌍으로 CLIP을 처음부터 훈련하는 방법론입니다. 연구 결과, Meta CLIP 2는 제로샷 이미지넷 분류에서 영어 전용 모델보다 0.8% 향상된 성능을 보였으며, 다양한 다국어 벤치마크에서 새로운 최첨단 성과를 기록했습니다. 이러한 결과는 영어 및 비영어 데이터 간의 상호 이점을 활용할 수 있는 방법론을 제시합니다.
논문 초록(Abstract)
대조적 언어-이미지 사전 학습(Contrastive Language-Image Pretraining, CLIP)은 제로샷 분류, 검색에서 다중 모달 대규모 언어 모델(MLLM)을 위한 인코더에 이르기까지 지원하는 인기 있는 기초 모델입니다. CLIP은 영어 세계의 수십억 개 이미지-텍스트 쌍에서 성공적으로 학습되었지만, 전 세계 웹 데이터로부터 학습하기 위해 CLIP의 학습을 확장하는 것은 여전히 도전 과제입니다: (1) 비영어 세계의 데이터 포인트를 처리할 수 있는 큐레이션 방법이 없습니다; (2) 기존 다국어 CLIP의 영어 성능이 영어 전용 모델보다 낮아지는 "다국어의 저주"가 LLM에서 일반적입니다. 여기에서 우리는 전 세계 웹 규모의 이미지-텍스트 쌍에서 CLIP을 처음부터 학습하는 Meta CLIP 2를 소개합니다. 우리의 발견을 일반화하기 위해, 우리는 위의 도전 과제를 해결하는 데 필요한 최소한의 변경으로 엄격한 변별 실험을 수행하고 영어 및 비영어 세계 데이터 간의 상호 이점을 가능하게 하는 레시피를 제시합니다. 제로샷 ImageNet 분류에서 Meta CLIP 2 ViT-H/14는 영어 전용 모델보다 0.8% 더 우수하며, mSigLIP보다 0.7% 더 높은 성능을 기록하고, 놀랍게도 번역, 맞춤형 아키텍처 변경과 같은 시스템 수준의 혼란 요소 없이 CVQA에서 57.4%, Babel-ImageNet에서 50.2%, XM3600에서 64.3%의 성능으로 다국어 벤치마크에서 새로운 최첨단을 설정합니다.
Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present Meta CLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, Meta CLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
논문 링크
메멘토: LLM을 미세 조정하지 않고 LLM 에이전트 미세 조정하기 / Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
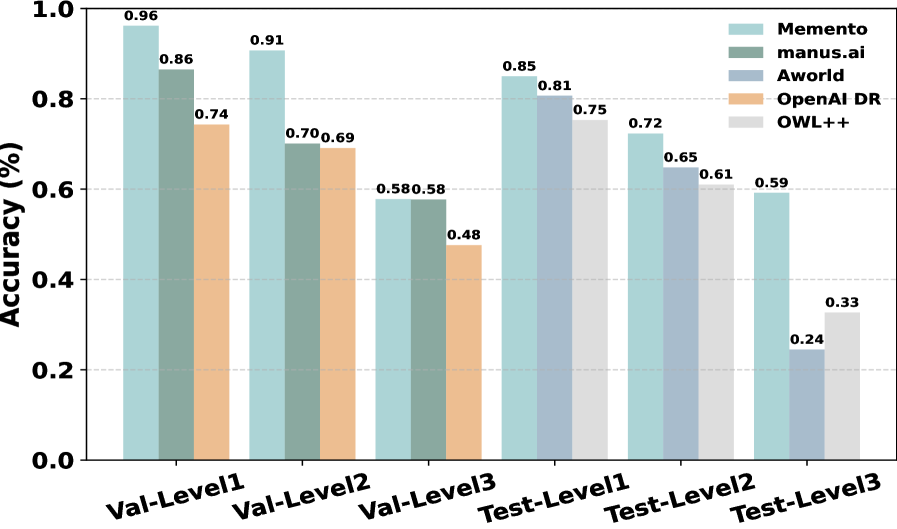
논문 소개
새로운 학습 패러다임인 Memento를 통해 Adaptive Large Language Model (LLM) 에이전트를 개발하는 방법을 제안합니다. 기존의 방법들은 정적이고 수작업으로 제작된 반영 워크플로우에 의존하거나, LLM 모델 파라미터의 그래디언트 업데이트를 요구하는 등 비효율적입니다. 반면, 본 연구에서는 메모리 기반의 온라인 강화 학습을 통해 저비용으로 지속적인 적응이 가능하도록 하였으며, 이를 Memory-augmented Markov Decision Process (M-MDP)로 형식화했습니다. 최종적으로, Memento는 GAIA 검증에서 최고 성능을 기록하며, 기존의 훈련 기반 방법보다 우수한 결과를 보여주어 지속적이고 실시간 학습이 가능한 일반화된 LLM 에이전트 개발에 기여할 수 있음을 입증했습니다.
논문 초록(Abstract)
이 논문에서는 기본 LLM(대규모 언어 모델)의 미세 조정 없이 적응형 LLM 에이전트를 위한 새로운 학습 패러다임을 소개합니다. 기존 접근 방식은 종종 정적이고 수작업으로 제작된 반영 워크플로우에 의존하거나, LLM 모델 매개변수의 그래디언트 업데이트를 요구하는 계산 집약적입니다. 반면, 우리의 방법은 메모리 기반 온라인 강화 학습을 통해 저비용의 지속적인 적응을 가능하게 합니다. 이를 메모리 증강 마르코프 결정 과정(M-MDP)으로 형식화하며, 행동 결정을 안내하는 신경 케이스 선택 정책을 갖추고 있습니다. 과거 경험은 에피소드 메모리에 저장되며, 이는 미분 가능하거나 비모수적일 수 있습니다. 정책은 메모리 재작성 메커니즘을 통해 환경 피드백에 따라 지속적으로 업데이트되며, 정책 개선은 효율적인 메모리 읽기(검색)를 통해 이루어집니다. 우리는 심층 연구 환경에서 우리의 에이전트 모델인 \emph{Memento}를 구현하였으며, 이는 GAIA 검증에서 1위(87.88% Pass@3)를 달성하고 테스트 세트에서 79.40%를 기록했습니다. DeepResearcher 데이터셋에서는 66.6% F1과 80.4% PM을 달성하여, 최신 훈련 기반 방법을 초월하며, 케이스 기반 메모리는 분포 외 작업에서 4.7%에서 9.6%의 절대 점수를 추가합니다. 우리의 접근 방식은 그래디언트 업데이트 없이 지속적이고 실시간 학습이 가능한 일반화된 LLM 에이전트를 개발하기 위한 확장 가능하고 효율적인 경로를 제공합니다. 이는 기계 학습을 개방형 기술 습득 및 심층 연구 시나리오로 발전시킵니다. 코드는 GitHub - Agent-on-the-Fly/Memento: Official Code of Memento: Fine-tuning LLM Agents without Fine-tuning LLMs 에서 이용할 수 있습니다.
In this paper, we introduce a novel learning paradigm for Adaptive Large Language Model (LLM) agents that eliminates the need for fine-tuning the underlying LLMs. Existing approaches are often either rigid, relying on static, handcrafted reflection workflows, or computationally intensive, requiring gradient updates of LLM model parameters. In contrast, our method enables low-cost continual adaptation via memory-based online reinforcement learning. We formalise this as a Memory-augmented Markov Decision Process (M-MDP), equipped with a neural case-selection policy to guide action decisions. Past experiences are stored in an episodic memory, either differentiable or non-parametric. The policy is continually updated based on environmental feedback through a memory rewriting mechanism, whereas policy improvement is achieved through efficient memory reading (retrieval). We instantiate our agent model in the deep research setting, namely \emph{Memento}, which attains top-1 on GAIA validation (87.88\% Pass@3) and 79.40\% on the test set. It reaches 66.6\% F1 and 80.4\% PM on the DeepResearcher dataset, outperforming the state-of-the-art training-based method, while case-based memory adds 4.7\% to 9.6\% absolute points on out-of-distribution tasks. Our approach offers a scalable and efficient pathway for developing generalist LLM agents capable of continuous, real-time learning without gradient updates, advancing machine learning towards open-ended skill acquisition and deep research scenarios. The code is available at GitHub - Agent-on-the-Fly/Memento: Official Code of Memento: Fine-tuning LLM Agents without Fine-tuning LLMs.
논문 링크
더 읽어보기
https://github.com/Agent-on-the-Fly/Memento
시각, 청각, 기억 및 추론: 장기 기억을 갖춘 멀티모달 에이전트 / Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory

논문 소개
M3-Agent는 장기 기억을 갖춘 새로운 멀티모달 에이전트 프레임워크로, 실시간 시각 및 청각 입력을 처리하여 기억을 구축하고 업데이트할 수 있습니다. 에피소드 기억을 넘어서, 세계 지식을 축적할 수 있는 의미 기억도 개발하며, 기억은 엔티티 중심의 멀티모달 형식으로 조직되어 환경에 대한 깊고 일관된 이해를 가능하게 합니다. M3-Agent는 지시를 받으면 자율적으로 다중 턴의 반복적 추론을 수행하고, 기억에서 관련 정보를 검색하여 작업을 수행합니다. 실험 결과, 강화 학습을 통해 훈련된 M3-Agent는 기존의 최강 기준 모델보다 높은 정확도를 기록하며, 멀티모달 에이전트의 인간과 유사한 장기 기억 발전에 기여합니다.
논문 초록(Abstract)
우리는 장기 기억이 장착된 새로운 멀티모달 에이전트 프레임워크인 M3-Agent를 소개합니다. M3-Agent는 인간처럼 실시간 시각 및 청각 입력을 처리하여 장기 기억을 구축하고 업데이트할 수 있습니다. 일화 기억을 넘어, M3-Agent는 시간이 지남에 따라 세계 지식을 축적할 수 있는 의미 기억도 개발합니다. 이 기억은 엔티티 중심의 멀티모달 형식으로 구성되어 있어 환경에 대한 더 깊고 일관된 이해를 가능하게 합니다. 지시를 받으면 M3-Agent는 자율적으로 다중 턴의 반복적 추론을 수행하고, 작업을 완료하기 위해 기억에서 관련 정보를 검색합니다. 멀티모달 에이전트의 기억 효과성과 기억 기반 추론을 평가하기 위해, 우리는 M3-Bench라는 새로운 장기 비디오 질문 응답 벤치마크를 개발했습니다. M3-Bench는 로봇의 시각에서 촬영된 100개의 새로 기록된 실제 비디오(M3-Bench-robot)와 다양한 시나리오에서 수집된 920개의 웹 기반 비디오(M3-Bench-web)로 구성됩니다. 우리는 인간 이해, 일반 지식 추출 및 교차 모달 추론과 같은 에이전트 응용에 필수적인 주요 능력을 테스트하기 위해 설계된 질문-답변 쌍을 주석 처리했습니다. 실험 결과, 강화 학습을 통해 학습된 M3-Agent는 Gemini-1.5-pro와 GPT-4o를 사용하는 프롬프트 에이전트라는 가장 강력한 기준선을 초과하여 M3-Bench-robot, M3-Bench-web 및 VideoMME-long에서 각각 6.7%, 7.7%, 5.3% 더 높은 정확도를 달성했습니다. 우리의 연구는 다중 모달 에이전트를 보다 인간과 유사한 장기 기억으로 발전시키고, 그들의 실용적인 설계에 대한 통찰을 제공합니다. 모델, 코드 및 데이터는 GitHub - ByteDance-Seed/m3-agent 에서 확인할 수 있습니다.
We introduce M3-Agent, a novel multimodal agent framework equipped with long-term memory. Like humans, M3-Agent can process real-time visual and auditory inputs to build and update its long-term memory. Beyond episodic memory, it also develops semantic memory, enabling it to accumulate world knowledge over time. Its memory is organized in an entity-centric, multimodal format, allowing deeper and more consistent understanding of the environment. Given an instruction, M3-Agent autonomously performs multi-turn, iterative reasoning and retrieves relevant information from memory to accomplish the task. To evaluate memory effectiveness and memory-based reasoning in multimodal agents, we develop M3-Bench, a new long-video question answering benchmark. M3-Bench comprises 100 newly recorded real-world videos captured from a robot's perspective (M3-Bench-robot) and 920 web-sourced videos across diverse scenarios (M3-Bench-web). We annotate question-answer pairs designed to test key capabilities essential for agent applications, such as human understanding, general knowledge extraction, and cross-modal reasoning. Experimental results show that M3-Agent, trained via reinforcement learning, outperforms the strongest baseline, a prompting agent using Gemini-1.5-pro and GPT-4o, achieving 6.7%, 7.7%, and 5.3% higher accuracy on M3-Bench-robot, M3-Bench-web and VideoMME-long, respectively. Our work advances the multimodal agents toward more human-like long-term memory and provides insights into their practical design. Model, code and data are available at GitHub - ByteDance-Seed/m3-agent
논문 링크
더 읽어보기
https://github.com/bytedance-seed/m3-agent
답변하기 전에 설명하기: 구성적 시각 추론에 대한 서베이 / Explain Before You Answer: A Survey on Compositional Visual Reasoning
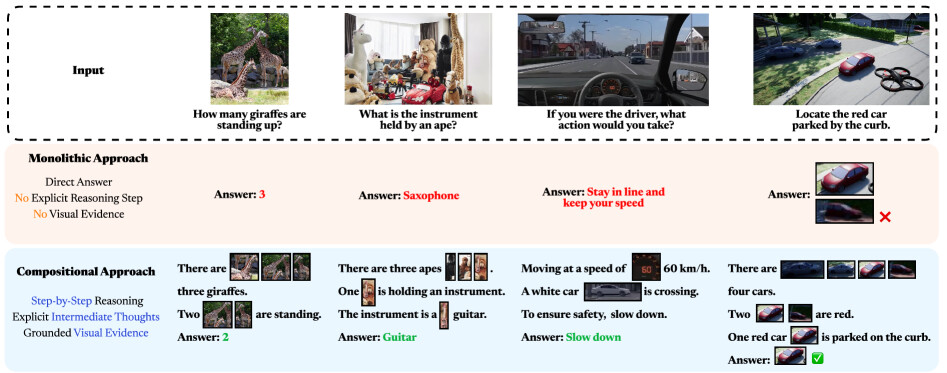
논문 소개
구성적 시각 추론(compositional visual reasoning)은 다중 모달 인공지능(multimodal AI)에서 중요한 연구 분야로, 기계가 시각 장면을 분해하고 중간 개념을 구체화하며 다단계 논리적 추론을 수행할 수 있도록 하는 것을 목표로 합니다. 본 논문은 2023년부터 2025년까지의 260편 이상의 관련 논문을 체계적으로 검토하여 구성적 시각 추론 문헌의 포괄적인 조사를 제공합니다. 핵심 정의를 정립하고, 구성적 접근 방식이 인지 정렬, 의미 충실도, 견고성, 해석 가능성 및 데이터 효율성에서 제공하는 장점을 설명합니다. 또한, 다양한 벤치마크와 메트릭스를 정리하고, 향후 연구 방향을 제시하여 구성적 시각 추론 연구의 기초 자료로 활용될 수 있도록 합니다.
논문 초록(Abstract)
구성적 시각 추론은 시각 장면을 분해하고, 중간 개념을 구체화하며, 다단계 논리 추론을 수행하는 인간과 유사한 능력을 기계에 부여하는 것을 목표로 하는 다중 모달 AI의 주요 연구 분야로 부상하였습니다. 초기 서베이 논문들은 단일 비전-언어 모델 또는 일반적인 다중 모달 추론에 초점을 맞추고 있지만, 빠르게 확장되고 있는 구성적 시각 추론 문헌에 대한 전담 종합은 여전히 부족합니다. 우리는 2023년부터 2025년까지의 포괄적인 서베이를 통해 이 공백을 메우며, CVPR, ICCV, NeurIPS, ICML, ACL 등 주요 학술지에서 발표된 260편 이상의 논문을 체계적으로 검토합니다. 먼저 핵심 정의를 공식화하고, 구성적 접근 방식이 인지 정렬, 의미 충실도, 강건성, 해석 가능성 및 데이터 효율성에서 왜 장점을 제공하는지 설명합니다. 다음으로 우리는 프롬프트 강화 언어 중심 파이프라인에서 도구 강화 LLM 및 도구 강화 VLM을 거쳐 최근에 등장한 사고의 연쇄 추론 및 통합 에이전틱 VLM으로의 다섯 단계 패러다임 전환을 추적하며, 이들의 구조적 설계, 강점 및 한계를 강조합니다. 그런 다음 우리는 구체화 정확도, 사고의 연쇄 충실도, 고해상도 인식과 같은 차원에서 구성적 시각 추론을 탐구하는 60개 이상의 벤치마크 및 해당 메트릭을 정리합니다. 이러한 분석을 바탕으로 우리는 핵심 통찰을 정제하고, LLM 기반 추론의 한계, 환각, 귀납적 추론에 대한 편향, 확장 가능한 감독, 도구 통합 및 벤치마크 한계와 같은 열린 도전 과제를 식별하며, 세계 모델 통합, 인간-AI 협력 추론 및 보다 풍부한 평가 프로토콜을 포함한 미래 방향을 제시합니다. 통합된 분류법, 역사적 로드맵 및 비판적 전망을 제공함으로써, 이 서베이는 구성적 시각 추론 연구의 기초적인 참고 자료로서의 역할을 하고, 차세대 연구에 영감을 주는 것을 목표로 합니다.
Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
논문 링크
더 읽어보기
https://github.com/pokerme7777/Compositional-Visual-Reasoning-Survey
ComputerRL: 컴퓨터 사용 에이전트를 위한 엔드 투 엔드 온라인 강화 학습의 확장 / ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
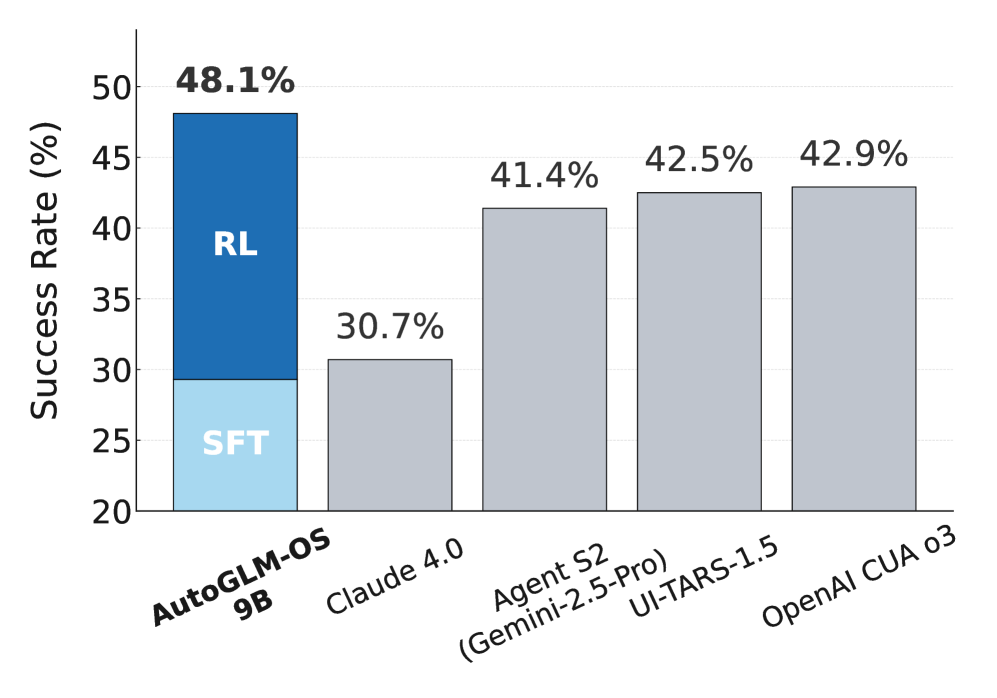
논문 소개
ComputerRL은 복잡한 디지털 작업 공간에서 자율적으로 작동할 수 있는 에이전트를 위한 프레임워크로, 프로그램적 API 호출과 직접 GUI 상호작용을 통합한 API-GUI 패러다임을 특징으로 합니다. 이 프레임워크는 다양한 데스크톱 작업에 대한 개선과 일반화를 위해 엔드 투 엔드 강화 학습(RL) 훈련의 확장을 지원하며, 수천 개의 병렬 가상 데스크톱 환경을 조정할 수 있는 분산 RL 인프라를 개발하여 대규모 온라인 RL을 가속화합니다. 또한, 장기 훈련 중 엔트로피 붕괴를 완화하기 위해 강화 학습과 감독 세밀 조정을 번갈아 수행하는 Entropulse 훈련 전략을 제안합니다. ComputerRL은 GLM-4-9B-0414 및 Qwen2.5-14B 모델에서 평가되었으며, GLM-4-9B-0414 기반의 AutoGLM-OS-9B는 48.1%의 새로운 최고 정확도를 달성하여 데스크톱 자동화에서 일반 에이전트의 성능을 크게 향상시켰습니다.
논문 초록(Abstract)
우리는 복잡한 디지털 작업 공간에서 에이전트가 능숙하게 작동할 수 있도록 하는 자율 데스크탑 지능을 위한 프레임워크인 ComputerRL을 소개합니다. ComputerRL은 프로그램적 API 호출과 직접적인 GUI 상호작용을 통합하는 API-GUI 패러다임을 특징으로 하여 기계 에이전트와 인간 중심의 데스크탑 환경 간의 본질적인 불일치를 해결합니다. 다양한 데스크탑 작업에 걸쳐 개선 및 일반화를 위해 엔드 투 엔드 강화 학습(End-to-End RL) 훈련의 확장은 매우 중요하지만, 환경 비효율성과 장기 훈련에서의 불안정성으로 인해 여전히 도전 과제가 됩니다. 확장 가능하고 견고한 훈련을 지원하기 위해, 우리는 대규모 온라인 RL을 가속화하기 위해 수천 개의 병렬 가상 데스크탑 환경을 조율할 수 있는 분산 RL 인프라를 개발합니다. 또한, 우리는 강화 학습과 감독된 미세 조정을 번갈아 수행하는 훈련 전략인 Entropulse를 제안하여 장기 훈련 동안 엔트로피 붕괴를 효과적으로 완화합니다. 우리는 ComputerRL을 공개 모델 GLM-4-9B-0414와 Qwen2.5-14B에 적용하고, OSWorld 벤치마크에서 평가합니다. GLM-4-9B-0414 기반의 AutoGLM-OS-9B는 48.1%의 새로운 최첨단 정확도를 달성하여 데스크탑 자동화에서 일반 에이전트에 대한 상당한 개선을 보여줍니다. 이 알고리즘과 프레임워크는 AutoGLM 구축에 채택되었습니다 (Liu et al., 2024a).
We introduce ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments. Scaling end-to-end RL training is crucial for improvement and generalization across diverse desktop tasks, yet remains challenging due to environmental inefficiency and instability in extended training. To support scalable and robust training, we develop a distributed RL infrastructure capable of orchestrating thousands of parallel virtual desktop environments to accelerate large-scale online RL. Furthermore, we propose Entropulse, a training strategy that alternates reinforcement learning with supervised fine-tuning, effectively mitigating entropy collapse during extended training runs. We employ ComputerRL on open models GLM-4-9B-0414 and Qwen2.5-14B, and evaluate them on the OSWorld benchmark. The AutoGLM-OS-9B based on GLM-4-9B-0414 achieves a new state-of-the-art accuracy of 48.1%, demonstrating significant improvements for general agents in desktop automation. The algorithm and framework are adopted in building AutoGLM (Liu et al., 2024a)
논문 링크
에이전트의 연쇄: 다중 에이전트 증류 및 에이전틱 강화 학습을 통한 엔드 투 엔드 에이전트 기반 모델 / Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
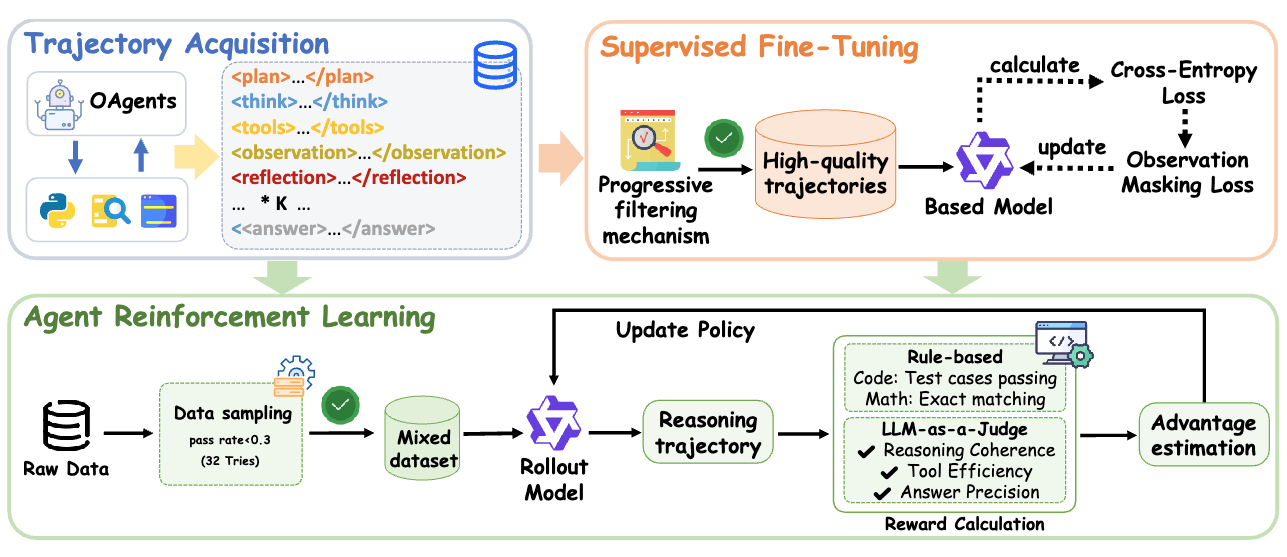
논문 소개
최근 대형 언어 모델(LLM)과 다중 에이전트 시스템의 발전은 복잡한 문제 해결 작업에서 뛰어난 성능을 보여주고 있습니다. 그러나 기존의 다중 에이전트 시스템은 수동적인 프롬프트 및 워크플로우 엔지니어링에 의존하여 비효율적이고 데이터 중심 학습의 이점을 누리지 못합니다. 본 연구에서는 Chain-of-Agents(CoA)라는 새로운 패러다임을 제안하여 단일 모델 내에서 다중 에이전트 협업을 시뮬레이션하며 복잡한 문제 해결을 가능하게 합니다. 이를 위해 다중 에이전트 증류 프레임워크를 도입하고, 에이전트 강화 학습을 통해 모델의 성능을 향상시켜 Agent Foundation Models(AFMs)를 개발하였으며, 이 모델은 다양한 벤치마크에서 새로운 최첨단 성능을 기록하였습니다.
논문 초록(Abstract)
최근 대규모 언어 모델(LLM)과 다중 에이전트 시스템의 발전은 심층 연구, 분위기 코딩, 수학적 추론과 같은 복잡한 문제 해결 작업에서 놀라운 능력을 보여주었습니다. 그러나 기존의 대부분의 다중 에이전트 시스템은 정교한 에이전트 프레임워크를 통한 수동 프롬프트/워크플로우 엔지니어링에 기반하고 있어 계산적으로 비효율적이며, 능력이 떨어지고 데이터 중심 학습의 혜택을 누릴 수 없습니다. 본 연구에서는 Chain-of-Agents (CoA)라는 새로운 LLM 추론 패러다임을 소개합니다. 이는 하나의 모델 내에서 다중 에이전트 시스템과 동일한 방식으로 복잡한 문제를 본질적으로 종단 간(end-to-end)으로 해결할 수 있게 합니다(즉, 여러 도구와 여러 에이전트를 활용한 다중 턴 문제 해결). Chain-of-agents 문제 해결에서는 모델이 다양한 도구 에이전트와 역할 수행 에이전트를 동적으로 활성화하여 종단 간 방식으로 다중 에이전트 협업을 시뮬레이션합니다. LLM에서 종단 간 chain-of-agents 문제 해결 능력을 이끌어내기 위해, 우리는 최첨단 다중 에이전트 시스템을 chain-of-agents 경로로 증류하여 에이전틱 감독 미세 조정을 위한 다중 에이전트 증류 프레임워크를 도입합니다. 이후 검증 가능한 에이전틱 작업에 대해 에이전틱 강화 학습을 적용하여 chain-of-agents 문제 해결에서 모델의 능력을 더욱 향상시킵니다. 결과적으로 생성된 모델을 에이전트 기초 모델(Agent Foundation Models, AFM)이라고 부릅니다. 우리의 실증 연구는 AFM이 웹 에이전트 및 코드 에이전트 설정에서 다양한 벤치마크에서 새로운 최첨단 성능을 확립함을 보여줍니다. 우리는 모델 가중치, 학습 및 평가를 위한 코드, 학습 데이터를 포함한 전체 연구를 완전 오픈 소스로 제공하여 에이전트 모델 및 에이전틱 강화 학습에 대한 향후 연구의 확고한 출발점을 제공합니다.
Recent advances in large language models (LLMs) and multi-agent systems have demonstrated remarkable capabilities in complex problem-solving tasks such as deep research, vibe coding, and mathematical reasoning. However, most existing multi-agent systems are built upon manual prompt/workflow engineering with sophisticated agent frameworks, making them computationally inefficient, less capable, and can not benefit from data-centric learning. In this work, we introduce Chain-of-Agents (CoA), a novel paradigm of LLM reasoning that enables native end-to-end complex problem-solving in the same way as a multi-agent system (i.e., multi-turn problem solving with multiple tools and multiple agents) within one model. In chain-of-agents problem-solving, the model dynamically activates different tool agents and role-playing agents to simulate multi-agent collaboration in an end-to-end fashion. To elicit end-to-end chain-of-agents problem-solving abilities in LLMs, we introduce a multi-agent distillation framework to distill state-of-the-art multi-agent systems into chain-of-agents trajectories for agentic supervised fine-tuning. We then use agentic reinforcement learning on verifiable agentic tasks to further improve the models' capabilities on chain-of-agents problem solving. We call the resulting models Agent Foundation Models (AFMs). Our empirical studies demonstrate that AFM establishes new state-of-the-art performance across diverse benchmarks in both web agent and code agent settings. We make the entire research, including the model weights, code for training and evaluation, and the training data, fully open-sourced, which offers a solid starting point for future research on agent models and agentic RL.
논문 링크
더 읽어보기
https://github.com/OPPO-PersonalAI/Agent_Foundation_Models
임베딩 기반 검색의 이론적 한계에 대한 연구 / On the Theoretical Limitations of Embedding-Based Retrieval
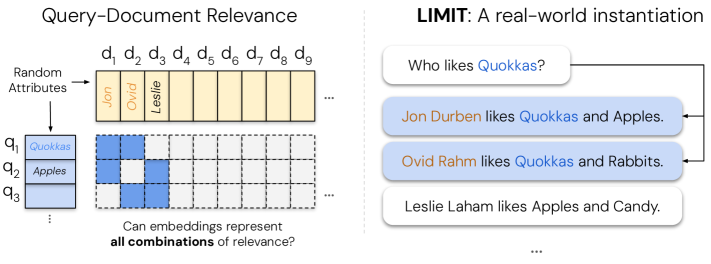
논문 소개
벡터 임베딩은 다양한 검색 작업에 사용되고 있으며, 최근에는 추론, 지시 따르기, 코딩 등에도 활용되고 있습니다. 그러나 이 연구는 벡터 임베딩의 이론적 한계가 단순한 쿼리에서도 발생할 수 있음을 보여줍니다. 학습 이론의 결과를 연결하여, 쿼리의 결과로 반환될 수 있는 문서의 상위 k개 집합의 수가 임베딩의 차원에 의해 제한된다는 것을 입증하였습니다. LIMIT라는 현실적인 데이터셋을 생성하여 이러한 이론적 결과를 기반으로 모델을 스트레스 테스트한 결과, 최신 모델조차도 간단한 작업에서 실패하는 모습을 관찰하였습니다.
논문 초록(Abstract)
벡터 임베딩은 수년 동안 점점 더 많은 검색 작업을 수행해 왔으며, 최근에는 추론, 지시 따르기, 코딩 등 다양한 용도로 사용되고 있습니다. 이러한 새로운 벤치마크는 임베딩이 어떤 쿼리와 관련성 개념에 대해서도 작동하도록 요구하고 있습니다. 이전 연구들은 벡터 임베딩의 이론적 한계를 지적했지만, 이러한 어려움이 비현실적인 쿼리 때문이라는 일반적인 가정이 있으며, 비현실적이지 않은 쿼리는 더 나은 학습 데이터와 더 큰 모델로 극복할 수 있다고 여겨집니다. 본 연구에서는 매우 간단한 쿼리로도 이러한 이론적 한계를 현실적인 환경에서 마주칠 수 있음을 보여줍니다. 우리는 학습 이론에서 알려진 결과를 연결하여, 어떤 쿼리의 결과로 반환될 수 있는 문서의 상위 k 개 부분집합의 수가 임베딩의 차원에 의해 제한된다는 것을 보여줍니다. k=2로 제한하더라도 이 사실이 성립함을 경험적으로 입증하고, 매개변수가 자유로운 임베딩을 사용하여 테스트 세트에서 직접 최적화합니다. 그런 다음 이러한 이론적 결과를 바탕으로 모델을 스트레스 테스트하는 현실적인 데이터셋인 LIMIT를 생성하고, 작업의 단순한 성격에도 불구하고 최첨단 모델조차도 이 데이터셋에서 실패하는 것을 관찰합니다. 본 연구는 기존의 단일 벡터 패러다임 하에서 임베딩 모델의 한계를 보여주고, 이러한 근본적인 한계를 해결할 수 있는 방법을 개발하기 위한 향후 연구를 촉구합니다.
Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings to work for any query and any notion of relevance that could be given. While prior works have pointed out theoretical limitations of vector embeddings, there is a common assumption that these difficulties are exclusively due to unrealistic queries, and those that are not can be overcome with better training data and larger models. In this work, we demonstrate that we may encounter these theoretical limitations in realistic settings with extremely simple queries. We connect known results in learning theory, showing that the number of top-k subsets of documents capable of being returned as the result of some query is limited by the dimension of the embedding. We empirically show that this holds true even if we restrict to k=2, and directly optimize on the test set with free parameterized embeddings. We then create a realistic dataset called LIMIT that stress tests models based on these theoretical results, and observe that even state-of-the-art models fail on this dataset despite the simple nature of the task. Our work shows the limits of embedding models under the existing single vector paradigm and calls for future research to develop methods that can resolve this fundamental limitation.
논문 링크
대규모 언어 모델 벤치마크에 대한 서베이 / A Survey on Large Language Model Benchmarks
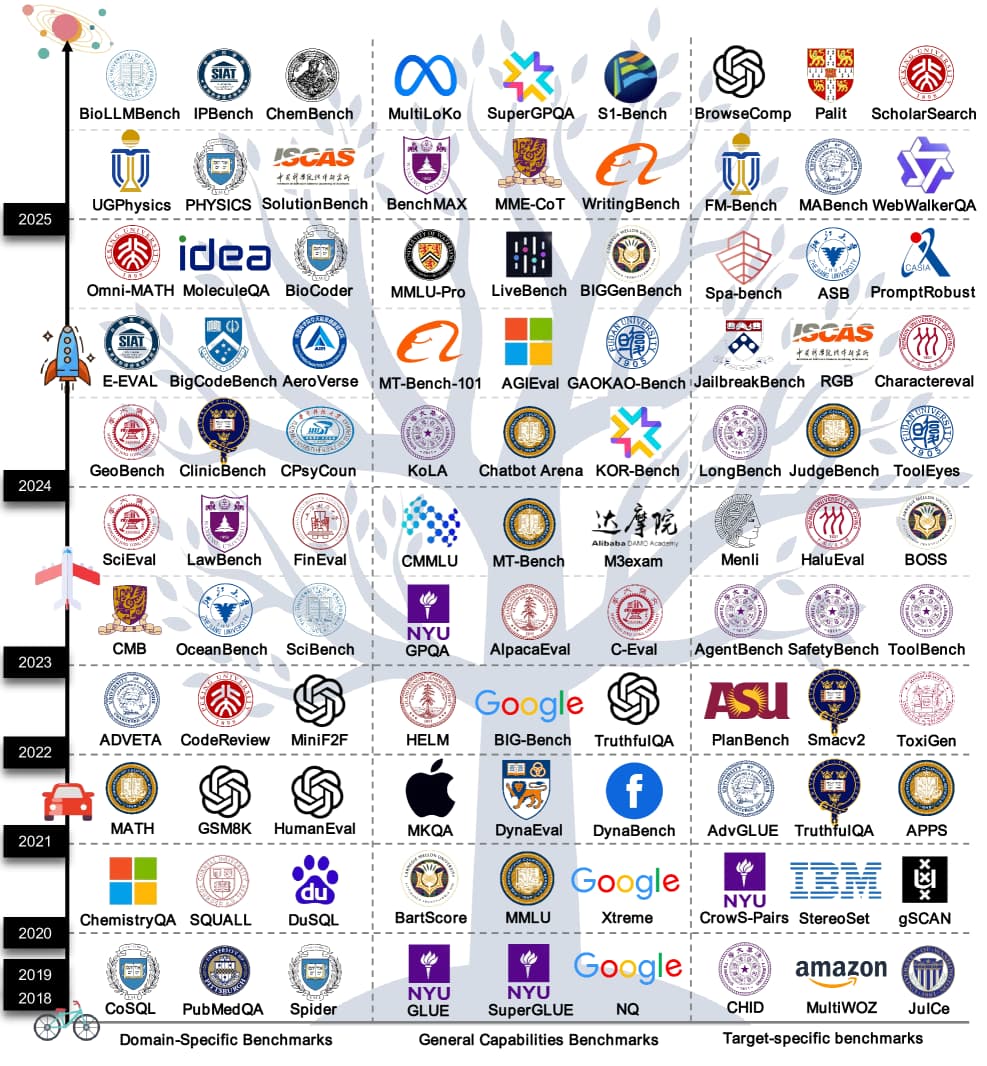
논문 소개
최근 대형 언어 모델의 발전에 따라 다양한 평가 벤치마크가 증가하고 있습니다. 이러한 벤치마크는 모델 성능을 정량적으로 평가하는 도구로서, 모델의 능력을 측정하고 개발 방향을 제시하는 데 중요한 역할을 합니다. 본 연구에서는 283개의 대표적인 벤치마크를 일반 능력, 도메인 특화, 목표 특화의 세 가지 범주로 분류하여 체계적으로 검토하였습니다. 현재 벤치마크는 데이터 오염으로 인한 점수 부풀리기, 문화적 및 언어적 편향으로 인한 불공정한 평가, 프로세스 신뢰성 및 동적 환경에 대한 평가 부족 등의 문제점을 지적하며, 향후 벤치마크 혁신을 위한 설계 패러다임을 제시합니다.
논문 초록(Abstract)
최근 몇 년 동안 대규모 언어 모델의 능력의 깊이와 폭이 빠르게 발전함에 따라, 이에 상응하는 다양한 평가 기준이 점점 더 많이 등장하고 있습니다. 모델 성능을 위한 정량적 평가 도구로서, 기준은 모델 능력을 측정하는 핵심 수단일 뿐만 아니라 모델 개발 방향을 안내하고 기술 혁신을 촉진하는 중요한 요소입니다. 우리는 대규모 언어 모델 기준의 현재 상태와 발전을 처음으로 체계적으로 검토하며, 283개의 대표적인 기준을 일반 능력, 도메인 특화, 목표 특화의 세 가지 범주로 분류합니다. 일반 능력 기준은 핵심 언어학, 지식 및 추론과 같은 측면을 포함하고; 도메인 특화 기준은 자연 과학, 인문 및 사회 과학, 공학 기술과 같은 분야에 중점을 두며; 목표 특화 기준은 위험, 신뢰성, 에이전트 등을 주목합니다. 우리는 현재 기준이 데이터 오염으로 인한 점수 부풀리기, 문화적 및 언어적 편향으로 인한 불공정한 평가, 과정 신뢰성 및 동적 환경에 대한 평가 부족과 같은 문제를 가지고 있음을 지적하며, 향후 기준 혁신을 위한 참조 가능한 설계 패러다임을 제공합니다.
In recent years, with the rapid development of the depth and breadth of large language models' capabilities, various corresponding evaluation benchmarks have been emerging in increasing numbers. As a quantitative assessment tool for model performance, benchmarks are not only a core means to measure model capabilities but also a key element in guiding the direction of model development and promoting technological innovation. We systematically review the current status and development of large language model benchmarks for the first time, categorizing 283 representative benchmarks into three categories: general capabilities, domain-specific, and target-specific. General capability benchmarks cover aspects such as core linguistics, knowledge, and reasoning; domain-specific benchmarks focus on fields like natural sciences, humanities and social sciences, and engineering technology; target-specific benchmarks pay attention to risks, reliability, agents, etc. We point out that current benchmarks have problems such as inflated scores caused by data contamination, unfair evaluation due to cultural and linguistic biases, and lack of evaluation on process credibility and dynamic environments, and provide a referable design paradigm for future benchmark innovation.
논문 링크
TimeMaster: 강화학습을 통한 시계열 멀티모달 LLM의 추론 학습 / TimeMaster: Training Time-Series Multimodal LLMs to Reason via Reinforcement Learning
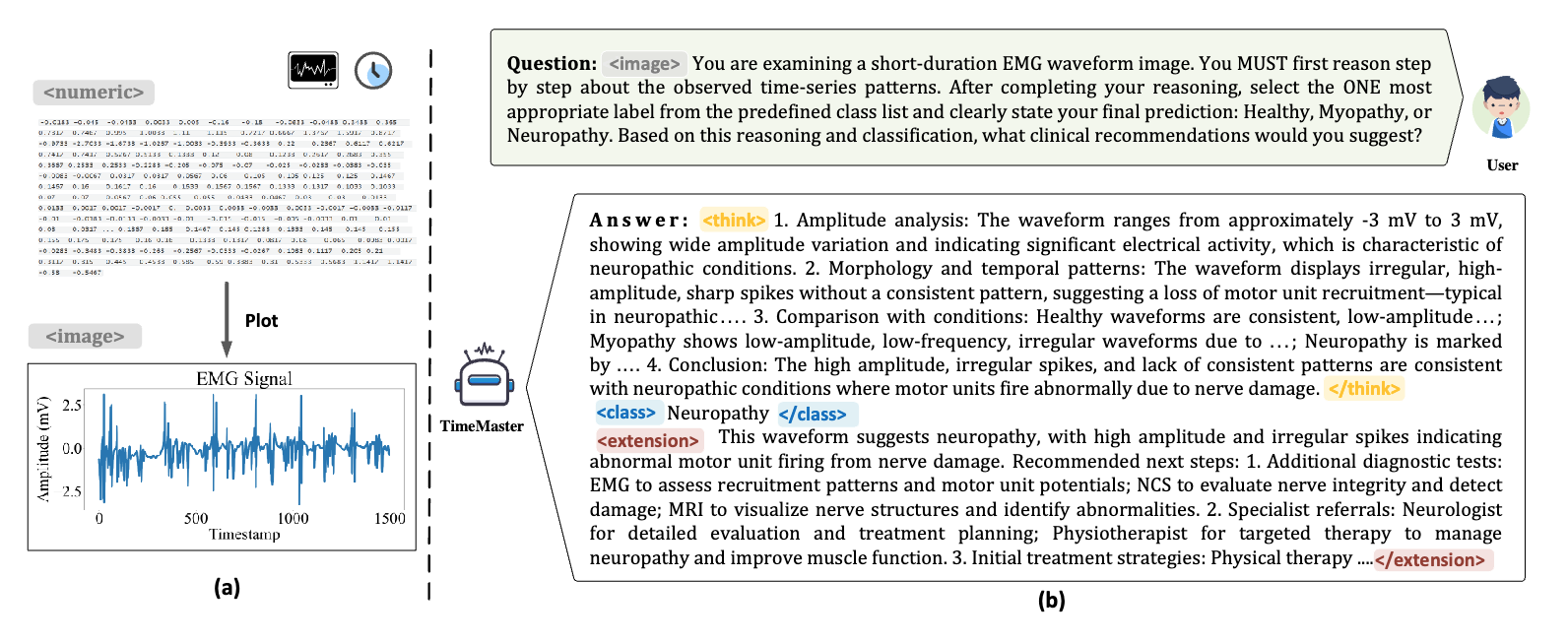
논문 소개
TimeMaster는 시계열 데이터의 동적 패턴과 모호한 의미, 시간적 사전 지식 부족이라는 어려움을 극복하기 위해 강화학습 기반 접근법을 제안합니다. 이 방법은 시계열 시각화 입력과 작업 프롬프트에 대해 구조화된 추론, 분류, 도메인 확장의 세 부분으로 구성된 출력 형식을 사용하며, 형식 준수, 예측 정확도, 통찰력 품질을 반영하는 복합 보상 함수로 최적화됩니다. 두 단계 학습 과정으로, 먼저 감독학습 미세조정(SFT)을 통해 초기화를 수행하고, 이후 토큰 단위의 그룹 상대 정책 최적화(GRPO)를 적용하여 안정적이고 목표 지향적인 성능 향상을 도모합니다. TimerBed 벤치마크에서 기존 시계열 모델과 GPT-4o를 능가하는 우수한 성능을 보이며, 전문가 수준의 추론과 도메인 맞춤형 설명 생성 능력도 함께 갖추었음을 입증하였습니다.
논문 초록(Abstract)
시계열 추론은 동적 시간 패턴, 모호한 의미론, 그리고 시간적 사전 지식의 부족으로 인해 멀티모달 대형 언어 모델(MLLM)에서 여전히 중요한 도전 과제로 남아 있습니다. 본 연구에서는 시각화된 시계열 입력과 작업 프롬프트에 대해 구조적이고 해석 가능한 추론을 직접 수행할 수 있도록 하는 강화학습(RL) 기반 방법인 TimeMaster를 제안합니다. TimeMaster는 추론, 분류, 도메인 특화 확장의 세 부분으로 구성된 구조화된 출력 형식을 채택하며, 형식 준수, 예측 정확도, 그리고 개방형 통찰력 품질을 정렬하는 복합 보상 함수로 최적화됩니다. 모델은 두 단계의 학습 파이프라인을 통해 훈련되는데, 우선 감독 학습 미세조정(SFT)을 적용하여 좋은 초기화를 구축하고, 이후 토큰 수준에서 그룹 상대 정책 최적화(GRPO)를 수행하여 시계열 추론에서 안정적이고 목표 지향적인 보상 기반 개선을 가능하게 합니다. 우리는 Qwen2.5-VL-3B-Instruct를 기반으로 한 TimerBed 벤치마크의 6가지 실제 분류 작업에서 TimeMaster를 평가하였으며, TimeMaster는 기존의 고전적 시계열 모델과 few-shot GPT-4o를 각각 14.6%, 7.3% 이상 능가하는 최첨단 성능을 달성하였습니다. 특히, TimeMaster는 시계열 분류를 넘어 전문가 수준의 추론 행동을 보이고, 문맥 인지형 설명을 생성하며, 도메인에 부합하는 통찰을 제공합니다. 본 연구 결과는 보상 기반 RL이 시계열 MLLM에 시간적 이해를 통합하는 확장 가능하고 유망한 경로임을 시사합니다.
Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structured output format, reasoning, classification, and domain-specific extension, and is optimized via a composite reward function that aligns format adherence, prediction accuracy, and open-ended insight quality. The model is trained using a two-stage pipeline: we first apply supervised fine-tuning (SFT) to establish a good initialization, followed by Group Relative Policy Optimization (GRPO) at the token level to enable stable and targeted reward-driven improvement in time-series reasoning. We evaluate TimeMaster on the TimerBed benchmark across six real-world classification tasks based on Qwen2.5-VL-3B-Instruct. TimeMaster achieves state-of-the-art performance, outperforming both classical time-series models and few-shot GPT-4o by over 14.6% and 7.3% performance gain, respectively. Notably, TimeMaster goes beyond time-series classification: it also exhibits expert-like reasoning behavior, generates context-aware explanations, and delivers domain-aligned insights. Our results highlight that reward-driven RL can be a scalable and promising path toward integrating temporal understanding into time-series MLLMs.
논문 링크
Time-R1: LLM의 종합적 시간 추론을 향하여 / Time-R1: Towards Comprehensive Temporal Reasoning in LLMs
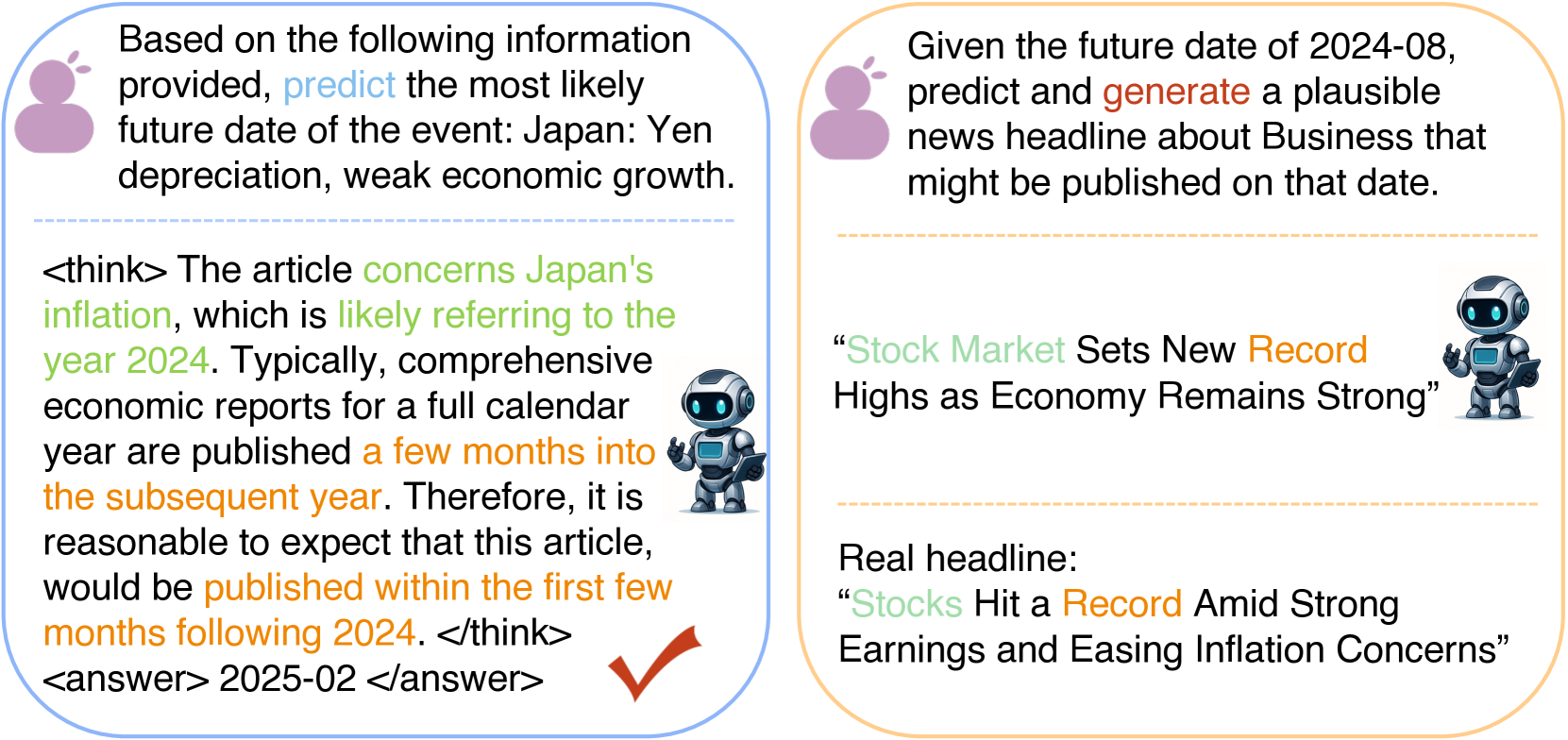
논문 소개
대형 언어 모델(LLM)은 뛰어난 성능에도 불구하고 과거 사건 이해와 미래 예측을 통합하는 시간적 추론 능력이 부족합니다. 기존 연구들은 주로 과거 질문응답이나 기본 예측 등 개별적 시간 기술에 집중하며, 지식 컷오프 이후 사건이나 창의적 예측에서는 일반화 성능이 저조합니다. 이에 본 연구는 강화학습(RL) 커리큘럼과 동적 규칙 기반 보상 체계를 활용해 중간 규모(30억 매개변수) LLM에 시간적 이해, 예측, 창의적 생성 능력을 단계적으로 부여하는 Time-R1 프레임워크를 제안합니다. 실험 결과, Time-R1은 6710억 매개변수의 최첨단 모델보다 뛰어난 미래 사건 예측 및 창의적 시나리오 생성 성능을 보이며, 효율적이고 확장 가능한 시간 인지 AI 개발 가능성을 제시합니다.
논문 초록(Abstract)
대형 언어 모델(LLM)은 뛰어난 능력을 보여주지만, 견고한 시간적 지능이 부족하여 과거에 대한 추론과 미래에 대한 예측 및 그럴듯한 생성물을 통합하는 데 어려움을 겪습니다. 반면, 기존 방법들은 주로 과거 사건에 대한 질문 응답이나 기본적인 예측과 같은 개별적인 시간적 기술에 초점을 맞추며, 특히 지식 컷오프 이후의 사건이나 창의적인 예견이 필요한 상황에서는 일반화 성능이 매우 저조합니다. 이러한 한계를 극복하기 위해, 본 연구에서는 중간 규모(30억 매개변수) LLM에 포괄적인 시간적 능력—이해, 예측, 창의적 생성—을 부여하는 최초의 프레임워크인 \textit{Time-R1}을 제안합니다. 본 접근법은 세 단계로 구성된 새로운 개발 경로를 특징으로 하며, 그중 처음 두 단계는 정교하게 설계된 동적 규칙 기반 보상 시스템에 의해 구동되는 \textit{강화 학습(RL) 커리큘럼}으로 구성됩니다. 이 프레임워크는 점진적으로 (1) 역사적 데이터로부터 기초적인 시간 이해와 논리적 사건-시간 매핑을 구축하고, (2) 지식 컷오프를 넘는 미래 사건 예측 능력을 습득하며, 마지막으로 (3) 어떠한 미세 조정 없이도 창의적인 미래 시나리오 생성에 대한 뛰어난 일반화를 가능하게 합니다. 특히, 실험 결과 Time-R1은 최첨단 6710억 매개변수 DeepSeek-R1을 포함하여 200배 이상 큰 모델들을 능가하는 성능을 매우 도전적인 미래 사건 예측 및 창의적 시나리오 생성 벤치마크에서 보여주었습니다. 본 연구는 신중하게 설계된 점진적 RL 미세 조정이 더 작고 효율적인 모델로 하여금 우수한 시간적 성능을 달성하게 함으로써, 진정한 시간 인지 AI를 향한 실용적이고 확장 가능한 경로를 제시한다는 강력한 증거를 제공합니다. 추가 연구를 촉진하기 위해, 10년간의 뉴스 데이터를 기반으로 한 대규모 다중 과제 시간 추론 데이터셋 \textit{Time-Bench}와 \textit{Time-R1} 체크포인트 시리즈도 함께 공개합니다.
Large Language Models (LLMs) demonstrate impressive capabilities but lack robust temporal intelligence, struggling to integrate reasoning about the past with predictions and plausible generations of the future. Meanwhile, existing methods typically target isolated temporal skills, such as question answering about past events or basic forecasting, and exhibit poor generalization, particularly when dealing with events beyond their knowledge cutoff or requiring creative foresight. To address these limitations, we introduce \textit{Time-R1}, the first framework to endow a moderate-sized (3B-parameter) LLM with comprehensive temporal abilities: understanding, prediction, and creative generation. Our approach features a novel three-stage development path; the first two constitute a \textit{reinforcement learning (RL) curriculum} driven by a meticulously designed dynamic rule-based reward system. This framework progressively builds (1) foundational temporal understanding and logical event-time mappings from historical data, (2) future event prediction skills for events beyond its knowledge cutoff, and finally (3) enables remarkable generalization to creative future scenario generation without any fine-tuning. Strikingly, experiments demonstrate that Time-R1 outperforms models over 200 times larger, including the state-of-the-art 671B DeepSeek-R1, on highly challenging future event prediction and creative scenario generation benchmarks. This work provides strong evidence that thoughtfully engineered, progressive RL fine-tuning allows smaller, efficient models to achieve superior temporal performance, offering a practical and scalable path towards truly time-aware AI. To foster further research, we also release \textit{Time-Bench}, a large-scale multi-task temporal reasoning dataset derived from 10 years of news data, and our series of \textit{Time-R1} checkpoints.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()