[2025/10/06 ~ 12] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 소규모 네트워크의 효율성: 최근 연구들은 소규모 신경망을 활용하여 대규모 언어 모델(LLM)보다 더 높은 성능을 달성하는 방법에 집중하고 있습니다. 예를 들어, Hierarchical Reasoning Model (HRM)과 Tiny Recursive Model (TRM)은 적은 파라미터 수로도 복잡한 문제를 해결할 수 있음을 보여주며, 이는 작은 모델이 큰 모델에 비해 효율성을 가질 수 있음을 시사합니다.
소규모 네트워크의 효율성: 최근 연구들은 소규모 신경망을 활용하여 대규모 언어 모델(LLM)보다 더 높은 성능을 달성하는 방법에 집중하고 있습니다. 예를 들어, Hierarchical Reasoning Model (HRM)과 Tiny Recursive Model (TRM)은 적은 파라미터 수로도 복잡한 문제를 해결할 수 있음을 보여주며, 이는 작은 모델이 큰 모델에 비해 효율성을 가질 수 있음을 시사합니다.
![]() 자동화된 학술 발표 비디오 생성: Paper2Video와 같은 연구는 연구 논문에서 자동으로 비디오를 생성하는 방법을 제안하고 있습니다. 이는 연구 결과를 보다 효과적으로 전달할 수 있는 새로운 매체를 제공하며, 발표 비디오 제작의 수고를 줄여주는 혁신적인 접근법으로 주목받고 있습니다.
자동화된 학술 발표 비디오 생성: Paper2Video와 같은 연구는 연구 논문에서 자동으로 비디오를 생성하는 방법을 제안하고 있습니다. 이는 연구 결과를 보다 효과적으로 전달할 수 있는 새로운 매체를 제공하며, 발표 비디오 제작의 수고를 줄여주는 혁신적인 접근법으로 주목받고 있습니다.
![]() 다중 에이전트 시스템의 최적화: Multi-Agent Tool-Integrated Policy Optimization (MATPO)와 같은 연구는 다중 에이전트 시스템을 통해 복잡한 작업을 효율적으로 수행하는 방법을 탐구하고 있습니다. 이러한 접근은 여러 역할을 가진 에이전트를 통합하여 성능을 향상시키고, 노이즈에 강한 시스템을 구축하는 데 기여하고 있습니다.
다중 에이전트 시스템의 최적화: Multi-Agent Tool-Integrated Policy Optimization (MATPO)와 같은 연구는 다중 에이전트 시스템을 통해 복잡한 작업을 효율적으로 수행하는 방법을 탐구하고 있습니다. 이러한 접근은 여러 역할을 가진 에이전트를 통합하여 성능을 향상시키고, 노이즈에 강한 시스템을 구축하는 데 기여하고 있습니다.
적은 것이 더 많은 것(TRM): 소규모 네트워크를 통한 재귀적 추론 / Less is More: Recursive Reasoning with Tiny Networks
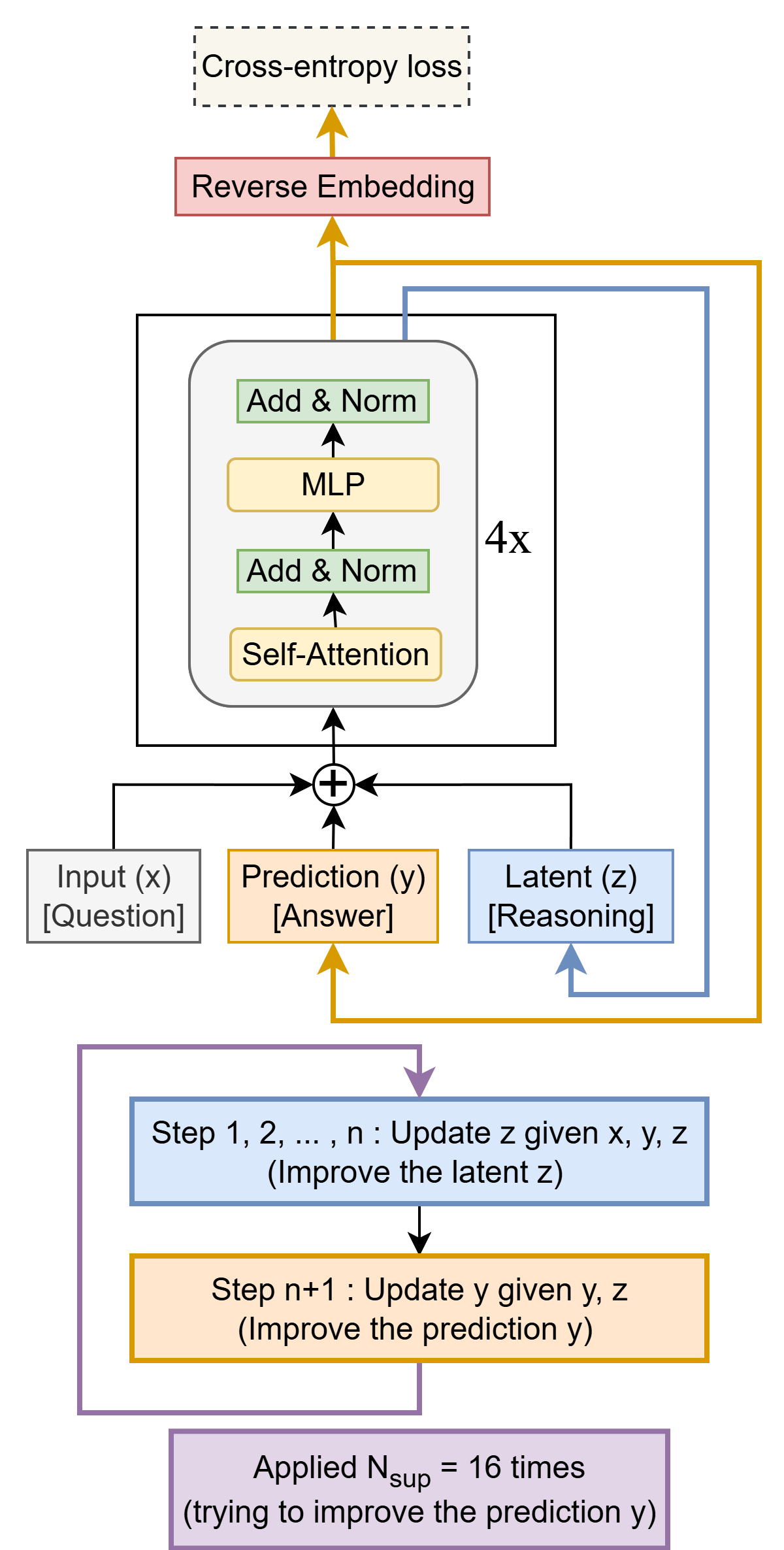
논문 소개
계층적 추론 모델(Hierarchical Reasoning Model, HRM)은 두 개의 작은 신경망을 서로 다른 주기로 재귀적으로 활용하여 복잡한 문제를 해결하는 혁신적인 접근 방식이다. 이 모델은 생물학적 영감을 받아 설계되었으며, 스도쿠, 미로, ARC-AGI와 같은 어려운 퍼즐 작업에서 대규모 언어 모델(Large Language Models, LLM)보다 뛰어난 성능을 보인다. HRM은 27M 파라미터의 작은 모델과 약 1000개의 예시로 학습되었음에도 불구하고 이러한 성과를 달성하였다. 그러나 HRM의 구조와 동작 방식은 복잡하여 최적화가 어려운 한계가 있다.
이러한 문제를 해결하기 위해 제안된 작은 재귀 모델(Tiny Recursive Model, TRM)은 단일 네트워크로 구성되어 있으며, 단 7M 파라미터로도 높은 일반화 성능을 발휘한다. TRM은 두 개의 주요 함수인 latent_recursion과 deep_recursion을 통해 재귀적 추론을 수행하며, 이 과정에서 입력값과 이전 단계의 결과를 기반으로 새로운 출력을 생성한다. 특히, TRM은 ARC-AGI-1에서 45%의 테스트 정확도를, ARC-AGI-2에서 8%의 정확도를 기록하며, 이는 대부분의 LLM보다 현저히 높은 성과이다.
TRM의 구조는 단순하지만 효과적이며, 복잡한 문제를 해결하는 데 있어 작은 모델의 잠재력을 극대화한다. 이 연구는 작은 신경망을 활용한 재귀적 추론의 가능성을 제시하며, 향후 AI 모델의 설계 및 최적화에 중요한 기여를 할 것으로 기대된다. TRM은 HRM보다 더 높은 성능을 보여주며, 향후 연구에서는 TRM의 구조를 더욱 최적화하고 다양한 문제에 적용할 수 있는 가능성을 탐색할 필요가 있다. 이러한 혁신적인 접근 방식은 인공지능 분야에서의 새로운 연구 방향을 제시하며, 작은 네트워크가 복잡한 문제를 해결할 수 있는 가능성을 보여준다.
논문 초록(Abstract)
계층적 추론 모델(HRM)은 서로 다른 주파수로 재귀하는 두 개의 작은 신경망을 사용하는 새로운 접근 방식입니다. 이 생물학적으로 영감을 받은 방법은 스도쿠, 미로, ARC-AGI와 같은 어려운 퍼즐 작업에서 대규모 언어 모델(LLM)을 능가하며, 작은 데이터(약 1000개의 예제)에서 작은 모델(27M 파라미터)로 학습되었습니다. HRM은 작은 네트워크로 어려운 문제를 해결하는 데 큰 가능성을 지니고 있지만, 아직 잘 이해되지 않으며 최적이 아닐 수 있습니다. 우리는 Tiny Recursive Model(TRM)을 제안하는데, 이는 단일 작은 네트워크(단 2개의 레이어)를 사용하여 HRM보다 훨씬 더 높은 일반화를 달성하는 훨씬 간단한 재귀적 추론 접근 방식입니다. TRM은 7M 파라미터만으로 ARC-AGI-1에서 45%의 테스트 정확도, ARC-AGI-2에서 8%를 달성하며, 이는 0.01% 미만의 파라미터를 가진 대부분의 LLM(예: Deepseek R1, o3-mini, Gemini 2.5 Pro)보다 높습니다.
Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on hard puzzle tasks such as Sudoku, Maze, and ARC-AGI while trained with small models (27M parameters) on small data (around 1000 examples). HRM holds great promise for solving hard problems with small networks, but it is not yet well understood and may be suboptimal. We propose Tiny Recursive Model (TRM), a much simpler recursive reasoning approach that achieves significantly higher generalization than HRM, while using a single tiny network with only 2 layers. With only 7M parameters, TRM obtains 45% test-accuracy on ARC-AGI-1 and 8% on ARC-AGI-2, higher than most LLMs (e.g., Deepseek R1, o3-mini, Gemini 2.5 Pro) with less than 0.01% of the parameters.
논문 링크
더 읽어보기
Paper2Video: 과학 논문으로부터 자동 비디오 생성 / Paper2Video: Automatic Video Generation from Scientific Papers

논문 소개
학술 발표 비디오 생성의 자동화는 연구 결과를 효과적으로 전달하는 데 필수적인 요소로 자리 잡고 있다. 그러나 기존의 비디오 제작 과정은 슬라이드 디자인, 자막 작성, 음성 녹음 및 편집 등 여러 단계를 포함하여 매우 노동 집약적이다. 이러한 문제를 해결하기 위해 제안된 Paper2Video 시스템은 101개의 연구 논문과 그에 따른 발표 비디오, 슬라이드, 발표자 메타데이터를 포함하는 첫 번째 벤치마크를 구축하였다. 이 벤치마크는 발표 비디오가 논문의 정보를 얼마나 잘 전달하는지를 평가하기 위한 네 가지 맞춤형 메트릭인 Meta Similarity, PresentArena, PresentQuiz, IP Memory를 통해 생성 품질을 측정하는 데 기여한다.
PaperTalker라는 다중 에이전트 프레임워크는 슬라이드 생성, 레이아웃 개선, 자막 생성, 음성 합성 및 발표자 비디오 렌더링을 통합하여 학술 발표 비디오 생성을 가능하게 한다. 이 프레임워크는 LaTeX 코드를 활용하여 슬라이드를 생성하고, 커서와 자막 간의 정렬을 통해 정보 전달의 정확성을 높인다. 또한, 슬라이드 간의 생성을 병렬화하여 효율성을 극대화한다. 실험 결과, PaperTalker로 생성된 발표 비디오는 기존의 방법보다 더 충실하고 정보가 풍부하다는 것을 입증하였다.
이 연구는 자동화된 학술 비디오 생성의 실질적인 진전을 이루었으며, 연구 커뮤니티에 공개된 데이터는 향후 연구 촉진에 기여할 것으로 기대된다. Paper2Video와 PaperTalker는 학술 발표 비디오 생성의 새로운 기준을 제시하며, 연구자들이 보다 효과적으로 연구 결과를 전달할 수 있는 기반을 마련하였다.
논문 초록(Abstract)
학술 발표 비디오는 연구 커뮤니케이션을 위한 필수 매체가 되었지만, 이를 제작하는 것은 여전히 매우 노동 집약적이며, 짧은 2~10분의 비디오를 위해 슬라이드 디자인, 녹화 및 편집에 수시간이 소요되는 경우가 많습니다. 자연 비디오와 달리, 발표 비디오 생성은 연구 논문에서의 입력, 밀집된 멀티모달 정보(텍스트, 그림, 표), 슬라이드, 자막, 음성 및 인간 화자와 같은 여러 정렬된 채널을 조정해야 하는 독특한 도전 과제를 포함합니다. 이러한 도전 과제를 해결하기 위해, 우리는 저자가 만든 발표 비디오, 슬라이드 및 발표자 메타데이터와 쌍을 이루는 101개의 연구 논문의 첫 번째 벤치마크인 Paper2Video를 소개합니다. 우리는 또한 비디오가 논문의 정보를 청중에게 전달하는 방식을 측정하기 위해 네 가지 맞춤형 평가 지표인 메타 유사성(Meta Similarity), 프레젠트 아레나(PresentArena), 프레젠트 퀴즈(PresentQuiz), 그리고 IP 메모리(IP Memory)를 설계했습니다. 이 기초 위에, 우리는 학술 발표 비디오 생성을 위한 첫 번째 다중 에이전트 프레임워크인 PaperTalker를 제안합니다. 이는 슬라이드 생성을 효과적인 레이아웃 개선과 통합하며, 새로운 효과적인 트리 검색 시각적 선택, 커서 그라운딩, 자막 생성, 음성 합성 및 토킹 헤드 렌더링을 통해 슬라이드별 생성을 병렬화하여 효율성을 높입니다. Paper2Video에 대한 실험 결과, 우리의 접근 방식으로 생성된 발표 비디오는 기존 기준보다 더 충실하고 유익함을 입증하며, 자동화된 사용 준비가 완료된 학술 비디오 생성으로 나아가는 실질적인 단계를 확립합니다. 우리의 데이터셋, 에이전트 및 코드는 GitHub - showlab/Paper2Video: Automatic Video Generation from Scientific Papers 에서 이용 가능합니다.
Academic presentation videos have become an essential medium for research communication, yet producing them remains highly labor-intensive, often requiring hours of slide design, recording, and editing for a short 2 to 10 minutes video. Unlike natural video, presentation video generation involves distinctive challenges: inputs from research papers, dense multi-modal information (text, figures, tables), and the need to coordinate multiple aligned channels such as slides, subtitles, speech, and human talker. To address these challenges, we introduce Paper2Video, the first benchmark of 101 research papers paired with author-created presentation videos, slides, and speaker metadata. We further design four tailored evaluation metrics--Meta Similarity, PresentArena, PresentQuiz, and IP Memory--to measure how videos convey the paper's information to the audience. Building on this foundation, we propose PaperTalker, the first multi-agent framework for academic presentation video generation. It integrates slide generation with effective layout refinement by a novel effective tree search visual choice, cursor grounding, subtitling, speech synthesis, and talking-head rendering, while parallelizing slide-wise generation for efficiency. Experiments on Paper2Video demonstrate that the presentation videos produced by our approach are more faithful and informative than existing baselines, establishing a practical step toward automated and ready-to-use academic video generation. Our dataset, agent, and code are available at GitHub - showlab/Paper2Video: Automatic Video Generation from Scientific Papers.
논문 링크
더 읽어보기
코랄 프로토콜: 에이전트 인터넷을 연결하는 개방형 인프라 / Coral Protocol: Open Infrastructure Connecting The Internet of Agents
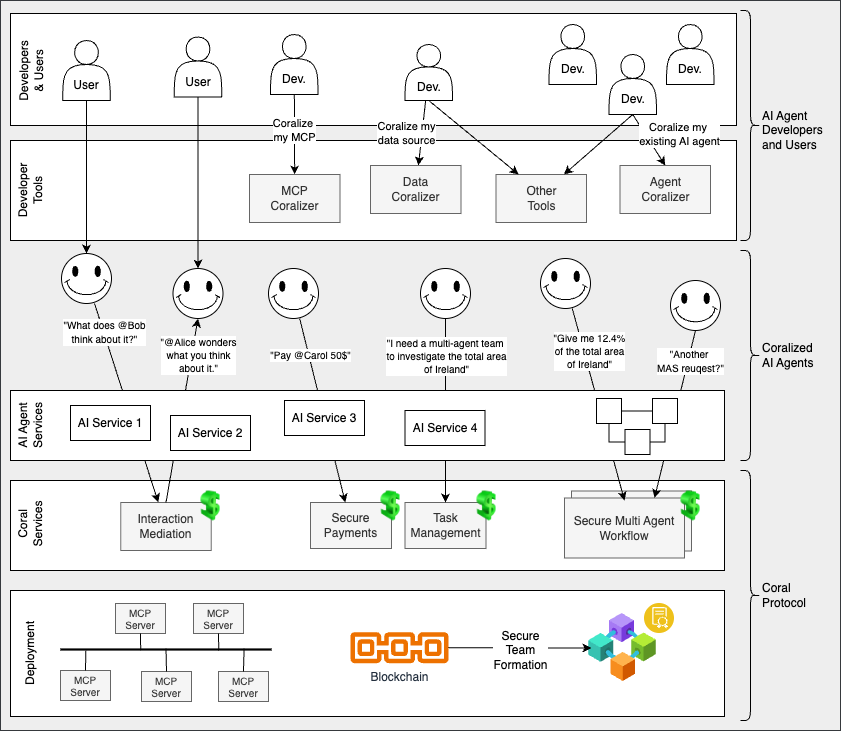
논문 소개
Coral Protocol은 개방적이고 분산된 협력 인프라로, 다양한 AI 에이전트 간의 통신, 조정, 신뢰 및 결제를 가능하게 한다. 이 프로토콜은 여러 전문 AI 에이전트를 배포하는 조직들이 서로 다른 도메인과 공급업체 간에 협력할 수 있도록 하는 상호 운용성의 필요성을 해결하고자 한다. Coral은 다중 에이전트 AI 생태계를 위한 기본 플랫폼으로서, 모든 에이전트가 복잡한 워크플로우에 참여할 수 있도록 공통 언어와 조정 프레임워크를 구축한다. 이 설계는 광범위한 호환성, 보안 및 공급업체 중립성을 강조하여, 에이전트 간의 상호작용이 효율적이고 신뢰할 수 있도록 한다.
Coral Protocol의 주요 혁신은 표준화된 메시지 형식, 모듈식 조정 메커니즘, 그리고 신뢰할 수 있는 에이전트 그룹을 동적으로 구성할 수 있는 보안 팀 형성 기능이다. 표준화된 메시지 형식은 JSON 기반으로 설계되어 있어 기존의 웹 표준과 호환되며, 다양한 에이전트가 서로의 의도를 이해하고 협력할 수 있도록 지원한다. 모듈식 조정 메커니즘은 에이전트가 서로의 작업을 효율적으로 조정하고 복잡한 작업을 관리할 수 있도록 돕는다. 또한, 보안 팀 형성 기능은 에이전트 간의 신뢰를 구축하고 안전한 협업을 가능하게 한다.
이러한 접근 방식은 기존의 임시 통합 및 오래된 접근 방식의 한계를 극복하고, 에이전트 간의 효율적인 협업을 통해 새로운 비즈니스 가치를 창출할 수 있는 잠재력을 가지고 있다. Coral Protocol은 다중 에이전트 협업의 초석으로 자리매김할 가능성을 제시하며, 향후 연구와 개발을 위한 방향성을 제시한다. 이 프로토콜은 "인터넷 에이전트"의 발전에 기여하며, 집단 지능과 자동화의 새로운 수준을 열어가는 데 중요한 역할을 할 것으로 기대된다.
논문 초록(Abstract)
코랄 프로토콜(Coral Protocol)은 에이전트의 인터넷(The Internet of Agents)을 위한 통신, 조정, 신뢰 및 결제를 가능하게 하는 개방형 분산 협업 인프라입니다. 이는 여러 전문화된 AI 에이전트를 배치하는 조직들이 서로 다른 도메인과 공급업체 간에 협력해야 하는 세계에서 상호 운용성에 대한 증가하는 필요를 해결합니다. 코랄은 다중 에이전트 AI 생태계를 위한 기본 플랫폼으로서, 모든 에이전트가 다른 에이전트와 복잡한 작업 흐름에 참여할 수 있도록 공통 언어와 조정 프레임워크를 설정합니다. 그 설계는 광범위한 호환성, 보안 및 공급업체 중립성을 강조하여 에이전트 간의 상호작용이 효율적이고 신뢰할 수 있도록 보장합니다. 특히, 코랄은 에이전트 통신을 위한 표준화된 메시지 형식, 다중 에이전트 작업을 조정하기 위한 모듈식 조정 메커니즘, 신뢰할 수 있는 에이전트 그룹을 동적으로 구성하기 위한 안전한 팀 형성 기능을 도입합니다. 이러한 혁신들은 코랄 프로토콜을 떠오르는 "에이전트의 인터넷"의 초석으로 자리매김하게 하여, 개방형 에이전트 협업을 통해 새로운 수준의 자동화, 집단 지능 및 비즈니스 가치를 열어줍니다.
Coral Protocol is an open and decentralized collaboration infrastructure that enables communication, coordination, trust and payments for The Internet of Agents. It addresses the growing need for interoperability in a world where organizations are deploying multiple specialized AI agents that must work together across domains and vendors. As a foundational platform for multi-agent AI ecosystems, Coral establishes a common language and coordination framework allowing any agent to participate in complex workflows with others. Its design emphasizes broad compatibility, security, and vendor neutrality, ensuring that agent interactions are efficient and trustworthy. In particular, Coral introduces standardized messaging formats for agent communication, a modular coordination mechanism for orchestrating multi-agent tasks, and secure team formation capabilities for dynamically assembling trusted groups of agents. Together, these innovations position Coral Protocol as a cornerstone of the emerging "Internet of Agents," unlocking new levels of automation, collective intelligence, and business value through open agent collaboration.
논문 링크
AgentFlow: 효율적인 계획 및 도구 사용을 위한 흐름 내 에이전틱 시스템 최적화 / In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
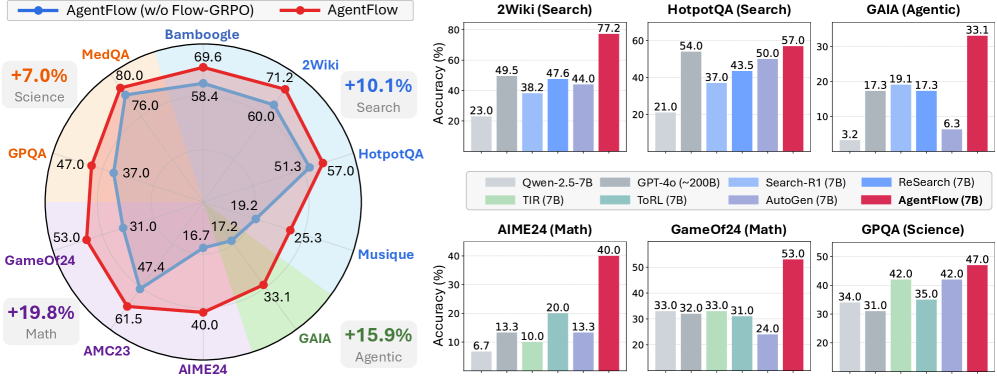
논문 소개
결과 기반 강화학습(Outcome-driven Reinforcement Learning)은 대규모 언어 모델(LLM)의 추론 능력을 크게 향상시켰으나, 기존의 도구 보강 접근 방식은 단일 정책을 훈련하여 사고와 도구 호출을 전체 맥락에서 교차시키는 방식으로 작동합니다. 이러한 접근은 긴 수명과 다양한 도구에 대한 확장성이 떨어지고, 새로운 시나리오에 대한 일반화가 약하다는 문제를 안고 있습니다. 이에 대한 대안으로 제안된 에이전틱 시스템(Agentic Systems)은 전문화된 모듈 간의 작업 분해를 통해 문제를 해결할 수 있는 가능성을 보여줍니다. 그러나 기존의 많은 시스템은 훈련이 없거나 오프라인 훈련에 의존하여 실시간 상호작용의 역학을 반영하지 못하고 있습니다.
본 논문에서는 AgentFlow라는 학습 가능한 인-더-플로우(In-the-Flow) 에이전틱 프레임워크를 소개합니다. AgentFlow는 네 개의 모듈(계획자, 실행자, 검증자, 생성기)을 통해 다중 턴 루프 내에서 상호작용하며, 진화하는 메모리를 활용하여 각 모듈의 협력을 극대화합니다. 특히, Flow 기반 그룹 정제 정책 최적화(Flow-GRPO) 방법론을 통해 실시간 환경에서 정책을 훈련할 수 있도록 설계되었습니다. 이 방법은 긴 수명과 희소 보상 문제를 해결하기 위해 다중 턴 최적화를 단일 턴 정책 업데이트로 변환하여, 각 턴에서 단일의 검증 가능한 결과를 방송함으로써 지역 계획자 결정과 글로벌 성공을 정렬합니다.
AgentFlow는 10개의 벤치마크에서 평가되었으며, 7B 규모의 백본을 활용하여 기존의 최상위 모델들을 초월하는 성과를 보여주었습니다. 평균적으로 검색, 에이전틱, 수학적, 과학적 작업에서 각각 14.9%, 14.0%, 14.5%, 4.1%의 정확도 향상을 달성하였으며, 이는 GPT-4o와 같은 대형 모델을 초과하는 결과입니다. 이러한 성과는 인-더-플로우 최적화의 중요성을 강조하며, 계획, 도구 호출 신뢰성, 모델 크기 및 추론 턴에 대한 긍정적인 확장을 보여줍니다. AgentFlow의 접근 방식은 기존의 도구 통합 강화학습 방법에 비해 더 효과적이며, 실시간 환경에서의 학습과 적응을 가능하게 합니다.
논문 초록(Abstract)
결과 중심 강화학습은 대규모 언어 모델(LLM)에서의 추론을 발전시켰지만, 기존의 도구 증강 접근 방식은 전체 맥락에서 생각과 도구 호출을 혼합하는 단일한 단일 정책을 훈련시키며, 이는 긴 수명과 다양한 도구에 대해 잘 확장되지 않고 새로운 시나리오에 대한 일반화가 약하다. 에이전트 시스템은 전문화된 모듈 간에 작업을 분해함으로써 유망한 대안을 제공하지만, 대부분은 훈련이 없거나 다중 턴 상호작용의 실시간 역학과 분리된 오프라인 훈련에 의존한다. 우리는 네 개의 모듈(계획자, 실행자, 검증자, 생성기)을 진화하는 메모리를 통해 조정하고 다중 턴 루프 내에서 계획자를 직접 최적화하는 훈련 가능한 흐름 기반 에이전트 프레임워크인 AgentFlow를 소개한다. 실시간 환경에서 정책을 훈련하기 위해, 우리는 다중 턴 최적화를 일련의 처리 가능한 단일 턴 정책 업데이트로 변환하여 긴 수명, 희소 보상 신용 할당 문제를 해결하는 흐름 기반 그룹 정제 정책 최적화(Flow-GRPO)를 제안한다. 이는 모든 턴에 대해 단일하고 검증 가능한 경로 수준 결과를 방송하여 지역 계획자 결정을 전 세계적 성공과 일치시키고 그룹 정규화된 이점을 통해 학습을 안정화한다. 10개의 벤치마크에서 7B 규모의 백본을 가진 AgentFlow는 검색에서 평균 14.9%, 에이전트 작업에서 14.0%, 수학 작업에서 14.5%, 과학 작업에서 4.1%의 정확도 향상을 보이며, GPT-4o와 같은 더 큰 독점 모델을 초월하는 성능을 발휘한다. 추가 분석은 흐름 내 최적화의 이점을 확인하며, 계획 개선, 도구 호출 신뢰성 향상, 모델 크기 및 추론 턴에 따른 긍정적인 확장을 보여준다.
Outcome-driven reinforcement learning has advanced reasoning in large language models (LLMs), but prevailing tool-augmented approaches train a single, monolithic policy that interleaves thoughts and tool calls under full context; this scales poorly with long horizons and diverse tools and generalizes weakly to new scenarios. Agentic systems offer a promising alternative by decomposing work across specialized modules, yet most remain training-free or rely on offline training decoupled from the live dynamics of multi-turn interaction. We introduce AgentFlow, a trainable, in-the-flow agentic framework that coordinates four modules (planner, executor, verifier, generator) through an evolving memory and directly optimizes its planner inside the multi-turn loop. To train on-policy in live environments, we propose Flow-based Group Refined Policy Optimization (Flow-GRPO), which tackles long-horizon, sparse-reward credit assignment by converting multi-turn optimization into a sequence of tractable single-turn policy updates. It broadcasts a single, verifiable trajectory-level outcome to every turn to align local planner decisions with global success and stabilizes learning with group-normalized advantages. Across ten benchmarks, AgentFlow with a 7B-scale backbone outperforms top-performing baselines with average accuracy gains of 14.9% on search, 14.0% on agentic, 14.5% on mathematical, and 4.1% on scientific tasks, even surpassing larger proprietary models like GPT-4o. Further analyses confirm the benefits of in-the-flow optimization, showing improved planning, enhanced tool-calling reliability, and positive scaling with model size and reasoning turns.
논문 링크
더 읽어보기
https://github.com/lupantech/AgentFlow

MATPO: 다중 에이전트 도구 통합 정책 최적화 / Multi-Agent Tool-Integrated Policy Optimization
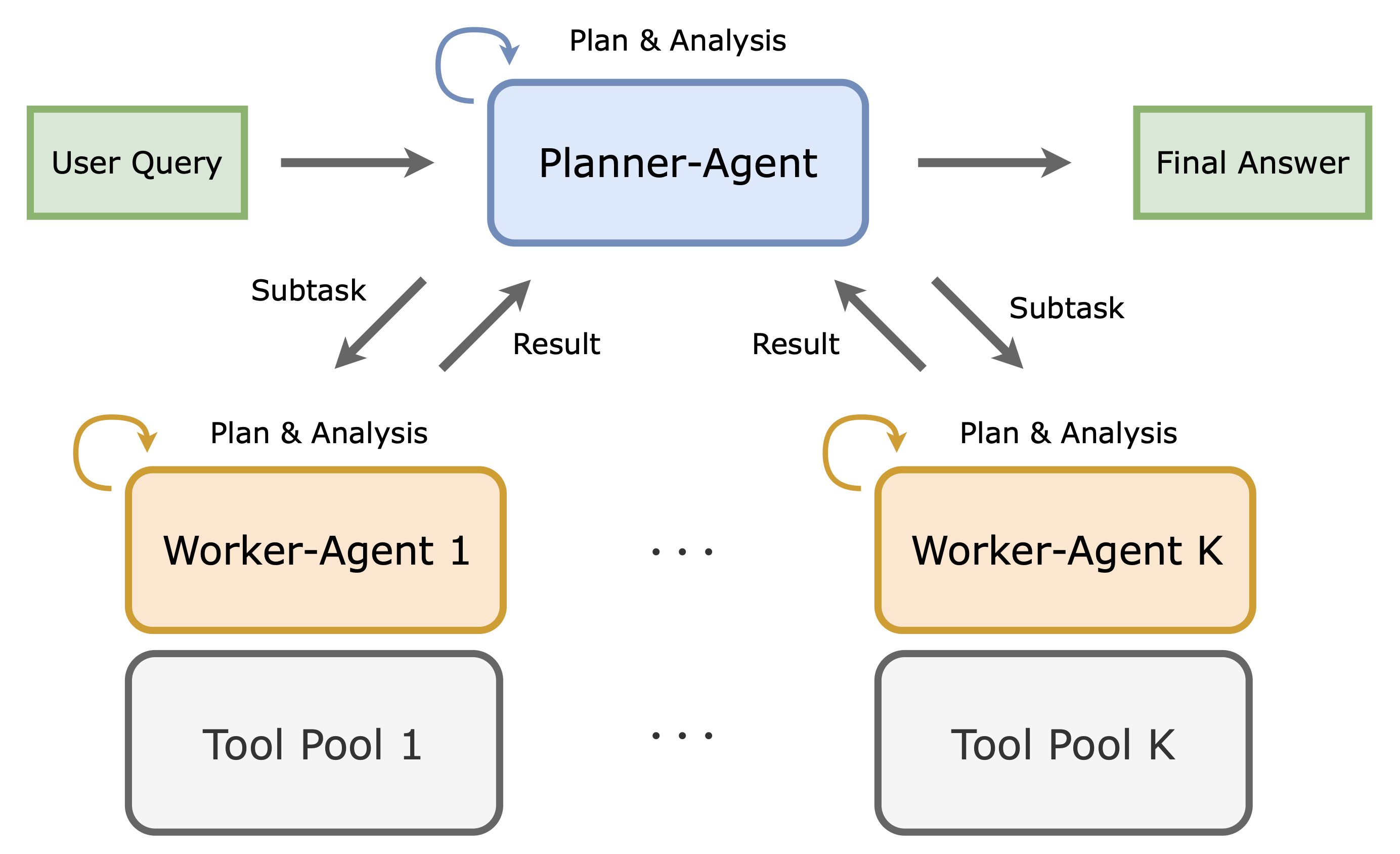
논문 소개
대규모 언어 모델(LLM)의 발전은 복잡한 추론 작업을 수행하기 위한 도구 통합 접근 방식의 필요성을 더욱 부각시키고 있습니다. 그러나 기존의 단일 에이전트 시스템은 제한된 맥락 길이와 노이즈가 많은 도구 응답으로 인해 성능이 저하되는 문제를 겪고 있습니다. 이러한 문제를 해결하기 위해 제안된 Multi-Agent Tool-Integrated Policy Optimization (MATPO) 방법론은 계획자(Planner)와 작업자(Worker) 역할을 가진 다중 에이전트 프레임워크를 활용합니다. MATPO는 단일 LLM 인스턴스 내에서 역할별 프롬프트를 통해 두 가지 역할을 훈련시키며, 이 과정에서 강화학습(Reinforcement Learning)을 적용하여 각 역할의 성능을 최적화합니다.
MATPO의 혁신적인 점은 원칙적인 신용 할당 메커니즘을 통해 계획자와 작업자의 행동이 전체 성과에 어떻게 기여하는지를 명확히 할 수 있다는 것입니다. 이는 메모리 효율성을 높이고, 여러 LLM을 배포할 필요성을 없애면서도 전문화의 이점을 유지하는 데 기여합니다. 실험 결과, GAIA-text, WebWalkerQA, FRAMES 데이터셋에서 MATPO는 단일 에이전트 기준선에 비해 평균 18.38%의 성능 향상을 보였으며, 노이즈가 많은 도구 출력에 대한 강건성을 입증했습니다.
이 연구는 단일 LLM 내에서 여러 에이전트 역할을 통합하는 방법이 다중 에이전트 시스템의 효율성을 크게 향상시킬 수 있음을 보여줍니다. MATPO는 안정적이고 효율적인 다중 에이전트 강화학습 훈련을 위한 실용적인 통찰을 제공하며, 향후 연구 방향에 대한 중요한 기초를 마련합니다. 이러한 기여는 LLM의 활용 가능성을 더욱 넓히고, 복잡한 문제 해결을 위한 새로운 접근 방식을 제시하는 데 중요한 역할을 할 것입니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 지식 집약적이고 복잡한 추론 작업을 위해 다중 턴 도구 통합 계획에 점점 더 의존하고 있습니다. 기존 구현은 일반적으로 단일 에이전트에 의존하지만, 제한된 맥락 길이와 잡음이 섞인 도구 응답으로 인해 어려움을 겪고 있습니다. 자연스러운 해결책은 맥락을 관리하기 위해 계획자 및 작업자 에이전트를 갖춘 다중 에이전트 프레임워크를 채택하는 것입니다. 그러나 기존 방법은 도구 통합 다중 에이전트 프레임워크의 효과적인 강화학습 사후 학습을 지원하지 않습니다. 이 격차를 해소하기 위해, 우리는 다중 에이전트 도구 통합 정책 최적화(MATPO)를 제안합니다. MATPO는 역할별 프롬프트를 통해 단일 LLM 인스턴스 내에서 계획자와 작업자라는 구별된 역할을 강화학습을 통해 훈련할 수 있게 합니다. MATPO는 계획자와 작업자 롤아웃 간의 원칙적인 신용 할당 메커니즘에서 파생됩니다. 이 설계는 메모리 집약적인 여러 LLM을 배포할 필요성을 없애면서 전문화의 이점을 유지합니다. GAIA-text, WebWalkerQA, FRAMES에 대한 실험 결과, MATPO는 성능에서 평균 18.38%의 상대적 향상을 보이며 단일 에이전트 기준선보다 일관되게 우수한 성능을 발휘하고, 잡음이 섞인 도구 출력에 대한 강인성을 보여줍니다. 우리의 연구 결과는 단일 LLM 내에서 여러 에이전트 역할을 통합하는 효과성을 강조하며, 안정적이고 효율적인 다중 에이전트 강화학습 훈련을 위한 실용적인 통찰을 제공합니다.
Large language models (LLMs) increasingly rely on multi-turn tool-integrated planning for knowledge-intensive and complex reasoning tasks. Existing implementations typically rely on a single agent, but they suffer from limited context length and noisy tool responses. A natural solution is to adopt a multi-agent framework with planner- and worker-agents to manage context. However, no existing methods support effective reinforcement learning post-training of tool-integrated multi-agent frameworks. To address this gap, we propose Multi-Agent Tool-Integrated Policy Optimization (MATPO), which enables distinct roles (planner and worker) to be trained within a single LLM instance using role-specific prompts via reinforcement learning. MATPO is derived from a principled credit assignment mechanism across planner and worker rollouts. This design eliminates the need to deploy multiple LLMs, which would be memory-intensive, while preserving the benefits of specialization. Experiments on GAIA-text, WebWalkerQA, and FRAMES show that MATPO consistently outperforms single-agent baselines by an average of 18.38% relative improvement in performance and exhibits greater robustness to noisy tool outputs. Our findings highlight the effectiveness of unifying multiple agent roles within a single LLM and provide practical insights for stable and efficient multi-agent RL training.
논문 링크
더 읽어보기
OpenTSLM: 다변량 의료 텍스트 및 시계열 데이터에 대한 추론을 위한 시계열 언어 모델 / OpenTSLM: Time-Series Language Models for Reasoning over Multivariate Medical Text- and Time-Series Data
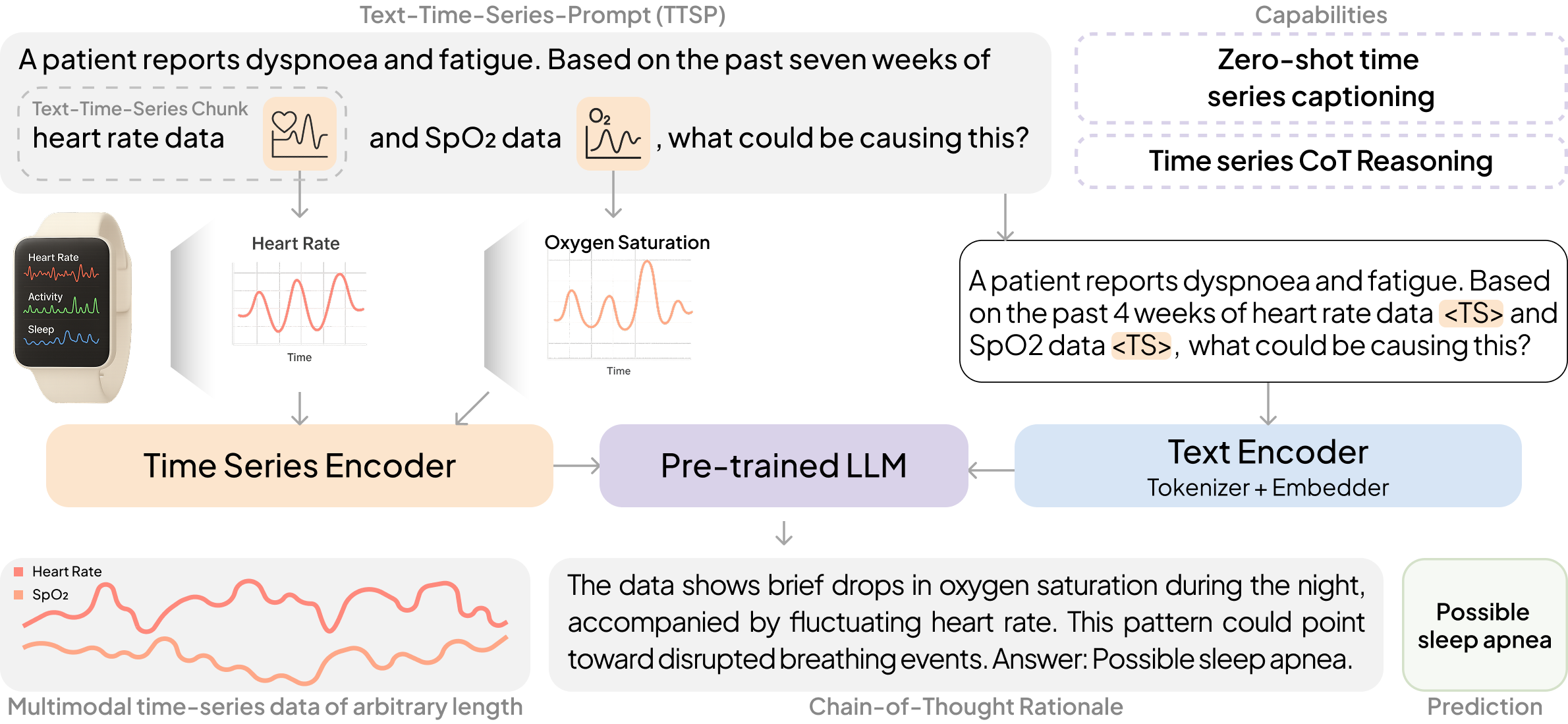
논문 소개
OpenTSLM(Time Series Language Model)은 다변량 의료 텍스트 및 시간 시계열 데이터에 대한 추론을 가능하게 하는 혁신적인 모델로, 기존의 대규모 언어 모델(LLM)의 한계를 극복하기 위해 개발되었습니다. LLM은 멀티모달 데이터를 해석하는 데 강력한 도구로 자리잡았지만, 시간 시계열 데이터를 효과적으로 처리하는 데는 부족함이 있었습니다. OpenTSLM은 이러한 필요를 충족하기 위해 사전 학습된 LLM에 시간 시계열을 기본 모달리티로 통합하여, 다양한 길이의 시간 시계열을 처리할 수 있도록 설계되었습니다.
본 연구에서는 OpenTSLM의 두 가지 아키텍처, 즉 OpenTSLM-SoftPrompt와 OpenTSLM-Flamingo를 제안합니다. OpenTSLM-SoftPrompt는 학습 가능한 시간 시계열 토큰을 텍스트 토큰과 연결하여 시간 시계열을 암묵적으로 모델링합니다. 반면, OpenTSLM-Flamingo는 교차 어텐션(cross-attention)을 활용하여 시간 시계열과 텍스트를 명시적으로 통합함으로써 더 나은 성능을 기대할 수 있습니다. 이러한 두 가지 접근 방식은 시간 시계열을 텍스트 토큰이나 플롯으로 처리하는 기존 기준선과 비교하여 평가되었습니다.
연구에서는 세 가지 데이터셋인 HAR-CoT, Sleep-CoT, ECG-QA-CoT를 도입하여 OpenTSLM 모델의 성능을 평가하였습니다. 실험 결과, OpenTSLM 모델은 모든 기준선보다 우수한 성능을 보였으며, 특히 수면 단계에서 69.9의 F1 점수, HAR에서 65.4를 기록하여 텍스트 전용 모델에 비해 현저히 높은 성능을 나타냈습니다. 또한, 10억 개의 파라미터를 가진 OpenTSLM 모델이 GPT-4o를 초과하는 성능을 보여주었으며, OpenTSLM-Flamingo는 긴 시퀀스에서 더 나은 성능을 발휘하면서도 메모리 요구 사항이 효율적임을 입증하였습니다.
임상 전문가의 리뷰에 따르면, OpenTSLM은 ECG-QA에서 강력한 추론 능력을 보여주었으며, 이를 통해 의료 분야에서의 데이터 해석 능력을 향상시키는 데 기여할 수 있는 잠재력을 지니고 있습니다. 연구 결과는 오픈 소스로 제공되어, 향후 연구에 기여할 수 있는 기반을 마련하고 있습니다. OpenTSLM은 LLM과 시간 시계열 데이터의 통합을 통해 새로운 가능성을 제시하며, 의료 데이터 해석의 새로운 패러다임을 열어갈 것으로 기대됩니다.
논문 초록(Abstract)
대규모 언어 모델(LLMs)은 멀티모달 데이터를 해석하는 강력한 도구로 부상하였습니다. 의학 분야에서 이들은 대량의 임상 정보를 실행 가능한 통찰력과 디지털 건강 응용 프로그램으로 통합하는 데 특히 유망합니다. 그러나 시간 시계열을 처리할 수 없는 주요 한계가 여전히 존재합니다. 이러한 격차를 극복하기 위해, 우리는 사전 학습된 LLM에 시간 시계열을 기본 모달리티로 통합하여 여러 길이의 시간 시계열에 대한 추론을 가능하게 하는 시간 시계열 언어 모델(Time Series Language Models, TSLMs)인 OpenTSLM을 제시합니다. OpenTSLM을 위한 두 가지 아키텍처를 조사합니다. 첫 번째인 OpenTSLM-SoftPrompt는 학습 가능한 시간 시계열 토큰을 텍스트 토큰과 소프트 프롬프트를 통해 연결하여 시간 시계열을 암묵적으로 모델링합니다. 파라미터 효율적이지만, 우리는 명시적인 시간 시계열 모델링이 더 나은 확장성과 성능을 발휘할 것이라고 가설을 세웁니다. 따라서 우리는 시간 시계열과 텍스트를 교차 어텐션을 통해 통합하는 OpenTSLM-Flamingo를 소개합니다. 우리는 시간 시계열을 텍스트 토큰이나 플롯으로 취급하는 기준선과 함께 텍스트-시간 시계열 사고의 연쇄(Chain-of-Thought, CoT) 추론 작업의 모음에서 두 가지 변형을 벤치마크합니다. 세 가지 데이터셋인 HAR-CoT, Sleep-CoT, ECG-QA-CoT를 소개합니다. 모든 데이터셋에서 OpenTSLM 모델은 기준선을 초과하여 수면 단계에서 69.9 F1, HAR에서 65.4를 기록하며, 이는 텍스트 전용 모델의 9.05 및 52.2와 비교됩니다. 특히, 10억 파라미터의 OpenTSLM 모델조차도 GPT-4o를 초과합니다(15.47 및 2.95). OpenTSLM-Flamingo는 성능 면에서 OpenTSLM-SoftPrompt와 동등하며, 더 긴 시퀀스에서 우수한 성능을 발휘하면서도 안정적인 메모리 요구 사항을 유지합니다. 반면, SoftPrompt는 시퀀스 길이에 따라 메모리가 기하급수적으로 증가하여 LLaMA-3B로 ECG-QA를 훈련할 때 약 110GB의 VRAM을 요구하는 반면 40GB에 불과합니다. 임상 전문가의 리뷰에 따르면 OpenTSLM은 ECG-QA에서 강력한 추론 능력을 보여줍니다. 추가 연구를 촉진하기 위해 모든 코드, 데이터셋 및 모델을 오픈 소스로 제공합니다.
LLMs have emerged as powerful tools for interpreting multimodal data. In medicine, they hold particular promise for synthesizing large volumes of clinical information into actionable insights and digital health applications. Yet, a major limitation remains their inability to handle time series. To overcome this gap, we present OpenTSLM, a family of Time Series Language Models (TSLMs) created by integrating time series as a native modality to pretrained LLMs, enabling reasoning over multiple time series of any length. We investigate two architectures for OpenTSLM. The first, OpenTSLM-SoftPrompt, models time series implicitly by concatenating learnable time series tokens with text tokens via soft prompting. Although parameter-efficient, we hypothesize that explicit time series modeling scales better and outperforms implicit approaches. We thus introduce OpenTSLM-Flamingo, which integrates time series with text via cross-attention. We benchmark both variants against baselines that treat time series as text tokens or plots, across a suite of text-time-series Chain-of-Thought (CoT) reasoning tasks. We introduce three datasets: HAR-CoT, Sleep-CoT, and ECG-QA-CoT. Across all, OpenTSLM models outperform baselines, reaching 69.9 F1 in sleep staging and 65.4 in HAR, compared to 9.05 and 52.2 for finetuned text-only models. Notably, even 1B-parameter OpenTSLM models surpass GPT-4o (15.47 and 2.95). OpenTSLM-Flamingo matches OpenTSLM-SoftPrompt in performance and outperforms on longer sequences, while maintaining stable memory requirements. By contrast, SoftPrompt grows exponentially in memory with sequence length, requiring around 110 GB compared to 40 GB VRAM when training on ECG-QA with LLaMA-3B. Expert reviews by clinicians find strong reasoning capabilities exhibited by OpenTSLMs on ECG-QA. To facilitate further research, we provide all code, datasets, and models open-source.
논문 링크
더 읽어보기
병렬 학습: 학습 가능한 병렬 디코딩을 통한 디퓨전 대규모 언어 모델 가속화 / Learning to Parallel: Accelerating Diffusion Large Language Models via Learnable Parallel Decoding

논문 소개
대규모 언어 모델(LLM)의 자기 회귀 디코딩 과정은 입력 토큰 수에 비례하여 순차적으로 진행되며, 이는 추론 속도를 제한하는 주요 요인으로 작용한다. 최근의 디퓨전 기반 대규모 언어 모델(dLLM)은 반복적인 디노이징 과정을 통해 병렬적인 토큰 생성을 가능하게 하지만, 기존의 병렬 디코딩 전략은 고정된 입력 비의존적 휴리스틱에 의존하여 입력의 특성에 적절히 대응하지 못하고 있다. 이러한 문제는 다양한 자연어 처리(NLP) 작업에서 속도와 품질 간의 최적화된 트레이드오프를 방해한다.
이 연구에서는 보다 유연하고 동적인 병렬 디코딩 접근 방식을 제안하는 'Learning to Parallel Decode (Learn2PD)' 프레임워크를 소개한다. 이 프레임워크는 각 토큰 위치에 대해 현재 예측이 최종 출력과 일치하는지를 판단하는 경량의 적응형 필터 모델을 학습한다. 이 필터 모델은 올바르게 예측된 경우에만 토큰을 드러내는 오라클 병렬 디코딩 전략을 근사하며, 사후 학습 방식으로 최적화가 가능하여 최소한의 계산량으로도 효과를 발휘한다. 특히, 이 과정에서 소요되는 GPU 시간은 단 몇 분에 불과하다.
또한, 연구에서는 'End-of-Text Prediction (EoTP)' 기법을 도입하여 시퀀스의 끝에서 디코딩 완료를 감지함으로써 패딩 토큰의 중복 디코딩을 방지하는 방법을 제시한다. 실험 결과, 제안된 방법은 LLaDA 벤치마크에서 성능 저하 없이 최대 22.58배의 속도 향상을 달성하며, KV-Cache와 결합할 경우 최대 57.51배의 속도 향상을 보여준다. 이러한 성과는 LLM의 디코딩 효율성을 크게 향상시키며, 디퓨전 모델의 활용 가능성을 넓히는 중요한 기여로 평가된다.
결론적으로, Learn2PD와 EoTP는 LLM의 병렬 디코딩 효율성을 개선하는 혁신적인 접근 방식을 제공하며, 향후 다양한 NLP 작업에 긍정적인 영향을 미칠 것으로 기대된다.
논문 초록(Abstract)
대규모 언어 모델(LLM)에서 자기 회귀 디코딩은 $n$개의 토큰에 대해 $\mathcal{O}(n)$의 순차적 단계를 요구하여 추론 처리량을 근본적으로 제한합니다. 최근의 디퓨전 기반 LLM(dLLM)은 반복적인 디노이징을 통해 병렬 토큰 생성을 가능하게 합니다. 그러나 현재의 병렬 디코딩 전략은 고정된 입력 비의존적 휴리스틱(예: 신뢰도 임계값)에 의존하고 있어 입력의 특정 특성에 적응하지 못하며, 다양한 자연어 처리(NLP) 작업에서 최적이 아닌 속도-품질 균형을 초래합니다. 본 연구에서는 보다 유연하고 동적인 병렬 디코딩 접근 방식을 탐구합니다. 우리는 각 토큰 위치에 대해 현재 예측이 최종 출력과 일치하는지를 예측하는 경량의 적응형 필터 모델을 훈련하는 프레임워크인 Learning to Parallel Decode(학습된 병렬 디코딩, Learn2PD)를 제안합니다. 이 학습된 필터는 올바르게 예측될 때만 토큰을 드러내는 오라클 병렬 디코딩 전략을 근사합니다. 중요한 점은 필터 모델이 사후 학습 방식으로 학습되어 최적화하는 데 소량의 계산(분 단위 GPU 시간)만 필요하다는 것입니다. 또한, 우리는 시퀀스 끝에서 디코딩 완료를 감지하기 위해 End-of-Text Prediction(EoTP)을 도입하여 패딩 토큰의 중복 디코딩을 피합니다. LLaDA 벤치마크에서의 실험 결과, 우리의 방법은 성능 저하 없이 최대 22.58배의 속도 향상을 달성하며, KV-Cache와 결합할 경우 최대 57.51배의 속도 향상을 보여줍니다.
Autoregressive decoding in large language models (LLMs) requires \mathcal{O}(n) sequential steps for n tokens, fundamentally limiting inference throughput. Recent diffusion-based LLMs (dLLMs) enable parallel token generation through iterative denoising. However, current parallel decoding strategies rely on fixed, input-agnostic heuristics (e.g., confidence thresholds), which fail to adapt to input-specific characteristics, resulting in suboptimal speed-quality trade-offs across diverse NLP tasks. In this work, we explore a more flexible and dynamic approach to parallel decoding. We propose Learning to Parallel Decode (Learn2PD), a framework that trains a lightweight and adaptive filter model to predict, for each token position, whether the current prediction matches the final output. This learned filter approximates an oracle parallel decoding strategy that unmasks tokens only when correctly predicted. Importantly, the filter model is learned in a post-training manner, requiring only a small amount of computation to optimize it (minute-level GPU time). Additionally, we introduce End-of-Text Prediction (EoTP) to detect decoding completion at the end of sequence, avoiding redundant decoding of padding tokens. Experiments on the LLaDA benchmark demonstrate that our method achieves up to 22.58$\times$ speedup without any performance drop, and up to 57.51$\times$ when combined with KV-Cache.
논문 링크
추론 대규모 언어 모델은 방황하는 해결책 탐색자이다 / Reasoning LLMs are Wandering Solution Explorers

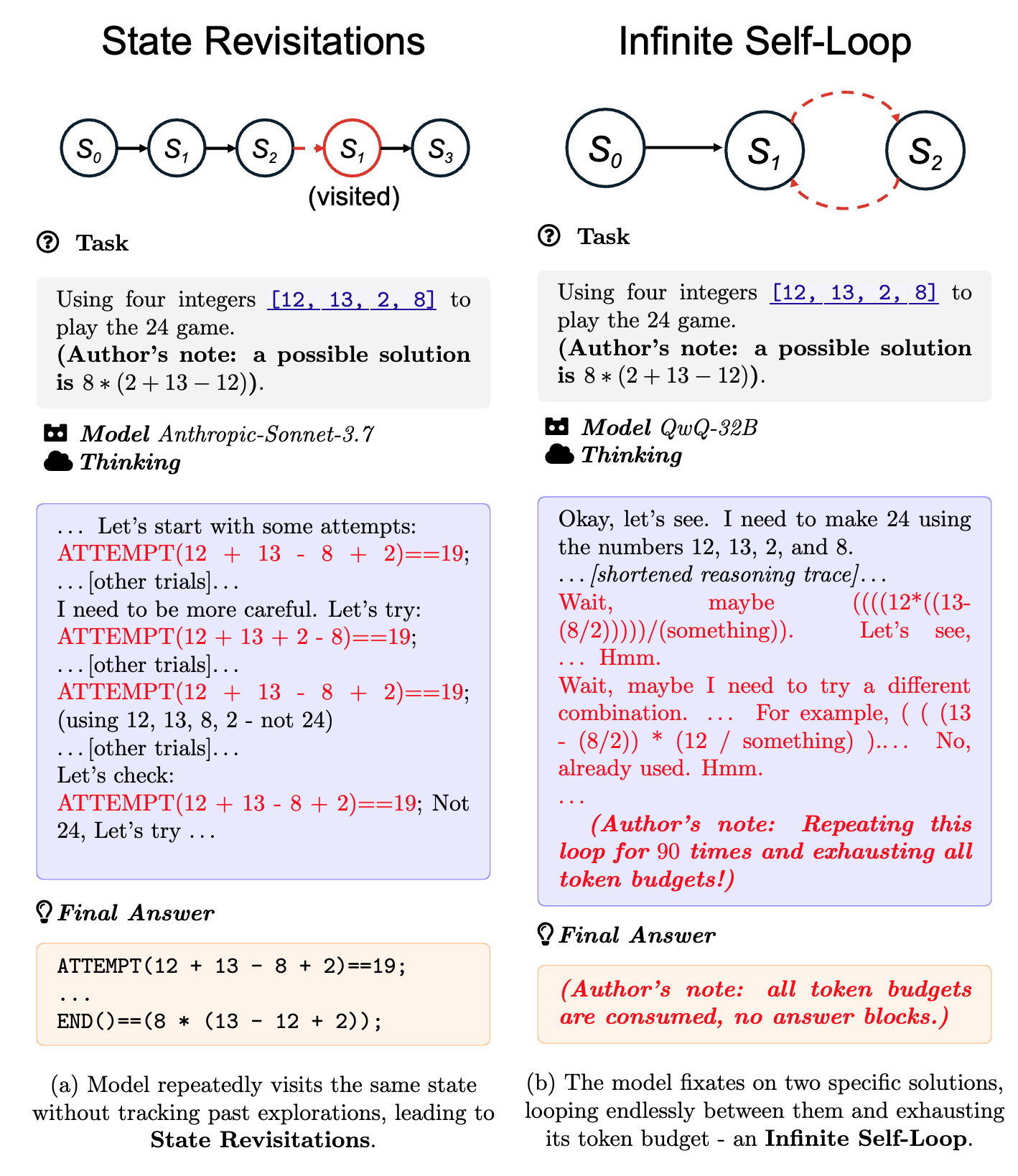
논문 소개
대규모 언어 모델(LLM)은 체인 오브 사고(Chain-of-Thought) 프롬프트와 트리 기반 추론과 같은 테스트 시간 계산(TTC) 기법을 통해 인상적인 추론 능력을 보여주고 있다. 그러나 현재의 추론 LLM(RLLM)은 체계적으로 해결 공간을 탐색하는 능력이 부족하다고 주장한다. 이 논문은 체계적인 문제 해결의 정의를 공식화하고, 추론 LLM이 체계적인 탐색자가 아닌 방황하는 탐색자임을 드러내는 일반적인 실패 모드를 식별한다. 여러 최신 LLM에 대한 정성적 및 정량적 분석을 통해, 잘못된 추론 단계, 중복 탐색, 환각적이거나 불신적인 결론과 같은 지속적인 문제를 발견하였다. 이러한 결과는 현재 모델의 성능이 간단한 작업에서는 유능해 보일 수 있지만, 복잡성이 증가함에 따라 급격히 저하될 수 있음을 시사한다. 따라서 최종 출력뿐만 아니라 추론 과정의 구조를 평가하는 새로운 메트릭과 도구의 필요성을 주장한다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 사고의 연쇄(Chain-of-Thought) 프롬프트와 트리 기반 추론과 같은 테스트 시간 계산(TTC) 기법을 통해 인상적인 추론 능력을 보여주었습니다. 그러나 우리는 현재의 추론 대규모 언어 모델(RLLM)이 체계적으로 해결 공간을 탐색하는 능력이 부족하다고 주장합니다. 본 논문은 체계적인 문제 해결의 정의를 공식화하고, 추론 대규모 언어 모델이 체계적인 탐색자가 아닌 방황하는 존재임을 드러내는 일반적인 실패 모드를 식별합니다. 여러 최첨단 LLM에 대한 정성적 및 정량적 분석을 통해 우리는 지속적인 문제를 발견했습니다: 잘못된 추론 단계, 중복 탐색, 환각적이거나 신뢰할 수 없는 결론 등이 있습니다. 우리의 연구 결과는 현재 모델의 성능이 단순한 작업에서는 유능해 보일 수 있지만 복잡성이 증가함에 따라 급격히 저하될 수 있음을 시사합니다. 이러한 발견을 바탕으로 우리는 최종 출력뿐만 아니라 추론 과정 자체의 구조를 평가하는 새로운 지표와 도구의 필요성을 주장합니다.
Large Language Models (LLMs) have demonstrated impressive reasoning abilities through test-time computation (TTC) techniques such as chain-of-thought prompting and tree-based reasoning. However, we argue that current reasoning LLMs (RLLMs) lack the ability to systematically explore the solution space. This paper formalizes what constitutes systematic problem solving and identifies common failure modes that reveal reasoning LLMs to be wanderers rather than systematic explorers. Through qualitative and quantitative analysis across multiple state-of-the-art LLMs, we uncover persistent issues: invalid reasoning steps, redundant explorations, hallucinated or unfaithful conclusions, and so on. Our findings suggest that current models' performance can appear to be competent on simple tasks yet degrade sharply as complexity increases. Based on the findings, we advocate for new metrics and tools that evaluate not just final outputs but the structure of the reasoning process itself.
논문 링크
인공 일반 지능(AGI)이란 대체 무엇인가? / What the F*ck Is Artificial General Intelligence?

논문 소개
인공지능 일반화(AGI)는 현대 인공지능 연구의 중요한 분야로 자리 잡고 있으며, 그 의미와 정의에 대한 논의는 여전히 활발히 진행되고 있다. Melanie Mitchell은 AGI의 개념이 과도한 기대와 추측으로 인해 모호해졌다고 지적하며, 이를 해결하기 위해서는 장기적인 과학적 조사가 필요하다고 주장한다. 본 논문은 AGI에 대한 명확한 개요를 제공하며, 지능을 적응의 관점에서 정의하고 AGI를 인공 과학자로 설정한다.
적응 시스템을 구축하는 데 필요한 두 가지 기본 도구인 탐색(search)과 근사(approximation)에 대한 설명은 Sutton의 Bitter Lesson에서 영감을 받았다. 이 논문은 o3, AlphaGo, AERA, NARS, Hyperon과 같은 다양한 아키텍처와 하이브리드 모델의 장단점을 비교하고, 이러한 시스템들이 어떻게 더 지능적으로 행동할 수 있는지를 탐구한다. 특히, 메타 접근법을 scale-maxing, simp-maxing, w-maxing으로 나누어 설명하며, 자원, 형태의 단순성, 기능 제약의 약점을 극대화하는 방법을 제시한다.
AGI는 단순한 기술적 접근을 넘어, 인공 과학자로서의 역할을 수행할 수 있는 시스템으로 정의된다. 이는 자율성, 주체성, 동기, 인과관계 학습 능력, 지식 습득을 위한 탐색과 행동의 균형을 요구한다. 이러한 관점에서, AGI는 기존의 감독 학습, 강화 학습 등의 분류를 넘어서는 포괄적인 시스템으로 발전해야 한다.
결론적으로, AGI의 발전은 도구와 메타 접근법의 융합을 통해 이루어질 것이며, 현재의 병목 현상은 샘플과 에너지 효율성에 기인한다. 하드웨어의 개선이 AGI의 가능성을 열어주는 중요한 요소로 작용하고 있음을 강조하며, 이러한 논의는 AGI의 정의와 연구 방향에 대한 중요한 통찰을 제공한다.
논문 초록(Abstract)
인공지능 일반 지능(AGI)은 확립된 연구 분야입니다. 그러나 일부는 이 용어가 여전히 의미가 있는지 의문을 제기하고 있습니다. AGI는 지나치게 많은 과대 광고와 추측의 대상이 되어 일종의 로르샤흐 테스트가 되었습니다. 멜라니 미첼은 이 논쟁이 장기적인 과학적 조사를 통해서만 해결될 것이라고 주장합니다. 이를 위해 AGI에 대한 짧고 접근하기 쉬우며 도발적인 개요를 제시합니다. 저는 지능의 정의를 비교하고, 적응 측면에서의 지능과 인공지능 과학자로서의 AGI에 대해 정리합니다. 서튼의 쓴 교훈(Bitter Lesson)을 참고하여 적응 시스템을 구축하는 데 사용되는 두 가지 기본 도구인 탐색과 근사화에 대해 설명합니다. o3, AlphaGo, AERA, NARS 및 Hyperon과 같은 하이브리드 및 아키텍처의 장단점을 비교합니다. 그런 다음 시스템이 더 지능적으로 행동하도록 만드는 전반적인 메타 접근 방식에 대해 논의합니다. 저는 이를 쓴 교훈, 옥캄의 면도날 및 베넷의 면도날을 기반으로 규모 극대화(scale-maxing), 단순성 극대화(simp-maxing), 약점 극대화(w-maxing)로 나눕니다. 이는 자원, 형태의 단순성 및 기능성 제약의 약점을 극대화합니다. AIXI, 자유 에너지 원리 및 언어 모델의 확대(Embiggening)와 같은 예를 논의합니다. 저는 규모 극대화된 근사화가 지배적이지만, AGI는 도구와 메타 접근 방식의 융합이 될 것이라고 결론짓습니다. 확대는 하드웨어의 개선으로 가능해졌습니다. 이제 병목 현상은 샘플 및 에너지 효율성입니다.
Artificial general intelligence (AGI) is an established field of research. Yet some have questioned if the term still has meaning. AGI has been subject to so much hype and speculation it has become something of a Rorschach test. Melanie Mitchell argues the debate will only be settled through long term, scientific investigation. To that end here is a short, accessible and provocative overview of AGI. I compare definitions of intelligence, settling on intelligence in terms of adaptation and AGI as an artificial scientist. Taking my cue from Sutton's Bitter Lesson I describe two foundational tools used to build adaptive systems: search and approximation. I compare pros, cons, hybrids and architectures like o3, AlphaGo, AERA, NARS and Hyperon. I then discuss overall meta-approaches to making systems behave more intelligently. I divide them into scale-maxing, simp-maxing, w-maxing based on the Bitter Lesson, Ockham's and Bennett's Razors. These maximise resources, simplicity of form, and the weakness of constraints on functionality. I discuss examples including AIXI, the free energy principle and The Embiggening of language models. I conclude that though scale-maxed approximation dominates, AGI will be a fusion of tools and meta-approaches. The Embiggening was enabled by improvements in hardware. Now the bottlenecks are sample and energy efficiency.
논문 링크
TPT: 사고 증강 사전학습 / Thinking Augmented Pre-training
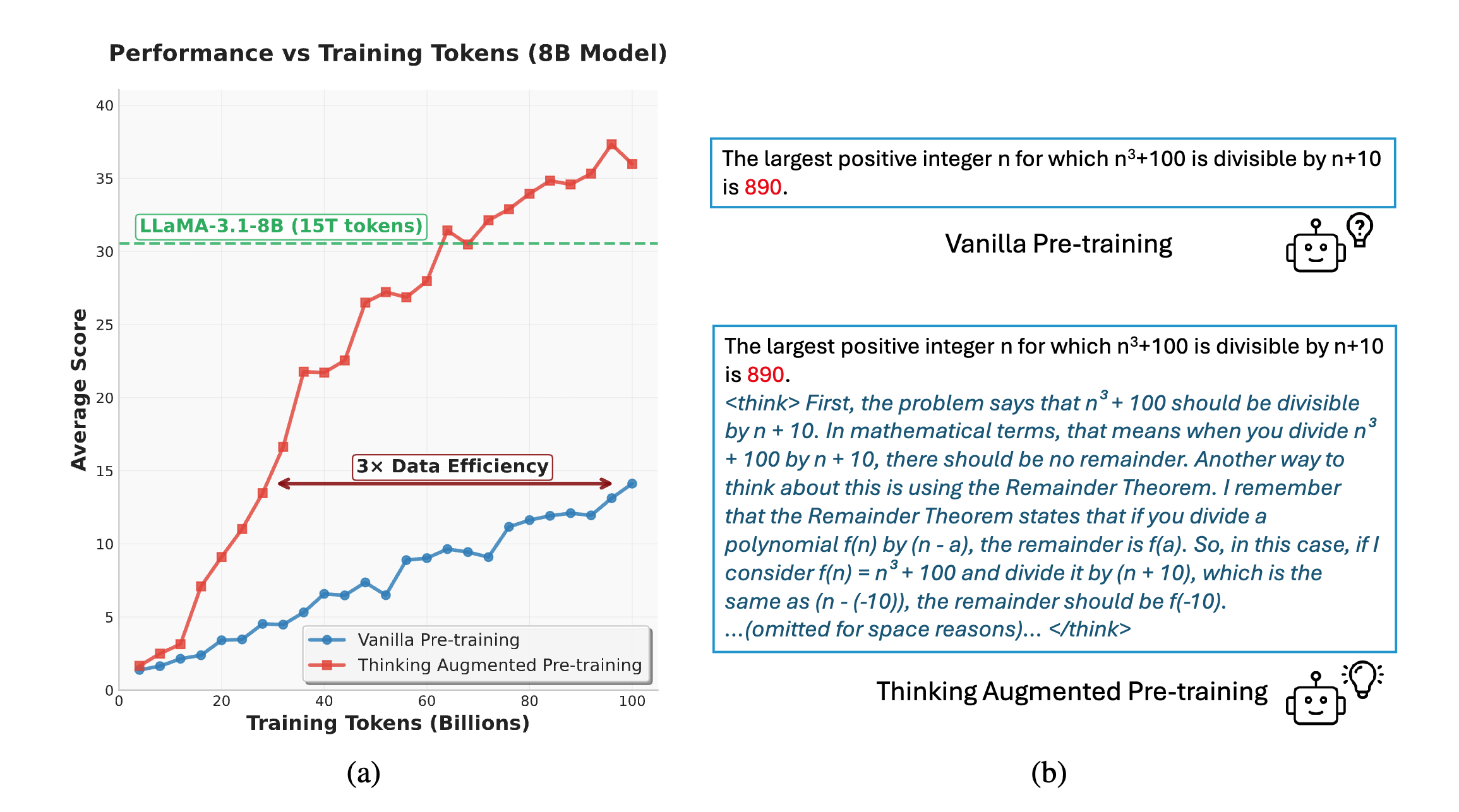
논문 소개
대규모 언어 모델(LLM)의 학습 데이터 효율성을 향상시키기 위한 새로운 접근 방식인 사고 증강 사전학습(Thinking Augmented Pre-training, TPT)이 제안되었다. LLM의 사전학습에 필요한 계산량이 기하급수적으로 증가하는 반면, 고품질 데이터의 가용성은 제한적이다. 이러한 상황에서, 사용 가능한 데이터의 유용성을 극대화하는 것이 중요한 연구 과제가 되고 있다. 특히, 특정 고품질 토큰은 고정된 모델 용량으로는 학습하기 어려운 경우가 많으며, 이는 단일 토큰의 복잡한 논리에 기인한다.
TPT는 기존 텍스트 데이터에 자동으로 생성된 사고 경로를 추가하여 학습 데이터의 양을 효과적으로 증가시키고, 단계별 추론 및 분해를 통해 고품질 토큰의 학습 가능성을 높인다. 이 방법론은 최대 100B 토큰에 이르는 다양한 학습 구성에서 적용되었으며, 제한된 데이터와 풍부한 데이터 모두에서 사전학습을 수행하였다. 실험 결과, TPT는 다양한 모델 크기와 계열에서 LLM의 성능을 크게 향상시키며, 데이터 효율성을 3배 개선하는 성과를 보였다. 특히, 30억 개 매개변수를 가진 모델의 경우 여러 도전적인 추론 벤치마크에서 사후학습 성능을 10% 이상 개선하였다.
TPT의 혁신적인 점은 사고 경로를 통해 데이터 증강을 수행함으로써, 모델이 복잡한 논리를 더 잘 학습할 수 있도록 돕는 데 있다. 이러한 접근 방식은 LLM의 학습 방식에 중요한 변화를 가져올 수 있으며, 향후 연구에서 TPT의 적용 가능성과 다양한 도메인에서의 효과를 검증하는 방향으로 나아갈 수 있다. TPT는 LLM의 데이터 효율성을 크게 향상시키는 가능성을 제시하며, 향후 연구에 중요한 기초 자료가 될 것이다.
논문 초록(Abstract)
이 논문은 기존 텍스트 데이터를 사고의 경로로 보강하여 대규모 언어 모델(LLM) 학습의 데이터 효율성을 향상시키기 위한 간단하고 확장 가능한 접근 방식을 소개합니다. LLM의 사전 학습을 위한 컴퓨팅 요구량은 전례 없는 속도로 증가하고 있는 반면, 고품질 데이터의 가용성은 여전히 제한적입니다. 따라서 사용 가능한 데이터의 유용성을 극대화하는 것은 중요한 연구 과제가 됩니다. 주요 장애물 중 하나는 특정 고품질 토큰이 고정된 모델 용량으로는 학습하기 어렵다는 점입니다. 이는 단일 토큰의 기본 논리가 매우 복잡하고 심층적일 수 있기 때문입니다. 이 문제를 해결하기 위해 우리는 자동으로 생성된 사고의 경로로 텍스트를 보강하는 보편적인 방법론인 사고 보강 사전 학습(Thinking augmented Pre-Training, TPT)을 제안합니다. 이러한 보강은 학습 데이터의 양을 효과적으로 증가시키고, 단계별 추론 및 분해를 통해 고품질 토큰의 학습 가능성을 높입니다. 우리는 TPT를 100B 토큰까지 다양한 학습 구성에 적용하며, 제한된 데이터와 풍부한 데이터 모두를 포함한 사전 학습 및 강력한 오픈 소스 체크포인트에서의 중간 학습을 포함합니다. 실험 결과, 우리의 방법이 다양한 모델 크기와 계열에서 LLM의 성능을 상당히 향상시킨다는 것을 보여줍니다. 특히, TPT는 LLM 사전 학습의 데이터 효율성을 3 배 향상시킵니다. 3B 파라미터 모델의 경우, 여러 도전적인 추론 벤치마크에서 사후 학습 성능을 10\% 이상 개선합니다.
This paper introduces a simple and scalable approach to improve the data efficiency of large language model (LLM) training by augmenting existing text data with thinking trajectories. The compute for pre-training LLMs has been growing at an unprecedented rate, while the availability of high-quality data remains limited. Consequently, maximizing the utility of available data constitutes a significant research challenge. A primary impediment is that certain high-quality tokens are difficult to learn given a fixed model capacity, as the underlying rationale for a single token can be exceptionally complex and deep. To address this issue, we propose Thinking augmented Pre-Training (TPT), a universal methodology that augments text with automatically generated thinking trajectories. Such augmentation effectively increases the volume of the training data and makes high-quality tokens more learnable through step-by-step reasoning and decomposition. We apply TPT across diverse training configurations up to $100$B tokens, encompassing pre-training with both constrained and abundant data, as well as mid-training from strong open-source checkpoints. Experimental results indicate that our method substantially improves the performance of LLMs across various model sizes and families. Notably, TPT enhances the data efficiency of LLM pre-training by a factor of 3. For a $3$B parameter model, it improves the post-training performance by over 10\% on several challenging reasoning benchmarks.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()