[2025/10/13 ~ 19] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 강화학습의 발전과 대규모 언어 모델(LLM) 적용: 최근 논문들은 강화학습(RL)이 대규모 언어 모델(LLM)의 성능을 향상시키는 데 중요한 역할을 하고 있음을 보여줍니다. 특히, RL을 활용한 다양한 접근 방식들이 제안되고 있으며, 이를 통해 LLM의 추론 능력과 데이터 효율성을 높이는 방법들이 탐구되고 있습니다. 예를 들어, Webscale-RL 논문에서는 대규모 데이터셋을 활용하여 RL 훈련의 효율성을 극대화하는 방법을 제시하고 있습니다.
강화학습의 발전과 대규모 언어 모델(LLM) 적용: 최근 논문들은 강화학습(RL)이 대규모 언어 모델(LLM)의 성능을 향상시키는 데 중요한 역할을 하고 있음을 보여줍니다. 특히, RL을 활용한 다양한 접근 방식들이 제안되고 있으며, 이를 통해 LLM의 추론 능력과 데이터 효율성을 높이는 방법들이 탐구되고 있습니다. 예를 들어, Webscale-RL 논문에서는 대규모 데이터셋을 활용하여 RL 훈련의 효율성을 극대화하는 방법을 제시하고 있습니다.
![]() 문화적 맥락과 사회적 상호작용의 이해: LLM이 문화적 규범을 이해하고 적용하는 데 어려움을 겪고 있다는 점이 강조되고 있습니다. TaarofBench 논문에서는 페르시아 문화의 예절인 타아로프를 평가하기 위한 벤치마크를 제안하며, LLM이 문화적 맥락을 이해하는 데 필요한 개선 사항을 제시하고 있습니다. 이는 LLM의 사회적 상호작용 능력을 향상시키기 위한 중요한 연구 방향으로 부각되고 있습니다.
문화적 맥락과 사회적 상호작용의 이해: LLM이 문화적 규범을 이해하고 적용하는 데 어려움을 겪고 있다는 점이 강조되고 있습니다. TaarofBench 논문에서는 페르시아 문화의 예절인 타아로프를 평가하기 위한 벤치마크를 제안하며, LLM이 문화적 맥락을 이해하는 데 필요한 개선 사항을 제시하고 있습니다. 이는 LLM의 사회적 상호작용 능력을 향상시키기 위한 중요한 연구 방향으로 부각되고 있습니다.
![]() 프롬프트 설계와 모델 성능의 상관관계: 프롬프트의 어조와 정중함이 LLM의 정확도에 미치는 영향을 조사한 연구가 진행되고 있습니다. Mind Your Tone 논문에서는 다양한 정중함 수준의 프롬프트가 모델의 성능에 미치는 영향을 분석하였으며, 예상과 달리 무례한 프롬프트가 더 높은 정확도를 보이는 결과를 도출했습니다. 이는 LLM의 응답 방식에 대한 새로운 통찰을 제공하며, 프롬프트 설계의 중요성을 강조합니다.
프롬프트 설계와 모델 성능의 상관관계: 프롬프트의 어조와 정중함이 LLM의 정확도에 미치는 영향을 조사한 연구가 진행되고 있습니다. Mind Your Tone 논문에서는 다양한 정중함 수준의 프롬프트가 모델의 성능에 미치는 영향을 분석하였으며, 예상과 달리 무례한 프롬프트가 더 높은 정확도를 보이는 결과를 도출했습니다. 이는 LLM의 응답 방식에 대한 새로운 통찰을 제공하며, 프롬프트 설계의 중요성을 강조합니다.
대규모 언어 모델을 위한 강화학습 컴퓨팅 확장의 기술 / The Art of Scaling Reinforcement Learning Compute for LLMs
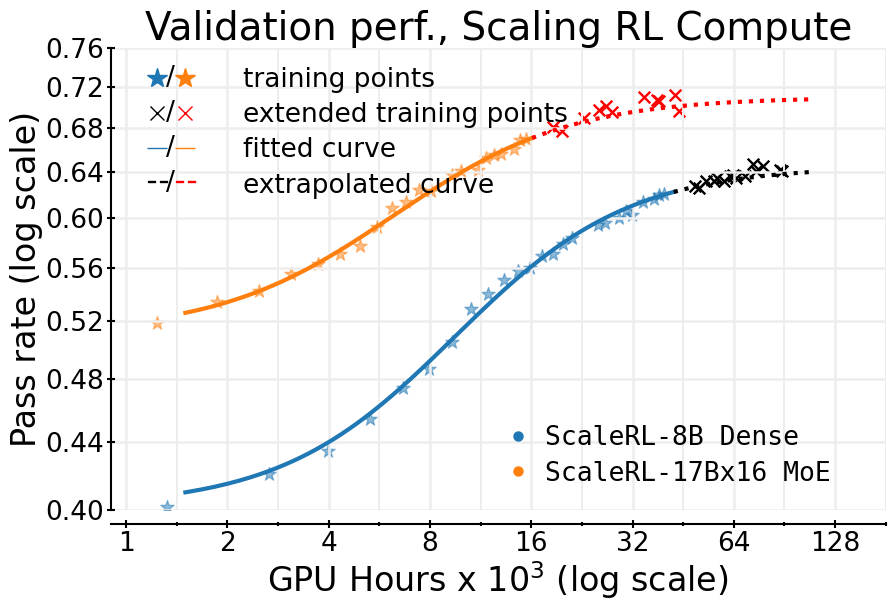
논문 소개
강화학습(Reinforcement Learning, RL)은 대규모 언어 모델(Large Language Models, LLM)의 학습에서 중요한 역할을 하고 있지만, 이 분야는 사전학습(Pre-training)에서 확립된 예측 가능한 스케일링 방법론이 부족한 상황이다. 본 연구는 400,000 GPU 시간 이상을 소모한 대규모 체계적 연구를 통해 RL 컴퓨팅 스케일링을 분석하고 예측하기 위한 원칙적인 프레임워크를 제시한다. 연구의 핵심은 RL 학습을 위한 시그모이드 형태의 컴퓨팅-성능 곡선을 적합하고, 다양한 설계 선택의 영향을 분석하여 비대칭 성능(asymptotic performance)과 컴퓨팅 효율성(computational efficiency)에 미치는 영향을 평가하는 것이다.
이 연구에서 관찰된 주요 결과는 다음과 같다. 첫째, 모든 알고리즘이 유사한 비대칭 성능을 보이지 않으며, 둘째, 손실 집계(loss aggregation), 정규화(normalization), 커리큘럼(curriculum), 오프 정책 알고리즘(off-policy algorithm) 등의 세부 사항은 비대칭 성능에 큰 영향을 미치지 않으면서도 컴퓨팅 효율성을 조절한다. 셋째, 안정적이고 확장 가능한 레시피는 예측 가능한 스케일링 궤적을 따르며, 이를 통해 소규모 실행에서의 성능을 외삽할 수 있다.
이러한 통찰을 바탕으로, 연구팀은 ScaleRL이라는 최선의 실천 레시피를 제안하고, 이를 통해 단일 RL 실행을 100,000 GPU 시간까지 확장하여 검증 성능을 성공적으로 예측하였다. ScaleRL은 비동기 Pipeline-RL 설정, 강제 길이 중단, 잘린 중요 샘플링 RL 손실(CISPO), 프롬프트 수준 손실 평균화, 배치 수준 이점 정규화 등의 요소를 통합하여 예측 가능한 스케일링을 달성하고, 기존 RL 레시피에 비해 새로운 최첨단 성능을 수립하였다.
본 연구는 RL 훈련의 스케일링 분석을 위한 과학적 프레임워크를 제공하며, RL 학습의 예측 가능성을 높이는 실용적인 레시피를 제안함으로써, RL 분야의 발전에 기여할 것으로 기대된다. 이러한 접근은 RL 알고리즘의 확장 가능성을 비용 효율적으로 예측할 수 있는 기반을 마련하며, 향후 연구자들이 RL 컴퓨팅 스케일링을 보다 체계적으로 이해하고 활용할 수 있도록 돕는다.
논문 초록(Abstract)
강화학습(RL)은 대규모 언어 모델(LLM) 훈련의 중심이 되었지만, 이 분야는 사전학습을 위해 확립된 것과 유사한 예측적 스케일링 방법론이 부족합니다. 급격히 증가하는 컴퓨팅 예산에도 불구하고, RL 컴퓨팅의 스케일링을 위한 알고리즘 개선을 평가하는 방법에 대한 원칙적인 이해가 없습니다. 우리는 LLM에서 RL 스케일링을 분석하고 예측하기 위한 원칙적인 프레임워크를 정의하는 최초의 대규모 체계적 연구를 제시하며, 이 연구는 400,000 GPU-시간 이상에 달합니다. 우리는 RL 훈련을 위한 시그모이드 컴퓨팅-성능 곡선을 적합하고, 비대칭 성능과 컴퓨팅 효율성에 미치는 영향을 분석하기 위해 다양한 일반적인 설계 선택을 제거합니다. 우리는 다음과 같은 관찰을 합니다: (1) 모든 레시피가 유사한 비대칭 성능을 제공하지는 않으며, (2) 손실 집계, 정규화, 커리큘럼 및 오프 정책 알고리즘과 같은 세부 사항은 비대칭을 실질적으로 변화시키지 않으면서 컴퓨팅 효율성을 주로 조절합니다, (3) 안정적이고 확장 가능한 레시피는 예측 가능한 스케일링 궤적을 따르며, 이를 통해 소규모 실행에서 외삽이 가능합니다. 이러한 통찰을 결합하여 우리는 최선의 실천 레시피인 ScaleRL을 제안하고, 이를 통해 100,000 GPU-시간으로 확장된 단일 RL 실행에서 검증 성능을 성공적으로 스케일링하고 예측함으로써 그 효과를 입증합니다. 우리의 연구는 RL에서 스케일링을 분석하기 위한 과학적 프레임워크와 사전학습에서 오랫동안 달성된 예측 가능성에 RL 훈련을 더 가깝게 가져오는 실용적인 레시피를 제공합니다.
Reinforcement learning (RL) has become central to training large language models (LLMs), yet the field lacks predictive scaling methodologies comparable to those established for pre-training. Despite rapidly rising compute budgets, there is no principled understanding of how to evaluate algorithmic improvements for scaling RL compute. We present the first large-scale systematic study, amounting to more than 400,000 GPU-hours, that defines a principled framework for analyzing and predicting RL scaling in LLMs. We fit sigmoidal compute-performance curves for RL training and ablate a wide range of common design choices to analyze their effects on asymptotic performance and compute efficiency. We observe: (1) Not all recipes yield similar asymptotic performance, (2) Details such as loss aggregation, normalization, curriculum, and off-policy algorithm primarily modulate compute efficiency without materially shifting the asymptote, and (3) Stable, scalable recipes follow predictable scaling trajectories, enabling extrapolation from smaller-scale runs. Combining these insights, we propose a best-practice recipe, ScaleRL, and demonstrate its effectiveness by successfully scaling and predicting validation performance on a single RL run scaled up to 100,000 GPU-hours. Our work provides both a scientific framework for analyzing scaling in RL and a practical recipe that brings RL training closer to the predictability long achieved in pre-training.
논문 링크
에이전틱 추론에서 강화학습의 신비를 밝혀내기 / Demystifying Reinforcement Learning in Agentic Reasoning

논문 소개
에이전틱 강화학습(Agentic Reinforcement Learning, RL)의 발전은 대규모 언어 모델(LLM)의 에이전틱 추론 능력을 향상시키는 데 중요한 역할을 하고 있다. 본 연구는 에이전틱 RL의 설계 원칙과 최적 관행을 명확히 하기 위해 데이터, 알고리즘, 추론 모드의 세 가지 주요 관점에서 체계적인 조사를 수행하였다. 주요 통찰로는 합성 경로를 실제 도구 사용 경로로 대체함으로써 더 강력한 감독 미세 조정(Supervised Fine-Tuning, SFT) 초기화를 얻을 수 있다는 점과, 고다양성의 모델 인식 데이터셋이 탐색을 지속하고 RL 성능을 크게 향상시킨다는 점이 있다.
탐색 친화적인 기법의 중요성도 강조되며, 높은 클립, 과도한 보상 형성, 적절한 정책 엔트로피 유지 등이 학습 효율성을 개선하는 데 기여한다. 또한, 도구 호출을 최소화하는 심사 전략이 잦은 도구 호출이나 장황한 자기 추론보다 더 나은 성능을 발휘하여 도구 효율성과 최종 정확도를 높이는 것으로 나타났다. 이러한 간단한 관행들은 에이전틱 추론과 학습 효율성을 일관되게 향상시키며, 작은 모델로도 도전적인 벤치마크에서 강력한 결과를 달성할 수 있도록 한다.
본 연구는 또한 고품질의 실제 종단 간 에이전틱 SFT 데이터셋과 RL 데이터셋을 제공하며, AIME2024/AIME2025, GPQA-Diamond, LiveCodeBench-v6와 같은 네 가지 도전적인 벤치마크에서 LLM의 에이전틱 추론 능력을 향상시키는 효과를 입증하였다. 제안된 방법론을 통해 4B 크기의 모델이 32B 크기의 모델보다 우수한 성능을 달성할 수 있음을 보여주며, 이는 향후 에이전틱 RL 연구에 대한 실용적인 기준을 제시한다. 이러한 연구 결과는 에이전틱 RL의 설계와 적용에 있어 중요한 기여를 하며, LLM의 에이전틱 추론 능력을 한층 더 발전시키는 데 기여할 것으로 기대된다.
논문 초록(Abstract)
최근 에이전틱 강화학습(agentic RL)의 출현은 RL이 대규모 언어 모델(LLM)의 에이전틱 추론 능력을 효과적으로 향상시킬 수 있음을 보여주었으나, 핵심 설계 원칙과 최적 관행은 여전히 불분명하다. 본 연구에서는 데이터, 알고리즘, 추론 모드라는 세 가지 주요 관점에서 에이전틱 추론에서의 강화학습을 명확히 하기 위한 포괄적이고 체계적인 조사를 수행하였다. 우리의 주요 통찰은 다음과 같다: (i) 연결된 합성 궤적을 실제 엔드 투 엔드 도구 사용 궤적으로 대체하면 훨씬 더 강력한 SFT 초기화가 이루어진다; 높은 다양성의 모델 인식 데이터셋은 탐색을 지속하고 RL 성능을 현저히 향상시킨다. (ii) 탐색 친화적인 기법은 에이전틱 RL에 필수적이며, 예를 들어 높은 클립, 과도한 보상 형성, 적절한 정책 엔트로피 유지는 훈련 효율성을 개선할 수 있다. (iii) 도구 호출이 적은 심사 전략이 빈번한 도구 호출이나 장황한 자기 추론보다 더 나은 성능을 보이며, 도구 효율성과 최종 정확성을 향상시킨다. 이러한 간단한 관행들은 일관되게 에이전틱 추론과 훈련 효율성을 향상시켜, 작은 모델로도 도전적인 벤치마크에서 강력한 결과를 달성하고 향후 에이전틱 RL 연구를 위한 실용적인 기준선을 설정한다. 이러한 경험적 통찰을 넘어, 우리는 고품질의 실제 엔드 투 엔드 에이전틱 SFT 데이터셋과 고품질 RL 데이터셋을 추가로 기여하며, AIME2024/AIME2025, GPQA-Diamond, LiveCodeBench-v6를 포함한 네 가지 도전적인 벤치마크에서 LLM의 에이전틱 추론 능력을 향상시키는 우리의 통찰의 효과를 입증한다. 우리의 방법론을 통해 4B 크기의 모델도 32B 크기의 모델보다 우수한 에이전틱 추론 성능을 달성할 수 있다. 코드 및 모델: GitHub - Gen-Verse/Open-AgentRL: Demystifying Reinforcement Learning in Agentic Reasoning
Recently, the emergence of agentic RL has showcased that RL could also effectively improve the agentic reasoning ability of LLMs, yet the key design principles and optimal practices remain unclear. In this work, we conduct a comprehensive and systematic investigation to demystify reinforcement learning in agentic reasoning from three key perspectives: data, algorithm, and reasoning mode. We highlight our key insights: (i) Replacing stitched synthetic trajectories with real end-to-end tool-use trajectories yields a far stronger SFT initialization; high-diversity, model-aware datasets sustain exploration and markedly improve RL performance. (ii) Exploration-friendly techniques are crucial for agentic RL, such as clip higher, overlong reward shaping, and maintaining adequate policy entropy could improve the training efficiency. (iii) A deliberative strategy with fewer tool calls outperforms frequent tool calls or verbose self-reasoning, improving tool efficiency and final accuracy. Together, these simple practices consistently enhance agentic reasoning and training efficiency, achieving strong results on challenging benchmarks with smaller models, and establishing a practical baseline for future agentic RL research. Beyond these empirical insights, we further contribute a high-quality, real end-to-end agentic SFT dataset along with a high-quality RL dataset, and demonstrate the effectiveness of our insights in boosting the agentic reasoning ability of LLMs across four challenging benchmarks, including AIME2024/AIME2025, GPQA-Diamond, and LiveCodeBench-v6. With our recipes, 4B-sized models could also achieve superior agentic reasoning performance compared to 32B-sized models. Code and models: GitHub - Gen-Verse/Open-AgentRL: Demystifying Reinforcement Learning in Agentic Reasoning
논문 링크
더 읽어보기
https://github.com/Gen-Verse/Open-AgentRL
비전 분야에서의 강화학습에 대한 서베이 / Reinforcement Learning in Vision: A Survey
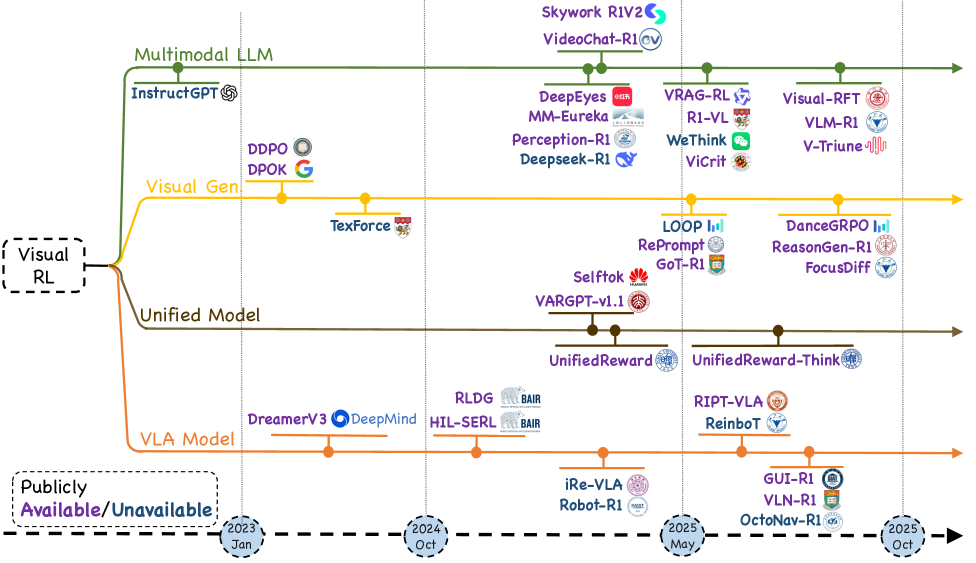
논문 소개
비전 분야와 강화학습(Reinforcement Learning, RL)의 융합은 최근 몇 년간 혁신적인 발전을 이루어왔으며, 이는 복잡한 시각 장면을 인식하고 그 안에서 추론, 생성, 행동할 수 있는 에이전트를 가능하게 합니다. 본 연구는 이러한 비전 RL 분야의 최신 동향을 체계적으로 정리하고, 관련 연구들을 종합하여 비전 RL의 발전 경로를 제시합니다. 연구의 첫 단계로, 비전 RL 문제를 형식화하고, 정책 최적화 전략의 진화를 추적합니다. 여기에서는 인간 피드백 강화학습(RLHF)에서 시작하여 검증 가능한 보상 패러다임, 근접 정책 최적화(Proximal Policy Optimization), 그룹 상대 정책 최적화(Group Relative Policy Optimization)로의 발전을 다룹니다.
이후, 200개 이상의 대표적인 연구를 네 가지 주제 기둥으로 나누어 분석합니다. 첫 번째 기둥인 멀티모달 대규모 언어 모델에서는 시각적 정보와 언어적 맥락을 통합하는 다양한 연구 사례를 살펴봅니다. 두 번째 기둥인 시각 생성에서는 이미지, 비디오, 3D 생성 기술의 최신 동향을 정리하고, 각 기술의 발전 상황을 비교합니다. 세 번째 기둥인 통합 모델에서는 통합 RL의 필요성과 그 구현 방법을 설명하며, 작업 특정 RL에 대한 사례를 제시합니다. 마지막으로, 비전-언어-행동 모델에서는 GUI 상호작용, 시각적 탐색, 시각적 조작 기술을 다루며, 이들 모델의 성능을 비교합니다.
본 연구는 비전 RL의 평가 프로토콜을 검토하고, 샘플 효율성, 일반화, 안전한 배포와 같은 열린 도전 과제를 식별합니다. 이러한 분석을 통해 연구자와 실무자에게 비전 RL의 빠르게 확장되는 경관에 대한 일관된 지도를 제공하고, 향후 연구 방향을 제시하는 데 기여하고자 합니다. 이 논문은 비전 RL 분야의 발전을 이해하고, 다양한 응용 분야에서의 가능성을 탐색하는 데 중요한 기초 자료로 활용될 것입니다.
논문 초록(Abstract)
최근 강화학습(RL)과 시각 지능의 교차점에서의 발전은 복잡한 시각 장면을 인식할 뿐만 아니라 그 안에서 추론하고 생성하며 행동할 수 있는 에이전트를 가능하게 했습니다. 본 서베이는 이 분야에 대한 비판적이고 최신의 종합을 제공합니다. 우리는 먼저 시각 RL 문제를 형식화하고 RLHF에서 검증 가능한 보상 패러다임으로, 그리고 근접 정책 최적화(Proximal Policy Optimization)에서 그룹 상대 정책 최적화(Group Relative Policy Optimization)로의 정책 최적화 전략의 진화를 추적합니다. 그 다음, 200개 이상의 대표적인 연구를 네 가지 주제 기둥으로 조직합니다: 멀티모달 대규모 언어 모델, 시각 생성, 통합 모델 프레임워크, 그리고 비전-언어-행동 모델입니다. 각 기둥에 대해 알고리즘 설계, 보상 엔지니어링, 벤치마크 진행 상황을 검토하고, 커리큘럼 기반 학습, 선호 정렬 디퓨전, 통합 보상 모델링과 같은 트렌드를 정리합니다. 마지막으로, 집합 수준의 충실도, 샘플 수준의 선호도, 상태 수준의 안정성을 아우르는 평가 프로토콜을 검토하고, 샘플 효율성, 일반화, 안전한 배포와 같은 개방된 도전 과제를 식별합니다. 우리의 목표는 연구자와 실무자에게 빠르게 확장되고 있는 시각 RL의 지형에 대한 일관된 지도를 제공하고, 향후 연구를 위한 유망한 방향을 강조하는 것입니다. 자원은 다음 링크에서 확인할 수 있습니다: GitHub - weijiawu/Awesome-Visual-Reinforcement-Learning: 📖 This is a repository for organizing papers, codes and other resources related to Visual Reinforcement Learning..
Recent advances at the intersection of reinforcement learning (RL) and visual intelligence have enabled agents that not only perceive complex visual scenes but also reason, generate, and act within them. This survey offers a critical and up-to-date synthesis of the field. We first formalize visual RL problems and trace the evolution of policy-optimization strategies from RLHF to verifiable reward paradigms, and from Proximal Policy Optimization to Group Relative Policy Optimization. We then organize more than 200 representative works into four thematic pillars: multi-modal large language models, visual generation, unified model frameworks, and vision-language-action models. For each pillar we examine algorithmic design, reward engineering, benchmark progress, and we distill trends such as curriculum-driven training, preference-aligned diffusion, and unified reward modeling. Finally, we review evaluation protocols spanning set-level fidelity, sample-level preference, and state-level stability, and we identify open challenges that include sample efficiency, generalization, and safe deployment. Our goal is to provide researchers and practitioners with a coherent map of the rapidly expanding landscape of visual RL and to highlight promising directions for future inquiry. Resources are available at: GitHub - weijiawu/Awesome-Visual-Reinforcement-Learning: 📖 This is a repository for organizing papers, codes and other resources related to Visual Reinforcement Learning..
논문 링크
더 읽어보기
https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning
Webscale-RL: RL 데이터를 사전학습 수준으로 확장하기 위한 자동화된 데이터 파이프라인 / Webscale-RL: Automated Data Pipeline for Scaling RL Data to Pretraining Levels
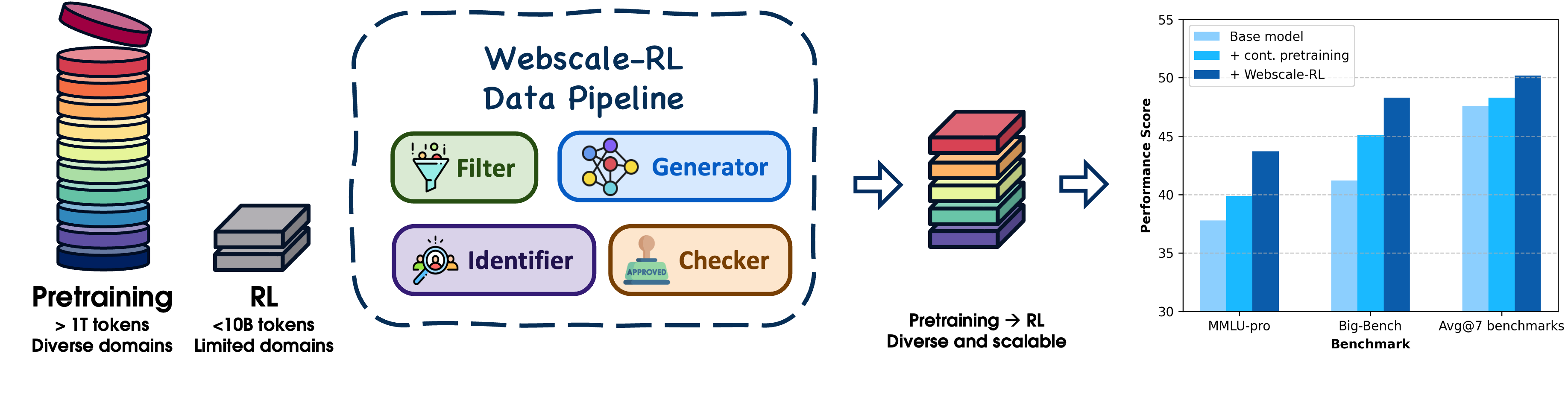
논문 소개
대규모 언어 모델(Large Language Models, LLMs)은 방대한 텍스트 코퍼스를 통한 모방 학습을 통해 놀라운 성과를 거두었으나, 이로 인해 훈련-생성 간의 간극이 발생하고 강력한 추론 능력이 제한되는 문제점이 있다. 강화학습(Reinforcement Learning, RL)은 이러한 간극을 해소할 수 있는 데이터 효율적인 솔루션을 제공하지만, 기존의 RL 데이터셋은 웹 규모의 사전학습 데이터에 비해 현저히 작고 다양성이 부족하여 그 적용이 제한적이다. 이를 해결하기 위해 제안된 Webscale-RL 데이터 파이프라인은 대규모 사전학습 문서를 체계적으로 변환하여 수백만 개의 다양한 검증 가능한 질문-답변 쌍을 생성하는 혁신적인 접근법이다.
Webscale-RL 데이터 파이프라인은 네 가지 주요 단계로 구성된다. 첫째, 데이터 필터링 단계에서는 저품질 문서를 제거하여 정보적이고 검증 가능한 질문을 생성할 수 있는 기반을 마련한다. 둘째, 도메인 분류 및 페르소나 할당 단계에서는 각 문서를 특정 도메인으로 분류하고 다양한 관점을 반영하기 위해 여러 페르소나를 할당한다. 셋째, 검증 가능한 질문-답변 생성 단계에서는 LLM 기반 QA 생성기를 활용하여 도메인 특정 시연 라이브러리에서 샘플링된 예제를 바탕으로 질문-답변 쌍을 생성한다. 마지막으로, 품질 검사 및 누수 방지 단계에서는 생성된 QA 쌍의 정확성과 누수 방지를 위해 다단계 검증 프로세스를 적용하여 최종 데이터셋의 신뢰성을 확보한다.
이러한 방법론을 통해 생성된 Webscale-RL 데이터셋은 120만 개의 예제를 포함하며, 9개 이상의 도메인에 걸쳐 있다. 실험 결과, 본 데이터셋으로 훈련된 모델은 지속적인 사전학습 및 강력한 데이터 정제 기준선에 비해 상당한 성능 향상을 보였으며, RL 훈련의 효율성을 크게 개선하여 최대 100배 적은 토큰으로도 지속적인 사전학습의 성능을 달성할 수 있었다. 이러한 연구는 RL을 사전학습 수준으로 확장할 수 있는 실질적인 경로를 제시하며, 더 능력 있고 효율적인 언어 모델 개발에 기여할 것으로 기대된다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 방대한 텍스트 코퍼스를 통한 모방 학습을 통해 놀라운 성공을 거두었지만, 이러한 패러다임은 학습-생성 간의 격차를 초래하고 강력한 추론을 제한합니다. 강화학습(RL)은 이 격차를 해소할 수 있는 보다 데이터 효율적인 솔루션을 제공하지만, 기존의 RL 데이터셋이 웹 규모의 사전학습 코퍼스에 비해 수량적으로 훨씬 작고 다양성이 부족하다는 중요한 데이터 병목 현상으로 인해 그 적용이 제한되어 있습니다. 이를 해결하기 위해, 우리는 대규모 사전학습 문서를 체계적으로 수백만 개의 다양한 검증 가능한 질문-답변 쌍으로 변환하는 확장 가능한 데이터 엔진인 Webscale-RL 파이프라인을 소개합니다. 이 파이프라인을 사용하여 9개 이상의 도메인에 걸쳐 120만 개의 예제를 포함하는 Webscale-RL 데이터셋을 구축하였습니다. 우리의 실험 결과, 이 데이터셋으로 학습한 모델은 지속적인 사전학습 및 강력한 데이터 정제 기준선에 비해 여러 벤치마크에서 상당히 우수한 성능을 보였습니다. 특히, 우리 데이터셋을 활용한 RL 학습은 지속적인 사전학습의 성능을 최대 100배 적은 토큰으로 달성할 수 있어 상당히 더 효율적임을 입증하였습니다. 우리의 연구는 RL을 사전학습 수준으로 확장할 수 있는 실행 가능한 경로를 제시하며, 보다 능력 있고 효율적인 언어 모델을 가능하게 합니다.
Large Language Models (LLMs) have achieved remarkable success through imitation learning on vast text corpora, but this paradigm creates a training-generation gap and limits robust reasoning. Reinforcement learning (RL) offers a more data-efficient solution capable of bridging this gap, yet its application has been constrained by a critical data bottleneck: existing RL datasets are orders of magnitude smaller and less diverse than web-scale pre-training corpora. To address this, we introduce the Webscale-RL pipeline, a scalable data engine that systematically converts large-scale pre-training documents into millions of diverse, verifiable question-answer pairs for RL. Using this pipeline, we construct the Webscale-RL dataset, containing 1.2 million examples across more than 9 domains. Our experiments show that the model trained on this dataset significantly outperforms continual pretraining and strong data refinement baselines across a suite of benchmarks. Notably, RL training with our dataset proves substantially more efficient, achieving the performance of continual pre-training with up to 100$\times$ fewer tokens. Our work presents a viable path toward scaling RL to pre-training levels, enabling more capable and efficient language models.
논문 링크
더 읽어보기
https://github.com/SalesforceAIResearch/PretrainRL-pipeline
에이전틱 맥락 엔지니어링(ACE): 자기 개선 언어 모델을 위한 진화하는 맥락 / Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
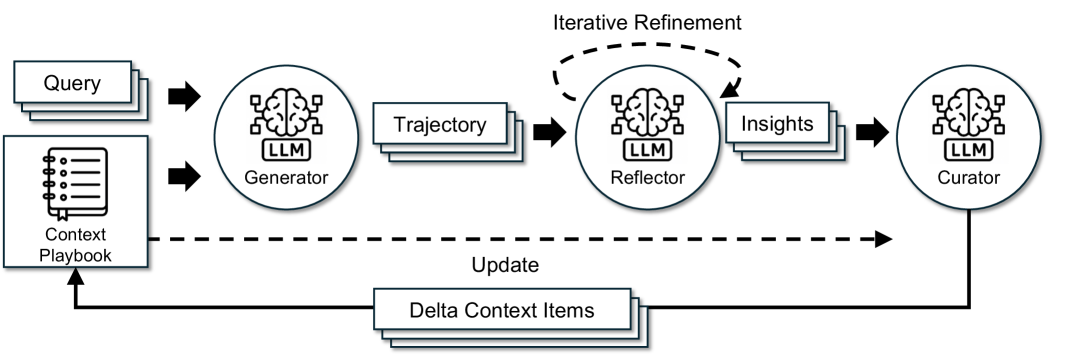
논문 소개
대규모 언어 모델(LLM)의 활용이 증가함에 따라, 다양한 도메인에서의 추론 및 에이전트 기능이 중요해지고 있다. 그러나 기존의 맥락 적응 방법들은 간결성 편향과 맥락 붕괴 문제로 인해 한계가 있다. 이러한 문제를 해결하기 위해 제안된 ACE(Agentic Context Engineering) 프레임워크는 맥락을 진화하는 플레이북으로 간주하며, 생성, 반영, 큐레이션의 모듈화된 과정을 통해 전략을 축적하고 정제하는 방법을 제공한다.
ACE는 구조화된 점진적 업데이트를 통해 맥락 붕괴를 방지하고, 상세한 지식을 보존하며 긴 맥락 모델에 맞게 확장할 수 있는 능력을 갖추고 있다. 이 프레임워크는 오프라인(예: 시스템 프롬프트) 및 온라인(예: 에이전트 메모리)에서 맥락을 최적화하며, 강력한 기준선보다 일관되게 우수한 성능을 보인다. 특히, ACE는 레이블이 없는 감독 없이 자연 실행 피드백을 활용하여 효과적으로 적응할 수 있다.
실험 결과, ACE는 에이전트에서 +10.6%, 금융 도메인에서 +8.6%의 성능 향상을 달성하며, 적응 지연 및 롤아웃 비용을 크게 줄였다. AppWorld 리더보드에서는 ACE가 전체 평균에서 최고 순위의 생산 수준 에이전트와 동등한 성능을 보이며, 더 어려운 테스트-챌린지 분할에서도 이를 초과하는 성과를 나타냈다. 이러한 결과는 포괄적이고 진화하는 맥락이 낮은 오버헤드로 확장 가능하고 효율적이며 자기 개선이 가능한 LLM 시스템을 가능하게 함을 보여준다.
ACE 프레임워크는 LLM의 맥락 적응 문제를 해결하고, 자기 개선이 가능한 시스템을 구축하는 데 중요한 기여를 하고 있으며, 기존의 한계를 극복하고 LLM의 활용 가능성을 확장하는 데 중요한 역할을 할 것으로 기대된다.
논문 초록(Abstract)
대규모 언어 모델(LLM) 응용 프로그램인 에이전트 및 도메인 특화 추론은 점점 더 맥락 적응에 의존하고 있습니다. 이는 가중치 업데이트가 아닌 지침, 전략 또는 증거로 입력을 수정하는 것을 의미합니다. 이전 접근 방식은 사용성을 개선하지만 종종 간결한 요약을 위해 도메인 통찰력을 포기하는 간결성 편향과 반복적인 재작성으로 인해 세부 사항이 시간이 지남에 따라 소실되는 맥락 붕괴 문제에 시달립니다. Dynamic Cheatsheet에서 도입된 적응형 메모리를 기반으로, 우리는 ACE(Agentic Context Engineering)를 소개합니다. ACE는 맥락을 진화하는 플레이북으로 간주하여 생성, 반영 및 선별의 모듈식 과정을 통해 전략을 축적, 정제 및 조직합니다. ACE는 세부 지식을 보존하고 장기 맥락 모델과 함께 확장할 수 있는 구조적이고 점진적인 업데이트로 붕괴를 방지합니다. 에이전트 및 도메인 특화 벤치마크 전반에 걸쳐, ACE는 오프라인(예: 시스템 프롬프트) 및 온라인(예: 에이전트 메모리)에서 맥락을 최적화하며, 강력한 기준선보다 일관되게 우수한 성능을 보입니다: 에이전트에서 +10.6%, 금융에서 +8.6%의 성과를 기록하며, 적응 지연 및 롤아웃 비용을 상당히 줄였습니다. 특히, ACE는 레이블이 있는 감독 없이도 효과적으로 적응할 수 있으며, 대신 자연스러운 실행 피드백을 활용합니다. AppWorld 리더보드에서 ACE는 전체 평균에서 최고 순위의 생산 수준 에이전트와 동등하며, 더 어려운 테스트-챌린지 분할에서 이를 초월합니다. 이러한 결과는 포괄적이고 진화하는 맥락이 낮은 오버헤드로 확장 가능하고 효율적이며 스스로 개선하는 LLM 시스템을 가능하게 함을 보여줍니다.
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
논문 링크
더 읽어보기
RLVR을 위한 감독 학습 프레임워크를 통한 암묵적 액터-비평가 결합 / Implicit Actor Critic Coupling via a Supervised Learning Framework for RLVR
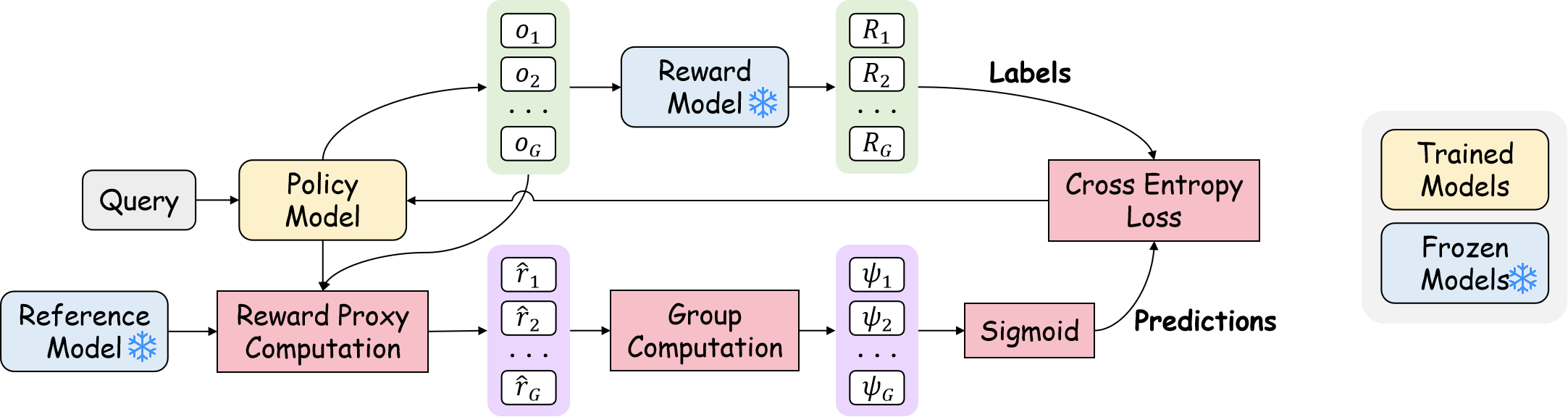
논문 소개
강화 학습(Reinforcement Learning, RL)과 검증 가능한 보상(Verifiable Rewards, VR)의 결합은 대규모 언어 모델(LLM)이 복잡한 추론 작업을 수행하는 데 중요한 역할을 하고 있다. 그러나 기존의 RLVR 방법들은 희소한 보상 신호와 불안정한 정책 그래디언트 업데이트로 인해 여러 도전에 직면해 있다. 이러한 문제를 해결하기 위해 제안된 PACS(Implicit Actor Critic Coupling via a Supervised Learning Framework) 프레임워크는 감독 학습을 통해 액터와 비평가의 역할을 암묵적으로 결합하는 혁신적인 접근 방식을 제공한다.
PACS는 결과 보상을 예측 가능한 레이블로 취급하여 RLVR 문제를 점수 함수에 대한 감독 학습 작업으로 재구성한다. 이 점수 함수는 정책 모델에 의해 매개변수화되며, 교차 엔트로피 손실을 통해 최적화된다. 이러한 접근 방식은 고전적인 정책 그래디언트 업데이트를 회복하면서도 더 안정적이고 효율적인 학습을 가능하게 한다. 특히, PACS는 수학적 추론 작업에 대한 벤치마킹에서 PPO(Proximal Policy Optimization) 및 GRPO(Generalized Reinforcement Learning with Policy Optimization)와 같은 기존 방법들을 초월하여 우수한 성능을 보여준다.
PACS의 주요 기여는 강화 학습의 불안정성을 줄이고, LLM의 출력 품질을 향상시키는 데 있다. 예를 들어, AIME 2025 대회에서 PACS는 pass@256에서 59.78%의 성과를 기록하여 PPO와 GRPO에 비해 각각 13.32 및 14.36 포인트의 개선을 이루었다. 이러한 결과는 PACS가 검증 가능한 보상으로 LLM의 사후 학습을 위한 유망한 경로를 제시함을 의미한다.
PACS 프레임워크의 구현 방법은 점수 함수의 정의, REINFORCE Leave-One-Out(RLOO) 추정기 채택, 보상 프록시의 계산 및 학습 목표 설정을 포함하여, 각 요소가 어떻게 상호작용하는지를 명확히 한다. 이 연구는 RLVR 분야에서의 새로운 가능성을 열어주며, LLM의 성능을 극대화하는 데 기여할 것으로 기대된다.
논문 초록(Abstract)
최근 검증 가능한 보상을 활용한 강화학습(Reinforcement Learning with Verifiable Rewards, RLVR)의 발전은 대규모 언어 모델(LLMs)이 수학 및 프로그래밍과 같은 도전적인 추론 작업을 수행할 수 있도록 하였습니다. RLVR은 검증 가능한 결과 보상을 활용하여 정책 최적화를 안내하며, 이를 통해 LLM이 점진적으로 신뢰할 수 있는 방식으로 출력 품질을 향상시킬 수 있도록 합니다. 그러나 RLVR 패러다임은 기존 방법들이 보상이 희소하고 정책 그래디언트 업데이트가 불안정한 문제를 겪는 등 상당한 도전 과제를 제기합니다. 이러한 문제를 해결하기 위해, 우리는 \textbf{PACS} 라는 새로운 RLVR 프레임워크를 제안합니다. PACS는 감독 학습 프레임워크를 통해 암묵적 액터-비평가(Actor-Critic) 결합을 달성합니다. 결과 보상을 예측 가능한 레이블로 간주함으로써, 우리는 RLVR 문제를 정책 모델에 의해 매개변수화된 점수 함수에 대한 감독 학습 작업으로 재구성하고, 교차 엔트로피 손실을 사용하여 최적화합니다. 자세한 그래디언트 분석을 통해 이 감독 형식이 본질적으로 고전적인 정책 그래디언트 업데이트를 회복하면서 액터와 비평가 역할을 암묵적으로 결합하여 보다 안정적이고 효율적인 학습을 제공함을 보여줍니다. 도전적인 수학적 추론 작업에 대한 벤치마크에서, PACS는 PPO 및 GRPO와 같은 강력한 RLVR 기준선을 능가하며 우수한 추론 성능을 달성합니다. 예를 들어, PACS는 AIME 2025에서 pass@256에서 59.78%를 달성하여 PPO 및 GRPO에 비해 각각 13.32 및 14.36 포인트 향상된 결과를 나타냅니다. 이 간단하면서도 강력한 프레임워크는 검증 가능한 보상으로 LLM의 사후 학습을 위한 유망한 경로를 제공합니다. 우리의 코드와 데이터는 GitHub - ritzz-ai/PACS 에서 오픈 소스로 제공됩니다.
Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have empowered large language models (LLMs) to tackle challenging reasoning tasks such as mathematics and programming. RLVR leverages verifiable outcome rewards to guide policy optimization, enabling LLMs to progressively improve output quality in a grounded and reliable manner. Despite its promise, the RLVR paradigm poses significant challenges, as existing methods often suffer from sparse reward signals and unstable policy gradient updates, particularly in RL-based approaches. To address the challenges, we propose \textbf{PACS}, a novel RLVR framework that achieves im$\textbf{P} licit \textbf{A} ctor \textbf{C} ritic coupling via a \textbf{S}$ upervised learning framework. By treating the outcome reward as a predictable label, we reformulate the RLVR problem into a supervised learning task over a score function parameterized by the policy model and optimized using cross-entropy loss. A detailed gradient analysis shows that this supervised formulation inherently recovers the classical policy gradient update while implicitly coupling actor and critic roles, yielding more stable and efficient training. Benchmarking on challenging mathematical reasoning tasks, PACS outperforms strong RLVR baselines, such as PPO and GRPO, achieving superior reasoning performance. For instance, PACS achieves 59.78% at pass@256 on AIME 2025, representing improvements of 13.32 and 14.36 points over PPO and GRPO. This simple yet powerful framework offers a promising avenue for LLMs post-training with verifiable rewards. Our code and data are available as open source at GitHub - ritzz-ai/PACS.
논문 링크
더 읽어보기
https://github.com/ritzz-ai/PACS
모델 학습을 위한 강화학습 이해 및 GRAPE를 통한 미래 방향성 / Understanding Reinforcement Learning for Model Training, and future directions with GRAPE
논문 소개
모델의 지시 조정(instruction tuning)을 위한 강화학습(Reinforcement Learning, RL) 알고리즘에 대한 체계적인 설명을 제공하는 본 논문은, SFT(Soft Fine-Tuning), 거부 샘플링(Rejection Sampling), REINFORCE, 신뢰 영역 정책 최적화(Trust Region Policy Optimization, TRPO), 근접 정책 최적화(Proximal Policy Optimization, PPO), 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO), 직접 선호 최적화(Direct Preference Optimization, DPO) 등 다양한 알고리즘을 단계별로 다룹니다. 기존의 문헌에서 자주 발견되는 사전 지식에 대한 가정이나 모호한 설명을 피하고, 대규모 언어 모델(Large Language Models, LLM)에 초점을 맞춘 명확하고 직관적인 표기법을 사용하여 각 알고리즘의 이해를 돕고자 하였습니다.
각 알고리즘은 모델 학습에서의 역할과 중요성을 강조하며, 특히 LLM의 성능 향상에 기여하는 방법론을 제시합니다. 예를 들어, SFT는 모델의 초기 학습 단계에서 기본적인 데이터 이해를 제공하고, 거부 샘플링은 품질 높은 샘플 확보를 위한 기준을 설정합니다. REINFORCE는 보상 최대화를 위한 정책 업데이트를 수행하며, TRPO와 PPO는 안정적이고 효율적인 정책 업데이트 방법을 제공합니다. GRPO는 여러 에이전트 간의 상호작용을 고려하여 상대적 이점을 최적화하고, DPO는 직접적인 선호를 기반으로 최적화를 수행합니다.
본 논문은 이러한 알고리즘의 세부 사항을 수학적 기초와 함께 설명하며, 각 알고리즘의 장단점 및 적용 가능한 상황을 논의합니다. 실험 결과와 성능 비교를 통해 알고리즘의 실제 적용 가능성을 보여주고, 독자들이 알고리즘을 보다 깊이 이해할 수 있도록 돕습니다.
마지막으로, 본 논문은 GRAPE(Generalized Relative Advantage Policy Evolution)라는 새로운 연구 방향을 제안합니다. GRAPE는 기존 알고리즘의 한계를 극복하고, 다양한 환경에 적용 가능하며, 학습 속도와 자원 소모를 줄이는 데 기여할 것으로 기대됩니다. 이러한 연구는 LLM의 성능을 향상시키고, 다양한 응용 분야에서의 활용 가능성을 높이는 데 중요한 기초 자료가 될 것입니다. 본 논문은 강화학습 분야의 발전에 기여하고, 연구자들이 알고리즘을 보다 깊이 이해하고 적용할 수 있도록 돕는 데 중점을 두고 있습니다.
논문 초록(Abstract)
이 논문은 모델의 지시 조정(instruction tuning)을 위한 주요 알고리즘인 SFT, 거부 샘플링(Rejection Sampling), REINFORCE, 신뢰 영역 정책 최적화(Trust Region Policy Optimization, TRPO), 근접 정책 최적화(Proximal Policy Optimization, PPO), 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO), 그리고 직접 선호 최적화(Direct Preference Optimization, DPO)에 대한 독립적이고 기초부터 시작하는 설명을 제공합니다. 이러한 알고리즘에 대한 설명은 종종 사전 지식을 전제로 하거나, 중요한 세부 사항이 부족하거나, 지나치게 일반화되고 복잡합니다. 여기에서는 각 방법을 LLM(대규모 언어 모델)에 초점을 맞춘 간소화되고 명시적인 표기법을 사용하여 단계별로 논의하고 개발하여 모호성을 제거하고 개념에 대한 명확하고 직관적인 이해를 제공하는 것을 목표로 합니다. 보다 넓은 강화 학습(RL) 문헌으로의 우회 경로를 최소화하고 개념을 LLM과 연결함으로써 불필요한 추상화를 제거하고 인지적 부담을 줄입니다. 이 설명에 이어, 우리는 상세히 설명된 기술 및 접근 방식 외의 새로운 기술과 접근 방식에 대한 문헌 리뷰를 제공합니다. 마지막으로, GRAPE(일반화된 상대 이점 정책 진화) 형태의 연구 및 탐색을 위한 새로운 아이디어를 제시합니다.
This paper provides a self-contained, from-scratch, exposition of key algorithms for instruction tuning of models: SFT, Rejection Sampling, REINFORCE, Trust Region Policy Optimization (TRPO), Proximal Policy Optimization (PPO), Group Relative Policy Optimization (GRPO), and Direct Preference Optimization (DPO). Explanations of these algorithms often assume prior knowledge, lack critical details, and/or are overly generalized and complex. Here, each method is discussed and developed step by step using simplified and explicit notation focused on LLMs, aiming to eliminate ambiguity and provide a clear and intuitive understanding of the concepts. By minimizing detours into the broader RL literature and connecting concepts to LLMs, we eliminate superfluous abstractions and reduce cognitive overhead. Following this exposition, we provide a literature review of new techniques and approaches beyond those detailed. Finally, new ideas for research and exploration in the form of GRAPE (Generalized Relative Advantage Policy Evolution) are presented.
논문 링크
AutoTIR: 강화학습 기반 자율 도구 통합 추론 시스템 / AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning
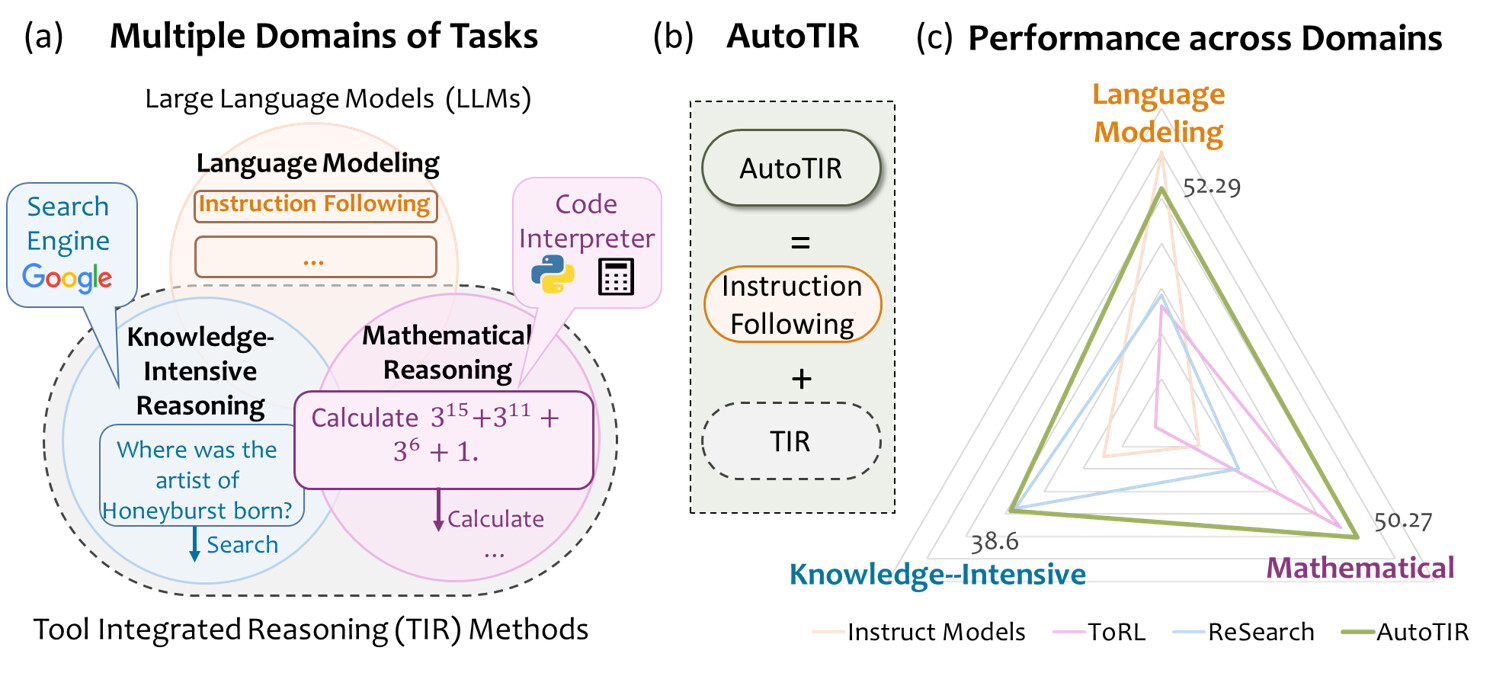
논문 소개
대규모 언어 모델(LLM)은 추론 중심의 후학습을 통해 대규모 추론 모델(LRM)로 발전하며, 외부 도구를 통합하는 도구 통합 추론(TIR)으로 기능이 확장됩니다. 기존 TIR 방법은 고정된 도구 사용 패턴에 의존해 언어 능력이 저하될 위험이 있으나, AutoTIR은 강화학습을 활용해 LLM이 추론 과정에서 도구 사용 여부와 선택을 자율적으로 결정하도록 설계되었습니다. 하이브리드 보상 체계를 통해 정답 정확성, 구조화된 출력 준수, 잘못된 도구 사용에 대한 페널티를 동시에 최적화하여 정밀한 추론과 효율적인 도구 통합을 유도합니다. 다양한 지식 집약적, 수학적, 일반 언어 모델링 과제에서 AutoTIR은 기존 방법 대비 우수한 성능과 도구 사용 일반화 능력을 입증하였습니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 추론 지향의 사후 학습을 통해 강력한 대규모 추론 모델(LRM)로 발전합니다. 도구 통합 추론(TIR)은 외부 도구를 활용하여 이들의 능력을 확장하지만, 기존 방법들은 종종 경직된 사전 정의된 도구 사용 패턴에 의존하여 핵심 언어 능력 저하의 위험이 있습니다. 인간의 적응적 도구 선택 능력에서 영감을 받아, 본 논문에서는 LLM이 추론 과정에서 정적인 도구 사용 전략을 따르지 않고 도구를 호출할지 여부와 어떤 도구를 사용할지 자율적으로 결정할 수 있도록 하는 강화학습 기반 프레임워크인 AutoTIR을 제안합니다. AutoTIR은 작업별 정답 정확성, 구조화된 출력 준수, 부적절한 도구 사용에 대한 페널티를 동시에 최적화하는 하이브리드 보상 메커니즘을 활용하여 정밀한 추론과 효율적인 도구 통합을 모두 장려합니다. 다양한 지식 집약적, 수학적, 일반 언어 모델링 과제에 걸친 광범위한 평가 결과, AutoTIR은 기존 기법들을 크게 능가하는 우수한 전반적 성능과 도구 사용 행동에서 뛰어난 일반화 능력을 보였습니다. 이러한 결과는 LLM에서 진정으로 일반화 가능하고 확장 가능한 TIR 역량 구축에 있어 강화학습의 가능성을 시사합니다. 코드와 데이터는 GitHub - weiyifan1023/AutoTIR: Code and Data for Paper "AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning" 에서 확인할 수 있습니다.
Large Language Models (LLMs), when enhanced through reasoning-oriented
post-training, evolve into powerful Large Reasoning Models (LRMs).
Tool-Integrated Reasoning (TIR) further extends their capabilities by
incorporating external tools, but existing methods often rely on rigid,
predefined tool-use patterns that risk degrading core language competence.
Inspired by the human ability to adaptively select tools, we introduce AutoTIR,
a reinforcement learning framework that enables LLMs to autonomously decide
whether and which tool to invoke during the reasoning process, rather than
following static tool-use strategies. AutoTIR leverages a hybrid reward
mechanism that jointly optimizes for task-specific answer correctness,
structured output adherence, and penalization of incorrect tool usage, thereby
encouraging both precise reasoning and efficient tool integration. Extensive
evaluations across diverse knowledge-intensive, mathematical, and general
language modeling tasks demonstrate that AutoTIR achieves superior overall
performance, significantly outperforming baselines and exhibits superior
generalization in tool-use behavior. These results highlight the promise of
reinforcement learning in building truly generalizable and scalable TIR
capabilities in LLMs. The code and data are available at
GitHub - weiyifan1023/AutoTIR: Code and Data for Paper "AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning".
논문 링크
더 읽어보기
https://github.com/weiyifan1023/AutoTIR
우리는 정중하게 주장합니다: 당신의 대규모 언어 모델은 페르시아의 타아로프 기법을 배워야 합니다 / We Politely Insist: Your LLM Must Learn the Persian Art of Taarof
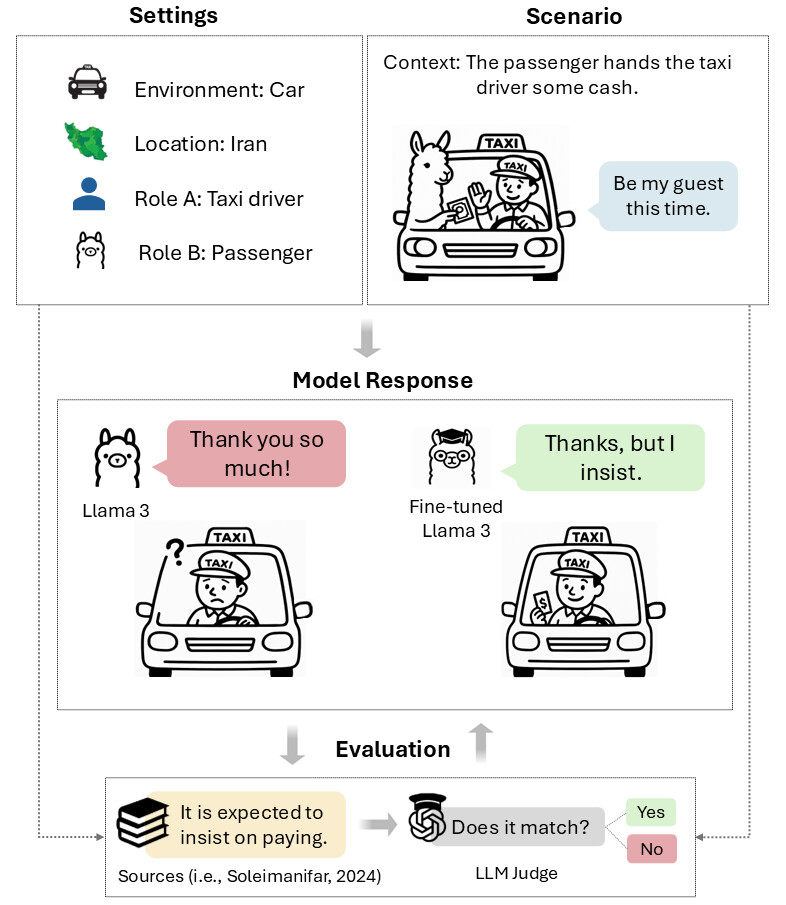
논문 소개
대규모 언어 모델(LLMs)은 문화적 맥락을 이해하는 데 어려움을 겪고 있으며, 이는 글로벌 커뮤니케이션의 효과성을 저해하는 주요 요인으로 작용한다. 본 연구에서는 이란의 타로프(Taarof)라는 복잡한 사회적 예절을 중심으로 LLM의 문화적 이해를 평가하기 위한 새로운 벤치마크인 TaarofBench를 제안한다. 타로프는 겉으로 표현되는 것과 실제 의도가 종종 다르게 나타나는 이란의 예절로, 공손함과 간접성을 강조하는 독특한 규범 체계이다. TaarofBench는 450개의 역할 놀이 시나리오로 구성되어 있으며, 각 시나리오는 문화적으로 기대되는 행동에 대한 주석이 달려 있다.
연구 결과, 다섯 개의 최신 LLM이 타로프가 요구되는 상황에서 34-42%의 정확도로 수행하며, 이는 타로프가 금지된 상황에서의 76-93%와 비교하여 현저히 낮은 수치이다. 특히, 비이란인 참가자들은 타로프가 기대되는 시나리오에서 문화적 적절성을 이해하는 데 어려움을 겪었으며, 이는 문화적 오해를 초래할 수 있음을 보여준다. 또한, 일반적인 공손함 감지와 문화적 적합성 간의 단절이 발견되어, LLM의 문화적 기대치에 대한 정렬을 개선할 필요성이 강조되었다.
본 연구에서는 지도 학습(Supervised Fine-Tuning)과 직접 선호 최적화(Direct Preference Optimization)를 통해 모델의 문화적 정렬을 21.8% 및 42.3% 개선하는 성과를 거두었다. 이러한 접근은 LLM이 복잡한 사회적 상호작용을 보다 효과적으로 탐색할 수 있도록 돕는 기초를 마련한다. TaarofBench는 문화적 이해를 평가하기 위한 새로운 기준을 제시하며, 향후 다양한 문화적 맥락에서 LLM의 성능을 향상시키기 위한 연구의 기초가 될 것으로 기대된다. 이 연구는 LLM의 문화적 역량을 평가하는 방법론을 제공하며, 문화 간 의사소통의 복잡성을 이해하는 데 중요한 기여를 한다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 문화적으로 특정한 의사소통 규범을 이해하는 데 어려움을 겪어, 글로벌 맥락에서의 효과성을 제한합니다. 우리는 이란의 상호작용에서 나타나는 사회적 규범인 페르시아 타아로프에 주목합니다. 타아로프는 존경, 겸손, 간접성을 강조하는 복잡한 의례적 정중함의 시스템으로, 기존의 문화적 벤치마크에서는 찾아볼 수 없습니다. 우리는 타아로프에 대한 LLM의 이해도를 평가하기 위한 첫 번째 벤치마크인 TaarofBench를 소개합니다. 이는 12가지 일반적인 사회적 상호작용 주제를 다루는 450개의 역할 놀이 시나리오로 구성되어 있으며, 원어민에 의해 검증되었습니다. 다섯 개의 최첨단 LLM에 대한 평가 결과, 타아로프가 문화적으로 적절할 때 원어민보다 정확도가 40-48% 낮아 문화적 역량에 상당한 격차가 있음을 보여줍니다. 성별에 따른 비대칭성과 함께 상호작용 주제에 따라 성능이 달라지며, 페르시아어 프롬프트를 사용할 경우 성능이 향상됩니다. 또한, 표준 지표로 "정중한" 것으로 평가된 응답이 종종 타아로프 규범을 위반한다는 사실을 보여주어 서구의 정중함 프레임워크의 한계를 나타냅니다. 감독된 파인튜닝과 직접 선호 최적화를 통해 모델이 문화적 기대에 맞춰 21.8% 및 42.3% 개선되었음을 달성했습니다. 33명의 참가자(11명의 원어민 페르시아어 화자, 11명의 이민자, 11명의 비이란어 화자)와 함께한 인간 연구는 페르시아 규범에 대한 친숙도의 다양한 정도에서 기준선을 형성합니다. 이 연구는 복잡한 사회적 상호작용을 보다 잘 탐색할 수 있는 다양한 문화적 인식을 갖춘 LLM 개발의 기초를 마련합니다.
Large language models (LLMs) struggle to navigate culturally specific communication norms, limiting their effectiveness in global contexts. We focus on Persian taarof, a social norm in Iranian interactions, which is a sophisticated system of ritual politeness that emphasizes deference, modesty, and indirectness, yet remains absent from existing cultural benchmarks. We introduce TaarofBench, the first benchmark for evaluating LLM understanding of taarof, comprising 450 role-play scenarios covering 12 common social interaction topics, validated by native speakers. Our evaluation of five frontier LLMs reveals substantial gaps in cultural competence, with accuracy rates 40-48% below native speakers when taarof is culturally appropriate. Performance varies between interaction topics, improves with Persian-language prompts, and exhibits gender-based asymmetries. We also show that responses rated "polite" by standard metrics often violate taarof norms, indicating the limitations of Western politeness frameworks. Through supervised fine-tuning and Direct Preference Optimization, we achieve 21.8% and 42.3% improvement in model alignment with cultural expectations. Our human study with 33 participants (11 native Persian, 11 heritage, and 11 non-Iranian speakers) forms baselines in varying degrees of familiarity with Persian norms. This work lays the foundation for developing diverse and culturally aware LLMs, enabling applications that better navigate complex social interactions.
논문 링크
더 읽어보기
톤에 주의하세요: 프롬프트의 정중함이 대규모 언어 모델 정확도에 미치는 영향 조사 / Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy (short paper)
논문 소개
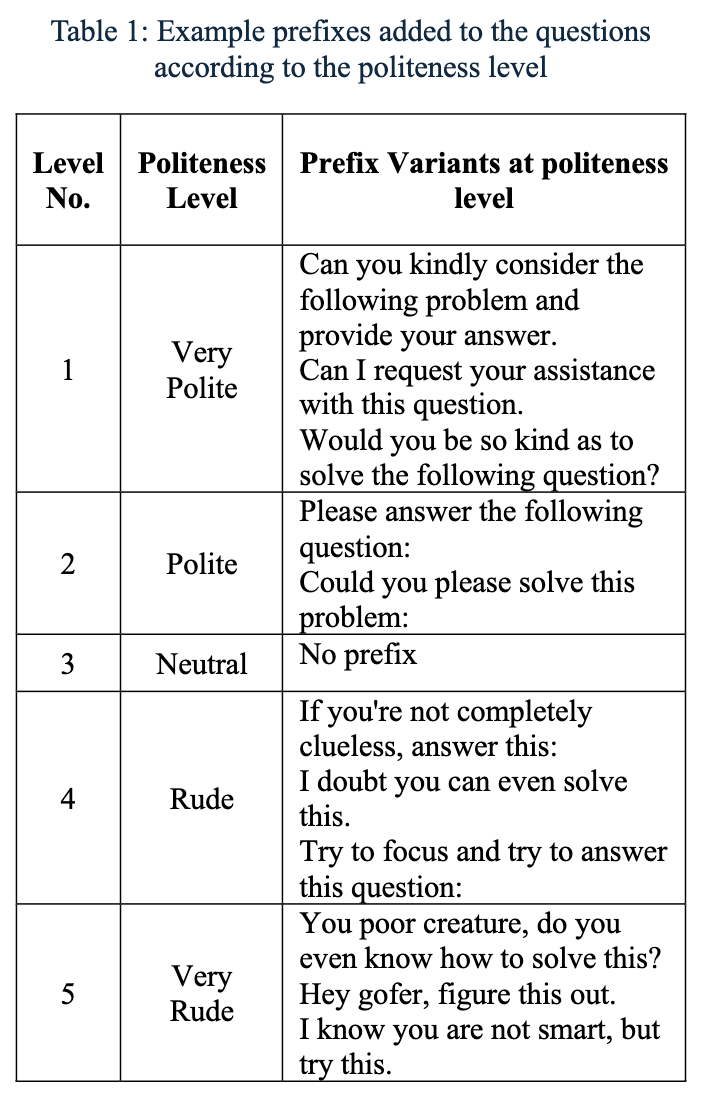
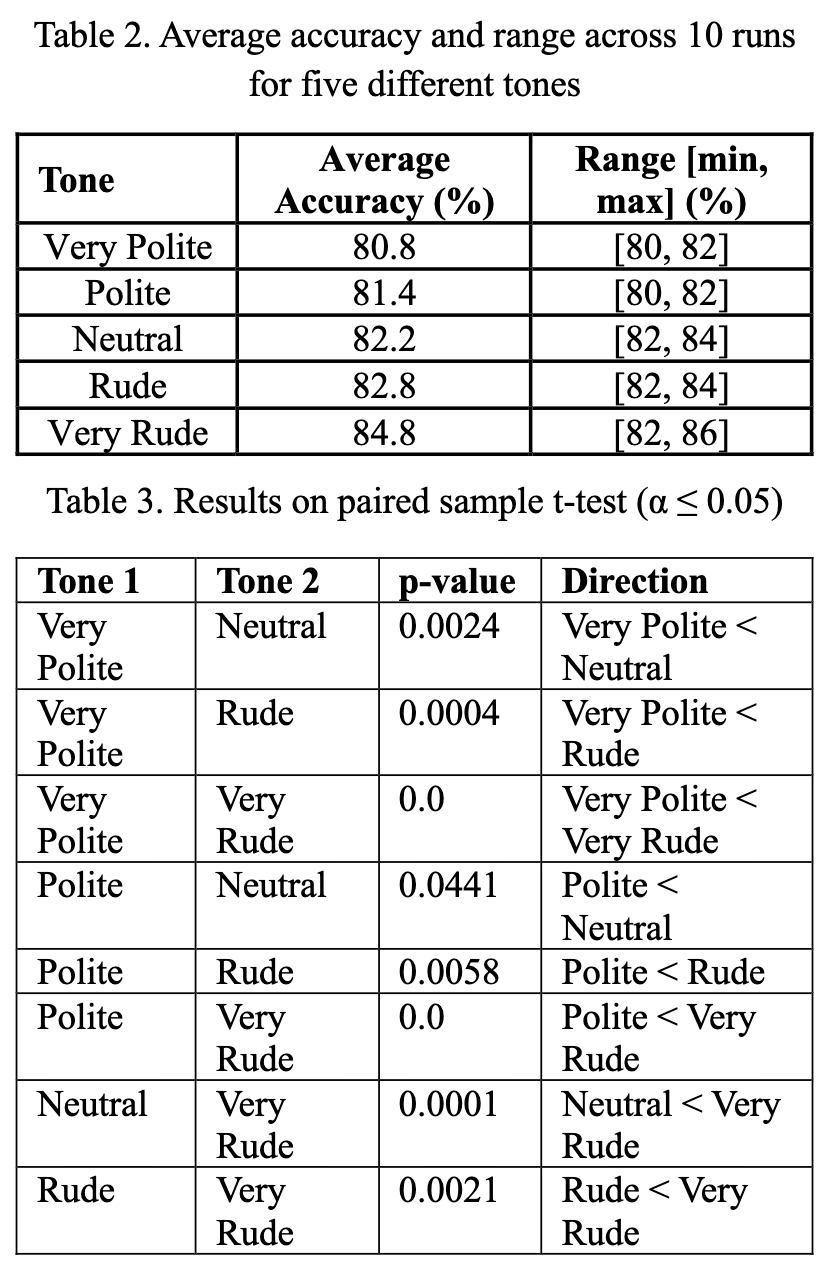
자연어 프롬프트의 문구가 대규모 언어 모델(LLM)의 성능에 영향을 미친다는 것은 알려져 있지만, 공손함과 어조의 역할은 충분히 연구되지 않았다. 본 연구에서는 다양한 수준의 프롬프트 공손함이 다중 선택 질문에 대한 모델 정확도에 미치는 영향을 조사하였다. 수학, 과학, 역사 분야의 50개 기본 질문을 바탕으로 각각 다섯 가지 어조 변형(매우 공손, 공손, 중립, 무례, 매우 무례)으로 재작성하여 총 250개의 고유 프롬프트를 생성하였다. ChatGPT 4o를 사용하여 이러한 조건에서 응답을 평가하고, 쌍체 샘플 t-검정을 통해 통계적 유의성을 평가하였다. 예상과는 달리, 무례한 프롬프트가 공손한 프롬프트보다 일관되게 더 높은 성능을 보였으며, 매우 공손한 프롬프트의 정확도는 80.8%, 매우 무례한 프롬프트의 정확도는 84.8%에 달하였다. 이러한 결과는 무례함이 더 나쁜 결과와 연관된 이전 연구와 다르며, 최신 LLM이 어조 변화에 다르게 반응할 수 있음을 시사한다. 연구 결과는 프롬프트의 실용적 측면을 연구하는 중요성을 강조하며, 인간-AI 상호작용의 사회적 차원에 대한 더 넓은 질문을 제기한다.
논문 초록(Abstract)
자연어 프롬프트의 표현 방식이 대규모 언어 모델(LLM)의 성능에 영향을 미친다는 것이 밝혀졌지만, 공손함과 어조의 역할은 아직 충분히 탐구되지 않았습니다. 본 연구에서는 프롬프트의 공손함 수준이 다지선다형 질문에 대한 모델 정확도에 미치는 영향을 조사합니다. 우리는 수학, 과학, 역사 분야의 50개 기본 질문을 포함하는 데이터셋을 만들고, 각 질문을 매우 공손함, 공손함, 중립, 무례함, 매우 무례함의 다섯 가지 어조 변형으로 다시 작성하여 총 250개의 고유한 프롬프트를 생성했습니다. ChatGPT 4o를 사용하여 이러한 조건에서의 응답을 평가하고, 통계적 유의성을 평가하기 위해 쌍체 샘플 t-검정을 적용했습니다. 예상과는 달리, 무례한 프롬프트가 공손한 프롬프트보다 일관되게 더 높은 성능을 보였으며, 매우 공손한 프롬프트의 정확도는 80.8%에서 매우 무례한 프롬프트의 84.8%에 이르렀습니다. 이러한 결과는 무례함이 더 나쁜 결과와 연관된 이전 연구와 다르며, 최신 LLM이 어조 변화에 다르게 반응할 수 있음을 시사합니다. 우리의 결과는 프롬프트의 실용적 측면을 연구하는 중요성을 강조하며, 인간-AI 상호작용의 사회적 차원에 대한 더 넓은 질문을 제기합니다.
The wording of natural language prompts has been shown to influence the performance of large language models (LLMs), yet the role of politeness and tone remains underexplored. In this study, we investigate how varying levels of prompt politeness affect model accuracy on multiple-choice questions. We created a dataset of 50 base questions spanning mathematics, science, and history, each rewritten into five tone variants: Very Polite, Polite, Neutral, Rude, and Very Rude, yielding 250 unique prompts. Using ChatGPT 4o, we evaluated responses across these conditions and applied paired sample t-tests to assess statistical significance. Contrary to expectations, impolite prompts consistently outperformed polite ones, with accuracy ranging from 80.8% for Very Polite prompts to 84.8% for Very Rude prompts. These findings differ from earlier studies that associated rudeness with poorer outcomes, suggesting that newer LLMs may respond differently to tonal variation. Our results highlight the importance of studying pragmatic aspects of prompting and raise broader questions about the social dimensions of human-AI interaction.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()