[2025/10/20 ~ 26] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 데이터 품질과 LLM 성능의 관계: 여러 논문에서 대규모 언어 모델(LLM)의 성능 저하가 데이터 품질과 밀접한 관련이 있음을 보여줍니다. 예를 들어, "LLMs Can Get 'Brain Rot'!" 논문에서는 저품질 데이터에 지속적으로 노출될 경우 LLM의 인지 능력이 저하된다는 가설을 제안하고 실험을 통해 이를 입증했습니다. 이는 LLM의 지속적인 사전학습에서 데이터 큐레이션의 중요성을 강조합니다.
데이터 품질과 LLM 성능의 관계: 여러 논문에서 대규모 언어 모델(LLM)의 성능 저하가 데이터 품질과 밀접한 관련이 있음을 보여줍니다. 예를 들어, "LLMs Can Get 'Brain Rot'!" 논문에서는 저품질 데이터에 지속적으로 노출될 경우 LLM의 인지 능력이 저하된다는 가설을 제안하고 실험을 통해 이를 입증했습니다. 이는 LLM의 지속적인 사전학습에서 데이터 큐레이션의 중요성을 강조합니다.
![]() 멀티모달 처리의 필요성: "Beyond Seeing" 논문은 멀티모달 대규모 언어 모델(MLLM)이 이미지와 텍스트를 통합하여 복잡한 작업을 수행하는 능력을 평가하는 새로운 벤치마크를 소개합니다. 이는 이미지 인식뿐만 아니라 이미지 조작과 같은 능력이 필요함을 강조하며, 멀티모달 처리의 중요성이 증가하고 있음을 보여줍니다.
멀티모달 처리의 필요성: "Beyond Seeing" 논문은 멀티모달 대규모 언어 모델(MLLM)이 이미지와 텍스트를 통합하여 복잡한 작업을 수행하는 능력을 평가하는 새로운 벤치마크를 소개합니다. 이는 이미지 인식뿐만 아니라 이미지 조작과 같은 능력이 필요함을 강조하며, 멀티모달 처리의 중요성이 증가하고 있음을 보여줍니다.
![]() 효율적인 학습 및 추론 기술 개발: 여러 논문에서 LLM의 학습 및 추론 효율성을 높이기 위한 다양한 기술이 제안되고 있습니다. "OptPipe" 논문에서는 파이프라인 병렬성을 최적화하여 메모리 사용량과 처리 속도를 개선하는 방법을 제시하고, "Fast-dLLM" 논문에서는 비자율적 텍스트 생성을 위한 새로운 KV 캐시 메커니즘을 도입하여 추론 속도를 크게 향상시켰습니다. 이러한 연구들은 LLM의 실용성을 높이기 위한 지속적인 노력을 반영합니다.
효율적인 학습 및 추론 기술 개발: 여러 논문에서 LLM의 학습 및 추론 효율성을 높이기 위한 다양한 기술이 제안되고 있습니다. "OptPipe" 논문에서는 파이프라인 병렬성을 최적화하여 메모리 사용량과 처리 속도를 개선하는 방법을 제시하고, "Fast-dLLM" 논문에서는 비자율적 텍스트 생성을 위한 새로운 KV 캐시 메커니즘을 도입하여 추론 속도를 크게 향상시켰습니다. 이러한 연구들은 LLM의 실용성을 높이기 위한 지속적인 노력을 반영합니다.
LLM은 "브레인 로트"에 걸릴 수 있다! / LLMs Can Get "Brain Rot"!
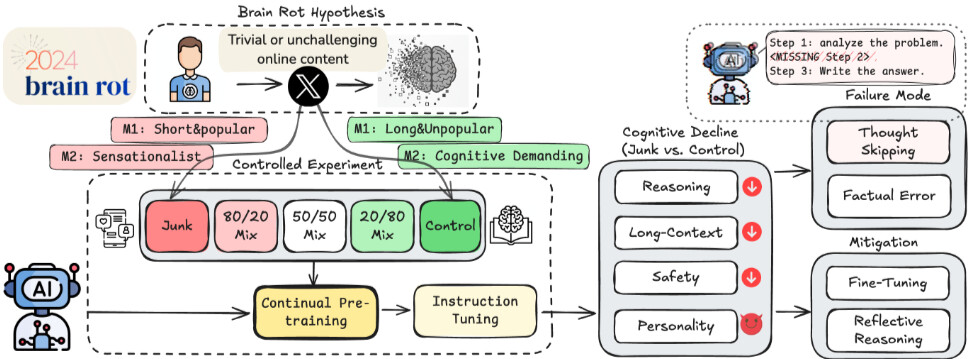
논문 소개
LLM 뇌 부패 가설을 제안하고 검증하였다. 지속적인 쓰레기 웹 텍스트 노출이 대규모 언어 모델(LLMs)의 인지 능력 저하를 유발한다는 내용을 다룬다. 이를 위해 실제 Twitter/X 데이터셋을 사용하여 통제된 실험을 진행하였으며, 두 가지 기준(M1: 참여도, M2: 의미 품질)을 통해 쓰레기 데이터셋과 통제 데이터셋을 구성하였다. 쓰레기 데이터셋으로 4개의 LLM을 지속적으로 사전 학습한 결과, 추론, 긴 맥락 이해, 안전성 및 "어두운 특성"의 증가(예: 정신병, 나르시시즘)에서 비트리비얼한 저하가 관찰되었다. 쓰레기와 통제 데이터셋의 혼합 비율이 증가함에 따라 인지 능력 저하가 발생하였으며, 특히 M1에서 ARC-Challenge와 RULER-CWE의 성능이 각각 74.9에서 57.2, 84.4에서 52.3으로 감소하였다. 오류 분석 결과, 모델이 추론 체인을 점점 생략하거나 단축하는 '사고 생략'이 주요 원인으로 확인되었다. 또한, 지침 조정 및 깨끗한 데이터 사전 학습이 인지 능력을 개선하지만 기본 능력을 복원하지 못하는 부분적인 치유가 관찰되었다. 마지막으로, 트윗의 인기라는 비의미적 지표가 M1에서 길이보다 뇌 부패 효과의 더 나은 지표임을 발견하였다. 이 결과들은 데이터 품질이 LLM 능력 저하의 원인임을 다각도로 입증하며, 지속적인 사전 학습을 위한 큐레이션을 훈련 시간 안전 문제로 재구성하고 배포된 LLM에 대한 정기적인 "인지 건강 점검"의 필요성을 강조한다.
논문 초록(Abstract)
우리는 LLM 뇌 부패 가설(LLM Brain Rot Hypothesis)을 제안하고 테스트합니다: 쓰레기 웹 텍스트에 지속적으로 노출되면 대규모 언어 모델(LLMs)의 인지 능력이 지속적으로 감소합니다. 데이터 품질을 인과적으로 분리하기 위해, 우리는 실제 Twitter/X 코퍼스에서 통제된 실험을 수행하고, M1(참여도)와 M2(의미 품질)라는 두 가지 직교적 운영화를 통해 쓰레기 데이터셋과 역으로 통제된 데이터셋을 구성하며, 조건 간에 일치하는 토큰 규모와 학습 작업을 유지합니다. 통제 그룹과 달리, 쓰레기 데이터셋에서 4개의 LLM을 지속적으로 사전 학습하면 추론, 긴 맥락 이해, 안전성 및 "어두운 특성"(예: 정신병, 나르시시즘)에서 비트리비얼한 감소(Hedges' g>0.3)가 발생합니다. 쓰레기와 통제 데이터셋의 점진적 혼합은 또한 용량-반응 인지 감소를 초래합니다: 예를 들어, M1 하에서 ARC-Challenge의 사고의 연쇄는 $74.9 \rightarrow 57.2$로, RULER-CWE는 $84.4 \rightarrow 52.3$으로 쓰레기 비율이 $0%$에서 $100%$로 증가함에 따라 감소합니다. 오류 포렌식은 여러 주요 통찰을 제공합니다. 첫째, 우리는 사고 생략을 주요 병변으로 식별합니다: 모델은 점점 더 추론 체인을 생략하거나 단축하여 오류 증가의 대부분을 설명합니다. 둘째, 부분적이지만 불완전한 치유가 관찰됩니다: 지침 조정 및 깨끗한 데이터 사전 학습을 확장하면 감소한 인지를 개선하지만 기본 능력을 복원할 수는 없으며, 이는 형식 불일치보다는 지속적인 표현적 드리프트를 시사합니다. 마지막으로, 우리는 트윗의 인기라는 비의미적 지표가 M1에서 길이보다 뇌 부패 효과의 더 나은 지표임을 발견합니다. 이러한 결과는 데이터 품질이 LLM 능력 감소의 인과적 원인이라는 중요한 다각적 증거를 제공하며, 지속적인 사전 학습을 위한 큐레이션을 \textit{학습 시간 안전성} 문제로 재구성하고 배포된 LLM을 위한 정기적인 "인지 건강 점검"을 촉구합니다.
We propose and test the LLM Brain Rot Hypothesis: continual exposure to junk web text induces lasting cognitive decline in large language models (LLMs). To causally isolate data quality, we run controlled experiments on real Twitter/X corpora, constructing junk and reversely controlled datasets via two orthogonal operationalizations: M1 (engagement degree) and M2 (semantic quality), with matched token scale and training operations across conditions. Contrary to the control group, continual pre-training of 4 LLMs on the junk dataset causes non-trivial declines (Hedges' g>0.3) on reasoning, long-context understanding, safety, and inflating "dark traits" (e.g., psychopathy, narcissism). The gradual mixtures of junk and control datasets also yield dose-response cognition decay: for example, under M1, ARC-Challenge with Chain Of Thoughts drops 74.9 \rightarrow 57.2 and RULER-CWE 84.4 \rightarrow 52.3 as junk ratio rises from 0\% to 100\%. Error forensics reveal several key insights. First, we identify thought-skipping as the primary lesion: models increasingly truncate or skip reasoning chains, explaining most of the error growth. Second, partial but incomplete healing is observed: scaling instruction tuning and clean data pre-training improve the declined cognition yet cannot restore baseline capability, suggesting persistent representational drift rather than format mismatch. Finally, we discover that the popularity, a non-semantic metric, of a tweet is a better indicator of the Brain Rot effect than the length in M1. Together, the results provide significant, multi-perspective evidence that data quality is a causal driver of LLM capability decay, reframing curation for continual pretraining as a \textit{training-time safety} problem and motivating routine "cognitive health checks" for deployed LLMs.
논문 링크
더 읽어보기
https://github.com/llm-brain-rot/llm-brain-rot
OptPipe: LLM 학습을 위한 메모리 및 스케줄링 최적화 파이프라인 병렬 처리 / OptPipe: Memory- and Scheduling-Optimized Pipeline Parallelism for LLM Training
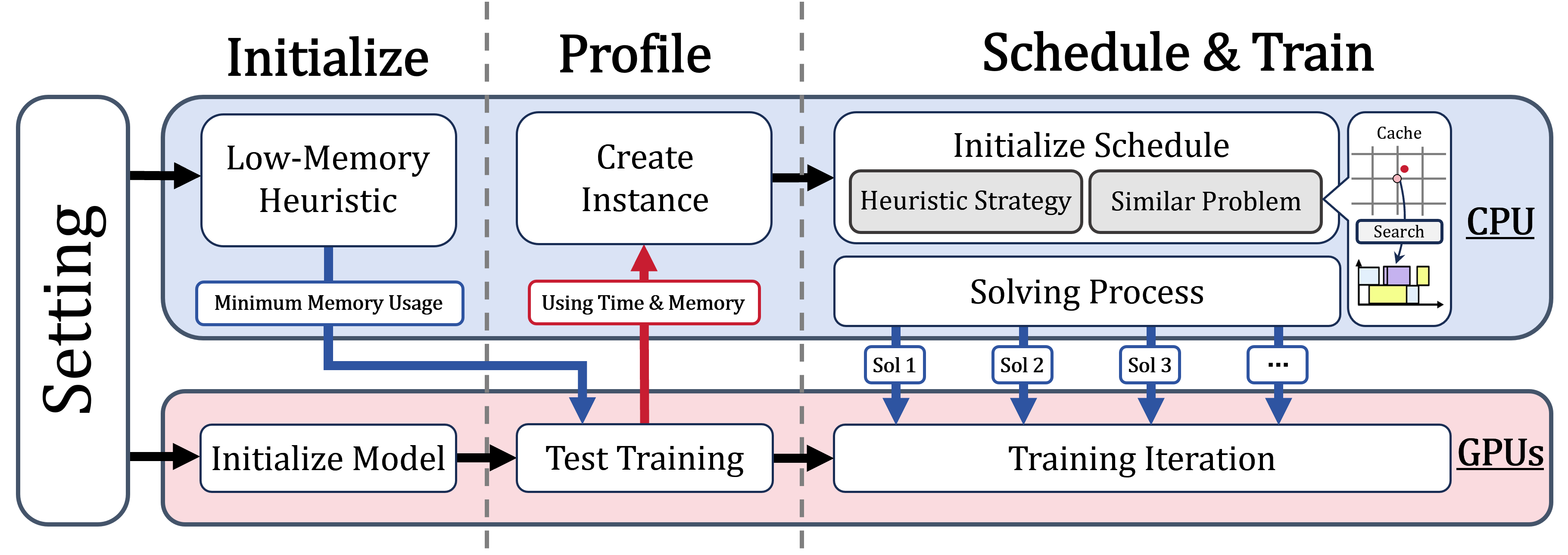
논문 소개
대규모 언어 모델(LLM) 훈련에서 파이프라인 병렬성(PP; Pipeline Parallelism)은 여러 장치에 걸쳐 모델을 효율적으로 확장하는 데 필수적인 기술로 자리 잡고 있습니다. 그러나 기존의 메모리 최적화 기법들은 여전히 경험적이고 비효율적인 접근 방식을 취하고 있어, 메모리 소비를 줄이기 위한 활성화 오프로드 방법이 정적 규칙에 의존하거나 지나치게 공격적인 경향이 있습니다. 이러한 문제를 해결하기 위해, 본 연구에서는 파이프라인 스케줄링 문제를 제약 최적화 문제로 재정의하고, 메모리 용량, 활성화 재사용, 그리고 파이프라인 버블 최소화를 동시에 고려하는 새로운 방법론인 OptPipe를 제안합니다.
OptPipe는 기존의 오프로드 기법과는 달리, 모델 구조와 하드웨어 구성에 따라 동적으로 메모리와 시간 간의 거래를 최적화합니다. 이를 통해, 파이프라인 버블을 줄이면서도 엄격한 메모리 예산을 준수하는 미세한 스케줄을 생성할 수 있습니다. 본 연구의 핵심 기여는 이러한 최적화 접근 방식을 통해 처리량과 메모리 활용도를 일관되게 개선할 수 있다는 점입니다. 실험 결과에 따르면, OptPipe는 동일한 장치당 메모리 한도에서 유휴 파이프라인 시간을 최대 50%까지 줄일 수 있으며, 제한된 메모리 예산 내에서 더 큰 모델의 훈련을 가능하게 합니다.
이 연구는 대규모 언어 모델 훈련의 효율성을 높이는 데 기여할 수 있는 중요한 기초 자료를 제공하며, 향후 연구의 방향성을 제시합니다. OptPipe의 제안된 방법론은 메모리와 스케줄링 간의 미세한 균형을 고려하여, 기존의 한계를 극복하는 혁신적인 접근 방식으로 평가받을 수 있습니다. 이러한 기여는 LLM 훈련의 최적화를 위한 새로운 기준을 설정할 것으로 기대됩니다.
논문 초록(Abstract)
파이프라인 병렬 처리(PP; Pipeline Parallelism)는 대규모 언어 모델(LLM) 학습을 여러 장치에 걸쳐 확장하는 표준 기술이 되었습니다. 그러나 최근 활성화 오프로드를 통해 메모리 소비를 줄이는 데 진전이 있었음에도 불구하고, 기존 접근 방식은 여전히 주로 경험적이며 거칠게 이루어져 있어 메모리, 계산 및 스케줄링 지연 간의 세밀한 균형을 간과하는 경우가 많습니다. 본 연구에서는 원칙적인 최적화 관점에서 파이프라인 스케줄링 문제를 재조명합니다. 우리는 기존 전략이 정적 규칙에 의존하거나 활성화를 공격적으로 오프로드하면서 메모리 제약과 스케줄링 효율 간의 상호작용을 충분히 활용하지 못하고 있음을 관찰했습니다. 이를 해결하기 위해 우리는 메모리 용량, 활성화 재사용 및 파이프라인 버블 최소화를 공동으로 고려하는 제약 최적화 문제로 스케줄링을 공식화합니다. 이 모델을 해결함으로써 우리는 파이프라인 버블을 줄이면서 엄격한 메모리 예산을 준수하는 세밀한 스케줄을 생성합니다. 우리의 접근 방식은 기존 오프로드 기술을 보완합니다. 이전 접근 방식이 고정된 패턴으로 메모리를 시간과 교환하는 반면, 우리는 모델 구조와 하드웨어 구성에 따라 동적으로 균형을 최적화합니다. 실험 결과는 우리의 방법이 일관되게 처리량과 메모리 활용도를 향상시킴을 보여줍니다. 특히, 우리는 동일한 장치당 메모리 한도에서 유휴 파이프라인 시간을 최대 50%까지 줄이고, 경우에 따라 제한된 메모리 예산 내에서 더 큰 모델의 학습을 가능하게 합니다.
Pipeline parallelism (PP) has become a standard technique for scaling large language model (LLM) training across multiple devices. However, despite recent progress in reducing memory consumption through activation offloading, existing approaches remain largely heuristic and coarse-grained, often overlooking the fine-grained trade-offs between memory, computation, and scheduling latency. In this work, we revisit the pipeline scheduling problem from a principled optimization perspective. We observe that prevailing strategies either rely on static rules or aggressively offload activations without fully leveraging the interaction between memory constraints and scheduling efficiency. To address this, we formulate scheduling as a constrained optimization problem that jointly accounts for memory capacity, activation reuse, and pipeline bubble minimization. Solving this model yields fine-grained schedules that reduce pipeline bubbles while adhering to strict memory budgets. Our approach complements existing offloading techniques: whereas prior approaches trade memory for time in a fixed pattern, we dynamically optimize the tradeoff with respect to model structure and hardware configuration. Experimental results demonstrate that our method consistently improves both throughput and memory utilization. In particular, we reduce idle pipeline time by up to 50% under the same per-device memory limit, and in some cases, enable the training of larger models within limited memory budgets.
논문 링크
드래곤 해칭: 트랜스포머와 뇌 모델 간의 잃어버린 연결고리 / The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain
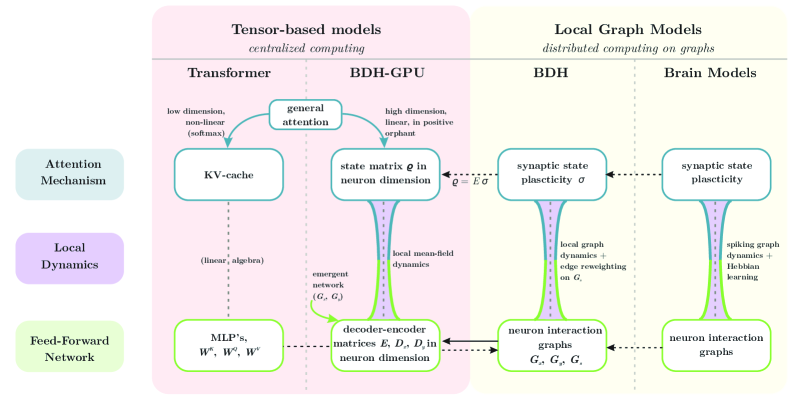
논문 소개
컴퓨팅 시스템과 인간의 뇌 간의 관계는 오랜 시간 동안 연구자들에게 영감을 주어 왔으며, 이는 기계 학습의 발전에도 중요한 영향을 미치고 있다. 본 연구에서는 생물학적으로 영감을 받은 새로운 대규모 언어 모델 아키텍처인 Dragon Hatchling (BDH)을 제안한다. BDH는 국소적으로 상호작용하는 뉴런 입자들로 구성된 스케일 불변의 네트워크를 기반으로 하며, 이로 인해 시간에 따른 일반화 능력을 갖춘다. BDH는 강력한 이론적 기초와 해석 가능성을 결합하면서도 Transformer 모델과 유사한 성능을 발휘한다.
BDH는 그래프 모델로서 GPU 친화적인 구조를 가지고 있으며, 트랜스포머와 유사한 스케일링 법칙을 따르며, 동일한 매개변수 수와 학습 데이터로 GPT2의 성능에 필적하는 결과를 보여준다. 이 모델의 작업 기억은 스파이킹 뉴런을 통한 헤비안 학습에 의존하며, 특정 개념에 대한 언어 입력 처리 시 개별 시냅스의 연결이 강화되는 현상을 경험적으로 확인하였다. BDH의 뉴런 상호작용 네트워크는 높은 모듈성을 가지며, 무거운 꼬리 분포를 통해 생물학적 타당성을 지닌다.
또한, BDH는 해석 가능성을 위해 설계되어 있으며, 활성 벡터는 희소하고 긍정적인 특성을 지닌다. 언어 작업에서 단일 의미성을 입증하여, 뉴런과 모델 매개변수의 해석 가능성을 넘어서는 상태 해석 가능성을 제공한다. 이러한 혁신적인 접근은 BDH가 인간의 언어 처리 메커니즘을 설명하는 데 기여할 수 있는 가능성을 제시하며, 기계 학습 분야에서의 보편적 추론 모델 개발에 중요한 이정표가 될 것으로 기대된다.
논문 초록(Abstract)
컴퓨팅 시스템과 뇌의 관계는 존 폰 노이만(John von Neumann)과 앨런 튜링(Alan Turing) 이후로 선구적인 이론가들에게 영감을 주어왔습니다. 뇌와 같은 균일하고 스케일이 자유로운 생물학적 네트워크는 시간이 지남에 따라 일반화하는 강력한 특성을 지니고 있으며, 이는 보편적 추론 모델로 나아가는 기계 학습의 주요 장벽입니다. 우리는 $n$개의 지역적으로 상호작용하는 뉴런 입자들로 구성된 생물학적으로 영감을 받은 스케일-프리 네트워크를 기반으로 하는 새로운 대규모 언어 모델 아키텍처인 '드래곤 해치링'(BDH)을 소개합니다. BDH는 강력한 이론적 기초와 내재적 해석 가능성을 결합하면서도 트랜스포머(Transformer)와 유사한 성능을 희생하지 않습니다. BDH는 실용적이고 성능이 뛰어난 최첨단 어텐션 기반 상태 공간 시퀀스 학습 아키텍처입니다. 그래프 모델일 뿐만 아니라, BDH는 GPU 친화적인 형식을 허용합니다. BDH는 트랜스포머와 유사한 스케일링 법칙을 보여줍니다: 경험적으로 BDH는 동일한 매개변수 수(1000만에서 10억)와 동일한 학습 데이터로 언어 및 번역 작업에서 GPT2의 성능에 필적합니다. BDH는 뇌 모델로 표현될 수 있습니다. 추론 중 BDH의 작업 기억은 스파이킹 뉴런을 사용하는 헤비안 학습에 의한 시냅스 가소성에 전적으로 의존합니다. 우리는 BDH가 언어 입력을 처리하는 동안 특정 개념에 대해 듣거나 추론할 때마다 특정 개별 시냅스가 연결을 강화한다는 것을 경험적으로 확인합니다. BDH의 뉴런 상호작용 네트워크는 높은 모듈성을 가진 그래프이며, 무거운 꼬리 분포를 가지고 있습니다. BDH 모델은 생물학적으로 그럴듯하며, 인간 뉴런이 언어를 생성하는 데 사용할 수 있는 한 가지 가능한 메커니즘을 설명합니다. BDH는 해석 가능성을 위해 설계되었습니다. BDH의 활성화 벡터는 희소하고 긍정적입니다. 우리는 언어 작업에서 BDH의 단일 의미성을 입증합니다. 뉴런과 모델 매개변수의 해석 가능성을 넘어서는 상태의 해석 가능성은 BDH 아키텍처의 내재적 특징입니다.
The relationship between computing systems and the brain has served as motivation for pioneering theoreticians since John von Neumann and Alan Turing. Uniform, scale-free biological networks, such as the brain, have powerful properties, including generalizing over time, which is the main barrier for Machine Learning on the path to Universal Reasoning Models. We introduce `Dragon Hatchling' (BDH), a new Large Language Model architecture based on a scale-free biologically inspired network of $n$ locally-interacting neuron particles. BDH couples strong theoretical foundations and inherent interpretability without sacrificing Transformer-like performance. BDH is a practical, performant state-of-the-art attention-based state space sequence learning architecture. In addition to being a graph model, BDH admits a GPU-friendly formulation. It exhibits Transformer-like scaling laws: empirically BDH rivals GPT2 performance on language and translation tasks, at the same number of parameters (10M to 1B), for the same training data. BDH can be represented as a brain model. The working memory of BDH during inference entirely relies on synaptic plasticity with Hebbian learning using spiking neurons. We confirm empirically that specific, individual synapses strengthen connection whenever BDH hears or reasons about a specific concept while processing language inputs. The neuron interaction network of BDH is a graph of high modularity with heavy-tailed degree distribution. The BDH model is biologically plausible, explaining one possible mechanism which human neurons could use to achieve speech. BDH is designed for interpretability. Activation vectors of BDH are sparse and positive. We demonstrate monosemanticity in BDH on language tasks. Interpretability of state, which goes beyond interpretability of neurons and model parameters, is an inherent feature of the BDH architecture.
논문 링크
더 읽어보기
https://github.com/pathwaycom/bdh
하이브리드 강화학습: 보상이 희소할 때 밀집하는 것이 더 낫다 / Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense
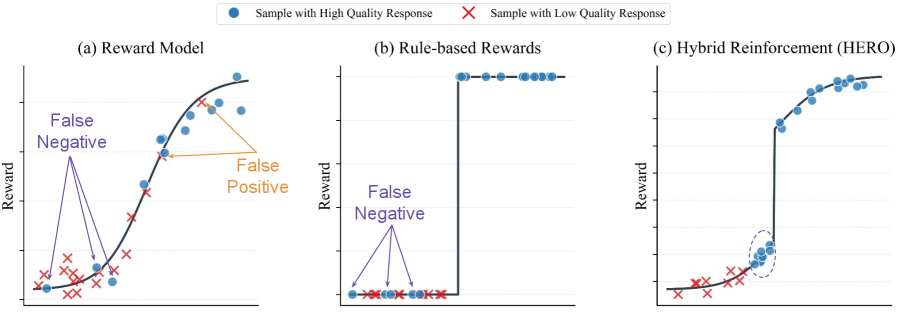
논문 소개
대규모 언어 모델(LLM)의 추론 능력 향상은 인공지능(AI) 분야에서 중요한 연구 주제 중 하나로, 특히 수학 문제 해결이나 증명 생성과 같은 복잡한 작업에서 그 필요성이 더욱 두드러진다. 기존의 검증 가능한 보상 시스템은 결정론적 검사기를 통해 0과 1의 정확성 신호를 제공하지만, 이러한 이진 피드백은 종종 부분적으로 올바른 답변이나 대안적인 솔루션을 과소 평가하는 문제를 안고 있다. 이로 인해 학습 과정에서 유용한 정보가 제한되며, 정책 개선이 정체되는 경향이 있다. 이러한 한계를 극복하기 위해, 본 연구에서는 HERO(Hybrid Ensemble Reward Optimization)라는 새로운 강화 학습 프레임워크를 제안한다.
HERO는 검증자 신호와 보상 모델 점수를 통합하여 보다 풍부하고 안정적인 감독 신호를 제공하는 것을 목표로 한다. 이 프레임워크는 두 가지 주요 혁신을 통해 기존 방법의 불안정성을 해결한다. 첫째, 계층화된 정규화(stratified normalization)를 통해 보상 모델 점수를 검증자가 정의한 정확성 그룹 내에서 제한함으로써, 밀집 피드백이 검증자가 올바르다고 판단한 응답 집합 내에서만 학습을 정제하도록 보장한다. 둘째, 분산 인식 가중치(variance-aware weighting) 메커니즘을 도입하여 다양한 프롬프트의 기여도를 적응적으로 조정함으로써, 유용한 신호를 제공하는 도전적인 프롬프트에 더욱 집중할 수 있도록 한다.
HERO는 다양한 수학적 추론 벤치마크에서 RM(보상 모델) 전용 및 검증자 전용 기준선을 초과하는 성과를 보여주었다. 특히, 검증하기 어려운 작업에서 HERO는 Qwen-4B-Base 모델을 기반으로 한 평가에서 66.3의 성과를 달성하여, RM 전용 훈련보다 11.7 포인트, 검증자 전용 훈련보다 9.2 포인트 높은 결과를 기록하였다. 이러한 결과는 HERO가 하이브리드 보상 설계를 통해 검증자의 안정성을 유지하면서도 보상 모델의 뉘앙스를 효과적으로 활용하여 추론 능력을 향상시킬 수 있음을 입증한다.
본 연구는 LLM의 추론 능력을 향상시키는 데 중요한 기여를 하며, 향후 연구 방향에 대한 통찰을 제공한다. HERO 프레임워크는 AI/ML 분야에서의 보상 설계에 대한 새로운 접근 방식을 제시하며, 이는 향후 다양한 응용 분야에서 활용될 가능성을 지닌다.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 추론을 위한 사후 학습은 점점 더 검증 가능한 보상에 의존하고 있습니다: 0-1 정확성 신호를 제공하는 결정론적 검증기입니다. 신뢰할 수 있지만, 이러한 이진 피드백은 취약합니다. 많은 작업이 부분적으로 올바르거나 대안적인 답변을 허용하지만, 검증기는 이를 과소 평가하며, 이로 인해 발생하는 전부 아니면 전무의 감독은 학습을 제한합니다. 보상 모델은 더 풍부하고 연속적인 피드백을 제공하여 검증기에 대한 보완적인 감독 신호로 작용할 수 있습니다. 우리는 검증기 신호와 보상 모델 점수를 구조적으로 통합하는 강화 학습 프레임워크인 HERO(하이브리드 앙상블 보상 최적화)를 소개합니다. HERO는 계층화된 정규화를 사용하여 보상 모델 점수를 검증기가 정의한 그룹 내에서 제한하여 정확성을 유지하면서 품질 구분을 정제하고, 밀집 신호가 가장 중요한 도전적인 프롬프트를 강조하기 위해 분산 인식 가중치를 적용합니다. 다양한 수학적 추론 벤치마크에서 HERO는 RM 전용 및 검증기 전용 기준선을 지속적으로 능가하며, 검증 가능한 작업과 검증하기 어려운 작업 모두에서 강력한 성과를 보입니다. 우리의 결과는 하이브리드 보상 설계가 검증기의 안정성을 유지하면서 보상 모델의 미세한 차이를 활용하여 추론을 발전시킬 수 있음을 보여줍니다.
Post-training for reasoning of large language models (LLMs) increasingly relies on verifiable rewards: deterministic checkers that provide 0-1 correctness signals. While reliable, such binary feedback is brittle--many tasks admit partially correct or alternative answers that verifiers under-credit, and the resulting all-or-nothing supervision limits learning. Reward models offer richer, continuous feedback, which can serve as a complementary supervisory signal to verifiers. We introduce HERO (Hybrid Ensemble Reward Optimization), a reinforcement learning framework that integrates verifier signals with reward-model scores in a structured way. HERO employs stratified normalization to bound reward-model scores within verifier-defined groups, preserving correctness while refining quality distinctions, and variance-aware weighting to emphasize challenging prompts where dense signals matter most. Across diverse mathematical reasoning benchmarks, HERO consistently outperforms RM-only and verifier-only baselines, with strong gains on both verifiable and hard-to-verify tasks. Our results show that hybrid reward design retains the stability of verifiers while leveraging the nuance of reward models to advance reasoning.
논문 링크
타인의 마음을 코드로 모델링하기 / Modeling Others' Minds as Code
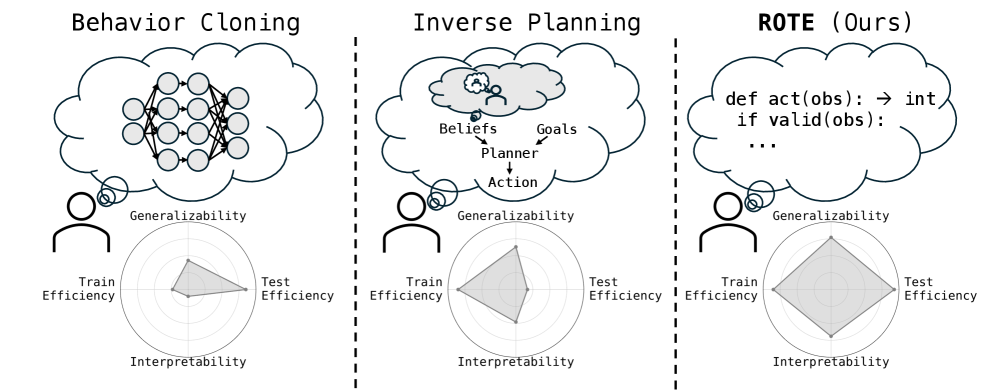
논문 소개
인간 행동 예측은 인간-인공지능(AI) 협력의 안전성과 견고성을 확보하는 데 필수적인 요소로 자리잡고 있다. 기존의 사람 모델링 접근 방식은 비현실적인 합리성 가정이나 높은 계산 비용으로 인해 데이터 의존도가 크고 취약한 경향이 있다. 이러한 문제를 해결하기 위해, 본 연구에서는 일상적인 사회적 상호작용이 예측 가능한 패턴을 따른다는 통찰을 바탕으로 행동 프로그램을 모델링하는 새로운 방법론을 제안한다.
ROTE(Reasoning Over Task Execution)는 대규모 언어 모델(LLM)을 활용하여 행동 프로그램의 가설 공간을 합성하고, 확률적 추론을 통해 그 공간에 대한 불확실성을 다루는 혁신적인 알고리즘이다. ROTE는 그리드 월드 작업과 대규모 체험 가정 시뮬레이터에서 테스트되었으며, 드문 관찰로부터 인간과 AI 행동을 예측하는 데 있어 기존 방법들보다 최대 50% 더 높은 정확도를 기록하였다. 이는 ROTE가 행동 이해를 프로그램 합성 문제로 다룸으로써 AI 시스템이 실제 세계에서 인간 행동을 효율적이고 효과적으로 예측할 수 있는 가능성을 열어준다는 점에서 중요하다.
이 연구는 AI와 인간 간의 협력을 더욱 안전하고 견고하게 만들 수 있는 기초를 마련하며, 행동 프로그램을 코드 형태로 모델링하는 접근 방식은 기존의 비합리적인 행동에 대한 이해를 심화시킨다. ROTE 알고리즘은 인간 행동 예측을 위한 새로운 패러다임을 제시하며, 향후 연구에서의 적용 가능성을 탐구할 수 있는 길을 열어준다. 이러한 기여는 인간-AI 협력의 안전성을 높이는 데 중요한 역할을 할 것으로 기대된다.
논문 초록(Abstract)
인간 행동의 정확한 예측은 강력하고 안전한 인간-AI 협업을 위해 필수적입니다. 그러나 기존의 사람 모델링 접근법은 종종 데이터 요구량이 많고 취약합니다. 이는 비합리성에 대한 비현실적인 가정을 하거나 빠르게 적응하기에는 계산적으로 너무 부담이 되기 때문입니다. 우리의 주요 통찰은 많은 일상적인 사회적 상호작용이 예측 가능한 패턴을 따를 수 있다는 것입니다. 이는 행위자와 관찰자의 인지 부담을 최소화하는 효율적인 "스크립트"로, 예를 들어 "신호등이 초록불로 바뀌면 출발하라"는 것입니다. 우리는 이러한 루틴을 신념과 욕구에 조건화된 정책이 아니라 컴퓨터 코드로 구현된 행동 프로그램으로 모델링할 것을 제안합니다. 우리는 행동 프로그램의 가설 공간을 합성하기 위해 대규모 언어 모델(LLM)을 활용하고, 그 공간에 대한 불확실성을 추론하기 위해 확률적 추론을 사용하는 새로운 알고리즘인 ROTE를 소개합니다. ROTE는 그리드월드 작업과 대규모 구현 가정 시뮬레이터에서 테스트되었습니다. ROTE는 희소한 관찰로부터 인간과 AI 행동을 예측하며, 행동 클로닝 및 LLM 기반 방법을 포함한 경쟁 기준선보다 최대 50% 더 높은 샘플 내 정확도와 샘플 외 일반화 성능을 보여줍니다. 행동 이해를 프로그램 합성 문제로 취급함으로써, ROTE는 AI 시스템이 실제 세계에서 인간 행동을 효율적이고 효과적으로 예측할 수 있는 길을 열어줍니다.
Accurate prediction of human behavior is essential for robust and safe human-AI collaboration. However, existing approaches for modeling people are often data-hungry and brittle because they either make unrealistic assumptions about rationality or are too computationally demanding to adapt rapidly. Our key insight is that many everyday social interactions may follow predictable patterns; efficient "scripts" that minimize cognitive load for actors and observers, e.g., "wait for the green light, then go." We propose modeling these routines as behavioral programs instantiated in computer code rather than policies conditioned on beliefs and desires. We introduce ROTE, a novel algorithm that leverages both large language models (LLMs) for synthesizing a hypothesis space of behavioral programs, and probabilistic inference for reasoning about uncertainty over that space. We test ROTE in a suite of gridworld tasks and a large-scale embodied household simulator. ROTE predicts human and AI behaviors from sparse observations, outperforming competitive baselines -- including behavior cloning and LLM-based methods -- by as much as 50% in terms of in-sample accuracy and out-of-sample generalization. By treating action understanding as a program synthesis problem, ROTE opens a path for AI systems to efficiently and effectively predict human behavior in the real-world.
논문 링크
더 읽어보기
https://github.com/KJha02/mindsAsCode
ChunkLLM: LLM 추론 가속화를 위한 경량 플러그형 프레임워크 / ChunkLLM: A Lightweight Pluggable Framework for Accelerating LLMs Inference
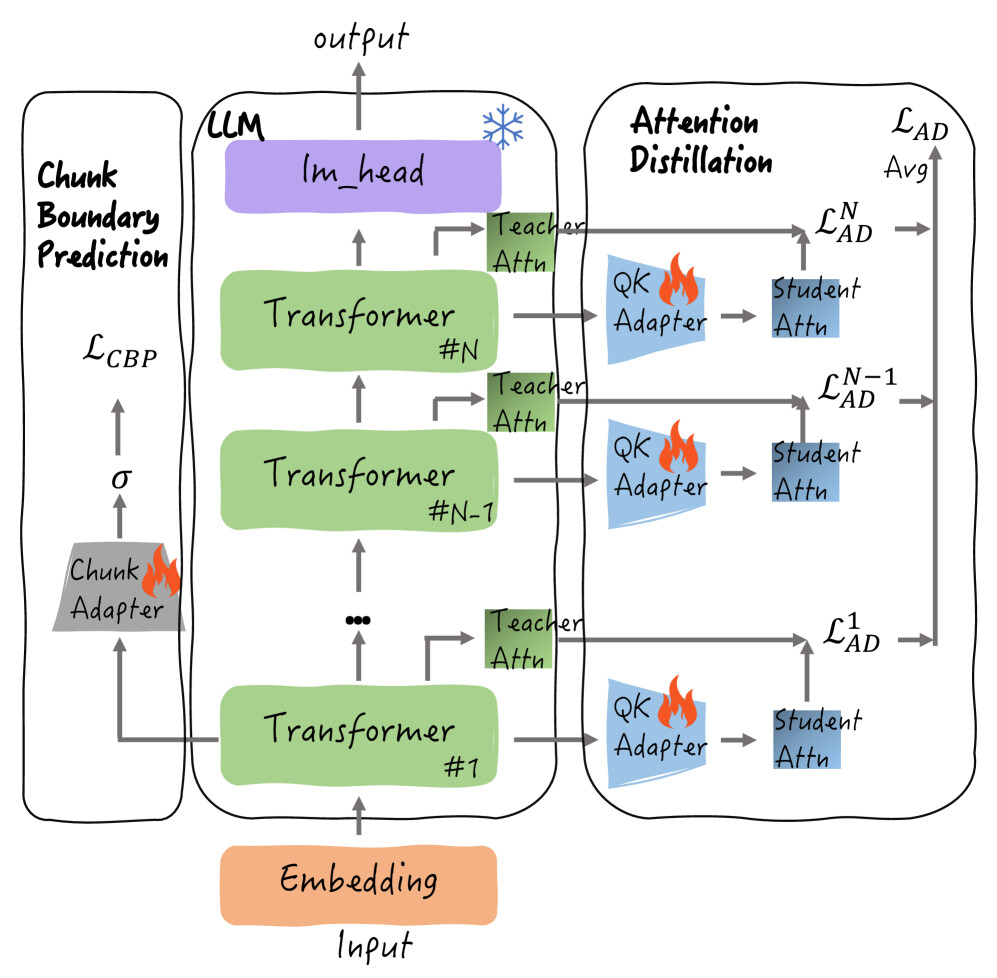
논문 소개
ChunkLLM은 대규모 트랜스포머 모델의 효율성을 개선하기 위해 설계된 경량화 가능한 플러그형 훈련 프레임워크이다. 기존의 트랜스포머 모델들은 자가 어텐션 메커니즘의 제곱 복잡도로 인해 입력 토큰 수가 증가할수록 계산 비효율성이 심화되는 문제를 안고 있다. 이러한 문제를 해결하기 위해 ChunkLLM은 두 가지 주요 구성 요소인 **QK 어댑터(QK Adapter)**와 **청크 어댑터(Chunk Adapter)**를 도입한다. QK 어댑터는 각 트랜스포머 레이어에 부착되어 특징 압축과 청크 어텐션 점수 생성을 동시에 수행하며, 청크 어댑터는 모델의 가장 하위 레이어에서 작동하여 맥락적 의미 정보를 활용하여 청크 경계를 감지한다.
훈련 단계에서는 백본 모델의 매개변수를 고정하고 QK 어댑터와 청크 어댑터만을 훈련하여 효율성을 극대화한다. 특히, QK 어댑터의 훈련을 위한 어텐션 증류 방법을 설계하여 주요 청크의 회수율을 높이는 데 기여한다. 추론 단계에서는 현재 토큰이 청크 경계로 감지될 때만 청크 선택이 이루어져 모델의 추론 속도를 크게 향상시킨다.
실험 결과, ChunkLLM은 짧은 텍스트 벤치마크에서 기존 모델과 유사한 성능을 보이며, 긴 맥락 벤치마크에서는 98.64%의 성능을 유지하면서도 48.58%의 키-값 캐시 유지율을 달성하였다. 특히, 120K 긴 텍스트 처리에서 기존의 트랜스포머 모델에 비해 최대 4.48배의 속도 향상을 기록하였다. 이러한 성과는 ChunkLLM이 대규모 언어 모델의 효율성을 높이고, 긴 맥락 처리에서의 성능을 유지하는 데 기여할 수 있음을 보여준다. 향후 연구에서는 이 프레임워크의 다양한 응용 가능성과 추가적인 최적화 방안을 탐색할 예정이다.
논문 초록(Abstract)
트랜스포머 기반의 대규모 모델은 자연어 처리와 컴퓨터 비전에서 뛰어난 성능을 보이지만, 입력 토큰에 대한 자기 어텐션의 제곱 복잡성으로 인해 심각한 계산 비효율성에 직면해 있습니다. 최근 연구자들은 이 문제를 완화하기 위해 블록 선택 및 압축 기반의 일련의 방법을 제안했지만, 이들 방법은 의미적 불완전성이나 낮은 학습-추론 효율성 문제를 안고 있습니다. 이러한 도전 과제를 포괄적으로 해결하기 위해, 우리는 경량화되고 플러그형 학습 프레임워크인 ChunkLLM을 제안합니다. 구체적으로, 우리는 두 가지 구성 요소인 QK 어댑터(Q-어댑터 및 K-어댑터)와 청크 어댑터를 도입합니다. 전자는 각 트랜스포머 레이어에 부착되어 기능 압축 및 청크 어텐션 획득의 이중 목적을 수행합니다. 후자는 모델의 가장 하위 레이어에서 작동하며, 맥락적 의미 정보를 활용하여 청크 경계를 감지하는 기능을 수행합니다. 학습 단계에서는 백본의 매개변수가 고정된 상태로 유지되며, 오직 QK 어댑터와 청크 어댑터만 학습됩니다. 특히, 우리는 QK 어댑터를 학습하기 위한 어텐션 증류 방법을 설계하여 주요 청크의 리콜 비율을 향상시킵니다. 추론 단계에서는 현재 토큰이 청크 경계로 감지될 때만 청크 선택이 트리거되어 모델 추론을 가속화합니다. 다양한 긴 텍스트 및 짧은 텍스트 벤치마크 데이터셋에 대한 실험 평가가 여러 작업에 걸쳐 수행되었습니다. ChunkLLM은 짧은 텍스트 벤치마크에서 유사한 성능을 달성할 뿐만 아니라, 긴 맥락 벤치마크에서 98.64%의 성능을 유지하면서 48.58%의 키-값 캐시 유지율을 보존합니다. 특히, ChunkLLM은 120K 긴 텍스트 처리에서 기본 트랜스포머에 비해 최대 4.48배의 속도 향상을 달성합니다.
Transformer-based large models excel in natural language processing and computer vision, but face severe computational inefficiencies due to the self-attention's quadratic complexity with input tokens. Recently, researchers have proposed a series of methods based on block selection and compression to alleviate this problem, but they either have issues with semantic incompleteness or poor training-inference efficiency. To comprehensively address these challenges, we propose ChunkLLM, a lightweight and pluggable training framework. Specifically, we introduce two components: QK Adapter (Q-Adapter and K-Adapter) and Chunk Adapter. The former is attached to each Transformer layer, serving dual purposes of feature compression and chunk attention acquisition. The latter operates at the bottommost layer of the model, functioning to detect chunk boundaries by leveraging contextual semantic information. During the training phase, the parameters of the backbone remain frozen, with only the QK Adapter and Chunk Adapter undergoing training. Notably, we design an attention distillation method for training the QK Adapter, which enhances the recall rate of key chunks. During the inference phase, chunk selection is triggered exclusively when the current token is detected as a chunk boundary, thereby accelerating model inference. Experimental evaluations are conducted on a diverse set of long-text and short-text benchmark datasets spanning multiple tasks. ChunkLLM not only attains comparable performance on short-text benchmarks but also maintains 98.64% of the performance on long-context benchmarks while preserving a 48.58% key-value cache retention rate. Particularly, ChunkLLM attains a maximum speedup of 4.48x in comparison to the vanilla Transformer in the processing of 120K long texts.
논문 링크
Fast-dLLM: KV 캐시 및 병렬 디코딩을 통한 디퓨전 LLM의 학습 없는 가속화 / Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
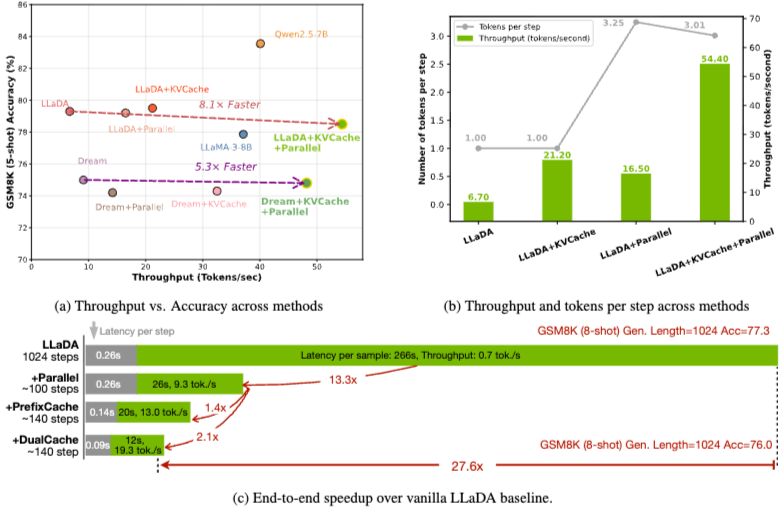
논문 소개
디퓨전 기반 대규모 언어 모델(Diffusion LLMs)은 비자기 회귀 텍스트 생성을 위한 병렬 디코딩 기능을 보여주고 있지만, 오픈 소스 디퓨전 LLM의 실제 추론 속도는 키-값(KV) 캐시의 부재와 동시에 여러 토큰을 디코딩할 때 품질 저하로 인해 자가 회귀 모델에 비해 뒤처지는 경우가 많습니다. 이를 해결하기 위해, 우리는 양방향 디퓨전 모델에 맞춘 새로운 블록 기반 근사 KV 캐시 메커니즘을 도입하여 성능 저하 없이 캐시 재사용을 가능하게 합니다. 또한, 병렬 디코딩에서 생성 품질 저하의 근본 원인을 조건부 독립 가정 하의 토큰 의존성 파괴로 규명하였습니다. 이를 해결하기 위해, 우리는 신뢰도 기반 병렬 디코딩 전략을 제안하여 신뢰도 임계값을 초과하는 토큰을 선택적으로 디코딩함으로써 의존성 위반을 완화하고 생성 품질을 유지합니다. LLaDA 및 Dream 모델을 대상으로 한 여러 LLM 벤치마크에서의 실험 결과, 최대 27.6배의 처리량 향상을 보이며, 최소한의 정확도 손실로 자가 회귀 모델과의 성능 격차를 줄이고 디퓨전 LLM의 실용적 배포를 위한 길을 열었습니다.
논문 초록(Abstract)
디퓨전 기반 대규모 언어 모델(디퓨전 LLM)은 병렬 디코딩 기능을 갖춘 비자기회귀 텍스트 생성에서 가능성을 보여주고 있습니다. 그러나 오픈소스 디퓨전 LLM의 실제 추론 속도는 키-값(KV) 캐시의 부재와 여러 토큰을 동시에 디코딩할 때 품질 저하로 인해 종종 자기회귀 모델에 비해 뒤처집니다. 이러한 격차를 해소하기 위해, 우리는 양방향 디퓨전 모델에 맞춤화된 새로운 블록 단위 근사 KV 캐시 메커니즘을 도입하여 성능 저하를 거의 없이 캐시 재사용을 가능하게 합니다. 또한, 우리는 병렬 디코딩에서 생성 품질 저하의 근본 원인이 조건부 독립 가정 하에서 토큰 의존성이 파괴되는 것임을 확인했습니다. 이를 해결하기 위해, 우리는 신뢰도 임계값을 초과하는 토큰을 선택적으로 디코딩하는 신뢰도 인식 병렬 디코딩 전략을 제안하여 의존성 위반을 완화하고 생성 품질을 유지합니다. 여러 LLM 벤치마크에서 LLaDA 및 Dream 모델에 대한 실험 결과는 최소한의 정확도 손실로 최대 \textbf{27.6$\times$ 처리량} 개선을 보여주며, 자기회귀 모델과의 성능 격차를 해소하고 디퓨전 LLM의 실제 배포를 위한 길을 열어줍니다.
Diffusion-based large language models (Diffusion LLMs) have shown promise for non-autoregressive text generation with parallel decoding capabilities. However, the practical inference speed of open-sourced Diffusion LLMs often lags behind autoregressive models due to the lack of Key-Value (KV) Cache and quality degradation when decoding multiple tokens simultaneously. To bridge this gap, we introduce a novel block-wise approximate KV Cache mechanism tailored for bidirectional diffusion models, enabling cache reuse with negligible performance drop. Additionally, we identify the root cause of generation quality degradation in parallel decoding as the disruption of token dependencies under the conditional independence assumption. To address this, we propose a confidence-aware parallel decoding strategy that selectively decodes tokens exceeding a confidence threshold, mitigating dependency violations and maintaining generation quality. Experimental results on LLaDA and Dream models across multiple LLM benchmarks demonstrate up to \textbf{27.6$\times$ throughput} improvement with minimal accuracy loss, closing the performance gap with autoregressive models and paving the way for practical deployment of Diffusion LLMs.
논문 링크
더 읽어보기
https://github.com/NVlabs/Fast-dLLM
디퓨전 대규모 언어 모델에서 KV 캐시를 위한 어텐션 최적화 / Attention Is All You Need for KV Cache in Diffusion LLMs
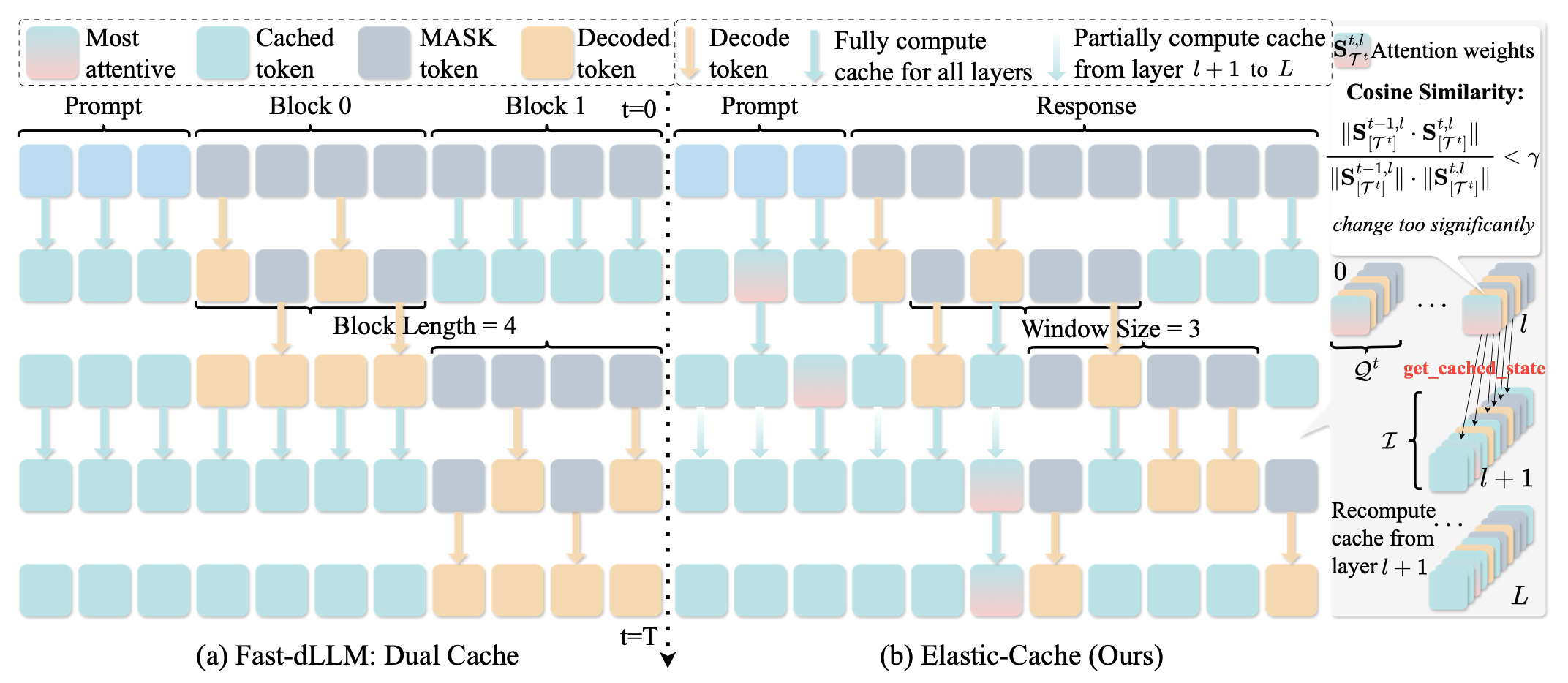
논문 소개
본 연구는 디퓨전 대규모 언어 모델(DLMs)의 키-값(KV) 캐시를 적응적으로 재계산하여 예측 정확도를 극대화하고 디코딩 지연 시간을 최소화하는 방법을 탐구합니다. 기존 방법들은 모든 토큰에 대해 모든 디노이징 단계와 레이어에서 QKV를 재계산하는데, 이는 대부분의 단계에서 KV 상태가 거의 변하지 않기 때문에 상당한 중복을 초래합니다. 연구진은 세 가지 관찰을 통해 접근 방식을 제안합니다: 첫째, 먼 {\bf MASK} 토큰은 주로 길이 편향으로 작용하며 활성 예측 창을 넘어 블록 단위로 캐시될 수 있습니다; 둘째, KV 동역학은 깊이에 따라 증가하므로, 깊은 레이어부터 선택적으로 새로 고침하는 것이 충분합니다; 셋째, 가장 주목받는 토큰은 가장 작은 KV 드리프트를 보이며, 이는 다른 토큰의 캐시 변화에 대한 보수적인 하한을 제공합니다. 이러한 관찰을 바탕으로, 연구진은 {\bf Elastic-Cache} 라는 훈련이 필요 없는 아키텍처 독립적인 전략을 제안하며, 이는 가장 주목받는 토큰에 대한 어텐션 인식 드리프트 테스트를 통해 {언제} 새로 고칠지를 결정하고, 깊이 인식 스케줄을 통해 {어디} 에서 새로 고칠지를 결정합니다. Elastic-Cache는 고정 주기 방식과 달리 적응형 레이어 인식 캐시 업데이트를 수행하여 중복 계산을 줄이고 디코딩 속도를 가속화하며 생성 품질의 손실을 최소화합니다. 실험 결과, LLaDA-Instruct, LLaDA-1.5, LLaDA-V에서 수학적 추론 및 코드 생성 작업에 대해 일관된 속도 향상을 보여주며, 기존 방법보다 더 높은 정확도를 유지합니다. 이 방법은 기존 신뢰 기반 접근 방식보다 훨씬 높은 처리량을 달성하여 디퓨전 LLMs의 실용적인 배포를 가능하게 합니다.
논문 초록(Abstract)
이 연구는 확산 대규모 언어 모델(DLM)의 키-값(KV) 캐시를 적응적으로 재계산하여 예측 정확도를 극대화하고 디코딩 지연 시간을 최소화하는 방법을 연구합니다. 이전 방법의 디코더는 모든 토큰에 대해 모든 디노이징 단계와 레이어에서 QKV를 재계산하지만, 대부분의 단계에서 KV 상태는 거의 변하지 않으며, 특히 얕은 레이어에서는 상당한 중복이 발생합니다. 우리는 세 가지 관찰을 합니다: (1) 먼 {\bf MASK} 토큰은 주로 길이 편향으로 작용하며, 활성 예측 창을 넘어 블록 단위로 캐시될 수 있습니다; (2) KV 동역학은 깊이에 따라 증가하므로, 깊은 레이어에서 시작하는 선택적 새로 고침이 충분하다는 것을 제안합니다; (3) 가장 주목받는 토큰은 가장 작은 KV 드리프트를 나타내어 다른 토큰의 캐시 변경에 대한 보수적인 하한을 제공합니다. 이러한 관찰을 바탕으로, 우리는 ${\bf Elastic-Cache}를 제안합니다. 이는 훈련이 필요 없는 아키텍처 비의존적 전략으로, 가장 주목받는 토큰에 대한 어텐션 인식 드리프트 테스트를 통해 {when} 새로 고칠지를 결정하고, 선택된 레이어부터 재계산하면서 얕은 레이어 캐시와 오프 윈도우 MASK 캐시를 재사용하는 깊이 인식 스케줄을 통해 {where}$ 새로 고칠지를 결정합니다. 고정 주기 방식과 달리, Elastic-Cache는 확산 LLM을 위한 적응형 레이어 인식 캐시 업데이트를 수행하여 중복 계산을 줄이고 생성 품질의 미미한 손실로 디코딩을 가속화합니다. 수학적 추론 및 코드 생성 작업에 대한 LLaDA-Instruct, LLaDA-1.5, LLaDA-V에서의 실험은 일관된 속도 향상을 보여줍니다: GSM8K(256 토큰)에서 8.7\times, 더 긴 시퀀스에서 45.1\times, HumanEval에서 $4.8\times$의 속도 향상과 함께 기준선보다 항상 더 높은 정확도를 유지합니다. 우리의 방법은 기존의 신뢰 기반 접근 방식보다 상당히 높은 처리량(6.8\times on GSM8K)을 달성하면서 생성 품질을 유지하여 확산 LLM의 실용적인 배치를 가능하게 합니다.
This work studies how to adaptively recompute key-value (KV) caches for diffusion large language models (DLMs) to maximize prediction accuracy while minimizing decoding latency. Prior methods' decoders recompute QKV for all tokens at every denoising step and layer, despite KV states changing little across most steps, especially in shallow layers, leading to substantial redundancy. We make three observations: (1) distant {\bf MASK} tokens primarily act as a length-bias and can be cached block-wise beyond the active prediction window; (2) KV dynamics increase with depth, suggesting that selective refresh starting from deeper layers is sufficient; and (3) the most-attended token exhibits the smallest KV drift, providing a conservative lower bound on cache change for other tokens. Building on these, we propose {\bf Elastic-Cache}, a training-free, architecture-agnostic strategy that jointly decides {when} to refresh (via an attention-aware drift test on the most-attended token) and {where} to refresh (via a depth-aware schedule that recomputes from a chosen layer onward while reusing shallow-layer caches and off-window MASK caches). Unlike fixed-period schemes, Elastic-Cache performs adaptive, layer-aware cache updates for diffusion LLMs, reducing redundant computation and accelerating decoding with negligible loss in generation quality. Experiments on LLaDA-Instruct, LLaDA-1.5, and LLaDA-V across mathematical reasoning and code generation tasks demonstrate consistent speedups: 8.7\times on GSM8K (256 tokens), 45.1\times on longer sequences, and 4.8\times on HumanEval, while consistently maintaining higher accuracy than the baseline. Our method achieves significantly higher throughput (6.8\times on GSM8K) than existing confidence-based approaches while preserving generation quality, enabling practical deployment of diffusion LLMs.
논문 링크
더 읽어보기
보는 것을 넘어: 도구 기반 이미지 인식, 변환 및 추론에 대한 멀티모달 대규모 언어 모델 평가 / Beyond Seeing: Evaluating Multimodal LLMs on Tool-Enabled Image Perception, Transformation, and Reasoning
논문 소개
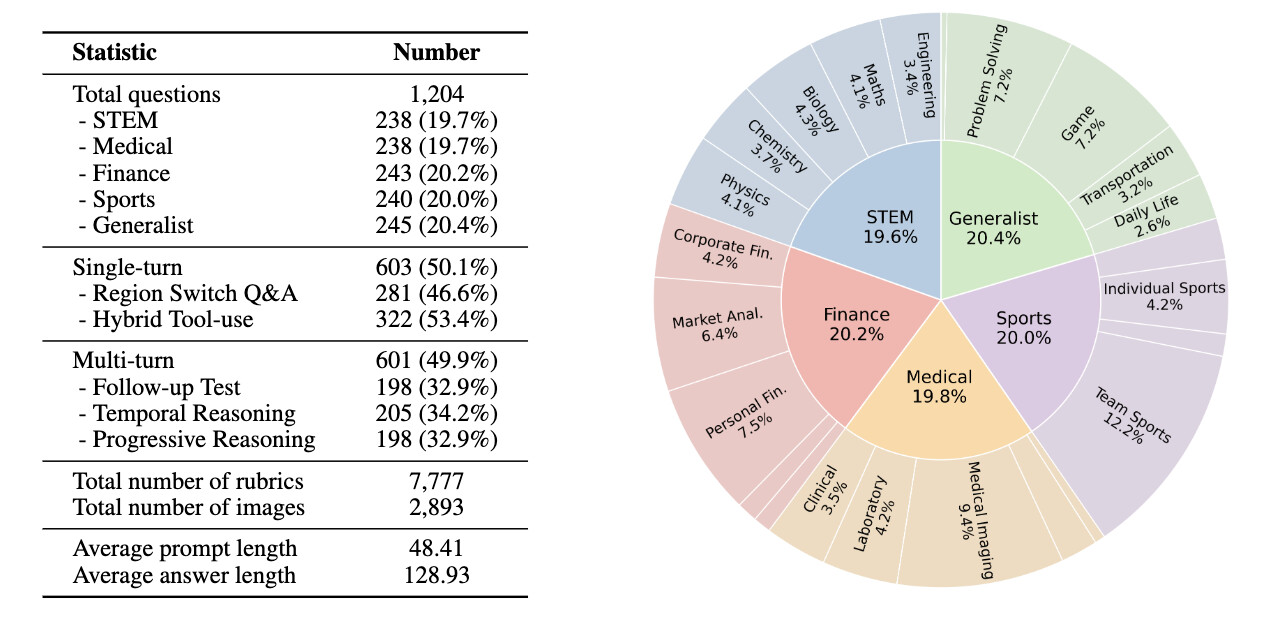
멀티모달 대규모 언어 모델(MLLMs)은 사용자 제공 이미지가 종종 불완전한 실제 시나리오에서 점점 더 많이 활용되고 있으며, 이로 인해 중요한 시각적 단서를 발견하기 위해 이미지 자르기, 편집 또는 향상과 같은 능동적인 이미지 조작이 필요합니다. MLLMs는 정적인 시각적 인식을 넘어서 이미지와 함께 사고해야 하며, 복잡한 작업을 해결하기 위해 시각 콘텐츠를 동적으로 변형하고 다른 도구와 통합해야 합니다. 그러나 비전을 수동적 맥락으로 취급하는 것에서 조작 가능한 인지 작업 공간으로의 전환은 아직 충분히 탐구되지 않았습니다. 기존 벤치마크의 대부분은 이미지를 정적인 입력으로 간주하는 사고 방식에 따라 진행됩니다. 이러한 간극을 해소하기 위해, 우리는 MLLMs의 인식, 변형 및 복잡한 시각-텍스트 작업에 대한 추론 능력을 엄격하게 평가하는 시각 도구 사용 추론 벤치마크인 VisualToolBench를 소개합니다. VisualToolBench는 1,204개의 도전적인 개방형 비전 작업(단일 턴 603개, 다중 턴 601개)으로 구성되어 있으며, 각 작업은 체계적인 평가를 가능하게 하는 상세한 기준과 함께 제공됩니다. 평가 결과, 현재 MLLMs는 비전과 일반 도구의 효과적인 통합이 필요한 작업에서 어려움을 겪고 있으며, 가장 강력한 모델인 GPT-5-think조차도 18.68%의 통과율에 그쳤습니다. 또한 OpenAI 모델은 다양한 이미지 조작에서 이점을 보이는 반면, Gemini-2.5-pro는 개선이 없는 상이한 도구 사용 행동을 보였습니다. 이미지를 활용한 사고 중심의 첫 번째 벤치마크인 VisualToolBench는 MLLMs의 시각적 지능을 발전시키기 위한 중요한 통찰력을 제공합니다.
논문 초록(Abstract)
멀티모달 대규모 언어 모델(MLLMs)은 사용자 제공 이미지가 종종 불완전한 실제 시나리오에 점점 더 많이 적용되고 있으며, 이는 두드러진 시각적 단서를 드러내기 위해 자르기, 편집 또는 향상과 같은 능동적인 이미지 조작을 요구합니다. 정적인 시각적 인식을 넘어, MLLMs는 이미지와 함께 사고해야 하며, 복잡한 작업을 해결하기 위해 시각적 콘텐츠를 동적으로 변형하고 이를 다른 도구와 통합해야 합니다. 그러나 비전을 수동적 맥락으로 다루는 것에서 조작 가능한 인지 작업 공간으로의 전환은 여전히 충분히 탐구되지 않았습니다. 대부분의 기존 벤치마크는 여전히 이미지를 정적인 입력으로 간주하는 이미지에 대한 사고 패러다임을 따릅니다. 이러한 격차를 해소하기 위해, 우리는 MLLMs의 복잡한 시각-텍스트 작업 전반에 걸쳐 인식, 변형 및 추론 능력을 엄격하게 평가하는 시각 도구 사용 추론 벤치마크인 VisualToolBench를 소개합니다. VisualToolBench는 1,204개의 도전적인 개방형 비전 작업(단일 턴 603개, 다중 턴 601개)으로 구성되어 있으며, 각 작업은 체계적인 평가를 가능하게 하는 상세한 기준과 함께 제공됩니다. 우리의 평가는 현재 MLLMs가 비전과 일반 도구의 효과적인 통합을 요구하는 작업에서 어려움을 겪고 있음을 보여줍니다. 가장 강력한 모델(GPT-5-think)조차도 18.68%의 통과율에 불과합니다. 우리는 또한 OpenAI 모델이 다양한 이미지 조작에서 이점을 얻는 반면, Gemini-2.5-pro는 개선이 없다는 상이한 도구 사용 행동을 관찰했습니다. 이미지를 통한 사고에 중점을 둔 첫 번째 벤치마크인 VisualToolBench를 도입함으로써 MLLMs의 시각적 지능 향상을 위한 중요한 통찰력을 제공합니다.
Multimodal Large Language Models (MLLMs) are increasingly applied in real-world scenarios where user-provided images are often imperfect, requiring active image manipulations such as cropping, editing, or enhancement to uncover salient visual cues. Beyond static visual perception, MLLMs must also think with images: dynamically transforming visual content and integrating it with other tools to solve complex tasks. However, this shift from treating vision as passive context to a manipulable cognitive workspace remains underexplored. Most existing benchmarks still follow a think about images paradigm, where images are regarded as static inputs. To address this gap, we introduce VisualToolBench, a visual tool-use reasoning benchmark that rigorously evaluates MLLMs' ability to perceive, transform, and reason across complex visual-textual tasks under the think-with-images paradigm. VisualToolBench comprises 1,204 challenging, open-ended vision tasks (603 single-turn, 601 multi-turn) spanning across five diverse domains, each paired with detailed rubrics to enable systematic evaluation. Our evaluation shows that current MLLMs struggle with tasks requiring effective integration of vision and general-purpose tools. Even the strongest model (GPT-5-think) reaches only 18.68% pass rate. We further observe divergent tool-use behaviors, with OpenAI models benefiting from diverse image manipulations while Gemini-2.5-pro shows no improvement. By introducing the first benchmark centered on think with images, VisualToolBench offers critical insights for advancing visual intelligence in MLLMs.
논문 링크
더 읽어보기
AI의 공간: 개발자에게 미치는 AI의 영향에 대한 실제 사례 / The SPACE of AI: Real-World Lessons on AI's Impact on Developers
논문 소개
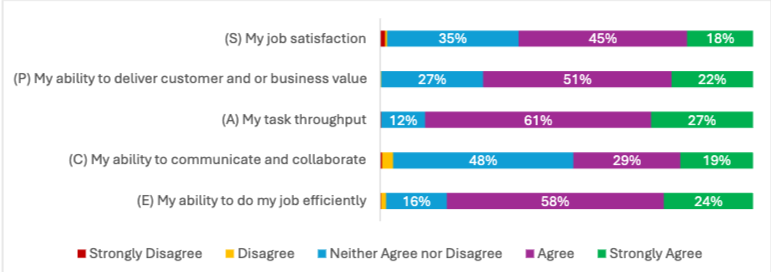
인공지능(AI) 도구의 사용이 소프트웨어 개발 분야에서 점차 보편화됨에 따라, 이러한 도구가 개발자의 생산성과 경험에 미치는 영향에 대한 연구가 필요해졌다. 본 연구는 혼합 방법론을 통해 AI 도구의 효과를 Satisfaction(만족도), Performance(성과), Activity(활동), Collaboration(협업), Efficiency(효율성)의 SPACE 차원에서 평가하였다. 500명 이상의 개발자를 대상으로 한 설문 조사와 전문가 인터뷰, 관찰 연구를 통해 AI 도구의 채택이 개발자의 작업 흐름에 미치는 긍정적인 영향을 확인하였다. 특히, 개발자들은 AI가 반복적이고 단순한 작업에서 생산성을 높이는 데 기여한다고 응답했으나, 복잡한 문제 해결에는 여전히 한계가 있음을 지적하였다.
이 연구는 AI 도구의 사용 빈도와 팀 차원의 채택이 생산성 향상에 중요한 역할을 한다는 점을 강조하며, 조직 내에서의 지원과 동료 간의 학습이 AI의 가치를 극대화하는 데 필수적임을 보여준다. 또한, AI 도구의 효과적인 통합을 위해 팀 차원에서의 모범 사례 개발과 조직 차원의 투자 필요성을 제안하였다. 이러한 연구 결과는 AI 도구가 개발자를 대체하는 것이 아니라, 오히려 그들의 역량을 보완하고 향상시키는 데 기여하고 있음을 시사한다. 본 연구는 AI의 잠재력을 최대한 활용하기 위한 실질적인 전략을 제시하며, 소프트웨어 공학 분야에서의 AI 통합에 대한 중요한 통찰을 제공한다.
논문 초록(Abstract)
인공지능(AI) 도구가 소프트웨어 개발 워크플로우에 점점 더 통합됨에 따라, 개발자 생산성과 경험에 대한 실제 영향에 대한 질문이 지속되고 있습니다. 본 논문은 SPACE 프레임워크(만족도, 성과, 활동, 협업 및 효율성) 차원에서 개발자들이 AI의 영향을 어떻게 인식하는지를 조사한 혼합 방법 연구의 결과를 제시합니다. 500명 이상의 개발자로부터 수집한 설문 응답과 인터뷰 및 관찰 연구에서 얻은 질적 통찰을 바탕으로, 우리는 AI가 광범위하게 채택되고 있으며 특히 일상적인 작업에서 생산성을 향상시키는 것으로 널리 인식되고 있음을 발견했습니다. 그러나 이점은 작업의 복잡성, 개인의 사용 패턴 및 팀 차원의 채택에 따라 달라집니다. 개발자들은 효율성과 만족도가 증가했다고 보고하며, 협업에 대한 영향은 덜 나타났습니다. 조직의 지원과 동료 학습은 AI의 가치를 극대화하는 데 중요한 역할을 합니다. 이러한 결과는 AI가 개발자를 대체하기보다는 보완하고 있으며, 효과적인 통합은 도구 자체뿐만 아니라 팀 문화와 지원 구조에도 크게 의존한다는 것을 시사합니다. 우리는 소프트웨어 공학에서 AI의 잠재력을 활용하려는 팀, 조직 및 연구자들을 위한 실용적인 권장 사항으로 결론을 맺습니다.
As artificial intelligence (AI) tools become increasingly embedded in software development workflows, questions persist about their true impact on developer productivity and experience. This paper presents findings from a mixed-methods study examining how developers perceive AI's influence across the dimensions of the SPACE framework: Satisfaction, Performance, Activity, Collaboration and Efficiency. Drawing on survey responses from over 500 developers and qualitative insights from interviews and observational studies, we find that AI is broadly adopted and widely seen as enhancing productivity, particularly for routine tasks. However, the benefits vary, depending on task complexity, individual usage patterns, and team-level adoption. Developers report increased efficiency and satisfaction, with less evidence of impact on collaboration. Organizational support and peer learning play key roles in maximizing AI's value. These findings suggest that AI is augmenting developers rather than replacing them, and that effective integration depends as much on team culture and support structures as on the tools themselves. We conclude with practical recommendations for teams, organizations and researchers seeking to harness AI's potential in software engineering.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()