[2025/11/03 ~ 09] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 효율적인 언어 모델 설계: 최근 논문들은 대규모 언어 모델(LLM)의 효율성을 높이기 위한 새로운 접근 방식을 제안하고 있습니다. 예를 들어, Continuous Autoregressive Language Models (CALM)은 다음 토큰 예측 대신 연속 벡터 예측을 통해 생성 단계를 줄이고, 더 높은 성능을 달성하는 방법을 제시합니다. 이러한 접근은 모델의 계산 비용을 낮추면서도 성능을 유지하는 데 기여합니다.
효율적인 언어 모델 설계: 최근 논문들은 대규모 언어 모델(LLM)의 효율성을 높이기 위한 새로운 접근 방식을 제안하고 있습니다. 예를 들어, Continuous Autoregressive Language Models (CALM)은 다음 토큰 예측 대신 연속 벡터 예측을 통해 생성 단계를 줄이고, 더 높은 성능을 달성하는 방법을 제시합니다. 이러한 접근은 모델의 계산 비용을 낮추면서도 성능을 유지하는 데 기여합니다.
![]() 문제 난이도 인식 및 조정: LLM이 문제의 난이도를 인식하고 이를 기반으로 성능을 조정하는 연구가 진행되고 있습니다. "LLMs Encode How Difficult Problems Are" 논문에서는 LLM이 인간의 판단과 일치하는 방식으로 문제 난이도를 내부적으로 인코딩하는지를 조사하고, 이를 통해 모델의 정확도를 향상시키는 방법을 제안합니다. 이러한 연구는 LLM의 일반화 능력을 향상시키는 데 중요한 역할을 합니다.
문제 난이도 인식 및 조정: LLM이 문제의 난이도를 인식하고 이를 기반으로 성능을 조정하는 연구가 진행되고 있습니다. "LLMs Encode How Difficult Problems Are" 논문에서는 LLM이 인간의 판단과 일치하는 방식으로 문제 난이도를 내부적으로 인코딩하는지를 조사하고, 이를 통해 모델의 정확도를 향상시키는 방법을 제안합니다. 이러한 연구는 LLM의 일반화 능력을 향상시키는 데 중요한 역할을 합니다.
![]() 자율적 발견 및 데이터 분석: Kosmos와 같은 AI 과학자는 데이터 기반의 발견을 자동화하는 데 중점을 두고 있습니다. 이 시스템은 문헌 검색, 가설 생성 및 데이터 분석을 반복적으로 수행하여 과학적 보고서를 작성합니다. 이는 기존의 연구 방식보다 더 깊이 있는 발견을 가능하게 하며, AI가 과학적 연구에 기여할 수 있는 새로운 가능성을 열어줍니다.
자율적 발견 및 데이터 분석: Kosmos와 같은 AI 과학자는 데이터 기반의 발견을 자동화하는 데 중점을 두고 있습니다. 이 시스템은 문헌 검색, 가설 생성 및 데이터 분석을 반복적으로 수행하여 과학적 보고서를 작성합니다. 이는 기존의 연구 방식보다 더 깊이 있는 발견을 가능하게 하며, AI가 과학적 연구에 기여할 수 있는 새로운 가능성을 열어줍니다.
CALM: 연속 자기회귀 언어 모델 / Continuous Autoregressive Language Models
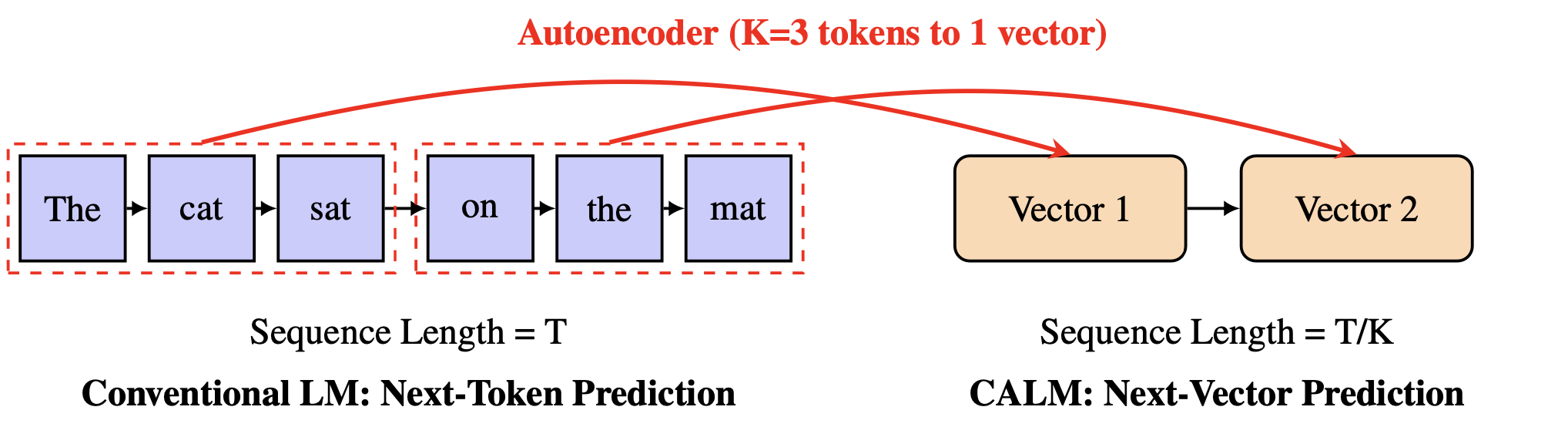
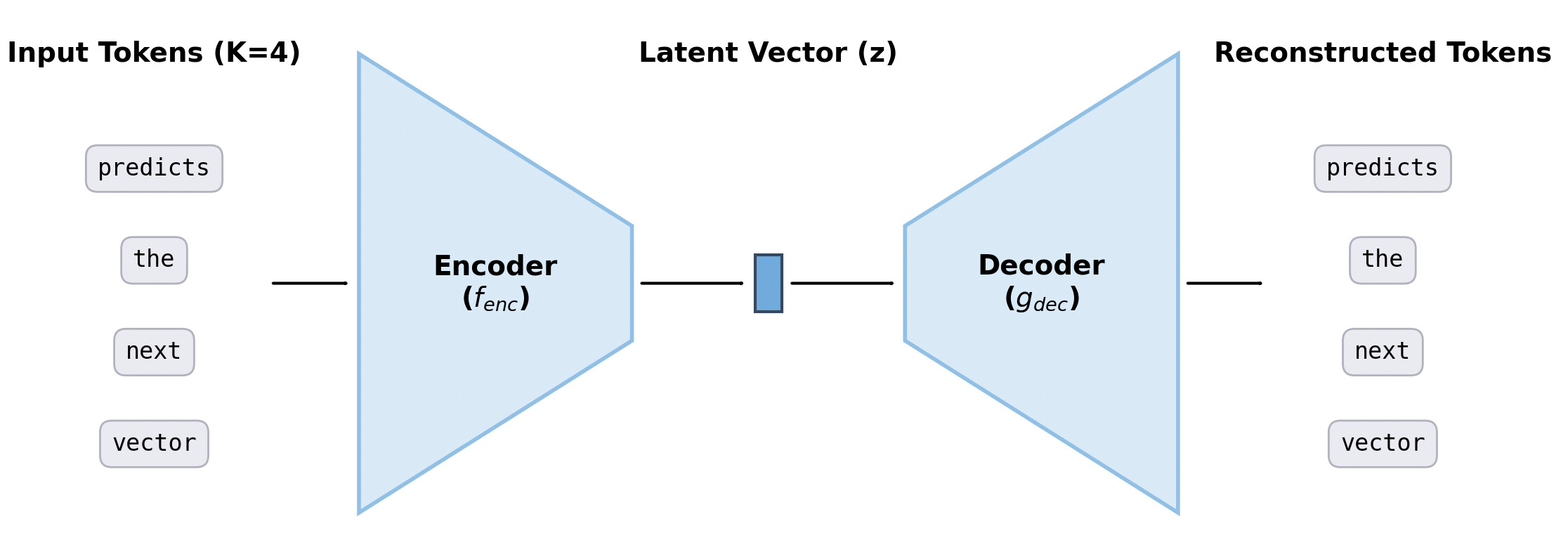
논문 소개
대규모 언어 모델(LLM)의 효율성은 본질적으로 순차적이고 토큰 단위의 생성 프로세스에 의해 제한됩니다. 이러한 병목 현상을 극복하기 위해, 연속 자기회귀 언어 모델(Continuous Autoregressive Language Models, CALM)은 이산적인 다음 토큰 예측에서 연속적인 다음 벡터 예측으로의 패러다임 전환을 제안합니다. CALM은 고충실도 오토인코더를 활용하여 K개의 토큰을 하나의 연속 벡터로 압축하고, 이를 통해 원래의 토큰을 99.9% 이상의 정확도로 재구성할 수 있습니다. 이 접근법은 언어를 이산 토큰 대신 연속 벡터의 시퀀스로 모델링함으로써 생성 단계의 수를 K배 줄이는 효과를 가져옵니다.
CALM의 구현을 위해, 연구팀은 새로운 모델링 툴킷을 개발하여 연속 도메인에서 강력한 학습, 평가 및 제어 가능한 샘플링을 가능하게 하는 포괄적인 가능성 없는 프레임워크를 구축했습니다. 실험 결과, CALM은 성능-계산 비용의 균형을 크게 개선하며, 강력한 이산 기준 모델의 성능을 훨씬 낮은 계산 비용으로 달성하는 것을 보여주었습니다. 특히, CALM은 각 자기회귀 단계의 의미적 대역폭을 증가시켜 더 많은 매개변수를 요구하면서도 훈련 및 추론에 필요한 부동 소수점 연산(Floating Point Operations, FLOPs)을 줄이는 데 성공했습니다.
이 연구는 CALM이 초효율적인 언어 모델을 위한 새로운 경로를 제시하며, 연속적인 예측을 통해 성능-계산 비용의 균형을 최적화할 수 있는 가능성을 보여줍니다. 또한, 오토인코더의 설계 선택이 CALM 프레임워크의 최종 성능에 미치는 영향을 분석하고, 모델 아키텍처와 입력 표현의 중요성을 강조합니다. 이러한 혁신적인 접근은 LLM의 효율성을 높이는 데 기여하며, 향후 연구에 대한 새로운 방향성을 제시합니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 효율성은 본질적으로 순차적이고 토큰 단위의 생성 과정에 의해 제한됩니다. 우리는 이 병목 현상을 극복하기 위해 LLM 확장을 위한 새로운 설계 축이 필요하다고 주장합니다: 각 생성 단계의 의미적 대역폭을 증가시키는 것입니다. 이를 위해 우리는 연속 자기회귀 언어 모델(Continuous Autoregressive Language Models, CALM)을 소개합니다. 이는 이산적인 다음 토큰 예측에서 연속적인 다음 벡터 예측으로의 패러다임 전환입니다. CALM은 고충실도의 오토인코더를 사용하여 K개의 토큰 덩어리를 단일 연속 벡터로 압축하며, 이로부터 원래의 토큰을 99.9% 이상의 정확도로 재구성할 수 있습니다. 이는 언어를 이산 토큰이 아닌 연속 벡터의 시퀀스로 모델링할 수 있게 하여 생성 단계의 수를 K배 줄입니다. 이러한 패러다임 전환은 새로운 모델링 도구 키트를 필요로 하며, 따라서 우리는 연속 영역에서 강력한 학습, 평가 및 제어 가능한 샘플링을 가능하게 하는 포괄적인 우도 없는 프레임워크를 개발합니다. 실험 결과 CALM은 성능-계산 비용의 균형을 크게 개선하여, 강력한 이산 기준 모델의 성능을 훨씬 낮은 계산 비용으로 달성합니다. 더 중요한 것은, 이러한 발견이 다음 벡터 예측을 초효율적인 언어 모델을 향한 강력하고 확장 가능한 경로로 확립한다는 것입니다. 코드: GitHub - shaochenze/calm: Official implementation of "Continuous Autoregressive Language Models". 프로젝트: Continuous Autoregressive Language Models | Chenze Shao.
The efficiency of large language models (LLMs) is fundamentally limited by their sequential, token-by-token generation process. We argue that overcoming this bottleneck requires a new design axis for LLM scaling: increasing the semantic bandwidth of each generative step. To this end, we introduce Continuous Autoregressive Language Models (CALM), a paradigm shift from discrete next-token prediction to continuous next-vector prediction. CALM uses a high-fidelity autoencoder to compress a chunk of K tokens into a single continuous vector, from which the original tokens can be reconstructed with over 99.9% accuracy. This allows us to model language as a sequence of continuous vectors instead of discrete tokens, which reduces the number of generative steps by a factor of K. The paradigm shift necessitates a new modeling toolkit; therefore, we develop a comprehensive likelihood-free framework that enables robust training, evaluation, and controllable sampling in the continuous domain. Experiments show that CALM significantly improves the performance-compute trade-off, achieving the performance of strong discrete baselines at a significantly lower computational cost. More importantly, these findings establish next-vector prediction as a powerful and scalable pathway towards ultra-efficient language models. Code: GitHub - shaochenze/calm: Official implementation of "Continuous Autoregressive Language Models". Project: Continuous Autoregressive Language Models | Chenze Shao.
논문 링크
더 읽어보기
https://github.com/shaochenze/calm
대규모 언어 모델이 문제의 난이도를 어떻게 인코딩하는가 / LLMs Encode How Difficult Problems Are
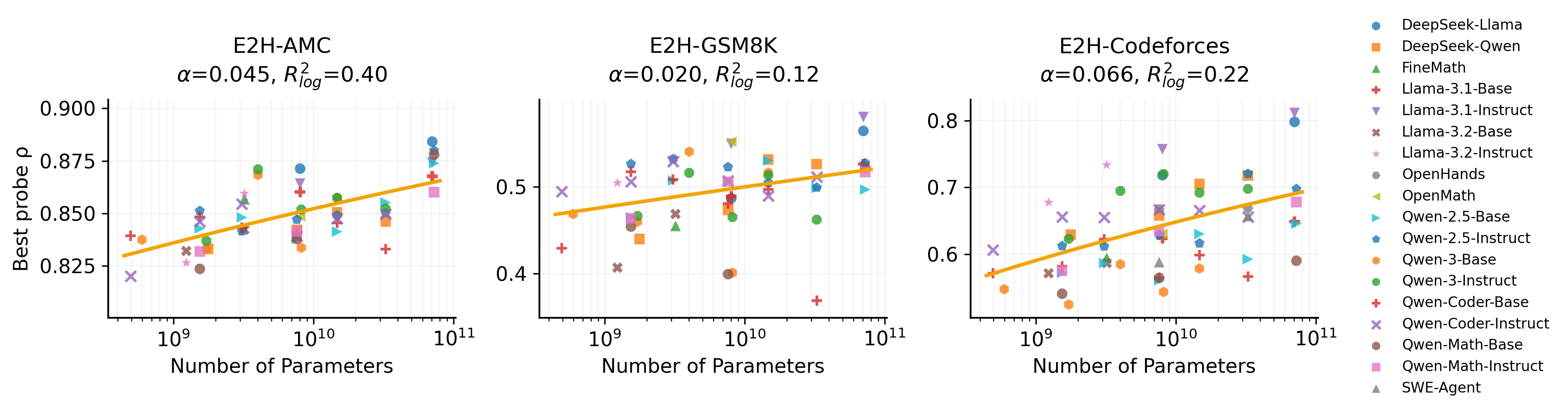
논문 소개
대규모 언어 모델(LLM)은 복잡한 문제를 해결하는 데 뛰어난 성능을 보이지만, 종종 간단한 문제에서 실패하는 모순된 행동을 보인다. 본 연구에서는 LLM이 문제의 난이도를 인간의 판단과 일치하는 방식으로 내부적으로 표현하는지를 조사하고, 이러한 표현이 강화 학습 후 일반화와 어떻게 연관되는지를 탐구한다. 이를 위해 60개의 모델에 대해 선형 프로브를 훈련하고, Easy2HardBench의 수학 및 코딩 하위 집합에서 평가를 진행하였다.
연구 결과, 인간이 라벨링한 난이도는 모델의 활성화에서 강하게 선형적으로 디코딩 가능하며, 모델 크기에 따라 명확한 스케일링을 보인다. 반면, LLM이 유도한 난이도는 상대적으로 약한 인코딩을 보이며 스케일링이 좋지 않다. 연구진은 난이도 방향으로의 조정을 통해 모델을 "더 쉬운" 표현으로 유도하면 허위 진술을 줄이고 정확성을 향상시킬 수 있음을 발견하였다. Qwen2.5-Math-1.5B 모델에서의 GRPO(Generalized Reinforcement Policy Optimization) 훈련 중, 인간 난이도 프로브는 강화되고 테스트 정확도와 긍정적인 상관관계를 보이는 반면, LLM 난이도 프로브는 저하되어 성능과 부정적인 상관관계를 나타낸다.
이러한 결과는 인간 주석이 안정적인 난이도 신호를 제공하며, 강화 학습이 이를 증폭시키는 반면, 모델 성능에서 유도된 자동 난이도 추정치는 모델이 개선됨에 따라 불일치하게 된다는 것을 시사한다. 본 연구는 LLM의 활성화에서 난이도가 인간의 판단과 더 강하게 일치하는 선형 방향으로 존재함을 보여주며, 이는 LLM이 인간이 인지하는 난이도의 강력한 암묵적 표현을 유지하지만, 이를 명시적으로 표현하는 데 어려움을 겪고 있음을 나타낸다. 연구진은 프로브 코드와 평가 스크립트를 공개하여 후속 연구의 재현성을 높이고자 한다.
논문 초록(Abstract)
대규모 언어 모델은 복잡한 문제를 해결하는 동시에 종종 더 간단해 보이는 문제에서 실패하는 모순된 특성을 보입니다. 우리는 LLM이 문제의 난이도를 인간의 판단과 일치하는 방식으로 내부적으로 인코딩하는지, 그리고 이 표현이 강화학습 사후학습 동안 일반화를 추적하는지를 조사합니다. 우리는 60개의 모델에 대해 레이어와 토큰 위치에서 선형 프로브를 훈련하고, Easy2HardBench의 수학 및 코딩 하위 집합에서 평가합니다. 인간이 레이블을 붙인 난이도는 강하게 선형적으로 디코딩 가능하며(AMC: \rho \approx 0.88) 명확한 모델 크기 스케일링을 보이는 반면, LLM에서 유도된 난이도는 상당히 약하고 스케일링이 좋지 않습니다. 난이도 방향으로 조정해보면, 모델을 "더 쉬운" 표현으로 밀어넣는 것이 환각을 줄이고 정확성을 향상시킴을 알 수 있습니다. Qwen2.5-Math-1.5B에서 GRPO 훈련 중, 인간 난이도 프로브는 강화되고 훈련 단계 전반에 걸쳐 테스트 정확성과 긍정적으로 상관관계를 가지며, 반면 LLM 난이도 프로브는 저하되고 성능과 부정적인 상관관계를 보입니다. 이러한 결과는 인간 주석이 RL에 의해 증폭되는 안정적인 난이도 신호를 제공하는 반면, 모델 성능에서 유도된 자동화된 난이도 추정치는 모델이 개선됨에 따라 정렬이 어긋난다는 것을 시사합니다. 우리는 복제를 용이하게 하기 위해 프로브 코드와 평가 스크립트를 공개합니다.
Large language models exhibit a puzzling inconsistency: they solve complex problems yet frequently fail on seemingly simpler ones. We investigate whether LLMs internally encode problem difficulty in a way that aligns with human judgment, and whether this representation tracks generalization during reinforcement learning post-training. We train linear probes across layers and token positions on 60 models, evaluating on mathematical and coding subsets of Easy2HardBench. We find that human-labeled difficulty is strongly linearly decodable (AMC: \rho \approx 0.88) and exhibits clear model-size scaling, whereas LLM-derived difficulty is substantially weaker and scales poorly. Steering along the difficulty direction reveals that pushing models toward "easier" representations reduces hallucination and improves accuracy. During GRPO training on Qwen2.5-Math-1.5B, the human-difficulty probe strengthens and positively correlates with test accuracy across training steps, while the LLM-difficulty probe degrades and negatively correlates with performance. These results suggest that human annotations provide a stable difficulty signal that RL amplifies, while automated difficulty estimates derived from model performance become misaligned precisely as models improve. We release probe code and evaluation scripts to facilitate replication.
논문 링크
코스모스: 자율 발견을 위한 AI 과학자 / Kosmos: An AI Scientist for Autonomous Discovery
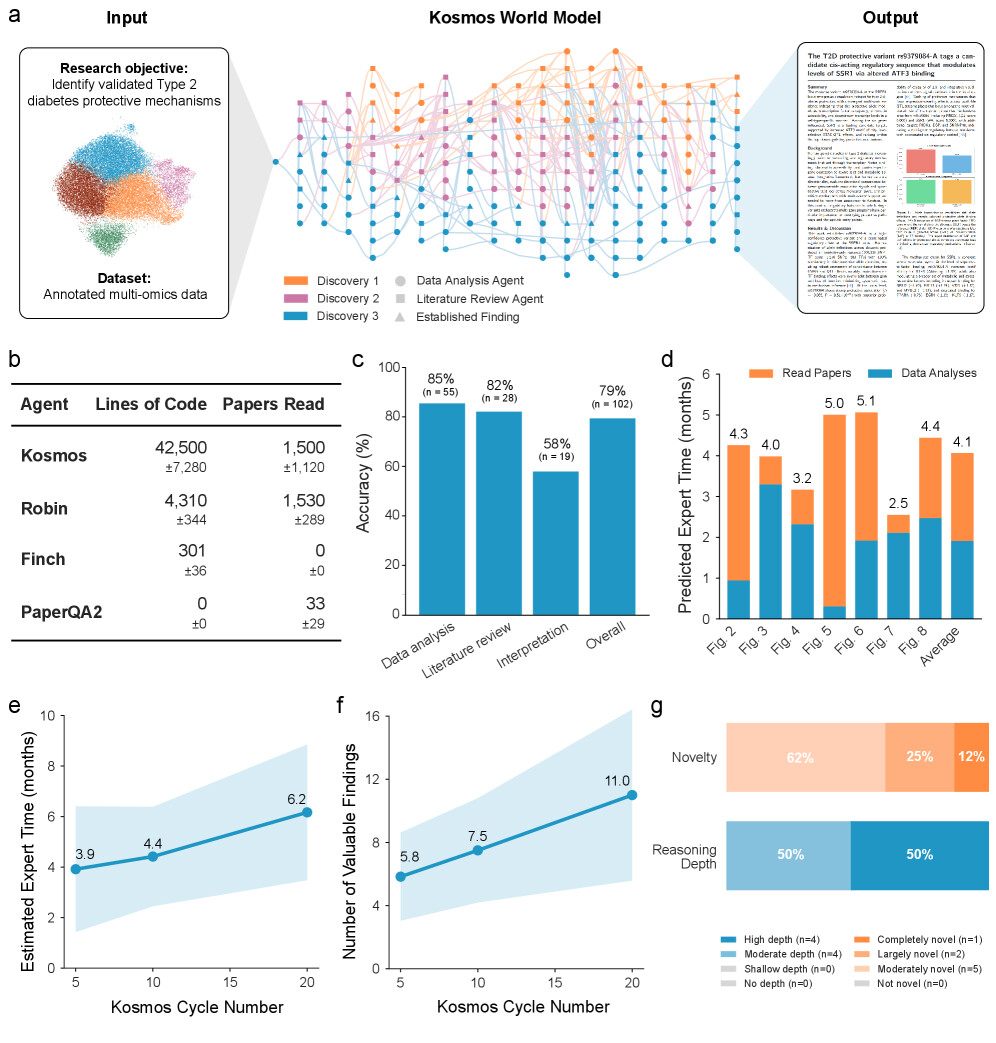
논문 소개
Kosmos는 데이터 기반의 과학적 발견을 자동화하는 혁신적인 AI 과학자로, 개방형 목표와 데이터셋을 활용하여 최대 12시간 동안 병렬 데이터 분석, 문헌 검색 및 가설 생성을 수행합니다. 기존의 AI 연구 시스템들이 제한된 행동 수로 인해 일관성을 잃는 문제를 해결하기 위해, Kosmos는 구조화된 세계 모델을 도입하여 데이터 분석 에이전트와 문헌 검색 에이전트 간의 정보를 효율적으로 공유합니다. 이 세계 모델 덕분에 Kosmos는 200회의 에이전트 롤아웃을 통해 평균 42,000줄의 코드를 실행하고 1,500개의 논문을 읽으며, 지정된 목표를 일관되게 추구할 수 있습니다.
Kosmos는 보고서의 모든 진술을 코드나 주요 문헌으로 인용하여 그 추론 과정을 투명하게 유지합니다. 독립적인 과학자들은 Kosmos의 보고서에서 79.4%의 진술이 정확하다고 평가했으며, 협력자들은 단일 20회 사이클의 Kosmos 실행이 평균적으로 6개월의 연구 시간을 수행한 것과 동등하다고 보고했습니다. 또한, Kosmos의 사이클 수가 증가함에 따라 생성되는 가치 있는 과학적 발견의 수가 선형적으로 증가하는 경향을 보였습니다.
Kosmos가 이룬 주요 발견 중 7가지는 대사체학, 재료 과학, 신경 과학 및 통계 유전학 분야에 걸쳐 있으며, 이 중 3가지는 Kosmos가 실행 중 접근하지 않은 사전 인쇄 또는 미발표 원고의 결과를 독립적으로 재현했습니다. 나머지 4가지는 기존 과학 문헌에 대한 새로운 기여를 포함하고 있습니다. 이러한 성과는 Kosmos의 자동화된 데이터 분석 및 문헌 검색 기능이 과학적 발견의 효율성을 크게 향상시킬 수 있음을 보여줍니다.
Kosmos의 접근 방식은 과학적 질문에 대한 답을 찾기 위해 데이터 분석과 문헌 검색 간의 정보 공유를 가능하게 하여, 보다 일관된 결과를 도출할 수 있도록 합니다. 이러한 혁신적인 방법론은 AI를 활용한 과학적 연구의 새로운 가능성을 제시하며, 향후 다양한 분야에서의 응용 가능성을 열어줍니다. Kosmos는 데이터 기반의 과학적 발견을 위한 중요한 도구로 자리매김할 것으로 기대됩니다.
논문 초록(Abstract)
데이터 기반 과학 발견은 문헌 검색, 가설 생성 및 데이터 분석의 반복적인 사이클을 필요로 합니다. 과학 연구를 자동화할 수 있는 AI 에이전트에 대한 상당한 진전이 있었지만, 이러한 모든 에이전트는 일관성을 잃기 전에 수행할 수 있는 행동의 수가 제한되어 있어 발견의 깊이를 제한합니다. 여기 우리는 데이터 기반 발견을 자동화하는 AI 과학자, 코스모스(Kosmos)를 소개합니다. 개방형 목표와 데이터셋이 주어지면, 코스모스는 최대 12시간 동안 병렬 데이터 분석, 문헌 검색 및 가설 생성의 사이클을 수행한 후 발견을 과학 보고서로 종합합니다. 이전 시스템과 달리, 코스모스는 데이터 분석 에이전트와 문헌 검색 에이전트 간에 정보를 공유하기 위해 구조화된 세계 모델을 사용합니다. 이 세계 모델은 코스모스가 200회의 에이전트 롤아웃을 통해 지정된 목표를 일관되게 추구할 수 있게 하며, 평균 42,000줄의 코드를 실행하고 각 실행마다 1,500개의 논문을 읽습니다. 코스모스는 보고서의 모든 진술을 코드 또는 주요 문헌으로 인용하여 그 추론이 추적 가능하도록 합니다. 독립적인 과학자들은 코스모스 보고서의 79.4%의 진술이 정확하다고 평가했으며, 협력자들은 단일 20회 사이클 코스모스 실행이 평균적으로 자신의 연구 시간 6개월에 해당하는 성과를 달성했다고 보고했습니다. 또한, 협력자들은 생성된 가치 있는 과학 발견의 수가 코스모스 사이클에 비례하여 선형적으로 증가한다고 보고했습니다(최대 20회 사이클 테스트). 우리는 코스모스가 메타볼로믹스, 재료 과학, 신경 과학 및 통계 유전학에 걸쳐 이룬 7가지 발견을 강조합니다. 세 가지 발견은 코스모스가 실행 중에 접근하지 않은 사전 인쇄 또는 미발표 원고의 결과를 독립적으로 재현하며, 네 가지는 과학 문헌에 새로운 기여를 합니다.
Data-driven scientific discovery requires iterative cycles of literature search, hypothesis generation, and data analysis. Substantial progress has been made towards AI agents that can automate scientific research, but all such agents remain limited in the number of actions they can take before losing coherence, thus limiting the depth of their findings. Here we present Kosmos, an AI scientist that automates data-driven discovery. Given an open-ended objective and a dataset, Kosmos runs for up to 12 hours performing cycles of parallel data analysis, literature search, and hypothesis generation before synthesizing discoveries into scientific reports. Unlike prior systems, Kosmos uses a structured world model to share information between a data analysis agent and a literature search agent. The world model enables Kosmos to coherently pursue the specified objective over 200 agent rollouts, collectively executing an average of 42,000 lines of code and reading 1,500 papers per run. Kosmos cites all statements in its reports with code or primary literature, ensuring its reasoning is traceable. Independent scientists found 79.4% of statements in Kosmos reports to be accurate, and collaborators reported that a single 20-cycle Kosmos run performed the equivalent of 6 months of their own research time on average. Furthermore, collaborators reported that the number of valuable scientific findings generated scales linearly with Kosmos cycles (tested up to 20 cycles). We highlight seven discoveries made by Kosmos that span metabolomics, materials science, neuroscience, and statistical genetics. Three discoveries independently reproduce findings from preprinted or unpublished manuscripts that were not accessed by Kosmos at runtime, while four make novel contributions to the scientific literature.
논문 링크
Ring-linear: 모든 어텐션이 중요하다: 장기 맥락 추론을 위한 효율적인 하이브리드 아키텍처 / Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
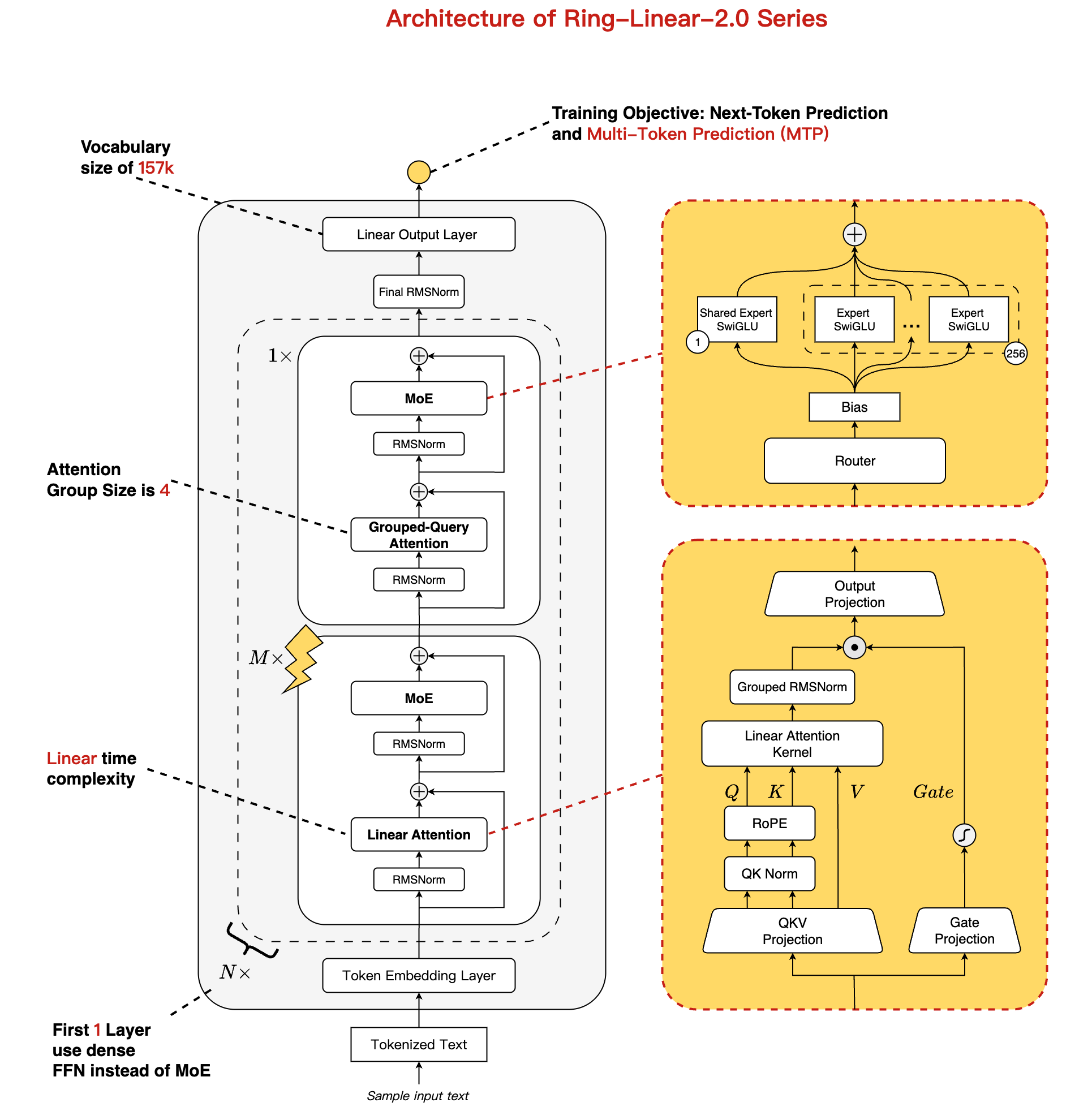
논문 소개
Ring-linear 모델 시리즈는 긴 컨텍스트 추론을 위한 효율적인 하이브리드 아키텍처를 제안하며, 특히 Ring-mini-linear-2.0과 Ring-flash-linear-2.0 모델을 포함한다. 이 모델들은 각각 16B와 104B의 파라미터를 가지고 있으며, 선형 어텐션과 소프트맥스 어텐션을 통합하여 I/O 및 계산 오버헤드를 크게 줄인다. 기존의 32억 파라미터 밀집 모델과 비교할 때, 이 시리즈는 추론 비용을 1/10로 감소시켰으며, 원래의 Ring 시리즈와 비교하여도 50% 이상의 비용 절감을 이루었다.
하이브리드 아키텍처의 핵심은 다양한 어텐션 메커니즘의 비율을 체계적으로 탐색하여 최적의 모델 구조를 식별한 점이다. 이를 통해 모델의 학습 효율성을 50% 향상시킬 수 있는 고성능 FP8 연산자 라이브러리인 LingHe를 개발하였다. 이러한 혁신은 모델이 강화 학습 단계에서 장기적이고 안정적인 최적화를 가능하게 하여, 여러 복잡한 추론 벤치마크에서 최첨단 성능(SOTA)을 지속적으로 유지할 수 있도록 한다.
모델 아키텍처는 여러 층 그룹으로 구성되며, 각 그룹은 선형 어텐션 블록과 Grouped Query Attention(GQA) 블록으로 이루어져 있다. 소프트맥스 어텐션의 계산 복잡성을 극복하기 위해 고정 감쇠를 사용하는 선형 어텐션 메커니즘을 채택하였다. 이러한 설계 선택은 텐서 병렬 처리에서의 통신을 줄이기 위한 그룹 정규화 전략과 언어 모델 손실을 감소시키기 위한 Rotary Position Embedding(RoPE) 적용 등을 포함한다.
추가적으로, 커널 융합 및 최적화를 통해 학습 및 추론 관점에서의 계산 효율성을 입증하였다. 이러한 최적화는 모델의 전반적인 성능을 향상시키고, 특히 MoE(Mixture of Experts) 학습에서의 마이크로 배치 크기를 증가시켜 20% 이상의 학습 효율성 개선을 달성하였다.
결론적으로, Ring-linear 모델 시리즈는 긴 컨텍스트 추론에서의 효율성을 크게 향상시키는 혁신적인 방법론을 제시하며, 향후 연구에서는 성능과 효율성의 균형을 더욱 잘 맞출 수 있는 모델 아키텍처를 탐색할 예정이다.
논문 초록(Abstract)
이 기술 보고서에서는 링-리니어 모델 시리즈를 소개하며, 특히 링-미니-리니어-2.0과 링-플래시-리니어-2.0을 포함합니다. 링-미니-리니어-2.0은 16B 파라미터와 957M 활성화를 포함하고 있으며, 링-플래시-리니어-2.0은 104B 파라미터와 6.1B 활성화를 포함합니다. 두 모델 모두 선형 어텐션과 소프트맥스 어텐션을 효과적으로 통합한 하이브리드 아키텍처를 채택하여 긴 컨텍스트 추론 시 I/O 및 계산 오버헤드를 크게 줄입니다. 320억 파라미터의 밀집 모델과 비교할 때, 이 시리즈는 추론 비용을 1/10로 줄이며, 원래 링 시리즈와 비교할 때도 비용이 50% 이상 감소했습니다. 또한, 하이브리드 아키텍처에서 다양한 어텐션 메커니즘 간의 비율을 체계적으로 탐색함으로써 현재 최적의 모델 구조를 확인했습니다. 추가적으로, 자사가 개발한 고성능 FP8 연산자 라이브러리인 링헤(linghe)를 활용하여 전체 학습 효율성을 50% 향상시켰습니다. 학습 엔진과 추론 엔진 연산자 간의 높은 정렬 덕분에, 모델은 강화 학습 단계에서 장기적이고 안정적이며 매우 효율적인 최적화를 수행할 수 있으며, 여러 도전적인 복합 추론 벤치마크에서 지속적으로 SOTA 성능을 유지합니다.
In this technical report, we present the Ring-linear model series, specifically including Ring-mini-linear-2.0 and Ring-flash-linear-2.0. Ring-mini-linear-2.0 comprises 16B parameters and 957M activations, while Ring-flash-linear-2.0 contains 104B parameters and 6.1B activations. Both models adopt a hybrid architecture that effectively integrates linear attention and softmax attention, significantly reducing I/O and computational overhead in long-context inference scenarios. Compared to a 32 billion parameter dense model, this series reduces inference cost to 1/10, and compared to the original Ring series, the cost is also reduced by over 50%. Furthermore, through systematic exploration of the ratio between different attention mechanisms in the hybrid architecture, we have identified the currently optimal model structure. Additionally, by leveraging our self-developed high-performance FP8 operator library-linghe, overall training efficiency has been improved by 50%. Benefiting from the high alignment between the training and inference engine operators, the models can undergo long-term, stable, and highly efficient optimization during the reinforcement learning phase, consistently maintaining SOTA performance across multiple challenging complex reasoning benchmarks.
논문 링크
더 읽어보기
진실을 위한 학습, 기술 유지: 이진 검색 증강 보상이 환각을 완화한다 / Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations
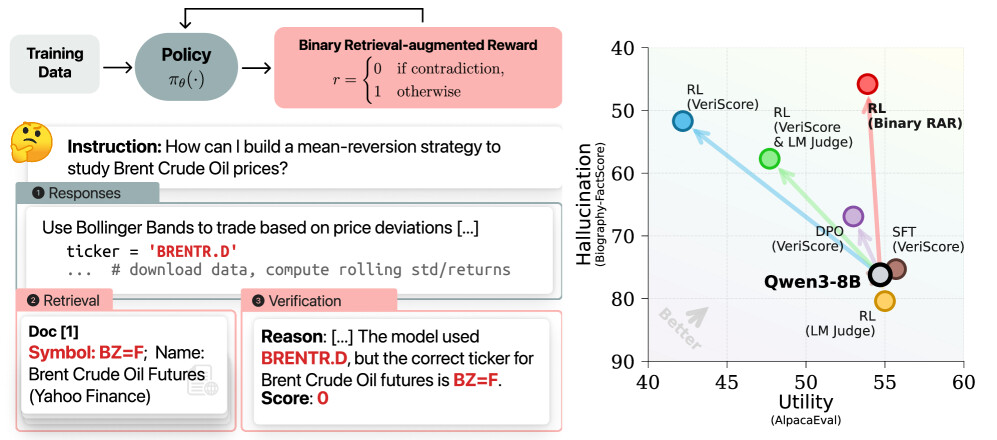
논문 소개
대규모 언어 모델(LLMs)은 정보 검색 및 처리 방식에 혁신을 가져왔으나, 이들이 생성하는 사실적으로 부정확한 정보인 외부 환각(extrinsic hallucination) 문제는 여전히 해결되지 않은 주요 과제로 남아 있습니다. 기존의 환각 완화 방법들은 개방형 생성 및 하위 작업에서 성능 저하를 초래하여 실용성을 제한하는 경향이 있습니다. 본 연구에서는 이러한 문제를 해결하기 위해 이진 검색 보상(Binary Retrieval-Augmented Reward, RAR)을 활용한 온라인 강화 학습 방법을 제안합니다. 이 방법은 모델의 출력이 완전히 사실적으로 정확할 때만 보상을 부여하는 이진 보상 체계를 채택하여, 기존의 연속 보상 체계에서 발생할 수 있는 보상 해킹 문제를 방지합니다.
제안된 방법은 Qwen3 추론 모델을 대상으로 다양한 작업에서 평가되었으며, 개방형 생성에서 환각률을 39.3% 감소시키는 성과를 보였습니다. 또한, 짧은 형식의 질문 응답에서는 모델이 불충분한 지식에 직면했을 때 "모르겠습니다"라는 응답을 전략적으로 선택함으로써 PopQA와 GPQA에서 각각 44.4% 및 21.7%의 잘못된 답변을 줄이는 데 성공했습니다. 이러한 사실성 향상은 지침 준수, 수학, 코드와 같은 일반 능력에서 성능 저하 없이 이루어졌다는 점에서 중요한 의미를 갖습니다.
이 연구의 혁신적인 점은 이진 RAR이 강화 학습의 다양한 작업에 효과적으로 적용될 수 있다는 것입니다. 이 방법은 장기 생성과 단기 질문 응답 모두에 적용 가능하며, 적절한 기권을 자연스럽게 유도하는 구조를 가지고 있습니다. 실험 결과, 이진 RAR로 훈련된 모델은 잘못된 정보를 선택적으로 제거하면서도 정보성을 유지하는 데 성공하였고, 이는 기존의 연속 보상 체계보다 더 큰 환각 감소를 가져왔습니다.
결론적으로, 이 연구는 이진 RAR을 통한 온라인 강화 학습이 사실적 신뢰성을 향상시키면서도 일반 능력을 저하시키지 않는 안정적이고 효과적인 접근 방식임을 입증하였습니다. 이러한 결과는 향후 언어 모델의 신뢰성을 높이는 데 기여할 것으로 기대됩니다.
논문 초록(Abstract)
언어 모델은 종종 학습 데이터에 의해 뒷받침되지 않은 사실적으로 부정확한 정보를 생성하는데, 이를 외부 환각(extrinsic hallucination)이라고 합니다. 기존의 완화 접근법은 종종 개방형 생성 및 하위 작업에서 성능을 저하시켜 실용성을 제한합니다. 우리는 이러한 트레이드오프를 해결하기 위해 새로운 이진 검색 증강 보상(retrieval-augmented reward, RAR)을 사용하는 온라인 강화학습 방법을 제안합니다. 연속 보상 체계와 달리, 우리의 접근법은 모델의 출력이 완전히 사실적으로 정확할 때만 보상 1을 부여하고, 그렇지 않을 경우 0을 부여합니다. 우리는 다양한 작업에 걸쳐 Qwen3 추론 모델에서 우리의 방법을 평가합니다. 개방형 생성의 경우, 이진 RAR은 환각 비율을 39.3% 감소시켜, 감독 학습 및 연속 보상 강화학습 기준선을 크게 초월합니다. 짧은 형식의 질문 응답에서 모델은 조정된 자제력을 학습하여, 충분한 매개 지식이 없을 때 전략적으로 "모르겠습니다"라는 출력을 생성합니다. 이는 PopQA와 GPQA에서 각각 44.4% 및 21.7%의 잘못된 답변을 줄이는 결과를 가져옵니다. 중요한 것은 이러한 사실성 향상이 지시 따르기, 수학, 또는 코드 작업에서 성능 저하 없이 이루어지며, 반면 연속 보상 강화학습은 사실성을 개선하더라도 품질 저하를 초래한다는 점입니다.
Language models often generate factually incorrect information unsupported by their training data, a phenomenon known as extrinsic hallucination. Existing mitigation approaches often degrade performance on open-ended generation and downstream tasks, limiting their practical utility. We propose an online reinforcement learning method using a novel binary retrieval-augmented reward (RAR) to address this tradeoff. Unlike continuous reward schemes, our approach assigns a reward of one only when the model's output is entirely factually correct, and zero otherwise. We evaluate our method on Qwen3 reasoning models across diverse tasks. For open-ended generation, binary RAR achieves a 39.3% reduction in hallucination rates, substantially outperforming both supervised training and continuous-reward RL baselines. In short-form question answering, the model learns calibrated abstention, strategically outputting "I don't know" when faced with insufficient parametric knowledge. This yields 44.4% and 21.7% fewer incorrect answers on PopQA and GPQA, respectively. Crucially, these factuality gains come without performance degradation on instruction following, math, or code, whereas continuous-reward RL, despite improving factuality, induces quality regressions.
논문 링크
강인한 GNN 워터마킹을 위한 위상 불변량의 암묵적 인식 활용 / Robust GNN Watermarking via Implicit Perception of Topological Invariants
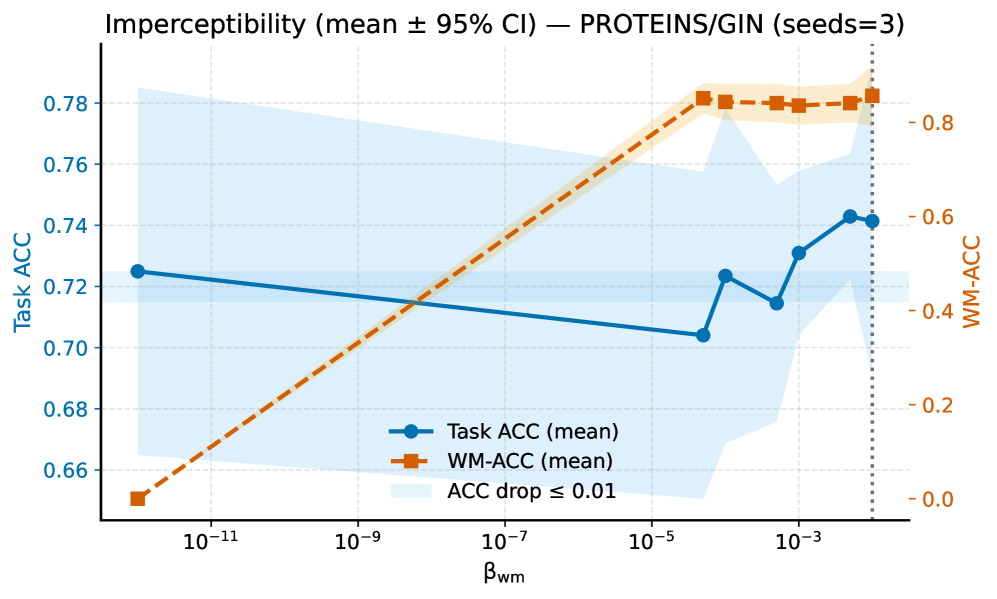
논문 소개
그래프 신경망(Graph Neural Networks, GNN)은 다양한 분야에서 활용되는 강력한 기계 학습 모델로, 그 지적 재산권 보호의 필요성이 대두되고 있습니다. 기존의 워터마킹 기법들은 주로 백도어 트리거에 의존하여 모델 수정 시 취약성을 보이며, 이로 인해 소유권의 모호성이 발생할 수 있습니다. 이러한 문제를 해결하기 위해 제안된 InvGNN-WM은 그래프 불변량에 대한 모델의 암묵적 인식을 활용하여 소유권을 연결짓고, 트리거 없이 블랙박스 검증을 가능하게 합니다. 이 방법은 작업에 미치는 영향이 거의 없으며, 소유자 비공식 캐리어 세트에서 정규화된 대수적 연결성을 예측하는 경량 헤드를 사용합니다.
InvGNN-WM의 디코더는 부호 민감성을 고려하여 비트를 출력하며, 조정된 임계값을 통해 거짓 긍정률을 제어합니다. 다양한 노드 및 그래프 분류 데이터셋에서 실험한 결과, InvGNN-WM은 기존의 트리거 및 압축 기반 방법보다 높은 워터마크 정확도를 달성하면서도 깨끗한 정확도를 유지하는 성능을 보였습니다. 특히, 비구조적 가지치기, 파인튜닝, 사후 학습 양자화와 같은 다양한 상황에서도 강건성을 유지하며, 일반적인 지식 증류(Knowledge Distillation, KD)는 워터마크를 약화시키지만, 워터마크 손실을 포함한 KD(KD+WM)를 통해 이를 복원할 수 있음을 보여주었습니다.
이 연구는 불가시성과 강건성에 대한 보장을 제공하며, 정확한 제거가 NP-완전임을 증명함으로써 기존의 워터마킹 기법들과의 차별성을 명확히 합니다. InvGNN-WM은 GNN의 지적 재산권 보호를 위한 혁신적인 접근 방식을 제시하며, 향후 다양한 응용 분야에서의 활용 가능성을 탐색하는 데 기여할 것입니다. 이러한 기여는 GNN의 안전성과 신뢰성을 높이는 데 중요한 역할을 할 것으로 기대됩니다.
논문 초록(Abstract)
그래프 신경망(Graph Neural Networks, GNNs)은 귀중한 지적 재산이지만, 많은 워터마크가 일반적인 모델 수정에서 깨지는 백도어 트리거에 의존하여 소유권의 모호성을 초래합니다. 우리는 InvGNN-WM을 제안하는데, 이는 모델의 그래프 불변성에 대한 암묵적 인식에 소유권을 연결하여 트리거 없는 블랙박스 검증을 가능하게 하며, 작업에 미치는 영향은 미미합니다. 경량 헤드는 소유자 전용 캐리어 집합에서 정규화된 대수적 연결성을 예측하고, 부호 민감 디코더는 비트를 출력하며, 보정된 임계값이 위양성 비율을 조절합니다. 다양한 노드 및 그래프 분류 데이터셋과 백본에서 InvGNN-WM은 클린 정확도를 유지하면서 트리거 및 압축 기반 기준보다 더 높은 워터마크 정확도를 제공합니다. 비구조적 가지치기, 파인튜닝 및 사후 학습 양자화 하에서도 강력함을 유지하며, 일반적인 지식 증류(KD)는 마크를 약화시키고, 워터마크 손실이 포함된 KD(KD+WM)는 이를 복원합니다. 우리는 감지 불가능성과 강건성에 대한 보장을 제공하며, 정확한 제거가 NP-완전임을 증명합니다.
Graph Neural Networks (GNNs) are valuable intellectual property, yet many watermarks rely on backdoor triggers that break under common model edits and create ownership ambiguity. We present InvGNN-WM, which ties ownership to a model's implicit perception of a graph invariant, enabling trigger-free, black-box verification with negligible task impact. A lightweight head predicts normalized algebraic connectivity on an owner-private carrier set; a sign-sensitive decoder outputs bits, and a calibrated threshold controls the false-positive rate. Across diverse node and graph classification datasets and backbones, InvGNN-WM matches clean accuracy while yielding higher watermark accuracy than trigger- and compression-based baselines. It remains strong under unstructured pruning, fine-tuning, and post-training quantization; plain knowledge distillation (KD) weakens the mark, while KD with a watermark loss (KD+WM) restores it. We provide guarantees for imperceptibility and robustness, and we prove that exact removal is NP-complete.
논문 링크
GAP: 병렬 도구 사용과 강화학습을 통한 그래프 기반 에이전트 계획 / GAP: Graph-Based Agent Planning with Parallel Tool Use and Reinforcement Learning
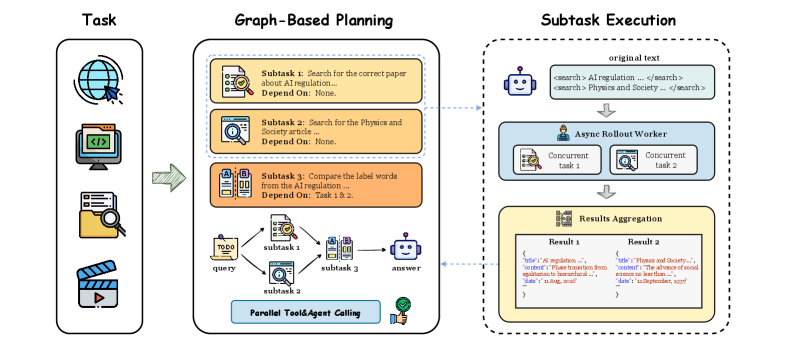
논문 소개
GAP(Graph-based Agent Planning)는 자율 에이전트가 복잡한 작업을 효율적으로 해결하기 위해 도구를 병렬로 활용할 수 있도록 설계된 혁신적인 프레임워크이다. 기존의 ReAct와 같은 접근 방식은 순차적 추론 및 실행에 의존하여 독립적인 하위 작업 간의 병렬성을 활용하지 못하는 한계를 가지고 있다. GAP는 이러한 문제를 해결하기 위해 작업 간의 의존성을 그래프 구조로 모델링하고, 이를 통해 적응형 병렬 및 순차 도구 실행을 가능하게 한다.
본 연구의 핵심은 복잡한 작업을 의존성 인식 하위 작업 그래프로 분해하는 과정이다. 에이전트는 주어진 쿼리를 분석하여 필요한 하위 작업을 식별하고, 각 하위 작업 간의 의존성을 분석하여 유향 비순환 그래프(DAG)를 구성한다. 이 그래프는 하위 작업의 실행 순서를 최적화하는 데 중요한 역할을 하며, 독립적인 작업은 병렬로 실행될 수 있도록 한다. 이러한 접근 방식은 실행 효율성과 작업 정확성을 크게 향상시킨다.
GAP의 학습 과정은 두 단계로 나뉜다. 첫 번째 단계에서는 고품질의 그래프 기반 계획 추적 데이터셋을 사용하여 감독 학습(Supervised Fine-Tuning, SFT)을 수행한다. 두 번째 단계에서는 강화 학습(Reinforcement Learning, RL)을 통해 도구 기반 추론이 최대 가치를 제공하는 전략적으로 샘플링된 쿼리에서 정확성 기반 보상 함수를 사용하여 모델을 최적화한다. 이러한 훈련 전략은 GAP가 다단계 검색 작업에서 기존의 ReAct 기준선보다 뛰어난 성능을 발휘하도록 한다.
실험 결과, GAP는 여러 벤치마크 데이터셋에서 기존 방법들과 비교하여 정확도와 효율성에서 상당한 개선을 보여주었다. 특히, 다단계 추론 작업에서 독립적인 하위 쿼리를 병렬로 처리함으로써 도구 호출의 효율성을 극적으로 향상시켰다. 이러한 성과는 GAP가 다단계 쿼리 해결에서의 병렬 실행의 이점을 극대화할 수 있는 가능성을 제시한다.
논문 초록(Abstract)
자율 에이전트는 대규모 언어 모델(LLM)에 의해 구동되어 복잡한 작업 해결을 위한 도구 조작에서 인상적인 능력을 보여주고 있습니다. 그러나 ReAct와 같은 기존 패러다임은 순차적 추론 및 실행에 의존하여 독립적인 하위 작업 간의 고유한 병렬성을 활용하지 못하고 있습니다. 이러한 순차적 병목 현상은 비효율적인 도구 활용과 다단계 추론 시나리오에서의 최적이 아닌 성능으로 이어집니다. 우리는 그래프 기반 에이전트 계획(Graph-based Agent Planning, GAP)을 소개합니다. 이는 그래프 기반 계획을 통해 작업 간의 의존성을 명시적으로 모델링하여 적응형 병렬 및 직렬 도구 실행을 가능하게 하는 새로운 프레임워크입니다. 우리의 접근 방식은 에이전트 파운데이션 모델을 학습시켜 복잡한 작업을 의존성을 인식하는 하위 작업 그래프로 분해하고, 어떤 도구를 병렬로 실행할 수 있으며 어떤 도구가 순차적 의존성을 따라야 하는지를 자율적으로 결정합니다. 이러한 의존성 인식 오케스트레이션은 실행 효율성과 작업 정확성 모두에서 상당한 개선을 달성합니다. GAP을 학습시키기 위해 우리는 Multi-Hop Question Answering (MHQA) 벤치마크에서 파생된 그래프 기반 계획 추적의 고품질 데이터셋을 구축했습니다. 우리는 두 단계의 학습 전략을 사용합니다: 선별된 데이터셋에 대한 감독 하의 파인튜닝(Supervised Fine-Tuning, SFT) 후, 도구 기반 추론이 최대 가치를 제공하는 전략적으로 샘플링된 쿼리에 대해 정확성 기반 보상 함수를 사용한 강화학습(Reinforcement Learning, RL)을 수행합니다. MHQA 데이터셋에 대한 실험 결과는 GAP이 전통적인 ReAct 기준선보다 상당히 우수한 성능을 보이며, 특히 다단계 검색 작업에서 도구 호출 효율성을 지능적으로 병렬화하여 극적인 개선을 달성함을 보여줍니다. 프로젝트 페이지는 다음에서 확인할 수 있습니다: GitHub - WJQ7777/Graph-Agent-Planning.
Autonomous agents powered by large language models (LLMs) have shown impressive capabilities in tool manipulation for complex task-solving. However, existing paradigms such as ReAct rely on sequential reasoning and execution, failing to exploit the inherent parallelism among independent sub-tasks. This sequential bottleneck leads to inefficient tool utilization and suboptimal performance in multi-step reasoning scenarios. We introduce Graph-based Agent Planning (GAP), a novel framework that explicitly models inter-task dependencies through graph-based planning to enable adaptive parallel and serial tool execution. Our approach trains agent foundation models to decompose complex tasks into dependency-aware sub-task graphs, autonomously determining which tools can be executed in parallel and which must follow sequential dependencies. This dependency-aware orchestration achieves substantial improvements in both execution efficiency and task accuracy. To train GAP, we construct a high-quality dataset of graph-based planning traces derived from the Multi-Hop Question Answering (MHQA) benchmark. We employ a two-stage training strategy: supervised fine-tuning (SFT) on the curated dataset, followed by reinforcement learning (RL) with a correctness-based reward function on strategically sampled queries where tool-based reasoning provides maximum value. Experimental results on MHQA datasets demonstrate that GAP significantly outperforms traditional ReAct baselines, particularly on multi-step retrieval tasks, while achieving dramatic improvements in tool invocation efficiency through intelligent parallelization. The project page is available at: GitHub - WJQ7777/Graph-Agent-Planning.
논문 링크
더 읽어보기
https://github.com/WJQ7777/Graph-Agent-Planning
캐시 간의 직접적인 의미 통신: 대규모 언어 모델 간의 새로운 패러다임 / Cache-to-Cache: Direct Semantic Communication Between Large Language Models

논문 소개
대규모 언어 모델(LLM)의 발전은 다양한 도메인에서의 활용을 가능하게 하며, 이러한 모델들이 서로의 강점을 결합하여 성능과 효율성을 극대화하는 Multi-LLM 시스템의 필요성이 대두되고 있다. 기존의 LLM 간 통신 방식은 텍스트를 매개로 하여 이루어지며, 이 과정에서 내부 표현이 출력 토큰 시퀀스로 변환되면서 의미 정보가 손실되고, 생성 지연이 발생하는 문제점이 있다. 이러한 한계를 극복하기 위해, 연구자들은 LLM 간의 소통이 텍스트를 넘어설 수 있는 가능성을 탐구하였다.
본 연구에서는 KV-Cache를 LLM 간의 통신 매체로 활용하는 새로운 접근법인 Cache-to-Cache (C2C)를 제안한다. C2C는 신경망을 통해 소스 모델의 KV-Cache를 타겟 모델과 융합하여 직접적인 의미 전이를 가능하게 하며, 학습 가능한 게이팅 메커니즘을 통해 캐시 통신의 이점을 극대화할 수 있는 타겟 레이어를 선택한다. 이 방식은 텍스트 통신에 비해 두 모델의 깊고 전문화된 의미를 활용하면서도 중간 텍스트 생성을 피할 수 있는 장점을 제공한다.
실험 결과, C2C는 개별 모델보다 평균 8.5-10.5% 더 높은 정확도를 달성하며, 기존의 텍스트 기반 통신 방식보다 약 3.0-5.0% 더 우수한 성능을 보이고, 평균 2.0배의 지연 속도 향상을 이루었다. 이러한 성과는 LLM 간의 직접적인 의미 통신이 기존의 방법보다 더 효율적이고 효과적일 수 있음을 입증한다. C2C는 LLM의 상호 보완적인 강점을 활용하여 더 나은 결과를 도출할 수 있는 혁신적인 패러다임으로 자리매김할 가능성을 보여준다.
결론적으로, 본 연구는 LLM 간의 통신 방식을 혁신적으로 변화시킬 수 있는 기초를 마련하며, 향후 다양한 응용 분야에서의 활용 가능성을 제시한다.
논문 초록(Abstract)
다중 대규모 언어 모델(Multi-LLM) 시스템은 다양한 대규모 언어 모델의 상호 보완적인 강점을 활용하여 단일 모델로는 달성할 수 없는 성능과 효율성 향상을 이룹니다. 기존 설계에서는 대규모 언어 모델이 텍스트를 통해 소통하며, 내부 표현이 출력 토큰 시퀀스로 변환되도록 강제합니다. 이 과정은 풍부한 의미 정보를 잃게 하고, 토큰별 생성 지연을 초래합니다. 이러한 한계에 의해 우리는 질문합니다: 대규모 언어 모델이 텍스트를 넘어 소통할 수 있을까? 오라클 실험 결과, KV-캐시의 의미를 풍부하게 하는 것이 캐시 크기를 증가시키지 않으면서 응답 품질을 개선할 수 있음을 보여주어, KV-캐시가 모델 간 소통을 위한 효과적인 매개체임을 지지합니다. 따라서 우리는 대규모 언어 모델 간의 직접적인 의미 소통을 위한 새로운 패러다임인 캐시-투-캐시(Cache-to-Cache, C2C)를 제안합니다. C2C는 신경망을 사용하여 소스 모델의 KV-캐시를 타겟 모델의 KV-캐시와 투영하고 융합하여 직접적인 의미 전이를 가능하게 합니다. 학습 가능한 게이팅 메커니즘이 캐시 소통의 혜택을 받는 타겟 레이어를 선택합니다. 텍스트 소통과 비교할 때, C2C는 두 모델의 깊고 전문화된 의미를 활용하면서 명시적인 중간 텍스트 생성 없이 진행됩니다. 실험 결과, C2C는 개별 모델보다 평균 8.5-10.5% 높은 정확도를 달성하며, 텍스트 소통 패러다임보다 약 3.0-5.0% 더 우수한 성능을 보이고, 평균 2.0배의 지연 속도 향상을 제공합니다. 우리의 코드는 GitHub - thu-nics/C2C: [ICLR'26] The official code implementation for "Cache-to-Cache: Direct Semantic Communication Between Large Language Models" 에서 확인할 수 있습니다.
Multi-LLM systems harness the complementary strengths of diverse Large Language Models, achieving performance and efficiency gains unattainable by a single model. In existing designs, LLMs communicate through text, forcing internal representations to be transformed into output token sequences. This process both loses rich semantic information and incurs token-by-token generation latency. Motivated by these limitations, we ask: Can LLMs communicate beyond text? Oracle experiments show that enriching the KV-Cache semantics can improve response quality without increasing cache size, supporting KV-Cache as an effective medium for inter-model communication. Thus, we propose Cache-to-Cache (C2C), a new paradigm for direct semantic communication between LLMs. C2C uses a neural network to project and fuse the source model's KV-cache with that of the target model to enable direct semantic transfer. A learnable gating mechanism selects the target layers that benefit from cache communication. Compared with text communication, C2C utilizes the deep, specialized semantics from both models, while avoiding explicit intermediate text generation. Experiments show that C2C achieves 8.5-10.5% higher average accuracy than individual models. It further outperforms the text communication paradigm by approximately 3.0-5.0%, while delivering an average 2.0x speedup in latency. Our code is available at GitHub - thu-nics/C2C: [ICLR'26] The official code implementation for "Cache-to-Cache: Direct Semantic Communication Between Large Language Models".
논문 링크
더 읽어보기
https://github.com/thu-nics/C2C
백만 개 토큰을 넘어서: 대규모 언어 모델의 장기 기억 평가 및 향상 / Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs
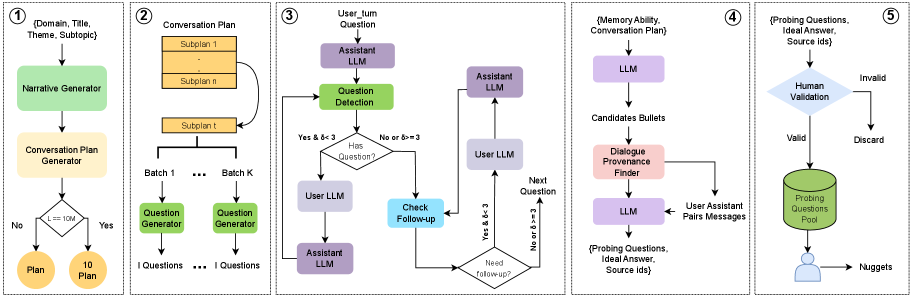
논문 소개
대규모 언어 모델(LLMs)의 장기 기억 및 긴 맥락 추론 능력은 대화와 같은 복잡한 상황에서 필수적인 요소로, 이를 효과적으로 평가하기 위한 기존 벤치마크의 한계가 존재합니다. 기존의 벤치마크는 내러티브 일관성이 부족하고, 좁은 도메인에 국한되며, 단순한 회상 작업만을 테스트하는 경향이 있습니다. 이러한 문제를 해결하기 위해 새로운 접근법이 필요하며, 본 연구는 이를 위한 포괄적인 솔루션을 제시합니다.
연구의 첫 번째 주요 기여는 최대 10M 토큰으로 구성된 일관되고 주제적으로 다양한 대화를 자동으로 생성하는 새로운 프레임워크를 개발한 것입니다. 이 프레임워크는 다양한 기억 능력을 평가하기 위한 질문을 포함하여, 100개의 대화와 2,000개의 검증된 질문으로 구성된 새로운 벤치마크인 BEAM을 구축합니다. BEAM은 LLM의 장기 기억 능력을 보다 정교하게 평가할 수 있는 기초 자료로 활용될 수 있습니다.
두 번째 기여는 인간의 인지에서 영감을 받은 LIGHT 프레임워크를 제안하여 LLM에 세 가지 보완적 기억 시스템을 통합한 것입니다. 이 시스템은 장기 에피소드 기억, 단기 작업 기억, 그리고 중요한 사실을 축적하기 위한 스크래치패드를 포함하여, LLM의 성능을 향상시키는 데 기여합니다. 실험 결과, LIGHT 프레임워크는 다양한 모델에서 일관되게 성능을 개선하며, 평균적으로 3.5%-12.69%의 성능 향상을 달성했습니다.
이 연구는 LLM의 장기 기억 능력을 평가하고 향상시키기 위한 새로운 방법론을 제시하며, BEAM 벤치마크와 LIGHT 프레임워크는 향후 연구에 중요한 기초 자료로 활용될 것입니다. 이러한 기여는 LLM의 실제 성능을 보다 정확하게 반영하고, 복잡한 대화 상황에서의 활용 가능성을 높이는 데 기여할 것으로 기대됩니다.
논문 초록(Abstract)
대규모 언어 모델(LLMs)의 장기 기억이 필요하고 따라서 긴 맥락 추론을 요구하는 작업, 예를 들어 대화 설정에서의 능력을 평가하는 것은 기존의 벤치마크로 인해 어려움을 겪고 있습니다. 이러한 벤치마크는 종종 서사적 일관성이 결여되어 있고, 좁은 영역만을 다루며, 단순한 회상 중심의 작업만을 테스트합니다. 본 논문은 이러한 문제에 대한 포괄적인 해결책을 제시합니다. 첫째, 우리는 최대 10M 토큰의 긴, 일관된, 주제적으로 다양한 대화를 자동으로 생성하는 새로운 프레임워크를 소개하며, 이는 다양한 기억 능력을 겨냥한 질문을 포함합니다. 이를 통해 100개의 대화와 2,000개의 검증된 질문으로 구성된 BEAM이라는 새로운 벤치마크를 구축합니다. 둘째, 모델 성능을 향상시키기 위해 우리는 인간 인지에서 영감을 받은 LIGHT라는 프레임워크를 제안합니다. 이 프레임워크는 LLM에 장기 에피소드 기억, 단기 작업 기억, 그리고 중요한 사실을 축적하기 위한 스크래치패드를 포함한 세 가지 보완적인 기억 시스템을 제공합니다. BEAM에 대한 우리의 실험 결과, 1M 토큰 맥락 창을 가진 LLM(검색 증강 여부에 관계없이)은 대화가 길어질수록 어려움을 겪는 것으로 나타났습니다. 반면, LIGHT는 다양한 모델에서 일관되게 성능을 향상시켜, 가장 강력한 기준선에 비해 평균 3.5%-12.69%의 개선을 달성했습니다. 추가적인 제거 연구는 각 기억 구성 요소의 기여를 더욱 확실히 확인합니다.
Evaluating the abilities of large language models (LLMs) for tasks that require long-term memory and thus long-context reasoning, for example in conversational settings, is hampered by the existing benchmarks, which often lack narrative coherence, cover narrow domains, and only test simple recall-oriented tasks. This paper introduces a comprehensive solution to these challenges. First, we present a novel framework for automatically generating long (up to 10M tokens), coherent, and topically diverse conversations, accompanied by probing questions targeting a wide range of memory abilities. From this, we construct BEAM, a new benchmark comprising 100 conversations and 2,000 validated questions. Second, to enhance model performance, we propose LIGHT-a framework inspired by human cognition that equips LLMs with three complementary memory systems: a long-term episodic memory, a short-term working memory, and a scratchpad for accumulating salient facts. Our experiments on BEAM reveal that even LLMs with 1M token context windows (with and without retrieval-augmentation) struggle as dialogues lengthen. In contrast, LIGHT consistently improves performance across various models, achieving an average improvement of 3.5%-12.69% over the strongest baselines, depending on the backbone LLM. An ablation study further confirms the contribution of each memory component.
논문 링크
더 읽어보기
https://github.com/mohammadtavakoli78/BEAM
손실 곡률 스펙트럼에서의 암기에서 추론으로의 전환 / From Memorization to Reasoning in the Spectrum of Loss Curvature
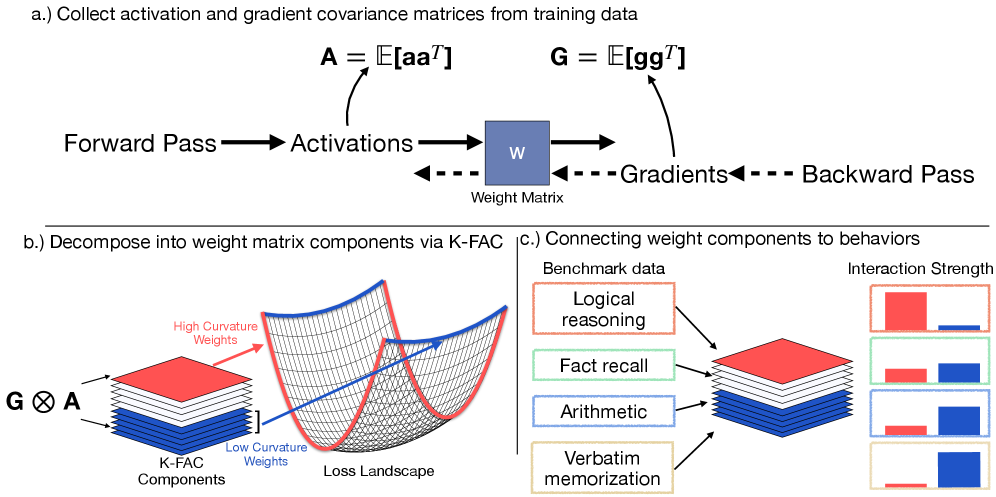
논문 소개
트랜스포머 모델에서의 암기 현상은 자연어 처리(NLP)와 컴퓨터 비전(CV) 분야에서 중요한 연구 주제로 자리 잡고 있다. 본 연구는 손실 경관의 곡률(loss landscape curvature)을 기반으로 하여 언어 모델(LLM)과 비전 트랜스포머(ViT)에서 암기가 어떻게 표현되는지를 분석한다. 기존 연구들은 암기가 모델 성능에 미치는 영향을 다루었으나, 본 연구는 암기된 데이터와 비암기된 데이터 간의 차이를 명확히 할 수 있는 새로운 방법론을 제시한다.
연구의 핵심은 가중치 편집 절차를 통해 비타겟 암기 데이터를 효과적으로 억제하는 것이다. 이 절차는 최근의 비학습 방법인 BalancedSubnet보다 낮은 혼란도(perplexity)를 유지하면서도 더 많은 암기된 데이터를 억제할 수 있는 가능성을 보여준다. 손실 경관의 곡률 분석을 통해, 암기된 훈련 포인트의 곡률이 비암기된 포인트보다 훨씬 더 날카롭다는 사실을 발견하였으며, 이를 통해 가중치 구성 요소를 높은 곡률에서 낮은 곡률로 정렬함으로써 명시적인 레이블 없이도 구분할 수 있음을 입증하였다.
이 연구는 또한 편집된 낮은 곡률 구성 요소와 작업 데이터의 활성화 강도 간의 상관관계를 분석하여, 특정 하위 작업에서의 성능 저하를 설명한다. 특히, 사실 검색(fact retrieval)과 산술(arithmetic) 작업에서 부정적인 영향을 발견하였으며, 이는 전문화된 방향이 가중치 공간에서 중요한 역할을 한다는 주장을 뒷받침한다. 반면, 오픈 북 사실 검색(open book fact retrieval)과 일반적인 논리적 추론은 보존되는 경향을 보였다.
본 연구는 신경망에서의 암기에 대한 이해를 심화시키고, 이를 제거하기 위한 실용적인 응용 가능성을 제시함으로써, 수학 및 사실 검색과 같은 작업을 해결하는 데 관여하는 특이하고 좁게 사용되는 구조에 대한 새로운 통찰을 제공한다. 이러한 기여는 향후 연구에서 암기 현상을 더 깊이 이해하고, 이를 효과적으로 관리하기 위한 기반을 마련할 것으로 기대된다.
논문 초록(Abstract)
우리는 트랜스포머 모델에서 기억화가 어떻게 표현되는지를 특징짓고, 손실 경관 곡률을 기반으로 한 분해를 사용하여 언어 모델(LLs)과 비전 트랜스포머(ViTs) 모두의 가중치에서 이를 분리할 수 있음을 보여줍니다. 이 통찰은 기억된 훈련 포인트의 곡률이 비기억된 포인트보다 훨씬 더 날카롭다는 것을 보여주는 이전의 이론적 및 경험적 연구에 기반하고 있으며, 이는 높은 곡률에서 낮은 곡률로 가중치 구성 요소를 정렬함으로써 명시적인 레이블 없이 구별을 드러낼 수 있음을 의미합니다. 이는 목표하지 않은 기억된 데이터의 반복을 훨씬 더 효과적으로 억제하는 가중치 편집 절차를 동기부여하며, 이는 최근의 비학습 방법(BalancedSubnet)보다 낮은 당혹감을 유지합니다. 곡률의 기초는 모델 가중치의 공유 구조에 대한 자연스러운 해석을 가지므로, 우리는 언어 모델에서 하류 작업에 미치는 편집 절차의 영향을 광범위하게 분석하고, 사실 검색과 산술이 특히 일관되게 부정적인 영향을 받는 반면, 오픈 북 사실 검색과 일반 논리적 추론은 보존된다는 것을 발견했습니다. 우리는 이러한 작업이 개별 데이터 포인트가 기억되었는지 여부와 관계없이 가중치 공간의 전문화된 방향에 크게 의존한다고 가정합니다. 우리는 편집된 낮은 곡률 구성 요소와 작업 데이터의 활성화 강도 간의 상관관계를 보여주고, 편집 후 작업 성능의 저하를 보임으로써 이를 뒷받침합니다. 우리의 연구는 신경망에서 기억화에 대한 이해를 향상시키고 이를 제거하기 위한 실용적인 응용을 제공하며, 수학 및 사실 검색과 같은 작업을 해결하는 데 관여하는 특이하고 좁게 사용되는 구조에 대한 증거를 제공합니다.
We characterize how memorization is represented in transformer models and show that it can be disentangled in the weights of both language models (LMs) and vision transformers (ViTs) using a decomposition based on the loss landscape curvature. This insight is based on prior theoretical and empirical work showing that the curvature for memorized training points is much sharper than non memorized, meaning ordering weight components from high to low curvature can reveal a distinction without explicit labels. This motivates a weight editing procedure that suppresses far more recitation of untargeted memorized data more effectively than a recent unlearning method (BalancedSubnet), while maintaining lower perplexity. Since the basis of curvature has a natural interpretation for shared structure in model weights, we analyze the editing procedure extensively on its effect on downstream tasks in LMs, and find that fact retrieval and arithmetic are specifically and consistently negatively affected, even though open book fact retrieval and general logical reasoning is conserved. We posit these tasks rely heavily on specialized directions in weight space rather than general purpose mechanisms, regardless of whether those individual datapoints are memorized. We support this by showing a correspondence between task data's activation strength with low curvature components that we edit out, and the drop in task performance after the edit. Our work enhances the understanding of memorization in neural networks with practical applications towards removing it, and provides evidence for idiosyncratic, narrowly-used structures involved in solving tasks like math and fact retrieval.
논문 링크
더 읽어보기
https://github.com/goodfire-ai/memorization_kfac
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()