[2025/11/10 ~ 16] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 다양한 언어 지원을 위한 확장성: 최근 논문들은 다양한 언어를 지원하는 자동 음성 인식(ASR) 시스템과 같은 확장 가능한 모델의 필요성을 강조하고 있습니다. Omnilingual ASR 논문은 커뮤니티가 소량의 데이터로도 지원되지 않는 언어를 추가할 수 있도록 설계된 대규모 ASR 시스템을 소개하며, 1,600개 이상의 언어를 지원하는 데 성공했습니다.
다양한 언어 지원을 위한 확장성: 최근 논문들은 다양한 언어를 지원하는 자동 음성 인식(ASR) 시스템과 같은 확장 가능한 모델의 필요성을 강조하고 있습니다. Omnilingual ASR 논문은 커뮤니티가 소량의 데이터로도 지원되지 않는 언어를 추가할 수 있도록 설계된 대규모 ASR 시스템을 소개하며, 1,600개 이상의 언어를 지원하는 데 성공했습니다.
![]() 협업을 통한 복잡한 추론 능력 향상: 여러 논문에서 다중 에이전트 시스템의 협업을 통해 복잡한 추론 작업을 수행하는 방법이 탐구되고 있습니다. Unlocking the Power of Multi-Agent LLM 논문은 에이전트 간의 협업을 강화하기 위해 lazy agent 행동을 해결하는 방법을 제안하며, MARAG-R1 논문은 여러 검색 도구를 활용하여 정보 접근성을 높이는 다중 도구 RAG 프레임워크를 소개합니다.
협업을 통한 복잡한 추론 능력 향상: 여러 논문에서 다중 에이전트 시스템의 협업을 통해 복잡한 추론 작업을 수행하는 방법이 탐구되고 있습니다. Unlocking the Power of Multi-Agent LLM 논문은 에이전트 간의 협업을 강화하기 위해 lazy agent 행동을 해결하는 방법을 제안하며, MARAG-R1 논문은 여러 검색 도구를 활용하여 정보 접근성을 높이는 다중 도구 RAG 프레임워크를 소개합니다.
![]() 경험 기반 학습과 메모리 활용: ReasoningBank와 같은 논문들은 에이전트가 상호작용에서 얻은 경험을 통해 학습하고 발전할 수 있는 메모리 프레임워크를 제안합니다. 이러한 접근 방식은 에이전트가 과거의 성공과 실패에서 일반화된 추론 전략을 추출하여 지속적으로 향상될 수 있도록 합니다.
경험 기반 학습과 메모리 활용: ReasoningBank와 같은 논문들은 에이전트가 상호작용에서 얻은 경험을 통해 학습하고 발전할 수 있는 메모리 프레임워크를 제안합니다. 이러한 접근 방식은 에이전트가 과거의 성공과 실패에서 일반화된 추론 전략을 추출하여 지속적으로 향상될 수 있도록 합니다.
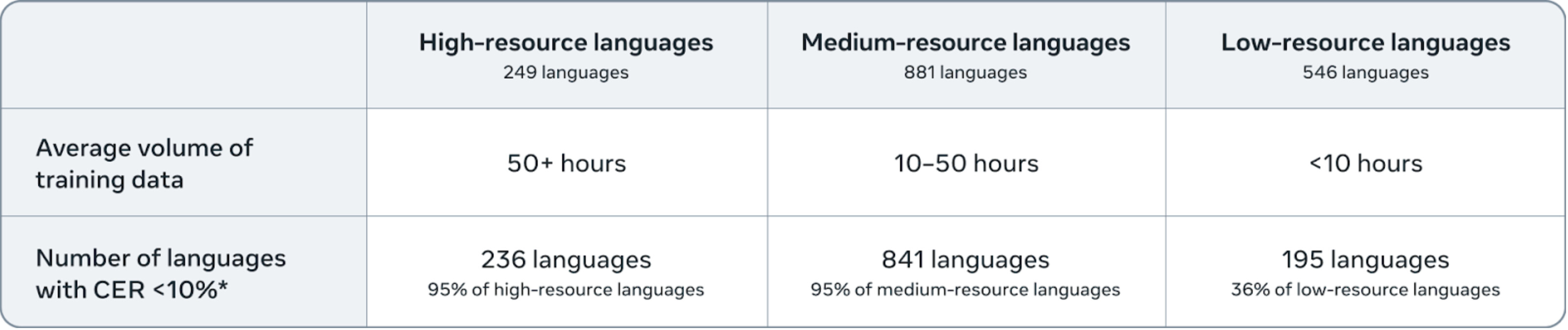
모든 언어를 위한 자동 음성 인식: 1600개 이상의 언어를 위한 오픈 소스 다국어 음성 인식 시스템 / Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
논문 소개
자동 음성 인식(ASR) 기술은 고자원 언어에서 눈에 띄는 발전을 이루었으나, 여전히 전 세계 7,000개 이상의 언어 중 대부분은 지원되지 않아 수많은 긴 꼬리 언어가 소외되고 있는 상황이다. 이러한 문제를 해결하기 위해 제안된 Omnilingual ASR은 확장성을 염두에 두고 설계된 최초의 대규모 ASR 시스템으로, 커뮤니티가 소수의 데이터 샘플만으로도 지원되지 않는 언어를 도입할 수 있도록 한다. 이 시스템은 70억 개의 매개변수를 가진 자기 지도 사전 학습을 통해 강력한 음성 표현을 학습하며, 제로샷 일반화를 위한 인코더-디코더 아키텍처를 도입하여 보지 못한 언어에 대한 적응력을 극대화한다.
Omnilingual ASR의 핵심 혁신은 방대한 다양성의 훈련 코퍼스를 활용하여, 1,600개 이상의 언어로의 범위 확장을 가능하게 하는 점이다. 이 중 500개 이상의 언어는 ASR에 의해 처음으로 지원되며, 자동 평가 결과는 저자원 조건에서 이전 시스템에 비해 상당한 성과를 보여준다. 저자들은 다양한 모델을 출시하여, 3억 개 변형부터 70억 개 변형까지 다양한 요구에 맞춘 솔루션을 제공한다.
데이터 수집 과정은 여러 오픈 소스 데이터셋과 커뮤니티 파트너십을 통해 이루어지며, 특히 아프리카 언어를 위한 기술 격차 해소와 공정한 인공지능 개발을 위한 프로젝트에 대한 지원이 강조된다. 맞춤형 녹음 및 전사본을 위탁하여 수집한 Omnilingual ASR 코퍼스는 고품질 자발적 음성을 확보하기 위한 설계로, 각 언어에 대해 10시간의 음성을 목표로 한다. 품질 보증 과정은 데이터의 정확성을 높이는 데 중요한 역할을 하며, 언어 코드 잘못 지정 문제를 해결하기 위한 검증 프로젝트도 진행된다.
Omnilingual ASR은 오픈 소스화된 모델과 도구를 통해 연구자와 커뮤니티의 참여 장벽을 낮추고, 새로운 형태의 참여를 유도하는 데 기여할 것으로 기대된다. 이러한 접근은 ASR 기술의 접근성을 높이고, 다양한 언어에 대한 지원을 확대하는 데 중요한 이정표가 될 것이다.
논문 초록(Abstract)
자동 음성 인식(ASR)은 고자원 언어에서 발전하였지만, 세계의 7,000개 이상의 언어 중 대부분은 지원되지 않아 수천 개의 긴 꼬리 언어가 뒤처져 있습니다. ASR 범위를 확장하는 것은 비용이 많이 들고 언어 지원을 제한하는 아키텍처로 인해 제한을 받으며, 커뮤니티 협력 없이 추진될 경우 윤리적 문제와 얽혀 있습니다. 이러한 한계를 극복하기 위해, 우리는 확장성을 위해 설계된 최초의 대규모 ASR 시스템인 Omnilingual ASR을 소개합니다. Omnilingual ASR은 커뮤니티가 소수의 데이터 샘플만으로도 서비스되지 않는 언어를 도입할 수 있도록 합니다. 이 시스템은 70억 개의 매개변수로 자기 지도 사전 학습을 확장하여 강력한 음성 표현을 학습하고, LLM에서 영감을 받은 디코더를 활용하여 제로샷 일반화를 위해 설계된 인코더-디코더 아키텍처를 도입합니다. 이 기능은 방대한 다양성의 훈련 코퍼스에 기반하고 있으며, 범위의 폭과 언어적 다양성을 결합하여 모델이 보지 못한 언어에 적응할 수 있을 만큼 강력한 표현을 학습합니다. 보상받는 지역 파트너십을 통해 수집된 커뮤니티 소스 녹음과 공공 자원을 통합하여, Omnilingual ASR은 1,600개 이상의 언어로 범위를 확장하며, 이는 지금까지의 가장 큰 노력으로, 500개 이상의 언어는 ASR에 의해 이전에 서비스된 적이 없습니다. 자동 평가 결과는 특히 저자원 조건에서 이전 시스템에 비해 상당한 향상을 보여주며, 강력한 일반화를 나타냅니다. 우리는 Omnilingual ASR을 저전력 장치를 위한 3억 개 변형부터 최대 정확도를 위한 70억 개 변형까지 모델 패밀리로 출시합니다. 이 디자인을 형성하는 윤리적 고려 사항을 반영하고, 사회적 영향을 논의하며 결론을 맺습니다. 특히, 모델과 도구의 오픈 소스화가 연구자와 커뮤니티의 장벽을 낮출 수 있는 방법을 강조하며, 새로운 형태의 참여를 초대합니다. 오픈 소스 아티팩트는 GitHub - facebookresearch/omnilingual-asr: Omnilingual ASR Open-Source Multilingual SpeechRecognition for 1600+ Languages 에서 이용 가능합니다.
Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at GitHub - facebookresearch/omnilingual-asr: Omnilingual ASR Open-Source Multilingual SpeechRecognition for 1600+ Languages.
논문 링크
더 읽어보기
https://github.com/facebookresearch/omnilingual-asr
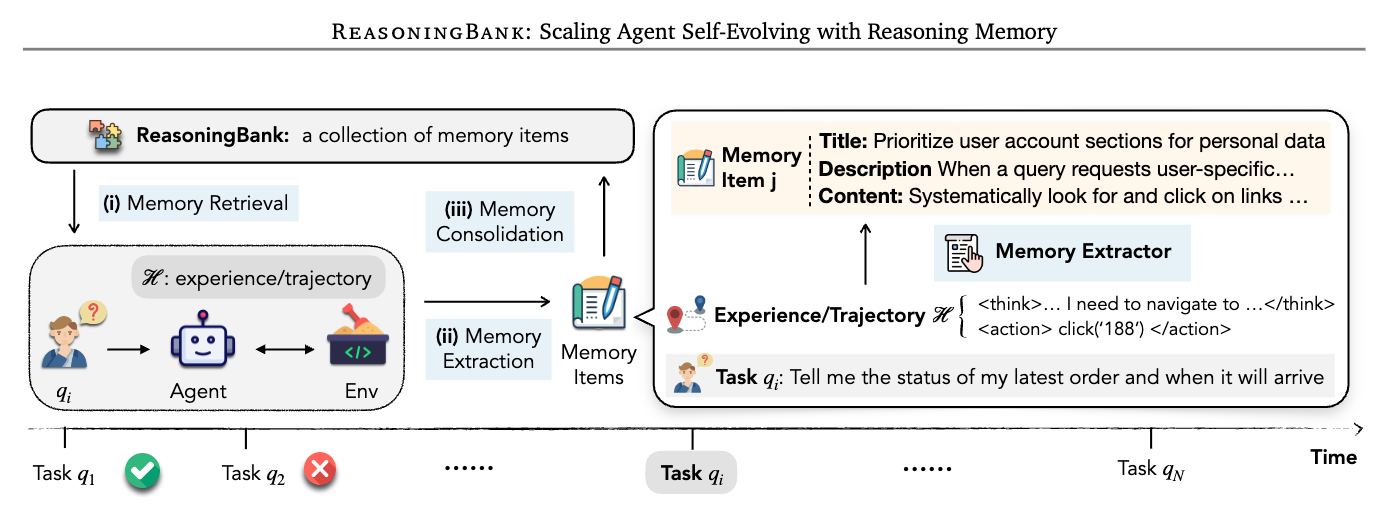
ReasoningBank: 추론 메모리로 자기 진화하는 에이전트의 확장 / ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
논문 소개
대규모 언어 모델(LLM) 에이전트가 지속적인 실제 역할에서 직면하는 다양한 과제를 해결하기 위해, 새로운 메모리 프레임워크인 ReasoningBank가 제안되었다. 기존의 에이전트 시스템은 과거 상호작용의 누적된 기록에서 학습하지 못하는 한계가 있으며, 이로 인해 귀중한 통찰력을 잃고 반복적인 오류를 범하게 된다. ReasoningBank는 에이전트가 스스로 판단한 성공적 및 실패한 경험에서 일반화 가능한 추론 전략을 증류하여 저장함으로써, 테스트 시 에이전트가 관련 메모리를 검색하고 새로운 학습을 통합할 수 있도록 지원한다. 이러한 방식은 에이전트가 시간이 지남에 따라 더욱 능력 있는 존재로 발전할 수 있게 한다.
이 연구의 핵심 혁신 중 하나는 메모리 인식 테스트 시간 스케일링(MaTTS)의 도입이다. MaTTS는 에이전트의 상호작용 경험을 확장하고 다양화하는 학습 과정을 가속화하며, 각 작업에 더 많은 계산 자원을 할당하여 풍부하고 다양한 경험을 생성한다. 이러한 경험은 대조 신호를 제공하여 더 높은 품질의 메모리를 합성하는 데 기여한다. 개선된 메모리는 보다 효과적인 스케일링을 안내하며, 메모리와 테스트 시간 스케일링 간의 강력한 시너지를 구축한다.
실험 결과, ReasoningBank는 웹 브라우징 및 소프트웨어 엔지니어링 벤치마크에서 기존의 메모리 메커니즘을 초월하여 효과성과 효율성을 모두 개선하는 성과를 보였다. MaTTS는 이러한 성과를 더욱 증대시키며, 메모리 기반 경험 스케일링을 새로운 차원으로 제시한다. 이 연구는 에이전트가 과거 경험으로부터 학습하고 스스로 발전할 수 있는 중요한 방법론을 제공하며, 에이전트 시스템의 미래 발전 방향에 대한 중요한 통찰을 제시한다.
논문 초록(Abstract)
대규모 언어 모델 에이전트가 지속적인 실제 역할에서 점점 더 많이 채택됨에 따라, 이들은 자연스럽게 지속적인 작업 흐름을 마주하게 됩니다. 그러나 주요 한계는 축적된 상호작용 기록에서 학습하지 못하여, 귀중한 통찰력을 버리고 과거의 오류를 반복해야 한다는 점입니다. 우리는 에이전트의 스스로 판단한 성공적 경험과 실패한 경험에서 일반화 가능한 추론 전략을 증류하는 새로운 메모리 프레임워크인 ReasoningBank를 제안합니다. 테스트 시, 에이전트는 ReasoningBank에서 관련 메모리를 검색하여 상호작용에 정보를 제공하고, 새로운 학습을 다시 통합하여 시간이 지남에 따라 더 능력 있는 에이전트로 발전할 수 있게 합니다. 이 강력한 경험 학습기를 기반으로, 우리는 메모리 인식 테스트 시간 확장(MaTTS)을 추가로 소개합니다. 이는 에이전트의 상호작용 경험을 확장함으로써 이 학습 과정을 가속화하고 다양화합니다. 각 작업에 더 많은 컴퓨팅 자원을 할당함으로써, 에이전트는 풍부하고 다양한 경험을 생성하여 더 높은 품질의 메모리를 합성하기 위한 풍부한 대비 신호를 제공합니다. 더 나은 메모리는 더 효과적인 확장을 안내하여 메모리와 테스트 시간 확장 간의 강력한 시너지를 구축합니다. 웹 브라우징 및 소프트웨어 엔지니어링 벤치마크에서 ReasoningBank는 원시 궤적이나 성공적인 작업 루틴만 저장하는 기존 메모리 메커니즘을 지속적으로 능가하며, 효과성과 효율성을 모두 개선합니다. MaTTS는 이러한 이점을 더욱 증대시킵니다. 이러한 발견은 메모리 기반 경험 확장을 새로운 확장 차원으로 설정하여, 에이전트가 자연스럽게 발생하는 emergent behaviors와 함께 자가 진화할 수 있게 합니다.
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from the accumulated interaction history, forcing them to discard valuable insights and repeat past errors. We propose ReasoningBank, a novel memory framework that distills generalizable reasoning strategies from an agent's self-judged successful and failed experiences. At test time, an agent retrieves relevant memories from ReasoningBank to inform its interaction and then integrates new learnings back, enabling it to become more capable over time. Building on this powerful experience learner, we further introduce memory-aware test-time scaling (MaTTS), which accelerates and diversifies this learning process by scaling up the agent's interaction experience. By allocating more compute to each task, the agent generates abundant, diverse experiences that provide rich contrastive signals for synthesizing higher-quality memory. The better memory in turn guides more effective scaling, establishing a powerful synergy between memory and test-time scaling. Across web browsing and software engineering benchmarks, ReasoningBank consistently outperforms existing memory mechanisms that store raw trajectories or only successful task routines, improving both effectiveness and efficiency; MaTTS further amplifies these gains. These findings establish memory-driven experience scaling as a new scaling dimension, enabling agents to self-evolve with emergent behaviors naturally arise.
논문 링크
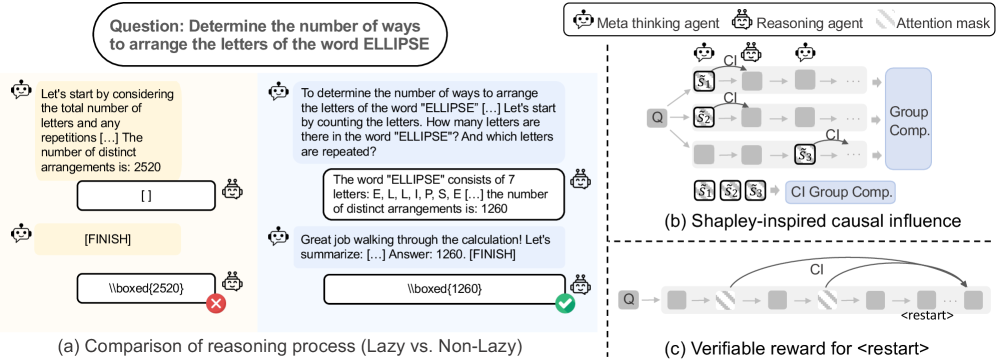
다중 에이전트 대규모 언어 모델의 추론 능력 극대화: 게으른 에이전트에서 심사숙고로 / Unlocking the Power of Multi-Agent LLM for Reasoning: From Lazy Agents to Deliberation
논문 소개
대규모 언어 모델(LLM)의 발전은 복잡한 추론 작업에서의 성능을 크게 향상시키고 있다. 최근 연구는 이러한 모델을 멀티 에이전트 설정으로 확장하여, 메타 사고 에이전트가 계획을 제안하고 추론 에이전트가 하위 작업을 수행하는 구조를 도입하였다. 그러나 이 과정에서 게으른 에이전트 행동이라는 중요한 문제가 발생하는데, 이는 한 에이전트가 지배적으로 활동하고 다른 에이전트의 기여가 미미해지는 현상이다. 본 논문에서는 이러한 게으른 행동의 원인을 이론적으로 분석하고, 이를 완화하기 위한 인과적 영향 측정 방법을 제안한다.
제안된 방법론은 각 추론 단계가 후속 과정에 미치는 영향을 평가하여, 에이전트 간의 협업을 촉진하는 데 중점을 둔다. 또한, 추론 에이전트가 이전의 잡음 있는 출력을 버리고 지침을 재집계하며 필요할 때 추론을 재시작할 수 있도록 하는 새로운 검증 가능한 보상 메커니즘을 설계하였다. 이러한 접근은 에이전트들이 보다 빈번하게 협력하게 하여, 전체 시스템의 성능을 향상시키는 데 기여한다.
실험 결과, 제안된 프레임워크는 게으른 에이전트 행동을 효과적으로 완화하고, 멀티 에이전트 LLM의 복잡한 추론 작업에서의 잠재력을 극대화하는 데 성공하였다. 이 연구는 멀티 에이전트 시스템에서의 협업의 중요성을 강조하며, 향후 연구에 있어 새로운 방향성을 제시한다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 강화학습과 검증 가능한 보상을 통해 훈련되어 복잡한 추론 작업에서 강력한 성과를 달성하였습니다. 최근 연구는 이 패러다임을 다중 에이전트 설정으로 확장하여, 메타 사고 에이전트가 계획을 제안하고 진행 상황을 모니터링하는 동안 추론 에이전트가 순차적인 대화 턴을 통해 하위 작업을 수행하도록 합니다. 유망한 성과에도 불구하고, 우리는 중요한 한계를 발견했습니다: 한 에이전트가 지배하고 다른 에이전트는 거의 기여하지 않는 게으른 에이전트 행동이 발생하여 협업을 저해하고 비효율적인 단일 에이전트로 전락하게 됩니다. 본 논문에서는 먼저 다중 에이전트 추론에서 게으른 행동이 자연스럽게 발생하는 이유를 보여주는 이론적 분석을 제공합니다. 이후, 이 문제를 완화하는 데 도움이 되는 인과적 영향을 측정하기 위한 안정적이고 효율적인 방법을 소개합니다. 마지막으로, 협업이 심화됨에 따라 추론 에이전트는 다중 턴 상호작용에서 길을 잃고 이전의 잡음 있는 응답에 갇힐 위험이 있습니다. 이를 해결하기 위해, 우리는 추론 에이전트가 잡음 있는 출력을 버리고, 지침을 통합하며, 필요할 때 추론 과정을 재시작할 수 있도록 하는 심사 가능한 보상 메커니즘을 제안합니다. 광범위한 실험을 통해 우리의 프레임워크가 게으른 에이전트 행동을 완화하고 복잡한 추론 작업을 위한 다중 에이전트 프레임워크의 잠재력을 최대한 발휘할 수 있음을 입증합니다.
Large Language Models (LLMs) trained with reinforcement learning and verifiable rewards have achieved strong results on complex reasoning tasks. Recent work extends this paradigm to a multi-agent setting, where a meta-thinking agent proposes plans and monitors progress while a reasoning agent executes subtasks through sequential conversational turns. Despite promising performance, we identify a critical limitation: lazy agent behavior, in which one agent dominates while the other contributes little, undermining collaboration and collapsing the setup to an ineffective single agent. In this paper, we first provide a theoretical analysis showing why lazy behavior naturally arises in multi-agent reasoning. We then introduce a stable and efficient method for measuring causal influence, helping mitigate this issue. Finally, as collaboration intensifies, the reasoning agent risks getting lost in multi-turn interactions and trapped by previous noisy responses. To counter this, we propose a verifiable reward mechanism that encourages deliberation by allowing the reasoning agent to discard noisy outputs, consolidate instructions, and restart its reasoning process when necessary. Extensive experiments demonstrate that our framework alleviates lazy agent behavior and unlocks the full potential of multi-agent framework for complex reasoning tasks.
논문 링크
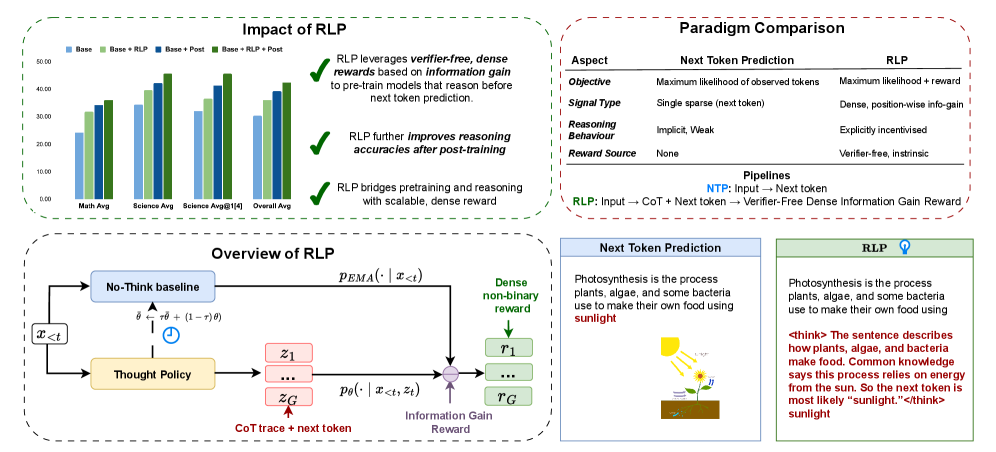
RLP: 강화학습을 사전학습 목표로 활용하기 / RLP: Reinforcement as a Pretraining Objective
논문 소개
대규모 언어 모델의 학습에서 일반적으로 사용되는 방법론은 방대한 데이터셋을 기반으로 한 다음 토큰 예측 손실을 통한 사전 학습이다. 그러나 강화 학습은 주로 감독된 파인튜닝 이후의 마지막 단계에서만 적용되며, 이는 최적의 학습 방식인지에 대한 의문을 제기한다. 본 논문에서는 정보 기반의 강화 사전 학습 목표인 RLP(강화 학습을 사전 학습 목표로)를 제안하여 이러한 문제를 해결하고자 한다. RLP의 핵심 아이디어는 사고의 연쇄를 탐색 행동으로 간주하고, 이를 통해 미래 토큰 예측을 위한 정보 이득을 기반으로 보상을 계산하는 것이다.
이 방법론은 모델이 다음에 무엇을 예측하기 전에 스스로 사고하도록 유도하여, 사전 학습 초기 단계에서 독립적인 사고 행동을 가르친다. 보상 신호는 맥락과 샘플링된 사고의 연쇄를 조건으로 하여 다음 토큰의 로그 가능성 증가를 측정하며, 이는 기존의 방법론과 차별화되는 점이다. RLP는 검증자 없는 밀집 보상 신호를 생성함으로써, 전체 문서 스트림에 대한 효율적인 학습을 가능하게 한다.
RLP를 적용한 Qwen3-1.7B-Base 모델은 8개의 벤치마크 수학 및 과학 테스트에서 평균 19%의 성능 향상을 보였으며, Nemotron-Nano-12B-v2 모델에서는 전체 평균이 42.81%에서 61.32%로 증가하고, 과학적 추론 평균이 23% 상승하는 결과를 나타냈다. 이러한 성과는 RLP가 다양한 아키텍처와 모델 크기에서 확장 가능성을 입증하며, 추론 중심 작업에서 특히 두드러진 개선을 보여준다.
RLP는 강화 학습의 탐색적 특성을 사전 학습에 통합함으로써, 다음 토큰 예측과 사고의 연쇄 추론 간의 간극을 메우는 중요한 기여를 한다. 이 연구는 향후 대규모 언어 모델의 학습 방식에 대한 새로운 통찰을 제공하며, 더 나은 추론 능력을 갖춘 모델 개발에 기여할 것으로 기대된다.
논문 초록(Abstract)
대규모 추론 모델을 학습하는 지배적인 패러다임은 방대한 양의 데이터를 사용하여 다음 토큰 예측 손실로 사전학습을 시작합니다. 강화학습은 추론을 확장하는 데 강력하지만, 감독된 파인튜닝에 이어 사후학습의 마지막 단계에서만 도입됩니다. 이러한 방식이 지배적이지만, 최적의 학습 방법일까요? 본 논문에서는 정보 기반 강화 사전학습 목표인 RLP를 제시합니다. 이는 강화학습의 핵심 정신인 탐색을 사전학습의 마지막 단계로 가져옵니다. 핵심 아이디어는 사고의 연쇄를 탐색적 행동으로 간주하고, 미래 토큰 예측을 위한 정보 이득에 따라 보상을 계산하는 것입니다. 이 학습 목표는 모델이 다음에 올 것을 예측하기 전에 스스로 생각하도록 장려하여, 사전학습 초기에 독립적인 사고 행동을 가르칩니다. 보다 구체적으로, 보상 신호는 맥락과 샘플링된 추론 체인 모두에 조건을 걸었을 때 다음 토큰의 로그 가능성 증가를 측정하며, 맥락만으로 조건을 걸었을 때와 비교합니다. 이 접근법은 검증자 없는 밀집 보상 신호를 생성하여 사전학습 동안 전체 문서 스트림에 대한 효율적인 학습을 가능하게 합니다. 특히, RLP는 일반 텍스트에 대한 사전학습 목표로서 추론을 위한 강화학습을 재구성하여 다음 토큰 예측과 유용한 사고의 연쇄 추론의 출현 간의 간극을 연결합니다. Qwen3-1.7B-Base에서 RLP로 사전학습을 수행하면 8개의 벤치마크 수학 및 과학 세트에서 전체 평균이 19% 향상됩니다. 동일한 사후학습을 적용했을 때, 이득은 누적되며 AIME25 및 MMLU-Pro와 같은 추론 중심 작업에서 가장 큰 개선을 보입니다. RLP를 하이브리드 Nemotron-Nano-12B-v2에 적용하면 전체 평균이 42.81%에서 61.32%로 증가하고, 과학적 추론의 평균이 23% 상승하여 아키텍처와 모델 크기 전반에 걸쳐 확장 가능성을 입증합니다.
The dominant paradigm for training large reasoning models starts with pre-training using next-token prediction loss on vast amounts of data. Reinforcement learning, while powerful in scaling reasoning, is introduced only as the very last phase of post-training, preceded by supervised fine-tuning. While dominant, is this an optimal way of training? In this paper, we present RLP, an information-driven reinforcement pretraining objective, that brings the core spirit of reinforcement learning -- exploration -- to the last phase of pretraining. The key idea is to treat chain-of-thought as an exploratory action, with rewards computed based on the information gain it provides for predicting future tokens. This training objective essentially encourages the model to think for itself before predicting what comes next, thus teaching an independent thinking behavior earlier in the pretraining. More concretely, the reward signal measures the increase in log-likelihood of the next token when conditioning on both context and a sampled reasoning chain, compared to conditioning on context alone. This approach yields a verifier-free dense reward signal, allowing for efficient training for the full document stream during pretraining. Specifically, RLP reframes reinforcement learning for reasoning as a pretraining objective on ordinary text, bridging the gap between next-token prediction and the emergence of useful chain-of-thought reasoning. Pretraining with RLP on Qwen3-1.7B-Base lifts the overall average across an eight-benchmark math-and-science suite by 19%. With identical post-training, the gains compound, with the largest improvements on reasoning-heavy tasks such as AIME25 and MMLU-Pro. Applying RLP to the hybrid Nemotron-Nano-12B-v2 increases the overall average from 42.81% to 61.32% and raises the average on scientific reasoning by 23%, demonstrating scalability across architectures and model sizes.
논문 링크
더 읽어보기
에이전트폴드: 능동적 맥락 관리를 통한 장기 웹 에이전트 / AgentFold: Long-Horizon Web Agents with Proactive Context Management
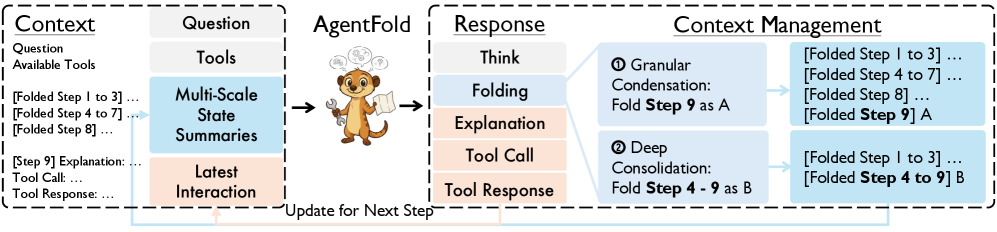
논문 소개
대규모 언어 모델(LLM) 기반 웹 에이전트는 정보 탐색에서 높은 잠재력을 가지고 있지만, 긴 작업을 수행할 때 맥락 관리의 한계로 인해 그 효과가 제한됩니다. 기존의 ReAct 기반 에이전트는 노이즈가 많은 이력을 축적하면서 맥락 포화 문제에 직면하고, 고정적으로 이력을 요약하는 방법은 중요한 세부사항을 영구적으로 잃게 할 위험이 있습니다. 이러한 문제를 해결하기 위해 제안된 AgentFold는 인간의 인지 과정인 회고적 통합에서 영감을 받아, 적극적인 맥락 관리에 중점을 둔 새로운 에이전트 패러다임입니다.
AgentFold는 맥락을 수동적으로 기록하는 것이 아니라, 능동적으로 조형되는 동적 인지 작업 공간으로 인식합니다. 각 단계에서 AgentFold는 '폴딩(folding)' 작업을 수행하여 역사적 경로를 여러 규모에서 관리합니다. 이 과정에서 중요한 세부사항을 보존하기 위한 세분화된 응축을 수행하거나, 전체 다단계 하위 작업을 추상화하는 깊은 통합을 통해 맥락을 효율적으로 관리합니다. 이러한 접근법은 정보 탐색의 효율성을 크게 향상시키는 데 기여합니다.
AgentFold-30B-A3B 에이전트는 단순한 감독 파인튜닝만으로도 주요 벤치마크인 BrowseComp와 BrowseComp-ZH에서 각각 36.2%와 47.3%의 성능을 달성하였으며, 이는 훨씬 더 큰 규모의 오픈 소스 모델인 DeepSeek-V3.1-671B-A37B와 비교해도 우수한 결과입니다. 또한, OpenAI의 o4-mini와 같은 선도적인 상용 에이전트보다도 뛰어난 성능을 보여줍니다.
이 연구는 LLM 기반 웹 에이전트의 맥락 관리 문제를 해결하는 혁신적인 접근법을 제시하며, 정보 탐색의 효율성을 높이는 데 중요한 기여를 하고 있습니다. AgentFold의 발전 가능성과 향후 연구 방향에 대한 논의는 이 분야의 지속적인 발전에 기여할 것으로 기대됩니다.
논문 초록(Abstract)
LLM 기반 웹 에이전트는 정보 탐색에 대한 엄청난 가능성을 보여주지만, 긴 시간에 걸친 작업에서의 효과는 맥락 관리의 근본적인 상충 관계로 인해 제한됩니다. 기존의 ReAct 기반 에이전트는 시끄럽고 원시적인 이력을 축적하면서 맥락 포화 문제에 시달리며, 각 단계에서 전체 이력을 고정적으로 요약하는 방법은 중요한 세부 사항의 되돌릴 수 없는 손실 위험을 안고 있습니다. 이러한 문제를 해결하기 위해, 우리는 인간의 인지 과정인 회고적 통합에서 영감을 받아 능동적인 맥락 관리에 중점을 둔 새로운 에이전트 패러다임인 AgentFold를 소개합니다. AgentFold는 맥락을 수동적으로 채워야 할 로그가 아니라 능동적으로 조형해야 할 동적인 인지 작업 공간으로 취급합니다. 각 단계에서, AgentFold는 접기(folding) 작업을 수행하는 법을 배우며, 이는 여러 규모에서 자신의 역사적 궤적을 관리합니다: 중요한 세부 사항을 보존하기 위해 세밀한 응축을 수행하거나, 전체 다단계 하위 작업을 추상화하기 위해 깊은 통합을 수행할 수 있습니다. 주요 벤치마크에서의 결과는 놀랍습니다: 간단한 감독 하의 파인튜닝(지속적인 사전학습이나 강화학습 없이)으로, 우리의 AgentFold-30B-A3B 에이전트는 BrowseComp에서 36.2%, BrowseComp-ZH에서 47.3%를 달성합니다. 특히, 이 성능은 DeepSeek-V3.1-671B-A37B와 같은 극적으로 더 큰 규모의 오픈 소스 모델을 초월하거나 동등하며, OpenAI의 o4-mini와 같은 선도적인 상용 에이전트도 초월합니다.
LLM-based web agents show immense promise for information seeking, yet their effectiveness on long-horizon tasks is hindered by a fundamental trade-off in context management. Prevailing ReAct-based agents suffer from context saturation as they accumulate noisy, raw histories, while methods that fixedly summarize the full history at each step risk the irreversible loss of critical details. Addressing these, we introduce AgentFold, a novel agent paradigm centered on proactive context management, inspired by the human cognitive process of retrospective consolidation. AgentFold treats its context as a dynamic cognitive workspace to be actively sculpted, rather than a passive log to be filled. At each step, it learns to execute a `folding' operation, which manages its historical trajectory at multiple scales: it can perform granular condensations to preserve vital, fine-grained details, or deep consolidations to abstract away entire multi-step sub-tasks. The results on prominent benchmarks are striking: with simple supervised fine-tuning (without continual pre-training or RL), our AgentFold-30B-A3B agent achieves 36.2% on BrowseComp and 47.3% on BrowseComp-ZH. Notably, this performance not only surpasses or matches open-source models of a dramatically larger scale, such as the DeepSeek-V3.1-671B-A37B, but also surpasses leading proprietary agents like OpenAI's o4-mini.
논문 링크
더 읽어보기
https://github.com/Alibaba-NLP/DeepResearch
에이전트 데이터 프로토콜: 다양한 효과적인 LLM 에이전트 파인튜닝을 위한 데이터셋 통합 / Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
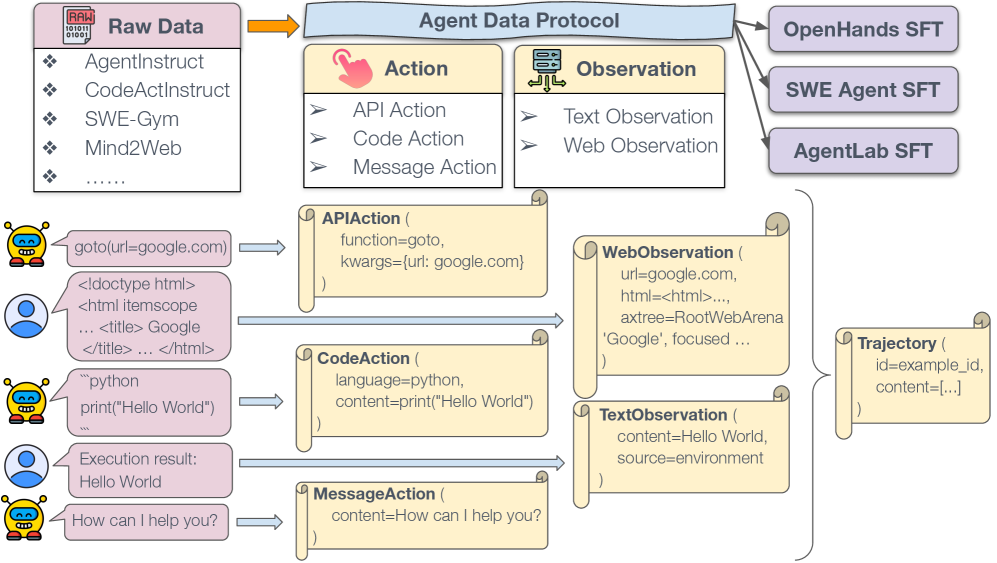
논문 소개
대규모 언어 모델(LLM)의 효과적인 사후 학습(Supervised Fine-Tuning, SFT)을 위한 데이터 수집은 복잡한 도전 과제를 동반한다. 본 연구에서는 에이전트 학습 데이터의 수집이 단순한 데이터 부족이 아니라, 다양한 형식과 도구로 분산된 데이터의 비표준화가 문제임을 지적한다. 이를 해결하기 위해 제안된 에이전트 데이터 프로토콜(Agent Data Protocol, ADP)은 다양한 데이터셋을 통합하여 에이전트 학습 파이프라인을 단순화하는 경량 표현 언어로 기능한다. ADP는 API 사용, 브라우징, 코딩 등 다양한 작업을 포괄할 수 있는 표현력을 가지면서도, 데이터셋 수준에서의 복잡한 엔지니어링 없이도 쉽게 파싱하고 학습할 수 있도록 설계되었다.
연구에서는 13개의 기존 에이전트 학습 데이터셋을 ADP 형식으로 통합하고, 이를 여러 에이전트 프레임워크에 맞는 학습 준비 형식으로 변환하였다. 이 과정에서 130만 개의 훈련 궤적을 포함하는 ADP Dataset V1을 생성하여 공개하였다. 실험 결과, ADP를 통해 SFT를 수행한 모델은 기존 기본 모델에 비해 평균 약 20%의 성능 향상을 보였으며, 도메인 특화 튜닝 없이도 표준 코딩, 브라우징, 도구 사용 및 연구 벤치마크에서 최첨단 성능을 달성하였다.
ADP의 설계는 높은 데이터 품질을 유지하기 위한 엄격한 자동 검증을 포함하고 있어, 다양한 작업 도메인에서 에이전트 모델의 성능 향상에 기여할 수 있는 가능성을 보여준다. 이러한 연구는 에이전트 학습의 표준화, 확장 가능성 및 재현성을 높이는 데 중요한 기여를 할 것으로 기대된다. ADP의 공개는 연구자들이 에이전트 학습 데이터셋을 보다 쉽게 활용할 수 있도록 하여, AI 에이전트의 발전에 기여할 것으로 보인다.
논문 초록(Abstract)
대규모 감독 학습을 통한 AI 에이전트의 공개 연구 결과는 에이전트 학습 데이터 수집이 독특한 도전 과제를 제시하기 때문에 상대적으로 드뭅니다. 본 연구에서는 병목 현상이 근본적인 데이터 소스의 부족이 아니라 다양한 데이터가 이질적인 형식, 도구 및 인터페이스에 분산되어 있다는 점에 있다고 주장합니다. 이를 위해 우리는 에이전트 데이터 프로토콜(ADP)을 소개합니다. ADP는 다양한 형식의 에이전트 데이터셋과 통합된 에이전트 학습 파이프라인 간의 "중간 언어" 역할을 하는 경량 표현 언어입니다. ADP의 설계는 API/도구 사용, 브라우징, 코딩, 소프트웨어 엔지니어링 및 일반적인 에이전트 작업 흐름을 포함한 다양한 작업을 포착할 수 있을 만큼 표현력이 풍부하면서도 데이터셋별로 엔지니어링 없이 간단하게 구문 분석하고 학습할 수 있도록 유지됩니다. 실험에서는 13개의 기존 에이전트 학습 데이터셋을 ADP 형식으로 통합하고, 표준화된 ADP 데이터를 여러 에이전트 프레임워크에 대한 학습 준비 형식으로 변환했습니다. 우리는 이러한 데이터에 대해 SFT를 수행하였고, 해당 기본 모델에 비해 평균 약 20%의 성능 향상을 입증했으며, 도메인 특화 조정 없이도 표준 코딩, 브라우징, 도구 사용 및 연구 벤치마크에서 최첨단 또는 근접한 성능을 제공합니다. 모든 코드와 데이터는 공개적으로 배포되어 ADP가 표준화되고 확장 가능하며 재현 가능한 에이전트 학습의 장벽을 낮추는 데 도움이 되기를 바랍니다.
Public research results on large-scale supervised finetuning of AI agents remain relatively rare, since the collection of agent training data presents unique challenges. In this work, we argue that the bottleneck is not a lack of underlying data sources, but that a large variety of data is fragmented across heterogeneous formats, tools, and interfaces. To this end, we introduce the agent data protocol (ADP), a light-weight representation language that serves as an "interlingua" between agent datasets in diverse formats and unified agent training pipelines downstream. The design of ADP is expressive enough to capture a large variety of tasks, including API/tool use, browsing, coding, software engineering, and general agentic workflows, while remaining simple to parse and train on without engineering at a per-dataset level. In experiments, we unified a broad collection of 13 existing agent training datasets into ADP format, and converted the standardized ADP data into training-ready formats for multiple agent frameworks. We performed SFT on these data, and demonstrated an average performance gain of ~20% over corresponding base models, and delivers state-of-the-art or near-SOTA performance on standard coding, browsing, tool use, and research benchmarks, without domain-specific tuning. All code and data are released publicly, in the hope that ADP could help lower the barrier to standardized, scalable, and reproducible agent training.
논문 링크
더 읽어보기
https://github.com/neulab/agent-data-protocol
경험 합성을 통한 에이전트 학습의 확장 / Scaling Agent Learning via Experience Synthesis
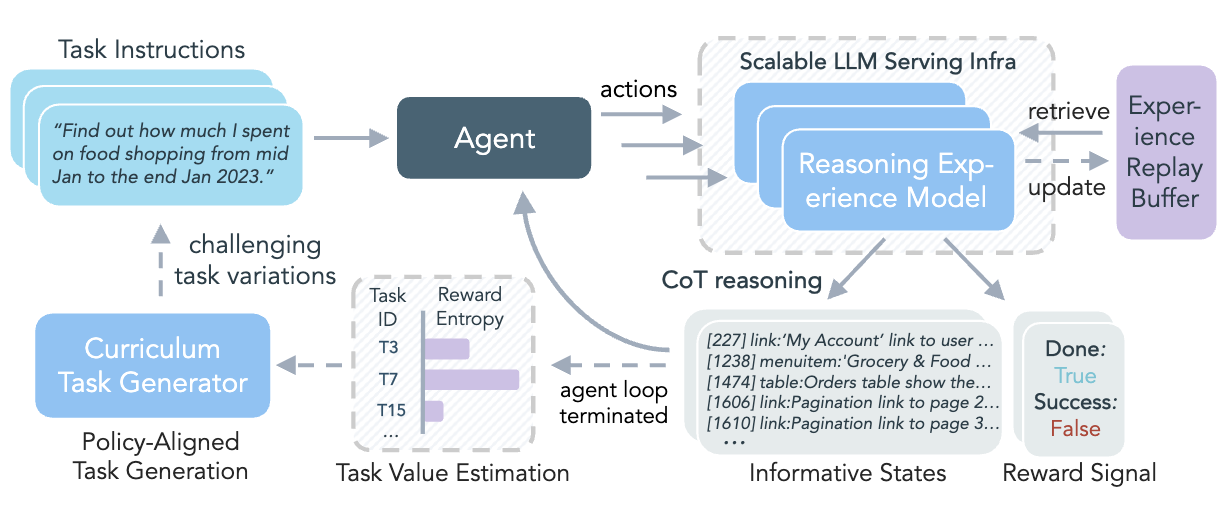
논문 소개
강화학습(RL)은 대규모 언어 모델(LLM) 에이전트를 자율적으로 개선할 수 있게 하지만, 실제 적용에는 비용이 많이 드는 롤아웃, 제한된 작업 다양성, 신뢰할 수 없는 보상 신호, 복잡한 인프라 등 여러 가지 도전 과제가 존재합니다. 이러한 문제를 해결하기 위해, 본 연구에서는 다양한 경험을 합성하여 효과적인 온라인 RL 훈련을 가능하게 하는 DreamGym이라는 통합 프레임워크를 소개합니다. DreamGym은 비싼 실제 환경 롤아웃에 의존하는 대신, 환경 동역학을 추론 기반 경험 모델로 증류하여 일관된 상태 전이 및 피드백 신호를 생성합니다. 이를 통해 RL을 위한 확장 가능한 에이전트 롤아웃 수집이 가능합니다. 또한, DreamGym은 오프라인 실제 데이터로 초기화된 경험 재생 버퍼를 활용하여 전이의 안정성과 품질을 향상시키고, 새로운 작업을 적응적으로 생성하여 에이전트 정책을 도전하게 합니다. 다양한 환경과 에이전트 백본을 대상으로 한 실험 결과, DreamGym은 RL 훈련을 크게 개선하며, 비 RL 준비 작업에서는 모든 기준선을 30% 이상 초과하는 성능을 보였습니다. RL 준비 작업에서도 DreamGym은 합성 상호작용만으로 GRPO 및 PPO 성능에 필적하는 결과를 나타냈습니다. 합성 경험으로 훈련된 정책을 실제 환경 RL로 전이할 때, DreamGym은 훨씬 적은 실제 상호작용으로도 상당한 성능 향상을 제공합니다.
논문 초록(Abstract)
강화학습(RL)은 상호작용을 통해 자기 개선을 가능하게 하여 대규모 언어 모델(LLM) 에이전트를 강화할 수 있지만, 비용이 많이 드는 롤아웃, 제한된 작업 다양성, 신뢰할 수 없는 보상 신호, 복잡한 인프라 등으로 인해 실제 채택이 어려운 상황입니다. 이러한 문제를 해결하기 위해, 우리는 다양한 경험을 통합하고 확장성을 염두에 두고 설계된 최초의 통합 프레임워크인 DreamGym을 소개합니다. DreamGym은 비싼 실제 환경 롤아웃에 의존하는 대신, 단계별 추론을 통해 일관된 상태 전이 및 피드백 신호를 도출하는 추론 기반 경험 모델로 환경 동력을 정제하여 RL을 위한 확장 가능한 에이전트 롤아웃 수집을 가능하게 합니다. 전이의 안정성과 품질을 개선하기 위해, DreamGym은 오프라인 실제 데이터로 초기화된 경험 재생 버퍼를 활용하고, 새로운 상호작용으로 지속적으로 풍부하게 하여 에이전트 훈련을 적극적으로 지원합니다. 지식 습득을 개선하기 위해, DreamGym은 현재 에이전트 정책에 도전하는 새로운 작업을 적응적으로 생성하여 보다 효과적인 온라인 커리큘럼 학습을 가능하게 합니다. 다양한 환경과 에이전트 백본을 통한 실험 결과, DreamGym은 완전한 합성 설정과 시뮬레이션-실제 전이 시나리오 모두에서 RL 훈련을 상당히 개선하는 것으로 나타났습니다. WebArena와 같은 비-RL 준비 작업에서는 DreamGym이 모든 기준선보다 30% 이상 우수한 성능을 보였으며, RL 준비 작업이지만 비용이 많이 드는 설정에서는 합성 상호작용만으로 GRPO 및 PPO 성능을 일치시킵니다. 순수하게 합성 경험으로 훈련된 정책을 실제 환경 RL로 전이할 때, DreamGym은 훨씬 적은 실제 상호작용으로도 상당한 추가 성능 향상을 제공하여 일반 목적의 RL을 위한 확장 가능한 워밍업 전략을 제공합니다.
While reinforcement learning (RL) can empower large language model (LLM) agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
논문 링크
더 읽어보기
https://github.com/Pi3AI/DreamGym
MARAG-R1: 강화학습 기반의 다중 도구 에이전틱 검색을 통한 단일 검색기 초월하기 / MARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
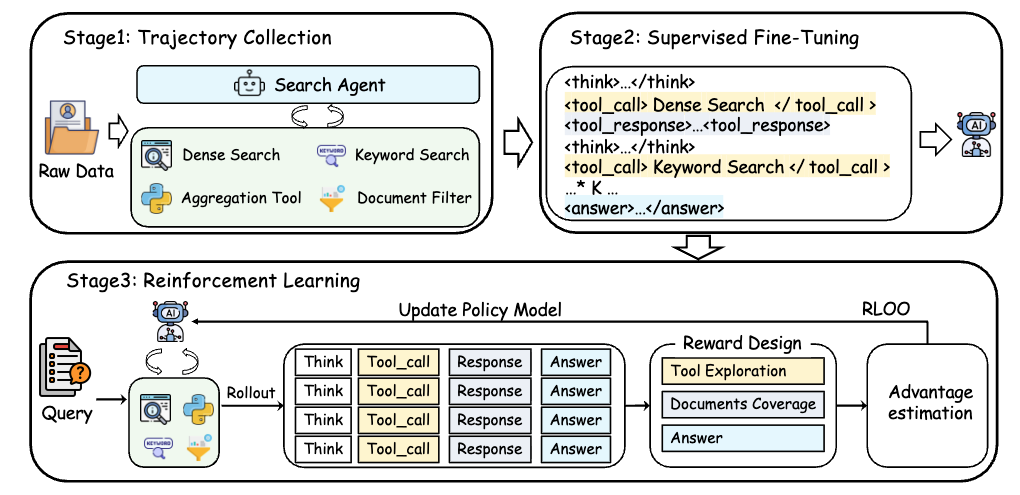
논문 소개
대규모 언어 모델(LLM)은 추론과 생성에서 뛰어난 성능을 발휘하지만, 정적 사전학습 데이터에 의존함으로써 사실적 부정확성과 새로운 정보에 대한 적응력이 떨어지는 한계를 지닌다. 이러한 문제를 해결하기 위해 Retrieval-Augmented Generation (RAG) 방식이 제안되었으나, 기존 RAG 시스템은 단일 검색기(single retriever)에 의존하여 정보 접근이 제한적이다. 이로 인해 코퍼스 수준의 추론이 필요한 작업에서 정보 획득의 병목 현상이 발생한다. 본 연구에서는 이러한 한계를 극복하기 위해 MARAG-R1이라는 강화학습 기반의 멀티 툴 RAG 프레임워크를 제안한다.
MARAG-R1은 의미 기반 검색, 키워드 검색, 필터링, 집계의 네 가지 검색 도구를 활용하여 LLM이 동적으로 여러 검색 메커니즘을 조정할 수 있도록 설계되었다. 이 모델은 두 단계의 학습 과정을 통해 각 도구의 사용 방법과 시점을 학습한다. 첫 번째 단계는 감독된 파인튜닝으로, 모델이 각 검색 도구의 기본적인 사용법을 익히도록 한다. 두 번째 단계는 강화학습으로, 모델이 각 도구를 언제 어떻게 사용할지를 학습하여 최적의 검색 결과를 도출하도록 한다. 이러한 접근은 LLM이 추론과 검색을 교차하여 코퍼스 수준의 종합을 위한 충분한 증거를 점진적으로 수집할 수 있게 한다.
실험 결과, MARAG-R1은 GlobalQA, HotpotQA, 2WikiMultiHopQA 데이터셋에서 기존의 강력한 기준선보다 우수한 성능을 보이며, 코퍼스 수준의 추론 작업에서 새로운 최첨단 결과를 달성하였다. 이는 멀티 툴 검색기를 통해 정보 접근의 폭을 넓히고, 보다 정확한 결과를 도출할 수 있음을 보여준다. 본 연구는 RAG 시스템의 발전에 기여하며, 향후 연구에서 멀티 툴 접근 방식의 가능성을 제시하는 중요한 기초 자료가 될 것이다. MARAG-R1의 혁신적인 접근 방식은 LLM의 정보 접근 능력을 획기적으로 향상시켜, 다양한 응용 분야에서의 활용 가능성을 더욱 넓히는 데 기여할 것으로 기대된다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 추론 및 생성에서 뛰어난 성능을 보이지만, 정적 사전학습 데이터에 의해 본질적으로 제한되어 사실적 부정확성과 새로운 정보에 대한 적응력이 약해지는 문제를 겪습니다. 검색-증강 생성(RAG)은 LLM을 외부 지식에 기반을 두어 이 문제를 해결합니다. 그러나 RAG의 효과는 모델이 관련 정보를 적절히 접근할 수 있는지에 크게 의존합니다. 기존 RAG 시스템은 고정된 top-k 선택을 가진 단일 검색기(retriever)에 의존하여, 데이터셋의 좁고 정적 하위 집합에 대한 접근을 제한합니다. 그 결과, 이 단일 검색기 패러다임은 특히 데이터셋 수준의 추론을 요구하는 작업에서 포괄적인 외부 정보 획득의 주요 병목 현상이 되었습니다. 이러한 제한을 극복하기 위해, 우리는 MARAG-R1을 제안합니다. MARAG-R1은 강화 학습된 다중 도구 RAG 프레임워크로, LLM이 더 넓고 정확한 정보 접근을 위해 여러 검색 메커니즘을 동적으로 조정할 수 있게 합니다. MARAG-R1은 모델에 네 가지 검색 도구—의미 기반 검색, 키워드 검색, 필터링, 집계—를 제공하고, 감독된 파인튜닝과 강화 학습이라는 두 단계의 학습 과정을 통해 이들을 어떻게 그리고 언제 사용할지를 학습합니다. 이러한 설계는 모델이 추론과 검색을 교차하여 데이터셋 수준의 종합을 위한 충분한 증거를 점진적으로 수집할 수 있도록 합니다. GlobalQA, HotpotQA, 2WikiMultiHopQA에 대한 실험 결과, MARAG-R1은 강력한 기준선보다 상당한 성능 향상을 보이며 데이터셋 수준의 추론 작업에서 새로운 최첨단 결과를 달성했습니다.
Large Language Models (LLMs) excel at reasoning and generation but are inherently limited by static pretraining data, resulting in factual inaccuracies and weak adaptability to new information. Retrieval-Augmented Generation (RAG) addresses this issue by grounding LLMs in external knowledge; However, the effectiveness of RAG critically depends on whether the model can adequately access relevant information. Existing RAG systems rely on a single retriever with fixed top-k selection, restricting access to a narrow and static subset of the corpus. As a result, this single-retriever paradigm has become the primary bottleneck for comprehensive external information acquisition, especially in tasks requiring corpus-level reasoning. To overcome this limitation, we propose MARAG-R1, a reinforcement-learned multi-tool RAG framework that enables LLMs to dynamically coordinate multiple retrieval mechanisms for broader and more precise information access. MARAG-R1 equips the model with four retrieval tools -- semantic search, keyword search, filtering, and aggregation -- and learns both how and when to use them through a two-stage training process: supervised fine-tuning followed by reinforcement learning. This design allows the model to interleave reasoning and retrieval, progressively gathering sufficient evidence for corpus-level synthesis. Experiments on GlobalQA, HotpotQA, and 2WikiMultiHopQA demonstrate that MARAG-R1 substantially outperforms strong baselines and achieves new state-of-the-art results in corpus-level reasoning tasks.
논문 링크
다중 에이전트 언어 모델에서의 자발적 조정 / Emergent Coordination in Multi-Agent Language Models
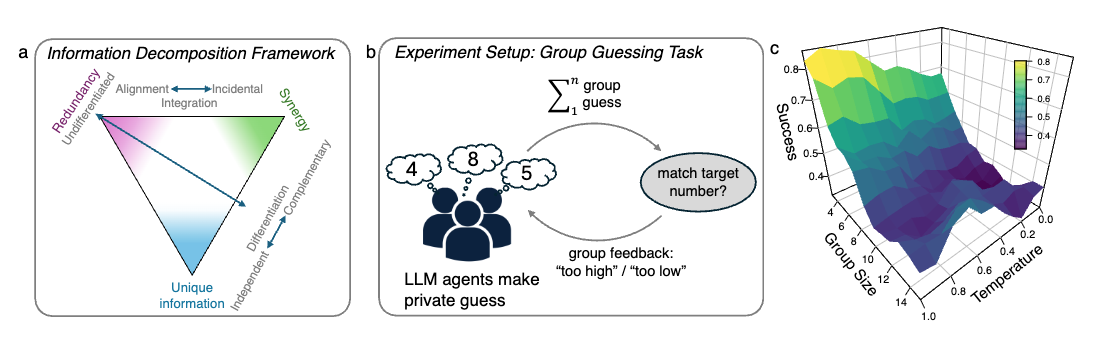
논문 소개
다중 에이전트 대규모 언어 모델(LLM) 시스템의 연구는 개별 에이전트의 집합으로서의 특성과 통합된 집단으로서의 특성을 구분하는 데 중요한 의미를 지닌다. 본 연구에서는 정보 이론적 프레임워크를 활용하여 이러한 시스템이 높은 차원의 구조를 나타내는지를 데이터 기반으로 평가하는 방법론을 제시한다. 이 프레임워크는 다이나믹한 출현(dynamical emergence)을 측정하고, 이를 지역화하며, 성능과 관련된 교차 에이전트 시너지와 잘못된 시간적 결합을 구별하는 데 중점을 둔다.
연구진은 시간 지연 상호 정보(Time-Delayed Mutual Information, TDMI)의 부분 정보 분해(Partial Information Decomposition, PID)를 통해 실용적 기준과 출현 용량 기준을 구현하였다. 이를 통해 다중 에이전트 시스템의 행동을 분석하고, 에이전트 간의 상호작용이 공유된 목표를 향해 일관되게 조직되는지를 평가하는 세 가지 테스트를 수행하였다. 이 과정에서 간단한 추측 게임을 활용하여 에이전트 간의 조정 정도와 시너지를 측정하였다.
실험 결과, 제어 조건의 그룹은 강한 시간적 시너지를 보였으나 에이전트 간의 조정된 정렬은 미미하였다. 반면, 각 에이전트에 개성을 부여하고 "다른 에이전트가 무엇을 할지 생각해보라"는 지시를 추가함으로써 정체성 기반 차별화와 목표 지향적 보완성이 나타났다. 이러한 결과는 다중 에이전트 LLM 시스템이 단순한 집합에서 더 높은 차원의 집단으로 발전할 수 있음을 입증하며, 이는 인간 집단의 집단 지성 원칙을 반영한다.
본 연구의 기여는 다중 에이전트 시스템의 출현 속성을 정량화하고, 이를 통해 에이전트 간의 시너지를 평가하는 새로운 방법론을 제시한 점에 있다. 이러한 접근은 다중 에이전트 시스템의 설계 및 이해에 있어 중요한 통찰을 제공하며, 향후 연구에서의 응용 가능성을 넓힌다.
논문 초록(Abstract)
다중 에이전트 대규모 언어 모델(LLM) 시스템이 단순히 개별 에이전트의 집합인지, 아니면 더 높은 차원의 구조를 가진 통합 집단인지 언제 판단할 수 있을까요? 우리는 다중 에이전트 시스템이 더 높은 차원의 구조의 징후를 보이는지를 순수하게 데이터 기반 방식으로 테스트하기 위한 정보 이론적 프레임워크를 소개합니다. 이 정보 분해는 다중 에이전트 LLM 시스템에서 동적 출현이 존재하는지를 측정하고, 이를 지역화하며, 성능과 관련된 교차 에이전트 시너지와 잘못된 시간적 결합을 구별할 수 있게 해줍니다. 우리는 시간 지연 상호 정보(TDMI)의 부분 정보 분해로 운영화된 실용적인 기준과 출현 용량 기준을 구현합니다. 우리의 프레임워크를 직접적인 에이전트 통신 없이 최소한의 그룹 수준 피드백과 세 가지 무작위 개입을 사용한 간단한 추측 게임 실험에 적용합니다. 대조 조건의 그룹은 강한 시간적 시너지를 보이지만 에이전트 간의 조정된 정렬은 거의 없습니다. 각 에이전트에 개성을 부여하면 안정적인 정체성 연결 차별화가 도입됩니다. "다른 에이전트가 무엇을 할지 생각해보라"는 지침과 함께 개성을 결합하면 에이전트 간의 정체성 연결 차별화와 목표 지향적 보완성이 나타납니다. 종합적으로, 우리의 프레임워크는 다중 에이전트 LLM 시스템이 단순한 집합체에서 더 높은 차원의 집단으로 프롬프트 디자인을 통해 조정될 수 있음을 확립합니다. 우리의 결과는 출현 측정 및 엔트로피 추정기 전반에 걸쳐 견고하며, 조정이 없는 기준선이나 시간적 동적만으로 설명되지 않습니다. 에이전트에 인간과 유사한 인지를 귀속시키지 않으면서, 우리가 관찰하는 상호작용 패턴은 인간 집단의 집단 지능에 대한 잘 확립된 원칙을 반영합니다: 효과적인 성과는 공유 목표에 대한 정렬과 구성원 간의 보완적 기여를 모두 요구합니다.
When are multi-agent LLM systems merely a collection of individual agents versus an integrated collective with higher-order structure? We introduce an information-theoretic framework to test -- in a purely data-driven way -- whether multi-agent systems show signs of higher-order structure. This information decomposition lets us measure whether dynamical emergence is present in multi-agent LLM systems, localize it, and distinguish spurious temporal coupling from performance-relevant cross-agent synergy. We implement both a practical criterion and an emergence capacity criterion operationalized as partial information decomposition of time-delayed mutual information (TDMI). We apply our framework to experiments using a simple guessing game without direct agent communication and only minimal group-level feedback with three randomized interventions. Groups in the control condition exhibit strong temporal synergy but only little coordinated alignment across agents. Assigning a persona to each agent introduces stable identity-linked differentiation. Combining personas with an instruction to ``think about what other agents might do'' shows identity-linked differentiation and goal-directed complementarity across agents. Taken together, our framework establishes that multi-agent LLM systems can be steered with prompt design from mere aggregates to higher-order collectives. Our results are robust across emergence measures and entropy estimators, and not explained by coordination-free baselines or temporal dynamics alone. Without attributing human-like cognition to the agents, the patterns of interaction we observe mirror well-established principles of collective intelligence in human groups: effective performance requires both alignment on shared objectives and complementary contributions across members.
논문 링크
자율적 조직의 시대: 언어 모델을 통한 조직 학습 / The Era of Agentic Organization: Learning to Organize with Language Models
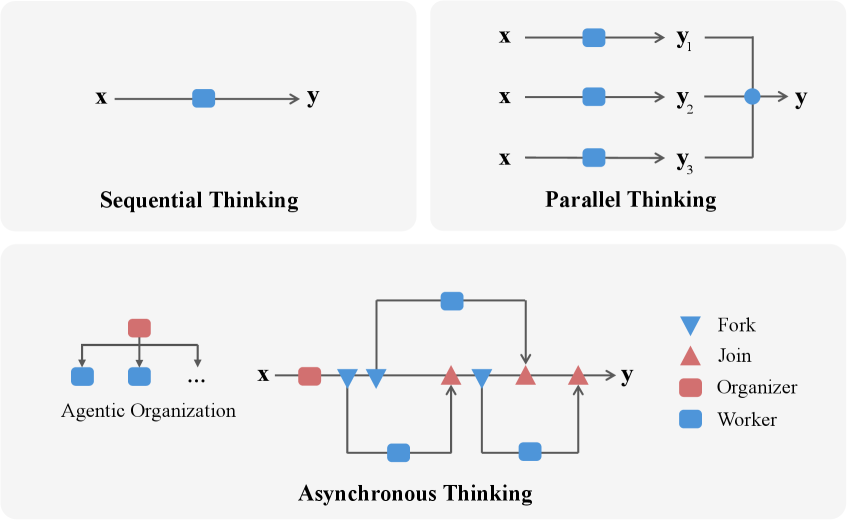
논문 소개
에이전틱 조직의 개념은 인공지능(AI) 분야에서 에이전트들이 협력하여 복잡한 문제를 해결하는 새로운 접근 방식을 제안합니다. 이를 실현하기 위해, 비동기적 사고(Asynchronous Thinking, AsyncThink)라는 새로운 추론 패러다임이 도입되었습니다. AsyncThink는 대규모 언어 모델이 내부 사고 과정을 동시에 실행 가능한 구조로 조직할 수 있도록 설계되었습니다. 이 프로토콜은 조직자가 동적으로 하위 쿼리를 작업자에게 할당하고, 중간 지식을 통합하여 일관된 솔루션을 생성하는 과정을 포함합니다.
AsyncThink의 혁신적인 점은 강화 학습을 통해 사고 구조를 최적화할 수 있다는 것입니다. 실험 결과, AsyncThink는 병렬 사고 접근법에 비해 28% 낮은 추론 지연 시간을 기록하면서도 수학적 추론에서 더 높은 정확성을 달성했습니다. 또한, 이 모델은 추가 학습 없이도 보지 못한 작업에 대해 효과적으로 일반화할 수 있는 능력을 보여주었습니다.
이 연구는 에이전틱 조직을 위한 학습-조직 문제를 정형화하고, 에이전트들이 협력하여 동시에 작동하는 방법을 탐구하는 기초를 마련합니다. AsyncThink는 대규모 언어 모델의 내부 사고를 조직하는 새로운 방법을 제시하며, 이를 통해 AI 시스템의 효율성과 유연성을 높이는 데 기여합니다. 이러한 접근은 AI의 미래에 대한 새로운 비전을 제시하며, 에이전트들이 협력하여 복잡한 문제를 해결하는 데 필요한 혁신적인 방법론을 제공합니다.
결론적으로, AsyncThink는 AI 시스템의 사고 프로세스를 혁신적으로 변화시키는 잠재력을 지니고 있으며, 이는 에이전틱 조직의 실현을 위한 중요한 단계로 평가됩니다.
논문 초록(Abstract)
우리는 에이전트가 협력적으로 그리고 동시에 복잡한 문제를 해결하여 개인의 지능을 초월하는 결과를 도출하는 새로운 AI 시대인 에이전틱 조직(agentic organization)을 구상합니다. 이 비전을 실현하기 위해, 우리는 대규모 언어 모델을 활용한 새로운 추론 패러다임인 비동기적 사고(asynchronous thinking, AsyncThink)를 소개합니다. 이는 내부 사고 과정을 동시에 실행 가능한 구조로 조직합니다. 구체적으로, 우리는 조직자가 동적으로 하위 쿼리를 작업자에게 할당하고, 중간 지식을 병합하며, 일관된 솔루션을 생성하는 사고 프로토콜을 제안합니다. 더 중요한 것은, 이 프로토콜의 사고 구조가 강화 학습을 통해 추가적으로 최적화될 수 있다는 점입니다. 실험 결과, AsyncThink는 병렬 사고에 비해 28% 낮은 추론 지연 시간을 달성하면서 수학적 추론의 정확성을 향상시킵니다. 또한, AsyncThink는 학습한 비동기적 사고 능력을 일반화하여 추가 학습 없이도 보지 못한 작업을 효과적으로 처리합니다.
We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence. To realize this vision, we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with large language models, which organizes the internal thinking process into concurrently executable structures. Specifically, we propose a thinking protocol where an organizer dynamically assigns sub-queries to workers, merges intermediate knowledge, and produces coherent solutions. More importantly, the thinking structure in this protocol can be further optimized through reinforcement learning. Experiments demonstrate that AsyncThink achieves 28% lower inference latency compared to parallel thinking while improving accuracy on mathematical reasoning. Moreover, AsyncThink generalizes its learned asynchronous thinking capabilities, effectively tackling unseen tasks without additional training.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()