[2025/11/17 ~ 23] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() AI 에이전트의 자율성 향상: 최근 논문들은 자율적으로 복잡한 작업을 수행할 수 있는 AI 에이전트의 발전에 초점을 맞추고 있습니다. 예를 들어, AgentEvolver는 대규모 언어 모델(LLM)의 이해력과 추론 능력을 활용하여 자율 에이전트 학습을 촉진하는 시스템을 제안합니다. 이러한 시스템은 수작업으로 생성된 데이터셋에 대한 의존도를 줄이고, 효율적인 탐색과 샘플 활용을 가능하게 합니다.
AI 에이전트의 자율성 향상: 최근 논문들은 자율적으로 복잡한 작업을 수행할 수 있는 AI 에이전트의 발전에 초점을 맞추고 있습니다. 예를 들어, AgentEvolver는 대규모 언어 모델(LLM)의 이해력과 추론 능력을 활용하여 자율 에이전트 학습을 촉진하는 시스템을 제안합니다. 이러한 시스템은 수작업으로 생성된 데이터셋에 대한 의존도를 줄이고, 효율적인 탐색과 샘플 활용을 가능하게 합니다.
![]() 대규모 언어 모델의 한계와 최적화: LLM의 확장성과 관련된 여러 논문은 이러한 모델들이 직면한 근본적인 한계들을 다루고 있습니다. 예를 들어, "On the Fundamental Limits of LLMs at Scale"에서는 환각, 맥락 압축, 추론 저하 등 다섯 가지 주요 한계를 제시하며, 이러한 한계들이 계산, 정보 및 학습의 기초적 한계와 어떻게 연결되는지를 설명합니다. 이는 LLM의 성능을 개선하기 위한 이론적 기초를 제공합니다.
대규모 언어 모델의 한계와 최적화: LLM의 확장성과 관련된 여러 논문은 이러한 모델들이 직면한 근본적인 한계들을 다루고 있습니다. 예를 들어, "On the Fundamental Limits of LLMs at Scale"에서는 환각, 맥락 압축, 추론 저하 등 다섯 가지 주요 한계를 제시하며, 이러한 한계들이 계산, 정보 및 학습의 기초적 한계와 어떻게 연결되는지를 설명합니다. 이는 LLM의 성능을 개선하기 위한 이론적 기초를 제공합니다.
![]() AI 기반 시스템 연구의 변화: AI가 시스템 연구의 프로세스를 자동화하고 혁신하는 경향이 나타나고 있습니다. "Barbarians at the Gate" 논문에서는 AI가 다양한 솔루션을 생성하고 이를 검증하는 과정을 통해 성능 지향 알고리즘의 설계 및 평가에 기여할 수 있음을 강조합니다. 이러한 접근 방식은 AI가 알고리즘 설계에서 중심적인 역할을 하게 됨에 따라 연구자들이 문제 정의와 전략적 안내에 더 집중하게 될 것임을 시사합니다.
AI 기반 시스템 연구의 변화: AI가 시스템 연구의 프로세스를 자동화하고 혁신하는 경향이 나타나고 있습니다. "Barbarians at the Gate" 논문에서는 AI가 다양한 솔루션을 생성하고 이를 검증하는 과정을 통해 성능 지향 알고리즘의 설계 및 평가에 기여할 수 있음을 강조합니다. 이러한 접근 방식은 AI가 알고리즘 설계에서 중심적인 역할을 하게 됨에 따라 연구자들이 문제 정의와 전략적 안내에 더 집중하게 될 것임을 시사합니다.
AgentEvolver: 효율적인 자기 진화 에이전트 시스템을 향하여 / AgentEvolver: Towards Efficient Self-Evolving Agent System
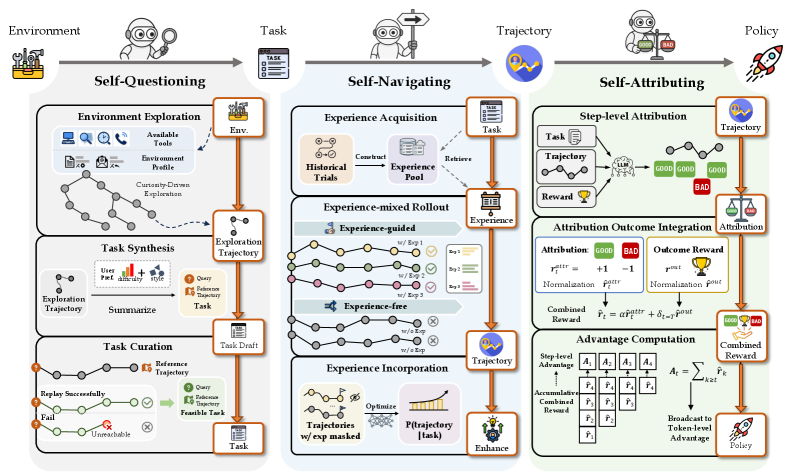
논문 소개
AgentEvolver는 자율 에이전트 시스템의 효율성을 높이기 위해 대규모 언어 모델(LLM)의 의미 이해 및 추론 능력을 활용하는 혁신적인 접근 방식을 제안한다. 기존의 강화학습(RL) 기반 방법들은 수작업으로 구축된 데이터셋과 광범위한 무작위 탐색을 요구하여 높은 비용과 비효율성을 초래하는 한계가 있었다. 이러한 문제를 해결하기 위해 AgentEvolver는 세 가지 상호 보완적인 메커니즘인 자기 질문, 자기 탐색, 자기 귀속을 도입하여 에이전트의 자율 학습을 촉진한다.
자기 질문 모듈은 에이전트가 새로운 환경에서 호기심을 기반으로 작업을 생성할 수 있도록 지원하며, 이를 통해 수작업 데이터셋에 대한 의존도를 줄인다. 자기 탐색 메커니즘은 경험 재사용과 하이브리드 정책 안내를 통해 탐색 효율성을 극대화하여, 에이전트가 이전 경험을 활용하여 새로운 작업을 수행할 수 있도록 한다. 마지막으로, 자기 귀속 메커니즘은 각 행동의 기여도를 평가하여 보다 정교한 보상 체계를 구축함으로써 샘플 효율성을 높인다.
AgentEvolver는 이러한 메커니즘을 통합하여 에이전트의 능력을 확장 가능하고 비용 효율적으로 개선할 수 있는 프레임워크를 제공한다. 초기 실험 결과는 AgentEvolver가 전통적인 RL 기반 방법에 비해 더 효율적인 탐색과 빠른 적응을 달성함을 보여준다. 이 연구는 자율 에이전트 개발의 새로운 패러다임을 제시하며, 향후 과제 중심 응용 및 LLM 수준의 자가 진화를 통해 AgentEvolver의 범위와 영향을 확장할 계획이다. 이러한 접근은 샘플 효율성, 견고성 및 환경 간 일반화에서 추가적인 이득을 기대하게 한다.
논문 초록(Abstract)
자율 에이전트는 대규모 언어 모델(LLM)에 의해 구동되어 다양한 환경에서 추론, 도구 사용 및 복잡한 작업 수행을 통해 인간의 생산성을 크게 향상시킬 잠재력을 가지고 있습니다. 그러나 현재 이러한 에이전트를 개발하는 접근 방식은 일반적으로 수작업으로 구성된 작업 데이터셋과 광범위한 무작위 탐색을 포함하는 강화학습(RL) 파이프라인을 필요로 하여 비용이 많이 들고 비효율적입니다. 이러한 한계는 데이터 구성 비용이 지나치게 높고 탐색 효율이 낮으며 샘플 활용도가 떨어지게 만듭니다. 이러한 문제를 해결하기 위해, 우리는 자율 에이전트 학습을 촉진하기 위해 LLM의 의미 이해 및 추론 능력을 활용하는 자기 진화 에이전트 시스템인 AgentEvolver를 제안합니다. AgentEvolver는 세 가지 상호 보완적인 메커니즘을 도입합니다: (i) 자기 질문(self-questioning)은 호기심 기반의 작업 생성을 가능하게 하여 수작업 데이터셋에 대한 의존도를 줄입니다; (ii) 자기 탐색(self-navigating)은 경험 재사용과 하이브리드 정책 안내를 통해 탐색 효율을 개선합니다; (iii) 자기 귀속(self-attributing)은 기여도에 따라 경로 상태와 행동에 차별화된 보상을 부여하여 샘플 효율성을 향상시킵니다. 이러한 메커니즘을 통합된 프레임워크로 결합함으로써, AgentEvolver는 에이전트 능력의 확장 가능하고 비용 효율적이며 지속적인 개선을 가능하게 합니다. 초기 실험 결과, AgentEvolver는 전통적인 RL 기반 기준선에 비해 더 효율적인 탐색, 더 나은 샘플 활용도 및 더 빠른 적응을 달성하는 것으로 나타났습니다.
Autonomous agents powered by large language models (LLMs) have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
논문 링크
더 읽어보기
https://github.com/modelscope/AgentEvolver
대규모 LLM의 근본적 한계에 대한 연구 / On the Fundamental Limits of LLMs at Scale
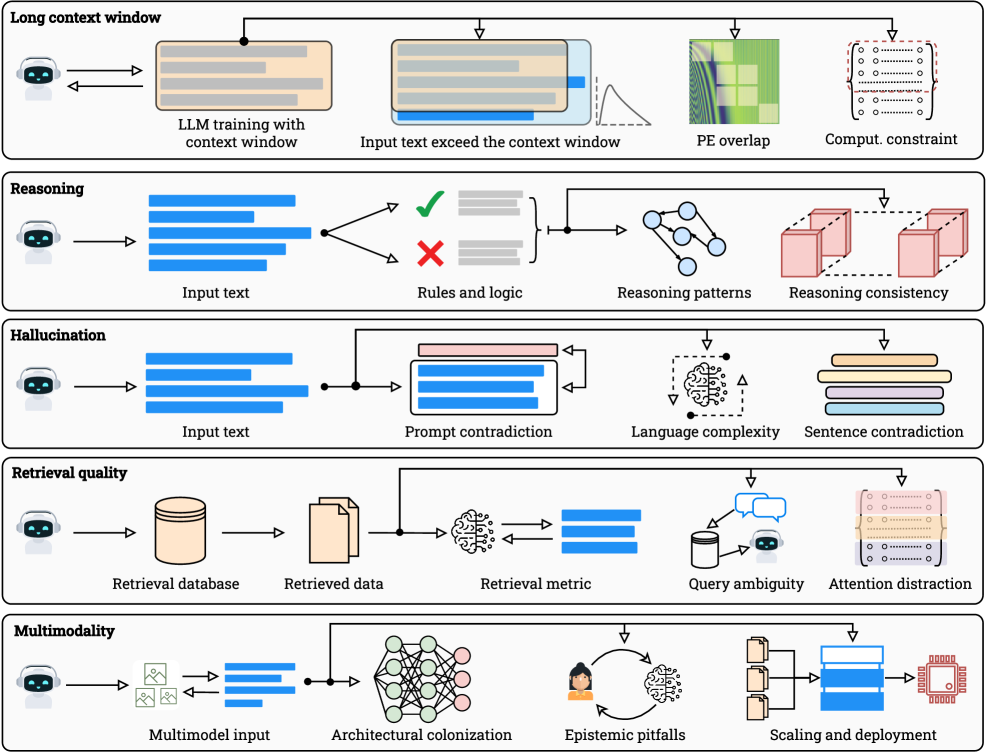
논문 소개
대규모 언어 모델(LLMs)의 발전은 최근 몇 년간 인공지능 분야에서 큰 주목을 받아왔으며, 스케일링을 통해 상당한 성과를 이루어냈다. 그러나 이러한 성과는 다섯 가지 근본적인 한계에 의해 제약을 받는다. 본 연구는 이러한 한계를 이론적으로 분석하고, LLM 스케일링의 고유한 이론적 한계를 형식화하는 통합된 프레임워크를 제시한다. 연구의 주요 초점은 계산 가능성과 비계산 가능성, 정보 이론적 제약, 기하학적 및 계산적 효과를 통해 LLM의 성능 한계를 규명하는 것이다.
계산 가능성과 비계산 가능성의 관점에서, 모든 계산 가능하게 열거 가능한 모델 가족에 대해 대각화는 특정 입력에서 모델이 실패해야 함을 보장한다. 이는 LLM이 특정한 문제에 대해 무한한 실패 집합을 가질 수 있음을 의미한다. 또한, 정보 이론적 제약은 결정 가능한 작업에서도 정확도의 한계를 설정하며, 유한한 설명 길이는 압축 오류를 유발한다. 이러한 이론적 배경은 LLM의 성능을 이해하는 데 필수적이다.
기하학적 및 계산적 효과는 긴 맥락을 압축하는 데 기여하며, 이는 모델의 성능 저하로 이어질 수 있다. 연구에서는 LLM이 패턴 완성을 선호하는 경향과 검색 과정에서 발생하는 의미적 드리프트 및 결합 노이즈 문제를 다룬다. 멀티모달 모델의 경우, 다양한 모달리티 간의 얕은 정렬 문제도 심각한 도전 과제가 된다.
이 논문은 이러한 한계를 극복하기 위한 여러 가지 해결책을 제안한다. 제한된 오라클 검색 및 위치적 커리큘럼과 같은 방법론은 LLM의 성능을 향상시키는 데 기여할 수 있으며, 희소 또는 계층적 어텐션 기법을 통해 모델의 한계를 극복할 가능성을 탐구한다. 각 섹션에서는 이론적 근거와 실험적 증거를 결합하여 스케일링의 효과와 한계를 명확히 하고, 향후 연구 방향을 제시한다.
결론적으로, LLM의 스케일링 한계를 이해하는 것은 멀티모달 모델의 설계 및 훈련에서 발생할 수 있는 여러 문제를 해결하는 데 중요한 기초를 제공한다. 본 연구는 신뢰성, 해석 가능성, 확장성 문제를 해결하기 위한 아키텍처적 및 방법론적 혁신의 필요성을 강조하며, 신경-상징적 기초와 실제 세계의 체화된 데이터와 같은 유망한 방향을 제시한다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 확장성 덕분에 엄청난 이점을 얻었지만, 이러한 이점은 다섯 가지 기본적인 한계에 의해 제한됩니다: (1) 환각, (2) 맥락 압축, (3) 추론 저하, (4) 검색 취약성, (5) 멀티모달 불일치. 기존의 서베이는 이러한 현상을 경험적으로 설명하지만, 이들을 계산, 정보 및 학습의 기초적 한계와 연결하는 엄밀한 이론적 종합이 부족합니다. 본 연구는 LLM 확장의 고유한 이론적 한계를 형식화하는 통합된 증명 기반 프레임워크를 제시하여 이 간극을 메웁니다. 첫째, 계산 가능성과 비계산 가능성은 오류의 줄일 수 없는 잔여물을 의미합니다: 계산 가능하게 열거 가능한 모델 패밀리의 경우, 대각선화는 일부 모델이 실패해야 하는 입력을 보장하며, 결정 불가능한 쿼리(예: 정지 스타일 작업)는 모든 계산 가능한 예측기에 대해 무한한 실패 집합을 유도합니다. 둘째, 정보 이론적 및 통계적 제약은 결정 가능한 작업에서도 달성 가능한 정확도를 제한하며, 유한한 설명 길이는 압축 오류를 강제하고, 긴 꼬리 사실 지식은 막대한 샘플 복잡성을 요구합니다. 셋째, 기하학적 및 계산적 효과는 위치의 저학습, 인코딩 감쇠 및 소프트맥스 혼잡으로 인해 긴 맥락을 명목상의 크기보다 훨씬 더 압축합니다. 우리는 또한 가능도 기반 학습이 추론보다 패턴 완성을 선호하는 방식, 토큰 제한 하의 검색이 의미적 드리프트와 결합 노이즈로 고통받는 방식, 그리고 멀티모달 확장이 얕은 교차 모달 정렬을 상속하는 방식을 보여줍니다. 각 섹션에서는 정리와 경험적 증거를 결합하여 확장이 도움이 되는 곳, 포화되는 곳, 그리고 진전을 이룰 수 없는 곳을 개략적으로 설명하며, 제한된 오라클 검색, 위치 커리큘럼, 희소 또는 계층적 어텐션과 같은 이론적 기초와 실용적인 완화 경로를 제공합니다.
Large Language Models (LLMs) have benefited enormously from scaling, yet these gains are bounded by five fundamental limitations: (1) hallucination, (2) context compression, (3) reasoning degradation, (4) retrieval fragility, and (5) multimodal misalignment. While existing surveys describe these phenomena empirically, they lack a rigorous theoretical synthesis connecting them to the foundational limits of computation, information, and learning. This work closes that gap by presenting a unified, proof-informed framework that formalizes the innate theoretical ceilings of LLM scaling. First, computability and uncomputability imply an irreducible residue of error: for any computably enumerable model family, diagonalization guarantees inputs on which some model must fail, and undecidable queries (e.g., halting-style tasks) induce infinite failure sets for all computable predictors. Second, information-theoretic and statistical constraints bound attainable accuracy even on decidable tasks, finite description length enforces compression error, and long-tail factual knowledge requires prohibitive sample complexity. Third, geometric and computational effects compress long contexts far below their nominal size due to positional under-training, encoding attenuation, and softmax crowding. We further show how likelihood-based training favors pattern completion over inference, how retrieval under token limits suffers from semantic drift and coupling noise, and how multimodal scaling inherits shallow cross-modal alignment. Across sections, we pair theorems and empirical evidence to outline where scaling helps, where it saturates, and where it cannot progress, providing both theoretical foundations and practical mitigation paths like bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention.
논문 링크
효율적인 전문가 혼합 언어 모델을 위한 스케일링 법칙 연구 / Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models
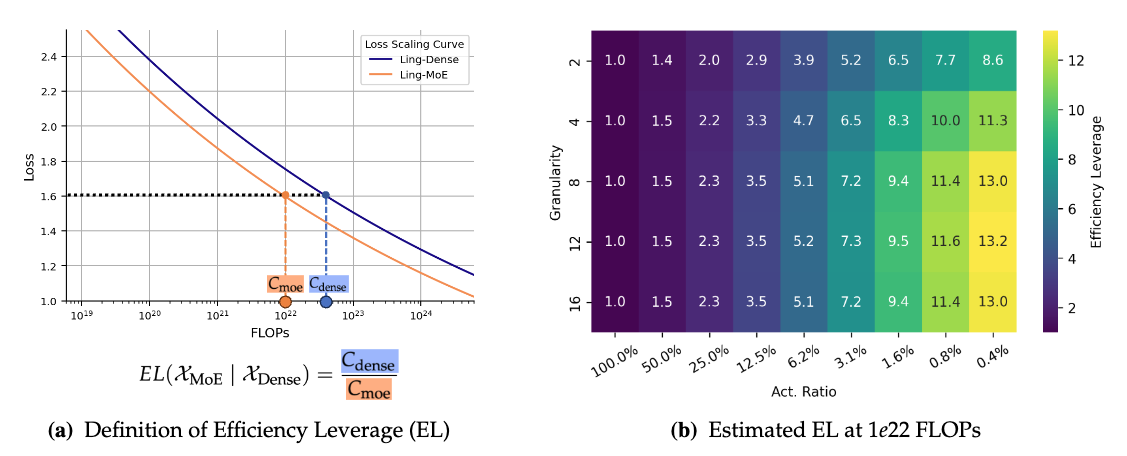
논문 소개
Mixture-of-Experts (MoE) 아키텍처는 대규모 언어 모델 (LLM)의 효율적인 확장을 위한 중요한 방법론으로 자리 잡고 있다. MoE는 총 매개변수 수와 계산 비용을 분리하여 모델의 용량을 극대화할 수 있는 잠재력을 제공하지만, 특정 MoE 구성에서의 모델 용량 예측은 여전히 해결되지 않은 문제로 남아 있다. 이러한 문제를 해결하기 위해, 연구진은 Efficiency Leverage (EL)라는 새로운 지표를 도입하여 MoE 모델의 계산적 이점을 정량화하고자 하였다.
이 연구에서는 300개 이상의 MoE 모델을 학습시키며, 다양한 구성 요소인 전문가 활성화 비율과 총 계산 예산이 EL에 미치는 영향을 체계적으로 분석하였다. 연구 결과, EL은 주로 전문가 활성화 비율과 총 계산 예산에 의해 주도되며, 이 두 요소는 예측 가능한 거듭제곱 법칙을 따른다는 사실이 밝혀졌다. 또한, 전문가 세분화는 비선형 조절자로 작용하여 최적의 범위가 존재함을 확인하였다. 이러한 발견은 MoE 아키텍처의 효율성을 높이기 위한 통합된 스케일링 법칙으로 정리되었다.
이 스케일링 법칙을 검증하기 위해, 연구진은 0.85B 활성 매개변수를 가진 Ling-mini-beta라는 파일럿 모델을 설계하고, 6.1B 밀집 모델과 비교하여 동일한 1T 고품질 토큰 데이터셋에서 학습하였다. 그 결과, Ling-mini-beta는 6.1B 밀집 모델과 동등한 성능을 발휘하면서도 7배 이상의 계산 자원을 절약하는 성과를 거두었다. 이러한 결과는 제안된 스케일링 법칙의 정확성을 입증하며, MoE 모델의 효율적 확장을 위한 원칙적이고 경험적으로 기반이 마련된 토대를 제공한다.
본 연구는 MoE 아키텍처의 효율성을 정량화하고 이를 기반으로 한 스케일링 법칙을 제시함으로써, 대규모 언어 모델의 발전에 기여하고 있으며, 향후 연구에 있어 중요한 참고자료가 될 것으로 기대된다.
논문 초록(Abstract)
혼합 전문가(Mixture-of-Experts, MoE)는 전체 매개변수를 계산 비용과 분리하여 대규모 언어 모델(LLM)을 효율적으로 확장하는 지배적인 아키텍처가 되었습니다. 그러나 이러한 분리는 중요한 도전 과제를 만들어냅니다: 주어진 MoE 구성(예: 전문가 활성화 비율 및 세분화)의 모델 용량을 예측하는 것은 해결되지 않은 문제로 남아 있습니다. 이 격차를 해소하기 위해, 우리는 MoE 모델이 밀집 모델에 비해 가지는 계산적 이점을 정량화하는 지표인 효율성 레버리지(Efficiency Leverage, EL)를 소개합니다. 우리는 300개 이상의 모델을 최대 28B 매개변수까지 학습시키는 대규모 실증 연구를 수행하여 MoE 아키텍처 구성과 EL 간의 관계를 체계적으로 조사합니다. 우리의 연구 결과는 EL이 주로 전문가 활성화 비율과 총 계산 예산에 의해 주도되며, 두 가지 모두 예측 가능한 거듭제곱 법칙을 따르는 반면, 전문가 세분화는 명확한 최적 범위를 가진 비선형 조절기로 작용한다는 것을 보여줍니다. 우리는 이러한 발견을 바탕으로 MoE 아키텍처의 구성을 기반으로 EL을 정확하게 예측하는 통합 스케일링 법칙을 통합합니다. 우리가 도출한 스케일링 법칙을 검증하기 위해, 우리는 0.85B의 활성 매개변수만 가진 Ling-2.0 시리즈의 파일럿 모델인 Ling-mini-beta를 설계하고 학습시켰으며, 비교를 위해 6.1B 밀집 모델도 함께 학습시켰습니다. 동일한 1T 고품질 토큰 데이터셋에서 학습했을 때, Ling-mini-beta는 6.1B 밀집 모델의 성능을 일치시키면서 7배 이상의 적은 계산 자원을 소비하여 우리의 스케일링 법칙의 정확성을 확인했습니다. 이 연구는 효율적인 MoE 모델의 확장을 위한 원칙적이고 실증적으로 기반한 토대를 제공합니다.
Mixture-of-Experts (MoE) has become a dominant architecture for scaling Large Language Models (LLMs) efficiently by decoupling total parameters from computational cost. However, this decoupling creates a critical challenge: predicting the model capacity of a given MoE configurations (e.g., expert activation ratio and granularity) remains an unresolved problem. To address this gap, we introduce Efficiency Leverage (EL), a metric quantifying the computational advantage of an MoE model over a dense equivalent. We conduct a large-scale empirical study, training over 300 models up to 28B parameters, to systematically investigate the relationship between MoE architectural configurations and EL. Our findings reveal that EL is primarily driven by the expert activation ratio and the total compute budget, both following predictable power laws, while expert granularity acts as a non-linear modulator with a clear optimal range. We integrate these discoveries into a unified scaling law that accurately predicts the EL of an MoE architecture based on its configuration. To validate our derived scaling laws, we designed and trained Ling-mini-beta, a pilot model for Ling-2.0 series with only 0.85B active parameters, alongside a 6.1B dense model for comparison. When trained on an identical 1T high-quality token dataset, Ling-mini-beta matched the performance of the 6.1B dense model while consuming over 7x fewer computational resources, thereby confirming the accuracy of our scaling laws. This work provides a principled and empirically-grounded foundation for the scaling of efficient MoE models.
논문 링크
문 앞의 야만인: AI가 시스템 연구를 어떻게 뒤엎고 있는가 / Barbarians at the Gate: How AI is Upending Systems Research
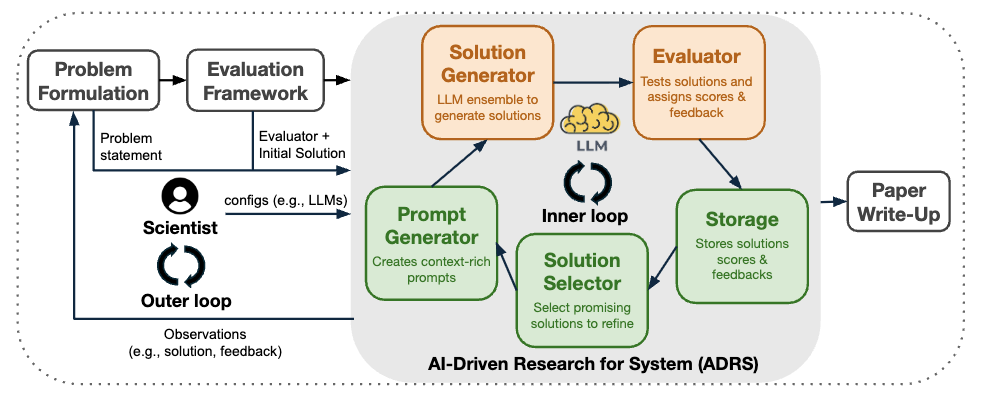
논문 소개
인공지능(AI)은 연구 프로세스를 혁신적으로 변화시키고 있으며, 특히 시스템 연구 분야에서 그 잠재력이 두드러진다. 본 연구에서는 AI를 활용하여 새로운 솔루션을 자동으로 발견하는 방법론인 **AI-Driven Research for Systems (ADRS)**를 제안한다. 이 접근 방식은 주어진 작업에 대해 다양한 솔루션을 생성하고, 이를 검증하여 최적의 해결책을 선택하는 과정을 포함한다. 시스템 연구는 성능 지향 알고리즘의 설계 및 평가에 중점을 두어 왔으며, 이러한 특성 덕분에 신뢰할 수 있는 검증자를 활용할 수 있는 환경을 제공한다.
ADRS는 반복적인 솔루션 생성, 평가 및 개선 과정을 통해 알고리즘을 진화시키며, 이를 위해 기존의 오픈 소스 도구인 OpenEvolve를 활용한다. 연구에서는 로드 밸런싱, 혼합 전문가 추론, LLM(대형 언어 모델) 기반 SQL 쿼리, 트랜잭션 스케줄링 등 다양한 도메인에서 사례 연구를 통해 ADRS의 유효성을 입증하였다. 이 과정에서 발견된 알고리즘은 기존의 인간 설계를 초월하여 최대 5.0배의 실행 시간 개선 및 50%의 비용 절감을 달성하였다.
저자들은 알고리즘 진화를 위한 최선의 관행을 정리하고, 프롬프트 설계 및 평가자 구축에 대한 구체적인 지침을 제공함으로써 ADRS의 적용 가능성을 높였다. 연구 결과는 AI가 시스템 연구에서 중심적인 역할을 맡게 됨에 따라, 인간 연구자들이 문제 정의와 전략적 방향 설정에 더욱 집중해야 할 필요성을 강조한다. 이러한 변화는 시스템 연구의 패러다임을 전환시키며, AI 시대에 적합한 새로운 연구 관행을 제안하는 중요한 기여로 평가된다.
결론적으로, 본 연구는 AI 기반 접근 방식이 시스템 성능 문제 해결에 어떻게 기여할 수 있는지를 명확히 보여주며, AI가 시스템 연구에 미치는 영향과 그로 인한 변화의 필요성을 강조한다.
논문 초록(Abstract)
인공지능(AI)은 새로운 솔루션 발견 과정을 자동화함으로써 우리가 알고 있는 연구 프로세스를 변화시키기 시작하고 있습니다. 주어진 작업에 대해 전형적인 AI 기반 접근 방식은 (i) 다양한 솔루션 집합을 생성하고, (ii) 이러한 솔루션을 검증하여 문제를 해결하는 하나를 선택하는 것입니다. 이 접근 방식은 신뢰할 수 있는 검증자가 존재한다고 가정하는데, 즉 주어진 문제를 해결하는지 여부를 정확하게 판단할 수 있는 검증자를 의미합니다. 우리는 새로운 성능 지향 알고리즘을 설계하고 평가하는 데 오랫동안 집중해온 시스템 연구가 AI 기반 솔루션 발견에 특히 적합하다고 주장합니다. 이는 시스템 성능 문제는 본질적으로 신뢰할 수 있는 검증자를 허용하기 때문입니다: 솔루션은 일반적으로 실제 시스템이나 시뮬레이터에 구현되며, 검증은 이러한 소프트웨어 아티팩트를 미리 정의된 작업 부하에 대해 실행하고 성능을 측정하는 것으로 축소됩니다. 우리는 이 접근 방식을 AI 기반 시스템 연구(AI-Driven Research for Systems, ADRS)라고 명명하며, 이는 솔루션을 반복적으로 생성, 평가 및 개선합니다. 기존의 오픈 소스 ADRS 인스턴스인 OpenEvolve를 사용하여, 다중 지역 클라우드 스케줄링을 위한 로드 밸런싱, 혼합 전문가 추론, LLM 기반 SQL 쿼리 및 트랜잭션 스케줄링 등 다양한 분야에서 사례 연구를 제시합니다. 여러 경우에 ADRS는 최첨단 인간 설계를 초월하는 알고리즘을 발견하며(예: 최대 5.0배의 실행 시간 개선 또는 50%의 비용 절감 달성), 알고리즘 진화를 안내하기 위한 모범 사례를 도출합니다. 우리는 기존 프레임워크에 대한 프롬프트 설계에서 평가자 구성까지의 과정을 논의합니다. 이후 AI가 알고리즘 설계에서 중심적인 역할을 맡게 됨에 따라, 인간 연구자들이 문제 정의 및 전략적 안내에 점점 더 집중할 것이라고 주장하며, 시스템 커뮤니티에 대한 더 넓은 의미를 논의합니다. 우리의 결과는 AI 시대에 시스템 연구 관행을 조정할 필요성과 파괴적인 잠재력을 강조합니다.
Artificial Intelligence (AI) is starting to transform the research process as we know it by automating the discovery of new solutions. Given a task, the typical AI-driven approach is (i) to generate a set of diverse solutions, and then (ii) to verify these solutions and select one that solves the problem. Crucially, this approach assumes the existence of a reliable verifier, i.e., one that can accurately determine whether a solution solves the given problem. We argue that systems research, long focused on designing and evaluating new performance-oriented algorithms, is particularly well-suited for AI-driven solution discovery. This is because system performance problems naturally admit reliable verifiers: solutions are typically implemented in real systems or simulators, and verification reduces to running these software artifacts against predefined workloads and measuring performance. We term this approach as AI-Driven Research for Systems (ADRS), which iteratively generates, evaluates, and refines solutions. Using penEvolve, an existing open-source ADRS instance, we present case studies across diverse domains, including load balancing for multi-region cloud scheduling, Mixture-of-Experts inference, LLM-based SQL queries, and transaction scheduling. In multiple instances, ADRS discovers algorithms that outperform state-of-the-art human designs (e.g., achieving up to 5.0x runtime improvements or 50% cost reductions). We distill best practices for guiding algorithm evolution, from prompt design to evaluator construction, for existing frameworks. We then discuss the broader implications for the systems community: as AI assumes a central role in algorithm design, we argue that human researchers will increasingly focus on problem formulation and strategic guidance. Our results highlight both the disruptive potential and the urgent need to adapt systems research practices in the age of AI.
논문 링크
더 읽어보기
https://github.com/UCB-ADRS/ADRS
AI 지원 코딩의 효과: Cursor가 소프트웨어 프로젝트에 미치는 영향에 대한 차이-차이 연구 / Does AI-Assisted Coding Deliver? A Difference-in-Differences Study of Cursor's Impact on Software Projects
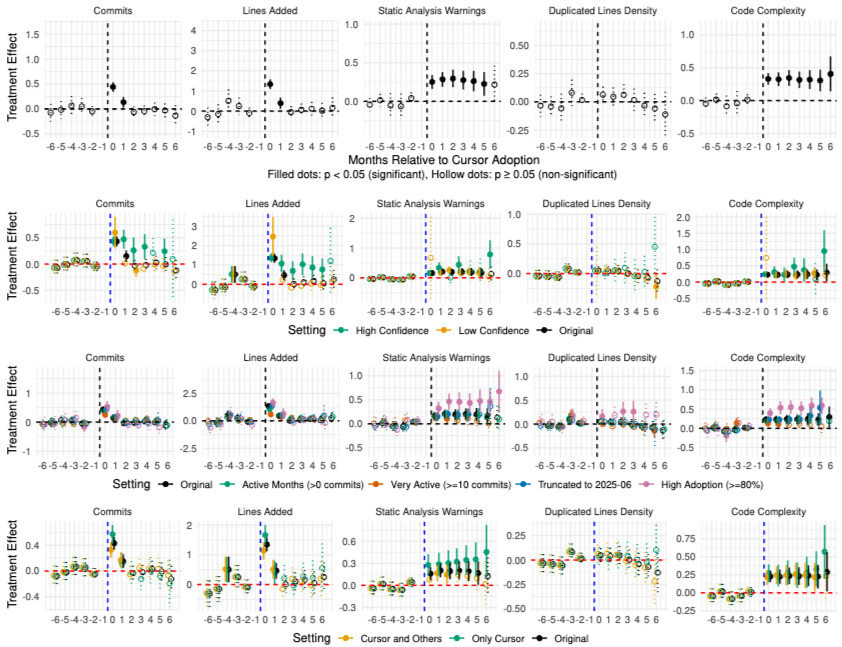
논문 소개
대규모 언어 모델(LLM)의 발전은 소프트웨어 공학 분야에 혁신적인 변화를 가져올 가능성을 보여주고 있으며, 이러한 도구들이 실제 개발 환경에서 어떻게 작용하는지에 대한 실증적 연구가 필요하다. 본 연구에서는 LLM 에이전트 보조 도구인 Cursor의 채택이 소프트웨어 프로젝트의 개발 속도와 품질에 미치는 영향을 분석하기 위해 차이의 차이(Difference-in-Differences, DiD) 설계를 활용하였다. 이 방법론은 Cursor를 채택한 807개의 GitHub 저장소와 이를 사용하지 않는 1,380개의 유사 저장소를 비교하여, 채택 시점의 자연 발생적 변화를 통해 인과적 효과를 식별하는 데 중점을 두었다.
연구 결과에 따르면, Cursor의 채택은 초기에는 개발 속도를 3-5배 증가시키는 긍정적인 효과를 나타냈으나, 이러한 효과는 두 달 후 사라지는 경향을 보였다. 동시에 정적 분석 경고는 30%, 코드 복잡성은 41% 증가하는 것으로 나타났다. 이러한 결과는 LLM 에이전트 도구가 제공하는 단기적인 생산성 향상이 장기적으로는 기술적 부채를 증가시켜 개발 속도를 저하시킬 수 있는 자가 강화 사이클을 형성할 수 있음을 시사한다.
이 연구는 LLM 에이전트 보조 도구의 실제 소프트웨어 프로젝트에 대한 영향을 대규모로 조사한 첫 번째 사례로, AI 지원 코딩에 대한 과도한 낙관론과 비관론 모두에 도전하는 중요한 증거를 제공한다. 또한, LLM의 능력과 개발자의 관행이 지속적으로 발전하고 있는 만큼, 향후 도구들은 현재 관찰된 품질 문제를 해결할 수 있는 가능성을 내포하고 있다. 이러한 연구 결과는 소프트웨어 공학 실무자와 LLM 도구 설계자, 연구자들에게 중요한 시사점을 제공하며, AI 시대의 개발 속도와 품질 보증 간의 균형을 이해하는 데 기여할 것이다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 소프트웨어 공학 분야에 혁신을 가져올 가능성을 보여주었습니다. 그 중에서도 LLM 에이전트는 소프트웨어 개발에 적용되는 데 빠르게 주목받고 있으며, 실무자들은 도입 후 생산성이 여러 배 증가했다고 주장하고 있습니다. 그러나 이러한 주장에 대한 실증적 증거는 부족합니다. 본 논문에서는 널리 사용되는 LLM 에이전트 어시스턴트인 Cursor의 채택이 개발 속도와 소프트웨어 품질에 미치는 인과적 효과를 추정합니다. 이 추정은 Cursor를 채택한 GitHub 프로젝트와 Cursor를 사용하지 않는 유사한 GitHub 프로젝트의 매칭된 대조군을 비교하는 최첨단 차이의 차이 설계를 통해 가능해졌습니다. 우리는 Cursor의 채택이 프로젝트 수준의 개발 속도를 상당히, 크게, 그러나 일시적으로 증가시키며, 정적 분석 경고와 코드 복잡성의 유의미하고 지속적인 증가를 초래한다는 것을 발견했습니다. 추가적인 패널 일반화 모멘트 추정은 정적 분석 경고와 코드 복잡성의 증가가 장기적인 속도 감소를 초래하는 주요 요인으로 작용함을 보여줍니다. 본 연구는 소프트웨어 공학 실무자, LLM 에이전트 어시스턴트 설계자, 연구자들에게 시사점을 제공합니다.
Large language models (LLMs) have demonstrated the promise to revolutionize the field of software engineering. Among other things, LLM agents are rapidly gaining momentum in their application to software development, with practitioners claiming a multifold productivity increase after adoption. Yet, empirical evidence is lacking around these claims. In this paper, we estimate the causal effect of adopting a widely popular LLM agent assistant, namely Cursor, on development velocity and software quality. The estimation is enabled by a state-of-the-art difference-in-differences design comparing Cursor-adopting GitHub projects with a matched control group of similar GitHub projects that do not use Cursor. We find that the adoption of Cursor leads to a significant, large, but transient increase in project-level development velocity, along with a significant and persistent increase in static analysis warnings and code complexity. Further panel generalized method of moments estimation reveals that the increase in static analysis warnings and code complexity acts as a major factor causing long-term velocity slowdown. Our study carries implications for software engineering practitioners, LLM agent assistant designers, and researchers.
논문 링크
와트당 지능: 로컬 AI의 지능 효율성 측정 / Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
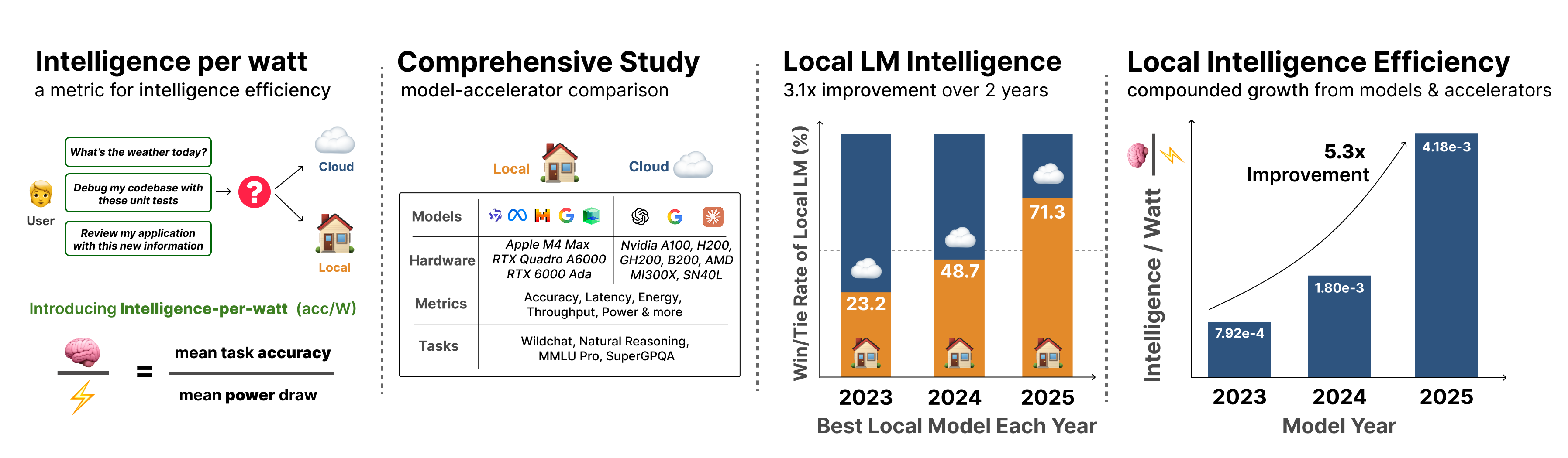
논문 소개
대규모 언어 모델(LLM)의 쿼리는 주로 중앙 집중식 클라우드 인프라에서 처리되지만, 이러한 전통적인 패러다임은 급증하는 수요로 인해 한계를 드러내고 있다. 이에 따라, 소형 LMs(활성 파라미터 20B 이하)의 성능이 프론티어 모델과 경쟁할 수 있는 수준으로 향상되었고, 로컬 가속기(예: Apple M4 Max)가 이러한 모델을 상호작용 지연 시간으로 실행할 수 있는 가능성이 제기되었다. 본 연구는 로컬 추론이 중앙 인프라의 수요를 재분배할 수 있는지를 탐구하며, 이를 위해 지능당 와트(Intelligence per Watt, IPW)라는 새로운 지표를 제안한다. IPW는 작업 정확도를 전력 단위로 나눈 값으로, 모델-가속기 쌍의 로컬 추론 능력과 효율성을 평가하는 데 사용된다.
연구는 20개 이상의 최첨단 로컬 LMs와 8개의 로컬 가속기를 활용하여 100만 개의 실제 단일 턴 채팅 및 추론 쿼리에 대한 대규모 실증 연구를 수행하였다. 각 쿼리에 대해 정확도, 에너지 소비, 지연 시간 및 전력 소비를 측정하여 IPW를 계산하였다. 분석 결과, 로컬 LMs는 88.7%의 정확도로 쿼리에 응답할 수 있으며, IPW는 2023년부터 2025년까지 5.3배 향상되었다. 또한, 로컬 가속기는 동일한 모델을 실행하는 클라우드 가속기보다 최소 1.4배 낮은 IPW를 기록하여 최적화를 위한 여지를 보여준다.
이러한 발견은 로컬 추론이 중앙 집중식 인프라의 수요를 의미 있게 재분배할 수 있음을 입증하며, IPW는 이 전환을 추적하는 중요한 지표로 작용한다. 연구 결과는 로컬 AI의 발전이 가져올 수 있는 잠재적 이점과 도전 과제를 제시하며, IPW 프로파일링 도구를 공개하여 체계적인 벤치마킹을 가능하게 한다. 이 연구는 로컬 AI의 효율성과 가능성을 재확인하며, 향후 연구 방향에 대한 통찰을 제공한다.
논문 초록(Abstract)
대규모 언어 모델(LLM) 쿼리는 주로 중앙 집중식 클라우드 인프라에서 최전선 모델에 의해 처리됩니다. 급증하는 수요는 이 패러다임에 부담을 주며, 클라우드 제공업체는 인프라를 신속하게 확장하는 데 어려움을 겪고 있습니다. 두 가지 발전이 이 패러다임을 재고할 수 있게 합니다: 소형 LMs(활성 매개변수 20B 이하)가 이제 많은 작업에서 최전선 모델과 경쟁력 있는 성능을 달성하고, 로컬 가속기(예: Apple M4 Max)가 이러한 모델을 대화형 지연 시간으로 실행할 수 있습니다. 이는 다음과 같은 질문을 제기합니다: 로컬 추론이 중앙 집중식 인프라에서 수요를 효과적으로 재분배할 수 있을까요? 이를 답하기 위해서는 로컬 LMs가 실제 쿼리에 정확하게 응답할 수 있는지, 그리고 전력 제약이 있는 장치(즉, 노트북)에서 실용적일 만큼 효율적으로 수행할 수 있는지를 측정해야 합니다. 우리는 모델-가속기 쌍 전반에 걸쳐 로컬 추론의 능력과 효율성을 평가하기 위한 지표로서 와트당 지능(intelligence per watt, IPW), 즉 작업 정확도를 전력 단위로 나눈 값을 제안합니다. 우리는 20개 이상의 최첨단 로컬 LMs, 8개의 가속기, 그리고 LLM 트래픽의 대표적인 하위 집합인 100만 개의 실제 단일 턴 채팅 및 추론 쿼리에 대한 대규모 실증 연구를 수행합니다. 각 쿼리에 대해 우리는 정확도, 에너지, 지연 시간 및 전력을 측정합니다. 우리의 분석은 세 가지 발견을 드러냅니다. 첫째, 로컬 LMs는 88.7%의 단일 턴 채팅 및 추론 쿼리에 정확하게 응답할 수 있으며, 정확도는 도메인에 따라 다릅니다. 둘째, 2023년부터 2025년까지 IPW는 5.3배 향상되었고 로컬 쿼리 범위는 23.2%에서 71.3%로 증가했습니다. 셋째, 로컬 가속기는 동일한 모델을 실행하는 클라우드 가속기보다 최소 1.4배 낮은 IPW를 달성하여 최적화를 위한 상당한 여지를 드러냅니다. 이러한 발견은 로컬 추론이 중앙 집중식 인프라에서 수요를 의미 있게 재분배할 수 있음을 보여주며, IPW는 이 전환을 추적하기 위한 중요한 지표로 작용합니다. 우리는 체계적인 와트당 지능 벤치마킹을 위한 IPW 프로파일링 장비를 공개합니다.
Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals 3 findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking this transition. We release our IPW profiling harness for systematic intelligence-per-watt benchmarking.
논문 링크
파이프라인을 넘어: 모델 네이티브 에이전틱 AI로의 패러다임 전환에 대한 서베이 / Beyond Pipelines: A Survey of the Paradigm Shift toward Model-Native Agentic AI
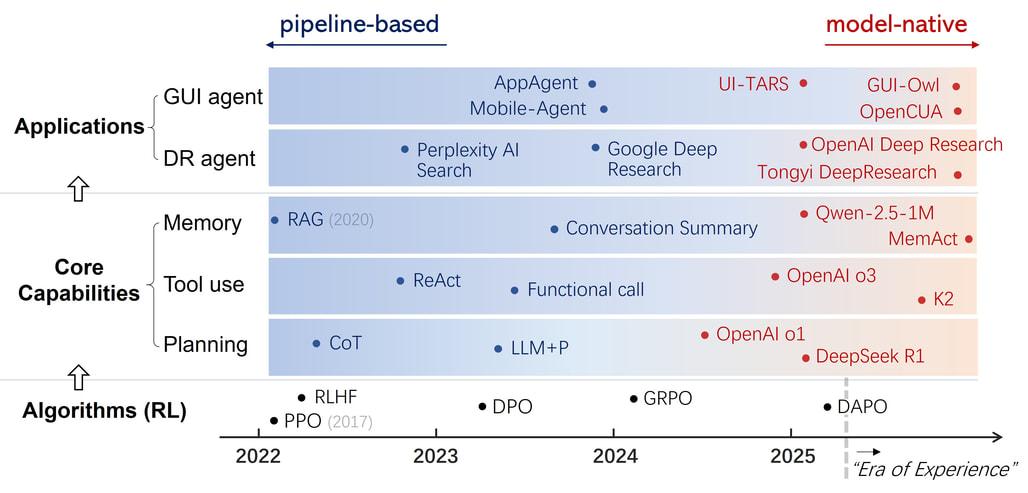
논문 소개
에이전틱 인공지능(Agentic AI)의 발전은 인공지능의 새로운 국면을 열고 있으며, 대규모 언어 모델(LLM)이 단순한 반응을 넘어 행동하고 추론하며 적응하는 능력을 갖추게 되었다. 이러한 변화는 파이프라인 기반 시스템에서 모델의 매개변수 내에 기능을 내재화하는 모델-네이티브 패러다임으로의 전환을 통해 이루어졌다. 이 연구에서는 강화학습(Reinforcement Learning, RL)이 이러한 패러다임 전환의 핵심 알고리즘으로 자리잡고 있음을 강조하며, RL이 정적 데이터를 모방하는 학습에서 결과 중심의 탐색으로 재구성됨으로써 LLM과 RL, 그리고 작업(Task)의 통합 솔루션을 제공하는 방법을 설명한다.
이 연구에서는 계획, 도구 사용, 기억과 같은 기능이 외부 스크립트 모듈에서 엔드 투 엔드 학습 행동으로 발전하는 과정을 체계적으로 검토한다. 특히, 딥 리서치 에이전트와 GUI 에이전트와 같은 주요 응용 프로그램에서 이러한 패러다임 전환이 어떻게 재구성되었는지를 분석하며, 다중 에이전트 협업 및 반성과 같은 대리인 기능의 지속적인 내재화가 미래의 대리인 AI에서 어떤 역할을 할 것인지에 대해 논의한다.
이 연구의 중요한 기여는 모델-네이티브 에이전틱 AI의 통합된 학습 및 상호작용 프레임워크를 제시함으로써, 지능을 적용하는 시스템에서 경험을 통해 지능을 성장시키는 모델로의 전환을 명확히 한 점이다. 이러한 발전은 AI 연구의 새로운 패러다임을 제시하며, 향후 에이전틱 AI의 기능이 지속적으로 내재화될 것임을 시사한다. 이 논문은 에이전틱 AI의 진화를 위한 방향성을 제시하며, AI 연구의 미래를 위한 중요한 기반을 마련하고 있다.
논문 초록(Abstract)
에이전틱 AI의 급속한 발전은 인공지능의 새로운 단계를 나타내며, 여기서 대규모 언어 모델(LLM)은 더 이상 단순히 반응하는 것이 아니라 행동하고, 추론하며, 적응합니다. 이 서베이는 에이전틱 AI 구축의 패러다임 전환을 추적합니다: 외부 논리에 의해 계획, 도구 사용 및 메모리가 조정되는 파이프라인 기반 시스템에서 이러한 기능이 모델의 매개변수 내에서 내재화되는 새로운 모델 네이티브 패러다임으로의 전환입니다. 우리는 먼저 강화학습(RL)을 이 패러다임 전환을 가능하게 하는 알고리즘 엔진으로 위치시킵니다. 정적 데이터 모방에서 결과 중심 탐색으로 학습을 재구성함으로써, RL은 언어, 비전 및 구현된 도메인 전반에 걸쳐 LLM + RL + 작업의 통합 솔루션을 뒷받침합니다. 이를 바탕으로, 서베이는 계획, 도구 사용 및 메모리라는 각 기능이 외부 스크립트 모듈에서 엔드 투 엔드 학습 행동으로 어떻게 발전해 왔는지를 체계적으로 검토합니다. 또한, 이 패러다임 전환이 주요 에이전트 응용 프로그램, 특히 장기적 추론을 강조하는 딥 리서치 에이전트와 구현된 상호작용을 강조하는 GUI 에이전트를 어떻게 재편성했는지를 살펴봅니다. 마지막으로, 다중 에이전트 협업 및 반성 같은 에이전틱 기능의 지속적인 내재화와 미래 에이전틱 AI에서 시스템 및 모델 계층의 진화하는 역할에 대해 논의합니다. 이러한 발전들은 지능을 적용하는 시스템을 구축하는 것에서 경험을 통해 지능을 성장시키는 모델 개발로의 전환을 나타내는 통합 학습 및 상호작용 프레임워크로서 모델 네이티브 에이전틱 AI로의 일관된 경로를 제시합니다.
The rapid evolution of agentic AI marks a new phase in artificial intelligence, where Large Language Models (LLMs) no longer merely respond but act, reason, and adapt. This survey traces the paradigm shift in building agentic AI: from Pipeline-based systems, where planning, tool use, and memory are orchestrated by external logic, to the emerging Model-native paradigm, where these capabilities are internalized within the model's parameters. We first position Reinforcement Learning (RL) as the algorithmic engine enabling this paradigm shift. By reframing learning from imitating static data to outcome-driven exploration, RL underpins a unified solution of LLM + RL + Task across language, vision and embodied domains. Building on this, the survey systematically reviews how each capability -- Planning, Tool use, and Memory -- has evolved from externally scripted modules to end-to-end learned behaviors. Furthermore, it examines how this paradigm shift has reshaped major agent applications, specifically the Deep Research agent emphasizing long-horizon reasoning and the GUI agent emphasizing embodied interaction. We conclude by discussing the continued internalization of agentic capabilities like Multi-agent collaboration and Reflection, alongside the evolving roles of the system and model layers in future agentic AI. Together, these developments outline a coherent trajectory toward model-native agentic AI as an integrated learning and interaction framework, marking the transition from constructing systems that apply intelligence to developing models that grow intelligence through experience.
논문 링크
더 읽어보기
https://github.com/ADaM-BJTU/model-native-agentic-ai
NVIDIA 네모트론 나노 V2 VL / NVIDIA Nemotron Nano V2 VL
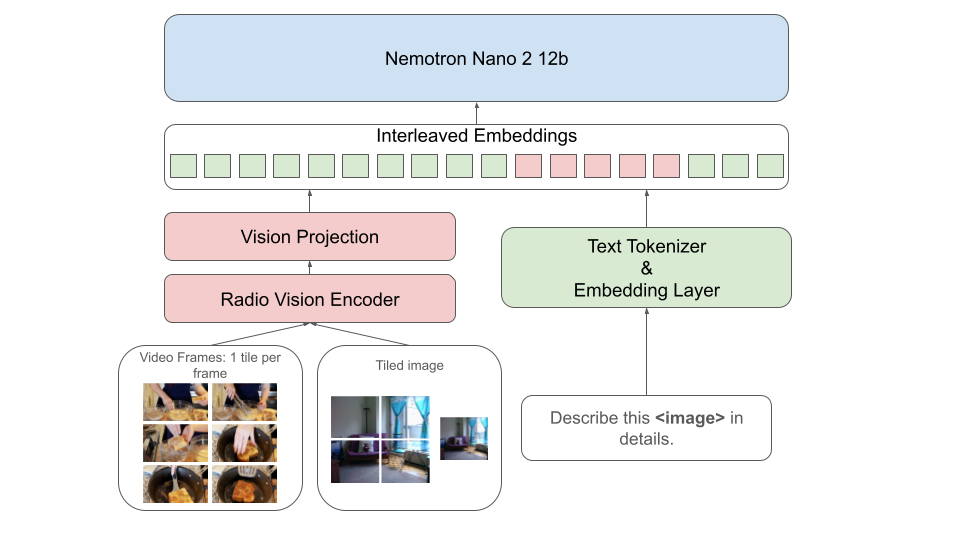
논문 소개
Nemotron Nano V2 VL은 강력한 실제 문서 이해, 긴 비디오 이해 및 추론 작업을 위해 설계된 최신 비전-언어 모델로, 이전 모델인 Llama-3.1-Nemotron-Nano-VL-8B에 비해 여러 면에서 개선된 성능을 자랑합니다. 이 모델은 하이브리드 Mamba-Transformer 아키텍처를 기반으로 하며, 긴 문서와 비디오 시나리오에서 높은 추론 처리량을 달성하기 위해 혁신적인 토큰 축소 기술을 적용하였습니다. 특히, 모델의 컨텍스트 길이를 16K에서 128K로 확장하여 복잡한 추론 작업을 보다 효과적으로 처리할 수 있게 되었습니다.
Nemotron Nano V2 VL은 OCRBench v2의 개인 데이터 리더보드에서 선도적인 정확도를 기록하며, 다양한 비전 및 텍스트 도메인에서 감독된 파인튜닝(Supervised Finetuning, SFT)을 통해 성능을 향상시킵니다. 이 과정에서 고품질의 추론 데이터와 확장된 OCR 데이터셋이 포함되어 모델의 학습에 기여하고 있습니다. 또한, Efficient Video Sampling (EVS) 기법을 통해 비디오 이해 작업에서 처리량을 두 배 이상 가속화하면서도 정확도에 미치는 영향을 최소화하였습니다.
모델은 비전 인코더와 언어 인코더를 통합하여 멀티모달 데이터를 효과적으로 처리하며, 이러한 설계는 다양한 입력 형식을 수용할 수 있는 유연성을 제공합니다. Nemotron Nano V2 VL은 추론 모드와 비추론 모드를 모두 지원하여, 복잡한 문제 해결을 위한 확장된 추론을 가능하게 합니다. 이러한 접근은 계산 효율성과 작업 성능 간의 균형을 이루도록 설계되었습니다.
마지막으로, 이 모델은 BF16, FP8 및 FP4 형식으로 공개된 체크포인트와 함께 대규모 데이터셋, 학습 레시피 및 코드베이스를 공유하여 지속적인 연구와 개발을 지원합니다. Nemotron Nano V2 VL의 혁신적인 접근은 비전-언어 모델의 발전에 기여하며, 향후 다양한 실제 응용 프로그램에 적용될 가능성을 보여줍니다.
논문 초록(Abstract)
우리는 강력한 실제 문서 이해, 긴 비디오 이해 및 추론 작업을 위해 설계된 Nemotron 비전-언어 시리즈의 최신 모델인 Nemotron Nano V2 VL을 소개합니다. Nemotron Nano V2 VL은 모델 아키텍처, 데이터셋 및 학습 레시피의 주요 개선을 통해 이전 모델인 Llama-3.1-Nemotron-Nano-VL-8B에 비해 모든 비전 및 텍스트 도메인에서 상당한 향상을 제공합니다. Nemotron Nano V2 VL은 하이브리드 맘바-트랜스포머 대규모 언어 모델인 Nemotron Nano V2를 기반으로 하며, 긴 문서 및 비디오 시나리오에서 더 높은 추론 처리량을 달성하기 위해 혁신적인 토큰 축소 기술을 적용했습니다. 우리는 BF16, FP8 및 FP4 형식의 모델 체크포인트를 공개하고, 데이터셋, 레시피 및 학습 코드를 대규모로 공유할 예정입니다.
We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
논문 링크
더 읽어보기
모든 단계가 진화한다: 조단위 사고 모델을 위한 강화학습의 확장 / Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
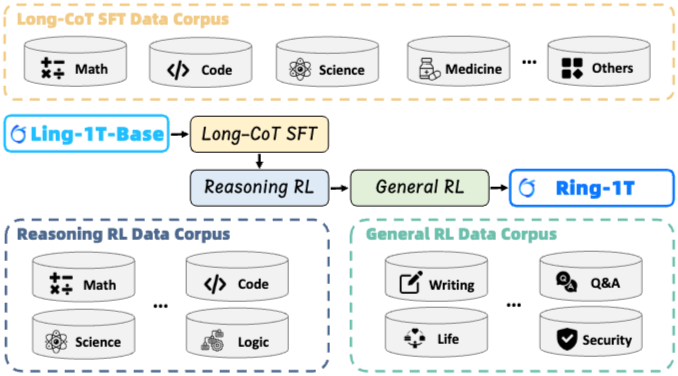
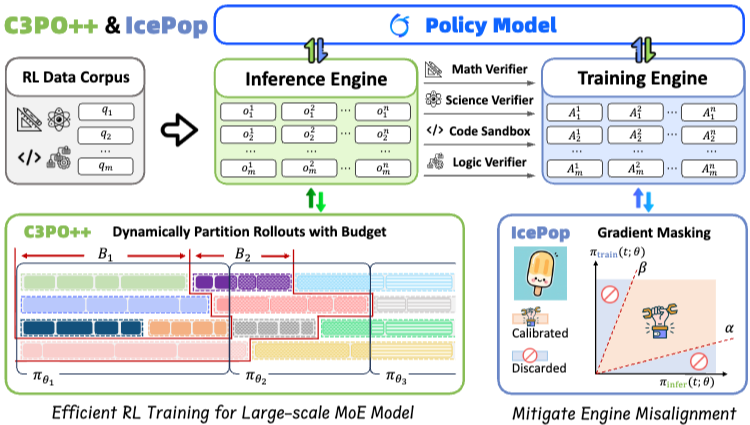
논문 소개
Ring-1T는 1조 개의 매개변수를 가진 최초의 오픈 소스 최첨단 사고 모델로, 각 토큰당 약 500억 개의 매개변수를 활성화합니다. 이러한 1조 매개변수 규모의 모델을 학습하는 것은 훈련-추론 불일치, 롤아웃 처리 비효율성, RL 시스템의 병목 현상 등 전례 없는 도전 과제를 수반합니다. 이를 해결하기 위해 세 가지 혁신을 도입했습니다: 첫째, IcePop은 토큰 수준의 불일치 마스킹 및 클리핑을 통해 RL 학습의 안정성을 높여 훈련-추론 불일치로 인한 불안정을 해결합니다. 둘째, C3PO++는 동적으로 롤아웃을 분할하여 자원 활용도를 개선하고 높은 시간 효율성을 달성합니다. 셋째, ASystem은 1조 매개변수 모델 학습을 방해하는 시스템 병목 현상을 극복하기 위해 설계된 고성능 RL 프레임워크입니다. Ring-1T는 AIME-2025에서 93.4, HMMT-2025에서 86.72, CodeForces에서 2088, ARC-AGI-v1에서 55.94의 획기적인 결과를 달성했습니다. 특히 IMO-2025에서 은메달 수준의 성과를 기록하여 뛰어난 추론 능력을 입증했습니다. 1T 매개변수 MoE 모델을 커뮤니티에 공개함으로써 연구자들에게 최첨단 추론 능력에 대한 직접적인 접근을 제공합니다. 이는 대규모 추론 지능의 민주화를 위한 중요한 이정표가 되며, 오픈 소스 모델 성능의 새로운 기준을 설정합니다.
논문 초록(Abstract)
우리는 1조 규모의 파라미터를 가진 최초의 오픈소스 최첨단 사고 모델인 Ring-1T를 소개합니다. 이 모델은 총 1조 개의 파라미터를 특징으로 하며, 토큰당 약 500억 개의 파라미터를 활성화합니다. 이러한 1조 파라미터 규모의 모델을 학습하는 것은 전례 없는 도전 과제를 수반하며, 여기에는 학습-추론 불일치, 롤아웃 처리의 비효율성, 강화학습 시스템의 병목 현상이 포함됩니다. 이를 해결하기 위해 우리는 세 가지 상호 연결된 혁신을 선도합니다: (1) IcePop은 토큰 수준의 불일치 마스킹 및 클리핑을 통해 강화학습 훈련을 안정화하여 학습-추론 불일치로 인한 불안정을 해결합니다; (2) C3PO++는 토큰 예산 하에서 롤아웃을 동적으로 분할하여 자원 활용을 개선함으로써 높은 시간 효율성을 달성합니다; (3) ASystem은 1조 파라미터 모델 훈련을 방해하는 시스템 병목 현상을 극복하기 위해 설계된 고성능 강화학습 프레임워크입니다. Ring-1T는 AIME-2025에서 93.4, HMMT-2025에서 86.72, CodeForces에서 2088, ARC-AGI-v1에서 55.94의 중요한 벤치마크에서 획기적인 결과를 제공합니다. 특히, IMO-2025에서 은메달 수준의 결과를 달성하여 뛰어난 추론 능력을 강조합니다. 1T 파라미터 MoE 모델의 전체 버전을 커뮤니티에 공개함으로써, 우리는 연구 커뮤니티에 최첨단 추론 능력에 대한 직접적인 접근을 제공합니다. 이 기여는 대규모 추론 지능의 민주화를 위한 중요한 이정표가 되며, 오픈소스 모델 성능의 새로운 기준을 설정합니다.
We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
논문 링크
더 읽어보기
https://github.com/inclusionAI/Ring-V2
AI 에이전트의 경제학 / An Economy of AI Agents

논문 소개
인공지능(AI) 에이전트의 경제적 역할과 그에 따른 시장 및 조직의 변화는 현대 경제학에서 중요한 연구 주제로 부각되고 있다. 최근 AI 기술의 발전으로 AI 에이전트는 단순한 도구에서 벗어나, 복잡한 작업을 계획하고 실행할 수 있는 독립적인 주체로 자리잡고 있다. 이 논문은 AI 에이전트가 경제적 상호작용에서 어떻게 기능할 수 있는지를 탐구하며, 경제학자들이 해결해야 할 여러 가지 중요한 질문들을 제기한다.
AI 에이전트의 발전은 기존의 경제 모델과 예측에 도전장을 내밀고 있다. 특히, AI 에이전트가 인간과 유사한 행동을 보일 수 있는지에 대한 연구는 아직 초기 단계에 있으며, AI의 행동이 인간의 경제적 결정과 얼마나 유사한지를 평가하는 데 필요한 데이터와 연구가 부족하다. AI 시스템은 최적화 원칙에 기반하여 설계되지만, 그 목표와 행동이 불투명하게 되는 '정렬 문제'가 발생하고 있다. 이러한 문제는 AI 에이전트가 실제로 무엇을 최적화하고 있는지를 이해하는 데 어려움을 초래한다.
AI 에이전트의 행동은 최근의 실험적 연구에 따르면 기대 효용 극대화와 일치하는 경향이 있지만, AI가 인간과 기능적으로 유사하다는 결론을 내리기에는 여전히 부족한 증거가 존재한다. 따라서 AI 에이전트의 행동을 이해하고 예측하기 위한 연구는 필수적이며, 이는 경제학의 전통적인 이론과의 간극을 메우는 데 기여할 수 있다. AI 에이전트가 시장에서 가격, 검색, 협상 및 금융에 미치는 영향은 경제적 구조와 상호작용을 재정의할 가능성을 지니고 있다.
이 논문은 AI 에이전트가 경제 내에서 어떻게 작동할 것인지에 대한 질문을 중심으로, AI 에이전트의 설계와 확산이 시장의 힘에 의해 어떻게 영향을 받을 수 있는지를 탐구한다. 또한, 조직 내 AI 에이전트의 통합과 그로 인한 생산의 복잡성, 기업 규모와 시장 권력의 상관관계에 대한 논의도 포함된다. 마지막으로, AI 에이전트를 위한 시장 경제의 제도를 어떻게 조정해야 하는지에 대한 법적 및 제도적 논의도 다루어진다.
이러한 연구는 AI 에이전트의 발전이 경제적 관계와 제도에 미치는 영향을 이해하는 데 중요한 기초 자료를 제공하며, 향후 AI 에이전트와 인간 간의 상호작용을 보다 효과적으로 관리하기 위한 정책 개발에 기여할 수 있을 것으로 기대된다.
논문 초록(Abstract)
다가오는 10년 동안, 인간의 직접적인 감독 없이도 복잡한 작업을 계획하고 실행할 수 있는 인공지능 에이전트가 경제 전반에 걸쳐 배치될 수 있습니다. 이 장에서는 최근 발전을 조사하고, AI 에이전트가 인간 및 서로 상호작용하고, 시장과 조직을 형성하며, 잘 작동하는 시장을 위해 어떤 제도가 필요할지에 대한 경제학자들의 열린 질문을 강조합니다.
In the coming decade, artificially intelligent agents with the ability to plan and execute complex tasks over long time horizons with little direct oversight from humans may be deployed across the economy. This chapter surveys recent developments and highlights open questions for economists around how AI agents might interact with humans and with each other, shape markets and organizations, and what institutions might be required for well-functioning markets.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()