[2025/12/01 ~ 07] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 도구 통합 추론의 발전: 여러 논문에서 도구를 활용한 통합 추론이 강조되고 있습니다. 예를 들어, Agent0-VL은 비전-언어 에이전트가 도구를 사용하여 자기 평가 및 자기 수정을 수행할 수 있도록 하여 지속적인 개선을 이루는 방법을 제안합니다. 이러한 접근은 모델이 복잡한 시각적 추론을 수행하는 데 있어 더 높은 정확성과 자율성을 제공합니다.
도구 통합 추론의 발전: 여러 논문에서 도구를 활용한 통합 추론이 강조되고 있습니다. 예를 들어, Agent0-VL은 비전-언어 에이전트가 도구를 사용하여 자기 평가 및 자기 수정을 수행할 수 있도록 하여 지속적인 개선을 이루는 방법을 제안합니다. 이러한 접근은 모델이 복잡한 시각적 추론을 수행하는 데 있어 더 높은 정확성과 자율성을 제공합니다.
![]() 효율적인 데이터 생성 및 처리: Matrix와 같은 논문에서는 분산형 피어-투-피어 구조를 통해 데이터 생성의 효율성을 높이는 방법을 제시하고 있습니다. 이러한 접근은 중앙 집중식 오케스트레이터의 필요성을 제거하고, 다양한 에이전트가 협력하여 더 높은 품질의 데이터를 생성할 수 있도록 합니다. 이는 대규모 언어 모델 훈련에 필요한 합성 데이터 생성의 중요성을 강조합니다.
효율적인 데이터 생성 및 처리: Matrix와 같은 논문에서는 분산형 피어-투-피어 구조를 통해 데이터 생성의 효율성을 높이는 방법을 제시하고 있습니다. 이러한 접근은 중앙 집중식 오케스트레이터의 필요성을 제거하고, 다양한 에이전트가 협력하여 더 높은 품질의 데이터를 생성할 수 있도록 합니다. 이는 대규모 언어 모델 훈련에 필요한 합성 데이터 생성의 중요성을 강조합니다.
![]() 다양한 일반화 및 추론 능력 향상: 여러 연구에서 모델의 일반화 능력과 추론 능력을 향상시키기 위한 다양한 방법론이 제안되고 있습니다. 예를 들어, Unlocking Out-of-Distribution Generalization in Transformers 논문에서는 Transformer 네트워크의 아키텍처를 개선하여 훈련 분포를 넘어서는 일반화 능력을 강화하는 방법을 탐구합니다. 이러한 연구는 모델이 새로운 상황에서도 효과적으로 작동할 수 있도록 하는 데 기여합니다.
다양한 일반화 및 추론 능력 향상: 여러 연구에서 모델의 일반화 능력과 추론 능력을 향상시키기 위한 다양한 방법론이 제안되고 있습니다. 예를 들어, Unlocking Out-of-Distribution Generalization in Transformers 논문에서는 Transformer 네트워크의 아키텍처를 개선하여 훈련 분포를 넘어서는 일반화 능력을 강화하는 방법을 탐구합니다. 이러한 연구는 모델이 새로운 상황에서도 효과적으로 작동할 수 있도록 하는 데 기여합니다.
Agent0-VL: 도구 통합 비전-언어 추론을 위한 자기 진화 에이전트 탐색 / Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning
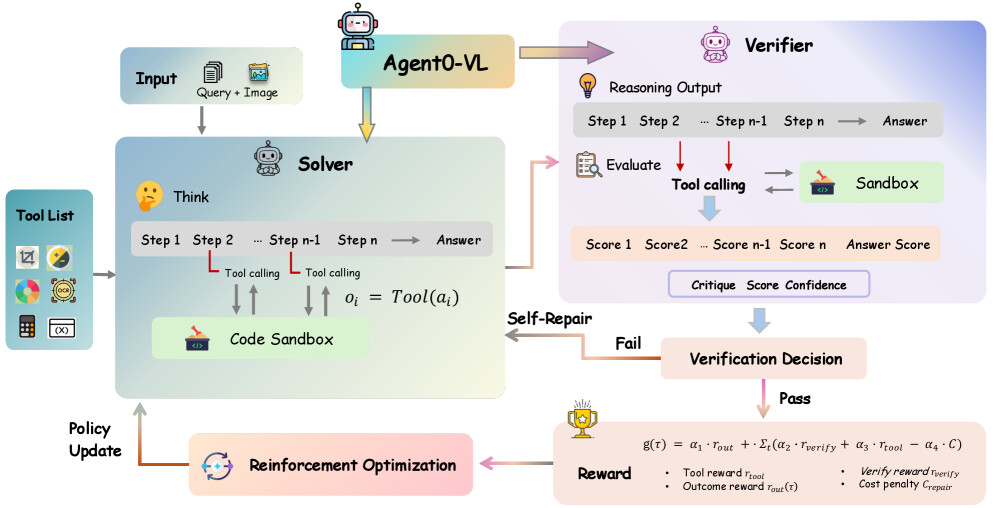
논문 소개
비전-언어 에이전트는 복잡한 멀티모달 추론 작업에서 뛰어난 성과를 보여주고 있으나, 인간 주석에 의한 감독의 한계로 인해 학습이 제약받고 있다. 이러한 문제를 해결하기 위해 최근 연구에서는 자기 보상 학습 접근법이 제안되었지만, 순수한 텍스트 기반 자기 평가는 복잡한 시각적 추론 단계를 검증하는 데 어려움을 겪고 있다. 이러한 한계를 극복하기 위해, 본 연구에서는 도구 통합 추론을 활용한 Agent0-VL이라는 자기 진화 비전-언어 에이전트를 제안한다.
Agent0-VL은 도구 사용을 추론뿐만 아니라 자기 평가 및 자기 수리 과정에 통합하여, 모델이 증거 기반 분석을 통해 자신의 추론을 반성하고 검증하며 개선할 수 있도록 한다. 이 모델은 멀티 턴 도구 통합 추론을 수행하는 Solver와 도구 기반 비평을 통해 구조화된 피드백 및 세분화된 자기 보상을 생성하는 Verifier라는 두 가지 상호작용하는 역할을 통합한다. 이러한 역할은 자기 진화 추론 사이클을 통해 상호작용하며, 도구 기반 검증과 강화 학습이 결합되어 안정적인 자기 개선을 위한 추론 및 평가 분포를 정렬한다.
본 연구의 중요한 기여는 외부 보상 없이도 지속적인 자기 개선을 가능하게 하는 Agent0-VL의 설계이다. 기하학적 문제 해결 및 시각적 과학 분석에 대한 실험 결과, 이 모델은 기본 모델에 비해 평균 12.5% 향상된 성능을 보였다. 이러한 성과는 비전-언어 에이전트의 학습 방식에 있어 새로운 패러다임을 제시하며, 도구 통합 추론의 가능성을 확장하는 데 기여한다.
논문 초록(Abstract)
비전-언어 에이전트는 다양한 멀티모달 추론 작업에서 놀라운 발전을 이루었으나, 그 학습은 인간 주석 감독의 한계에 의해 제약받고 있다. 최근의 자기 보상 접근법은 모델이 스스로 비평가 또는 보상 제공자로 작용하도록 하여 이러한 제약을 극복하려고 시도하고 있다. 그러나 순수한 텍스트 기반 자기 평가 방식은 복잡한 시각적 추론 단계를 검증하는 데 어려움을 겪으며, 종종 평가 환각 현상에 시달린다. 이러한 문제를 해결하기 위해, 우리는 도구 통합 추론의 최근 발전에 영감을 받아 Agent0-VL을 제안한다. Agent0-VL은 도구 통합 추론을 통해 지속적인 개선을 이루는 자기 진화 비전-언어 에이전트이다. Agent0-VL은 추론뿐만 아니라 자기 평가 및 자기 수정을 위한 도구 사용을 통합하여, 모델이 증거 기반 분석을 통해 자신의 추론을 반성하고 검증하며 정제할 수 있도록 한다. 이 모델은 다중 턴 도구 통합 추론을 수행하는 Solver와 도구 기반 비평을 통해 구조화된 피드백과 세분화된 자기 보상을 생성하는 Verifier라는 두 가지 시너지 역할을 단일 LVLM 내에서 통합한다. 이러한 역할은 도구 기반 검증과 강화 학습이 함께 추론 및 평가 분포를 정렬하여 안정적인 자기 개선을 이루는 자기 진화 추론 주기를 통해 상호 작용한다. 이 제로 외부 보상 진화를 통해 Agent0-VL은 인간 주석이나 외부 보상 모델 없이 자신의 추론 및 검증 행동을 정렬하여 지속적인 자기 개선을 달성한다. 기하학적 문제 해결 및 시각적 과학 분석에 대한 실험 결과, Agent0-VL은 기본 모델에 비해 12.5% 향상을 달성하였다. 우리의 코드는 GitHub - aiming-lab/Agent0: Agent0 Series: Self-Evolving Agents from Zero Data 에서 확인할 수 있다.
Vision-language agents have achieved remarkable progress in a variety of multimodal reasoning tasks; however, their learning remains constrained by the limitations of human-annotated supervision. Recent self-rewarding approaches attempt to overcome this constraint by allowing models to act as their own critics or reward providers. Yet, purely text-based self-evaluation struggles to verify complex visual reasoning steps and often suffers from evaluation hallucinations. To address these challenges, inspired by recent advances in tool-integrated reasoning, we propose Agent0-VL, a self-evolving vision-language agent that achieves continual improvement with tool-integrated reasoning. Agent0-VL incorporates tool usage not only into reasoning but also into self-evaluation and self-repair, enabling the model to introspect, verify, and refine its reasoning through evidence-grounded analysis. It unifies two synergistic roles within a single LVLM: a Solver that performs multi-turn tool-integrated reasoning, and a Verifier that generates structured feedback and fine-grained self-rewards through tool-grounded critique. These roles interact through a Self-Evolving Reasoning Cycle, where tool-based verification and reinforcement learning jointly align the reasoning and evaluation distributions for stable self-improvement. Through this zero-external-reward evolution, Agent0-VL aligns its reasoning and verification behaviors without any human annotation or external reward models, achieving continual self-improvement. Experiments on geometric problem solving and visual scientific analysis show that Agent0-VL achieves an 12.5% improvement over the base model. Our code is available at GitHub - aiming-lab/Agent0: Agent0 Series: Self-Evolving Agents from Zero Data.
논문 링크
더 읽어보기
매트릭스: 피어 투 피어 다중 에이전트 합성 데이터 생성 프레임워크 / Matrix: Peer-to-Peer Multi-Agent Synthetic Data Generation Framework
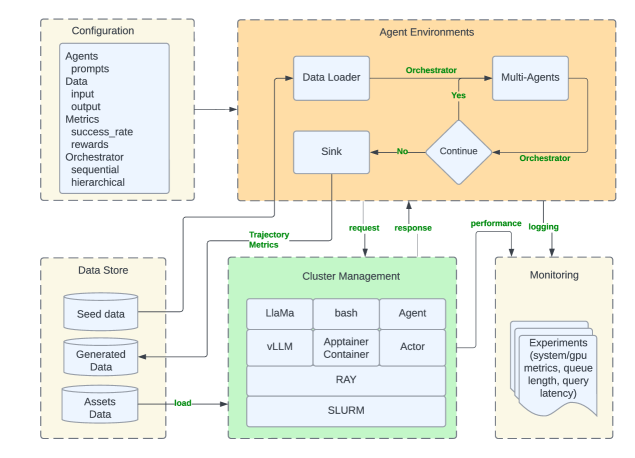
논문 소개
합성 데이터는 대규모 언어 모델 학습에 필수적인 요소로 자리 잡고 있으며, 특히 실제 데이터가 부족하거나 비쌀 때, 또는 개인 정보 보호가 중요한 경우에 그 중요성이 더욱 부각됩니다. 기존의 다중 에이전트 합성 프레임워크는 중앙 집중식 조정자에 의존하여 확장성의 병목 현상을 초래하거나 특정 도메인에 하드코딩되어 유연성이 제한되는 문제를 안고 있었습니다. 이러한 문제를 해결하기 위해 제안된 Matrix는 분산형 아키텍처를 통해 에이전트 간의 협업을 촉진하며, 더 높은 품질과 다양성을 갖춘 데이터를 생성할 수 있도록 설계되었습니다.
Matrix는 제어 및 데이터 흐름을 분산 큐를 통해 전달되는 직렬화된 메시지로 표현하여 중앙 조정자를 제거합니다. 각 에이전트는 독립적으로 작업을 수행하며, 경량화된 구조 덕분에 계산 집약적인 작업은 분산 서비스에 의해 처리됩니다. 이로 인해 시스템의 확장성이 크게 향상되며, 수만 개의 동시 에이전트 워크플로우를 지원할 수 있는 능력을 갖추게 됩니다. Matrix는 Ray 프레임워크 위에 구축되어 다양한 데이터 생성 작업에 쉽게 적응할 수 있는 모듈식 설계를 제공합니다.
다양한 합성 시나리오에서 Matrix의 성능을 평가한 결과, 동일한 하드웨어 자원 하에서도 데이터 생성 처리량이 2배에서 15배까지 증가하였으며, 출력 품질은 저하되지 않았습니다. 이러한 결과는 Matrix가 기존의 중앙 집중식 시스템보다 더 나은 성능을 발휘하며, 다양한 데이터 생성 작업에 적합하다는 것을 입증합니다.
결론적으로, Matrix는 분산형 다중 에이전트 시스템을 통해 합성 데이터 생성의 새로운 가능성을 열어주며, 향후 다양한 분야에서의 적용 가능성을 보여줍니다. 이 시스템은 데이터 생성의 효율성을 높이고, 다양한 도메인에 쉽게 적응할 수 있는 유연성을 제공합니다. 향후 연구는 Matrix의 기능을 확장하고, 더 다양한 시나리오에서의 성능을 평가하는 방향으로 진행될 것입니다.
논문 초록(Abstract)
합성 데이터는 실제 데이터가 부족하거나 비싸거나 개인 정보 보호에 민감할 때, 대규모 언어 모델 학습에 점점 더 중요해지고 있습니다. 이러한 생성 작업의 많은 경우에는 전문화된 에이전트들이 협력하여 더 높은 품질, 더 다양한, 그리고 구조적으로 더 풍부한 데이터를 생성하는 조정된 다중 에이전트 워크플로우가 필요합니다. 그러나 기존의 다중 에이전트 합성 프레임워크는 종종 중앙 집중식 조정자에 의존하여 확장성 병목 현상을 초래하거나 특정 도메인에 하드코딩되어 유연성을 제한합니다. 우리는 제어와 데이터 흐름을 분산 큐를 통해 전달되는 직렬화된 메시지로 표현하는 분산 프레임워크인 \textbf{Matrix} 를 제안합니다. 이 피어 투 피어 디자인은 중앙 조정자를 제거합니다. 각 작업은 경량 에이전트를 통해 독립적으로 진행되며, LLM 추론이나 컨테이너화된 환경과 같은 계산 집약적인 작업은 분산 서비스에 의해 처리됩니다. Ray를 기반으로 구축된 Matrix는 수만 개의 동시 에이전트 워크플로우로 확장되며, 다양한 데이터 생성 워크플로우에 쉽게 적응할 수 있는 모듈식 구성 디자인을 제공합니다. 우리는 다중 에이전트 협업 대화, 웹 기반 추론 데이터 추출, 고객 서비스 환경에서의 도구 사용 궤적 생성과 같은 다양한 합성 시나리오에서 Matrix를 평가합니다. 모든 경우에 Matrix는 동일한 하드웨어 자원 하에서 2-15\times 더 높은 데이터 생성 처리량을 달성하며, 출력 품질을 저하시키지 않습니다.
Synthetic data has become increasingly important for training large language models, especially when real data is scarce, expensive, or privacy-sensitive. Many such generation tasks require coordinated multi-agent workflows, where specialized agents collaborate to produce data that is higher quality, more diverse, and structurally richer. However, existing frameworks for multi-agent synthesis often depend on a centralized orchestrator, creating scalability bottlenecks, or are hardcoded for specific domains, limiting flexibility. We present \textbf{Matrix}, a decentralized framework that represents both control and data flow as serialized messages passed through distributed queues. This peer-to-peer design eliminates the central orchestrator. Each task progresses independently through lightweight agents, while compute-intensive operations, such as LLM inference or containerized environments, are handled by distributed services. Built on Ray, Matrix scales to tens of thousands of concurrent agentic workflows and provides a modular, configurable design that enables easy adaptation to a wide range of data generation workflows. We evaluate Matrix across diverse synthesis scenarios, such as multi-agent collaborative dialogue, web-based reasoning data extraction, and tool-use trajectory generation in customer service environments. In all cases, Matrix achieves 2--15\times higher data generation throughput under identical hardware resources, without compromising output quality.
논문 링크
더 읽어보기
Z-Image: 단일 스트림 디퓨전 트랜스포머 기반의 효율적인 이미지 생성 파운데이션 모델 / Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
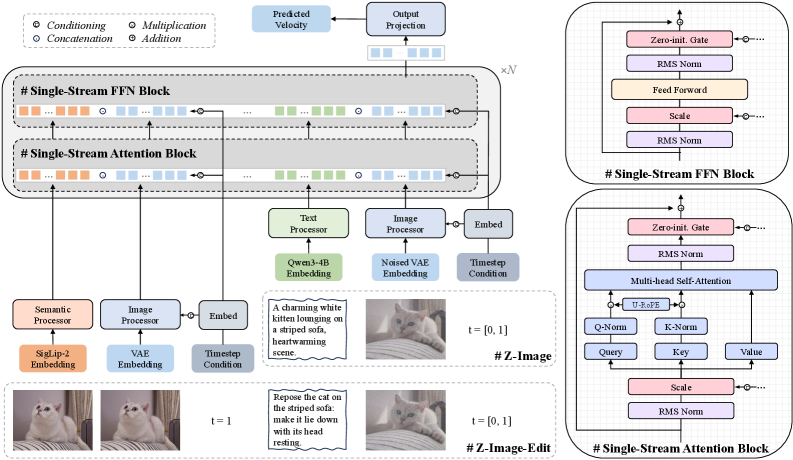
논문 소개
Z-Image는 효율적인 이미지 생성 모델로, Scalable Single-Stream Diffusion Transformer (S3-DiT) 아키텍처를 기반으로 설계되었다. 현재의 이미지 생성 모델들은 대규모 매개변수 수에 의존하여 높은 성능을 추구하고 있지만, 이러한 접근 방식은 소비자급 하드웨어에서의 활용을 어렵게 만든다. Z-Image는 60억 개의 매개변수로 구성되어 있어, 고성능을 유지하면서도 실용적인 사용이 가능하도록 최적화되었다.
이 모델은 정제된 데이터 인프라와 간소화된 학습 커리큘럼을 통해 전체 학습 워크플로우를 단 314K H800 GPU 시간에 완료할 수 있으며, 이는 기존의 대규모 모델들과 비교했을 때 매우 효율적이다. Z-Image는 몇 단계의 증류 과정을 통해 Z-Image-Turbo를 생성하였으며, 이 모델은 서브 초 단위의 추론 지연 시간을 제공하여 기업급 및 소비자급 하드웨어 모두에서 원활하게 작동할 수 있다.
또한, Z-Image는 옴니 사전 학습 패러다임을 통해 Z-Image-Edit라는 편집 모델을 효율적으로 학습시킬 수 있는 능력을 갖추고 있다. 정성적 및 정량적 실험 결과, Z-Image는 포토리얼리스틱 이미지 생성과 이중 언어 텍스트 렌더링에서 뛰어난 성능을 보이며, 기존의 상업 모델들과 경쟁할 수 있는 결과를 도출하였다.
이러한 성과는 Z-Image가 계산 자원 소모를 최소화하면서도 최첨단 결과를 달성할 수 있음을 입증하며, 연구자와 개발자들에게 접근 가능하고 예산 친화적인 이미지 생성 모델의 개발을 촉진할 수 있는 기회를 제공한다. 연구팀은 코드, 가중치 및 온라인 데모를 공개하여, 더 많은 사용자들이 이 혁신적인 기술을 활용할 수 있도록 지원하고자 한다.
논문 초록(Abstract)
현재 고성능 이미지 생성 모델의 분야는 Nano Banana Pro와 Seedream 4.0과 같은 독점 시스템이 지배하고 있습니다. Qwen-Image, Hunyuan-Image-3.0 및 FLUX.2를 포함한 주요 오픈 소스 대안들은 매개변수 수가 200억에서 800억에 이르며, 이는 소비자급 하드웨어에서의 추론 및 파인튜닝을 비현실적으로 만듭니다. 이러한 격차를 해소하기 위해, 우리는 "비용을 무릅쓰고 규모를 키운다"는 패러다임에 도전하는 확장 가능한 단일 스트림 디퓨전 트랜스포머(Scalable Single-Stream Diffusion Transformer, S3-DiT) 아키텍처를 기반으로 한 효율적인 60억 매개변수 파운데이션 생성 모델인 Z-Image를 제안합니다. 우리는 선별된 데이터 인프라에서 간소화된 학습 커리큘럼에 이르기까지 전체 모델 생애 주기를 체계적으로 최적화하여 단 314K H800 GPU 시간(약 63만 달러) 만에 전체 학습 워크플로우를 완료합니다. 보상 사후 학습을 포함한 우리의 몇 단계 증류 방식은 Z-Image-Turbo를 생성하여, 기업급 H800 GPU에서의 서브 초 단위 추론 지연 시간과 소비자급 하드웨어(<16GB VRAM)와의 호환성을 제공합니다. 또한, 우리의 전방위 사전 학습 패러다임은 인상적인 지시 따르기 능력을 가진 편집 모델인 Z-Image-Edit의 효율적인 학습도 가능하게 합니다. 정성적 및 정량적 실험 모두에서 우리의 모델이 다양한 차원에서 주요 경쟁자들과 동등하거나 이를 초월하는 성능을 달성했음을 보여줍니다. 특히, Z-Image는 포토리얼리스틱 이미지 생성 및 이중 언어 텍스트 렌더링에서 뛰어난 능력을 보이며, 최상급 상업 모델과 경쟁할 수 있는 결과를 제공합니다. 이는 최첨단 결과가 상당히 줄어든 계산 오버헤드로도 달성 가능하다는 것을 보여줍니다. 우리는 접근 가능하고 예산 친화적이며 최첨단 생성 모델의 개발을 촉진하기 위해 코드, 가중치 및 온라인 데모를 공개합니다.
The landscape of high-performance image generation models is currently dominated by proprietary systems, such as Nano Banana Pro and Seedream 4.0. Leading open-source alternatives, including Qwen-Image, Hunyuan-Image-3.0 and FLUX.2, are characterized by massive parameter counts (20B to 80B), making them impractical for inference, and fine-tuning on consumer-grade hardware. To address this gap, we propose Z-Image, an efficient 6B-parameter foundation generative model built upon a Scalable Single-Stream Diffusion Transformer (S3-DiT) architecture that challenges the "scale-at-all-costs" paradigm. By systematically optimizing the entire model lifecycle -- from a curated data infrastructure to a streamlined training curriculum -- we complete the full training workflow in just 314K H800 GPU hours (approx. $630K). Our few-step distillation scheme with reward post-training further yields Z-Image-Turbo, offering both sub-second inference latency on an enterprise-grade H800 GPU and compatibility with consumer-grade hardware (<16GB VRAM). Additionally, our omni-pre-training paradigm also enables efficient training of Z-Image-Edit, an editing model with impressive instruction-following capabilities. Both qualitative and quantitative experiments demonstrate that our model achieves performance comparable to or surpassing that of leading competitors across various dimensions. Most notably, Z-Image exhibits exceptional capabilities in photorealistic image generation and bilingual text rendering, delivering results that rival top-tier commercial models, thereby demonstrating that state-of-the-art results are achievable with significantly reduced computational overhead. We publicly release our code, weights, and online demo to foster the development of accessible, budget-friendly, yet state-of-the-art generative models.
논문 링크
더 읽어보기
DiP: 픽셀 공간에서 디퓨전 모델 다루기 / DiP: Taming Diffusion Models in Pixel Space
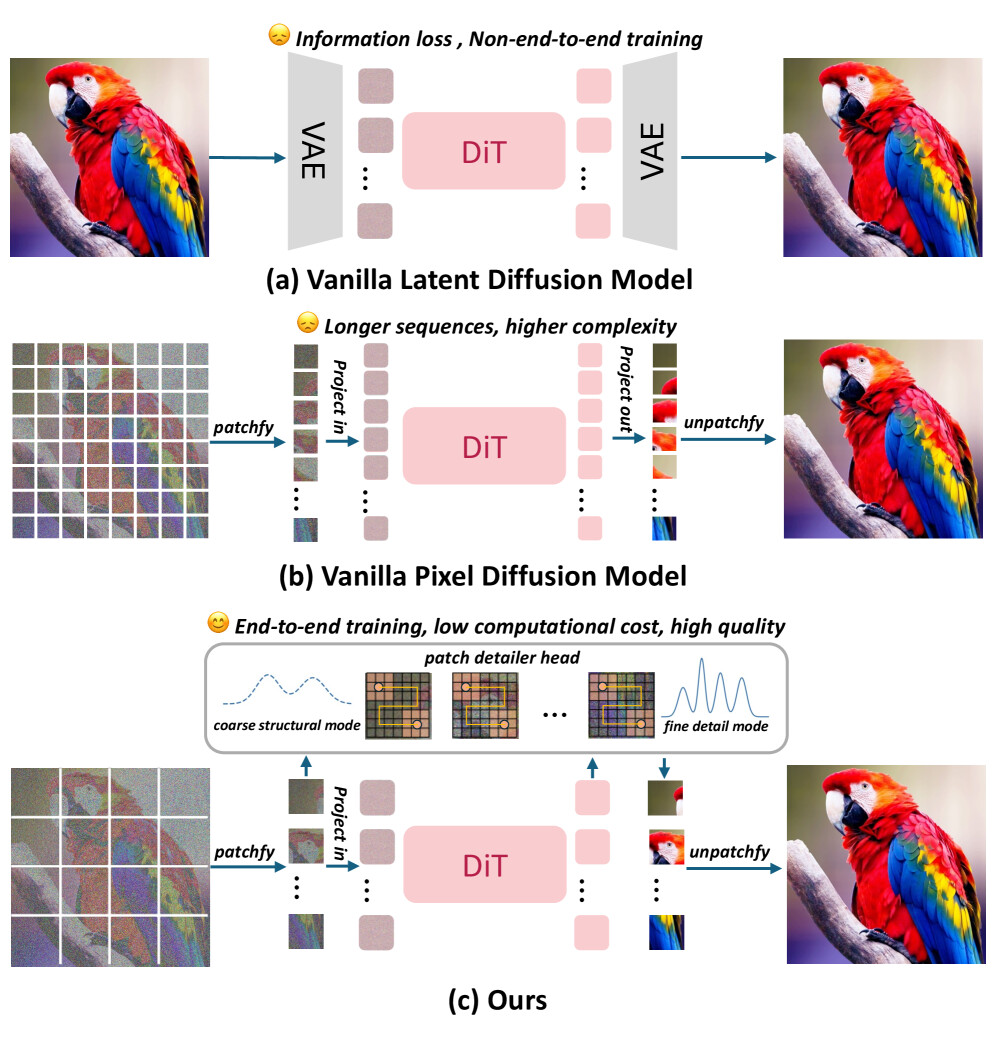
논문 소개
디퓨전 모델은 생성 품질과 계산 효율성 간의 트레이드오프 문제에 직면해 있으며, 이는 특히 고해상도 이미지 생성에서 두드러진다. 기존의 잠재 디퓨전 모델(Latent Diffusion Models, LDMs)은 효율성을 제공하지만 정보 손실과 비종단적 학습의 문제를 안고 있다. 반면, 픽셀 공간 모델은 변분 오토인코더(Variational Autoencoder, VAE)를 우회하지만 계산적으로 부담이 크다. 이러한 문제를 해결하기 위해 제안된 DiP(Diffusion in Pixel space) 프레임워크는 글로벌 및 로컬 생성을 분리하여 효율성을 극대화한다.
DiP는 디퓨전 트랜스포머(Diffusion Transformer, DiT) 백본을 통해 대형 패치에서 글로벌 구조를 효율적으로 생성하고, 공동 학습된 경량 패치 디테일러 헤드(Patch Detailer Head)를 통해 세밀한 로컬 세부사항을 복원한다. 이러한 시너지 디자인은 VAE에 의존하지 않으면서도 LDM과 유사한 계산 효율성을 달성한다. DiP는 이전 방법보다 최대 10배 빠른 추론 속도를 기록하며, 매개변수 수는 0.3%만 증가시키면서도 ImageNet 256×256에서 1.79의 Fréchet Inception Distance (FID) 점수를 달성하였다.
DiP의 핵심은 글로벌 데이터의 저주파 신호에 초점을 맞춘 DiT의 구조에 로컬 세부사항을 효과적으로 처리할 수 있는 패치 디테일러 헤드를 결합한 것이다. 이로 인해 고주파 신호의 정밀한 처리가 가능해지며, 전체적인 생성 품질이 향상된다. 또한, DiP는 패치 수준에서의 정보 전파를 통해 예측의 정확성을 높이는 혁신적인 접근 방식을 제공한다.
이 연구는 디퓨전 모델의 효율성을 높이는 동시에 생성 품질을 유지할 수 있는 새로운 방향성을 제시하며, 향후 고해상도 이미지 생성 및 다양한 응용 분야에 기여할 것으로 기대된다. DiP는 디퓨전 모델의 발전에 중요한 기여를 하며, 기존의 한계를 극복하는 데 중요한 역할을 한다.
논문 초록(Abstract)
디퓨전 모델은 생성 품질과 계산 효율성 간의 근본적인 트레이드오프에 직면해 있습니다. 잠재 디퓨전 모델(Latent Diffusion Models, LDMs)은 효율적인 솔루션을 제공하지만 잠재적인 정보 손실과 비엔드투엔드 학습의 문제를 겪습니다. 반면, 기존의 픽셀 공간 모델은 변분 오토인코더(Variational Autoencoders, VAEs)를 우회하지만 고해상도 합성에 대해서는 계산적으로 부담이 큽니다. 이러한 딜레마를 해결하기 위해, 우리는 DiP라는 효율적인 픽셀 공간 디퓨전 프레임워크를 제안합니다. DiP는 생성을 글로벌 단계와 로컬 단계로 분리합니다: 디퓨전 트랜스포머(Diffusion Transformer, DiT) 백본은 효율적인 글로벌 구조 생성을 위해 큰 패치에서 작동하며, 공동 학습된 경량 패치 디테일러 헤드(Patch Detailer Head)는 맥락적 특징을 활용하여 세밀한 로컬 디테일을 복원합니다. 이러한 시너지 디자인은 VAE에 의존하지 않으면서 LDM과 유사한 계산 효율성을 달성합니다. DiP는 이전 방법보다 최대 10배 빠른 추론 속도를 달성하면서 전체 파라미터 수는 단 0.3%만 증가시키고, ImageNet 256×256에서 1.79 FID 점수를 기록합니다.
Diffusion models face a fundamental trade-off between generation quality and computational efficiency. Latent Diffusion Models (LDMs) offer an efficient solution but suffer from potential information loss and non-end-to-end training. In contrast, existing pixel space models bypass VAEs but are computationally prohibitive for high-resolution synthesis. To resolve this dilemma, we propose DiP, an efficient pixel space diffusion framework. DiP decouples generation into a global and a local stage: a Diffusion Transformer (DiT) backbone operates on large patches for efficient global structure construction, while a co-trained lightweight Patch Detailer Head leverages contextual features to restore fine-grained local details. This synergistic design achieves computational efficiency comparable to LDMs without relying on a VAE. DiP is accomplished with up to 10$\times$ faster inference speeds than previous method while increasing the total number of parameters by only 0.3%, and achieves an 1.79 FID score on ImageNet 256$\times$256.
논문 링크
더 읽어보기
AI 에이전트 프레임워크에서 에이전트 개발자 관행에 대한 실증 연구 / An Empirical Study of Agent Developer Practices in AI Agent Frameworks
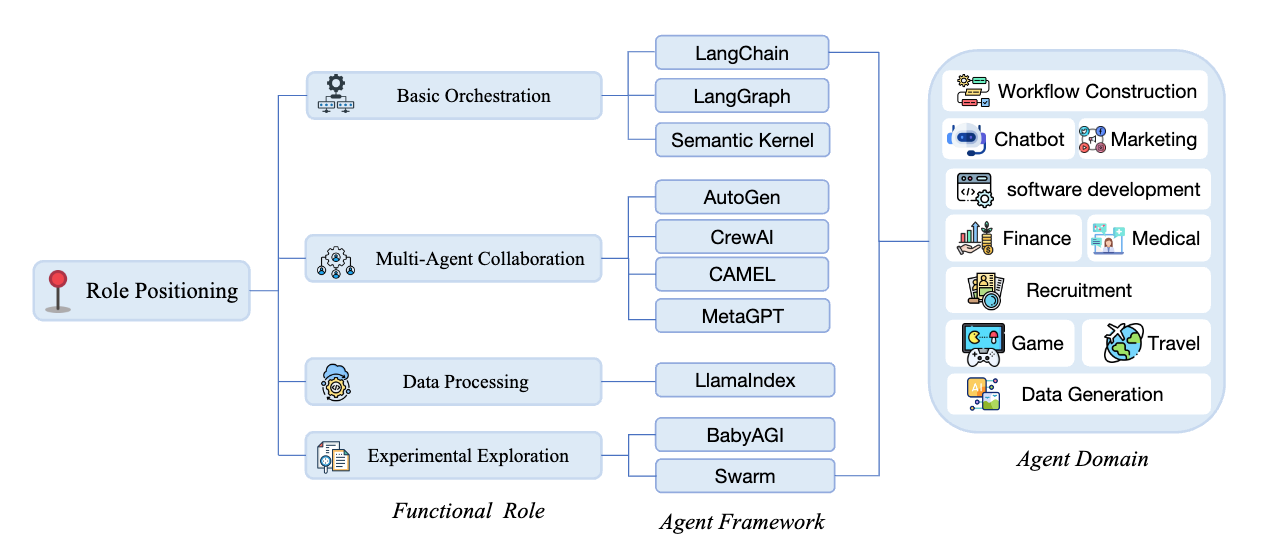

논문 소개
대규모 언어 모델(LLM)의 발전은 에이전트 프레임워크에 대한 관심을 급증시키며, 이로 인해 다양한 소프트웨어 툴킷과 라이브러리가 등장하게 되었다. 에이전트 프레임워크는 개발자들이 자율 에이전트를 구축하는 데 필요한 표준화된 구성 요소와 오케스트레이션 메커니즘을 제공하지만, 이러한 프레임워크의 실제 활용과 개발 과정에서의 영향에 대한 연구는 부족한 실정이다. 본 연구는 LLM 기반 에이전트 프레임워크의 사용 경험을 실증적으로 조사하여, 개발자들이 겪는 도전 과제를 파악하고 이를 해결하기 위한 기초 자료를 제공하고자 하였다.
연구는 1,575개의 GitHub 리포지토리에서 수집된 8,710개의 개발자 논의를 분석하여, 10개의 대표적인 에이전트 프레임워크들(LangChain, LangGraph, Semantic Kernel, AutoGen, CrewAI, CAMEL, MetaGPT, LlamaIndex, BabyAGI, Swarm)을 선정하였다. 이러한 프레임워크의 기능과 사용 방식, 인기 추세를 조사하며, 소프트웨어 개발 생애주기(SDLC) 전반에 걸친 도전 과제를 분류하는 체계를 구축하였다. 특히, 11,910개의 논의를 통해 개발자들이 직면하는 문제를 다섯 가지 차원(개발 효율성, 기능 추상화, 학습 비용, 성능 최적화, 유지 관리성)에서 비교 분석하였다.
분석 결과, 각 프레임워크 간에는 개발자의 요구를 충족하는 데 있어 유의미한 차이가 존재함을 확인하였다. 예를 들어, Langchain과 CrewAI는 초보자에게 기술적 장벽을 낮추는 데 효과적이며, AutoGen과 LangChain은 빠른 프로토타입 제작에서 뛰어난 성능을 보였다. 그러나 모든 프레임워크에서 성능 최적화는 공통적인 단점으로 나타났다. 이러한 결과는 에이전트 개발자와 프레임워크 설계자에게 실질적인 권장 사항을 제공하며, 향후 LLM 기반 에이전트 프레임워크의 설계와 개선 방향에 대한 통찰을 제시한다.
본 연구는 에이전트 개발 생애주기 전반에 걸쳐 AI 에이전트 프레임워크에 대한 개발자들의 참여 및 적응 방식을 대규모로 실증적으로 분석한 첫 번째 연구로, 에이전트 시스템의 복잡한 요구를 충족하기 위해 여러 프레임워크를 사용하는 경향을 보여준다. 이러한 발견은 에이전트 프레임워크 생태계의 발전에 기여할 것으로 기대된다.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 출현은 에이전트에 대한 관심을 불러일으켰고, 이는 에이전트 프레임워크의 빠른 성장을 초래했습니다. 에이전트 프레임워크는 에이전트 개발을 단순화하기 위해 표준화된 구성 요소, 추상화 및 오케스트레이션 메커니즘을 제공하는 소프트웨어 툴킷 및 라이브러리입니다. 에이전트 프레임워크가 널리 사용되고 있음에도 불구하고, 이들의 실제 응용 및 에이전트 개발 과정에 미치는 영향은 여전히 충분히 탐구되지 않았습니다. 다양한 에이전트 프레임워크는 사용 중 유사한 문제에 직면하고 있으며, 이는 이러한 반복적인 문제가 더 많은 주의를 받을 가치가 있음을 나타내며 에이전트 프레임워크 설계에서의 추가 개선을 요구합니다. 한편, 에이전트 프레임워크의 수가 계속 증가하고 발전함에 따라, 80% 이상의 개발자가 특정 개발 요구 사항을 가장 잘 충족하는 프레임워크를 식별하는 데 어려움을 겪고 있다고 보고하고 있습니다. 본 논문에서는 LLM 기반 에이전트 프레임워크에 대한 첫 번째 실증 연구를 수행하여 AI 에이전트를 구축하는 개발자의 실제 경험을 탐구합니다. 에이전트 프레임워크가 개발자의 요구를 얼마나 잘 충족하는지를 비교하기 위해, 이전에 식별된 10개의 에이전트 프레임워크에 대한 개발자 논의를 수집하여 총 11,910개의 논의를 도출했습니다. 마지막으로, 이러한 논의를 분석하여 개발 효율성, 기능적 추상화, 학습 비용, 성능 최적화 및 유지보수성의 다섯 가지 차원에서 프레임워크를 비교합니다. 유지보수성은 개발자가 프레임워크 자체와 그 위에 구축된 에이전트를 시간에 따라 얼마나 쉽게 업데이트하고 확장할 수 있는지를 의미합니다. 우리의 비교 분석은 에이전트 개발자의 요구를 충족하는 방식에서 프레임워크 간에 상당한 차이가 있음을 보여줍니다. 전반적으로, 우리는 LLM 기반 AI 에이전트 프레임워크 생태계에 대한 일련의 발견과 시사점을 제공하며, 향후 LLM 기반 에이전트 프레임워크 및 에이전트 개발자의 설계에 대한 통찰을 제공합니다.
The rise of large language models (LLMs) has sparked a surge of interest in agents, leading to the rapid growth of agent frameworks. Agent frameworks are software toolkits and libraries that provide standardized components, abstractions, and orchestration mechanisms to simplify agent development. Despite widespread use of agent frameworks, their practical applications and how they influence the agent development process remain underexplored. Different agent frameworks encounter similar problems during use, indicating that these recurring issues deserve greater attention and call for further improvements in agent framework design. Meanwhile, as the number of agent frameworks continues to grow and evolve, more than 80% of developers report difficulties in identifying the frameworks that best meet their specific development requirements. In this paper, we conduct the first empirical study of LLM-based agent frameworks, exploring real-world experiences of developers in building AI agents. To compare how well the agent frameworks meet developer needs, we further collect developer discussions for the ten previously identified agent frameworks, resulting in a total of 11,910 discussions. Finally, by analyzing these discussions, we compare the frameworks across five dimensions: development efficiency, functional abstraction, learning cost, performance optimization, and maintainability, which refers to how easily developers can update and extend both the framework itself and the agents built upon it over time. Our comparative analysis reveals significant differences among frameworks in how they meet the needs of agent developers. Overall, we provide a set of findings and implications for the LLM-driven AI agent framework ecosystem and offer insights for the design of future LLM-based agent frameworks and agent developers.
논문 링크
왜 디퓨전 모델은 기억하지 않는가: 학습에서 암묵적 동적 정규화의 역할 / Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training
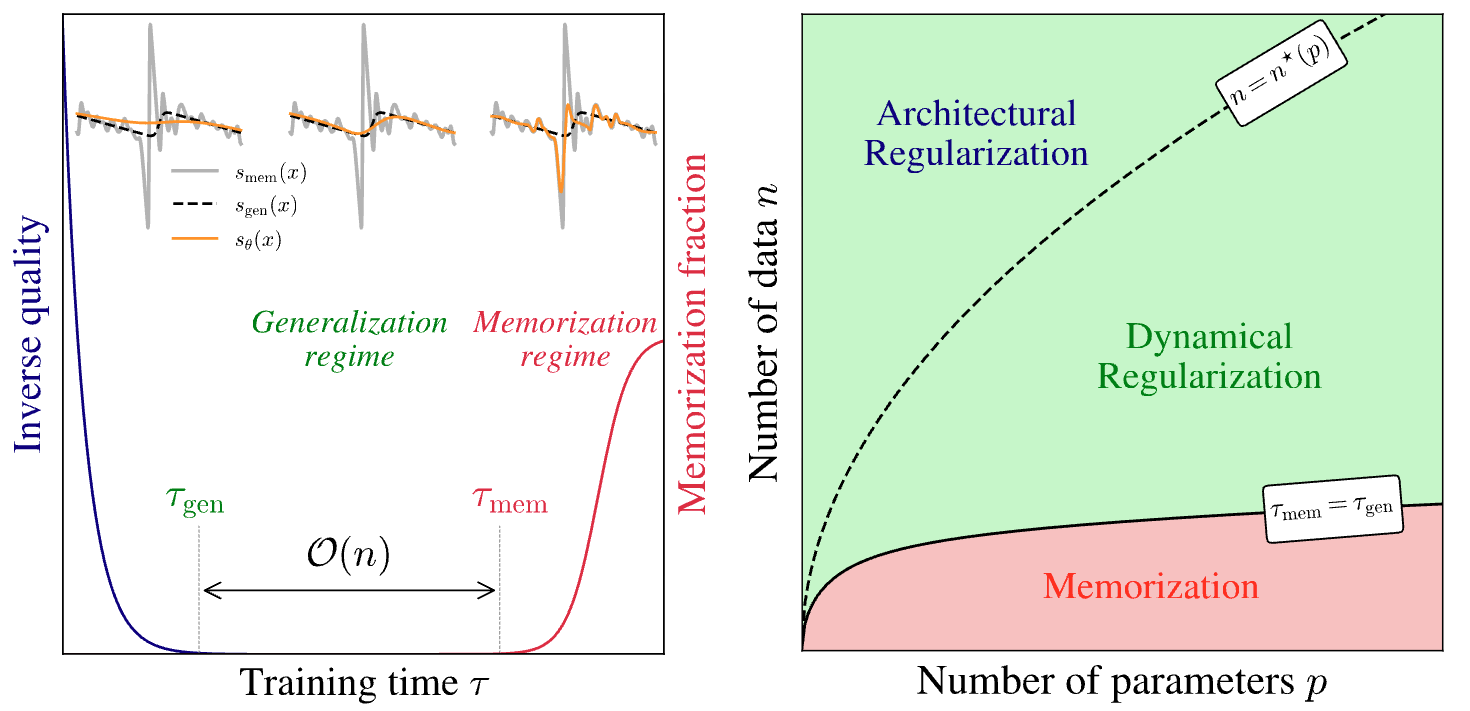
논문 소개
디퓨전 모델은 최근 다양한 생성 작업에서 뛰어난 성능을 보여주고 있지만, 훈련 데이터를 메모리화하지 않고 일반화할 수 있는 메커니즘에 대한 이해는 여전히 중요한 연구 과제로 남아 있다. 본 연구에서는 이러한 일반화와 메모리화 간의 전환에서 훈련 동역학의 역할을 깊이 있게 조사하였다. 실험과 이론적 분석을 통해 두 가지 주요 시간 척도인 초기 시간 τ_\mathrm{gen} 과 메모리화가 발생하는 시간 τ_\mathrm{mem} 을 식별하였다. 특히, τ_\mathrm{mem} 은 훈련 세트 크기 $n$에 따라 선형적으로 증가하는 반면, τ_\mathrm{gen} 은 일정하게 유지되어, 훈련 시간이 증가함에 따라 모델이 효과적으로 일반화할 수 있는 창이 형성됨을 발견하였다.
이 연구의 핵심 기여는 훈련 동역학에서의 암묵적 동적 정규화(implicit dynamical regularization) 개념을 도입하여, 고도로 과매개변수화된 설정에서도 메모리화를 피할 수 있는 방법을 제시한 것이다. 또한, 훈련 세트 크기가 모델 의존적인 임계값을 초과할 때만 과적합이 사라진다는 점을 강조하였다. 이러한 발견은 디퓨전 모델의 훈련 과정에서 메모리화가 발생하는 시점을 이해하는 데 중요한 통찰을 제공하며, 모델의 일반화 능력을 유지하는 데 필수적인 요소로 작용한다.
본 연구는 현실적 및 합성 데이터셋에 대한 표준 U-Net 아키텍처를 활용한 수치 실험과 고차원 한계에서의 처리 가능한 랜덤 피처 모델을 통한 이론적 분석을 통해 뒷받침되었다. 이러한 접근 방식은 디퓨전 모델의 훈련 동역학을 이해하는 데 기여하며, 향후 연구에서 일반화와 메모리화 간의 복잡한 관계를 탐구하는 데 중요한 기반이 될 것으로 기대된다.
논문 초록(Abstract)
디퓨전 모델은 다양한 생성 작업에서 놀라운 성공을 거두었습니다. 주요 도전 과제는 훈련 데이터를 기억하지 않도록 방지하는 메커니즘을 이해하고 일반화를 가능하게 하는 것입니다. 본 연구에서는 일반화에서 기억으로의 전환에서 훈련 역학의 역할을 조사합니다. 광범위한 실험과 이론적 분석을 통해, 우리는 두 가지 뚜렷한 시간 척도를 식별합니다: 모델이 고품질 샘플을 생성하기 시작하는 초기 시간 τ_\mathrm{gen} 과 기억이 나타나는 이후의 시간 τ_\mathrm{mem} 입니다. 중요한 점은 τ_\mathrm{mem} 이 훈련 세트 크기 n 에 따라 선형적으로 증가하는 반면, τ_\mathrm{gen} 은 일정하게 유지된다는 것입니다. 이는 훈련이 그 시점을 넘어 계속될 경우 강한 기억을 보이면서도 모델이 효과적으로 일반화하는 훈련 시간의 증가하는 윈도우를 생성합니다. $n$이 모델 의존 임계값보다 커질 때만 과적합이 무한 훈련 시간에서 사라집니다. 이러한 발견은 훈련 역학에서 암묵적인 동적 정규화를 나타내며, 이는 고도로 과매개변수화된 설정에서도 기억을 피할 수 있게 합니다. 우리의 결과는 현실적이고 합성된 데이터셋에 대한 표준 U-Net 아키텍처를 사용한 수치 실험과 고차원 한계에서 연구된 다루기 쉬운 랜덤 피처 모델을 이용한 이론적 분석에 의해 뒷받침됩니다.
Diffusion models have achieved remarkable success across a wide range of generative tasks. A key challenge is understanding the mechanisms that prevent their memorization of training data and allow generalization. In this work, we investigate the role of the training dynamics in the transition from generalization to memorization. Through extensive experiments and theoretical analysis, we identify two distinct timescales: an early time τ_\mathrm{gen} at which models begin to generate high-quality samples, and a later time τ_\mathrm{mem} beyond which memorization emerges. Crucially, we find that τ_\mathrm{mem} increases linearly with the training set size n, while τ_\mathrm{gen} remains constant. This creates a growing window of training times with n where models generalize effectively, despite showing strong memorization if training continues beyond it. It is only when n becomes larger than a model-dependent threshold that overfitting disappears at infinite training times. These findings reveal a form of implicit dynamical regularization in the training dynamics, which allow to avoid memorization even in highly overparameterized settings. Our results are supported by numerical experiments with standard U-Net architectures on realistic and synthetic datasets, and by a theoretical analysis using a tractable random features model studied in the high-dimensional limit.
논문 링크
더 읽어보기
추론 학습: GPT-OSS 또는 DeepSeek R1 추론 흔적을 활용한 대규모 언어 모델 훈련 / Learning to Reason: Training LLMs with GPT-OSS or DeepSeek R1 Reasoning Traces
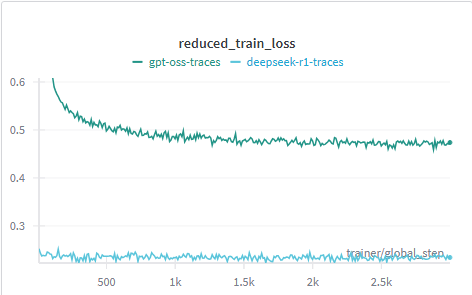
논문 소개
대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 연구는 최근 인공지능 분야에서 중요한 주제로 떠오르고 있다. 본 연구에서는 DeepSeek-R1과 OpenAI의 gpt-oss에서 생성된 두 가지 추론 흔적을 활용하여 중형 LLM을 훈련하고, 이들이 수학 문제 해결에 미치는 영향을 비교하였다. 연구의 핵심 방법론은 test-time scaling을 통해 모델의 정확성을 향상시키는 것으로, 이는 추가적인 계산을 통해 복잡한 문제를 해결하는 과정에서 모델이 목표를 이해하고, 계획을 세우며, 중간 단계를 검토한 후 최종 답변을 도출하는 방식이다.
실험에서는 Nemotron-Post-Training-Dataset-v1에서 300,000개의 수학 대화를 샘플링하여, 두 모델의 추론 흔적을 비교 분석하였다. 특히, DeepSeek-R1은 평균적으로 gpt-oss보다 약 4.4배 많은 토큰을 생성하며, 이는 두 모델의 추론 스타일에서의 차이를 나타낸다. 이러한 차이는 모델의 학습 과정에서의 효율성과 관련이 있으며, 더 많은 토큰을 사용하는 것이 항상 더 나은 성능으로 이어지지 않음을 보여준다.
본 연구의 주요 기여는 두 가지 서로 다른 추론 스타일의 효과를 비교함으로써, LLM의 추론 능력을 향상시키기 위한 새로운 접근 방식을 제시한 점이다. 실험 결과, 두 스타일 모두 유사한 정확도를 달성하였으나, gpt-oss 스타일이 훨씬 적은 토큰을 요구하여 추론 효율성을 높이는 데 기여하였다. 이러한 발견은 실제 응용 프로그램에서의 지연 시간 및 비용 절감으로 이어질 수 있으며, 향후 연구에서는 다양한 도메인에 대한 확장 가능성을 탐색할 예정이다.
결론적으로, 본 연구는 LLM의 추론 능력을 향상시키기 위한 효과적인 방법론을 제시하며, 생성된 데이터셋은 향후 연구를 위한 귀중한 자원으로 활용될 수 있을 것이다.
논문 초록(Abstract)
테스트 시간 스케일링은 추론 중 추가적인 계산을 활용하여 모델 정확성을 향상시키는 방법으로, 목표를 이해하고 이 목표를 계획으로 전환하며, 중간 단계를 거치고, 답변하기 전에 자신의 작업을 점검하는 복잡한 문제를 추론할 수 있는 새로운 종류의 대규모 언어 모델(LLM)을 가능하게 했습니다. DeepSeek-R1과 OpenAI의 gpt-oss와 같은 최전선 대규모 언어 모델은 최종 답변을 제시하기 전에 중간 추론 흔적을 생성하여 복잡한 문제를 해결할 때 동일한 절차를 따릅니다. 현재 이러한 모델은 비싼 인간 큐레이션 없이 추론 능력을 가르치기 위해 소형 및 중형 언어 모델의 사후 학습을 위한 고품질 감독 데이터 역할을 하는 추론 흔적을 생성하는 데 점점 더 많이 사용되고 있습니다. 본 연구에서는 두 가지 종류의 추론 흔적에 대한 사후 학습 후 수학 문제에 대한 중형 LLM의 성능을 비교합니다. 우리는 정확성과 추론 효율성 측면에서 DeepSeek-R1과 gpt-oss LLM이 생성한 추론 흔적의 영향을 비교합니다.
Test-time scaling, which leverages additional computation during inference to improve model accuracy, has enabled a new class of Large Language Models (LLMs) that are able to reason through complex problems by understanding the goal, turning this goal into a plan, working through intermediate steps, and checking their own work before answering . Frontier large language models with reasoning capabilities, such as DeepSeek-R1 and OpenAI's gpt-oss, follow the same procedure when solving complex problems by generating intermediate reasoning traces before giving the final answer. Today, these models are being increasingly used to generate reasoning traces that serve as high-quality supervised data for post-training of small and medium-sized language models to teach reasoning capabilities without requiring expensive human curation. In this work, we compare the performance of medium-sized LLMs on Math problems after post-training on two kinds of reasoning traces. We compare the impact of reasoning traces generated by DeepSeek-R1 and gpt-oss LLMs in terms of accuracy and inference efficiency.
논문 링크
영상에서의 새로운 시간적 전파를 보이는 이미지 디퓨전 모델 / Image Diffusion Models Exhibit Emergent Temporal Propagation in Videos
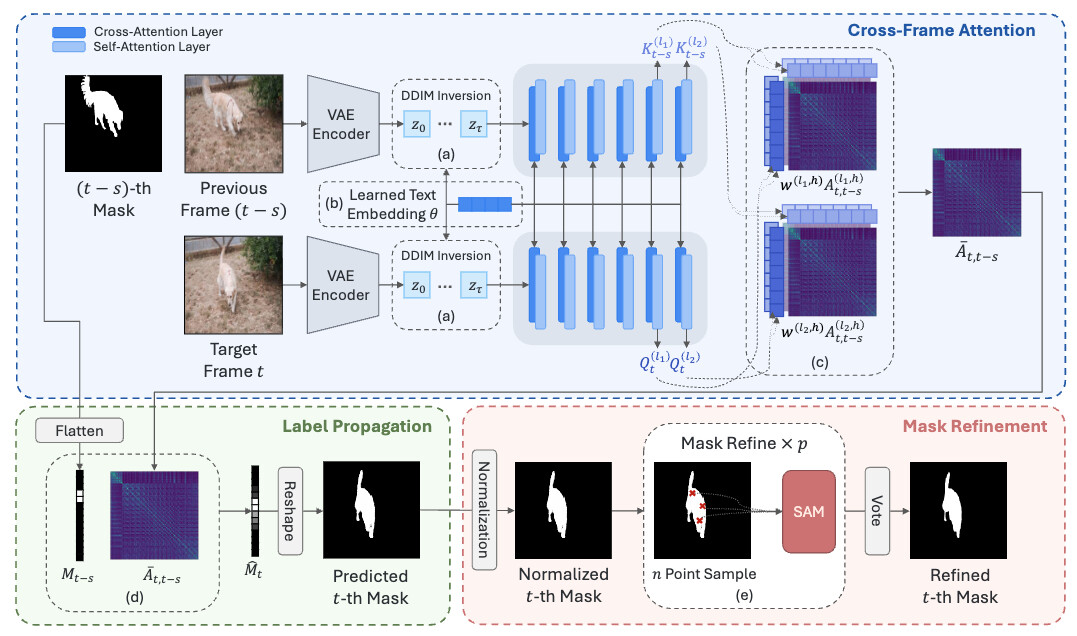
논문 소개
이미지 디퓨전 모델은 원래 이미지 생성을 위해 설계되었으나, 본 연구에서는 이러한 모델이 다양한 인식 및 위치 지정 작업을 수행할 수 있는 풍부한 의미 구조를 암묵적으로 포착하고 있음을 강조한다. 연구의 핵심은 자기 어텐션 맵을 의미 레이블 전파 커널로 재해석하여, 관련 이미지 영역 간의 강력한 픽셀 수준의 대응 관계를 제공하는 것이다. 이 메커니즘을 프레임 간에 확장함으로써 시간적 전파 커널이 생성되며, 이를 통해 제로샷 객체 추적을 위한 세분화가 가능해진다.
본 연구는 테스트 시간 최적화 전략인 DDIM(Deterministic Denoising Implicit Models) 역전환, 텍스트 역전환, 적응형 헤드 가중치 조정 등을 통해 디퓨전 특징을 강력하고 일관된 레이블 전파를 위해 어떻게 활용할 수 있는지를 보여준다. 이러한 전략들은 모델의 성능을 극대화하는 데 중요한 역할을 하며, 특히 제로샷 설정에서의 효과를 입증한다.
DRIFT(Deep Reinforcement Image Feature Tracking)라는 새로운 프레임워크를 소개하며, 이는 사전 학습된 이미지 디퓨전 모델과 SAM(Segmentation-Aware Mask) 기반 마스크 정제를 활용하여 비디오에서 객체 추적을 수행한다. DRIFT는 표준 비디오 객체 세분화 벤치마크에서 최첨단 제로샷 성능을 달성하며, 기존 방법들과 비교했을 때 상당한 개선을 보여준다.
이 연구는 이미지 디퓨전 모델이 비디오 분석 및 객체 추적 분야에서 어떻게 혁신적으로 활용될 수 있는지를 입증하며, 제로샷 설정에서도 높은 성능을 유지할 수 있음을 강조한다. 제안된 DRIFT 프레임워크는 향후 비디오 분석 및 객체 추적 연구에 중요한 기여를 할 것으로 기대된다.
논문 초록(Abstract)
이미지 디퓨전 모델은 원래 이미지 생성을 위해 개발되었지만, 합성을 넘어 다양한 인식 및 위치 지정 작업을 가능하게 하는 풍부한 의미 구조를 암묵적으로 포착합니다. 본 연구에서는 이 모델의 자기 어텐션 맵이 의미 레이블 전파 커널로 재해석될 수 있음을 조사하여, 관련 이미지 영역 간의 강력한 픽셀 수준의 대응 관계를 제공합니다. 이 메커니즘을 프레임 간에 확장하면, 비디오에서 세분화를 통한 제로샷 객체 추적을 가능하게 하는 시간적 전파 커널이 생성됩니다. 우리는 또한 테스트 시 최적화 전략인 DDIM 역전환, 텍스트 역전환, 적응형 헤드 가중치 조정이 디퓨전 특징을 강력하고 일관된 레이블 전파에 적응시키는 데 효과적임을 보여줍니다. 이러한 발견을 바탕으로, 우리는 SAM-guided 마스크 정제를 활용한 사전 학습된 이미지 디퓨전 모델을 이용한 비디오 객체 추적을 위한 프레임워크인 DRIFT를 소개하며, 표준 비디오 객체 세분화 벤치마크에서 최첨단 제로샷 성능을 달성합니다.
Image diffusion models, though originally developed for image generation, implicitly capture rich semantic structures that enable various recognition and localization tasks beyond synthesis. In this work, we investigate their self-attention maps can be reinterpreted as semantic label propagation kernels, providing robust pixel-level correspondences between relevant image regions. Extending this mechanism across frames yields a temporal propagation kernel that enables zero-shot object tracking via segmentation in videos. We further demonstrate the effectiveness of test-time optimization strategies-DDIM inversion, textual inversion, and adaptive head weighting-in adapting diffusion features for robust and consistent label propagation. Building on these findings, we introduce DRIFT, a framework for object tracking in videos leveraging a pretrained image diffusion model with SAM-guided mask refinement, achieving state-of-the-art zero-shot performance on standard video object segmentation benchmarks.
논문 링크
트랜스포머에서 재귀적 잠재 공간 추론을 통한 분포 외 일반화의 해법 / Unlocking Out-of-Distribution Generalization in Transformers via Recursive Latent Space Reasoning
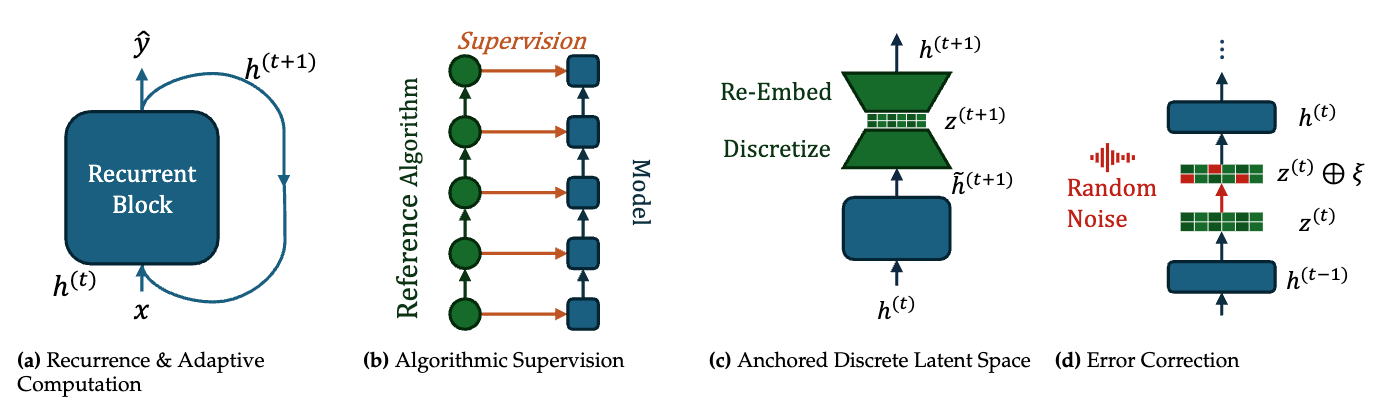
논문 소개
체계적이고 조합적인 일반화는 기계 학습 분야에서 여전히 해결해야 할 중요한 과제로, 특히 현대 언어 모델의 추론 능력에 큰 영향을 미친다. 본 연구는 트랜스포머(Transformer) 네트워크에서 아웃 오브 디스트리뷰션(Out-of-Distribution, OOD) 일반화를 향상시키기 위한 새로운 접근 방식을 제안한다. 이를 위해 GSM8K 스타일의 모듈형 산술을 수행하는 계산 그래프 작업을 테스트베드로 활용하여, 네 가지 주요 아키텍처 메커니즘을 도입하였다.
첫째, 입력 적응형 재귀(input-adaptive recurrence)는 모델이 입력 데이터의 특성에 따라 동적으로 재귀 구조를 조정할 수 있도록 한다. 둘째, 알고리즘적 감독(algorithmic supervision)은 모델이 특정 알고리즘을 학습하도록 유도하여, 보다 정확한 추론을 가능하게 한다. 셋째, 이산 병목(discrete bottleneck)을 통한 고정된 잠재 표현은 모델의 잠재 공간에서의 정보 처리를 최적화하며, 마지막으로 명시적 오류 수정 메커니즘은 모델이 예측 오류를 인식하고 수정할 수 있는 능력을 부여한다.
이러한 메커니즘들은 트랜스포머 네트워크의 내재적(latent) 공간에서의 사고의 연쇄(Chain-of-Thought, CoT)를 가능하게 하여, 알고리즘적 일반화 능력을 크게 향상시킨다. 연구 결과는 이러한 메커니즘이 OOD 일반화 능력을 어떻게 강화하는지를 보여주는 상세한 기계적 해석 분석을 통해 뒷받침된다.
본 연구는 트랜스포머 모델의 아키텍처적 최적화를 통해 새로운 문제 해결 능력을 제공하며, 기계 학습 분야에서의 OOD 일반화에 대한 이해를 심화시키는 데 기여한다. 이러한 접근 방식은 향후 다양한 응용 분야에서의 모델 성능 향상에 중요한 역할을 할 것으로 기대된다.
논문 초록(Abstract)
시스템적이고 구성적인 일반화는 학습 분포를 넘어서는 머신러닝의 핵심 도전 과제로, 현대 언어 모델의 새로운 추론 능력에 대한 중요한 병목 현상입니다. 본 연구는 Transformer 네트워크에서 OOD(분포 외) 일반화를 조사하며, 이를 위해 계산 그래프 작업에서 GSM8K 스타일의 모듈러 산술을 테스트베드로 사용합니다. 우리는 OOD 일반화를 향상시키기 위한 네 가지 구조적 메커니즘을 도입하고 탐구합니다: (i) 입력 적응형 재귀; (ii) 알고리즘적 감독; (iii) 이산 병목을 통한 고정된 잠재 표현; (iv) 명시적인 오류 수정 메커니즘. 이러한 메커니즘은 Transformer 네트워크에서 본질적이고 확장 가능한 잠재 공간 추론을 위한 구조적 접근 방식을 제공하며, 강력한 알고리즘적 일반화 능력을 갖추고 있습니다. 우리는 이러한 경험적 결과를 보완하기 위해, 이러한 메커니즘이 어떻게 강력한 OOD 일반화 능력을 발휘하는지를 드러내는 상세한 기계적 해석 분석을 제공합니다.
Systematic, compositional generalization beyond the training distribution remains a core challenge in machine learning -- and a critical bottleneck for the emergent reasoning abilities of modern language models. This work investigates out-of-distribution (OOD) generalization in Transformer networks using a GSM8K-style modular arithmetic on computational graphs task as a testbed. We introduce and explore a set of four architectural mechanisms aimed at enhancing OOD generalization: (i) input-adaptive recurrence; (ii) algorithmic supervision; (iii) anchored latent representations via a discrete bottleneck; and (iv) an explicit error-correction mechanism. Collectively, these mechanisms yield an architectural approach for native and scalable latent space reasoning in Transformer networks with robust algorithmic generalization capabilities. We complement these empirical results with a detailed mechanistic interpretability analysis that reveals how these mechanisms give rise to robust OOD generalization abilities.
논문 링크
더 읽어보기
프로그래밍 비전을 통한 사고: 이미지를 활용한 사고의 통합적 관점으로 나아가기 / Thinking with Programming Vision: Towards a Unified View for Thinking with Images
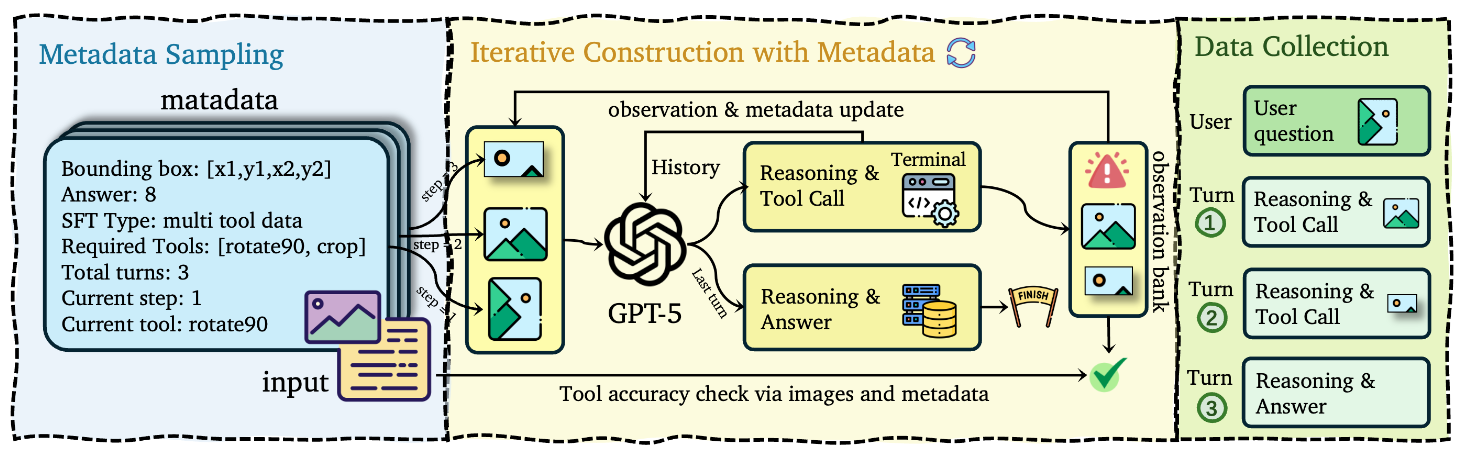
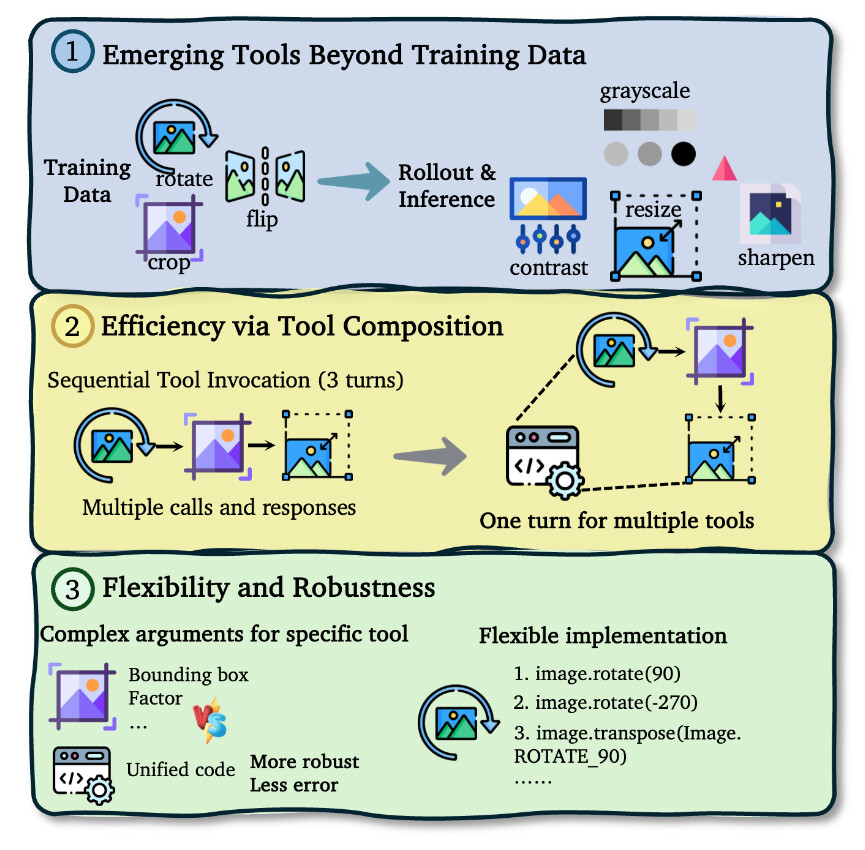
논문 소개
멀티모달 대규모 언어 모델(MLLMs)은 이미지와 같은 시각적 입력을 처리하고 도구를 사용하여 상호작용적으로 추론할 수 있는 능력을 갖추고 있다. 그러나 현재의 접근 방식은 제한된 도구 세트에 의존하고 있어 실제 응용에서의 필요성과 확장성이 부족하다는 점이 지적된다. 본 연구에서는 이러한 문제를 해결하기 위해 CodeVision이라는 혁신적인 코드-도구 프레임워크를 제안한다. 이 프레임워크는 모델이 모든 이미지 작업을 수행하기 위해 코드를 생성할 수 있는 보편적인 인터페이스를 제공하며, 고정된 도구 레지스트리를 넘어서는 유연성을 갖춘다.
연구의 핵심 방법론은 두 단계로 구성된다. 첫 번째 단계는 지도 파인튜닝(Supervised Fine-Tuning, SFT)으로, 복잡한 다중 턴 도구 조합 및 오류 복구를 위해 고품질 데이터셋에서 모델을 학습시킨다. 두 번째 단계는 강화학습(Reinforcement Learning, RL)으로, 새로운 밀집 프로세스 보상 함수를 사용하여 모델이 전략적이고 효율적으로 도구를 활용하도록 유도한다. 이를 통해 모델은 다양한 이미지 작업을 보다 효과적으로 수행할 수 있게 된다.
본 연구에서는 새로운 SFT 및 RL 데이터셋을 구축하고, 방향 변화 및 다중 도구 추론에 대한 강건성을 평가하기 위한 도전적인 벤치마크 세트를 도입하였다. 실험 결과, Qwen2.5-VL 및 Qwen3-VL 시리즈에서 CodeVision의 접근 방식이 모델 성능을 크게 향상시키고, 유연한 도구 조합, 효율적인 연쇄 실행, 그리고 런타임 피드백으로부터의 강력한 오류 복구와 같은 emergent capabilities를 촉진함을 보여주었다.
이 연구는 MLLMs의 기존 한계를 극복하는 데 기여하며, 시각적 입력 처리에 대한 새로운 가능성을 제시한다. CodeVision 프레임워크는 향후 다양한 응용 분야에서의 활용 가능성을 열어줄 것으로 기대된다.
논문 초록(Abstract)
다음은 AI/ML 분야의 논문 초록입니다. 멀티모달 대규모 언어 모델(MLLMs)은 이미지를 통해 사고할 수 있으며, 시각적 입력에 대해 도구를 상호작용적으로 사용하여 추론할 수 있지만, 현재의 접근 방식은 종종 제한된 실제 필요성과 확장성을 가진 좁은 범위의 도구에 의존합니다. 본 연구에서는 먼저 중요한 이전에 간과된 약점을 드러냅니다: 최신 MLLMs조차도 놀랍도록 취약하여, 간단한 방향 변화나 자연적인 손상이 있는 이미지에서 성능 저하가 두드러지며, 이는 보다 강력한 도구 기반 추론의 필요성을 강조합니다. 이를 해결하기 위해, 우리는 코드-비전(CodeVision)이라는 유연하고 확장 가능한 코드-도구 프레임워크를 제안합니다. 이 프레임워크에서는 모델이 모든 이미지 작업을 호출하기 위한 보편적인 인터페이스로 코드를 생성하여 고정된 도구 레지스트리를 넘어섭니다. 우리는 복잡한 다중 턴 도구 구성 및 오류 복구를 위해 큐레이션된 고품질 데이터셋에서 감독된 파인튜닝(Supervised Fine-Tuning, SFT)으로 시작하는 두 단계 방법론을 사용하여 모델을 훈련하고, 전략적이고 효율적인 도구 사용을 장려하기 위해 새로운 밀집 프로세스 보상 함수를 사용하는 강화학습(Reinforcement Learning, RL)을 진행합니다. 이 연구를 촉진하기 위해, 우리는 새로운 SFT 및 RL 데이터셋을 구축하고 방향 변화 및 다중 도구 추론에 대한 강건성을 엄격하게 평가하기 위해 설계된 도전적인 새로운 벤치마크 세트를 도입합니다. Qwen2.5-VL 및 Qwen3-VL 시리즈에 대한 실험 결과, 우리의 접근 방식이 모델 성능을 크게 향상시키고 유연한 도구 구성, 효율적인 연쇄 실행 및 런타임 피드백으로부터의 강력한 오류 복구와 같은 emergent capabilities를 촉진함을 보여줍니다. 코드는 GitHub - ByteDance-BandAI/CodeVision: Thinking with Programming Vision: Towards a Unified View for Thinking with Images 에서 이용 가능합니다.
Multimodal large language models (MLLMs) that think with images can interactively use tools to reason about visual inputs, but current approaches often rely on a narrow set of tools with limited real-world necessity and scalability. In this work, we first reveal a critical and previously overlooked weakness: even state-of-the-art MLLMs are surprisingly brittle, showing significant performance degradation on images with simple orientation changes or natural corruptions, underscoring the need for more robust tool-based reasoning. To address this, we propose CodeVision, a flexible and scalable code-as-tool framework where the model generates code as a universal interface to invoke any image operation, moving beyond fixed tool registries. We train our model using a two-stage methodology, beginning with Supervised Fine-Tuning (SFT) on a high-quality dataset curated for complex, multi-turn tool composition and error recovery, followed by Reinforcement Learning (RL) with a novel and dense process reward function to encourage strategic and efficient tool use. To facilitate this research, we construct new SFT and RL datasets and introduce a challenging new benchmark suite designed to rigorously evaluate robustness to orientation changes and multi-tool reasoning. Experiments on Qwen2.5-VL and Qwen3-VL series show that our approach significantly improves model performance and fosters emergent capabilities such as flexible tool composition, efficient chained execution, and robust error recovery from runtime feedback. Code is available at GitHub - ByteDance-BandAI/CodeVision: Thinking with Programming Vision: Towards a Unified View for Thinking with Images.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()