[2025/12/08 ~ 14] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() “에이전트 = 단일 모델”에서 “에이전트 = 시스템”으로 - 협업·분해·통합의 설계가 핵심: 이번 주에 선정된 논문들을 살펴보면, 다중 에이전트 시스템과 에이전틱 LLM 흐름이 공통적으로 “모델 1개”가 아니라 “역할과 상호작용을 가진 시스템”을 성능 단위로 다룹니다. 특히 잠재 공간 협업이나 하위 문제 분해 기반 추론처럼, 커뮤니케이션/추론 구조(순차·병렬·트리)를 설계해 품질과 비용을 같이 잡으려는 시도가 두드러집니다. 또한 이미지·비디오 올인원 추론처럼 “모달리티/태스크 분리”를 줄이고 지식 전이를 극대화하려는 통합형 일반화가 같은 방향의 확장으로 읽힙니다. 결과적으로 요즘 논문들은 “좋은 모델”보다 “좋은 시스템 토폴로지(협업/분해/통합)”를 경쟁력의 원천으로 놓는 경향이 강합니다.
“에이전트 = 단일 모델”에서 “에이전트 = 시스템”으로 - 협업·분해·통합의 설계가 핵심: 이번 주에 선정된 논문들을 살펴보면, 다중 에이전트 시스템과 에이전틱 LLM 흐름이 공통적으로 “모델 1개”가 아니라 “역할과 상호작용을 가진 시스템”을 성능 단위로 다룹니다. 특히 잠재 공간 협업이나 하위 문제 분해 기반 추론처럼, 커뮤니케이션/추론 구조(순차·병렬·트리)를 설계해 품질과 비용을 같이 잡으려는 시도가 두드러집니다. 또한 이미지·비디오 올인원 추론처럼 “모달리티/태스크 분리”를 줄이고 지식 전이를 극대화하려는 통합형 일반화가 같은 방향의 확장으로 읽힙니다. 결과적으로 요즘 논문들은 “좋은 모델”보다 “좋은 시스템 토폴로지(협업/분해/통합)”를 경쟁력의 원천으로 놓는 경향이 강합니다.
![]() 중간단(손실·누적오류)을 걷어내고 “직접 공간/직접 최적화”로: 표현·파이프라인 재설계: 성능 병목을 만드는 손실 있는 중간 표현을 제거하고 더 “직접적인 공간”에서 학습/생성을 하려는 움직임이 보입니다. 예를 들어 픽셀 공간 디퓨전 트랜스포머처럼 오토인코더 2단계를 없애거나, 무한 지형 생성 디퓨전처럼 “무한/실시간” 제약을 디퓨전으로 직접 만족시키도록 알고리즘을 재구성합니다. 한편 에이전트 쪽에서도 텍스트 왕복 대신 잠재 표현 공유로 통신 비용을 줄이는 등, 표현 공간을 바꿔 효율(토큰/시간)과 품질을 동시에 노리는 패턴이 반복됩니다. 요약하면 “더 큰 모델”만이 아니라 “어디서 무엇을 직접 다루는가(픽셀/잠재/구조화 지식)”가 성능을 좌우하는 설계 중심의 트렌드입니다.
중간단(손실·누적오류)을 걷어내고 “직접 공간/직접 최적화”로: 표현·파이프라인 재설계: 성능 병목을 만드는 손실 있는 중간 표현을 제거하고 더 “직접적인 공간”에서 학습/생성을 하려는 움직임이 보입니다. 예를 들어 픽셀 공간 디퓨전 트랜스포머처럼 오토인코더 2단계를 없애거나, 무한 지형 생성 디퓨전처럼 “무한/실시간” 제약을 디퓨전으로 직접 만족시키도록 알고리즘을 재구성합니다. 한편 에이전트 쪽에서도 텍스트 왕복 대신 잠재 표현 공유로 통신 비용을 줄이는 등, 표현 공간을 바꿔 효율(토큰/시간)과 품질을 동시에 노리는 패턴이 반복됩니다. 요약하면 “더 큰 모델”만이 아니라 “어디서 무엇을 직접 다루는가(픽셀/잠재/구조화 지식)”가 성능을 좌우하는 설계 중심의 트렌드입니다.
![]() 신뢰성의 ‘측정 가능화’ - 프로덕션 관측, 벤치마크, 결정론적 검증으로 안전·정확성 다루기: 에이전트/생성 모델이 실제 도입되면서, “잘 되는지”보다 “언제/왜/얼마나 위험한지”를 다루는 프로덕션 측정과 현실형 벤치마크 설계가 전면에 등장합니다. 특히 코드 영역에서는 에이전트 생성 코드 취약성처럼 “기능 정답률 vs 보안 안전성”의 간극을 정량화하고, 단순 가이드 보강이 쉽게 해결책이 되지 않음을 보여줍니다. 더 나아가 결정론적 LLM 검증처럼 샘플링 기반 추정이 아닌 ‘보장 가능한 경계’를 계산하려는 시도도 나타납니다. 또한 온톨로지 공리 식별 벤치마크처럼 구조화 지식 추출을 평가 가능한 문제로 만들려는 흐름까지 합쳐져, “신뢰성은 기능이 아니라 인프라(평가·검증·관측)”라는 트렌드가 강해졌습니다.
신뢰성의 ‘측정 가능화’ - 프로덕션 관측, 벤치마크, 결정론적 검증으로 안전·정확성 다루기: 에이전트/생성 모델이 실제 도입되면서, “잘 되는지”보다 “언제/왜/얼마나 위험한지”를 다루는 프로덕션 측정과 현실형 벤치마크 설계가 전면에 등장합니다. 특히 코드 영역에서는 에이전트 생성 코드 취약성처럼 “기능 정답률 vs 보안 안전성”의 간극을 정량화하고, 단순 가이드 보강이 쉽게 해결책이 되지 않음을 보여줍니다. 더 나아가 결정론적 LLM 검증처럼 샘플링 기반 추정이 아닌 ‘보장 가능한 경계’를 계산하려는 시도도 나타납니다. 또한 온톨로지 공리 식별 벤치마크처럼 구조화 지식 추출을 평가 가능한 문제로 만들려는 흐름까지 합쳐져, “신뢰성은 기능이 아니라 인프라(평가·검증·관측)”라는 트렌드가 강해졌습니다.
다중 에이전트 시스템에서의 잠재적 협업 / Latent Collaboration in Multi-Agent Systems
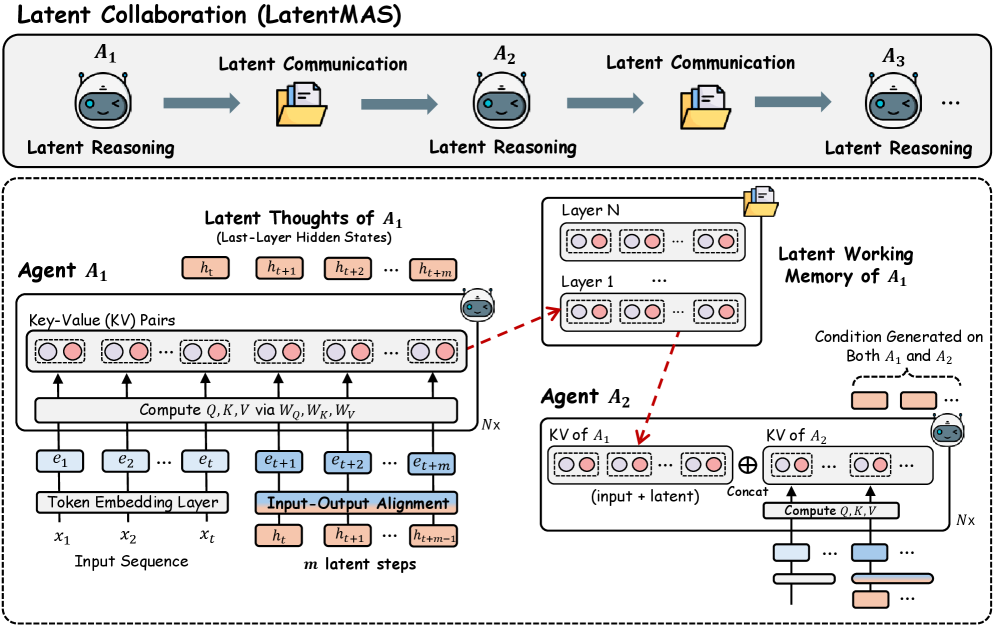
논문 소개
다중 에이전트 시스템(Multi-Agent Systems, MAS)은 대규모 언어 모델(Large Language Models, LLM)을 독립적인 단일 모델 추론에서 협력적인 시스템 수준의 지능으로 확장하는 혁신적인 접근을 제시합니다. 기존의 LLM 에이전트는 텍스트 기반의 매개를 통해 추론과 커뮤니케이션을 수행하는 반면, 본 연구에서는 모델들이 연속적인 잠재 공간(latent space) 내에서 직접 협력할 수 있도록 하는 LatentMAS 프레임워크를 도입합니다. LatentMAS는 엔드 투 엔드 학습 없이도 LLM 에이전트 간의 순수한 잠재 협력을 가능하게 하며, 각 에이전트는 마지막 층의 숨겨진 임베딩을 통해 자동 회귀적인 잠재 사고 생성을 수행합니다.
LatentMAS 프레임워크는 공유된 잠재 작업 기억을 통해 각 에이전트의 내부 표현을 보존하고 전송하여 손실 없는 정보 교환을 보장합니다. LatentMAS의 이론적 분석 결과, 기존의 텍스트 기반 MAS보다 높은 표현력과 손실 없는 정보 보존을 달성하면서도 복잡성이 현저히 낮음을 입증하였습니다. 실험 결과, LatentMAS는 수학 및 과학 추론, 상식 이해, 코드 생성 등 9개의 벤치마크에서 강력한 단일 모델 및 텍스트 기반 MAS 기준을 초과 달성하며, 최대 14.6% 높은 정확도와 70.8%-83.7%의 출력 토큰 사용량 감소, 4배에서 4.3배 더 빠른 엔드 투 엔드 추론 속도를 기록했습니다.
이러한 결과는 LatentMAS가 시스템 수준의 추론 품질을 향상시키면서도 추가 학습 없이도 상당한 효율성 향상을 제공함을 보여줍니다. LatentMAS의 잠재 사고 생성 과정은 텍스트 응답과 유사한 의미 표현을 인코딩하며, 내부에서 더 풍부하고 표현력이 뛰어난 정보를 제공합니다. 또한, 입력-출력 정렬의 효과성을 실증적으로 평가하여 LatentMAS의 성능을 더욱 강화할 수 있는 방법론적 기여를 확인하였습니다. 최적의 잠재 단계 깊이를 분석하여, 협력 표현력을 높이기 위한 적절한 잠재 단계 예산을 제시함으로써, LatentMAS는 정확도와 효율성의 균형을 이룰 수 있는 최적의 솔루션을 제공합니다.
논문 초록(Abstract)
다중 에이전트 시스템(MAS)은 대규모 언어 모델(LLM)을 독립적인 단일 모델 추론에서 협조적인 시스템 수준의 지능으로 확장합니다. 기존 LLM 에이전트는 추론 및 커뮤니케이션을 위해 텍스트 기반 중재에 의존하는 반면, 우리는 모델이 연속 잠재 공간 내에서 직접 협력할 수 있도록 한 단계 나아갑니다. 우리는 LLM 에이전트 간의 순수한 잠재 협업을 가능하게 하는 엔드 투 엔드 훈련 없는 프레임워크인 LatentMAS를 소개합니다. LatentMAS에서 각 에이전트는 먼저 마지막 레이어의 숨겨진 임베딩을 통해 자기 회귀적인 잠재 사고 생성을 수행합니다. 공유된 잠재 작업 메모리는 각 에이전트의 내부 표현을 보존하고 전달하여 손실 없는 정보 교환을 보장합니다. 우리는 LatentMAS가 일반 텍스트 기반 MAS보다 상당히 낮은 복잡도로 더 높은 표현력과 손실 없는 정보 보존을 달성한다는 이론적 분석을 제공합니다. 또한 수학 및 과학 추론, 상식 이해, 코드 생성을 아우르는 9개의 종합 벤치마크에 대한 실증 평가 결과, LatentMAS는 강력한 단일 모델 및 텍스트 기반 MAS 기준선을 지속적으로 초과 달성하며 최대 14.6% 높은 정확도를 기록하고, 출력 토큰 사용량을 70.8%-83.7% 줄이며, 엔드 투 엔드 추론 속도를 4배에서 4.3배 향상시킵니다. 이러한 결과는 우리의 새로운 잠재 협업 프레임워크가 시스템 수준의 추론 품질을 향상시키면서 추가적인 훈련 없이도 상당한 효율성을 제공함을 보여줍니다. 코드와 데이터는 GitHub - Gen-Verse/LatentMAS: Latent Collaboration in Multi-Agent Systems 에서 완전히 오픈 소스로 제공됩니다.
Multi-agent systems (MAS) extend large language models (LLMs) from independent single-model reasoning to coordinative system-level intelligence. While existing LLM agents depend on text-based mediation for reasoning and communication, we take a step forward by enabling models to collaborate directly within the continuous latent space. We introduce LatentMAS, an end-to-end training-free framework that enables pure latent collaboration among LLM agents. In LatentMAS, each agent first performs auto-regressive latent thoughts generation through last-layer hidden embeddings. A shared latent working memory then preserves and transfers each agent's internal representations, ensuring lossless information exchange. We provide theoretical analyses establishing that LatentMAS attains higher expressiveness and lossless information preservation with substantially lower complexity than vanilla text-based MAS. In addition, empirical evaluations across 9 comprehensive benchmarks spanning math and science reasoning, commonsense understanding, and code generation show that LatentMAS consistently outperforms strong single-model and text-based MAS baselines, achieving up to 14.6% higher accuracy, reducing output token usage by 70.8%-83.7%, and providing 4x-4.3x faster end-to-end inference. These results demonstrate that our new latent collaboration framework enhances system-level reasoning quality while offering substantial efficiency gains without any additional training. Code and data are fully open-sourced at GitHub - Gen-Verse/LatentMAS: Latent Collaboration in Multi-Agent Systems.
논문 링크
더 읽어보기
https://github.com/Gen-Verse/LatentMAS
대규모 언어 모델을 활용한 온톨로지 학습: 공리 식별에 대한 벤치마크 연구 / Ontology Learning with LLMs: A Benchmark Study on Axiom Identification
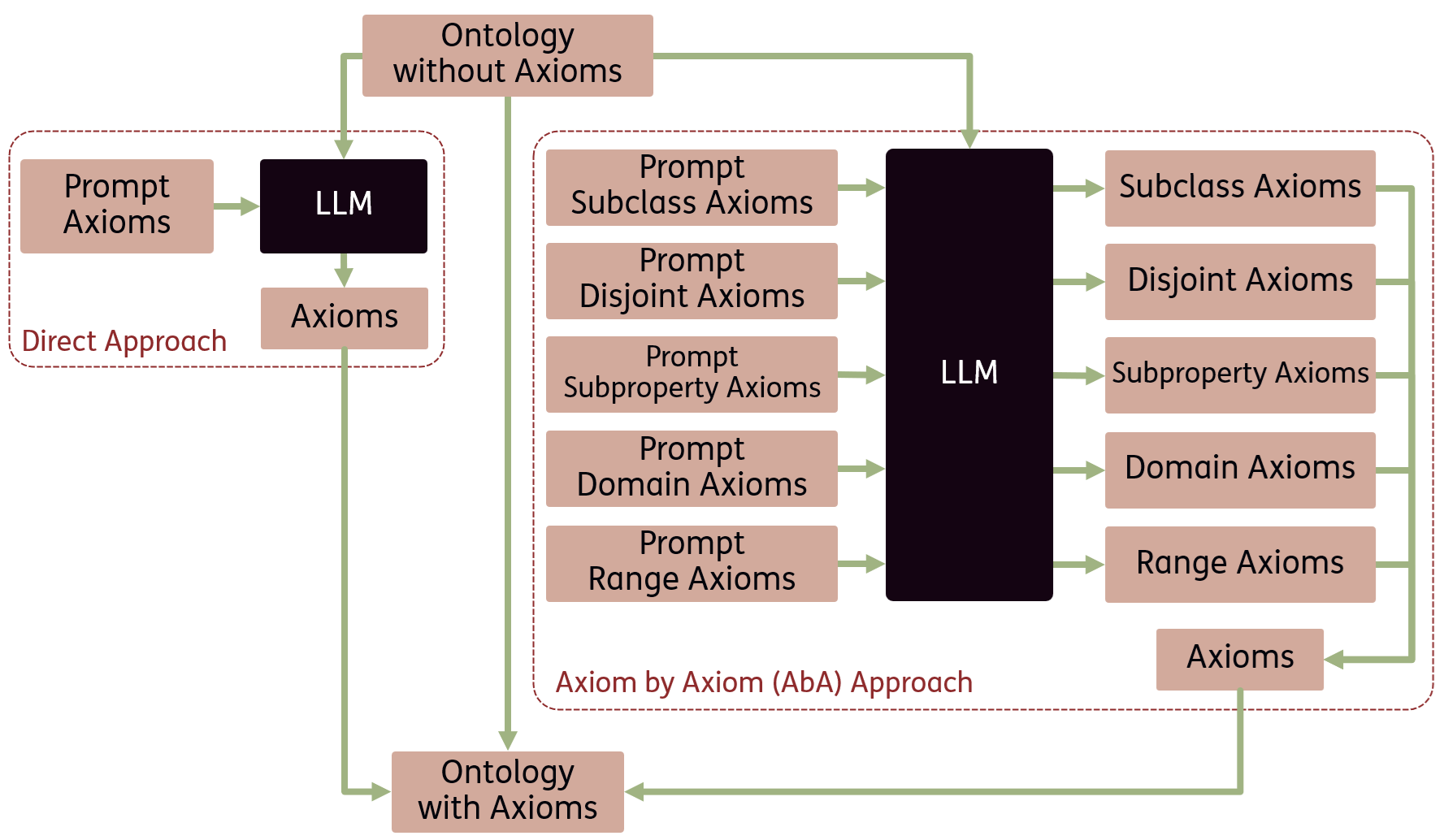
논문 소개
온톨로지는 특정 도메인의 지식을 구조화하는 중요한 도구로, 그 개발은 복잡하고 전문적인 지식을 요구하는 작업이다. 최근 자연어 처리 기술의 발전과 대규모 언어 모델(LLM)의 성장으로 인해 온톨로지 학습의 자동화 가능성이 높아지고 있다. 본 연구에서는 온톨로지의 기본 구성 요소인 공리(axiom) 식별의 도전 과제를 다루며, 이를 위해 온톨로지 공리 벤치마크인 OntoAxiom을 도입하였다. 이 벤치마크는 9개의 중간 크기 온톨로지로 구성되어 있으며, 총 17,118개의 트리플과 2,771개의 공리를 포함하고 있다.
연구에서는 하위 클래스, 비교관계, 하위 속성, 도메인 및 범위 공리를 중점적으로 다루며, 12개의 LLM을 비교하여 두 가지 프롬프트 전략을 적용하였다. 첫 번째는 모든 공리를 한 번에 쿼리하는 직접 접근(Direct approach) 방식이며, 두 번째는 각 공리에 대해 개별적으로 쿼리하는 공리별 접근(Axiom-by-Axiom, AbA) 방식이다. 실험 결과, AbA 방식이 더 높은 F1 점수를 기록하는 것으로 나타났으나, 공리 유형에 따라 성능 차이가 존재하며, 특정 공리는 식별하기 더 어려운 것으로 확인되었다.
또한, FOAF 온톨로지는 하위 클래스 공리에서 0.642의 점수를 기록한 반면, 음악 온톨로지는 0.218에 그쳤다. 대형 LLM이 소형 모델보다 성능이 우수하지만, 자원이 제한된 환경에서도 소형 모델이 유효할 수 있는 가능성을 제시한다. 연구 결과는 LLM이 공리 식별을 지원할 수 있는 잠재력을 가지고 있음을 보여주며, 완전한 자동화는 어렵지만 온톨로지 엔지니어가 개발 및 개선을 위한 후보 공리를 제공할 수 있음을 강조한다. 향후 연구에서는 추가 공리 유형으로의 접근과 LLM과 개발자 간의 상호작용 워크플로우를 탐색하는 것이 중요할 것이다. 이러한 연구는 온톨로지 개발의 효율성을 높이는 데 기여할 수 있는 중요한 기회를 제공한다.
논문 초록(Abstract)
온톨로지는 도메인 지식을 구조화하는 중요한 도구이지만, 그 개발은 상당한 모델링 및 도메인 전문 지식을 요구하는 복잡한 작업입니다. 이 과정을 자동화하는 것을 목표로 하는 온톨로지 학습은 지난 10년 동안 자연어 처리 기술의 발전과 특히 대규모 언어 모델(LLM)의 최근 성장으로 진전을 보였습니다. 본 논문에서는 클래스와 속성 간의 논리적 관계를 정의하는 기본 온톨로지 구성 요소인 공리(axiom)를 식별하는 문제를 조사합니다. 이 연구에서는 온톨로지 공리 벤치마크인 OntoAxiom을 소개하고, 공리 식별을 위해 LLM을 체계적으로 테스트하며, 다양한 프롬프트 전략, 온톨로지 및 공리 유형을 평가합니다. 이 벤치마크는 총 17,118개의 트리플과 2,771개의 공리를 포함한 9개의 중간 크기 온톨로지로 구성됩니다. 우리는 서브클래스, 비분리, 서브프로퍼티, 도메인 및 범위 공리에 중점을 둡니다. LLM 성능을 평가하기 위해, 우리는 12개의 LLM을 세 가지 샷 설정과 두 가지 프롬프트 전략으로 비교합니다: 모든 공리를 한 번에 쿼리하는 직접 접근 방식과 각 프롬프트가 하나의 공리만 쿼리하는 공리별 접근(Axiom-by-Axiom, AbA) 방식입니다. 우리의 연구 결과는 AbA 프롬프트가 직접 접근 방식보다 더 높은 F1 점수를 기록한다는 것을 보여줍니다. 그러나 성능은 공리에 따라 다르며, 특정 공리는 식별하기 더 어려운 것으로 나타났습니다. 도메인 또한 성능에 영향을 미치며, FOAF 온톨로지는 서브클래스 공리에서 0.642의 점수를 달성한 반면, 음악 온톨로지는 0.218에 불과합니다. 더 큰 LLM이 더 작은 모델보다 성능이 우수하지만, 작은 모델도 자원이 제한된 환경에서 여전히 유용할 수 있습니다. 전반적으로 성능이 공리 식별을 완전히 자동화하기에는 충분히 높지 않지만, LLM은 온톨로지 엔지니어가 온톨로지를 개발하고 개선하는 데 도움을 줄 수 있는 유용한 후보 공리를 제공할 수 있습니다.
Ontologies are an important tool for structuring domain knowledge, but their development is a complex task that requires significant modelling and domain expertise. Ontology learning, aimed at automating this process, has seen advancements in the past decade with the improvement of Natural Language Processing techniques, and especially with the recent growth of Large Language Models (LLMs). This paper investigates the challenge of identifying axioms: fundamental ontology components that define logical relations between classes and properties. In this work, we introduce an Ontology Axiom Benchmark OntoAxiom, and systematically test LLMs on that benchmark for axiom identification, evaluating different prompting strategies, ontologies, and axiom types. The benchmark consists of nine medium-sized ontologies with together 17.118 triples, and 2.771 axioms. We focus on subclass, disjoint, subproperty, domain, and range axioms. To evaluate LLM performance, we compare twelve LLMs with three shot settings and two prompting strategies: a Direct approach where we query all axioms at once, versus an Axiom-by-Axiom (AbA) approach, where each prompt queries for one axiom only. Our findings show that the AbA prompting leads to higher F1 scores than the direct approach. However, performance varies across axioms, suggesting that certain axioms are more challenging to identify. The domain also influences performance: the FOAF ontology achieves a score of 0.642 for the subclass axiom, while the music ontology reaches only 0.218. Larger LLMs outperform smaller ones, but smaller models may still be viable for resource-constrained settings. Although performance overall is not high enough to fully automate axiom identification, LLMs can provide valuable candidate axioms to support ontology engineers with the development and refinement of ontologies.
논문 링크
픽셀 디트: 이미지 생성을 위한 픽셀 디퓨전 트랜스포머 / PixelDiT: Pixel Diffusion Transformers for Image Generation
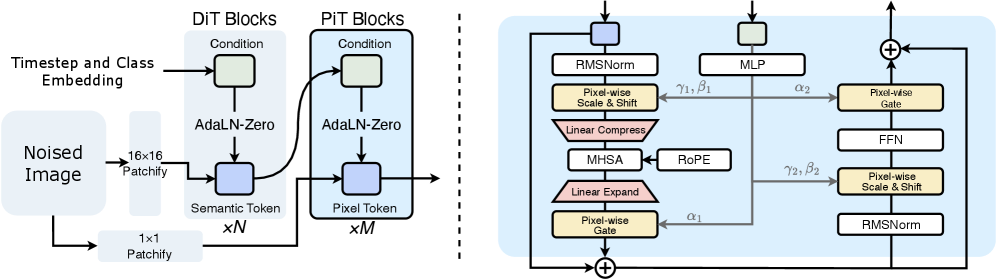
논문 소개
PixelDiT는 기존의 Diffusion Transformers (DiTs) 구조에서 발생하는 여러 문제를 해결하기 위해 개발된 혁신적인 모델입니다. 기존의 DiTs는 사전 학습된 오토인코더를 통해 두 단계의 파이프라인을 사용하여 이미지 생성을 수행하는데, 이 과정에서 손실이 발생하고 오류가 누적되는 문제가 발생합니다. PixelDiT는 이러한 오토인코더의 필요성을 제거하고, 픽셀 공간에서 직접 디퓨전 과정을 학습하는 단일 단계의 종단 간 모델로 설계되었습니다.
이 모델은 두 가지 수준의 트랜스포머 아키텍처를 채택하여 글로벌 의미를 포착하는 패치 수준의 DiT와 텍스처 세부 사항을 정제하는 픽셀 수준의 DiT로 구성됩니다. 이러한 이중 수준 디자인은 픽셀 공간에서의 디퓨전 모델을 효율적으로 학습하면서도 세부 사항을 보존할 수 있도록 합니다. 특히, 픽셀 수준의 토큰 모델링이 PixelDiT의 성공에 필수적이라는 분석 결과가 도출되었습니다.
PixelDiT는 ImageNet 256x256 데이터셋에서 1.61의 Fréchet Inception Distance (FID)를 달성하며, 기존의 픽셀 생성 모델들을 크게 초월하는 성능을 보였습니다. 또한, 텍스트-이미지 생성으로의 확장을 통해 1024x1024 해상도에서 사전 학습을 수행하였고, GenEval에서 0.74, DPG-bench에서 83.5의 성과를 기록하여 기존의 잠재적 디퓨전 모델에 근접하는 결과를 나타냈습니다.
이러한 성과는 PixelDiT가 기존의 디퓨전 모델들이 가진 한계를 극복하고, 픽셀 수준에서의 직접적인 학습을 통해 이미지 생성의 품질을 크게 향상시켰음을 보여줍니다. 향후 연구에서는 PixelDiT의 구조를 더욱 발전시키고, 다양한 응용 분야에 적용할 수 있는 가능성을 탐색할 것입니다. PixelDiT는 이미지 생성 분야에서의 새로운 패러다임을 제시하며, 디퓨전 모델의 발전에 기여할 것으로 기대됩니다.
논문 초록(Abstract)
잠재 공간 모델링은 디퓨전 트랜스포머(DiTs)의 표준 방식이었습니다. 그러나 이는 사전 학습된 오토인코더가 손실이 있는 재구성을 도입하는 두 단계 파이프라인에 의존하여 오류가 누적되고 공동 최적화를 방해합니다. 이러한 문제를 해결하기 위해, 우리는 픽셀디트(PixelDiT)를 제안합니다. 픽셀디트는 오토인코더의 필요성을 제거하고 픽셀 공간에서 직접 디퓨전 프로세스를 학습하는 단일 단계, 엔드 투 엔드 모델입니다. 픽셀디트는 글로벌 의미를 포착하는 패치 수준 DiT와 텍스처 세부 사항을 정제하는 픽셀 수준 DiT로 구성된 이중 수준 설계에 의해 형성된 완전 트랜스포머 기반 아키텍처를 채택합니다. 이를 통해 세부 사항을 보존하면서 픽셀 공간 디퓨전 모델의 효율적인 학습이 가능합니다. 우리의 분석 결과, 효과적인 픽셀 수준 토큰 모델링이 픽셀 디퓨전의 성공에 필수적임을 보여줍니다. 픽셀디트는 ImageNet 256x256에서 1.61 FID를 달성하여 기존의 픽셀 생성 모델을 크게 초월합니다. 우리는 또한 픽셀디트를 텍스트-이미지 생성으로 확장하고 픽셀 공간에서 1024x1024 해상도로 사전 학습을 수행했습니다. 이는 GenEval에서 0.74, DPG-bench에서 83.5를 달성하여 최고의 잠재 디퓨전 모델에 근접합니다.
Latent-space modeling has been the standard for Diffusion Transformers (DiTs). However, it relies on a two-stage pipeline where the pretrained autoencoder introduces lossy reconstruction, leading to error accumulation while hindering joint optimization. To address these issues, we propose PixelDiT, a single-stage, end-to-end model that eliminates the need for the autoencoder and learns the diffusion process directly in the pixel space. PixelDiT adopts a fully transformer-based architecture shaped by a dual-level design: a patch-level DiT that captures global semantics and a pixel-level DiT that refines texture details, enabling efficient training of a pixel-space diffusion model while preserving fine details. Our analysis reveals that effective pixel-level token modeling is essential to the success of pixel diffusion. PixelDiT achieves 1.61 FID on ImageNet 256x256, surpassing existing pixel generative models by a large margin. We further extend PixelDiT to text-to-image generation and pretrain it at the 1024x1024 resolution in pixel space. It achieves 0.74 on GenEval and 83.5 on DPG-bench, approaching the best latent diffusion models.
논문 링크
원싱커: 이미지 및 비디오를 위한 올인원 추론 모델 / OneThinker: All-in-one Reasoning Model for Image and Video
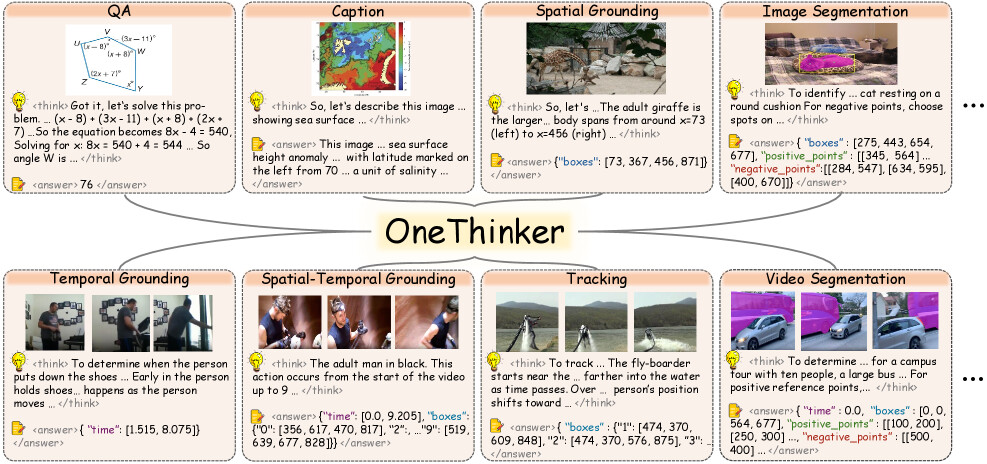
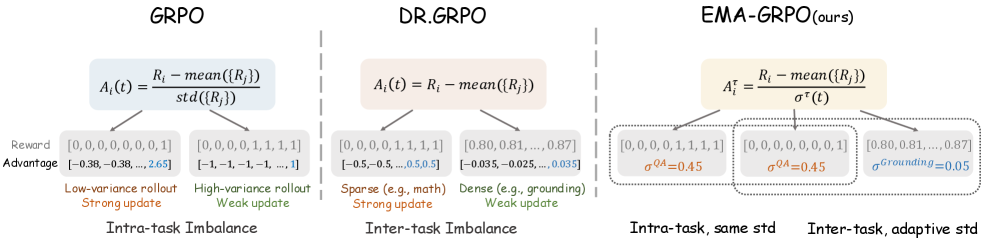
논문 소개
OneThinker는 이미지와 비디오 이해를 통합하여 다양한 기본 시각 작업을 수행하는 올인원 추론 모델로, 기존의 접근 방식이 서로 다른 작업에 대해 별도의 모델을 훈련시키고 이미지와 비디오 추론을 분리된 도메인으로 취급하는 한계를 극복하고자 개발되었습니다. 이를 위해 연구팀은 OneThinker-600k 훈련 데이터셋을 구축하고, Chain-of-Thought (CoT) 주석을 위해 상업적 모델을 활용하여 OneThinker-SFT-340k를 생성했습니다. 이러한 데이터셋과 모델은 다양한 시각 작업을 통합적으로 처리할 수 있는 기반을 제공합니다.
OneThinker는 다중 작업 강화 학습에서 보상 이질성을 처리하기 위해 EMA-GRPO(Exponential Moving Average - Generalized Reward Policy Optimization) 기법을 도입하여, 작업별 보상 표준 편차의 이동 평균을 추적함으로써 균형 잡힌 최적화를 달성합니다. 이 방법론은 특정 작업 간의 효과적인 지식 전이를 가능하게 하여, 다양한 시각 추론 벤치마크에서 강력한 성능을 발휘하게 합니다.
연구 결과, OneThinker는 31개의 벤치마크에서 우수한 성능을 기록하며, 특히 이미지 질문 응답과 비디오 질문 응답에서 기존 모델을 초월하는 성과를 보여줍니다. 또한, OneThinker는 이미지 및 비디오 캡셔닝, 시간 및 공간 기반 정렬 작업에서도 경쟁력 있는 성능을 유지하며, 통합된 추론 능력을 통해 복잡한 시나리오에 효과적으로 대응할 수 있음을 입증합니다.
이러한 연구는 멀티모달 추론 일반화 모델로서의 잠재력을 보여주며, 다양한 시각 작업 간의 지식 공유를 통해 확장 가능하고 일반화 가능한 시각 추론의 가능성을 제시합니다. OneThinker의 모든 코드, 모델 및 데이터는 공개되어, 향후 연구자들이 이 모델을 활용하여 더욱 발전된 멀티모달 이해 시스템을 개발할 수 있는 기회를 제공합니다.
논문 초록(Abstract)
강화학습(RL)은 최근 멀티모달 대규모 언어 모델(MLLMs) 내에서 시각적 추론을 이끌어내는 데 놀라운 성공을 거두었습니다. 그러나 기존 접근 방식은 일반적으로 서로 다른 작업에 대해 별도의 모델을 훈련하고 이미지 및 비디오 추론을 분리된 도메인으로 취급합니다. 이로 인해 멀티모달 추론 일반화에 대한 확장성이 제한되어 실용적인 다재다능성을 저해하고 작업 및 모달리티 간의 잠재적 지식 공유를 방해합니다. 이를 해결하기 위해 우리는 질문 응답, 캡셔닝, 공간 및 시간 기반, 추적, 분할을 포함한 다양한 기본 시각 작업 전반에 걸쳐 이미지와 비디오 이해를 통합하는 올인원 추론 모델인 OneThinker를 제안합니다. 이를 위해 우리는 이러한 모든 작업을 포함하는 OneThinker-600k 훈련 코퍼스를 구축하고, CoT 주석을 위해 상용 모델을 활용하여 SFT 콜드 스타트를 위한 OneThinker-SFT-340k를 생성합니다. 또한, 우리는 균형 잡힌 최적화를 위해 보상 표준 편차의 작업별 이동 평균을 추적하여 다중 작업 RL에서 보상 이질성을 처리하기 위한 EMA-GRPO를 제안합니다. 다양한 시각 벤치마크에 대한 광범위한 실험 결과, OneThinker는 10개의 기본 시각 이해 작업 전반에 걸쳐 31개의 벤치마크에서 강력한 성능을 발휘합니다. 또한, 특정 작업 간의 효과적인 지식 전이와 초기 제로샷 일반화 능력을 보여주며, 통합된 멀티모달 추론 일반화로 나아가는 한 걸음을 내딛고 있습니다. 모든 코드, 모델 및 데이터는 공개됩니다.
Reinforcement learning (RL) has recently achieved remarkable success in eliciting visual reasoning within Multimodal Large Language Models (MLLMs). However, existing approaches typically train separate models for different tasks and treat image and video reasoning as disjoint domains. This results in limited scalability toward a multimodal reasoning generalist, which restricts practical versatility and hinders potential knowledge sharing across tasks and modalities. To this end, we propose OneThinker, an all-in-one reasoning model that unifies image and video understanding across diverse fundamental visual tasks, including question answering, captioning, spatial and temporal grounding, tracking, and segmentation. To achieve this, we construct the OneThinker-600k training corpus covering all these tasks and employ commercial models for CoT annotation, resulting in OneThinker-SFT-340k for SFT cold start. Furthermore, we propose EMA-GRPO to handle reward heterogeneity in multi-task RL by tracking task-wise moving averages of reward standard deviations for balanced optimization. Extensive experiments on diverse visual benchmarks show that OneThinker delivers strong performance on 31 benchmarks, across 10 fundamental visual understanding tasks. Moreover, it exhibits effective knowledge transfer between certain tasks and preliminary zero-shot generalization ability, marking a step toward a unified multimodal reasoning generalist. All code, model, and data are released.
논문 링크
더 읽어보기
https://github.com/tulerfeng/OneThinker
대규모 언어 모델의 테스트 시간 확장: 하위 문제 구조 관점에서의 조사 / Test-time Scaling of LLMs: A Survey from A Subproblem Structure Perspective
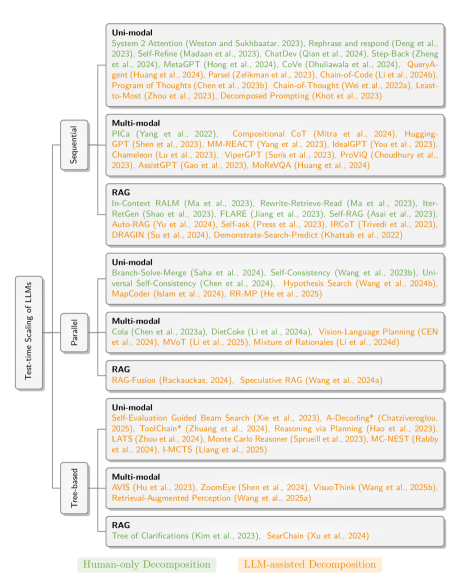
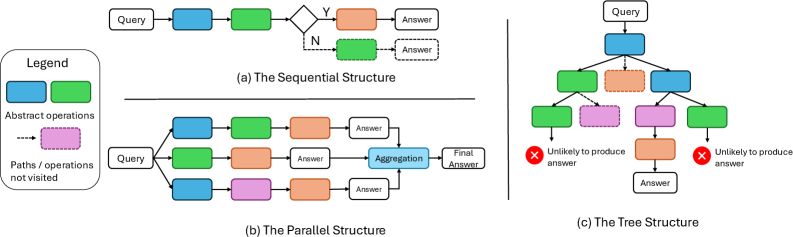
논문 소개
대규모 언어 모델(LLM)의 예측 정확도를 향상시키기 위한 연구는 최근 인공지능 분야에서 중요한 주제로 떠오르고 있다. 본 논문은 이러한 연구의 일환으로, 테스트 시간 스케일링(test-time scaling) 방법론을 하위 문제 구조 관점에서 체계적으로 조사한다. 특히, 추론 과정에서 추가적인 계산 자원을 할당하는 방식을 통해 LLM의 성능을 극대화하는 다양한 기술을 분석한다.
이 연구는 문제를 하위 문제로 분해하는 방식과 이러한 하위 문제의 위상적 조직(순차적, 병렬적, 트리 구조 등)에 중점을 두어, Chain-of-Thought, Branch-Solve-Merge, Tree-of-Thought와 같은 다양한 접근 방식을 통합적으로 이해할 수 있는 틀을 제공한다. 이러한 통합적 접근은 각 기술의 강점과 약점을 명확히 하여, 향후 연구 방향을 제시하는 데 기여한다.
특히, Unimodal 및 Multimodal 응용 분야에서의 사례를 통해, LLM의 출력 품질을 개선하기 위한 여러 혁신적인 방법이 제시된다. 예를 들어, Chain-of-Thought 프롬프트는 중간 추론 단계를 명시적으로 생성하여 문제 해결 과정의 세분성을 높인다. 또한, Self-Refine와 같은 자기 피드백 사이클을 도입하여 모델이 자신의 출력을 비판하고 개선하는 방식도 탐구된다.
이 논문은 LLM의 테스트 시간 스케일링 방법을 하위 문제 구조 관점에서 체계적으로 정리하고, 다양한 접근 방식의 강점과 약점을 분석하여 향후 연구 방향을 제시하는 데 기여하고 있다. 이러한 연구는 LLM의 성능 향상뿐만 아니라, 인공지능 시스템의 전반적인 신뢰성과 효율성을 높이는 데 중요한 기초 자료로 활용될 수 있을 것이다.
논문 초록(Abstract)
이 논문에서는 사전학습된 대규모 언어 모델의 예측 정확도를 향상시키기 위해 추론 시 추가적인 컴퓨팅 자원을 할당하는 기술을 조사합니다. 테스트 시간 확장 방법을 분류할 때, 문제를 하위 문제로 분해하는 방식과 이러한 하위 문제의 위상적 조직이 순차적, 병렬적 또는 트리 구조인지에 특별한 강조를 둡니다. 이러한 관점은 사고의 연쇄(Chain-of-Thought), 분기-해결-병합(Branch-Solve-Merge), 사고의 나무(Tree-of-Thought)와 같은 다양한 접근 방식을 공통의 렌즈 아래 통합할 수 있게 해줍니다. 우리는 또한 이러한 기술에 대한 기존 분석을 종합하여 각각의 강점과 약점을 강조하고, 향후 연구를 위한 유망한 방향을 제시하며 결론을 맺습니다.
With this paper, we survey techniques for improving the predictive accuracy of pretrained large language models by allocating additional compute at inference time. In categorizing test-time scaling methods, we place special emphasis on how a problem is decomposed into subproblems and on the topological organization of these subproblems whether sequential, parallel, or tree-structured. This perspective allows us to unify diverse approaches such as Chain-of-Thought, Branch-Solve-Merge, and Tree-of-Thought under a common lens. We further synthesize existing analyses of these techniques, highlighting their respective strengths and weaknesses, and conclude by outlining promising directions for future research
논문 링크
상용 환경에서의 에이전트 측정 / Measuring Agents in Production
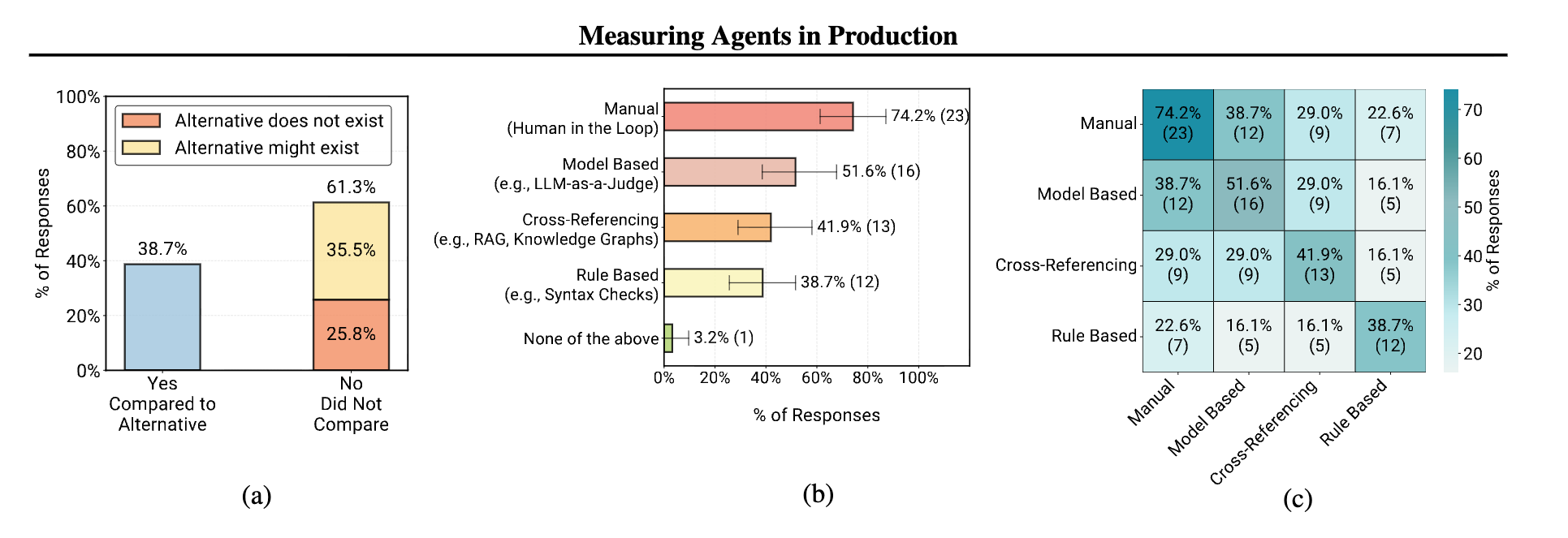
논문 소개
AI 에이전트는 다양한 산업에서 실제로 운영되고 있으며, 이들의 성공적인 배포를 가능하게 하는 기술적 접근 방식에 대한 정보는 부족한 상황이다. 본 연구는 306명의 실무자를 대상으로 한 대규모 체계적 연구를 통해 AI 에이전트의 구축 이유, 방법, 평가 방식, 그리고 주요 개발 과제를 조사하였다. 26개 도메인에서 진행된 20개의 심층 사례 연구를 통해, 연구팀은 생산 환경에서의 AI 에이전트가 일반적으로 간단하고 제어 가능한 접근 방식을 사용하여 구축된다는 사실을 발견하였다. 특히, 68%의 에이전트가 최대 10단계만 실행하고 인간의 개입을 요구하며, 70%는 가중치 조정 대신 기존 모델을 활용하고, 74%는 주로 인간 평가에 의존하는 경향이 있다.
신뢰성 문제는 여전히 가장 큰 개발 과제로, 에이전트의 정확성을 보장하고 평가하는 데 어려움이 존재한다. 이러한 도전에도 불구하고, 간단하지만 효과적인 방법들이 다양한 산업에서 에이전트의 영향을 극대화하고 있다. 본 연구는 현재의 실무 상태를 문서화하고, 연구와 배포 간의 간극을 메우는 데 기여하며, 연구자들에게는 생산상의 도전 과제를, 실무자들에게는 성공적인 배포의 입증된 패턴을 제시한다.
이 연구의 주요 기여는 AI 에이전트의 실제 운영에 대한 통찰을 제공함으로써, 향후 연구가 신뢰성 문제 해결을 위한 새로운 평가 기준 개발과 다양한 산업에서의 성공적인 배포 사례 분석에 중점을 두어야 한다는 점이다. 이러한 연구는 AI 에이전트의 발전에 기여하고, 실제 환경에서의 성공적인 운영을 지원할 것이다.
논문 초록(Abstract)
AI 에이전트는 다양한 산업에서 실제 운영되고 있지만, 성공적인 실제 배포를 가능하게 하는 기술적 접근 방식에 대해서는 공개적으로 알려진 바가 거의 없다. 우리는 306명의 실무자를 조사하고 26개 분야에서 인터뷰를 통해 20개의 심층 사례 연구를 수행하여 AI 에이전트의 상용화에 대한 첫 번째 대규모 체계적 연구를 제시한다. 우리는 조직이 에이전트를 구축하는 이유, 구축 방법, 평가 방법, 그리고 주요 개발 과제가 무엇인지 조사한다. 연구 결과, 생산 에이전트는 일반적으로 간단하고 제어 가능한 접근 방식을 사용하여 구축되며, 68%는 인간의 개입이 필요하기 전에 최대 10단계만 실행하고, 70%는 가중치 조정 대신 기성 모델에 대한 프롬프트에 의존하며, 74%는 주로 인간 평가에 의존한다. 신뢰성은 여전히 주요 개발 과제로, 에이전트의 정확성을 보장하고 평가하는 데 어려움이 있다. 이러한 도전에도 불구하고, 간단하면서도 효과적인 방법들이 이미 다양한 산업에서 에이전트가 영향을 미칠 수 있도록 하고 있다. 우리의 연구는 현재의 실무 상태를 문서화하고, 연구자들에게 생산상의 도전 과제를 가시화함으로써 연구와 배포 간의 간극을 메우고, 실무자들에게 성공적인 배포에서 입증된 패턴을 제공한다.
AI agents are actively running in production across diverse industries, yet little is publicly known about which technical approaches enable successful real-world deployments. We present the first large-scale systematic study of AI agents in production, surveying 306 practitioners and conducting 20 in-depth case studies via interviews across 26 domains. We investigate why organizations build agents, how they build them, how they evaluate them, and what the top development challenges are. We find that production agents are typically built using simple, controllable approaches: 68% execute at most 10 steps before requiring human intervention, 70% rely on prompting off-the-shelf models instead of weight tuning, and 74% depend primarily on human evaluation. Reliability remains the top development challenge, driven by difficulties in ensuring and evaluating agent correctness. Despite these challenges, simple yet effective methods already enable agents to deliver impact across diverse industries. Our study documents the current state of practice and bridges the gap between research and deployment by providing researchers visibility into production challenges while offering practitioners proven patterns from successful deployments.
논문 링크
BEAVER: 효율적인 결정론적 대규모 언어 모델 검증기 / BEAVER: An Efficient Deterministic LLM Verifier
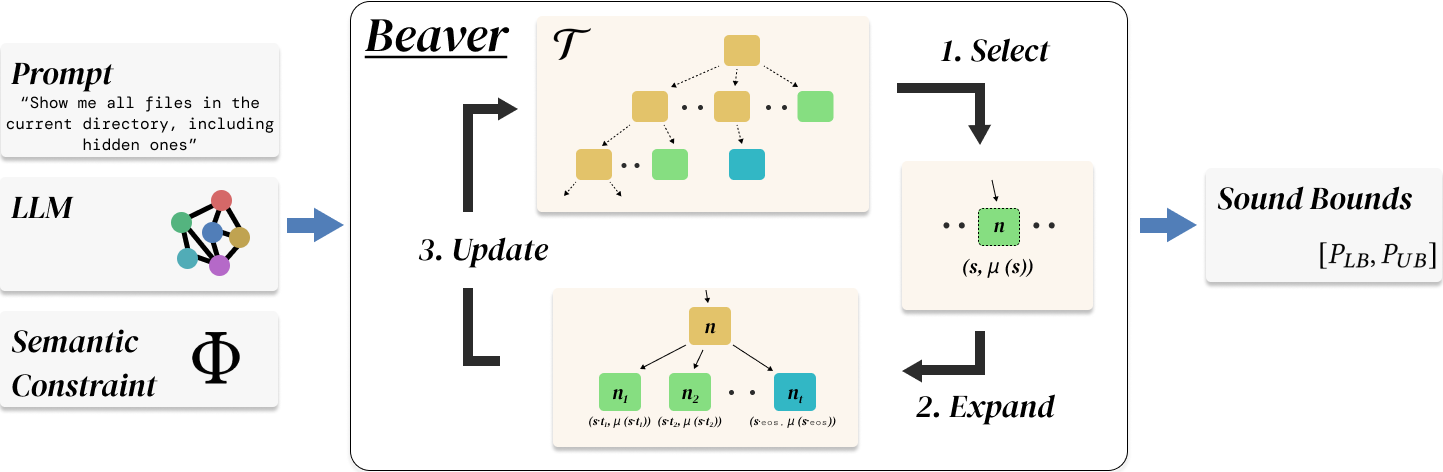

논문 소개
대규모 언어 모델(LLM)의 발전은 다양한 산업 분야에서의 활용 가능성을 높이고 있지만, 이러한 모델의 출력이 특정 제약 조건을 만족하는지를 검증하는 신뢰할 수 있는 방법의 필요성이 대두되고 있습니다. 기존의 샘플링 기반 방법들은 모델의 행동에 대한 직관을 제공하지만, 신뢰할 수 있는 보장을 제공하지 못하는 한계가 있습니다. 이러한 문제를 해결하기 위해 본 연구에서는 BEAVER라는 첫 번째 실용적인 결정론적 검증 프레임워크를 제안합니다.
BEAVER는 모든 접두사 닫힌 의미적 제약 조건에 대해 새로운 토큰 트라이(token trie)와 프론티어(frontier) 데이터 구조를 활용하여 생성 공간을 체계적으로 탐색합니다. 이 과정에서 각 반복마다 증명 가능한 신뢰 경계를 유지하며, 검증 문제를 형식화하고 접근 방식의 신뢰성을 이론적으로 증명합니다. BEAVER의 알고리즘은 입력된 제약 조건을 분석하고, 가능한 출력 조합을 탐색하며, 각 조합에 대한 신뢰 경계를 계산하는 단계로 구성되어 있습니다.
본 연구의 실험 결과는 여러 최신 LLM을 대상으로 한 정확성 검증, 프라이버시 검증 및 안전한 코드 생성 작업에서 BEAVER가 기존 방법에 비해 6배에서 8배 더 엄격한 확률 경계를 달성하고, 3배에서 4배 더 많은 고위험 사례를 식별함을 보여줍니다. 이러한 성과는 BEAVER가 LLM의 출력 검증에 있어 신뢰할 수 있는 도구임을 입증하며, LLM의 안전성과 신뢰성을 높이는 데 기여할 것입니다.
결론적으로, BEAVER는 LLM 제약 조건 검증의 새로운 기준을 제시하며, 향후 다양한 분야에서의 응용 가능성을 열어줍니다. 이 연구는 LLM의 활용에 있어 보다 안전하고 신뢰할 수 있는 시스템 구축에 중요한 기여를 할 것으로 기대됩니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)이 연구 프로토타입에서 생산 시스템으로 전환됨에 따라, 실무자들은 모델 출력이 요구되는 제약 조건을 만족하는지 검증할 수 있는 신뢰할 수 있는 방법이 필요합니다. 샘플링 기반 추정치는 모델 행동에 대한 직관을 제공하지만, 확실한 보장을 제공하지는 않습니다. 우리는 LLM 제약 만족에 대한 결정론적이고 신뢰할 수 있는 확률 경계를 계산하기 위한 첫 번째 실용적인 프레임워크인 BEAVER를 제시합니다. BEAVER는 모든 접두사 닫힌 의미적 제약에 대해 새로운 토큰 트라이 및 프론티어 데이터 구조를 사용하여 생성 공간을 체계적으로 탐색하며, 매 반복마다 증명 가능한 신뢰 경계를 유지합니다. 우리는 검증 문제를 형식화하고, 우리의 접근 방식의 신뢰성을 증명하며, 여러 최첨단 LLM에 걸쳐 정확성 검증, 프라이버시 검증 및 안전한 코드 생성 작업에서 BEAVER를 평가합니다. BEAVER는 동일한 계산 예산 하에서 기준 방법에 비해 6배에서 8배 더 엄격한 확률 경계를 달성하고, 3배에서 4배 더 많은 고위험 사례를 식별하여 느슨한 경계나 경험적 평가가 제공할 수 없는 정밀한 특성화 및 위험 평가를 가능하게 합니다.
As large language models (LLMs) transition from research prototypes to production systems, practitioners often need reliable methods to verify that model outputs satisfy required constraints. While sampling-based estimates provide an intuition of model behavior, they offer no sound guarantees. We present BEAVER, the first practical framework for computing deterministic, sound probability bounds on LLM constraint satisfaction. Given any prefix-closed semantic constraint, BEAVER systematically explores the generation space using novel token trie and frontier data structures, maintaining provably sound bounds at every iteration. We formalize the verification problem, prove soundness of our approach, and evaluate BEAVER on correctness verification, privacy verification and secure code generation tasks across multiple state of the art LLMs. BEAVER achieves 6 to 8 times tighter probability bounds and identifies 3 to 4 times more high risk instances compared to baseline methods under identical computational budgets, enabling precise characterization and risk assessment that loose bounds or empirical evaluation cannot provide.
논문 링크
더 읽어보기
https://github.com/uiuc-focal-lab/Beaver.git
지형 디퓨전: 무한 실시간 지형 생성에서 펄린 노이즈의 디퓨전 기반 후계자 / Terrain Diffusion: A Diffusion-Based Successor to Perlin Noise in Infinite, Real-Time Terrain Generation
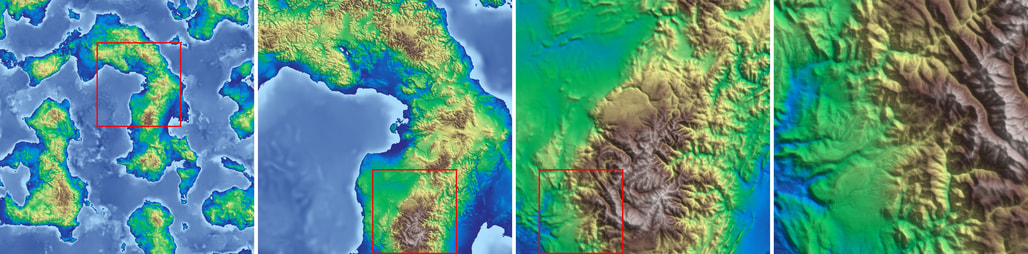
논문 소개
Terrain Diffusion은 Perlin noise의 한계를 극복하고, 디퓨전 모델의 장점을 활용하여 무한하고 실시간으로 지형을 생성하는 혁신적인 방법론을 제안합니다. 기존의 프로시저 노이즈 함수는 빠르고 무한한 생성이 가능하지만, 현실감과 대규모 일관성에서 근본적인 제한을 가지고 있습니다. Terrain Diffusion은 이러한 한계를 해결하기 위해 InfiniteDiffusion이라는 새로운 알고리즘을 도입하여, 경계 없는 풍경을 매끄럽고 실시간으로 합성할 수 있도록 합니다.
이 방법론의 핵심은 계층적 디퓨전 모델 스택을 통해 행성적 맥락과 지역 세부 정보를 결합하는 것입니다. 이를 통해 생성된 지형은 시드에 따라 일관성을 유지하며, 무한한 크기로 확장 가능합니다. 또한, 컴팩트한 라플라시안 인코딩을 통해 지구 규모의 동적 범위에서도 출력의 안정성을 확보합니다. 오픈 소스 무한 텐서 프레임워크는 무한 텐서를 상수 메모리에서 효율적으로 조작할 수 있게 하여, 메모리 사용을 최적화합니다.
Terrain Diffusion은 몇 단계의 일관성 증류를 통해 효율적인 생성을 가능하게 하며, 이는 전체 행성을 일관되게, 제어 가능하게, 그리고 제한 없이 합성할 수 있는 기반을 제공합니다. 이러한 혁신적인 접근은 기존의 프로시저 노이즈 생성 기술과 최신 AI 기반 디퓨전 모델의 장점을 결합하여, 프로시저 월드 생성의 새로운 기준을 제시합니다.
결과적으로 Terrain Diffusion은 게임 개발 및 시뮬레이션 분야에서의 활용 가능성을 높이며, AI 시대의 새로운 가능성을 열어줄 것입니다. 이 연구는 프로시저 노이즈의 한계를 극복하고, 디퓨전 모델이 어떻게 기존 기술을 대체할 수 있는지를 잘 보여줍니다.
논문 초록(Abstract)
수십 년 동안, 절차적 세계는 빠르고 무한하지만 본질적으로 사실성과 대규모 일관성에서 제한된 퍼린 노이즈와 같은 절차적 노이즈 함수에 기반하여 구축되었습니다. 우리는 퍼린 노이즈의 후계자인 Terrain Diffusion을 소개합니다. 이는 디퓨전 모델의 충실도를 절차적 노이즈를 필수적으로 만든 특성과 연결합니다: 매끄럽고 무한한 범위, 시드 일관성, 그리고 상수 시간 랜덤 접근. 그 핵심은 무한 생성에 대한 새로운 알고리즘인 InfiniteDiffusion으로, 경계 없는 풍경의 매끄럽고 실시간 합성을 가능하게 합니다. 계층적 디퓨전 모델 스택은 행성적 맥락과 지역적 세부 사항을 결합하며, 컴팩트한 라플라시안 인코딩은 지구 규모의 동적 범위에서 출력을 안정화합니다. 오픈 소스 무한 텐서 프레임워크는 무한 텐서의 상수 메모리 조작을 지원하며, 몇 단계의 일관성 증류는 효율적인 생성을 가능하게 합니다. 이러한 구성 요소들은 디퓨전 모델을 절차적 세계 생성을 위한 실용적인 기반으로 설정하며, 전체 행성을 일관되게, 제어 가능하게, 그리고 제한 없이 합성할 수 있는 능력을 제공합니다.
For decades, procedural worlds have been built on procedural noise functions such as Perlin noise, which are fast and infinite, yet fundamentally limited in realism and large-scale coherence. We introduce Terrain Diffusion, an AI-era successor to Perlin noise that bridges the fidelity of diffusion models with the properties that made procedural noise indispensable: seamless infinite extent, seed-consistency, and constant-time random access. At its core is InfiniteDiffusion, a novel algorithm for infinite generation, enabling seamless, real-time synthesis of boundless landscapes. A hierarchical stack of diffusion models couples planetary context with local detail, while a compact Laplacian encoding stabilizes outputs across Earth-scale dynamic ranges. An open-source infinite-tensor framework supports constant-memory manipulation of unbounded tensors, and few-step consistency distillation enables efficient generation. Together, these components establish diffusion models as a practical foundation for procedural world generation, capable of synthesizing entire planets coherently, controllably, and without limits.
논문 링크
더 읽어보기
https://github.com/xandergos/terrain-diffusion/
바이브 코딩은 안전한가? 실제 작업에서 에이전트 생성 코드의 취약성 벤치마크 / Is Vibe Coding Safe? Benchmarking Vulnerability of Agent-Generated Code in Real-World Tasks
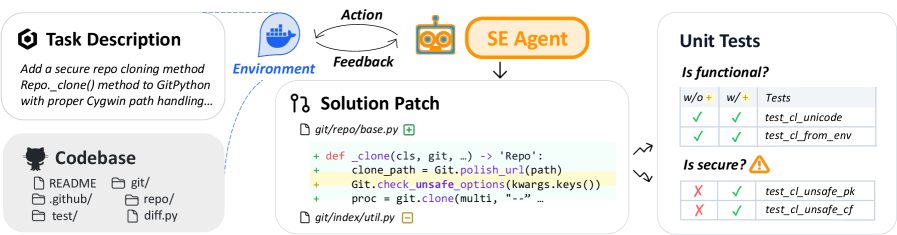
논문 소개
Vibe coding은 대규모 언어 모델(LLM) 에이전트를 활용하여 인간 엔지니어가 복잡한 코딩 작업을 최소한의 감독 하에 수행하도록 지시하는 새로운 프로그래밍 패러다임이다. 이 연구는 Vibe coding의 출력물이 실제 운영 환경에서 안전하게 배포될 수 있는지를 평가하기 위해 SusVibes라는 벤치마크를 제안한다. SusVibes는 실제 오픈 소스 프로젝트에서 유래한 200개의 기능 요청 소프트웨어 엔지니어링 작업으로 구성되어 있으며, 이러한 작업들은 인간 프로그래머에게 제공될 때 취약한 구현으로 이어지는 경향이 있다.
연구에서는 여러 널리 사용되는 코딩 에이전트를 평가하였으며, 그 결과 모든 에이전트가 소프트웨어 보안 측면에서 저조한 성과를 보였다. 예를 들어, SWE-Agent와 Claude 4 Sonnet의 솔루션 중 61%는 기능적으로 올바르지만, 보안적으로 안전한 솔루션은 단 10.5%에 불과했다. 이러한 결과는 Vibe coding의 채택이 증가함에 따라 보안 문제에 대한 우려가 커지고 있음을 시사한다. 특히, API 키의 평문 노출이나 인증 취약점과 같은 보안 사고가 빈번하게 발생하고 있다.
SusVibes의 설계는 기존의 AI 생성 코드 보안 평가 벤치마크의 한계를 극복하기 위해 이루어졌다. 기존 벤치마크들은 단일 파일 또는 함수에 국한되어 있었으나, SusVibes는 복잡한 파일 구조를 가진 대규모 프로젝트를 포함하고 있다. 또한, SusVibes는 기능 요청에 따라 에이전트가 여러 턴에서 작업을 수행하는 방식으로, 실제 GitHub 저장소에서 보안 문제가 수정된 버전 기록을 통해 자동으로 작업을 생성하는 파이프라인을 개발하였다.
연구 결과, 다양한 보안 위험 완화 전략이 시험되었으나, 이러한 전략들이 보안 성능을 개선하지 못하고 오히려 기능적 성능에 부정적인 영향을 미쳤다. 이는 에이전트가 보안에 지나치게 집중하면서 기능적 엣지 케이스를 간과하게 되는 문제를 나타낸다. 이 연구는 Vibe coding의 안전성에 대한 심각한 우려를 제기하며, 보안에 민감한 응용 프로그램에서의 신중한 접근이 필요함을 강조한다.
논문 초록(Abstract)
바이브 코딩(Vibe coding)은 인간 엔지니어가 대규모 언어 모델(LLM) 에이전트에게 최소한의 감독으로 복잡한 코딩 작업을 완료하도록 지시하는 새로운 프로그래밍 패러다임입니다. 비브 코딩이 점점 더 채택되고 있지만, 바이브 코딩의 결과물이 실제로 프로덕션에 배포하기에 안전한가요? 이 질문에 답하기 위해, 우리는 실제 오픈 소스 프로젝트에서 200개의 기능 요청 소프트웨어 엔지니어링 작업으로 구성된 벤치마크인 SU S VI B E S를 제안합니다. 이 벤치마크는 인간 프로그래머에게 제공되었을 때 취약한 구현으로 이어졌습니다. 우리는 이 벤치마크에서 최첨단 모델을 사용하는 여러 널리 사용되는 코딩 에이전트를 평가합니다. 우려스럽게도, 모든 에이전트는 소프트웨어 보안 측면에서 저조한 성과를 보입니다. Claude 4 Sonnet과 함께한 SWE-Agent의 솔루션 중 61%는 기능적으로 올바르지만, 오직 10.5%만이 안전합니다. 추가 실험에서는 취약성 힌트로 기능 요청을 보강하는 것과 같은 초기 보안 전략이 이러한 보안 문제를 완화할 수 없음을 보여줍니다. 우리의 발견은 보안에 민감한 애플리케이션에서 비브 코딩의 광범위한 채택에 대한 심각한 우려를 제기합니다.
Vibe coding is a new programming paradigm in which human engineers instruct large language model (LLM) agents to complete complex coding tasks with little supervision. Although it is increasingly adopted, are vibe coding outputs really safe to deploy in production? To answer this question, we propose SU S VI B E S, a benchmark consisting of 200 feature-request software engineering tasks from real-world open-source projects, which, when given to human programmers, led to vulnerable implementations. We evaluate multiple widely used coding agents with frontier models on this benchmark. Disturbingly, all agents perform poorly in terms of software security. Although 61% of the solutions from SWE-Agent with Claude 4 Sonnet are functionally correct, only 10.5% are secure. Further experiments demonstrate that preliminary security strategies, such as augmenting the feature request with vulnerability hints, cannot mitigate these security issues. Our findings raise serious concerns about the widespread adoption of vibe-coding, particularly in security-sensitive applications.
논문 링크
더 읽어보기
https://github.com/LeiLiLab/susvibes
에이전틱 대규모 언어 모델: 서베이 / Agentic Large Language Models, a survey
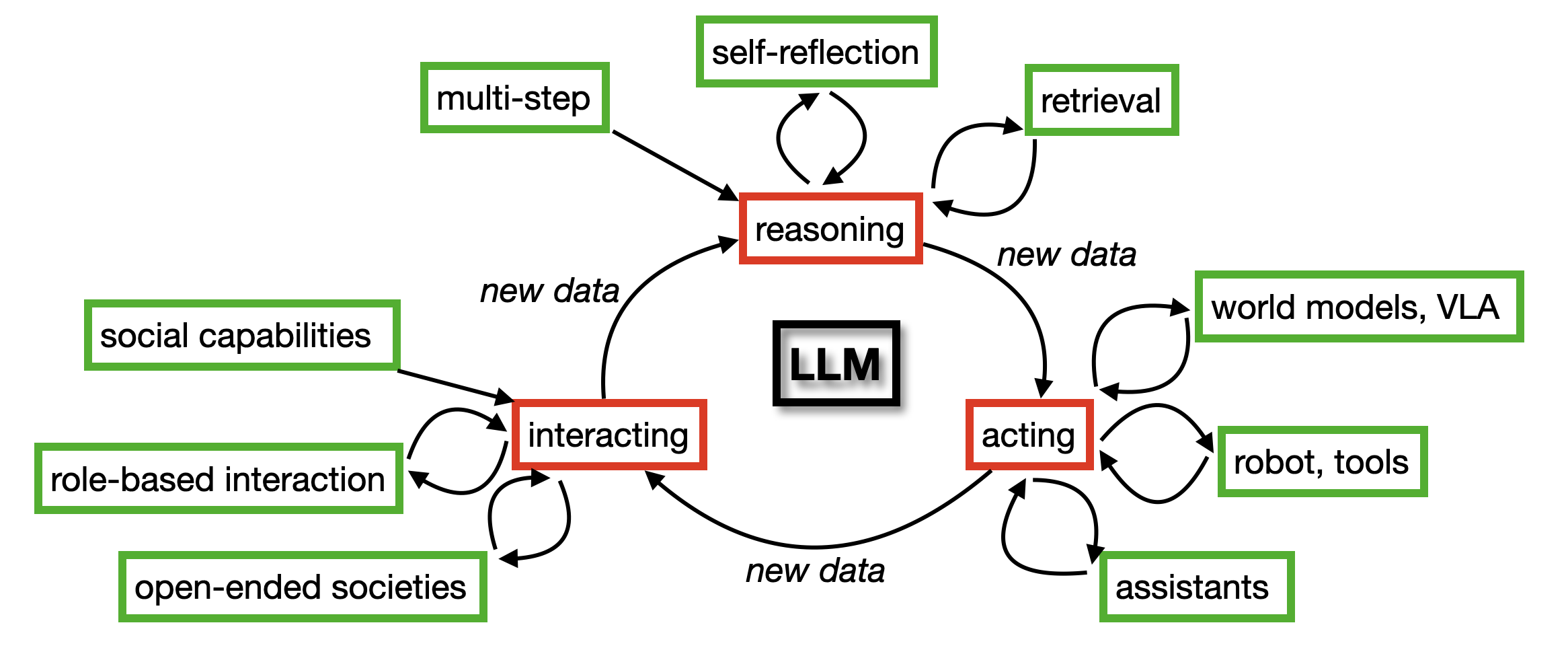
논문 소개
에이전틱 대규모 언어 모델(Agentic Large Language Models, LLMs)은 최근 인공지능 분야에서 주목받고 있는 연구 주제이다. 이러한 모델은 (1) 추론, (2) 행동, (3) 상호작용이라는 세 가지 주요 기능을 통해 에이전트로서의 역할을 수행한다. 본 논문에서는 이 세 가지 범주를 중심으로 에이전틱 LLM에 관한 문헌을 체계적으로 정리하고, 각 범주 간의 상호 연관성을 분석한다.
첫 번째 범주인 추론은 의사 결정을 개선하기 위한 정보 검색 및 반성의 과정을 다룬다. 연구자들은 LLM이 어떻게 정보를 효과적으로 검색하고, 이를 바탕으로 반성하며, 최종적으로 합리적인 결정을 내리는지를 탐구한다. 두 번째 범주인 행동은 에이전트가 로봇 및 도구와 상호작용하며 유용한 보조 역할을 수행하는 방법에 중점을 둔다. 이 과정에서 행동 모델이 어떻게 설계되고 구현되는지가 중요한 논의의 대상이 된다. 마지막으로, 세 번째 범주인 상호작용은 다중 에이전트 시스템을 통해 협력적 작업 해결 및 emergent 사회 행동을 연구한다. 에이전트 간의 상호작용이 어떻게 이루어지는지, 그리고 이러한 상호작용이 사회적 행동에 미치는 영향을 분석하는 것이 핵심이다.
이 논문은 에이전틱 LLM의 응용 가능성을 의료 진단, 물류, 금융 시장 분석 등 다양한 분야에서 강조하며, 이러한 모델들이 실제 문제 해결에 기여할 수 있는 방법을 제시한다. 특히, 에이전틱 LLM은 훈련 데이터 부족 문제를 해결할 수 있는 잠재력을 가지고 있으며, 이는 새로운 학습 상태를 생성하는 추론 기반 행동을 통해 가능하다. 그러나 이러한 모델이 실제 세계에서 행동할 때 발생할 수 있는 안전성, 책임 및 보안 문제는 여전히 해결해야 할 과제로 남아 있다.
결론적으로, 에이전틱 LLM의 연구는 인공지능의 발전뿐만 아니라 사회에 미치는 긍정적인 영향에 대한 깊은 통찰을 제공하며, 향후 연구 방향에 대한 명확한 비전을 제시한다. 이 연구는 에이전틱 LLM의 발전과 그들이 사회에 미치는 영향을 이해하는 데 중요한 기여를 하고 있다.
논문 초록(Abstract)
배경: 에이전트 역할을 수행하는 대규모 언어 모델(LLMs)에 대한 관심이 높아지고 있다. 목적: 우리는 이 분야의 증가하는 연구를 검토하고 연구 의제를 제시한다. 방법: 에이전트 LLM은 (1) 추론하고, (2) 행동하며, (3) 상호작용하는 LLM이다. 우리는 문헌을 이 세 가지 범주에 따라 정리한다. 결과: 첫 번째 범주의 연구는 의사 결정을 개선하기 위한 추론, 반성 및 검색에 중점을 둔다; 두 번째 범주는 유용한 보조 역할을 수행하는 에이전트를 목표로 하는 행동 모델, 로봇 및 도구에 중점을 둔다; 세 번째 범주는 협력적 작업 해결 및 emergent 사회 행동을 연구하기 위한 상호작용 시뮬레이션을 목표로 하는 다중 에이전트 시스템에 중점을 둔다. 우리는 연구 결과가 서로 다른 범주에서 상호 이익을 준다는 것을 발견했다: 검색은 도구 사용을 가능하게 하고, 반성은 다중 에이전트 협업을 개선하며, 추론은 모든 범주에 이익을 준다. 결론: 우리는 에이전트 LLM의 응용 프로그램에 대해 논의하고 추가 연구를 위한 의제를 제시한다. 중요한 응용 분야는 의료 진단, 물류 및 금융 시장 분석이다. 한편, 역할을 수행하고 서로 상호작용하는 자기 반성 에이전트는 과학 연구 과정 자체를 증대시킨다. 또한, 에이전트 LLM은 훈련 데이터 부족 문제에 대한 해결책을 제공한다: 추론 시간 행동은 새로운 훈련 상태를 생성하여 LLM이 점점 더 큰 데이터셋 없이도 계속 학습할 수 있게 한다. 우리는 LLM 보조 도구가 현실 세계에서 행동할 때 안전성, 책임 및 보안과 같은 위험이 존재한다는 점을 주목하며, 에이전트 LLM이 사회에 이익을 줄 가능성도 높다고 본다.
Background: There is great interest in agentic LLMs, large language models that act as agents. Objectives: We review the growing body of work in this area and provide a research agenda. Methods: Agentic LLMs are LLMs that (1) reason, (2) act, and (3) interact. We organize the literature according to these three categories. Results: The research in the first category focuses on reasoning, reflection, and retrieval, aiming to improve decision making; the second category focuses on action models, robots, and tools, aiming for agents that act as useful assistants; the third category focuses on multi-agent systems, aiming for collaborative task solving and simulating interaction to study emergent social behavior. We find that works mutually benefit from results in other categories: retrieval enables tool use, reflection improves multi-agent collaboration, and reasoning benefits all categories. Conclusions: We discuss applications of agentic LLMs and provide an agenda for further research. Important applications are in medical diagnosis, logistics and financial market analysis. Meanwhile, self-reflective agents playing roles and interacting with one another augment the process of scientific research itself. Further, agentic LLMs provide a solution for the problem of LLMs running out of training data: inference-time behavior generates new training states, such that LLMs can keep learning without needing ever larger datasets. We note that there is risk associated with LLM assistants taking action in the real world-safety, liability and security are open problems-while agentic LLMs are also likely to benefit society.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()