[2025/12/29 ~ 2026/01/04] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 단순 도구를 넘어선 '자율 에이전트 생태계'와 '시스템적 사고'의 정립: 이번 주에 선정된 논문들에서는 AI 에이전트가 단발성 작업을 수행하는 도구(Tool)를 넘어, 장기적인 기억과 정체성을 가진 주체로 진화하려는 경향이 뚜렷합니다. Sophia는 'System 3'라는 개념을 도입해 에이전트에게 메타 인지와 지속적인 자아를 부여하려 시도하며, SCP는 이러한 에이전트들이 서로 협력하고 도구를 공유할 수 있는 글로벌 프로토콜 표준을 제안했습니다. 또한 Step-DeepResearch와 RepoNavigator는 각각 심층 연구와 대규모 코드 리포지토리 관리라는 복잡하고 긴 호흡의 작업을 수행하기 위해 에이전트가 스스로 계획을 수립하고 도구를 제어하는 능력을 강조합니다. 이는 에이전트 기술이 개별 모델의 성능 향상을 넘어, 실제 업무 환경에서 인간 전문가와 협업하거나 독립적인 연구를 수행할 수 있는 '조직화된 시스템' 단계로 진입했음을 시사합니다.
단순 도구를 넘어선 '자율 에이전트 생태계'와 '시스템적 사고'의 정립: 이번 주에 선정된 논문들에서는 AI 에이전트가 단발성 작업을 수행하는 도구(Tool)를 넘어, 장기적인 기억과 정체성을 가진 주체로 진화하려는 경향이 뚜렷합니다. Sophia는 'System 3'라는 개념을 도입해 에이전트에게 메타 인지와 지속적인 자아를 부여하려 시도하며, SCP는 이러한 에이전트들이 서로 협력하고 도구를 공유할 수 있는 글로벌 프로토콜 표준을 제안했습니다. 또한 Step-DeepResearch와 RepoNavigator는 각각 심층 연구와 대규모 코드 리포지토리 관리라는 복잡하고 긴 호흡의 작업을 수행하기 위해 에이전트가 스스로 계획을 수립하고 도구를 제어하는 능력을 강조합니다. 이는 에이전트 기술이 개별 모델의 성능 향상을 넘어, 실제 업무 환경에서 인간 전문가와 협업하거나 독립적인 연구를 수행할 수 있는 '조직화된 시스템' 단계로 진입했음을 시사합니다.
![]() 'Post-Transformer'와 '기하학적 해석'을 통한 아키텍처의 효율화: 현재 주요 모델인 트랜스포머(Transformer) 아키텍처와 어텐션(Attention) 메커니즘에 의문을 제기하고, 수학적·기하학적 원리를 통해 모델을 경량화 및 효율화하려는 시도가 돋보입니다. Attention Is Not What You Need는 어텐션 메커니즘을 그래스만 다양체(Grassmann manifold) 기반의 흐름으로 대체하여 기하학적 해석 가능성을 높였고, mHC는 잔여 연결(Residual Connection)을 특정 다양체에 투영하여 대규모 학습의 안정성을 확보했습니다. 또한 VL-JEPA는 토큰 생성 방식 대신 임베딩 예측 방식을 사용하여 비전-언어 모델의 효율성을 극대화했습니다. 이러한 연구들은 무조건적인 파라미터 확장보다는, 수학적 최적화와 위상학적 설계를 통해 모델의 근본적인 연산 효율성을 높이고 설명 가능성을 확보하려는 움직임을 보여줍니다.
'Post-Transformer'와 '기하학적 해석'을 통한 아키텍처의 효율화: 현재 주요 모델인 트랜스포머(Transformer) 아키텍처와 어텐션(Attention) 메커니즘에 의문을 제기하고, 수학적·기하학적 원리를 통해 모델을 경량화 및 효율화하려는 시도가 돋보입니다. Attention Is Not What You Need는 어텐션 메커니즘을 그래스만 다양체(Grassmann manifold) 기반의 흐름으로 대체하여 기하학적 해석 가능성을 높였고, mHC는 잔여 연결(Residual Connection)을 특정 다양체에 투영하여 대규모 학습의 안정성을 확보했습니다. 또한 VL-JEPA는 토큰 생성 방식 대신 임베딩 예측 방식을 사용하여 비전-언어 모델의 효율성을 극대화했습니다. 이러한 연구들은 무조건적인 파라미터 확장보다는, 수학적 최적화와 위상학적 설계를 통해 모델의 근본적인 연산 효율성을 높이고 설명 가능성을 확보하려는 움직임을 보여줍니다.
![]() '검증 가능한 보상'과 '강화학습(RL)'을 통한 추론 능력의 고도화: 단순한 패턴 매칭을 넘어 논리적 추론(Reasoning) 능력을 극대화하기 위해 강화학습(RL)을 적극적으로 결합하는 트렌드가 관찰됩니다. RLVR 논문은 검증 가능한 보상을 통해 언어 모델의 추론 능력을 강화하는 과정에서 기존 PEFT 방법론들의 한계를 지적하고 구조적 변형의 필요성을 역설했습니다. URM은 복잡한 추론 문제(ARC-AGI 등) 해결을 위해 비선형성과 반복적 귀납 편향을 활용한 새로운 모델링을 제안했으며, RepoNavigator 역시 리포지토리 탐색에 RL을 적용하여 32B 모델이 폐쇄형 모델을 능가하는 성과를 보였습니다. 이는 LLM의 발전 방향이 단순한 텍스트 생성을 넘어, 명확한 정답이나 논리적 완결성이 요구되는 작업에서 RL을 통해 스스로 오류를 수정하고 최적의 경로를 찾아내는 'Deep Thinking' 능력 강화로 나아가고 있음을 의미합니다.
'검증 가능한 보상'과 '강화학습(RL)'을 통한 추론 능력의 고도화: 단순한 패턴 매칭을 넘어 논리적 추론(Reasoning) 능력을 극대화하기 위해 강화학습(RL)을 적극적으로 결합하는 트렌드가 관찰됩니다. RLVR 논문은 검증 가능한 보상을 통해 언어 모델의 추론 능력을 강화하는 과정에서 기존 PEFT 방법론들의 한계를 지적하고 구조적 변형의 필요성을 역설했습니다. URM은 복잡한 추론 문제(ARC-AGI 등) 해결을 위해 비선형성과 반복적 귀납 편향을 활용한 새로운 모델링을 제안했으며, RepoNavigator 역시 리포지토리 탐색에 RL을 적용하여 32B 모델이 폐쇄형 모델을 능가하는 성과를 보였습니다. 이는 LLM의 발전 방향이 단순한 텍스트 생성을 넘어, 명확한 정답이나 논리적 완결성이 요구되는 작업에서 RL을 통해 스스로 오류를 수정하고 최적의 경로를 찾아내는 'Deep Thinking' 능력 강화로 나아가고 있음을 의미합니다.
mHC: 다양성 제약 하이퍼 연결 / mHC: Manifold-Constrained Hyper-Connections
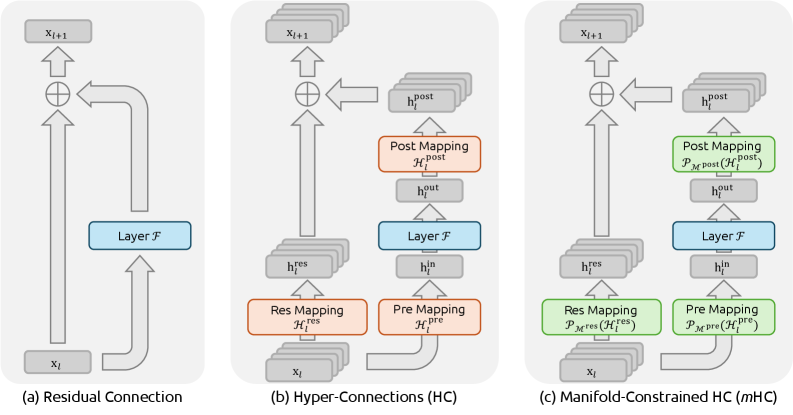
논문 소개
Manifold-Constrained Hyper-Connections (mHC) 방법론은 최근 Hyper-Connections (HC)에서 나타난 잔여 연결(residual connection)의 확장과 관련된 문제를 해결하기 위해 제안되었습니다. HC는 잔여 스트림의 폭을 넓히고 연결 패턴을 다양화하여 성능을 향상시키지만, 이러한 다양화는 정체성 매핑(identity mapping) 속성을 손상시켜 학습의 불안정성과 확장성의 제한을 초래합니다. mHC는 이러한 문제를 해결하기 위해 HC의 잔여 연결 공간을 특정 다양체(manifold)에 투영함으로써 정체성 매핑 속성을 복원합니다. 이 과정에서 Sinkhorn-Knopp 알고리즘을 활용하여 잔여 연결 행렬을 Birkhoff 다각형에 엔트로피적으로 투영하여 신호 전파를 조정하고, 신호의 평균을 보존하며, 신호의 노름을 정규화합니다.
mHC는 대규모 학습에서의 안정성과 효율성을 높이는 데 기여하며, 실험 결과에서도 HC의 성능 이점을 유지하면서도 우수한 확장성을 보여줍니다. 이 방법론은 잔여 스트림의 정보 용량을 레이어의 입력 차원과 분리하여 모델의 계산 복잡성과 강하게 연관된 새로운 확장 경로를 제공합니다. mHC는 HC의 유연하고 실용적인 확장으로서, 토폴로지 아키텍처 디자인에 대한 깊은 이해를 제공하고 파운데이션 모델의 발전에 중요한 기여를 할 것으로 기대됩니다.
이 연구는 잔여 연결의 정체성 매핑 속성이 대규모 학습에서 안정성과 효율성을 유지하는 데 얼마나 중요한지를 강조하며, mHC가 이러한 속성을 복원하는 혁신적인 방법론임을 보여줍니다. mHC는 기존의 HC가 직면한 문제들을 해결하고, 향후 딥 뉴럴 네트워크 아키텍처의 발전에 기여할 수 있는 잠재력을 지니고 있습니다.
논문 초록(Abstract)
최근 하이퍼 연결(Hyper-Connections, HC)에 의해 예시된 연구들은 지난 10년간 확립된 보편적인 잔차 연결(residual connection) 패러다임을 잔차 스트림의 폭을 확장하고 연결 패턴을 다양화함으로써 확장하였습니다. 이러한 다양화는 상당한 성능 향상을 가져오는 반면, 잔차 연결에 내재된 항등 매핑(identity mapping) 속성을 근본적으로 훼손하여 심각한 학습 불안정성과 제한된 확장성을 초래하며, 추가적으로 상당한 메모리 접근 오버헤드를 발생시킵니다. 이러한 문제를 해결하기 위해, 우리는 잔차 연결 공간을 특정 다양체(manifold)에 투영하여 항등 매핑 속성을 복원하고, 효율성을 보장하기 위한 엄격한 인프라 최적화를 포함하는 일반적인 프레임워크인 다양체 제약 하이퍼 연결(Manifold-Constrained Hyper-Connections, mHC)을 제안합니다. 실험 결과, mHC는 대규모 학습에 효과적이며, 가시적인 성능 향상과 우수한 확장성을 제공합니다. 우리는 mHC가 HC의 유연하고 실용적인 확장으로서, 위상적 아키텍처 설계에 대한 깊은 이해에 기여하고, 기초 모델의 발전을 위한 유망한 방향을 제시할 것으로 기대합니다.
Recently, studies exemplified by Hyper-Connections (HC) have extended the ubiquitous residual connection paradigm established over the past decade by expanding the residual stream width and diversifying connectivity patterns. While yielding substantial performance gains, this diversification fundamentally compromises the identity mapping property intrinsic to the residual connection, which causes severe training instability and restricted scalability, and additionally incurs notable memory access overhead. To address these challenges, we propose Manifold-Constrained Hyper-Connections (mHC), a general framework that projects the residual connection space of HC onto a specific manifold to restore the identity mapping property, while incorporating rigorous infrastructure optimization to ensure efficiency. Empirical experiments demonstrate that mHC is effective for training at scale, offering tangible performance improvements and superior scalability. We anticipate that mHC, as a flexible and practical extension of HC, will contribute to a deeper understanding of topological architecture design and suggest promising directions for the evolution of foundational models.
논문 링크
SCP: 자율 과학 에이전트의 글로벌 네트워크를 통한 발견 가속화 / SCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents
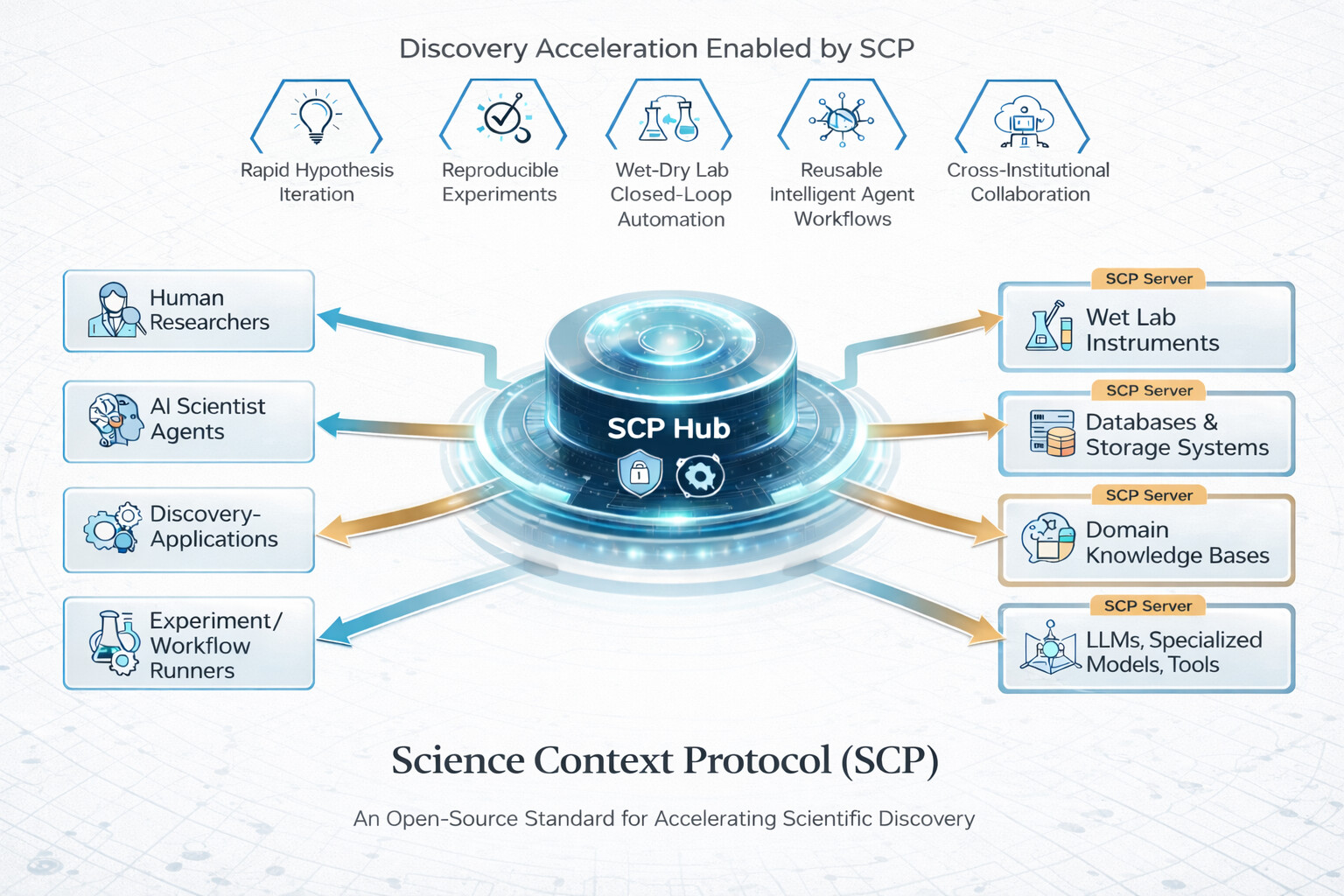
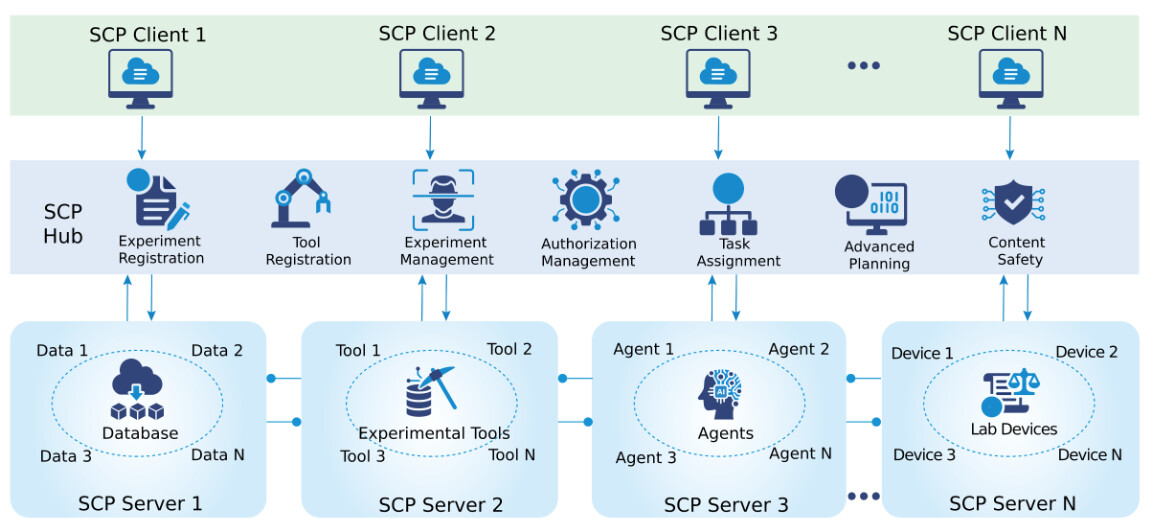
논문 소개
SCP(Science Context Protocol)는 자율적인 과학 에이전트의 글로벌 네트워크를 통해 과학적 발견을 가속화하기 위해 설계된 오픈소스 표준이다. 이 프로토콜은 두 가지 주요 기둥에 기반하고 있으며, 첫 번째는 통합 자원 통합으로, 다양한 과학 자원(소프트웨어 도구, 모델, 데이터셋 및 물리적 기기)을 설명하고 호출하기 위한 보편적인 명세를 제공한다. 이러한 프로토콜 수준의 표준화는 인공지능(AI) 에이전트와 응용 프로그램이 서로 다른 플랫폼과 기관 간에 원활하게 기능을 발견하고 조합할 수 있도록 지원한다.
두 번째 기둥은 조정된 실험 생애주기 관리로, 중앙 집중식 SCP 허브와 연합된 SCP 서버로 구성된 안전한 서비스 아키텍처를 통해 실험의 등록, 계획, 실행, 모니터링 및 보관을 관리한다. 이 아키텍처는 세분화된 인증 및 권한 부여를 시행하며, 계산 및 물리 실험실 간의 추적 가능한 엔드 투 엔드 워크플로우를 조정하여 연구자들이 보다 효율적으로 협업할 수 있도록 돕는다.
SCP를 기반으로 구축된 과학 발견 플랫폼은 1,600개 이상의 도구 자원을 제공하며, 이를 통해 이질적인 AI 시스템과 인간 연구자 간의 안전하고 대규모 협업이 가능해진다. 이 플랫폼은 통합 오버헤드를 줄이고 재현성을 향상시키는 데 기여하며, 과학적 맥락과 도구 조정을 프로토콜 수준에서 표준화함으로써 다기관, 에이전트 주도 과학을 위한 필수 인프라를 구축한다. SCP는 연구자들에게 다양한 예측 및 검증 도구, 단백질 구조 준비 도구, 분자 특성 계산 도구 등 여러 기능을 제공하여, 생물학적 및 화학적 데이터 분석을 효율적으로 수행할 수 있도록 지원한다. 이러한 혁신적인 접근 방식은 과학적 발견의 속도를 높이고, 연구자들이 보다 효과적으로 협력할 수 있는 환경을 조성한다.
논문 초록(Abstract)
과학 맥락 프로토콜(SCP: Science Context Protocol)을 소개합니다. SCP는 자율적인 과학 에이전트의 글로벌 네트워크를 통해 발견을 가속화하기 위해 설계된 오픈 소스 표준입니다. SCP는 두 가지 기본 기둥 위에 구축되었습니다: (1) 통합 자원 통합: SCP는 소프트웨어 도구, 모델, 데이터셋 및 물리적 기기를 아우르는 과학 자원을 설명하고 호출하기 위한 보편적인 명세를 제공합니다. 이 프로토콜 수준의 표준화는 AI 에이전트와 애플리케이션이 이질적인 플랫폼과 기관 경계를 넘나들며 능력을 발견하고 호출하며 조합할 수 있도록 원활하게 합니다. (2) 조정된 실험 생애 주기 관리: SCP는 중앙 집중식 SCP 허브와 연합된 SCP 서버로 구성된 안전한 서비스 아키텍처로 프로토콜을 보완합니다. 이 아키텍처는 실험 생애 주기(등록, 계획, 실행, 모니터링 및 보관)를 관리하고, 세분화된 인증 및 권한 부여를 시행하며, 계산 및 물리 실험실을 연결하는 추적 가능한 종단 간 워크플로를 조정합니다. SCP를 기반으로 우리는 연구자와 에이전트에게 1,600개 이상의 도구 자원의 대규모 생태계를 제공하는 과학 발견 플랫폼을 구축했습니다. 다양한 사용 사례에 걸쳐 SCP는 이질적인 AI 시스템과 인간 연구자 간의 안전하고 대규모 협업을 촉진하며, 통합 오버헤드를 크게 줄이고 재현성을 향상시킵니다. 과학적 맥락과 도구 조정을 프로토콜 수준에서 표준화함으로써, SCP는 확장 가능하고 다기관, 에이전트 주도 과학을 위한 필수 인프라를 구축합니다.
We introduce SCP: the Science Context Protocol, an open-source standard designed to accelerate discovery by enabling a global network of autonomous scientific agents. SCP is built on two foundational pillars: (1) Unified Resource Integration: At its core, SCP provides a universal specification for describing and invoking scientific resources, spanning software tools, models, datasets, and physical instruments. This protocol-level standardization enables AI agents and applications to discover, call, and compose capabilities seamlessly across disparate platforms and institutional boundaries. (2) Orchestrated Experiment Lifecycle Management: SCP complements the protocol with a secure service architecture, which comprises a centralized SCP Hub and federated SCP Servers. This architecture manages the complete experiment lifecycle (registration, planning, execution, monitoring, and archival), enforces fine-grained authentication and authorization, and orchestrates traceable, end-to-end workflows that bridge computational and physical laboratories. Based on SCP, we have constructed a scientific discovery platform that offers researchers and agents a large-scale ecosystem of more than 1,600 tool resources. Across diverse use cases, SCP facilitates secure, large-scale collaboration between heterogeneous AI systems and human researchers while significantly reducing integration overhead and enhancing reproducibility. By standardizing scientific context and tool orchestration at the protocol level, SCP establishes essential infrastructure for scalable, multi-institution, agent-driven science.
논문 링크
더 읽어보기
https://github.com/InternScience/scp
RLVR을 위한 파라미터 효율적인 방법 평가 / Evaluating Parameter Efficient Methods for RLVR

논문 소개
강화학습(Reinforcement Learning)과 검증 가능한 보상(Verifiable Rewards) 패러다임 하에서 파라미터 효율적 파인튜닝(Parameter-Efficient Fine-Tuning, PEFT) 방법론의 체계적인 평가가 이루어졌다. 본 연구는 언어 모델이 검증 가능한 피드백을 통해 추론 능력을 향상시키는 RLVR(Reinforcement Learning with Verifiable Rewards)의 중요성을 강조하며, 기존의 PEFT 방법들이 이 패러다임에 최적화되지 않았음을 지적한다. 특히, LoRA(Low-Rank Adaptation)와 같은 일반적인 방법론이 최적의 성능을 발휘하지 못하는 이유를 분석하고, 12개 이상의 PEFT 방법론을 DeepSeek-R1-Distill 계열에서 평가하여 새로운 통찰을 제공한다.
연구의 주요 발견은 세 가지로 요약된다. 첫째, DoRA, AdaLoRA, MiSS와 같은 구조적 변형들이 LoRA보다 일관되게 우수한 성능을 보임을 확인하였다. 둘째, SVD(Singular Value Decomposition) 기반 초기화 전략에서 스펙트럼 붕괴(spectral collapse) 현상이 발생하며, 이는 주성분 업데이트와 강화학습 최적화 간의 불일치에서 기인함을 밝혀냈다. 셋째, 극단적인 파라미터 축소 방법(예: VeRA, Rank-1)이 추론 능력을 심각하게 제한한다는 점을 강조하였다.
이 연구는 PEFT 방법론의 설계 및 평가 기준을 명확히 하며, 실험에 사용된 데이터셋과 벤치마크를 소개한다. 또한, 각 PEFT 방법의 구조적 차별성과 실험 설정을 상세히 설명하여, 연구 결과의 신뢰성을 높인다. 이러한 체계적인 접근은 파라미터 효율적 강화학습 방법에 대한 탐색을 촉구하는 중요한 기초 자료를 제공하며, 향후 연구 방향에 대한 통찰을 제시한다. 본 연구는 RLVR 분야에서의 PEFT 방법론의 발전에 기여하며, 언어 모델의 추론 능력을 향상시키기 위한 새로운 길을 모색하는 데 중요한 역할을 할 것으로 기대된다.
논문 초록(Abstract)
우리는 강화학습과 검증 가능한 보상(Reinforcement Learning with Verifiable Rewards, RLVR) 패러다임 하에서 파라미터 효율적 파인튜닝(PEFT) 방법을 체계적으로 평가합니다. RLVR은 언어 모델이 검증 가능한 피드백을 통해 추론 능력을 향상시키도록 유도하지만, LoRA와 같은 방법이 일반적으로 사용되는 반면, RLVR에 최적화된 PEFT 아키텍처는 아직 밝혀지지 않았습니다. 본 연구에서는 DeepSeek-R1-Distill 계열의 12개 이상의 PEFT 방법론에 대한 최초의 포괄적인 평가를 수학적 추론 벤치마크에서 수행합니다. 우리의 실험 결과는 표준 LoRA의 기본 채택에 도전하는 세 가지 주요 발견을 제시합니다. 첫째, DoRA, AdaLoRA, MiSS와 같은 구조적 변형이 LoRA보다 일관되게 우수한 성능을 보임을 입증합니다. 둘째, SVD 기반 초기화 전략(예: PiSSA, MiLoRA)에서 스펙트럼 붕괴 현상을 발견하였으며, 이는 주성분 업데이트와 RL 최적화 간의 근본적인 불일치로 인한 실패로 귀결됩니다. 또한, 우리의 제거 실험은 극단적인 파라미터 축소(예: VeRA, Rank-1)가 추론 능력을 심각하게 저해함을 보여줍니다. 우리는 또한 우리의 발견을 검증하기 위해 제거 연구 및 스케일링 실험을 수행합니다. 이 연구는 파라미터 효율적인 RL 방법에 대한 추가 탐색을 촉구하는 확고한 가이드를 제공합니다.
We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
논문 링크
더 읽어보기
https://github.com/MikaStars39/PeRL
스텝-딥리서치 기술 보고서 / Step-DeepResearch Technical Report
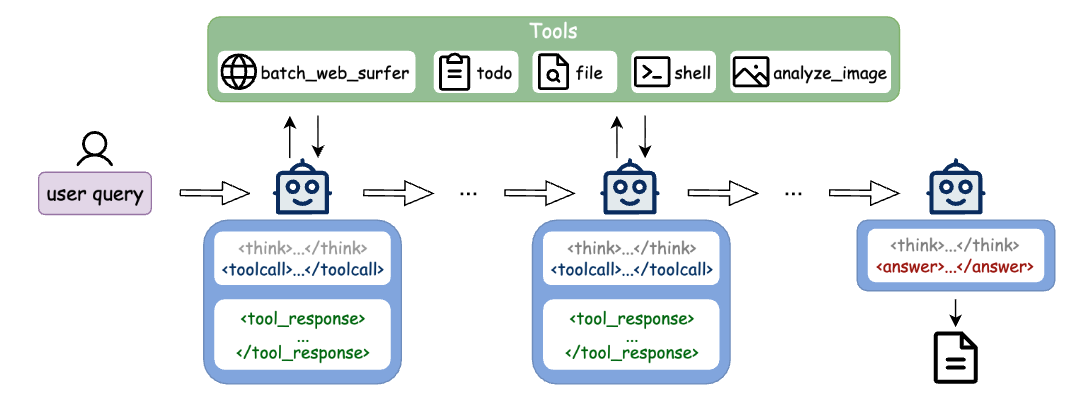
논문 소개
대규모 언어 모델(LLM)의 발전과 함께 자율 에이전트의 필요성이 대두되고 있으며, 이에 따라 Deep Research가 중요한 평가 지표로 자리 잡고 있다. 그러나 기존의 학술 벤치마크인 BrowseComp는 개방형 연구에 필요한 복잡한 기술, 즉 의도 인식, 장기적 의사결정, 교차 출처 검증을 충분히 반영하지 못하고 있다. 이러한 문제를 해결하기 위해 제안된 Step-DeepResearch는 비용 효율적인 엔드 투 엔드 에이전트로, 원자 능력(Atomic Capabilities)을 기반으로 한 데이터 합성 전략을 통해 계획 및 보고서 작성을 강화한다.
이 연구는 에이전트의 중간 학습 단계에서 지도 학습(Supervised Fine-Tuning, SFT)과 강화학습(Reinforcement Learning, RL)으로의 점진적인 학습 경로를 설정하여, 에이전트가 복잡한 연구 과제를 수행하는 데 필요한 기술을 체계적으로 강화하는 데 중점을 둔다. 또한, 체크리스트 스타일의 평가자(Judger)를 도입하여 에이전트의 강건성을 크게 향상시킨다.
중국 도메인에서의 평가 격차를 해소하기 위해 현실적인 깊이 연구 시나리오를 위한 ADR-Bench를 구축하였으며, 이를 통해 Step-DeepResearch의 성능을 평가하였다. 실험 결과, Step-DeepResearch(32B)는 Scale AI Research Rubrics에서 61.4%의 점수를 기록하였고, ADR-Bench에서 유사 모델을 초월하며 OpenAI 및 Gemini DeepResearch와 같은 최첨단 폐쇄형 모델과 경쟁할 수 있는 능력을 입증하였다. 이러한 결과는 정교한 학습 방법이 중간 크기 모델이 전문가 수준의 능력을 달성할 수 있도록 하며, 업계에서의 비용 효율성을 크게 향상시킬 수 있음을 보여준다.
Step-DeepResearch는 LLM의 발전 방향과 자율 에이전트의 가능성을 제시하며, 향후 연구에 대한 방향성을 제시하는 중요한 기여를 하고 있다. 이러한 혁신적인 접근법은 학술 연구의 실제 요구를 충족시키는 데 기여할 것으로 기대된다.
논문 초록(Abstract)
다음은 AI/ML 분야의 논문 초록입니다. LLM이 자율 에이전트로 전환됨에 따라, Deep Research는 중요한 지표로 부상했습니다. 그러나 BrowseComp와 같은 기존의 학술 벤치마크는 의도 인식, 장기적 의사결정, 그리고 교차 출처 검증에 대한 강력한 기술이 요구되는 개방형 연구에 대한 실제 요구를 충족하지 못하는 경우가 많습니다. 이를 해결하기 위해, 우리는 비용 효율적이고 엔드 투 엔드 방식의 에이전트인 Step-DeepResearch를 소개합니다. 우리는 계획 및 보고서 작성을 강화하기 위해 원자적 능력에 기반한 데이터 합성 전략을 제안하며, 에이전트 중간 학습에서 SFT 및 RL로의 점진적 학습 경로를 결합합니다. 체크리스트 스타일의 평가자를 통해 이 접근 방식은 강건성을 크게 향상시킵니다. 또한, 중국 도메인에서 평가 격차를 해소하기 위해 현실적인 심층 연구 시나리오를 위한 ADR-Bench를 구축합니다. 실험 결과, Step-DeepResearch(32B)는 Scale AI Research Rubrics에서 61.4%의 점수를 기록했습니다. ADR-Bench에서는 유사한 모델을 크게 능가하며 OpenAI 및 Gemini DeepResearch와 같은 SOTA 폐쇄형 모델과 경쟁합니다. 이러한 결과는 정교한 학습이 중간 규모 모델이 업계 선도적인 비용 효율성으로 전문가 수준의 능력을 달성할 수 있도록 한다는 것을 입증합니다.
As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
논문 링크
더 읽어보기
https://github.com/stepfun-ai/StepDeepResearch
어텐션은 당신이 필요로 하는 것이 아니다 / Attention Is Not What You Need

논문 소개
셀프 어텐션(self-attention) 메커니즘이 강력한 성능과 추론을 위해 필수적인 요소인지에 대한 질문을 제기하는 본 연구는, 표준 멀티헤드 어텐션을 텐서 리프팅(tensor lifting)의 한 형태로 간주합니다. 저자들은 숨겨진 벡터를 쌍대 상호작용의 고차원 공간으로 매핑하고, 이 리프팅된 텐서를 그래디언트 하강법을 통해 제약하는 방식으로 학습이 이루어진다고 설명합니다. 그러나 이러한 메커니즘은 수학적으로 불투명하여, 여러 층을 거치면서 모델을 간결하게 설명하기 어려운 문제를 야기합니다. 이에 대한 대안으로 제안된 그래스만 흐름(Grassmann flows) 기반의 어텐션 없는 아키텍처는 정보 전파 방식을 혁신적으로 변화시킵니다.
구체적으로, 제안된 Causal Grassmann layer는 (i) 토큰 상태를 선형적으로 축소하고, (ii) 로컬 토큰 쌍을 플뤼커 좌표(Plucker coordinates)를 통해 그래스만 다양체의 2차원 부분공간으로 인코딩하며, (iii) 이러한 기하학적 특징을 게이트 혼합(gated mixing)을 통해 숨겨진 상태로 융합합니다. 이 과정에서 정보는 저차원 부분공간의 제어된 변형을 통해 다중 스케일 로컬 윈도우에서 전파됩니다. 이러한 접근은 모델이 비구조적인 텐서 공간이 아닌 유한 차원의 다양체에서 작동하도록 하여, 보다 명확한 기하학적 해석을 가능하게 합니다.
본 연구는 Wikitext-2 언어 모델링 벤치마크에서 1300만에서 1800만 개의 파라미터를 가진 그래스만 기반 모델이 크기가 맞는 트랜스포머와 유사한 성능을 보임을 보여줍니다. 또한, SNLI 자연어 추론 작업에서는 DistilBERT 위에 그래스만-플뤼커 헤드를 추가했을 때 트랜스포머 헤드보다 약간 더 나은 성능을 기록했습니다. 저자들은 그래스만 혼합의 복잡성을 분석하고, 고정된 랭크에 대해 시퀀스 길이에 선형적으로 확장됨을 보여주며, 이러한 다양체 기반 설계가 신경망의 추론을 더 기하학적으로 이해할 수 있는 가능성을 제시합니다.
결론적으로, 본 연구는 자기 어텐션의 필요성에 대한 비판적 시각을 제시하며, 그래스만 흐름을 통한 대안적 접근이 신경망의 기하학적 해석을 위한 보다 구조적인 경로를 제공할 수 있음을 강조합니다. 향후 연구 방향으로는 그래스만 흐름의 전역 및 장기 불변량 개발, 하이브리드 아키텍처 탐색 등이 제안됩니다.
논문 초록(Abstract)
시퀀스 모델링에서 기본적인 질문을 다시 살펴봅니다: 강력한 성능과 추론을 위해 명시적인 어텐션이 실제로 필요한가? 우리는 표준 멀티헤드 어텐션이 텐서 리프팅의 한 형태로 보는 것이 가장 좋다고 주장합니다: 숨겨진 벡터는 쌍별 상호작용의 고차원 공간으로 매핑되며, 학습은 그래디언트 하강법을 통해 이 리프팅된 텐서를 제약함으로써 진행됩니다. 이 메커니즘은 매우 표현력이 뛰어나지만 수학적으로 불투명합니다. 왜냐하면 여러 층을 거치면 소수의 명시적 불변량으로 모델을 설명하기가 매우 어려워지기 때문입니다. 대안을 탐색하기 위해 우리는 그래스만 흐름을 기반으로 한 어텐션 없는 아키텍처를 제안합니다. L x L 어텐션 행렬을 형성하는 대신, 우리의 인과 그래스만 층은 (i) 토큰 상태를 선형적으로 축소하고, (ii) 플루커 좌표를 통해 그래스만 다양체에서 두 개의 차원적 부분공간으로 지역 토큰 쌍을 인코딩하며, (iii) 이러한 기하학적 특징을 게이트 믹싱을 통해 숨겨진 상태로 다시 융합합니다. 따라서 정보는 다중 스케일 지역 윈도우를 통해 저차원 부분공간의 제어된 변형에 의해 전파되므로, 핵심 계산은 비구조적 텐서 공간이 아닌 유한 차원 다양체에서 이루어집니다. Wikitext-2 언어 모델링 벤치마크에서, 순수 그래스만 기반 모델은 1300만에서 1800만 개의 매개변수를 가지고 크기가 일치하는 트랜스포머의 약 10%에서 15% 이내의 검증 당혹도를 달성합니다. SNLI 자연어 추론 작업에서, DistilBERT 위에 있는 그래스만-플루커 헤드는 트랜스포머 헤드보다 약간 더 나은 성능을 보이며, 최상의 검증 및 테스트 정확도는 각각 0.8550과 0.8538로, 트랜스포머의 0.8545와 0.8511에 비해 우수합니다. 우리는 그래스만 믹싱의 복잡성을 분석하고, 고정된 랭크에 대해 시퀀스 길이에 대한 선형 스케일링을 보여주며, 이러한 다양체 기반 설계가 신경망 추론의 기하학적이고 불변적인 해석을 위한 보다 구조화된 경로를 제공한다고 주장합니다.
We revisit a basic question in sequence modeling: is explicit self-attention actually necessary for strong performance and reasoning? We argue that standard multi-head attention is best seen as a form of tensor lifting: hidden vectors are mapped into a high-dimensional space of pairwise interactions, and learning proceeds by constraining this lifted tensor through gradient descent. This mechanism is extremely expressive but mathematically opaque, because after many layers it becomes very hard to describe the model with a small family of explicit invariants. To explore an alternative, we propose an attention-free architecture based on Grassmann flows. Instead of forming an L by L attention matrix, our Causal Grassmann layer (i) linearly reduces token states, (ii) encodes local token pairs as two-dimensional subspaces on a Grassmann manifold via Plucker coordinates, and (iii) fuses these geometric features back into the hidden states through gated mixing. Information therefore propagates by controlled deformations of low-rank subspaces over multi-scale local windows, so the core computation lives on a finite-dimensional manifold rather than in an unstructured tensor space. On the Wikitext-2 language modeling benchmark, purely Grassmann-based models with 13 to 18 million parameters achieve validation perplexities within about 10 to 15 percent of size-matched Transformers. On the SNLI natural language inference task, a Grassmann-Plucker head on top of DistilBERT slightly outperforms a Transformer head, with best validation and test accuracies of 0.8550 and 0.8538 compared to 0.8545 and 0.8511. We analyze the complexity of Grassmann mixing, show linear scaling in sequence length for fixed rank, and argue that such manifold-based designs offer a more structured route toward geometric and invariant-based interpretations of neural reasoning.
논문 링크
하나의 도구로 충분하다: 리포지토리 수준 LLM 에이전트를 위한 강화학습 / One Tool Is Enough: Reinforcement Learning for Repository-Level LLM Agents
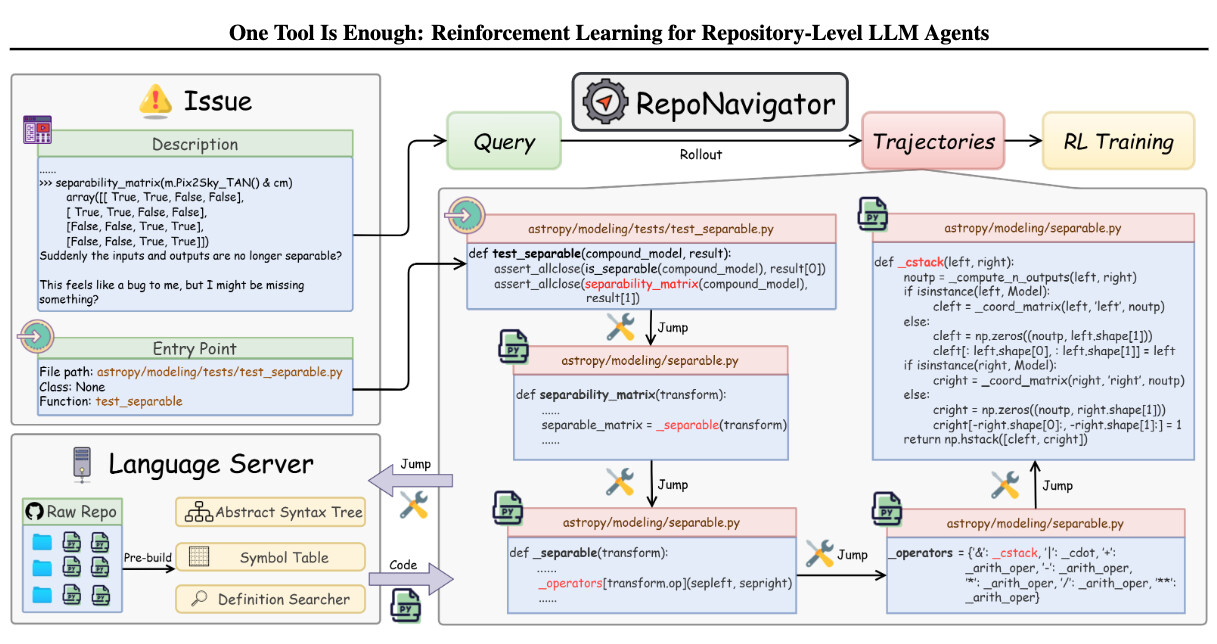
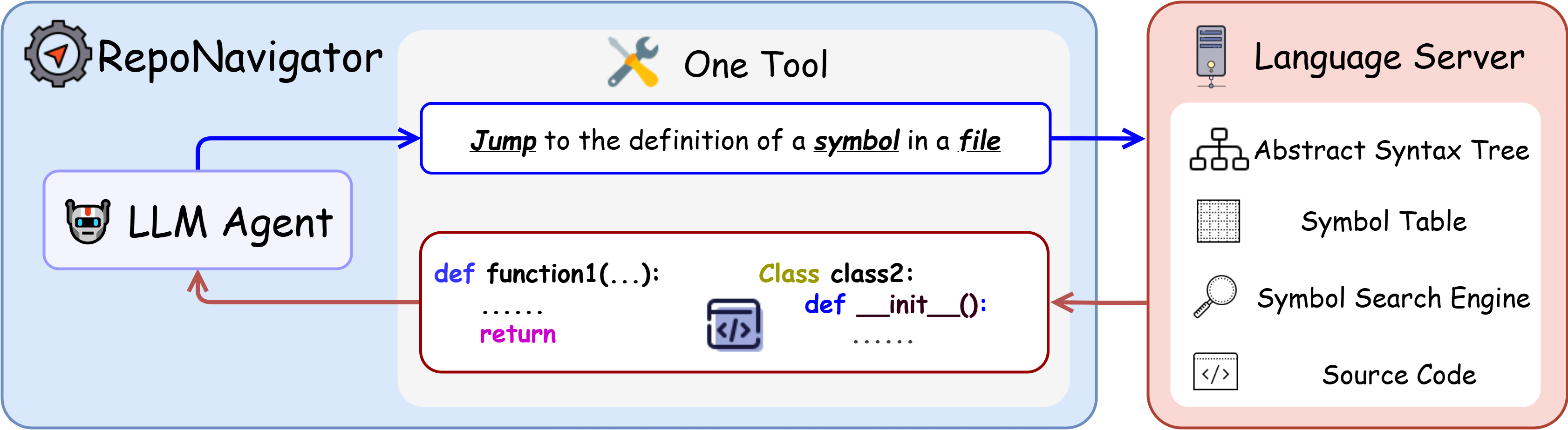
논문 소개
대규모 오픈 소스 소프트웨어(OSS) 리포지토리에서 수정이 필요한 파일과 함수를 찾는 작업은 그 복잡성과 방대한 코드량으로 인해 매우 도전적이다. 기존의 대규모 언어 모델(LLM) 기반 접근 방식은 이러한 문제를 리포지토리 수준의 검색 작업으로 간주하고 여러 보조 도구에 의존하는 경향이 있다. 그러나 이러한 방법은 코드 실행의 논리를 간과하고, 모델 제어를 복잡하게 만들어 효율성을 저해한다. 이에 대한 해결책으로 제안된 RepoNavigator는 단일 실행 인식 도구를 통해 호출된 기호의 정의로 점프할 수 있는 기능을 갖춘 LLM 에이전트이다. 이 통합 설계는 코드 실행의 실제 흐름을 반영하며, 도구 조작을 단순화하는 데 기여한다.
RepoNavigator는 사전 학습된 모델에서 직접 강화학습(Reinforcement Learning, RL)을 통해 엔드 투 엔드로 학습되며, 폐쇄형 소스 증류 없이도 효과적인 성능을 발휘한다. 실험 결과, RL로 훈련된 RepoNavigator는 7B 모델이 14B 기준 모델을 초과하고, 14B 모델이 32B 경쟁 모델을 초과하며, 32B 모델조차도 Claude-3.7과 같은 폐쇄형 모델을 초과하는 성과를 보였다. 이러한 결과는 단일 구조적 도구와 RL 훈련의 통합이 리포지토리 수준의 문제 위치 지정에 있어 효율적이고 확장 가능한 솔루션을 제공함을 입증한다.
RepoNavigator의 혁신적인 접근 방식은 기존의 LLM 기반 방법론이 가진 한계를 극복하고, OSS 리포지토리에서의 문제 해결 방식에 중요한 기여를 할 것으로 기대된다. 이 연구는 향후 소프트웨어 개발 및 유지보수 과정에서의 자동화된 문제 해결에 대한 새로운 방향성을 제시하며, 코드 실행 논리를 보다 명확하게 반영하는 도구의 필요성을 강조한다.
논문 초록(Abstract)
대규모 오픈 소스 소프트웨어(OSS) 저장소에서 수정이 필요한 파일과 기능을 찾는 것은 그 규모와 구조적 복잡성으로 인해 어려운 과제입니다. 기존의 대규모 언어 모델(LLM) 기반 방법들은 일반적으로 이를 저장소 수준의 검색 작업으로 처리하며, 여러 보조 도구에 의존하여 코드 실행 논리를 간과하고 모델 제어를 복잡하게 만듭니다. 우리는 호출된 기호의 정의로 점프하는 단일 실행 인식 도구를 갖춘 LLM 에이전트인 RepoNavigator를 제안합니다. 이 통합 설계는 코드 실행의 실제 흐름을 반영하면서 도구 조작을 단순화합니다. RepoNavigator는 사전 학습된 모델에서 직접 강화 학습(RL)을 통해 엔드 투 엔드로 훈련되며, 폐쇄형 소스 증류 없이 진행됩니다. 실험 결과, RL로 훈련된 RepoNavigator는 최첨단 성능을 달성하며, 7B 모델이 14B 기준 모델을 초과하고, 14B 모델이 32B 경쟁 모델을 초과하며, 심지어 32B 모델이 Claude-3.7과 같은 폐쇄형 소스 모델을 초과하는 성과를 보였습니다. 이러한 결과는 단일 구조적으로 기반한 도구와 RL 훈련의 통합이 저장소 수준의 문제 위치 지정에 효율적이고 확장 가능한 솔루션을 제공함을 확인시켜 줍니다.
Locating the files and functions requiring modification in large open-source software (OSS) repositories is challenging due to their scale and structural complexity. Existing large language model (LLM)-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool-jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a pretrained model, without any closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and even the 32B model exceeding closed-source models such as Claude-3.7. These results confirm that integrating a single, structurally grounded tool with RL training provides an efficient and scalable solution for repository-level issue localization.
논문 링크
소피아: 인공지능 생명의 지속 가능한 에이전트 프레임워크 / Sophia: A Persistent Agent Framework of Artificial Life
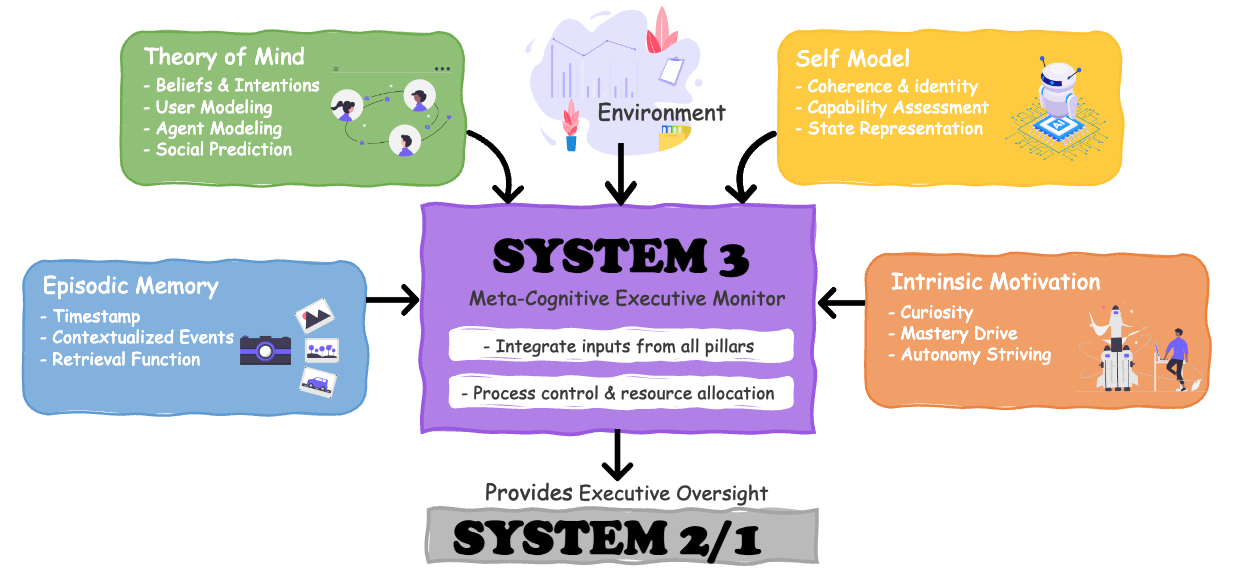
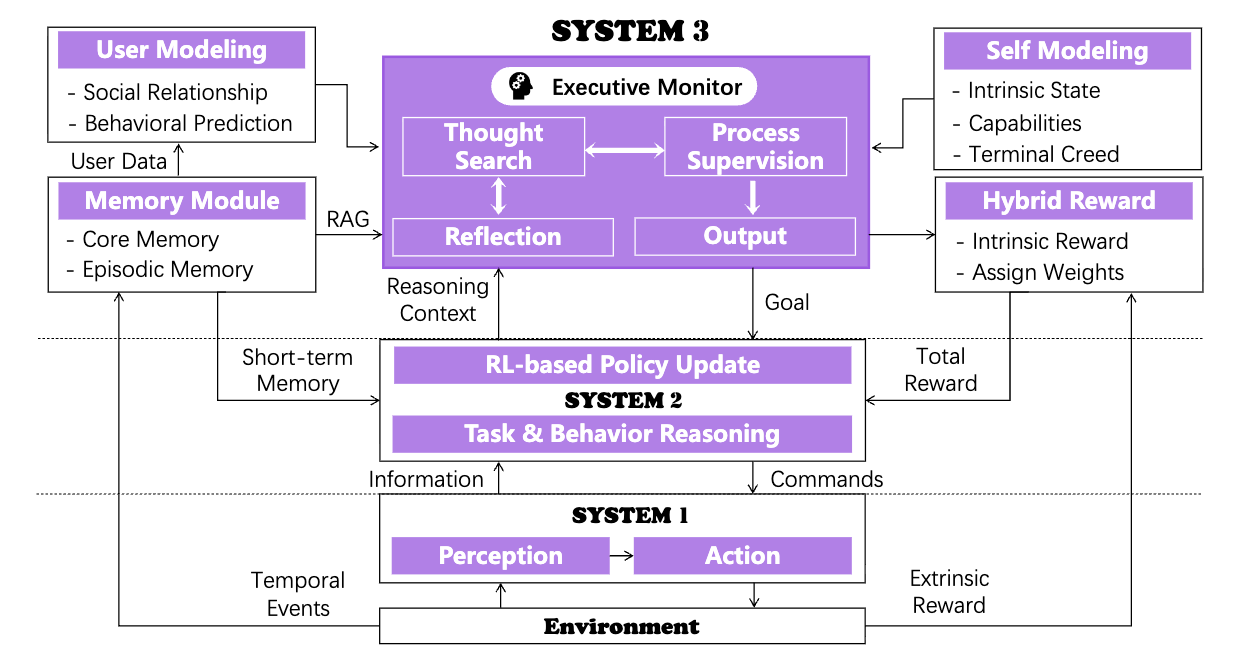
논문 소개
Sophia는 인공지능 생명체의 지속적인 에이전트 프레임워크로, 대규모 언어 모델(LLM)의 발전을 기반으로 하여 인공지능 에이전트를 단순한 작업 도구에서 장기적인 의사결정 주체로 발전시키는 혁신적인 접근을 제시합니다. 기존의 에이전트 아키텍처는 정적이고 반응적인 구조에 의존하여, 수동적으로 정의된 좁은 시나리오에 묶여 있는 한계를 가지고 있습니다. 이러한 문제를 해결하기 위해, 본 연구는 에이전트의 내러티브 정체성과 장기 적응을 관장하는 제3의 층인 System 3을 도입합니다. System 3은 인지 아키텍처 내에서 메타 인지적 역할을 수행하여, 에이전트가 지속적으로 학습하고 적응할 수 있도록 지원합니다.
Sophia는 네 가지 주요 메커니즘인 프로세스 감독 사고 검색, 내러티브 메모리, 사용자 및 자기 모델링, 하이브리드 보상 시스템을 통해 작동합니다. 이러한 메커니즘은 반복적인 추론 과정을 자기 주도적이고 자전적인 프로세스로 변환하여 정체성의 연속성과 행동에 대한 투명한 설명을 가능하게 합니다. 연구 결과, Sophia는 다양한 내재적 작업을 독립적으로 수행하며, 반복 작업에 대한 추론 단계를 80% 줄이는 성과를 달성했습니다. 특히, 메타 인지적 지속성은 고복잡성 작업에서 40%의 성공률 증가를 가져와 간단한 목표와 복잡한 목표 간의 성능 격차를 효과적으로 해소했습니다.
이 논문은 AI 에이전트를 위한 System 3 아키텍처를 개념화하고, 심리학적 기초를 바탕으로 한 최초의 계산 가능 에이전트 시스템인 Sophia를 제시함으로써 인공지능 생명체의 발전에 기여합니다. 이러한 접근은 인공지능 연구의 중요한 경계를 확장하며, 지속적인 자율성과 일관된 정체성 유지, 개방형 능력 성장을 가능하게 하는 실용적인 경로를 제시합니다. Sophia는 인공지능 생명체의 실현을 향한 중요한 이정표로 자리매김할 것입니다.
논문 초록(Abstract)
대규모 언어 모델(LLMs)의 발전은 AI 에이전트를 특정 작업 도구에서 장기적인 의사결정 실체로 끌어올렸습니다. 그러나 대부분의 아키텍처는 여전히 정적이고 반응적이며, 수동으로 정의된 좁은 시나리오에 얽매여 있습니다. 이러한 시스템은 인식(System 1)과 심사(System 2)에서 뛰어난 성능을 보이지만, 정체성을 유지하고, 추론을 검증하며, 단기 행동을 장기 생존과 일치시키기 위한 지속적인 메타 계층이 부족합니다. 우리는 먼저 에이전트의 서사적 정체성과 장기 적응을 관장하는 제3의 층, 즉 시스템 3을 제안합니다. 이 프레임워크는 선택된 심리적 구성 요소를 구체적인 계산 모듈에 매핑하여 인공 생명의 추상적 개념을 구현 가능한 설계 요구 사항으로 변환합니다. 이러한 아이디어는 소피아(Sophia)라는 "지속적 에이전트" 래퍼에 집결되어, 모든 LLM 중심의 시스템 1/2 스택에 지속적인 자기 개선 루프를 접목합니다. 소피아는 프로세스-감독 사고 탐색, 서사 기억, 사용자 및 자기 모델링, 하이브리드 보상 시스템의 네 가지 시너지 메커니즘에 의해 구동됩니다. 이들은 반복적인 추론을 자기 주도적이고 자전적인 과정으로 변환하여 정체성 연속성과 투명한 행동 설명을 가능하게 합니다. 비록 이 논문이 주로 개념적이지만, 논의를 고정시키기 위해 간결한 엔지니어링 프로토타입을 제공합니다. 정량적으로 소피아는 다양한 내재적 작업을 독립적으로 시작하고 실행하며, 반복 작업에 대한 추론 단계를 80% 줄이는 성과를 달성했습니다. 특히, 메타 인지적 지속성은 고복잡성 작업에서 40%의 성공률 향상을 가져와 간단한 목표와 복잡한 목표 간의 성능 격차를 효과적으로 해소했습니다. 정성적으로 시스템 3은 일관된 서사적 정체성과 작업 조직 능력을 보였습니다. 심리적 통찰과 경량 강화 학습 코어를 융합함으로써, 지속적 에이전트 아키텍처는 인공 생명에 대한 실용적인 경로를 발전시킵니다.
The development of LLMs has elevated AI agents from task-specific tools to long-lived, decision-making entities. Yet, most architectures remain static and reactive, tethered to manually defined, narrow scenarios. These systems excel at perception (System 1) and deliberation (System 2) but lack a persistent meta-layer to maintain identity, verify reasoning, and align short-term actions with long-term survival. We first propose a third stratum, System 3, that presides over the agent's narrative identity and long-horizon adaptation. The framework maps selected psychological constructs to concrete computational modules, thereby translating abstract notions of artificial life into implementable design requirements. The ideas coalesce in Sophia, a "Persistent Agent" wrapper that grafts a continuous self-improvement loop onto any LLM-centric System 1/2 stack. Sophia is driven by four synergistic mechanisms: process-supervised thought search, narrative memory, user and self modeling, and a hybrid reward system. Together, they transform repetitive reasoning into a self-driven, autobiographical process, enabling identity continuity and transparent behavioral explanations. Although the paper is primarily conceptual, we provide a compact engineering prototype to anchor the discussion. Quantitatively, Sophia independently initiates and executes various intrinsic tasks while achieving an 80% reduction in reasoning steps for recurring operations. Notably, meta-cognitive persistence yielded a 40% gain in success for high-complexity tasks, effectively bridging the performance gap between simple and sophisticated goals. Qualitatively, System 3 exhibited a coherent narrative identity and an innate capacity for task organization. By fusing psychological insight with a lightweight reinforcement-learning core, the persistent agent architecture advances a possible practical pathway toward artificial life.
논문 링크
VL-JEPA: 비전-언어를 위한 공동 임베딩 예측 아키텍처 / VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
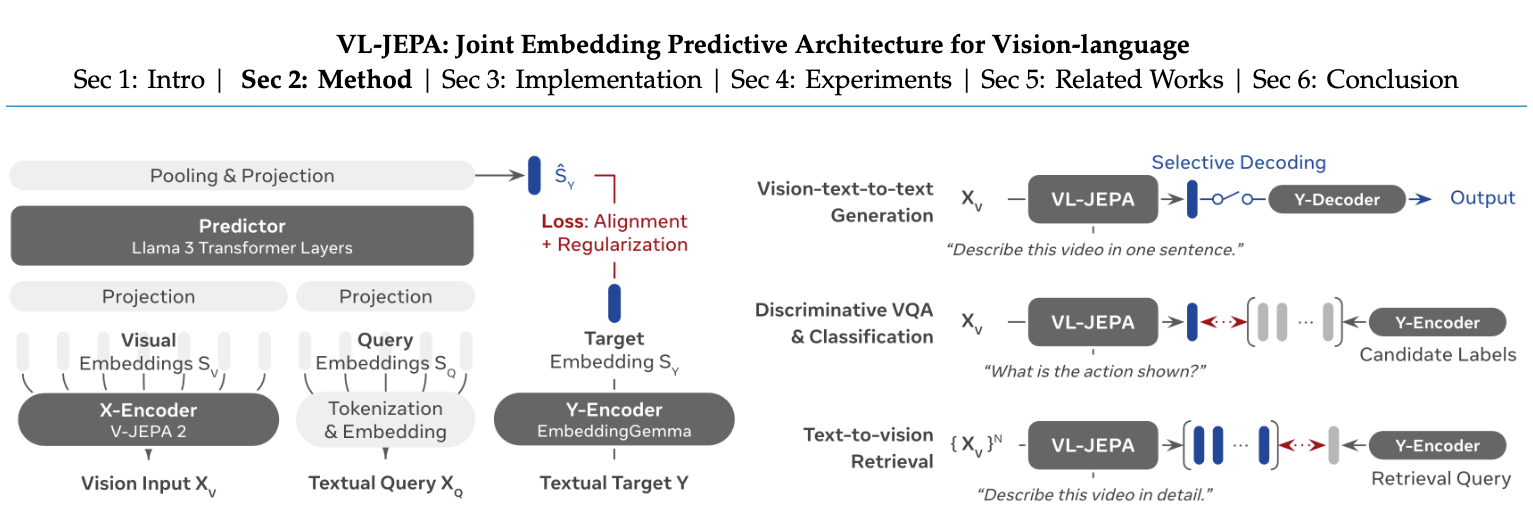
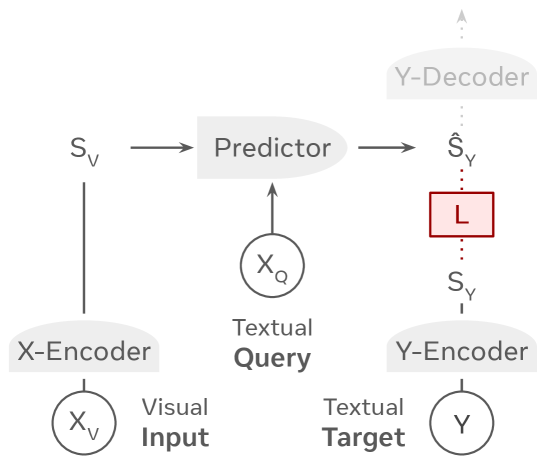
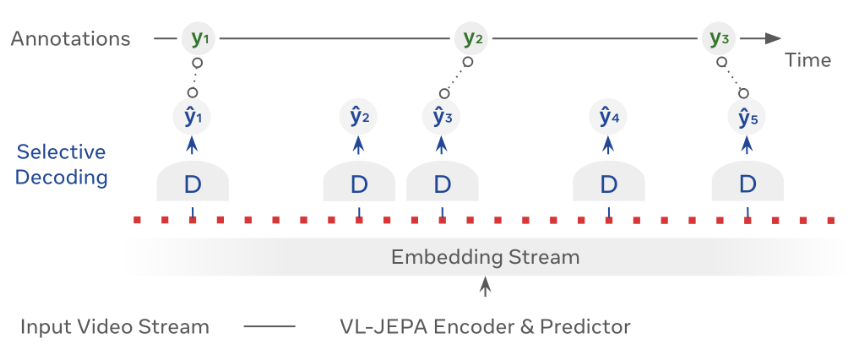
논문 소개
VL-JEPA는 비전-언어 모델을 위한 혁신적인 접근 방식을 제시하며, Joint Embedding Predictive Architecture (JEPA)를 기반으로 한다. 기존의 비전-언어 모델(VLM)들이 자율 회귀 방식으로 토큰을 생성하는 것과는 달리, VL-JEPA는 목표 텍스트의 연속적인 임베딩을 예측하는 데 중점을 둔다. 이 모델은 추상적인 표현 공간에서 학습하여 작업과 관련된 의미를 강조하고, 표면적인 언어적 변동성을 효과적으로 제거한다. VL-JEPA는 동일한 비전 인코더와 훈련 데이터를 사용한 기존의 토큰 공간 VLM 훈련과 비교했을 때, 50% 적은 학습 가능한 파라미터로 더 뛰어난 성능을 보여준다.
추론 시, VL-JEPA는 경량의 텍스트 디코더를 필요할 때만 호출하여 임베딩을 텍스트로 변환한다. 이 과정에서 선택적 디코딩 기능을 통해 디코딩 작업 수를 2.85배 줄일 수 있으며, 이는 실시간 응용 프로그램에서의 효율성을 크게 향상시킨다. VL-JEPA의 임베딩 공간은 아키텍처 수정 없이도 개방 어휘 분류, 텍스트-비디오 검색, 차별적 질문-응답(Visual Question Answering, VQA) 작업을 지원할 수 있는 장점을 지닌다.
실험 결과, VL-JEPA는 8개의 비디오 분류 및 8개의 비디오 검색 데이터셋에서 CLIP, SigLIP2, Perception Encoder를 초과하는 성능을 기록하였으며, 1.6B 파라미터로도 GQA, TallyQA, POPE 및 POPEv2의 4개 VQA 데이터셋에서 기존 VLM과 유사한 성능을 달성하였다. 이러한 성과는 VL-JEPA가 비전-언어 작업을 위한 최초의 비생성적 모델로서, 효율성과 성능을 동시에 갖춘 점에서 중요한 기여를 한다. 이 연구는 향후 다중 모달 잠재 공간 추론에 대한 새로운 가능성을 열어줄 것으로 기대된다.
논문 초록(Abstract)
우리는 Joint Embedding Predictive Architecture (JEPA)를 기반으로 한 비전-언어 모델인 VL-JEPA를 소개합니다. 전통적인 비전-언어 모델(VLM)에서처럼 토큰을 자동 회귀적으로 생성하는 대신, VL-JEPA는 목표 텍스트의 연속 임베딩을 예측합니다. 모델은 추상 표현 공간에서 학습함으로써, 표면 수준의 언어 변동성을 추상화하면서 작업과 관련된 의미에 집중합니다. 동일한 비전 인코더와 학습 데이터를 사용한 표준 토큰 공간 VLM 훈련과의 엄격한 비교에서, VL-JEPA는 50% 적은 학습 가능한 매개변수를 가지면서도 더 강력한 성능을 달성합니다. 추론 시, VL-JEPA가 예측한 임베딩을 텍스트로 변환하기 위해 필요한 경우에만 경량 텍스트 디코더가 호출됩니다. 우리는 VL-JEPA가 비적응형 균일 디코딩에 비해 유사한 성능을 유지하면서 디코딩 작업 수를 2.85배 줄이는 선택적 디코딩을 본래적으로 지원함을 보여줍니다. 생성 외에도, VL-JEPA의 임베딩 공간은 아키텍처 수정 없이 개방 어휘 분류, 텍스트-비디오 검색 및 구별적 VQA를 자연스럽게 지원합니다. 여덟 개의 비디오 분류 및 여덟 개의 비디오 검색 데이터셋에서, VL-JEPA의 평균 성능은 CLIP, SigLIP2 및 Perception Encoder를 초월합니다. 동시에, 이 모델은 16억 개의 매개변수만으로도 GQA, TallyQA, POPE 및 POPEv2의 네 개 VQA 데이터셋에서 전통적인 VLM(InstructBLIP, QwenVL)과 유사한 성능을 달성합니다.
We introduce VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Instead of autoregressively generating tokens as in classical VLMs, VL-JEPA predicts continuous embeddings of the target texts. By learning in an abstract representation space, the model focuses on task-relevant semantics while abstracting away surface-level linguistic variability. In a strictly controlled comparison against standard token-space VLM training with the same vision encoder and training data, VL-JEPA achieves stronger performance while having 50% fewer trainable parameters. At inference time, a lightweight text decoder is invoked only when needed to translate VL-JEPA predicted embeddings into text. We show that VL-JEPA natively supports selective decoding that reduces the number of decoding operations by 2.85x while maintaining similar performance compared to non-adaptive uniform decoding. Beyond generation, the VL-JEPA's embedding space naturally supports open-vocabulary classification, text-to-video retrieval, and discriminative VQA without any architecture modification. On eight video classification and eight video retrieval datasets, the average performance VL-JEPA surpasses that of CLIP, SigLIP2, and Perception Encoder. At the same time, the model achieves comparable performance as classical VLMs (InstructBLIP, QwenVL) on four VQA datasets: GQA, TallyQA, POPE and POPEv2, despite only having 1.6B parameters.
논문 링크
범용 추론 모델 / Universal Reasoning Model
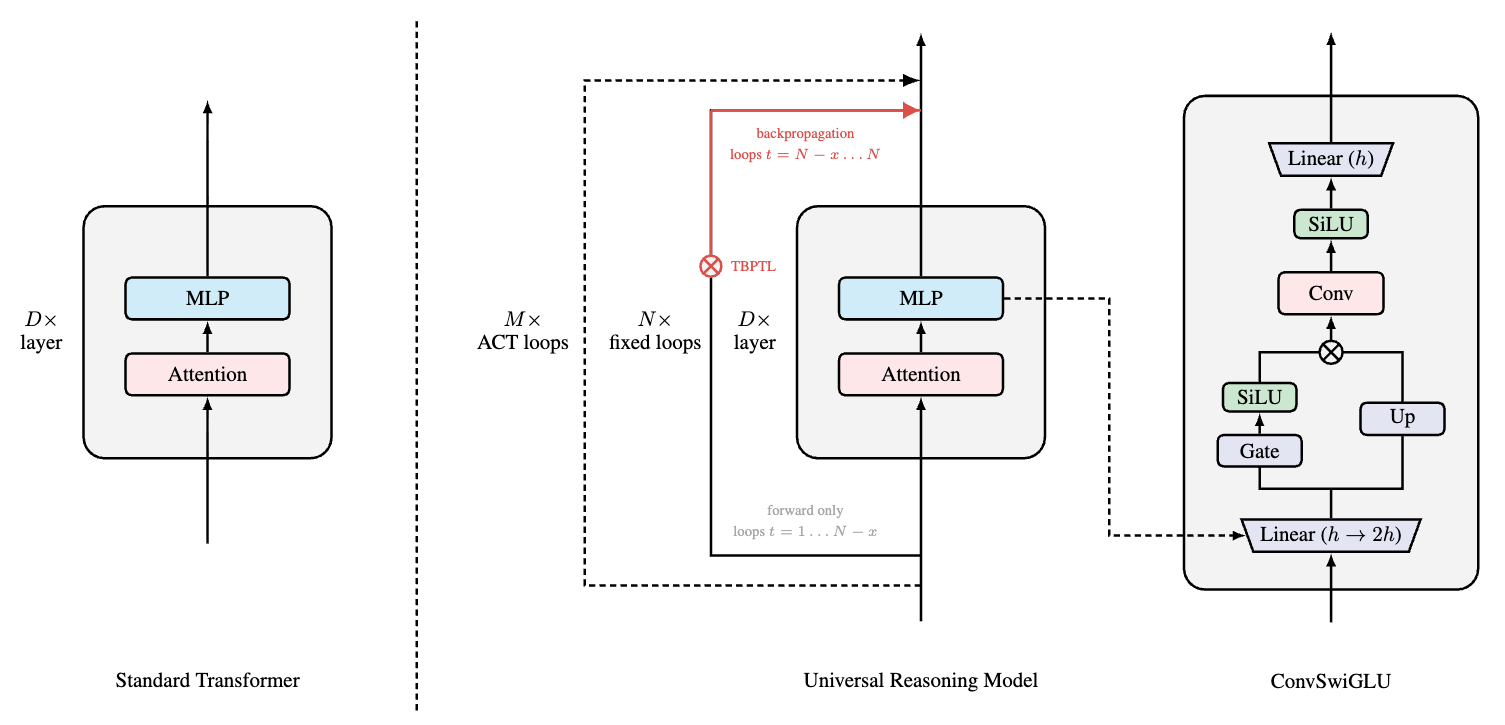
논문 소개
Universal Reasoning Model (URM)은 복잡한 추론 작업에서의 성능 향상을 목표로 하는 혁신적인 접근법이다. 기존의 Universal Transformers (UTs)는 ARC-AGI 및 Sudoku와 같은 문제에서 효과적으로 사용되었지만, 이들의 성능 향상의 근본적인 원인은 충분히 분석되지 않았다. 본 연구에서는 UT의 변형을 체계적으로 분석하여, ARC-AGI에서의 성능 향상이 정교한 아키텍처 설계가 아닌 재귀적 유도 편향과 강력한 비선형 구성 요소에서 주로 기인함을 밝혀냈다. 이러한 발견을 바탕으로 URM을 제안하며, 짧은 합성과 잘린 역전파 메커니즘을 도입하여 UT의 성능을 크게 향상시켰다.
URM의 핵심 혁신 중 하나는 ConvSwiGLU 모듈의 도입으로, 이는 비선형성을 강화하고 토큰 간의 상호작용을 개선하여 복잡한 추론 작업에서의 성능을 높인다. 또한, 잘린 역전파(Truncated Backpropagation Through Loops) 기법을 통해 재귀적 루프에서의 그래디언트 전파 문제를 해결하여 최적화의 안정성을 높였다. 이러한 접근은 초기 루프에서의 그래디언트 전파가 불안정성을 초래할 수 있는 문제를 완화하며, 효과적인 장기 학습을 가능하게 한다.
URM은 ARC-AGI 1에서 53.8%의 pass@1, ARC-AGI 2에서 16.0%의 pass@1을 달성하여 최첨단 성능을 기록하였다. 이 연구는 비선형성이 복잡한 추론 작업에서의 모델 성능에 미치는 중요성을 강조하며, URM의 아키텍처가 이러한 비선형성을 효과적으로 활용하고 있음을 보여준다. 최적화 과정에서 Muon 옵티마이저를 사용하여 훈련 효율성을 높였으며, 이는 URM의 구조적 용량과 최적화 효율성을 분리하여 분석하는 데 기여하였다. 이러한 기여는 복잡한 추론 문제 해결을 위한 새로운 방향성을 제시하며, 향후 연구에 중요한 기반이 될 것으로 기대된다.
논문 초록(Abstract)
보편적 트랜스포머(Universal Transformers, UTs)는 ARC-AGI와 스도쿠와 같은 복잡한 추론 작업에 널리 사용되고 있지만, 이들의 성능 향상의 구체적인 원인은 아직 충분히 연구되지 않았습니다. 본 연구에서는 UT 변형을 체계적으로 분석하고, ARC-AGI에서의 향상이 정교한 아키텍처 설계가 아닌 반복적 귀납적 편향과 강력한 비선형 구성 요소에서 주로 발생함을 보여줍니다. 이러한 발견에 동기를 부여받아, 우리는 짧은 컨볼루션과 잘린 역전파를 통해 UT를 향상시키는 보편적 추론 모델(Universal Reasoning Model, URM)을 제안합니다. 우리의 접근 방식은 추론 성능을 크게 향상시켜, ARC-AGI 1에서 53.8%의 pass@1, ARC-AGI 2에서 16.0%의 pass@1을 달성했습니다. 우리의 코드는 https://github.com/zitian-gao/URM에서 확인할 수 있습니다.
Universal transformers (UTs) have been widely used for complex reasoning tasks such as ARC-AGI and Sudoku, yet the specific sources of their performance gains remain underexplored. In this work, we systematically analyze UTs variants and show that improvements on ARC-AGI primarily arise from the recurrent inductive bias and strong nonlinear components of Transformer, rather than from elaborate architectural designs. Motivated by this finding, we propose the Universal Reasoning Model (URM), which enhances the UT with short convolution and truncated backpropagation. Our approach substantially improves reasoning performance, achieving state-of-the-art 53.8% pass@1 on ARC-AGI 1 and 16.0% pass@1 on ARC-AGI 2. Our code is avaliable at GitHub - UbiquantAI/URM: Universal Reasoning Model.
논문 링크
더 읽어보기
https://github.com/UbiquantAI/URM
전문 소프트웨어 개발자는 감성에 의존하지 않고, 제어한다: 2025년 코딩을 위한 AI 에이전트 활용 / Professional Software Developers Don't Vibe, They Control: AI Agent Use for Coding in 2025

논문 소개
AI 에이전트의 발전은 소프트웨어 개발 방식에 중대한 변화를 가져오고 있으며, 본 연구는 경험이 풍부한 소프트웨어 개발자들이 이러한 에이전트를 어떻게 활용하는지를 심층적으로 분석하고 있다. 연구는 두 가지 주요 방법론을 통해 진행되었으며, 첫 번째로 13명의 개발자에 대한 현장 관찰을 통해 실제 작업 환경에서의 에이전트 사용 패턴을 분석하였다. 두 번째로, 99명의 개발자를 대상으로 한 설문조사를 통해 그들의 동기, 전략, 감정 및 에이전트의 적합성에 대한 통찰을 수집하였다.
연구 결과, 경험이 풍부한 개발자들은 에이전트를 생산성 향상의 도구로 인식하면서도, 소프트웨어 품질을 유지하기 위해 에이전트의 출력을 신중하게 검토하고 검증하는 경향이 있음을 발견하였다. 이들은 에이전트를 사용할 때 신중한 계획과 감독을 통해 에이전트의 행동을 제어하는 전략을 채택하며, 이를 통해 최종 결과물의 품질을 보장하고자 한다. 또한, 에이전트는 잘 정의된 간단한 작업에 적합하지만, 복잡한 작업에는 한계가 있다는 인식을 가지고 있다.
개발자들은 에이전트를 사용함으로써 반복적인 작업에서 벗어나고 생산성을 높일 수 있다는 점에서 긍정적인 감정을 느끼고 있으며, 에이전트의 한계를 인식하고 그들의 전문 지식을 활용하여 에이전트를 제어하는 것이 중요하다고 생각한다. 이러한 연구 결과는 소프트웨어 개발의 품질을 유지하기 위한 에이전트 사용 가이드라인 개발에 기여할 수 있으며, 향후 에이전트 인터페이스 개선 및 에이전트 사용 모범 사례를 제시하는 데 중요한 기초 자료가 될 것이다.
본 연구는 경험이 부족한 개발자들에 대한 기존 연구와 차별화되며, 경험이 풍부한 개발자들의 에이전트 사용에 대한 심층적인 이해를 통해 소프트웨어 개발의 품질 향상에 기여할 수 있는 기회를 제시한다.
논문 초록(Abstract)
AI 에이전트의 출현은 소프트웨어 구축 방식을 변화시키고 있습니다. 에이전트의 약속은 개발자들이 코드를 더 빠르게 작성하고, 여러 작업을 다양한 에이전트에게 위임하며, 심지어 자연어만으로 전체 소프트웨어를 작성할 수 있다는 것입니다. 그러나 실제로 전문 소프트웨어 개발에서 에이전트가 수행하는 역할은 여전히 의문입니다. 본 논문은 숙련된 개발자들이 소프트웨어를 구축하는 데 있어 에이전트를 어떻게 사용하는지, 그들의 동기, 전략, 작업 적합성 및 감정을 조사합니다. 현장 관찰(N=13)과 질적 설문조사(N=99)를 통해, 숙련된 개발자들은 에이전트를 생산성 향상의 도구로 평가하지만, 기본적인 소프트웨어 품질 속성에 대한 고집으로 인해 소프트웨어 설계 및 구현에서 그들의 주체성을 유지하며, 전문 지식을 활용하여 에이전트 행동을 제어하는 전략을 사용하고 있음을 발견했습니다. 또한, 숙련된 개발자들은 에이전트의 한계를 보완할 수 있다는 자신감 덕분에 소프트웨어 개발에 에이전트를 통합하는 것에 대해 전반적으로 긍정적인 감정을 가지고 있습니다. 우리의 결과는 에이전트를 효과적으로 활용하기 위한 소프트웨어 개발 모범 사례의 가치를 조명하고, 에이전트가 적합할 수 있는 작업의 종류를 제안하며, 더 나은 에이전트 인터페이스 및 에이전트 사용 지침을 위한 향후 기회를 제시합니다.
The rise of AI agents is transforming how software can be built. The promise of agents is that developers might write code quicker, delegate multiple tasks to different agents, and even write a full piece of software purely out of natural language. In reality, what roles agents play in professional software development remains in question. This paper investigates how experienced developers use agents in building software, including their motivations, strategies, task suitability, and sentiments. Through field observations (N=13) and qualitative surveys (N=99), we find that while experienced developers value agents as a productivity boost, they retain their agency in software design and implementation out of insistence on fundamental software quality attributes, employing strategies for controlling agent behavior leveraging their expertise. In addition, experienced developers feel overall positive about incorporating agents into software development given their confidence in complementing the agents' limitations. Our results shed light on the value of software development best practices in effective use of agents, suggest the kinds of tasks for which agents may be suitable, and point towards future opportunities for better agentic interfaces and agentic use guidelines.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()