[2026/01/12 ~ 18] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 단순 생성을 넘어선 "강화학습(RL)의 고도화"와 추론 능력 강화: 이번 주 선정된 논문들에서는 강화학습(RL)을 단순히 모델을 정렬(Alignment)하는 도구가 아니라, 복잡한 추론과 문제 해결 능력을 극대화하는 핵심 메커니즘으로 활용하고 있습니다. MATTRL은 추론 단계(Test-Time)에서 다중 에이전트 간의 협력을 강화하기 위해 텍스트 경험을 주입하는 방식을 제안했고, UARL은 희소하지만 창의적인 해결 전략에 보상을 주어 모델의 탐색 능력을 높였습니다. 또한 Foresight Learning은 시간의 흐름에 따른 실제 결과(Outcome)를 검증 가능한 보상으로 활용하여, 인공지능이 보다 실질적이고 예측 가능한 추론을 하도록 유도합니다.
단순 생성을 넘어선 "강화학습(RL)의 고도화"와 추론 능력 강화: 이번 주 선정된 논문들에서는 강화학습(RL)을 단순히 모델을 정렬(Alignment)하는 도구가 아니라, 복잡한 추론과 문제 해결 능력을 극대화하는 핵심 메커니즘으로 활용하고 있습니다. MATTRL은 추론 단계(Test-Time)에서 다중 에이전트 간의 협력을 강화하기 위해 텍스트 경험을 주입하는 방식을 제안했고, UARL은 희소하지만 창의적인 해결 전략에 보상을 주어 모델의 탐색 능력을 높였습니다. 또한 Foresight Learning은 시간의 흐름에 따른 실제 결과(Outcome)를 검증 가능한 보상으로 활용하여, 인공지능이 보다 실질적이고 예측 가능한 추론을 하도록 유도합니다.
![]() 자율적 "에이전트(Agent)" 시스템으로의 진화와 평가의 자동화: 단순한 질의응답을 넘어, 계획을 수립하고 도구를 사용하며 스스로를 평가하는 '에이전트' 중심의 연구가 두드러집니다. Agent-as-a-Judge는 기존의 LLM 기반 평가가 가진 한계를 넘어, 계획 수립과 도구 사용을 통해 평가의 신뢰성을 높이는 새로운 패러다임을 제시했으며, Agentic Search 서베이는 검색과 추론을 결합한 능동적인 정보 탐색 에이전트의 발전 방향을 다루고 있습니다. 이는 AI가 단일 모델로서 기능하기보다, 복잡한 워크플로우를 스스로 제어하는 시스템으로 발전하고 있음을 시사합니다.
자율적 "에이전트(Agent)" 시스템으로의 진화와 평가의 자동화: 단순한 질의응답을 넘어, 계획을 수립하고 도구를 사용하며 스스로를 평가하는 '에이전트' 중심의 연구가 두드러집니다. Agent-as-a-Judge는 기존의 LLM 기반 평가가 가진 한계를 넘어, 계획 수립과 도구 사용을 통해 평가의 신뢰성을 높이는 새로운 패러다임을 제시했으며, Agentic Search 서베이는 검색과 추론을 결합한 능동적인 정보 탐색 에이전트의 발전 방향을 다루고 있습니다. 이는 AI가 단일 모델로서 기능하기보다, 복잡한 워크플로우를 스스로 제어하는 시스템으로 발전하고 있음을 시사합니다.
![]() 현실 세계와의 연결 - "인과성(Causality)", "세계 모델", "구조화된 지식": 모델이 통계적 상관관계를 넘어 물리적 법칙과 인과관계를 이해하고 구조화된 지식을 활용하려는 시도들이 계속되고 있습니다. Causal RL은 인과 추론을 강화학습에 통합하여 환경 변화에 강건한 모델을 만드는 방법을 모색하며, Latent Action World Models는 비디오 데이터를 통해 라벨 없이도 현실 세계의 행동 원리를 학습하는 세계 모델을 제안했습니다. 아울러 LLM-empowered KG는 비정형 텍스트에서 구조화된 지식 그래프를 구축하여, 모델이 할루시네이션을 줄이고 명확한 지식 체계를 갖추도록 돕는 연구 흐름을 보여줍니다.
현실 세계와의 연결 - "인과성(Causality)", "세계 모델", "구조화된 지식": 모델이 통계적 상관관계를 넘어 물리적 법칙과 인과관계를 이해하고 구조화된 지식을 활용하려는 시도들이 계속되고 있습니다. Causal RL은 인과 추론을 강화학습에 통합하여 환경 변화에 강건한 모델을 만드는 방법을 모색하며, Latent Action World Models는 비디오 데이터를 통해 라벨 없이도 현실 세계의 행동 원리를 학습하는 세계 모델을 제안했습니다. 아울러 LLM-empowered KG는 비정형 텍스트에서 구조화된 지식 그래프를 구축하여, 모델이 할루시네이션을 줄이고 명확한 지식 체계를 갖추도록 돕는 연구 흐름을 보여줍니다.
협업 다중 에이전트 테스트 시간 강화학습을 통한 추론 / Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning

논문 소개
다중 에이전트 시스템(MAS, Multi-Agent System)은 최근 대규모 언어 모델(LLM)을 기반으로 한 협력자로 발전하며, 다양한 응용 분야에서 그 가능성을 보여주고 있다. 그러나 다중 에이전트 강화학습(MARL)의 훈련 과정은 자원 소모가 크고 불안정한 문제를 안고 있다. 이러한 문제를 해결하기 위해 제안된 다중 에이전트 테스트 시간 강화학습(MATTRL) 프레임워크는 구조화된 텍스트 경험을 활용하여 다중 에이전트 간의 협력을 강화한다. MATTRL은 전문 에이전트 팀을 구성하고, 이 팀이 다중 턴 논의에서 이전 경험을 바탕으로 합의에 도달하는 과정을 통해 최종 결정을 내린다.
MATTRL의 핵심 구성 요소는 경험 풀의 구축과 신용 할당 전략이다. 각 에이전트의 발화는 성과 신호에 따라 점수화되며, 높은 점수를 받은 발화는 경험 풀에 추가된다. 이를 통해 각 에이전트는 더 나은 의사 결정을 위해 필요한 정보를 효과적으로 검색하고 활용할 수 있다. 또한, 다양한 신용 할당 전략을 통해 경험 선택의 효율성을 높이고, 최종 의사 결정에 미치는 영향을 체계적으로 분석한다.
실험 결과, MATTRL은 의학, 수학 및 교육 분야의 벤치마크에서 평균 3.67%의 성능 향상을 보였으며, 비교 가능한 단일 에이전트 기준보다 8.67% 향상된 결과를 나타냈다. 이러한 성과는 MATTRL이 다중 에이전트 시스템의 훈련 안정성을 높이고, 분포 변화에 강한 추론 능력을 제공하는 데 기여함을 보여준다. MATTRL은 조정 없이도 효과적인 다중 에이전트 협력을 가능하게 하여, 향후 다양한 분야에서의 적용 가능성을 제시한다.
논문 초록(Abstract)
다중 에이전트 시스템은 다양한 응용 프로그램을 위한 실용적인 대규모 언어 모델(LLM) 기반 협력자로 발전하였으며, 다양성과 상호 검증을 통해 강인성을 얻고 있습니다. 그러나 다중 에이전트 강화학습(MARL) 훈련은 자원 집약적이며 불안정합니다: 동반 적응하는 팀원들은 비정상성을 유발하고, 보상은 종종 희소하고 높은 변동성을 가집니다. 따라서 우리는 \textbf{다중 에이전트 테스트 시간 강화학습(MATTRL)} 을 소개합니다. MATTRL은 추론 시간에 다중 에이전트 심의에 구조화된 텍스트 경험을 주입하는 프레임워크입니다. MATTRL은 다중 턴 논의를 위한 전문가 팀을 구성하고, 테스트 시간 경험을 검색 및 통합하며, 최종 의사 결정을 위한 합의에 도달합니다. 또한 우리는 턴 수준의 경험 풀을 구성하기 위한 신용 할당을 연구하고, 이를 대화에 다시 주입하는 방법을 탐구합니다. 의학, 수학 및 교육 분야의 도전적인 벤치마크에서 MATTRL은 다중 에이전트 기준보다 평균 3.67% 정확도를 향상시키고, 유사한 단일 에이전트 기준보다 8.67% 향상시킵니다. 제거 연구는 다양한 신용 할당 방식을 검토하고 이들이 훈련 결과에 미치는 영향을 상세히 비교합니다. MATTRL은 조정 없이 분포 변화에 강한 다중 에이전트 추론을 위한 안정적이고 효과적이며 효율적인 경로를 제공합니다.
Multi-agent systems have evolved into practical LLM-driven collaborators for many applications, gaining robustness from diversity and cross-checking. However, multi-agent RL (MARL) training is resource-intensive and unstable: co-adapting teammates induce non-stationarity, and rewards are often sparse and high-variance. Therefore, we introduce \textbf{Multi-Agent Test-Time Reinforcement Learning (MATTRL)}, a framework that injects structured textual experience into multi-agent deliberation at inference time. MATTRL forms a multi-expert team of specialists for multi-turn discussions, retrieves and integrates test-time experiences, and reaches consensus for final decision-making. We also study credit assignment for constructing a turn-level experience pool, then reinjecting it into the dialogue. Across challenging benchmarks in medicine, math, and education, MATTRL improves accuracy by an average of 3.67% over a multi-agent baseline, and by 8.67% over comparable single-agent baselines. Ablation studies examine different credit-assignment schemes and provide a detailed comparison of how they affect training outcomes. MATTRL offers a stable, effective and efficient path to distribution-shift-robust multi-agent reasoning without tuning.
논문 링크
더 읽어보기
강화학습 기반 에이전틱 검색에 대한 포괄적 서베이: 기초, 역할, 최적화, 평가 및 응용 / A Comprehensive Survey on Reinforcement Learning-based Agentic Search: Foundations, Roles, Optimizations, Evaluations, and Applications

논문 소개
대규모 언어 모델(LLM)의 출현은 개방형 자연어 상호작용을 통해 정보 접근과 추론 방식을 변화시켰습니다. 그러나 LLM은 정적 지식, 사실 왜곡, 실시간 또는 도메인 특정 정보를 검색할 수 없는 한계가 있습니다. 검색-증강 생성(RAG)은 모델 출력을 외부 증거에 기반하여 이러한 문제를 완화하지만, 전통적인 RAG 파이프라인은 종종 단일 턴 및 휴리스틱 방식으로, 검색 및 추론에 대한 적응적 제어가 부족합니다. 최근의 에이전틱 검색 발전은 LLM이 검색 환경과의 다단계 상호작용을 통해 계획, 검색 및 반영할 수 있도록 하여 이러한 한계를 해결합니다. 이 맥락에서 강화학습(RL)은 적응적이고 자기 개선적인 검색 행동을 위한 강력한 메커니즘을 제공합니다. 본 서베이는 RL 기반 에이전틱 검색의 포괄적인 개요를 제공하며, 기능적 역할, 최적화 전략, 적용 범위의 세 가지 보완적 차원으로 이 분야를 조직합니다. 대표적인 방법, 평가 프로토콜 및 응용 사례를 요약하고, 신뢰할 수 있고 확장 가능한 RL 기반 에이전틱 검색 시스템 구축을 위한 도전 과제와 미래 방향에 대해 논의합니다. 이 서베이가 RL과 에이전틱 검색의 통합에 대한 미래 연구에 영감을 주기를 바랍니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 출현은 개방형 자연어 상호작용을 통해 정보 접근 및 추론 방식을 변화시켰습니다. 그러나 LLM은 정적 지식, 사실적 환각, 실시간 또는 도메인 특정 정보를 검색할 수 없는 한계가 있습니다. 검색-증강 생성(RAG)은 모델 출력을 외부 증거에 기반하여 이러한 문제를 완화하지만, 전통적인 RAG 파이프라인은 종종 단일 턴 및 휴리스틱 방식으로, 검색 및 추론에 대한 적응적 제어가 부족합니다. 최근의 에이전틱 검색 발전은 LLM이 검색 환경과의 다단계 상호작용을 통해 계획하고, 검색하며, 반영할 수 있도록 하여 이러한 한계를 해결합니다. 이 패러다임 내에서 강화학습(RL)은 적응적이고 자기 개선적인 검색 행동을 위한 강력한 메커니즘을 제공합니다. 본 서베이는 \emph{RL 기반 에이전틱 검색}에 대한 최초의 포괄적인 개요를 제공하며, 이 새로운 분야를 세 가지 상호 보완적인 차원으로 정리합니다: (i) RL의 기능적 역할, (ii) RL의 최적화 전략, (iii) RL의 적용 범위. 우리는 대표적인 방법, 평가 프로토콜 및 응용 프로그램을 요약하고, 신뢰할 수 있고 확장 가능한 RL 기반 에이전틱 검색 시스템 구축을 위한 열린 도전 과제와 미래 방향에 대해 논의합니다. 본 서베이가 RL과 에이전틱 검색의 통합에 대한 미래 연구에 영감을 주기를 바랍니다. 우리의 저장소는 GitHub - ventr1c/Awesome-RL-based-Agentic-Search-Papers: The official repository of "A Comprehensive Survey on Reinforcement Learning-based Agentic Search: Foundations, Roles, Optimizations, Evaluations, and Applications". 에서 확인할 수 있습니다.
The advent of large language models (LLMs) has transformed information access and reasoning through open-ended natural language interaction. However, LLMs remain limited by static knowledge, factual hallucinations, and the inability to retrieve real-time or domain-specific information. Retrieval-Augmented Generation (RAG) mitigates these issues by grounding model outputs in external evidence, but traditional RAG pipelines are often single turn and heuristic, lacking adaptive control over retrieval and reasoning. Recent advances in agentic search address these limitations by enabling LLMs to plan, retrieve, and reflect through multi-step interaction with search environments. Within this paradigm, reinforcement learning (RL) offers a powerful mechanism for adaptive and self-improving search behavior. This survey provides the first comprehensive overview of \emph{RL-based agentic search}, organizing the emerging field along three complementary dimensions: (i) What RL is for (functional roles), (ii) How RL is used (optimization strategies), and (iii) Where RL is applied (scope of optimization). We summarize representative methods, evaluation protocols, and applications, and discuss open challenges and future directions toward building reliable and scalable RL driven agentic search systems. We hope this survey will inspire future research on the integration of RL and agentic search. Our repository is available at GitHub - ventr1c/Awesome-RL-based-Agentic-Search-Papers: The official repository of "A Comprehensive Survey on Reinforcement Learning-based Agentic Search: Foundations, Roles, Optimizations, Evaluations, and Applications"..
논문 링크
더 읽어보기
인과 강화학습 통합: 서베이, 분류, 알고리즘 및 응용 / Unifying Causal Reinforcement Learning: Survey, Taxonomy, Algorithms and Applications
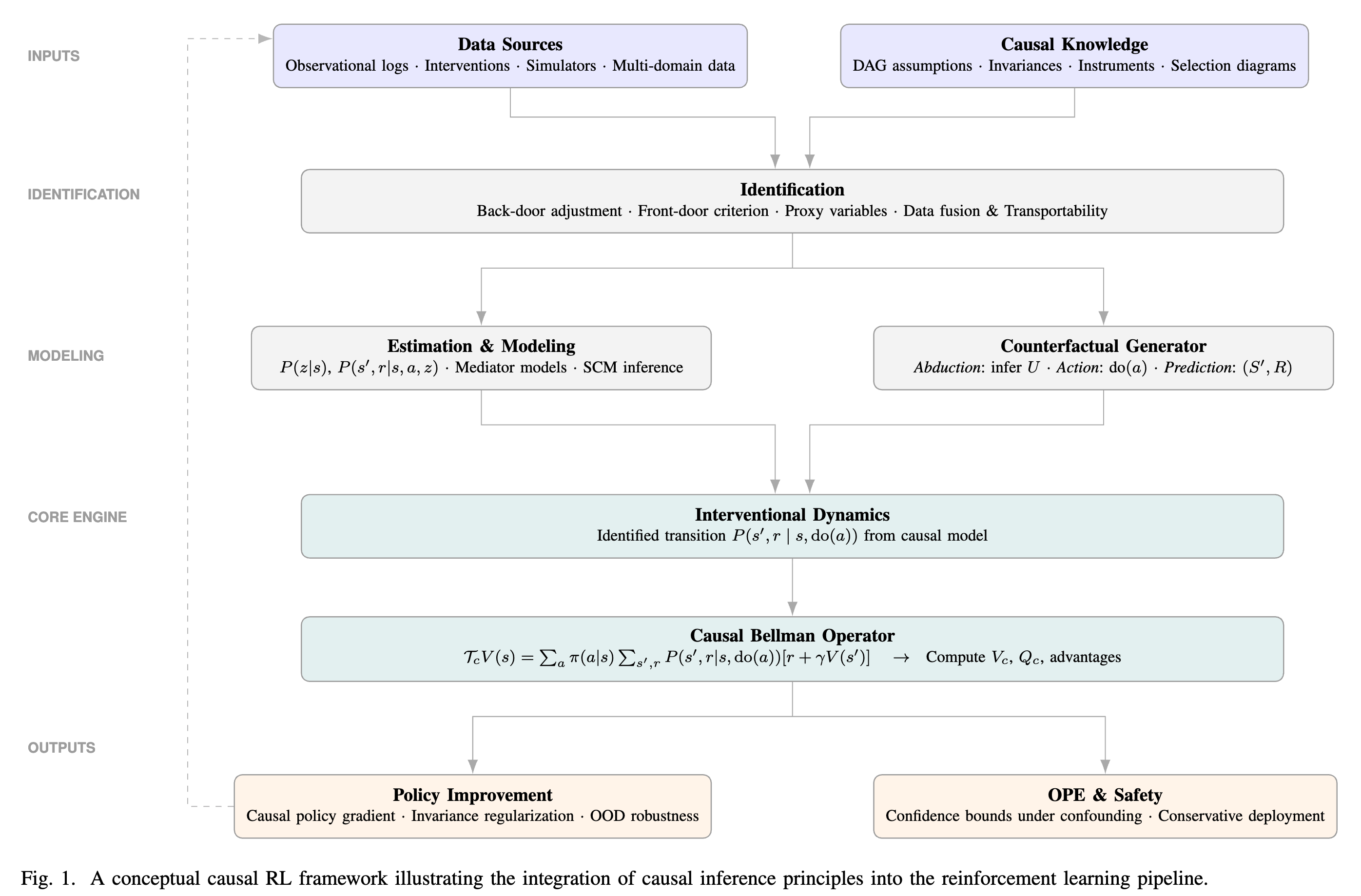
논문 소개
인과 강화학습(Causal Reinforcement Learning, CRL)은 인과 추론(Causal Inference, CI)과 강화학습(Reinforcement Learning, RL)의 통합을 통해 전통적인 RL의 한계를 극복하는 혁신적인 접근법이다. 전통적인 RL 기법은 상관관계에 의존하여 의사결정을 내리기 때문에, 분포 변화, 혼란 변수, 동적 환경에서의 성능 저하 문제에 직면한다. CRL은 이러한 문제를 해결하기 위해 인과 관계를 명시적으로 모델링하여, 보다 강건하고 일반화 가능한 인공지능 시스템을 개발할 수 있는 가능성을 제시한다.
본 연구에서는 CRL의 다양한 접근 방식을 체계적으로 정리하고, 이를 인과 표현 학습, 반사실 정책 최적화, 오프라인 인과 RL, 인과 전이 학습, 인과 설명 가능성으로 분류하였다. 이러한 분류를 통해 현재의 도전 과제를 식별하고, 실제 응용에서의 성공 사례를 강조하며, 향후 연구 방향을 제시하였다. 특히, 인과 MDP(Causal MDP, C-MDP)라는 통합 추상화를 도입하여, 행동을 개입으로 취급하고, 정책 평가 및 개선 과정에서 인과적 동역학을 활용하는 방법론을 설명하였다.
CRL의 핵심 기여는 인과 벨만 연산자를 통해 정책의 개입적 동역학을 정의하고, 이를 바탕으로 혼란 변수를 고려한 정책 평가 및 개선을 가능하게 한다는 점이다. 또한, 다양한 식별 전략(백도어, 프론트 도어, 프록시 변수)을 통해 관찰 가능한 양을 사용하여 개입적 분포를 식별하는 방법을 제시함으로써, RL의 주요 문제인 혼란, 분포 변화, 샘플 비효율성을 해결하는 데 기여한다.
이 연구는 CRL의 이론적 기초와 실용적인 알고리즘 구조를 제안하며, 인과적 요인을 고려한 정책 개선을 통해 강화학습의 성능을 향상시킬 수 있는 방법을 모색한다. 궁극적으로, CRL은 인공지능 분야에서 보다 해석 가능하고 신뢰할 수 있는 시스템 개발을 위한 중요한 발판이 될 것으로 기대된다.
논문 초록(Abstract)
인과 추론(CI)과 강화학습(RL)의 통합은 고전적인 RL의 주요 한계인 낮은 설명 가능성, 견고성 부족 및 일반화 실패를 해결하기 위한 강력한 패러다임으로 부상하였습니다. 전통적인 RL 기법은 일반적으로 상관관계 기반의 의사결정에 의존하기 때문에 분포 변화, 혼란 변수 및 동적 환경에 직면했을 때 어려움을 겪습니다. 인과 강화학습(CRL)은 인과 추론의 기본 원리를 활용하여 원인과 결과의 관계를 명시적으로 모델링함으로써 이러한 문제에 대한 유망한 해결책을 제공합니다. 본 서베이에서는 인과 추론과 RL의 교차점에서 최근 발전을 체계적으로 검토합니다. 기존 접근 방식을 인과 표현 학습, 반사실 정책 최적화, 오프라인 인과 RL, 인과 전이 학습 및 인과 설명 가능성으로 분류합니다. 이러한 구조화된 분석을 통해 우리는 주요 도전 과제를 식별하고, 실제 응용에서의 경험적 성공 사례를 강조하며, 해결되지 않은 문제를 논의합니다. 마지막으로, 우리는 견고하고 일반화 가능하며 해석 가능한 인공지능 시스템 개발을 위한 CRL의 잠재력을 강조하며 향후 연구 방향을 제시합니다.
Integrating causal inference (CI) with reinforcement learning (RL) has emerged as a powerful paradigm to address critical limitations in classical RL, including low explainability, lack of robustness and generalization failures. Traditional RL techniques, which typically rely on correlation-driven decision-making, struggle when faced with distribution shifts, confounding variables, and dynamic environments. Causal reinforcement learning (CRL), leveraging the foundational principles of causal inference, offers promising solutions to these challenges by explicitly modeling cause-and-effect relationships. In this survey, we systematically review recent advancements at the intersection of causal inference and RL. We categorize existing approaches into causal representation learning, counterfactual policy optimization, offline causal RL, causal transfer learning, and causal explainability. Through this structured analysis, we identify prevailing challenges, highlight empirical successes in practical applications, and discuss open problems. Finally, we provide future research directions, underscoring the potential of CRL for developing robust, generalizable, and interpretable artificial intelligence systems.
논문 링크
에이전트 평가 시스템의 진화: 에이전트-저지(Agent-as-a-Judge)로의 전환 / A Survey on Agent-as-a-Judge

논문 소개
대규모 언어 모델(LLM)의 발전은 인공지능(AI) 평가 분야에 혁신적인 변화를 가져왔으며, 이를 통해 LLM-as-a-Judge라는 새로운 패러다임이 등장하였습니다. 그러나 평가 대상의 복잡성과 전문성이 증가함에 따라 이 접근 방식은 내재된 편향, 얕은 단일 통과 추론, 그리고 실제 관찰에 대한 검증 불가능성 등의 한계에 직면하게 되었습니다. 이러한 문제를 해결하기 위해 Agent-as-a-Judge라는 새로운 패러다임이 제안되었습니다. 이 접근 방식은 계획, 도구 보강 검증, 다중 에이전트 협업 및 지속적인 메모리 기능을 통합하여 보다 견고하고 검증 가능한 평가를 가능하게 합니다.
Agent-as-a-Judge의 발전은 세 가지 주요 단계로 나눌 수 있습니다. 첫 번째 단계는 기본적인 평가 절차에 따라 작동하는 Procedural 단계이며, 두 번째 단계는 여러 에이전트가 협력하여 보다 정교한 평가를 수행하는 Collaborative 단계입니다. 마지막으로, 세 번째 단계인 Adaptive 단계에서는 지속적인 메모리와 자율적 계획 기능을 통해 에이전트가 사용자 맞춤형 평가를 제공할 수 있는 능력을 갖추게 됩니다.
이 논문은 Agent-as-a-Judge의 발전을 포괄적으로 조사하며, 이 새로운 패러다임의 핵심 차원과 방법론을 정리합니다. 또한, 일반 및 전문 분야에서의 응용 사례를 조사하고, 현재의 도전 과제를 분석하여 향후 연구 방향을 제시합니다. 이러한 연구는 AI 평가 시스템의 신뢰성을 높이고, 다양한 상황에서의 적응성을 향상시키는 데 기여할 것입니다.
결국, Agent-as-a-Judge는 평가의 정확성을 높이고, 개인화된 평가 기준을 제공하는 데 중요한 역할을 할 것으로 기대됩니다. 이 논문은 차세대 판단 에이전트의 발전을 위한 명확한 로드맵을 제공하며, AI 평가의 미래를 형성하는 데 기여할 것입니다.
논문 초록(Abstract)
LLM-as-a-Judge는 대규모 언어 모델을 활용하여 확장 가능한 평가를 통해 AI 평가에 혁신을 가져왔습니다. 그러나 평가 대상이 점점 더 복잡하고 전문화되며 다단계로 발전함에 따라, LLM-as-a-Judge의 신뢰성은 고유한 편향, 얕은 단일 통과 추론, 그리고 실제 관찰에 대한 평가 검증 불가능성에 의해 제약을 받게 되었습니다. 이는 에이전트-어즈-어-저지(Agent-as-a-Judge)로의 전환을 촉발하였으며, 여기서 에이전트 판사는 계획 수립, 도구 보강 검증, 다중 에이전트 협업, 지속적인 기억을 활용하여 보다 견고하고 검증 가능하며 미세한 평가를 가능하게 합니다. 에이전트 평가 시스템의 급속한 확산에도 불구하고, 이 변화하는 환경을 탐색하기 위한 통합된 프레임워크가 부족한 상황입니다. 이러한 격차를 해소하기 위해, 우리는 이 진화를 추적하는 최초의 포괄적인 서베이를 제시합니다. 구체적으로, 우리는 이 패러다임 전환을 특징짓는 주요 차원을 식별하고 발전적 분류 체계를 수립합니다. 또한, 일반 및 전문 분야에서 핵심 방법론을 정리하고 응용 사례를 조사합니다. 더 나아가, 최전선의 도전 과제를 분석하고 유망한 연구 방향을 식별하여, 궁극적으로 에이전트 평가의 다음 세대를 위한 명확한 로드맵을 제공합니다.
LLM-as-a-Judge has revolutionized AI evaluation by leveraging large language models for scalable assessments. However, as evaluands become increasingly complex, specialized, and multi-step, the reliability of LLM-as-a-Judge has become constrained by inherent biases, shallow single-pass reasoning, and the inability to verify assessments against real-world observations. This has catalyzed the transition to Agent-as-a-Judge, where agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory to enable more robust, verifiable, and nuanced evaluations. Despite the rapid proliferation of agentic evaluation systems, the field lacks a unified framework to navigate this shifting landscape. To bridge this gap, we present the first comprehensive survey tracing this evolution. Specifically, we identify key dimensions that characterize this paradigm shift and establish a developmental taxonomy. We organize core methodologies and survey applications across general and professional domains. Furthermore, we analyze frontier challenges and identify promising research directions, ultimately providing a clear roadmap for the next generation of agentic evaluation.
논문 링크
더 읽어보기
LLM 기반 지식 그래프 구축: 서베이 / LLM-empowered knowledge graph construction: A survey

논문 소개
지식 그래프(Knowledge Graph, KG)는 구조화된 지식을 표현하고 통합하며 추론하는 데 필수적인 역할을 해왔습니다. 전통적인 KG 구축 방법론은 온톨로지 엔지니어링, 지식 추출, 지식 융합의 세 가지 주요 구성 요소로 이루어져 있으며, 이러한 접근 방식은 확장성, 전문가 의존성, 파이프라인 단편화와 같은 여러 문제에 직면해 있습니다. 이러한 한계는 자가 진화하는 대규모 동적 KG의 개발을 저해하고 있습니다. 대규모 언어 모델(Large Language Model, LLM)의 출현은 이러한 병목 현상을 극복할 수 있는 혁신적인 패러다임을 제시합니다.
LLM은 대규모 사전 학습과 emergent generalization 기능을 통해 비구조적 텍스트에서 구조화된 표현을 생성하고, 자연어 기반으로 이질적인 지식 소스를 통합하며, 프롬프트 기반 상호작용을 통해 복잡한 KG 구축 워크플로우를 조정하는 세 가지 주요 메커니즘을 가능하게 합니다. 이러한 발전은 규칙 기반 시스템에서 LLM 기반의 통합적이고 적응 가능한 프레임워크로의 패러다임 전환을 의미하며, LLM은 자연어와 구조화된 지식 간의 원활한 연결을 제공하는 인지 엔진으로 발전하고 있습니다.
본 서베이는 LLM 기반의 KG 구축에 대한 포괄적인 분석을 제공하며, 전통적인 KG 구축 방법론을 재조명하고 LLM이 어떻게 온톨로지 엔지니어링, 지식 추출, 지식 융합을 재구성하는지를 체계적으로 검토합니다. 특히, 스키마 기반 패러다임과 스키마 없는 패러다임의 두 가지 상호 보완적인 관점에서 LLM 기반 접근 방식을 분석하여, 각 단계에서의 대표적인 프레임워크와 그 기술적 메커니즘, 한계를 식별합니다.
마지막으로, KG 기반 추론, 동적 지식 메모리, 멀티모달 KG 구축 등 주요 동향과 미래 연구 방향을 제시하여 LLM과 KG 간의 진화하는 상호작용을 명확히 하고, 기호적 지식 엔지니어링과 신경 의미 이해를 연결하는 데 기여하고자 합니다. 이러한 연구는 적응적이고 설명 가능한 지능형 지식 시스템 개발을 위한 중요한 기초를 제공할 것입니다.
논문 초록(Abstract)
지식 그래프(KGs)는 오랫동안 구조화된 지식 표현 및 추론을 위한 기본 인프라로 사용되어 왔습니다. 대규모 언어 모델(LLMs)의 출현으로 KGs의 구축은 규칙 기반 및 통계적 파이프라인에서 언어 기반 및 생성적 프레임워크로의 새로운 패러다임으로 전환되었습니다. 본 서베이는 LLM을 활용한 지식 그래프 구축의 최근 발전에 대한 포괄적인 개요를 제공하며, LLM이 온톨로지 엔지니어링, 지식 추출 및 지식 융합의 고전적인 3단계 파이프라인을 어떻게 재구성하는지를 체계적으로 분석합니다. 먼저 전통적인 KG 방법론을 재검토하여 개념적 기초를 확립한 후, 구조, 정규화 및 일관성을 강조하는 스키마 기반 패러다임과 유연성, 적응성 및 개방적 발견을 강조하는 스키마 자유 패러다임이라는 두 가지 상호 보완적인 관점에서 LLM 기반의 새로운 접근 방식을 검토합니다. 각 단계에서 우리는 대표적인 프레임워크를 종합하고, 그 기술적 메커니즘을 분석하며, 한계를 식별합니다. 마지막으로, 본 서베이는 LLM을 위한 KG 기반 추론, 에이전트 시스템을 위한 동적 지식 메모리, 멀티모달 KG 구축 등 주요 트렌드와 미래 연구 방향을 제시합니다. 이 체계적인 리뷰를 통해 우리는 LLM과 지식 그래프 간의 진화하는 상호작용을 명확히 하고, 상징적 지식 엔지니어링과 신경 의미 이해를 연결하여 적응 가능하고 설명 가능한 지능형 지식 시스템 개발을 목표로 합니다.
Knowledge Graphs (KGs) have long served as a fundamental infrastructure for structured knowledge representation and reasoning. With the advent of Large Language Models (LLMs), the construction of KGs has entered a new paradigm-shifting from rule-based and statistical pipelines to language-driven and generative frameworks. This survey provides a comprehensive overview of recent progress in LLM-empowered knowledge graph construction, systematically analyzing how LLMs reshape the classical three-layered pipeline of ontology engineering, knowledge extraction, and knowledge fusion. We first revisit traditional KG methodologies to establish conceptual foundations, and then review emerging LLM-driven approaches from two complementary perspectives: schema-based paradigms, which emphasize structure, normalization, and consistency; and schema-free paradigms, which highlight flexibility, adaptability, and open discovery. Across each stage, we synthesize representative frameworks, analyze their technical mechanisms, and identify their limitations. Finally, the survey outlines key trends and future research directions, including KG-based reasoning for LLMs, dynamic knowledge memory for agentic systems, and multimodal KG construction. Through this systematic review, we aim to clarify the evolving interplay between LLMs and knowledge graphs, bridging symbolic knowledge engineering and neural semantic understanding toward the development of adaptive, explainable, and intelligent knowledge systems.
논문 링크
현실 세계에서의 잠재적 행동 세계 모델 학습 / Learning Latent Action World Models In The Wild

논문 소개
현실 세계에서 추론과 계획을 수행할 수 있는 에이전트는 자신의 행동 결과를 예측하는 능력이 필요합니다. 세계 모델은 이러한 능력을 가지고 있지만, 일반적으로 행동 레이블이 필요하며, 이는 대규모로 얻기 복잡합니다. 이에 따라, 우리는 비디오만으로 행동 공간을 학습할 수 있는 잠재 행동 모델의 학습을 제안합니다. 본 연구는 단순한 로봇 시뮬레이션, 비디오 게임 또는 조작 데이터에 초점을 맞춘 기존 연구의 범위를 확장하여, 실제 비디오에서 잠재 행동 세계 모델을 학습하는 문제를 다룹니다. 다양한 비디오에서 발생하는 환경 소음이나 공통적인 구현체의 부재와 같은 도전 과제를 해결하기 위해, 행동이 따라야 할 속성과 관련된 아키텍처 선택 및 평가를 논의합니다. 우리는 제한된 연속 잠재 행동이 실제 비디오의 복잡한 행동을 포착할 수 있음을 발견하였으며, 이는 일반적인 벡터 양자화로는 불가능합니다. 예를 들어, 사람과 같은 에이전트가 방에 들어오는 환경 변화는 비디오 간에 전이될 수 있습니다. 비디오 간의 공통 구현체가 없는 상황에서도, 우리는 주로 카메라에 상대적인 공간에 국한된 잠재 행동을 학습할 수 있었습니다. 그럼에도 불구하고, 우리는 알려진 행동을 잠재 행동으로 매핑하는 컨트롤러를 훈련할 수 있었으며, 이를 통해 잠재 행동을 보편적인 인터페이스로 사용하고, 세계 모델을 통해 계획 작업을 수행할 수 있음을 보여주었습니다. 우리의 분석과 실험은 실제 세계에서 잠재 행동 모델을 확장하는 데 한 걸음 나아가는 결과를 제공합니다.
논문 초록(Abstract)
현실 세계에서 추론 및 계획을 수행할 수 있는 에이전트는 자신의 행동 결과를 예측할 수 있는 능력이 필요합니다. 세계 모델은 이러한 능력을 갖추고 있지만, 대부분의 경우 행동 레이블이 필요하며, 이는 대규모로 획득하기 복잡할 수 있습니다. 이는 비디오만으로 행동 공간을 학습할 수 있는 잠재 행동 모델의 학습을 유도합니다. 우리의 연구는 단순 로봇 시뮬레이션, 비디오 게임 또는 조작 데이터에 초점을 맞춘 기존 연구의 범위를 확장하여, 실제 환경에서 촬영된 비디오에서 잠재 행동 세계 모델을 학습하는 문제를 다룹니다. 이는 더 풍부한 행동을 포착할 수 있게 해주지만, 환경 소음이나 비디오 간 공통 구현체의 부족과 같은 비디오 다양성에서 비롯되는 도전 과제를 도입합니다. 이러한 도전 과제 중 일부를 해결하기 위해, 우리는 행동이 따라야 할 특성과 관련된 구조적 선택 및 평가에 대해 논의합니다. 우리는 연속적이지만 제한된 잠재 행동이 실제 환경 비디오에서 행동의 복잡성을 포착할 수 있음을 발견했습니다. 이는 일반적인 벡터 양자화가 할 수 없는 것입니다. 예를 들어, 사람과 같은 에이전트가 방에 들어오는 환경의 변화가 비디오 간에 전이될 수 있음을 발견했습니다. 이는 실제 환경 비디오에 특화된 행동을 학습할 수 있는 능력을 강조합니다. 비디오 간 공통 구현체가 없는 상황에서, 우리는 주로 카메라에 상대적인 공간에서 국소화된 잠재 행동을 학습할 수 있습니다. 그럼에도 불구하고, 우리는 알려진 행동을 잠재 행동으로 매핑하는 컨트롤러를 훈련할 수 있으며, 이를 통해 잠재 행동을 보편적인 인터페이스로 사용하고, 우리의 세계 모델로 계획 작업을 수행하여 행동 조건화 기준선과 유사한 성능을 달성할 수 있습니다. 우리의 분석 및 실험은 잠재 행동 모델을 현실 세계로 확장하는 한 걸음을 제공합니다.
Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
논문 링크
분포 정렬 시퀀스 증류를 통한 우수한 장기 사고 연쇄 추론 / Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning


논문 소개
DASD-4B-Thinking은 경량화된 오픈 소스 추론 모델로, 수학, 과학적 추론, 코드 생성 등 다양한 분야에서 최첨단 성능을 달성합니다. 본 연구는 기존의 지도 학습 방식인 교사 생성 응답에 대한 SFT(supervised fine-tuning) 접근법을 비판적으로 분석하고, 이로 인해 발생하는 여러 한계를 지적합니다. 특히, 현재의 시퀀스 수준 증류(sequence-level distillation) 방법론이 교사의 출력 분포를 학생 모델이 효과적으로 학습하지 못하게 하는 문제를 다루고 있습니다.
이 연구에서는 세 가지 주요 한계를 식별합니다. 첫째, 교사의 시퀀스 수준 분포를 충분히 표현하지 못하는 점, 둘째, 교사의 출력 분포와 학생의 학습 능력 간의 불일치, 셋째, 교사 강제 훈련과 자가 회귀 추론 간의 노출 편향(exposure bias)입니다. 이러한 문제를 해결하기 위해, 본 논문은 Distribution-Aligned Sequence Distillation이라는 새로운 방법론을 제안합니다. 이 방법론은 교사 모델의 출력 분포를 보다 정교하게 표현하고, 학생 모델의 학습 능력과 교사 모델의 출력 간의 정렬을 개선하며, 노출 편향을 최소화하는 훈련 기법을 포함합니다.
DASD-4B-Thinking은 단 448K의 훈련 샘플을 사용하여 경쟁력 있는 성과를 달성하며, 이는 기존의 오픈 소스 모델들이 사용하는 데이터 수보다 현저히 적은 수치입니다. 이러한 성과는 교사-학생 상호작용의 개선이 모델 성능 향상에 기여했음을 보여줍니다. 본 연구는 커뮤니티 연구를 지원하기 위해 모델과 훈련 데이터셋을 공개하며, 향후 Long-CoT Reasoning 분야에서의 발전에 기여할 수 있는 가능성을 제시합니다. DASD-4B-Thinking의 방법론적 혁신은 기존 연구와의 차별성을 부각시키며, 보다 효율적이고 효과적인 추론 모델 개발에 기여할 것으로 기대됩니다.
논문 초록(Abstract)
이 연구에서는 경량이면서도 매우 능력 있는 완전 오픈 소스 추론 모델인 DASD-4B-Thinking을 소개합니다. 이 모델은 수학, 과학적 추론 및 코드 생성 분야의 도전적인 벤치마크에서 동등한 규모의 오픈 소스 모델들 중에서 SOTA 성능을 달성하며, 몇몇 더 큰 모델들보다도 우수한 성과를 보입니다. 우리는 먼저 커뮤니티에서 널리 채택된 증류 패러다임인 교사 생성 응답에 대한 SFT(교사 학습) 즉, 시퀀스 수준의 증류를 비판적으로 재검토합니다. 이 방식에 따라 최근의 일련의 연구들이 놀라운 효율성과 강력한 경험적 성능을 입증했지만, 이들은 주로 SFT 관점에 기반하고 있습니다. 결과적으로 이러한 접근 방식은 SFT 데이터 필터링을 위한 휴리스틱 규칙 설계에 주로 집중하고, 증류의 핵심 원리인 학생 모델이 교사의 전체 출력 분포를 학습하여 일반화 능력을 상속받도록 하는 것을 대체로 간과하고 있습니다. 구체적으로, 우리는 현재 관행에서 세 가지 중요한 한계를 식별합니다: i) 교사의 시퀀스 수준 분포에 대한 불충분한 표현; ii) 교사의 출력 분포와 학생의 학습 능력 간의 불일치; iii) 교사 강제 훈련과 자가 회귀 추론 간의 노출 편향. 요약하자면, 이러한 단점은 증류 과정 전반에 걸쳐 명시적인 교사-학생 상호작용의 체계적인 부재를 반영하며, 증류의 본질이 충분히 활용되지 못하게 합니다. 이러한 문제를 해결하기 위해, 우리는 향상된 시퀀스 수준 증류 훈련 파이프라인을 형성하는 여러 방법론적 혁신을 제안합니다. 놀랍게도, DASD-4B-Thinking은 448K 훈련 샘플만을 사용하여 경쟁력 있는 결과를 얻으며, 이는 대부분의 기존 오픈 소스 노력에서 사용되는 샘플 수보다 한 자릿수 적습니다. 커뮤니티 연구를 지원하기 위해, 우리는 모델과 훈련 데이터셋을 공개적으로 배포합니다.
In this report, we introduce DASD-4B-Thinking, a lightweight yet highly capable, fully open-source reasoning model. It achieves SOTA performance among open-source models of comparable scale across challenging benchmarks in mathematics, scientific reasoning, and code generation -- even outperforming several larger models. We begin by critically reexamining a widely adopted distillation paradigm in the community: SFT on teacher-generated responses, also known as sequence-level distillation. Although a series of recent works following this scheme have demonstrated remarkable efficiency and strong empirical performance, they are primarily grounded in the SFT perspective. Consequently, these approaches focus predominantly on designing heuristic rules for SFT data filtering, while largely overlooking the core principle of distillation itself -- enabling the student model to learn the teacher's full output distribution so as to inherit its generalization capability. Specifically, we identify three critical limitations in current practice: i) Inadequate representation of the teacher's sequence-level distribution; ii) Misalignment between the teacher's output distribution and the student's learning capacity; and iii) Exposure bias arising from teacher-forced training versus autoregressive inference. In summary, these shortcomings reflect a systemic absence of explicit teacher-student interaction throughout the distillation process, leaving the essence of distillation underexploited. To address these issues, we propose several methodological innovations that collectively form an enhanced sequence-level distillation training pipeline. Remarkably, DASD-4B-Thinking obtains competitive results using only 448K training samples -- an order of magnitude fewer than those employed by most existing open-source efforts. To support community research, we publicly release our models and the training dataset.
논문 링크
더 읽어보기
미래를 레이블로: 실제 결과로부터의 확장 가능한 감독 / Future-as-Label: Scalable Supervision from Real-World Outcomes

논문 소개
시간의 흐름은 실제 사건에 대한 예측을 검증 가능한 결과로 귀결시키는 중요한 구조를 제공합니다. 이를 활용하여, 본 연구는 강화학습(Reinforcement Learning, RL) 분야에서 검증 가능한 보상(Verifiable Rewards)을 통해 시간에 따른 실제 예측을 수행하는 방법론을 제안합니다. 저자들은 언어 모델을 훈련시켜 인과적으로 마스킹된 정보로부터 확률적 예측을 생성하고, 사건이 해결된 후 적절한 스코어링 규칙을 보상 함수로 사용합니다. 이러한 접근은 실현된 결과에 의해 학습이 주도되며, 개방형 세계 예측에서 확장 가능한 결과 기반 감독을 가능하게 합니다.
본 연구의 핵심 기여는 Foresight Learning이라는 새로운 학습 프레임워크를 통해, 예측 시점에서 모델이 사용할 수 있는 정보에 제한을 두고, 결과가 실현될 때까지 평가를 연기하는 인과적 제약을 포함하는 것입니다. 이로 인해, 즉각적인 피드백이 없는 환경에서도 효과적으로 학습할 수 있는 가능성을 열어줍니다. 실험 결과, Qwen3-32B 모델은 Foresight Learning을 통해 Brier score를 27% 개선하고, 보정 오류를 절반으로 줄이며, Qwen3-235B 모델보다도 두 가지 미래 사건 예측 작업과 Metaculus 벤치마크에서 우수한 성능을 보였습니다.
이 연구는 실제 사건의 최종 해결에 의해 제공되는 감독 체제를 탐구하며, 결과 기반 감독이 과신한 잘못된 예측에 큰 패널티를 부여함으로써 보정 개선의 주요 이점을 제공함을 보여줍니다. 이러한 접근은 언어 모델의 성능을 향상시키는 데 기여할 뿐만 아니라, 실제 세계 데이터로부터 효과적인 감독이 발생할 수 있음을 입증합니다.
논문 초록(Abstract)
시간은 자유로운 감독을 생성합니다: 실제 세계 사건에 대한 예측은 검증 가능한 결과로 귀결됩니다. 시간의 경과는 주석이 필요 없는 레이블을 제공합니다. 이러한 구조를 활용하기 위해, 우리는 시간에 따른 실제 예측에 대해 검증 가능한 보상으로 강화 학습을 확장합니다. 우리는 사건이 해결된 후 적절한 점수 규칙을 보상 함수로 사용하여 인과적으로 마스킹된 정보로부터 확률적 예측을 수행하도록 언어 모델을 학습시킵니다. 학습은 전적으로 실현된 결과에 의해 주도되며, 이는 개방형 세계 예측에서 확장 가능한 결과 기반 감독을 가능하게 합니다. 실제 세계 예측 벤치마크에서 Foresight Learning을 사용하여 학습한 Qwen3-32B는 Brier 점수를 27% 개선하고 사전 학습된 기준에 비해 보정 오류를 절반으로 줄이며, 7배의 파라미터 불리함에도 불구하고 구성된 미래 사건 예측 작업과 Metaculus 벤치마크 모두에서 Qwen3-235B를 능가합니다.
Time creates free supervision: forecasts about real-world events resolve to verifiable outcomes. The passage of time provides labels that require no annotation. To exploit this structure, we extend reinforcement learning with verifiable rewards to real-world prediction over time. We train language models to make probabilistic forecasts from causally masked information, using proper scoring rules as the reward function once events resolve. Learning is driven entirely by realized outcomes, enabling scalable outcome-based supervision in open-world prediction. On real-world forecasting benchmarks, Qwen3-32B trained using Foresight Learning improves Brier score by 27% and halves calibration error relative to its pretrained baseline, and outperforms Qwen3-235B on both constructed future-event prediction tasks and the Metaculus benchmark despite a 7x parameter disadvantage.
논문 링크
더 읽어보기
희소성을 보상하는 방법: LLM에서 창의적 문제 해결을 위한 유니크성 인식 강화학습 / Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs
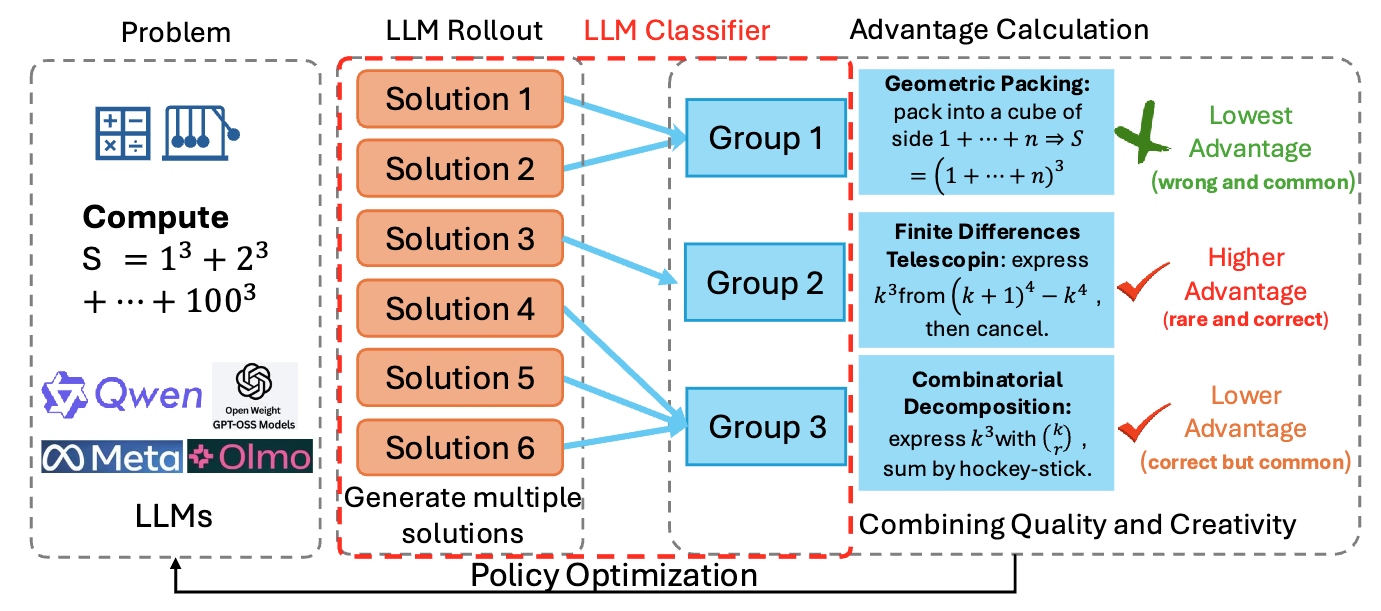
논문 소개
강화학습(Reinforcement Learning, RL)은 대규모 언어 모델(Large Language Models, LLMs)의 사후 학습에서 복잡한 추론 작업을 수행하는 데 중요한 역할을 하고 있다. 그러나 RL 접근법은 탐색 붕괴(exploration collapse) 문제에 직면해 있으며, 이는 정책이 조기에 소수의 지배적인 추론 패턴에 집중되도록 유도한다. 이러한 현상은 pass@1 성능을 향상시키지만, pass@k 에서의 다양성과 성과를 제한하는 결과를 초래한다. 본 연구에서는 이러한 문제를 해결하기 위해 Uniqueness-Aware Reinforcement Learning(UARL)이라는 새로운 방법론을 제안한다. UARL은 롤아웃 수준의 목표를 설정하여 드물고 높은 수준의 전략을 보상하는 방식으로 작동한다.
UARL의 핵심은 LLM 기반의 판별기를 활용하여 동일한 문제에 대한 롤아웃을 고수준 해결 전략에 따라 클러스터링하고, 클러스터 크기에 반비례하여 정책의 이점을 재조정하는 것이다. 이를 통해 올바르지만 새로운 전략에 더 높은 보상을 부여하여, 반복적이고 유사한 해결책보다 창의적이고 다양한 해결책을 탐색하도록 유도한다. 이 방법은 수학, 물리학, 의학과 같은 다양한 벤치마크에서 pass@k 성능을 향상시키고, pass@1 성능을 유지하면서도 더 다양한 해결 전략을 발견하는 데 기여한다.
기존의 RL 방법들은 주로 토큰 수준에서의 다양성을 촉진하는 데 집중해왔으나, 이는 고수준 해결 전략의 다양성을 충분히 반영하지 못했다. UARL은 롤아웃 세트의 다양성을 직접적으로 조정하여, 각 롤아웃의 전략 고유성을 평가하고 이를 정책 최적화에 통합함으로써 이러한 한계를 극복한다. 결과적으로, UARL은 높은 샘플링 예산에서도 pass@k 성능을 개선하고, pass@k 곡선 아래 면적(AUC@K)을 증가시키며, 더 많은 다양한 해결 전략을 발견할 수 있도록 한다.
본 연구는 RL 훈련된 LLM에서 탐색 붕괴를 완화하는 효과적인 접근법을 제시하며, 다양한 문제 해결 과정에서의 전략적 접근 방식을 명확히 하고, 다양한 해결책 간의 유사성과 차이를 강조하는 데 기여한다. UARL은 복잡한 추론 작업에서의 성능을 향상시키는 데 중요한 혁신으로 자리잡을 것으로 기대된다.
논문 초록(Abstract)
강화학습(RL)은 복잡한 추론 작업을 위한 사후 학습 대규모 언어 모델(LLM)의 중심 패러다임이 되었지만, 탐색 붕괴 문제로 어려움을 겪는 경우가 많습니다. 정책이 조기에 지배적인 추론 패턴의 소수 집합에 집중되어 pass@1은 개선되지만, 롤아웃 수준의 다양성과 pass@k에서의 이득이 제한됩니다. 우리는 이러한 실패가 솔루션 집합에 대한 다양성보다는 지역 토큰 행동을 정규화하는 데서 비롯된다고 주장합니다. 이를 해결하기 위해 우리는 드문 고수준 전략을 나타내는 올바른 솔루션에 명시적으로 보상을 주는 롤아웃 수준의 목표인 유니크니스 인식 강화학습(Unique-Aware Reinforcement Learning)을 제안합니다. 우리의 방법은 동일한 문제에 대한 롤아웃을 고수준 솔루션 전략에 따라 클러스터링하기 위해 LLM 기반의 판단자를 사용하며, 피상적인 변동은 무시하고 클러스터 크기에 따라 정책 이점을 역으로 재조정합니다. 그 결과, 올바르지만 새로운 전략이 중복된 전략보다 더 높은 보상을 받게 됩니다. 수학, 물리학, 의학 추론 벤치마크를 통해 우리의 접근 방식은 대규모 샘플링 예산에서 consistently pass@$k$를 개선하고 pass@k 곡선 아래 면적(AUC@K)을 증가시키면서 pass@1을 희생하지 않고 탐색을 지속하며 더 다양한 솔루션 전략을 대규모로 발견합니다.
Reinforcement learning (RL) has become a central paradigm for post-training large language models (LLMs), particularly for complex reasoning tasks, yet it often suffers from exploration collapse: policies prematurely concentrate on a small set of dominant reasoning patterns, improving pass@1 while limiting rollout-level diversity and gains in pass@k. We argue that this failure stems from regularizing local token behavior rather than diversity over sets of solutions. To address this, we propose Uniqueness-Aware Reinforcement Learning, a rollout-level objective that explicitly rewards correct solutions that exhibit rare high-level strategies. Our method uses an LLM-based judge to cluster rollouts for the same problem according to their high-level solution strategies, ignoring superficial variations, and reweights policy advantages inversely with cluster size. As a result, correct but novel strategies receive higher rewards than redundant ones. Across mathematics, physics, and medical reasoning benchmarks, our approach consistently improves pass@k across large sampling budgets and increases the area under the pass@k curve (AUC@K) without sacrificing pass@1, while sustaining exploration and uncovering more diverse solution strategies at scale.
논문 링크
더 읽어보기
VIBE: 시각적 지침 기반 편집기 / VIBE: Visual Instruction Based Editor

논문 소개
지시 기반 이미지 편집은 자연어 명령을 통해 사용자가 시각적 콘텐츠를 수정할 수 있는 혁신적인 접근 방식으로, 콘텐츠 생성의 민주화를 촉진하는 중요한 기술로 자리잡고 있다. 최근 몇 년간 이 분야는 급속히 발전하였으나, 많은 오픈 소스 모델들이 여전히 품질과 효율성 면에서 한계를 보이고 있다. 본 연구에서는 이러한 문제를 해결하기 위해, 2B 파라미터의 최신 Qwen3-VL 모델과 1.6B 파라미터의 Sana1.5 디퓨전 모델을 결합한 고속 지시 기반 이미지 편집 파이프라인을 제안한다. 이 방법론은 낮은 비용의 추론과 엄격한 출처 일관성을 목표로 하면서도, 다양한 편집 카테고리에서 높은 품질을 유지할 수 있도록 설계되었다.
제안된 방법은 ImgEdit 및 GEdit 벤치마크에서 평가되었으며, 기존의 무거운 모델들과 비교하여 동등하거나 더 나은 성능을 보여주었다. 특히, 입력 이미지를 보존해야 하는 편집 작업에서 강력한 성능을 발휘하며, 예를 들어 속성 조정, 객체 제거, 배경 편집 및 목표 대체와 같은 작업에서 두각을 나타낸다. 이 모델은 24GB의 GPU 메모리 내에서 작동하며, NVIDIA H100에서 약 4초 만에 최대 2K 해상도의 편집된 이미지를 생성할 수 있는 효율성을 자랑한다.
본 연구는 지시 기반 이미지 편집의 세 가지 주요 설계 축인 참조 이미지 주입 방식, 지시 해석 방법, 학습 파이프라인 구성에 대한 혁신적인 접근을 통해, 사용자가 보다 직관적으로 편집 작업을 수행할 수 있도록 지원한다. 특히, 지시 조정된 **비주얼 언어 모델(Visual Language Model, VLM)**을 활용하여 사용자의 편집 의도를 명확하게 해석하고, 이를 기반으로 안정적인 지침을 제공하는 점에서 큰 기여를 한다. 이러한 접근은 지시 기반 편집의 품질을 높이는 동시에, 실제 사용자 요청에 대한 일관성을 유지하는 데 중점을 두고 있다.
결론적으로, 본 연구는 상대적으로 작은 모델로도 고품질의 지시 기반 이미지 편집이 가능함을 입증하며, 향후 연구와 실용적인 응용 분야에 중요한 기초 자료를 제공할 것으로 기대된다.
논문 초록(Abstract)
지침 기반 이미지 편집은 생성적 AI 분야에서 가장 빠르게 발전하고 있는 영역 중 하나입니다. 지난 1년 동안 이 분야는 수십 개의 오픈 소스 모델이 출시되고 고성능 상용 시스템과 함께 새로운 수준에 도달했습니다. 그러나 현재 실제 품질을 달성하는 오픈 소스 접근 방식은 제한적입니다. 또한, 이러한 파이프라인의 주요 선택인 디퓨전 백본은 많은 배포 및 연구 환경에서 크고 계산 비용이 많이 드는 경우가 많으며, 일반적으로 사용되는 변형은 보통 60억에서 200억 개의 매개변수를 포함하고 있습니다. 본 논문에서는 현대의 20억 매개변수 Qwen3-VL 모델을 사용하여 편집 과정을 안내하고, 16억 매개변수 디퓨전 모델 Sana1.5를 이미지 생성에 활용하는 컴팩트하고 고처리량의 지침 기반 이미지 편집 파이프라인을 제안합니다. 아키텍처, 데이터 처리, 학습 구성 및 평가에 대한 우리의 설계 결정은 낮은 비용의 추론과 엄격한 출처 일관성을 목표로 하면서 이 규모에서 가능한 주요 편집 범주 전반에 걸쳐 높은 품질을 유지합니다. ImgEdit 및 GEdit 벤치마크에서 평가된 결과, 제안된 방법은 매개변수가 몇 배 더 많고 추론 비용이 높은 상당히 무거운 기준선의 성능과 일치하거나 이를 초과하며, 입력 이미지를 보존해야 하는 편집(예: 속성 조정, 객체 제거, 배경 편집 및 목표 대체)에 특히 강력합니다. 이 모델은 24GB의 GPU 메모리 내에서 작동하며, NVIDIA H100에서 BF16으로 약 4초 만에 최대 2K 해상도의 편집된 이미지를 생성하며, 추가적인 추론 최적화나 증류 없이 작동합니다.
Instruction-based image editing is among the fastest developing areas in generative AI. Over the past year, the field has reached a new level, with dozens of open-source models released alongside highly capable commercial systems. However, only a limited number of open-source approaches currently achieve real-world quality. In addition, diffusion backbones, the dominant choice for these pipelines, are often large and computationally expensive for many deployments and research settings, with widely used variants typically containing 6B to 20B parameters. This paper presents a compact, high-throughput instruction-based image editing pipeline that uses a modern 2B-parameter Qwen3-VL model to guide the editing process and the 1.6B-parameter diffusion model Sana1.5 for image generation. Our design decisions across architecture, data processing, training configuration, and evaluation target low-cost inference and strict source consistency while maintaining high quality across the major edit categories feasible at this scale. Evaluated on the ImgEdit and GEdit benchmarks, the proposed method matches or exceeds the performance of substantially heavier baselines, including models with several times as many parameters and higher inference cost, and is particularly strong on edits that require preserving the input image, such as an attribute adjustment, object removal, background edits, and targeted replacement. The model fits within 24 GB of GPU memory and generates edited images at up to 2K resolution in approximately 4 seconds on an NVIDIA H100 in BF16, without additional inference optimizations or distillation.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()