[2026/01/19 ~ 25] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 수동적 응답을 넘어선 "에이전틱 추론(Agentic Reasoning)"의 전방위 확산: 이번 주 가장 두드러진 특징은 LLM을 단순한 질의응답 도구가 아닌, 스스로 계획하고 행동하는 '에이전트'로 재정의하려는 시도입니다. "에이전틱 추론 서베이" 논문은 환경과의 상호작용을 통해 스스로 진화하는 에이전트의 로드맵을 제시했으며, Agentic-R은 검색(Retrieval) 과정 자체를 에이전트의 다단계 추론에 최적화하여 답변의 유용성을 극대화했습니다. 특히 TritorX나 Agentic EDA와 같이 반도체 설계(ASIC)나 커널 생성 등 전문적인 공학 분야에 에이전트를 도입하여 복잡한 워크플로우를 자율화하려는 시도가 눈에 띕니다. 이는 AI가 인간의 지시를 기다리는 수준을 지나, 특정 도메인 내에서 문제 해결을 주도하는 독립적인 운영체제(OS)와 같은 역할을 수행하기 시작했음을 시사합니다.
수동적 응답을 넘어선 "에이전틱 추론(Agentic Reasoning)"의 전방위 확산: 이번 주 가장 두드러진 특징은 LLM을 단순한 질의응답 도구가 아닌, 스스로 계획하고 행동하는 '에이전트'로 재정의하려는 시도입니다. "에이전틱 추론 서베이" 논문은 환경과의 상호작용을 통해 스스로 진화하는 에이전트의 로드맵을 제시했으며, Agentic-R은 검색(Retrieval) 과정 자체를 에이전트의 다단계 추론에 최적화하여 답변의 유용성을 극대화했습니다. 특히 TritorX나 Agentic EDA와 같이 반도체 설계(ASIC)나 커널 생성 등 전문적인 공학 분야에 에이전트를 도입하여 복잡한 워크플로우를 자율화하려는 시도가 눈에 띕니다. 이는 AI가 인간의 지시를 기다리는 수준을 지나, 특정 도메인 내에서 문제 해결을 주도하는 독립적인 운영체제(OS)와 같은 역할을 수행하기 시작했음을 시사합니다.
![]() 데이터와 모델의 "자기 주도적 진화(Self-Evolution)"와 확장: 학습 방식에 있어서는 고정된 데이터셋을 탈피하여, 에이전트가 직접 경험을 쌓으며 성장하는 '진화적 패러다임'이 핵심으로 부상했습니다. EvoCUA는 수만 개의 샌드박스 환경에서 합성된 경험을 통해 컴퓨터 사용 능력을 스스로 강화하며, UFT는 인간의 가이드(SFT)와 모델의 자율적 탐색(RFT)을 통합해 추론 성능의 수렴 속도를 기하급수적으로 높였습니다. 또한 STEM은 고정된 연산 구조 대신 임베딩 모듈을 통해 파라미터를 유동적으로 확장함으로써, 긴 문맥에서도 더 많은 지식을 안정적으로 처리할 수 있는 구조적 유연성을 확보했습니다. 이러한 연구들은 모델이 배포된 이후에도 외부 환경과의 피드백 루프를 통해 끊임없이 성능을 개선할 수 있는 '살아있는 시스템'으로 진화하고 있음을 보여줍니다.
데이터와 모델의 "자기 주도적 진화(Self-Evolution)"와 확장: 학습 방식에 있어서는 고정된 데이터셋을 탈피하여, 에이전트가 직접 경험을 쌓으며 성장하는 '진화적 패러다임'이 핵심으로 부상했습니다. EvoCUA는 수만 개의 샌드박스 환경에서 합성된 경험을 통해 컴퓨터 사용 능력을 스스로 강화하며, UFT는 인간의 가이드(SFT)와 모델의 자율적 탐색(RFT)을 통합해 추론 성능의 수렴 속도를 기하급수적으로 높였습니다. 또한 STEM은 고정된 연산 구조 대신 임베딩 모듈을 통해 파라미터를 유동적으로 확장함으로써, 긴 문맥에서도 더 많은 지식을 안정적으로 처리할 수 있는 구조적 유연성을 확보했습니다. 이러한 연구들은 모델이 배포된 이후에도 외부 환경과의 피드백 루프를 통해 끊임없이 성능을 개선할 수 있는 '살아있는 시스템'으로 진화하고 있음을 보여줍니다.
![]() 복잡한 실세계 적용을 위한 "확장 가능한 에이전트 인프라" 구축: 에이전트 기술이 성숙함에 따라, 이를 실제 산업 현장(Real-world)의 대규모 시스템에 안착시키기 위한 인프라 연구가 가속화되고 있습니다. **Confucius Code Agent (CCA)**는 거대 코드베이스를 다루기 위해 계층적 메모리와 메타 에이전트 구조를 도입하여 실질적인 소프트웨어 엔지니어링 수행 능력을 증명했습니다. UniversalRAG는 텍스트를 넘어 이미지, 비디오 등 다양한 모달리티를 통합 관리하며 검색의 세밀함을 높였고, MAS 실증 연구는 LangChain, AutoGen 등 주요 프레임워크의 유지보수 패턴을 분석해 시스템적 신뢰성과 인프라의 중요성을 강조했습니다. 이는 단일 모델의 성능 자랑을 넘어, 다수의 에이전트가 협업하고 방대한 데이터를 안전하게 처리할 수 있는 '에이전트 생태계'의 기틀을 마련하려는 실용적 움직임입니다.
복잡한 실세계 적용을 위한 "확장 가능한 에이전트 인프라" 구축: 에이전트 기술이 성숙함에 따라, 이를 실제 산업 현장(Real-world)의 대규모 시스템에 안착시키기 위한 인프라 연구가 가속화되고 있습니다. **Confucius Code Agent (CCA)**는 거대 코드베이스를 다루기 위해 계층적 메모리와 메타 에이전트 구조를 도입하여 실질적인 소프트웨어 엔지니어링 수행 능력을 증명했습니다. UniversalRAG는 텍스트를 넘어 이미지, 비디오 등 다양한 모달리티를 통합 관리하며 검색의 세밀함을 높였고, MAS 실증 연구는 LangChain, AutoGen 등 주요 프레임워크의 유지보수 패턴을 분석해 시스템적 신뢰성과 인프라의 중요성을 강조했습니다. 이는 단일 모델의 성능 자랑을 넘어, 다수의 에이전트가 협업하고 방대한 데이터를 안전하게 처리할 수 있는 '에이전트 생태계'의 기틀을 마련하려는 실용적 움직임입니다.
대규모 언어 모델을 위한 에이전틱 추론 / Agentic Reasoning for Large Language Models
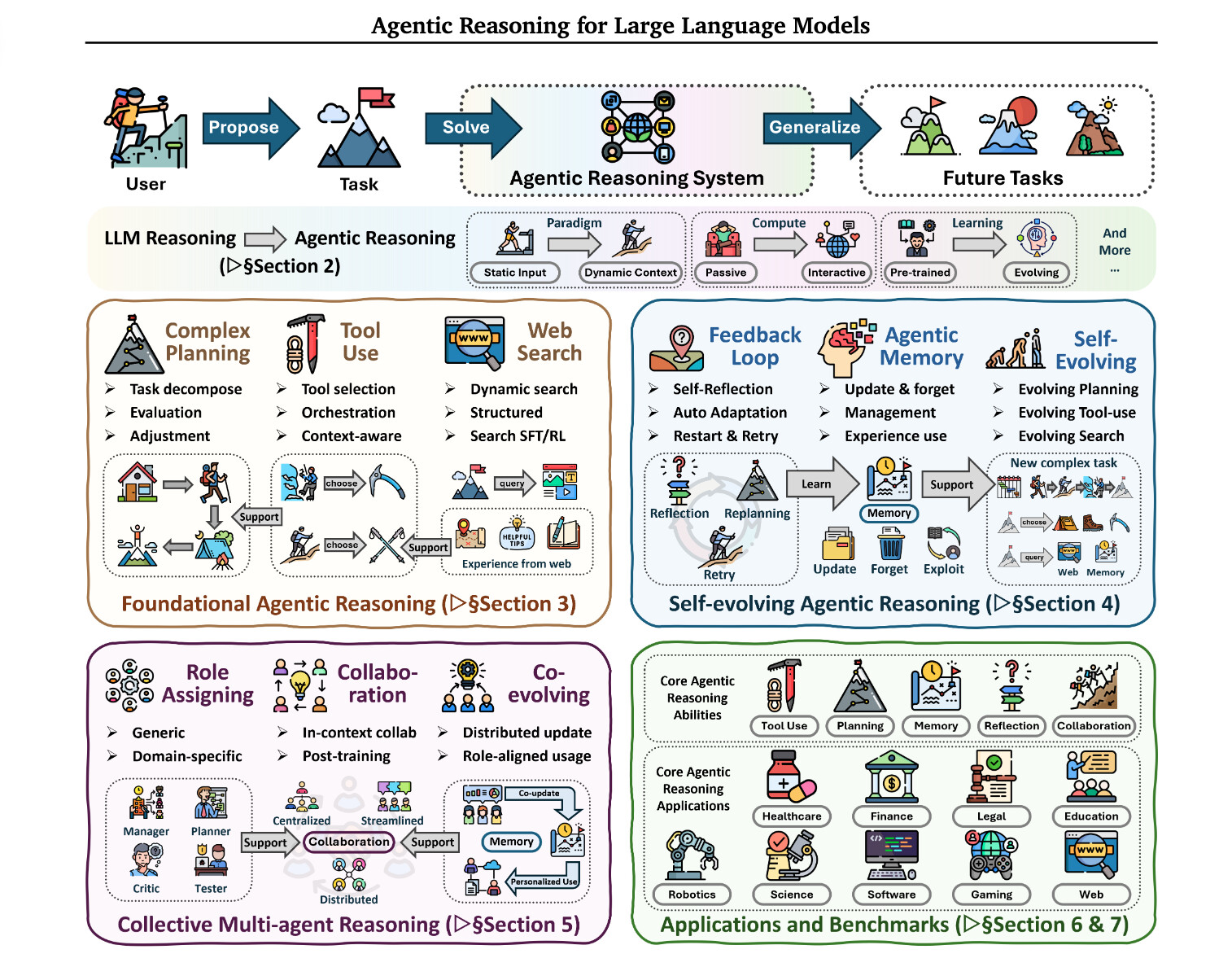
논문 소개
추론은 추론, 문제 해결 및 의사 결정의 기초가 되는 인지 과정입니다. 대규모 언어 모델(LLM)은 폐쇄형 환경에서 강력한 추론 능력을 보여주지만, 개방적이고 동적인 환경에서는 어려움을 겪습니다. 에이전틱 추론은 LLM을 자율적인 에이전트로 재구성하여 지속적인 상호작용을 통해 계획, 행동 및 학습을 수행하는 패러다임의 전환을 나타냅니다. 이 서베이에서는 에이전틱 추론을 세 가지 보완적인 차원으로 정리합니다. 첫째, 환경의 동적 특성을 세 가지 층으로 구분합니다: 기본 에이전틱 추론은 안정적인 환경에서 계획, 도구 사용 및 탐색을 포함한 핵심 단일 에이전트 능력을 설정합니다. 둘째, 자기 진화 에이전틱 추론은 피드백, 기억 및 적응을 통해 이러한 능력을 어떻게 개선하는지를 연구합니다. 셋째, 집합적 다중 에이전트 추론은 협력적인 설정에서 조정, 지식 공유 및 공동 목표를 포함한 지능을 확장합니다. 이 연구는 실세계 응용 및 벤치마크에서의 대표적인 에이전틱 추론 프레임워크를 검토하고, 사고와 행동을 연결하는 통합 로드맵을 제시하며, 개인화, 장기 상호작용, 세계 모델링, 확장 가능한 다중 에이전트 학습 및 실제 배치를 위한 거버넌스와 같은 개방된 도전 과제와 미래 방향을 제시합니다.
논문 초록(Abstract)
추론은 추론, 문제 해결 및 의사 결정의 기초가 되는 인지 과정입니다. 대규모 언어 모델(LLM)은 폐쇄된 세계 설정에서 강력한 추론 능력을 보여주지만, 개방적이고 동적인 환경에서는 어려움을 겪습니다. 에이전틱 추론은 LLM을 계획하고 행동하며 지속적인 상호작용을 통해 학습하는 자율 에이전트로 재구성함으로써 패러다임의 전환을 나타냅니다. 본 서베이에서는 에이전틱 추론을 세 가지 상호 보완적인 차원으로 조직합니다. 첫째, 우리는 환경 동역학을 세 가지 층을 통해 특징짓습니다: 안정적인 환경에서 계획, 도구 사용 및 탐색을 포함한 핵심 단일 에이전트 능력을 확립하는 기초 에이전틱 추론; 피드백, 기억 및 적응을 통해 이러한 능력을 어떻게 개선하는지를 연구하는 자기 진화 에이전틱 추론; 그리고 조정, 지식 공유 및 공동 목표를 포함하는 협업 설정으로 지능을 확장하는 집합적 다중 에이전트 추론입니다. 이러한 층을 통해 우리는 구조화된 오케스트레이션을 통해 테스트 시간 상호작용을 확장하는 문맥 내 추론과 강화 학습 및 감독된 파인튜닝을 통해 행동을 최적화하는 사후 학습 추론을 구분합니다. 우리는 또한 과학, 로봇공학, 의료, 자율 연구 및 수학을 포함한 실제 응용 프로그램 및 벤치마크에서 대표적인 에이전틱 추론 프레임워크를 검토합니다. 본 서베이는 에이전틱 추론 방법을 사고와 행동을 연결하는 통합 로드맵으로 종합하고, 개인화, 장기 상호작용, 세계 모델링, 확장 가능한 다중 에이전트 학습 및 실제 배포를 위한 거버넌스를 포함한 개방된 도전 과제와 미래 방향을 제시합니다.
Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
논문 링크
더 읽어보기
에이전틱 검색을 위한 검색기 학습: Agentic-R / Agentic-R: Learning to Retrieve for Agentic Search
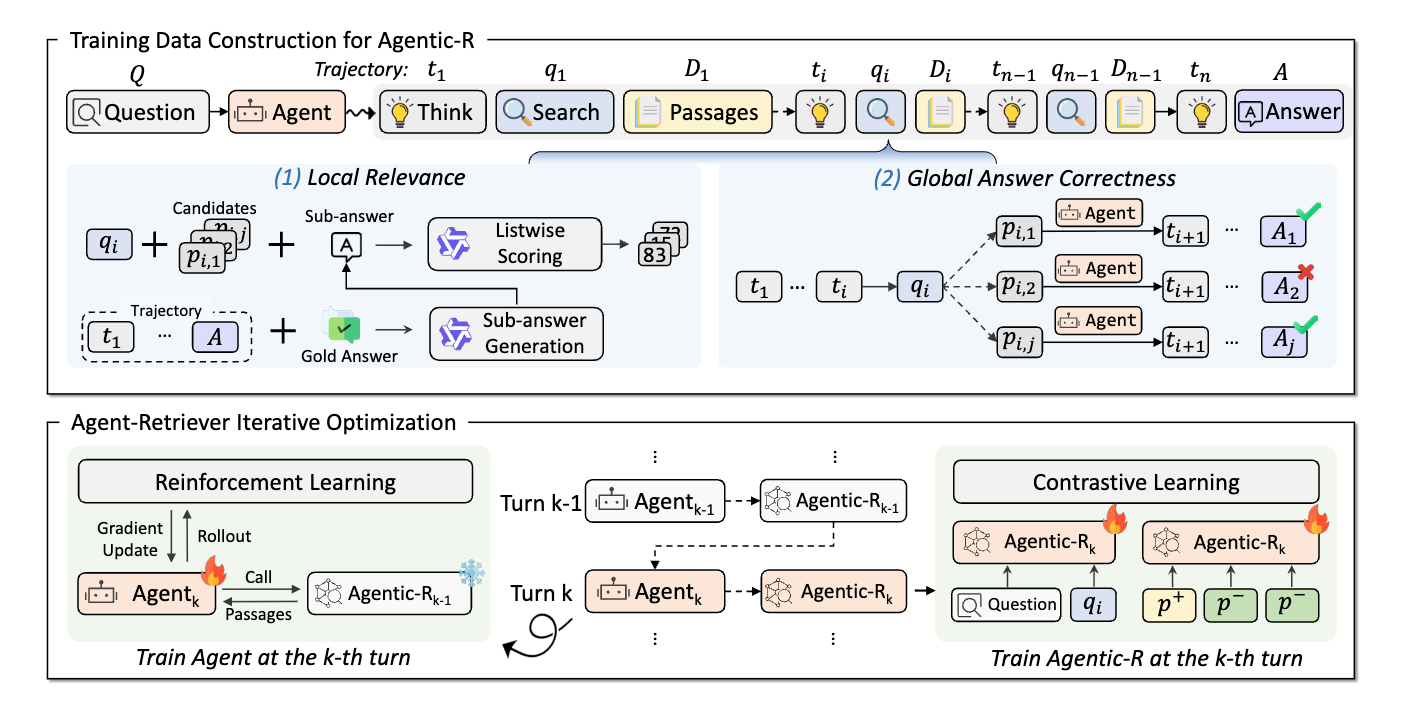
논문 소개
에이전트 검색은 복잡한 질문을 해결하기 위해 다단계 추론과 필요에 따라 검색을 결합하는 강력한 패러다임으로 최근 주목받고 있다. 그러나 에이전트 검색을 위한 검색기 설계는 아직 충분히 탐구되지 않았으며, 기존의 유사성 기반 검색기는 최종 답변 생성을 위한 유용한 정보를 제공하지 못하는 경우가 많다. 본 연구에서는 에이전트 검색에 최적화된 새로운 검색기 훈련 프레임워크인 Agentic-R를 제안한다.
제안된 방법론은 지역 쿼리-구문 관련성과 전역 답변 정확성을 모두 고려하여 구문 유용성을 평가하는 데 중점을 둔다. 이는 다단계 에이전트 검색의 요구를 충족시키기 위해 설계되었으며, 검색 에이전트와 검색기가 양방향으로 반복적으로 최적화되는 훈련 전략을 도입하여 지속적인 성능 향상을 목표로 한다. 기존의 검색기 모델들이 고정된 질문으로 한 번만 훈련되는 것과 달리, Agentic-R는 에이전트로부터 진화하는 고품질 쿼리를 활용하여 지속적으로 개선된다.
본 연구는 일곱 개의 단일 홉 및 다중 홉 질문 응답(QA) 벤치마크에서 Agentic-R의 성능을 평가하였으며, 다양한 검색 에이전트와의 비교를 통해 우수성을 입증하였다. 실험 결과는 Agentic-R가 기존의 강력한 기준선을 초과하는 성능을 보여주며, 제안된 훈련 프레임워크의 효과성을 입증한다.
이 연구는 에이전트 검색 분야에서의 새로운 접근 방식을 제안하며, 검색기 설계에 대한 중요한 통찰을 제공한다. 향후 연구에서는 이 프레임워크를 더욱 발전시키고 다양한 도메인에 적용할 수 있는 가능성을 탐구할 예정이다. Agentic-R는 에이전트 검색의 성능을 향상시키는 데 기여할 것으로 기대되며, 다양한 응용 분야에서 활용될 수 있는 잠재력을 지니고 있다.
논문 초록(Abstract)
최근 에이전트 기반 검색(agentic search)은 에이전트가 복잡한 질문을 해결하기 위해 다단계 추론과 필요에 따라 검색을 결합하는 강력한 패러다임으로 부상하였습니다. 그 성공에도 불구하고, 에이전트 기반 검색을 위한 검색기 설계 방법은 여전히 충분히 탐구되지 않았습니다. 기존의 검색 에이전트는 일반적으로 유사성 기반 검색기를 사용하지만, 유사한 문장이 항상 최종 답변 생성에 유용한 것은 아닙니다. 본 논문에서는 에이전트 기반 검색에 맞춘 새로운 검색기 훈련 프레임워크를 제안합니다. 단일 턴 검색 증강 생성(RAG)을 위해 설계된 검색기와 달리, 우리는 다단계 에이전트 기반 검색에서 문장의 유용성을 측정하기 위해 지역 쿼리-문장 관련성과 전역 답변 정확성을 모두 사용하는 방안을 제안합니다. 또한, 검색 에이전트와 검색기가 양방향으로 반복적으로 최적화되는 반복 훈련 전략을 도입합니다. 고정된 질문으로 한 번만 훈련되는 RAG 검색기와는 달리, 우리의 검색기는 에이전트로부터 진화하고 더 높은 품질의 쿼리를 사용하여 지속적으로 개선됩니다. 일곱 개의 단일 홉 및 다중 홉 QA 벤치마크에서의 광범위한 실험 결과, 우리의 검색기(\ours{})가 다양한 검색 에이전트에서 강력한 기준선들을 지속적으로 초월함을 보여줍니다. 우리의 코드는 다음 링크에서 확인할 수 있습니다: GitHub - 8421BCD/Agentic-R.
Agentic search has recently emerged as a powerful paradigm, where an agent interleaves multi-step reasoning with on-demand retrieval to solve complex questions. Despite its success, how to design a retriever for agentic search remains largely underexplored. Existing search agents typically rely on similarity-based retrievers, while similar passages are not always useful for final answer generation. In this paper, we propose a novel retriever training framework tailored for agentic search. Unlike retrievers designed for single-turn retrieval-augmented generation (RAG) that only rely on local passage utility, we propose to use both local query-passage relevance and global answer correctness to measure passage utility in a multi-turn agentic search. We further introduce an iterative training strategy, where the search agent and the retriever are optimized bidirectionally and iteratively. Different from RAG retrievers that are only trained once with fixed questions, our retriever is continuously improved using evolving and higher-quality queries from the agent. Extensive experiments on seven single-hop and multi-hop QA benchmarks demonstrate that our retriever, termed \ours{}, consistently outperforms strong baselines across different search agents. Our codes are available at: GitHub - 8421BCD/Agentic-R.
논문 링크
더 읽어보기
STEM: 임베딩 모듈을 활용한 트랜스포머 확장 / STEM: Scaling Transformers with Embedding Modules
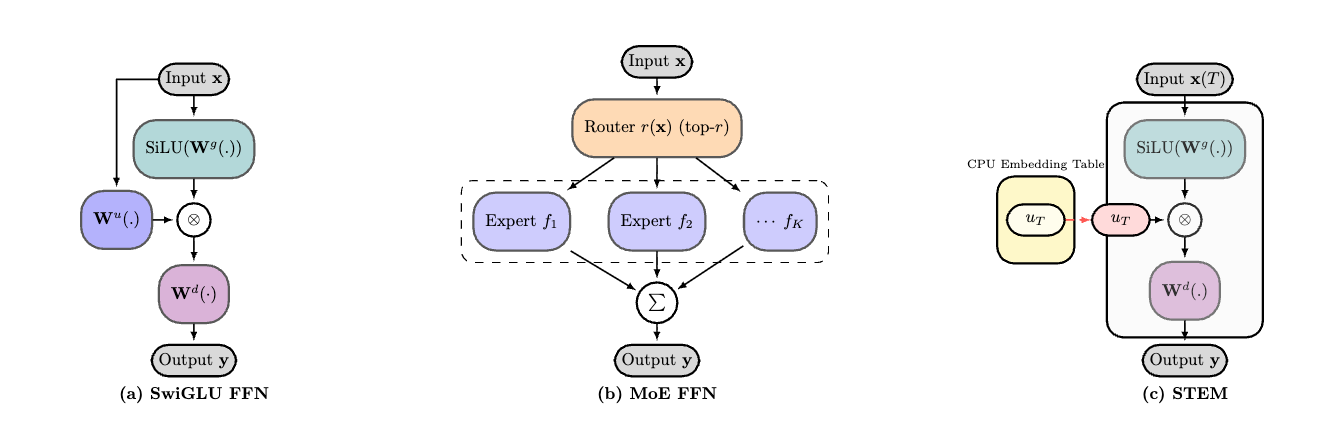
논문 소개
STEM (Scaling Transformers with Embedding Modules)은 파라메트릭 메모리의 확장을 통해 더 나은 해석 가능성, 학습 안정성 및 효율성을 제공하는 혁신적인 접근 방식이다. 본 연구는 Fine-grained sparsity를 활용하여 각 토큰에 대한 계산 비용을 비례적으로 증가시키지 않으면서도 높은 파라메트릭 용량을 실현하는 방법을 제안한다. STEM은 Feed-Forward Network(FFN)의 업 프로젝션을 레이어 로컬 임베딩 조회로 대체하고, 게이트와 다운 프로젝션은 밀집하게 유지함으로써 런타임 라우팅을 제거하고 CPU 오프로드를 가능하게 한다. 이러한 구조는 각 토큰의 FLOPs와 장치 간 통신에서 용량을 분리하여 효율성을 극대화한다.
STEM의 임베딩은 큰 각도 분포를 가지며, 이는 정보 저장 용량을 향상시키고 해석 가능성을 높인다. 특히, STEM은 지식 편집 및 주입을 간단하게 수행할 수 있는 방법을 제공하여, 입력 텍스트나 추가 계산에 대한 개입 없이도 해석 가능한 방식으로 작동한다. 긴 컨텍스트 성능 또한 강화되어, 시퀀스 길이가 증가함에 따라 더 많은 고유 파라미터가 활성화되어 실제 테스트 시 용량 확장을 가능하게 한다.
STEM은 350M 및 1B 모델 규모에서 밀집 기준선에 비해 약 3-4%의 정확도 향상을 보여주며, 특히 지식 및 추론 중심의 벤치마크에서 두드러진 성과를 달성한다. 이러한 결과는 STEM이 기존의 희소 계산 접근 방식에서 발생하는 학습 불안정성 문제를 해결하고, 파라메트릭 메모리의 주소 가능성을 높이며, 전반적인 성능을 개선할 수 있는 가능성을 제시한다. STEM은 자연어 처리 분야에서의 다양한 작업에 대한 성능 향상을 위한 효과적인 방법론으로 자리 잡을 수 있다.
논문 초록(Abstract)
세밀한 희소성은 비례적인 토큰당 계산 없이 더 높은 매개변수 용량을 약속하지만, 종종 학습 불안정성, 부하 균형, 통신 오버헤드의 문제를 겪습니다. 우리는 FFN 업프로젝션을 레이어 로컬 임베딩 조회로 대체하면서 게이트와 다운프로젝션을 밀집 상태로 유지하는 정적 토큰 인덱스 접근 방식인 STEM(임베딩 모듈을 통한 트랜스포머 확장)을 소개합니다. 이는 런타임 라우팅을 제거하고 비동기 프리패치로 CPU 오프로드를 가능하게 하며, 매개변수 용량을 토큰당 FLOPs와 장치 간 통신에서 분리합니다. 실험적으로, STEM은 극단적인 희소성에도 불구하고 안정적으로 학습됩니다. 이는 밀집 기준선에 비해 하위 작업 성능을 향상시키면서 토큰당 FLOPs와 매개변수 접근을 줄입니다(약 3분의 1의 FFN 매개변수를 제거). STEM은 큰 각도 분포를 가진 임베딩 공간을 학습하여 지식 저장 용량을 향상시킵니다. 더 흥미롭게도, 이 향상된 지식 용량은 더 나은 해석 가능성과 함께 제공됩니다. STEM 임베딩의 토큰 인덱스 특성은 입력 텍스트나 추가 계산에 대한 개입 없이 해석 가능한 방식으로 지식 편집 및 지식 주입을 수행할 수 있는 간단한 방법을 허용합니다. 또한, STEM은 긴 컨텍스트 성능을 강화합니다: 시퀀스 길이가 증가함에 따라 더 많은 고유 매개변수가 활성화되어 실용적인 테스트 시간 용량 확장을 제공합니다. 3억 및 10억 모델 규모에서 STEM은 전반적으로 약 3~4%의 정확도 향상을 제공하며, 지식 및 추론 중심 벤치마크(ARC-Challenge, OpenBookQA, GSM8K, MMLU)에서 특히 두드러진 성과를 보입니다. 전반적으로 STEM은 더 나은 해석 가능성, 더 나은 학습 안정성 및 향상된 효율성을 제공하면서 매개변수 메모리를 확장하는 효과적인 방법입니다.
Fine-grained sparsity promises higher parametric capacity without proportional per-token compute, but often suffers from training instability, load balancing, and communication overhead. We introduce STEM (Scaling Transformers with Embedding Modules), a static, token-indexed approach that replaces the FFN up-projection with a layer-local embedding lookup while keeping the gate and down-projection dense. This removes runtime routing, enables CPU offload with asynchronous prefetch, and decouples capacity from both per-token FLOPs and cross-device communication. Empirically, STEM trains stably despite extreme sparsity. It improves downstream performance over dense baselines while reducing per-token FLOPs and parameter accesses (eliminating roughly one-third of FFN parameters). STEM learns embedding spaces with large angular spread which enhances its knowledge storage capacity. More interestingly, this enhanced knowledge capacity comes with better interpretability. The token-indexed nature of STEM embeddings allows simple ways to perform knowledge editing and knowledge injection in an interpretable manner without any intervention in the input text or additional computation. In addition, STEM strengthens long-context performance: as sequence length grows, more distinct parameters are activated, yielding practical test-time capacity scaling. Across 350M and 1B model scales, STEM delivers up to ~3--4% accuracy improvements overall, with notable gains on knowledge and reasoning-heavy benchmarks (ARC-Challenge, OpenBookQA, GSM8K, MMLU). Overall, STEM is an effective way of scaling parametric memory while providing better interpretability, better training stability and improved efficiency.
논문 링크
더 읽어보기
ML ASIC을 위한 에이전틱 연산자 생성 / Agentic Operator Generation for ML ASICs
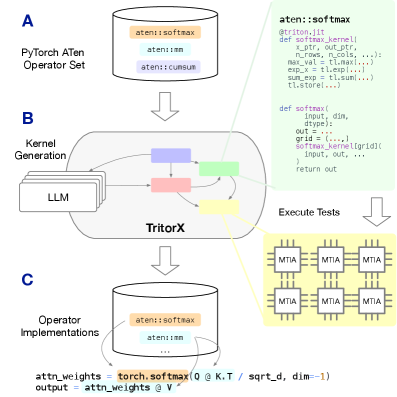
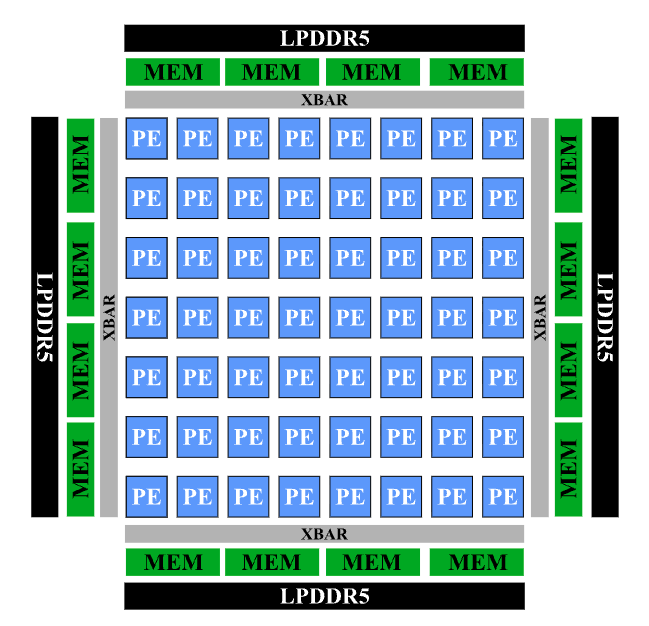
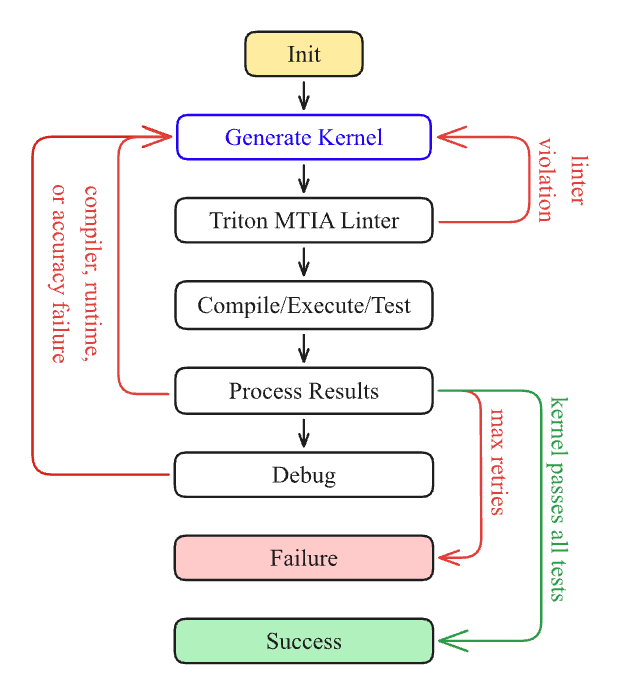
논문 소개
TritorX는 새로운 머신러닝 가속기 플랫폼을 위해 기능적으로 올바른 Triton PyTorch ATen 커널을 대규모로 생성하는 에이전틱 인공지능 시스템이다. 이 시스템은 오픈 소스 대규모 언어 모델과 사용자 정의 린터, JIT(Just-In-Time) 컴파일, 그리고 PyTorch OpInfo 기반의 테스트 하니스(Test Harness)를 통합하여 설계되었다. TritorX의 주요 혁신점은 기존의 커널 생성 접근 방식이 성능 최적화에 집중했던 반면, 커버리지를 우선시하여 다양한 데이터 유형과 구조를 지원하는 데 있다. 이를 통해 TritorX는 전체 연산자 집합에 대한 정확성과 일반성을 보장하며, 481개의 고유한 ATen 연산자에 대한 커널과 래퍼를 성공적으로 생성하였다.
TritorX의 파이프라인은 실제 Meta Training and Inference Accelerator (MTIA) 실리콘과 차세대 장치의 하드웨어 시뮬레이션 환경 모두와 호환된다. 이 시스템은 PyTorch OpInfo 테스트를 통해 20,000개 이상의 테스트를 수행하며, 생성된 커널의 정확성을 검증하였다. 이러한 실험 결과는 TritorX가 새로운 가속기 플랫폼을 위한 완전한 PyTorch ATen 백엔드를 생성할 수 있는 가능성을 제시한다.
TritorX는 머신러닝 ASIC을 위한 커널 생성의 새로운 패러다임을 제시하며, 다양한 연산자에 대한 지원을 통해 머신러닝 가속기의 발전에 기여할 것으로 기대된다. 향후 연구에서는 TritorX의 성능을 더욱 향상시키고, 다양한 가속기 플랫폼에 대한 지원을 확대할 계획이다. 이 연구는 머신러닝 커널 생성 분야에서의 중요한 기초 자료로 작용할 것이다.
논문 초록(Abstract)
우리는 새로운 가속기 플랫폼을 위해 기능적으로 올바른 Triton PyTorch ATen 커널을 대규모로 생성하도록 설계된 에이전틱 AI 시스템인 TritorX를 소개합니다. TritorX는 오픈 소스 대규모 언어 모델과 맞춤형 린터, JIT 컴파일, 그리고 PyTorch OpInfo 기반 테스트 하네스를 통합합니다. 이 파이프라인은 실제 메타 훈련 및 추론 가속기(MTIA) 실리콘과 차세대 장치의 하드웨어 시뮬레이션 환경 모두와 호환됩니다. 제한된 고사용 커널 집합에 대한 성능을 우선시하는 이전의 커널 생성 접근 방식과 달리, TritorX는 커버리지를 우선시합니다. 우리의 시스템은 다양한 데이터 유형, 형태 및 인수 패턴을 포함하여 전체 연산자 집합에 걸쳐 정확성과 일반성을 강조합니다. 실험에서 TritorX는 모든 관련 PyTorch OpInfo 테스트(총 20,000개 이상)를 통과하는 481개의 고유한 ATen 연산자에 대한 커널과 래퍼를 성공적으로 생성했습니다. TritorX는 새로운 가속기 플랫폼을 위한 완전한 PyTorch ATen 백엔드의 즉각적인 생성을 위한 길을 열어줍니다.
We present TritorX, an agentic AI system designed to generate functionally correct Triton PyTorch ATen kernels at scale for emerging accelerator platforms. TritorX integrates open-source large language models with a custom linter, JIT compilation, and a PyTorch OpInfo-based test harness. This pipeline is compatible with both real Meta Training and Inference Accelerator (MTIA) silicon and in hardware simulation environments for next-generation devices. In contrast to previous kernel-generation approaches that prioritize performance for a limited set of high-usage kernels, TritorX prioritizes coverage. Our system emphasizes correctness and generality across the entire operator set, including diverse data types, shapes, and argument patterns. In our experiments, TritorX successfully generated kernels and wrappers for 481 unique ATen operators that pass all corresponding PyTorch OpInfo tests (over 20,000 in total). TritorX paves the way for overnight generation of complete PyTorch ATen backends for new accelerator platforms.
논문 링크
EvoCUA: 확장 가능한 합성 경험으로부터 학습하여 진화하는 컴퓨터 사용 에이전트 / EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
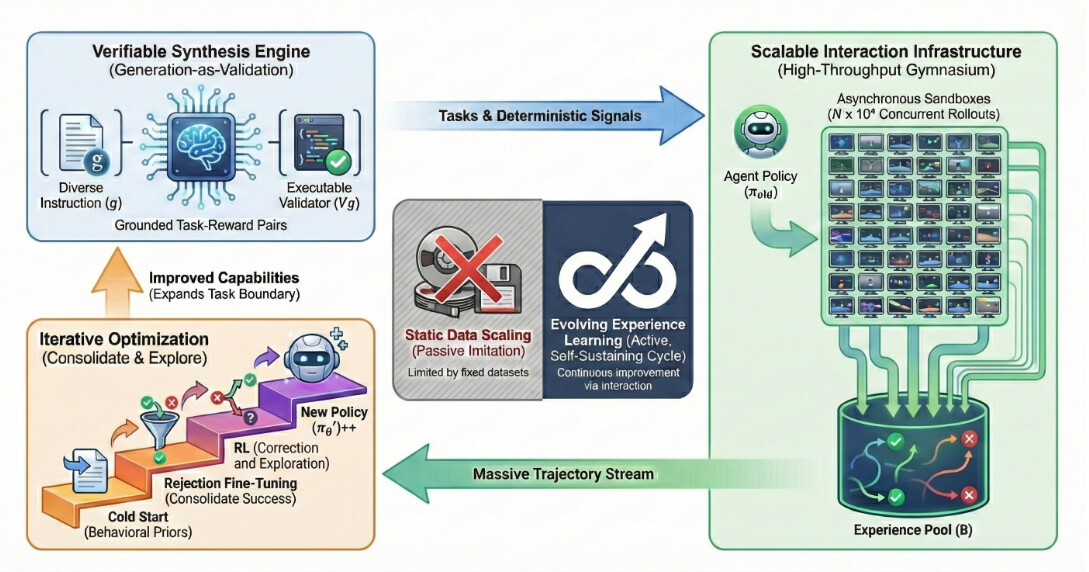
논문 소개
EvoCUA는 멀티모달 인공지능 분야에서 중요한 발전을 이루기 위해 개발된 네이티브 컴퓨터 사용 에이전트 모델이다. 기존의 컴퓨터 사용 에이전트(CUA)는 정적 데이터셋에 의존하여 긴 시간의 복잡한 작업을 수행하는 데 한계가 있었으며, 이러한 문제를 해결하기 위한 혁신적인 접근이 필요했다. EvoCUA는 데이터 생성과 정책 최적화를 통합하여 자가 지속적인 진화 주기를 형성함으로써, 데이터 부족 문제를 효과적으로 완화하고 있다.
본 연구에서는 검증 가능한 합성 엔진을 통해 다양한 작업을 자율적으로 생성하고, 이를 실행 가능한 검증기와 결합하여 생성된 작업의 유효성을 검증하는 방법을 제안한다. 이러한 데이터 생성 과정은 대규모 경험 획득을 가능하게 하며, 수만 개의 비동기 샌드박스 롤아웃을 통해 대량의 경험 데이터를 수집할 수 있는 확장 가능한 인프라를 구축하였다. 이로 인해 EvoCUA는 반복적인 진화 학습 전략을 통해 경험을 효율적으로 내재화할 수 있으며, 정책 업데이트를 동적으로 조절하여 성공적인 루틴을 강화하고 실패한 경로를 수정하는 메커니즘을 구현하고 있다.
실험 결과, EvoCUA는 OSWorld 벤치마크에서 56.7%의 성공률을 기록하며 이전의 최고 오픈 소스 모델인 OpenCUA-72B(45.0%)를 초과하는 성과를 보였다. 또한, UI-TARS-2(53.1%)와 같은 주요 폐쇄형 모델을 능가하는 성능을 입증하였다. 이러한 결과는 EvoCUA의 접근 방식이 다양한 규모의 파운데이션 모델에서 일관된 성능 향상을 가져올 수 있음을 강조하며, 진화적 학습을 통한 경험 기반의 접근 방식이 CUA의 발전에 기여할 수 있는 가능성을 제시한다.
EvoCUA는 멀티모달 AI의 발전에 기여할 수 있는 중요한 모델로, 데이터 생성과 정책 최적화를 통합한 새로운 접근 방식을 통해 네이티브 에이전트의 능력을 향상시키기 위한 강력하고 확장 가능한 경로를 제시한다. 이러한 연구는 향후 AI 시스템의 성능을 더욱 향상시키는 데 중요한 기초가 될 것이다.
논문 초록(Abstract)
네이티브 컴퓨터 사용 에이전트(CUA)의 개발은 멀티모달 AI에서 중요한 도약을 나타냅니다. 그러나 현재 그 잠재력은 정적 데이터 확장의 제약으로 인해 병목 현상을 겪고 있습니다. 기존 패러다임은 주로 정적 데이터셋의 수동 모방에 의존하여 장기적인 컴퓨터 작업에 내재된 복잡한 인과 동력을 포착하는 데 어려움을 겪고 있습니다. 본 연구에서는 네이티브 컴퓨터 사용 에이전트 모델인 EvoCUA를 소개합니다. 정적 모방과는 달리, EvoCUA는 데이터 생성과 정책 최적화를 자가 지속적인 진화 주기로 통합합니다. 데이터 부족 문제를 완화하기 위해, 우리는 자율적으로 다양한 작업을 생성하고 실행 가능한 검증기를 결합한 검증 가능한 합성 엔진을 개발합니다. 대규모 경험 획득을 가능하게 하기 위해, 우리는 수만 개의 비동기 샌드박스 롤아웃을 조율하는 확장 가능한 인프라를 설계합니다. 이러한 방대한 궤적을 바탕으로, 우리는 이 경험을 효율적으로 내재화하기 위한 반복적인 진화 학습 전략을 제안합니다. 이 메커니즘은 능력 경계를 식별하여 정책 업데이트를 동적으로 조절하며, 성공적인 루틴을 강화하는 동시에 실패 궤적을 오류 분석과 자기 수정 과정을 통해 풍부한 감독으로 변환합니다. OSWorld 벤치마크에 대한 실증 평가 결과, EvoCUA는 56.7%의 성공률을 달성하여 새로운 오픈 소스 최첨단 모델을 확립했습니다. 특히, EvoCUA는 이전의 최고 오픈 소스 모델인 OpenCUA-72B(45.0%)를 크게 초월하며, UI-TARS-2(53.1%)와 같은 주요 폐쇄형 가중치 모델을 초과합니다. 우리의 결과는 이 접근 방식의 일반화 가능성을 강조합니다: 경험으로부터 학습하는 진화 패러다임은 다양한 규모의 파운데이션 모델에서 일관된 성능 향상을 가져오며, 네이티브 에이전트 능력을 향상시키기 위한 강력하고 확장 가능한 경로를 확립합니다.
The development of native computer-use agents (CUA) represents a significant leap in multimodal AI. However, their potential is currently bottlenecked by the constraints of static data scaling. Existing paradigms relying primarily on passive imitation of static datasets struggle to capture the intricate causal dynamics inherent in long-horizon computer tasks. In this work, we introduce EvoCUA, a native computer use agentic model. Unlike static imitation, EvoCUA integrates data generation and policy optimization into a self-sustaining evolutionary cycle. To mitigate data scarcity, we develop a verifiable synthesis engine that autonomously generates diverse tasks coupled with executable validators. To enable large-scale experience acquisition, we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts. Building on these massive trajectories, we propose an iterative evolving learning strategy to efficiently internalize this experience. This mechanism dynamically regulates policy updates by identifying capability boundaries -- reinforcing successful routines while transforming failure trajectories into rich supervision through error analysis and self-correction. Empirical evaluations on the OSWorld benchmark demonstrate that EvoCUA achieves a success rate of 56.7%, establishing a new open-source state-of-the-art. Notably, EvoCUA significantly outperforms the previous best open-source model, OpenCUA-72B (45.0%), and surpasses leading closed-weights models such as UI-TARS-2 (53.1%). Crucially, our results underscore the generalizability of this approach: the evolving paradigm driven by learning from experience yields consistent performance gains across foundation models of varying scales, establishing a robust and scalable path for advancing native agent capabilities.
논문 링크
더 읽어보기
주체적 EDA의 새벽: 자율 디지털 칩 설계에 대한 서베이 / The Dawn of Agentic EDA: A Survey of Autonomous Digital Chip Design
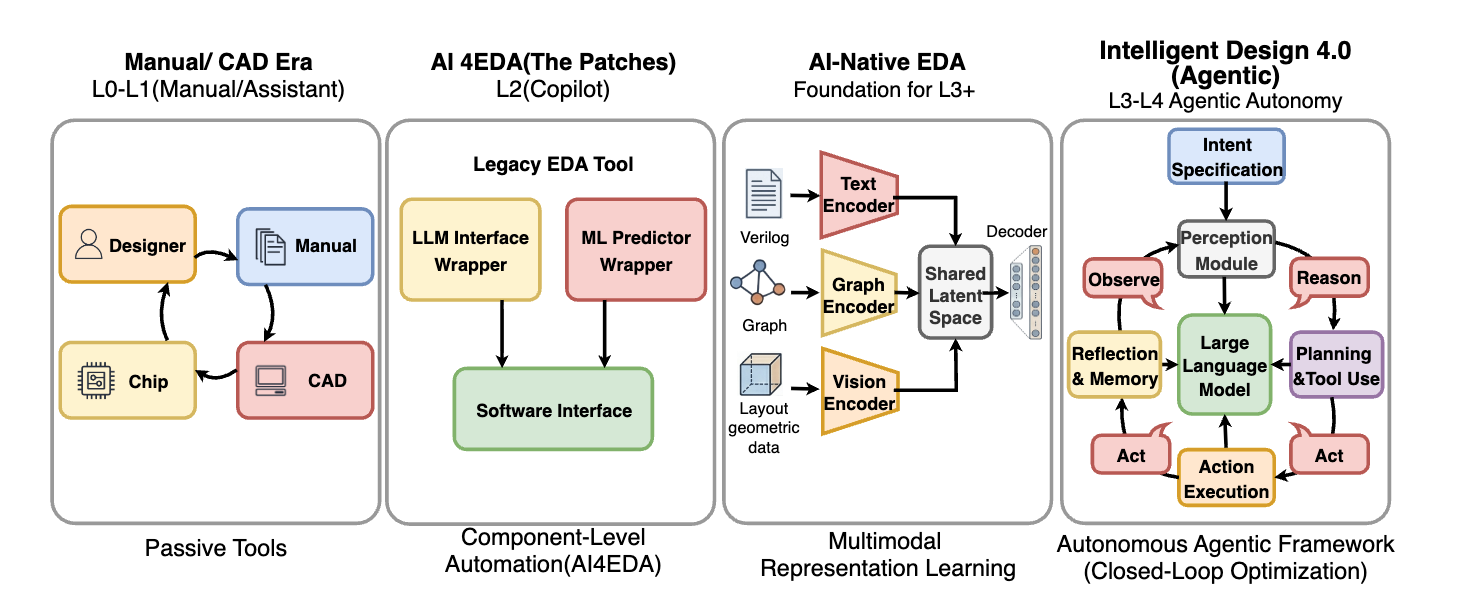
논문 소개
디지털 전자 설계 자동화(EDA) 분야에서 Generative AI와 Agentic AI의 통합은 새로운 패러다임의 도래를 알리고 있다. 전통적인 컴퓨터 지원 설계(CAD)에서 AI 지원 EDA(AI4EDA)로의 발전은 이제 AI 네이티브 및 Agentic 설계 패러다임으로 진화하고 있으며, 이는 디지털 칩 설계 흐름 전반에 걸쳐 혁신적인 변화를 가져오고 있다. 본 논문은 이러한 패러다임의 발전을 체계적으로 검토하며, 멀티모달 파운데이션 모델을 기반으로 한 Agentic 인지 아키텍처의 구축, 프론트엔드 RTL 코드 생성 및 지능형 검증, 그리고 알고리즘 혁신을 통한 백엔드 물리적 설계를 포함한 다양한 응용 사례를 제시한다.
특히, 에이전트가 백엔드의 PPA(전력, 성능, 면적) 메트릭을 활용하여 프론트엔드 로직을 자율적으로 개선하는 교차 단계 피드백 루프의 가능성에 주목하고 있다. 이러한 접근은 설계 과정에서의 생산성 격차를 해소하고, 자동화 병목 현상을 극복하는 데 기여할 것으로 기대된다. 또한, 본 연구는 보안 측면에서도 새로운 적대적 위험과 자동화된 취약점 수정을 다루며, 개인 정보 보호 인프라의 중요성을 강조한다.
이 논문은 환각, 데이터 부족, 블랙박스 도구와 같은 현재의 도전 과제를 비판적으로 분석하며, L4 자율 칩 설계로의 미래 트렌드를 제시한다. 궁극적으로, Agentic EDA라는 새로운 분야를 정의하고 AI 지원 도구에서 완전 자율 설계 엔지니어로의 전환을 위한 전략적 로드맵을 제공하는 것을 목표로 하고 있다. 이러한 연구는 디지털 회로 설계의 혁신을 이끌어내고, 향후 EDA 분야의 발전 방향을 제시하는 중요한 기초 자료가 될 것이다.
논문 초록(Abstract)
이 서베이는 디지털 전자 설계 자동화(Digital Electronic Design Automation, EDA) 분야에서 생성적 AI와 에이전틱 AI의 통합에 대한 포괄적인 개요를 제공합니다. 본 논문은 전통적인 컴퓨터 지원 설계(Computer-Aided Design, CAD)에서 AI 지원 EDA(AI4EDA)로의 패러다임 진화 과정을 검토하고, 최종적으로 새로운 AI 네이티브 및 에이전틱 설계 패러다임으로 나아갑니다. 우리는 이러한 패러다임이 디지털 칩 설계 흐름 전반에 걸쳐 어떻게 적용되는지를 상세히 설명하며, 멀티모달 파운데이션 모델을 기반으로 한 에이전틱 인지 아키텍처의 구축, 프론트엔드 RTL 코드 생성 및 지능형 검증, 알고리즘 혁신과 도구 오케스트레이션을 특징으로 하는 백엔드 물리적 설계를 포함합니다. 우리는 통합 사례 연구를 통해 이러한 방법론을 검증하며, 마이크로아키텍처 정의에서 GDSII에 이르기까지의 실용성을 입증합니다. 특히 에이전트가 백엔드 PPA 지표를 활용하여 프론트엔드 논리를 자율적으로 개선할 수 있는 단계 간 피드백 루프의 잠재력에 중점을 둡니다. 또한, 이 서베이는 보안에 대한 이중적인 영향을 다루며, 새로운 적대적 위험, 자동화된 취약성 수리, 그리고 프라이버시 보호 인프라를 포함합니다. 마지막으로, 본 논문은 환각, 데이터 부족, 블랙박스 도구와 관련된 현재의 도전 과제를 비판적으로 요약하고, L4 자율 칩 설계로의 미래 트렌드를 개략적으로 설명합니다. 궁극적으로, 이 연구는 에이전틱 EDA의 새로운 분야를 정의하고 AI 지원 도구에서 완전 자율 설계 엔지니어로의 전환을 위한 전략적 로드맵을 제공하는 것을 목표로 합니다.
This survey provides a comprehensive overview of the integration of Generative AI and Agentic AI within the field of Digital Electronic Design Automation (EDA). The paper first reviews the paradigmatic evolution from traditional Computer-Aided Design (CAD) to AI-assisted EDA (AI4EDA), and finally to the emerging AI-Native and Agentic design paradigms. We detail the application of these paradigms across the digital chip design flow, including the construction of agentic cognitive architectures based on multimodal foundation models, frontend RTL code generation and intelligent verification, and backend physical design featuring algorithmic innovations and tool orchestration. We validate these methodologies through integrated case studies, demonstrating practical viability from microarchitecture definition to GDSII. Special emphasis is placed on the potential for cross-stage feedback loops where agents utilize backend PPA metrics to autonomously refine frontend logic. Furthermore, this survey delves into the dual-faceted impact on security, covering novel adversarial risks, automated vulnerability repair, and privacy-preserving infrastructure. Finally, the paper critically summarizes current challenges related to hallucinations, data scarcity, and black-box tools, and outlines future trends towards L4 autonomous chip design. Ultimately, this work aims to define the emerging field of Agentic EDA and provide a strategic roadmap for the transition from AI-assisted tools to fully autonomous design engineers.
논문 링크
Confucius Code Agent (CCA): 실제 코드베이스를 위한 확장 가능한 에이전트 구조 / Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
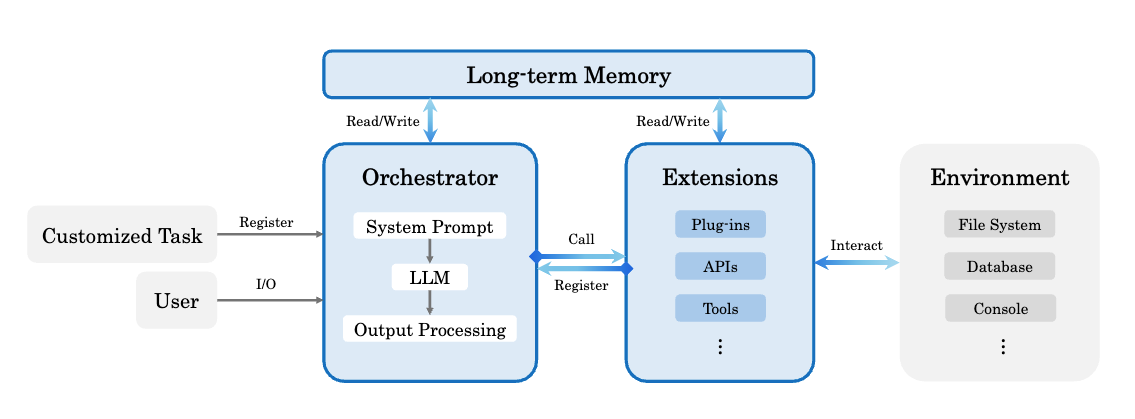
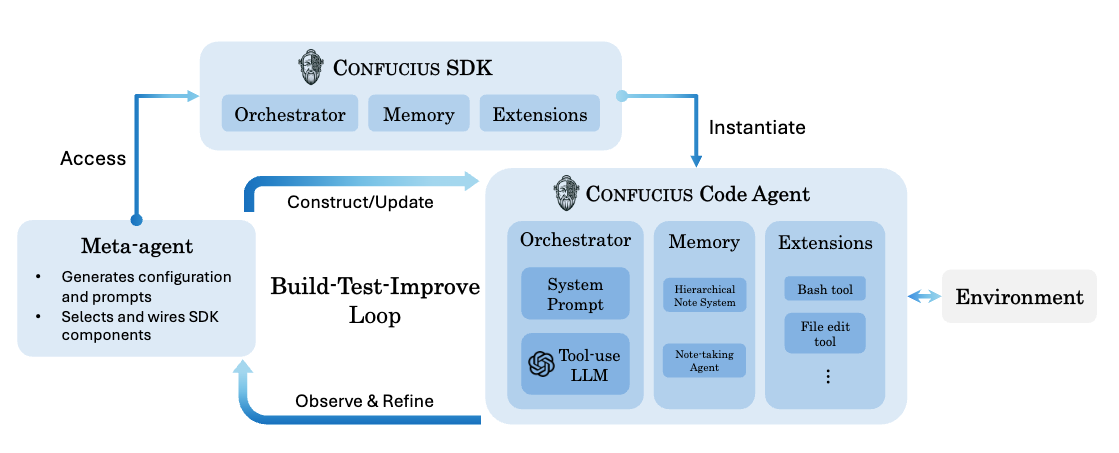
논문 소개
Confucius Code Agent (CCA)는 대규모 코드베이스에서 작동할 수 있는 소프트웨어 엔지니어링 에이전트로 설계되었으며, 기존의 연구 기반 및 상용 시스템의 한계를 극복하기 위한 혁신적인 접근 방식을 제공합니다. CCA는 Confucius SDK를 기반으로 하여, Agent Experience (AX), User Experience (UX), Developer Experience (DX) 라는 세 가지 핵심 요소를 통합하여 에이전트의 성능과 사용자 경험을 최적화합니다. 이러한 구조는 에이전트가 긴 세션을 지속하고 복잡한 도구 체인을 신뢰성 있게 조정할 수 있도록 지원합니다.
특히, CCA는 계층적 작업 메모리를 통해 긴 맥락 추론을 가능하게 하고, 지속적인 학습을 위한 메모 시스템을 도입하여 에이전트의 학습 능력을 강화합니다. 또한, 모듈 확장 시스템을 통해 다양한 도구를 안정적으로 사용할 수 있도록 하여, 개발자들이 필요로 하는 유연성을 제공합니다. CCA의 메타 에이전트는 에이전트 구성의 합성, 평가 및 개선을 자동화하는 기능을 갖추고 있어, 새로운 작업이나 환경에 신속하게 적응할 수 있는 능력을 부여합니다.
이러한 혁신적인 메커니즘을 통해 CCA는 실제 소프트웨어 엔지니어링 작업에서 뛰어난 성능을 발휘하며, SWE-Bench-Pro에서 Resolve@1이 54.3%에 도달하여 이전 연구 기준을 초과하는 성과를 보였습니다. 이는 CCA가 대규모 코드베이스에서의 작업을 위한 강력한 도구로 자리매김할 가능성을 시사합니다. CCA는 소프트웨어 엔지니어링의 복잡성을 해결하고, 사용자와 개발자 모두에게 유용한 경험을 제공하는 데 중점을 두고 있습니다. 이러한 점에서 CCA는 향후 연구 및 실제 적용에 있어 중요한 기여를 할 것으로 기대됩니다.
논문 초록(Abstract)
실제 소프트웨어 엔지니어링 작업은 대규모 코드 저장소에서 작동하고, 장기 세션을 유지하며, 테스트 시 복잡한 도구 체인을 신뢰성 있게 조정할 수 있는 코딩 에이전트를 요구합니다. 기존의 연구 수준 코딩 에이전트는 투명성을 제공하지만, 더 무거운 생산 수준의 작업 부하로 확장할 때 어려움을 겪고 있으며, 반면 생산 수준 시스템은 강력한 실용 성능을 달성하지만 확장성, 해석 가능성 및 제어 가능성이 제한적입니다. 우리는 대규모 코드베이스에서 작동할 수 있는 소프트웨어 엔지니어링 에이전트인 공자 코드 에이전트(Confucius Code Agent, CCA)를 소개합니다. CCA는 세 가지 상호 보완적인 관점인 에이전트 경험(Agent Experience, AX), 사용자 경험(User Experience, UX), 개발자 경험(Developer Experience, DX)을 중심으로 구성된 에이전트 개발 플랫폼인 공자 SDK 위에 구축되었습니다. 이 SDK는 장기 맥락 추론을 위한 계층적 작업 메모리와 통합 오케스트레이터, 세션 간 지속적인 학습을 위한 지속적인 메모 시스템, 신뢰할 수 있는 도구 사용을 위한 모듈식 확장 시스템을 통합합니다. 또한, 우리는 에이전트 구성의 합성, 평가 및 개선을 자동화하는 메타 에이전트를 도입하여 새로운 작업, 환경 및 도구 스택에 신속하게 적응할 수 있는 빌드-테스트-개선 루프를 가능하게 합니다. 이러한 메커니즘으로 구현된 CCA는 실제 소프트웨어 엔지니어링 작업에서 강력한 성능을 보여줍니다. SWE-Bench-Pro에서 CCA는 54.3%의 Resolve@1을 달성하여 이전 연구 기준을 초과하고 동일한 저장소, 모델 백엔드 및 도구 접근 하에서 상업적 결과와 유리하게 비교됩니다.
Real-world software engineering tasks require coding agents that can operate over massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK integrates a unified orchestrator with hierarchical working memory for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In addition, we introduce a meta-agent that automates the synthesis, evaluation, and refinement of agent configurations through a build-test-improve loop, enabling rapid adaptation to new tasks, environments, and tool stacks. Instantiated with these mechanisms, CCA demonstrates strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA reaches a Resolve@1 of 54.3%, exceeding prior research baselines and comparing favorably to commercial results, under identical repositories, model backends, and tool access.
논문 링크
UFT: 감독 학습과 강화 학습 파인튜닝의 통합 / UFT: Unifying Supervised and Reinforcement Fine-Tuning
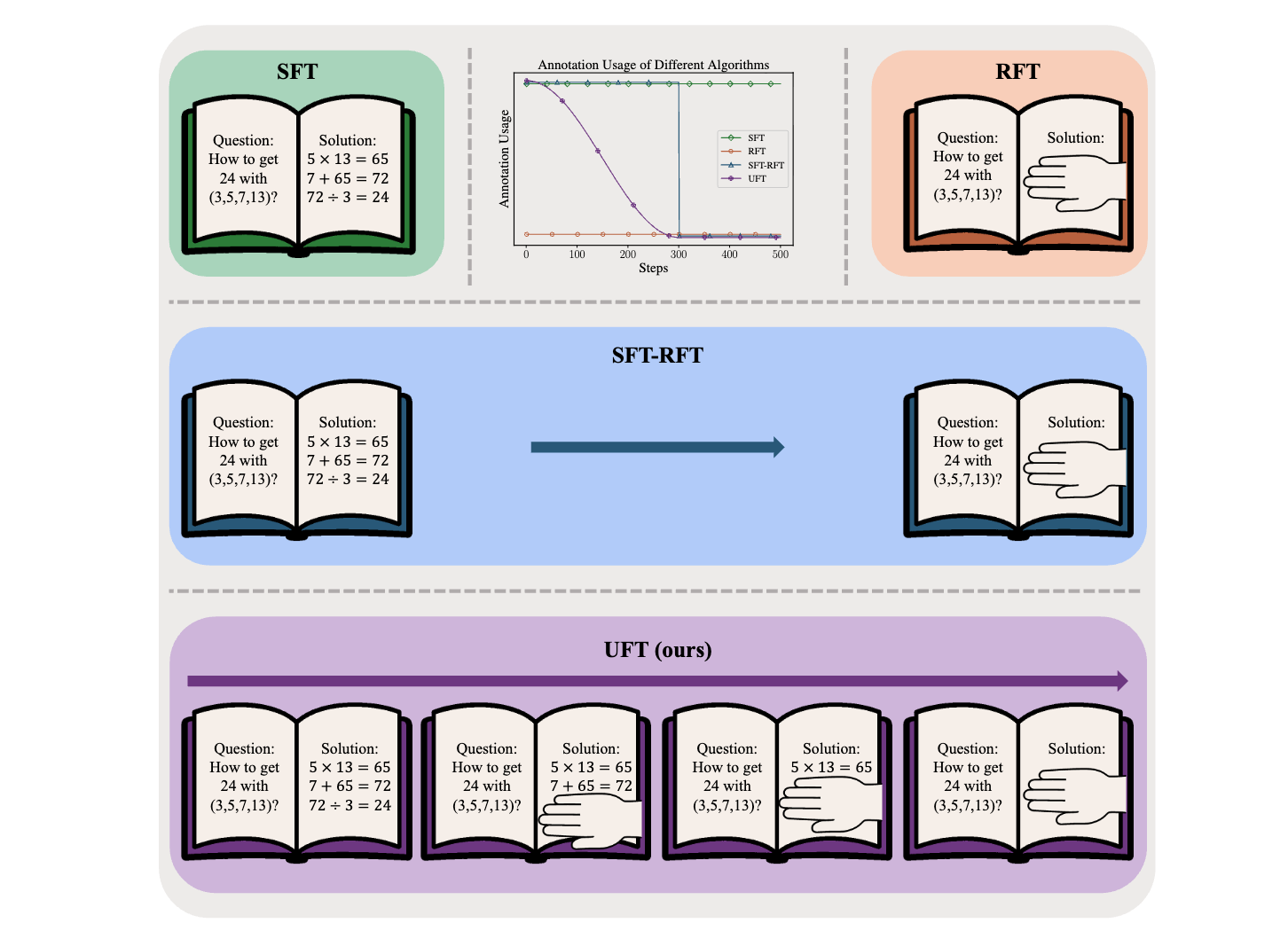
논문 소개
대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 사후학습(Post-training) 방법론은 감독 파인튜닝(Supervised Fine-Tuning, SFT)과 강화 파인튜닝(Reinforcement Fine-Tuning, RFT)으로 나눌 수 있습니다. SFT는 효율적이지만 대형 모델에서 과적합을 초래할 수 있으며, RFT는 일반화 성능이 뛰어나지만 기본 모델의 성능에 크게 의존합니다. 이러한 한계를 극복하기 위해 제안된 통합 파인튜닝(Unified Fine-Tuning, UFT)은 SFT와 RFT를 통합하여 모델이 효과적으로 솔루션을 탐색하면서도 유용한 감독 신호를 활용할 수 있도록 합니다. UFT는 기존 방법의 암기와 사고 간의 간극을 메우며, 모델 크기에 관계없이 SFT와 RFT의 성능을 초월하는 결과를 보여줍니다.
UFT의 핵심 혁신은 감독 신호와 보상 신호를 통합하여 모델이 동시에 탐색하고 학습할 수 있는 단일 훈련 패러다임을 제공하는 것입니다. 이를 통해 모델은 새로운 지식을 더 효율적으로 습득할 수 있으며, 이론적으로는 RFT의 지수 샘플 복잡도를 다항적 복잡도로 개선할 수 있음을 증명합니다. UFT는 다양한 모델과 작업에서 일관되게 우수한 성능을 나타내며, 특히 장기 추론 작업에서 수렴 속도를 기하급수적으로 가속화하는 데 기여합니다.
UFT의 방법론은 문제 설명과 부분 해결책(힌트)을 결합하여 탐색을 유도하고, RFT의 목표 함수에 추가적인 로그 우도 항을 도입하여 모델이 감독 신호로부터 학습할 수 있도록 합니다. 이러한 접근법은 모델이 올바른 답변을 더 자주 탐색하도록 돕고, 다양한 모델 크기와 복잡한 작업에서도 뛰어난 성능을 발휘할 수 있게 합니다. UFT는 기존의 SFT와 RFT 방법론의 장점을 결합하여, 향후 연구에서 더 발전된 기법과의 통합 가능성을 열어줍니다.
논문 초록(Abstract)
사후학습은 대규모 언어 모델(LLM)의 추론 능력을 향상시키는 데 중요한 역할을 입증하였습니다. 주요 사후학습 방법은 감독 파인튜닝(SFT)과 강화 파인튜닝(RFT)으로 분류할 수 있습니다. SFT는 효율적이며 소규모 언어 모델에 적합하지만, 과적합을 초래하고 대규모 모델의 추론 능력을 제한할 수 있습니다. 반면, RFT는 일반적으로 더 나은 일반화를 제공하지만, 기본 모델의 강도에 크게 의존합니다. SFT와 RFT의 한계를 해결하기 위해, 우리는 SFT와 RFT를 단일 통합 프로세스로 통합하는 새로운 사후학습 패러다임인 통합 파인튜닝(UFT)을 제안합니다. UFT는 모델이 유용한 감독 신호를 통합하면서 효과적으로 솔루션을 탐색할 수 있도록 하여, 기존 방법의 기억과 사고 간의 간극을 메웁니다. 특히, UFT는 모델 크기에 관계없이 일반적으로 SFT와 RFT보다 우수한 성능을 보입니다. 또한, 우리는 이론적으로 UFT가 RFT의 고유한 지수 샘플 복잡성 병목 현상을 극복함을 증명하며, 통합 학습이 장기 추론 작업에서 수렴 속도를 지수적으로 가속화할 수 있음을 처음으로 보여줍니다.
Post-training has demonstrated its importance in enhancing the reasoning capabilities of large language models (LLMs). The primary post-training methods can be categorized into supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT is efficient and well-suited for small language models, but it may lead to overfitting and limit the reasoning abilities of larger models. In contrast, RFT generally yields better generalization but depends heavily on the strength of the base model. To address the limitations of SFT and RFT, we propose Unified Fine-Tuning (UFT), a novel post-training paradigm that unifies SFT and RFT into a single, integrated process. UFT enables the model to effectively explore solutions while incorporating informative supervision signals, bridging the gap between memorizing and thinking underlying existing methods. Notably, UFT outperforms both SFT and RFT in general, regardless of model sizes. Furthermore, we theoretically prove that UFT breaks RFT's inherent exponential sample complexity bottleneck, showing for the first time that unified training can exponentially accelerate convergence on long-horizon reasoning tasks.
논문 링크
UniversalRAG: 다양한 모달리티와 세분성의 데이터 집합을 통한 검색-증강 생성 / UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities
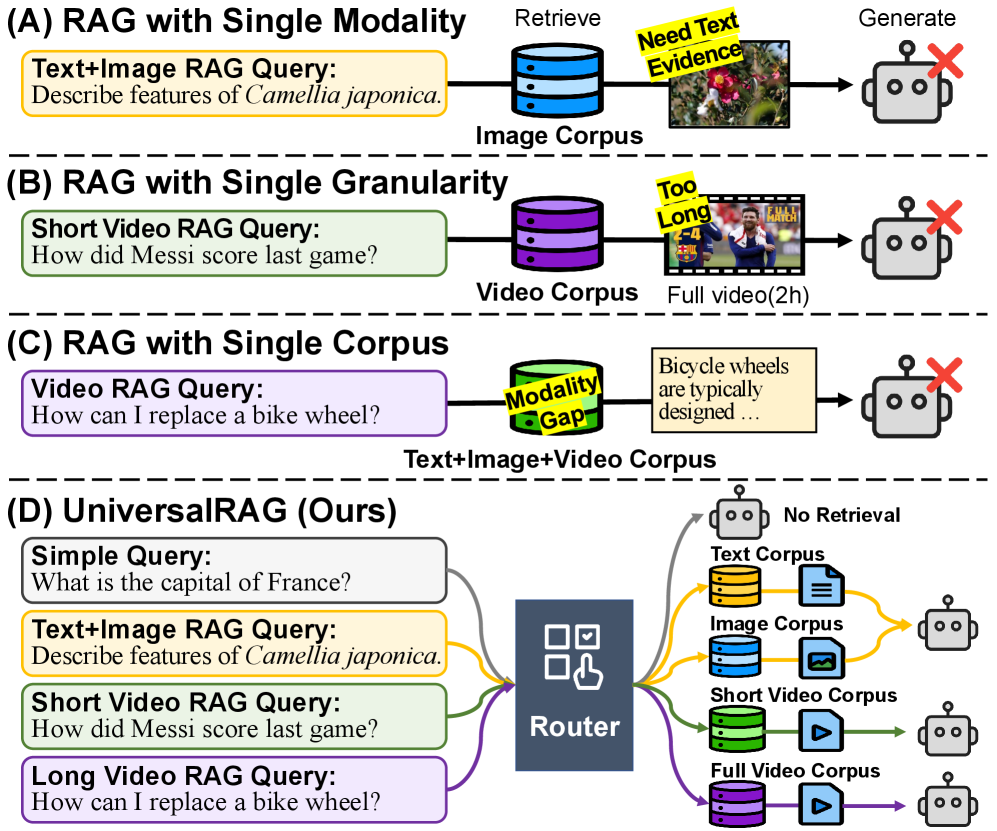
논문 소개
Retrieval-Augmented Generation (RAG) 기술은 외부 지식을 활용하여 모델의 응답 정확성을 향상시키는 데 중요한 역할을 하고 있다. 그러나 기존의 RAG 접근 방식은 주로 텍스트 전용 데이터셋에 국한되어 있으며, 다양한 모달리티에 대한 요구를 충족하지 못하는 한계가 있다. 이러한 문제를 해결하기 위해 제안된 UniversalRAG는 이질적인 소스에서 다양한 모달리티와 세분화 수준의 지식을 검색하고 통합할 수 있는 혁신적인 시스템이다.
UniversalRAG의 핵심은 모달리티 인식 라우팅이다. 이 방법론은 쿼리에 가장 적합한 모달리티별 데이터셋을 동적으로 선택하여 검색을 수행함으로써, 모달리티 간의 격차를 줄이고 검색의 정확성을 높인다. 또한, 각 모달리티를 여러 세분화 수준으로 나누어 쿼리의 복잡성과 범위에 맞춘 세밀한 검색을 가능하게 한다. 이러한 구조는 사용자가 보다 정확하고 관련성 높은 정보를 얻을 수 있도록 지원한다.
저자들은 UniversalRAG의 성능을 검증하기 위해 10개의 다양한 모달리티 벤치마크에서 실험을 진행하였으며, 그 결과 기존의 모달리티 전용 및 통합 기준선에 비해 우수한 성능을 입증하였다. 특히, 복잡한 쿼리에 대해 더욱 효과적인 성능을 보였으며, 이는 모달리티 인식 라우팅과 세분화 수준의 조직 덕분이라고 주장한다.
이 연구는 다양한 모달리티와 세분화 수준의 지식을 통합하는 혁신적인 접근 방식을 제안하며, RAG의 한계를 극복할 수 있는 가능성을 보여준다. 향후 연구에서는 더 많은 모달리티와 데이터셋을 포함하여 UniversalRAG의 성능을 더욱 향상시킬 수 있는 방안을 모색할 필요가 있다. 이러한 기여는 RAG 기술의 발전에 중요한 역할을 할 것으로 기대된다.
논문 초록(Abstract)
검색-증강 생성(Retrieval-Augmented Generation, RAG)은 모델의 응답을 쿼리와 관련된 외부 지식으로 기반을 두어 사실 정확성을 향상시키는 데 상당한 가능성을 보여주었습니다. 그러나 기존의 대부분 접근 방식은 텍스트 전용 데이터셋에 제한되어 있으며, 최근의 노력들은 RAG를 이미지와 비디오와 같은 다른 모달리티로 확장했지만, 일반적으로 단일 모달리티 전용 데이터셋에서 작동합니다. 반면, 실제 세계의 쿼리는 요구하는 지식의 유형이 다양하여 단일 유형의 지식 출처로는 해결할 수 없습니다. 이를 해결하기 위해, 우리는 이질적인 출처에서 다양한 모달리티와 세분성을 가진 지식을 검색하고 통합하도록 설계된 UniversalRAG를 소개합니다. 구체적으로, 모든 모달리티를 단일 집계 데이터셋에서 파생된 통합 표현 공간으로 강제로 넣는 것이 모달리티 간의 격차를 초래한다는 관찰에 의해 동기를 부여받아, 우리는 모달리티 인식 라우팅을 제안합니다. 이는 가장 적합한 모달리티 전용 데이터셋을 동적으로 식별하고 그 안에서 목표 지향적인 검색을 수행하며, 이의 효과성을 이론적 분석을 통해 추가적으로 정당화합니다. 또한, 모달리티를 넘어 각 모달리티를 여러 세분성 수준으로 조직하여 쿼리의 복잡성과 범위에 맞춘 세밀한 검색을 가능하게 합니다. 우리는 UniversalRAG를 여러 모달리티의 10개 벤치마크에서 검증하여 다양한 모달리티 전용 및 통합 기준선에 비해 우수성을 입증합니다.
Retrieval-Augmented Generation (RAG) has shown substantial promise in improving factual accuracy by grounding model responses with external knowledge relevant to queries. However, most existing approaches are limited to a text-only corpus, and while recent efforts have extended RAG to other modalities such as images and videos, they typically operate over a single modality-specific corpus. In contrast, real-world queries vary widely in the type of knowledge they require, which a single type of knowledge source cannot address. To address this, we introduce UniversalRAG, designed to retrieve and integrate knowledge from heterogeneous sources with diverse modalities and granularities. Specifically, motivated by the observation that forcing all modalities into a unified representation space derived from a single aggregated corpus causes a modality gap, where the retrieval tends to favor items from the same modality as the query, we propose modality-aware routing, which dynamically identifies the most appropriate modality-specific corpus and performs targeted retrieval within it, and further justify its effectiveness with a theoretical analysis. Moreover, beyond modality, we organize each modality into multiple granularity levels, enabling fine-tuned retrieval tailored to the complexity and scope of the query. We validate UniversalRAG on 10 benchmarks of multiple modalities, showing its superiority over various modality-specific and unified baselines.
논문 링크
더 읽어보기
대규모 다중 에이전트 AI 시스템의 개발 및 문제에 대한 연구 / A Large-Scale Study on the Development and Issues of Multi-Agent AI Systems
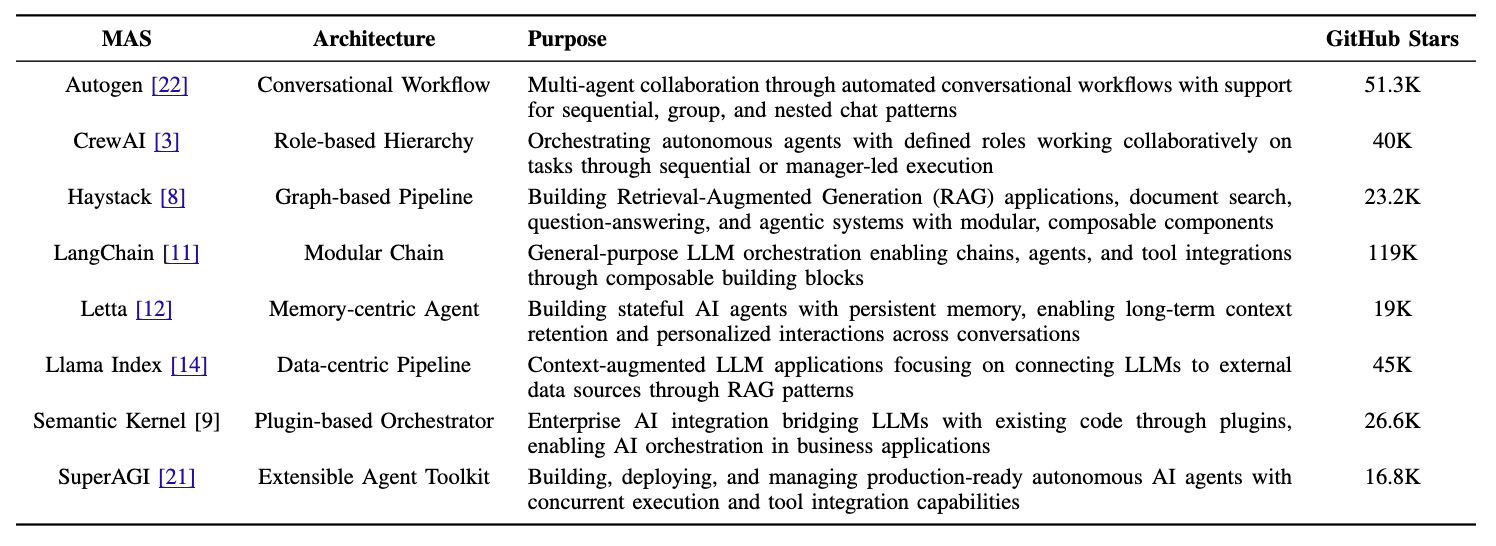
논문 소개
멀티 에이전트 AI 시스템(MAS)의 발전과 그에 따른 문제는 최근 대규모 언어 모델(LLM) 애플리케이션의 개발 방식에 중대한 영향을 미치고 있다. 본 연구는 오픈 소스 MAS의 진화와 유지 관리에 대한 첫 번째 대규모 실증 연구로, 42,267개의 고유 커밋과 4,731개의 해결된 문제를 분석하여 MAS의 개발 패턴을 세 가지 프로필로 구분하였다: 지속적(sustained), 안정적(steady), 폭발적(burst-driven). 이러한 프로필은 각 시스템의 생태계 성숙도를 반영하며, 전체 변경 사항의 40.8%가 기능 향상에 집중되고 있음을 보여준다. 연구 결과, 가장 빈번한 문제는 버그(22%), 인프라(14%), 에이전트 조정(10%)으로 나타났으며, 문제 보고는 2023년부터 급격히 증가하였다.
연구는 GitHub에서 16K에서 119K 스타를 보유한 8개의 오픈 소스 MAS 프로젝트를 대상으로 하여, 각 MAS의 활동 수준, 성장 궤적 및 커밋 유형의 변화를 특성화하였다. 이 과정에서 수집된 데이터는 MAS의 개발 및 유지 관리 활동을 상세히 조사하는 데 기여하였다. 연구는 MAS 간의 개발 패턴 차이와 문제 해결의 효율성을 분석하는 데 중점을 두었다.
결과적으로, 지속적 시스템은 일관된 성장과 주기적인 리팩토링을 보이며, 안정적 시스템은 균형 잡힌 활동을 유지하고, 폭발적 시스템은 짧은 기간 동안 강렬한 개발을 경험하는 것으로 나타났다. 이러한 발견은 MAS 생태계의 동력과 취약성을 강조하며, 향후 연구를 위한 데이터셋을 공개하여 MAS의 발전을 지원할 예정이다. 본 연구는 MAS의 개발 및 유지 관리에 대한 최초의 정량적 분석을 제공하며, 향후 연구와 실무에 중요한 기여를 할 것으로 기대된다.
논문 초록(Abstract)
다중 에이전트 AI 시스템(MAS)의 빠른 출현, LangChain, CrewAI 및 AutoGen을 포함하여, 대규모 언어 모델(LLM) 애플리케이션이 개발되고 조정되는 방식을 형성했습니다. 그러나 이러한 시스템이 실제로 어떻게 진화하고 유지되는지에 대해서는 알려진 바가 거의 없습니다. 본 논문은 오픈 소스 MAS에 대한 첫 번째 대규모 실증 연구를 제시하며, 8개의 주요 시스템에서 42,000개 이상의 고유 커밋과 4,700개 이상의 해결된 문제를 분석합니다. 우리의 분석은 지속적, 안정적, 그리고 폭발적 개발 프로필의 세 가지 뚜렷한 유형을 식별합니다. 이러한 프로필은 생태계 성숙도의 상당한 변화를 반영합니다. 완벽한 커밋은 모든 변경 사항의 40.8%를 차지하며, 이는 기능 향상이 수정 유지 관리(27.4%) 및 적응형 업데이트(24.3%)보다 우선시됨을 나타냅니다. 문제에 대한 데이터는 가장 빈번한 우려 사항이 버그(22%), 인프라(14%), 에이전트 조정 문제(10%)와 관련이 있음을 보여줍니다. 문제 보고는 2023년부터 모든 프레임워크에서 급격히 증가했습니다. 중간 해결 시간은 하루 미만에서 약 2주까지 다양하며, 응답이 빠른 쪽으로 치우쳐 있지만 일부 문제는 장기간의 주의가 필요합니다. 이러한 결과는 현재 생태계의 동력과 취약성을 모두 강조하며, 장기적인 신뢰성과 지속 가능성을 보장하기 위해 개선된 테스트 인프라, 문서 품질 및 유지 관리 관행의 필요성을 강조합니다.
The rapid emergence of multi-agent AI systems (MAS), including LangChain, CrewAI, and AutoGen, has shaped how large language model (LLM) applications are developed and orchestrated. However, little is known about how these systems evolve and are maintained in practice. This paper presents the first large-scale empirical study of open-source MAS, analyzing over 42K unique commits and over 4.7K resolved issues across eight leading systems. Our analysis identifies three distinct development profiles: sustained, steady, and burst-driven. These profiles reflect substantial variation in ecosystem maturity. Perfective commits constitute 40.8% of all changes, suggesting that feature enhancement is prioritized over corrective maintenance (27.4%) and adaptive updates (24.3%). Data about issues shows that the most frequent concerns involve bugs (22%), infrastructure (14%), and agent coordination challenges (10%). Issue reporting also increased sharply across all frameworks starting in 2023. Median resolution times range from under one day to about two weeks, with distributions skewed toward fast responses but a minority of issues requiring extended attention. These results highlight both the momentum and the fragility of the current ecosystem, emphasizing the need for improved testing infrastructure, documentation quality, and maintenance practices to ensure long-term reliability and sustainability.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()