[2026/02/16 ~ 22] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 매개변수와 연산의 극한 최적화를 통한 효율성 극대화: 이번 주 논문들에서는 모델의 덩치를 무작정 키우기보다, 훈련 및 추론 과정의 자원 소모를 극적으로 줄이는 '가성비' 높은 최적화 기법들이 두드러졌습니다. 13개 매개변수로 추론 학습하기 논문은 TinyLoRA와 강화학습을 결합해 단 13개의 훈련 매개변수만으로도 모델의 추론 성능을 90% 이상 회복하는 놀라운 파라미터 효율성을 보여주었습니다. 또한 수퍼 모델(Souper-Model) 은 추가적인 재학습 없이 비상관 카테고리의 전문가 모델 가중치를 똑똑하게 병합하여 성능을 끌어올렸으며, 어텐션 매칭을 통한 빠른 KV 압축과 프롬프트 반복 연구 역시 모델의 구조적 병목이나 지연 시간 증가 없이 추론 성능을 크게 향상시켰습니다. 이는 거대 모델의 막대한 유지 비용을 절감하면서도 성능을 한계까지 쥐어짜내려는 실용적인 엔지니어링 접근이 고도화되고 있음을 의미합니다.
매개변수와 연산의 극한 최적화를 통한 효율성 극대화: 이번 주 논문들에서는 모델의 덩치를 무작정 키우기보다, 훈련 및 추론 과정의 자원 소모를 극적으로 줄이는 '가성비' 높은 최적화 기법들이 두드러졌습니다. 13개 매개변수로 추론 학습하기 논문은 TinyLoRA와 강화학습을 결합해 단 13개의 훈련 매개변수만으로도 모델의 추론 성능을 90% 이상 회복하는 놀라운 파라미터 효율성을 보여주었습니다. 또한 수퍼 모델(Souper-Model) 은 추가적인 재학습 없이 비상관 카테고리의 전문가 모델 가중치를 똑똑하게 병합하여 성능을 끌어올렸으며, 어텐션 매칭을 통한 빠른 KV 압축과 프롬프트 반복 연구 역시 모델의 구조적 병목이나 지연 시간 증가 없이 추론 성능을 크게 향상시켰습니다. 이는 거대 모델의 막대한 유지 비용을 절감하면서도 성능을 한계까지 쥐어짜내려는 실용적인 엔지니어링 접근이 고도화되고 있음을 의미합니다.
![]() 에이전트 시스템의 구조화 및 엄격한 성능 검증: 자율적으로 동작하는 LLM 에이전트의 활용이 늘어남에 따라, 이들이 활동할 수 있는 환경을 체계적으로 구축하고 실제 유용성을 냉정하게 평가하려는 흐름도 돋보입니다. 웹 월드 모델(Web World Models) 은 에이전트가 환각 없이 일관되게 상호작용할 수 있도록 일반 웹 코드 기반의 구조화된 '세계 모델'을 제안하여 에이전트의 안정적인 활동 무대를 마련했습니다. 반면 SkillsBench와 AGENTS.md 평가 논문은 개발자가 부여한 스킬이나 컨텍스트 파일이 복잡한 작업에서 에이전트에게 늘 도움이 되는 것은 아니며, 오히려 LLM이 생성한 불필요한 제약이 성능을 떨어뜨릴 수 있음을 실증적으로 밝혀냈습니다. 여기에 대규모 언어 모델의 추론 실패 분석 서베이까지 더해져, 이제 AI 학계는 에이전트의 표면적인 성공을 넘어 근본적인 실패 원인을 규명하고 거품을 걷어내는 검증의 단계로 진입했음을 보여줍니다.
에이전트 시스템의 구조화 및 엄격한 성능 검증: 자율적으로 동작하는 LLM 에이전트의 활용이 늘어남에 따라, 이들이 활동할 수 있는 환경을 체계적으로 구축하고 실제 유용성을 냉정하게 평가하려는 흐름도 돋보입니다. 웹 월드 모델(Web World Models) 은 에이전트가 환각 없이 일관되게 상호작용할 수 있도록 일반 웹 코드 기반의 구조화된 '세계 모델'을 제안하여 에이전트의 안정적인 활동 무대를 마련했습니다. 반면 SkillsBench와 AGENTS.md 평가 논문은 개발자가 부여한 스킬이나 컨텍스트 파일이 복잡한 작업에서 에이전트에게 늘 도움이 되는 것은 아니며, 오히려 LLM이 생성한 불필요한 제약이 성능을 떨어뜨릴 수 있음을 실증적으로 밝혀냈습니다. 여기에 대규모 언어 모델의 추론 실패 분석 서베이까지 더해져, 이제 AI 학계는 에이전트의 표면적인 성공을 넘어 근본적인 실패 원인을 규명하고 거품을 걷어내는 검증의 단계로 진입했음을 보여줍니다.
![]() 다중 에이전트 환경과 사회적 상호작용의 역학 탐구: AI 모델이 단독으로 작동하는 것을 넘어, 다른 에이전트나 인류 사회와 상호작용할 때 발생하는 복잡한 역학 관계를 탐구하는 연구들 역시 중요한 트렌드를 형성했습니다. 다중 에이전트 협력 연구는 별도의 복잡한 규칙 없이도 시퀀스 모델이 문맥 내 학습(In-context learning)을 통해 상대방의 전략을 파악하고 자생적으로 협력적 행동을 유도할 수 있음을 증명했습니다. 반대로 설계에 의한 분극화 논문은 AI를 활용한 저비용 설득 기술이 정치적 엘리트들에 의해 의도적인 여론 양극화 전략으로 악용될 수 있음을 수학적 동적 모델로 경고합니다. 이러한 연구들은 AI가 다수의 참여자가 존재하는 복잡계에 투입되었을 때 나타나는 협력과 통제 메커니즘을 이해하고, 그 거시적인 사회적 파급력을 대비하기 위한 필수적인 고민을 담고 있습니다.
다중 에이전트 환경과 사회적 상호작용의 역학 탐구: AI 모델이 단독으로 작동하는 것을 넘어, 다른 에이전트나 인류 사회와 상호작용할 때 발생하는 복잡한 역학 관계를 탐구하는 연구들 역시 중요한 트렌드를 형성했습니다. 다중 에이전트 협력 연구는 별도의 복잡한 규칙 없이도 시퀀스 모델이 문맥 내 학습(In-context learning)을 통해 상대방의 전략을 파악하고 자생적으로 협력적 행동을 유도할 수 있음을 증명했습니다. 반대로 설계에 의한 분극화 논문은 AI를 활용한 저비용 설득 기술이 정치적 엘리트들에 의해 의도적인 여론 양극화 전략으로 악용될 수 있음을 수학적 동적 모델로 경고합니다. 이러한 연구들은 AI가 다수의 참여자가 존재하는 복잡계에 투입되었을 때 나타나는 협력과 통제 메커니즘을 이해하고, 그 거시적인 사회적 파급력을 대비하기 위한 필수적인 고민을 담고 있습니다.
대규모 언어 모델의 추론 실패 분석 / Large Language Model Reasoning Failures
논문 소개
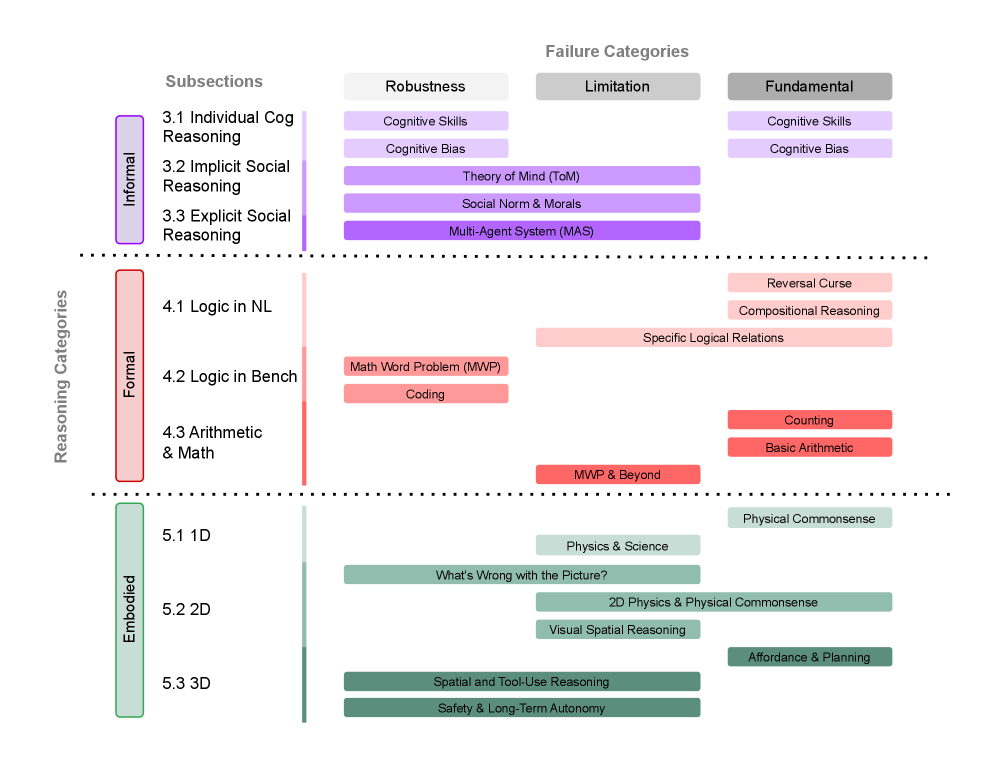
대규모 언어 모델(LLM)은 자연어 처리(NLP) 분야에서 뛰어난 성과를 보여주었으나, 여전히 간단한 상황에서도 추론 실패가 발생하는 문제를 안고 있다. 이러한 추론 실패를 체계적으로 이해하고 해결하기 위해 본 연구는 LLM의 추론 실패에 대한 최초의 포괄적인 서베이를 제시한다. 연구의 핵심은 새로운 분류 프레임워크를 도입하여 추론을 구체화된(embodied) 추론과 비구체화된(non-embodied) 추론으로 나누고, 비구체화된 추론은 다시 비공식적(informal)과 공식적(formal)으로 세분화하는 것이다.
추론 실패는 세 가지 유형으로 분류된다. 첫째, LLM 아키텍처에 내재된 기본 실패는 하위 작업에 광범위한 영향을 미친다. 둘째, 응용 특정 제한은 특정 도메인에서 나타나는 문제로, 특정 작업의 성능 저하를 초래한다. 셋째, 강건성 문제는 미세한 변동에 따라 성능이 일관되지 않는 문제로, 이는 LLM의 신뢰성을 저하시킨다. 각 실패 유형에 대해 명확한 정의를 제공하고, 기존 연구를 분석하며, 근본 원인을 탐구하고 완화 전략을 제시한다.
본 연구는 단편화된 연구 노력을 통합하여 LLM의 추론 실패를 체계적으로 분석하며, 이를 통해 향후 연구가 더 강력하고 신뢰할 수 있는 LLM을 개발하는 데 기여할 수 있는 기초 자료를 제공한다. 또한, LLM 추론 실패에 관한 연구 자료를 종합한 GitHub 저장소를 제공하여 이 분야에 대한 접근성을 높인다. 이러한 체계적인 접근은 LLM의 추론 능력을 향상시키고, 연구자들이 더 나은 모델을 개발하는 데 필요한 통찰을 제공할 것으로 기대된다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 놀라운 추론 능력을 보여주며, 다양한 작업에서 인상적인 결과를 달성했습니다. 이러한 발전에도 불구하고, 간단해 보이는 시나리오에서도 여전히 상당한 추론 실패가 발생하고 있습니다. 이러한 단점을 체계적으로 이해하고 해결하기 위해, 우리는 LLM의 추론 실패에 전념한 최초의 포괄적인 서베이를 제시합니다. 우리는 추론을 구체화된 유형과 비구체화된 유형으로 구분하는 새로운 분류 프레임워크를 도입하며, 후자는 비공식(직관적) 추론과 공식(논리적) 추론으로 추가 세분화됩니다. 동시에, 우리는 추론 실패를 세 가지 유형으로 보완적인 축을 따라 분류합니다: LLM 아키텍처에 내재된 근본적인 실패로, 이는 하위 작업에 광범위한 영향을 미치며; 특정 도메인에서 나타나는 응용 프로그램별 제한; 그리고 사소한 변동에 따라 일관되지 않은 성능으로 특징지어지는 강건성 문제입니다. 각 추론 실패에 대해 명확한 정의를 제공하고, 기존 연구를 분석하며, 근본 원인을 탐구하고, 완화 전략을 제시합니다. 단편화된 연구 노력을 통합함으로써, 우리의 서베이는 LLM 추론의 체계적 약점에 대한 구조화된 관점을 제공하고, 더 강력하고 신뢰할 수 있으며 강건한 추론 능력을 구축하기 위한 미래 연구를 안내하는 귀중한 통찰을 제공합니다. 또한, 우리는 이 분야에 대한 쉽게 접근할 수 있는 출발점을 제공하기 위해 LLM 추론 실패에 관한 연구 작업의 포괄적인 컬렉션을 GitHub 저장소(GitHub - Peiyang-Song/Awesome-LLM-Reasoning-Failures: Repo for "Large Language Model Reasoning Failures")로 공개합니다.
Large Language Models (LLMs) have exhibited remarkable reasoning capabilities, achieving impressive results across a wide range of tasks. Despite these advances, significant reasoning failures persist, occurring even in seemingly simple scenarios. To systematically understand and address these shortcomings, we present the first comprehensive survey dedicated to reasoning failures in LLMs. We introduce a novel categorization framework that distinguishes reasoning into embodied and non-embodied types, with the latter further subdivided into informal (intuitive) and formal (logical) reasoning. In parallel, we classify reasoning failures along a complementary axis into three types: fundamental failures intrinsic to LLM architectures that broadly affect downstream tasks; application-specific limitations that manifest in particular domains; and robustness issues characterized by inconsistent performance across minor variations. For each reasoning failure, we provide a clear definition, analyze existing studies, explore root causes, and present mitigation strategies. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities. We additionally release a comprehensive collection of research works on LLM reasoning failures, as a GitHub repository at GitHub - Peiyang-Song/Awesome-LLM-Reasoning-Failures: Repo for "Large Language Model Reasoning Failures", to provide an easy entry point to this area.
논문 링크
더 읽어보기
AGENTS.md 평가: 리포지토리 수준의 컨텍스트 파일이 코딩 에이전트에 도움이 되는가? / Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
논문 소개
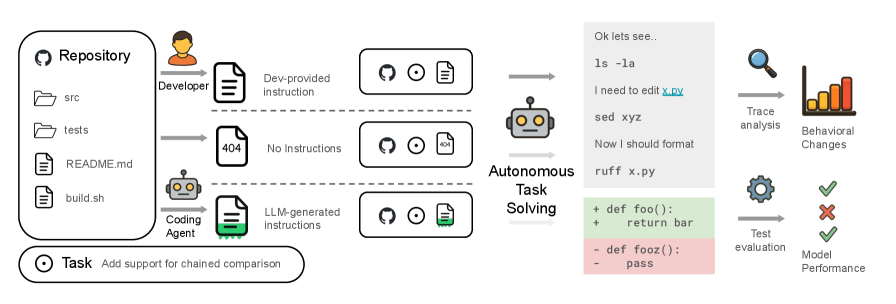
코딩 에이전트는 소프트웨어 엔지니어링(SWE) 분야에서 점차 널리 사용되고 있으며, AGENTS.md와 같은 컨텍스트 파일을 통해 특정 리포지토리에 맞춰 조정되고 있다. 이러한 컨텍스트 파일은 개발자들에 의해 권장되지만, 실제로 이들이 복잡한 소프트웨어 엔지니어링 작업에 미치는 영향은 충분히 연구되지 않았다. 본 연구에서는 AGENTS.md와 같은 컨텍스트 파일의 효과를 평가하기 위해 새로운 벤치마크인 AGENTbench를 제안하고, 이를 통해 개발자가 제공한 컨텍스트 파일과 대규모 언어 모델(LLM)이 생성한 컨텍스트 파일의 성능 차이를 분석하였다.
연구는 두 가지 주요 설정에서 수행되었다. 첫째, 기존의 SWE-bench 작업을 활용하여 LLM이 생성한 컨텍스트 파일의 효과를 평가하였고, 둘째, 개발자가 직접 작성한 컨텍스트 파일이 포함된 새로운 이슈 세트를 통해 그 성능을 비교하였다. 실험 결과, LLM이 생성한 컨텍스트 파일은 작업 성공률을 감소시키고, 인퍼런스 비용을 20% 이상 증가시키는 경향이 있었다. 반면, 개발자가 작성한 컨텍스트 파일은 약간의 성능 향상을 보였지만, 여전히 불필요한 요구 사항이 작업을 더 어렵게 만들 수 있음을 발견하였다.
AGENTbench는 코드베이스, 테스트 스위트, 패치, 이슈 등 네 가지 요소로 구성된 인스턴스를 통해 코딩 에이전트의 작업을 정의하고, 이를 통해 에이전트의 성능을 평가하는 데 필요한 기초를 마련한다. 또한, 다양한 코딩 에이전트와 모델을 사용하여 실험을 진행하였으며, 각 에이전트의 설정을 통해 최적의 성능을 이끌어내기 위한 방법론을 제시하였다.
이 연구는 코딩 에이전트와 모델 개발자들에게 LLM이 생성한 컨텍스트 파일의 유용성을 향상시키기 위한 기초 자료를 제공하며, 향후 연구에서는 자동으로 생성된 간결하고 작업 관련 지침의 개발 필요성을 강조하고 있다. 이러한 결과는 소프트웨어 개발 환경에서 코딩 에이전트의 성능을 개선하는 데 기여할 것으로 기대된다.
논문 초록(Abstract)
소프트웨어 개발에서 널리 퍼진 관행은 AGENTS.md와 같은 컨텍스트 파일을 사용하여 코딩 에이전트를 저장소에 맞추는 것으로, 이를 수동으로 또는 자동으로 생성하는 방법이 있습니다. 이 관행은 에이전트 개발자들에 의해 강력히 권장되지만, 현재 이러한 컨텍스트 파일이 실제 작업에 효과적인지에 대한 철저한 조사는 이루어지지 않고 있습니다. 본 연구에서는 이 질문을 다루고, 두 가지 보완적인 설정에서 코딩 에이전트의 작업 완료 성능을 평가합니다: 인기 있는 저장소의 기존 SWE-bench 작업과 에이전트 개발자 추천에 따라 LLM이 생성한 컨텍스트 파일을 사용하는 작업, 그리고 개발자가 작성한 컨텍스트 파일을 포함하는 저장소의 새로운 이슈 모음입니다. 여러 코딩 에이전트와 LLM을 통해, 우리는 컨텍스트 파일이 저장소 컨텍스트를 제공하지 않을 때에 비해 작업 성공률을 감소시키는 경향이 있으며, 추론 비용을 20% 이상 증가시킨다는 것을 발견했습니다. 행동적으로, LLM이 생성한 컨텍스트 파일과 개발자가 제공한 컨텍스트 파일 모두 더 폭넓은 탐색(예: 더 철저한 테스트 및 파일 탐색)을 장려하며, 코딩 에이전트는 이들의 지침을 따르는 경향이 있습니다. 궁극적으로, 우리는 컨텍스트 파일의 불필요한 요구 사항이 작업을 더 어렵게 만들며, 인간이 작성한 컨텍스트 파일은 최소한의 요구 사항만을 설명해야 한다고 결론지었습니다.
A widespread practice in software development is to tailor coding agents to repositories using context files, such as AGENTS.md, by either manually or automatically generating them. Although this practice is strongly encouraged by agent developers, there is currently no rigorous investigation into whether such context files are actually effective for real-world tasks. In this work, we study this question and evaluate coding agents' task completion performance in two complementary settings: established SWE-bench tasks from popular repositories, with LLM-generated context files following agent-developer recommendations, and a novel collection of issues from repositories containing developer-committed context files. Across multiple coding agents and LLMs, we find that context files tend to reduce task success rates compared to providing no repository context, while also increasing inference cost by over 20%. Behaviorally, both LLM-generated and developer-provided context files encourage broader exploration (e.g., more thorough testing and file traversal), and coding agents tend to respect their instructions. Ultimately, we conclude that unnecessary requirements from context files make tasks harder, and human-written context files should describe only minimal requirements.
논문 링크
SkillsBench: 다양한 작업에서 에이전트 기술의 효과를 평가하는 벤치마크 / SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
논문 소개
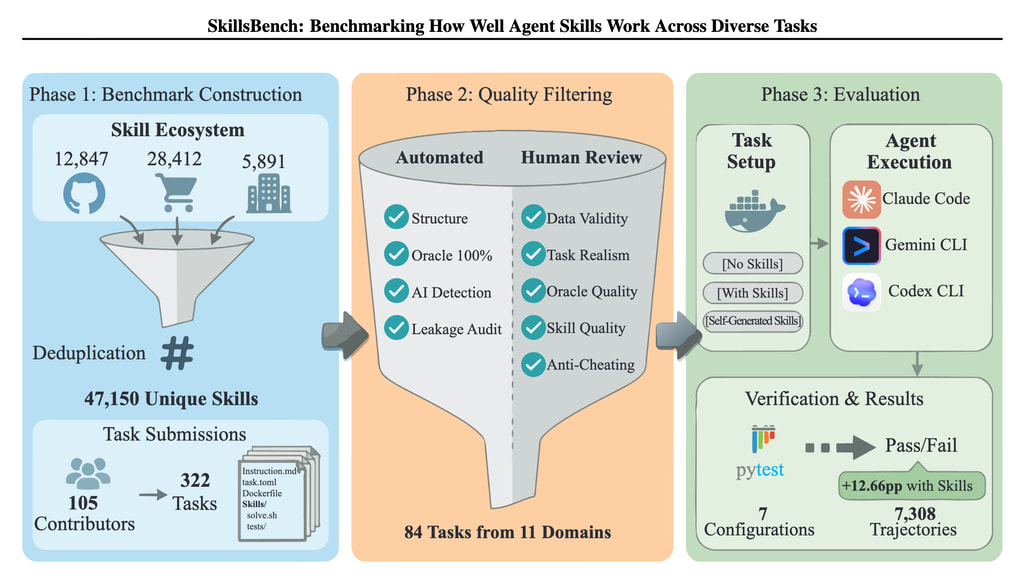
SkillsBench는 LLM(대규모 언어 모델) 에이전트의 기술 효과를 평가하기 위한 새로운 벤치마크로, 11개 도메인에서 86개의 작업을 포함하고 있습니다. 이 연구의 주요 목적은 에이전트 기술이 실제로 얼마나 효과적인지를 측정할 수 있는 표준 방법을 제시하는 것입니다. 각 작업은 세 가지 조건에서 평가되며, 이 조건은 기술 없음, 선별된 기술, 자가 생성된 기술로 구분됩니다. 연구에서는 7개의 에이전트 모델 구성을 통해 7,308개의 궤적을 테스트하였으며, 그 결과 선별된 기술이 평균적으로 통과율을 16.2% 포인트 향상시키는 것으로 나타났습니다. 그러나 이 효과는 도메인에 따라 상이하며, 소프트웨어 공학에서는 +4.5p.p., 헬스케어에서는 +51.9p.p.의 향상이 관찰되었습니다. 흥미롭게도, 84개 작업 중 16개는 오히려 부정적인 변화를 보였습니다.
자가 생성된 기술은 평균적으로 이점을 제공하지 않는 것으로 나타났으며, 이는 모델이 소비하는 절차적 지식을 신뢰성 있게 생성할 수 없음을 시사합니다. 연구 결과에 따르면, 2-3개의 모듈로 구성된 집중 기술이 포괄적인 문서보다 더 나은 성능을 보였고, 기술을 가진 소형 모델이 기술이 없는 대형 모델과 동등한 성능을 발휘할 수 있음을 보여줍니다. 이러한 발견은 에이전트 기술의 효과를 체계적으로 평가할 수 있는 기반을 마련하며, 향후 연구에서 SkillsBench를 활용할 수 있는 가능성을 제시합니다.
SkillsBench는 LLM 에이전트의 성능 향상을 위한 중요한 기초 자료를 제공하며, 다양한 도메인에서의 에이전트 기술의 효과를 이해하는 데 기여할 것입니다. 이 연구는 에이전트 기술의 효과를 평가하기 위한 새로운 기준을 제시하며, 향후 연구에서의 활용 가능성을 열어줍니다.
논문 초록(Abstract)
에이전트 스킬은 추론 시 LLM 에이전트를 보강하는 절차적 지식의 구조화된 패키지입니다. 빠른 채택에도 불구하고, 이들이 실제로 도움이 되는지를 측정하는 표준 방법은 없습니다. 우리는 11개 도메인에서 86개의 작업으로 구성된 벤치마크인 SkillsBench를 제시하며, 이는 선별된 스킬과 결정론적 검증기와 쌍을 이룹니다. 각 작업은 스킬이 없는 경우, 선별된 스킬이 있는 경우, 자가 생성된 스킬이 있는 경우의 세 가지 조건에서 평가됩니다. 우리는 7,308개의 경로에 대해 7개의 에이전트-모델 구성을 테스트했습니다. 선별된 스킬은 평균 통과율을 16.2 퍼센트 포인트(pp) 높였지만, 효과는 도메인에 따라 크게 다릅니다(+4.5pp는 소프트웨어 공학, +51.9pp는 헬스케어). 84개 작업 중 16개는 부정적인 델타를 보였습니다. 자가 생성된 스킬은 평균적으로 이점을 제공하지 않으며, 이는 모델이 소비하는 절차적 지식을 신뢰성 있게 작성할 수 없음을 보여줍니다. 2-3개의 모듈로 구성된 집중된 스킬은 포괄적인 문서보다 더 나은 성과를 내며, 스킬이 있는 작은 모델은 스킬이 없는 큰 모델과 동등한 성능을 발휘할 수 있습니다.
Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
논문 링크
어텐션 매칭을 통한 빠른 KV 압축 / Fast KV Compaction via Attention Matching
논문 소개
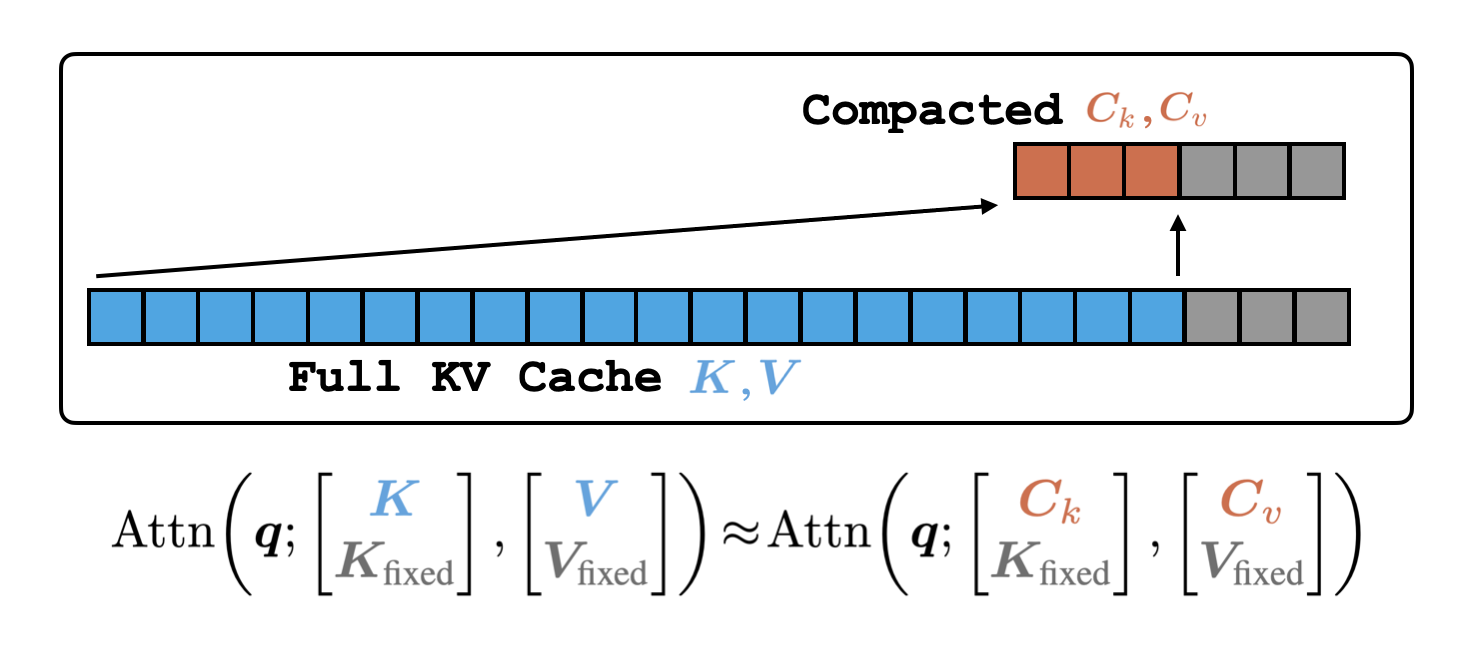
대규모 언어 모델의 발전은 긴 컨텍스트를 효과적으로 처리하는 데 있어 메모리 관리의 중요성을 강조하고 있다. 특히, 키-값(KV) 캐시의 크기는 이러한 모델의 성능을 제한하는 주요 요인으로 작용한다. 기존의 압축 방법들은 종종 성능 저하를 초래하는 손실적인 요약에 의존해 왔으나, 본 연구에서는 어텐션 매칭(Attention Matching)을 통해 잠재 공간에서의 빠른 KV 압축을 제안한다. 이 접근법은 압축된 키와 값을 구성하여 어텐션 출력을 재현하고, 각 KV 헤드 수준에서 어텐션 질량을 보존하는 데 중점을 둔다.
제안된 방법론은 간단한 하위 문제로 분해될 수 있으며, 일부는 효율적인 폐쇄형 해법을 통해 해결 가능하다. 이를 통해 연구팀은 압축 시간과 품질 간의 파레토 경계를 크게 확장하는 다양한 방법을 개발하였다. 실험 결과, 이 방법은 특정 데이터셋에서 최대 50배의 압축을 몇 초 만에 달성하면서도 품질 손실을 최소화하는 성과를 보였다.
어텐션 매칭을 통한 KV 압축은 기존의 그래디언트 기반 최적화 방법을 피하고, 압축된 키와 값의 집합을 구성하는 데 있어 효율성을 극대화한다. 이 과정에서 참조 쿼리를 활용하여 압축된 키와 값의 적합성을 높이고, 비균일 압축을 통해 각 어텐션 헤드의 특성에 맞춘 최적의 압축 비율을 적용한다.
이 연구는 대규모 언어 모델의 긴 컨텍스트 처리에 있어 새로운 압축 기술의 발전을 목표로 하며, 향후 다양한 응용 분야에서의 활용 가능성을 제시한다. 이러한 혁신적인 접근은 언어 모델의 효율성을 한층 높이는 데 기여할 것으로 기대된다.
논문 초록(Abstract)
언어 모델을 긴 컨텍스트로 확장하는 것은 종종 키-값(KV) 캐시의 크기에 의해 병목 현상이 발생합니다. 배포된 환경에서는 긴 컨텍스트가 일반적으로 요약을 통한 토큰 공간의 압축으로 관리됩니다. 그러나 요약은 매우 손실이 클 수 있으며, 이는 하위 작업의 성능에 상당한 해를 끼칠 수 있습니다. 최근 Cartridges에 대한 연구는 잠재 공간에서 전체 컨텍스트 성능과 밀접하게 일치하는 매우 압축된 KV 캐시를 훈련할 수 있음을 보여주었지만, 이는 느리고 비용이 많이 드는 종단 간 최적화의 대가를 치러야 합니다. 본 연구는 어텐션 매칭을 통한 잠재 공간에서의 빠른 컨텍스트 압축 접근 방식을 설명하며, 이는 압축된 키와 값을 구성하여 어텐션 출력을 재현하고 KV 헤드별로 어텐션 질량을 보존합니다. 우리는 이 공식화가 자연스럽게 간단한 하위 문제로 분해되며, 그 중 일부는 효율적인 닫힌 형태의 해를 허용함을 보여줍니다. 이 프레임워크 내에서 우리는 압축 시간과 품질 간의 파레토 경계를 크게 확장하는 방법군을 개발하여, 일부 데이터셋에서 품질 손실이 거의 없이 몇 초 만에 최대 50배의 압축을 달성합니다.
Scaling language models to long contexts is often bottlenecked by the size of the key-value (KV) cache. In deployed settings, long contexts are typically managed through compaction in token space via summarization. However, summarization can be highly lossy, substantially harming downstream performance. Recent work on Cartridges has shown that it is possible to train highly compact KV caches in latent space that closely match full-context performance, but at the cost of slow and expensive end-to-end optimization. This work describes an approach for fast context compaction in latent space through Attention Matching, which constructs compact keys and values to reproduce attention outputs and preserve attention mass at a per-KV-head level. We show that this formulation naturally decomposes into simple subproblems, some of which admit efficient closed-form solutions. Within this framework, we develop a family of methods that significantly push the Pareto frontier of compaction time versus quality, achieving up to 50x compaction in seconds on some datasets with little quality loss.
논문 링크
더 읽어보기
TinyLoRA: 13개 매개변수로 추론 학습하기 / Learning to Reason in 13 Parameters
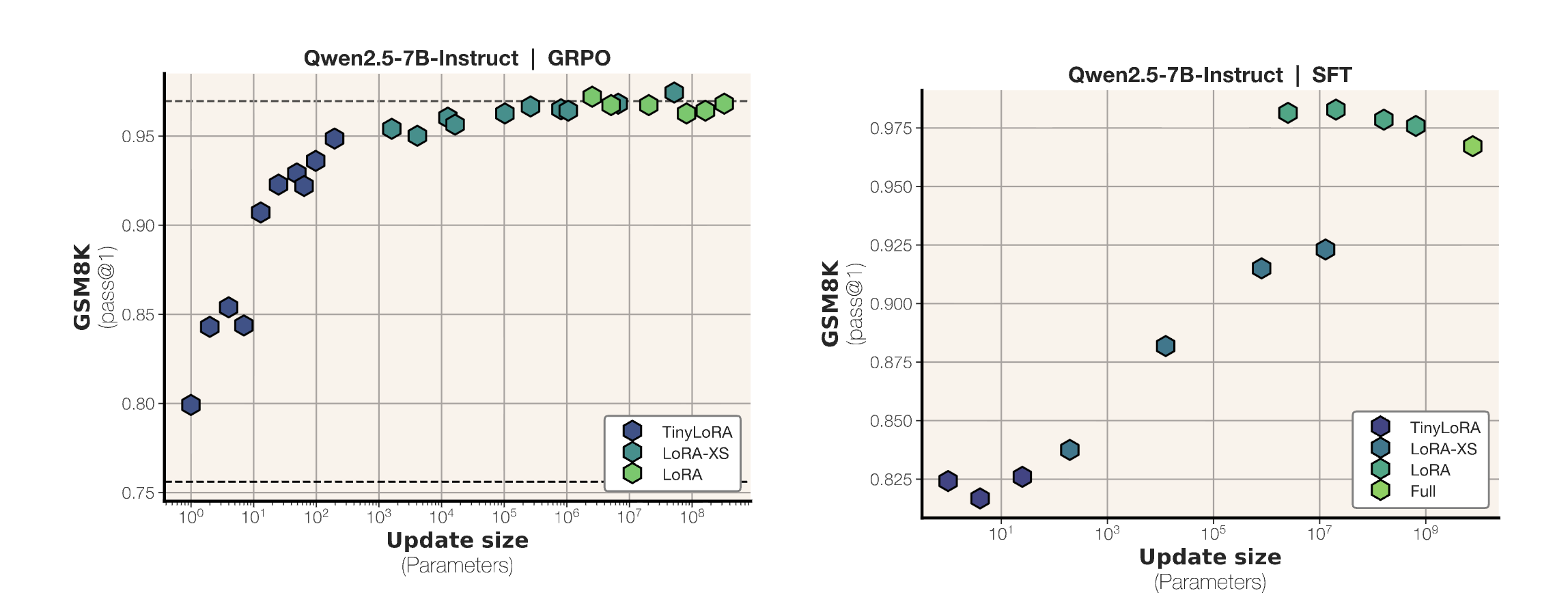
논문 소개
최근 언어 모델의 추론 능력 향상에 대한 연구가 활발히 진행되고 있으며, 특히 강화학습을 통한 접근 방식이 주목받고 있다. 기존의 저차원 어댑터(LoRA) 방식은 모델 차원 이하로 확장할 수 없는 한계가 있었고, 이에 대한 해결책으로 제안된 TinyLoRA는 매개변수를 단 하나로 줄이면서도 저차원 어댑터를 확장할 수 있는 혁신적인 방법론이다. 본 연구에서는 Qwen2.5 모델을 활용하여 GSM8K 데이터셋에서 91%의 정확도를 달성하는 동시에, 단 13개의 매개변수만으로도 성능 개선의 90%를 회복할 수 있음을 입증하였다.
TinyLoRA의 핵심은 저차원 매개변수화의 새로운 접근 방식으로, 이를 통해 모델의 수학적 추론 능력을 극대화하면서도 학습된 매개변수의 수를 최소화하는 데 성공하였다. 연구진은 GSM8K와 MATH 훈련 세트를 포함한 다양한 벤치마크에서 실험을 진행하였으며, 특히 그룹 상대 정책 최적화(GRPO)를 활용한 강화학습을 통해 뛰어난 성능을 이끌어냈다. 기존의 지도 파인튜닝(SFT) 방식과 비교할 때, 강화학습을 통한 접근이 100배에서 1000배 더 적은 업데이트로도 유사한 성능을 달성할 수 있음을 보여주었다.
이 연구는 언어 모델의 추론 능력 향상에 있어 매개변수 효율성을 극대화하는 방법론을 제시하며, 기존의 연구에서 나타난 한계를 극복하는 데 기여하고 있다. TinyLoRA는 특히 저차원 어댑터의 적용 가능성을 넓히고, 다양한 난이도의 수학 문제 해결에 있어 모델의 성능을 향상시키는 데 중요한 역할을 한다. 이러한 접근은 향후 언어 모델의 발전에 있어 중요한 이정표가 될 것으로 기대된다.
논문 초록(Abstract)
최근 연구에 따르면 언어 모델이 종종 강화 학습을 통해 \textit{추론}을 학습할 수 있다는 사실이 밝혀졌습니다. 일부 연구에서는 추론을 위한 저차원 매개변수를 훈련하기도 하지만, 기존의 LoRA는 모델 차원 이하로 확장할 수 없습니다. 우리는 추론을 학습하는 데 rank=1 LoRA가 정말 필요한지 의문을 제기하고, 하나의 매개변수만으로 저차원 어댑터를 확장할 수 있는 방법인 TinyLoRA를 제안합니다. 우리의 새로운 매개변수화 방식 내에서, 우리는 Qwen2.5의 80억 매개변수 크기를 GSM8K에서 단 13개의 훈련된 매개변수(bf16, 총 26바이트)로 91% 정확도로 훈련할 수 있었습니다. 우리는 이 경향이 일반적으로 유지된다는 것을 발견했습니다: AIME, AMC, MATH500과 같은 더 어려운 추론 학습 벤치마크에서 1000x 더 적은 매개변수를 훈련하면서 성능 개선의 90%를 회복할 수 있었습니다. 특히, 우리는 RL을 사용하여 이러한 강력한 성능을 달성할 수 있었으며, SFT를 사용하여 훈련된 모델은 동일한 성능에 도달하기 위해 100-1000x 더 큰 업데이트가 필요합니다.
Recent research has shown that language models can learn to \textit{reason}, often via reinforcement learning. Some work even trains low-rank parameterizations for reasoning, but conventional LoRA cannot scale below the model dimension. We question whether even rank=1 LoRA is necessary for learning to reason and propose TinyLoRA, a method for scaling low-rank adapters to sizes as small as one parameter. Within our new parameterization, we are able to train the 8B parameter size of Qwen2.5 to 91% accuracy on GSM8K with only 13 trained parameters in bf16 (26 total bytes). We find this trend holds in general: we are able to recover 90% of performance improvements while training 1000x fewer parameters across a suite of more difficult learning-to-reason benchmarks such as AIME, AMC, and MATH500. Notably, we are only able to achieve such strong performance with RL: models trained using SFT require 100-1000x larger updates to reach the same performance.
논문 링크
설계에 의한 분극화: 엘리트가 대중의 선호를 형성할 수 있는 방법과 AI가 설득 비용을 줄이는 방식 / Polarization by Design: How Elites Could Shape Mass Preferences as AI Reduces Persuasion Costs
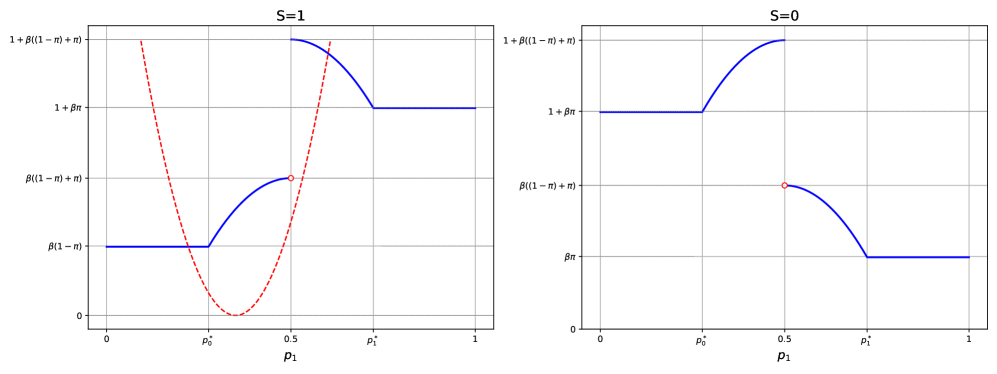
논문 소개
민주주의 체제에서 정책 결정은 대중의 지지에 의해 이루어지며, 엘리트는 이러한 지지를 확보하기 위해 다양한 전략을 사용해야 한다. 본 연구에서는 인공지능(AI) 기반의 설득 기술이 엘리트의 정책 선호 형성과 대중 여론의 분극화에 미치는 영향을 분석하기 위해 동적 모델을 개발하였다. 이 모델은 엘리트가 설득 비용과 다수결 제약을 고려하여 정책 선호의 분포를 조정하는 과정을 설명한다.
단일 엘리트의 경우, 최적의 개입은 사회를 더욱 분극화된 의견 프로필로 이끌며, 이는 설득 기술의 발전에 의해 가속화된다. 반면, 두 명의 경쟁 엘리트가 존재할 때는 서로의 의견을 견제하기 위해 사회를 '준 잠금(semi-lock)' 상태로 유지하려는 유인이 발생하여, 이 경우 분극화가 완화될 수 있음을 보여준다. 이러한 연구 결과는 설득 기술이 단순한 사회적 부산물이 아닌, 민주적 통치의 전략적 도구로 작용할 수 있음을 시사한다.
본 논문은 기존의 분극화 문헌과의 차별성을 강조하며, 분극화를 엘리트의 선택 결과로 간주하는 새로운 관점을 제시한다. AI 기술의 발전이 민주적 안정성에 미치는 영향은 향후 정치적 결과에 중대한 변화를 가져올 수 있으며, 이는 엘리트가 대중 여론을 형성하는 방식에 대한 이해를 심화시키는 데 기여할 것이다. 이러한 분석은 설득 기술의 개선이 여론의 장기적 분포와 분극화의 역학을 연결하는 실행 가능한 메커니즘을 제공함으로써, 민주주의의 미래 방향성을 탐구하는 데 중요한 기초 자료가 된다.
논문 초록(Abstract)
민주주의에서 주요 정책 결정은 일반적으로 다수결 또는 합의의 형태를 요구하므로, 엘리트는 통치를 위해 대중의 지지를 확보해야 합니다. 역사적으로 엘리트는 교육 및 대중 매체와 같은 제한된 수단을 통해서만 지지를 형성할 수 있었습니다. 그러나 AI 기반의 설득 기술의 발전은 대중 여론 형성의 비용을 크게 줄이고 정밀성을 높여, 선호의 분포 자체를 의도적으로 설계하는 대상이 되게 합니다. 우리는 엘리트가 설득 비용과 다수결 규칙 제약을 고려하여 정책 선호의 분포를 얼마나 재구성할지를 선택하는 동적 모델을 개발했습니다. 단일 엘리트의 경우, 최적의 개입은 사회를 더 극단적인 의견 프로필로 밀어내는 경향이 있으며 - 이를 '극단화 끌림'이라고 합니다 - 설득 기술의 발전은 이러한 흐름을 가속화합니다. 두 명의 대립하는 엘리트가 권력을 번갈아 가질 때, 동일한 기술은 사회를 '반 잠금' 지역에 주차시키려는 유인을 만들어내며, 이 지역에서는 의견이 더 응집력 있고 경쟁자가 뒤집기 어려워집니다. 따라서 설득의 발전은 환경에 따라 극단화를 심화시키거나 완화시킬 수 있습니다. 종합적으로 볼 때, 저렴한 설득 기술은 극단화를 순수하게 발생하는 사회적 부산물이 아니라 전략적 통치 수단으로 재편성하며, 이는 AI 능력이 발전함에 따라 민주적 안정성에 중요한 함의를 갖습니다.
In democracies, major policy decisions typically require some form of majority or consensus, so elites must secure mass support to govern. Historically, elites could shape support only through limited instruments like schooling and mass media; advances in AI-driven persuasion sharply reduce the cost and increase the precision of shaping public opinion, making the distribution of preferences itself an object of deliberate design. We develop a dynamic model in which elites choose how much to reshape the distribution of policy preferences, subject to persuasion costs and a majority rule constraint. With a single elite, any optimal intervention tends to push society toward more polarized opinion profiles - a
polarization pull'' - and improvements in persuasion technology accelerate this drift. When two opposed elites alternate in power, the same technology also creates incentives to park society insemi-lock'' regions where opinions are more cohesive and harder for a rival to overturn, so advances in persuasion can either heighten or dampen polarization depending on the environment. Taken together, cheaper persuasion technologies recast polarization as a strategic instrument of governance rather than a purely emergent social byproduct, with important implications for democratic stability as AI capabilities advance.
논문 링크
수퍼 모델: 간단한 산술이 최첨단 대규모 언어 모델 성능을 여는 방법 / Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
논문 소개
대규모 언어 모델(LLM)의 발전은 다양한 분야에서 뛰어난 성능을 보여주고 있으나, 그 훈련 과정은 막대한 자원과 시간이 소모되는 복잡한 작업입니다. 이러한 문제를 해결하기 위해, 모델 수프링(model souping)이라는 기법이 주목받고 있으며, 이는 동일한 아키텍처의 여러 모델의 가중치를 평균화하여 성능을 향상시키는 방법입니다. 본 연구에서는 **Soup Of Category Experts (SoCE)**라는 새로운 접근법을 제안하여, 모델 수프링의 효율성을 극대화하고자 하였습니다.
SoCE는 벤치마크 구성(composition)을 활용하여 최적의 모델 후보를 식별하고, 비균일 가중 평균을 적용하여 성능을 극대화하는 원칙적인 방법론을 채택하고 있습니다. 기존의 균일 평균화 접근법과는 달리, SoCE는 벤치마크 카테고리 간의 낮은 상관관계를 활용하여 각 카테고리 클러스터에 대한 "전문가" 모델을 선택하고, 이들 모델을 최적화된 가중치로 결합합니다. 이러한 접근은 다국어 능력, 도구 호출, 수학 문제 해결 등 여러 도메인에서 성능과 강건성을 향상시키는 데 기여하며, Berkeley Function Calling Leaderboard에서 최첨단 결과를 달성하는 성과를 거두었습니다.
SoCE의 방법론은 두 가지 주요 구성 요소로 이루어져 있습니다. 첫째, 상관관계 패턴을 분석하여 비상관 카테고리에 대한 전문가 모델을 식별합니다. 둘째, 이러한 전문가 모델에 적절한 가중치를 부여하여 결합함으로써, 성능 향상을 도모합니다. 이 과정에서 Shapley 값 분석을 통해 각 모델 후보의 기여도를 평가하고, SoCE의 후보 선택 전략이 성능 향상에 중요한 역할을 한다는 점을 입증하였습니다.
결과적으로, SoCE는 LLM의 성능을 향상시키는 효과적인 방법으로 자리매김하며, 향후 연구와 실용적 응용에서도 중요한 기여를 할 것으로 기대됩니다. 이 연구는 모델 수프링 분야에서의 새로운 접근법을 제시하며, 다양한 도메인에서의 적용 가능성을 보여줍니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 다양한 분야에서 놀라운 능력을 보여주고 있지만, 그 학습은 자원과 시간이 많이 소모되며, 막대한 컴퓨팅 파워와 학습 절차의 세심한 조정이 필요합니다. 모델 수프(Model souping) - 동일한 아키텍처의 여러 모델의 가중치를 평균화하는 방법 - 은 비싼 재학습 없이 성능을 향상시킬 수 있는 유망한 사전 및 사후 학습 기법으로 부상하였습니다. 본 논문에서는 최적의 모델 후보를 식별하기 위해 벤치마크 조합을 활용하고 성능을 극대화하기 위해 비균일 가중 평균을 적용하는 모델 수프를 위한 원칙적인 접근법인 카테고리 전문가 수프(Soup Of Category Experts, SoCE)를 소개합니다. 이전의 균일 평균 접근법과는 달리, 우리의 방법은 벤치마크 카테고리가 종종 모델 성능에서 낮은 상관관계를 보인다는 관찰을 활용합니다. SoCE는 각 약한 상관관계 카테고리 클러스터에 대한 "전문가" 모델을 식별하고 균일 가중치가 아닌 최적화된 가중 평균을 사용하여 이들을 결합합니다. 우리는 제안된 방법이 다국어 능력, 도구 호출, 수학 등 여러 분야에서 성능과 강인성을 향상시키며, 버클리 함수 호출 리더보드에서 최첨단 결과를 달성함을 보여줍니다.
Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
논문 링크
더 읽어보기
웹 월드 모델 / Web World Models
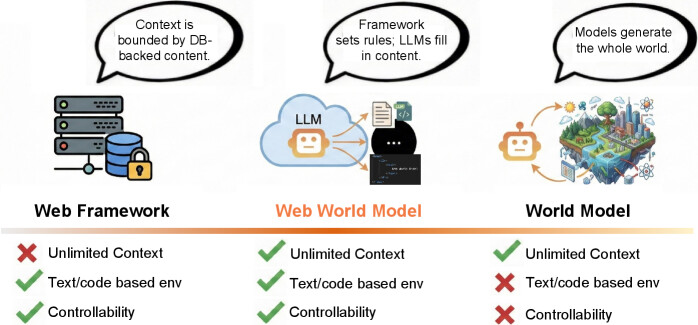
논문 소개
현대 언어 에이전트는 작동, 기억 및 학습이 가능한 지속적인 환경을 필요로 하며, 이를 위해 기존의 접근 방식은 두 가지 극단으로 나뉩니다. 전통적인 웹 프레임워크는 신뢰성 있는 고정된 맥락을 제공하지만, 이는 개발자가 미리 정의한 스키마에 의해 제한됩니다. 반면, 완전 생성형 세계 모델은 무제한의 환경을 목표로 하지만 제어가 어렵고 디버깅이 힘든 단점이 있습니다. 이러한 문제를 해결하기 위해 제안된 Web World Model (WWM) 은 세계의 상태와 "물리학"을 일반 웹 코드로 구현하여 논리적 일관성을 보장합니다. 대규모 언어 모델은 이 구조화된 잠재 상태 위에서 맥락과 내러티브를 생성하여, 에이전트가 상호작용할 수 있는 풍부한 환경을 제공합니다.
WWM은 현실적인 웹 스택을 기반으로 하여, 실제 지리에 기반한 무한 여행 아틀라스, 허구의 은하 탐험가, 웹 규모의 백과사전 및 내러티브 세계, 그리고 시뮬레이션 및 게임과 같은 다양한 환경을 구축합니다. 이러한 시스템들은 WWM을 위한 실용적인 설계 원칙을 도출하는 데 기여하며, 여기에는 코드 정의 규칙과 모델 주도 상상력의 분리, 잠재 상태를 유형화된 웹 인터페이스로 표현하는 것, 그리고 결정론적 생성을 통한 무한하지만 구조화된 탐색이 포함됩니다.
이 연구는 웹 스택이 세계 모델을 위한 확장 가능한 기초로 작용할 수 있음을 시사하며, 제어 가능하면서도 개방적인 환경을 가능하게 합니다. WWM의 구현은 특정 작업이나 장르에 국한되지 않으며, 실제 또는 허구의 세계, 지식 중심 또는 상호작용 중심의 다양한 환경을 호스팅할 수 있는 잠재력을 지니고 있습니다. 이러한 접근 방식은 향후 대규모 언어 모델 기반 환경 및 에이전트 설계에 중요한 기여를 할 것으로 기대됩니다.
논문 초록(Abstract)
언어 에이전트는 점점 더 행동하고 기억하며 학습할 수 있는 지속적인 세계를 필요로 합니다. 기존 접근 방식은 두 가지 극단에 위치합니다: 전통적인 웹 프레임워크는 데이터베이스에 의해 뒷받침되는 신뢰할 수 있지만 고정된 맥락을 제공하며, 완전 생성적 세계 모델은 제어 가능성과 실용적 엔지니어링을 희생하면서 무한한 환경을 목표로 합니다. 본 연구에서는 세계 상태와 "물리학"이 일반 웹 코드로 구현되어 논리적 일관성을 보장하는 중간 지점인 웹 월드 모델(Web World Model, WWM)을 소개합니다. 대규모 언어 모델은 이 구조화된 잠재 상태 위에서 맥락, 서사 및 고수준 결정을 생성합니다. 우리는 실제 웹 스택을 기반으로 한 WWM의 모음을 구축하였으며, 여기에는 실제 지리학에 기반한 무한 여행 아틀라스, 허구의 은하 탐험가, 웹 규모의 백과사전 및 서사 세계, 그리고 시뮬레이션 및 게임과 유사한 환경이 포함됩니다. 이러한 시스템 전반에 걸쳐 우리는 WWM을 위한 실용적인 설계 원칙을 식별합니다: 코드로 정의된 규칙과 모델 주도 상상력을 분리하고, 잠재 상태를 유형화된 웹 인터페이스로 표현하며, 결정론적 생성을 활용하여 무한하지만 구조화된 탐색을 달성합니다. 우리의 결과는 웹 스택 자체가 세계 모델을 위한 확장 가능한 기초로 작용할 수 있으며, 제어 가능하면서도 개방적인 환경을 가능하게 한다는 것을 시사합니다. 프로젝트 페이지: GitHub - Princeton-AI2-Lab/Web-World-Models: Official Project Page for Web World Models (https://arxiv.org/abs/2512.23676).
Language agents increasingly require persistent worlds in which they can act, remember, and learn. Existing approaches sit at two extremes: conventional web frameworks provide reliable but fixed contexts backed by databases, while fully generative world models aim for unlimited environments at the expense of controllability and practical engineering. In this work, we introduce the Web World Model (WWM), a middle ground where world state and ``physics'' are implemented in ordinary web code to ensure logical consistency, while large language models generate context, narratives, and high-level decisions on top of this structured latent state. We build a suite of WWMs on a realistic web stack, including an infinite travel atlas grounded in real geography, fictional galaxy explorers, web-scale encyclopedic and narrative worlds, and simulation- and game-like environments. Across these systems, we identify practical design principles for WWMs: separating code-defined rules from model-driven imagination, representing latent state as typed web interfaces, and utilizing deterministic generation to achieve unlimited but structured exploration. Our results suggest that web stacks themselves can serve as a scalable substrate for world models, enabling controllable yet open-ended environments. Project Page: GitHub - Princeton-AI2-Lab/Web-World-Models: Official Project Page for Web World Models (https://arxiv.org/abs/2512.23676).
논문 링크
더 읽어보기
맥락 내 공동 플레이어 추론을 통한 다중 에이전트 협력 / Multi-agent cooperation through in-context co-player inference

논문 소개
다중 에이전트 시스템에서 자기 이익을 추구하는 에이전트 간의 협력은 여전히 해결해야 할 중요한 문제로 남아 있다. 본 연구에서는 에이전트들이 서로의 학습 과정을 인식하고 이를 통해 협력적 행동을 유도할 수 있는 새로운 방법론을 제안한다. 기존의 접근법들은 종종 비일관적인 가정에 의존하거나, "순진한 학습자"와 "메타 학습자" 간의 엄격한 분리를 강제하는 경향이 있었다. 그러나 본 연구에서는 시퀀스 모델의 문맥 내 학습 능력을 활용하여, 이러한 하드코딩된 가정이나 명시적인 시간 척도 분리 없이도 공동 플레이어 학습 인식을 가능하게 한다.
연구의 핵심은 다양한 공동 플레이어와의 학습을 통해 에이전트가 자연스럽게 문맥 내 최적 반응 전략을 유도하는 것이다. 이를 통해 에이전트는 빠른 에피소드 내 시간 척도에서 학습 알고리즘으로 기능하게 된다. 연구 결과, extortion에 대한 취약성이 상호 형성을 유도하며, 이는 협력 행동의 학습으로 이어진다는 점이 확인되었다. 이러한 발견은 협력 행동 학습을 위한 확장 가능한 경로를 제시하며, 표준 분산 강화 학습과 시퀀스 모델의 결합이 효과적임을 보여준다.
본 연구는 다중 에이전트 강화 학습 분야에서 협력 행동을 유도하기 위한 새로운 접근법을 제시하며, 에이전트 간의 상호작용을 통해 협력적 행동을 자연스럽게 학습할 수 있는 가능성을 열어준다. 이러한 방법론은 향후 다중 에이전트 시스템의 설계 및 구현에 있어 중요한 기여를 할 것으로 기대된다.
논문 초록(Abstract)
자기 이익을 추구하는 에이전트 간의 협력을 달성하는 것은 다중 에이전트 강화학습에서 여전히 근본적인 도전 과제입니다. 최근 연구에서는 "학습 인식" 에이전트 간의 상호 협력이 가능하다는 것을 보여주었으며, 이들은 공동 플레이어의 학습 역학을 고려하고 형성합니다. 그러나 기존 접근 방식은 일반적으로 공동 플레이어의 학습 규칙에 대한 하드코딩된, 종종 일관되지 않은 가정에 의존하거나 "단순 학습자"가 빠른 시간 척도에서 업데이트하는 것과 "메타 학습자"가 이러한 업데이트를 관찰하는 것 사이에 엄격한 분리를 강제합니다. 여기에서는 시퀀스 모델의 문맥 내 학습 능력이 하드코딩된 가정이나 명시적인 시간 척도 분리 없이 공동 플레이어 학습 인식을 가능하게 한다는 것을 보여줍니다. 우리는 다양한 공동 플레이어 분포에 대해 시퀀스 모델 에이전트를 훈련시키면 자연스럽게 문맥 내 최적 반응 전략이 유도되어 빠른 에피소드 내 시간 척도에서 학습 알고리즘으로 효과적으로 작용함을 보여줍니다. 이전 연구에서 확인된 협력 메커니즘, 즉 강탈에 대한 취약성이 상호 형성을 유도하는 현상이 이 설정에서 자연스럽게 나타납니다: 문맥 내 적응은 에이전트를 강탈에 취약하게 만들고, 그 결과 상대방의 문맥 내 학습 역학을 형성하려는 상호 압력이 협력 행동의 학습으로 이어집니다. 우리의 결과는 시퀀스 모델에 대한 표준 분산 강화학습과 공동 플레이어 다양성을 결합하면 협력 행동을 학습하는 확장 가능한 경로를 제공한다는 것을 시사합니다.
Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between "learning-aware" agents that account for and shape the learning dynamics of their co-players. However, existing approaches typically rely on hardcoded, often inconsistent, assumptions about co-player learning rules or enforce a strict separation between "naive learners" updating on fast timescales and "meta-learners" observing these updates. Here, we demonstrate that the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation. We show that training sequence model agents against a diverse distribution of co-players naturally induces in-context best-response strategies, effectively functioning as learning algorithms on the fast intra-episode timescale. We find that the cooperative mechanism identified in prior work-where vulnerability to extortion drives mutual shaping-emerges naturally in this setting: in-context adaptation renders agents vulnerable to extortion, and the resulting mutual pressure to shape the opponent's in-context learning dynamics resolves into the learning of cooperative behavior. Our results suggest that standard decentralized reinforcement learning on sequence models combined with co-player diversity provides a scalable path to learning cooperative behaviors.
논문 링크
프롬프트 반복이 비추론 대규모 언어 모델의 성능을 향상시킨다 / Prompt Repetition Improves Non-Reasoning LLMs
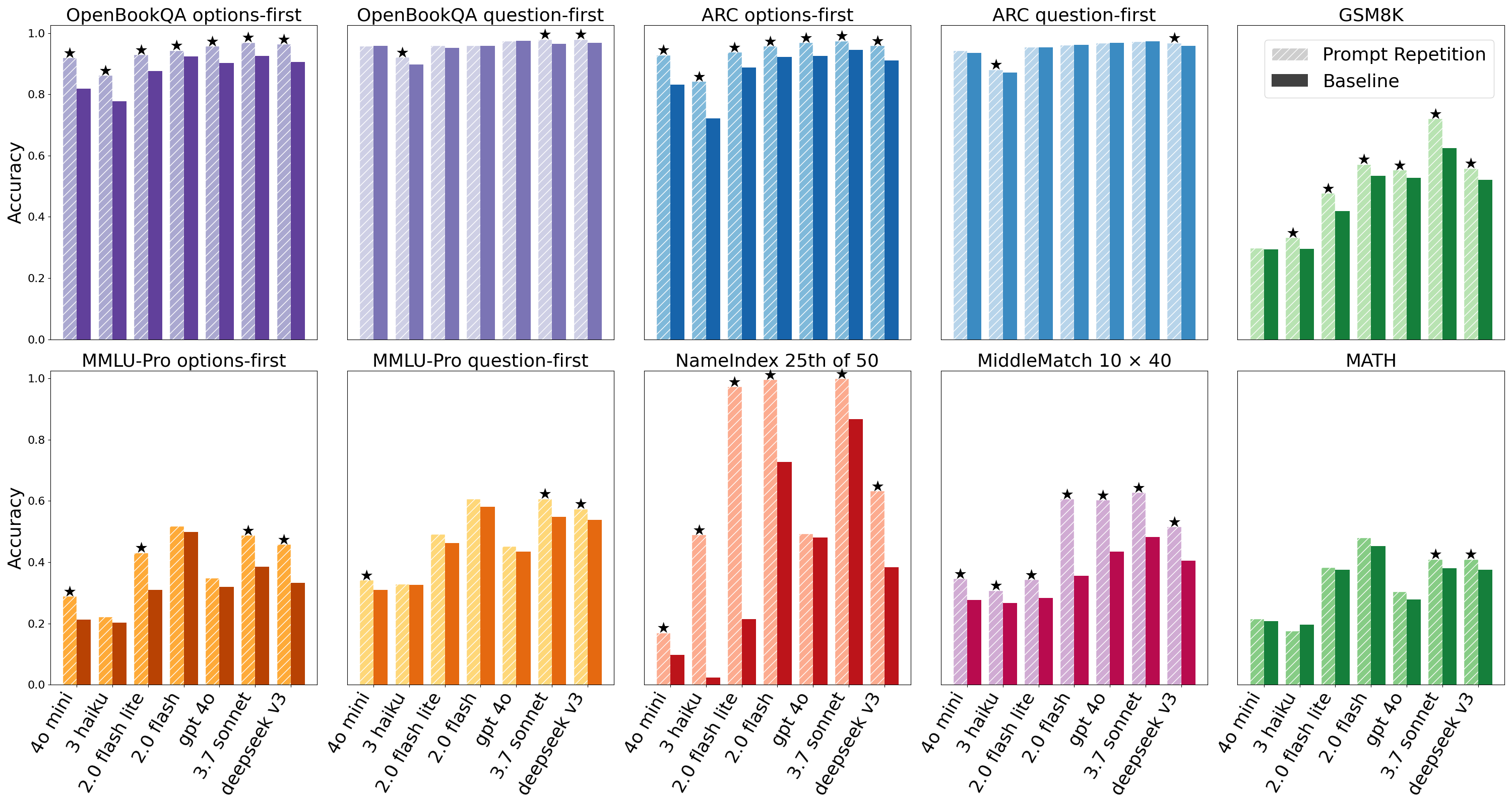
논문 소개
비추론 대규모 언어 모델(LLM)의 성능 향상에 대한 연구는 최근 인공지능 분야에서 중요한 주제로 떠오르고 있다. 본 연구에서는 입력 프롬프트를 반복하는 간단한 방법이 Gemini, GPT, Claude, Deepseek와 같은 인기 모델에서 성능을 유의미하게 개선할 수 있음을 보여준다. 특히, 프롬프트 반복은 생성되는 토큰 수나 지연 시간을 증가시키지 않으면서도 응답 품질을 높이는 효과를 나타낸다. 이러한 접근은 비추론 상황에서도 모델의 응답 품질을 향상시킬 수 있는 새로운 전략으로, LLM의 활용 가능성을 더욱 확장하는 기초를 제공한다.
기존 연구들은 주로 복잡한 추론 과정을 필요로 하는 상황에서의 성능 향상에 집중해왔으나, 본 연구는 비추론 상황에서도 성능을 개선할 수 있는 가능성을 탐구한다. 프롬프트 반복은 비추론 모델의 성능을 높이기 위한 다양한 방법론 중 하나로, 기존의 복잡한 접근 방식과 차별화된다. 연구에서는 각 모델에 대해 동일한 입력 프롬프트를 반복하여 제공하고, 이를 통해 성능 변화를 측정하는 실험을 진행하였다.
실험은 다양한 데이터셋을 사용하여 수행되었으며, 각 모델의 응답 품질을 평가하기 위한 기준이 설정되었다. 결과적으로, 모든 모델에서 프롬프트 반복이 성능을 유의미하게 향상시켰음을 정량적으로 평가하였으며, 반복 횟수가 증가할수록 응답의 품질이 개선되는 경향이 관찰되었다. 이러한 발견은 프롬프트 반복이 비추론 LLM의 성능을 향상시키는 간단하면서도 효과적인 방법임을 강조하며, 향후 연구 방향에 대한 제언을 포함하고 있다.
결론적으로, 본 연구는 비추론 LLM의 성능 향상을 위한 새로운 접근 방식을 제시하며, 프롬프트 반복의 효과를 실증적으로 보여주는 중요한 기여를 하고 있다. 이러한 연구 결과는 LLM의 활용 가능성을 넓히고, 비추론 상황에서도 성능을 극대화할 수 있는 전략으로 자리 잡을 수 있음을 시사한다.
논문 초록(Abstract)
입력을 추론 없이 반복할 경우, 생성된 토큰 수나 지연 시간을 증가시키지 않으면서 인기 모델(제미니, GPT, 클로드, 딥시크)의 성능을 향상시킵니다.
When not using reasoning, repeating the input prompt improves performance for popular models (Gemini, GPT, Claude, and Deepseek) without increasing the number of generated tokens or latency.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()