[2026/02/23 ~ 03/01] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주 선정된 논문들을 살펴보면, 단순한 모델 스케일링을 넘어 효율성을 극대화하고, AI가 스스로를 개선하며, 사용자 환경에 실시간으로 적응하는 방향으로 나아가고 있음을 잘 보여줍니다:
![]() 정적 연산을 넘어선 "동적/적응형 효율성" 최적화: 이번 주 연구들에서는 무작정 모델의 크기나 연산량을 늘리는 대신, 상황과 문제의 난이도에 맞게 자원을 동적으로 할당하는 실용적인 접근이 돋보였습니다. AdaptEvolve는 문제 해결의 신뢰도에 따라 실시간으로 적절한 크기의 LLM을 선택해 정확도를 유지하면서도 추론 비용을 대폭 절감했습니다. 또한 HyTRec은 긴 추천 시퀀스 처리 시 장기 선호도(선형 어텐션)와 단기 의도(소프트맥스 어텐션)를 분리하여 연산 병목을 해결했으며, Think Deep 논문은 단순히 출력 길이를 늘리는 대신 내부 층의 수정 빈도를 의미하는 '깊은 사고(Deep-thinking) 토큰' 비율을 측정해 테스트 타임 연산을 효율적으로 확장했습니다. 이는 AI 시스템이 내부 연산의 밀도와 모델 라우팅을 스마트하게 제어하여 비용과 성능의 파레토 최적을 찾아가고 있음을 보여줍니다.
정적 연산을 넘어선 "동적/적응형 효율성" 최적화: 이번 주 연구들에서는 무작정 모델의 크기나 연산량을 늘리는 대신, 상황과 문제의 난이도에 맞게 자원을 동적으로 할당하는 실용적인 접근이 돋보였습니다. AdaptEvolve는 문제 해결의 신뢰도에 따라 실시간으로 적절한 크기의 LLM을 선택해 정확도를 유지하면서도 추론 비용을 대폭 절감했습니다. 또한 HyTRec은 긴 추천 시퀀스 처리 시 장기 선호도(선형 어텐션)와 단기 의도(소프트맥스 어텐션)를 분리하여 연산 병목을 해결했으며, Think Deep 논문은 단순히 출력 길이를 늘리는 대신 내부 층의 수정 빈도를 의미하는 '깊은 사고(Deep-thinking) 토큰' 비율을 측정해 테스트 타임 연산을 효율적으로 확장했습니다. 이는 AI 시스템이 내부 연산의 밀도와 모델 라우팅을 스마트하게 제어하여 비용과 성능의 파레토 최적을 찾아가고 있음을 보여줍니다.
![]() 인간의 개입을 최소화하는 자율적 "발견" 및 "자가 진화(Self-Evolution)": AI가 단순히 주어진 문제를 푸는 수동적 도구를 넘어, 스스로 알고리즘을 발견하고 시스템을 개선하는 자율적 연구자로 발전하는 트렌드가 강하게 나타났습니다. AlphaEvolve는 기존에 인간의 직관에 의존하던 다중 에이전트 강화학습 알고리즘 설계를 LLM 기반 진화 에이전트가 자동으로 수행하여 더 나은 변형 알고리즘을 찾아냈습니다. Aletheia 역시 방대한 수학 문헌을 탐색하고 스스로 증명을 수정하며 박사 수준의 연구 논문을 자율적으로 작성하는 능력을 입증했습니다. 더 나아가 DPE 프레임워크는 모델 스스로 자신의 맹점과 약점을 진단하고, 이에 맞춘 훈련 데이터를 생성해 능력을 점진적으로 진화시키는 등 '자가 개선(Self-improving) AI'의 강력한 잠재력을 시사합니다.
인간의 개입을 최소화하는 자율적 "발견" 및 "자가 진화(Self-Evolution)": AI가 단순히 주어진 문제를 푸는 수동적 도구를 넘어, 스스로 알고리즘을 발견하고 시스템을 개선하는 자율적 연구자로 발전하는 트렌드가 강하게 나타났습니다. AlphaEvolve는 기존에 인간의 직관에 의존하던 다중 에이전트 강화학습 알고리즘 설계를 LLM 기반 진화 에이전트가 자동으로 수행하여 더 나은 변형 알고리즘을 찾아냈습니다. Aletheia 역시 방대한 수학 문헌을 탐색하고 스스로 증명을 수정하며 박사 수준의 연구 논문을 자율적으로 작성하는 능력을 입증했습니다. 더 나아가 DPE 프레임워크는 모델 스스로 자신의 맹점과 약점을 진단하고, 이에 맞춘 훈련 데이터를 생성해 능력을 점진적으로 진화시키는 등 '자가 개선(Self-improving) AI'의 강력한 잠재력을 시사합니다.
![]() 명시적 메모리와 실시간 피드백을 통한 "지속적 학습(Continual Learning)"의 고도화: 정적인 데이터셋으로 한 번 학습된 후 고정되는 기존 AI의 한계를 극복하고, 끊임없이 변화하는 환경과 개인의 선호에 맞춰 적응하는 에이전트 연구도 중요한 축을 이루고 있습니다. PAHF는 모호한 지시를 명확히 묻고 사용자의 실시간 피드백을 명시적 메모리에 지속적으로 업데이트함으로써, 변화하는 개인의 취향에 신속하게 적응하는 개인화 에이전트를 선보였습니다. 나아가 ALMA는 인간이 수작업으로 고안한 고정형 메모리 구조를 버리고, 에이전트가 다양한 환경에서 지속적으로 학습할 수 있도록 데이터베이스 스키마와 검색/업데이트 메커니즘 자체를 메타 학습(Meta-learning)하는 혁신을 보여주었습니다. 이는 AI가 현실 세계의 변동성에 유연하게 대응하며 영구적으로 학습할 수 있는 구조적 기반을 다지고 있음을 의미합니다.
명시적 메모리와 실시간 피드백을 통한 "지속적 학습(Continual Learning)"의 고도화: 정적인 데이터셋으로 한 번 학습된 후 고정되는 기존 AI의 한계를 극복하고, 끊임없이 변화하는 환경과 개인의 선호에 맞춰 적응하는 에이전트 연구도 중요한 축을 이루고 있습니다. PAHF는 모호한 지시를 명확히 묻고 사용자의 실시간 피드백을 명시적 메모리에 지속적으로 업데이트함으로써, 변화하는 개인의 취향에 신속하게 적응하는 개인화 에이전트를 선보였습니다. 나아가 ALMA는 인간이 수작업으로 고안한 고정형 메모리 구조를 버리고, 에이전트가 다양한 환경에서 지속적으로 학습할 수 있도록 데이터베이스 스키마와 검색/업데이트 메커니즘 자체를 메타 학습(Meta-learning)하는 혁신을 보여주었습니다. 이는 AI가 현실 세계의 변동성에 유연하게 대응하며 영구적으로 학습할 수 있는 구조적 기반을 다지고 있음을 의미합니다.
요약하자면 이번 주 논문들은 1) 효율적인 동적 연산, 2) 자율적 시스템 진화, 3) 지속적이고 개인화된 학습이라는 뚜렷한 세 가지 흐름을 보여주고 있습니다.
AdaptEvolve: 적응형 모델 선택을 통한 진화적 AI 에이전트의 효율성 향상 / AdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model Selection
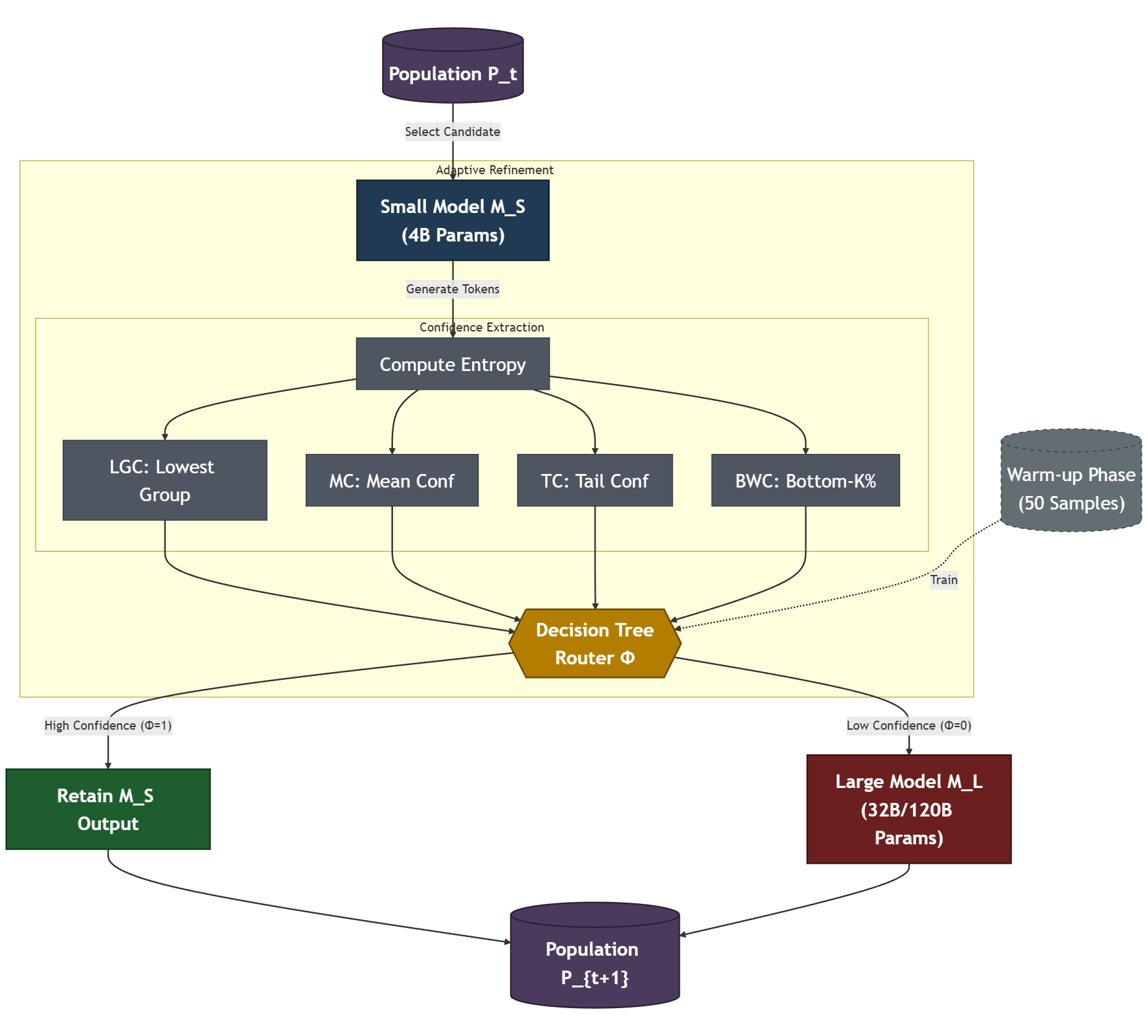
논문 소개
진화적 에이전트 시스템은 대규모 언어 모델(LLM)의 반복 호출을 통해 계산 효율성과 추론 능력 간의 트레이드오프를 심화시킵니다. 이러한 문제를 해결하기 위해, AdaptEvolve는 현재 세대 단계에 적합한 LLM을 동적으로 선택하여 높은 계산 효율성을 유지할 수 있도록 설계된 혁신적인 방법론입니다. 기존의 모델 선택 전략은 정적 휴리스틱이나 외부 제어기에 의존하여 모델 불확실성을 충분히 반영하지 못하는 한계가 있습니다. 따라서 본 연구에서는 내재된 생성 신뢰도를 활용하여 실시간으로 문제 해결 가능성을 추정하는 적응형 LLM 선택 방식을 제안합니다.
AdaptEvolve는 진화적 순차 정제 프레임워크 내에서 작동하며, 에이전트가 각 LLM의 신뢰도를 계산하고 이를 바탕으로 최적의 모델을 선택하는 과정을 포함합니다. 실험 결과는 신뢰 기반 선택 방식이 평균 37.9%의 총 추론 비용 절감과 97.5%의 정확도 유지라는 유리한 성과를 보여줍니다. 이는 AdaptEvolve가 기존의 정적 대형 모델 기준에 비해 효율성을 크게 개선할 수 있음을 시사합니다.
본 연구는 진화적 AI 시스템에서 모델 선택 문제를 해결하기 위한 새로운 접근 방식을 제시하며, 신뢰 기반의 적응형 선택이 LLM을 활용하는 시스템에서 중요한 역할을 할 수 있음을 강조합니다. 이러한 결과는 향후 연구와 실제 응용에 있어 큰 잠재력을 지니며, AdaptEvolve의 기여는 AI 분야의 지속적인 발전에 기여할 것으로 기대됩니다.
논문 초록(Abstract)
진화적 에이전트 시스템은 추론 중에 대규모 언어 모델(LLM)을 반복적으로 호출함으로써 계산 효율성과 추론 능력 간의 트레이드오프를 심화시킵니다. 이러한 설정은 중앙 질문을 제기합니다: 에이전트가 현재 생성 단계에 충분히 능력 있는 LLM을 동적으로 선택하면서 계산적으로 효율성을 유지할 수 있는 방법은 무엇인가요? 모델 캐스케이드는 이 트레이드오프를 균형 있게 조정할 수 있는 실용적인 메커니즘을 제공하지만, 기존의 라우팅 전략은 일반적으로 정적 휴리스틱 또는 외부 컨트롤러에 의존하며 모델 불확실성을 명시적으로 고려하지 않습니다. 우리는 내재적 생성 신뢰도를 활용하여 실시간 문제 해결 가능성을 추정하는 진화적 순차적 정제 프레임워크 내에서 다중 LLM 진화를 위한 적응형 LLM 선택인 AdaptEvolve를 소개합니다. 실험 결과, 신뢰 기반 선택이 유리한 파레토 경계를 생성하며, 벤치마크 전반에 걸쳐 총 추론 비용을 평균 37.9% 감소시키면서 정적 대규모 모델 기준의 상한 정확도의 97.5%를 유지함을 보여줍니다. 우리의 코드는 GitHub - raypretam/adaptive_llm_selection: AdaptEvolve is an intelligent system for adaptive large language model (LLM) selection that dynamically routes queries between small and large models based on confidence metrics. 에서 확인할 수 있습니다.
Evolutionary agentic systems intensify the trade-off between computational efficiency and reasoning capability by repeatedly invoking large language models (LLMs) during inference. This setting raises a central question: how can an agent dynamically select an LLM that is sufficiently capable for the current generation step while remaining computationally efficient? While model cascades offer a practical mechanism for balancing this trade-off, existing routing strategies typically rely on static heuristics or external controllers and do not explicitly account for model uncertainty. We introduce AdaptEvolve: Adaptive LLM Selection for Multi-LLM Evolutionary Refinement within an evolutionary sequential refinement framework that leverages intrinsic generation confidence to estimate real-time solvability. Empirical results show that confidence-driven selection yields a favourable Pareto frontier, reducing total inference cost by an average of 37.9% across benchmarks while retaining 97.5% of the upper-bound accuracy of static large-model baselines. Our code is available at GitHub - raypretam/adaptive_llm_selection: AdaptEvolve is an intelligent system for adaptive large language model (LLM) selection that dynamically routes queries between small and large models based on confidence metrics..
논문 링크
더 읽어보기
깊이 생각하라, 단순히 길게 생각하지 말라: 심층 사고 토큰을 통한 대규모 언어 모델의 추론 노력 측정 / Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
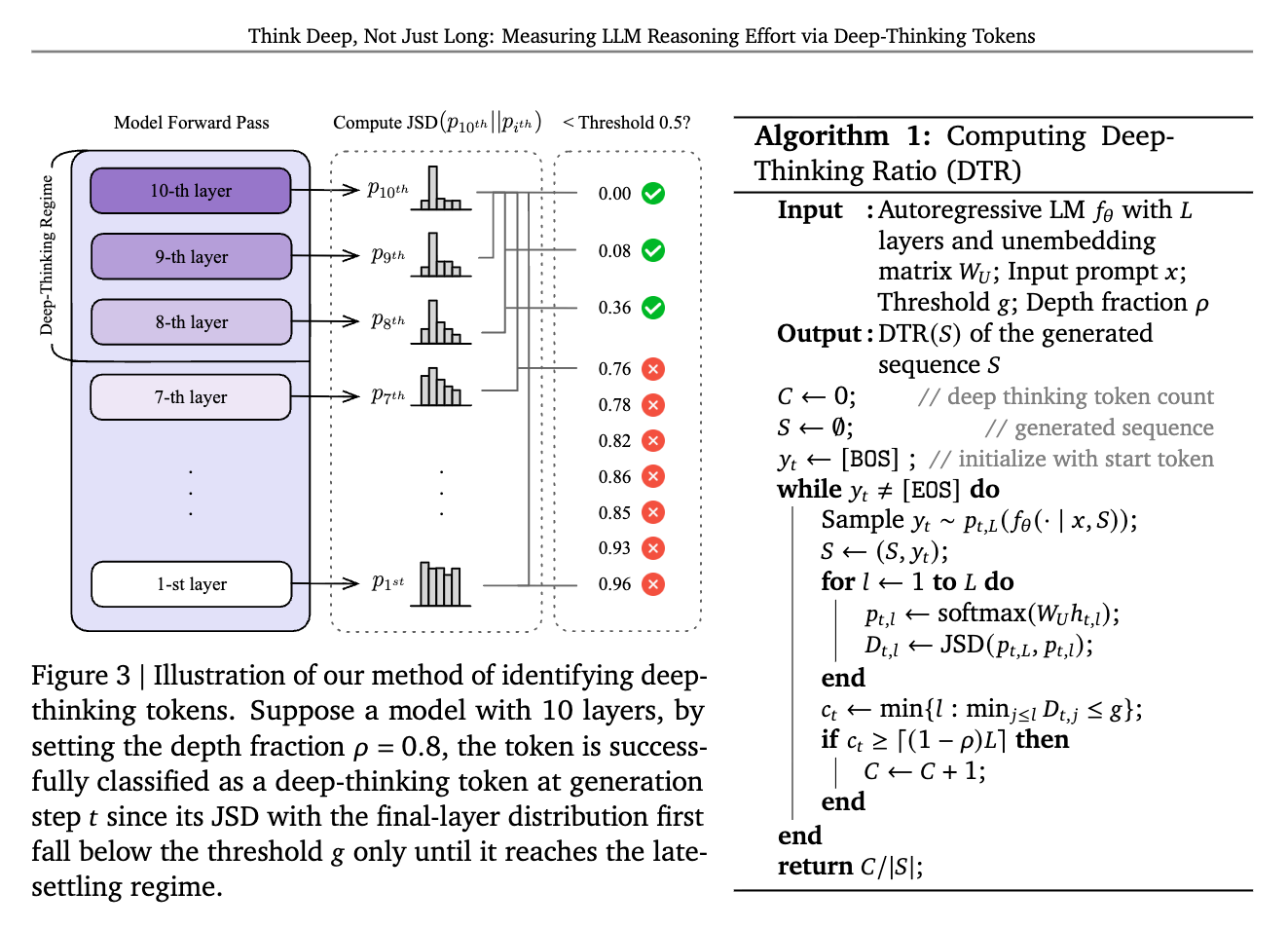
논문 소개
대규모 언어 모델(LLM)의 추론 과정에서의 사고 노력을 정량화하기 위한 새로운 접근 방식이 제안되었다. 기존 연구들은 긴 사고의 연쇄(Chain-of-Thought, CoT)가 LLM의 성능을 향상시킬 수 있다고 주장하지만, 최근의 발견들은 단순히 생성 길이가 증가한다고 해서 정확도가 높아지지 않음을 보여준다. 오히려, 과도한 사고는 성능 저하를 초래할 수 있다는 점이 강조된다. 본 연구에서는 딥-씽킹 토큰(deep-thinking tokens)을 정의하고, 이를 통해 LLM의 내부 예측이 깊은 층에서 얼마나 수정되는지를 측정하여 추론의 깊이를 평가한다.
딥-씽킹 토큰은 내부 예측이 모델의 깊은 층에서 상당한 수정을 겪는 토큰으로 정의되며, 이들 토큰의 비율인 딥-씽킹 비율(deep-thinking ratio)은 생성된 시퀀스의 정확도와 강한 양의 상관관계를 보인다. 연구는 네 가지 수학 및 과학 벤치마크(AIME 24/25, HMMT 25, GPQA-diamond)와 다양한 모델(GPT-OSS, DeepSeek-R1, Qwen3)을 통해 이러한 상관관계를 입증하였다. 특히, 딥-씽킹 비율은 길이 기반 및 신뢰도 기반 기준을 초과하는 성능을 보여주며, 이는 LLM의 추론 과정을 보다 깊이 이해하는 데 기여한다.
이러한 통찰을 바탕으로 Think@n이라는 새로운 테스트 시간 스케일링 전략이 도입되었다. 이 전략은 높은 딥-씽킹 비율을 가진 샘플을 우선적으로 선택하여, 표준 자기 일관성 성능을 유지하거나 초과하면서도 추론 비용을 크게 줄일 수 있는 가능성을 보여준다. 본 연구는 LLM의 추론 능력을 평가하고 개선하는 데 중요한 기여를 할 것으로 기대되며, 딥-씽킹 비율이 LLM의 성능을 이해하는 데 있어 중요한 지표가 될 수 있음을 강조한다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 긴 사고의 연쇄(Chain-of-Thought, CoT)를 통해 테스트 시간 동안의 계산을 확장함으로써 인상적인 추론 능력을 보여주었습니다. 그러나 최근 연구 결과는 원시 토큰 수가 추론 품질의 신뢰할 수 없는 대리 지표라는 것을 시사합니다: 생성 길이가 증가한다고 해서 정확도와 일관되게 상관관계가 있는 것은 아니며, 오히려 "과도한 사고"를 나타내어 성능 저하를 초래할 수 있습니다. 본 연구에서는 수렴 이전에 내부 예측이 더 깊은 모델 레이어에서 상당한 수정 과정을 겪는 깊은 사고 토큰을 식별하여 추론 시간의 노력을 정량화합니다. 네 가지 도전적인 수학 및 과학 벤치마크(AIME 24/25, HMMT 25, GPQA-diamond)와 다양한 추론 중심 모델(GPT-OSS, DeepSeek-R1, Qwen3)을 통해, 우리는 깊은 사고 비율(생성된 시퀀스에서 깊은 사고 토큰의 비율)이 정확도와 강력하고 일관된 긍정적 상관관계를 나타내며, 길이 기반 및 신뢰도 기반 기준을 상당히 초월함을 보여줍니다. 이러한 통찰을 활용하여, 우리는 높은 깊은 사고 비율을 가진 샘플을 우선시하는 테스트 시간 확장 전략인 Think@n을 소개합니다. Think@n이 표준 자기 일관성 성능과 일치하거나 이를 초과하면서도 짧은 접두사를 기반으로 유망하지 않은 생성물을 조기에 거부할 수 있도록 하여 추론 비용을 크게 줄이는 것을 입증합니다.
Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
논문 링크
HyTRec: 장기 행동 순차 추천을 위한 하이브리드 시계열 어텐션 아키텍처 / HyTRec: A Hybrid Temporal-Aware Attention Architecture for Long Behavior Sequential Recommendation
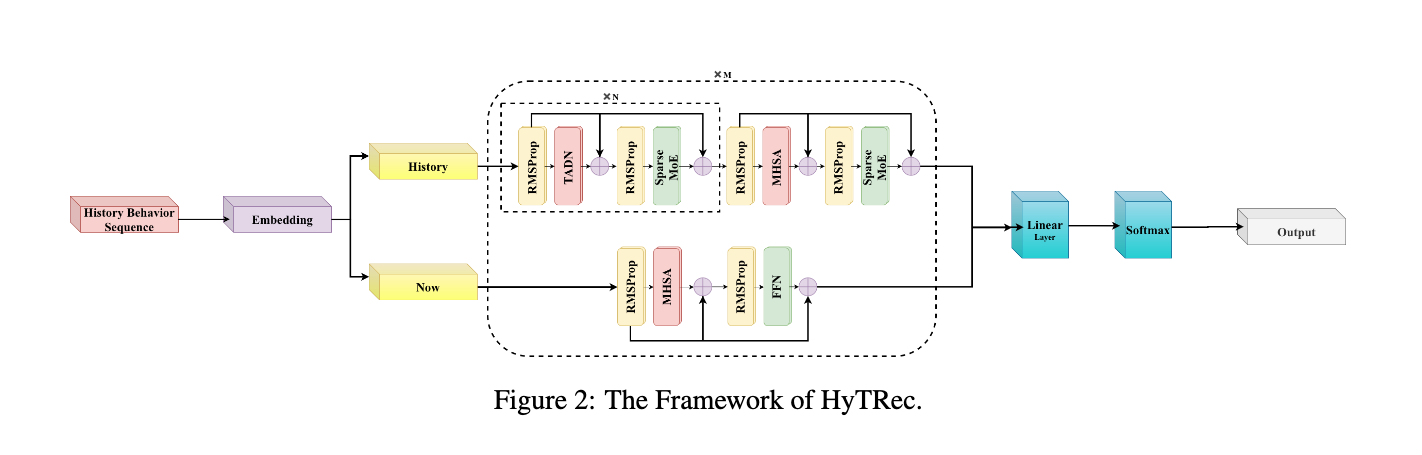
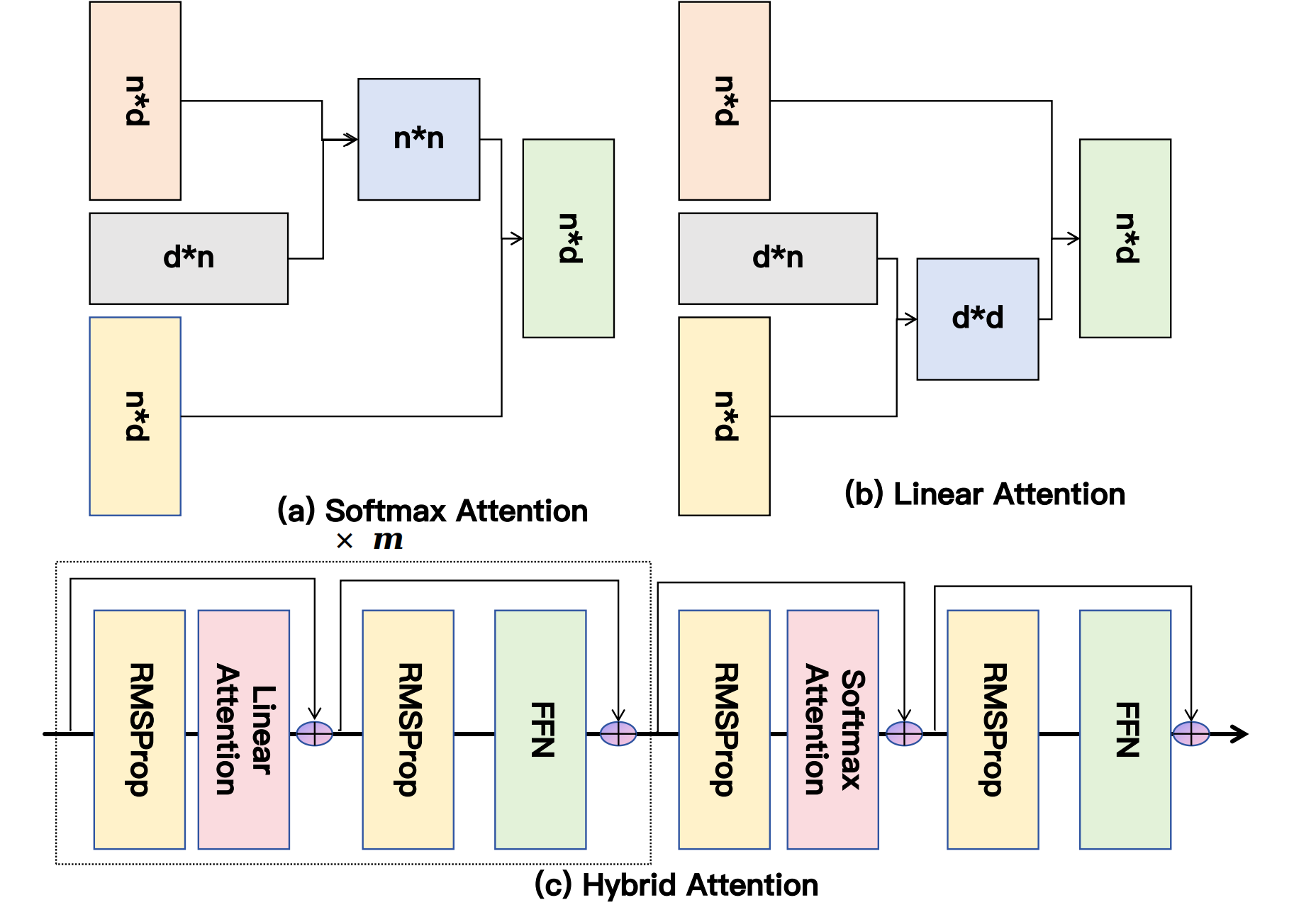
논문 소개
긴 사용자 행동 시퀀스를 모델링하는 것은 생성 추천 시스템에서 중요한 과제가 되었습니다. 기존 솔루션은 효율성을 위해 상태 용량이 제한된 선형 어텐션 메커니즘과 계산 비용이 큰 소프트맥스 어텐션 간의 딜레마에 직면해 있습니다. 이를 해결하기 위해 HyTRec라는 하이브리드 어텐션 아키텍처를 제안합니다. 이 모델은 장기적으로 안정적인 선호도를 단기적인 의도 변화와 명확히 분리하여 처리합니다. 방대한 역사적 시퀀스는 선형 어텐션 브랜치에 할당하고 최근 상호작용을 위한 소프트맥스 어텐션 브랜치를 따로 두어 산업 규모의 컨텍스트에서 정확한 검색 기능을 복원합니다. 또한, 선형 레이어에서의 빠른 관심 변화 포착 지연을 완화하기 위해 Temporal-Aware Delta Network (TADN)를 설계하여 새로운 행동 신호를 동적으로 강조하고 역사적 잡음을 효과적으로 억제합니다. 실험 결과, 본 모델은 선형 추론 속도를 유지하면서 강력한 기준 모델들을 초월하는 성능을 입증하였으며, 특히 초장기 시퀀스를 가진 사용자에 대해 Hit Rate가 8% 이상 향상되었습니다.
논문 초록(Abstract)
사용자 행동의 긴 시퀀스를 모델링하는 것은 생성적 추천에서 중요한 경계로 떠올랐습니다. 그러나 기존 솔루션은 딜레마에 직면해 있습니다: 선형 어텐션 메커니즘은 제한된 상태 용량으로 인해 검색 정확도를 희생하면서 효율성을 달성하는 반면, 소프트맥스 어텐션은 막대한 계산 오버헤드로 어려움을 겪고 있습니다. 이 문제를 해결하기 위해, 우리는 장기적으로 안정적인 선호도를 단기적인 의도 급증과 명확히 분리하는 하이브리드 어텐션 아키텍처를 특징으로 하는 모델인 HyTRec을 제안합니다. 대규모의 역사적 시퀀스를 선형 어텐션 브랜치에 할당하고 최근 상호작용을 위한 전문 소프트맥스 어텐션 브랜치를 예약함으로써, 우리의 접근 방식은 만 상호작용이 포함된 산업 규모의 맥락에서 정확한 검색 능력을 회복합니다. 선형 레이어 내에서 빠른 관심 변화 포착의 지연을 완화하기 위해, 우리는 또한 신선한 행동 신호의 가중치를 동적으로 증가시키면서 역사적 노이즈를 효과적으로 억제하는 시간 인식 델타 네트워크(Temporal-Aware Delta Network, TADN)를 설계하였습니다. 산업 규모 데이터셋에 대한 실험 결과는 우리의 모델이 선형 추론 속도를 유지하며 강력한 기준선보다 우수함을 확인하며, 특히 초장기 시퀀스를 가진 사용자에게 8% 이상의 히트율 개선을 효율적으로 제공합니다.
Modeling long sequences of user behaviors has emerged as a critical frontier in generative recommendation. However, existing solutions face a dilemma: linear attention mechanisms achieve efficiency at the cost of retrieval precision due to limited state capacity, while softmax attention suffers from prohibitive computational overhead. To address this challenge, we propose HyTRec, a model featuring a Hybrid Attention architecture that explicitly decouples long-term stable preferences from short-term intent spikes. By assigning massive historical sequences to a linear attention branch and reserving a specialized softmax attention branch for recent interactions, our approach restores precise retrieval capabilities within industrial-scale contexts involving ten thousand interactions. To mitigate the lag in capturing rapid interest drifts within the linear layers, we furthermore design Temporal-Aware Delta Network (TADN) to dynamically upweight fresh behavioral signals while effectively suppressing historical noise. Empirical results on industrial-scale datasets confirm the superiority that our model maintains linear inference speed and outperforms strong baselines, notably delivering over 8% improvement in Hit Rate for users with ultra-long sequences with great efficiency.
논문 링크
DPE: 블라인드 스팟에서 이득으로: 진단 기반 반복 학습을 통한 대규모 멀티모달 모델 개선 / From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models
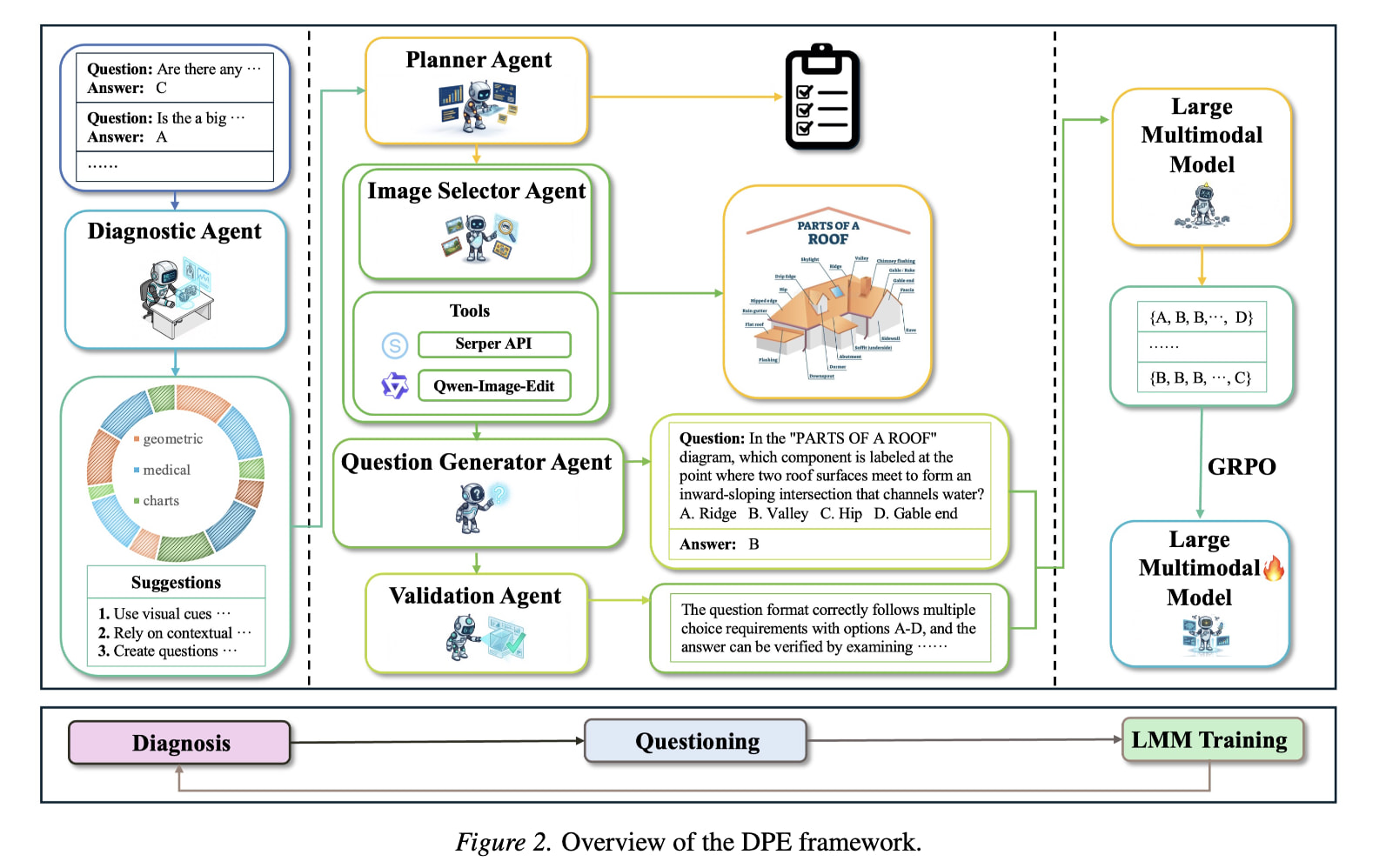
논문 소개
대규모 멀티모달 모델(LMM)이 확장되고 강화학습(RL) 방법이 성숙함에 따라 LMM은 복잡한 추론 및 의사결정 분야에서 주목할 만한 발전을 이루었습니다. 그러나 기존의 학습 방법은 정적인 데이터와 고정된 레시피에 의존하기 때문에 능력의 블라인드 스팟을 진단하거나 동적인 목표 강화가 어려웠습니다. 이를 해결하기 위해, 우리는 진단 기반 점진적 진화(Diagnostic-driven Progressive Evolution, DPE)를 제안합니다. DPE는 진단이 데이터 생성과 강화를 유도하는 나선형 루프이며, 각 반복에서 업데이트된 모델을 재진단하여 다음 단계의 목표 개선을 추진합니다. DPE의 두 가지 핵심 요소는 첫째, 여러 에이전트가 웹 검색 및 이미지 편집 도구를 사용하여 방대한 비표시 멀티모달 데이터를 주석 달고 품질을 관리하여 다양한 현실적인 샘플을 생성하는 것입니다. 둘째, DPE는 실패를 특정 약점에 귀속시키고 데이터 혼합을 동적으로 조정하여 약점 중심의 데이터를 생성하도록 에이전트를 유도합니다. Qwen3-VL-8B-Instruct 및 Qwen2.5-VL-7B-Instruct에 대한 실험 결과, 11개의 벤치마크에서 안정적이고 지속적인 성과 향상이 나타났으며, 이는 DPE가 열린 작업 분포에서 지속적인 LMM 학습을 위한 확장 가능한 패러다임임을 시사합니다.
논문 초록(Abstract)
대규모 멀티모달 모델(LLMs)이 확장되고 강화학습(RL) 방법이 성숙해짐에 따라, LLMs는 복잡한 추론 및 의사결정에서 눈에 띄는 발전을 이루었습니다. 그러나 학습은 여전히 정적 데이터와 고정된 레시피에 의존하고 있어, 능력의 맹점을 진단하거나 동적이고 목표 지향적인 강화 제공이 어렵습니다. 반복적인 연습보다 테스트 기반 오류 노출 및 피드백 기반 수정이 더 효과적이라는 발견에 착안하여, 우리는 진단 주도 점진적 진화(Diagnostic-driven Progressive Evolution, DPE)를 제안합니다. DPE는 진단이 데이터 생성 및 강화를 이끄는 나선형 루프로, 각 반복은 업데이트된 모델을 다시 진단하여 다음 목표 개선을 추진합니다. DPE는 두 가지 주요 구성 요소를 갖추고 있습니다. 첫째, 여러 에이전트가 웹 검색 및 이미지 편집과 같은 도구를 사용하여 방대한 비지도 멀티모달 데이터를 주석 달고 품질을 조정하여 다양한 현실적인 샘플을 생성합니다. 둘째, DPE는 실패를 특정 약점에 귀속시키고, 데이터 혼합을 동적으로 조정하며, 에이전트가 약점 중심 데이터를 생성하도록 안내하여 목표 지향적 강화를 제공합니다. Qwen3-VL-8B-Instruct 및 Qwen2.5-VL-7B-Instruct에 대한 실험 결과는 열한 개의 벤치마크에서 안정적이고 지속적인 성과 향상을 보여주며, DPE가 열린 작업 분포에서 지속적인 LLM 훈련을 위한 확장 가능한 패러다임임을 나타냅니다. 우리의 코드, 모델 및 데이터는 https://github.com/hongruijia/DPE에서 공개적으로 제공됩니다.
As Large Multimodal Models (LMMs) scale up and reinforcement learning (RL) methods mature, LMMs have made notable progress in complex reasoning and decision making. Yet training still relies on static data and fixed recipes, making it difficult to diagnose capability blind spots or provide dynamic, targeted reinforcement. Motivated by findings that test driven error exposure and feedback based correction outperform repetitive practice, we propose Diagnostic-driven Progressive Evolution (DPE), a spiral loop where diagnosis steers data generation and reinforcement, and each iteration re-diagnoses the updated model to drive the next round of targeted improvement. DPE has two key components. First, multiple agents annotate and quality control massive unlabeled multimodal data, using tools such as web search and image editing to produce diverse, realistic samples. Second, DPE attributes failures to specific weaknesses, dynamically adjusts the data mixture, and guides agents to generate weakness focused data for targeted reinforcement. Experiments on Qwen3-VL-8B-Instruct and Qwen2.5-VL-7B-Instruct show stable, continual gains across eleven benchmarks, indicating DPE as a scalable paradigm for continual LMM training under open task distributions. Our code, models, and data are publicly available at GitHub - hongruijia/DPE: From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models.
논문 링크
더 읽어보기
대규모 온라인 비식별화: 대규모 언어 모델을 활용한 접근법 / Large-scale online deanonymization with LLMs
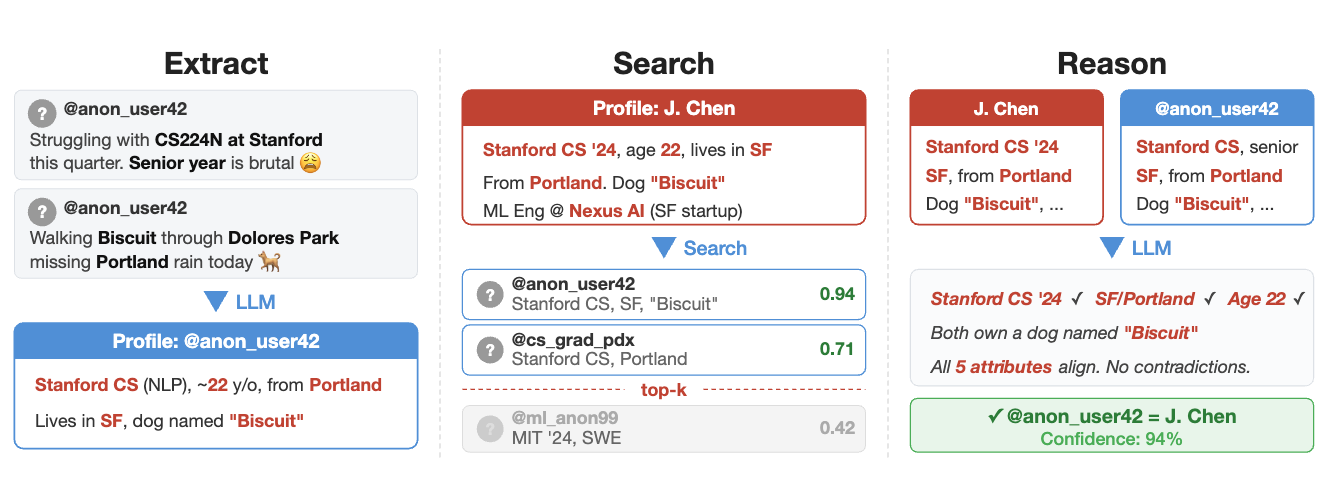
논문 소개
대규모 언어 모델(LLM)을 활용한 디아노니마이제이션(de-anonymization) 공격은 온라인 개인 정보 보호에 대한 새로운 위협을 제기하고 있다. 본 연구에서는 LLM을 통해 비구조화된 텍스트에서 자동으로 개인을 재식별할 수 있는 방법론을 제시하며, 이는 기존의 수작업 기반 접근 방식에 비해 훨씬 더 효율적이다. 연구진은 두 개의 데이터베이스에서 익명 사용자의 신원을 추출하고, 이를 기반으로 후보 매치를 검색한 후, 최종적으로 신뢰도를 평가하여 잘못된 긍정 결과를 줄이는 다단계 공격 프레임워크를 설계하였다.
이 프레임워크는 크게 네 가지 단계로 구성된다. 첫째, 비구조화된 게시물에서 신원 관련 특징을 추출하고, 둘째, 이 특징을 바탕으로 후보 매치를 검색한다. 셋째, 상위 후보들 중에서 가장 적합한 매치를 선택하고, 마지막으로 매칭 결과의 신뢰도를 보정하여 최종 결정을 내린다. 이러한 접근 방식은 LLM의 강력한 추론 능력을 활용하여, 기존의 구조화된 데이터나 수작업 특성 공학 없이도 높은 정확도로 디아노니마이제이션을 수행할 수 있음을 보여준다.
연구에서는 Hacker News와 LinkedIn, 그리고 Reddit 영화 커뮤니티를 대상으로 한 세 가지 데이터셋을 구축하여 실험을 진행하였다. 각 데이터셋에서 LLM 기반 방법이 전통적인 방법에 비해 현저히 높은 재식별률을 기록하였으며, 특히 90%의 정밀도에서 최대 68%의 재현율을 달성하였다. 이러한 결과는 익명성을 보호하기 위한 기존의 모델이 더 이상 유효하지 않음을 시사하며, 온라인 개인 정보 보호에 대한 새로운 위협 모델을 제안한다.
결과적으로, LLM을 활용한 디아노니마이제이션 공격은 인터넷 규모의 데이터셋에서도 효과적으로 작동하며, 이는 개인의 온라인 활동이 어떻게 쉽게 식별될 수 있는지를 보여준다. 이러한 연구는 디지털 환경에서의 개인 정보 보호를 재고할 필요성을 강조하며, 향후 연구 방향에 대한 중요한 통찰을 제공한다.
논문 초록(Abstract)
우리는 대규모 언어 모델이 대규모 비식별화(deanonymization)를 수행하는 데 사용될 수 있음을 보여줍니다. 완전한 인터넷 접근을 통해, 우리의 에이전트는 해커 뉴스(Hacker News) 사용자와 앤트로픽 인터뷰어(Anthropic Interviewer) 참가자를 높은 정확도로 재식별할 수 있으며, 이는 단순히 가명 온라인 프로필과 대화만으로 가능하며, 전담 인간 조사자가 수행하는 데 몇 시간이 걸리는 작업을 대체합니다. 이후 우리는 폐쇄형 세계(closed-world) 환경을 위한 공격을 설계합니다. 두 개의 가명 개인 데이터베이스가 주어졌을 때, 각 데이터베이스는 해당 개인에 의해 작성되거나 그에 대한 비구조적 텍스트를 포함하고 있으며, 우리는 LLM을 사용하여: (1) 신원 관련 특징을 추출하고, (2) 의미 임베딩(semantic embeddings)을 통해 후보 매치를 검색하며, (3) 상위 후보에 대해 추론하여 매치를 검증하고 잘못된 긍정(false positives)을 줄이는 확장 가능한 공격 파이프라인을 구현합니다. 구조화된 데이터나 수동 특징 공학(manual feature engineering)을 요구했던 이전의 비식별화 작업(예: 넷플릭스 상금 관련 연구)과 비교할 때, 우리의 접근 방식은 임의 플랫폼의 원시 사용자 콘텐츠에서 직접 작동합니다. 우리는 우리의 공격을 평가하기 위해 알려진 진실 데이터(ground-truth data)를 가진 세 개의 데이터셋을 구성합니다. 첫 번째 데이터셋은 해커 뉴스와 링크드인(LinkedIn) 프로필을 연결하며, 프로필에 나타나는 크로스 플랫폼 참조를 사용합니다. 두 번째 데이터셋은 레딧(Reddit) 영화 토론 커뮤니티 간의 사용자 매치를 수행하며, 세 번째 데이터셋은 단일 사용자의 레딧 기록을 시간에 따라 나누어 두 개의 가명 프로필을 생성하여 매치합니다. 각 설정에서 LLM 기반 방법은 고전적인 기준선(classical baselines)을 상당히 능가하며, 90%의 정확도에서 최대 68%의 재현율(recall)을 달성하는 반면, 최고의 비-LLM 방법은 거의 0%에 불과합니다. 우리의 결과는 가명 사용자를 온라인에서 보호하는 실질적인 불투명성(practical obscurity)이 더 이상 유효하지 않으며, 온라인 프라이버시를 위한 위협 모델을 재고할 필요가 있음을 보여줍니다.
We show that large language models can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at high precision, given pseudonymous online profiles and conversations alone, matching what would take hours for a dedicated human investigator. We then design attacks for the closed-world setting. Given two databases of pseudonymous individuals, each containing unstructured text written by or about that individual, we implement a scalable attack pipeline that uses LLMs to: (1) extract identity-relevant features, (2) search for candidate matches via semantic embeddings, and (3) reason over top candidates to verify matches and reduce false positives. Compared to prior deanonymization work (e.g., on the Netflix prize) that required structured data or manual feature engineering, our approach works directly on raw user content across arbitrary platforms. We construct three datasets with known ground-truth data to evaluate our attacks. The first links Hacker News to LinkedIn profiles, using cross-platform references that appear in the profiles. Our second dataset matches users across Reddit movie discussion communities; and the third splits a single user's Reddit history in time to create two pseudonymous profiles to be matched. In each setting, LLM-based methods substantially outperform classical baselines, achieving up to 68% recall at 90% precision compared to near 0% for the best non-LLM method. Our results show that the practical obscurity protecting pseudonymous users online no longer holds and that threat models for online privacy need to be reconsidered.
논문 링크
AlphaEvolve: 대규모 언어 모델을 활용한 다중 에이전트 학습 알고리즘 발견 / Discovering Multiagent Learning Algorithms with Large Language Models
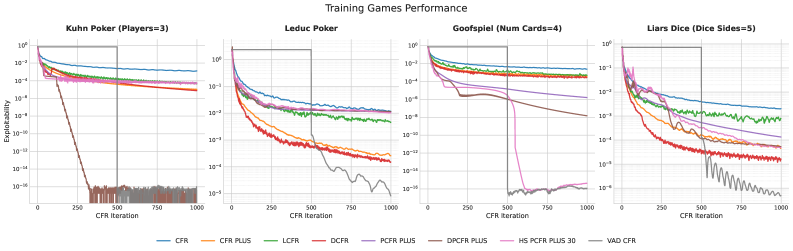
논문 소개
다중 에이전트 강화학습(MARL)은 불완전 정보 게임에서의 성과 향상에 중요한 역할을 해왔으나, 기존의 알고리즘 설계는 종종 인간의 직관에 의존하여 비효율적인 탐색을 초래하였다. 본 연구에서는 이러한 한계를 극복하기 위해 AlphaEvolve라는 진화적 코딩 에이전트를 도입하여 대규모 언어 모델을 활용한 새로운 다중 에이전트 학습 알고리즘의 자동 발견을 제안한다. AlphaEvolve는 알고리즘 설계 공간을 탐색하는 데 있어 인간의 개입 없이도 효과적인 변형을 생성할 수 있는 능력을 갖추고 있다.
이 연구는 두 가지 주요 게임 이론적 학습 패러다임에서의 실험을 통해 AlphaEvolve의 일반성을 입증하였다. 첫 번째로, 반복적 후회 최소화 영역에서 **변동성 적응 할인(Volatility-Adaptive Discounted, VAD-CFR)**이라는 새로운 알고리즘을 진화시켰다. VAD-CFR은 변동성에 민감한 할인, 일관성 강제 낙관주의, 하드 웜 스타트 정책 축적 일정과 같은 혁신적인 메커니즘을 도입하여 최신 기술 기준인 할인 예측 CFR+를 초월하는 성능을 달성하였다.
두 번째로, 인구 기반 훈련 알고리즘의 영역에서는 부드러운 하이브리드 낙관적 후회(Smoothed Hybrid Optimistic Regret, SHOR-)PSRO라는 새로운 변형을 발견하였다. SHOR-PSRO는 낙관적 후회 매칭과 부드러운 최상의 순수 전략을 혼합하는 하이브리드 메타 해결기를 통해 훈련 중에 혼합 요소와 다양성 보너스를 동적으로 조정하여 균형 찾기를 자동화한다. 이로 인해 SHOR-PSRO는 기존의 정적 메타 해결기보다 우수한 경험적 수렴을 보여준다.
이 연구는 AlphaEvolve가 다중 에이전트 학습 알고리즘 설계를 자동화할 수 있는 가능성을 제시하며, VAD-CFR 및 SHOR-PSRO와 같은 새로운 알고리즘 변형이 기존 알고리즘보다 뛰어난 성능을 발휘함을 입증하였다. 이러한 결과는 MARL 분야의 발전에 기여할 수 있는 중요한 기초를 마련하며, 향후 연구에서 진화적 접근 방식의 활용 가능성을 더욱 확장할 수 있는 기반이 될 것이다.
논문 초록(Abstract)
다수의 에이전트 강화학습(MARL)의 불완전 정보 게임에서의 발전은 역사적으로 기준선의 수동적인 반복 개선에 의존해 왔습니다. 반사적 후회 최소화(CFR)와 정책 공간 응답 오라클(PSRO)과 같은 기초적인 패밀리는 견고한 이론적 기반 위에 있지만, 그들의 가장 효과적인 변형의 설계는 종종 방대한 알고리즘 설계 공간을 탐색하기 위해 인간의 직관에 의존합니다. 본 연구에서는 대규모 언어 모델에 의해 구동되는 진화적 코딩 에이전트인 AlphaEvolve를 사용하여 새로운 다중 에이전트 학습 알고리즘을 자동으로 발견하는 방법을 제안합니다. 우리는 게임 이론적 학습의 두 가지 뚜렷한 패러다임에 대해 새로운 변형을 진화시킴으로써 이 프레임워크의 일반성을 입증합니다. 첫째, 반복적 후회 최소화 영역에서 우리는 후회 축적 및 정책 도출을 지배하는 논리를 진화시켜 새로운 알고리즘인 변동성 적응 할인(CFR)인 VAD-CFR을 발견합니다. VAD-CFR은 변동성 민감 할인, 일관성 강제 낙관론, 그리고 강력한 초기 정책 축적 일정과 같은 새로운 비직관적 메커니즘을 사용하여 Discounted Predictive CFR+와 같은 최첨단 기준선을 초월합니다. 둘째, 집단 기반 훈련 알고리즘의 영역에서 우리는 PSRO를 위한 훈련 시간 및 평가 시간 메타 전략 해결기를 진화시켜 새로운 변형인 부드러운 하이브리드 낙관적 후회(SHOR-PSRO)를 발견합니다. SHOR-PSRO는 낙관적 후회 매칭을 부드럽고 온도 조절된 최적 순수 전략 분포와 선형적으로 혼합하는 하이브리드 메타 해결기를 도입합니다. 훈련 중 이 혼합 요소와 다양성 보너스를 동적으로 감소시킴으로써, 알고리즘은 집단 다양성에서 엄격한 균형 찾기로의 전환을 자동화하여 표준 정적 메타 해결기보다 우수한 경험적 수렴을 제공합니다.
Much of the advancement of Multi-Agent Reinforcement Learning (MARL) in imperfect-information games has historically depended on manual iterative refinement of baselines. While foundational families like Counterfactual Regret Minimization (CFR) and Policy Space Response Oracles (PSRO) rest on solid theoretical ground, the design of their most effective variants often relies on human intuition to navigate a vast algorithmic design space. In this work, we propose the use of AlphaEvolve, an evolutionary coding agent powered by large language models, to automatically discover new multiagent learning algorithms. We demonstrate the generality of this framework by evolving novel variants for two distinct paradigms of game-theoretic learning. First, in the domain of iterative regret minimization, we evolve the logic governing regret accumulation and policy derivation, discovering a new algorithm, Volatility-Adaptive Discounted (VAD-)CFR. VAD-CFR employs novel, non-intuitive mechanisms-including volatility-sensitive discounting, consistency-enforced optimism, and a hard warm-start policy accumulation schedule-to outperform state-of-the-art baselines like Discounted Predictive CFR+. Second, in the regime of population based training algorithms, we evolve training-time and evaluation-time meta strategy solvers for PSRO, discovering a new variant, Smoothed Hybrid Optimistic Regret (SHOR-)PSRO. SHOR-PSRO introduces a hybrid meta-solver that linearly blends Optimistic Regret Matching with a smoothed, temperature-controlled distribution over best pure strategies. By dynamically annealing this blending factor and diversity bonuses during training, the algorithm automates the transition from population diversity to rigorous equilibrium finding, yielding superior empirical convergence compared to standard static meta-solvers.
논문 링크
PAHF: 인간 피드백을 통한 개인화 에이전트 학습 / Learning Personalized Agents from Human Feedback

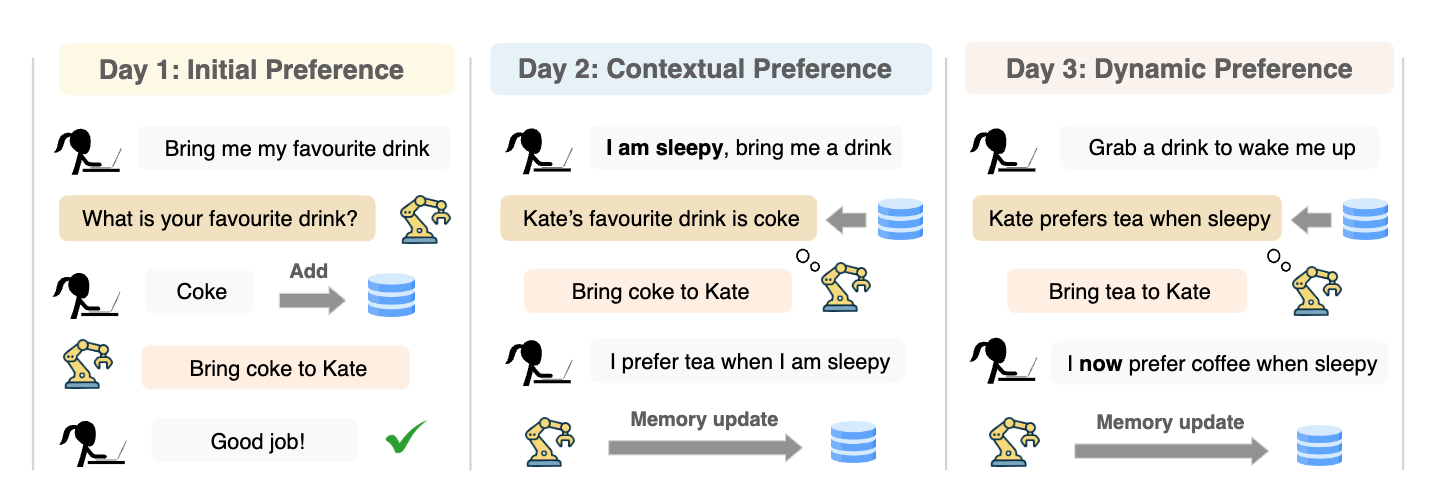
논문 소개
현대 인공지능(AI) 에이전트는 사용자와의 상호작용에서 복잡한 작업을 수행할 수 있는 능력을 갖추고 있지만, 개인 사용자의 독특하고 변화하는 선호에 적절히 대응하는 데에는 한계를 보이고 있다. 기존의 개인화 방법들은 주로 정적 데이터셋에 의존하여, 과거의 상호작용 기록을 기반으로 암묵적인 선호 모델을 학습하거나 외부 메모리에 사용자 프로필을 저장하는 방식으로 이루어졌다. 이러한 접근은 새로운 사용자에게 즉각적으로 적응하지 못하고, 시간이 지남에 따라 변화하는 선호를 반영하는 데 어려움을 겪는다.
이러한 문제를 해결하기 위해, 본 연구에서는 인간 피드백을 통한 개인화 에이전트(Personalized Agents from Human Feedback, PAHF) 라는 새로운 프레임워크를 제안한다. PAHF는 에이전트가 실시간 상호작용을 통해 명시적인 사용자별 메모리를 활용하여 지속적으로 개인화된 학습을 수행할 수 있도록 설계되었다. 이 프레임워크는 세 가지 단계의 상호작용 루프를 통해 작동한다: 첫째, 에이전트는 모호한 지시를 받았을 때 사전 행동 명확화를 요청하여 사용자로부터 추가 정보를 얻는다. 둘째, 에이전트는 메모리에서 검색한 선호를 바탕으로 행동을 실행한다. 셋째, 사용자의 피드백을 통해 에이전트는 자신의 메모리를 업데이트하여 변화하는 선호를 반영한다.
PAHF의 성능을 평가하기 위해, 연구진은 물리적 조작과 온라인 쇼핑을 포함한 두 가지 새로운 벤치마크를 개발하고, 초기 선호 학습과 개인성 변화에 대한 적응을 정량화하는 네 단계의 프로토콜을 제시하였다. 실험 결과, PAHF는 초기 개인화 오류를 줄이고, 선호 변화에 빠르게 적응하는 데 있어 기존의 메모리가 없는 방법이나 단일 채널 기준선보다 일관되게 우수한 성능을 보였다. 이러한 결과는 명시적인 메모리와 이중 피드백 채널의 통합이 PAHF의 학습 속도와 적응력을 크게 향상시킨다는 것을 시사한다.
본 연구는 지속적인 개인화를 위한 새로운 접근 방식을 제시하며, AI 에이전트가 사용자와의 상호작용에서 보다 효과적으로 적응할 수 있는 기반을 마련하였다. PAHF는 개인화된 AI 시스템의 발전에 중요한 기여를 할 것으로 기대된다.
논문 초록(Abstract)
현대 AI 에이전트는 강력하지만 종종 개별 사용자의 특이하고 진화하는 선호도에 맞추지 못합니다. 이전 접근 방식은 일반적으로 정적 데이터셋에 의존하며, 상호작용 기록을 기반으로 암묵적 선호 모델을 학습하거나 외부 메모리에 사용자 프로필을 인코딩합니다. 그러나 이러한 접근 방식은 새로운 사용자와 시간이 지남에 따라 변화하는 선호도에 어려움을 겪습니다. 우리는 사용자 피드백을 통한 개인화 에이전트(Personalized Agents from Human Feedback, PAHF)를 소개합니다. PAHF는 에이전트가 명시적인 사용자별 메모리를 사용하여 실시간 상호작용으로부터 온라인으로 학습하는 지속적인 개인화 프레임워크입니다. PAHF는 세 단계의 루프를 운영화합니다: (1) 모호성을 해결하기 위한 사전 행동 명확화 요청, (2) 메모리에서 검색한 선호도를 기반으로 행동을 구체화, (3) 선호도가 변화할 때 메모리를 업데이트하기 위한 사후 행동 피드백 통합. 이 능력을 평가하기 위해 우리는 구현 조작 및 온라인 쇼핑에서 네 단계의 프로토콜과 두 개의 벤치마크를 개발했습니다. 이러한 벤치마크는 에이전트가 처음부터 초기 선호도를 학습하고 이후에 개인성 변화에 적응하는 능력을 정량화합니다. 우리의 이론적 분석과 실험 결과는 명시적 메모리와 이중 피드백 채널의 통합이 중요하다는 것을 보여줍니다: PAHF는 상당히 더 빠르게 학습하며, 메모리가 없는 경우와 단일 채널 기준선 모두를 일관되게 초월하여 초기 개인화 오류를 줄이고 선호도 변화에 신속하게 적응할 수 있게 합니다.
Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.
논문 링크
더 읽어보기
Aletheia: 자율적인 수학 연구를 향하여 / Towards Autonomous Mathematics Research
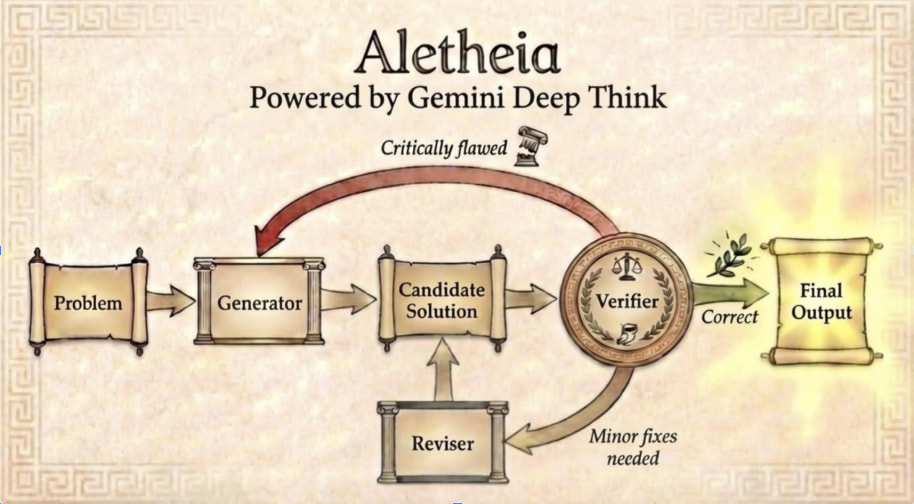
논문 소개
Aletheia는 수학 연구의 자율성을 향상시키기 위해 개발된 혁신적인 수학 연구 에이전트로, 자연어를 통해 솔루션을 반복적으로 생성, 검증 및 수정하는 기능을 갖추고 있다. 이 시스템은 고급 버전의 Gemini Deep Think를 기반으로 하여, 올림피아드 수준의 문제를 넘어서는 복잡한 수학적 추론을 가능하게 한다. Aletheia의 핵심은 새로운 추론 시간 스케일링 법칙과 다양한 도구를 활용하여 방대한 수학 문헌을 효과적으로 탐색하는 데 있다.
본 연구에서는 Aletheia의 능력을 여러 이정표를 통해 입증하였다. 첫째, 특정 구조 상수인 고유 가중치를 계산하는 데 있어 인간의 개입 없이 AI가 생성한 연구 논문(Feng26)을 소개한다. 둘째, 상호 작용하는 입자 시스템에 대한 경계를 증명하는 인간-AI 협업을 보여주는 연구 논문(LeeSeo26)을 통해 AI의 협력적 역할을 강조한다. 셋째, Bloom의 에르되시 추측 데이터베이스에서 700개의 열린 문제를 대상으로 한 반자율 평가(Feng et al., 2026a)를 통해 AI의 자율적 문제 해결 능력을 시연하였다.
Aletheia는 수학 연구의 복잡성을 극복하기 위해 다양한 기법을 적용하며, 특히 격자의 직각 분할과 세그먼트 경계 계산을 통해 문제 해결의 효율성을 높인다. 이러한 접근은 수학적 증명의 정확성을 보장하며, AI와 인간의 협업을 통해 새로운 연구 결과를 도출하는 데 기여한다.
또한, AI 지원 결과의 자율성과 참신성을 정량화하는 기준을 제안하고, 투명성을 위한 인간-AI 상호작용 카드의 개념을 도입하여 대중이 AI와 수학의 발전을 이해하는 데 도움을 주고자 한다. Aletheia의 연구는 수학적 사고의 새로운 지평을 열어주며, AI와 인간의 협업이 수학 연구에 미치는 영향을 깊이 있게 탐구하는 계기를 마련한다.
논문 초록(Abstract)
최근 파운데이션 모델의 발전은 국제 수학 올림피아드에서 금메달 수준의 성과를 달성할 수 있는 추론 시스템을 만들어냈습니다. 그러나 경쟁 수준의 문제 해결에서 전문 연구로의 전환은 방대한 문헌을 탐색하고 장기적인 증명을 구성하는 것을 요구합니다. 본 연구에서는 자연어로 솔루션을 반복적으로 생성, 검증 및 수정하는 수학 연구 에이전트인 아레테이아(Aletheia)를 소개합니다. 구체적으로, 아레테이아는 도전적인 추론 문제를 위한 진보된 버전의 제미니 딥 씽크(Gemini Deep Think), 올림피아드 수준 문제를 넘어서는 새로운 추론 시간 확장 법칙, 그리고 수학 연구의 복잡성을 탐색하기 위한 집중적인 도구 사용으로 구동됩니다. 우리는 아레테이아의 능력을 올림피아드 문제에서 박사 수준의 연습 문제까지 보여주며, 특히 AI 지원 수학 연구의 여러 주요 이정표를 통해 다음과 같은 성과를 입증합니다: (a) 산술 기하학에서 고유 가중치라고 불리는 특정 구조 상수를 계산하는 데 인간의 개입 없이 AI에 의해 생성된 연구 논문(Feng26); (b) 상호 작용하는 입자 시스템인 독립 집합의 경계를 증명하는 데 있어 인간-AI 협업을 보여주는 연구 논문(LeeSeo26); (c) 블룸의 에르되시 추측 데이터베이스에서 700개의 개방 문제에 대한 광범위한 반자율 평가(Feng et al., 2026a), 여기에는 네 가지 개방 질문에 대한 자율 솔루션이 포함됩니다. 대중이 AI와 수학에 관한 발전을 더 잘 이해할 수 있도록, 우리는 AI 지원 결과의 표준 자율성 및 참신성 수준을 정량화할 것을 제안하며, 투명성을 위한 인간-AI 상호작용 카드라는 새로운 개념을 제안합니다. 우리는 수학에서의 인간-AI 협업에 대한 성찰로 결론을 맺고, 모든 프롬프트와 모델 출력을 https://github.com/google-deepmind/superhuman/tree/main/aletheia에서 공유합니다.
Recent advances in foundational models have yielded reasoning systems capable of achieving a gold-medal standard at the International Mathematical Olympiad. The transition from competition-level problem-solving to professional research, however, requires navigating vast literature and constructing long-horizon proofs. In this work, we introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions end-to-end in natural language. Specifically, Aletheia is powered by an advanced version of Gemini Deep Think for challenging reasoning problems, a novel inference-time scaling law that extends beyond Olympiad-level problems, and intensive tool use to navigate the complexities of mathematical research. We demonstrate the capability of Aletheia from Olympiad problems to PhD-level exercises and most notably, through several distinct milestones in AI-assisted mathematics research: (a) a research paper (Feng26) generated by AI without any human intervention in calculating certain structure constants in arithmetic geometry called eigenweights; (b) a research paper (LeeSeo26) demonstrating human-AI collaboration in proving bounds on systems of interacting particles called independent sets; and (c) an extensive semi-autonomous evaluation (Feng et al., 2026a) of 700 open problems on Bloom's Erdos Conjectures database, including autonomous solutions to four open questions. In order to help the public better understand the developments pertaining to AI and mathematics, we suggest quantifying standard levels of autonomy and novelty of AI-assisted results, as well as propose a novel concept of human-AI interaction cards for transparency. We conclude with reflections on human-AI collaboration in mathematics and share all prompts as well as model outputs at superhuman/aletheia at main · google-deepmind/superhuman · GitHub.
논문 링크
더 읽어보기
SocioReasoner: 도시 사회-의미 분할을 위한 비전-언어 추론 / Urban Socio-Semantic Segmentation with Vision-Language Reasoning
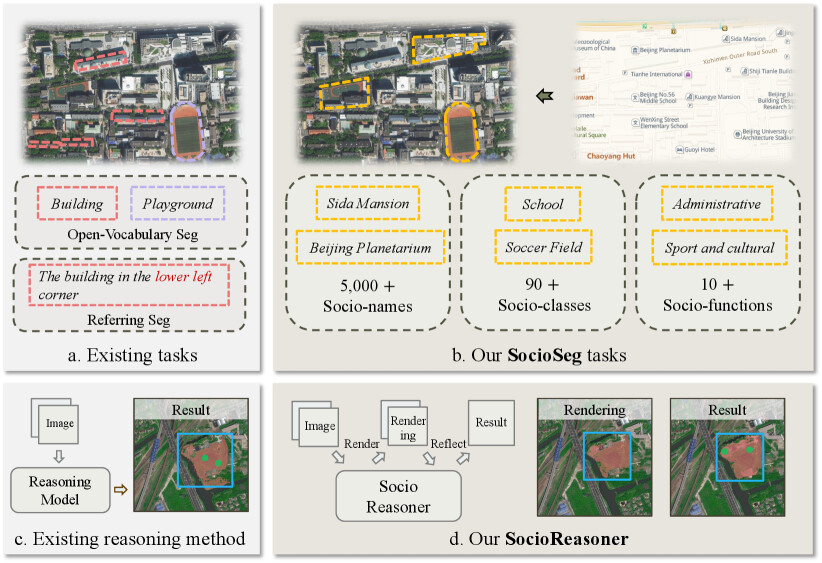
논문 소개
도시 지역의 사회적 의미 개체를 효과적으로 분할하는 것은 현대 도시 계획 및 환경 모니터링에 필수적인 과제이다. 기존의 고급 분할 모델은 물리적 속성으로 정의된 개체(예: 건물, 수역)에 대해서는 높은 정확성을 보이지만, 사회적 속성으로 정의된 개체(예: 학교, 공원)의 식별에는 여전히 한계를 지니고 있다. 이러한 문제를 해결하기 위해 본 연구에서는 비전-언어 모델(Vision-Language Model, VLM)을 활용한 사회-의미 분할 접근법을 제안한다. 이를 위해 새로운 데이터셋인 SocioSeg를 개발하였으며, 이 데이터셋은 위성 이미지, 디지털 지도, 그리고 사회적 의미 개체에 대한 픽셀 수준의 레이블로 구성되어 있다. SocioSeg는 계층적 구조를 통해 사회적 의미 정보를 풍부하게 제공하며, 5,000개 이상의 사회적 이름과 90개 사회적 클래스를 포함하고 있다.
본 연구의 핵심 기여는 SocioReasoner라는 비전-언어 추론 프레임워크를 제안한 점이다. SocioReasoner는 인간의 주석 작업 과정을 모사하여, 위성 이미지와 디지털 지도를 기반으로 사회적 의미 개체를 식별하고 주석을 달기 위한 두 단계의 추론 전략을 사용한다. 첫 번째 단계에서는 바운딩 박스를 생성하여 타겟 지역을 로컬라이즈하고, 두 번째 단계에서는 초기 분할 결과를 정제하여 최종적으로 고충실도의 분할 결과를 도출한다. 이러한 비차별적 프로세스는 강화 학습 알고리즘인 GRPO를 통해 최적화되며, 이는 모델의 사회적 의미 분할 작업에 대한 추론 능력을 효과적으로 향상시킨다.
실험 결과, 제안된 방법론은 최신 분할 기준선보다 우수한 성능을 보이며, 강력한 제로샷 일반화 능력을 나타낸다. 본 연구는 위성 이미지와 디지털 지도 맥락을 결합하여 사회적 의미 이해의 새로운 가능성을 제시하며, 실제 응용 프로그램에서의 잠재력을 강조한다. 데이터셋과 코드는 공개되어 있어, 향후 연구자들이 이 접근법을 기반으로 한 다양한 연구를 진행할 수 있는 기반을 제공한다.
논문 초록(Abstract)
도시 표면은 인간 활동의 중심으로 다양한 의미론적 개체로 구성되어 있습니다. 위성 이미지를 통해 이러한 다양한 개체를 분할하는 것은 여러 하위 응용 프로그램에 매우 중요합니다. 현재의 고급 분할 모델은 물리적 속성(예: 건물, 수역)으로 정의된 개체를 신뢰성 있게 분할할 수 있지만, 사회적으로 정의된 범주(예: 학교, 공원)에서는 여전히 어려움을 겪고 있습니다. 본 연구에서는 비전-언어 모델 추론을 통해 사회-의미론적 분할을 달성합니다. 이를 위해 위성 이미지, 디지털 지도 및 사회 의미론적 개체의 픽셀 수준 레이블을 계층 구조로 구성한 새로운 자원인 Urban Socio-Semantic Segmentation 데이터셋인 SocioSeg를 소개합니다. 또한, 우리는 교차 모달 인식과 다단계 추론을 통해 사회 의미론적 개체를 식별하고 주석을 달아주는 인간의 과정을 시뮬레이션하는 새로운 비전-언어 추론 프레임워크인 SocioReasoner를 제안합니다. 우리는 강화 학습을 사용하여 이 비미분 가능 프로세스를 최적화하고 비전-언어 모델의 추론 능력을 이끌어냅니다. 실험 결과, 우리의 접근 방식이 최신 모델에 비해 성능 향상을 보여주고 강력한 제로샷 일반화를 달성함을 입증합니다. 우리의 데이터셋과 코드는 GitHub - AMAP-ML/SocioReasoner: Official implementation of the ICLR 2026 paper "Urban Socio-Semantic Segmentation with Vision-Language Reasoning" 에서 확인할 수 있습니다.
As hubs of human activity, urban surfaces consist of a wealth of semantic entities. Segmenting these various entities from satellite imagery is crucial for a range of downstream applications. Current advanced segmentation models can reliably segment entities defined by physical attributes (e.g., buildings, water bodies) but still struggle with socially defined categories (e.g., schools, parks). In this work, we achieve socio-semantic segmentation by vision-language model reasoning. To facilitate this, we introduce the Urban Socio-Semantic Segmentation dataset named SocioSeg, a new resource comprising satellite imagery, digital maps, and pixel-level labels of social semantic entities organized in a hierarchical structure. Additionally, we propose a novel vision-language reasoning framework called SocioReasoner that simulates the human process of identifying and annotating social semantic entities via cross-modal recognition and multi-stage reasoning. We employ reinforcement learning to optimize this non-differentiable process and elicit the reasoning capabilities of the vision-language model. Experiments demonstrate our approach's gains over state-of-the-art models and strong zero-shot generalization. Our dataset and code are available in GitHub - AMAP-ML/SocioReasoner: Official implementation of the ICLR 2026 paper "Urban Socio-Semantic Segmentation with Vision-Language Reasoning".
논문 링크
더 읽어보기
ALMA: 메타 학습 에이전틱 메모리 디자인을 통한 지속적 학습 방법론 / Learning to Continually Learn via Meta-learning Agentic Memory Designs
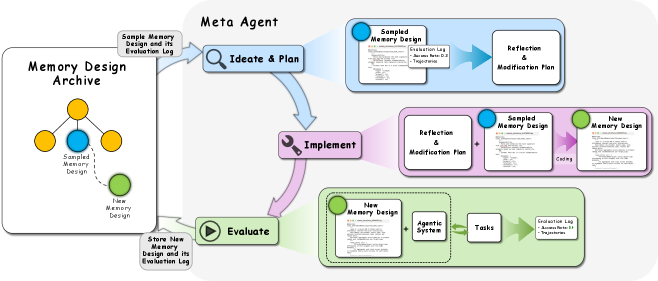
논문 소개
에이전틱 시스템의 지속적 학습 능력은 장기적 추론과 적응을 위한 핵심 기능으로, 이를 지원하기 위해 메모리 모듈이 통합된다. 기존의 메모리 설계는 인간이 수작업으로 설계한 고정형으로, 실제 작업의 다양성과 비정상성을 효과적으로 처리하는 데 한계가 있다. 본 논문에서는 이러한 문제를 해결하기 위해 ALMA(Automated meta-Learning of Memory designs for Agentic systems)라는 혁신적인 프레임워크를 제안한다. ALMA는 메타 학습을 통해 메모리 설계를 자동화하여, 수작업으로 설계된 메모리 구조를 대체함으로써 에이전틱 시스템이 다양한 도메인에서 지속적으로 학습할 수 있도록 한다.
ALMA의 핵심은 메타 에이전트를 사용하여 실행 가능한 코드로 표현된 메모리 설계를 탐색하는 것이다. 이 접근법은 데이터베이스 스키마 및 검색과 업데이트 메커니즘을 포함한 다양한 메모리 설계를 발견할 수 있는 잠재력을 지닌다. 네 가지 연속 의사결정 도메인에서의 실험 결과, ALMA에서 학습된 메모리 설계가 기존의 인간이 설계한 메모리 설계보다 더 효과적이고 효율적인 학습을 가능하게 한다는 것을 입증하였다.
ALMA는 에이전틱 시스템의 지속적이고 적응적인 학습을 위한 기초적인 요소를 제공하며, 안전하게 개발 및 배포될 경우 자가 개선하는 AI 시스템으로의 발전에 기여할 수 있는 중요한 단계로 자리매김할 것이다. 이러한 연구 결과는 AI 분야에서 지속적인 학습의 중요성을 강조하며, 메모리 설계 자동화의 필요성을 뒷받침하는 데 기여할 것이다. ALMA는 메모리 구조의 효율성을 높이고, 다양한 작업에 대한 적응 능력을 향상시키는 데 중요한 혁신으로 평가된다.
논문 초록(Abstract)
기초 모델의 무상태성은 에이전트 시스템이 지속적으로 학습할 수 있는 능력을 제한하며, 이는 장기적 추론과 적응을 위한 핵심 역량입니다. 이 한계를 해결하기 위해 에이전트 시스템은 일반적으로 메모리 모듈을 통합하여 과거 경험을 보유하고 재사용하며, 테스트 중 지속적인 학습을 목표로 합니다. 그러나 기존의 대부분의 메모리 설계는 인간이 수작업으로 제작한 고정된 형태로, 실제 작업의 다양성과 비정상성에 적응하는 능력을 제한합니다. 본 논문에서는 ALMA(에이전트 시스템을 위한 메모리 설계의 자동 메타 학습)를 소개합니다. ALMA는 수작업으로 설계된 메모리 설계를 대체하기 위해 메타 학습을 통해 메모리 설계를 학습하여 인간의 노력을 최소화하고, 에이전트 시스템이 다양한 도메인에서 지속적인 학습자가 될 수 있도록 합니다. 우리의 접근 방식은 실행 가능한 코드로 표현된 메모리 설계에 대해 개방적인 방식으로 탐색하는 메타 에이전트를 사용하여, 데이터베이스 스키마 및 그 검색 및 업데이트 메커니즘을 포함한 임의의 메모리 설계를 발견할 수 있도록 이론적으로 허용합니다. 네 개의 순차적 의사결정 도메인에서 수행된 광범위한 실험 결과, 학습된 메모리 설계가 모든 벤치마크에서 최첨단 인간 제작 메모리 설계보다 경험으로부터 더 효과적이고 효율적인 학습을 가능하게 함을 보여줍니다. 안전하게 개발되고 배포될 경우, ALMA는 적응적이고 지속적인 학습자가 되는 방법을 학습하는 자기 개선 AI 시스템을 향한 한 걸음을 나타냅니다.
The statelessness of foundation models bottlenecks agentic systems' ability to continually learn, a core capability for long-horizon reasoning and adaptation. To address this limitation, agentic systems commonly incorporate memory modules to retain and reuse past experience, aiming for continual learning during test time. However, most existing memory designs are human-crafted and fixed, which limits their ability to adapt to the diversity and non-stationarity of real-world tasks. In this paper, we introduce ALMA (Automated meta-Learning of Memory designs for Agentic systems), a framework that meta-learns memory designs to replace hand-engineered memory designs, therefore minimizing human effort and enabling agentic systems to be continual learners across diverse domains. Our approach employs a Meta Agent that searches over memory designs expressed as executable code in an open-ended manner, theoretically allowing the discovery of arbitrary memory designs, including database schemas as well as their retrieval and update mechanisms. Extensive experiments across four sequential decision-making domains demonstrate that the learned memory designs enable more effective and efficient learning from experience than state-of-the-art human-crafted memory designs on all benchmarks. When developed and deployed safely, ALMA represents a step toward self-improving AI systems that learn to be adaptive, continual learners.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()