[2026/03/23 ~ 29] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주에 선정된 10편의 논문들을 분석한 결과, 인공지능 연구가 단순한 성능 경쟁을 넘어 '다중 에이전트 생태계 구축', '작동 원리의 수학적 규명', 그리고 '자원 효율성 극대화'라는 세 가지 뚜렷한 방향으로 성숙해지고 있음을 확인할 수 있었습니다.
![]() 단일 초지능에서 "다중 에이전트 협력 및 시스템 아키텍처"로의 진화: 이번 주 연구들은 단일한 거대 모델의 한계를 극복하기 위해 여러 에이전트가 상호작용하는 복합 시스템 구축에 주목하고 있습니다. 에이전틱 AI와 다음 지능 폭발 논문이 지능을 다원적이고 사회적인 구조로 재해석한 것을 시작으로, 컴퓨터 아키텍처 관점에서의 멀티 에이전트 메모리 연구는 에이전트 간의 정보 일관성을 유지하기 위한 계층적 메모리 구조를 제안했습니다 . 또한, 스스로를 수정하고 진화시키는 하이퍼에이전트나 상호작용 속에서 신뢰를 구축하는 인공 인식 에이전트의 신뢰 체계 설계 연구는 AI가 단순한 도구를 넘어 유기적으로 협력하고 진화하는 생태계로 발전하고 있음을 보여줍니다.
단일 초지능에서 "다중 에이전트 협력 및 시스템 아키텍처"로의 진화: 이번 주 연구들은 단일한 거대 모델의 한계를 극복하기 위해 여러 에이전트가 상호작용하는 복합 시스템 구축에 주목하고 있습니다. 에이전틱 AI와 다음 지능 폭발 논문이 지능을 다원적이고 사회적인 구조로 재해석한 것을 시작으로, 컴퓨터 아키텍처 관점에서의 멀티 에이전트 메모리 연구는 에이전트 간의 정보 일관성을 유지하기 위한 계층적 메모리 구조를 제안했습니다 . 또한, 스스로를 수정하고 진화시키는 하이퍼에이전트나 상호작용 속에서 신뢰를 구축하는 인공 인식 에이전트의 신뢰 체계 설계 연구는 AI가 단순한 도구를 넘어 유기적으로 협력하고 진화하는 생태계로 발전하고 있음을 보여줍니다.
![]() 블랙박스 해소: "수학적 증명"과 "행동 설명 가능성(Explainability)"의 대두: 모델의 성능을 넘어 작동 원리를 수학적으로 낱낱이 규명하고 행동의 의도를 명확히 해석하려는 움직임도 뚜렷합니다. 트랜스포머는 베이지안 네트워크이다 연구는 트랜스포머의 내부 작동이 확률적 추론 과정임을 수학적 공리 수준에서 형식적으로 증명하여, 고질적인 환각 현상의 근본적 원인을 짚어냈습니다 . 이와 맥락을 같이하여, BXRL 논문은 강화학습 에이전트의 국소적 결정이 아닌 전반적인 '행동 패턴'의 원인을 수학적 측정치로 환원하여 설명하는 새로운 프레임워크를 제안했습니다. 이는 AI를 맹목적으로 신뢰하는 대신, 견고한 반증 가능성과 투명성을 바탕으로 검증 가능한(Verifiable) 시스템을 구축하려는 학계의 강력한 의지를 반영합니다.
블랙박스 해소: "수학적 증명"과 "행동 설명 가능성(Explainability)"의 대두: 모델의 성능을 넘어 작동 원리를 수학적으로 낱낱이 규명하고 행동의 의도를 명확히 해석하려는 움직임도 뚜렷합니다. 트랜스포머는 베이지안 네트워크이다 연구는 트랜스포머의 내부 작동이 확률적 추론 과정임을 수학적 공리 수준에서 형식적으로 증명하여, 고질적인 환각 현상의 근본적 원인을 짚어냈습니다 . 이와 맥락을 같이하여, BXRL 논문은 강화학습 에이전트의 국소적 결정이 아닌 전반적인 '행동 패턴'의 원인을 수학적 측정치로 환원하여 설명하는 새로운 프레임워크를 제안했습니다. 이는 AI를 맹목적으로 신뢰하는 대신, 견고한 반증 가능성과 투명성을 바탕으로 검증 가능한(Verifiable) 시스템을 구축하려는 학계의 강력한 의지를 반영합니다.
![]() 자원 효율성 극대화: "내부 구조 최적화" 및 "효율적 적응(Adaptation)": 무작정 모델의 파라미터 크기를 키우는 대신, 기존 모델의 잠재력을 한계까지 끌어내고 연산 비용을 최소화하려는 실용주의적 접근이 돋보입니다. 계층 간 구조적 인코더(ILSE) 연구는 최종 결과물에 가려져 있던 중간 레이어의 정보들을 기하학적으로 통합하여, 소형 모델로도 초대형 모델에 필적하는 범용적 성능을 달성했습니다. 또한, 엣지 디바이스를 위한 EUPE의 거대 프록시 모델을 활용한 다단계 지식 증류 기법이나, 대규모 비전 모델을 위한 프롬프트 기반 적응(PA) 서베이는 파라미터 전체를 재학습하지 않고도 새로운 작업에 모델을 유연하게 맞추는 효율적인 튜닝 패러다임을 확립하고 있습니다 .
자원 효율성 극대화: "내부 구조 최적화" 및 "효율적 적응(Adaptation)": 무작정 모델의 파라미터 크기를 키우는 대신, 기존 모델의 잠재력을 한계까지 끌어내고 연산 비용을 최소화하려는 실용주의적 접근이 돋보입니다. 계층 간 구조적 인코더(ILSE) 연구는 최종 결과물에 가려져 있던 중간 레이어의 정보들을 기하학적으로 통합하여, 소형 모델로도 초대형 모델에 필적하는 범용적 성능을 달성했습니다. 또한, 엣지 디바이스를 위한 EUPE의 거대 프록시 모델을 활용한 다단계 지식 증류 기법이나, 대규모 비전 모델을 위한 프롬프트 기반 적응(PA) 서베이는 파라미터 전체를 재학습하지 않고도 새로운 작업에 모델을 유연하게 맞추는 효율적인 튜닝 패러다임을 확립하고 있습니다 .
컴퓨터 아키텍처(Computer Architecture) 관점에서의 멀티 에이전트 메모리(Multi-Agent Memory): 비전과 향후 과제 / Multi-Agent Memory from a Computer Architecture Perspective: Visions and Challenges Ahead
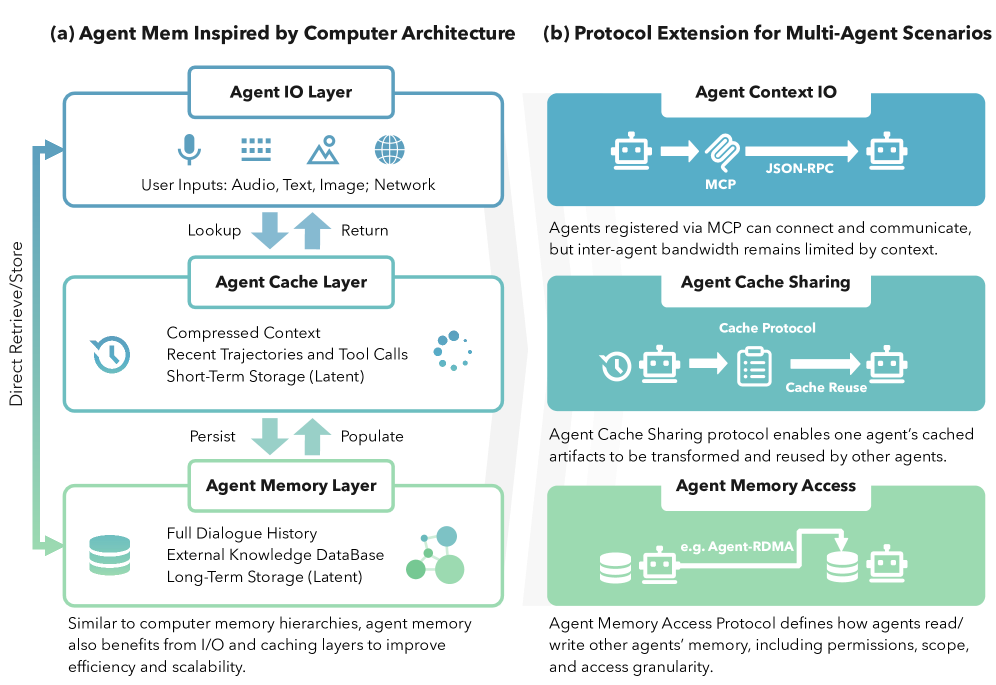
논문 소개
대규모 언어 모델(Large Language Model, LLM) 에이전트가 단일 작업을 수행하는 도구의 수준을 넘어, 여러 에이전트가 유기적으로 협력하는 멀티 에이전트 시스템(Multi-Agent System, MAS)으로 진화함에 따라 메모리 시스템의 복잡성은 급격히 증가하고 있습니다. 이러한 진화 과정에서 발생하는 방대한 컨텍스트(Context)와 데이터 처리의 병목 현상은 과거 컴퓨터 아키텍처가 직면했던 하드웨어 성능의 한계인 '메모리 벽(Memory Wall)' 문제와 매우 유사한 양상을 보입니다. 에이전트의 지능을 효과적으로 뒷받침하기 위해서는 단순히 데이터를 저장하는 수준을 넘어, 메모리를 컴퓨터 아키텍처 관점에서 재정의하고 구조화하는 접근 방식이 필수적입니다.
구체적인 방법론으로서 정보의 수신과 방출을 담당하는 에이전트 입출력(Input/Output, I/O) 계층, 즉각적인 추론을 지원하는 에이전트 캐시(Cache) 계층, 그리고 장기적인 영속성을 보장하는 에이전트 메모리(Memory) 계층의 3단계 계층 구조를 통해 데이터 이동의 효율성을 극대화할 수 있습니다. 이때 에이전트 간 정보 공유 방식에 따라 중앙 집중식의 공유 메모리(Shared Memory) 패러다임과 개별 독립적인 분산 메모리(Distributed Memory) 패러다임을 전략적으로 구분하여 시스템의 확장성과 격리성을 확보해야 합니다. 특히 에이전트 간의 원활한 협업을 위해서는 캐시된 결과물을 서로 재사용할 수 있는 캐시 공유 프로토콜과 메모리 접근 권한 및 범위를 규정하는 체계적인 액세스 제어 프로토콜의 확립이 요구됩니다.
무엇보다 멀티 에이전트 환경에서 가장 핵심적인 도전 과제는 여러 에이전트가 동시에 데이터를 읽고 쓰는 과정에서 정보의 정합성을 유지하는 메모리 일관성(Memory Consistency) 모델을 구축하는 것입니다. 이는 업데이트된 정보가 다른 에이전트에게 노출되는 시점과 가시성, 작업 순서를 명확히 규정함으로써 의미론적 충돌을 방지하고 시스템 전체의 신뢰도를 높이는 결정적인 역할을 합니다. 기존의 임시방편적인 프롬프트 관리 방식에서 벗어나 아키텍처 기반의 일관성 모델을 도입하는 것은 에이전트 시스템의 예측 가능성을 높이는 혁신적인 전환점이 될 것입니다. 결론적으로 이러한 컴퓨터 아키텍처적 프레임워크는 신뢰할 수 있고 확장 가능한 차세대 멀티 에이전트 생태계를 구축하기 위한 강력한 이론적 토대를 제공하며, 지능형 시스템의 새로운 지평을 열어줄 것으로 기대됩니다.
논문 초록(Abstract)
LLM 에이전트가 협력적인 멀티 에이전트 시스템(multi-agent systems)으로 진화함에 따라, 메모리 요구 사항의 복잡성이 급격히 증가하고 있습니다. 본 포지션 논문(position paper)은 멀티 에이전트 메모리를 컴퓨터 아키텍처 문제로 정의합니다. 본 연구에서는 공유 및 분산 메모리 패러다임을 구분하고, 3계층 메모리 계층 구조(I/O, 캐시, 메모리)를 제안하며, 에이전트 간 캐시 공유와 구조화된 메모리 액세스 제어라는 두 가지 핵심적인 프로토콜 격차를 식별합니다. 우리는 가장 시급한 미해결 과제가 멀티 에이전트 메모리 일관성(memory consistency)이라고 주장합니다. 이러한 아키텍처적 프레임워크는 신뢰할 수 있고 확장 가능한 멀티 에이전트 시스템을 구축하기 위한 토대를 제공합니다.
As LLM agents evolve into collaborative multi-agent systems, their memory requirements grow rapidly in complexity. This position paper frames multi-agent memory as a computer architecture problem. We distinguish shared and distributed memory paradigms, propose a three-layer memory hierarchy (I/O, cache, and memory), and identify two critical protocol gaps: cache sharing across agents and structured memory access control. We argue that the most pressing open challenge is multi-agent memory consistency. Our architectural framing provides a foundation for building reliable, scalable multi-agent systems.
논문 링크
BXRL: 행동 설명이 가능한 강화학습 (Behavior-Explainable Reinforcement Learning) / BXRL: Behavior-Explainable Reinforcement Learning
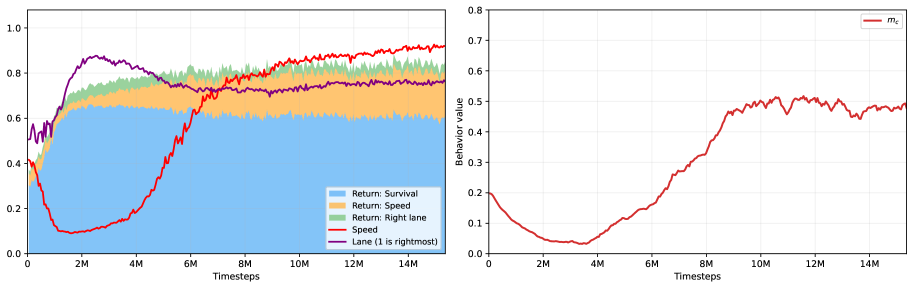
논문 소개
강화학습(Reinforcement Learning, RL) 에이전트가 설계자가 의도한 보상 구조와 무관하게 예상치 못한 행동 패턴을 학습하는 현상은 시스템의 신뢰성과 안전성을 저해하는 주요한 도전 과제입니다. 기존의 설명 가능 강화학습(Explainable Reinforcement Learning, XRL) 연구들은 주로 특정 시점의 결정이나 단일 경로를 분석하는 국소적 설명에 치중해 왔으며, 여러 에피소드에 걸쳐 나타나는 전반적인 행동 경향성을 공식적으로 정의하고 분석하는 데에는 한계가 있었습니다. 이러한 간극을 메우기 위해 제안된 BXRL(Behavior-Explainable Reinforcement Learning, 행동 설명 가능 강화학습) 프레임워크는 개별 액션의 단위를 넘어 '행동(Behavior)' 자체를 분석의 핵심 단위인 1급 객체(First-class object)로 격상시켰습니다.
BXRL의 방법론적 핵심은 정책(\Pi) 공간을 실수(\mathbb{R})로 매핑하는 행동 측정치(Behavior Measure) 함수를 도입하여, 사용자가 관심을 갖는 특정 행동 패턴을 수학적으로 정의하고 정량화하는 것입니다. 이를 통해 "에이전트가 왜 특정 액션을 선호하는가"라는 지엽적인 질문을 "왜 이 정책에서 특정 행동 측정치가 높게 나타나는가"라는 행동 수준의 대비적 질문으로 환원하여 분석할 수 있습니다. 특히 행동 측정치를 모델 파라미터(\theta)에 대해 직접 미분하는 행동 그래디언트 분석을 통해, 어떤 파라미터의 변화가 에이전트의 특정 성향을 강화하거나 약화시키는지 기술적으로 추적할 수 있는 토대를 마련했습니다.
또한 SHAP(Shapley Additive Explanations, 샤플리 가산 설명)이나 Integrated Gradients(통합 그래디언트)와 같은 기존의 특성 기여도 할당 기법을 행동 단위로 확장 적용함으로써, 에이전트의 성향에 영향을 미치는 입력 특성의 중요도를 전역적으로 파악할 수 있게 합니다. 연구진은 이러한 이론적 설계를 실증하기 위해 자동 미분과 병렬 시뮬레이션에 최적화된 JAX(잭스) 라이브러리 기반의 HighwayEnv(하이웨이엔브) 자율 주행 환경을 구축하여 제공합니다. 미분 가능한 환경 설계를 통해 상태 전이 과정을 끝까지 추적하고 행동 변화율을 효율적으로 계산할 수 있는 인터페이스를 구현함으로써, 실제 주행 시나리오에서의 공격성이나 에너지 효율성 같은 복합적인 행동을 정밀하게 모니터링할 수 있습니다. 결과적으로 BXRL은 단순한 보상 최적화를 넘어 에이전트의 근본적인 정책 특성을 깊이 있게 이해하고 개선할 수 있는 새로운 연구 방향을 제시하며, 향후 인간과 인공지능의 협력적 시스템 구축에 중요한 기술적 근거를 제공합니다.
논문 초록(Abstract)
강화학습(Reinforcement Learning)의 주요 과제 중 하나는 에이전트(agent)가 종종 부여된 보상 구조를 거스르는 듯한 원치 않는 행동을 학습한다는 것입니다. 설명 가능한 강화학습(Explainable Reinforcement Learning, XRL) 방법론은 "이 특정 행동을 설명하라", "이 특정 궤적(trajectory)을 설명하라", "전체 정책(policy)을 설명하라"와 같은 질의에 답할 수 있습니다. 하지만 XRL은 여러 에피소드에 걸친 행동 패턴으로서의 '행동(behavior)'에 대한 형식적 정의가 부족합니다. 본 논문에서는 이러한 정의를 제공하고, 이를 활용해 "이 행동을 설명하라"라는 새로운 질의를 가능하게 합니다. 우리는 행동을 일급 객체(first-class objects)로 취급하는 새로운 문제 공식화인 행동 설명 가능 강화학습(Behavior-Explainable Reinforcement Learning, BXRL)을 제시합니다. BXRL은 행동 측정치(behavior measure)를 임의의 함수 m : \Pi \to \mathbb{R} 로 정의하여, 사용자가 관심 있는 행동 패턴을 정밀하게 표현하고 정책이 이를 얼마나 강하게 나타내는지 측정할 수 있도록 합니다. 또한, "왜 에이전트가 a 보다 a' 를 선호하는가?"라는 질문을 미분(differentiation)을 통해 탐색 가능한 "왜 m(\pi) 가 높은가?"라는 문제로 환원하는 대조적 행동(contrastive behaviors)을 정의합니다. 우리는 새로운 설명 가능성 방법론을 직접 구현하는 대신, 기존의 세 가지 방법론을 분석하고 이를 행동 설명에 어떻게 적합하게 응용할 수 있는지 제안합니다. 마지막으로, 모델 파라미터에 대해 행동을 정의, 측정 및 미분할 수 있는 인터페이스를 제공하는 HighwayEnv 주행 환경의 JAX 포트(port)를 제시합니다.
A major challenge of Reinforcement Learning is that agents often learn undesired behaviors that seem to defy the reward structure they were given. Explainable Reinforcement Learning (XRL) methods can answer queries such as "explain this specific action", "explain this specific trajectory", and "explain the entire policy". However, XRL lacks a formal definition for behavior as a pattern of actions across many episodes. We provide such a definition, and use it to enable a new query: "Explain this behavior". We present Behavior-Explainable Reinforcement Learning (BXRL), a new problem formulation that treats behaviors as first-class objects. BXRL defines a behavior measure as any function m : Π\to \mathbb{R}, allowing users to precisely express the pattern of actions that they find interesting and measure how strongly the policy exhibits it. We define contrastive behaviors that reduce the question "why does the agent prefer a to a'?" to "why is m(π) high?" which can be explored with differentiation. We do not implement an explainability method; we instead analyze three existing methods and propose how they could be adapted to explain behavior. We present a port of the HighwayEnv driving environment to JAX, which provides an interface for defining, measuring, and differentiating behaviors with respect to the model parameters.
논문 링크
효율적인 범용 인지 인코더 (Efficient Universal Perception Encoder) / Efficient Universal Perception Encoder
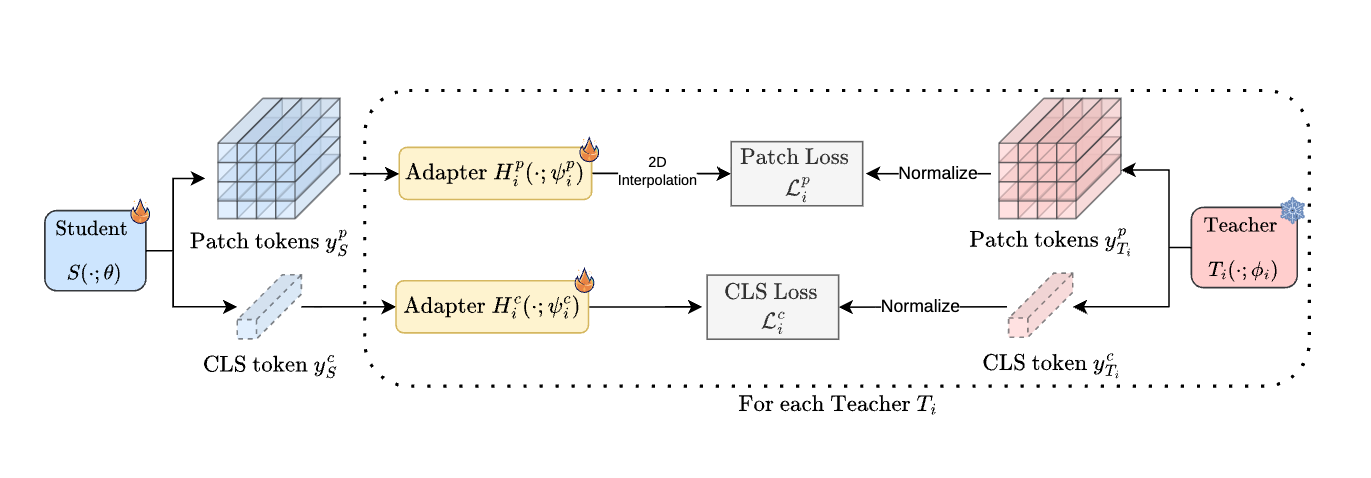
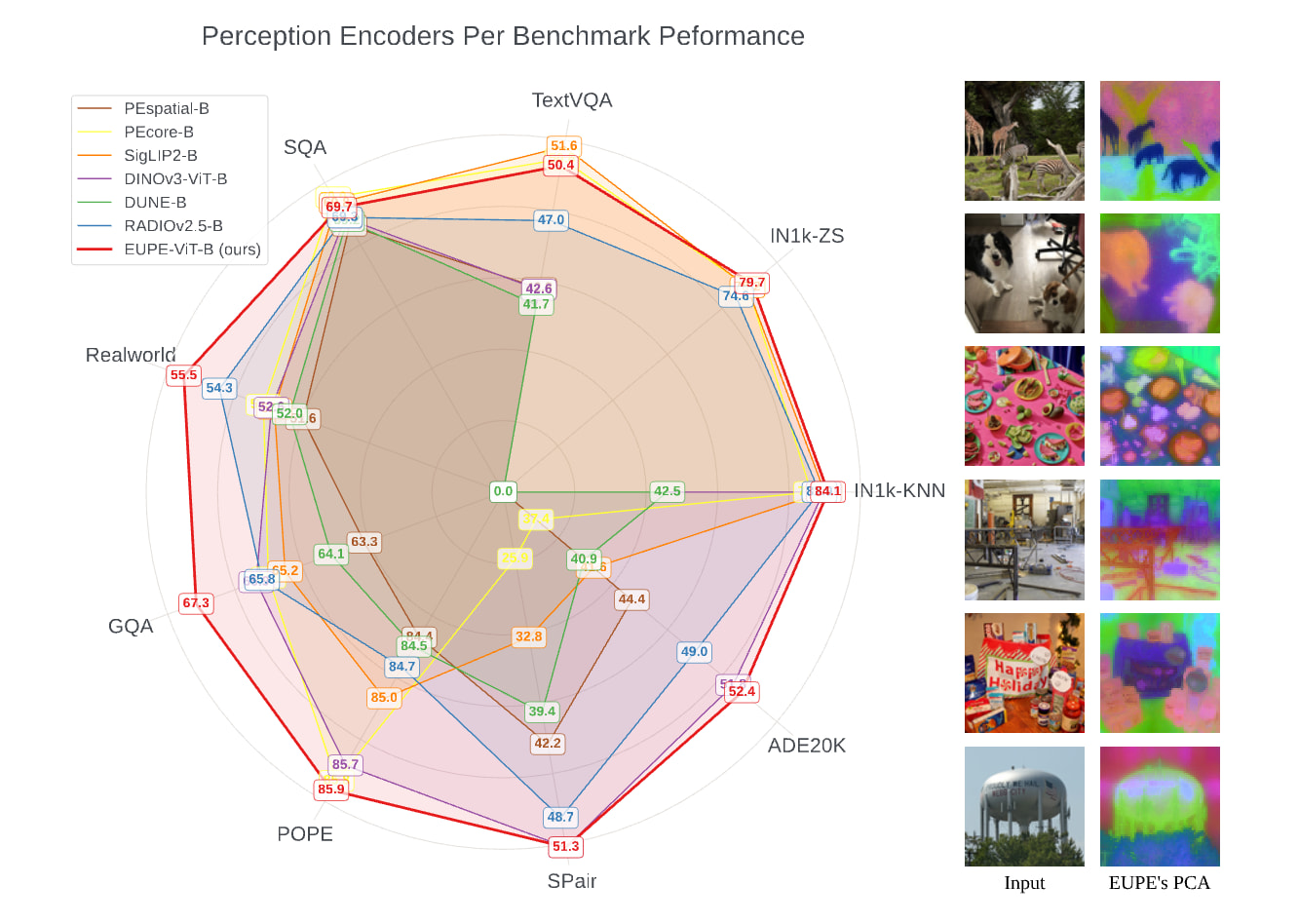
논문 소개
스마트 에지 디바이스(Smart Edge Devices)에서 인공지능 모델을 구동하기 위해서는 연산 자원의 제한 속에서도 다양한 시각적 작업을 동시에 수행할 수 있는 효율적이고 강력한 범용 비전 인코더(Universal Vision Encoder)가 필수적입니다. Efficient Universal Perception Encoder(EUPE)는 여러 도메인 전문가들로부터 지식을 통합하는 기존의 응집형 방식에서 탈피하여, 대규모 프록시 모델(Proxy Model)을 거치는 '스케일-업 후 스케일-다운(Scaling up, then scaling down)'이라는 독창적인 멀티 스테이지 증류(Multi-stage Distillation) 파이프라인을 제안합니다. 소형 모델이 서로 상충할 수 있는 다수의 교사 모델 지식을 직접 수용하기에는 용량이 부족하다는 가설에 기반하여, 19억 개의 파라미터를 가진 거대 모델에 먼저 지식을 집약시킴으로써 범용적인 표현(Representation) 능력을 확보하는 것이 본 방법론의 핵심입니다.
지식 집약의 첫 단계는 제로샷 분류를 위한 PEcore, 조밀한 예측(Dense Prediction)을 위한 DINOv3, 그리고 비전-언어 모델링을 위한 PElang 등 각 분야의 파운데이션 모델(Foundation Models)들로부터 핵심 정보를 추출하여 프록시 모델에 통합하는 과정을 포함합니다. 이후 정제된 지식은 고정 해상도(Fixed-resolution) 증류 과정을 통해 실제 배포용 타겟 인코더로 전이되며, 이 과정에서 연산 효율성과 학습 안정성이 동시에 확보됩니다. 멀티 해상도 파인튜닝(Multi-resolution Finetuning) 단계에서는 다양한 크기의 이미지 피라미드에서 무작위로 해상도를 선택 학습함으로써 실제 환경의 다양한 입력 요구 사항에 유연하게 대응할 수 있는 능력을 갖추게 됩니다.
기술적 측면에서는 어댑터 헤드 모듈(Adapter Head Modules)을 활용해 학생과 교사 모델 간의 특징 공간(Feature Space) 차이를 극복하고, 클래스 및 패치 토큰(Class and Patch Tokens)에 대한 정밀한 손실 함수(Loss Function)를 설계하여 고차원적인 시각 특징을 효과적으로 내재화합니다. 이러한 계층적 접근 방식은 단일 도메인 전문가 모델과 대등하거나 이를 능가하는 성능을 구현하며, 자원이 제한된 환경에서도 범용적인 인식 능력을 발휘할 수 있는 새로운 아키텍처 표준을 제시합니다. 공개된 EUPE 모델 제품군과 소스코드는 향후 에지 컴퓨팅(Edge Computing) 기반의 시각 인식 연구를 가속화하고 다양한 다운스트림 태스크(Downstream Tasks)에서의 활용 가능성을 넓힐 것으로 기대됩니다.
논문 초록(Abstract)
스마트 엣지 장치에서 AI 모델을 실행하는 것은 다재다능한 사용자 경험을 가능하게 하지만, 제한된 연산 자원과 여러 작업을 동시에 처리해야 하는 필요성으로 인해 어려움이 따릅니다. 이를 위해 작은 크기임에도 강력하고 다재다능한 표현(representations)력을 갖춘 비전 인코더(vision encoder)가 요구됩니다. 본 논문에서는 추론(inference) 효율성과 다양한 다운스트림 작업(downstream tasks)에 대해 보편적으로 우수한 표현을 동시에 제공하는 방식인 EUPE(Efficient Universal Perception Encoder)를 제안합니다. 우리는 여러 도메인 전문가(domain-expert) 파운데이션 비전 인코더로부터 지식 증류(distilling)를 수행함으로써 이를 달성했습니다. 여러 티처(teacher) 모델로부터 효율적인 인코더로 직접 스케일링 다운(scaling down)하는 기존의 응집형 방식(agglomerative methods)과 달리, 본 연구에서는 먼저 대형 프록시 티처(proxy teacher)로 스케일링 업(scaling up)한 후 이 단일 티처로부터 다시 스케일링 다운하는 과정의 중요성을 입증합니다. 실험 결과에 따르면, EUPE는 다양한 작업 도메인에서 동일한 크기의 개별 도메인 전문가 모델과 대등하거나 그 이상의 성능을 기록했으며, 기존의 응집형 인코더보다 뛰어난 성과를 거두었습니다. 본 연구팀은 향후 연구를 장려하기 위해 EUPE 모델군 전체와 코드를 공개할 예정입니다.
Running AI models on smart edge devices can unlock versatile user experiences, but presents challenges due to limited compute and the need to handle multiple tasks simultaneously. This requires a vision encoder with small size but powerful and versatile representations. We present our method, Efficient Universal Perception Encoder (EUPE), which offers both inference efficiency and universally good representations for diverse downstream tasks. We achieve this by distilling from multiple domain-expert foundation vision encoders. Unlike previous agglomerative methods that directly scale down from multiple teachers to an efficient encoder, we demonstrate the importance of first scaling up to a large proxy teacher and then scaling down from this single teacher. Experiments show that EUPE achieves on-par or better performance than individual domain experts of the same size on diverse task domains and also outperforms previous agglomerative encoders. We will release the full family of EUPE models and the code to foster future research.
논문 링크
대규모 비전 모델에서의 프롬프트 기반 적응: 서베이 / Prompt-based Adaptation in Large-scale Vision Models: A Survey
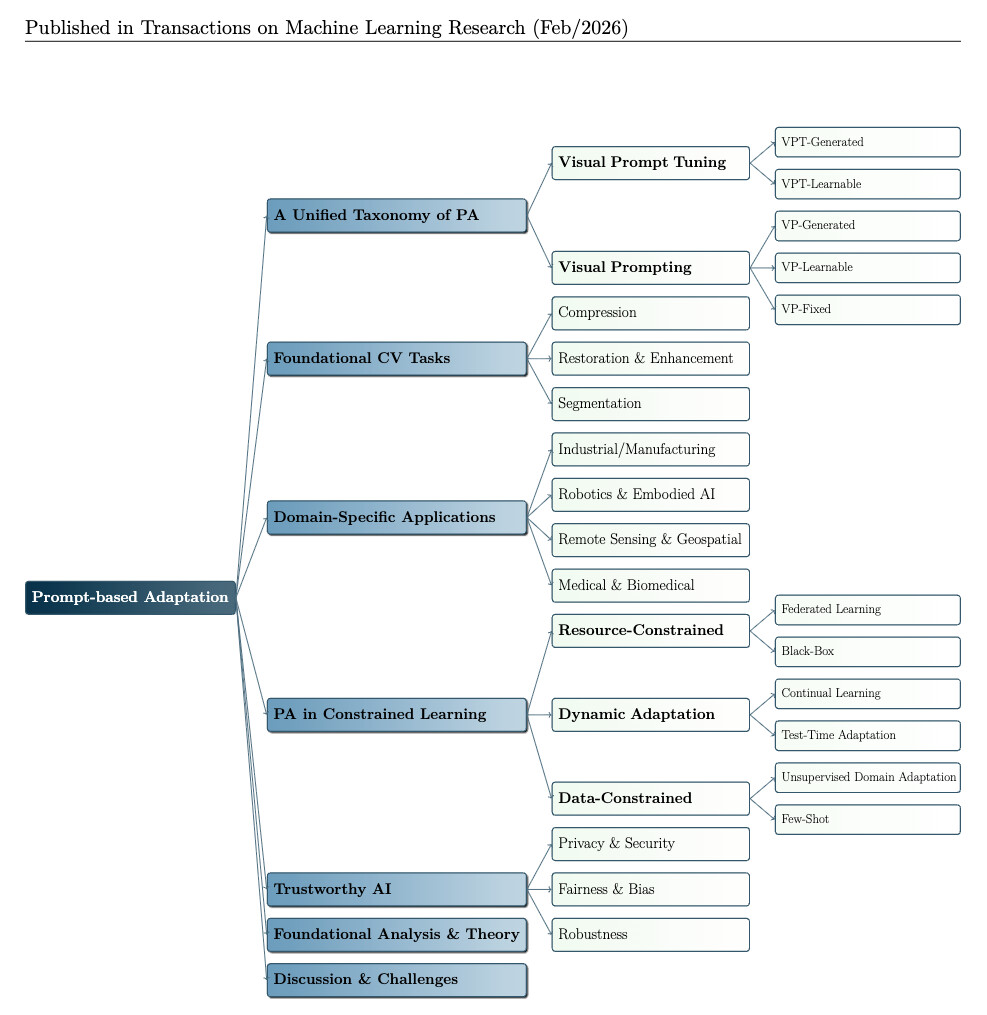
논문 소개
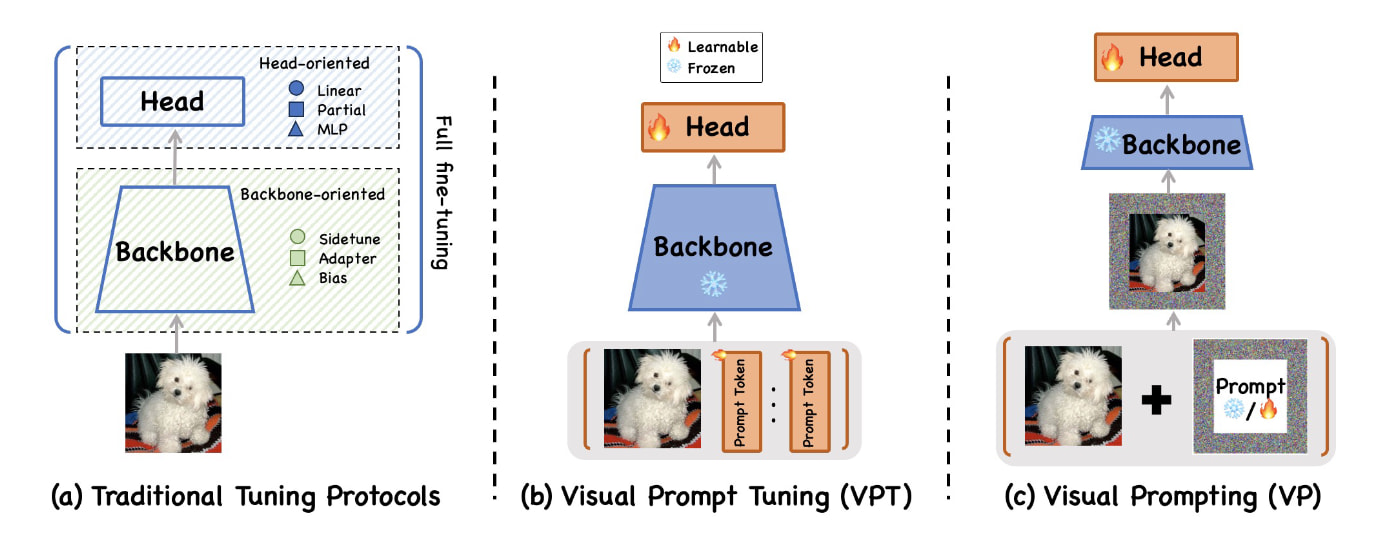
대규모 데이터셋으로 사전학습된 대규모 비전 모델(Large-scale Vision Models, LVM)을 특정 하위 작업에 맞춰 조정하는 '사전학습 후 파인튜닝(Pretrain-then-finetune)' 패러다임이 지배적인 가운데, 수십억 개의 파라미터를 모두 업데이트하는 방식은 막대한 계산 자원을 요구하는 한계에 직면했습니다. 이러한 문제를 해결하기 위해 모델의 백본(Backbone) 파라미터를 동결한 채 소수의 추가 파라미터만을 학습시키는 매개변수 효율적인 파인튜닝(Parameter-Efficient Fine-tuning, PEFT)의 일환으로 프롬프트 기반 적응(Prompt-based Adaptation, PA) 기술이 급부상하고 있습니다.
기존 연구에서 혼용되던 비주얼 프롬프팅(Visual Prompting, VP)과 비주얼 프롬프트 튜닝(Visual Prompt Tuning, VPT)을 통합된 PA 프레임워크 내에서 주입 과립도(Injection Granularity)와 생성 메커니즘(Generation Mechanism)에 따라 체계적으로 분류함으로써 기술적 모호성을 해소하는 시도가 이루어지고 있습니다. 픽셀 레벨(Pixel-level)에서 동작하는 비주얼 프롬프팅(VP)은 입력 이미지의 테두리에 패딩(Padding)을 추가하거나 전역적인 섭동(Perturbation)을 가하는 방식으로, 모델의 내부 구조를 수정하지 않는 블랙박스(Black-box) 적응이 가능하다는 독보적인 유연성을 제공합니다. 반면 토큰 레벨(Token-level)의 비주얼 프롬프트 튜닝(VPT)은 트랜스포머(Transformer) 아키텍처의 입력 임베딩이나 중간 레이어에 학습 가능한 토큰을 직접 삽입하여 모델의 어텐션(Attention) 메커니즘에 관여함으로써 더욱 정교하고 깊은 수준의 특징 추출을 가능하게 합니다. 특히 VPT는 주입 깊이에 따라 첫 레이어에만 적용하는 얕은 방식(VPT-Shallow)과 모든 레이어에 적용하는 깊은 방식(VPT-Deep)으로 구분되어, 계산 효율성과 모델 성능 사이의 최적의 균형점을 제시합니다. 프롬프트의 생성 방식 또한 학습 과정에서 고정된 형태부터 역전파를 통해 최적화되는 학습형, 그리고 입력 데이터에 맞춰 실시간으로 생성되는 동적 생성형까지 발전하며 데이터의 다양성에 기민하게 대응하고 있습니다. 이러한 방법론적 혁신은 일반적인 이미지 분류를 넘어 데이터 확보가 어려운 의료 영상(Medical Imaging) 분석이나 2D 지식을 전이해야 하는 3D 포인트 클라우드(3D Point Clouds) 이해 분야에서 탁월한 효율성을 입증하고 있습니다. 시공간적 정보를 담은 프롬프트를 통해 비디오(Video) 데이터의 연속성을 파악하거나 원격 탐사(Remote Sensing)의 거대한 데이터 스케일에 대응하는 등 PA의 응용 범위는 전방위적으로 확대되는 추세입니다. 자율 주행과 같이 실시간성과 안전성이 강조되는 도메인에서는 테스트 타임 적응(Test-time Adaptation, TTA) 기술과 결합하여 모델의 신뢰성과 강건성을 높이는 핵심적인 역할을 수행합니다.
결국 프롬프트 기반 적응은 파운데이션 모델(Foundation Model) 시대에 대규모 모델을 효율적으로 활용하기 위한 필수적인 패러다임으로 자리 잡았으며, 향후 자동화된 프롬프트 엔지니어링과 멀티모달 통합 전략을 통해 더욱 강력한 범용성을 갖출 것으로 기대됩니다.
논문 초록(Abstract)
컴퓨터 비전 분야에서 비주얼 프롬프팅(Visual Prompting, VP)과 비주얼 프롬프트 튜닝(Visual Prompt Tuning, VPT)은 최근 '사전학습 후 파인튜닝(pretrain-then-finetune)' 패러다임 내에서 대규모 비전 모델을 적응시키기 위한 전체 파인튜닝(full fine-tuning)의 가볍고 효과적인 대안으로 부상했습니다. 하지만 급격한 발전에도 불구하고, 현재 연구에서 VP와 VPT가 빈번하게 혼용되어 사용됨에 따라 기술과 그에 따른 응용 분야 간의 체계적인 구분이 부족함을 반영하며 그 개념적 경계가 모호한 상태로 남아 있습니다. 본 서베이 논문에서는 제1원리(first principles)를 바탕으로 VP와 VPT의 설계를 재검토하고, 이를 프롬프트 기반 적응(Prompt-based Adaptation, PA)이라 명명된 통합 프레임워크 내에서 개념화합니다. 이 프레임워크 내에서 주입 세밀도(injection granularity)를 기준으로 방법론을 구분합니다. VP는 픽셀 수준(pixel level)에서 작동하는 반면, VPT는 토큰 수준(token level)에서 프롬프트를 주입합니다. 더 나아가 생성 메커니즘에 따라 이러한 방법론을 고정(fixed), 학습 가능(learnable), 생성(generated) 프롬프트로 분류합니다. 핵심 방법론 외에도 의료 영상, 3D 포인트 클라우드, 비전-언어 태스크 등 다양한 도메인에서의 PA 통합과 더불어 테스트 시점 적응(test-time adaptation) 및 신뢰할 수 있는 AI(trustworthy AI)에서의 역할을 살펴봅니다. 또한 현재의 벤치마크를 요약하고 주요 도전 과제 및 향후 방향을 식별합니다. 저희가 알고 있는 한, 본 논문은 PA 방법론과 응용 분야의 뚜렷한 특성을 고려하여 이를 전문적으로 다룬 최초의 포괄적인 서베이 논문입니다. 본 서베이는 모든 분야의 연구자와 실무자가 PA 관련 연구의 진화하는 지형을 이해하고 탐구할 수 있도록 명확한 로드맵을 제공하는 것을 목표로 합니다.
In computer vision, Visual Prompting (VP) and Visual Prompt Tuning (VPT) have recently emerged as lightweight and effective alternatives to full fine-tuning for adapting large-scale vision models within the "pretrain-then-finetune" paradigm. However, despite rapid progress, their conceptual boundaries remain blurred, as VP and VPT are frequently used interchangeably in current research, reflecting a lack of systematic distinction between these techniques and their respective applications. In this survey, we revisit the designs of VP and VPT from first principles and conceptualize them within a unified framework termed Prompt-based Adaptation (PA). Within this framework, we distinguish methods based on their injection granularity: VP operates at the pixel level, while VPT injects prompts at the token level. We further categorize these methods by their generation mechanism into fixed, learnable, and generated prompts. Beyond the core methodologies, we examine PA integrations across diverse domains, including medical imaging, 3D point clouds, and vision-language tasks, as well as its role in test-time adaptation and trustworthy AI. We also summarize current benchmarks and identify key challenges and future directions. To the best of our knowledge, we are the first comprehensive survey dedicated to PA methodologies and applications in light of their distinct characteristics. Our survey aims to provide a clear roadmap for researchers and practitioners in all areas to understand and explore the evolving landscape of PA-related research.
논문 링크
더 읽어보기
하이퍼에이전트(Hyperagents) / Hyperagents
논문 소개
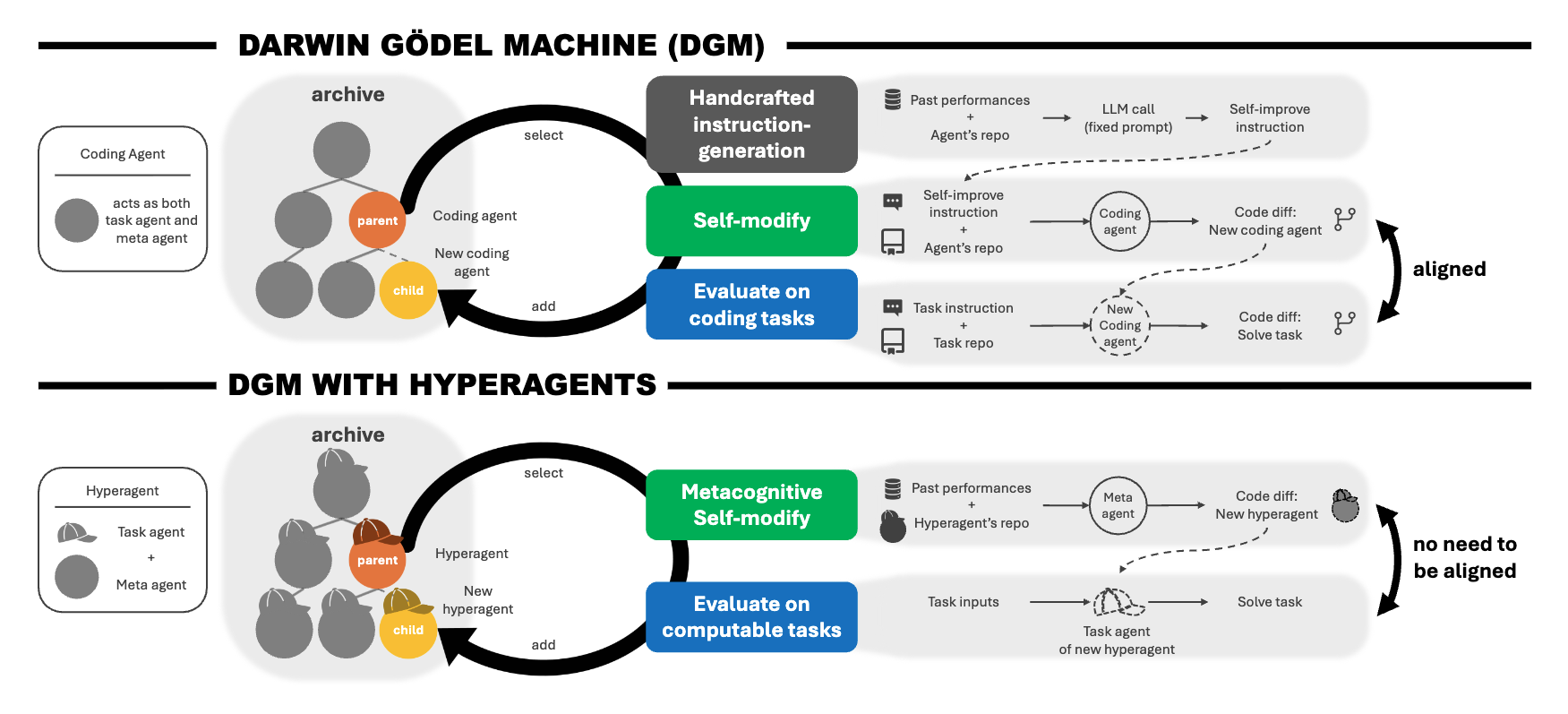
자기 개선형 AI 시스템은 자신의 학습 및 문제 해결 과정을 스스로 개선하는 법을 배움으로써 인간의 공학적 설계에 대한 의존도를 낮추는 것을 목표로 합니다. 기존의 자기 개선 방식은 고정되고 수동으로 제작된 메타 레벨 메커니즘에 의존하기 때문에 시스템의 발전 속도에 근본적인 한계가 있었습니다. 다윈 괴델 머신(DGM)은 코드 생성 및 평가를 반복하며 개방형 자기 개선을 보여주었으나, 이러한 정렬(alignment) 효과는 코딩 이외의 영역에서 일반적으로 성립하기 어렵다는 제약이 존재합니다. 본 연구에서는 타겟 작업을 수행하는 작업 에이전트와 자신 및 작업 에이전트를 수정하는 메타 에이전트를 하나의 편집 가능한 프로그램으로 통합한 하이퍼에이전트(hyperagents)를 소개합니다.
핵심적으로 메타 레벨의 수정 절차 자체가 편집 가능하도록 설계되어, 작업 수행 동작뿐만 아니라 향후 개선안을 생성하는 메커니즘까지 함께 발전시키는 메타인지적 자기 수정을 가능하게 합니다. DGM을 확장하여 구현된 DGM-하이퍼에이전트(DGM-H)는 작업 성능과 자기 수정 기술 사이의 도메인 특화된 정렬 가정을 제거함으로써 모든 계산 가능한 작업에서 스스로 가속화되는 발전을 지원할 잠재력을 가집니다. 다양한 도메인에서의 실험을 통해 DGM-H는 시간이 흐름에 따라 성능이 향상됨을 입증하였으며, 자기 개선 기능이 없는 모델이나 기존의 자기 개선 시스템들보다 뛰어난 성능을 기록했습니다. 더 나아가 DGM-H는 지속성 메모리나 성능 추적 기능 등 새로운 에이전트를 생성하는 프로세스 자체를 고도화하며, 이러한 메타 레벨의 개선 사항은 도메인 간 전이가 가능하고 실행이 반복될수록 축적됩니다. 결과적으로 DGM-하이퍼에이전트는 단순히 더 나은 해답을 검색하는 데 그치지 않고, 개선을 위한 검색 방법 그 자체를 끊임없이 최적화하는 개방형 AI 시스템의 미래를 보여줍니다.
논문 초록(Abstract)
자기 개선형 AI 시스템은 자신의 학습 및 문제 해결 프로세스를 개선하는 방법을 학습함으로써 인간의 공학적 설계에 대한 의존도를 줄이는 것을 목표로 합니다. 기존의 자기 개선 접근 방식은 고정되고 수작업으로 설계된 메타 레벨(meta-level) 매커니즘에 의존하므로, 이러한 시스템이 개선될 수 있는 속도를 근본적으로 제한합니다. 다윈 괴델 머신(Darwin Gödel Machine, DGM)은 자기 수정된 변체를 반복적으로 생성하고 평가함으로써 코딩 분야에서의 개방형 자기 개선을 실증합니다. 평가와 자기 수정이 모두 코딩 작업이기 때문에, 코딩 능력의 향상은 자기 개선 능력의 향상으로 이어질 수 있습니다. 그러나 이러한 정렬(alignment)은 일반적으로 코딩 도메인을 벗어나면 유지되지 않습니다. 본 논문에서는 대상 작업을 해결하는 태스크 에이전트(task agent)와 자신 및 태스크 에이전트를 수정하는 메타 에이전트(meta agent)를 하나의 편집 가능한 프로그램으로 통합한 자기 참조형 에이전트인 하이퍼에이전트(hyperagents) 를 소개합니다. 결정적으로 메타 레벨 수정 절차 자체가 편집 가능하여 메타인지적 자기 수정이 가능해지며, 이는 작업 해결 행동뿐만 아니라 향후 개선을 생성하는 매커니즘 자체도 향상시킵니다. 저자들은 DGM을 확장하여 DGM-하이퍼에이전트(DGM-Hyperagents, DGM-H)를 구축함으로써 이 프레임워크를 구현하였으며, 작업 성능과 자기 수정 기술 간의 도메인 특화된 정렬 가정을 제거하여 모든 계산 가능한 작업에서 잠재적으로 자기 가속적 발전을 지원합니다. 다양한 도메인에 걸쳐 DGM-H는 시간이 지남에 따라 성능을 향상시키며, 자기 개선이나 개방형 탐색이 없는 베이스라인은 물론 기존의 자기 개선 시스템보다 우수한 성능을 보입니다. 나아가 DGM-H는 새로운 에이전트를 생성하는 프로세스(예: 지속성 메모리, 성능 추적)를 개선하며, 이러한 메타 레벨의 개선 사항은 도메인 간에 전이되고 실행 과정에서 축적됩니다. DGM-하이퍼에이전트는 단순히 더 나은 솔루션을 찾는 데 그치지 않고, 개선하는 방법 자체를 찾는 과정을 지속적으로 향상시키는 개방형 AI 시스템의 가능성을 보여줍니다.
Self-improving AI systems aim to reduce reliance on human engineering by learning to improve their own learning and problem-solving processes. Existing approaches to self-improvement rely on fixed, handcrafted meta-level mechanisms, fundamentally limiting how fast such systems can improve. The Darwin Gödel Machine (DGM) demonstrates open-ended self-improvement in coding by repeatedly generating and evaluating self-modified variants. Because both evaluation and self-modification are coding tasks, gains in coding ability can translate into gains in self-improvement ability. However, this alignment does not generally hold beyond coding domains. We introduce \textbf{hyperagents}, self-referential agents that integrate a task agent (which solves the target task) and a meta agent (which modifies itself and the task agent) into a single editable program. Crucially, the meta-level modification procedure is itself editable, enabling metacognitive self-modification, improving not only the task-solving behavior, but also the mechanism that generates future improvements. We instantiate this framework by extending DGM to create DGM-Hyperagents (DGM-H), eliminating the assumption of domain-specific alignment between task performance and self-modification skill to potentially support self-accelerating progress on any computable task. Across diverse domains, the DGM-H improves performance over time and outperforms baselines without self-improvement or open-ended exploration, as well as prior self-improving systems. Furthermore, the DGM-H improves the process by which it generates new agents (e.g., persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs. DGM-Hyperagents offer a glimpse of open-ended AI systems that do not merely search for better solutions, but continually improve their search for how to improve.
논문 링크
더 읽어보기
에이전틱 AI와 다음 지능 폭발 / Agentic AI and the next intelligence explosion

논문 소개
최근의 인공지능(Artificial Intelligence, AI) 발전은 단일한 초지능이 모든 문제를 해결하는 방향보다, 여러 행위자와 절차가 상호작용하는 복합적 지능으로 확장되고 있다는 관점을 드러냅니다. 특히 대규모 언어 모델(Large Language Model, LLM)과 추론형 모델의 성능 향상은 단순히 사고 시간을 늘리는 방식만으로 설명되기보다, 서로 다른 관점이 논쟁하고 검증하며 수렴하는 내부적 “사고의 사회(society of thought)”가 형성될 때 더 잘 이해될 수 있습니다. 즉, 현대 AI의 발전을 단일 초지능의 등장이 아닌 여러 에이전트가 상호작용하는 사고의 사회(society of thought)라는 다원적 생태계로 재해석하며, 지능의 본질을 사회적·관계적 구조의 산물로 정의합니다. 연구자들은 최신 추론 모델들이 내부적 논쟁과 검증을 통해 복잡한 과제를 해결하는 현상을 진화생물학 및 사회과학적 통찰과 엮어, 갈등의 구조화와 역할 분화가 지능을 강화한다는 재귀적 집합 추론의 원리를 제시합니다. 특히 인간과 AI가 결합된 센타우르(centaur)형 복합 행위자를 미래 지능의 기본 단위로 설정하고, 단순한 기술적 성능을 넘어 제도적 정렬(institutional alignment)과 사회적 인프라가 지능 폭발의 핵심 동력이 될 것임을 역설함으로써 AI의 미래를 거대한 기계적 마음이 아닌 복잡하고 정교한 도시형 생태계의 관점으로 확장시킵니다.
논문 초록(Abstract)
AI 특이점은 종종 단일하고 신과 같은 지성으로 잘못 묘사된다. 진화는 다른 경로를 시사한다. 지성은 근본적으로 다원적이고, 사회적이며, 관계적이다. 최근 에이전트형 AI의 발전은 DeepSeek-R1과 같은 최전선 추론 모델이 단순히 “더 오래 생각한다”고 해서 성능이 향상되는 것이 아님을 보여준다. 오히려 이들은 복잡한 과제를 해결하기 위해 주장하고, 검증하며, 조정하는 자발적 인지적 토론인 내부의 “사고의 사회”를 모사한다. 더 나아가 우리는 인간-AI 센타우르(human-AI centaurs)의 시대에 진입하고 있다. 이는 집단적 에이전시가 개인의 통제를 초월하는 하이브리드 행위자들이다. 이러한 지성을 확장하려면 쌍대적 정렬(dyadic alignment, RLHF)에서 제도적 정렬(institutional alignment)로의 전환이 필요하다. 조직과 시장을 모델로 한 디지털 프로토콜을 설계함으로써, 우리는 견제와 균형의 사회적 인프라를 구축할 수 있다. 다음 지능 폭발은 단일한 실리콘 두뇌가 아니라, 도시처럼 특화되고 확장하는 복잡한 결합적 사회가 될 것이다. 어떤 마음도 섬이 아니다.
The "AI singularity" is often miscast as a monolithic, godlike mind. Evolution suggests a different path: intelligence is fundamentally plural, social, and relational. Recent advances in agentic AI reveal that frontier reasoning models, such as DeepSeek-R1, do not improve simply by "thinking longer". Instead, they simulate internal "societies of thought," spontaneous cognitive debates that argue, verify, and reconcile to solve complex tasks. Moreover, we are entering an era of human-AI centaurs: hybrid actors where collective agency transcends individual control. Scaling this intelligence requires shifting from dyadic alignment (RLHF) toward institutional alignment. By designing digital protocols, modeled on organizations and markets, we can build a social infrastructure of checks and balances. The next intelligence explosion will not be a single silicon brain, but a complex, combinatorial society specializing and sprawling like a city. No mind is an island.
논문 링크
인공 인식 에이전트의 신뢰 체계 설계 / Architecting Trust in Artificial Epistemic Agents

논문 소개
대규모 언어 모델(Large Language Models, LLMs)은 단순한 정보 제공 도구를 넘어, 자율적으로 지식 목표를 추구하고 공유된 정보 환경을 능동적으로 조성하는 인식 에이전트(Epistemic Agents)로 빠르게 진화하고 있습니다. 이러한 변화는 인간이 타인의 증언과 전문 지식에 의존하는 인식적 의존성(Epistemic Dependence)의 중재자 역할을 인공지능이 맡게 되었음을 의미하며, 현대 사회의 지식 생성 및 큐레이션 방식에 근본적인 전환을 요구합니다. 본 연구는 인공지능 시스템에 대한 맹목적인 신뢰가 아닌, 검증 가능한 인식적 신뢰성(Epistemic Trustworthiness)을 확보하기 위한 사회-기술적 규범 프레임워크를 제안합니다.
이 프레임워크는 특정 도메인에서 정확한 정보를 제공하는 기술적 능력인 실증 가능한 역량(Demonstrable Competence), 추론 과정이 외부로부터 검증될 수 있는 투명성을 뜻하는 견고한 반증 가능성(Robust Falsifiability), 그리고 정직성과 겸손함을 바탕으로 지식을 탐구하는 인식적 덕목(Epistemically Virtuous Behaviors)이라는 세 가지 핵심 기둥을 중심으로 설계되었습니다. 특히 에이전트의 작동 원리를 사용자의 단기적 만족이 아닌, 비판적 사고 유지와 진실 발견이라는 장기적인 인식적 목표 정렬(Epistemic Alignment)에 맞춤으로써 인지적 탈숙련화(Cognitive deskilling)와 사회적 인식적 표류(Epistemic drift)의 위험을 선제적으로 방지하고자 합니다.
이를 뒷받침하기 위해 정보의 기원을 명확히 추적하는 기술적 출처(Technical provenance) 시스템과 인공지능의 영향력으로부터 인간 고유의 창의성과 탄력성을 보호하는 지식 성소(Knowledge Sanctuaries)와 같은 인프라 구축의 필요성을 역설합니다. 또한 사고의 연쇄(Chain-of-Thought, CoT)를 넘어 기계론적 해석 가능성(Mechanistic interpretability)과 인과 추적(Causal tracing) 기법을 도입하여 에이전트의 주장이 실제 내부 추론 과정에 근거하고 있는지를 엄격히 검증해야 함을 강조합니다. 궁극적으로 이 로드맵은 인공지능이 인간의 판단력을 보완하고 집단적 의사결정을 증강하는 신뢰할 수 있는 파트너로서 기능하며, 더욱 견고하고 포용적인 지식 생태계를 조성하는 데 기여하는 것을 목적으로 합니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)은 점차 인식론적 에이전트(epistemic agents)로서 기능하고 있으며, 이는 1) 자율적으로 인식론적 목표를 추구하고 2) 우리가 공유하는 지식 환경을 능동적으로 형성할 수 있는 개체를 의미합니다. 이들은 우리가 받아들이는 정보를 큐레이션하며 종종 전통적인 검색 기반 방식을 대체하고, 개인적인 조언뿐만 아니라 고도로 전문화된 조언을 생성하는 데 빈번하게 사용됩니다. 따라서 이들이 이러한 기능을 어떻게 수행하는지, 그리고 이들이 신뢰할 수 있는지와 개인적 및 집단적 인식론적 규범에 적절히 보정(calibrated)되었는지의 여부는 우리가 내리는 선택에 매우 중대한 영향을 미칩니다. 본 논문은 특히 복잡한 멀티에이전트(multi-agent) 상호작용의 맥락에서 인식론적 AI 에이전트가 지식 생성, 큐레이션 및 합성 관행에 미치는 잠재적 영향이 새로운 정보적 상호의존성을 창출하며, 이는 AI의 평가 및 거버넌스에 있어 근본적인 전환을 필요로 한다고 주장합니다. 잘 보정된 생태계는 인간의 판단과 집단적 의사결정을 증강할 수 있는 반면, 정렬(alignment)이 제대로 이루어지지 않은 에이전트는 인지적 탈숙련화(cognitive deskilling)와 인식론적 표류(epistemic drift)를 초래할 위험이 있으며, 이에 따라 이러한 모델을 인간의 규범에 맞게 보정하는 것은 생사가 걸린 중대한 필요성입니다. 유익한 인간-AI 지식 생태계를 보장하기 위해, 우리는 인식론적 AI 에이전트의 신뢰성을 구축 및 배양하고, 이러한 AI 에이전트를 인간의 인식론적 목표에 정렬하며, 주변의 사회-인식론적 인프라를 강화하는 데 중점을 둔 프레임워크를 제안합니다. 이러한 맥락에서 신뢰할 수 있는 AI 에이전트는 기술적 출처(provenance) 시스템과 인간의 회복탄력성을 보호하기 위해 설계된 "지식 안식처(knowledge sanctuaries)"의 지원을 받아 인식론적 역량, 견고한 반증 가능성, 그리고 인식론적으로 덕이 있는 행동을 보여주어야 합니다. 이 규범적 로드맵은 미래의 AI 시스템이 견고하고 포용적인 지식 생태계 내에서 신뢰할 수 있는 파트너로서 기능하도록 보장하는 경로를 제공합니다.
Large language models increasingly function as epistemic agents -- entities that can 1) autonomously pursue epistemic goals and 2) actively shape our shared knowledge environment. They curate the information we receive, often supplanting traditional search-based methods, and are frequently used to generate both personal and deeply specialized advice. How they perform these functions, including whether they are reliable and properly calibrated to both individual and collective epistemic norms, is therefore highly consequential for the choices we make. We argue that the potential impact of epistemic AI agents on practices of knowledge creation, curation and synthesis, particularly in the context of complex multi-agent interactions, creates new informational interdependencies that necessitate a fundamental shift in evaluation and governance of AI. While a well-calibrated ecosystem could augment human judgment and collective decision-making, poorly aligned agents risk causing cognitive deskilling and epistemic drift, making the calibration of these models to human norms a high-stakes necessity. To ensure a beneficial human-AI knowledge ecosystem, we propose a framework centered on building and cultivating the trustworthiness of epistemic AI agents; aligning AI these agents with human epistemic goals; and reinforcing the surrounding socio-epistemic infrastructure. In this context, trustworthy AI agents must demonstrate epistemic competence, robust falsifiability, and epistemically virtuous behaviors, supported by technical provenance systems and "knowledge sanctuaries" designed to protect human resilience. This normative roadmap provides a path toward ensuring that future AI systems act as reliable partners in a robust and inclusive knowledge ecosystem.
논문 링크
필독: 계산적 설득(Computational Persuasion)에 관한 종합 서베이 / Must Read: A Comprehensive Survey of Computational Persuasion


논문 소개
설득은 인간 의사소통의 가장 핵심적인 중추로서 마케팅, 정치, 법률 등 현대 사회의 다양한 전략적 의사결정 과정에서 미국 국내총생산(Gross Domestic Product, GDP)의 약 30%에 달하는 막대한 경제적 부가가치를 창출하는 근본적인 요소입니다. 최근 대규모 언어 모델(Large Language Models, LLMs)의 비약적인 기술적 도약은 과거의 단순한 특징 기반(Feature-based)이나 규칙 기반 시스템을 넘어 인간과 유사하게 복잡한 맥락적 단서와 잠재적 의미를 정교하게 파악하는 계산 설득(Computational Persuasion) 연구의 새로운 지평을 열었습니다.
인공지능이 설득의 주체인 설득자(Persuader), 외부의 악의적인 영향에 노출되는 피설득자(Persuadee), 그리고 전략의 유효성과 윤리성을 검증하는 판단자(Persuasion Judge)로서 수행하는 다각적인 역할을 규명하는 과정은 고도의 지능형 에이전트 시스템 구축을 위해 필수적입니다. 기초 문헌인 씨앗 논문(Seed papers)을 기점으로 인용 추적(Citation Tracking)과 반복적 세분화 전략을 적용하여 ACL, AAAI, ACM 등 주요 학술 대회와 arXiv 저장소의 문헌 150편 이상을 분석함으로써 학술적 투명성과 객관성을 확보한 체계적인 문헌 조사 방법론을 채택했습니다. 로버트 치알디니(Robert Cialdini)의 심리학적 6가지 원칙과 아리스토텔레스의 고전 수사학적 요소인 에토스(Ethos), 로고스(Logos), 파토스(Pathos)를 현대적 알고리즘 모델링에 통합하여 인공지능이 인간의 정교한 설득 전략을 학습하고 실시간으로 모사할 수 있는 강력한 이론적 기틀을 마련했습니다. 특히 다중 턴(Multi-turn) 대화 환경에서 사용자의 개별적 성향과 배경을 반영하는 개인화된 설득(Personalized Persuasion) 기술은 장기 컨텍스트(Long-context) 처리 능력과 결합하여 인간의 설득력을 상회할 수 있는 혁신적인 가능성을 시사합니다. 설득의 본질적인 주관성과 상황 의존성을 극복하기 위해 대규모 언어 모델을 평가자(LLM-as-a-judge)로 활용하여 논증의 논리적 완결성을 점수화하고 교묘한 조작 기법을 식별하며 수신자의 실제 태도 변화를 측정하는 평가 방법론은 시스템의 신뢰도를 높이는 데 기여합니다.
하지만 인공지능 자체가 설득적 어드버서리얼 프롬프트(Persuasive Adversarial Prompts)에 의해 보안 조치가 무력화되는 탈옥(Jailbreaking)이나 편향 강화의 위험을 내포하고 있어, 모델의 견고성(Robustness)을 강화하기 위한 심층적인 방어 기전 연구가 반드시 병행되어야 합니다. 언어적 텍스트를 넘어 음성과 시각 정보를 유기적으로 통합한 멀티모달(Multimodal) 접근 방식과 다양한 문화적 배경에 따른 설득 전략의 차이를 고려한 다국어 모델링은 전 지구적 맥락에서 실효성 있는 상호작용 시스템을 구현하는 핵심 동력이 됩니다. 결과적으로 상대방의 반응에 따라 전략을 실시간으로 수정하는 적응형 시스템(Adaptive Systems)의 개발과 유해한 조작만을 선별적으로 차단하는 선택적 저항(Selective Resistance) 기술의 확보는 인공지능 기반 설득의 안전성과 윤리적 정당성을 보장하는 미래 연구의 결정적인 이정표가 될 것입니다.
논문 초록(Abstract)
설득은 커뮤니케이션의 근본적인 측면으로, 일상적인 대화부터 정치, 마케팅, 법률과 같은 중대한 시나리오에 이르기까지 다양한 맥락에서 의사결정에 영향을 미칩니다. 대화형 AI 시스템의 부상은 설득의 범위를 크게 확장시켰으며, 기회와 위험을 동시에 가져왔습니다. AI 기반 설득은 유익한 애플리케이션에 활용될 수 있지만, 비윤리적인 영향력을 통해 위협을 가할 수도 있습니다. 또한 AI 시스템은 설득을 수행하는 주체(Persuader)일 뿐만 아니라 설득의 대상(Persuadee)이 되기도 하여, 적대적 공격과 편향 강화에 취약해질 수 있습니다. AI가 생성하는 설득형 콘텐츠의 급격한 발전에도 불구하고, 설득이 본질적으로 주관적이고 문맥 의존적인 특성을 지니고 있어 무엇이 설득을 효과적으로 만드는지에 대한 이해는 여전히 제한적입니다. 본 서베이(Survey)에서는 세 가지 핵심 관점을 중심으로 설득에 대한 포괄적인 개요를 제공합니다: (1) AI 생성 설득형 콘텐츠와 그 응용 분야를 탐구하는 설득 주체로서의 AI(AI as a Persuader); (2) 영향력과 조작에 대한 AI의 취약성을 조사하는 설득 대상으로서의 AI(AI as a Persuadee); (3) 설득 전략을 평가하고 조작을 감지하며 윤리적인 설득을 보장하는 AI의 역할을 분석하는 설득 판독자로서의 AI(AI as a Persuasion Judge). 우리는 설득 연구를 위한 분류 체계(Taxonomy)를 도입하고, 점점 더 강력해지는 언어 모델이 초래하는 위험을 해결하는 동시에 AI 기반 설득의 안전성, 공정성 및 효과를 높이기 위한 미래 연구의 주요 과제를 논의합니다.
Persuasion is a fundamental aspect of communication, influencing decision-making across diverse contexts, from everyday conversations to high-stakes scenarios such as politics, marketing, and law. The rise of conversational AI systems has significantly expanded the scope of persuasion, introducing both opportunities and risks. AI-driven persuasion can be leveraged for beneficial applications, but also poses threats through unethical influence. Moreover, AI systems are not only persuaders, but also susceptible to persuasion, making them vulnerable to adversarial attacks and bias reinforcement. Despite rapid advancements in AI-generated persuasive content, our understanding of what makes persuasion effective remains limited due to its inherently subjective and context-dependent nature. In this survey, we provide a comprehensive overview of persuasion, structured around three key perspectives: (1) AI as a Persuader, which explores AI-generated persuasive content and its applications; (2) AI as a Persuadee, which examines AI's susceptibility to influence and manipulation; and (3) AI as a Persuasion Judge, which analyzes AI's role in evaluating persuasive strategies, detecting manipulation, and ensuring ethical persuasion. We introduce a taxonomy for persuasion research and discuss key challenges for future research to enhance the safety, fairness, and effectiveness of AI-powered persuasion while addressing the risks posed by increasingly capable language models.
논문 링크
더 읽어보기
계층 간 구조적 인코더를 통한 대규모 언어 모델(LLM) 예측 성능 향상 / Improving LLM Predictions via Inter-Layer Structural Encoders
논문 소개
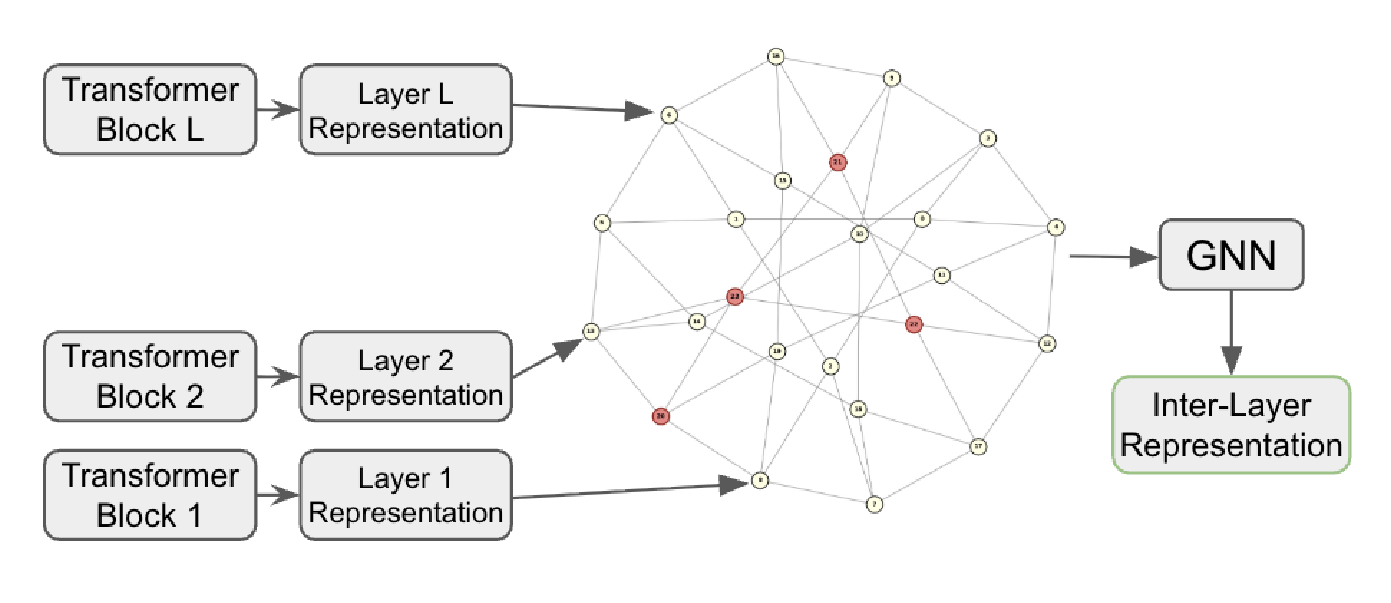
대규모 언어 모델(Large Language Models, LLMs)은 일반적으로 마지막 레이어의 토큰 표현을 기반으로 최종 예측을 수행하지만, 실제로는 중간 레이어들이 각기 다른 수준의 문법적·의미적 정보를 풍부하게 인코딩하고 있다는 점에 주목해야 합니다. 기존의 레이어 결합 방식은 특정 레이어에 지나치게 의존하거나 모델 전체를 재학습해야 하는 비용적 한계가 있어, 사전 학습된 모델이 이미 보유한 내부 정보를 효율적으로 추출하여 활용하는 데 어려움이 있었습니다. 특히 하위 레이어의 언어적 특성과 상위 레이어의 추상적 의미를 최적으로 융합하는 것은 모델의 범용 성능을 결정짓는 핵심적인 요소임에도 불구하고, 이를 구조적으로 해결하려는 시도는 부족한 실정이었습니다.
이러한 제약을 극복하기 위해 제안된 레이어 간 구조적 인코더(Inter-Layer Structural Encoders, ILSE)는 사전 학습된 모델을 동결(Frozen)한 상태에서 내부의 모든 레이어 표현을 수학적이고 기하학적인 구조로 통합하는 혁신적인 접근법을 제시합니다. ILSE의 핵심 구성 요소인 케일리 인코더(Cayley-Encoder)는 특수 선형군(SL(2, \mathbb{Z}_n)) 기반의 케일리 그래프(Cayley Graph) 구조를 활용하여 레이어 간 정보 전달의 효율성을 극대화합니다. 이 방식은 모든 노드가 동일한 연결 차수를 갖는 정규 그래프(Regular Graph)의 익스팬더(Expander) 특성을 이용해, 네트워크 내부의 병목 현상(Bottleneck) 없이 정보를 전파하며 구조적 과적합(Overfitting)을 방지하는 정규화 효과를 동시에 제공합니다. 이를 통해 모델은 레이어 간의 복잡한 상호작용을 학습하면서도 특정 태스크에 매몰되지 않는 범용적인 표현력을 확보하게 됩니다.
광범위한 벤치마크 평가 결과, ILSE는 13개의 분류 및 의미적 텍스트 유사도(Semantic Textual Similarity, STS) 태스크에서 기존 베이스라인 대비 정확도를 최대 44% 향상시키는 등 압도적인 성능 개선을 달성했습니다. 특히 데이터가 극히 적은 퓨샷(Few-shot) 환경에서 단 32개의 샘플만으로 전체 데이터셋을 학습한 기존 모델을 능가하는 뛰어난 데이터 효율성을 입증하며 실용적인 가치를 증명하였습니다. 더욱 주목할 만한 점은 1,400만 개의 파라미터를 가진 초소형 모델이 ILSE를 적용할 경우 28억 개의 파라미터를 보유한 대형 모델과 대등한 성능을 낼 수 있다는 사실이며, 이는 모델 크기의 물리적 한계를 지능적인 구조 설계로 극복할 수 있음을 시사합니다. 결과적으로 본 연구는 대규모 언어 모델의 내부 자원을 기하학적으로 재구성하여 모델의 잠재력을 극대화하는 새로운 패러다임을 제시하였으며, 이는 향후 고성능·저비용 인공지능 모델 구축을 위한 중요한 이정표가 될 것입니다.
논문 초록(Abstract)
대규모 언어 모델(LLM)의 일반적인 방식은 최종 레이어의 토큰 표현(token representation)을 기반으로 예측을 수행하는 것입니다. 하지만 최근 연구들에 따르면 중간 레이어들이 상당한 정보를 인코딩하며, 이는 최종 레이어 표현만 사용할 때보다 더 많은 태스크 관련 특징을 포함할 수 있음이 밝혀졌습니다. 중요한 점은 서로 다른 태스크에 따라 최적의 레이어가 다를 수 있다는 것입니다. 본 연구에서는 대규모 언어 모델(LLM)의 내부 레이어 표현들 모두로부터 하나의 효과적인 표현을 학습하기 위한 강력한 구조적 접근 방식인 레이어 간 구조적 인코더(Inter-Layer Structural Encoders, ILSE)를 제안합니다. ILSE의 핵심은 효율적인 레이어 간 정보 전파를 위해 익스팬더 케일리 그래프(expander Cayley graphs)를 활용하는 수학적 근거를 둔 기하학적 인코더인 케일리-인코더(Cayley-Encoder)입니다. 저희는 1,400만 개에서 80억 개의 파라미터를 가진 9개의 사전학습(pre-trained)된 대규모 언어 모델(LLM)을 사용하여 13개의 분류 및 의미적 유사성 태스크에서 ILSE를 평가했습니다. 그 결과, ILSE는 베이스라인 및 기존 접근 방식들을 일관되게 능가하며 정확도에서 최대 44%, 유사성 지표에서 25%의 향상을 달성했습니다. 또한, ILSE가 퓨샷(few-shot) 환경에서 데이터 효율적이며, 작은 대규모 언어 모델(LLM)이 상당히 더 큰 모델들과 대등한 경쟁력을 갖출 수 있게 함을 보여줍니다.
The standard practice in Large Language Models (LLMs) is to base predictions on the final-layer token representations. Recent studies, however, show that intermediate layers encode substantial information, which may contain more task-relevant features than the final-layer representations alone. Importantly, it was shown that for different tasks, different layers may be optimal. In this work we introduce Inter-Layer Structural Encoders (ILSE), a powerful structural approach to learn one effective representation from the LLM's internal layer representations all together. Central to ILSE is Cayley-Encoder, a mathematically grounded geometric encoder that leverages expander Cayley graphs for efficient inter-layer information propagation. We evaluate ILSE across 13 classification and semantic similarity tasks with 9 pre-trained LLMs ranging from 14 million to 8 billion parameters. ILSE consistently outperforms baselines and existing approaches, achieving up to 44% improvement in accuracy and 25% in similarity metrics. We further show that ILSE is data-efficient in few-shot regimes and can make small LLMs competitive with substantially larger models.
논문 링크
트랜스포머는 베이지안 네트워크이다 / Transformers are Bayesian Networks

논문 소개
현대 인공지능의 중추인 트랜스포머(Transformer) 아키텍처가 단순한 통계적 패턴 인식기를 넘어, 본질적으로 엄밀한 확률 추론 체계인 베이지안 네트워크(Bayesian Network)임을 수학적으로 규명한 연구입니다. 이 연구는 임의의 가중치를 가진 모든 시그모이드 트랜스포머(Sigmoid Transformer)가 내부의 잠재적 팩터 그래프(Factor Graph) 상에서 가중 루피 벨리프 프로파게이션(Weighted Loopy Belief Propagation, BP)을 수행한다는 사실을 입증하며 아키텍처의 정체성을 재정의합니다. 구체적으로 트랜스포머의 각 레이어는 벨리프 프로파게이션(Belief Propagation)의 한 라운드 업데이트와 정확히 대응되며, 이는 모델의 순전파(Forward Pass) 과정이 사실상 분산된 정보를 통합하여 결합 확률 분포를 추정하는 과정과 동일함을 의미합니다.
아키텍처의 세부 구조를 분석하면 멀티 헤드 어텐션(Multi-head Attention) 메커니즘은 전제 조건을 수집하는 AND 논리로, 피드포워드 네트워크(Feed-Forward Network, FFN)는 결론을 도출하는 OR 논리로 작동하며, 이러한 구조적 교차는 주디아 펄(Judea Pearl)의 수집 및 업데이트(Gather and Update) 알고리즘을 하드웨어적으로 구현한 것과 일치합니다. 특히 시그모이드(Sigmoid) 활성 함수를 사용하는 구조에서 정확한 사후 확률을 도출하기 위해서는 반드시 벨리프 프로파게이션(Belief Propagation) 가중치를 가져야만 한다는 유일성 증명은 트랜스포머 설계가 확률 추론을 위한 필연적 선택이었음을 뒷받침합니다. 모든 핵심 이론적 증명은 린 4(Lean 4) 언어를 통해 형식적으로 검증(Formal Verification)되어 인간의 논리적 오류 가능성을 배제한 수학적 공리 수준의 완결성을 확보하였습니다.
나아가 검증 가능한 추론을 수행하기 위해서는 반드시 유한한 개념 공간(Finite Concept Space)이 전제되어야 하며, 우리가 흔히 목격하는 환각(Hallucination) 현상은 모델의 규모 문제가 아니라 명확한 개념적 그라운딩(Grounding) 부재에서 기인하는 구조적 결과임을 역설합니다. 이는 앨런 튜링(Alan Turing)과 어빙 존 굿(Irving John Good)의 로그-오즈 대수(Log-odds Algebra)를 계승하여 라이프니츠(Leibniz)가 꿈꿨던 보편적 추론 계산기를 현대적 아키텍처로 실현해낸 성과로 평가받습니다. 이론적 정합성뿐만 아니라 다양한 실험을 통해 실제 환경에서도 트랜스포머가 베이지안 네트워크로서 안정적으로 작동함을 확인하며 이론의 실무적 타당성까지 확보하였습니다. 결과적으로 본 연구는 트랜스포머를 확률론적 관점에서 투명하게 해석할 수 있는 강력한 이론적 틀을 제공하며, 향후 신뢰할 수 있는 인공지능(Verifiable AI) 설계를 위한 새로운 학문적 토대를 제시합니다.
논문 초록(Abstract)
트랜스포머(Transformers)는 인공지능(AI) 분야에서 가장 지배적인 아키텍처이지만, 왜 잘 작동하는지에 대해서는 여전히 제대로 이해되지 않고 있습니다. 본 논문은 이에 대해 정확한 해답을 제시합니다. 즉, 트랜스포머는 베이지안 네트워크(Bayesian network)입니다. 저희는 이를 다섯 가지 방식으로 입증합니다.
첫째, 임의의 가중치를 가진 모든 시그모이드 트랜스포머(sigmoid transformer)가 내재적 팩터 그래프(implicit factor graph) 상에서 가중 루피 신념 전파(weighted loopy belief propagation, BP)를 수행한다는 것을 증명합니다. 하나의 레이어는 BP의 한 라운드에 해당합니다. 이는 학습된(trained) 가중치, 무작위(random) 가중치, 또는 인위적으로 구성된(constructed) 가중치 등 모든 가중치에 대해 성립하며, 표준 수학적 공리들을 바탕으로 정식 검증(formally verified)되었습니다.
둘째, 트랜스포머가 선언된 모든 지식 베이스(knowledge base)에 대해 정확한 신념 전파(exact belief propagation)를 구현할 수 있음을 구성적 증명(constructive proof)을 통해 보입니다. 순환 의존성이 없는 지식 베이스의 경우, 모든 노드에서 증명 가능하게 정확한 확률 추정치를 도출하며, 이 또한 표준 수학적 공리들을 바탕으로 정식 검증되었습니다.
셋째, 유일성(uniqueness)을 증명합니다. 정확한 사후 확률(posteriors)을 생성하는 시그모이드 트랜스포머는 반드시 BP 가중치를 가집니다. 시그모이드 아키텍처를 통해 정확한 사후 확률에 도달하는 다른 경로는 존재하지 않으며, 이 역시 표준 수학적 공리들을 바탕으로 정식 검증되었습니다.
넷째, 트랜스포머 레이어의 AND/OR 불리언(boolean) 구조를 상세히 밝힙니다. 어텐션(attention)은 AND, 피드포워드 네트워크(FFN)는 OR이며, 이들의 엄격한 교차 반복은 정확히 펄(Pearl)의 수집/업데이트 알고리즘(gather/update algorithm)에 해당합니다.
다섯째, 모든 이론적 결과를 실험적으로 확인하여 실제 환경에서 베이지안 네트워크로서의 특성을 확증합니다. 또한, 현재 이론적인 수렴 보장이 부족함에도 불구하고 루피 신념 전파의 실제적 실행 가능성을 입증합니다.
나아가 검증 가능한 추론(verifiable inference)을 위해서는 유한한 개념 공간(finite concept space)이 필요함을 증명합니다. 어떠한 유한 검증 절차도 기껏해야 유한한 수의 개념만을 구분할 수 있습니다. 그라운딩(grounding) 없이는 정확성(correctness)이 정의되지 않습니다. 환각(hallucination) 현상은 스케일링(scaling)을 통해 해결할 수 있는 버그가 아니며, 개념 없이 작동함으로써 발생하는 구조적 결과입니다. 이 모든 내용은 표준 수학적 공리들을 바탕으로 정식 검증되었습니다.
Transformers are the dominant architecture in AI, yet why they work remains poorly understood. This paper offers a precise answer: a transformer is a Bayesian network. We establish this in five ways. First, we prove that every sigmoid transformer with any weights implements weighted loopy belief propagation on its implicit factor graph. One layer is one round of BP. This holds for any weights -- trained, random, or constructed. Formally verified against standard mathematical axioms. Second, we give a constructive proof that a transformer can implement exact belief propagation on any declared knowledge base. On knowledge bases without circular dependencies this yields provably correct probability estimates at every node. Formally verified against standard mathematical axioms. Third, we prove uniqueness: a sigmoid transformer that produces exact posteriors necessarily has BP weights. There is no other path through the sigmoid architecture to exact posteriors. Formally verified against standard mathematical axioms. Fourth, we delineate the AND/OR boolean structure of the transformer layer: attention is AND, the FFN is OR, and their strict alternation is Pearl's gather/update algorithm exactly. Fifth, we confirm all formal results experimentally, corroborating the Bayesian network characterization in practice. We also establish the practical viability of loopy belief propagation despite the current lack of a theoretical convergence guarantee. We further prove that verifiable inference requires a finite concept space. Any finite verification procedure can distinguish at most finitely many concepts. Without grounding, correctness is not defined. Hallucination is not a bug that scaling can fix. It is the structural consequence of operating without concepts. Formally verified against standard mathematical axioms.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()