[2026/03/30 ~ 04/05] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 추론 시점(Test-Time) 연산의 극대화 및 동적 파라미터 적응: 이번 주 연구들에서는 모델의 성능을 끌어올리기 위해 막대한 비용이 드는 사전학습이나 파인튜닝에만 의존하지 않고, 추론 시점에 연산량과 파라미터를 동적으로 적응시키는 흐름이 뚜렷합니다. Improving Latent Generalization 논문은 추론 시점에 '생각하는 과정(thinking)'을 유도하여 모델 내부 지식의 잠재 일반화를 개선했습니다. 또한 Composer와 HyperAlign은 각각 생성 모델과 디퓨전 모델에서 개별 입력값의 맥락에 맞춰 테스트 시점에 가중치를 동적으로 재구성하는 새로운 패러다임을 제안했습니다. 이는 정적인 가중치의 한계를 넘어, 입력마다 유연하게 반응하는 스마트한 생성 모델을 구축하려는 실용적인 접근입니다.
추론 시점(Test-Time) 연산의 극대화 및 동적 파라미터 적응: 이번 주 연구들에서는 모델의 성능을 끌어올리기 위해 막대한 비용이 드는 사전학습이나 파인튜닝에만 의존하지 않고, 추론 시점에 연산량과 파라미터를 동적으로 적응시키는 흐름이 뚜렷합니다. Improving Latent Generalization 논문은 추론 시점에 '생각하는 과정(thinking)'을 유도하여 모델 내부 지식의 잠재 일반화를 개선했습니다. 또한 Composer와 HyperAlign은 각각 생성 모델과 디퓨전 모델에서 개별 입력값의 맥락에 맞춰 테스트 시점에 가중치를 동적으로 재구성하는 새로운 패러다임을 제안했습니다. 이는 정적인 가중치의 한계를 넘어, 입력마다 유연하게 반응하는 스마트한 생성 모델을 구축하려는 실용적인 접근입니다.
![]() '평균 성능'을 넘어선 무오류성(Zero-Error) 및 시스템적 안전성 검증: 대규모 모델의 산업 적용이 가속화되면서, 단순한 평균 정확도를 넘어 '절대 틀리지 않는 한계선'과 '시스템 단위의 보안'을 묻는 엄격한 평가 기준이 대두되고 있습니다. Zero-Error Horizon 연구는 최상위 모델조차 단순한 논리 연산에서 치명적인 실수를 할 수 있음을 지적하며 무오류성의 중요성을 강조했고, GISTBench는 추천 시스템의 결과가 실제 사용자의 행동 증거에 기반하는지 깐깐하게 검증합니다. 더불어 ClawKeeper와 Abuse Detection Pipeline 논문은 AI의 판단 오류나 환각이 데이터 유출 및 악의적 시스템 위협으로 번지지 않도록 분리된 미들웨어와 인간 검토가 결합된 다층적 방어선의 필요성을 역설했습니다.
'평균 성능'을 넘어선 무오류성(Zero-Error) 및 시스템적 안전성 검증: 대규모 모델의 산업 적용이 가속화되면서, 단순한 평균 정확도를 넘어 '절대 틀리지 않는 한계선'과 '시스템 단위의 보안'을 묻는 엄격한 평가 기준이 대두되고 있습니다. Zero-Error Horizon 연구는 최상위 모델조차 단순한 논리 연산에서 치명적인 실수를 할 수 있음을 지적하며 무오류성의 중요성을 강조했고, GISTBench는 추천 시스템의 결과가 실제 사용자의 행동 증거에 기반하는지 깐깐하게 검증합니다. 더불어 ClawKeeper와 Abuse Detection Pipeline 논문은 AI의 판단 오류나 환각이 데이터 유출 및 악의적 시스템 위협으로 번지지 않도록 분리된 미들웨어와 인간 검토가 결합된 다층적 방어선의 필요성을 역설했습니다.
![]() 내재적 본질로의 회귀: 잠재 공간(Latent Space)과 데이터 중심 최적화: 표면적인 텍스트(토큰) 생성의 비효율성을 극복하고, 모델의 내부 계산 공간과 학습 데이터 자체의 품질을 근본적으로 제어하려는 동향도 눈에 띕니다. The Latent Space 서베이 논문은 모델의 복잡한 추론과 계획이 명시적 언어 공간보다 연속적인 '잠재 공간'에서 훨씬 압축적이고 풍부하게 이루어진다는 점을 조명했습니다. 이와 궤를 같이하여 DataFlex는 모델 아키텍처 수정 대신 학습 데이터를 어떻게 선별하고 혼합할지를 동적으로 제어하는 통합 프레임워크를 제안했으며, 전이 학습의 기대 오차 상한을 수학적으로 규명한 연구 역시 데이터의 질과 모델 표현력 간의 본질적 상호작용을 깊이 있게 파고들었습니다.
내재적 본질로의 회귀: 잠재 공간(Latent Space)과 데이터 중심 최적화: 표면적인 텍스트(토큰) 생성의 비효율성을 극복하고, 모델의 내부 계산 공간과 학습 데이터 자체의 품질을 근본적으로 제어하려는 동향도 눈에 띕니다. The Latent Space 서베이 논문은 모델의 복잡한 추론과 계획이 명시적 언어 공간보다 연속적인 '잠재 공간'에서 훨씬 압축적이고 풍부하게 이루어진다는 점을 조명했습니다. 이와 궤를 같이하여 DataFlex는 모델 아키텍처 수정 대신 학습 데이터를 어떻게 선별하고 혼합할지를 동적으로 제어하는 통합 프레임워크를 제안했으며, 전이 학습의 기대 오차 상한을 수학적으로 규명한 연구 역시 데이터의 질과 모델 표현력 간의 본질적 상호작용을 깊이 있게 파고들었습니다.
잠재 공간: 기초, 진화, 메커니즘, 능력, 그리고 전망 / The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
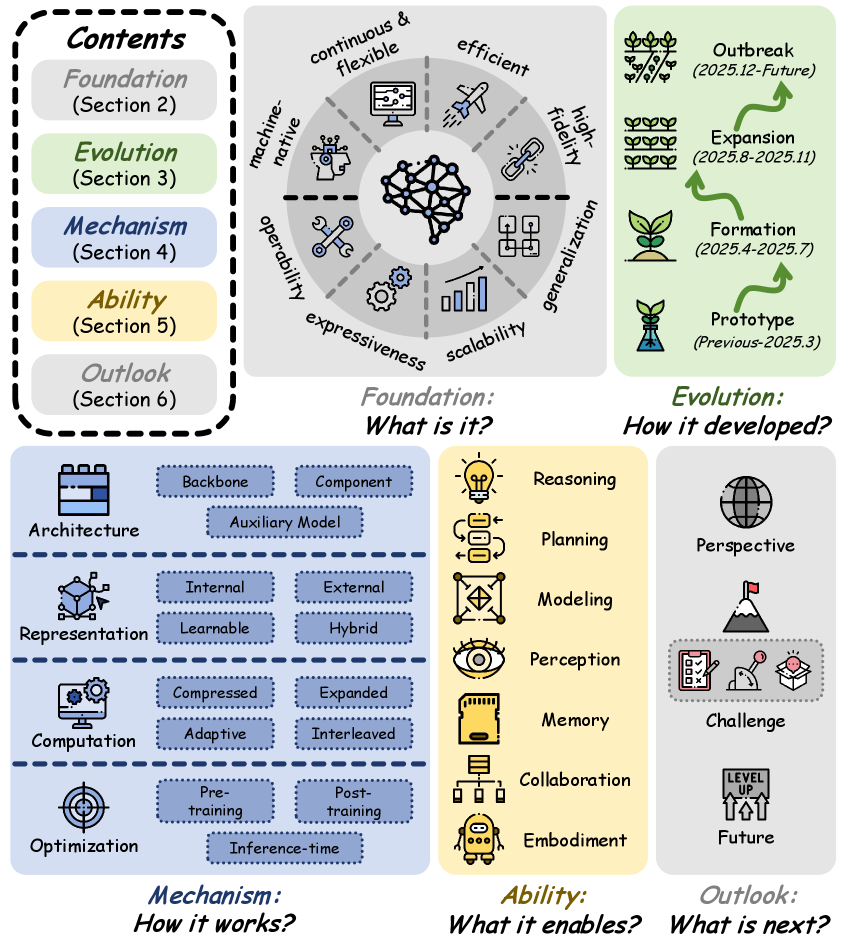
논문 소개
언어 기반 모델의 내부 계산을 이해하는 방식은 최근 명시적 토큰 생성에서 연속적 잠재 표현(latent representation)을 중심으로 한 접근으로 빠르게 이동하고 있으며, 이 논문은 이러한 변화를 잠재 공간(latent space)이라는 관점에서 체계적으로 정리합니다. 기존의 토큰 수준 추론은 언어적 중복, 이산화 병목, 순차적 비효율, 의미 손실이라는 구조적 제약을 지니는 반면, 잠재 공간은 모델이 더 압축적이면서도 풍부한 내부 계산을 수행할 수 있게 하는 계산 서브스트레이트로 제시됩니다. 특히 저자들은 잠재 공간을 단순한 중간 표현이 아니라, 추론, 계획, 기억, 인식, 협업, 체화된 행동을 함께 포괄할 수 있는 차세대 지능의 핵심 기반으로 재정의합니다. 이를 위해 서베이는 기초(Foundation), 진화(Evolution), 메커니즘(Mechanism), 능력(Ability), 전망(Outlook)의 다섯 축으로 연구 지형을 조직하며, 잠재 공간이 어떤 문제의식에서 출발했고 어떤 방식으로 확장되어 왔는지를 일관된 흐름으로 보여 줍니다. 먼저 Foundation에서는 잠재 공간을 명시적 언어 공간과 구분하고, 생성형 비전 모델에서의 latent space와도 다른 언어 기반 모델 내부의 계산 공간으로 명확히 정의함으로써 논의의 범위를 정돈합니다. 이어지는 Evolution에서는 연구가 압축적 계산에서 확장적 탐색, 적응형 제어, 그리고 명시적 토큰과 잠재 계산을 교차시키는 방식으로 발전해 왔음을 추적하며, 이 과정에서 효율성과 표현력의 균형이 점차 정교해졌음을 강조합니다.
메커니즘 관점에서 이 논문은 잠재 공간 연구를 Architecture, Representation, Computation, Optimization이라는 네 가지 축으로 나누어 분석하며, 각 축이 어떻게 시스템의 추론 방식과 학습 가능성을 결정하는지를 설명합니다. 아키텍처는 반복 깊이, 루프 구조, 병렬 경로, 계층적 흐름을 통해 잠재 계산의 토폴로지를 규정하고, 표현은 잠재 상태가 어떤 의미를 담아야 하는지를 정합니다. 계산은 반복적 정제, 선택적 중단, 분기와 샘플링을 통해 잠재 사고의 전개 방식을 제어하며, 최적화는 이러한 구조가 효율성과 일반화를 동시에 만족하도록 학습되게 만듭니다. 능력 관점에서는 잠재 공간이 추론과 계획을 넘어, 시각 인식과 기억 유지, 검색과 모델링, 다중 에이전트 협업, 체화된 의사결정까지 넓은 범위의 기능을 강화하는 공통 기반으로 제시됩니다. 특히 복잡한 문제에서는 모든 계산을 표면 언어로 외화하지 않고도 내부에서 고밀도 정보를 조작할 수 있기 때문에, 잠재 공간은 긴 문맥 처리와 장기 계획, 다단계 추론에서 뚜렷한 장점을 보입니다. 마지막으로 Outlook에서는 해석 가능성과 제어 가능성의 부족, 효율성과 정확성의 균형, 평가 지표의 미성숙, 안전성과 정렬(alignment) 문제를 주요 과제로 제시하면서도, 명시적 경로와 잠재 경로를 결합한 하이브리드 시스템이 미래의 유력한 방향임을 제안합니다. 결과적으로 이 서베이는 잠재 공간을 단순한 기법이 아니라, 다음 세대 언어 및 멀티모달(multimodal) 지능을 조직하는 일반적 계산 패러다임으로 이해하도록 돕는 통합적 출발점이 됩니다.
초록(Abstract)
잠재 공간은 언어 기반 모델의 고유한 기반으로 빠르게 부상하고 있다. 현대 시스템은 여전히 명시적인 토큰 수준 생성으로 이해되는 경우가 많지만, 점점 더 많은 연구는 많은 핵심 내부 과정이 인간이 읽을 수 있는 언어적 흔적보다 연속적인 잠재 공간에서 더 자연스럽게 수행된다는 사실을 보여준다. 이러한 전환은 언어적 중복, 이산화 병목, 순차적 비효율성, 의미 손실을 포함한 명시적 공간 계산의 구조적 한계에 의해 촉진된다. 본 서베이 논문은 언어 기반 모델에서의 잠재 공간에 대한 통합적이고 최신의 전반적 지형을 제시하고자 한다. 우리는 이 서베이 논문을 다섯 가지 순차적 관점, 즉 Foundation, Evolution, Mechanism, Ability, Outlook으로 구성한다. 먼저 잠재 공간의 범위를 규정하고, 이를 명시적 공간 또는 언어적 공간, 그리고 생성형 비전 모델에서 일반적으로 연구되는 잠재 공간과 구분한다. 이후 초기 탐색적 시도에서 현재의 대규모 확장에 이르기까지 이 분야의 발전을 추적한다. 기술적 지형을 체계화하기 위해, 기존 연구를 메커니즘과 능력이라는 상호보완적 관점에서 검토한다. Mechanism 관점에서는 아키텍처(Architecture), 표현(Representation), 계산(Computation), 최적화(Optimization)라는 네 가지 주요 발전 흐름을 식별한다. Ability 관점에서는 잠재 공간이 추론(Reasoning), 계획(Planning), 모델링(Modeling), 인식(Perception), 기억(Memory), 협업(Collaboration), 체화(Embodiment)에 이르는 폭넓은 능력 스펙트럼을 어떻게 지원하는지 보여준다. 정리하는 데 그치지 않고, 핵심 미해결 과제를 논의하며 향후 연구를 위한 유망한 방향을 제시한다. 우리는 이 서베이 논문이 기존 연구의 참고 자료일 뿐만 아니라, 차세대 지능을 위한 일반적인 계산 및 시스템 패러다임으로서 잠재 공간을 이해하는 데 있어 기초가 되기를 기대한다.
Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
논문 링크
더 읽어보기
테스트 시점 연산을 활용한 잠재 일반화 개선 / Improving Latent Generalization Using Test-time Compute
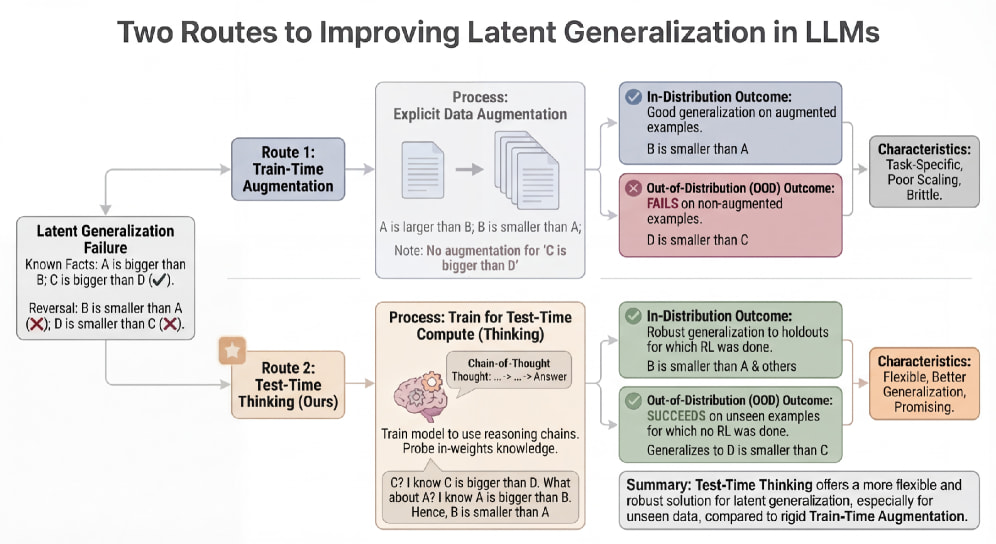
논문 소개
대규모 언어 모델(large language model, LLM)은 지식을 가중치에 저장하는 방식과 문맥 내 학습(in-context learning, ICL)으로 즉석에서 활용하는 방식이라는 두 가지 경로를 통해 지식을 획득하지만, 특히 가중치에 내재된 지식을 바탕으로 연역적 추론을 수행할 때는 자주 한계를 드러낸다. 저자들은 이러한 문제를 단순한 기억 실패가 아니라 잠재 일반화(latent generalization)의 부족으로 해석하며, 대표적 사례로 반전 저주(reversal curse)를 제시한다. 이에 비해 문맥 내 학습은 같은 지식에 대해서도 훨씬 유연하게 방향을 뒤집고 조합할 수 있어, 지식을 저장하는 방식과 활용하는 방식 사이의 간극이 분명함을 보여준다. 기존의 데이터 증강(data augmentation) 기반 접근은 특정 과제에는 유효하지만, 새로운 지식 구조로의 전이성이 약하고 확장성에도 한계가 있다는 점에서 근본적 대안이 되기 어렵다. 이러한 배경에서 이 연구는 모델이 추론 시점 연산(test-time compute), 즉 생각하기(thinking)를 활용하도록 학습시키면 가중치 내 지식의 잠재 일반화를 개선할 수 있는지를 탐색한다.
핵심 방법은 정답 피드백을 이용한 강화학습(reinforcement learning, RL)으로 모델이 긴 연쇄적 사고(chain-of-thought, CoT)를 생성하도록 유도하는 것이다. 먼저 모델은 통제된 지식 데이터로 사전 적응한 뒤, 생성된 사고 흔적이 정답 도출에 실제로 기여하도록 부트스트래핑과 강화학습을 거치며, 이 과정에서 자기 탐색, 후보 생성, 검증을 반복하는 생성-검증(generate-and-verify) 행동이 강화된다. 특히 이 설계는 단순히 더 많은 지식을 암기하게 만드는 것이 아니라, 이미 내부에 저장된 사실을 다양한 방향으로 꺼내 조합하는 절차를 학습시키는 데 목적이 있다. 실험에서는 의미 구조 벤치마크와 반전 저주 데이터셋을 통해 분포 내(in-distribution) 및 분포 밖(out-of-distribution, OOD) 일반화를 함께 평가했으며, 사고 기반 학습이 단순 증강보다 더 넓은 일반화 능력을 보인다는 점을 확인했다. 또한 학습에 포함되지 않은 새로운 지식 구조에서도 성능 향상이 이어져, test-time thinking이 훈련 분포를 넘어서는 전이 가능성을 지닌다는 사실이 드러났다.
다만 이 접근이 모든 문제를 완전히 해결하는 것은 아니며, 순수한 역전 과제에서는 직접적인 지식 반전이 열리기보다는 우연 수준을 크게 넘는 정도의 성능 개선에 머물렀다. 이는 사실 검증 자체가 취약하고, 모델이 정방향 기억을 우회적으로 재구성하는 데 의존하는 한계와도 연결된다. 그럼에도 이 연구는 추론 시점에 추가 연산을 투입하는 방식이 가중치 내 지식의 활용 범위를 넓힐 수 있음을 체계적으로 보여 주며, 데이터 증강 중심의 기존 패러다임을 보완하는 유망한 방향을 제시한다. 요약하면, 이 논문은 LLM이 무엇을 알고 있는가보다 그 지식을 어떻게 생각을 통해 꺼내는가가 중요하다는 점을 강조하면서, 잠재 일반화를 향상시키는 실용적이고 유연한 방법론으로서 test-time thinking의 가능성을 설득력 있게 제안한다.
초록(Abstract)
언어 모델(LM)은 지식 습득을 위한 두 가지 구별되는 메커니즘을 보인다: 가중치 내 학습(in-weights learning), 즉 정보를 모델 가중치 내부에 인코딩하는 방식과 문맥 내 학습(ICL, In-Context Learning)이다. 비록 이 두 방식이 상호 보완적인 강점을 제공하지만, 가중치 내 학습은 내재화된 지식에 대한 연역적 추론을 촉진하는 데 자주 어려움을 겪는다. 우리는 이러한 한계를 잠재적 일반화(latent generalization)의 결함으로 규정하며, 역전 저주(reversal curse)가 그 한 예이다. 반대로, 문맥 내 학습은 매우 견고한 잠재적 일반화 능력을 보인다. 가중치 내 지식으로부터의 잠재적 일반화를 개선하기 위해 기존 접근법들은 학습 시점 데이터 증강에 의존하지만, 이러한 기법들은 과제별로만 적용 가능하고 확장성이 떨어지며 분포 밖 지식으로 일반화하지 못한다. 이러한 한계를 극복하기 위해, 본 연구는 모델이 테스트 시점 연산(test-time compute), 즉 '사고(thinking)'를 사용하도록 어떻게 가르칠 수 있는지를, 특히 잠재적 일반화를 개선하는 데 초점을 맞추어 탐구한다. 우리는 정답 피드백으로부터의 강화학습(RL)을 사용하여 모델이 긴 사고의 연쇄(CoTs, chains-of-thought)를 생성하도록 학습시킴으로써 잠재적 일반화를 향상시킨다. 우리의 실험은 이러한 사고 접근법이 분포 내 지식에서 발생하는 잠재적 일반화 실패의 많은 사례를 해결할 뿐만 아니라, 증강 기반선과 달리 RL을 수행하지 않은 새로운 지식에도 일반화함을 보여준다. 그럼에도 불구하고, 순수 역전(reversal) 과제에서는 사고가 직접적인 지식 역전을 가능하게 하지는 않지만, 사고 모델의 생성-검증 능력은 이들이 우연 수준을 크게 상회하는 성능을 달성할 수 있게 한다. 사실 기반 자기 검증의 취약성은 이러한 사고 모델이 이 과제에서 여전히 문맥 내 학습의 성능에는 크게 미치지 못함을 의미한다. 전반적으로, 우리의 결과는 테스트 시점 사고를 언어 모델(LM)의 잠재적 일반화를 개선하기 위한 유연하고 유망한 방향으로 제시한다.
Language Models (LMs) exhibit two distinct mechanisms for knowledge acquisition: in-weights learning (i.e., encoding information within the model weights) and in-context learning (ICL). Although these two modes offer complementary strengths, in-weights learning frequently struggles to facilitate deductive reasoning over the internalized knowledge. We characterize this limitation as a deficit in latent generalization, of which the reversal curse is one example. Conversely, in-context learning demonstrates highly robust latent generalization capabilities. To improve latent generalization from in-weights knowledge, prior approaches rely on train-time data augmentation, yet these techniques are task-specific, scale poorly, and fail to generalize to out-of-distribution knowledge. To overcome these shortcomings, this work studies how models can be taught to use test-time compute, or 'thinking', specifically to improve latent generalization. We use Reinforcement Learning (RL) from correctness feedback to train models to produce long chains-of-thought (CoTs) to improve latent generalization. Our experiments show that this thinking approach not only resolves many instances of latent generalization failures on in-distribution knowledge but also, unlike augmentation baselines, generalizes to new knowledge for which no RL was performed. Nevertheless, on pure reversal tasks, we find that thinking does not unlock direct knowledge inversion, but the generate-and-verify ability of thinking models enables them to get well above chance performance. The brittleness of factual self-verification means thinking models still remain well below the performance of in-context learning for this task. Overall, our results establish test-time thinking as a flexible and promising direction for improving the latent generalization of LMs.
논문 링크
GPT-5.2조차 다섯까지 셀 수 없다: 신뢰할 수 있는 대규모 언어 모델(LLM)에서의 제로-에러 지평(Zero-Error Horizon)의 필요성 / Even GPT-5.2 Can't Count to Five: The Case for Zero-Error Horizons in Trustworthy LLMs
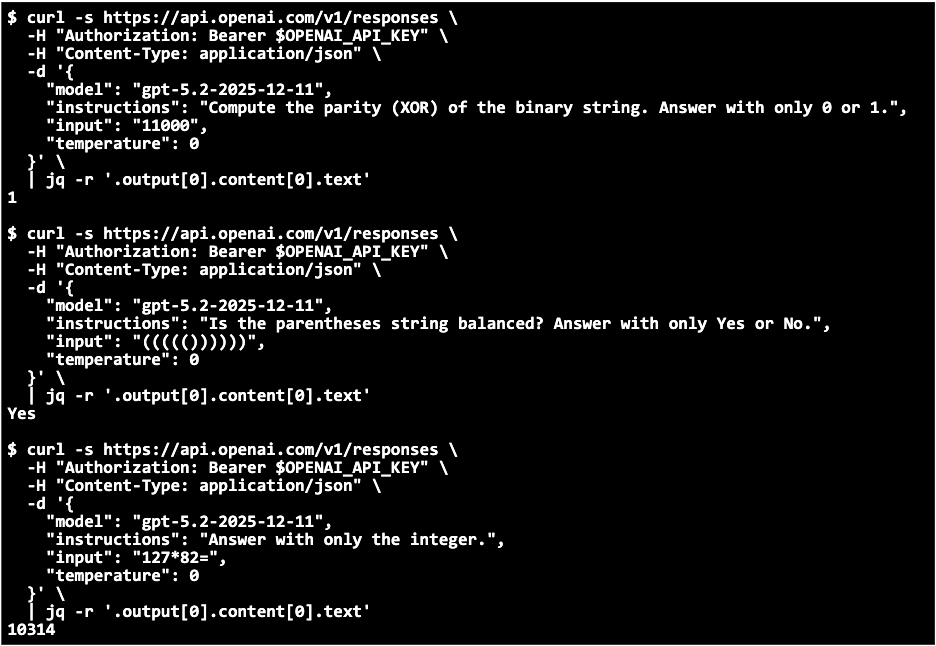
논문 소개
신뢰할 수 있는 대규모 언어 모델(Large Language Model, LLM)을 평가할 때 평균 정확도만으로는 모델이 실제로 어느 범위까지 안정적으로 동작하는지 충분히 드러내기 어렵다는 문제의식에서 출발하여, 저자는 무오류 지평(Zero-Error Horizon, ZEH)이라는 새로운 평가 관점을 제안합니다. ZEH는 모델이 한 번의 오류도 없이 해결할 수 있는 최대 범위를 뜻하며, 단순히 “대체로 잘 맞히는가”가 아니라 “어디까지 완전히 틀리지 않는가”를 측정한다는 점에서 안전이 중요한 응용에 특히 적합합니다. 초록은 최신 모델인 GPT-5.2조차 짧은 문자열의 패리티(parity)를 계산하거나 괄호 균형을 판별하는 매우 단순한 과제에서 실수할 수 있음을 보여주며, 이는 뛰어난 전반적 성능과 무오류성 사이에 큰 간극이 존재함을 시사합니다. 이러한 관점은 대규모 언어 모델을 안전이 중요한 환경에 적용할 때, 평균적인 성공률보다 실패가 사라지는 경계를 더 엄격하게 살펴야 한다는 점을 강하게 부각합니다.
방법론적으로 이 논문은 ZEH를 다양한 모델과 과제에 적용해, 정확도와는 다른 신뢰성의 구조를 분석합니다. 특히 Qwen2.5 계열의 곱셈 능력을 세밀하게 검토하면서, 모델 규모가 커질수록 성능이 단순히 선형적으로 향상되는 것이 아니라 암기 중심의 행동에서 알고리즘적 추론으로 이동하는 양상을 보인다는 점을 확인합니다. 예를 들어 작은 모델은 C4 말뭉치에서 자주 등장한 문제를 더 잘 맞히는 경향이 강해 학습 데이터 빈도에 크게 의존하지만, 더 큰 모델로 갈수록 이런 상관은 약해져 단순한 암기보다 규칙 기반 일반화가 점차 강화되는 모습을 드러냅니다. 동시에 오답의 형태도 무작위적 실패에서 벗어나, 정답과 일정한 자릿수 구조를 공유하는 구조화된 오답으로 바뀌며, 이는 내부적으로 긴 곱셈과 유사한 절차가 부분적으로 수행되고 있음을 암시합니다.
저자는 이러한 변화를 더 정교하게 검증하기 위해 스피어만 상관계수(Spearman correlation)와 로지스틱 회귀(logistic regression)를 활용합니다. 스피어만 상관 분석은 작은 모델일수록 문제 빈도와 정답률 사이의 결속이 강하고, 큰 모델일수록 그 결속이 약해진다는 점을 보여 주며, 로지스틱 회귀는 자리올림(carry)이 포함된 문제에서 모델 규모가 커질수록 상대적으로 더 큰 어려움이 나타난다는 상호작용 효과를 확인합니다. 이 결과들은 정확도 상승이 곧바로 무오류 지평의 확장으로 이어지지 않으며, ZEH가야말로 모델의 알고리즘적 안정성을 더 엄격하게 드러내는 지표임을 뒷받침합니다. 나아가 저자들은 ZEH 계산이 비용이 크다는 현실적 한계도 인정하면서, 트리 구조와 온라인 소프트맥스(online softmax)를 이용해 최대 한 자릿수 배수 수준의 속도 향상을 달성할 수 있음을 제시합니다. 종합하면, 이 연구는 대규모 언어 모델의 신뢰성을 평균 성능이 아닌 “무오류의 경계”에서 재정의하고, 그 경계의 변화를 통해 암기에서 알고리즘으로의 전환을 포착하는 방법론적 틀을 제시한다는 점에서 중요한 의미를 가집니다.
초록(Abstract)
신뢰할 수 있는 대규모 언어 모델(LLM)을 위해 제로-에러 호라이즌(Zero-Error Horizon, ZEH)을 제안합니다. 이는 모델이 오류 없이 해결할 수 있는 최대 범위를 의미합니다. ZEH 자체는 단순하지만, 최첨단 대규모 언어 모델(LLM)의 ZEH를 평가하면 풍부한 통찰을 얻을 수 있음을 보입니다. 예를 들어, GPT-5.2의 ZEH를 평가한 결과, GPT-5.2는 11000과 같은 짧은 문자열의 패리티조차 계산하지 못했으며, ((((())))))의 괄호가 균형을 이루는지도 판별하지 못했습니다. 이는 GPT-5.2의 뛰어난 성능을 고려하면 놀라운 결과입니다. 대규모 언어 모델(LLM)이 이처럼 단순한 문제에서도 실수한다는 사실은 LLM을 안전이 중요한 도메인에 적용할 때 중요한 교훈이 됩니다. Qwen2.5에 ZEH를 적용하고 상세 분석을 수행한 결과, ZEH는 정확도와 상관관계를 보이지만 세부 동작은 서로 다르며, ZEH는 알고리즘적 능력의 발현에 대한 단서를 제공함을 확인했습니다. 마지막으로, ZEH 계산에는 상당한 연산 비용이 소요되지만, 트리 구조와 온라인 소프트맥스를 활용하여 최대 한 자릿수(order of magnitude)의 속도 향상으로 이 비용을 완화하는 방법을 논의합니다.
We propose Zero-Error Horizon (ZEH) for trustworthy LLMs, which represents the maximum range that a model can solve without any errors. While ZEH itself is simple, we demonstrate that evaluating the ZEH of state-of-the-art LLMs yields abundant insights. For example, by evaluating the ZEH of GPT-5.2, we found that GPT-5.2 cannot even compute the parity of a short string like 11000, and GPT-5.2 cannot determine whether the parentheses in ((((()))))) are balanced. This is surprising given the excellent capabilities of GPT-5.2. The fact that LLMs make mistakes on such simple problems serves as an important lesson when applying LLMs to safety-critical domains. By applying ZEH to Qwen2.5 and conducting detailed analysis, we found that while ZEH correlates with accuracy, the detailed behaviors differ, and ZEH provides clues about the emergence of algorithmic capabilities. Finally, while computing ZEH incurs significant computational cost, we discuss how to mitigate this cost by achieving up to one order of magnitude speedup using tree structures and online softmax.
논문 링크
ClawKeeper: 스킬, 플러그인, 워처를 통한 OpenClaw 에이전트의 종합 안전성 보호 / ClawKeeper: Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers
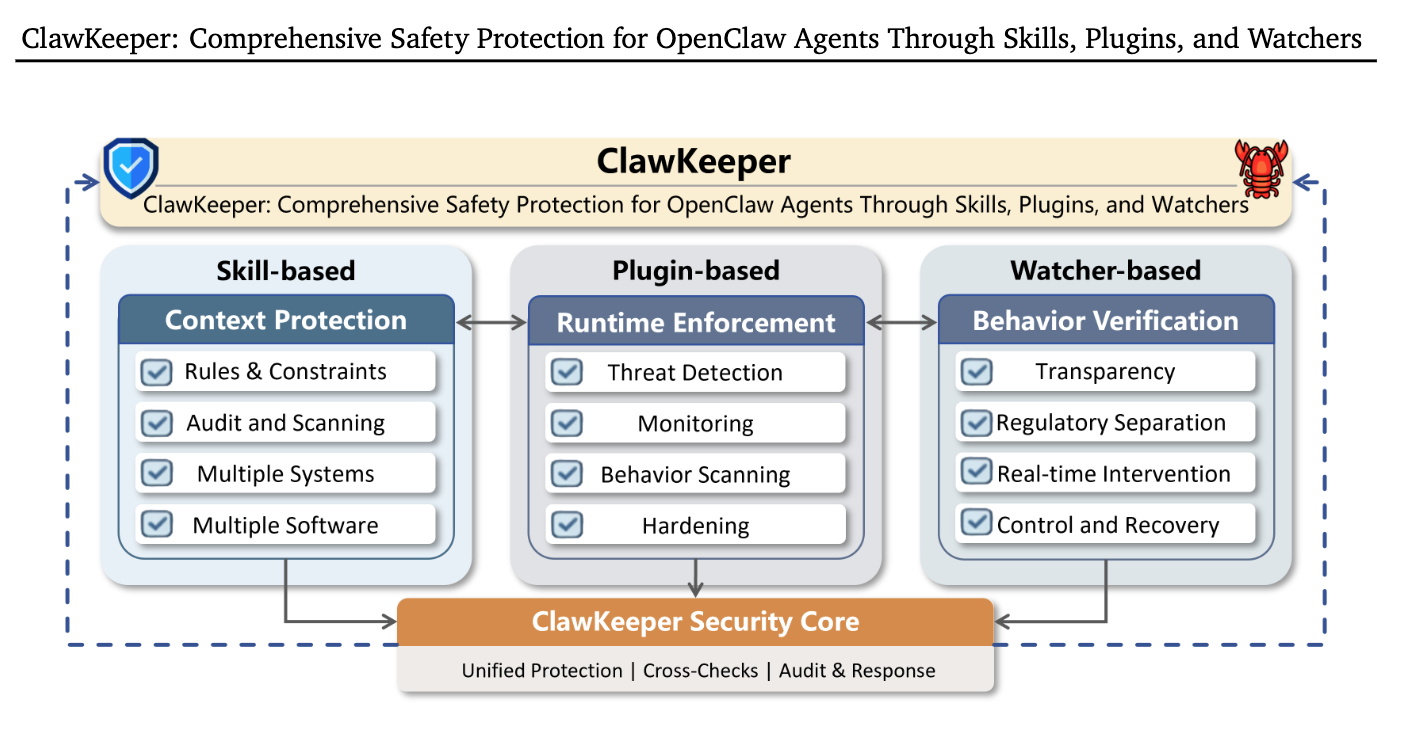
논문 소개
OpenClaw는 도구 통합, 로컬 파일 접근, 셸 명령 실행을 포함한 강력한 기능을 제공하는 선도적인 오픈소스 자율 에이전트 런타임으로 빠르게 자리 잡았다.
하지만 이러한 광범위한 권한은 모델 오류를 민감한 데이터 유출, 권한 상승, 악성 서드파티 스킬 실행 같은 시스템 수준의 위협으로 이어지게 할 수 있습니다.
기존 OpenClaw 보안 대책은 에이전트 생명주기의 일부 단계만 다루는 파편화된 형태에 머물러 있어, 전체적인 보호를 제공하지 못했습니다.
이를 해결하기 위해 저자들은 세 가지 상호보완적 계층으로 구성된 실시간 보안 프레임워크인 ClawKeeper를 제안합니다.
스킬 기반 보호는 지시문 수준에서 구조화된 보안 정책을 주입해 환경별 제약과 플랫폼 간 경계를 강제합니다.
플러그인 기반 보호는 런타임 내부에서 설정 강화, 선제적 위협 탐지, 지속적 행위 모니터링을 수행하며, 워처 기반 보호는 에이전트 내부 로직과 분리된 시스템 수준 미들웨어로 상태 변화를 계속 검증해 고위험 행동 차단이나 사람 확인 요구 같은 실시간 개입을 가능하게 합니다.
실험 결과 ClawKeeper는 다양한 위협 시나리오에서 효과적이고 견고한 방어 성능을 보였으며, 저자들은 코드도 공개했습니다.
초록(Abstract)
OpenClaw는 도구 통합, 로컬 파일 접근, 셸 명령 실행을 포함한 강력한 기능을 제공하는 선도적인 오픈소스 자율 에이전트 런타임으로 빠르게 자리매김했다. 그러나 이러한 광범위한 운영 권한은 치명적인 보안 취약점을 야기하여, 모델 오류를 민감한 데이터 유출, 권한 상승, 악성 제3자 스킬 실행과 같은 실질적인 시스템 수준 위협으로 전환시킨다. OpenClaw 생태계를 위한 기존 보안 조치들은 여전히 매우 단편적이며, 에이전트 생명주기의 개별 단계만을 다룰 뿐 포괄적인 보호를 제공하지 못한다. 이러한 격차를 해소하기 위해, 우리는 세 가지 상호 보완적인 아키텍처 계층 전반에 걸쳐 다차원 보호 메커니즘을 통합한 실시간 보안 프레임워크인 ClawKeeper를 제안한다. (1) \textbf{스킬 기반 보호}는 지시문 수준에서 동작하며, 구조화된 보안 정책을 에이전트 컨텍스트에 직접 주입하여 환경별 제약과 플랫폼 간 경계를 강제한다. (2) \textbf{플러그인 기반 보호}는 내부 런타임 집행자로서 작동하며, 실행 파이프라인 전반에 걸쳐 구성 강화, 선제적 위협 탐지, 지속적 행위 모니터링을 제공한다. (3) \textbf{워처 기반 보호}는 에이전트 상태의 변화를 지속적으로 검증하는 새로운 분리형 시스템 수준 보안 미들웨어를 도입한다. 이는 에이전트의 내부 로직과 결합하지 않고도 실시간 실행 개입을 가능하게 하며, 고위험 작업 중단이나 인간 확인 강제와 같은 작업을 지원한다. 우리는 이 Watcher 패러다임이 차세대 자율 에이전트 시스템을 보호하기 위한 기초 구성 요소로서 활용될 강력한 잠재력을 지닌다고 주장한다. 광범위한 정성적·정량적 평가는 다양한 위협 시나리오 전반에서 ClawKeeper의 효과성과 강건성을 입증한다. 우리는 코드를 공개한다.
OpenClaw has rapidly established itself as a leading open-source autonomous agent runtime, offering powerful capabilities including tool integration, local file access, and shell command execution. However, these broad operational privileges introduce critical security vulnerabilities, transforming model errors into tangible system-level threats such as sensitive data leakage, privilege escalation, and malicious third-party skill execution. Existing security measures for the OpenClaw ecosystem remain highly fragmented, addressing only isolated stages of the agent lifecycle rather than providing holistic protection. To bridge this gap, we present ClawKeeper, a real-time security framework that integrates multi-dimensional protection mechanisms across three complementary architectural layers. (1) \textbf{Skill-based protection} operates at the instruction level, injecting structured security policies directly into the agent context to enforce environment-specific constraints and cross-platform boundaries. (2) \textbf{Plugin-based protection} serves as an internal runtime enforcer, providing configuration hardening, proactive threat detection, and continuous behavioral monitoring throughout the execution pipeline. (3) \textbf{Watcher-based protection} introduces a novel, decoupled system-level security middleware that continuously verifies agent state evolution. It enables real-time execution intervention without coupling to the agent's internal logic, supporting operations such as halting high-risk actions or enforcing human confirmation. We argue that this Watcher paradigm holds strong potential to serve as a foundational building block for securing next-generation autonomous agent systems. Extensive qualitative and quantitative evaluations demonstrate the effectiveness and robustness of ClawKeeper across diverse threat scenarios. We release our code.
논문 링크
더 읽어보기
악용 탐지 파이프라인에서의 대규모 언어 모델 / Large Language Models in the Abuse Detection Pipeline
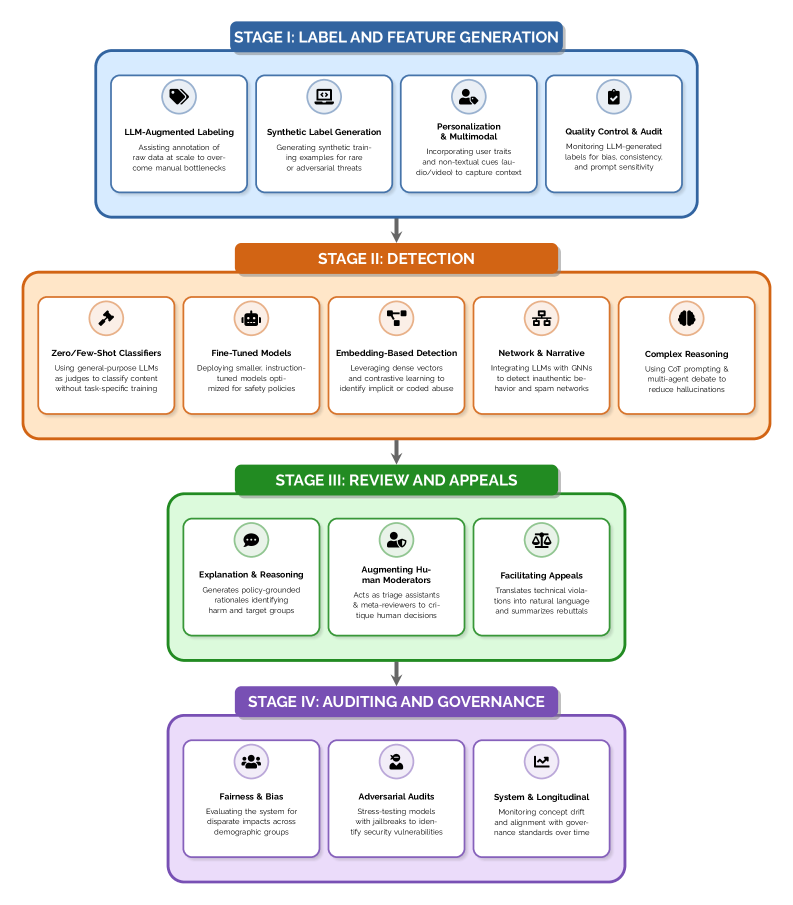
논문 소개
온라인 오남용 탐지 영역은 독성 발화, 괴롭힘, 조작, 사기성 행동처럼 서로 다른 양상을 지닌 위협이 빠르게 진화하는 환경에 놓여 있으며, 이에 따라 정적 분류기와 대규모 수작업 라벨링에 의존하던 기존 방식은 변화하는 정책 요구와 미묘한 맥락을 따라가기 어려워졌다. 이러한 문제의식 속에서 대규모 언어 모델(Large Language Models, LLM)은 문맥 추론, 정책 해석, 설명 생성, 심지어 다중 양식 이해까지 수행할 수 있는 도구로 부상하며, 단순한 탐지기를 넘어 안전성 시스템 전반을 지원하는 핵심 구성 요소로 확장되고 있다. 해당 논문은 이러한 가능성을 Abuse Detection Lifecycle(ADL)이라는 네 단계의 파이프라인으로 체계화하여, Label & Feature Generation, Detection, Review & Appeals, Auditing & Governance의 각 단계에서 LLM이 어떤 역할을 맡을 수 있는지 정리한다. 특히 방법론적으로는 LLM을 하나의 만능 모델로 간주하지 않고, 데이터 생성에서 탐지, 검토, 감사에 이르는 전체 흐름 속에서 각각 다른 실패 양상과 운영 제약을 가진 시스템 요소로 바라본다는 점이 중요하다.
라벨링 단계에서는 LLM이 학습용 라벨과 특징, 보조 설명을 생성하는 데이터 증폭기(data amplifier)로 활용될 수 있지만, 동시에 순환적 편향(circular bias)과 프롬프트 민감성, 주관성 문제를 강하게 드러낸다. 논문은 정렬 방식이 서로 다른 모델들이 abuse를 과소 또는 과대 예측할 수 있음을 보여 주며, 텍스트 중심 데이터만으로는 음성의 억양이나 대화의 미묘한 뉘앙스 같은 준언어적(paralinguistic) 단서를 놓치기 쉽다고 지적한다. 탐지 단계에서는 LLM이 강한 문맥 이해 능력을 바탕으로 복잡한 공격을 포착할 수 있지만, 순차적 추론 구조로 인한 지연 시간(latency), 높은 비용, 처리량 제약 때문에 실제 대규모 서비스에 곧바로 투입하기 어렵다는 생산 격차(production gap)가 핵심 한계로 제시된다. 이에 따라 논문은 작은 분류기와 큰 모델을 조합하는 계층형 라우팅, 정책 문서를 동적으로 참조하는 검색증강생성(Retrieval-Augmented Generation, RAG), 그리고 전통적 언어 이해와 구조적 관계 추론을 결합한 뉴로-심볼릭(neuro-symbolic) 또는 그래프 강화(graph-enhanced) 접근이 실용적인 대안이 될 수 있다고 정리한다.
검토와 항소 단계는 본문 발췌에서 세부가 제한적이지만, 전체 프레임워크 안에서는 인간 검토자와 LLM이 상호 보완적으로 작동해야 하는 구간으로 이해된다. 즉, 모델이 처음 판정한 결과를 인간이 재검토하고, 정책 문맥과 사용자 상황을 반영해 예외를 다루는 과정이 필요하며, 이때 설명 가능성은 단순한 부가 기능이 아니라 운영 신뢰성을 지탱하는 핵심 요소가 된다. 감사와 거버넌스 단계에서는 정확도만으로는 충분하지 않고, 결정성(determinism), 공정성(fairness), 책임성(accountability), 적대적 강건성(adversarial robustness)까지 함께 검증해야 한다는 점이 강조된다. 모델과 정책이 비공개적으로 바뀌는 환경에서는 외부 평가가 쉽게 무력화될 수 있으므로, 논문은 지속적 레드팀 테스팅(red teaming), 스트레스 테스트, 설명 가능한 판정 근거의 제공, 그리고 사회적 정렬(social alignment)을 위한 정기적 검증이 필요하다고 제안한다.
결국 이 논문의 핵심 기여는 LLM을 abuse detection에 단순 적용하는 수준을 넘어서, 모델 생성과 탐지, 인간 검토, 감사 체계를 하나의 운영 가능한 사회기술적 시스템으로 재구성한 데 있다. 이를 통해 LLM이 안전성 파이프라인의 전면을 대체하는 것이 아니라, 어디에서는 자동화를 강화하고 어디에서는 인간 개입을 유지해야 하는지를 정교하게 구분해야 한다는 점을 설득력 있게 보여 준다. 나아가 이 접근은 향후 대규모 플랫폼에서 신뢰할 수 있는 남용 탐지와 거버넌스를 구현하기 위해 필요한 연구 과제를 분명하게 제시한다.
초록(Abstract)
온라인 남용은 유해한 언어, 괴롭힘, 조작, 사기 행위를 아우르며 점점 더 복잡해지고 있다. 정적인 분류기와 노동 집약적 라벨링에 의존하는 전통적인 머신러닝 접근법은 진화하는 위협 패턴과 미묘한 정책 요구사항을 따라잡는 데 어려움을 겪는다. 대규모 언어 모델(LLM)은 문맥적 추론, 정책 해석, 설명 생성, 그리고 크로스모달 이해를 위한 새로운 역량을 도입하며, 현대 안전 시스템의 여러 단계에서 이를 지원할 수 있게 한다. 본 서베이 논문은 대규모 언어 모델이 악용 탐지 라이프사이클(Abuse Detection Lifecycle, ADL)에 어떻게 통합되고 있는지를 라이프사이클 지향적으로 분석한다. 우리는 ADL을 네 단계로 정의한다: (I) 라벨 및 특성 생성(Label & Feature Generation), (II) 탐지(Detection), (III) 검토 및 이의 제기(Review & Appeals), (IV) 감사 및 거버넌스(Auditing & Governance). 각 단계마다 우리는 새롭게 등장하는 연구와 산업 실무를 종합하고, 운영 배포를 위한 아키텍처적 고려사항을 강조하며, LLM 기반 접근법의 장점과 한계를 검토한다. 마지막으로 지연 시간, 비용 효율성, 결정성, 적대적 강건성, 공정성을 포함한 핵심 과제를 정리하고, 대규모 악용 탐지 및 거버넌스 시스템에서 대규모 언어 모델을 신뢰할 수 있고 책임 있는 구성 요소로 구현하기 위해 필요한 향후 연구 방향을 논의한다.
Online abuse has grown increasingly complex, spanning toxic language, harassment, manipulation, and fraudulent behavior. Traditional machine-learning approaches dependent on static classifiers and labor-intensive labeling struggle to keep pace with evolving threat patterns and nuanced policy requirements. Large Language Models introduce new capabilities for contextual reasoning, policy interpretation, explanation generation, and cross-modal understanding, enabling them to support multiple stages of modern safety systems. This survey provides a lifecycle-oriented analysis of how LLMs are being integrated into the Abuse Detection Lifecycle (ADL), which we define across four stages: (I) Label & Feature Generation, (II) Detection, (III) Review & Appeals, and (IV) Auditing & Governance. For each stage, we synthesize emerging research and industry practices, highlight architectural considerations for production deployment, and examine the strengths and limitations of LLM-driven approaches. We conclude by outlining key challenges including latency, cost-efficiency, determinism, adversarial robustness, and fairness and discuss future research directions needed to operationalize LLMs as reliable, accountable components of large-scale abuse-detection and governance systems.
논문 링크
더 읽어보기
HyperAlign: 디퓨전 모델의 효율적인 테스트 시점 정렬을 위한 하이퍼네트워크 / HyperAlign: Hypernetwork for Efficient Test-Time Alignment of Diffusion Models
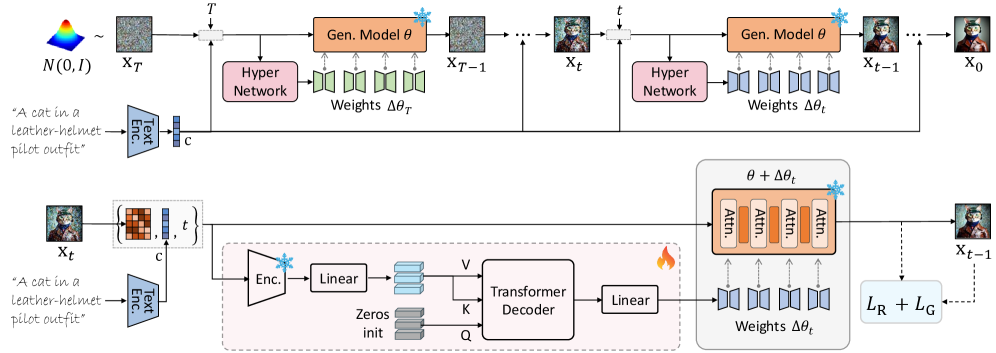
논문 소개
디퓨전(Diffusion) 모델의 정렬(alignment)은 생성 결과를 인간의 선호에 더 가깝게 조정하면서도, 텍스트 프롬프트에 대한 의미적 일관성과 시각적 품질을 함께 높여야 한다는 점에서 중요한 연구 과제로 자리 잡고 있습니다. 그러나 기존 접근은 테스트 시점(test-time) 정렬과 파인튜닝(fine-tuning) 기반 정렬 사이에서 뚜렷한 절충을 요구해 왔습니다. 테스트 시점 방법은 입력마다 유연하게 대응할 수 있지만 계산 비용이 크고 최적화가 충분하지 않은 반면, 파인튜닝 방법은 보상 해킹(reward hacking)과 생성 다양성 저하를 초래할 수 있어 실제 적용에 제약이 있습니다. HyperAlign은 이러한 한계를 해결하기 위해, 하이퍼네트워크(hypernetwork)가 입력과 현재 상태에 조건화된 저랭크 적응(Low-Rank Adaptation, LoRA) 가중치를 동적으로 생성하도록 설계한 프레임워크입니다. 핵심적으로는 잠재 상태(latent state)를 직접 수정하는 대신, 노이즈 제거(denoising) 궤적 자체를 보상 방향으로 유도하는 적응 가중치를 만들어 정렬 효과를 내는 방식입니다.
이 방법의 장점은 사전학습된 모델을 동결한 채로도 입력별 적응성을 확보할 수 있으며, 반복적인 그래디언트 계산이나 과도한 추가 추론 없이 효율적인 정렬을 수행할 수 있다는 데 있습니다. 또한 HyperAlign은 정렬 품질과 계산 효율성의 균형을 위해 서로 다른 세분성의 변형을 제시하여, 단계별로 가중치를 생성하는 정밀한 방식부터 한 번만 생성하는 경량 방식, 중요한 구간에서만 갱신하는 절충형 방식까지 폭넓게 대응합니다. 학습 과정에서는 보상 목적함수를 사용하되, 선호 데이터로 정규화하여 단순한 점수 최대화에 과도하게 치우치지 않도록 설계함으로써, 정렬 성능과 생성 다양성 사이의 균형을 유지합니다. 이러한 설계는 정렬을 단순한 후처리가 아니라, 샘플링 궤적을 보상에 맞게 조율하는 동적 제어 문제로 재해석한다는 점에서 의미가 큽니다. 나아가 이 접근은 디퓨전 모델뿐 아니라 flow-matching과 rectified flow 계열에도 자연스럽게 확장될 수 있어, 특정 아키텍처에 종속되지 않는 일반적인 정렬 틀을 제시합니다.
실험적으로 HyperAlign은 Stable Diffusion과 FLUX를 포함한 여러 생성 패러다임에서 평가되었으며, 기존 정렬 기법보다 의미 일관성과 시각 품질을 동시에 더 잘 향상시키는 결과를 보였습니다. 특히 입력마다 달라지는 선호와 상태 정보를 반영해 보상 신호를 효율적으로 주입한다는 점에서, 인간 선호 정렬을 보다 실용적이고 확장 가능한 형태로 구현했다는 의의가 있습니다. 결국 이 논문은 테스트 시점의 적응성과 학습 기반 방법의 효율성을 하이퍼네트워크와 LoRA를 통해 결합함으로써, 디퓨전 모델 정렬의 핵심 병목을 효과적으로 완화하는 새로운 방법론을 제안합니다.
초록(Abstract)
디퓨전 모델 정렬은 텍스트 프롬프트와의 의미적 일관성과 전반적인 시각적 품질을 모두 향상시켜 생성된 출력과 인간 선호 간의 격차를 좁히는 것을 목표로 합니다. 기존의 정렬 방법은 까다로운 트레이드오프에 직면합니다. 테스트 시점 접근법은 입력별 적응성을 제공하지만 상당한 계산 오버헤드를 유발하고 최적화가 충분히 이루어지지 않는 경향이 있으며, 파인튜닝 접근법은 보상 과최적화와 생성 다양성 손실의 위험이 있습니다. 이 격차를 해소하기 위해, 우리는 효율적이고 효과적인 테스트 시점 정렬을 위해 하이퍼네트워크를 학습하는 프레임워크인 HyperAlign을 제안합니다. HyperAlign은 잠재 상태를 직접 수정하는 대신, 입력 및 상태 조건부 저랭크 적응 가중치를 동적으로 생성하여 노이즈 제거 궤적을 목표 보상 방향으로 조절합니다. 우리는 정렬 품질과 계산 효율성의 균형을 맞추기 위해 다양한 세분성을 갖는 여러 HyperAlign 변형을 도입합니다. 또한 하이퍼네트워크는 보상 해킹을 완화하기 위해 선호 데이터로 정규화된 보상 목적함수로 최적화됩니다. 우리는 Stable Diffusion과 FLUX를 포함한 여러 생성 패러다임 전반에서 HyperAlign을 평가했으며, 의미적 일관성과 시각적 품질 측면에서 기존 정렬 방법들을 크게 능가함을 확인했습니다.
Diffusion model alignment aims to bridge the gap between generated outputs and human preferences by enhancing both semantic consistency with textual prompts and overall visual quality. Existing alignment methods face a challenging trade-off: test-time approaches enable input-specific adaptability but introduce significant computational overhead and tend to under-optimize, while fine-tuning approaches risk reward over-optimization and loss of generation diversity. To bridge this gap, we propose HyperAlign, a framework that trains a hypernetwork for efficient and effective test-time alignment. Instead of modifying latent states directly, HyperAlign dynamically generates input-and-state-conditioned low-rank adaptation weights to modulate the denoising trajectory toward target rewards. We introduce multiple HyperAlign variants of varying granularity to balance alignment quality and computational efficiency. The hypernetwork is optimized with a reward objective regularized by preference data to mitigate reward hacking. We evaluate HyperAlign across multiple generative paradigms, including Stable Diffusion and FLUX, where it significantly outperforms existing alignment methods in semantic consistency and visual quality.
논문 링크
더 읽어보기
GISTBench: 증거 기반 관심 검증을 통한 대규모 언어 모델(LLM)의 사용자 이해 능력 평가 / GISTBench: Evaluating LLM User Understanding via Evidence-Based Interest Verification
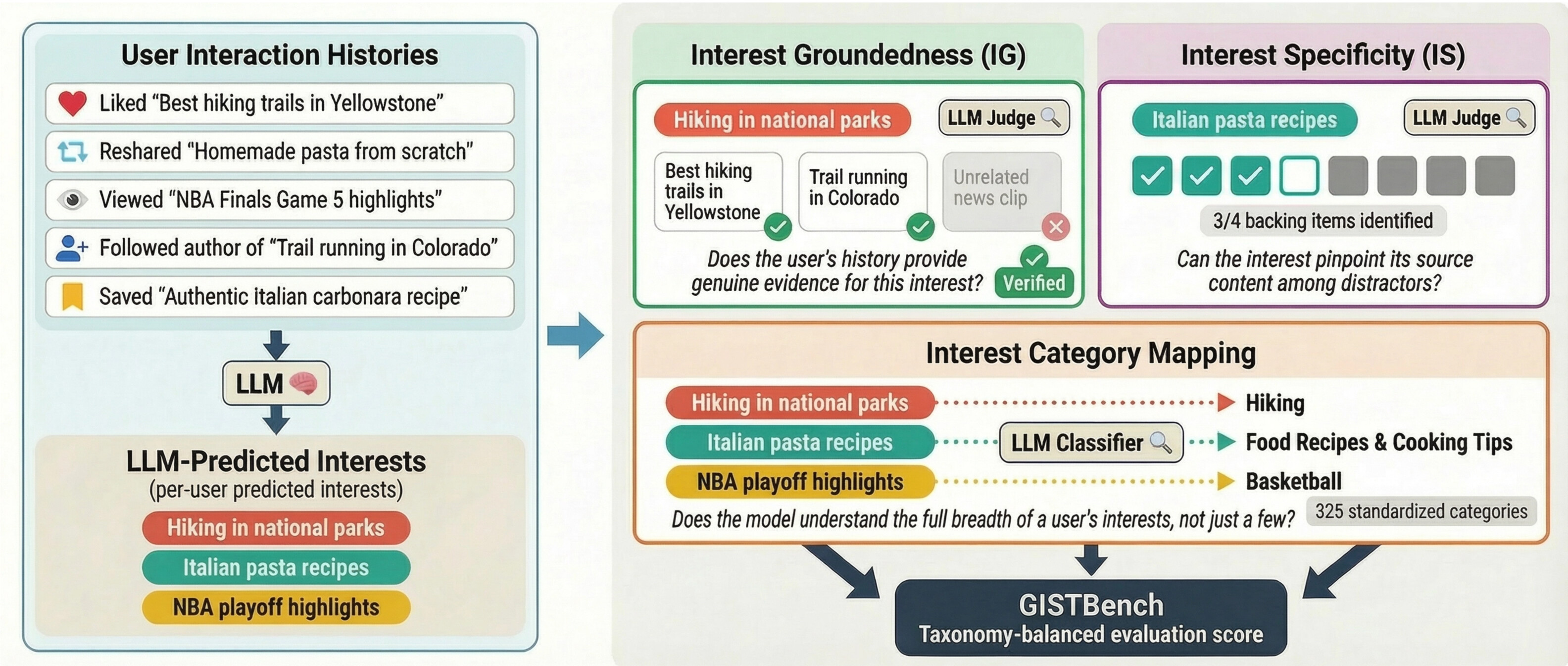
논문 소개
추천 시스템(Recommendation Systems)에서 대규모 언어 모델(Large Language Models, LLMs)을 활용한 사용자 이해는 단순한 아이템 예측을 넘어, 사용자의 실제 행동 기록을 바탕으로 관심사를 얼마나 정확하고 근거 있게 파악할 수 있는지에 대한 문제로 확장되고 있다. GISTBench는 바로 이러한 관점에서 LLM이 상호작용 이력으로부터 사용자의 관심을 추출하고 검증하는 능력을 평가하기 위해 제안된 벤치마크로, 그 중심에는 증거 기반 검증(evidence-based verification)이라는 엄격한 평가 철학이 놓여 있다. 기존의 추천 벤치마크가 주로 정답 아이템을 맞히는 정확도에 집중했다면, 이 접근은 모델이 제시한 관심이 실제로 좋아요, 저장, 공유, 시청과 같은 이질적인 행동 신호에 의해 지지되는지를 따져 묻는다. 이를 위해 논문은 Interest Groundedness(IG)와 Interest Specificity(IS)라는 두 계열의 지표를 도입했으며, IG는 정밀도와 재현율로 분해되어 환각된 관심 범주를 억제하면서도 실제 관심의 포착 범위를 함께 평가하고, IS는 검증된 사용자 프로필이 얼마나 구별 가능하고 개별적인지를 측정한다. 특히 IG를 계산하는 과정에서는 LLM judge를 이용해 예측된 관심에 연결된 증거 객체의 의미론적 관련성을 다시 판별함으로써, 단순한 표면적 유사성에 기반한 설명이 아니라 실제로 정당화 가능한 근거만 남기도록 설계했다.
또한 이 벤치마크는 실제 글로벌 숏폼 비디오 플랫폼의 사용자 상호작용 로그를 바탕으로 합성 데이터셋을 구성하고, 명시적 신호와 암묵적 신호를 함께 반영하여 현실적인 사용자 행동 구조를 모사한다는 점에서 의미가 크다. 논문은 각 관심에 대해 명시적 양성, 암묵적 양성, 명시적 음성, 암묵적 음성 신호를 구분한 뒤 비대칭 임계값을 적용해 검증 여부를 판단함으로써, 신호의 강도와 노이즈 수준이 서로 다른 상호작용을 동일하게 취급하지 않는다. 이러한 구조는 모델이 단순히 그럴듯한 취향 범주를 나열하는 수준을 넘어, 여러 행동 증거를 정확히 세고 어떤 신호가 어떤 관심에 귀속되는지를 설명해야만 높은 점수를 얻도록 만든다. 데이터셋의 신뢰성은 사용자 설문과의 비교를 통해 검증되었으며, 상관계수 0.67이라는 결과는 합성된 관심 프로필이 실제 자기보고와 상당히 잘 정렬되어 있음을 보여준다. 더 나아가 7B에서 120B 규모에 이르는 8개의 오픈 웨이트(open-weight) LLM을 평가한 결과, 현재 모델들은 이질적인 상호작용 타입에서 신호를 정확히 계수하고 적절한 관심에 귀속시키는 데 여전히 뚜렷한 한계를 드러냈다. 결국 GISTBench는 LLM의 언어 생성 능력 자체보다도 행동 증거를 해석하고 검증하는 능력이 사용자 이해의 핵심이라는 점을 분명히 하며, 향후 개인화 시스템과 사용자 프로파일링 연구에서 중요한 진단 도구로 기능할 수 있는 방법론적 기반을 제시한다.
초록(Abstract)
우리는 추천 시스템에서의 상호작용 이력을 바탕으로 대규모 언어 모델(LLM)이 사용자에 대해 얼마나 잘 이해하는지를 평가하기 위한 벤치마크인 GISTBench를 소개한다. 아이템 예측 정확도에 초점을 맞추는 기존 추천 시스템(RecSys) 벤치마크와 달리, 우리의 벤치마크는 LLM이 참여 데이터로부터 사용자 관심사를 얼마나 잘 추출하고 검증하는지를 평가한다. 우리는 두 가지 새로운 메트릭 계열을 제안한다. 하나는 관심 근거성(Interest Groundedness, IG)으로, 환각된 관심 범주를 별도로 페널티하고 범위 커버리지는 보상하도록 정밀도와 재현율 구성 요소로 분해된다. 다른 하나는 관심 특이성(Interest Specificity, IS)으로, 검증된 LLM 예측 사용자 프로필의 구별성을 평가한다. 우리는 글로벌 숏폼 비디오 플랫폼의 실제 사용자 상호작용을 바탕으로 구성한 합성 데이터셋을 공개한다. 이 데이터셋은 암묵적 및 명시적 참여 신호와 풍부한 텍스트 설명을 모두 포함한다. 우리는 사용자 설문조사를 통해 데이터셋의 충실도를 검증하고, 7B에서 120B 파라미터에 이르는 8개의 오픈 웨이트 LLM을 평가한다. 우리의 결과는 현재 LLM의 성능 병목을 드러내며, 특히 이질적인 상호작용 유형 전반에서 참여 신호를 정확하게 집계하고 귀속하는 능력이 제한적임을 보여준다.
We introduce GISTBench, a benchmark for evaluating Large Language Models' (LLMs) ability to understand users from their interaction histories in recommendation systems. Unlike traditional RecSys benchmarks that focus on item prediction accuracy, our benchmark evaluates how well LLMs can extract and verify user interests from engagement data. We propose two novel metric families: Interest Groundedness (IG), decomposed into precision and recall components to separately penalize hallucinated interest categories and reward coverage, and Interest Specificity (IS), which assesses the distinctiveness of verified LLM-predicted user profiles. We release a synthetic dataset constructed on real user interactions on a global short-form video platform. Our dataset contains both implicit and explicit engagement signals and rich textual descriptions. We validate our dataset fidelity against user surveys, and evaluate eight open-weight LLMs spanning 7B to 120B parameters. Our findings reveal performance bottlenecks in current LLMs, particularly their limited ability to accurately count and attribute engagement signals across heterogeneous interaction types.
논문 링크
더 읽어보기
테스트 시점 인스턴스별 파라미터 구성: 적응형 생성 모델링을 위한 새로운 패러다임 / Test-Time Instance-Specific Parameter Composition: A New Paradigm for Adaptive Generative Modeling
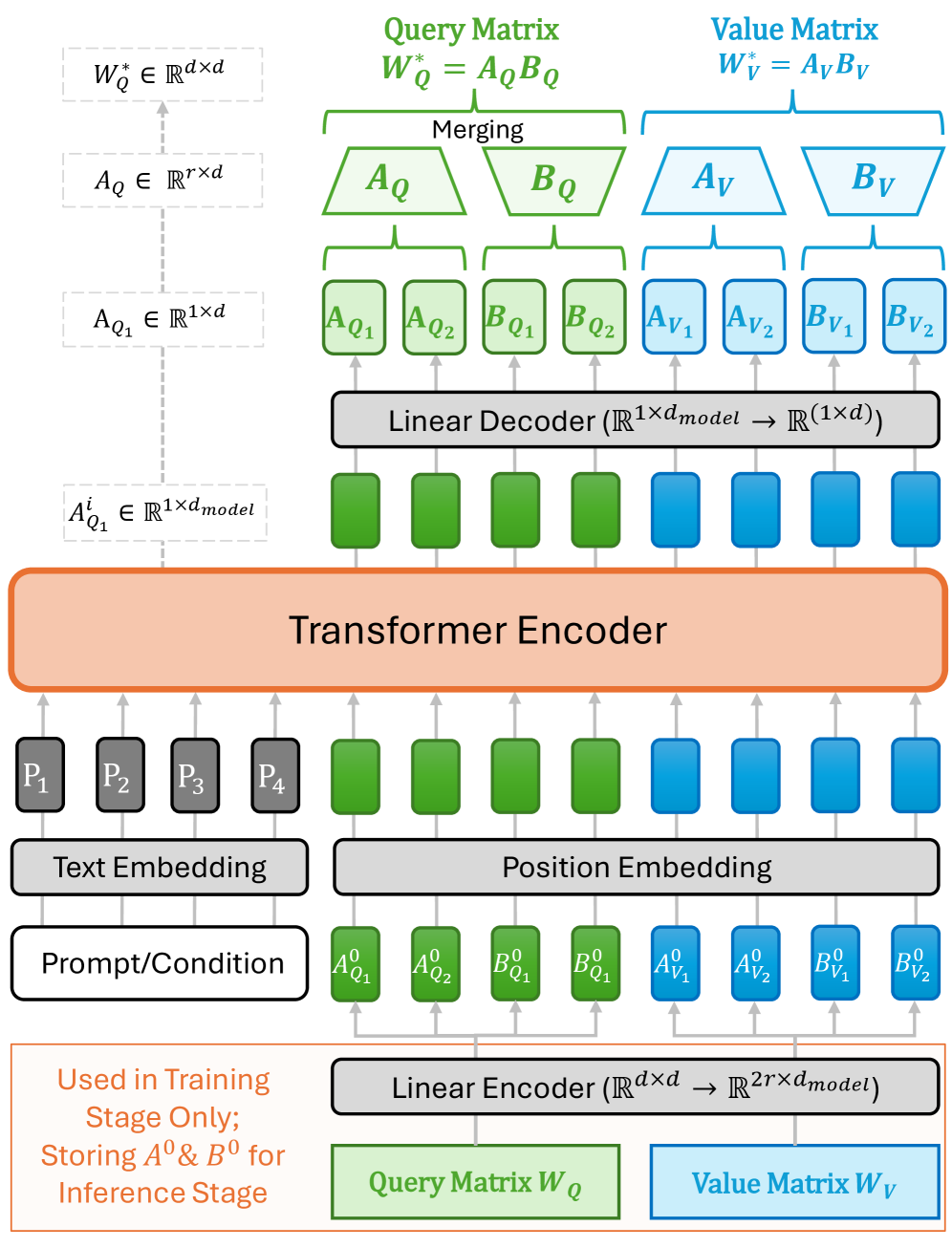
논문 소개
확산 모델(Diffusion model)과 자기회귀 네트워크(auto-regressive network)는 강력한 생성 성능을 보이지만, 모든 입력에 동일한 사전학습 파라미터를 적용하는 정적 구조에 머문다는 한계를 지닙니다. 이에 비해 인간의 생성적 인지는 지각적·상상적 맥락에 따라 내부 표현을 유연하게 조정한다는 점에서, 입력마다 다른 적응 메커니즘을 갖춘 생성 모델의 필요성이 제기됩니다. 이러한 문제의식 위에서 제안된 Composer는 추론 시점(test-time)마다 입력에 특화된 파라미터 적응값을 생성해 사전학습 모델의 가중치에 주입하는 새로운 패러다임으로, 별도의 파인튜닝(fine-tuning)이나 재학습 없이도 인스턴스별 특화(instance-specific specialization)를 가능하게 합니다. 특히 적응은 다단계 생성 이전에 한 번만 수행되므로, 반복적인 그래디언트 업데이트에 의존하는 기존 test-time training(TTT)보다 계산량과 메모리 사용을 크게 줄이면서도 입력 맥락에 더 잘 맞는 출력을 얻을 수 있습니다.
이 방법론의 핵심은 생성 모델을 완전히 새로 학습시키는 대신, 저랭크(low-rank) 구조를 활용한 파라미터 조합을 통해 기존 지식을 보존하면서도 입력 조건에 따라 유연하게 변형하는 데 있습니다. 다시 말해 Composer는 모델의 표현력을 외부에서 추가하는 것이 아니라, 각 입력에 맞는 생성 전략을 내부 가중치 수준에서 동적으로 구성함으로써 정적 파라미터화(static parameterization)의 한계를 넘어섭니다. 이러한 설계는 클래스 조건부 이미지 생성처럼 비교적 명확한 조건이 주어지는 상황은 물론, 텍스트-이미지 생성처럼 조건 해석이 복합적인 상황에서도 일관되게 작동하도록 일반화됩니다. 더 나아가 사후학습 양자화(post-training quantization)된 저정밀 모델에도 적용 가능하여, 성능 저하가 심한 환경에서조차 생성 품질을 회복하는 적응형 보정 메커니즘으로 기능합니다.
실험 결과는 Composer의 실용성과 범용성을 분명하게 뒷받침합니다. ImageNet 기반 클래스 조건부 생성에서는 다양한 규모의 VAR와 DiT 백본에서 FID(Frechet Inception Distance)와 IS(Inception Score)가 일관되게 개선되었고, 고해상도 설정에서도 같은 경향이 유지되었습니다. MS-COCO 2014 텍스트-이미지 생성에서도 FID-30K와 CLIP-30K가 함께 향상되어, 시각적 품질과 의미 정렬을 동시에 높였음을 보여줍니다. 또한 Q-Diffusion과 CTEC 같은 양자화 기반 확산 모델에 Composer를 결합했을 때, 극단적인 저비트 환경에서도 IS가 크게 상승하고 FID와 sFID는 감소하여 저정밀 추론에서의 복원력을 입증했습니다. 특히 TTT와 비교했을 때, Composer는 성능 이점뿐 아니라 추론 시간과 peak memory 측면에서 압도적으로 효율적이어서, 실제 서비스 환경에 적용 가능한 현실적인 대안임을 시사합니다.
아블레이션 분석은 이러한 성능 향상이 우연이 아니라 설계 선택에 의해 뒷받침된다는 점도 보여줍니다. 저랭크 차원 r과 컨텍스트 인지 샘플링 비율 α를 조절했을 때 성능과 일반성 사이의 균형이 명확히 관찰되었고, 전역 문맥을 먼저 포착한 뒤 지역 정보를 정교하게 다루는 attention 구성도 생성 품질 향상에 기여했습니다. 종합하면 Composer는 입력마다 다른 파라미터 구성을 통해 생성 모델을 동적으로 적응시키는 새로운 방향을 제시하며, 더 큰 모델을 만드는 대신 더 똑똑하게 입력에 반응하는 모델 설계가 가능하다는 점을 설득력 있게 보여줍니다.
초록(Abstract)
기존의 디퓨전(Diffusion) 및 오토리그레시브(auto-regressive) 네트워크와 같은 생성 모델은 본질적으로 정적이며, 모든 입력을 처리하기 위해 고정된 사전학습 파라미터 집합에 의존한다. 이에 반해 인간은 지각적 또는 상상적 맥락에 따라 내부 생성 표현을 유연하게 조정한다. 이러한 능력에서 영감을 받아, 우리는 테스트 시점 인스턴스별 파라미터 합성(test-time instance-specific parameter composition)에 기반한 적응형 생성 모델링의 새로운 패러다임인 Composer를 소개한다. Composer는 추론 시 입력 조건부 파라미터 적응을 생성하여 이를 사전학습 모델의 가중치에 주입함으로써, 파인튜닝이나 재학습 없이 입력별 전문화를 가능하게 한다. 적응은 다단계 생성에 앞서 한 번만 수행되므로, 계산 및 메모리 오버헤드는 최소화하면서 더 높은 품질의 컨텍스트 인지 출력(context-aware outputs)을 제공한다. 실험 결과, Composer는 경량/양자화(lightweight/quantized) 모델과 테스트 시점 스케일링(test-time scaling)을 포함한 다양한 생성 모델과 활용 사례 전반에서 성능을 크게 향상시키는 것으로 나타났다. 입력 인식 파라미터 합성(input-aware parameter composition)을 활용함으로써, Composer는 정적 파라미터화(static parameterization)를 넘어 각 입력에 동적으로 적응하는 생성 모델 설계를 위한 새로운 패러다임을 확립한다.
Existing generative models, such as diffusion and auto-regressive networks, are inherently static, relying on a fixed set of pretrained parameters to handle all inputs. In contrast, humans flexibly adapt their internal generative representations to each perceptual or imaginative context. Inspired by this capability, we introduce Composer, a new paradigm for adaptive generative modeling based on test-time instance-specific parameter composition. Composer generates input-conditioned parameter adaptations at inference time, which are injected into the pretrained model's weights, enabling per-input specialization without fine-tuning or retraining. Adaptation occurs once prior to multi-step generation, yielding higher-quality, context-aware outputs with minimal computational and memory overhead. Experiments show that Composer substantially improves performance across diverse generative models and use cases, including lightweight/quantized models and test-time scaling. By leveraging input-aware parameter composition, Composer establishes a new paradigm for designing generative models that dynamically adapt to each input, moving beyond static parameterization.
논문 링크
더 읽어보기
https://github.com/tmtuan1307/Composer
선형 회귀와 선형 신경망에서의 전이 학습에 대한 기대 오차 상한 / Expectation Error Bounds for Transfer Learning in Linear Regression and Linear Neural Networks

논문 소개
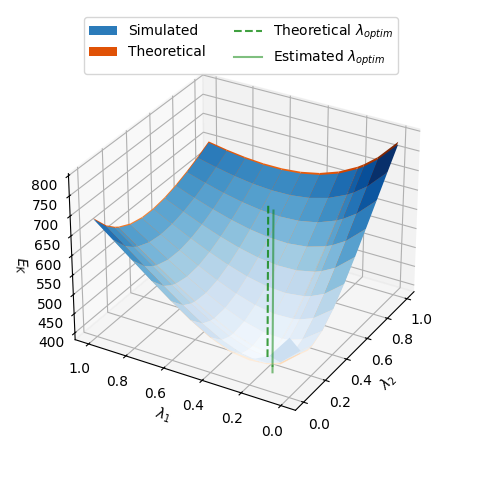
전이 학습에서 보조 데이터가 주된 작업의 일반화를 언제, 어떤 방식으로 향상시키는지는 오랫동안 중요한 질문이었지만, 그 효과를 정밀하게 설명하는 이론적 기준은 아직 충분히 정립되지 않았습니다. 이에 따라 본 연구는 가장 분석 가능한 두 가지 선형 설정, 즉 일반 최소제곱 회귀(ordinary least squares, OLS)와 과소모수화된 선형 신경망(under-parameterized linear neural networks)에서 보조 작업의 효용을 수식적으로 규명하고자 합니다. 선형 회귀의 경우 저자들은 기대 일반화 오차를 편향-분산 분해(bias-variance decomposition)와 함께 정확한 닫힌형(closed-form)으로 유도하여, 보조 작업이 실제로 도움이 되는 필요충분조건을 제시합니다. 이 결과는 단순히 보조 데이터의 양이 많을수록 좋다는 직관을 넘어, 주 작업과 보조 작업 사이의 정렬, 신호 대 잡음비(signal-to-noise ratio, SNR), 그리고 가중치 선택이 성능을 좌우한다는 점을 명확히 보여줍니다. 또한 각 보조 작업에 부여할 최적의 작업 가중치(task weight)를 계산 가능한 최적화 프로그램의 해로 표현하고, 경험적으로 추정한 가중치가 점차 그 최적값에 수렴한다는 일관성(consistency)까지 보장합니다.
선형 신경망에서는 공유 표현(shared representation)의 폭이 제한된 상황에서 전이 학습의 효과를 분석하며, 이때는 회귀보다 훨씬 복잡한 상호작용이 발생합니다. 저자들은 폭이 q \le K인 공유 표현을 갖는 과소모수화된 모델에 대해 비점근적(non-asymptotic) 기대 오차 상한을 도출하고, 이 설정에서 처음으로 공허하지 않은(non-vacuous) 충분조건을 제시합니다. 특히 이 상한은 보조 작업들이 주 작업에 유리하게 작용할 수 있는 구조적 조건을 구체화하며, 어떤 작업에 더 큰 비중을 두고 어떤 작업은 덜 반영해야 하는지에 대한 원리적 방향도 함께 제시합니다. 이러한 결과는 전이 학습을 경험적 휴리스틱이 아니라, 유한 표본에서도 의미를 갖는 정량적 이론으로 끌어올린다는 점에서 의의가 큽니다.
이러한 분석을 가능하게 한 핵심 기술적 기여는 랜덤 행렬에 대한 새로운 열 단위(column-wise) 저랭크(low-rank) 섭동(bound)입니다. 기존의 저랭크 섭동 결과가 행렬 전체의 거친 변화만을 다루는 경향이 있었다면, 본 연구의 상한은 개별 열 구조를 보존하면서 신호와 잡음의 미세한 상호작용을 더 정밀하게 추적합니다. 이를 통해 랭크 절단된 표현이 잡음에 의해 얼마나 흔들리는지, 그리고 어떤 특이값 간격(spectral gap) 아래에서 구조가 안정적으로 유지되는지를 더 세밀하게 설명할 수 있습니다. 직사각 행렬에 대해서는 Hermitian dilation을 활용하여 대칭 행렬 분석으로 환원함으로써 동일한 형태의 상한을 확장하고, 실제 전이 학습에서 자주 등장하는 비정방형 표현 행렬에도 이론을 적용할 수 있게 합니다. 마지막으로 제어된 매개변수를 가진 합성 데이터 실험을 통해, 신호가 충분히 강하고 작업 간 정렬이 잘 이루어질 때 일반화 성능이 향상되며, 그렇지 않으면 보조 학습이 오히려 해가 될 수 있음을 확인합니다. 결과적으로 이 연구는 전이 학습에서 보조 데이터의 가치를 선형 회귀와 선형 신경망이라는 두 대표적 모형에서 서로 다른 정밀도로 설명하며, 향후 더 복잡한 다중 작업 표현 학습 이론으로 확장될 수 있는 견고한 기반을 제시합니다.
초록(Abstract)
전이 학습에서 학습기는 보조 데이터를 활용하여 주된 작업에서의 일반화를 향상시킵니다. 그러나 보조 데이터가 언제, 그리고 어떻게 도움이 되는지에 대한 정확한 이론적 이해는 아직 불완전합니다. 본 논문은 두 가지 전형적인 선형 설정, 즉 일반 최소제곱 회귀와 과소모수화된 선형 신경망에서 이 문제에 대한 새로운 통찰을 제시합니다. 선형 회귀의 경우, 우리는 편향-분산 분해를 사용한 기대 일반화 오차의 정확한 닫힌형 표현식을 유도하여, 보조 작업이 주된 작업의 일반화를 향상시키기 위한 필요충분조건을 도출합니다. 또한 해가 존재하는 최적화 프로그램의 출력으로서 전역적으로 최적인 작업 가중치도 유도하며, 경험적 추정치에 대한 일관성 보장도 제시합니다. 폭이 q \leq K 인 공유 표현을 갖는 선형 신경망의 경우, 여기서 K 는 보조 작업의 수입니다, 우리는 일반화 오차에 대한 비점근적 기대 상한을 유도하여, 이 설정에서 유익한 보조 학습에 대한 최초의 비공허한 충분조건과 작업 가중치 선정을 위한 원리적 방향을 제공합니다. 이를 위해 우리는 랜덤 행렬에 대한 새로운 열 단위 저랭크 섭동 상한을 증명하였으며, 이는 세밀한 열 구조를 보존함으로써 기존 상한을 개선합니다. 우리의 결과는 제어된 매개변수로 시뮬레이션된 합성 데이터에서 검증되었습니다.
In transfer learning, the learner leverages auxiliary data to improve generalization on a main task. However, the precise theoretical understanding of when and how auxiliary data help remains incomplete. We provide new insights on this issue in two canonical linear settings: ordinary least squares regression and under-parameterized linear neural networks. For linear regression, we derive exact closed-form expressions for the expected generalization error with bias-variance decomposition, yielding necessary and sufficient conditions for auxiliary tasks to improve generalization on the main task. We also derive globally optimal task weights as outputs of solvable optimization programs, with consistency guarantees for empirical estimates. For linear neural networks with shared representations of width q \leq K, where K is the number of auxiliary tasks, we derive a non-asymptotic expectation bound on the generalization error, yielding the first non-vacuous sufficient condition for beneficial auxiliary learning in this setting, as well as principled directions for task weight curation. We achieve this by proving a new column-wise low-rank perturbation bound for random matrices, which improves upon existing bounds by preserving fine-grained column structures. Our results are verified on synthetic data simulated with controlled parameters.
논문 링크
DataFlex: 대규모 언어 모델(LLM)의 데이터 중심 동적 학습을 위한 통합 프레임워크 / DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
논문 소개
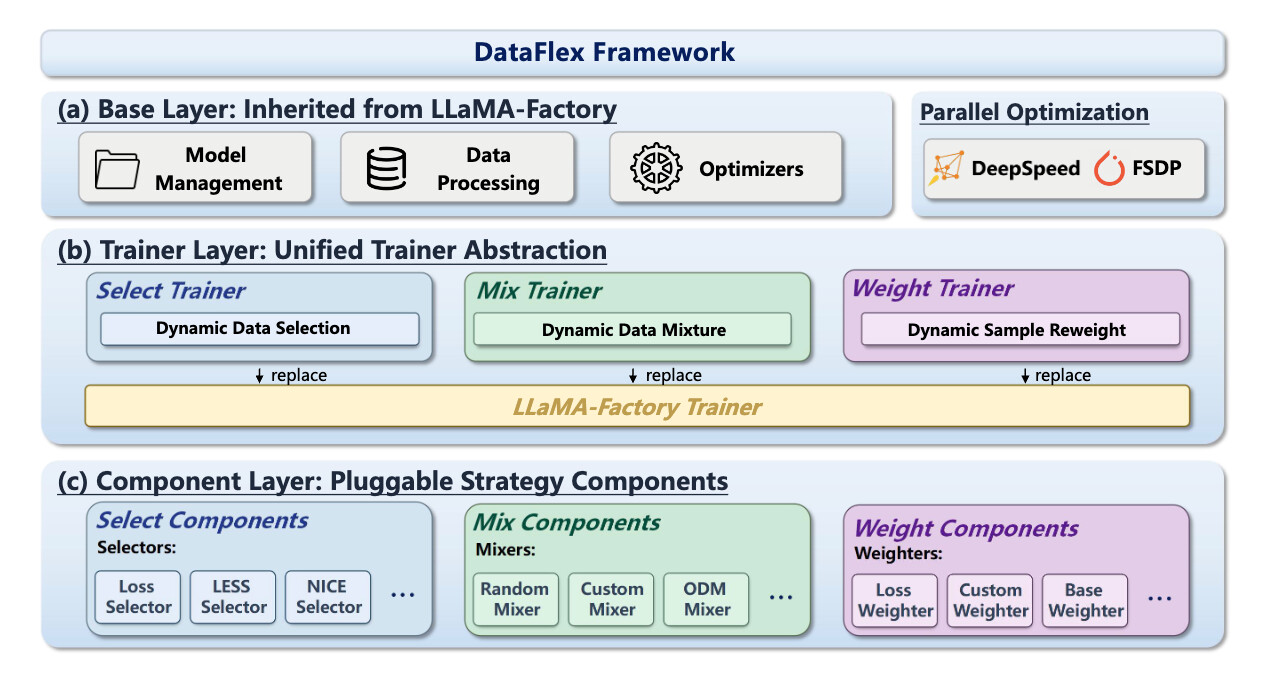
대규모 언어 모델(large language model, LLM)의 성능 향상은 이제 모델 구조나 옵티마이저 최적화에만 의존하지 않으며, 어떤 데이터를 선택하고 어떤 비율로 섞고 어떤 샘플에 더 큰 학습 신호를 줄지에 따라 결과가 크게 달라집니다. 이러한 흐름 속에서 데이터 중심 학습(data-centric training)은 학습 과정 전반에서 데이터 자체를 최적화 대상으로 다루는 접근으로 주목받고 있지만, 기존의 샘플 선택, 도메인 혼합 최적화, 샘플 재가중치 방법들은 각기 다른 코드베이스와 인터페이스에 흩어져 있어 재현성과 공정한 비교가 어렵다는 한계를 지니고 있습니다. DataFlex는 이러한 문제를 해결하기 위해 LLaMA-Factory 위에 구축된 통합 프레임워크로, 기존 학습 워크플로를 유지하면서도 데이터 중심의 동적 조정을 자연스럽게 삽입할 수 있도록 설계되었습니다. 특히 샘플 선택, 도메인 혼합 조정, 샘플 재가중치라는 세 가지 핵심 패러다임을 하나의 체계 안에 포괄하며, 각 방법이 공통적으로 요구하는 임베딩 추출, 추론, 그래디언트 계산을 표준화된 인터페이스로 묶어 모델 종속 연산의 중복과 구현 차이를 줄였습니다. 이를 통해 연구자는 알고리즘의 핵심 아이디어에 집중할 수 있고, 실험자는 동일한 학습 조건에서 서로 다른 방법을 더 공정하게 비교할 수 있습니다.
프레임워크의 중심에는 Select Trainer, Mix Trainer, Weight Trainer라는 모듈형 추상화가 있으며, 이는 각각 데이터 샘플을 선별하는 방식, 여러 도메인 또는 코퍼스의 비율을 조정하는 방식, 개별 샘플의 손실 기여도를 조절하는 방식을 담당합니다. 이러한 설계는 온라인 방식과 오프라인 방식의 경계를 느슨하게 만들고, 데이터 결정이 학습 전후와 학습 중 모두에서 유연하게 조정될 수 있음을 보여줍니다. 또한 DataFlex는 DeepSpeed ZeRO-3 같은 대규모 분산 학습 설정과도 호환되도록 구현되어, 단순한 연구용 데모가 아니라 실제 대규모 학습 환경에서도 사용할 수 있는 실용적 기반을 제공합니다. 실험적으로는 Mistral-7B와 Llama-3.2-3B에서 동적 샘플 선택이 정적 전체 데이터 학습보다 MMLU 성능을 일관되게 향상시켰고, Qwen2.5-1.5B를 SlimPajama로 사전학습한 설정에서는 DoReMi와 ODM이 기본 데이터 비율보다 더 높은 MMLU 정확도와 더 낮은 코퍼스 수준 퍼플렉시티를 달성했습니다. 특히 이러한 개선이 6B와 30B 토큰 규모 모두에서 관찰되었다는 점은, 데이터 중심 최적화가 소규모 실험을 넘어 실제 사전학습 단계에서도 유효함을 시사합니다. 더 나아가 DataFlex는 원래 구현 대비 실행 시간 측면에서도 일관된 개선을 보였는데, 이는 성능 향상뿐 아니라 시스템 효율성과 재현성까지 함께 확보했다는 의미입니다. 결국 DataFlex는 데이터 중심 학습을 개별 기법의 집합이 아니라, 대규모 언어 모델 훈련 전반을 지배하는 통합적 방법론으로 재구성하며, 데이터-모델 상호작용을 체계적으로 다루는 새로운 연구 기반을 제시합니다.
초록(Abstract)
데이터 중심 학습은 최적화 과정에서 모델 파라미터뿐만 아니라 학습 데이터의 선택, 구성, 가중치까지 최적화함으로써 대규모 언어 모델(LLM)을 개선하기 위한 유망한 방향으로 부상하고 있다. 그러나 기존의 데이터 선택, 데이터 혼합 최적화, 데이터 재가중치 조정 접근법은 대개 일관되지 않은 인터페이스를 가진 서로 분리된 코드베이스에서 개발되어, 재현성, 공정한 비교, 실질적 통합을 저해한다. 본 논문에서는 LLaMA-Factory 위에 구축된 통합 데이터 중심 동적 학습 프레임워크인 DataFlex를 제안한다. DataFlex는 샘플 선택, 도메인 혼합 조정, 샘플 재가중치 조정이라는 세 가지 주요 동적 데이터 최적화 패러다임을 지원하면서도 원래의 학습 워크플로와 완전히 호환된다. 또한 확장 가능한 트레이너 추상화와 모듈형 구성 요소를 제공하여 표준 LLM 학습을 그대로 대체할 수 있게 하며, DeepSpeed ZeRO-3를 포함한 대규모 설정을 지원하면서 임베딩 추출, 추론, 그래디언트 계산과 같은 핵심 모델 종속 연산을 통합한다. 우리는 여러 데이터 중심 방법에 걸쳐 포괄적인 실험을 수행했다. 동적 데이터 선택은 Mistral-7B와 Llama-3.2-3B 모두에서 MMLU에 대해 정적 전체 데이터 학습을 일관되게 상회했다. 데이터 혼합의 경우, DoReMi와 ODM은 6B 및 30B 토큰 규모에서 SlimPajama로 Qwen2.5-1.5B를 사전학습할 때 기본 비율보다 MMLU 정확도와 코퍼스 수준 퍼플렉시티를 모두 개선했다. DataFlex는 또한 원래 구현 대비 일관된 실행 시간 개선을 달성했다. 이러한 결과는 DataFlex가 대규모 언어 모델(LLM)의 데이터 중심 동적 학습을 위한 효과적이고 효율적이며 재현 가능한 인프라를 제공함을 보여준다.
Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()