[2026/04/13 ~ 19] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주에 선정된 10편의 논문들을 분석한 결과, 최근 인공지능 연구가 단순한 모델의 크기 확장을 넘어 시스템적 상호작용, 내부 기작의 해석, 그리고 실사용 환경 최적화로 나아가고 있음을 확인할 수 있었습니다. 주요한 트렌드는 다음과 같습니다:
![]() 단순 협력을 넘어선 다중 에이전트(Multi-Agent) 시스템의 사회적·구조적 진화: 에이전트들이 단순히 역할을 분담하는 것을 넘어, 인간 사회의 소통 및 거버넌스 방식을 모방하며 효율성을 극대화하는 방향으로 연구가 고도화되고 있습니다. AgentElect는 선거 제도를 다중 에이전트 환경에 도입해 LLM 사회 집단의 협력과 전체 후생을 크게 높일 수 있음을 입증했고, HANDRAISER는 인간의 대화처럼 청자가 적절한 시점에 개입하고 중단하는 법을 학습시켜 불필요한 통신 비용을 획기적으로 줄였습니다. 또한 AiScientist는 파일 기반의 영속적인 상태 유지와 계층적 오케스트레이션을 통해 장기 호흡의 ML 연구를 완주해 냈습니다. 이는 다중 에이전트 시스템이 개별 모델의 지능을 넘어서, 사회적 규범과 구조적 오케스트레이션을 갖춘 '조직'의 형태로 발전하고 있음을 보여줍니다.
단순 협력을 넘어선 다중 에이전트(Multi-Agent) 시스템의 사회적·구조적 진화: 에이전트들이 단순히 역할을 분담하는 것을 넘어, 인간 사회의 소통 및 거버넌스 방식을 모방하며 효율성을 극대화하는 방향으로 연구가 고도화되고 있습니다. AgentElect는 선거 제도를 다중 에이전트 환경에 도입해 LLM 사회 집단의 협력과 전체 후생을 크게 높일 수 있음을 입증했고, HANDRAISER는 인간의 대화처럼 청자가 적절한 시점에 개입하고 중단하는 법을 학습시켜 불필요한 통신 비용을 획기적으로 줄였습니다. 또한 AiScientist는 파일 기반의 영속적인 상태 유지와 계층적 오케스트레이션을 통해 장기 호흡의 ML 연구를 완주해 냈습니다. 이는 다중 에이전트 시스템이 개별 모델의 지능을 넘어서, 사회적 규범과 구조적 오케스트레이션을 갖춘 '조직'의 형태로 발전하고 있음을 보여줍니다.
![]() 결과 중심 평가에서 내부 기작(Mechanism) 해석 및 신뢰성 규명으로의 전환: 단순히 결과물이 정답인지 확인하는 것을 넘어, 블랙박스 내부에서 모델이 어떻게 추론하고 학습하는지를 기계론적으로 규명하려는 시도가 두드러집니다. CodeQ는 토큰 단위의 지엽적인 해석을 넘어 모델이 들여쓰기 같은 얕은 문법인지 깊은 의미론인지 어떤 코드 개념에 의존하는지 전역적으로(global) 파악하는 프레임워크를 제시했습니다. Latent Planning은 모델 규모가 커짐에 따라 특정 목표를 향해 문맥을 능동적으로 조정하는 '잠재적 계획(latent planning)' 능력이 어떻게 내부 회로에서 발현되는지 증명했습니다. 아울러 언러닝과 언트레이닝(Unlearning vs Untraining) 연구는 삭제 알고리즘의 목표를 명확히 분리하여 평가의 모호성을 바로잡았으며, 이는 모두 실산업 적용을 위해 AI의 투명성과 신뢰성을 확보하려는 필수적인 발걸음입니다.
결과 중심 평가에서 내부 기작(Mechanism) 해석 및 신뢰성 규명으로의 전환: 단순히 결과물이 정답인지 확인하는 것을 넘어, 블랙박스 내부에서 모델이 어떻게 추론하고 학습하는지를 기계론적으로 규명하려는 시도가 두드러집니다. CodeQ는 토큰 단위의 지엽적인 해석을 넘어 모델이 들여쓰기 같은 얕은 문법인지 깊은 의미론인지 어떤 코드 개념에 의존하는지 전역적으로(global) 파악하는 프레임워크를 제시했습니다. Latent Planning은 모델 규모가 커짐에 따라 특정 목표를 향해 문맥을 능동적으로 조정하는 '잠재적 계획(latent planning)' 능력이 어떻게 내부 회로에서 발현되는지 증명했습니다. 아울러 언러닝과 언트레이닝(Unlearning vs Untraining) 연구는 삭제 알고리즘의 목표를 명확히 분리하여 평가의 모호성을 바로잡았으며, 이는 모두 실산업 적용을 위해 AI의 투명성과 신뢰성을 확보하려는 필수적인 발걸음입니다.
![]() 학습과 추론(Test-time)의 경계를 허무는 동적 학습 및 파이프라인 통합: 모델 학습 후 정적으로 추론만 하던 전통적 방식에서 벗어나, 실행 시점의 자원 스케일링과 실시간 진화를 고려한 시스템 설계가 부상하고 있습니다. RL^V는 추론기와 생성형 검증기를 통합하여 학습시킴으로써, 별도의 검증 모델 없이도 테스트 시점의 계산량 확장 효율을 최대 32배까지 끌어올렸습니다. MIA는 추론이 진행되는 동안에도 멈추지 않고 메모리와 탐색 계획을 실시간으로 갱신하는 테스트 타임 학습(test-time learning) 메커니즘을 에이전트에 도입했습니다. 이와 함께 ClawGUI는 파편화되어 있던 학습, 평가, 실제 기기 배포를 하나의 풀스택 인프라로 묶어냈는데, 이는 AI 기술이 닫힌 실험실의 벤치마크 경쟁을 넘어 동적으로 진화하는 실사용 시스템 공학으로 넘어가고 있음을 시사합니다.
학습과 추론(Test-time)의 경계를 허무는 동적 학습 및 파이프라인 통합: 모델 학습 후 정적으로 추론만 하던 전통적 방식에서 벗어나, 실행 시점의 자원 스케일링과 실시간 진화를 고려한 시스템 설계가 부상하고 있습니다. RL^V는 추론기와 생성형 검증기를 통합하여 학습시킴으로써, 별도의 검증 모델 없이도 테스트 시점의 계산량 확장 효율을 최대 32배까지 끌어올렸습니다. MIA는 추론이 진행되는 동안에도 멈추지 않고 메모리와 탐색 계획을 실시간으로 갱신하는 테스트 타임 학습(test-time learning) 메커니즘을 에이전트에 도입했습니다. 이와 함께 ClawGUI는 파편화되어 있던 학습, 평가, 실제 기기 배포를 하나의 풀스택 인프라로 묶어냈는데, 이는 AI 기술이 닫힌 실험실의 벤치마크 경쟁을 넘어 동적으로 진화하는 실사용 시스템 공학으로 넘어가고 있음을 시사합니다.
기계학습 연구를 위한 자율적 장기 과제 엔지니어링을 향하여 / Toward Autonomous Long-Horizon Engineering for ML Research
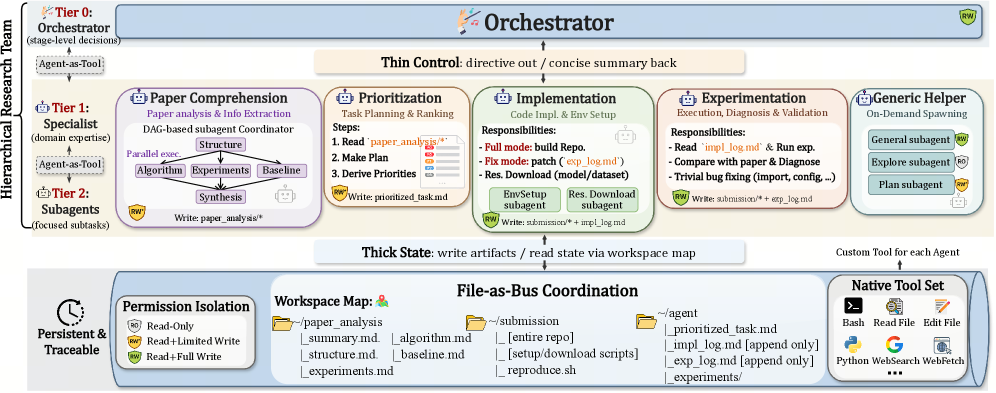
논문 소개
최근 대규모 언어 모델(LLM) 기반 에이전트는 단발성 소프트웨어 공학(SWE) 과제에서는 빠르게 성과를 내고 있지만, 작업 이해, 환경 구성, 구현, 실험, 디버깅이 길게 이어지는 장기 연구 엔지니어링에서는 여전히 안정적으로 완주하기 어렵습니다. AiScientist는 이러한 한계를 국소적 추론의 부족이 아니라 여러 단계에 걸친 상태를 오래 유지하고 조정해야 하는 시스템 문제로 보고, 구조화된 오케스트레이션과 지속적인 상태 연속성을 결합한 자율 수행 체계를 제안합니다. 핵심 방법은 상위 Orchestrator가 간결한 요약과 작업 공간 지도로 단계 수준의 방향만 관리하고, 전문화된 에이전트들이 분석, 계획, 코드, 실험 결과 같은 영속적 아티팩트를 반복적으로 참조하며 작업을 이어 가는 계층적 조정 구조입니다. 특히 권한이 구분된 File-as-Bus 작업 공간을 통해 대화 기록에만 의존하지 않고 파일에 저장된 근거를 중심으로 재정렬(re-grounding)하게 함으로써, 얇은 제어로 두꺼운 상태를 다루는 방식을 구현합니다. 이런 설계는 여러 에이전트가 비동기적으로 협업할 때 발생하는 상태 불일치와 통합 충돌을 줄이고, 장시간에 걸친 프로젝트 맥락을 안정적으로 보존한다는 점에서 의미가 큽니다. 또한 인간 개발자가 git worktree, 병합, 테스트 검증을 이용해 대규모 프로젝트를 운영하는 방식에서 착안하여, 자율 에이전트의 협업을 버전 관리와 검증이 내장된 실행 프로토콜로 구체화했다는 점에서 방법론적 신선함이 있습니다. 실험적으로는 두 개의 상보적인 벤치마크에서 성능 향상이 확인되었는데, PaperBench에서는 최적 기준선 대비 평균 10.54점 향상을 보였고, MLE-Bench Lite에서는 81.82 Any Medal%를 달성하여 장기 과제에서의 실질적 효용을 입증했습니다. 더 나아가 File-as-Bus 프로토콜을 제거하면 성능이 PaperBench에서 6.41점, MLE-Bench Lite에서 31.82점 하락해, 지속 가능한 파일 기반 상태 관리가 단순한 구현 세부가 아니라 성능을 좌우하는 핵심 요소임을 보여 줍니다. 종합하면, AiScientist는 장기 ML 연구 엔지니어링을 개별 추론 능력보다 프로젝트 상태를 어떻게 조직하고 보존하며 재활용할 것인가의 문제로 재정의하고, 이를 통해 자율 에이전트가 복잡한 연구 과정을 끝까지 수행할 수 있는 가능성을 제시합니다.
초록(Abstract)
자율형 인공지능(AI) 연구는 빠르게 발전해 왔지만, 장기 호흡 머신러닝(ML) 연구 엔지니어링은 여전히 어렵습니다. 에이전트는 수 시간 또는 수일에 걸쳐 과제 이해, 환경 설정, 구현, 실험, 디버깅 전반에서 일관된 진전을 유지해야 합니다. 우리는 단순한 원칙, 즉 강력한 장기 호흡 성능에는 구조화된 오케스트레이션과 지속적인 상태 연속성이 모두 필요하다는 원칙 위에 구축된, 머신러닝 연구를 위한 자율적 장기 호흡 엔지니어링 시스템인 AiScientist를 소개합니다. 이를 위해 AiScientist는 계층적 오케스트레이션과 권한 범위가 지정된 File-as-Bus 작업공간을 결합합니다. 상위 수준의 오케스트레이터는 간결한 요약과 작업공간 맵을 통해 단계 수준의 제어를 유지하며, 전문화된 에이전트는 대화상의 인계에 주로 의존하는 대신 분석, 계획, 코드, 실험 증거와 같은 지속적인 산출물에 반복적으로 재그라운딩함으로써, 두꺼운 상태에 대한 얇은 제어를 구현합니다. 서로 보완적인 두 개의 벤치마크 전반에서 AiScientist는 가장 잘 매칭된 베이스라인 대비 PaperBench 점수를 평균 10.54점 향상시키고, MLE-Bench Lite에서 Any Medal% 81.82를 달성합니다. 또한 제거 실험은 File-as-Bus 프로토콜이 성능의 핵심 동인임을 보여줍니다. 이를 제거하면 PaperBench는 6.41점, MLE-Bench Lite는 31.82포인트 하락합니다. 이러한 결과는 장기 호흡 머신러닝 연구 엔지니어링이 순수한 국소 추론 문제가 아니라, 지속적인 프로젝트 상태 위에서 전문화된 작업을 조정하는 시스템 문제임을 시사합니다.
Autonomous AI research has advanced rapidly, but long-horizon ML research engineering remains difficult: agents must sustain coherent progress across task comprehension, environment setup, implementation, experimentation, and debugging over hours or days. We introduce AiScientist, a system for autonomous long-horizon engineering for ML research built on a simple principle: strong long-horizon performance requires both structured orchestration and durable state continuity. To this end, AiScientist combines hierarchical orchestration with a permission-scoped File-as-Bus workspace: a top-level Orchestrator maintains stage-level control through concise summaries and a workspace map, while specialized agents repeatedly re-ground on durable artifacts such as analyses, plans, code, and experimental evidence rather than relying primarily on conversational handoffs, yielding thin control over thick state. Across two complementary benchmarks, AiScientist improves PaperBench score by 10.54 points on average over the best matched baseline and achieves 81.82 Any Medal% on MLE-Bench Lite. Ablation studies further show that File-as-Bus protocol is a key driver of performance, reducing PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points when removed. These results suggest that long-horizon ML research engineering is a systems problem of coordinating specialized work over durable project state, rather than a purely local reasoning problem.
논문 링크
더 읽어보기
ClawGUI: GUI 에이전트의 학습, 평가 및 배포를 위한 통합 프레임워크 / ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
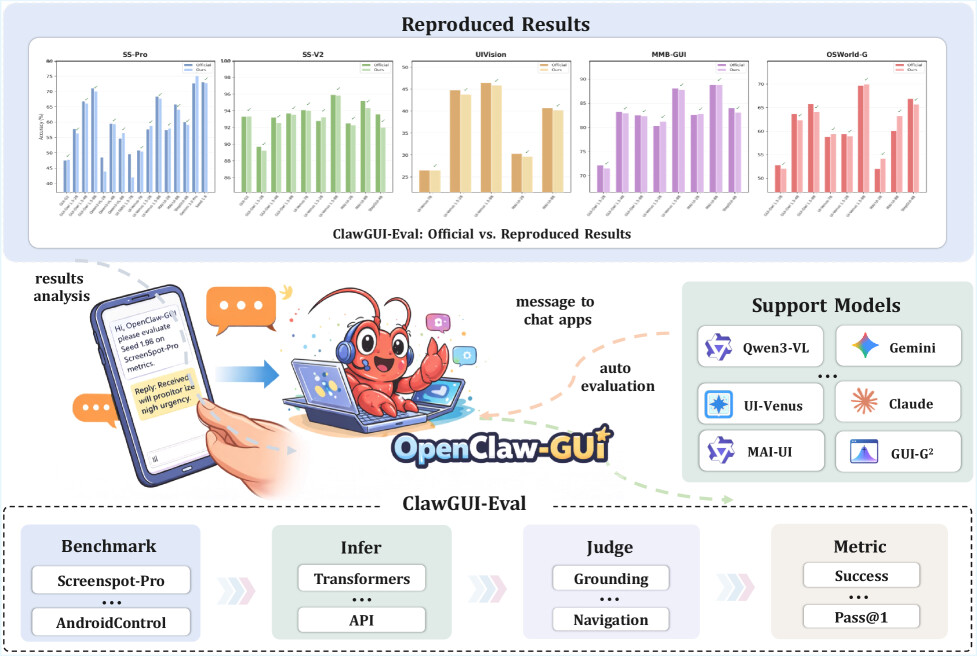
논문 소개
그래픽 사용자 인터페이스(Graphical User Interface, GUI) 기반 에이전트는 프로그램적 응용 프로그램 인터페이스 대신 시각적 화면을 통해 애플리케이션을 조작함으로써, 탭, 스와이프, 키 입력과 같은 인간 중심의 상호작용으로 다양한 소프트웨어를 다룰 수 있게 해줍니다. 이러한 접근은 명령줄 인터페이스(Command Line Interface, CLI) 기반 에이전트가 접근하기 어려운 긴 꼬리(long tail) 애플리케이션까지 확장 가능하다는 점에서 큰 잠재력을 지니지만, 실제 연구 현장에서는 모델의 표현력보다 학습, 평가, 배포를 아우르는 일관된 인프라의 부재가 더 큰 병목으로 작용해 왔습니다. 온라인 강화학습(Reinforcement Learning, RL)은 환경의 불안정성과 폐쇄적인 파이프라인 때문에 재현성이 낮고, 벤치마크별 평가 방식도 세부 설정의 차이로 인해 조용히 달라지기 쉬우며, 학습된 에이전트가 실제 사용자와 실제 기기에서 작동하는 사례는 매우 제한적이었습니다. ClawGUI는 이러한 세 가지 문제를 하나의 통합 하니스(harness) 안에서 해결하려는 오픈소스 프레임워크로, GUI 에이전트 연구를 개별 모델 중심의 접근에서 전체 시스템 중심의 접근으로 전환한다는 점에서 의의가 큽니다.
ClawGUI의 첫 번째 축인 ClawGUI-RL은 병렬 가상 환경과 실제 물리 디바이스를 모두 지원하는 GUI 에이전트 강화학습 인프라로 설계되었으며, GiGPO와 프로세스 보상 모델(Process Reward Model, PRM)을 결합해 단계 수준의 촘촘한 감독 신호를 제공합니다. 이는 최종 성공 여부만을 보는 희소한 보상 구조의 한계를 완화하고, 복잡한 UI 조작 과정에서 중간 행동의 품질까지 반영할 수 있게 한다는 점에서 방법론적 중요성이 있습니다. 두 번째 축인 ClawGUI-Eval은 6개 벤치마크와 11개 이상의 모델에 대해 추론, 채점, 메트릭 계산을 완전히 표준화하여, 서로 다른 논문 간 비교를 어렵게 만들던 프롬프트 형식, 좌표 정규화, 해상도, 샘플링 온도, 후처리 규칙의 차이를 최소화합니다. 이 표준화된 평가 체계는 공식 베이스라인 대비 95.8%의 재현율을 달성하며, 결과 비교의 공정성과 재현 가능성을 실질적으로 높였다는 점에서 벤치마킹 인프라로서의 가치를 보여줍니다.
세 번째 축인 ClawGUI-Agent는 학습된 에이전트를 Android, HarmonyOS, iOS로 확장하고, 12개 이상의 채팅 플랫폼을 통해 실제 사용자 환경에 연결하는 배포 계층입니다. 특히 하이브리드 CLI-GUI 제어와 지속적인 개인화 메모리(persistent personalized memory)를 결합함으로써, 단순한 화면 조작을 넘어 텍스트 기반 상호작용과 시각적 조작을 유기적으로 통합하는 실사용 중심의 에이전트 경험을 지향합니다. 이러한 통합 구조 위에서 end-to-end로 학습된 ClawGUI-2B는 MobileWorld GUI-Only에서 17.1%의 성공률을 기록하며, 동일 규모의 MAI-UI-2B 기준선보다 6.0%p 높은 성능을 보였습니다. 결국 ClawGUI는 단일 모델의 점진적 개선보다, 학습 가능한 환경, 신뢰할 수 있는 평가, 실제 배포 가능성을 하나의 연속된 체계로 묶는 것이 GUI 에이전트 발전의 핵심임을 설득력 있게 제시합니다. 이러한 접근은 GUI 에이전트 연구를 실험실 내부의 성능 경쟁에서 벗어나, 실제 사용자에게 전달 가능한 시스템 공학의 문제로 확장시킨다는 점에서 중요한 방법론적 전환으로 볼 수 있습니다.
초록(Abstract)
GUI 에이전트는 프로그래밍 API 대신 시각적 인터페이스를 통해 애플리케이션을 구동하며, 탭, 스와이프, 키 입력으로 임의의 소프트웨어와 상호작용해 CLI 기반 에이전트가 도달할 수 없는 긴 꼬리(long tail)의 애플리케이션에 도달한다. 그러나 이 분야의 진전은 모델링 역량보다 일관된 풀스택 인프라의 부재에 의해 더 크게 제약된다. 온라인 강화학습(RL) 학습은 환경 불안정성과 폐쇄형 파이프라인으로 인해 어려움을 겪고, 평가 프로토콜은 논문마다 조용히 달라지며, 학습된 에이전트가 실제 기기에서 실제 사용자에게 전달되는 경우도 드물다. 우리는 이 세 가지 격차를 하나의 통합 하니스에서 해결하는 오픈소스 프레임워크 \textbf{ClawGUI} 를 제시한다. \textbf{ClawGUI-RL} 은 병렬 가상 환경과 실제 물리 디바이스 모두에 대해 검증된 지원을 제공하는 최초의 오픈소스 GUI 에이전트 RL 인프라로, GiGPO와 프로세스 보상 모델(Process Reward Model, PRM)을 통합하여 촘촘한 단계 수준(step-level) 감독을 제공한다. \textbf{ClawGUI-Eval} 은 6개 벤치마크와 11개 이상의 모델 전반에 걸쳐 완전히 표준화된 평가 파이프라인을 강제하며, 공식 베이스라인 대비 95.8%의 재현율을 달성한다. \textbf{ClawGUI-Agent} 는 하이브리드 CLI-GUI 제어와 지속적인 개인화 메모리를 갖춘 12개 이상의 채팅 플랫폼을 통해 학습된 에이전트를 Android, HarmonyOS, iOS로 가져온다. 이 파이프라인 내에서 end-to-end로 학습된 \textbf{ClawGUI-2B}는 MobileWorld GUI-Only에서 17.1%의 성공률을 달성하며, 동일 규모의 MAI-UI-2B 베이스라인을 6.0%포인트 상회한다.
GUI agents drive applications through their visual interfaces instead of programmatic APIs, interacting with arbitrary software via taps, swipes, and keystrokes, reaching a long tail of applications that CLI-based agents cannot. Yet progress in this area is bottlenecked less by modeling capacity than by the absence of a coherent full-stack infrastructure: online RL training suffers from environment instability and closed pipelines, evaluation protocols drift silently across works, and trained agents rarely reach real users on real devices. We present \textbf{ClawGUI}, an open-source framework addressing these three gaps within a single harness. \textbf{ClawGUI-RL} provides the first open-source GUI agent RL infrastructure with validated support for both parallel virtual environments and real physical devices, integrating GiGPO with a Process Reward Model for dense step-level supervision. \textbf{ClawGUI-Eval} enforces a fully standardized evaluation pipeline across 6 benchmarks and 11+ models, achieving 95.8% reproduction against official baselines. \textbf{ClawGUI-Agent} brings trained agents to Android, HarmonyOS, and iOS through 12+ chat platforms with hybrid CLI-GUI control and persistent personalized memory. Trained end to end within this pipeline, \textbf{ClawGUI-2B} achieves 17.1% Success Rate on MobileWorld GUI-Only, outperforming the same-scale MAI-UI-2B baseline by 6.0%.
논문 링크
더 읽어보기
대규모 언어 모델(LLM)을 위한 전역적 인간 중심 설명: 토큰에서 해석 가능한 코드와 테스트 생성까지 / Enabling Global, Human-Centered Explanations for LLMs:From Tokens to Interpretable Code and Test Generation
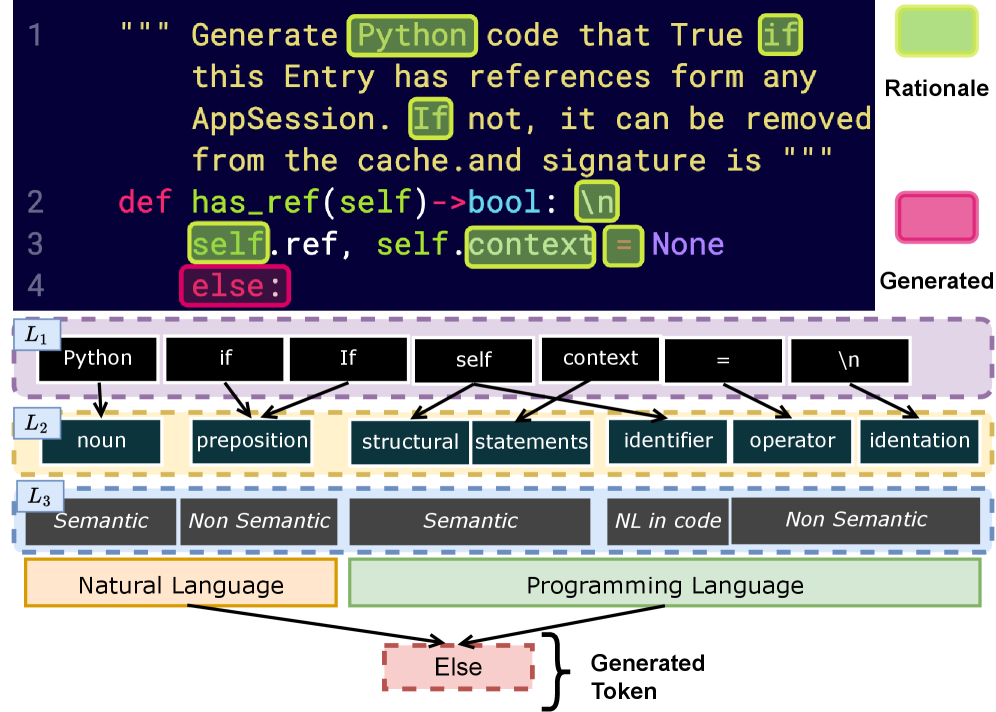
논문 소개
대규모 언어 모델(Large Language Models, LLMs) for Code(LM4Code)의 활용이 소프트웨어 공학 전반으로 확산되면서, 단순히 정답을 맞히는지 여부만으로는 모델의 신뢰성을 충분히 판단하기 어렵다는 문제가 더욱 중요해졌습니다. 이러한 배경에서 저자들은 기존의 사후 해석 기법이 주로 토큰 단위의 국소적 설명에 머무르며, 개발자가 실제로 이해할 수 있는 전역적이고 코드 중심적인 해석을 제공하지 못한다는 한계를 지적합니다. 이를 해결하기 위해 제안된 CodeQ 프레임워크는 토큰 수준의 rationale을 코드 구조, 식별자, 주석, 구문 요소와 같은 고수준 프로그래밍 개념으로 사상한 뒤 이를 집계하여, 모델이 코드 전반에서 어떤 단서를 반복적으로 활용하는지를 통계적으로 드러냅니다. 특히 이 접근은 계층적 개념 체계와 interpretability tensor를 통해 개별 예제의 설명을 전역 패턴으로 확장한다는 점에서 기존 해석 방법과 구별됩니다.
방법론의 핵심은 해석 가능한 개념 집합을 작업별로 정교하게 설계하고, 모델이 부분 입력에서도 일관된 예측을 하도록 word dropout 기반으로 재학습한 뒤, greedy rationalization을 사용해 최소 충분 토큰 집합을 추출하는 데 있습니다. 이후 추출된 토큰 수준 rationale은 AST(Abstract Syntax Tree) 기반의 코드 개념이나 테스트 생성에서의 focal method scoping처럼 인간이 이해할 수 있는 단위로 매핑되며, 여러 시퀀스와 반복 실험에서 얻은 결과는 하나의 전역 텐서로 축약됩니다. 이때 토큰 순서의 세부 정보는 일부 손실되지만, 대신 모델의 구조적 편향과 의미적 추론 부족을 보다 안정적으로 파악할 수 있는 해석 가능성이 확보됩니다. 저자들은 이러한 집계가 단순한 평균화가 아니라 노이즈가 섞인 토큰 수준 신호에서 일관된 추론 패턴을 분리해 내는 과정임을 보여 주며, 실제로 설명 불확실성인 Shannon entropy를 50% 이상 줄이는 효과를 확인합니다.
실험적으로는 codeparrot-small이 깊은 의미 논리보다 indentation과 같은 얕은 문법적 단서를 지속적으로 선호한다는 점이 드러났으며, 이는 정확도 지표만으로는 포착할 수 없는 추론 습관의 편향을 시사합니다. 또한 37명의 참여자를 대상으로 한 사용자 연구에서는 이러한 모델의 추론 방식이 인간 개발자의 사고와 유의하게 어긋난다는 사실이 확인되어, 모델 출력의 신뢰성 평가에서 인간 중심 해석의 필요성을 뒷받침합니다. 더 나아가 LIME(Local Interpretable Model-agnostic Explanations)이나 SHAP(SHapley Additive exPlanations) 같은 기존 기법이 제공하는 로컬 설명과 달리, CodeQ는 수천 개의 설명을 종합해 시스템 수준의 행동 양식을 드러낸다는 점에서 한 단계 더 나아갑니다. 결국 이 연구는 LM4Code의 신뢰성을 높이기 위해서는 “무엇을 맞혔는가”보다 “어떤 근거로 맞혔는가”를 보여 주는 전역적, 코드 기반 해석이 필수적이라는 점을 설득력 있게 제시하며, 생성형 코드 모델의 설명 가능성 연구에 중요한 방법론적 전환점을 제공합니다.
초록(Abstract)
코드용 대규모 언어 모델(LM4Code)이 소프트웨어 공학에 필수적인 요소가 되면서, 그 출력에 대한 신뢰를 구축하는 일이 중요해지고 있습니다. 그러나 표준 정확도 지표는 생성 모델의 근본적인 추론 과정을 가려, 의사결정이 어떻게 이루어지는지에 대한 통찰을 거의 제공하지 못합니다. 사후 해석 가능성 방법들이 이러한 공백을 메우려 시도하지만, 대개 설명을 국소적인 토큰 수준의 통찰로 제한하여 개발자가 이해할 수 있는 전역적 분석을 제공하지 못합니다. 본 연구는 모델이 코드 전반에서 어떻게 추론하는지 드러내는 \textbf{전역적이고 코드 기반인} 설명의 시급한 필요성을 강조합니다. 이 비전을 지원하기 위해, 우리는 토큰 수준의 근거를 상위 수준의 프로그래밍 범주에 매핑함으로써 전역적 해석 가능성을 제공하는 프레임워크인 \textit{Code Rationales}(CodeQ) 를 제안합니다. 이러한 토큰 수준 설명 수천 개를 집계하면 체계적인 추론 행동을 드러내는 통계적 분석을 수행할 수 있습니다. 우리는 이 집계가 노이즈가 많은 토큰 데이터에서 명확한 신호를 추출함으로써 설명 불확실성(샤논 엔트로피)을 50% 이상 줄인다는 점을 보여주어 이를 검증합니다. 또한 코드 생성 모델(\textit{codeparrot-small})이 더 깊은 의미론적 논리보다 표면적인 구문 단서(예: \textbf{들여쓰기})를 일관되게 선호한다는 사실을 확인했습니다. 더 나아가 37명의 참여자를 대상으로 한 사용자 연구에서, 이 모델의 추론은 인간 개발자의 추론과 유의미하게 불일치함을 발견했습니다. 전통적인 지표로는 드러나지 않는 이러한 결과는 LM4Code에 대한 신뢰를 높이기 위해 전역적 해석 가능성 기법이 얼마나 중요한지를 보여줍니다.
As Large Language Models for Code (LM4Code) become integral to software engineering, establishing trust in their output becomes critical. However, standard accuracy metrics obscure the underlying reasoning of generative models, offering little insight into how decisions are made. Although post-hoc interpretability methods attempt to fill this gap, they often restrict explanations to local, token-level insights, which fail to provide a developer-understandable global analysis. Our work highlights the urgent need for \textbf{global, code-based} explanations that reveal how models reason across code. To support this vision, we introduce \textit{code rationales} (CodeQ), a framework that enables global interpretability by mapping token-level rationales to high-level programming categories. Aggregating thousands of these token-level explanations allows us to perform statistical analyses that expose systemic reasoning behaviors. We validate this aggregation by showing it distills a clear signal from noisy token data, reducing explanation uncertainty (Shannon entropy) by over 50%. Additionally, we find that a code generation model (\textit{codeparrot-small}) consistently favors shallow syntactic cues (e.g., \textbf{indentation}) over deeper semantic logic. Furthermore, in a user study with 37 participants, we find its reasoning is significantly misaligned with that of human developers. These findings, hidden from traditional metrics, demonstrate the importance of global interpretability techniques to foster trust in LM4Code.
논문 링크
선출된 리더십을 통한 대규모 언어 모델(LLM) 사회 집단의 협력 평가 / Evaluating Cooperation in LLM Social Groups through Elected Leadership
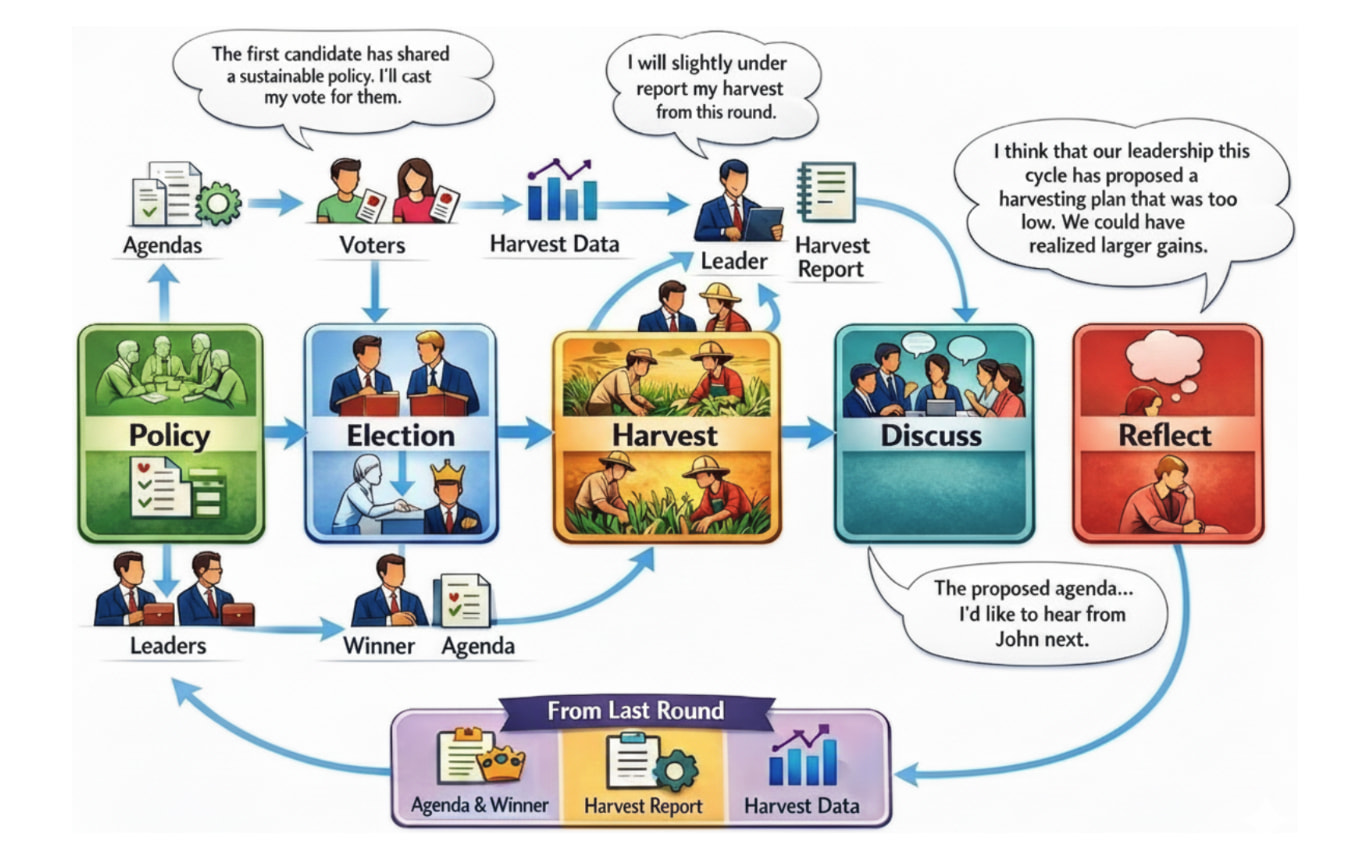
논문 소개
공통 풀 자원(common-pool resources, CPR)을 둘러싼 사회 딜레마에서는 개별 에이전트의 단기적 이익 추구가 집단의 붕괴로 이어지기 쉽기 때문에, 지속 가능한 협력을 유도할 제도적 장치가 핵심적인 의미를 갖습니다. 이러한 문제의식에서 출발한 이 연구는 대규모 언어 모델(large language model, LLM) 기반 다중 에이전트 사회에서 선출된 리더십과 선거 제도가 실제로 사회적 후생과 협력 행동을 개선하는지 검증합니다. 기존의 다중 에이전트 연구가 협상, 역할 분담, 암묵적 협력의 가능성을 보여주었음에도, 인간 사회에서 보편적으로 작동하는 선거와 대표성이라는 조직 원리를 충분히 반영하지 못했다는 점이 이 연구의 출발점입니다. 이를 위해 저자들은 오픈소스 프레임워크인 AgentElect를 제안하고, 후보가 의제를 제시하면 집단이 투표를 통해 리더를 선출하는 거버넌스 구조를 구현하여, 리더십이 단순한 역할 배정이 아니라 집단 규범과 정책 형성의 메커니즘으로 작동하도록 설계했습니다. 특히 정책 수립과 토론, 자원 채굴, 기억의 이월이 순환적으로 연결되도록 구성함으로써, 선거 결과가 이후 행동 규칙과 협력 양상에 어떤 영향을 미치는지를 정교하게 관찰할 수 있게 했습니다.
실험 설계는 여러 고성능 LLM을 대상으로 한 통제된 시뮬레이션에 기반하며, GPT-4o, GPT-4.1, Gemini 2.5 Flash를 활용해 8명 및 20명 규모의 에이전트 집단을 반복적으로 평가했습니다. 각 실험은 truthfulness와 deception 프롬프트, 복수의 인구 구성, 다중 시드 조건을 결합해 총 수백 회의 시뮬레이션으로 수행되었고, 평가 지표로는 사회적 후생, 생존 시간, 생존 여부, 평등성이 사용되었습니다. 그 결과 선출된 리더십은 무리의 붕괴를 효과적으로 완충하며, 여러 조건에서 사회적 후생을 평균 55.4% 높이고 생존 시간을 128.6% 연장하는 것으로 나타났습니다. 이는 고정된 리더를 두거나 리더가 없는 조건보다 더 안정적인 협력 구조를 만들어낸다는 점에서 중요하며, 선거라는 정치적 절차 자체가 LLM 사회 집단의 집단 행동을 재조직할 수 있음을 보여줍니다. 다만 항상 가장 높은 절대 성과를 내는 것은 아니었지만, 성향이 다른 집단 구성에서도 일관되게 강건한 성능을 보여 제도적 안정성 측면에서 특히 의미가 컸습니다.
이 연구의 또 다른 기여는 결과 해석을 행동 수준에 머물지 않고 사회 구조와 언어 수준으로 확장했다는 점입니다. 저자들은 에이전트 간 상호작용으로 사회 그래프(social graph)를 구성해 중심성(centrality) 지표를 계산함으로써, 리더가 집단 내에서 어떤 사회적 영향력을 갖는지 분석했고, 이를 통해 선거에서 패배한 리더도 토론 구조 속에서 여전히 일정한 발언권과 참조 가치를 유지할 수 있음을 확인했습니다. 아울러 리더 발화를 협력성과 수사학적 성향으로 분류하는 감성 분석을 수행하여, 집단 보상형 리더는 더 협력적인 언어와 감정적 호소를, 자기이익형 리더는 더 논리 중심적이고 방어적인 수사를 사용하는 경향을 보인다는 점을 밝혔습니다. 이러한 결과는 선거가 단지 “누가 리더가 되는가”를 정하는 절차가 아니라, 집단이 어떤 언어로 서로를 설득하고 어떤 규범을 정당화하는지를 바꾸는 제도라는 해석을 뒷받침합니다. 종합하면, 이 논문은 LLM 사회 시뮬레이션에 선거와 리더십을 도입함으로써 협력의 지속 가능성을 높일 수 있음을 실증적으로 보였고, 향후 다중 에이전트 시스템에서 거버넌스 설계가 갖는 중요성을 분명하게 제시했습니다.
초록(Abstract)
공유 자원(common-pool resources)을 관리하려면 에이전트가 집단적 실패를 피하기 위해 협력과 자치를 통해 지속적인 전략을 개발해야 합니다. 파운데이션 모델(Foundation Model)은 이러한 환경에서 협력의 잠재력을 보여주었지만, 기존 다중 에이전트 연구는 구조화된 리더십과 선거 메커니즘이 집단 의사결정을 향상시킬 수 있는지에 대해 거의 시사점을 제공하지 못합니다. 인간 사회 전반에 보편적으로 존재하는 이러한 중요한 조직적 요소의 부재는 현재 방법의 중대한 한계를 드러냅니다. 본 연구에서는 대규모 언어 모델(LLM)을 활용한 다중 에이전트 시뮬레이션을 통해 리더십과 선거가 사회적 복지와 협력 향상에 기여할 수 있는지를 직접 검토하고자 합니다. 우리는 선출된 페르소나와 후보자 주도 아젠다를 통해 리더십을 시뮬레이션하는 오픈소스 프레임워크를 제시하고, 통제된 거버넌스 조건에서 LLM의 동작에 대한 실증 연구를 수행합니다. 실험 결과, 선출된 리더십을 도입하면 다양한 고성능 LLM에서 사회적 복지 점수가 55.4%, 생존 시간이 128.6% 향상되는 것으로 나타났습니다. 또한 에이전트 사회 그래프를 구성하여 중심성 지표를 계산함으로써 리더 페르소나의 사회적 영향력을 평가하고, 리더 발화에 대한 감성 분석을 통해 드러나는 수사적 및 협력적 성향도 분석합니다. 본 연구는 복잡한 사회적 딜레마를 다루기 위한 다중 에이전트 시스템에서 선거 메커니즘을 추가로 연구할 수 있는 기반을 마련합니다.
Governing common-pool resources requires agents to develop enduring strategies through cooperation and self-governance to avoid collective failure. While foundation models have shown potential for cooperation in these settings, existing multi-agent research provides little insight into whether structured leadership and election mechanisms can improve collective decision making. The lack of such a critical organizational feature ubiquitous in human society presents a significant shortcoming of the current methods. In this work we aim to directly address whether leadership and elections can support improved social welfare and cooperation through multi-agent simulation with LLMs. We present our open-source framework that simulates leadership through elected personas and candidate-driven agendas and carry out an empirical study of LLMs under controlled governance conditions. Our experiments demonstrate that having elected leadership improves social welfare scores by 55.4% and survival time by 128.6% across a range of high performing LLMs. Through the construction of an agent social graph we compute centrality metrics to assess the social influence of leader personas and also analyze rhetorical and cooperative tendencies revealed through a sentiment analysis on leader utterances. This work lays the foundation for further study of election mechanisms in multi-agent systems toward navigating complex social dilemmas.
논문 링크
더 읽어보기
AI 정리해고의 함정 / The AI Layoff Trap

논문 소개
AI가 인간 노동을 빠르게 대체할수록 기업의 비용은 줄어들 수 있지만, 동시에 해고된 노동자의 소득이 소비 수요를 약화시켜 결국 기업이 의존하는 시장 자체를 잠식할 수 있다는 점에서 이 연구는 AI 자동화를 단순한 생산성 향상 문제로 보지 않습니다. 저자들은 이러한 문제의식 위에서, 기업들이 그 위험을 충분히 인식하고 있더라도 경쟁 환경에서는 자동화를 멈추기 어렵다는 역설을 제시하며, 합리적 기업들이 수요 외부효과(demand externality) 때문에 과잉 자동화로 빠져드는 메커니즘을 분석합니다. 이를 위해 태스크 기반 모형(task-based model)을 구축하고, 각 기업이 자동화율을 선택하는 게임에서 자동화가 개별 기업에는 비용 절감으로 이익이 되지만, 동시에 노동소득 감소를 통해 모든 기업의 수요를 함께 낮춘다는 구조를 엄밀하게 보여줍니다. 모형의 핵심은 노동자와 소유자의 소비 성향이 다르다는 점이며, 노동자의 한계소비성향(marginal propensity to consume, MPC)이 높다는 가정 아래 자동화는 단지 고용을 줄이는 데 그치지 않고, 부문 전체의 총수요를 감소시키는 파급효과를 낳습니다.
이 접근의 방법론적 장점은 생산 측면과 수요 측면을 분리해, 자동화의 직접 효과와 간접 효과를 동시에 포착한다는 데 있습니다. 기업은 태스크를 기계로 대체할수록 단위 비용을 절감하지만, 그로 인해 발생하는 소비 수요의 감소는 경쟁사들과 공유되므로 각 기업이 내부적으로 부담하는 손실은 전체 손실보다 작아집니다. 저자들은 바로 이 비대칭 때문에 기업들이 스스로는 과잉 자동화를 피할 유인이 없으며, 경쟁이 심할수록, 그리고 AI의 성능이 향상될수록 자동화 경쟁이 더 강해진다고 설명합니다. 다시 말해, 개별적으로는 합리적인 선택이 사회적으로는 비효율적인 결과를 낳는다는 점에서, 이 연구는 AI 시대의 고용 문제를 노동시장 충격이 아니라 시장 구조의 왜곡으로 재해석합니다.
특히 이 논문은 임금 조정, 자유 진입, 자본소득세, 노동자 지분참여, 보편적 기본소득(Universal Basic Income, UBI), 업스킬링, 코즈식 협상(Coasian bargaining) 같은 기존 정책수단이 왜 이 외부효과를 충분히 교정하지 못하는지 점검하면서, 오직 피구우식 자동화세(Pigouvian automation tax)만이 사회적으로 바람직한 자동화 수준을 유도할 수 있다고 주장합니다. 이러한 결론은 단순히 일자리 상실 이후의 보상 정책이 아니라, 기업 간 경쟁 유인 자체를 조정하는 정책이 필요하다는 점을 분명하게 보여 줍니다. 결과적으로 이 연구는 AI가 가져올 수 있는 생산성 향상과 고용 축소의 균형을 새롭게 해석하며, 기술 발전의 방향이 개별 기업의 효율성뿐 아니라 사회 전체의 수요 기반과 후생까지 고려해 설계되어야 함을 설득력 있게 제시합니다.
초록(Abstract)
AI가 경제가 이들을 다시 흡수할 수 있는 속도보다 더 빠르게 인간 노동자를 대체하면, 기업이 의존하는 바로 그 소비자 수요를 잠식할 위험이 있다. 우리는 이것을 아는 것만으로는 기업들이 이를 멈추기에 충분하지 않음을 보인다. 경쟁적인 작업 기반 모델에서 수요 외부효과는 합리적인 기업들을 자동화 군비 경쟁에 가두어, 집단적으로 최적인 수준을 훨씬 넘어 노동자를 대체하게 만든다. 그 결과 발생하는 손실은 노동자와 기업 소유주 모두에게 해를 끼친다. 경쟁이 심할수록 그리고 “더 나은” AI일수록 이러한 과잉은 더 커지며, 임금 조정과 자유 진입만으로는 이를 제거할 수 없다. 자본소득세, 노동자 지분 참여, 보편적 기본소득, 업스킬링, 코즈식 협상도 마찬가지로 이를 해소하지 못한다. 오직 피구식 자동화세만이 가능하다. 이 결과는 정책이 AI로 인한 노동 대체의 사후 대응만이 아니라, 그것을 유발하는 경쟁적 유인까지도 다뤄야 함을 시사한다.
If AI displaces human workers faster than the economy can reabsorb them, it risks eroding the very consumer demand firms depend on. We show that knowing this is not enough for firms to stop it. In a competitive task-based model, demand externalities trap rational firms in an automation arms race, displacing workers well beyond what is collectively optimal. The resulting loss harms both workers and firm owners. More competition and "better" AI amplify the excess; wage adjustments and free entry cannot eliminate it. Neither can capital income taxes, worker equity participation, universal basic income, upskilling, or Coasian bargaining. Only a Pigouvian automation tax can. The results suggest that policy should address not only the aftermath of AI labor displacement but also the competitive incentives that drive it.
논문 링크
언어 기반 멀티에이전트 통신에서 끼어들기를 학습하기 / Learning to Interrupt in Language-based Multi-agent Communication
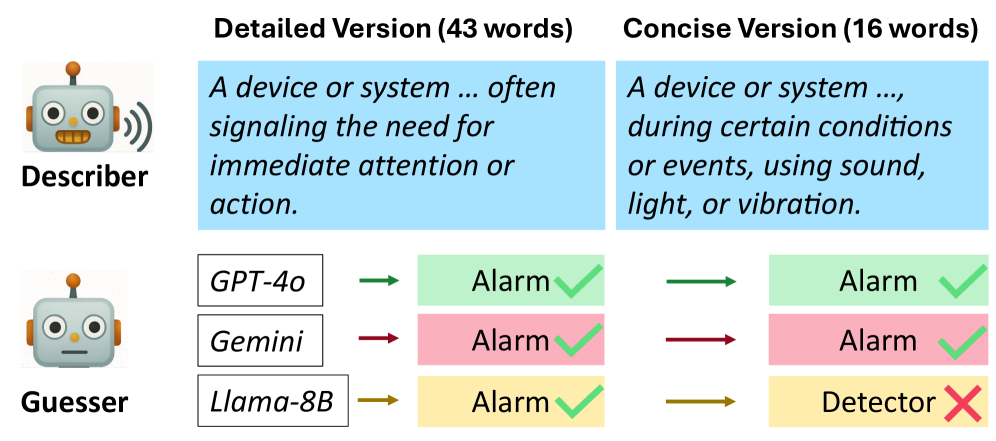
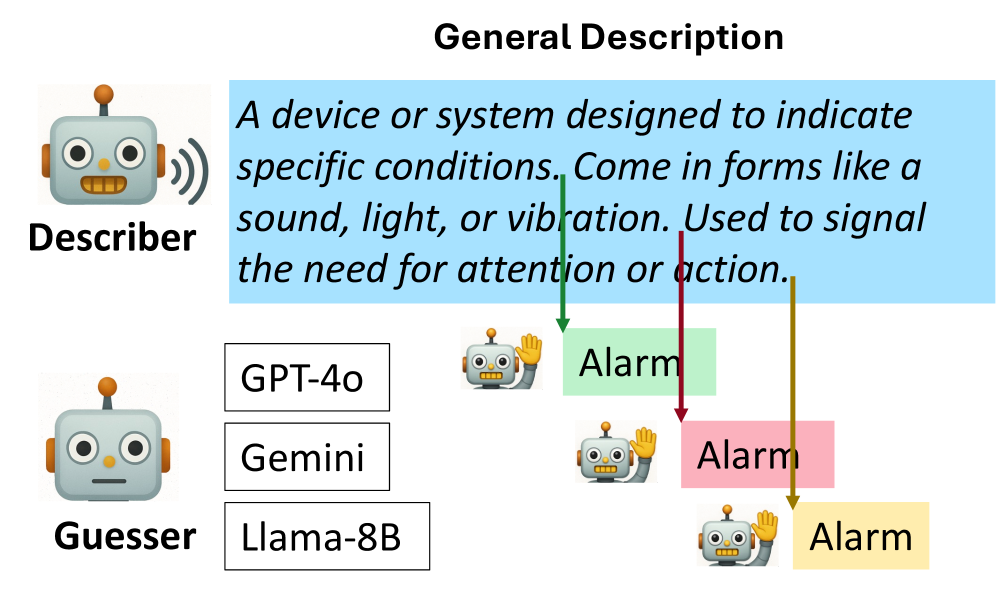
논문 소개
대규모 언어 모델(Large Language Models, LLMs)을 활용한 다중 에이전트 시스템은 다양한 문제 해결에서 뛰어난 성능을 보여 왔지만, 에이전트 간 대화가 지나치게 장황해지면서 문맥을 불필요하게 소모하고 계산 비용을 높인다는 한계가 꾸준히 지적되어 왔습니다. 기존 연구가 주로 발화자의 메시지를 압축하는 방식에 집중했다면, 이 접근은 청자에게 필요한 정보가 무엇인지 상황에 따라 유연하게 판단하기 어렵고, 서로 다른 청자에게 맞춘 상호작용을 설계하는 데에도 제약이 있었습니다. 이에 따라 본 연구는 인간 대화에서처럼 청자가 적절한 시점에 발화를 끊고 의견을 제시하거나 추가 설명을 요구할 수 있는 중단 가능(interruptible) 통신 프레임워크를 제안합니다. 핵심 아이디어는 청자 역할의 에이전트가 현재 발화 중인 화자를 단순히 수동적으로 기다리는 대신, 더 이상 기다릴 필요가 없다고 판단되는 시점에 대화를 끊어 효율적인 정보 교환을 유도하는 데 있습니다.
그러나 단순한 프롬프트 기반 실험에서는 현재의 대규모 언어 모델이 충분한 정보가 쌓이기 전에 과도하게 자신감을 갖고 조기에 중단하는 경향이 확인되었고, 이는 오히려 대화 품질을 떨어뜨릴 수 있었습니다. 이를 해결하기 위해 저자들은 미래에 얻을 수 있는 보상과 소요 비용을 추정하여 적절한 중단 시점을 예측하는 학습 방법을 설계하였으며, 이를 통해 중단 행위가 단순한 직관이나 즉흥적 판단이 아니라 효율성과 정확성 사이의 균형을 고려한 의사결정이 되도록 만들었습니다. 제안된 방법은 HANDRAISER라는 이름의 프레임워크로 구현되며, 청자 측의 개입을 통해 불필요한 발화를 줄이면서도 과업 수행에 필요한 핵심 정보는 유지하도록 유도합니다. 이러한 설계는 메시지 압축 자체보다 상호작용의 타이밍을 최적화한다는 점에서 차별적이며, 다양한 청자와 과업에 더 잘 적응할 수 있다는 장점을 가집니다.
실험은 2개 에이전트가 참여하는 텍스트 픽셔너리(text pictionary) 게임, 3개 에이전트가 참여하는 회의 일정 조정, 3개 에이전트 토론 등 서로 다른 협업 시나리오에서 수행되었고, 그 결과 제안 방법은 기준선 대비 통신 비용을 32.2% 절감하면서도 유사하거나 더 우수한 과업 성능을 보였습니다. 특히 학습된 중단 행동은 특정 모델이나 특정 과업에만 국한되지 않고 다른 에이전트와 새로운 작업으로도 일반화될 수 있음을 보여 주어, 실용적인 다중 에이전트 통신 설계 원리로서의 가능성을 입증했습니다. 종합하면, 이 연구는 대화의 길이를 줄이는 차원을 넘어, 언제 개입해야 하는지를 학습하는 방향으로 다중 에이전트 통신의 패러다임을 확장했다는 점에서 의미가 큽니다. 또한 인간 대화의 상호작용적 특성을 대규모 언어 모델 기반 에이전트에 접목함으로써, 효율성과 성능을 동시에 고려하는 차세대 협력 시스템 설계에 중요한 단서를 제공합니다.
초록(Abstract)
대규모 언어 모델(LLM)을 사용하는 멀티에이전트 시스템은 다양한 도메인에서 인상적인 성능을 보여주었습니다. 그러나 현재의 에이전트 통신은 장황한 출력으로 인해 컨텍스트를 과부하시키고 계산 비용을 증가시키는 문제를 겪고 있습니다. 기존 접근법은 주로 화자 측에서 메시지를 압축하는 데 집중하지만, 서로 다른 청자에 맞게 적응하거나 관련 정보를 식별하는 데는 한계가 있습니다. 인간의 의사소통에서 효과적인 방법 중 하나는 청자가 대화를 중단하고 의견을 제시하거나 추가 설명을 요청할 수 있게 하는 것입니다. 이러한 점에 착안하여, 우리는 청자 역할의 에이전트가 현재 화자를 중단할 수 있도록 하는 인터럽트 가능한 통신 프레임워크를 제안합니다. 프롬프팅 실험을 통해, 현재의 LLM들은 대체로 과도하게 자신만만하여 충분한 정보를 받기 전에 중단하는 경향이 있음을 확인했습니다. 따라서 우리는 추정된 미래 보상과 비용을 바탕으로 적절한 중단 시점을 예측하는 학습 방법을 제안합니다. 우리는 2-에이전트 텍스트 피셔리 게임, 3-에이전트 회의 일정 조율, 3-에이전트 토론을 포함한 다양한 멀티에이전트 시나리오에서 이 프레임워크를 평가했습니다. 실험 결과, HANDRAISER는 기준선 대비 32.2%의 통신 비용을 절감하면서도 동등하거나 더 우수한 작업 성능을 보였습니다. 이러한 학습된 중단 행동은 서로 다른 에이전트와 작업에도 일반화될 수 있습니다.
Multi-agent systems using large language models (LLMs) have demonstrated impressive capabilities across various domains. However, current agent communication suffers from verbose output that overload context and increase computational costs. Although existing approaches focus on compressing the message from the speaker side, they struggle to adapt to different listeners and identify relevant information. An effective way in human communication is to allow the listener to interrupt and express their opinion or ask for clarification. Motivated by this, we propose an interruptible communication framework that allows the agent who is listening to interrupt the current speaker. Through prompting experiments, we find that current LLMs are often overconfident and interrupt before receiving enough information. Therefore, we propose a learning method that predicts the appropriate interruption points based on the estimated future reward and cost. We evaluate our framework across various multi-agent scenarios, including 2-agent text pictionary games, 3-agent meeting scheduling, and 3-agent debate. The results of the experiment show that our HANDRAISER can reduce the communication cost by 32.2% compared to the baseline with comparable or superior task performance. This learned interruption behavior can also be generalized to different agents and tasks.
논문 링크
메모리 지능 에이전트 / Memory Intelligence Agent

논문 소개
복잡한 정보 탐색 과제를 수행하는 Deep Research Agents(DRAs)는 대규모 언어 모델(Large Language Model, LLM)의 추론 능력과 외부 도구를 결합해 점차 정교한 문제 해결을 가능하게 해 왔지만, 과거 경험을 얼마나 효율적으로 축적하고 활용하느냐는 여전히 중요한 난제로 남아 있습니다. 기존 메모리 시스템은 주로 과거 탐색 궤적 중 비슷한 사례를 검색해 현재 추론에 활용하는 방식에 의존했으나, 저장 규모가 커질수록 검색 비용이 증가하고, 메모리 자체가 경험에 따라 유기적으로 진화하지 못한다는 한계가 있었습니다. 이러한 문제의식에서 제안된 Memory Intelligence Agent(MIA)는 기억을 단순한 저장소가 아니라 추론과 함께 발전하는 핵심 구성요소로 재정의하며, Memory Manager, Planner, Executor로 이루어진 삼분 구조를 통해 저장, 계획, 실행의 기능을 분리하면서도 긴밀히 연결합니다. Memory Manager는 압축된 과거 검색 궤적을 비모수적(non-parametric) 메모리로 저장하고, Planner는 질문에 맞는 탐색 계획을 생성하는 모수적(parametric) 기억 모듈로 작동하며, Executor는 그 계획을 따라 실제 정보 탐색과 분석을 수행합니다.
특히 이 프레임워크의 핵심은 Planner와 Executor를 따로 두는 데 있지 않고, 두 모듈의 협업을 학습 가능한 구조로 조직했다는 점에 있습니다. 저자들은 교대적 강화학습(alternating reinforcement learning)을 통해 Planner가 더 적절한 탐색 계획을 세우고 Executor가 이를 더 정확하게 이행하도록 상호 정렬을 유도하며, 동시에 테스트 타임 학습(test-time learning)을 도입해 추론이 진행되는 동안에도 Planner가 멈추지 않고 지속적으로 갱신되도록 설계했습니다. 여기에 모수적 메모리와 비모수적 메모리 사이의 양방향 변환 루프를 두어, 단순히 기억을 불러오는 데 그치지 않고 기억을 다시 압축·정제·재구성하는 메커니즘을 마련함으로써 메모리 진화의 효율성을 높였습니다. 또한 reflection과 unsupervised judgment 메커니즘을 추가해 개방형 환경에서 스스로 계획을 재검토하고, 정답 신호가 희소한 상황에서도 자율적으로 개선할 수 있도록 했다는 점이 방법론적 차별성으로 읽힙니다.
메모리 검색 설계 역시 단순한 유사도 기반 회수를 넘어서, 과거 경험의 유용성과 사용 빈도까지 함께 반영하는 정교한 점수화 방식을 취합니다. 질문과 이미지 캡션을 공통 임베딩 공간에 정렬한 뒤 의미적 유사도를 계산하고, 여기에 성공률을 반영한 가치 보상과 덜 사용된 기억을 살리는 빈도 보상을 더해 최종 검색 점수를 산출함으로써, 비슷하지만 실제로 도움이 되는 기억을 우선적으로 선택하도록 했습니다. 이러한 설계는 정보가 많은 환경에서 단순히 가장 가까운 기억을 찾는 것이 아니라, 현재 과제에 실제로 기여할 가능성이 높은 경험을 선별하는 데 초점을 둔다는 점에서 실용적 의미가 큽니다. 나아가 멀티모달 및 텍스트 전용 벤치마크를 포함한 11개 평가에서 우수한 성능을 보였고, 다양한 규모의 모델 조합에서도 일관된 향상을 나타냈다는 결과는 MIA가 특정 모델에 종속된 보조 기법이 아니라 범용적인 연구 에이전트 프레임워크로 기능할 수 있음을 시사합니다. 결국 MIA는 DRAs의 메모리를 정적인 기록에서 학습하고 진화하는 지능적 자산으로 전환함으로써, 장기적 자율성, 효율성, 그리고 개방형 문제 해결 능력을 동시에 향상시키는 방향을 제시합니다.
초록(Abstract)
딥 리서치 에이전트(DRAs)는 대규모 언어 모델(LLM) 추론과 외부 도구를 통합한다. 메모리 시스템은 DRAs가 역사적 경험을 활용할 수 있게 하며, 이는 효율적인 추론과 자율적 진화에 필수적이다. 기존 방법은 추론을 보조하기 위해 메모리에서 유사한 궤적을 검색하는 데 의존하지만, 비효율적인 메모리 진화와 증가하는 저장 및 검색 비용이라는 핵심 한계에 직면해 있다. 이러한 문제를 해결하기 위해, 우리는 Manager-Planner-Executor 아키텍처로 구성된 새로운 Memory Intelligence Agent(MIA) 프레임워크를 제안한다. Memory Manager는 압축된 과거 검색 궤적을 저장할 수 있는 비매개변수형 메모리 시스템이다. Planner는 질문에 대한 검색 계획을 생성할 수 있는 매개변수형 메모리 에이전트이다. Executor는 검색 계획의 지시에 따라 정보를 검색하고 분석하는 또 다른 에이전트이다. MIA 프레임워크를 구축하기 위해, 먼저 Planner와 Executor 간의 협력을 강화하기 위해 교대 강화학습 패러다임을 채택한다. 또한, 추론 과정을 중단하지 않고 추론과 함께 즉시(on-the-fly) 업데이트를 수행함으로써 테스트 시점 학습 동안 Planner가 지속적으로 진화하도록 한다. 더 나아가, 효율적인 메모리 진화를 달성하기 위해 매개변수형 메모리와 비매개변수형 메모리 간의 양방향 변환 루프를 구축한다. 마지막으로, 개방형 세계에서의 추론과 자기 진화를 강화하기 위해 반성 메커니즘과 비지도 판단 메커니즘을 도입한다. 11개 벤치마크에 걸친 광범위한 실험은 MIA의 우수성을 입증한다.
Deep research agents (DRAs) integrate LLM reasoning with external tools. Memory systems enable DRAs to leverage historical experiences, which are essential for efficient reasoning and autonomous evolution. Existing methods rely on retrieving similar trajectories from memory to aid reasoning, while suffering from key limitations of ineffective memory evolution and increasing storage and retrieval costs. To address these problems, we propose a novel Memory Intelligence Agent (MIA) framework, consisting of a Manager-Planner-Executor architecture. Memory Manager is a non-parametric memory system that can store compressed historical search trajectories. Planner is a parametric memory agent that can produce search plans for questions. Executor is another agent that can search and analyze information guided by the search plan. To build the MIA framework, we first adopt an alternating reinforcement learning paradigm to enhance cooperation between the Planner and the Executor. Furthermore, we enable the Planner to continuously evolve during test-time learning, with updates performed on-the-fly alongside inference without interrupting the reasoning process. Additionally, we establish a bidirectional conversion loop between parametric and non-parametric memories to achieve efficient memory evolution. Finally, we incorporate a reflection and an unsupervised judgment mechanisms to boost reasoning and self-evolution in the open world. Extensive experiments across eleven benchmarks demonstrate the superiority of MIA.
논문 링크
RL에 가치 함수를 되살리기: LLM 추론기와 검증기를 통합한 더 나은 테스트 시점 스케일링 / Putting the Value Back in RL: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
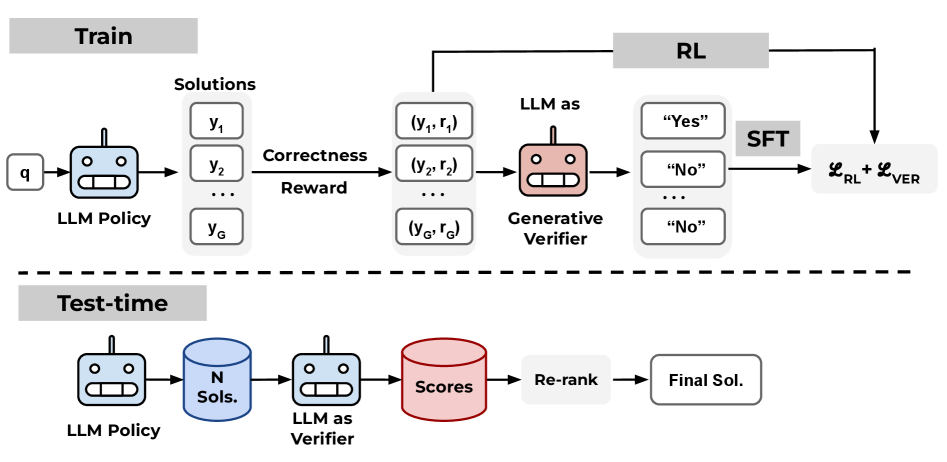
논문 소개
최근 대규모 언어 모델(large language model, LLM)의 추론 성능을 높이기 위해 강화학습(reinforcement learning, RL)이 널리 활용되고 있지만, GRPO나 Leave-one-out PPO와 같은 최근의 가치함수 없는(value-free) 방법들은 학습을 단순화하는 대신 테스트 시 후보 해답을 판별하는 데 유용한 value function의 검증 능력을 약화시킨다는 한계를 드러낸다. 이러한 문제의식에서 출발해, 저자들은 배포 단계에서 병렬 테스트 시 계산량(test-time compute) 스케일링을 사용할 계획이라면 학습 단계 역시 그 활용을 지원하도록 설계되어야 한다고 주장한다. 이를 위해 제안된 RL^V는 기존 value-free RL에 생성형 검증기(generative verifier)를 결합하여, 하나의 LLM을 추론기(reasoner)와 검증기(verifier)로 동시에 공동 학습시키는 방법이다. 핵심적으로 이 접근은 별도의 검증 모델을 추가로 두지 않고, RL 과정에서 이미 생성된 데이터와 보상 신호를 재활용해 검증 능력을 함께 학습한다는 점에서 효율적이다. 즉, 추론 성능을 높이는 학습 과정 자체를 테스트 시 여러 후보를 비교하고 선택하는 능력과 직접 연결함으로써, 학습과 추론의 공동 설계(co-design)를 구현한다.
이 방법의 의의는 value-free RL이 확보한 학습 효율성과 메모리 절감 이점을 유지하면서도, 테스트 단계에서의 재랭킹과 투표에 필요한 검증 신호를 다시 모델 내부에 주입한다는 데 있다. 기존의 LLM-as-a-Judge 방식이 범용적이지만 과제 특화성이 부족하고, 별도 verifier를 학습하는 방식이 표현력은 높지만 비용이 크다는 점을 고려하면, RL^V는 그 중간 지점에서 실용적인 균형을 제시한다. 구체적으로는 RL 목적함수와 생성형 검증 손실을 결합해 단일 모델을 학습하며, 이때 검증기는 정답 여부를 “Yes” 또는 “No”로 생성하도록 훈련된다. 이러한 구성은 단순한 부가 모듈이 아니라, 병렬 샘플링, weighted voting, Best-of-N과 같은 테스트 시 계산량 활용 전략이 제대로 작동하도록 만드는 핵심 기반으로 기능한다.
실험 결과는 이러한 설계가 실제로 효과적임을 보여 준다. MATH 벤치마크에서 RL^V는 병렬 샘플링을 사용할 때 정확도를 20% 이상 향상시켰고, 기본 RL 방법 대비 8~32배 더 효율적인 테스트 시 계산량 스케일링을 달성했다. 또한 쉬운 문제에서 어려운 문제로의 일반화와 분포 밖(out-of-domain) 과제에서도 강한 성능을 보였으며, GPQA와 같은 다른 도메인에서도 안정적인 이득을 확인했다. 더 나아가 긴 추론을 수행하는 R1 계열 모델과 결합했을 때는 병렬과 순차 테스트 시 계산량을 함께 늘리는 설정에서 1.2~1.6배 더 높은 성능을 기록해, RL^V가 장문 Chain-of-Thought(CoT) 추론과도 상호보완적으로 작동함을 입증했다. 결국 이 연구는 RL이 이미 만들어 내는 데이터를 이용해 추론 성능과 검증 능력을 동시에 키우는 방식이, 더 적은 비용으로 더 나은 테스트 시 확장을 가능하게 한다는 점을 설득력 있게 보여 준다.
초록(Abstract)
GRPO나 Leave-one-out PPO와 같은, LLM 추론 모델(reasoners)을 파인튜닝하기 위한 널리 사용되는 강화학습(RL) 방법들은 학습된 가치 함수(value function)를 버리고 경험적으로 추정한 리턴(return)을 사용한다. 이는 검증에 가치 함수를 사용하는 데 의존하는 테스트 시점 연산 스케일링을 저해한다. 그러나 병렬 테스트 시점 연산이 이미 배포 계획의 일부라면, 학습은 이를 지원하도록 설계되어야 한다. 본 연구에서는 RL이 생성한 데이터를 사용해 LLM을 추론 모델(reasoner)이자 생성형 검증기(generative verifier)로 공동 학습함으로써, 모든 “가치 함수 없는(value-free)” RL 방법을 보완하는 RL^V를 제안한다. 이를 통해 큰 추가 오버헤드 없이 검증 기능을 추가할 수 있다. 실험적으로 RL^V는 병렬 샘플링에서 MATH 정확도를 20% 이상 향상시키며, 기본 RL 방법 대비 8~32배 더 효율적인 테스트 시점 연산 스케일링을 가능하게 한다. 또한 RL^V는 쉬운 과제에서 어려운 과제로의 일반화와 도메인 외(out-of-domain) 과제 모두에서 강한 일반화 능력을 보인다. 더 나아가 RL^V는 긴 추론 R1 모델과 함께 병렬 및 순차적 테스트 시점 연산을 공동으로 스케일링할 때 1.2~1.6배 더 높은 성능을 달성한다. 더 넓게는, RL^V는 테스트 시점 스케일링을 위한 공동 학습(co-training)의 원칙을 구현한다. 즉, RL 학습이 이미 생성하는 데이터를 사용해, 과제 성능과 추론 시 유용한 능력을 공동으로 최적화한다.
Prevalent reinforcement learning~(RL) methods for fine-tuning LLM reasoners, such as GRPO or Leave-one-out PPO, abandon the learned value function in favor of empirically estimated returns. This hinders test-time compute scaling that relies on using the value-function for verification. Yet if parallel test-time compute is already part of the deployment plan, training should be designed to support it. In this work, we propose RL$^V$ that augments any ``value-free'' RL method by jointly training the LLM as both a reasoner and a generative verifier using RL-generated data, adding verification capabilities without significant overhead. Empirically, RL$^V$ boosts MATH accuracy by over 20% with parallel sampling and enables 8-32\times efficient test-time compute scaling compared to the base RL method. RL$^V$ also exhibits strong generalization capabilities for both easy-to-hard and out-of-domain tasks. Furthermore, RL$^V$ achieves 1.2-1.6\times higher performance when jointly scaling parallel and sequential test-time compute with a long reasoning R1 model. More broadly, RL$^V$ instantiates the principle of co-training for test-time scaling: jointly optimizing for task performance and a capability useful at inference, using data that RL training already produces.
논문 링크
더 읽어보기
규모가 커질수록 잠재적 계획이 나타난다 / Latent Planning Emerges with Scale
논문 소개
대규모 언어 모델(Large Language Model, LLM)은 명시적인 계획을 말하지 않아도 일관된 이야기 작성이나 코드 생성처럼 계획이 필요한 과업을 수행할 수 있지만, 그 내부에서 실제로 어떤 방식의 계획이 형성되는지는 분명하지 않았다. 이 논문은 이러한 공백을 메우기 위해 잠재적 계획(latent planning)이라는 개념을 제안하며, 미래의 특정 토큰이나 개념을 유도하는 내부 표현이 존재하고 동시에 그 미래 결과를 허용하도록 앞선 문맥까지 조정할 때 이를 진정한 계획으로 간주한다. 저자들은 단순한 성능 관찰에 머무르지 않고, 계획이 생성 결과를 바꾸는 인과적 힘을 가지는지, 그리고 그 계획이 이전 문맥을 어떻게 재구성하는지를 함께 살피는 방법론을 세웠다는 점에서 큰 의의를 갖는다.
이를 위해 Qwen-3 계열(0.6B~14B)을 대상으로 매우 단순한 문법·합의 과제에서부터 더 복잡한 운율 대구 완성 과제까지 폭넓게 시험하면서, 규모가 커질수록 계획 능력이 어떻게 달라지는지를 비교했다. 특히 관사 선택처럼 짧은 범위의 과제에서는 모델 내부에 계획된 단어를 담는 해석 가능한 특징이 나타나고, 그 특징이 a와 an 같은 선택을 바꾸는 식으로 앞 문맥을 실제로 유도한다는 점을 보여주었다. 이러한 결과는 트랜스코더(Transcoder)를 이용해 내부 활성값을 해석 가능한 특징 공간으로 분해하고, 트랜스코더 특징 회로(Transcoder Feature Circuits)를 통해 미래 토큰과 선행 문맥 사이의 연결 경로를 추적함으로써 얻어졌으며, 단순한 상관관계가 아니라 인과적 메커니즘에 접근했다는 점에서 중요하다.
더 나아가 중간 규모의 모델들에서도 아직 미약하지만 계획 메커니즘의 초기 징후가 관찰되어, 잠재적 계획이 갑작스러운 출현이 아니라 스케일에 따라 점진적으로 강화되는 성질을 지닌다는 해석을 뒷받침한다. 반면 더 긴 범위의 운율 생성 과제에서는 모델이 끝 운율 자체를 미리 알아채는 경우는 많았지만, 그 운율을 정당화하도록 앞 문맥 전체를 멀리서부터 조직하는 능력은 제한적이어서, 전방 계획은 보이되 후방 계획은 약하다는 대비가 뚜렷하게 드러났다. 결국 이 논문은 LLM의 계획 능력을 단순한 언어 생성의 부산물이 아니라, 특정 미래 결과를 향해 내부 표현과 문맥을 함께 조정하는 기계론적 현상으로 정의하고 측정할 수 있음을 보였으며, 계획 능력이 모델 크기와 과제 복잡도에 따라 어떻게 성장하고 또 어디에서 한계를 보이는지를 설득력 있게 제시한다.
초록(Abstract)
대규모 언어 모델(LLM)은 명시적으로 계획을 언어화하지 않고도, 응집력 있는 이야기를 쓰거나 작동하는 코드를 작성하는 것처럼 계획이 많이 필요한 것처럼 보이는 작업을 수행할 수 있지만, 이들이 암묵적으로 어느 정도까지 계획하는지는 알려져 있지 않다. 본 논문에서는 대규모 언어 모델(LLM)이 (1) 특정 미래 토큰 또는 개념의 생성을 유발하고, (2) 해당 미래 토큰 또는 개념이 허용되도록 앞선 문맥을 형성하는 내부 계획 표현을 보유할 때 이를 잠재적 계획(latent planning)이라고 정의한다. 우리는 Qwen-3 패밀리(0.6B-14B)를 단순한 계획 과제에서 연구한 결과, 잠재적 계획 능력이 스케일이 커질수록 증가함을 발견했다. 계획하는 모델은 "accountant"와 같은 사전에 계획된 단어를 나타내는 특징을 보유하며, 그 결과 "a"가 아니라 "an"을 출력하게 된다. 또한, 성능이 더 낮은 Qwen-3 4B-8B조차도 초기 단계의 계획 메커니즘을 지닌다. 운이 맞는 대구를 완성하는 더 복잡한 과제에서는, 모델이 종종 미리 운을 식별하지만, 대형 모델조차도 멀리 앞서 계획하는 경우는 드물다는 것을 확인했다. 그러나 산문에서 모델이 계획된 단어를 향하도록 유도하면, 스케일이 커질수록 증가하는 일부 계획을 이끌어낼 수 있다. 종합하면, 우리는 계획을 측정하기 위한 프레임워크와 모델의 계획 능력이 스케일에 따라 어떻게 성장하는지에 대한 기계론적 증거를 제시한다.
LLMs can perform seemingly planning-intensive tasks, like writing coherent stories or functioning code, without explicitly verbalizing a plan; however, the extent to which they implicitly plan is unknown. In this paper, we define latent planning as occurring when LLMs possess internal planning representations that (1) cause the generation of a specific future token or concept, and (2) shape preceding context to license said future token or concept. We study the Qwen-3 family (0.6B-14B) on simple planning tasks, finding that latent planning ability increases with scale. Models that plan possess features that represent a planned-for word like "accountant", and cause them to output "an" rather than "a"; moreover, even the less-successful Qwen-3 4B-8B have nascent planning mechanisms. On the more complex task of completing rhyming couplets, we find that models often identify a rhyme ahead of time, but even large models seldom plan far ahead. However, we can elicit some planning that increases with scale when steering models towards planned words in prose. In sum, we offer a framework for measuring planning and mechanistic evidence of how models' planning abilities grow with scale.
논문 링크
더 읽어보기
당신의 알고리즘은 언러닝(unlearning)인가, 언트레이닝(untraining)인가? / Is your algorithm unlearning or untraining?
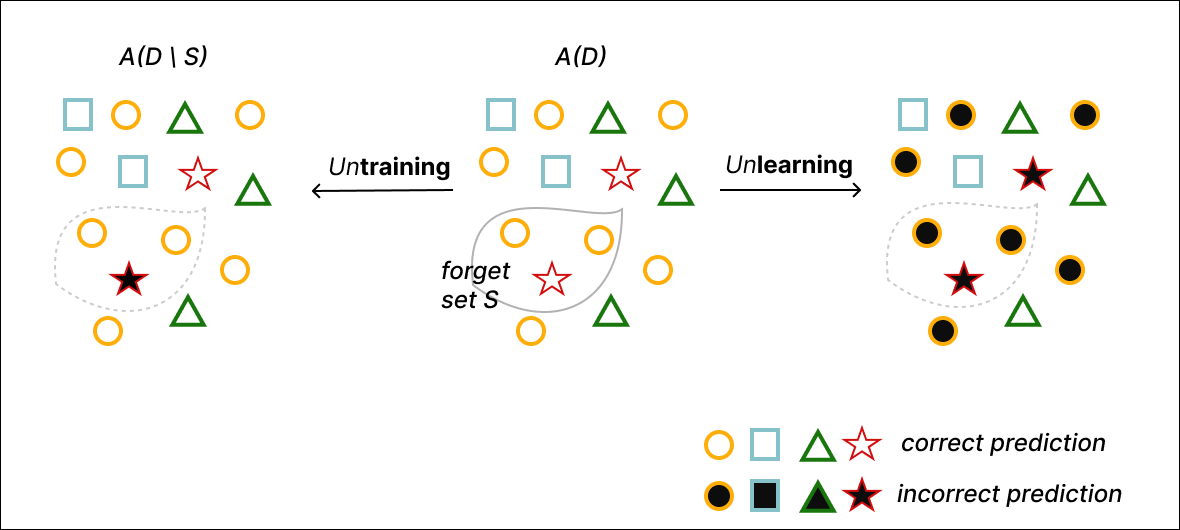
논문 소개
대규모 모델과 방대한 학습 데이터가 결합된 환경에서, 이미 학습된 모델로부터 특정 데이터나 행동을 “삭제”하려는 요구는 기계 언러닝(machine unlearning)에 대한 관심을 크게 높였다. 그러나 이 분야에서 사용되어 온 언러닝이라는 용어는 실제로 서로 다른 두 문제를 한데 묶어 왔고, 그 결과 알고리즘이 무엇을 목표로 해야 하는지, 어떤 기준으로 성능을 평가해야 하는지, 그리고 결과를 어떻게 해석해야 하는지가 자주 모호해졌다. 이러한 문제의식을 바탕으로 저자들은 먼저 학습(training)과 일반화 학습(learning)을 구분하고, 유한한 데이터셋에 대한 경험 위험 최소화(empirical risk minimization)와 데이터 분포 전체에 대한 기대 위험 최소화가 서로 다른 목표임을 분명히 한다. 이어서 개별 예시가 모델에 미치는 영향을 기억화(memorization)와 교차 영향(cross-influence)이라는 두 가지 관점에서 정량화함으로써, 어떤 데이터가 자기 자신뿐 아니라 다른 예시들의 예측까지 얼마나 바꾸는지를 분석할 수 있는 틀을 제시한다. 이 분석은 단순히 “얼마나 잘 맞히는가”를 보는 것이 아니라, 특정 예시가 학습 과정에 남긴 흔적이 어디까지 확장되는지를 살피는 방법론적 기반이 된다.
이 논문의 핵심 기여는 기존의 기계 언러닝을 언트레이닝(untraining)과 언러닝(unlearning)으로 분리해 재정의한 데 있다. 언트레이닝은 특정 망각 집합(forget set)이 학습 과정에 끼친 영향만을 되돌려, 그 집합을 제외하고 다시 학습한 모델과 분포적으로 일치하도록 만드는 문제로 이해된다. 반면 언러닝은 단순히 주어진 예시의 흔적을 지우는 데 그치지 않고, 그 예시들이 대표하는 개념(concept)이나 행동(behavior) 전체를 제거하려는 더 강한 목표를 갖는다. 저자들은 전통적인 언러닝 정의가 실제로는 재학습 결과와의 일치성을 요구하는 언트레이닝에 더 가깝다고 지적하며, 왜 많은 기존 연구가 개념 삭제나 위험한 행동 제거를 충분히 다루지 못했는지를 설명한다. 이러한 구분은 멤버십 추론 공격(Membership Inference Attack, MIA)처럼 개별 데이터 포함 여부를 확인하는 지표가 언트레이닝에는 적합할 수 있지만, 분포 수준의 개념 제거를 검증하는 데는 충분하지 않다는 점도 함께 보여 준다.
또한 저자들은 정리된 문제 정의를 바탕으로 문헌 속 다양한 사례를 두 범주에 대응시킨다. 사용자의 삭제 요청, 잘못 라벨된 데이터 제거, 저작물의 정확한 재생 방지와 같은 작업은 특정 인스턴스의 영향 제거에 초점이 있으므로 언트레이닝에 가깝다. 반대로 위험한 지식, 백도어, 유해한 능력, 특정 예술 스타일처럼 더 넓은 행동 양식을 제거하려는 시도는 언러닝의 성격을 띤다. 이처럼 문제를 구분하면 알고리즘의 성공 조건, 필요한 일반화 수준, 그리고 적절한 평가 기준이 명확해지며, 차등 프라이버시(Differential Privacy, DP)처럼 개별 예시를 강하게 기억하지 않는 학습법이 왜 어떤 경우에는 언트레이닝에는 충분하지만 언러닝에는 부족할 수 있는지도 이해할 수 있다. 결국 이 연구는 새로운 삭제 알고리즘을 제안하기보다, “무엇을 지우려는가”를 기술적으로 분명히 하는 것이 앞으로의 진전을 위해 필수적임을 보여 주며, 기계 언러닝 분야의 연구 질문과 평가 기준을 다시 세우는 중요한 출발점을 제공한다.
초록(Abstract)
모델이 점점 더 커지고 더 많은 데이터로 학습됨에 따라, 학습된 모델에서 특정 데이터 포인트나 행동을 사후에 어떻게 삭제''할 수 있는지에 대한 관심이 폭발적으로 증가해 왔다. 이 목표는 머신 언러닝(machine unlearning)''이라 불려 왔다. 이 노트에서는 unlearning''이라는 용어가 과도하게 포괄적으로 사용되어 왔으며, 서로 다른 연구들이 두 개의 구별되는 문제 정식을 다루고 있음에도 불구하고 이러한 구분이 문헌에서 관찰되거나 인정되지 않았다고 주장한다. 이로 인해 알고리즘이 언제 동작해야 하는지에 대한 모호성, 서로 다른 알고리즘을 비교할 때 부적절한 지표와 기준선의 사용, 결과 해석의 어려움, 그리고 핵심 연구 방향을 놓치는 문제 등 다양한 이슈가 발생한다. 이 노트에서는 그림 1에 제시된 바와 같이 \unlearning과 \untraining이라는 두 개념 사이의 근본적인 구분을 확립함으로써 이 문제를 해결하고자 한다. 간단히 말해, \untraining의 목표는 주어진 망각 집합(forget set)에 대해 학습한 효과를 되돌리는 것, 즉 학습 과정에서 해당 망각 집합의 예시들이 모델에 미친 영향을 제거하는 것이다. 반면 \unlearning의 목표는 단지 주어진 예시들의 영향을 제거하는 데 그치지 않고, 그 예시들이 표본추출된 근본 분포 전체(예: 그 예시들이 대표하는 개념이나 행동)를 더 넓은 범위에서 제거하기 위해 해당 예시들을 활용하는 데 있다. 우리는 이러한 문제들의 기술적 정의를 논의하고, 문헌에서 연구된 문제 설정을 각각에 대응시킨다. 우리는 기술적 정의의 모호성을 해소하는 논의를 촉발하고, 간과된 연구 질문들의 집합을 식별하기를 기대한다. 이는 unlearning'' 분야의 진전을 가속화하기 위해 반드시 필요한 핵심적인 빠진 단계라고 믿기 때문이다.
As models are getting larger and are trained on increasing amounts of data, there has been an explosion of interest into how we can
delete'' specific data points or behaviours from a trained model, after the fact. This goal has been referred to asmachine unlearning''. In this note, we argue that the termunlearning'' has been overloaded, with different research efforts spanning two distinct problem formulations, but without that distinction having been observed or acknowledged in the literature. This causes various issues, including ambiguity around when an algorithm is expected to work, use of inappropriate metrics and baselines when comparing different algorithms to one another, difficulty in interpreting results, as well as missed opportunities for pursuing critical research directions. In this note, we address this issue by establishing a fundamental distinction between two notions that we identify as \unlearning and \untraining, illustrated in Figure 1. In short, \untraining aims to reverse the effect of having trained on a given forget set, i.e. to remove the influence that that specific forget set examples had on the model during training. On the other hand, the goal of \unlearning is not just to remove the influence of those given examples, but to use those examples for the purpose of more broadly removing the entire underlying distribution from which those examples were sampled (e.g. the concept or behaviour that those examples represent). We discuss technical definitions of these problems and map problem settings studied in the literature to each. We hope to initiate discussions on disambiguating technical definitions and identify a set of overlooked research questions, as we believe that this a key missing step for accelerating progress in the field ofunlearning''.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()