[2026/04/20 ~ 26] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주 선정된 10편의 논문들을 살펴보면서, 최근 연구들은 단순히 모델의 크기를 키우는 확장을 넘어, 시스템적 안정성, 복잡한 정보의 구조적 처리, 그리고 아키텍처의 근본적 효율성을 고민하는 방향으로 나아가는 것을 발견할 수 있었습니다.
![]() RAG의 진화: 단순 검색을 넘어선 '추론 인지' 및 '오류 복구' 파이프라인: 이번 주 논문들에서는 단순한 텍스트 매칭을 넘어, 검색 결과의 품질과 맥락을 능동적으로 제어하는 고도화된 RAG 시스템들이 돋보였습니다. AgentIR은 에이전트의 검색 의도와 추론 과정을 검색기에 직접 반영해 다단계 탐색 환경에서의 문맥적 정확도를 크게 높였습니다. MASS-RAG는 단일 생성기에 의존하는 대신 다중 에이전트를 도입하여, 노이즈가 많은 검색 결과를 역할별(요약, 추출, 추론)로 나누어 분석하고 종합하는 구조를 제안했습니다. 또한 Skill-RAG는 검색 실패를 단순히 재시도하는 것을 넘어, 은닉 상태(hidden state)를 분석해 원인을 진단하고 맞춤형 복구 스킬을 실행하는 폐쇄 루프(closed-loop) 구조를 선보였습니다. 이는 RAG가 표면적인 정보 검색 도구를 넘어, 복잡한 증거를 스스로 종합하고 오류를 수정하는 지능형 시스템으로 진화하고 있음을 보여줍니다.
RAG의 진화: 단순 검색을 넘어선 '추론 인지' 및 '오류 복구' 파이프라인: 이번 주 논문들에서는 단순한 텍스트 매칭을 넘어, 검색 결과의 품질과 맥락을 능동적으로 제어하는 고도화된 RAG 시스템들이 돋보였습니다. AgentIR은 에이전트의 검색 의도와 추론 과정을 검색기에 직접 반영해 다단계 탐색 환경에서의 문맥적 정확도를 크게 높였습니다. MASS-RAG는 단일 생성기에 의존하는 대신 다중 에이전트를 도입하여, 노이즈가 많은 검색 결과를 역할별(요약, 추출, 추론)로 나누어 분석하고 종합하는 구조를 제안했습니다. 또한 Skill-RAG는 검색 실패를 단순히 재시도하는 것을 넘어, 은닉 상태(hidden state)를 분석해 원인을 진단하고 맞춤형 복구 스킬을 실행하는 폐쇄 루프(closed-loop) 구조를 선보였습니다. 이는 RAG가 표면적인 정보 검색 도구를 넘어, 복잡한 증거를 스스로 종합하고 오류를 수정하는 지능형 시스템으로 진화하고 있음을 보여줍니다.
![]() 단일 모델을 넘어선 '자율 에이전트 시스템'의 구조화 및 외부 검증 루프: LLM을 단일 텍스트 생성기로 사용하는 것을 넘어, 복잡하고 긴 작업을 수행하는 '에이전트 시스템'으로 안전하게 구조화하려는 흐름이 뚜렷합니다. Claude Code 논문은 권한 관리, 컨텍스트 압축, 서브에이전트 위임 등 모델 외부를 둘러싼 운영 체계가 실제 에이전트의 성능과 안전성을 결정한다는 점을 명확히 짚어냈습니다. 에이전틱 코딩을 위한 테스트 타임 컴퓨트 스케일링 연구 역시 긴 실행 궤적을 구조화된 요약으로 변환하고 평가하여 장기 과제의 성공률을 높였습니다. 아울러 See2Refine은 VLM의 시각적 피드백을 통해 eHMI 행동 설계를 수정하고, AutoOR은 실제 솔버(Solver)의 실행 결과를 보상으로 삼아 모델을 정렬하는 등, 외부 환경의 명시적인 피드백을 활용한 자가 검증 루프가 필수적인 요소로 자리 잡고 있습니다.
단일 모델을 넘어선 '자율 에이전트 시스템'의 구조화 및 외부 검증 루프: LLM을 단일 텍스트 생성기로 사용하는 것을 넘어, 복잡하고 긴 작업을 수행하는 '에이전트 시스템'으로 안전하게 구조화하려는 흐름이 뚜렷합니다. Claude Code 논문은 권한 관리, 컨텍스트 압축, 서브에이전트 위임 등 모델 외부를 둘러싼 운영 체계가 실제 에이전트의 성능과 안전성을 결정한다는 점을 명확히 짚어냈습니다. 에이전틱 코딩을 위한 테스트 타임 컴퓨트 스케일링 연구 역시 긴 실행 궤적을 구조화된 요약으로 변환하고 평가하여 장기 과제의 성공률을 높였습니다. 아울러 See2Refine은 VLM의 시각적 피드백을 통해 eHMI 행동 설계를 수정하고, AutoOR은 실제 솔버(Solver)의 실행 결과를 보상으로 삼아 모델을 정렬하는 등, 외부 환경의 명시적인 피드백을 활용한 자가 검증 루프가 필수적인 요소로 자리 잡고 있습니다.
![]() 트랜스포머의 구조적 한계 극복 및 동적 '상태 추적(State Tracking)' 재조명: 모델의 깊이와 컨텍스트 길이를 무작정 늘리는 피드포워드(feedforward) 방식의 비효율성을 지적하고, 아키텍처의 근본적인 동역학적 변화를 모색하는 연구들도 주목받았습니다. MoDA는 모델이 깊어질수록 얕은 층의 핵심 정보가 손실되는 신호 저하 현상을 해결하기 위해, 과거 층의 정보에 다시 접근하는 '혼합 깊이 어텐션'을 도입해 연산 효율과 성능을 동시에 끌어올렸습니다. 한편 트랜스포머의 위상학적 난제 논문은 순수 트랜스포머 구조가 지속적인 환경 변화를 반영하는 시간적 상태 추적에 근본적인 한계가 있음을 지적했습니다. 이를 극복하기 위해 현대 파운데이션 모델에 재귀적(recurrent) 아키텍처나 강화된 상태공간모델(SSM)을 통합해야 한다는 방향성을 강력히 제기했습니다. 이는 연산량을 늘리는 스케일링을 넘어, 정보의 흐름과 내부 상태 유지를 최적화하려는 아키텍처 혁신의 움직임입니다.
트랜스포머의 구조적 한계 극복 및 동적 '상태 추적(State Tracking)' 재조명: 모델의 깊이와 컨텍스트 길이를 무작정 늘리는 피드포워드(feedforward) 방식의 비효율성을 지적하고, 아키텍처의 근본적인 동역학적 변화를 모색하는 연구들도 주목받았습니다. MoDA는 모델이 깊어질수록 얕은 층의 핵심 정보가 손실되는 신호 저하 현상을 해결하기 위해, 과거 층의 정보에 다시 접근하는 '혼합 깊이 어텐션'을 도입해 연산 효율과 성능을 동시에 끌어올렸습니다. 한편 트랜스포머의 위상학적 난제 논문은 순수 트랜스포머 구조가 지속적인 환경 변화를 반영하는 시간적 상태 추적에 근본적인 한계가 있음을 지적했습니다. 이를 극복하기 위해 현대 파운데이션 모델에 재귀적(recurrent) 아키텍처나 강화된 상태공간모델(SSM)을 통합해야 한다는 방향성을 강력히 제기했습니다. 이는 연산량을 늘리는 스케일링을 넘어, 정보의 흐름과 내부 상태 유지를 최적화하려는 아키텍처 혁신의 움직임입니다.
깊이 혼합 어텐션(Mixture-of-Depths Attention) / Mixture-of-Depths Attention
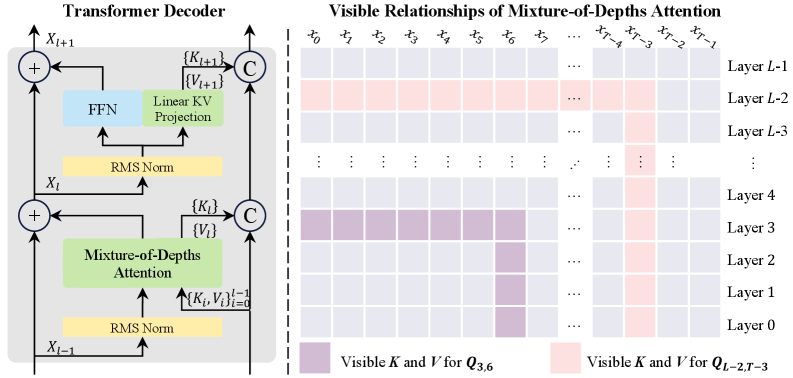
논문 소개
대규모 언어 모델의 발전은 깊이 확장에 크게 의존하고 있으며, 그 과정에서 발생하는 신호 손실 문제는 모델 성능의 저하를 초래하는 주요 요인으로 지적되고 있다. 이러한 문제를 해결하기 위해 새롭게 제안된 혼합 깊이 어텐션(Mixture-of-Depths Attention, MoDA) 메커니즘은 각 어텐션 헤드가 현재 레이어의 키-값(KV) 쌍과 이전 레이어의 깊이 KV 쌍 모두에 주의를 기울일 수 있도록 설계되었다. 이 방식은 정보 손실을 최소화하고, 더욱 깊은 레이어에서도 중요한 특징을 효과적으로 복구할 수 있게 한다. MoDA 알고리즘은 하드웨어 효율성을 고려하여 비연속 메모리 접근 패턴을 해결함으로써, 64K 시퀀스 길이에서도 FlashAttention-2의 97.3%에 달하는 효율성을 달성하였다.
15억 개의 파라미터를 가진 모델을 대상으로 한 실험에서는 MoDA가 강력한 기준선 모델보다 일관되게 우수한 성능을 보였으며, 특히 10개의 검증 벤치마크에서 평균 당혹도를 0.2 향상시키고, 10개의 다운스트림 작업에서 평균 성능을 2.11% 증가시켰다. 이 과정에서 MoDA는 계산 오버헤드가 3.7%에 불과하여, 실제 적용 시 높은 효율성을 유지할 수 있음을 입증하였다. 또한, MoDA와 사후 정규화(post-norm)를 결합했을 때 성능이 사전 정규화(pre-norm)와 결합했을 때보다 더 뛰어난 결과를 보여, MoDA의 구조적 장점이 더욱 부각되었다.
결론적으로, MoDA는 대규모 언어 모델의 깊이 확장을 위한 유망한 기초 요소로 자리잡을 가능성이 있으며, 향후 연구에서의 발전 가능성을 시사한다. 이러한 혁신적인 접근 방식은 딥 뉴럴 네트워크에서 발생하는 정보 손실 문제를 해결하고, 모델의 전반적인 성능 향상에 기여할 수 있을 것으로 기대된다.
초록(Abstract)
대규모 언어 모델(LLM)의 핵심 동력은 깊이 확장입니다. 그러나 LLM이 깊어짐에 따라 신호 저하 현상이 발생하는 경우가 많습니다. 즉, 얕은 층에서 형성된 유용한 특징들이 반복적인 잔여 업데이트에 의해 점차 희석되어 깊은 층에서 복구하기 어려워집니다. 우리는 각 어텐션 헤드가 현재 층의 시퀀스 KV 쌍과 이전 층의 깊이 KV 쌍에 주목할 수 있도록 하는 혼합 깊이 어텐션(Mixture-of-Depths Attention, MoDA) 메커니즘을 소개합니다. 또한, 비연속 메모리 접근 패턴을 해결하는 MoDA의 하드웨어 효율적인 알고리즘을 설명하며, 시퀀스 길이가 64K일 때 FlashAttention-2의 효율성의 97.3%를 달성합니다. 15억 매개변수 모델에 대한 실험 결과, MoDA는 강력한 기준선보다 일관되게 우수한 성능을 보였습니다. 특히, 10개의 검증 벤치마크에서 평균 퍼플렉서티를 0.2 향상시키고, 10개의 다운스트림 작업에서 평균 성능을 2.11% 증가시키며, 3.7%의 미미한 FLOPs 계산 오버헤드를 기록했습니다. 또한, MoDA를 포스트-노름과 결합할 경우 프리-노름과 사용할 때보다 더 나은 성능을 발휘한다는 것을 발견했습니다. 이러한 결과는 MoDA가 깊이 확장을 위한 유망한 원시 요소임을 시사합니다. 코드는 GitHub - hustvl/MoDA: An hardware-aware Efficient Implementation for "Mixture-of-Depths Attention". · GitHub 에서 공개됩니다.
Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at GitHub - hustvl/MoDA: An hardware-aware Efficient Implementation for "Mixture-of-Depths Attention". · GitHub .
논문 링크
더 읽어보기
See2Refine: 비전-언어 피드백으로 개선하는 LLM 기반 eHMI 행동 설계자 / See2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
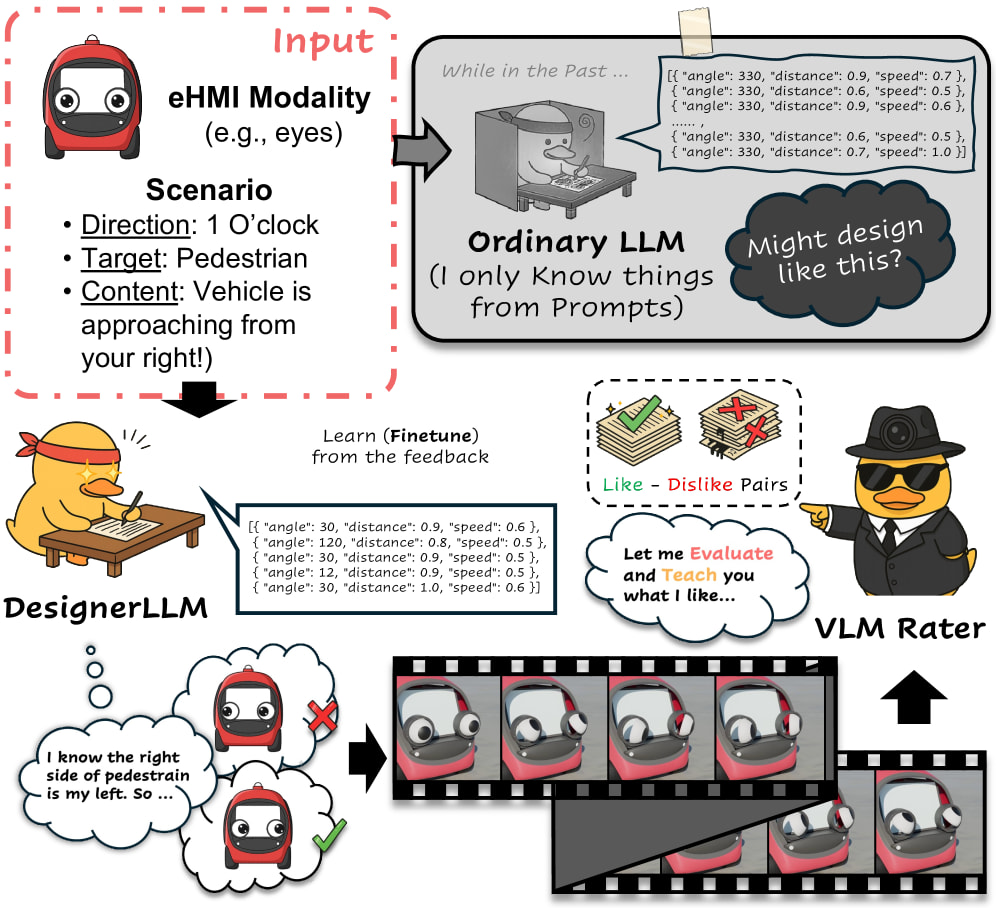
논문 소개
자율주행차가 보행자와 자전거 이용자 등 다른 도로 이용자에게 의도를 자연스럽게 전달하기 어렵다는 문제는, 공유 도로 환경에서 신뢰와 안전을 보장하기 위한 외부 인간-기계 인터페이스(external Human-Machine Interfaces, eHMIs)의 필요성을 부각시킨다. 그러나 기존 eHMI 연구는 대체로 개발자가 미리 정의한 메시지-행동 쌍에 의존해 왔기 때문에, 교통 맥락이 빠르게 바뀌는 현실 환경에 유연하게 대응하기 어렵고 설계와 유지 비용도 높다는 한계를 지닌다. 이러한 배경에서 저자들은 대규모 언어 모델(Large Language Models, LLMs)을 문맥 조건부 eHMI 행동을 생성하는 행동 디자이너로 활용하는 가능성에 주목하지만, 생성 결과가 시각적으로 얼마나 적절한지 스스로 검증하지 못하고 프롬프트 품질에 크게 좌우된다는 점을 핵심 문제로 지적한다. 이를 해결하기 위해 제안된 See2Refine는 비전-언어 모델(Vision-Language Models, VLMs)의 지각적 평가를 자동 피드백으로 활용하는 인간 비의존적 폐루프(human-free, closed-loop) 정제 프레임워크이며, 차량 주행 맥락과 후보 eHMI 행동을 함께 입력받아 그 적절성을 평가한 뒤 그 결과를 다시 LLM의 수정 과정에 반영한다. 다시 말해, 생성과 검증을 분리하되 서로를 순환적으로 연결함으로써, 인간 주석 없이도 행동 설계를 점진적으로 개선하는 구조를 구현한 것이다. 이 접근의 중요한 점은 단순히 텍스트를 더 자연스럽게 만드는 것이 아니라, lightbar, eyes, arm처럼 서로 다른 시각적 표현 양식에서 “해당 상황에 어울리는가”라는 지각적 적합성을 직접 다룬다는 데 있다. 실험에서는 여러 크기의 LLM과 세 가지 eHMI 양식을 비교했으며, 제안 기법은 프롬프트만 사용한 LLM 디자이너와 수동 기준선보다 전반적으로 우수한 성능을 보였다. 특히 VLM 기반 평가와 인간 대상 평가 모두에서 일관된 향상을 보여, 자동 피드백이 실제 사용자 선호와 상당히 잘 정렬된다는 점을 확인했다. 이러한 결과는 See2Refine가 단순한 후처리 기법이 아니라, 다양한 교통 상황에 맞춰 eHMI 행동을 확장 가능하게 설계할 수 있는 실용적 방법론임을 시사한다. 더 나아가, 비교적 작은 모델에서도 성능 향상이 가능하다는 점은 고비용의 인간 주석에 의존하지 않으면서도 eHMI 설계를 반복적으로 고도화할 수 있는 가능성을 열어 주며, 향후 자율주행차의 대외 커뮤니케이션을 더 정교하고 신뢰할 수 있는 방향으로 발전시키는 데 중요한 기반을 제공한다.
초록(Abstract)
자율주행 차량은 다른 도로 이용자와의 자연스러운 통신 채널이 부족하기 때문에, 공유 환경에서 의도를 전달하고 신뢰를 유지하기 위해 외부 인간-기계 인터페이스(eHMI)가 필수적이다. 그러나 대부분의 eHMI 연구는 개발자가 설계한 메시지-행동 쌍에 의존하며, 이는 다양한 동적 교통 상황에 맞게 조정하기 어렵다. 유망한 대안으로는 대규모 언어 모델(LLM)을 행동 디자이너로 사용하여 문맥 조건부 eHMI 행동을 생성하는 방법이 있지만, 이러한 디자이너는 지각적 검증이 부족하고, 일반적으로 개선을 위해 고정된 프롬프트나 비용이 많이 드는 인간 주석 피드백에 의존한다. 우리는 비전-언어 모델(VLM)의 지각 평가를 자동화된 시각적 피드백으로 활용하여 LLM 기반 eHMI 행동 디자이너를 개선하는, 인간 개입이 없는 폐루프 프레임워크인 See2Refine을 제안한다. 주행 문맥과 후보 eHMI 행동이 주어지면, VLM은 해당 행동의 지각된 적절성을 평가하고, 이 피드백은 디자이너의 출력을 반복적으로 수정하는 데 사용되어 인간 감독 없이도 체계적인 개선을 가능하게 한다. 우리는 세 가지 eHMI 양식(lightbar, eyes, arm)과 여러 LLM 모델 크기에서 이 프레임워크를 평가했다. 모든 설정에서, 우리의 프레임워크는 VLM 기반 지표와 인간 대상 평가 모두에서 프롬프트만 사용한 LLM 디자이너 및 수동으로 지정한 기준선보다 일관되게 우수한 성능을 보였다. 또한 결과는 이러한 개선이 양식 전반으로 일반화되며, VLM 평가가 인간 선호와 잘 정렬되어 있어, 확장 가능한 행동 설계를 위한 See2Refine의 견고성과 효과성을 뒷받침함을 보여준다.
Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
논문 링크
더 읽어보기
AgentIR: 딥 리서치 에이전트를 위한 추론 인지형 검색 / AgentIR: Reasoning-Aware Retrieval for Deep Research Agents
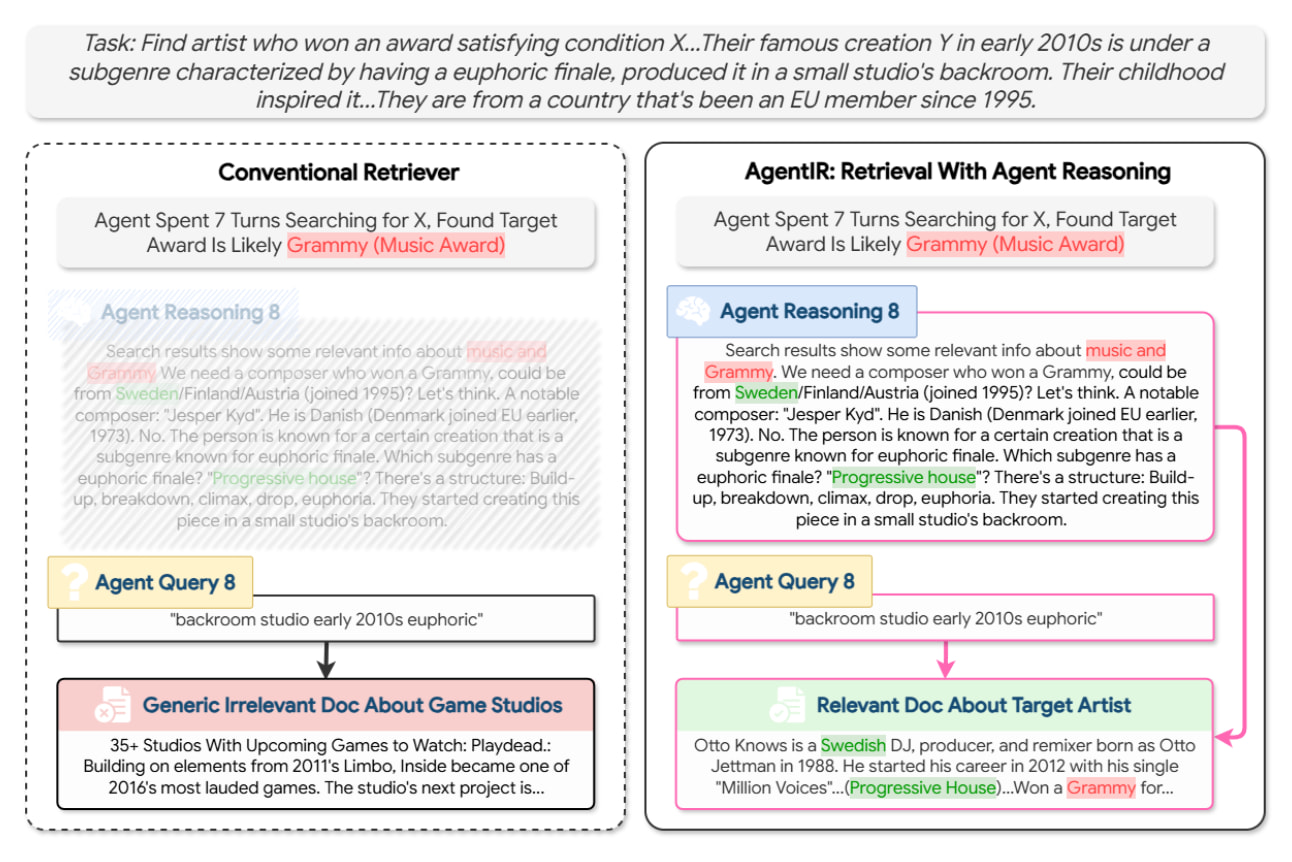
논문 소개
복잡한 조사형 과제에서 현대 검색 시스템의 핵심 사용자는 더 이상 사람에만 국한되지 않으며, 특히 딥 리서치 에이전트(Deep Research agents)는 검색 직전에 자연어 형태의 추론 과정을 명시적으로 생성한다는 점에서 기존 사용자와 뚜렷이 구분된다. 이러한 추론 흔적에는 단순한 질의 문장만으로는 포착하기 어려운 하위 목표, 맥락, 제약 조건이 포함되어 있음에도, 기존 검색기는 이를 거의 활용하지 못한 채 표면적인 쿼리 의미에만 의존해 왔다. AgentIR은 바로 이 지점을 문제의 출발점으로 삼아, 에이전트가 “무엇을 찾고 싶은가”뿐 아니라 “왜 지금 그것을 찾아야 하는가”까지 검색 표현에 반영하는 새로운 접근을 제안한다. 핵심 방법론인 이유 인지형 검색(Reasoning-Aware Retrieval)은 에이전트의 추론 흔적과 검색 쿼리를 분리된 입력이 아니라 하나의 공동 표현으로 임베딩하여, 검색기가 질의의 문맥적 의도까지 반영하도록 설계되었다. 이를 통해 동일한 질의라도 추론 맥락이 달라지면 서로 다른 문서를 선호할 수 있게 되어, 다단계 탐색과 반복적 의사결정이 중요한 딥 리서치 환경에 더욱 적합한 검색이 가능해진다.
또 다른 중요한 기여는 DR-Synth라는 데이터 합성 방법이다. 실제 딥 리서치 로그는 수집 비용이 높고 희소하기 때문에, 저자들은 표준 질의응답(QA, Question Answering) 데이터셋을 활용해 딥 리서치 검색기 학습에 필요한 형태의 데이터를 합성하는 방식을 제안했다. 이는 에이전트의 추론과 정답 문서 간 대응 관계를 인위적으로 구성함으로써, 별도의 대규모 주석 없이도 reasoning-aware retrieval 모델을 효과적으로 학습시킬 수 있게 한다는 점에서 실용성이 높다. 특히 이 두 구성 요소는 각각도 성능 향상에 기여하지만, 결합될 때 더 큰 상승 효과를 내며 최종적으로 AgentIR-4B라는 임베딩 모델로 구현된다.
실험은 까다로운 벤치마크인 BrowseComp-Plus에서 수행되었으며, 오픈 웨이트 에이전트인 Tongyi-DeepResearch와 결합한 AgentIR-4B는 68%의 정확도를 달성했다. 이는 같은 조건에서 기존 임베딩 모델이 보인 50% 정확도보다 현저히 높은 수치이며, 전통적인 BM25(Best Matching 25) 기반 검색의 37%와 비교하면 그 차이는 더욱 분명하다. 이러한 결과는 단순히 모델 크기를 키우는 것만으로는 얻기 어려운 성능 향상이, 에이전트의 추론 신호를 검색 과정에 직접 통합할 때 실현될 수 있음을 보여준다. 다시 말해, AgentIR은 검색을 표면적 의미 매칭의 문제에서 추론 맥락을 이해하는 문제로 확장함으로써, 딥 리서치 에이전트 시대에 적합한 retrieval 패러다임을 제시한다. 결국 이 연구는 검색 시스템이 인간의 짧은 질의뿐 아니라 기계가 생성한 사고 과정까지 해석해야 하는 방향으로 진화해야 함을 설득력 있게 보여주며, 향후 에이전트 기반 정보탐색 연구의 중요한 기준점을 마련한다.
초록(Abstract)
딥 리서치 에이전트는 현대 검색 시스템의 주요 소비자로 빠르게 부상하고 있습니다. 인간 사용자는 중간 사고 과정을 문서화하지 않은 채 쿼리를 발행하고 수정하는 반면, 딥 리서치 에이전트는 각 검색 호출 전에 명시적인 자연어 추론을 생성하여, 기존 검색기가 전혀 활용하지 않는 풍부한 의도와 문맥 정보를 드러냅니다. 이 간과된 신호를 활용하기 위해, 우리는 다음 두 가지를 제안합니다. (1) 에이전트의 추론 흔적을 쿼리와 함께 공동 임베딩하는 검색 패러다임인 Reasoning-Aware Retrieval, 그리고 (2) 표준 QA 데이터셋으로부터 딥 리서치 검색기 학습 데이터를 생성하는 데이터 합성 방법 DR-Synth입니다. 우리는 두 구성 요소가 각각 독립적으로 효과적이며, 이 둘을 결합하면 상당한 성능 향상을 보이는 학습된 임베딩 모델 AgentIR-4B가 도출됨을 보입니다. 까다로운 BrowseComp-Plus 벤치마크에서 AgentIR-4B는 오픈 가중치 에이전트인 Tongyi-DeepResearch와 함께 사용했을 때 68%의 정확도를 달성했으며, 이는 크기가 두 배인 기존 임베딩 모델의 50%와 BM25의 37%와 비교됩니다. 코드와 데이터는 다음에서 확인할 수 있습니다: AgentIR: Reasoning-Aware Retrieval for Deep Research Agents.
Deep Research agents are rapidly emerging as primary consumers of modern retrieval systems. Unlike human users who issue and refine queries without documenting their intermediate thought processes, Deep Research agents generate explicit natural language reasoning before each search call, revealing rich intent and contextual information that existing retrievers entirely ignore. To exploit this overlooked signal, we introduce: (1) Reasoning-Aware Retrieval, a retrieval paradigm that jointly embeds the agent's reasoning trace alongside its query; and (2) DR-Synth, a data synthesis method that generates Deep Research retriever training data from standard QA datasets. We demonstrate that both components are independently effective, and their combination yields a trained embedding model, AgentIR-4B, with substantial gains. On the challenging BrowseComp-Plus benchmark, AgentIR-4B achieves 68% accuracy with the open-weight agent Tongyi-DeepResearch, compared to 50% with conventional embedding models twice its size, and 37% with BM25. Code and data are available at: AgentIR: Reasoning-Aware Retrieval for Deep Research Agents.
논문 링크
더 읽어보기
MASS-RAG: 다중 에이전트 합성 검색-증강 생성 / MASS-RAG: Multi-Agent Synthesis Retrieval-Augmented Generation
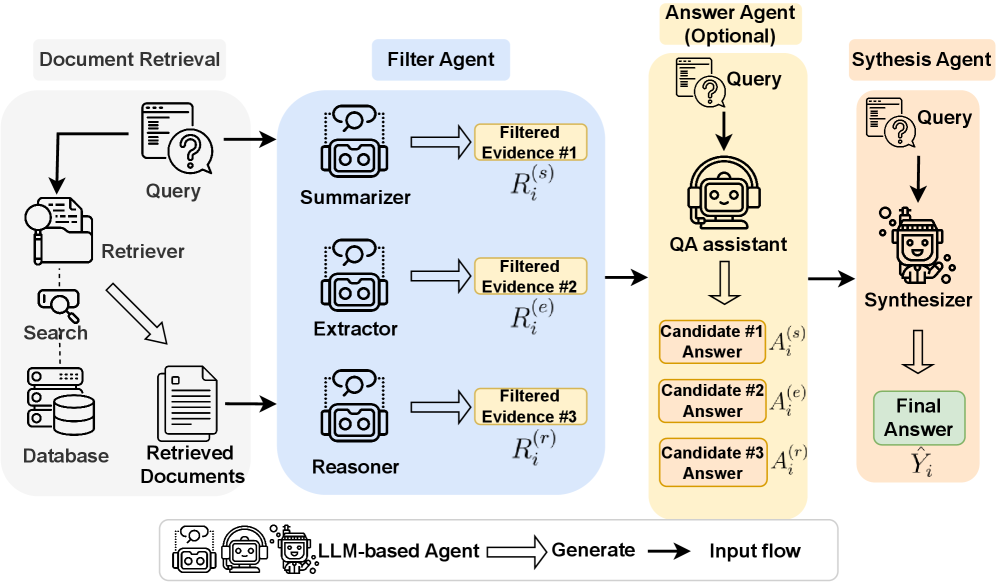
논문 소개
대규모 언어 모델(Large Language Model, LLM)은 검색-증강 생성(Retrieval-Augmented Generation, RAG)을 통해 외부 지식을 추론 시점에 활용함으로써 사실성과 최신성을 높여 왔지만, 검색된 문맥이 노이즈가 많거나 불완전하고 서로 이질적일 때는 단일 생성 경로만으로 여러 근거를 안정적으로 통합하기 어렵습니다. MASS-RAG(Multi-Agent Synthesis Retrieval-Augmented Generation)는 이러한 문제를 모델 자체의 용량 한계보다 증거를 처리하는 구조의 한계로 보고, 검색된 문서를 하나의 답변 생성기로 곧바로 넘기지 않고 역할이 분화된 여러 에이전트로 나누어 처리하는 방식을 제안합니다. 구체적으로 이 방법은 증거 요약(Summarizer), 증거 추출(Extractor), 증거 추론(Reasoner)이라는 서로 다른 관점의 필터 에이전트를 통해 동일한 문맥을 병렬로 재해석하게 하고, 각 에이전트가 만든 중간 표현을 바탕으로 후보 답변을 형성한 뒤 최종 합성(Synthesis) 단계에서 이를 통합해 최종 응답을 생성합니다. 이러한 설계는 하나의 관점에서 놓치기 쉬운 단서를 다른 관점이 보완하도록 만들며, 관련 정보가 여러 문서에 분산된 상황에서 특히 강점을 보입니다. 다시 말해 MASS-RAG의 핵심은 더 긴 문맥을 단순히 많이 넣는 것이 아니라, 문맥을 서로 다른 증거 뷰로 분해한 뒤 다시 조정하고 결합하는 데 있습니다. 또한 이 프레임워크는 학습이 없는(training-free) 추론 절차로 제시되어, 별도의 파인튜닝 없이도 기존 RAG 시스템에 적용할 수 있다는 실용적 장점을 지닙니다. 실험은 TriviaQA-unfiltered, PopQA, ALCE-ASQA, ARC-Challenge의 네 가지 벤치마크에서 수행되었으며, MASS-RAG는 강력한 기존 RAG 기준선과 다중 에이전트 기준선인 MAIN-RAG, 그리고 SELF-RAG와 비교해 전반적으로 더 우수한 성능을 보여 주었습니다. 특히 관련 증거가 검색 문맥 전반에 흩어져 있는 오픈도메인 질의응답(Open-Domain Question Answering, ODQA)과 긴 서술형 질문응답에서 개선 폭이 컸다는 점은, 이 방법이 단순한 생성 최적화가 아니라 분산된 근거를 구조적으로 모으는 데 효과적임을 시사합니다. 저자들은 추가 분석을 통해 각 필터 에이전트가 서로 다른 유형의 근거를 상보적으로 포착하며, 필요에 따라 후보 답변 생성 에이전트를 포함했을 때 사실형 과제에서 특히 더 큰 이득이 나타난다는 점도 확인했습니다. 결국 MASS-RAG는 검색 결과의 품질이 완벽하지 않더라도, 증거를 여러 역할로 나누어 해석하고 이를 합성하는 절차를 통해 더 신뢰도 높은 답변을 이끌어낼 수 있음을 보여 주며, RAG 연구에서 중요한 방향성을 제시합니다.
초록(Abstract)
대규모 언어 모델(LLM)은 추론 시 외부 지식을 통합하기 위해 검색-증강 생성(RAG)에서 널리 사용됩니다. 그러나 검색된 컨텍스트가 노이즈가 많거나 불완전하거나 이질적일 경우, 단일 생성 과정만으로는 증거를 효과적으로 조합하는 데 어려움을 겪는 경우가 많습니다. 우리는 \textbf{MASS-RAG}를 제안합니다. 이는 검색-증강 생성을 위한 멀티 에이전트 합성 접근법으로, 증거 처리를 여러 역할 특화 에이전트로 구조화합니다. MASS-RAG는 증거 요약, 증거 추출, 그리고 검색된 문서에 대한 추론을 위해 서로 다른 에이전트를 적용하고, 전용 합성 단계를 통해 이들의 출력을 결합하여 최종 답변을 생성합니다. 이러한 설계는 여러 중간 증거 관점을 드러내어, 모델이 답변 생성 전에 보완적인 정보를 비교하고 통합할 수 있게 합니다. 4개 벤치마크에서의 실험 결과, MASS-RAG는 강력한 RAG 기준선보다 일관되게 더 나은 성능을 보였으며, 특히 관련 증거가 검색된 컨텍스트 전반에 분산되어 있는 설정에서 그 향상이 두드러졌습니다.
Large language models (LLMs) are widely used in retrieval-augmented generation (RAG) to incorporate external knowledge at inference time. However, when retrieved contexts are noisy, incomplete, or heterogeneous, a single generation process often struggles to reconcile evidence effectively. We propose \textbf{MASS-RAG}, a multi-agent synthesis approach to retrieval-augmented generation that structures evidence processing into multiple role-specialized agents. MASS-RAG applies distinct agents for evidence summarization, evidence extraction, and reasoning over retrieved documents, and combines their outputs through a dedicated synthesis stage to produce the final answer. This design exposes multiple intermediate evidence views, allowing the model to compare and integrate complementary information before answer generation. Experiments on four benchmarks show that MASS-RAG consistently improves performance over strong RAG baselines, particularly in settings where relevant evidence is distributed across retrieved contexts.
논문 링크
AutoOR: 운영 연구 문제를 자동 형식화하도록 대규모 언어 모델(LLM)을 확장 가능하게 사후학습하기 / AutoOR: Scalably Post-training LLMs to Autoformalize Operations Research Problems
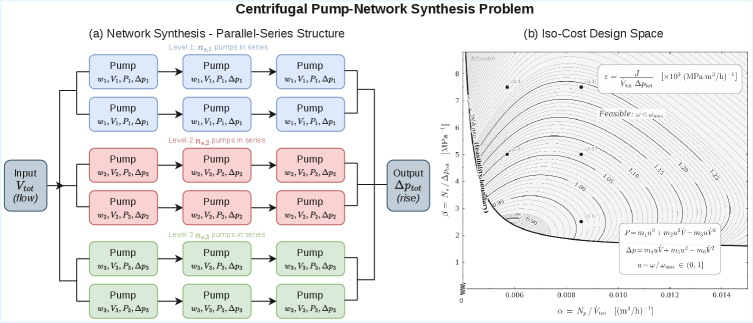
논문 소개
제조, 물류, 스케줄링과 같은 산업 의사결정에서 운영 연구(operations research, OR) 기반 최적화 문제는 매우 중요한 역할을 하지만, 이를 자연어 설명에서 바로 솔버 실행 가능한 수식으로 옮기는 작업은 숙련된 전문가의 판단을 필요로 해 대규모로 확장하기 어렵습니다. 복잡한 문제 서술에서 목적함수, 제약식, 변수 범위, 정수성 조건, 나아가 비선형 동역학까지 정확히 추출해야 하므로, 단순한 텍스트 생성이나 일반적인 사후학습만으로는 실행 가능성과 해의 품질을 동시에 확보하기 힘듭니다. 이러한 한계를 해결하기 위해 AutoOR는 합성 데이터 생성과 강화학습(reinforcement learning, RL)을 결합한 사후학습 파이프라인을 제안하며, 표준 최적화 형식에서 검증된 학습 데이터를 자동으로 만들어 대규모 언어 모델(large language model, LLM)을 정밀하게 정렬합니다. 특히 선형, 혼합정수, 비선형 범주의 문제를 하나의 틀에서 다루도록 설계하여, 다양한 OR 문제를 자연어에서 형식화하는 능력을 체계적으로 학습시킨다는 점이 특징적입니다. 학습의 핵심 신호는 별도의 보상 모델이 아니라 실제 솔버 실행 결과에서 직접 얻어지며, 이를 통해 모델은 그럴듯한 표현보다 실제로 풀 수 있는 형식화를 우선적으로 학습하게 됩니다. 또한 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)를 활용해 동일한 프롬프트에서 생성된 여러 후보를 서로 비교하며 정책을 업데이트함으로써, 보상 스케일의 불안정성을 줄이고 실행 실패와 성공을 구분하는 데 더 적합한 학습을 구현합니다. 이러한 방식으로 8B 규모 모델만으로도 여섯 개의 확립된 OR 벤치마크에서 최첨단 또는 경쟁력 있는 성능을 달성했으며, 훨씬 더 큰 프런티어 모델과도 맞먹는 결과를 보여 주었습니다. 더 나아가 물리 동역학이 포함된 고난도 비선형 문제처럼 기존 모델이 거의 성과를 내지 못하던 영역에서는, 소량의 초기 데이터에서 시작해 난도를 점진적으로 높이는 커리큘럼 강화학습(curriculum RL)을 도입하여 학습 가능성을 열었습니다. 결과적으로 AutoOR는 언어 모델을 단순한 텍스트 생성기가 아니라 솔버와 연결된 형식화 엔진으로 확장하는 접근을 제시하며, 향후 산업 현장의 의사결정 자동화를 크게 가속할 수 있는 실용적 방법론으로 평가됩니다.
초록(Abstract)
최적화 문제는 제조, 물류, 스케줄링 및 기타 산업 환경에서 의사결정의 핵심입니다. 이러한 문제에 대한 복잡한 설명을 솔버에 바로 사용할 수 있는 형식으로 변환하려면 전문적인 운영 연구(operations research, OR) 지식이 필요하므로 확장하기가 어렵습니다. 우리는 자연어로 기술된 최적화 문제를 선형, 혼합정수, 비선형 범주 전반에서 자동 형식화하도록 대규모 언어 모델(LLM)을 학습시키는 확장 가능한 합성 데이터 생성 및 강화학습 파이프라인 AutoOR를 제안합니다. AutoOR는 표준 최적화 형식에서 검증된 학습 데이터를 생성하고, 솔버 실행 피드백을 강화학습(RL) 사후학습의 보상 신호로 사용합니다. AutoOR를 8B 모델에 적용하면 6개의 확립된 운영 연구(OR) 벤치마크 전반에서 최고 성능 수준 또는 경쟁력 있는 결과를 달성하며, 훨씬 더 큰 최첨단 모델들과 맞먹습니다. 프런티어 모델들이 거의 0%를 기록하는 물리적 동역학을 포함하는 비선형 문제 범주에 대해서는, 제한된 초기 학습 데이터에서 부트스트랩하여 이 범주를 사후학습으로 다룰 수 있게 하는 커리큘럼 RL 전략을 도입합니다. 우리는 AutoOR와 같은 방법이 AI를 활용한 산업 의사결정을 크게 가속할 수 있다고 믿습니다.
Optimization problems are central to decision-making in manufacturing, logistics, scheduling, and other industrial settings. Translating complicated descriptions of these problems into solver-ready formulations requires specialized operations research (OR) expertise, making it hard to scale. We present AutoOR, a scalable synthetic data generation and reinforcement learning pipeline that trains LLMs to autoformalize optimization problems specified in natural language across linear, mixed-integer, and non-linear categories. AutoOR generates verified training data from standard optimization forms and uses solver execution feedback as the reward signal for RL post-training. AutoOR applied to an 8B model achieves state-of-the-art or competitive results across six established OR benchmarks, matching significantly larger frontier models. For a non-linear problem class involving physical dynamics, where frontier models score near 0%, we introduce a curriculum RL strategy that bootstraps from limited initial training data to make this class tractable for post-training. We believe that methods such as AutoOR can significantly accelerate industrial decision-making with AI.
논문 링크
Skill-RAG: 히든 스테이트 프로빙과 스킬 라우팅을 통한 실패 상태 인식 검색 증강 / Skill-RAG: Failure-State-Aware Retrieval Augmentation via Hidden-State Probing and Skill Routing
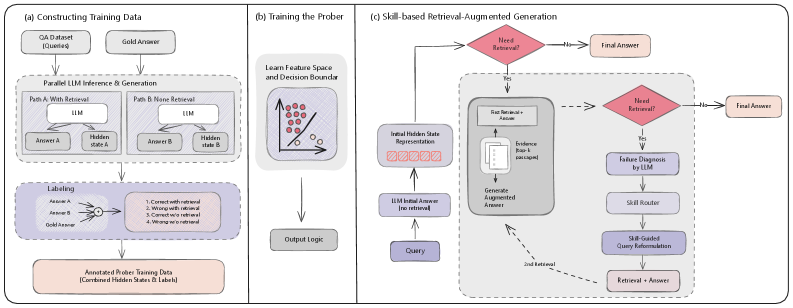
논문 소개
검색-증강 생성(Retrieval-Augmented Generation, RAG)은 대규모 언어 모델이 외부 지식에 근거해 답변하도록 만드는 핵심 접근이지만, 실제 환경에서는 검색이 한 번 실패했을 때 단순히 다시 검색하는 방식만으로는 반복적인 오류를 충분히 줄이기 어렵습니다. Skill-RAG는 이러한 한계를 질의와 증거 사이의 정렬(alignment) 실패로 해석하고, 실패를 단순한 재시도 신호가 아니라 진단 가능한 상태로 다루는 실패 상태 인식형(framework)으로 제안됩니다. 이 방법의 핵심은 가벼운 hidden-state prober가 생성 과정의 은닉 상태를 바탕으로 현재 상태가 충분한지 실패 상태인지 먼저 판별하고, 실패가 감지되면 프롬프트 기반 skill router가 그 원인을 해석해 다음 행동을 선택한다는 점에 있습니다. 여기서 스킬은 질의 재작성(query rewriting), 질문 분해(question decomposition), 증거 집중(evidence focusing), 그리고 더 이상의 복구가 어렵다고 판단될 때 검색을 멈추는 종료(exit)로 구성되며, 단순 재검색보다 훨씬 세밀한 복구 전략을 제공합니다. 특히 이 구조는 검색 전, 검색 후, 재검색 전의 상태를 계층적으로 점검하는 폐쇄 루프(closed-loop) 방식으로 작동해, 잘못된 검색 경로가 누적되며 발생하는 드리프트를 억제합니다. 프로버는 HotpotQA, Natural Questions(NQ), TriviaQA 같은 인도메인 데이터로 학습되며, Chain-of-Thought(CoT) 추론 과정에서 추출한 후반부 은닉 표현을 활용해 저비용으로 상태를 판별하도록 설계되었습니다. 반면 라우터는 원래 질문, 실패한 추론, 잘못된 답, 검색된 증거를 함께 고려해 실패 유형을 진단하므로, 질의 표현의 불일치, 다중 홉 추론의 복잡성, 증거 범위의 과도한 확장 같은 서로 다른 문제를 구분해 대응할 수 있습니다. 실험 결과에서도 Skill-RAG는 Exact Match(EM)와 Accuracy(ACC) 모두에서 강한 성능을 보였고, 특히 MuSiQue와 2WikiMultiHopQA 같은 분포 밖(out-of-distribution, OOD) 데이터셋에서 더 큰 향상을 보여 실패 상태 진단의 일반화 가능성을 입증했습니다. 더 나아가 표현 공간 분석에서는 실패가 하나의 단일한 현상이 아니라 질의-증거 불일치와 복구 불가능한 사례처럼 구조적으로 구분되는 유형적(typed) 상태임이 드러났으며, 이는 소수의 잘 정의된 스킬만으로도 실패 공간을 효과적으로 해석하고 제어할 수 있음을 시사합니다. 결국 Skill-RAG는 더 많은 검색을 반복하는 접근보다, 현재 실패가 왜 발생했는지를 먼저 읽고 그에 맞는 처방을 선택하는 것이 RAG의 성능과 안정성을 함께 높이는 더 본질적인 전략임을 보여줍니다.
초록(Abstract)
검색-증강 생성(RAG)은 외부 지식에 대규모 언어 모델(LLM)을 그라운딩하기 위한 기초적인 패러다임으로 부상했다. 적응형 검색 메커니즘은 검색 효율성을 향상시켰지만, 기존 접근법은 검색 후 실패를 진단의 신호가 아니라 재시도의 신호로 취급하며, 그로 인해 질의-증거 불일치의 구조적 원인을 해결하지 못하고 있다. 우리는 지속적인 검색 실패의 상당 부분이 관련 증거의 부재가 아니라 질의와 증거 공간 사이의 정렬 격차에서 비롯된다는 점을 관찰했다. 이에 우리는 경량 은닉 상태 프로버(hidden-state prober)와 프롬프트 기반 스킬 라우터를 결합한 실패 인지형 RAG 프레임워크인 Skill-RAG를 제안한다. 프로버는 파이프라인의 두 단계에서 검색을 게이팅하며, 실패 상태를 감지하면 스킬 라우터가 근본 원인을 진단하고 질의 재작성, 질문 분해, 증거 집중, 그리고 정말로 환원 불가능한 사례를 위한 종료 스킬의 네 가지 검색 스킬 중 하나를 선택하여 다음 생성 시도 전에 불일치를 교정한다. 여러 오픈도메인 QA 및 복잡한 추론 벤치마크에 대한 실험 결과, Skill-RAG는 다중 턴 검색 이후에도 남는 어려운 사례에서 정확도를 크게 향상시켰으며, 특히 분포 밖 데이터셋에서 더욱 강한 향상을 보였다. 또한 표현 공간 분석은 제안된 스킬들이 실패 상태 공간 내에서 구조화되고 분리 가능한 영역을 차지함을 보여주며, 질의-증거 불일치가 단일한 현상이 아니라 유형화된 현상이라는 관점을 뒷받침한다.
Retrieval-Augmented Generation (RAG) has emerged as a foundational paradigm for grounding large language models in external knowledge. While adaptive retrieval mechanisms have improved retrieval efficiency, existing approaches treat post-retrieval failure as a signal to retry rather than to diagnose -- leaving the structural causes of query-evidence misalignment unaddressed. We observe that a significant portion of persistent retrieval failures stem not from the absence of relevant evidence but from an alignment gap between the query and the evidence space. We propose Skill-RAG, a failure-aware RAG framework that couples a lightweight hidden-state prober with a prompt-based skill router. The prober gates retrieval at two pipeline stages; upon detecting a failure state, the skill router diagnoses the underlying cause and selects among four retrieval skills -- query rewriting, question decomposition, evidence focusing, and an exit skill for truly irreducible cases -- to correct misalignment before the next generation attempt. Experiments across multiple open-domain QA and complex reasoning benchmarks show that Skill-RAG substantially improves accuracy on hard cases persisting after multi-turn retrieval, with particularly strong gains on out-of-distribution datasets. Representation-space analyses further reveal that the proposed skills occupy structured, separable regions of the failure state space, supporting the view that query-evidence misalignment is a typed rather than monolithic phenomenon.
논문 링크
재현 가능한 합성 / Replicable Composition
논문 소개
재현성(replicability)은 알고리즘을 독립적으로 다시 뽑은 데이터에 대해 반복 실행했을 때 결론이 일관되게 유지되는 성질로, 단순한 정확도와는 다른 안정성의 기준을 제시합니다. 이러한 관점에서 핵심적으로 남아 있던 질문은, 각각 재현적 알고리즘으로 풀 수 있는 여러 문제를 동시에 조합할 때 샘플 복잡도가 어떻게 누적되는가 하는 점이었습니다. 기존의 단순한 분석은 \widetilde O(nk^2) 수준의 비용을 요구했고, 차등프라이버시(differential privacy)로의 환원을 이용한 결과도 \widetilde O(n^2k) 에 머물러, 최적에 가까운 \widetilde O(nk) 또는 일반화된 \widetilde O(\sum_i n_i) 스케일이 가능한지는 열려 있었습니다. 이에 따라 본 연구는 각 문제의 샘플 복잡도가 서로 다르더라도, 문제들을 한꺼번에 해결하면서도 상수 수준 재현성을 유지하는 조합 정리를 확립합니다.
방법론의 핵심은 재현적 알고리즘을 곧바로 합치는 대신, 먼저 이를 완전 일반화(perfect generalization)된 형태로 변환한 뒤 차등프라이버시 분석과 유사한 조합 기법을 적용하고, 마지막에 상호상관 샘플링(correlated sampling)으로 다시 재현성의 언어로 되돌리는 데 있습니다. 이 우회적 구조는 재현성과 일반화 사이의 관계를 정교하게 연결하며, 단순한 합성보다 훨씬 강한 상계를 가능하게 합니다. 그 결과로 저자들은 재현성에 대한 첫 번째 advanced composition theorem을 제시하고, 이질적인 샘플 복잡도 n_1,\ldots,n_k 를 가진 문제들도 총 \widetilde O(\sum_i n_i) 샘플로 함께 다룰 수 있음을 보입니다. 이는 각 문제의 비용이 거의 선형적으로 누적된다는 점에서, 기존의 이차적 비효율을 제거한 중요한 진전입니다.
또한 연구는 재현적 알고리즘의 성공 확률을 높이는 boosting theorem을 도입하여, 실패 확률이 재현성 매개변수 \rho 와 분리된 가산항으로 나타나는 넓은 문제군에 대해 추가적인 샘플 절감이 가능함을 보입니다. 이 결과는 재현성과 성공 확률을 함께 다루는 분석이 단순한 보조기술이 아니라, 실제 샘플 복잡도를 개선하는 핵심 도구임을 보여줍니다. 더 나아가 저자들은 적응적 조합(adaptive composition)에서는 본질적으로 더 큰 비용이 필요함을 증명하며, \Omega(nk^2) 하한을 통해 비적응적 조합과의 이차 분리(quadratic separation)를 확립합니다. 이 하한 증명의 중심에는 phantom run이라는 기법이 있으며, 이는 서로 다른 히스토리를 가진 실행을 직접 비교하기 어려운 상황에서 가상의 독립 실행을 삽입해 오차를 추적하는 구조적 장치로 기능합니다.
종합하면, 이 연구는 재현성을 개별 알고리즘의 속성이 아니라 조합 가능성과 하한까지 함께 드러나는 구조적 개념으로 정리합니다. 상계에서는 완전 일반화와 상호상관 샘플링을 매개로 거의 최적의 선형 스케일을 달성하고, 하한에서는 phantom run을 통해 적응적 설정의 근본적 비용을 분명히 밝혀냅니다. 따라서 재현성 조합 문제가 어떤 조건에서 효율적으로 해결될 수 있는지, 그리고 어디에서 더 이상 개선이 어려운지를 함께 제시하는 균형 잡힌 이론적 틀을 제공한다는 점에서 의의가 큽니다.
초록(Abstract)
재현 가능성은 독립적으로 추출된 데이터에 대해 알고리즘적 결론을 다시 실행했을 때도 일관되게 유지될 것을 요구한다. 핵심적인 구조적 질문은 합성이다. 표본 복잡도 n을 갖는 ρ-재현 가능한 알고리즘을 각각 허용하는 k 개의 문제에 대해, 재현 가능성을 보존하면서 이들을 함께 해결하려면 얼마나 많은 표본이 필요한가? 단순 분석으로는 \widetilde{O}(nk^2) 개의 표본이 도출되며, Bun et al. (STOC'23)은 차등 프라이버시를 통한 환원이 \widetilde{O}(n^2k) 의 대안적 경계를 제공함을 보였다. 이에 따라 최적의 \widetilde{O}(nk) 스케일링이 가능한지는 미해결 문제로 남아 있었다. 우리는 이 미해결 문제를 해결하며, 더 일반적으로 표본 복잡도가 n_1,\ldots,n_k 인 문제들을 상수 재현 가능성을 보존한 채 \widetilde{O}(\sum_i n_i)\) 개의 표본으로 함께 해결할 수 있음을 보인다. 우리의 접근법은 각 재현 가능한 알고리즘을 완전 일반화하는 알고리즘으로 변환한 뒤, 프라이버시 스타일의 분석을 통해 이를 합성하고, 상관 샘플링을 통해 다시 되돌리는 방식이다. 이는 재현 가능성에 대한 최초의 고급 합성 정리를 제공한다. 이 과정에서 우리는 이질적 매개변수를 갖는 완전 일반화 알고리즘의 합성에 대한 새로운 경계를 얻는다. 또한 결과의 일환으로, 재현 가능한 알고리즘의 성공 확률에 대한 부스팅 정리를 제시한다. 넓은 범주의 문제들에서 실패 확률은 ρ와 무관한 별도의 가법 항으로 나타나며, 이는 여러 문제에 대해 즉시 개선된 표본 복잡도 경계를 도출한다. 마지막으로, 우리는 적응적 합성에 대해 Ω(nk^2) 의 하한을 증명하여 비적응적 설정과의 이차적 분리를 확립한다. 우리가 phantom run이라 부르는 핵심 기법은 독립적으로도 흥미로운 구조적 결과를 산출한다.
Replicability requires that algorithmic conclusions remain consistent when rerun on independently drawn data. A central structural question is composition: given k problems each admitting a ρ-replicable algorithm with sample complexity n, how many samples are needed to solve all jointly while preserving replicability? The naive analysis yields \widetilde{O}(nk^2) samples, and Bun et al. (STOC'23) observed that reductions through differential privacy give an alternative \widetilde{O}(n^2k) bound, leaving open whether the optimal \widetilde{O}(nk) scaling is achievable. We resolve this open problem and, more generally, show that problems with sample complexities n_1,\ldots,n_k can be jointly solved with \widetilde{O}(\sum_i n_i) samples while preserving constant replicability. Our approach converts each replicable algorithm into a perfectly generalizing one, composes them via a privacy-style analysis, and maps back via correlated sampling. This yields the first advanced composition theorem for replicability. En route, we obtain new bounds for the composition of perfectly generalizing algorithms with heterogeneous parameters. As part of our results, we provide a boosting theorem for the success probability of replicable algorithms. For a broad class of problems, the failure probability appears as a separate additive term independent of ρ, immediately yielding improved sample complexity bounds for several problems. Finally, we prove an Ω(nk^2) lower bound for adaptive composition, establishing a quadratic separation from the non-adaptive setting. The key technique, which we call the phantom run, yields structural results of independent interest.
논문 링크
트랜스포머의 위상학적 난제 / The Topological Trouble With Transformers
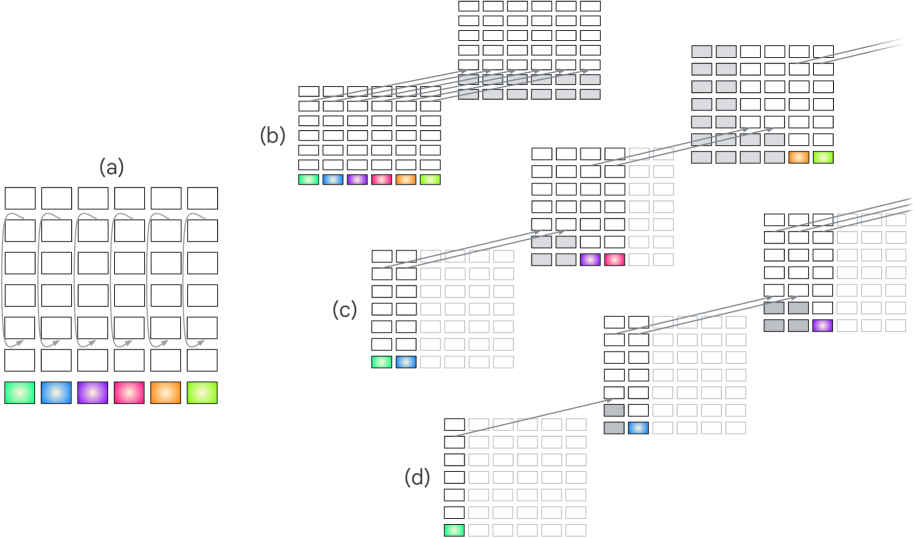
논문 소개
트랜스포머(Transformer)는 긴 문맥을 활용해 시퀀스의 구조를 효과적으로 포착하는 데 탁월하지만, 본질적으로 피드포워드(feedforward) 아키텍처라는 점 때문에 변화하는 환경의 내부 상태를 반복적으로 갱신하는 일에는 구조적 한계를 드러낸다. 저자들은 이러한 상태 추적(state tracking)을 단순한 기억 유지가 아니라, 잠재 변수(latent variables)가 시간에 따라 점진적으로 업데이트되는 순차적 계산으로 정의하며, 트랜스포머가 새로운 입력이 들어올 때마다 상태 표현을 더 깊은 층으로 밀어 올리는 방식으로만 이를 처리하려 한다고 지적한다. 그 결과 최신 상태는 얕은 층에서 접근하기 어려워지고, 모델의 깊이는 사실상 상태를 보관하는 비용으로 소진되기 쉽다. 이 논문은 바로 이 문제를 “더 긴 문맥”의 문제로 축소하지 않고, 시간적으로 확장된 인지에는 암묵적인 활성 동역학과 재귀적(recurrent) 구조가 필요하다는 관점에서 재해석한다. 특히 상태 추적을 잘 수행하려면 과거 토큰을 다시 조회하는 능력만으로는 부족하며, 환경 변화에 맞춰 내부 표현을 지속적으로 갱신하는 계산 메커니즘이 별도로 필요하다는 점을 강조한다.
이러한 문제의식 위에서 논문은 재귀적 및 연속 사고(continuous-thought) 계열의 트랜스포머 아키텍처를 체계적으로 정리하는 분류 체계를 제안한다. 저자들은 모델을 재귀 축(recurrence axis)과 입력 토큰 대비 재귀 단계 수의 비율이라는 두 기준으로 나누어, 깊이 방향에서 반복이 일어나는지, 입력 스텝 방향에서 일어나는지, 혹은 둘이 결합되는지를 구분한다. 이 틀은 단순히 여러 변형 모델을 나열하는 데 그치지 않고, looped transformer, blockwise recurrent 모델, latent-thought 모델, 상태공간모델(State-Space Model, SSM) 등을 하나의 좌표계에 올려놓고 비교할 수 있게 해 준다. 또한 동적 깊이(dynamic depth)나 명시적·잠재적 사고(explicit or latent thinking)처럼 계산을 외부로 늘리는 우회책이 성능을 높일 수는 있어도, 계산량과 메모리 측면에서 비효율적이라는 점을 비판적으로 짚는다. 대신 저자들은 더 유망한 방향으로 강화된 상태공간모델과 거친 재귀(coarse-grained recurrence)를 제안하며, 이는 현대 파운데이션 모델에 상태 추적을 보다 자연스럽게 통합하기 위한 설계 원리로 제시된다. 결국 이 논문의 핵심 기여는 트랜스포머의 한계를 단순한 표현력 부족으로 보지 않고, 상태를 어디에 저장하고 어떤 방식으로 갱신할 것인가라는 동역학적 질문으로 전환했다는 데 있다. 이런 관점은 트랜스포머가 강한 이유를 재조회와 지름길 추론에만 두지 않고, 앞으로의 연구가 더 정교한 재귀 구조를 통해 실제 의미의 상태 추적을 구현해야 한다는 방향을 분명하게 제시한다.
초록(Abstract)
트랜스포머(Transformer)는 확장되는 문맥 이력을 통해 시퀀스 내 구조를 인코딩한다. 그러나 순수한 피드포워드(feedforward) 아키텍처는 동적 상태 추적을 근본적으로 제한한다. 상태 추적은 진화하는 환경을 반영하는 잠재 변수의 반복적 업데이트를 의미하며, 본질적으로 순차적 의존성을 포함하기 때문에 피드포워드 네트워크는 이를 유지하는 데 어려움을 겪는다. 그 결과, 피드포워드 모델은 새로운 입력 단계가 들어올 때마다 진화하는 상태 표현을 레이어 스택의 더 깊은 층으로 밀어 넣어, 얕은 층에서는 정보를 접근할 수 없게 만들고 궁극적으로 모델의 깊이를 소진한다. 이러한 깊이 한계는 동적 깊이 모델과 상태 표현을 외재화하는 명시적 또는 잠재적 사고를 통해 우회할 수 있지만, 이러한 해결책은 계산과 메모리 측면에서 비효율적이다. 본 논문에서는 시간적으로 확장된 인지가 명시적 사고 흔적이 아니라 순환 아키텍처를 통한 암묵적 활성화 동역학에 초점을 다시 맞춰야 한다고 주장한다. 우리는 순환 및 연속 사고 트랜스포머(recurrent and continuous-thought transformer) 아키텍처의 분류 체계를 제시하며, 이를 순환 축(깊이 대 단계)과 입력 토큰 대비 순환 단계의 비율에 따라 분류한다. 마지막으로, 강화된 상태공간 모델과 거친 수준의 순환(coarse-grained recurrence)을 포함한 유망한 연구 방향을 제시하여, 상태 추적을 현대의 파운데이션 모델에 더 잘 통합할 수 있는 방법을 제안한다.
Transformers encode structure in sequences via an expanding contextual history. However, their purely feedforward architecture fundamentally limits dynamic state tracking. State tracking -- the iterative updating of latent variables reflecting an evolving environment -- involves inherently sequential dependencies that feedforward networks struggle to maintain. Consequently, feedforward models push evolving state representations deeper into their layer stack with each new input step, rendering information inaccessible in shallow layers and ultimately exhausting the model's depth. While this depth limit can be bypassed by dynamic depth models and by explicit or latent thinking that externalizes state representations, these solutions are computationally and memory inefficient. In this article, we argue that temporally extended cognition requires refocusing from explicit thought traces to implicit activation dynamics via recurrent architectures. We introduce a taxonomy of recurrent and continuous-thought transformer architectures, categorizing them by their recurrence axis (depth versus step) and their ratio of input tokens to recurrence steps. Finally, we outline promising research directions, including enhanced state-space models and coarse-grained recurrence, to better integrate state tracking into modern foundation models.
논문 링크
에이전틱 코딩을 위한 테스트 타임 컴퓨트 스케일링 / Scaling Test-Time Compute for Agentic Coding
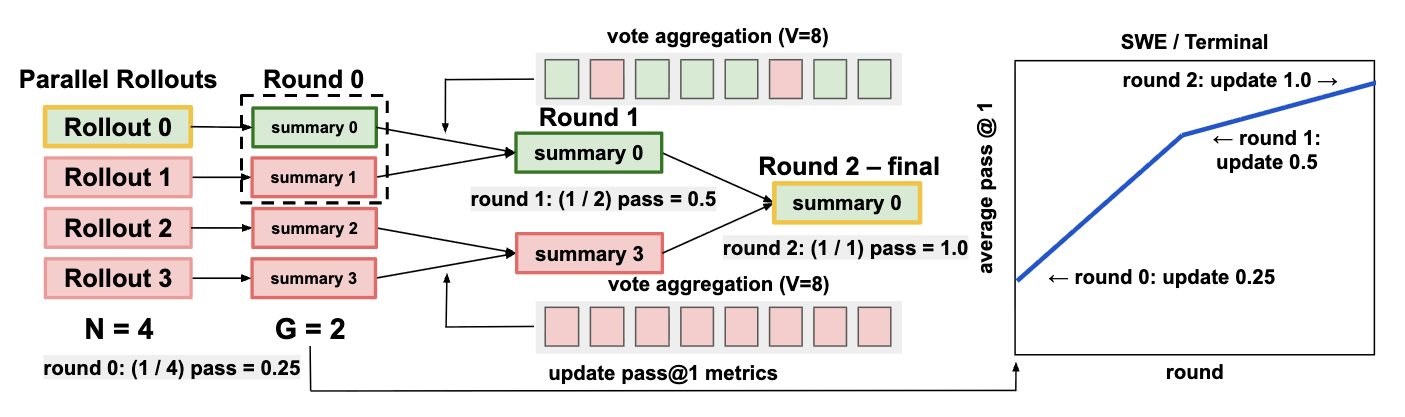
논문 소개
테스트 시점 스케일링(test-time scaling)은 대규모 언어 모델(LLM)을 향상시키는 강력한 방법이 되었습니다.
하지만 기존 방법은 짧고 경계가 분명한 출력에는 잘 맞는 반면, 장기적인 코드 에이전트(agentic coding)의 긴 실행 궤적에는 잘 적용되지 않습니다.
이 설정에서는 단순히 더 많은 시도를 생성하는 것보다, 이전 경험을 효과적으로 선택하고 재사용할 수 있는 형태로 표현하는 것이 핵심 과제가 됩니다.
저자들은 각 롤아웃(rollout) 궤적을 중요한 가설, 진행 상황, 실패 양상을 보존하는 구조화된 요약으로 변환하는 테스트 시점 스케일링 프레임워크를 제안합니다.
이 표현을 바탕으로 병렬 스케일링(parallel scaling)에서는 Recursive Tournament Voting(RTV)을 통해 소규모 비교를 반복하며 롤아웃 요약의 집단을 점진적으로 좁혀 나갑니다.
순차 스케일링(sequential scaling)에서는 Parallel-Distill-Refine(PDR)을 에이전트 환경에 맞게 확장해, 이전 시도에서 정제된 요약을 조건으로 새로운 롤아웃을 생성합니다.
이 방법은 SWE-Bench Verified와 Terminal-Bench v2.0에서 최신 코드 에이전트의 성능을 일관되게 향상시켰으며, 예를 들어 Claude-4.5-Opus는 SWE-Bench Verified에서 70.9%에서 77.6%로, Terminal-Bench v2.0에서 46.9%에서 59.1%로 개선되었습니다.
초록(Abstract)
테스트 시점 스케일링(test-time scaling)은 대규모 언어 모델을 개선하는 강력한 방법이 되었다. 그러나 기존 방법은 직접 비교, 순위화, 또는 정제가 가능한 짧고 경계가 명확한 출력에 가장 적합하다. 장기 지평(long-horizon) 코딩 에이전트는 이러한 전제를 위반한다. 각 시도는 에이전트가 수행한 행동, 관찰, 오류, 그리고 부분적인 진전을 담은 확장된 궤적을 생성하기 때문이다. 이러한 설정에서 핵심 과제는 더 많은 시도를 생성하는 것이 아니라, 이전 경험을 효과적으로 선택하고 재사용할 수 있는 형태로 표현하는 것이다. 우리는 롤아웃 궤적의 압축된 표현을 기반으로 한 에이전트형 코딩(agentic coding)용 테스트 시점 스케일링 프레임워크를 제안한다. 우리의 프레임워크는 각 롤아웃을 구조화된 요약으로 변환하여, 핵심 가설, 진행 상황, 실패 모드를 보존하는 동시에 신호가 낮은 추적(trace) 세부 정보는 제거한다. 이 표현은 상호 보완적인 두 가지 추론 시점 스케일링 형태를 가능하게 한다. 병렬 스케일링을 위해, 우리는 소규모 그룹 비교를 통해 롤아웃 요약의 집단을 재귀적으로 축소하는 Recursive Tournament Voting(RTV)을 도입한다. 순차 스케일링을 위해서는, 이전 시도로부터 증류된 요약을 조건으로 새로운 롤아웃을 생성하도록 Parallel-Distill-Refine(PDR)을 에이전트 설정에 맞게 조정한다. 우리의 방법은 SWE-Bench Verified와 Terminal-Bench v2.0 전반에서 프런티어 코딩 에이전트의 성능을 일관되게 향상시킨다. 예를 들어, 우리의 방법을 사용하면 Claude-4.5-Opus는 SWE-Bench Verified(mini-SWE-agent)에서 70.9%에서 77.6%로, Terminal-Bench v2.0(Terminus 1)에서 46.9%에서 59.1%로 향상된다. 우리의 결과는 장기 지평 에이전트를 위한 테스트 시점 스케일링이 본질적으로 표현, 선택, 재사용의 문제임을 시사한다.
Test-time scaling has become a powerful way to improve large language models. However, existing methods are best suited to short, bounded outputs that can be directly compared, ranked or refined. Long-horizon coding agents violate this premise: each attempt produces an extended trajectory of actions, observations, errors, and partial progress taken by the agent. In this setting, the main challenge is no longer generating more attempts, but representing prior experience in a form that can be effectively selected from and reused. We propose a test-time scaling framework for agentic coding based on compact representations of rollout trajectories. Our framework converts each rollout into a structured summary that preserves its salient hypotheses, progress, and failure modes while discarding low-signal trace details. This representation enables two complementary forms of inference-time scaling. For parallel scaling, we introduce Recursive Tournament Voting (RTV), which recursively narrows a population of rollout summaries through small-group comparisons. For sequential scaling, we adapt Parallel-Distill-Refine (PDR) to the agentic setting by conditioning new rollouts on summaries distilled from prior attempts. Our method consistently improves the performance of frontier coding agents across SWE-Bench Verified and Terminal-Bench v2.0. For example, by using our method Claude-4.5-Opus improves from 70.9% to 77.6% on SWE-Bench Verified (mini-SWE-agent) and 46.9% to 59.1% on Terminal-Bench v2.0 (Terminus 1). Our results suggest that test-time scaling for long-horizon agents is fundamentally a problem of representation, selection, and reuse.
논문 링크
Claude Code 깊이 들여다보기: 오늘날과 미래의 AI 에이전트 시스템 설계 공간 / Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
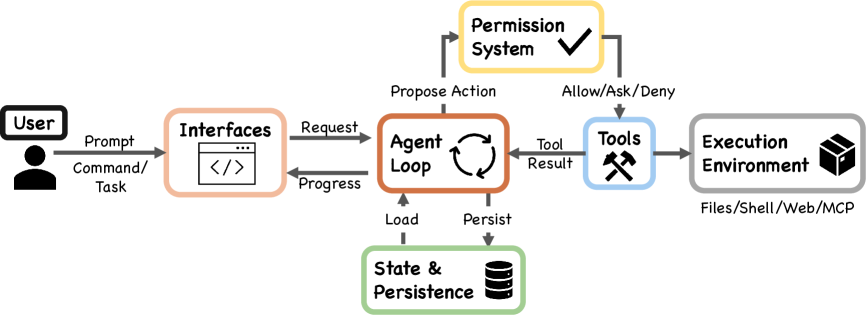
논문 소개
Claude Code는 사용자를 대신해 셸 명령을 실행하고 파일을 수정하며 외부 서비스를 호출할 수 있는 에이전틱 코딩 도구로, 최근 인공지능(AI) 에이전트 시스템이 실제 작업 수행 단계로 진입했음을 보여주는 대표 사례로 다뤄진다. 이 연구는 공개된 타입스크립트(TypeScript) 소스 코드를 정밀하게 분석하고, 서로 다른 배포 맥락에서 유사한 설계 질문에 응답하는 오픈소스 시스템 OpenClaw와 비교함으로써, 에이전트 아키텍처가 어떤 가치와 제약 위에서 형성되는지를 설명한다. 특히 인간의 결정 권한, 안전성과 보안, 신뢰할 수 있는 실행, 역량 증폭, 문맥 적응성이라는 다섯 가지 인간 중심의 요구를 출발점으로 삼아, 이를 열세 개의 설계 원칙과 구체적 구현 선택으로 연결한 점이 인상적이다. 중심 구조는 모델을 호출하고 도구를 실행한 뒤 이를 반복하는 단순한 while-loop이지만, 실제 시스템의 복잡성은 그 바깥에 배치된 권한 관리, 컨텍스트 압축, 확장성, 위임, 세션 저장 장치에 집중되어 있다. 다시 말해, 이 시스템의 핵심은 거대한 모델 자체보다도 모델이 안전하고 일관되게 행동하도록 둘러싼 운영 체계에 있다고 볼 수 있다.
구체적으로 Claude Code는 일곱 가지 모드와 기계학습 기반 분류기를 갖춘 권한 시스템을 통해 행동 단위의 통제를 수행하고, 다섯 단계의 컨텍스트 압축 파이프라인으로 긴 실행 과정에서도 중요한 맥락을 유지한다. 또한 모델 컨텍스트 프로토콜(Model Context Protocol, MCP), 플러그인(plugins), 스킬(skills), 훅(hooks)이라는 네 가지 확장 메커니즘을 제공해 기능을 외부에서 유연하게 주입할 수 있도록 하며, 서브에이전트(subagent) 위임과 워크트리(worktree) 격리를 통해 복잡한 작업을 분산하고 부작용을 줄인다. 세션 저장소 역시 덮어쓰기보다 누적을 중시하는 append-oriented 방식으로 설계되어, 에이전트가 수행한 행동의 이력과 재현 가능성을 확보한다. 이러한 구성은 자율성을 무제한으로 확대하기보다, 인간의 통제권을 보존한 상태에서 실질적인 업무 수행 능력을 증폭시키는 방향으로 조정되어 있다. OpenClaw와의 비교는 이 점을 더욱 분명하게 드러내며, 동일한 설계 문제라도 게이트웨이 중심의 배포 환경에서는 경계 수준의 접근 제어와 플랫폼 전역의 기능 등록이 더 적합한 해법이 될 수 있음을 보여준다. 따라서 이 논문은 단순한 기능 소개를 넘어, 미래의 인공지능 에이전트가 어떤 철학과 구조 위에서 설계되어야 하는지를 체계적으로 제시하며, 모델 중심의 관점에서 시스템 중심의 관점으로 연구 초점을 확장하는 데 중요한 의의를 갖는다.
초록(Abstract)
Claude Code는 사용자를 대신하여 셸 명령을 실행하고, 파일을 편집하며, 외부 서비스를 호출할 수 있는 에이전틱 코딩 도구이다. 본 연구는 공개된 TypeScript 소스 코드를 분석하고, 또한 다른 배포 맥락에서 동일한 설계 질문의 상당수에 답하는 독립적인 오픈소스 AI 에이전트 시스템인 OpenClaw와 비교함으로써, Claude Code의 포괄적인 아키텍처를 설명한다. 우리의 분석은 이 아키텍처를 움직이는 다섯 가지 인간의 가치, 철학, 요구를 식별하고(인간의 결정 권한, 안전성 및 보안, 신뢰할 수 있는 실행, 역량 증폭, 그리고 문맥 적응성), 이를 13개의 설계 원칙과 구체적인 구현 선택으로 추적한다. 시스템의 핵심은 모델을 호출하고, 도구를 실행하고, 이를 반복하는 단순한 while 루프다. 그러나 코드의 대부분은 이 루프를 둘러싼 시스템에 존재한다. 여기에는 7개 모드와 기계학습(ML) 기반 분류기를 갖춘 권한 시스템, 컨텍스트 관리를 위한 5단계 압축 파이프라인, 4개의 확장성 메커니즘(MCP, 플러그인, 스킬, 훅), 워크트리 격리를 갖춘 서브에이전트 위임 메커니즘, 그리고 추가 중심의 세션 저장소가 포함된다. 다채널 개인 비서 게이트웨이인 OpenClaw와의 비교는 배포 맥락이 달라질 때 동일한 반복적 설계 질문이 서로 다른 아키텍처적 해답을 낳는다는 점을 보여준다. 예를 들어, 개별 동작별 안전성 분류는 경계 수준의 접근 제어로, 단일 CLI 루프는 게이트웨이 제어 평면에 내장된 런타임으로, 컨텍스트 윈도우 확장은 게이트웨이 전반의 기능 등록으로 바뀐다. 마지막으로 우리는 최근의 실증적, 아키텍처적, 정책적 문헌에 근거하여, 향후 에이전트 시스템을 위한 여섯 가지 개방형 설계 방향을 식별한다.
Claude Code is an agentic coding tool that can run shell commands, edit files, and call external services on behalf of the user. This study describes its comprehensive architecture by analyzing the publicly available TypeScript source code and further comparing it with OpenClaw, an independent open-source AI agent system that answers many of the same design questions from a different deployment context. Our analysis identifies five human values, philosophies, and needs that motivate the architecture (human decision authority, safety and security, reliable execution, capability amplification, and contextual adaptability) and traces them through thirteen design principles to specific implementation choices. The core of the system is a simple while-loop that calls the model, runs tools, and repeats. Most of the code, however, lives in the systems around this loop: a permission system with seven modes and an ML-based classifier, a five-layer compaction pipeline for context management, four extensibility mechanisms (MCP, plugins, skills, and hooks), a subagent delegation mechanism with worktree isolation, and append-oriented session storage. A comparison with OpenClaw, a multi-channel personal assistant gateway, shows that the same recurring design questions produce different architectural answers when the deployment context changes: from per-action safety classification to perimeter-level access control, from a single CLI loop to an embedded runtime within a gateway control plane, and from context-window extensions to gateway-wide capability registration. We finally identify six open design directions for future agent systems, grounded in recent empirical, architectural, and policy literature.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()