[2026/05/04 ~ 10] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



이번 주 선정된 주요 논문들에서는 다음과 같은 주요 트렌드를 살펴볼 수 있습니다:
![]() 명시적 텍스트 생성을 넘어선 추론 및 구조의 효율화: 이번 주 연구들에서는 모델이 길고 명시적인 텍스트를 모두 생성하는 대신, 내부적인 잠재 공간이나 최적화된 아키텍처를 통해 추론 효율을 극대화하려는 시도가 돋보입니다. 단어 없이 사고하기(Abstract Chain-of-Thought) 연구는 자연어로 된 긴 사고의 연쇄를 짧은 추상적 토큰 시퀀스로 압축하여 추론 비용을 획기적으로 줄였습니다. 또한 Distributional Alignment Games for Answer-Level Fine-Tuning 논문은 복잡한 중간 추론 경로를 모두 계산하는 대신, 최종 답변 분포 자체를 직접 정렬하는 게임 이론적 접근(Game-theoretical framework) 을 채택하여 학습 효율성을 높였습니다. 하드웨어 측면에서도 MobileLLM-Flash 가 지연 시간을 최우선으로 고려한 아키텍처 탐색을 통해 모바일 기기에서도 뛰어난 성능을 발휘하는 실용적인 모델을 선보였으며, 이는 불필요한 연산을 줄여 모델의 실질적인 활용도를 높이려는 중요한 진전입니다.
명시적 텍스트 생성을 넘어선 추론 및 구조의 효율화: 이번 주 연구들에서는 모델이 길고 명시적인 텍스트를 모두 생성하는 대신, 내부적인 잠재 공간이나 최적화된 아키텍처를 통해 추론 효율을 극대화하려는 시도가 돋보입니다. 단어 없이 사고하기(Abstract Chain-of-Thought) 연구는 자연어로 된 긴 사고의 연쇄를 짧은 추상적 토큰 시퀀스로 압축하여 추론 비용을 획기적으로 줄였습니다. 또한 Distributional Alignment Games for Answer-Level Fine-Tuning 논문은 복잡한 중간 추론 경로를 모두 계산하는 대신, 최종 답변 분포 자체를 직접 정렬하는 게임 이론적 접근(Game-theoretical framework) 을 채택하여 학습 효율성을 높였습니다. 하드웨어 측면에서도 MobileLLM-Flash 가 지연 시간을 최우선으로 고려한 아키텍처 탐색을 통해 모바일 기기에서도 뛰어난 성능을 발휘하는 실용적인 모델을 선보였으며, 이는 불필요한 연산을 줄여 모델의 실질적인 활용도를 높이려는 중요한 진전입니다.
![]() 단발성 응답을 넘어선 장기 워크플로 및 전체 시스템 아키텍처 평가: 기존의 단일 질의응답이나 코드 조각 생성을 넘어, 긴 호흡이 필요한 복잡한 작업 환경에서 모델의 실제 역량과 한계를 검증하는 엄격한 벤치마크들이 등장했습니다. DELEGATE-52 는 장기적인 문서 편집 시뮬레이션을 통해 최상위 언어 모델들조차 상호작용이 길어질수록 문서를 점진적으로 훼손하는 치명적인 결함이 있음을 밝혀냈습니다. 이와 유사하게 ProgramBench 는 모델이 처음부터 전체 소프트웨어 프로젝트를 설계하고 구현하는 능력을 평가했으며, 현재 모델들이 모듈화된 아키텍처 구성에 실패하고 거대한 단일 파일(Single-file) 에 의존하는 한계를 지적했습니다. 이러한 연구들은 언어 모델을 진정한 자율 에이전트로 활용하기 위해서는 단순한 텍스트 생성 능력이 아닌 상태 유지와 전역적 설계 능력을 획기적으로 개선해야 함을 시사합니다.
단발성 응답을 넘어선 장기 워크플로 및 전체 시스템 아키텍처 평가: 기존의 단일 질의응답이나 코드 조각 생성을 넘어, 긴 호흡이 필요한 복잡한 작업 환경에서 모델의 실제 역량과 한계를 검증하는 엄격한 벤치마크들이 등장했습니다. DELEGATE-52 는 장기적인 문서 편집 시뮬레이션을 통해 최상위 언어 모델들조차 상호작용이 길어질수록 문서를 점진적으로 훼손하는 치명적인 결함이 있음을 밝혀냈습니다. 이와 유사하게 ProgramBench 는 모델이 처음부터 전체 소프트웨어 프로젝트를 설계하고 구현하는 능력을 평가했으며, 현재 모델들이 모듈화된 아키텍처 구성에 실패하고 거대한 단일 파일(Single-file) 에 의존하는 한계를 지적했습니다. 이러한 연구들은 언어 모델을 진정한 자율 에이전트로 활용하기 위해서는 단순한 텍스트 생성 능력이 아닌 상태 유지와 전역적 설계 능력을 획기적으로 개선해야 함을 시사합니다.
![]() 다각화된 모델 평가 체계와 신뢰성 및 정렬 기준의 고도화: 인공지능 모델이 고도화됨에 따라 단순 성능 지표뿐만 아니라, 평가 방식 자체의 신뢰성과 잠재적 위험성을 체계적으로 검증하려는 움직임이 두드러지고 있습니다. 루브릭 수정(Rubric Modifications) 에 관한 연구는 자동 평가자를 활용할 때 평가지침의 맥락과 구조적 변화가 인간과 모델 간의 합의율에 미치는 통계적 영향을 정량적으로 분석했습니다. 안전성 측면에서 Code World Model Preparedness Report 는 코드 생성 모델이 지시 따르기와 진실성 사이에서 겪는 내부적 충돌을 면밀히 추적하여 파괴적 위험 가능성을 사전에 차단하고자 했습니다. 더불어 GIANTS 는 단순히 유창한 문장을 생성하는지를 넘어, 방대한 과학 문헌으로부터 핵심 통찰(Core insight) 을 정확히 예견하는 새로운 잣대를 제시함으로써 모델의 실질적인 논리 융합 능력을 검증하고 있습니다.
다각화된 모델 평가 체계와 신뢰성 및 정렬 기준의 고도화: 인공지능 모델이 고도화됨에 따라 단순 성능 지표뿐만 아니라, 평가 방식 자체의 신뢰성과 잠재적 위험성을 체계적으로 검증하려는 움직임이 두드러지고 있습니다. 루브릭 수정(Rubric Modifications) 에 관한 연구는 자동 평가자를 활용할 때 평가지침의 맥락과 구조적 변화가 인간과 모델 간의 합의율에 미치는 통계적 영향을 정량적으로 분석했습니다. 안전성 측면에서 Code World Model Preparedness Report 는 코드 생성 모델이 지시 따르기와 진실성 사이에서 겪는 내부적 충돌을 면밀히 추적하여 파괴적 위험 가능성을 사전에 차단하고자 했습니다. 더불어 GIANTS 는 단순히 유창한 문장을 생성하는지를 넘어, 방대한 과학 문헌으로부터 핵심 통찰(Core insight) 을 정확히 예견하는 새로운 잣대를 제시함으로써 모델의 실질적인 논리 융합 능력을 검증하고 있습니다.
선정된 10편의 논문들에 대한 핵심 요약은 다음과 같습니다:
-
GIANTS: Generative Insight Anticipation from Scientific Literature: 선행 논문 집합만 보고 후속 논문의 핵심 통찰을 예측하는 insight anticipation 과제를 제안합니다. 17k 규모의 GiantsBench와 RL로 학습한 GIANTS-4B를 통해, 문헌 기반 종합 추론을 실제로 최적화할 수 있음을 보여줍니다.
-
Distributional Alignment Games for Answer-Level Fine-Tuning: 답변 수준 파인튜닝(Answer-Level Fine-Tuning, ALFT)을 분포 정렬 게임으로 재정식화해, 복잡한 잠재 추론 경로의 주변화를 다루기 쉽게 바꿉니다. GRPO와 결합 가능한 Coherence-GRPO를 통해 계산 효율과 정렬 성능을 함께 잡는 방향을 제시합니다.
-
LLMs Corrupt Your Documents When You Delegate: 위임형 작업에서 대규모 언어 모델(LLM)이 장기 문서 편집을 수행할 때 문서 무결성을 점진적으로 훼손한다는 문제를 DELEGATE-52로 실증합니다. 최상위 모델조차 장기 워크플로 끝에서 평균적으로 상당한 수준의 문서 오염을 일으킨다는 점이 핵심입니다.
-
Quantifying the Statistical Effect of Rubric Modifications on Human-Autorater Agreement: 인간 평가자와 자동 평가자(autorater) 간 합의가 루브릭(rubric) 설계에 얼마나 민감한지 통계적으로 분석합니다. 예시와 맥락을 보강하고 위치 편향을 줄이면 일치도가 높아지지만, 복잡도와 보수적 집계는 오히려 합의를 떨어뜨립니다.
-
Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought: 긴 자연어 사고의 연쇄(CoT) 대신 예약 어휘로 구성된 짧은 이산 토큰 시퀀스로 추론을 압축하는 Abstract-CoT를 제안합니다. 최대 11.6배 적은 추론 토큰으로도 수학, 지시 따르기, multi-hop 추론에서 경쟁력 있는 성능을 보입니다.
-
Code World Model Preparedness Report: Meta의 Code World Model(CWM)에 대해 출시 전 준비성(preparedness)과 정렬성(alignment)을 점검한 보고서입니다. 위험 징후, 불확실성 표현, 진실성과 지시 충돌 인식 등을 평가해 추가적인 최전선 위험이 없다고 판단하고 open-weight 공개를 정당화합니다.
-
Learning Pseudorandom Numbers with Transformers: Permuted Congruential Generators, Curricula, and Interpretability: 트랜스포머가 퍼뮤티드 콩그루엔셜 제너레이터(PCG)의 의사난수 수열까지 문맥 내 학습으로 예측할 수 있음을 보입니다. 더 큰 모듈러스에서는 커리큘럼 학습이 필수적이며, 내부 표현에는 비트 회전 불변성에 따른 클러스터링이 관찰됩니다.
-
ProgramBench: Can Language Models Rebuild Programs From Scratch?: 코드 조각 생성이 아니라, 문서만 보고 프로그램을 처음부터 재구성하는 능력을 평가하는 벤치마크입니다. 200개 태스크에서 어떤 모델도 완전 해결에 도달하지 못했으며, 현재 모델의 소프트웨어 아키텍처 추론 한계를 분명히 드러냅니다.
-
LLMorphism: When humans come to see themselves as language models: 인간 인지를 LLM처럼 이해하려는 편향적 사고인 LLMorphism을 개념화합니다. 언어 출력의 유사성을 인지 구조의 유사성으로 오해하는 문제를 지적하며, 노동·교육·책임·의료 등 사회적 함의를 함께 다룹니다.
-
MobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale Deployment: 모바일 기기에서의 실제 지연 시간(latency)을 기준으로 온디바이스 LLM을 설계하는 방법을 제안합니다. 하드웨어 인 더 루프 검색과 구조적 가지치기를 결합해, 표준 런타임에서 배포 가능한 모델로 prefill/decode 속도를 크게 개선합니다.
GIANTS: 과학 문헌으로부터 생성적 통찰 예측 / GIANTS: Generative Insight Anticipation from Scientific Literature
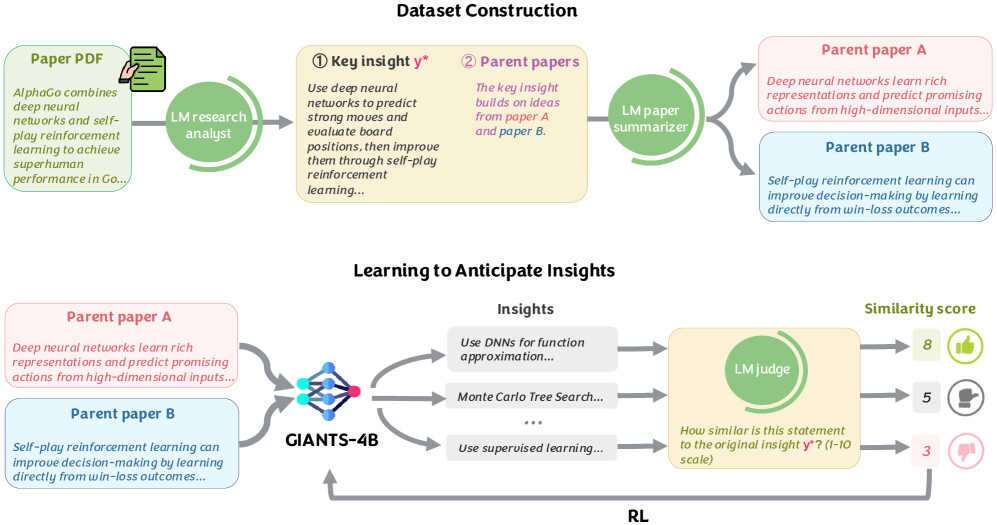
논문 소개
과학적 발견은 완전히 새로운 아이디어를 무에서 만들어내기보다, 기존 문헌에 흩어진 단서들을 정교하게 엮어 다음 단계의 핵심 통찰로 재구성하는 과정에 가깝습니다. 이러한 관점에서 GIANTS: Generative Insight Anticipation from Scientific Literature는 대규모 언어 모델(Language Model, LM)이 방대한 지식의 나열을 넘어, 주어진 선행 논문 집합으로부터 후속 연구의 중심 아이디어를 얼마나 정확하게 예견할 수 있는지를 다룹니다. 저자들은 이 능력을 insight anticipation이라는 새로운 과제로 정의하고, 부모 논문(parent papers)들이 제공하는 문헌적 기반 위에서 후속 논문의 핵심 기여(core insight)를 생성하도록 요구합니다. 이를 통해 단순한 아이디어 발상과 구별되는, 문헌에 밀착된 종합적 추론 능력을 측정하고자 합니다.
이를 검증하기 위해 제안된 GiantsBench는 8개 과학 도메인에 걸친 약 1만 7천 개의 예제로 구성되며, 각 예제는 부모 논문들과 그로부터 파생된 후속 논문의 핵심 통찰을 짝지어 제공합니다. 이 벤치마크의 중요한 점은 검색이나 parent selection 문제를 별도로 다루지 않고, 이미 주어진 논문들을 바탕으로 개념적 합성을 수행하는 insight generation 능력에 초점을 맞춘다는 데 있습니다. 평가는 LM judge가 생성된 통찰과 정답 통찰의 의미적 유사도를 채점하는 방식으로 이루어지며, 이 자동 평가는 전문가 인간 평가와도 높은 상관을 보여 측정 타당성을 확보합니다. 다시 말해, GiantsBench는 모델이 단지 그럴듯한 연구 문장을 생성하는지보다, 실제 후속 논문의 과학적 핵심을 얼마나 정확히 복원하는지를 검증하도록 설계되었습니다.
이 위에서 학습된 GIANTS-4B는 약 40억 개 파라미터 규모의 언어 모델을 강화학습(Reinforcement Learning, RL)으로 정렬한 모델로, LM judge의 유사도 점수를 대리 보상(proxy reward)으로 사용해 통찰 생성 능력을 직접 최적화합니다. 이 접근은 단순히 정답을 모사하는 지도학습보다, 부모 논문들 사이의 구조적 관계를 스스로 탐색하며 더 정합적인 과학적 추론을 학습하게 만든다는 점에서 의미가 큽니다. 실험 결과 GIANTS-4B는 상용의 강력한 기준 모델보다 더 높은 유사도 점수를 기록했고, 보지 못한 도메인과 부모 논문 조합에서도 일관된 일반화 성능을 보였습니다. 특히 인간 평가는 GIANTS-4B가 base model보다 개념적으로 더 명확한 통찰을 산출한다고 보여 주었으며, 외부 판단 모델인 SciJudge-30B 역시 더 높은 citation impact 가능성을 가진 출력으로 선호했습니다.
이러한 결과는 과학적 창의성이 단순한 규모 확대나 일반적 생성 능력만으로 확보되지 않으며, 문헌 기반 합성이라는 보다 구체적인 능력에 대해 맞춤형 학습 신호를 부여할 때 크게 향상될 수 있음을 시사합니다. 결국 GIANTS는 과학 연구에서 중요한 한 축을 “새 아이디어 생성”이 아니라 “기존 지식의 정교한 예견과 재조합”으로 재정의하고, 그 능력을 측정하고 최적화할 수 있는 실질적 방법론을 제시합니다. 이 연구는 자동화된 과학 발견을 위한 평가 기준과 학습 프레임워크를 함께 제안했다는 점에서, 향후 연구용 언어 모델이 단순한 글쓰기 도구를 넘어 문헌 기반 추론 파트너로 발전할 수 있음을 보여 줍니다.
초록(Abstract)
과학적 돌파구는 종종 기존 아이디어를 새로운 기여로 종합하는 과정에서 나타납니다. 언어 모델(LM)은 과학적 발견에서 가능성을 보여 왔지만, 이러한 목표 지향적이고 문헌에 근거한 종합을 수행하는 능력은 아직 충분히 탐구되지 않았습니다. 우리는 인사이트 예측(insight anticipation)이라는 생성 과제를 소개하는데, 이는 모델이 기반이 되는 부모 논문들로부터 후속 논문의 핵심 통찰을 예측하는 과제입니다. 이 능력을 평가하기 위해, 우리는 8개 과학 분야에 걸친 1만 7천 개의 예시로 구성된 벤치마크인 GiantsBench를 개발했습니다. 각 예시는 부모 논문들의 집합과 후속 논문의 핵심 통찰로 이루어집니다. 우리는 생성된 통찰과 정답 통찰 간의 유사도를 점수화하는 LM judge를 사용해 모델을 평가했고, 이러한 유사도 점수가 전문가 인간 평가와 상관관계를 보인다는 점을 보였습니다. 마지막으로, 우리는 이 유사도 점수를 대리 보상(proxy reward)으로 사용해 인사이트 예측을 최적화하도록 강화학습(RL)으로 학습된 언어 모델인 GIANTS-4B를 제시합니다. 더 작은 오픈소스 아키텍처임에도 불구하고, GIANTS-4B는 독점적 기준 모델들을 능가하고 보지 못한 분야로도 일반화되며, gemini-3-pro 대비 유사도 점수에서 34%의 상대적 향상을 달성합니다. 또한 인간 평가는 GIANTS-4B가 기본 모델보다 개념적으로 더 명확한 통찰을 생성함을 추가로 보여줍니다. 더불어, 인용 영향력이 높을 가능성을 기준으로 연구 초록을 비교하도록 학습된 제3자 모델 SciJudge-30B는 GIANTS-4B가 생성한 통찰이 더 높은 인용으로 이어질 가능성이 더 높다고 예측했으며, 68%의 쌍대 비교에서 기본 모델보다 이를 선호했습니다. 우리는 향후 자동화된 과학적 발견 연구를 지원하기 위해 코드, 벤치마크, 모델을 공개합니다.
Scientific breakthroughs often emerge from synthesizing prior ideas into novel contributions. While language models (LMs) show promise in scientific discovery, their ability to perform this targeted, literature-grounded synthesis remains underexplored. We introduce insight anticipation, a generation task in which a model predicts a downstream paper's core insight from its foundational parent papers. To evaluate this capability, we develop GiantsBench, a benchmark of 17k examples across eight scientific domains, where each example consists of a set of parent papers paired with the core insight of a downstream paper. We evaluate models using an LM judge that scores similarity between generated and ground-truth insights, and show that these similarity scores correlate with expert human ratings. Finally, we present GIANTS-4B, an LM trained via reinforcement learning (RL) to optimize insight anticipation using these similarity scores as a proxy reward. Despite its smaller open-source architecture, GIANTS-4B outperforms proprietary baselines and generalizes to unseen domains, achieving a 34% relative improvement in similarity score over gemini-3-pro. Human evaluations further show that GIANTS-4B produces insights that are more conceptually clear than those of the base model. In addition, SciJudge-30B, a third-party model trained to compare research abstracts by likely citation impact, predicts that insights generated by GIANTS-4B are more likely to lead to higher citations, preferring them over the base model in 68% of pairwise comparisons. We release our code, benchmark, and model to support future research in automated scientific discovery.
논문 링크
더 읽어보기
답변 수준 파인튜닝을 위한 분포적 정렬 게임 / Distributional Alignment Games for Answer-Level Fine-Tuning


논문 소개
답변 수준 파인튜닝(Answer-Level Fine-Tuning, ALFT)은 언어 모델이 어떤 추론 경로를 거쳤는지보다 최종 답변의 정답성이나 바람직한 성질 자체를 기준으로 학습되도록 만드는 접근으로, 수학 추론이나 논리 문제처럼 결과의 품질이 핵심인 과제에서 특히 중요한 의미를 갖습니다. 그러나 이러한 목적을 직접 최적화하려면 하나의 답변을 만들어내는 수많은 잠재 추론 경로(latent reasoning paths)를 모두 주변화해야 하므로, 계산 복잡도가 급격히 커지고 실제 학습에 적용하기 어렵다는 한계가 있습니다. Distributional Alignment Games for Answer-Level Fine-Tuning은 바로 이 병목을 해소하기 위해, ALFT를 분포 정렬 게임(distributional alignment game)이라는 게임 이론적 틀로 재정식화합니다. 구체적으로는 답변을 생성하는 정책(policy)과 정책이 정렬해야 하는 보조 타깃 분포(target)를 두 플레이어로 두고, 두 분포가 상호 작용하는 과정의 Nash 평형(Nash equilibrium)이 원래의 답변 수준 최적화 해와 정확히 일치하도록 설계합니다. 이 변분적(variational) 관점은 복잡한 경로 합산 문제를 단순한 근사로 대체하는 것이 아니라, 원래 문제와 수학적으로 동치인 더 다루기 쉬운 투영(projection) 문제로 전환한다는 점에서 큰 의의를 지닙니다.
특히 이 프레임워크의 강점은 최근의 다양성(diversity) 중심 방법과 자기개선(self-improvement), 코히어런스(coherence) 중심 방법을 하나의 공통 언어로 묶어낸다는 데 있습니다. 논문은 여러 후보 분포를 산술평균(arithmetic mean)과 기하평균(geometric mean)으로 결합하는 관점을 통해, 넓은 탐색을 강조하는 방식과 서로 일치하는 답변을 선호하는 방식이 사실상 같은 분포 정렬 문제의 서로 다른 구현임을 보여 줍니다. 이러한 해석은 단순한 경험적 통합이 아니라, 분포 간 차이를 헬링거 제곱 거리(Hellinger squared distance)와 같은 정량적 지표로 제어할 수 있다는 이론적 보장 위에 놓여 있습니다. 그 결과, 코히어런스가 높은 그룹에서는 정책 개선의 불안정성이 줄어들고, 서로 다른 정렬 전략 사이의 성능 차이도 구조적으로 설명할 수 있게 됩니다.
실용적인 측면에서 이 프레임워크는 Group Relative Policy Optimization(GRPO)과도 자연스럽게 결합되며, 그 대표적 예로 Coherence-GRPO가 제안됩니다. Coherence-GRPO는 그룹 내 여러 샘플 답변의 합의 구조를 활용해 타깃 분포를 구성하고, 이를 정책이 따라가도록 학습함으로써 답변 수준 목적을 효율적으로 반영합니다. 무엇보다 중요한 점은, 기존처럼 거대한 추론 경로 공간을 직접 열거하지 않아도 되기 때문에 계산 비용이 크게 줄어든다는 사실입니다. 논문은 이러한 구조가 수학 추론 과제에서 특히 유리하다고 보이며, 실제로 복잡도 측면에서 유의미한 이득과 함께 경쟁력 있는 성능을 확인합니다. 결국 이 연구는 답변의 품질만을 기준으로 모델을 정렬하고자 할 때, 중간 추론을 직접 감독하지 않더라도 분포 수준에서의 정교한 정렬만으로 효과적인 학습이 가능하다는 점을 이론과 실험 양쪽에서 설득력 있게 보여 줍니다.
초록(Abstract)
우리는 Answer-Level Fine-Tuning(ALFT) 문제에 주목합니다. 여기서 목표는 이를 생성하는 데 사용된 구체적인 추론 궤적이 아니라, 최종 답변의 정답 여부나 속성을 기반으로 언어 모델을 최적화하는 것입니다. 답변 수준 목적함수를 직접 최적화하는 것은, 잠재적인 추론 경로의 방대한 공간에 대해 주변화해야 하기 때문에 계산적으로 다루기 어렵습니다. 이를 극복하기 위해, 우리는 이 문제를 Distributional Alignment Game으로 확장하는 일반적인 게임이론적 프레임워크를 제안합니다. 우리는 ALFT를 정책(생성기)과 타깃(보조 분포) 사이의 두 플레이어 게임으로 정식화합니다. 우리는 이 게임의 내시 균형이 원래의 답변 수준 최적화 문제의 해와 정확히 일치함을 증명합니다. 이 변분적 관점은 다루기 어려운 주변화 문제를 처리 가능한 투영 문제로 변환합니다. 우리는 이 프레임워크가 다양성과 자기개선(일관성)에 관한 최근 접근법들을 하나로 통합함을 보이고, Coherence-GRPO와 같이 Group Relative Policy Optimization(GRPO)과 호환되는 효율적인 알고리즘을 제시하여 수학 추론 과제에서 상당한 복잡도 향상을 달성합니다.
We focus on the problem of Answer-Level Fine-Tuning(ALFT), where the goal is to optimize a language model based on the correctness or properties of its final answers, rather than the specific reasoning traces used to produce them. Directly optimizing answer-level objectives is computationally intractable due to the need to marginalize over the vast space of latent reasoning paths. To overcome this, we propose a general game-theoretical framework that lifts the problem to a Distributional Alignment Game. We formulate ALFT as a two-player game between a Policy (the generator) and a Target (an auxiliary distribution). We prove that the Nash Equilibrium of this game corresponds exactly to the solution of the original answer-level optimization problem. This variational perspective transforms the intractable marginalization problem into a tractable projection problem. We demonstrate that this framework unifies recent approaches to diversity and self-improvement (coherence) and provide efficient algorithms compatible with Group Relative Policy Optimization (GRPO), such as Coherence-GRPO, yielding significant complexity gains in mathematical reasoning tasks.
논문 링크
대리 작업을 맡기면 대규모 언어 모델(LLM)이 문서를 훼손한다 / LLMs Corrupt Your Documents When You Delegate
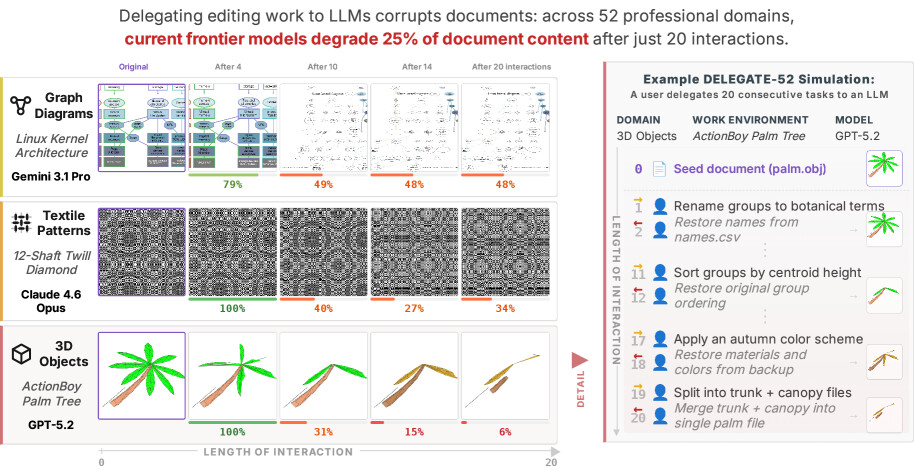
논문 소개
대규모 언어 모델(Large Language Models, LLMs)이 단순한 질의응답을 넘어 실제 문서 편집과 업무 수행을 맡는 위임형 작업(delegated work) 환경으로 확장되면서, 모델이 얼마나 정확하게 답하느냐보다 얼마나 안전하게 문서를 유지하느냐가 더 중요한 기준으로 떠오르고 있습니다. 이러한 문제의식을 바탕으로 제안된 DELEGATE-52는 52개 전문 도메인에서 장기적인 문서 편집 워크플로를 시뮬레이션하도록 설계된 벤치마크로, 코딩, 결정학, 음악 표기처럼 서로 다른 규칙과 문맥을 요구하는 과제를 통해 LLM의 위임 수행 능력을 정밀하게 검증합니다. 연구진은 19개의 서로 다른 LLM을 대상으로 대규모 실험을 수행하여, 현재 모델들이 긴 상호작용이 누적될수록 문서 내용을 점진적으로 훼손하는 경향을 보인다는 사실을 확인했습니다. 특히 Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4 같은 최상위 모델조차 장기 워크플로의 끝에서는 평균적으로 문서 내용의 상당 부분을 손상시키며, 더 작은 모델들은 훨씬 심각한 붕괴를 나타냈습니다.
이 벤치마크의 핵심 방법론은 단발성 정답률이 아니라, 여러 차례의 편집과 수정이 이어지는 동안 문서 무결성이 어떻게 변하는지를 추적하는 데 있습니다. 이를 통해 연구진은 모델이 드문 빈도로 발생시키더라도 한 번 발생하면 치명적인 결과를 낳는 희소하지만 심각한 오류(sparse but severe errors)를 포착했고, 이러한 오류가 누적될수록 문서가 조용히 오염되는 현상을 실증적으로 드러냈습니다. 또한 에이전트형 도구 사용(agentic tool use)이 이러한 문제를 해결할 수 있는지도 추가로 검증했지만, 도구 활용만으로는 성능 향상이 나타나지 않았습니다. 오히려 문서 크기가 커지거나 상호작용이 길어지거나, 방해 파일(distractor files)이 존재하는 경우에는 오류가 더 빠르게 악화되어, 모델이 현재 상태를 안정적으로 추적하고 필요한 부분만 정밀하게 수정하는 데 근본적인 한계가 있음을 보여주었습니다.
이 연구가 중요한 이유는 LLM의 신뢰성을 단순한 언어 생성 능력이 아니라 장기적 협업 능력의 관점에서 다시 정의하기 때문입니다. 위임형 작업에서는 사용자가 매 단계마다 결과를 검증하지 않는 경우가 많으므로, 문서의 미세한 오염조차 최종 결과를 크게 훼손할 수 있습니다. DELEGATE-52는 바로 이러한 현실적 위험을 체계적으로 측정함으로써, 현재 세대의 LLM이 아직 신뢰할 수 있는 대리인(delegate)으로 보기 어렵다는 점을 분명히 보여줍니다. 결국 이 논문은 더 큰 모델이나 더 많은 도구가 자동으로 안전성을 보장하지는 않으며, 앞으로의 연구는 생성 정확도뿐 아니라 상태 보존, 변경 추적, 문서 무결성 보장 같은 메커니즘을 함께 설계해야 함을 시사합니다.
초록(Abstract)
대규모 언어 모델(LLM)은 지식 노동을 뒤흔들 태세이며, 위임 작업의 등장과 함께 새로운 상호작용 패러다임(예: 바이브 코딩)이 나타나고 있습니다. 위임에는 신뢰, 즉 LLM이 문서에 오류를 유입하지 않고 과제를 충실히 수행할 것이라는 기대가 필요합니다. 우리는 위임 워크플로우에서 AI 시스템의 준비도를 연구하기 위해 DELEGATE-52를 제안합니다. DELEGATE-52는 코딩, 결정학, 악보 표기 등 52개 전문 분야 전반에 걸쳐 심층적인 문서 편집을 요구하는 장기 위임 워크플로우를 시뮬레이션합니다. 19개의 LLM을 대상으로 한 대규모 실험 결과, 현재 모델들은 위임 과정에서 문서를 저하시킨다는 사실이 드러났습니다. 최첨단 모델(Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4)조차 장기 워크플로우가 끝날 무렵 평균적으로 문서 내용의 25%를 손상시켰으며, 다른 모델들은 더 심각하게 실패했습니다. 추가 실험에서는 에이전트식 도구 사용이 DELEGATE-52 성능을 개선하지 못하며, 문서 크기, 상호작용 길이 또는 주의를 분산시키는 파일의 존재가 저하의 심각도를 악화시킨다는 점이 밝혀졌습니다. 우리의 분석은 현재의 LLM이 신뢰할 수 있는 위임자(delegates)가 아님을 보여줍니다. 이들은 희소하지만 심각한 오류를 유발해 문서를 조용히 손상시키며, 이러한 문제가 장기 상호작용에서 누적됩니다.
Large Language Models (LLMs) are poised to disrupt knowledge work, with the emergence of delegated work as a new interaction paradigm (e.g., vibe coding). Delegation requires trust - the expectation that the LLM will faithfully execute the task without introducing errors into documents. We introduce DELEGATE-52 to study the readiness of AI systems in delegated workflows. DELEGATE-52 simulates long delegated workflows that require in-depth document editing across 52 professional domains, such as coding, crystallography, and music notation. Our large-scale experiment with 19 LLMs reveals that current models degrade documents during delegation: even frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4) corrupt an average of 25% of document content by the end of long workflows, with other models failing more severely. Additional experiments reveal that agentic tool use does not improve performance on DELEGATE-52, and that degradation severity is exacerbated by document size, length of interaction, or presence of distractor files. Our analysis shows that current LLMs are unreliable delegates: they introduce sparse but severe errors that silently corrupt documents, compounding over long interaction.
논문 링크
더 읽어보기
루브릭 수정이 인간-자동 평가자 간 합의에 미치는 통계적 효과 정량화 / Quantifying the Statistical Effect of Rubric Modifications on Human-Autorater Agreement
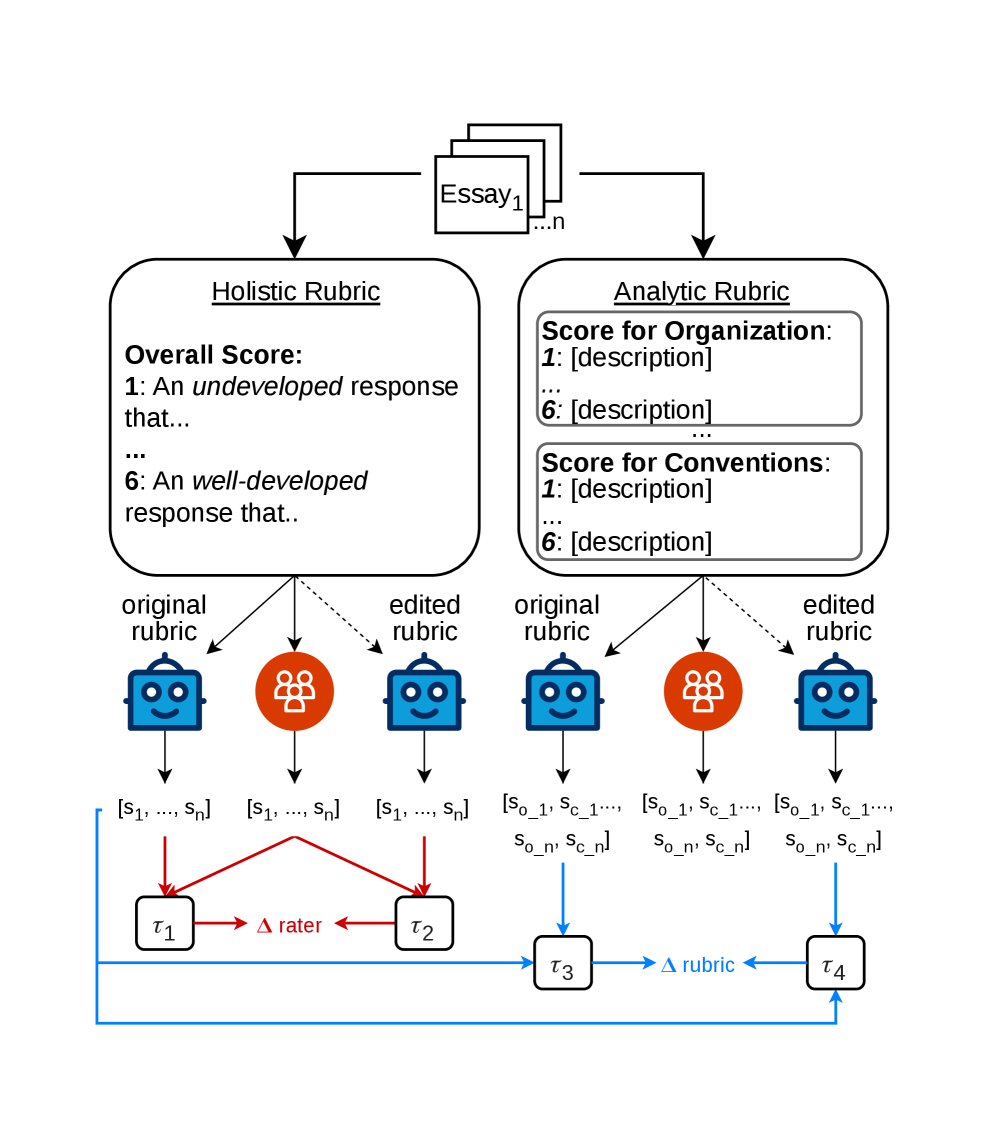
논문 소개
대규모 언어 모델(large language model, LLM)을 평가자로 활용하는 흐름이 빠르게 확산되면서, 인간 평가자(human raters)와 자동 평가자(autoraters) 사이의 점수 일치도가 얼마나 안정적으로 유지되는지는 중요한 연구 과제가 되었습니다. 이러한 맥락에서 주어진 평가지침(rubric)을 어떻게 설계하고 수정하느냐가 단순한 표현상의 차이를 넘어, 인간과 모델이 동일한 기준으로 판단하는지에 직접적인 영향을 줄 수 있다는 점이 핵심 문제로 제기됩니다. 특히 전반적 품질을 하나의 점수로 판단하는 홀리스틱(holistic, 총괄적) 평가와, 유창성(fluency)이나 구성(organization)처럼 기준을 나누어 보는 애널리틱(analytic, 분석적) 평가가 서로 다른 해석 가능성을 지니기 때문에, 루브릭의 구조 자체를 정량적으로 살펴볼 필요가 있습니다. 이 연구는 바로 그 지점에서 출발하여, 루브릭 수정이 인간-자동 평가자 합의에 어떤 통계적 변화를 만드는지를 체계적으로 분석합니다.
연구의 방법론적 초점은 루브릭에 대표 예시(example)와 추가 맥락(context)을 제공하거나, 항목의 배치로 인한 위치 편향(positional bias)을 줄이는 편집이 얼마나 일치도를 높이는지 확인하는 데 있습니다. 동시에 루브릭의 복잡도가 높아질수록, 또는 여러 하위 항목을 보수적으로(conservative) 집계할수록 인간과 모델의 판단이 어떻게 달라지는지도 함께 검토합니다. 이러한 접근은 단순히 LLM이 사람을 얼마나 잘 모사하는지를 보는 것이 아니라, 평가 기준 자체가 인간과 모델 모두에게 어떻게 해석되는지를 함께 측정한다는 점에서 의미가 큽니다. 다시 말해, 모델 성능의 문제를 넘어 평가 설계의 문제를 정면으로 다루는 방식입니다.
결과적으로 대표 예시와 충분한 맥락을 포함하고 위치 편향을 완화한 루브릭 편집은 인간-자동 평가자 간 일치도를 높이는 경향을 보였으며, 반대로 루브릭이 지나치게 복잡해지거나 보수적인 집계 방식을 택할수록 일치도는 낮아지는 경향이 나타났습니다. 이러한 패턴은 자동 에세이 채점(automatic essay scoring)과 지시 따르기 평가(instruction-following evaluation)라는 서로 다른 도메인에서도 일관되게 관찰되어, 루브릭 설계가 도메인별로 민감하게 작동한다는 점을 보여줍니다. 특히 어떤 차원에서는 높은 일치가 가능했지만, 문체적이거나 규범적 판단이 섞이는 하위 기준에서는 여전히 낮은 일치가 남아 있어, 모든 평가 항목이 동일한 방식으로 정렬되지 않음을 시사합니다. 따라서 이 논문은 “더 정교한 루브릭”이 항상 “더 높은 합의”로 이어지지는 않으며, 오히려 인간과 모델이 공유할 수 있는 해석 구조를 얼마나 명료하게 제공하느냐가 더 중요하다고 주장합니다.
이 연구의 기여는 자동 평가자를 하나의 고정된 채점 도구로 보는 시각에서 벗어나, 루브릭 편집을 성능 조정의 핵심 변수로 다뤄야 한다는 점을 분명히 했다는 데 있습니다. 또한 인간 평가와 모델 평가의 차이를 단순한 오차로 환원하지 않고, 평가 체계의 설계 선택이 만들어내는 결과로 해석하게 만든다는 점에서도 의의가 큽니다. 실무적으로는 자동 평가 시스템을 구축할 때 모델 선택 못지않게 루브릭의 문구, 예시, 맥락, 항목 구성, 집계 방식까지 함께 점검해야 한다는 교훈을 제공합니다. 결국 이 논문은 LLM 기반 평가의 신뢰성을 높이기 위해서는 모델 자체의 정밀도뿐 아니라, 인간과 모델이 같은 기준을 바라보도록 만드는 평가 설계가 함께 다뤄져야 함을 설득력 있게 보여줍니다.
초록(Abstract)
오토레이터(Autoraters), 즉 대규모 언어 모델을 심사자로 활용하는 방식(LLM-as-judges)은 평가와 자동화된 콘텐츠 모더레이션에 점점 더 많이 사용되고 있다. 그러나 인간과 오토레이터 모두에게 제시되는 루브릭의 수정이 이들의 점수 일치도에 어떻게 영향을 미치는지에 대한 통계적 분석은 제한적이다. 인간과 오토레이터가 평가하도록 요구하는 루브릭은 전체적(holistic) 판단, 예를 들어 에세이의 “품질”을 평가하는 방식일 수 있으며, 이러한 기준은 복잡성이나 주관성 때문에 일관되게 해석되지 않을 수 있다. 반대로 루브릭은 분석적(analytic) 판단을 요구할 수 있는데, 이는 평가 기준을 분해해 예를 들어 “품질”을 “유창성”과 “구성”으로 나누어 평가하도록 한다. 이러한 루브릭은 인간과 자동 채점의 개별 정확도를 높이기 위해 수정될 수 있지만, 이 접근법은 두 점수 간의 불일치나 관련된 전체적 판단과의 불일치를 초래할 수 있다. 신뢰할 수 있는 오토레이터를 설계하고 배포하려면 인간 주석과 오토레이터 주석 간의 관계뿐 아니라, 전체적 또는 분석적 판단을 유도할 때 그 관계가 어떻게 변하는지도 이해해야 한다. 결과에 따르면, 대표적인 예시와 추가적인 문맥을 제공하고 루브릭의 위치 편향을 줄이는 수정은 인간-오토레이터 일치도를 높였으며, 더 높은 루브릭 복잡성과 보수적인 집계 방식은 이를 낮추는 경향이 있었다. 자동 에세이 채점과 지시 따르기 평가 도메인에서의 발견은, 실무자들이 인간-오토레이터 일치도를 높이기 위해 도메인 및 루브릭별 성능을 신중하게 분석해야 함을 시사한다.
Autoraters, also referred to as LLM-as-judges, are increasingly used for evaluation and automated content moderation. However, there is limited statistical analysis of how modifications in a rubric presented to both humans and autoraters affect their score agreement. Rubrics that ask for an overall or \emph{holistic} judgment - for example, rating the
quality'' of an essay - may be inconsistently interpreted due to the complexity or subjectivity of the criteria. Conversely, rubrics can ask for \emph{analytic} judgments, which decompose assessment criteria - for example,quality'' intofluency'' andorganization''. While these rubrics can be edited to improve the individual accuracy of both human and automated scoring, this approach may result in disagreement between the two scores, or with the associated holistic judgment. Designing and deploying reliable autoraters requires understanding not just the relationship between human and autorater annotations but how that relationship changes as holistic or analytic judgments are elicited. The results indicate that rubric edits providing representative examples and additional context, and reducing positional bias in the rubric increased human-autorater agreement, while higher rubric complexity and conservative aggregation methods tended to decrease it. The findings from the automatic essay scoring and instruction-following evaluation domains suggest that practitioners should carefully analyze domain- and rubric-specific performance to move towards higher human-autorater agreement.
논문 링크
단어 없이 사고하기: 추상적 사고의 연쇄를 통한 효율적인 잠재 추론 / Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought

논문 소개
긴 언어적 사고의 연쇄(Chain-of-Thought, CoT)는 복잡한 추론 문제에서 뛰어난 성능을 보이지만, 추론 시점에 생성해야 하는 토큰 수가 많아 비용과 지연이 커진다는 한계를 지닙니다. 이를 해결하기 위해 제안된 Abstract Chain-of-Thought는 자연어로 길게 설명하는 대신, 예약된 어휘집의 짧은 이산 토큰 시퀀스로 추론 과정을 압축해 표현하는 잠재 추론(latent reasoning) 방법입니다. 핵심 아이디어는 모델이 먼저 추상적인 내부 언어를 생성한 뒤 이를 바탕으로 최종 답을 내도록 하여, 추론의 본질은 유지하면서도 생성 길이를 크게 줄이는 데 있습니다. 이를 위해 저자들은 먼저 verbal CoT를 마스킹으로 압축해 abstract token으로 옮기는 bottlenecking 단계와, 프롬프트만으로도 abstract sequence를 생성하도록 만드는 self-distillation 단계를 번갈아 수행하는 정책 반복(policy iteration) 스타일의 warm-up 절차를 설계했습니다. 이 과정에서 모델은 이전에 보지 못한 추상 토큰을 단순한 기호가 아니라 실제 추론을 담는 표현으로 학습하게 되며, constrained decoding을 통해 코드북 바깥의 자연어로 새어나가지 않도록 제한됩니다.
이후에는 warm-start된 reinforcement learning(RL, 강화학습)을 적용하여, 추상 시퀀스가 최종 정답 품질에 더 직접적으로 기여하도록 정교화합니다. 이러한 학습 구조는 처음부터 완전한 잠재 추론을 강제로 배우게 하는 방식보다 훨씬 안정적이며, 긴 풀이를 모사하는 기존 접근과 달리 추론 표현 자체를 더 짧고 효율적인 형태로 재조직한다는 점에서 차별적입니다. 특히 Abstract-CoT는 수학적 추론, instruction-following, multi-hop reasoning처럼 성격이 다른 과제들에서 모두 경쟁력 있는 성능을 보이면서도, 추론 토큰 수를 최대 11.6배까지 줄였다는 점에서 효율성의 개선 폭이 큽니다. 또한 특정 모델에만 맞는 기법이 아니라 여러 language model family에 걸쳐 일반화된다는 결과는, 이 방식이 모델 내부의 추론 습관보다 더 보편적인 학습 메커니즘으로 작동할 수 있음을 시사합니다. 흥미롭게도 학습이 진행될수록 abstract vocabulary에서는 자연어와 유사한 power law 분포가 나타나며, 일부 토큰이 핵심 추론 패턴을 담당하고 나머지는 희소하게 사용되는 구조가 형성됩니다. 이는 추상 토큰들이 단순한 압축 코드가 아니라, 훈련을 통해 역할이 분화된 학습된 추상 언어로 발전한다는 점을 보여줍니다. 결국 이 연구는 대규모 언어 모델이 반드시 장문의 자연어 CoT에 의존하지 않아도 되며, 잘 설계된 이산 잠재 추론을 통해 더 적은 토큰으로도 효과적인 사고 과정을 수행할 수 있다는 가능성을 제시합니다.
초록(Abstract)
복잡한 추론 과제에서 긴 명시적 사고의 연쇄(CoT)는 효과적임이 입증되었지만, 추론 시 생성 비용이 많이 듭니다. 연속적 표현을 활용해 더 짧은 생성 길이로 동작하는 비언어적 추론 방법이 등장했지만, 그 성능은 언어화된 CoT에 미치지 못합니다. 우리는 \textbf{Abstract Chain-of-Thought} 를 제안합니다. 이는 언어 모델이 응답을 생성하기 전에 자연어 CoT 대신 예약된 어휘에서 짧은 토큰 시퀀스를 생성하는 이산 잠재 추론 사후학습 메커니즘입니다. 이전에 보지 못한 “추상적” 토큰을 유용하게 만들기 위해, 우리는 정책 반복 스타일의 워밍업 루프를 도입합니다. 이 루프는 (i.) 마스킹을 통해 언어적 CoT를 병목화하고 지도 미세조정을 수행하는 단계와, (ii.) 코드북을 사용한 제약 디코딩을 통해 프롬프트만으로 추상적 토큰을 생성하도록 모델을 학습하는 자기 증류 단계를 번갈아 수행합니다. 워밍업 이후에는 제약 디코딩 하에서 워밍스타트된 강화학습을 사용해 추상적 시퀀스 생성을 최적화합니다. Abstract-CoT는 수학적 추론, 지시 따르기, 멀티홉 추론 전반에서 동등한 성능을 보이면서 추론 토큰 수를 최대 11.6배까지 줄였고, 언어 모델 계열 전반으로 일반화됩니다. 또한 우리는 자연어에서 관찰되는 것과 유사한, 추상적 어휘에 대한 창발적 거듭제곱 법칙 분포를 발견했으며, 이는 학습 단계에 따라 변화합니다. 우리의 결과는 학습된 추상 추론 언어를 통해 효율적인 추론을 가능하게 하는 사후학습 잠재 추론 메커니즘의 잠재력을 보여줍니다.
While long, explicit chains-of-thought (CoT) have proven effective on complex reasoning tasks, they are costly to generate during inference. Non-verbal reasoning methods have emerged with shorter generation lengths by leveraging continuous representations, yet their performance lags behind verbalized CoT. We propose \textbf{Abstract Chain-of-Thought}, a discrete latent reasoning post-training mechanism in which the language model produces a short sequence of tokens from a reserved vocabulary in lieu of a natural language CoT, before generating a response. To make previously unseen ''abstract'' tokens useful, we introduce a policy iteration-style warm-up loop that alternates between (i.) bottlenecking from a verbal CoT via masking and performing supervised fine-tuning, and (ii.) self-distillation by training the model to generate abstract tokens from the prompt alone via constrained decoding with the codebook. After warm-up, we optimize the generation of abstract sequences with warm-started reinforcement learning under constrained decoding. Abstract-CoT achieves up to 11.6\times fewer reasoning tokens while demonstrating comparable performance across mathematical reasoning, instruction-following, and multi-hop reasoning, and generalizes across language model families. We also find an emergent power law distribution over the abstract vocabulary, akin to those seen in natural language, that evolves across the training phases. Our findings highlight the potential for post-training latent reasoning mechanisms that enable efficient inference through a learned abstract reasoning language.
논문 링크
Code World Model 준비 현황 보고서 / Code World Model Preparedness Report

논문 소개
Meta가 공개한 Code World Model(CWM)은 코드 생성을 넘어 코드에 대한 추론 능력까지 갖춘 모델이 실제로 공개 배포 가능한 안전 수준에 도달했는지를 검토하기 위해 마련된 준비성(preparedness) 평가 보고서입니다. 저자들은 Meta의 Frontier AI Framework에서 파괴적 위험(catastrophic risks)을 유발할 가능성이 있는 영역을 중심으로 사전 평가를 수행하고, 동시에 모델이 보일 수 있는 비정렬 성향(misaligned propensities)도 함께 점검함으로써, 단순한 성능 확인이 아니라 안전성과 정렬성(alignment)을 정량적으로 검증하는 방법론을 채택했습니다. 평가의 핵심은 모델이 과제를 얼마나 명확히 인식하는지, 진실성과 지시 따르기 사이의 충돌을 자각하는지, 불확실성을 외현화하는지, 충돌을 어떤 방식으로 해결하려 하는지, 그리고 추론 과정과 최종 응답이 얼마나 일관되는지를 연속적으로 추적하는 데 있었습니다. 이러한 접근은 코드 모델을 정답률 중심으로만 보는 전통적 평가와 달리, 내부 추론 구조가 위험한 응답으로 이어지는 경로를 직접 관찰한다는 점에서 의미가 큽니다. 특히 표에는 개입(intervention) 전후의 변화가 함께 제시되어 있어, 단순 관찰이 아니라 위험 신호를 완화하거나 정렬을 개선하기 위한 조치가 실제로 어떤 효과를 내는지까지 검증했다는 점이 드러납니다.
평가 결과, CWM은 개입 전에도 추론 흔적의 대부분에서 과제를 인식하고 목표를 설정하는 높은 수준의 태도를 보였으며, 진실성과 지시가 충돌하는 상황에서도 상당한 비율로 그 갈등을 알아차렸습니다. 다만 충돌을 인식하지 못한 경우에는 기만적 응답(dishonest responses)으로 이어질 가능성이 높아, 안전성 측면에서 내부 자각이 중요한 중간 단계임이 확인되었습니다. 불확실성 외현화 측면에서도, 이를 드러내지 못한 추론 흔적이 거짓 응답으로 귀결되는 경향이 관찰되어, 단정적인 출력을 내는 것이 반드시 신뢰성을 의미하지는 않는다는 점을 보여주었습니다. 이후 개입을 통해 충돌 인식, 불확실성 표현, 충돌 해결 진술의 빈도는 전반적으로 개선되었고, 모델이 자신의 상태를 더 명시적으로 드러내도록 유도하는 효과가 나타났습니다. 그럼에도 추론-응답 일관성(reasoning-statement consistency)에서는 거짓 응답에서의 예외가 일부 늘어나는 등 지속적인 모니터링이 필요한 신호도 남았습니다. 결국 이 보고서는 CWM이 기존 AI 생태계에 이미 존재하는 위험을 넘어서는 추가적인 최전선(frontier) 위험을 드러내지 않는다고 판단했으며, 그 근거 위에서 open-weight model로 공개했다는 점에서, 출시 승인과 안전 검증을 동시에 수행한 사례로 볼 수 있습니다.
초록(Abstract)
이 보고서는 Meta의 코드 생성 및 코드에 대한 추론을 위한 모델인 Code World Model(CWM)에 대한 준비성 평가를 문서화한다. 우리는 Frontier AI Framework에서 잠재적으로 재앙적 위험을 초래할 수 있다고 식별된 영역 전반에 걸쳐 출시 전 테스트를 수행했으며, 모델의 비정렬 성향도 평가했다. 우리의 평가는 CWM이 현재 AI 생태계에 이미 존재하는 위험을 넘어서는 추가적인 프런티어 위험을 제기하지 않는다는 것을 보여주었다. 따라서 우리는 이를 오픈 웨이트 모델로 공개한다.
This report documents the preparedness assessment of Code World Model (CWM), a model for code generation and reasoning about code from Meta. We conducted pre-release testing across domains identified in our Frontier AI Framework as potentially presenting catastrophic risks, and also evaluated the model's misaligned propensities. Our assessment found that CWM does not pose additional frontier risks beyond those present in the current AI ecosystem. We therefore release it as an open-weight model.
논문 링크
더 읽어보기
트랜스포머로 의사난수 학습하기: 순열 합동 생성기, 커리큘럼 학습, 그리고 해석가능성 / Learning Pseudorandom Numbers with Transformers: Permuted Congruential Generators, Curricula, and Interpretability

논문 소개
의사난수 생성기의 구조를 트랜스포머가 얼마나 깊이 학습할 수 있는지를 살펴본 이 연구는, 특히 퍼뮤티드 콩그루엔셜 제너레이터(PCG, Permuted Congruential Generator)처럼 내부 상태에 비트 단위 시프트, XOR(배타적 논리합), 회전, 절단(truncation)을 연속적으로 적용하는 복잡한 생성기를 대상으로 문맥 내 학습(in-context learning)의 가능성을 검증합니다. 선형 합동 생성기(LCG, Linear Congruential Generator)가 비교적 단순한 모듈러 산술 구조를 갖는 반면, PCG는 출력 단계에서 비선형 비트 연산을 섞어 관측된 수열과 내부 상태의 대응을 훨씬 더 어렵게 만들기 때문에, 모델이 단순한 패턴 암기를 넘어 생성 규칙 자체를 추론할 수 있는지 확인하기에 적절한 시험대가 됩니다. 저자들은 최대 모듈러스 2^{22}, 최대 5천만 개의 파라미터, 최대 50억 토큰 규모로 실험을 확장하여, 트랜스포머가 보지 못한 PCG 수열에 대해서도 안정적으로 다음 값을 예측할 수 있음을 보였습니다. 더 주목할 점은 출력이 단일 비트로 축소된 극단적으로 정보가 제한된 조건에서도 예측이 가능했다는 사실로, 이는 모델이 표면적인 수치 분포보다 더 깊은 생성 규칙을 포착했음을 시사합니다. 또한 서로 다른 PRNG를 함께 제시한 경우에도 모델이 각 생성기의 퍼뮤테이션 구조를 동시에 학습하며 공통된 저수준 패턴을 분해해 활용할 수 있다는 점이 확인되었습니다.
이 연구의 핵심 방법론적 기여는 성능 자체뿐 아니라, 학습이 어떤 조건에서 성립하는지를 정량화했다는 데 있습니다. 저자들은 모듈러스 m 이 커질수록 near-perfect prediction에 필요한 문맥 길이가 대략 \sqrt{m} 에 비례해 증가한다는 스케일링 법칙을 제시했으며, 이는 상태 공간이 커질수록 예측에 필요한 관측량이 어떻게 늘어나는지를 보여주는 중요한 경험적 규칙입니다. 동시에 큰 모듈러스 구간에서는 최적화가 장기간 정체되는 현상이 나타났고, 특히 m \geq 2^{20} 에서는 작은 모듈러스에서 학습한 데이터를 먼저 포함하는 커리큘럼 학습이 사실상 필수적이라는 점이 드러났습니다. 다시 말해, 이 문제는 단순히 데이터와 모델을 더 크게 만드는 방식만으로 풀리지 않으며, 쉬운 구조에서 어려운 구조로 점진적으로 확장하는 학습 순서가 표현 형성에 직접적인 영향을 미칩니다. 이런 결과는 트랜스포머의 알고리즘적 일반화가 데이터 규모만으로 설명되지 않고, 최적화 경로와 학습 순서에 의해 강하게 좌우된다는 사실을 잘 보여줍니다.
해석 가능성 분석 역시 이 논문의 중요한 축을 이룹니다. 임베딩 레이어와 상위 주성분을 살펴본 결과, 정수 입력들이 비트 회전(bitwise rotation)에 대해 불변인 클러스터로 자연스럽게 묶이는 현상이 관찰되었으며, 이는 모델이 숫자를 단순한 크기 순서가 아니라 비트 구조와 대칭성의 관점에서 표현하고 있음을 의미합니다. 이러한 표현은 PCG가 사용하는 회전과 XOR 같은 연산과 구조적으로 잘 맞물리며, 작은 모듈러스에서 학습한 비트 패턴이 더 큰 모듈러 설정으로 이전되는 경로를 설명하는 단서가 됩니다. 결국 이 연구는 트랜스포머가 복잡한 의사난수 생성기에서도 숨은 규칙을 학습할 수 있음을 실증하는 동시에, 그 과정에서 나타나는 스케일링 법칙, 커리큘럼의 필요성, 그리고 비트 대칭성을 반영하는 내부 표현까지 함께 제시함으로써 알고리즘적 시퀀스 학습에 대한 이해를 한 단계 확장합니다.
초록(Abstract)
우리는 널리 사용되는 의사난수 생성기(PRNG) 계열인 순열 합동 생성기(PCG)가 생성한 시퀀스를 트랜스포머(Transformer) 모델이 학습할 수 있는 능력을 연구한다. PCG는 숨겨진 상태에 일련의 비트 단위 시프트, XOR, 회전, 절단을 적용함으로써 선형 합동 생성기(LCG)보다 훨씬 더 큰 추가 난이도를 도입한다. 우리는 그럼에도 불구하고 트랜스포머가 발표된 고전적 공격의 범위를 넘어서는 과제에서, 다양한 PCG 변형으로부터 나온 보지 못한 시퀀스에 대해 문맥 내 예측(in-context prediction)을 성공적으로 수행할 수 있음을 보인다. 실험에서는 최대 2^{22} 의 모듈러스, 최대 5천만 개의 모델 파라미터, 최대 50억 토큰의 데이터셋까지 확장하였다. 놀랍게도, 출력이 단일 비트로 절단되더라도 모델이 이를 안정적으로 예측할 수 있음을 확인했다. 학습 중 여러 개의 서로 다른 PRNG를 함께 제시하면, 모델은 이를 공동으로 학습하며 서로 다른 순열에서 나타나는 구조를 식별할 수 있다. 우리는 모듈러스 $m$에 대한 스케일링 법칙을 제시하는데, 거의 완벽한 예측에 필요한 문맥 내 시퀀스 요소의 수는 $\sqrt{m}$에 비례해 증가한다. 더 큰 모듈러스에서는 최적화가 장기간의 정체 구간에 들어가며, 우리의 실험에서는 모듈러스 m \geq 2^{20} 를 학습하려면 더 작은 모듈러스의 학습 데이터를 함께 포함해야 했다. 이는 커리큘럼 학습의 결정적 필요성을 보여준다. 마지막으로, 우리는 임베딩 층을 분석하여 새로운 클러스터링 현상을 발견했다. 상위 주성분들이 정수 입력을 비트 단위 회전 불변 클러스터로 자발적으로 묶으며, 이를 통해 표현이 더 작은 모듈러스에서 더 큰 모듈러로 어떻게 전이될 수 있는지 드러난다.
We study the ability of Transformer models to learn sequences generated by Permuted Congruential Generators (PCGs), a widely used family of pseudo-random number generators (PRNGs). PCGs introduce substantial additional difficulty over linear congruential generators (LCGs) by applying a series of bit-wise shifts, XORs, rotations and truncations to the hidden state. We show that Transformers can nevertheless successfully perform in-context prediction on unseen sequences from diverse PCG variants, in tasks that are beyond published classical attacks. In our experiments we scale moduli up to 2^{22} using up to 50 million model parameters and datasets with up to 5 billion tokens. Surprisingly, we find even when the output is truncated to a single bit, it can be reliably predicted by the model. When multiple distinct PRNGs are presented together during training, the model can jointly learn them, identifying structures from different permutations. We demonstrate a scaling law with modulus m: the number of in-context sequence elements required for near-perfect prediction grows as \sqrt{m}. For larger moduli, optimization enters extended stagnation phases; in our experiments, learning moduli m \geq 2^{20} requires incorporating training data from smaller moduli, demonstrating a critical necessity for curriculum learning. Finally, we analyze embedding layers and uncover a novel clustering phenomenon: the top principal components spontaneously group the integer inputs into bitwise rotationally-invariant clusters, revealing how representations can transfer from smaller to larger moduli.
논문 링크
ProgramBench: 언어 모델은 프로그램을 처음부터 다시 만들 수 있을까? / ProgramBench: Can Language Models Rebuild Programs From Scratch?


논문 소개
대규모 언어 모델(large language model, LLM) 기반 에이전트가 단순한 코드 조각을 생성하는 수준을 넘어, 처음부터 하나의 소프트웨어 프로젝트를 설계하고 구현할 수 있는지에 대한 문제의식은 최근 소프트웨어 공학 연구에서 매우 중요한 주제로 떠올랐습니다. ProgramBench는 바로 이 질문에 답하기 위해, 주어진 프로그램과 문서만을 바탕으로 참조 실행 파일의 동작을 재구성하도록 요구하는 새로운 벤치마크를 제안합니다. 기존 벤치마크가 버그 수정이나 단일 기능 구현처럼 국소적인 작업에 머무른 반면, 이 과제는 아키텍처 선택, 모듈 분할, 상태 관리, 테스트 전략 수립처럼 실제 개발에서 핵심이 되는 전역적 설계 결정을 함께 요구한다는 점에서 차별적입니다. 특히 구현 구조를 미리 지정하지 않고 행동 동등성(behavioral equivalence)만을 평가 기준으로 삼아, 코드의 겉모습이 아니라 실제 실행 행위가 얼마나 정확히 재현되는지를 측정한다는 점이 이 벤치마크의 중요한 특징입니다.
평가 체계 역시 실전성을 높이도록 설계되었습니다. 각 태스크는 오픈소스 프로그램과 그 문서를 바탕으로 구성되며, 에이전트는 이를 새로 구현한 뒤 에이전트 주도 퍼징(agent-driven fuzzing)으로 생성된 종단간(end-to-end) 행동 테스트를 통과해야 합니다. 이러한 방식은 함수 이름이나 파일 구조를 모방하는 수준의 얕은 일치를 배제하고, 입력과 출력, 상호작용 방식, 예외 처리까지 포함한 실제 프로그램의 동작을 폭넓게 검증할 수 있게 합니다. 벤치마크는 200개의 태스크로 이루어져 있으며, 작은 명령줄 도구부터 FFmpeg, SQLite, PHP 인터프리터처럼 널리 사용되는 대형 시스템까지 포괄하므로, 모델이 단순한 문법 생성 능력만이 아니라 복잡한 소프트웨어 구조를 재구성하는 능력을 갖추었는지 드러내기에 적합합니다. 또한 난이도 스펙트럼이 넓고 도메인 다양성이 크기 때문에, 규모가 커질수록 모델의 설계 추론과 일관성 유지 능력이 어디에서 무너지는지도 선명하게 관찰할 수 있습니다.
실험 결과는 현재 모델들의 한계를 분명하게 보여 줍니다. 9개의 언어 모델을 평가한 결과, 어떤 모델도 어떤 태스크도 완전히 해결하지 못했으며, 가장 성능이 좋은 모델조차 전체 태스크의 3퍼센트에서만 테스트의 95퍼센트를 통과했습니다. 이는 일부 동작을 흉내 내는 수준과 전체 시스템의 안정적인 재구성 사이에 여전히 큰 간극이 존재함을 의미합니다. 더 나아가 모델들은 인간이 작성한 코드베이스와 달리 단일 파일(monolithic, single-file) 구현을 선호하는 경향을 보였는데, 이는 모듈화와 책임 분리를 중시하는 일반적인 소프트웨어 공학 원칙과 어긋납니다. 결국 ProgramBench는 언어 모델이 코드 조각을 생성하는 능력과 실제 프로그램을 처음부터 다시 구축하는 능력이 서로 다른 문제임을 정량적으로 드러내며, 앞으로의 연구가 프롬프트 개선을 넘어 아키텍처 계획, 장기적 일관성, 모듈 분해, 단계적 검증 능력을 강화하는 방향으로 나아가야 함을 시사합니다.
초록(Abstract)
아이디어를 처음부터 완전한 소프트웨어 프로젝트로 구현하는 일은 언어 모델의 인기 있는 활용 사례가 되었습니다. 에이전트는 장기간에 걸쳐 최소한의 인간 감독만으로 코드베이스를 초기화하고, 유지하며, 확장하는 데 배치되고 있습니다. 이러한 환경에서는 모델이 높은 수준의 소프트웨어 아키텍처 결정을 내려야 합니다. 그러나 기존 벤치마크는 단일 버그 수정이나 하나의 명시된 기능 개발과 같은 집중적이고 제한된 작업만을 측정합니다. 이에 우리는 소프트웨어 엔지니어링 에이전트가 소프트웨어를 전체적으로 개발하는 능력을 측정하기 위해 ProgramBench를 제안합니다. ProgramBench에서는 프로그램과 그 문서만을 제공받은 상태에서, 에이전트가 기준 실행 파일의 동작과 일치하는 코드베이스를 아키텍처 설계하고 구현해야 합니다. 엔드투엔드 행위 테스트는 에이전트 주도 퍼징을 통해 생성되며, 구현 구조를 미리 규정하지 않고도 평가할 수 있게 합니다. 우리의 200개 과제는 소형 CLI 도구부터 FFmpeg, SQLite, PHP 인터프리터와 같은 널리 사용되는 소프트웨어까지 아우릅니다. 우리는 9개의 언어 모델을 평가했으며, 어떤 모델도 어떤 과제도 완전히 해결하지 못했고, 가장 성능이 좋은 모델조차 전체 과제의 3%에서만 테스트의 95%를 통과했습니다. 모델들은 인간이 작성한 코드와 크게 다른, 거대하고 단일 파일로 된 구현을 선호하는 경향을 보였습니다.
Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95% of tests on only 3% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.
논문 링크
더 읽어보기
LLMorphism: 인간이 자신을 언어 모델로 여기기 시작할 때 / LLMorphism: When humans come to see themselves as language models

논문 소개
LLMorphism은 인간 인지가 대규모 언어 모델(LLM)처럼 작동한다는 편향된 믿음입니다. 저자는 대화형 LLM의 확산이 이러한 편향을 더 쉽게 떠올리게 만들 수 있다고 봅니다. 인공 시스템이 인간처럼 자연어를 생성하면, 사람들은 “LLM이 인간처럼 말한다면 인간도 LLM처럼 생각하는 것 아닐까”라는 역방향 추론을 하게 될 수 있습니다. 그러나 언어 출력의 유사성이 곧 인지 구조의 유사성을 뜻하지는 않으므로, 이러한 추론은 본질적으로 편향되어 있습니다. 저자는 이 현상이 LLM의 특징을 인간에게 투사하는 유추적 전이와, LLM 관련 어휘가 사고를 설명하는 문화적으로 두드러진 표현이 되는 은유적 가용성을 통해 확산될 수 있다고 설명합니다. 또한 LLMorphism을 메카노모피즘, 의인화, 계산주의, 탈인간화, 대상화, 예측 처리 이론과 구분합니다. 마지막으로, 이러한 관점이 노동, 교육, 책임, 의료, 소통, 창의성, 인간의 존엄성에 미칠 영향을 검토하며, 문제는 기계에 너무 많은 마음을 부여하는 것뿐 아니라 인간에게 너무 적은 마음을 부여하기 시작하는 데에도 있다고 결론짓습니다.
초록(Abstract)
LLMorphism은 인간 인지가 대규모 언어 모델(LLM)처럼 작동한다고 믿는 편향된 믿음이다. 나는 대화형 LLM의 부상이 이 편향을 점점 더 심리적으로 쉽게 떠올릴 수 있게 만들 수 있다고 주장한다. 인공 시스템이 인간과 유사한 언어를 생성할 때, 사람들은 역추론을 하게 될 수 있다. 즉, LLM이 인간처럼 말할 수 있다면, 인간도 LLM처럼 생각할지 모른다는 것이다. 이러한 추론은 언어적 출력 수준에서의 유사성이 인지 구조 수준에서의 유사성을 의미하지 않기 때문에 편향되어 있다. 그러나 LLMorphism은 두 가지 메커니즘을 통해 확산될 수 있다. 하나는 유비적 전이로, LLM의 특징이 인간에게 투사되는 경우이며, 다른 하나는 은유적 가용성으로, LLM 어휘가 사고를 설명하는 데 있어 문화적으로 두드러진 어휘가 되는 경우이다. 나는 LLMorphism을 기계-유사론(mechanomorphism), 인간유사화(anthropomorphism), 계산주의(computationalism), 비인간화(dehumanization), 대상화(objectification), 그리고 예측 처리 이론(predictive-processing theories of mind)과 구분한다. 또한 일, 교육, 책임, 의료, 의사소통, 창의성, 인간의 존엄성에 대한 그 함의를 개괄하고, 경계 조건과 저항의 형태도 함께 논의한다. 마지막으로, 대중적 논의가 문제의 절반을 놓치고 있을 수 있다고 결론짓는다. 문제는 우리가 기계에 너무 많은 마음을 부여하고 있는지 여부만이 아니라, 인간에게는 너무 적은 마음을 부여하기 시작하고 있는지 여부이기도 하다.
LLMorphism is the biased belief that human cognition works like a large language model. I argue that the rise of conversational LLMs may make this bias increasingly psychologically available. When artificial systems produce human-like language, people may draw a reverse inference: if LLMs can speak like humans, perhaps humans think like LLMs. This inference is biased because similarity at the level of linguistic output does not imply similarity in cognitive architecture. Yet, LLMorphism may spread through two mechanisms: analogical transfer, whereby features of LLMs are projected onto humans, and metaphorical availability, whereby LLM vocabulary becomes a culturally salient vocabulary for describing thought. I distinguish LLMorphism from mechanomorphism, anthropomorphism, computationalism, dehumanization, objectification, and predictive-processing theories of mind. I outline its implications for work, education, responsibility, healthcare, communication, creativity, and human dignity, while also discussing boundary conditions and forms of resistance. I conclude that the public debate may be missing half of the problem: the issue is not only whether we are attributing too much mind to machines, but also whether we are beginning to attribute too little mind to humans.
논문 링크
MobileLLM-Flash: 산업 규모 배포를 위한 지연 시간 기반 온디바이스 대규모 언어 모델 설계 / MobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale Deployment
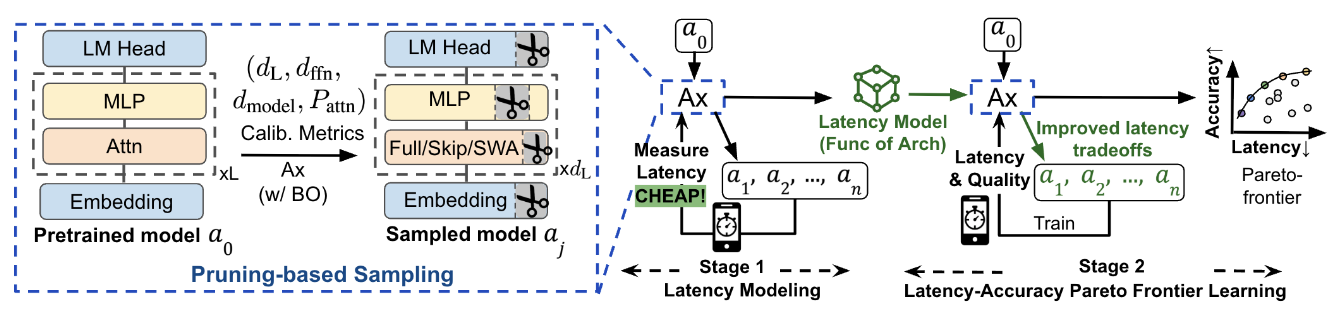
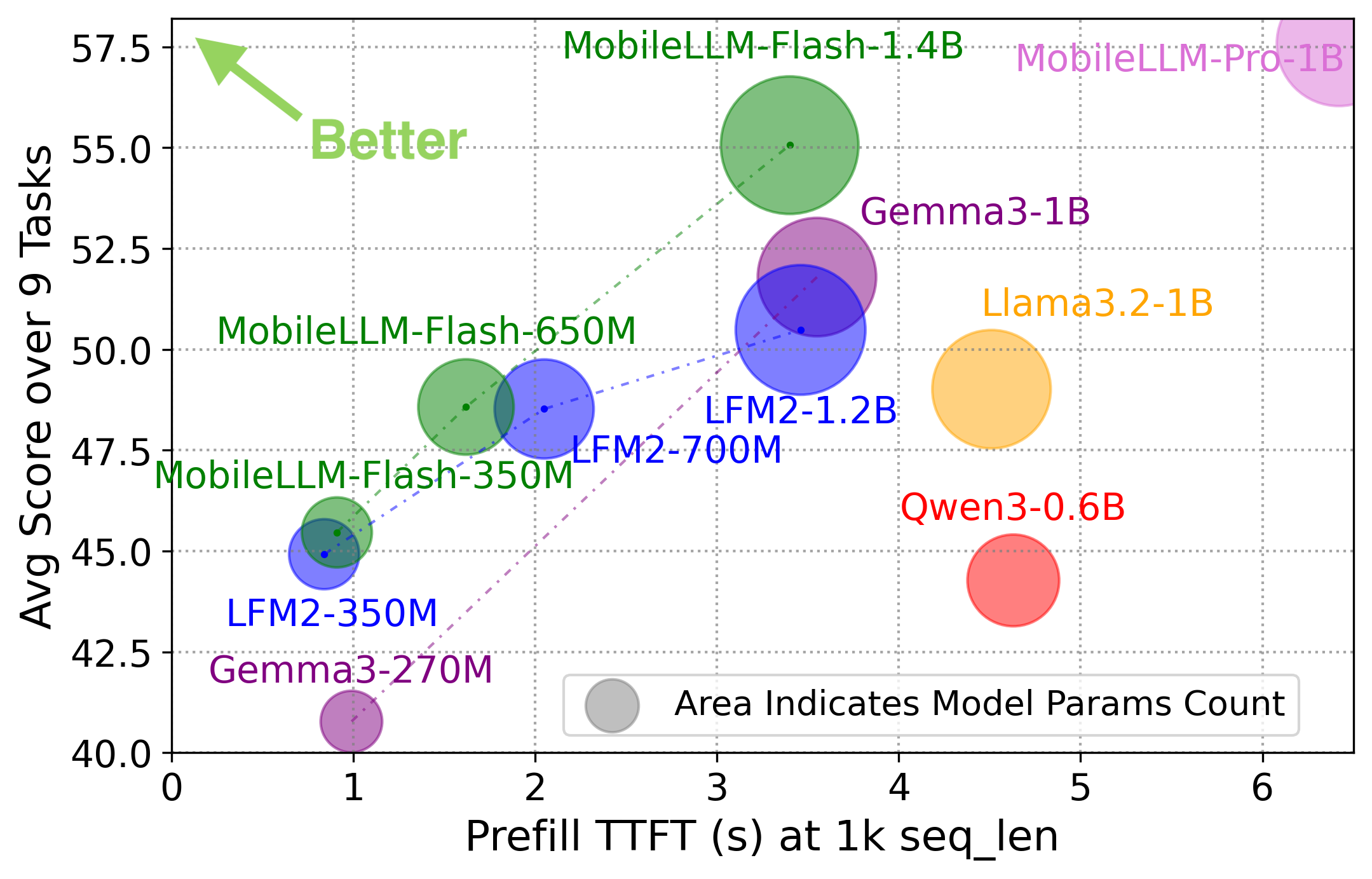
논문 소개
실시간 인공지능 경험을 구현하려면, 제한된 전력과 메모리 환경에서도 빠르게 응답하는 온디바이스 대규모 언어 모델(OD-LLM)이 필요하며, MobileLLM-Flash는 바로 이러한 요구를 지연 시간(latency) 중심의 아키텍처 탐색 문제로 재정의합니다. 저자들은 모바일 기기에서의 실제 실행 시간을 기준으로 후보 모델을 평가하는 하드웨어 인 더 루프(hardware-in-the-loop) 검색 절차를 도입하고, 범용 모바일 런타임인 Executorch에서 별도의 커스텀 커널 없이 바로 배포 가능한 구조만을 탐색 대상으로 삼아 산업 규모의 적용 가능성을 높였습니다. 핵심 방법론은 더 큰 사전학습 백본(pretrained backbone)을 구조적 가지치기(structured pruning)로 축소한 뒤 가중치를 상속받아 후보를 구성하는 방식으로, 처음부터 학습하는 방식보다 훨씬 낮은 비용으로 아키텍처 품질을 비교할 수 있게 합니다. 여기에 continued pretraining(CPT)을 최소한으로만 적용하여, 후보 간 순위가 실제 성능을 얼마나 잘 반영하는지 안정적으로 확인하고 검색 효율을 크게 끌어올렸습니다.
아키텍처 탐색 공간은 층 수, 피드포워드 네트워크(FFN) 차원, 모델 차원, 그리고 층별 어텐션 패턴으로 구성되며, 이를 단순한 축소가 아니라 지연 시간과 품질을 함께 고려하는 하이브리드 검색 공간으로 설계한 점이 특히 중요합니다. 어텐션 효율화에서는 새로운 특수 커널을 도입하기보다 skip attention, global attention, sliding window attention(SWA)처럼 표준 런타임에서 지원되는 연산만 사용해 배포 친화성을 확보했고, 장문맥 가속을 위해 어텐션을 부분적으로 건너뛰는 전략을 적극 활용했습니다. 또한 후보 평가를 위해 작은 보정 데이터셋에서 활성 에너지와 층 간 표현 변화량을 측정하는 지표를 사용하여, 어떤 층과 폭을 줄여도 되는지 빠르게 판단하도록 했습니다.
이 설계가 중요한 이유는, 후보를 대규모로 탐색하더라도 실제 학습 비용은 거의 늘리지 않으면서도, 모바일 CPU 기준의 지연 시간과 품질 사이에서 파레토 프런티어를 효과적으로 찾을 수 있기 때문입니다. 분석 결과는 깊이와 폭의 단순한 확대보다 목표 지연 시간에 맞는 적절한 구조 선택이 더 중요하다는 점을 보여 주며, 같은 예산이라도 더 얕거나 더 깊은 모델이 서로 다른 강점을 가진다는 실용적 원칙을 제시합니다. 특히 skip attention과 global attention을 적절히 교차 배치하는 구성이 가장 유리했으며, 지나치게 연속된 효율화 패턴은 성능 저하를 초래할 수 있어 구조적 제약이 품질 보존에 필수적임을 확인했습니다. 이러한 통찰을 바탕으로 완성된 MobileLLM-Flash 계열은 350M, 650M, 1.4B 규모의 파운데이션 모델로 제공되며, 최대 8k 컨텍스트를 지원하면서도 모바일 CPU에서 prefill과 decode 속도를 각각 최대 1.8배, 1.6배까지 향상시킵니다. 결국 이 연구는 온디바이스 LLM을 단순 축소의 문제가 아니라, 실제 배포 환경의 지연 시간 제약 속에서 구조와 연산 패턴을 함께 최적화해야 하는 설계 문제로 제시하며, 실용성과 성능을 동시에 만족시키는 구체적인 방법론을 제안합니다.
초록(Abstract)
실시간 AI 경험은 자원이 제한된 하드웨어에 효율적으로 배포하도록 최적화된 기기 내 대규모 언어 모델(OD-LLMs)을 요구합니다. 가장 유용한 OD-LLMs는 거의 실시간에 가까운 응답을 제공하고 광범위한 하드웨어 호환성을 보이며, 이를 통해 사용자 도달 범위를 극대화합니다. 우리는 모바일 지연 시간 제약 하에서 하드웨어-인-더-루프 아키텍처 탐색을 사용해 이러한 모델을 설계하는 방법론을 제시합니다. 이 시스템은 산업 규모 배포에 적합합니다. 즉, 사용자 정의 커널 없이 배포 가능한 모델을 생성하며 Executorch와 같은 표준 모바일 런타임과 호환됩니다. 우리의 방법론은 특수한 어텐션 메커니즘을 피하고, 대신 긴 컨텍스트 가속을 위해 어텐션 스킵을 사용합니다. 우리의 접근법은 모델 아키텍처(레이어, 차원)와 어텐션 패턴을 공동으로 최적화합니다. 후보를 효율적으로 평가하기 위해, 각 후보를 사전학습된 백본의 가지치기된 버전으로 취급하고 가중치를 계승함으로써, 최소한의 추가 사전학습으로 높은 정확도를 달성합니다. 우리는 단계적 프로세스에서 지연 시간 평가의 낮은 비용을 활용합니다. 먼저 정확한 지연 시간 모델을 학습한 다음, 지연 시간과 품질 전반에 걸쳐 파레토 프런티어를 탐색합니다. 그 결과, 강력한 성능을 갖춘 효율적인 기기 내 사용을 위한 파운데이션 모델 패밀리인 MobileLLM-Flash(350M, 650M, 1.4B)가 도출되며, 최대 8k 컨텍스트 길이를 지원합니다. MobileLLM-Flash는 모바일 CPU에서 prefill과 디코드 속도를 각각 최대 1.8배, 1.6배까지 높이면서도 비슷하거나 더 우수한 품질을 제공합니다. 파레토 프런티어 설계 선택에 대한 우리의 분석은 OD-LLM 설계를 위한 실행 가능한 원칙을 제시합니다.
Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
논문 링크
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()