지난 3월 말일, A Survey of Large Language Models 라는 이름의 논문이 arXiv에 올라왔었는데요,
언제나처럼(...) 읽을거리 큐에 넣어두고 잊고있었는데 W&B 블로그에 요약 글이 올라와서 힘을 모아 함께 읽어보고자(...) 올려봅니다 ㅎㅎㅎ
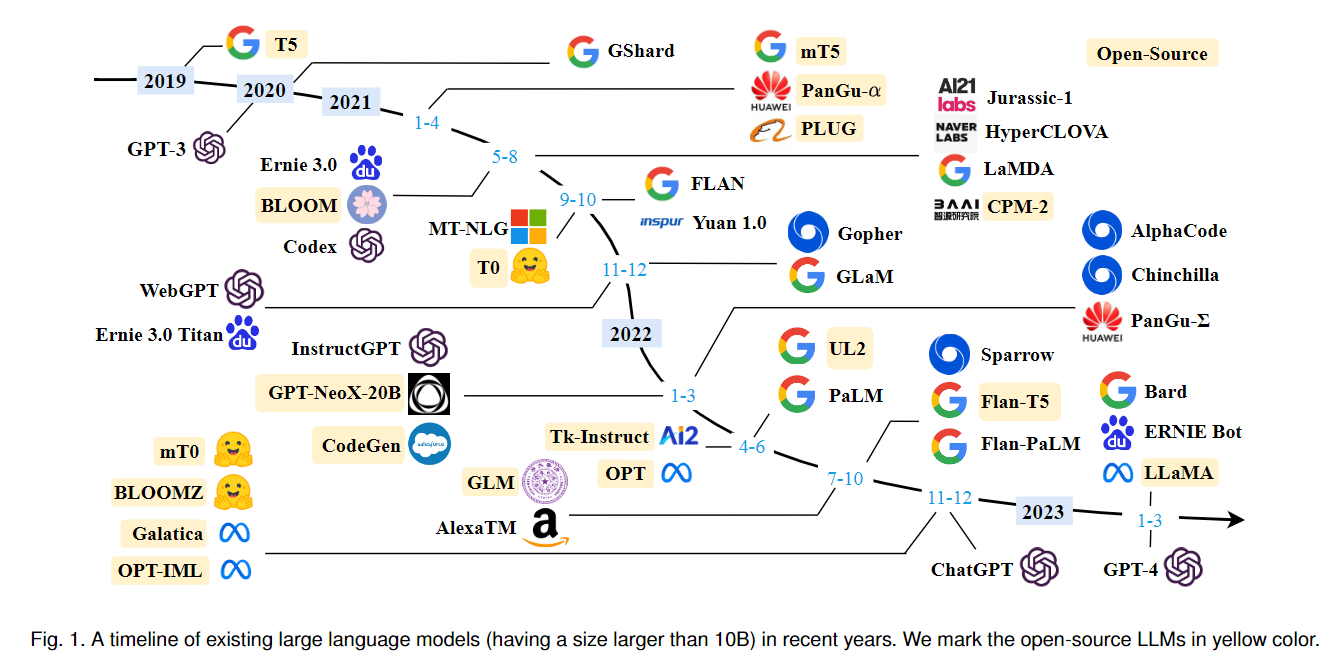
전체 글은 아래 링크에서 보실 수 있고, Intro 부분만 DeepL로 살짝 돌려 아래 첨부하였습니다.
Intro
Language modeling (LM), the field of predicting the next words in word sequences, can be divided into 4 developmental stages:
Statisical Language Modeling (SLM): methods from the 1990s where a simple n-gram model predicts the next word based on recent context (Markov assumption)
Neural Language Models (NLM): use neural networks like RNNs, LSTMs, GRUs, word2vec
Large Language Models (LLM): larger PLMs like GPT-4, ChatGPT, PaLM, Sparrow, Claude, Microsoft 365's AI, etc
소개
단어 시퀀스에서 다음 단어를 예측하는 분야인 언어 모델링(LM)은 크게 4가지 발전 단계로 나눌 수 있습니다:
통계적 언어 모델링(SLM): 1990년대부터 사용된 방법으로, 간단한 n-그램 모델이 최근 문맥을 기반으로 다음 단어를 예측합니다(마르코프 가정).
신경망 언어 모델(NLM): RNN, LSTM, GRU, word2vec과 같은 신경망을 사용합니다.
대규모 언어 모델(LLM): GPT-4, ChatGPT, PaLM, Sparrow, Claude, Microsoft 365의 AI와 같은 대규모 PLM 등
Characteristics
The paper describes 3 characteristics of LLMs that differentiate them from PLMs:
surprising emergent abilities
LLMs revolutionize the way we develop and use AI algorithms
development of LLM draws no clear distinction between research and engineering
I believe this is to say, in other words, that due to the dawning newfound capabilities of LLMs, we have not just found it relevant in research but also in industry and application, demanding skills from engineers and researchers to intermingle.
특성
이 백서에서는 PLM과 차별화되는 LLM들의 3가지 특징에 대해 설명합니다:
(의도치 않게 발현된) 놀라운 기능들
LLM은 AI 알고리즘 개발 및 사용 방식을 혁신합니다.
LLM의 개발에는 연구와 엔지니어링의 구분이 명확하지 않습니다.
다시 말해, LLM의 새로운 기능으로 인해 연구뿐 아니라 산업 및 응용 분야에서도 관련성을 발견하고 엔지니어와 연구원이 서로 융합할 수 있는 기술을 요구하고 있습니다.
Uncertainties
There still exist some questions about:
why do these emergent abilities occur?
difficulties training LLMs in research as they are primarily trained in industry
the alignment problem (aligning LLM behavior with human values)
This paper covers 4 themes:
how to pre-train,
adaptation tuning for effectiveness and safety,
how to use LLMs for downstream tasks (utilization), and
evaluation (how to evaluate LLMs).
불확실성
여전히 몇 가지 의문점이 존재합니다:
어떻게 이러한 새로운 능력이 발현되었는가?
주로 산업 분야에서 교육받은 LLM을 연구 분야에서 교육하는 데 어려움
정렬 문제(LLM의 행동을 인간의 가치와 일치시키는 것)
이 백서에서는 4가지 주제를 다룹니다:
사전 훈련 방법
효과와 안전성을 위한 적응 튜닝,
다운스트림 작업(활용)에 LLM을 사용하는 방법, 그리고
평가(LLM을 평가하는 방법).