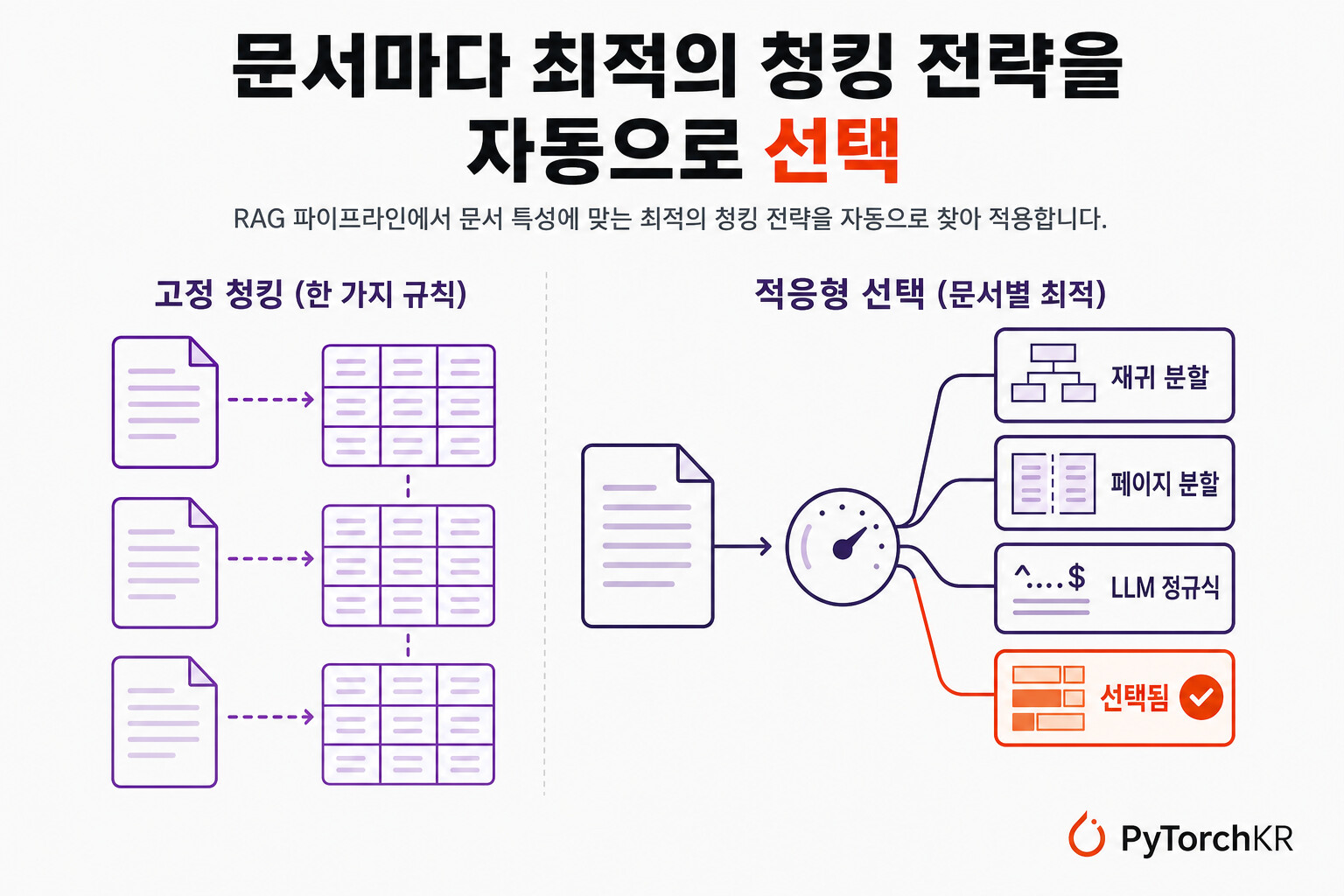
Adaptive Chunking 소개
방대한 문서 더미에서 필요한 한 문장을 찾아야 한다고 상상해 봅시다. 똑같은 내용이라도 문서를 어떤 단위로 잘라 정리해 두었느냐에 따라, 원하는 정보를 찾는 속도와 정확도는 완전히 달라집니다. 잘 정리된 목차와 색인이 있는 책에서는 한 페이지를 펼치면 답이 나오지만, 단락이 어중간하게 끊긴 책에서는 같은 정보가 여기저기 흩어져 있어 결국 헤매게 됩니다.
이 글에서 다루는 논문은 검색 증강 생성(Retrieval-Augmented Generation, RAG)에서 의외로 과소평가되어 온 청킹(Chunking) 단계를 정면으로 다룹니다. 청킹이란 문서를 색인과 검색을 위해 더 작은 단위로 잘라내는 작업을 말합니다. 논문의 핵심 주장은 단순합니다. 모든 문서에 똑같은 청킹 방식을 적용하는 "만능 해법(one-size-fits-all)"은 존재하지 않으며, 문서마다 가장 적합한 청킹 전략이 다르다는 것입니다. 컨설팅과 데이터 사이언스 기업 Ekimetrics 의 Paulo Roberto de Moura Junior, Jean Lelong, Annabelle Blangero 는 청킹 품질을 직접 측정하는 5가지 내재적 지표를 제안하고, 이 지표로 문서별 최적 방법을 자동 선택하는 Adaptive Chunking 프레임워크를 선보입니다. 이 연구는 자연어 처리 학회인 LREC 2026 에 채택된 논문 "Adaptive Chunking: Optimizing Chunking-Method Selection for RAG" 으로 발표되었으며, 공식 구현체가 함께 공개되어 있습니다.
본 게시물에서는 Adaptive Chunking이 풀려는 문제와 동작 방식, 다섯 가지 평가 지표, 두 가지 새로운 청커, 논문에 보고된 벤치마크 결과, 그리고 설치 및 사용법까지 차례로 정리합니다.
배경: 청킹은 RAG의 숨은 병목
RAG는 외부 지식 기반에서 관련 정보를 검색(retrieval)하고, 이를 맥락으로 삼아 대형 언어 모델(Large Language Model, LLM)이 답변을 생성(generation)하는 두 단계로 이루어집니다. 이때 RAG의 성능은 사용자 질의에 맞는 적절한 맥락을 얼마나 잘 검색해 오느냐에 크게 좌우됩니다. LLM의 컨텍스트 창이 계속 커지고 있음에도, 효율적인 검색을 위해서는 문서를 어떤 단위로 쪼갤지가 여전히 결정적인 변수로 남아 있습니다.
문제는 현재의 청킹 방식들이 종종 임의의 경계를 강제하면서 맥락적 연결을 끊어버린다는 점입니다. 논문은 이를 "맥락 보존 딜레마(context-preservation dilemma)"라고 부릅니다. 하나의 완결된 정보가 서로 떨어진 여러 청크로 흩어지면, 검색 단계에서 그 정보를 온전히 길어 올리지 못하고 결국 답변 품질이 떨어집니다. 예를 들어 질의가 대명사를 포함하는데 정작 그 대명사가 가리키는 대상이 다른 청크에 들어가 있다면, 검색된 맥락만으로는 답을 구성할 수 없습니다.
기존 청킹 방식과 그 한계
저자들은 기존 청킹 방식을 검토하며 각각의 구체적인 한계를 지적합니다. 이 부분이 논문의 문제의식을 가장 잘 보여주는 대목입니다.
문장 기반 분할(Sentence-based splitting) 은 텍스트를 고정된 개수의 의미적으로 응집된 문장으로 나눕니다. 의미 단위로는 깔끔하지만, 단락(paragraph)처럼 더 큰 논리 블록을 자주 끊어버린다는 단점이 있습니다.
재귀적 분할(Recursive splitting), 대표적으로 LangChain의 RecursiveCharacterTextSplitter 는 구분자 계층을 순서대로 적용해 길이 제약을 맞춥니다. 하지만 길이만 맞추다 보니 서로 무관한 주제를 한 청크에 묶어버려 응집성이 떨어질 수 있습니다.
의미 기반 청킹(Semantic chunking) 은 임베딩을 이용해 의미적 경계에서 텍스트를 자릅니다. 응집성은 좋아지지만 임베딩을 반복 계산해야 하므로 연산 비용이 매우 큽니다.
마지막으로 LLM 기반 분할(LLM-driven splitting) 은 언어 모델로 자연스러운 경계를 추론합니다. 완결성은 높아지지만, 여전히 코퍼스 전체에 단일한 전략을 가정하며 상당한 오버헤드가 따릅니다.
이들의 공통된 한계는 명확합니다. 문서의 구조적, 맥락적 차이를 무시한 채 모든 문서에 하나의 고정된 청킹 전략을 적용한다는 점입니다. 최근 연구들도 점점 "만능 청킹 전략은 부적절하며, 최적의 접근은 문서의 구조와 내용에 본질적으로 의존한다"는 데 의견을 모으고 있습니다.
발상의 전환: 평가 지표를 먼저 만들자
여기에 더해, 저자들은 더 근본적인 공백을 짚습니다. 바로 청킹을 위한 전용 평가 체계가 없다는 것입니다. 지금까지 대부분의 연구는 청킹 품질을 Hits@k, Recall@K, nDCG@K 같은 다운스트림 검색 지표로 간접 측정해 왔습니다. 이 방식으로는 청킹 자체의 효과를 다른 요인과 분리해 평가하기가 어렵습니다. 청킹을 바꿨더니 성능이 올랐다 해도, 그것이 청킹 덕분인지 다른 요소 덕분인지 알 수 없는 것입니다.
그래서 이 논문은 순서를 뒤집습니다. 먼저 청크 품질을 문서 단위로 직접 측정하는 내재적 지표(intrinsic metrics) 를 설계하고, 그 지표를 나침반 삼아 문서별로 가장 좋은 청킹 방법을 고르자는 것입니다. 이상적인 청크가 갖춰야 할 네 가지 속성을 다음과 같이 가정합니다. (1) 홀로 읽어도 이해되는 자기 완결성(self-contained), (2) 임베딩 모델의 토큰 한계를 존중하는 적정 길이(length compliance), (3) 하나의 주제에 집중하는 의미적 응집성(semantic cohesion), (4) 문서의 자연스러운 구조와 정렬되는 맥락 보존(context-preserving)입니다.
논문의 기여는 세 가지로 요약됩니다. 첫째, 청크 품질을 직접 재는 5가지 내재적 지표. 둘째, LLM 정규식 분할기와 분할 후 병합 재귀 분할기라는 두 가지 새로운 청킹 기법과 후처리. 셋째, 검색 품질과 다운스트림 RAG 성능을 함께 측정하는 평가 파이프라인입니다.
실제로 이 프레임워크는 모델이나 프롬프트를 전혀 바꾸지 않고도, 답변 정확도 관련 종합 점수를 62 ~ 64\% 수준에서 72\% 가까이로 끌어올렸고, 성공적으로 답변한 질문 수를 30\% 이상 늘렸습니다($65$개 대 $49$개). 청킹이라는 한 단계만 손봤을 뿐인데 말이죠.
Adaptive Chunking의 동작 방식

핵심 아이디어는 단순합니다. 하나의 문서에 대해 여러 청킹 방법을 각각 실행한 뒤, 그 결과물(청크 집합)을 다섯 가지 품질 지표로 채점하고, 점수가 가장 높은 방법의 결과를 그 문서의 최종 청크로 채택합니다. 이 과정은 문서 단위로 독립적으로 일어나므로, 같은 코퍼스 안에서도 어떤 문서는 재귀 분할로, 다른 문서는 페이지 분할로 나뉠 수 있습니다.
기본으로 제공되는 청킹 방법은 네 가지입니다. 재귀 분할기(target 1100 토큰)는 구분자 우선순위에 따라 텍스트를 나눈 뒤 작은 조각을 병합하는 split-then-merge 방식이고, 600 토큰 버전은 같은 분할기를 더 작은 목표 크기로 돌려 더 세밀한 청크를 만듭니다. 페이지 분할은 페이지 경계를 기준으로 나누되 크기 제약을 후처리로 맞추며, LLM 정규식 방법은 LLM에게 해당 문서에 맞는 분할용 정규식 패턴을 생성하도록 요청합니다. 재귀 분할기는 저장소의 splitters.py 에, 나머지는 paper/splitters.py 에 구현되어 있고, 텍스트를 받아 청크 리스트를 반환하는 어떤 호출 가능 객체든 새 방법으로 등록할 수 있습니다.
문서 입력 단계에서는 세 가지 PDF 파싱 백엔드를 지원합니다. 기본값은 오픈소스 Docling이며, 가벼운 PyMuPDF와 클라우드 기반 Azure Document Intelligence를 선택할 수 있고 Excel 입력도 처리합니다.
청크 품질을 재는 5가지 내재적 지표
Adaptive Chunking의 심장은 청크 품질을 정량화하는 다섯 가지 지표입니다. 이 지표들은 모두 정답(ground-truth) 없이 계산된다는 공통점이 있습니다. 즉, 별도의 라벨링 작업 없이 청크 자체의 구조와 의미적 일관성만으로 품질을 판단합니다. 모든 지표는 문서 단위로 계산되어 문서별 튜닝과 코퍼스 전체 최적화를 모두 가능하게 하며, metrics.py 에 구현되어 사용자 정의 채점 함수로 확장할 수 있습니다.
| 지표 | 측정 내용 |
|---|---|
| References Completeness (RC) | 개체와 대명사 쌍 같은 상호참조 사슬이 청크 경계를 넘어 끊기지 않은 비율 |
| Block Integrity (BI) | 문단, 표, 그림 같은 구조적 블록이 온전히 유지된 비율 |
| Intrachunk Cohesion (ICC) | 청크 내 문장들과 청크 전체 임베딩 사이의 의미적 유사도 |
| Document Contextual Coherence (DCC) | 각 청크와 그 주변 컨텍스트 윈도우 사이의 유사도 |
| Size Compliance (SC) | 목표 토큰 수 범위 안에 들어오는 청크의 비율 |
각 지표가 어떤 실패 모드를 겨냥하는지 차례로 살펴보겠습니다.
References Completeness (RC): 참조의 완결성
References Completeness(RC) 는 개체와 대명사 쌍(entity-pronoun pair)이 같은 청크 안에 온전히 남아 있는 비율을 측정합니다. 앞서 언급한 대명사 문제를 직접 겨냥하는 지표입니다. 만약 "그녀"라는 대명사와 그것이 가리키는 인물이 서로 다른 청크로 갈라지면, 그 대명사가 포함된 질의에 대해 검색이 불완전해집니다.
계산은 먼저 Maverick 상호참조 해소(coreference resolution) 모델로 멘션 클러스터를 추출한 뒤, 개체-대명사 쌍을 뽑아내는 방식으로 이루어집니다. 개체-대명사 쌍 집합을 P = \{(e_i, p_i)\}_{i=1}^{N} 라 하고, 각 쌍의 경계를 s_i 와 t_i 로 둘 때 RC는 다음과 같이 정의됩니다.
여기서 m_i 는 개체와 대명사 사이에 청크 경계 b 가 끼어들면 1 이 되는 지시 함수입니다. 다만 Maverick 모델이 영어만 지원하므로, RC는 영어 문서에 대해서만 계산할 수 있다는 제약이 있습니다.
Block Integrity (BI): 구조 블록의 무결성
Block Integrity(BI) 는 단락, 표, 그림, 제목-본문 쌍 같은 구조적 단위가 끊기지 않고 보존되는지를 평가합니다. 표가 두 청크로 쪼개지면 그 표는 사실상 쓸모없어지는 것처럼, 구조 블록이 깨지면 해석 가능성이 크게 떨어지기 때문입니다. BI는 파서가 제공한 블록 경계를 기준으로 온전히 보존된 블록의 비율을 계산하며, 오탐을 막기 위해 \tau = 5 글자의 허용 오차를 둡니다. 즉, 어떤 청크 경계도 블록 내부에 \tau 이상 깊이 들어오지 않으면 그 블록은 온전한 것으로 간주합니다.
Intrachunk Cohesion (ICC): 청크 내부 응집성
Intrachunk Cohesion(ICC) 는 한 청크 안에서 문장들이 얼마나 같은 주제를 향하는지를 측정합니다. 각 청크에 대해, 문장 임베딩과 청크 전체 임베딩 사이의 평균 코사인 유사도로 계산하며, 임베딩은 Jina AI의 jina-embeddings-v3 모델을 사용합니다. 청크 c_k 안의 문장 임베딩 v(s_{kj}) 와 청크 임베딩 v(c_k) 에 대해 응집도는 다음과 같습니다.
이를 유효한 청크 전체에 대해 평균 낸 값이 ICC입니다. 마치 한 단락이 여러 문장으로 이루어졌더라도 결국 하나의 메시지를 향해야 잘 쓴 글인 것처럼, ICC가 높은 청크는 내부적으로 한 주제에 집중되어 있어 검색 신호가 선명합니다.
Document Contextual Coherence (DCC): 문서 맥락과의 일관성
Document Contextual Coherence(DCC) 는 각 청크가 주변의 더 넓은 지역적 맥락과 얼마나 잘 정렬되는지를 평가합니다. ICC가 청크 내부를 본다면, DCC는 청크와 그 주변의 관계를 봅니다. 최대 3{,}000 토큰의 슬라이딩 윈도우(sliding window)를 구성하고, 각 청크와 그 윈도우 임베딩 사이의 평균 코사인 유사도를 계산합니다. 이렇게 하면 청크가 홀로도 이해되면서 동시에 문서 수준의 맥락을 잃지 않았는지를 확인할 수 있습니다.
Size Compliance (SC): 크기 준수
마지막으로 Size Compliance(SC) 는 토큰 길이가 사전 정의된 범위(실험에서는 100 ~ 1{,}100 토큰) 안에 드는 청크의 비율을 잽니다. 너무 큰 청크는 하나의 임베딩 벡터에 너무 많은 서로 다른 개념을 욱여넣어 의미를 희석시키고, 너무 작은 청크는 정보가 빈약한 채로 검색 슬롯만 낭비합니다. 청크 집합 C = \{c_1, \dots, c_K\} 에 대해 SC는 다음과 같이 단순한 준수 비율입니다.
두 가지 새로운 청커와 후처리
지표만으로는 부족합니다. 선택지가 다양해야 "고를" 의미가 있기 때문입니다. 저자들은 구조 인식과 효율성의 균형을 노린 두 가지 새로운 청킹 기법을 제안합니다.
LLM 정규식 분할기 (LLM Regex Splitter)
첫 번째는 LLM Regex Splitter 입니다. 언어 모델의 구조 분석 능력과 정규식(regex) 기반 분할의 결정론적 특성을 결합한 방식입니다. 동작은 이렇습니다. 먼저 LLM에게 청킹 가이드라인과 출력 스키마, 예시를 제공한 뒤, 문서의 앞부분(실험에서는 처음 8{,}000 토큰)을 샘플로 보여줍니다. 그러면 LLM이 이 문서에 적합한 정규식 패턴 하나를 생성하고, 이 패턴을 Python의 re.split 으로 문서 전체에 적용합니다.
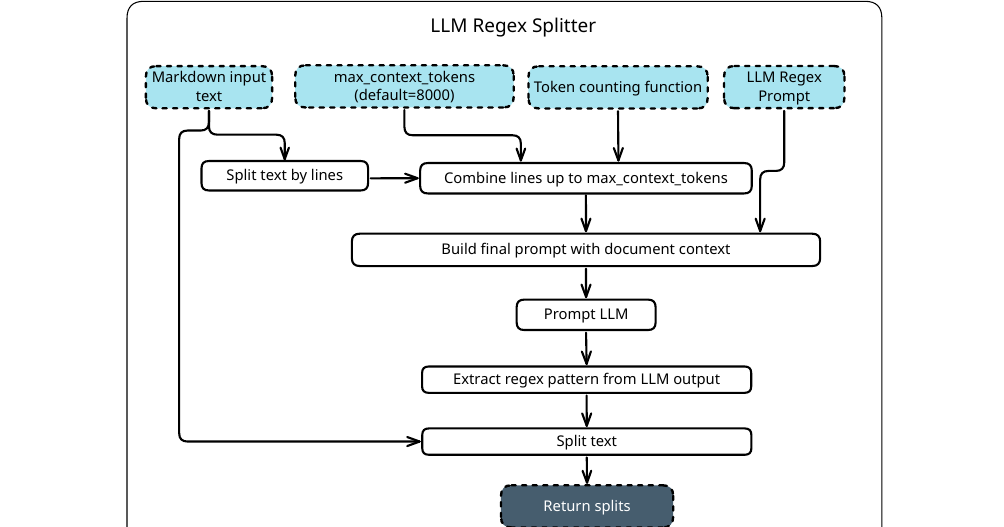
이 접근의 묘미는 LLM을 모든 청크 경계마다 호출하는 대신 구분자 패턴 하나만 뽑아내는 데 있습니다. 덕분에 LLM 기반 방식의 유연함을 누리면서도 적용 단계는 결정론적이고 빠릅니다. 특히 조항 구분자처럼 자연스러운 경계를 존중하는 것이 중요한 법률 문서 같은 구조화된 텍스트에서 효과적입니다. 조항의 길이가 들쭉날쭉하거나 여러 페이지에 걸쳐 있어도 패턴 하나로 일관되게 나눌 수 있기 때문입니다.
분할 후 병합 재귀 분할기 (Split-then-Merge Recursive Splitter)
두 번째는 Split-then-Merge Recursive Splitter 입니다. LangChain의 재귀 분할기에서 영감을 받았지만, 작고 맥락이 빈약한 청크가 양산되는 문제를 줄이기 위해 두 번의 패스(two-pass)로 동작합니다.
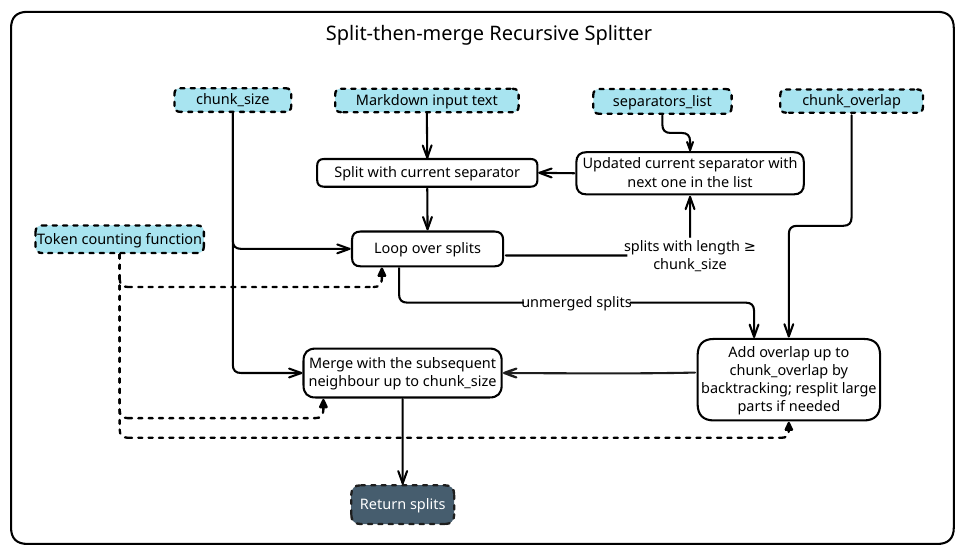
1차 패스에서는 우선순위가 매겨진 구분자 목록(제목 → 섹션 → 문장 → 글자)을 따라 각 조각이 크기 S 이하가 될 때까지 재귀적으로 분할합니다. 2차 패스에서는 인접한 조각들을 S 를 넘지 않는 선에서 탐욕적으로 병합하되, 필요하면 백트래킹하여 오버랩(overlap)을 유지하고 너무 커진 부분은 다시 쪼갭니다. 이 설계는 단일 단계 재귀 방식에 비해 크기 준수(SC)를 개선하면서도 맥락을 더 잘 보존합니다. 실험에서는 목표 크기가 1{,}100 토큰인 변형과 600 토큰인 변형 두 가지를 사용했습니다.
후처리: 크기 정규화
두 청커는 모두 마지막 정규화 단계로 두 가지 후처리(post-processing)를 거칩니다. 과대 청크 분할은 최대 크기(1{,}100 토큰)를 넘는 청크를 동일한 구분자 계층으로 다시 쪼개고, 과소 청크 병합은 최소 크기(100 토큰)보다 작은 청크를 인접 조각과 합칩니다(합친 크기가 1{,}150 토큰을 넘지 않는 선에서). 작아 보이는 이 단계의 효과는 의외로 큽니다. 후처리는 SC와 평균 내재적 점수를 방법에 따라 6 ~ 16 퍼센트포인트(pp)나 끌어올렸습니다. 특히 원래 청크 크기 편차가 컸던 LLM 정규식 방식(원본 SC 58.3\% 에서 최종 SC 99.6\%)과 의미 기반 청커(원본 SC 48.1\% 에서 최종 SC 99.9\%)에서 효과가 두드러졌습니다.
실험 설계: 청킹만 바꾸고 나머지는 고정
청킹의 효과를 깨끗하게 분리해 측정하려면, 청킹을 제외한 모든 변수를 고정해야 합니다. 저자들은 이를 위해 키워드 검색과 의미 검색을 결합한 하이브리드 검색 파이프라인을 구성했습니다.
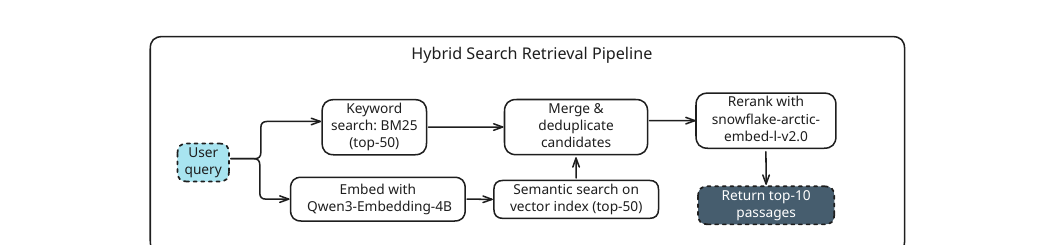
파이프라인은 다음 단계로 흐릅니다. 사용자 질의를 Qwen3-Embedding-4B 로 임베딩하고, BM25로 어휘 유사도 기반 상위 $50$개를 뽑는 동시에 의미 검색으로 상위 $50$개를 뽑습니다. 두 결과($100$개 후보)를 합쳐 중복을 제거한 뒤, snowflake-arctic-embed-l-v2.0 리랭커(reranker)로 가장 관련성 높은 상위 $10$개를 선별합니다. 마지막으로 이 $10$개 청크를 맥락으로 GPT-4.1(temperature =0, top-p =1)에 넘겨 답변을 생성합니다. 모델은 맥락이 불충분하면 "제공된 맥락만으로는 알 수 없습니다"라고 답하도록 지시받습니다.
실험 코퍼스는 Ekimetrics의 CLAIR 프로젝트에서 가져온 $33$개의 실제 PDF 문서로, 법률, 기술, 사회과학 도메인을 아우릅니다. 문서들은 형식, 어휘, 길이 면에서 의도적으로 다양하며(문서당 평균 토큰 수가 기술 도메인 5{,}257, 법률 30{,}895, 사회과학 $79{,}862$로 크게 차이남), 파싱 후 총 약 $118$만 토큰에 이릅니다. 문서는 Microsoft Azure AI Document Intelligence로 마크다운으로 변환했습니다.
평가는 두 가지 상보적인 지표로 이루어집니다. Retrieval Completeness(검색 완전성) 는 검색된 맥락이 정답을 얼마나 잘 뒷받침하는지를 GPT-4.1 심판이 불완전(0), 부분 완전(1), 완전(2)으로 평가한 뒤 [0, 1] 로 정규화한 값입니다. Answer Correctness(답변 정확도) 는 G-Eval로 생성된 답변을 정답과 사실 정합성 측면에서 0 ~ 1 척도로 비교한 값입니다.
실험 결과 및 분석
청킹 품질: 단일 승자는 없다
먼저 다섯 지표로 청킹 방법들을 비교한 결과입니다(논문 Table 3, 모든 비교 방법 대비 Wilcoxon 부호 순위 검정 p < 0.001). 문서별로 최선의 방법을 고르는 Adaptive 정책이 코퍼스 전체 평균 91.07 로 가장 높았습니다. 어떤 단일 방법도 모든 문서를 지배하지 못한다는 신호입니다.
| 방법 | RC | ICC | DCC | BI | SC | 평균 |
|---|---|---|---|---|---|---|
| Adaptive Chunking | 99.0 | 68.2 | 88.8 | 99.4 | 99.9 | 91.07 |
| LLM regex (GPT) | 98.0 | 70.9 | 82.4 | 98.1 | 99.6 | 89.80 |
| LangChain recursive | 96.1 | 65.6 | 88.8 | 95.0 | 97.7 | 88.62 |
| Semantic | 97.5 | 69.3 | 76.3 | 91.3 | 48.1 | 76.49 |
| Sentence | 86.3 | 78.4 | 72.5 | 61.9 | 67.2 | 73.26 |
표를 지표별로 뜯어보면 각 방법의 설계 의도가 그대로 드러납니다. 문장 기반 청킹은 작은 단위 덕에 주제 혼합이 적어 청크 내부 응집성(ICC)에서 78.4 로 가장 높았고, 재귀 분할 계열은 개체-대명사 분리가 적고 크기를 잘 맞춰 참조 완결성(RC)과 크기 준수(SC)에서 강했습니다. 반면 의미 기반 청킹은 응집성은 준수하지만 크기 준수(SC)가 48.1 로 크게 뒤처졌습니다. 어떤 단일 지표에서 1등인 방법도 다른 지표에서는 약점을 드러내는 이 분포가, 단일 지표 최적화가 아니라 문서별 선택 정책이 필요한 이유입니다.
지표들은 서로 다른 것을 본다
그렇다면 다섯 지표는 서로 중복되는 것을 재는 걸까요? 저자들은 지표들 사이의 스피어만 상관(Spearman correlation)을 계산해 이 질문에 답합니다.
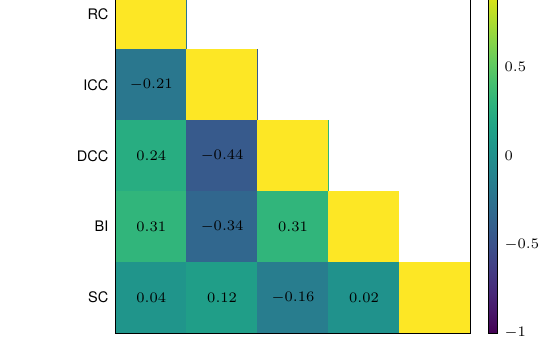
상관계수는 -0.44 < \rho < 0.31 로 약하거나 중간 수준에 머물렀습니다. 다섯 지표가 하나의 잠재 요인을 다른 각도에서 재는 것이 아니라, 서로 보완적인 현상을 포착한다는 뜻입니다. 특히 두 가지 긴장 관계가 눈에 띕니다.
첫째, ICC와 DCC의 상충입니다. 청크가 작을수록 내부적으로 더 응집되지만(높은 ICC) 주변 신호를 잃습니다(낮은 DCC). 반대로 청크가 클수록 지역 맥락을 잘 보존하지만(높은 DCC) 주제가 섞일 위험이 커집니다(낮은 ICC). 둘째, ICC와 BI의 상충입니다. 구조 단위를 온전히 유지하려다 보면(높은 BI) 제목, 표, 본문 같은 이질적 요소가 한 청크에 들어가 ICC를 떨어뜨릴 수 있습니다. 바로 이런 상충 관계가 단일 지표 최적화가 아니라 다중 지표 목적 함수와 문서별 선택 정책을 정당화합니다.
Adaptive 선택은 실제로 어떻게 움직이는가
평균 내재적 점수가 가장 높은 방법이 있더라도, Adaptive 정책의 실제 선택은 한쪽으로 쏠리지 않았습니다. 후처리된 페이지 청킹을 전체 문서의 48\% 에 대해 골랐고, 재귀 분할기(s=1100)를 42\% 에 대해 선택했으며, 나머지는 LLM 정규식(6\%)과 재귀 분할기(s=600, 3\%)가 차지했습니다.
이 분산은 코퍼스의 이질성을 그대로 반영합니다. 표, 각주, 페이지에 정렬된 조항 머리글처럼 강한 페이지 단위 의미를 가진 문서는 페이지 수준의 무결성에서 이득을 보고, 길게 이어지는 서술형이나 위계적 콘텐츠는 크기와 오버랩을 조율한 재귀 분할에서 이득을 봅니다. 선택 데이터 자체가 어떤 단일 방법도 보편적으로 최적이 아니다라는 논문의 핵심 주장을 뒷받침합니다.
검색과 생성에 미친 영향
진짜 중요한 질문은 이것입니다. 내재적 지표를 개선하면 실제 RAG 성능이 좋아질까요? 결과는 분명한 "그렇다"입니다(논문 Table 5, Retrieval Completeness에 대해 Wilcoxon p < 0.05).
| 지표 | Adaptive Chunking | LC 재귀 (기본) | 페이지 (원본) |
|---|---|---|---|
| Retrieval Completeness | \mathbf{67.68\%} | 58.08\% | 59.09\% |
| Answer Correctness | \mathbf{78.01\%} | 70.11\% | 73.33\% |
| 종합 평균 | \mathbf{71.77\%} | 62.07\% | 63.80\% |
| 답변한 질문 수 | \mathbf{65}/99 | 49/99 | 49/99 |
Adaptive Chunking은 Retrieval Completeness를 67.68\% 로 끌어올려, LangChain 재귀 기본값(58.08\%)보다 $9.60$pp, 원본 페이지 청킹(59.09\%)보다 $8.59$pp 높았습니다. 상대적으로는 약 16.5 ~ 18.0\% 의 향상입니다. Answer Correctness도 78.01\% 로 두 베이스라인(70.11\%, 73.33\%)을 모두 앞섰습니다. 검색 맥락이 더 완전해지자 모델이 답을 회피하는 일이 줄면서, 답변한 질문 수도 $49$개에서 $65$개로 늘었습니다($+16$개, +32.7\%).
증폭 효과: 작은 차이가 큰 격차로
이 논문에서 특히 인상적인 분석은 증폭 효과(amplification effect) 입니다. 상위권 청킹 방법들 사이의 내재적 지표 차이는 0.4 ~ $2.4$pp로 그리 크지 않았습니다. 그런데 이 미세한 차이가 RAG 성능에서는 Retrieval Completeness 8 ~ $10$pp, Answer Correctness 5 ~ $8$pp라는 훨씬 큰 격차로 증폭되었습니다.
왜일까요? 청크 품질의 작은 개선이 검색과 생성 파이프라인을 거치며 복리처럼 누적되기 때문입니다. 약간 더 나은 청크는 약간 더 관련성 높은 구절을 검색해 오게 하고, 그렇게 검색된 맥락이 다시 더 완전하고 정확한 답변으로 이어집니다. 청킹이 RAG의 "숨은 병목"이라는 처음의 문제의식이 데이터로 확인되는 순간입니다.
런타임과 확장성
비용 측면도 짚어볼 만합니다. LLM 정규식 방식은 LLM 호출 때문에 평균 런타임이 가장 길었지만($146.85$초, 비동기 호출 기준), 재귀 분할기들은 28 ~ $31$초로 효율적이었습니다. Adaptive 파이프라인 전체는 약 $210$초로, 여러 후보 청커를 돌리고 문서마다 지표를 계산하는 비용을 포함합니다. 다만 이 비용은 색인 시점(indexing time)에 한 번만 발생하므로 실제 서비스 질의 응답 속도에는 영향을 주지 않습니다. 평가 단계에서는 Document Contextual Coherence($15$분 $58$초)와 개체-대명사 추출($13$분 $13$초)이 시간의 대부분을 차지했는데, 저자들은 토큰 임베딩 캐싱과 배치 상호참조 처리로 이를 줄일 수 있다고 제안합니다.
한계점 및 향후 연구 방향
저자들은 프레임워크의 한계를 솔직하게 밝힙니다.
계산 효율성: 평가 파이프라인이 적지 않은 오버헤드를 유발하며, 특히 DCC와 개체-대명사 추출이 병목입니다. DCC가 슬라이딩 윈도우마다 토큰 임베딩을 다시 계산하는 비효율이 주된 원인으로, 문서 단위로 한 번만 계산해 재사용하면 크게 개선될 여지가 있습니다.
언어 및 도메인 범위: Maverick 상호참조 모델이 영어만 지원하는 탓에 RC는 영어 문서로 제한됩니다. 또한 코퍼스가 법률, 기술, 사회과학 같은 형식적 문서에 집중되어 있어, 비형식적 텍스트나 창작 글, 멀티모달 콘텐츠로의 일반화는 추가 검증이 필요합니다.
하이퍼파라미터의 휴리스틱함: 청크 크기 범위(100 ~ 1{,}100 토큰), 슬라이딩 윈도우 크기(3{,}000 토큰), 동일한 지표 가중치 같은 선택들이 여전히 경험적이고 사용자에 의존적입니다.
질의 비적응성: 청킹 전략은 색인 시점에 한 번 선택되며 질의 특성이나 태스크 요구에 맞춰 적응하지는 않습니다. 또한 여러 후보 청커를 문서마다 돌리는 비용은 고처리량 운영 환경에서 부담이 될 수 있어, 사전 선별(pre-screening) 같은 기법으로 줄일 여지가 있습니다.
결론: 문서를 존중하는 청킹
이 연구가 던지는 메시지는 RAG를 다루는 실무자에게 특히 유용합니다. 저자들은 세 가지 실용적 제언을 제시합니다. 첫째, 전역 기본값보다 문서 인식 선택을 우선하라. 단일 청커가 평균 점수에서 가장 좋더라도, 문서별 선택이 더 높은 검색 완전성과 답변율을 가져옵니다. 둘째, 항상 크기를 정규화하라. 과소 청크 병합과 과대 청크 재분할은 미미한 비용으로 일관된 이득을 줍니다. 셋째, 응집성과 맥락의 균형을 잡으라. 하나의 차원만 최적화하지 말고 다섯 지표를 함께 보는 다중 지표 점수를 쓰라는 것입니다.
Adaptive Chunking은 화려한 새 모델을 제안하지 않습니다. 대신, 그동안 RAG 파이프라인에서 가장 덜 주목받던 청킹 단계를 측정 가능한 문제로 끌어올리고, 모델과 프롬프트를 건드리지 않고도 의미 있는 성능 향상을 얻을 수 있음을 보여줍니다. 더 큰 모델과 더 긴 컨텍스트만이 답이 아니라, 데이터를 문서의 구조에 맞춰 정성껏 자르는 것만으로도 RAG를 더 견고하게 만들 수 있다는 점을 일깨워 주는 연구입니다.
Adaptive Chunking 설치 및 사용법
저장소를 복제(clone)한 뒤 필요한 의존성만 골라 설치할 수 있습니다:
git clone https://github.com/ekimetrics/adaptive-chunking.git
cd adaptive-chunking
pip install -e ".[dev]"
일부 지표는 spaCy 모델을 필요로 합니다.
python -m spacy download en_core_web_sm
가장 간단한 사용법은 chunk_files 한 줄로 PDF 파싱과 청킹을 함께 수행하는 것입니다(PDF 파싱은 pip install -e ".[parsing]" 필요).
from adaptive_chunking import chunk_files
# 디렉토리 또는 단일 파일 경로를 받아 청크 리스트를 반환합니다
chunks = chunk_files("path/to/pdfs/", chunk_size=600, chunk_overlap=50)
# 각 청크는 doc_name, chunk_index, chunk_text, chunk_pages, titles_context, chunk_len 키를 가집니다
for chunk in chunks:
print(chunk["doc_name"], chunk["chunk_index"], chunk["chunk_len"])
분할기와 지표를 따로 가져와 직접 조합할 수도 있습니다.
from adaptive_chunking.splitters import RecursiveSplitter
splitter = RecursiveSplitter(
chunk_size=600,
chunk_overlap=50,
separators=["\n\n", "\n", " ", ""],
merging="small_only",
min_chunk_tokens=100,
)
chunks = splitter.split_text(document_text)
논문 결과 재현에 필요한 33개 사전 파싱 문서와 사전 계산된 상호참조 정보는 저장소의 data/clair/ 디렉토리에 포함되어 있어, python -m adaptive_chunking.paper.replicate 명령으로 Table 3 등을 재현할 수 있습니다.
Adaptive Chunking의 라이선스
Adaptive Chunking은 MIT 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용할 수 있습니다. 다만 선택 의존성인 상호참조 해소(coreference resolution) 구성 요소(pip install -e ".[coref]")는 CC BY-NC-SA 4.0(비상업적) 라이선스를 따르므로, 상업적 환경에서는 이 옵션 없이 사용해야 합니다.
 Adaptive Chunking: Optimizing Chunking-Method Selection for RAG 논문
Adaptive Chunking: Optimizing Chunking-Method Selection for RAG 논문
LREC 2026에 채택된 논문으로, 다섯 가지 내재적 지표와 두 가지 새로운 청커를 통해 문서별 최적 청킹 전략을 자동 선택하는 프레임워크를 제안합니다.
 ekimetrics/adaptive-chunking GitHub 저장소
ekimetrics/adaptive-chunking GitHub 저장소
논문에서 제안한 청커, 내재적 지표, 평가 파이프라인의 구현 코드가 공개되어 있습니다.
더 읽어보기
-
LLM 데이터 엔지니어링 2탄 - RAG 성능의 한 끝, '스마트 청킹(Smart Chunking)'으로 검색 정확도 높이기
-
PageIndex: 벡터 DB와 청킹 없이 LLM 추론으로 문서를 검색하는 계층형 인덱스 기반 RAG 시스템
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()