- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

소개
최근 대규모 언어 모델(Large Language Models, LLMs)의 실세계 응용이 ChatGPT의 출시와 함께 크게 가속화되었습니다. 이러한 모델들은 원치 않는 결과를 유발할 수 있는 적대적 공격(advversarial ataack)이나 잠금 해제(Jailbreak) 프롬프트에 취약할 수 있습니다. 이 글은 특히 텍스트를 다루는 LLMs에 적용되는 다양한 적대적 공격 방법들을 조명합니다.
적대적 공격에 대한 기본 (Basics)
-
적대적 공격은 모델이 원치 않는 출력을 하도록 유도하는 입력입니다. 초기 연구는 분류 작업에 주로 사용하였으나, 최근에는 생성 모델의 출력에 대한 연구가 증가하고 있습니다.
-
위협 모델 (Threat Model): 이 글에서는 공격이 추론 시에만 발생한다고 가정하며, 모델의 가중치는 고정되어 있다고 가정합니다.
-
분류 (Classification): 과거 연구 커뮤니티는 이미지 분야의 분류기에 대한 적대적 공격에 더 많은 관심을 기울였습니다. 분류 작업에서의 적대적 공격은 미세한 차이를 가진 입력을 찾아 분류기가 서로 다른 결과를 내도록 합니다. 텍스트 생성 작업에서는 모델이 안전한 동작을 위반하는 출력을 하도록 유도합니다
-
텍스트 생성 (Text Generation): 적대적 공격은 모델이 안전하지 않은 내용을 출력하도록 유도할 수 있으며, 공격의 성공 여부를 판단하기 위해서는 고품질의 분류기(classifier) 또는 사람의 검토가 필요합니다.
-
화이트박스 대 블랙박스 (White-box vs Black-box) 공격: 화이트박스 공격은 공격자가 모델의 가중치, 구조, 학습 파이프라인에 전체적으로 접근할 수 있다고 가정합니다. 반면, 블랙박스 공격은 공격자가 API와 같은 서비스를 통해 입력을 제공하고 샘플을 받는 것으로 가정합니다.
적대적 공격의 유형 (Types of Adversarial Attacks)
- 다양한 방법으로 LLMs를 공격하여 원치 않는 출력을 유도할 수 있습니다. 주요 공격 유형에는 토큰 조작, 기울기 기반 공격, 재브레이크 프롬프팅, 인간 레드팀, 모델 레드팀 등이 있습니다.
-
토큰 조작(Token Manipulation): 입력 텍스트의 토큰을 조금 변경하여 모델 실패를 유도합니다. 예를 들어, TextFooler는 워드 임베딩 코사인 유사성을 기반으로 상위 동의어를 교체합니다. BERT-Attack은 BERT를 사용하여 의미상 유사한 단어로 교체합니다.
-
기울기 기반 공격(Gradient based Attacks): 모델의 매개변수와 아키텍처에 대한 전체 접근을 기반으로 합니다. 이는 주로 오픈 소스 LLMs에서 사용됩니다.
-
잠금 해제 프롬프팅(Jailbreak Prompting): 잠금 해제 유도는 모델이 완화되어야 할 유해한 콘텐츠를 출력하도록 유도하는 '블랙박스' 공격입니다.
-
사람이 참여한 적대적 생성(Human in the Loop Red-teaming): 인간 참여 적대적 생성은 모델을 깨뜨리기 위한 도구를 제공하여 인간이 모델을 공격하도록 합니다.
-
모델 기반의 적대적 생성(Model Red-teaming): 모델 기반 적대적 팀 작업은 모델을 효과적으로 공격하는 데 필요한 전문 지식을 요구할 수 있지만 확장하기 어려울 수 있습니다.
모델의 견고함을 위한 제안(Peek into Mitigation)
적대적 공격에 대한 모델의 방어 메커니즘에 대한 개요를 제공하며, 이러한 방어 전략들은 모델의 견고성을 향상시키기 위한 여러 접근 방식을 포함합니다.
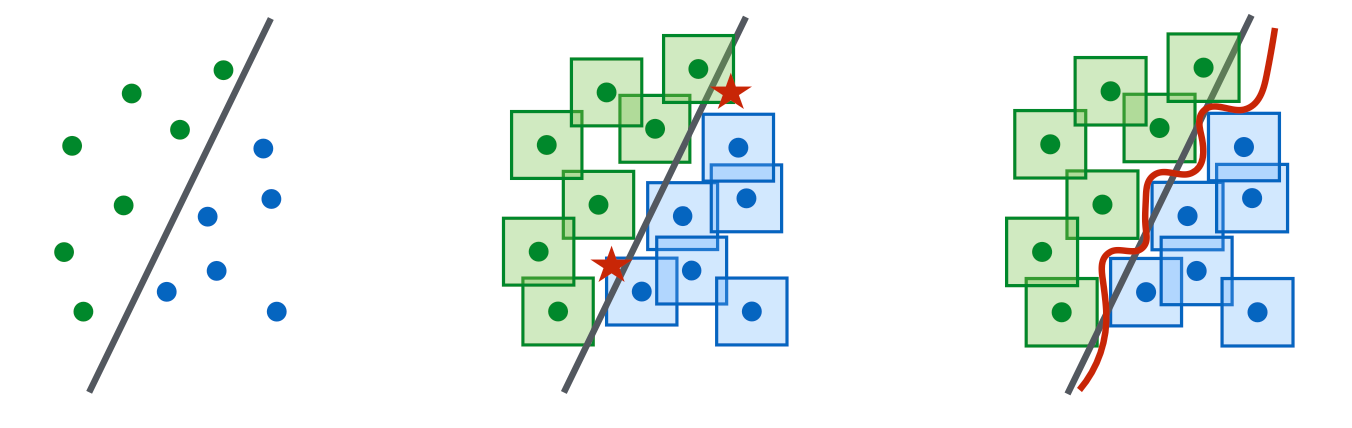
안장점 문제(Saddle Point Problem)
적대적 견고성(robustness)을 모델링하는 하나의 틀은, 견고성 최적화의 관점에서 안장점 문제(saddle point problem)로 보고 모델링하는 것입니다. 이 틀은 연속 입력에 대한 분류 작업에 제안되었으며, 이중 최적화 과정의 수학적 공식화를 제공합니다.
-
내부 최대화: 가장 효과적인 적대적 데이터 포인트를 찾아 손실을 최대화합니다.
-
외부 최소화: 내부 최대화에서 유도된 가장 효과적인 공격에 대한 손실을 최소화하는 모델 매개변수를 찾습니다.
LLM 견고성(LLM Robustness)에 대한 연구
적대적 공격에 대항하는 모델을 방어하는 간단하고 직관적인 방법은 모델에 해로운 콘텐츠를 생성하지 않도록 명시적으로 지시하는 것입니다.
-
적대적 훈련(Adversarial Training): 적대적 공격 샘플에 대한 모델 훈련은 가장 강력한 방어 방법으로 간주되지만, 견고성과 모델 성능 사이의 트레이드오프를 초래합니다.
-
화이트박스 공격은 종종 말도 안 되는 적대적 유도문을 초래하므로, 이를 복잡성을 통해 감지할 수 있습니다.