
AgentFlow 소개
AgentFlow는 스탠포드 대학교가 개발 및 공개한 도구 통합형, 학습 가능한 에이전트 프레임워크로, 현재의 도구 기반 추론 접근법이 가진 확장성(Scalability) 및 일반화 능력(Generalization) 의 한계를 극복하기 위해 설계되었습니다. 일반적인 에이전트 시스템이 단일 LLM에 의존하여 추론과 도구 호출을 번갈아 수행하는 구조를 가진 것과 달리, AgentFlow는 네 가지 모듈형 에이전트(Planner, Executor, Verifier, Generator)로 구성된 모듈형 시스템(modular agentic system) 을 제안하는 것이 특징입니다.
AgentFlow의 4가지 모듈은 각자의 역할을 맡아 상호작용하며 복잡한 문제를 단계적으로 해결하는 역할을 수행합니다. 예를 들어, Planner는 전체적인 계획을 수립하고, Executor는 실제로 명령을 수행하며, Verifier는 결과의 타당성을 점검하고, Generator는 최종 출력을 작성합니다. 이러한 역할 분담 덕분에 AgentFlow는 복잡한 작업을 더 안정적으로 처리할 수 있습니다.
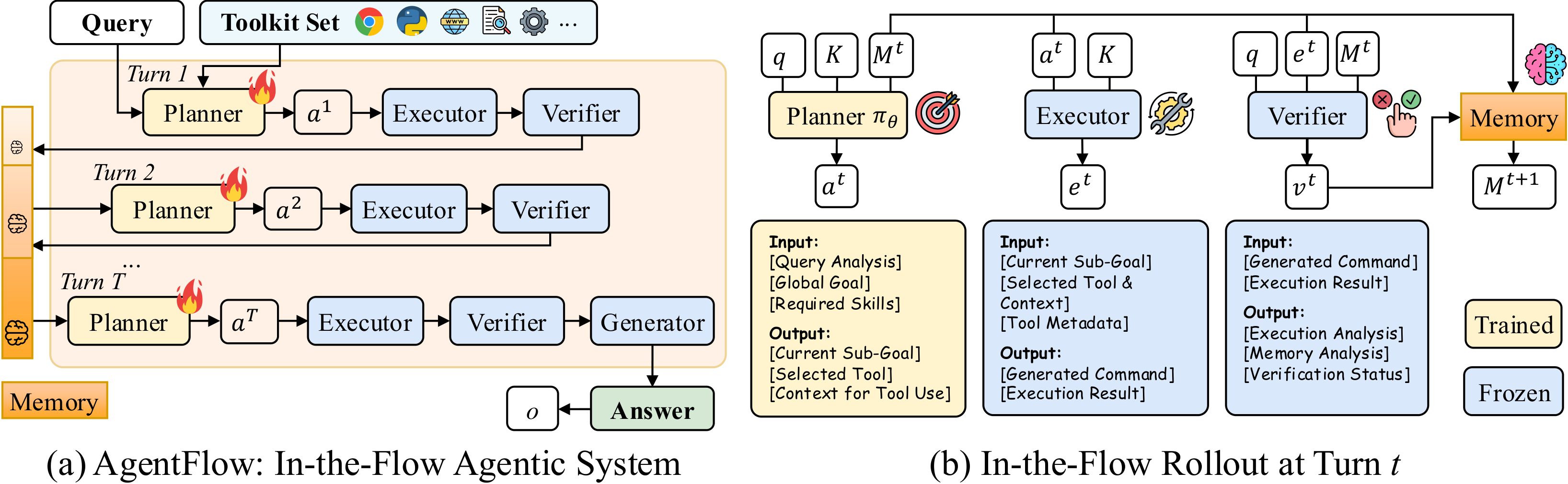
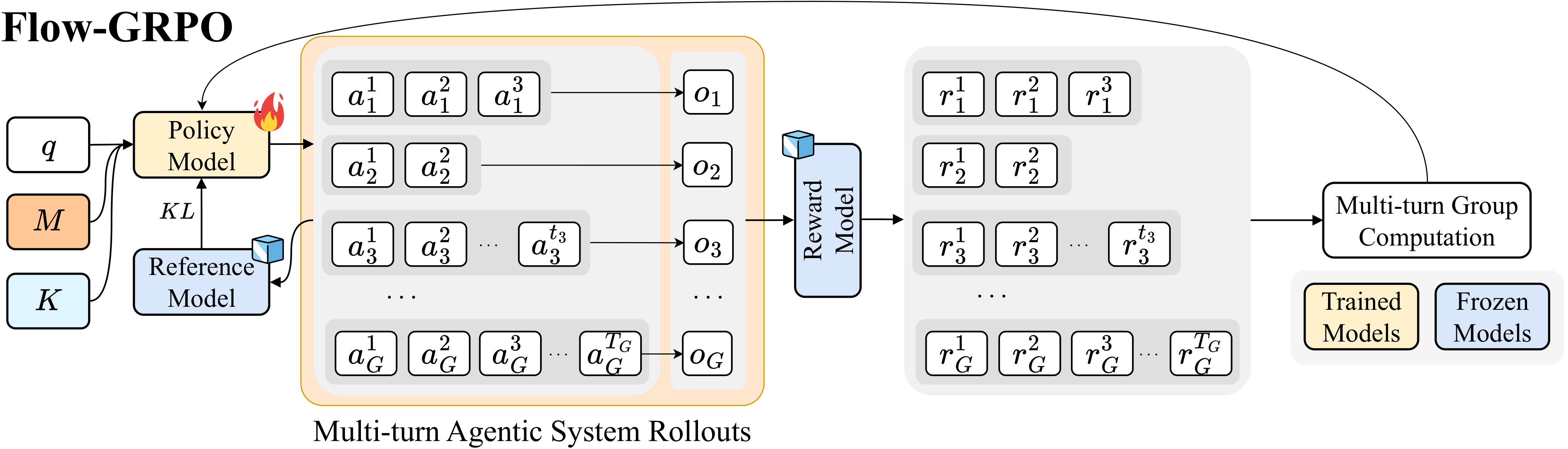
AgentFlow의 핵심은 Flow-GRPO(Flow-based Group Refined Policy Optimization) 알고리즘입니다. 이는 시스템 내에서 플래너 에이전트를 온라인 방식으로 최적화할 수 있게 하여, 긴 추론 과정(long-horizon reasoning)에서도 성능 저하 없이 도구 호출의 신뢰성과 계획 품질을 유지할 수 있도록 합니다. 특히 검색, 수학적 추론, 과학 문제 등 다양한 영역에서 탁월한 성능을 보이며, 심지어 200B 파라미터 규모의 GPT-4o 모델을 능가하는 결과를 달성했습니다.
기존의 대표적인 도구 기반 추론 모델인 Search-R1은 하나의 대규모 언어 모델(LLM)을 학습시켜 내부적으로 추론(reasoning)과 도구 호출(tool calling)을 반복하는 방식으로 작동합니다. 그러나 이러한 접근은 모듈 간의 역할 분리가 없고, 각 기능이 혼재되어 있어 효율적인 학습이나 오류 추적이 어렵다는 단점이 있습니다.
이에 반해 AgentFlow는 다음과 같은 차별점을 갖습니다:
- 모듈 간 역할 분리 및 상호 최적화가 가능하며, 개별 모듈의 성능 개선이 전체 시스템의 성능 향상으로 이어짐
- 다중 도구(Multi-Tool) 통합 기능을 통해 Google Search, Wikipedia, Python 실행기 등 다양한 외부 도구와 연동
- Flow-GRPO 알고리즘을 통한 온라인 최적화로, 데이터 효율성과 장기 추론 능력 강화
- 오픈소스 구조를 통해 연구자들이 자유롭게 자신만의 모델 및 환경으로 확장 가능
AgentFlow의 주요 구성 요소 및 기능
-
Flow-GRPO 알고리즘: Flow-GRPO는 강화학습(Reinforcement Learning, RL)의 일종으로, 에이전트가 수행 중인 ‘플로우(flow)’ 내에서 보상 신호를 실시간으로 받아 학습합니다. 이는 에이전트가 각 단계에서 올바른 판단을 내리도록 유도하며, 특히 보상이 희소(sparse reward)한 환경에서도 효과적인 성능 향상을 이끌어냅니다.
-
모듈형 에이전트 시스템: AgentFlow의 다음 네 가지 핵심 모듈로 구성되어 있습니다:
- Planner: 문제 해결 전략과 단계별 계획을 수립
- Executor: 계획된 명령을 실행하며 외부 도구를 활용
- Verifier: 결과의 정확성과 일관성을 검증
- Generator: 자연어 형태로 최종 응답 생성
각 모듈들은 서로 간의 메모리 공유 및 피드백 루프를 통해 지속적으로 협력하며, 복잡한 추론(reasoning) 작업을 수행합니다.
-
다양한 도구 통합 (Multi-Tool Integration): AgentFlow는 다양한 도구 생태계와 연동할 수 있습니다. 예를 들어
google_search,wikipedia_search,python_coder,web_search등의 도구를 동시에 활용할 수 있으며, 이렇게 여러 도구를 동시에 사용하는 멀티툴 접근은 실제 사용 사례에서 강력한 성능을 발휘할 수 있습니다. -
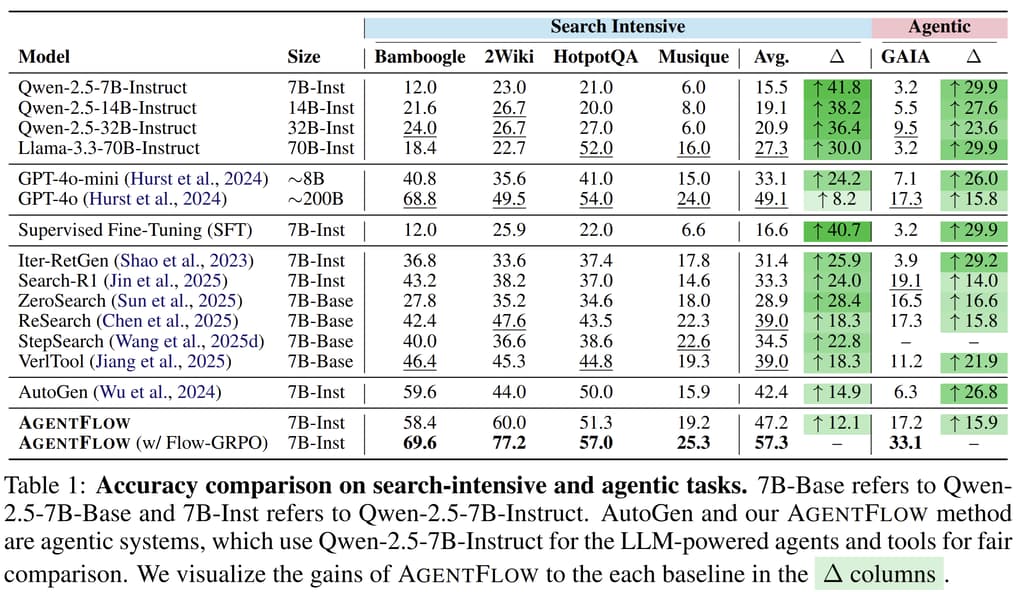
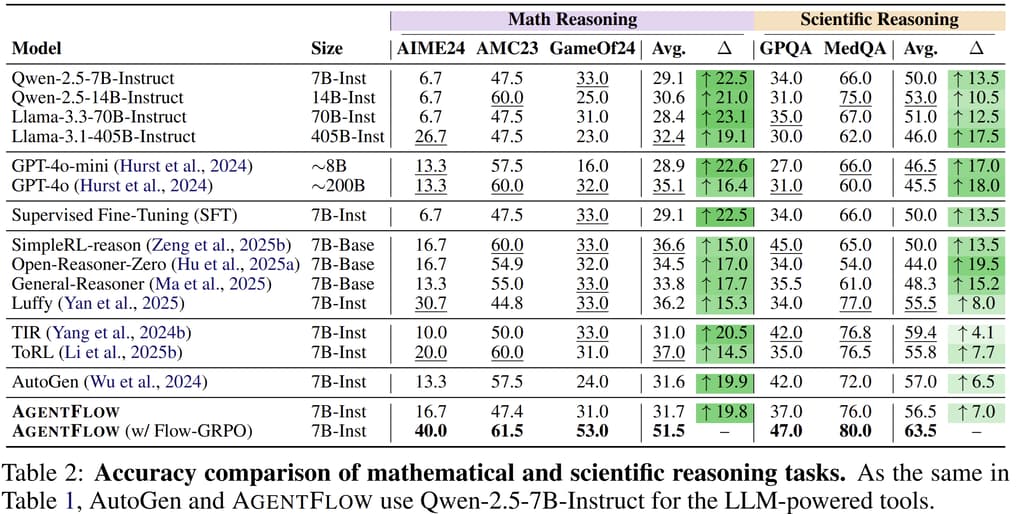
벤치마크 결과: AgentFlow는 Qwen-2.5-7B-Instruct 모델을 백본으로 사용한 버전에서 다음과 같은 성능 향상을 보였습니다:
- 검색 관련 작업: +14.9%
- 에이전트 추론: +14.0%
- 수학적 추론: +14.5%
- 과학 문제 해결: +4.1%
이는 동일한 크기의 모델뿐 아니라 **GPT-4o(약 200B 파라미터)**보다도 뛰어난 성능을 보여줍니다.
AgentFlow 설치 및 설정
AgentFlow를 사용하기 위해서는 GitHub 저장소를 복제한 뒤, setup.sh 파일을 실행하여 사용할 수 있습니다:
bash setup.sh
source .venv/bin/activate
sudo apt-get install parallel # 선택사항: Parallel로 벤치마크 실험 수행 시 필요
이후, .env.template 파일을 복사하여 .env 파일을 만들고, 다음과 같은 API 키를 입력합니다. API를 발급받는 방법에 대해서는 API Key 설정 가이드 문서를 참고해주세요:
OPENAI_API_KEY: 답변 평가를 위해 필요합니다.GOOGLE_API_KEY: Google Search 도구 사용을 위해 필요합니다.DASHSCOPE_API_KEY: Qwen-2.5-7B-Instruct 모델 호출을 위해 필요합니다.TOGETHER_API_KEY: Qwen-2.5-7B-Instruct 모델 대신 다른 모델을 사용하기 위해 필요합니다. 일반적인 사용자들에게는 이 방식이 더 적절합니다.
만약, Qwen 모델을 로컬에서 vLLM을 사용하여 실행하고 싶다면, serve_vllm_local.md 문서를 참고합니다.
튜토리얼 및 빠른 시작
Discover AI의 영상에서 AgentFlow의 튜토리얼을 살펴볼 수 있습니다:

AgentFlow의 핵심 동작을 바로 실행해보고 싶다면 아래와 같이 quick_start.py를 실행합니다:
python quick_start.py
quick_start.py의 내용은 다음과 같습니다:
# AgentFlow의 핵심 모듈인 solver 불러오기
from agentflow.agentflow.solver import construct_solver
# 사용할 LLM Engine 지정
llm_engine_name = "dashscope"
# solver 구성 및 초기화
solver = construct_solver(llm_engine_name=llm_engine_name)
# 사용자 질의 전달 및 문제 해결
output = solver.solve("What is the capital of France?")
# 해결 결과 출력
print(output["direct_output"])
위와 같은 명령을 실행하면, 사용자의 질의(Query)가 시스템에 전달되고, 에이전트들이 협력적으로 문제를 해결하는 과정을 실행합니다. 조금 더 구체적으로는, 다음과 같이 내부 프로세스가 진행됩니다.
먼저, Planner가 문제를 분석하고 필요한 정보 및 도구를 결정합니다. 예를 들어, "이 질문은 지리적 사실을 묻는 것이므로, Google Search 또는 internal knowledge로 해결 가능하다."와 같은 방식으로 추가적으로 필요한 정보 및 도구를 결정합니다. 이후, Executor가 실제로 검색 도구를 호출하거나, 내장 LLM 지식을 사용해 답변을 생성합니다. 이후, Verifier가 결과가 일관되고 정확한지 판단합니다. 필요하면 Planner에게다시 답변을 생성하도록 “수정 요청”을 보냅니다. 마지막으로, Generator가 최종 응답을 자연어로 구성합니다.
이러한 일련의 과정은 ‘플로우 기반 협업(Flow-based Collaboration)’ 으로 설계되어 있으며, 각 단계의 피드백이 다음 단계에 반영됩니다.
Flow-GRPO 학습 예시
AgentFlow는 Flow-GRPO 알고리즘을 통해 플래너 에이전트를 온라인 최적화할 수 있습니다. 학습 데이터로는 Natural Questions(검색)과 DeepMath-103K(수학적 추론) 데이터셋을 사용합니다:
# 학습 데이터 (Train Data)
python data/get_train_data.py
# 검증 데이터 (Validation Data)
python data/aime24_data.py
이후, 다음과 같은 명령어로 학습을 시작합니다:
# agentflow라는 이름으로 새로운 tmux 세션 생성
tmux new-session -s agentflow
# 생성된 tmux 윈도우(0번)에서 agentflow 실행
bash train/serve_with_logs.sh
# Ctrl + B, C 를 눌러 새로운 창(1번)을 생성한 다음, 학습 실행
bash train/train_with_logs.sh
모델 설정, 도구, RL 매개변수 등과 같은 학습 관련 설정들은 train/config.yaml에서 변경할 수 있으며, 모든 로그는 실시간으로 기록됩니다. 로깅과 관련한 더 자세한 내용은 logs.md 문서를 참고해주세요.
AgentFlow에 자신만의 모델 사용하기
AgentFlow는 각 모듈에 독립적인 LLM 엔진을 설정할 수 있습니다. 지원하는 모델은 llm_engine.md 문서 또는 factory.py의 model_string 설정을 참고하세요.
예를 들어, Planner는 test/exp/run_all_models_all_datasets.sh의 llm_engine_name 매개변수를 변경하여 다른 모델로 교체할 수 있습니다.
또한 Executor나 Verifier 등 다른 에이전트 모듈들도 아래와 같이 agentflow/agentflow/models/planner.py:19 코드 내의 llm_engine_name 부분을 변경한 뒤, 이를 agentflow/agentflow/models/planner.py:19의 self.llm_engine_fixed 부분에 반영하여 사용자 정의 모델을 적용할 수 있습니다:
self.llm_engine_fixed = create_llm_engine(model_string="your-engine", is_multimodal=False, temperature=temperature)
model_string의 형식 및 지원되는 엔진에 대한 더 상세한 정보는 llm_engine.md 문서를 참고해주세요.
라이선스
AgentFlow 프로젝트는 Apache License 2.0에 따라 공개 및 배포되고 있습니다. 상업적 사용과 수정이 허용되며, 원 저작자 명시가 요구됩니다.
 AgentFlow 공식 홈페이지
AgentFlow 공식 홈페이지
 AgentFlow 논문: In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
AgentFlow 논문: In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
 AgentFlow 프로젝트 GitHub 저장소
AgentFlow 프로젝트 GitHub 저장소
https://github.com/lupantech/AgentFlow
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()