
AI 유창성 지수(AI Fluency Index) 소개
인공지능(AI) 기술이 소프트웨어 개발 및 일상적인 업무의 핵심 도구로 자리 잡으면서, 단순한 기술 도입 여부를 넘어 AI를 얼마나 능숙하게 다루는지가 중요한 과제로 떠오르고 있습니다. 그동안 업계의 많은 연구가 AI 모델 자체의 성능 발전이나 기업의 기술 도입률에 초점을 맞추었지만, 실제 사용자가 AI와 효과적으로 협업하는 역량 자체를 정량적으로 측정하는 시도는 상대적으로 부족했습니다. 이러한 배경 속에서 Anthropic은 2026년 2월, 사용자의 실질적인 AI 활용 능력을 분석한 AI Fluency Index(AI 활용 역량 지표) 보고서를 발표했습니다. 이 보고서는 사람들이 AI를 단순한 작업 지시 대상이 아닌 생각의 파트너(Thought Partner)로 활용할 때 어떤 행동 패턴을 보이는지 심층적으로 탐구합니다. 이를 통해 개발자와 일반 사용자들이 AI 도구를 더욱 안전하고 효과적으로 사용하는 데 필요한 객관적인 통찰을 제공하고 있습니다.
이 AI Fluency Index는 Rick Dakan 교수와 Joseph Feller 교수가 Anthropic과 협력하여 개발한 4D AI Fluency Framework를 기반으로 도출되었습니다. 4D AI Fluency Framework 프레임워크는 AI와의 안전하고 효과적인 협업을 보여주는 24가지 구체적인 행동 지표를 정의하고 있으며, 사용자의 실질적인 협업 능력을 평가하는 데 중점을 둡니다.
Anthropic은 프라이버시가 철저히 보호되는 자체 분석 도구를 활용해 2026년 1월 중 7일 동안 Claude.ai에서 이루어진 9,830건의 익명화된 다중 턴(multi-turn) 대화를 면밀히 분석했습니다. 이 과정에서 채팅 인터페이스를 통해 직접 관찰 가능한 11가지 행동 지표의 발생 여부를 추적하고, 이를 언어별 및 요일별로 교차 검증하여 분석 결과의 신뢰성을 확보했습니다. 이렇게 구축된 기준선(Baseline)은 현대 사용자들이 AI와 협업하는 방식과 습관에 대한 귀중한 정량적 데이터로 기능합니다.

이번 연구는 사용자가 AI와 상호작용하는 방식에 따라 결과물의 질과 문제 해결 능력이 극명하게 달라진다는 점을 실증적인 데이터로 입증했다는 데 큰 의의가 있습니다. 특히 코드 작성, 문서화, 앱 개발 등 소프트웨어 엔지니어들이 주로 수행하는 복잡한 산출물(Artifact) 생성 과정에서 나타나는 사용자의 흥미로운 인지적 편향을 정확히 짚어냈습니다. 즉, AI가 시각적으로나 기능적으로 완성도 높은 결과물을 제시할 때 사용자의 비판적 사고가 오히려 감소한다는 역설적인 발견은, 기술의 우수성이 자칫 검증의 부재로 이어질 수 있음을 강하게 경고합니다.
따라서 이 AI 유창성 지수와 관련한 보고서는 단순한 프롬프트 작성 요령을 넘어서, 개발자들이 AI를 실무에 도입할 때 반드시 갖춰야 할 비판적 사고방식과 체계적인 대화 설계의 중요성을 일깨워주는 이정표 역할을 할 것입니다.
4D AI 유창성 프레임워크 및 11가지 + 13가지 행동들
AI Fluency Index의 근간이 되는 4D AI 유창성 프레임워크(4D AI Fluency Framework)는 인간과 인공지능의 성공적인 협업을 네 가지 핵심 차원으로 분류하여 설명합니다. 이 4가지 핵심 영역(위임-Delegation, 설명-Description, 판별-Discernment, 성실성-Diligence)을 각각 살펴보면 다음과 같습니다:
- 첫 번째 차원인 위임(Delegation) 은 사용자가 자신의 목표와 의도를 인공지능에게 명확하게 전달하는 역량을 의미합니다.
- 두 번째 차원인 설명(Description) 은 추상적인 지시를 넘어 구체적인 맥락과 형식, 그리고 기대하는 결과물의 예시를 상세히 제공하는 행동을 포괄합니다.
- 세 번째 차원인 판별(Discernment) 은 인공지능이 생성한 출력물의 정확성을 꼼꼼하게 검증하고 그 한계를 비판적인 시각으로 검토하는 능력을 말합니다.
- 마지막으로 성실성(Diligence) 은 인공지능을 책임감 있고 윤리적인 방식으로 활용하려는 사용자의 근본적인 태도를 나타냅니다.
관찰 가능한 11가지 행동들

4D AI Fluency Framework는 사용자가 인공지능과 상호작용할 때 보여주어야 할 총 24가지의 구체적인 행동 지표를 정의하고 있습니다. 이 중에서 사용자가 클로드 웹사이트나 클로드 코드(Claude Code)를 사용할 때 채팅 인터페이스 내에서 직접적으로 관찰할 수 있는 행동은 11가지입니다.
이러한 11가지 행동에는 대화의 목표를 명확히 하는 행동, 출력될 결과물의 형식을 구체적으로 지정하는 행동, 인공지능의 논리적 추론 과정에 대해 질문하는 행동, 그리고 제공된 정보에서 누락된 맥락을 지적하는 행동 등이 포함됩니다. 연구진은 데이터 프라이버시를 철저히 보호하는 분석 도구를 활용하여 이 11가지 관찰 가능한 지표가 개별 대화에서 얼마나 빈번하게 나타나는지를 측정하고 이를 지수화했습니다.
관찰 불가능한 13가지 행동들
반면, 24가지 지표 중 나머지 13가지는 채팅창 외부에서 발생하기 때문에 정량적인 로그 데이터만으로는 추적하기 어렵습니다. 예를 들어, 본인의 업무나 창작물에 인공지능이 기여한 바를 타인에게 정직하게 밝히는 윤리적 행동이나, 인공지능이 생성한 결과물을 외부에 공유했을 때 발생할 수 있는 사회적 파급력을 사전에 고려하는 행동 등이 이에 해당합니다.
Anthropic은 이러한 미관찰 지표들이 AI 유창성을 구성하는 가장 중요하고 본질적인 요소일 수 있다고 강조합니다. 따라서 현재의 정량적 지표 측정에 머무르지 않고, 향후에는 사용자 인터뷰나 관찰 조사와 같은 정성적인 연구 방법론을 도입하여 보이지 않는 유창성 지표들까지 포괄적으로 평가하고 보완할 계획입니다.
핵심 발견 1: 반복과 개선(Iteration and Refinement)이 역량을 결정 (Fluency is strongly associated with conversations that exhibit iteration and refinement)
이번 연구에서 도출된 가장 강력하고 핵심적인 발견은 사용자와 인공지능 간의 점진적인 반복 및 개선(Iteration and refinement) 과정이 유창성을 결정짓는 가장 중요한 척도라는 사실입니다.

분석된 전체 대화의 85.7%에서 첫 번째 답변을 그대로 수용하지 않고 추가적인 지시를 통해 결과물을 다듬어가는 패턴이 관찰되었습니다. 대화 기록을 분석한 결과, 반복적인 대화를 수행한 사용자 그룹은 평균적으로 2.67개의 유창성 행동 지표를 나타내어, 반복 대화를 하지 않은 그룹의 평균인 1.33개에 비해 2배 가량 높은 부가적인 AI Fluency 행동을 기록했습니다.
특히, 비판적 검토 역량에서 극적인 차이가 드러났는데, 프롬프트를 지속적으로 수정하며 대화를 이어간 사용자들은 그렇지 않은 사용자에 비해 인공지능의 추론 과정에 대해 5.6배나 더 많이 질문을 던졌습니다. 또한 인공지능이 간과하거나 누락한 맥락을 짚어내는 빈도 역시 4배 이상 높았습니다. 이는 인공지능을 단순한 자동화 도구로 취급하지 않고 상호작용이 가능한 지적 파트너로 인식할 때, 사용자의 비판적 사고 능력이 극대화되며 최종 결과물의 품질 또한 비약적으로 향상될 수 있음을 수학적으로 증명하는 결과입니다.
핵심 발견 2: 산출물(Artifact) 생성 시 나타나는 평가의 역설 (When creating outputs, users become more directive but less evaluative)
하지만 코딩 스크립트 작성, 웹 애플리케이션 프로토타입 구현, 포맷팅된 문서 생성 등 시각적으로 완성도가 높은 산출물(Artifact)을 만들어내는 대화에서는 이와 상반되는 우려스러운 패턴이 발견되었습니다.

즉, 코드, 문서, 대화형 도구 등 구체적인 산출물을 만들어내는 12.3%의 대화(n=1,209)에서는 사용자들의 상반된 행동 양식이 나타났습니다. 연구 결과에 따르면 단 30%의 대화에서만 사용자가 인공지능에게 작동 방식을 구체적으로 지시한 것으로 나타났습니다.
산출물을 만들어야 할 때, 사용자들은 목표를 명확히 하고(+14.7%p), 포맷을 구체적으로 지정하며(+14.5%p), 예시를 제공하는(+13.4%p) 등 대화 초반에 AI를 훨씬 더 정교하게 지시하는 초기 지시의 구체화(Description & Delegation 상승) 경향을 보였습니다.
하지만, AI가 그럴듯한 산출물을 내놓았을 때 이를 비판적으로 평가하는 행동은 눈에 띄게 줄어들었습니다. 누락된 맥락을 확인하는 비율은 5.2%p 감소했고, 사실 확인은 3.7%p, 모델의 추론 논리를 묻는 비율은 3.1%p 하락했습니다. 즉, 시각적으로 뛰어난 산출물에 대해서는 검증과 평가가 부재(Discernment 하락)하는 결과가 나타났습니다.
Anthropic은 AI가 겉보기에 완벽하고 매끄러운 형태의 결과물을 만들어낼수록 사용자가 이를 무비판적으로 수용할 위험이 커진다고 지적하며, 출력물의 품질이 좋아질수록 오히려 비판적 검증 역량이 더욱 중요해진다고 강조했습니다.
또한, 최상의 결과를 얻기 위해서는 프롬프트를 작성할 때 단순히 질문만 던지는 것을 넘어, 사용자의 가정에 오류가 있다면 지적해 달라고 요구하거나 최종 답변을 도출하기 전에 사고 과정을 먼저 설명해 달라는 등의 메타적인 지침을 포함해야 합니다. 이러한 명시적인 규칙 설정은 인공지능이 수동적인 정보 제공자를 넘어 사용자의 사고를 확장시키는 진정한 지적 조력자로 기능하게 만듭니다.
AI 활용 역량(Fluency) 향상을 위한 3가지 권장 사항
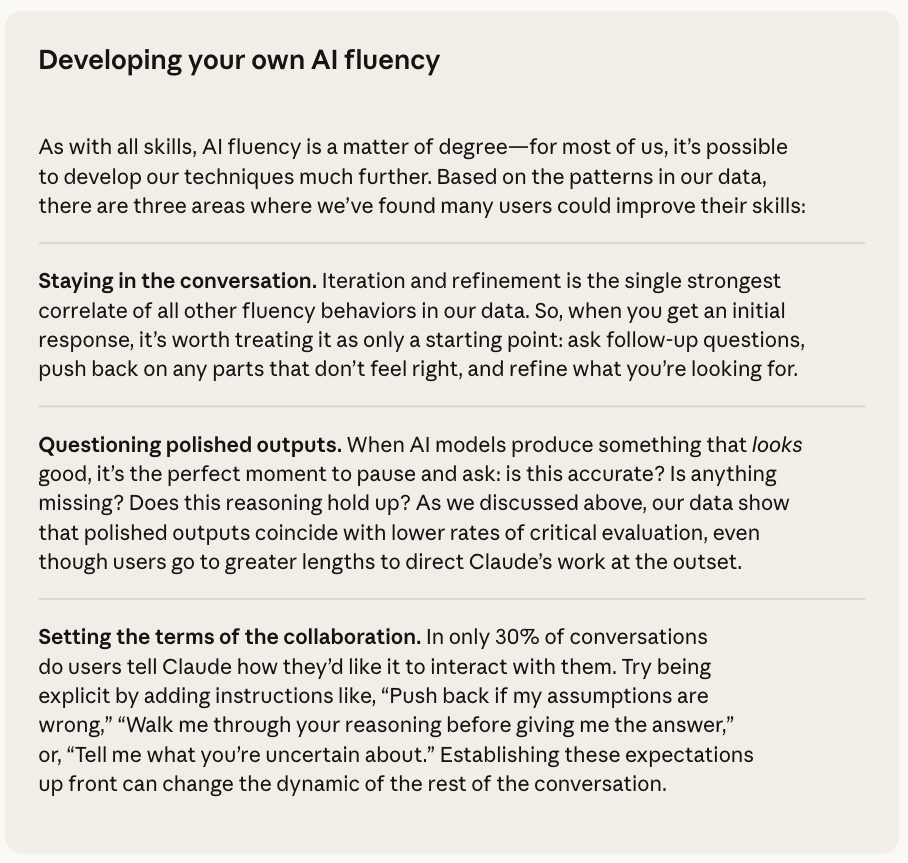
Anthropic은 데이터에 나타난 패턴을 바탕으로, 누구나 자신의 AI 활용 능력을 한 단계 높일 수 있는 3가지 구체적인 실천 방안을 제안하고 있습니다:
 대화에 계속 머무르기 (Staying in the conversation)
대화에 계속 머무르기 (Staying in the conversation)
AI가 제공하는 첫 번째 응답을 작업의 최종 결과물이 아닌 시작점, 즉 브레인스토밍의 출발점이나 초안으로 취급해야 합니다. 데이터가 증명하듯, 만족스럽지 않은 부분이나 개선할 점을 찾아내어 인공지능에게 지속적인 피드백을 제공하고 결과물을 점진적으로 다듬어가는 반복 과정 자체가 작업의 수준을 결정적으로 끌어올리는 가장 중요한 열쇠입니다.
따라서, 답변 내용 중 어색한 부분을 지적하고, 추가 질문을 던지며 원하는 결과를 얻을 때까지 집요하게 대화를 다듬어 나가는 습관을 들여야 합니다.
 완성된 결과물일수록 철저히 의심하기 (Questioning polished outputs)
완성된 결과물일수록 철저히 의심하기 (Questioning polished outputs)
시각적으로 세련되고 완성된 것처럼 보이는 결과물에 대해서 더욱 엄격하고 비판적인 시각을 유지해야 합니다. 표나 차트, 깔끔하게 정리된 코드나 문서가 출력되더라도 그 이면에 숨겨진 논리적 비약이나 사실적 오류(Hallucination)가 존재할 수 있습니다.
따라서, 겉모습에 현혹되지 않고 구체적인 근거를 요구하거나 논리의 빈틈을 적극적으로 파고들어 반문하는 의도적인 검증 절차를 반드시 거쳐야 합니다. 기술적 숙련도가 높아지는 것만큼이나 비판적 평가 능력을 병행하여 발전시키는 것이 안전한 인공지능 활용의 핵심입니다.
즉, 인공지능이 에러가 없어 보이는 깔끔한 코드나 문서를 출력했을 때가 바로 검증의 골든 타임이므로, 스스로 "이 논리가 타당한가?", "고려되지 않은 엣지 케이스(Edge case)나 누락된 맥락은 없는가?"라고 질문하는 습관을 들여야 합니다.
 협업의 규칙 미리 설정하기 (Setting the terms of the collaboration)
협업의 규칙 미리 설정하기 (Setting the terms of the collaboration)
마지막으로 대화를 시작하는 초기 단계에 인공지능과의 협업 방식과 상호작용 규칙을 명확하게 설정하는 것이 매우 중요합니다. 연구 결과에 따르면 단 30%의 대화에서만 사용자가 인공지능에게 작동 방식을 구체적으로 지시한 것으로 나타났습니다.
최상의 결과를 얻기 위해서는 프롬프트를 작성할 때 단순히 질문만 던지는 것을 넘어, 사용자의 가정에 오류가 있다면 지적해 달라고 요구하거나 최종 답변을 도출하기 전에 사고 과정을 먼저 설명해 달라는 등의 메타적인 지침을 포함해야 합니다. 이러한 명시적인 규칙 설정은 인공지능이 수동적인 정보 제공자를 넘어 사용자의 사고를 확장시키는 진정한 지적 조력자로 기능하게 만듭니다.
즉, 프롬프트 작성 시 "내 전제가 잘못되었다면 주저 없이 지적해 줘"라거나, "최종 코드를 작성하기 전에 너의 추론 과정을 먼저 설명해 줘"와 같이 명확한 협업의 규칙(Ground Rules)을 설정하면 결과물의 신뢰도를 크게 높일 수 있습니다.
연구의 한계점 및 향후 과제
Anthropic은 본 연구가 지닌 명확한 한계점과 이를 보완할 향후 연구 방향도 투명하게 밝혔습니다.
한계점
본 연구는 2026년 1월이라는 특정 주간의 데이터에 의존하고 있으며, 초기 기술 수용자(Early Adopters) 중심의 샘플일 가능성이 큽니다. 또한 행동의 발현 여부만을 0과 1로 측정하는 이진 분류(Binary classification)를 사용해 미묘한 뉘앙스를 담아내지 못했고, 코드 테스트 등 대화창 밖에서 암묵적으로 일어나는 사용자의 검증 행동을 포착하지 못했다는 한계가 있습니다.
향후 계획
향후에는 사용 기간에 따른 역량 변화를 추적하는 코호트 분석과, 관찰 불가능한 윤리적 지표를 평가하기 위한 정성적 연구를 병행할 예정입니다. 특히 소프트웨어 개발자들이 핵심 사용층인 Claude Code 환경에서의 Fluency 행동 패턴을 추가적으로 심층 연구할 계획입니다.
 AI Fluency Index 소개 블로그
AI Fluency Index 소개 블로그
더 읽어보기
-
[GN⁺] HashiCorp 공동 창업자 Mitchell Hashimoto의 AI 도입 여정(My AI Adoption Journey)
-
Google, 실용적인 AI 기술을 평가하는 Google AI Professional Certificate 인증 출시
-
[GN] Claude Code 창시자 Boris Cherny의 Claude Code 커스터마이징 팁 12가지
-
OpenClaw 개발자 Peter Steinberger, '단순히 데이터를 보여주고 관리하던 기존 App의 80% 가량은 불필요해질 것'
-
Knowledge Work Plugins: 지식 근로자를 위한, Claude Cowork 및 Claude Code용 플러그인 (Anthropic 공식)
-
Awesome AI Coding Tools: 개발자를 위한 100여가지 AI 코딩 도구 소개 목록 (feat. AI for Developers)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()