
AI-research-SKILLs 소개
AI-research-SKILLs는 AI 모델(Claude, Gemini, GPT-4 등)이 실제 AI 연구 및 엔지니어링 작업을 자율적으로 수행할 수 있도록 돕기 위해 구축된 포괄적인 오픈소스 스킬 라이브러리입니다. Orchestra Research에서 유지 관리하는 이 프로젝트는 단순히 인간을 위한 학습 자료가 아니라, AI 에이전트에게 '엔지니어링 능력(Engineering Ability)'을 부여하여 가설 설정부터 실험 검증까지의 과정을 수행하게 만드는 것을 목표로 합니다.
현재의 대형 언어 모델(LLM)들은 코딩 능력이 뛰어나지만, 특정 프레임워크(예: Axolotl을 이용한 파인튜닝, Ray Data를 이용한 분산 데이터 처리)를 사용하여 복잡한 연구 파이프라인을 처음부터 끝까지 구축하고 실행하는 데에는 종종 한계를 보입니다. 이는 최신 라이브러리에 대한 구체적인 '실행 지식'이나 '트러블슈팅 경험'이 부족하기 때문입니다. 이 프로젝트는 이러한 간극을 메우기 위해 AI 에이전트가 참조하고 실행할 수 있는 고품질의 스킬 셋(Skill Set)을 제공합니다.

이 저장소에는 약 70개 이상의 전문적인 연구/엔지니어링 라이브러리 및 도구들을 포함하고 있으며, 여기에는 모델 아키텍처, 토크나이제이션, 파인튜닝, 데이터 처리, 분산 학습, MLOps 등 AI 연구의 전 과정을 포괄합니다. 개발자는 이 스킬들을 자신의 AI 에이전트(예: Claude Code, 커스텀 에이전트 시스템)에 패키징하여, 에이전트가 마치 숙련된 연구 엔지니어처럼 작동하도록 만들 수 있습니다.
스킬 라이브러리 구조 (Skill Structure)
각 기술 디렉토리는 AI 에이전트가 해당 기술을 완벽히 습득하고 실행할 수 있도록 다음과 같은 표준화된 구조를 따릅니다.
- SKILL.md: 전문가 수준의 가이드 문서 (100~600라인 분량). 해당 기술의 핵심 개념, 사용법, 주의사항 등이 정리되어 있습니다.
- references/: 공식 소스에서 가져온 지원 문서들입니다. 에이전트가 환각(Hallucination) 없이 정확한 API를 사용하도록 돕습니다.
- Code Examples: 실제 작동하는 코드 예제와 워크플로우입니다.
- Troubleshooting Guides: 자주 발생하는 오류와 그 해결책을 포함하여 에이전트가 에러를 스스로 수정할 수 있게 합니다.
 사용 가능한 스킬 (70/70 로드맵 완료!)
사용 가능한 스킬 (70/70 로드맵 완료!)
양보다 질(Quality over quantity): 각 스킬은 실제 코드 예제, 문제 해결 가이드, 그리고 바로 상용화 가능한 워크플로우를 포함한 포괄적인 전문가 수준의 가이드를 제공합니다.
 모델 구조 / Model Architecture (5 skills)
모델 구조 / Model Architecture (5 skills)
- LitGPT - Lightning AI의 20개 이상의 깔끔한 LLM 구현체 및 상용 학습 레시피 (462라인 + 4개 참조)
- Mamba - O(n) 복잡도를 가진 상태 공간 모델(State-space models), Transformer보다 5배 빠름 (253라인 + 3개 참조)
- RWKV - RNN과 Transformer의 하이브리드, 무한 컨텍스트, 리눅스 재단 프로젝트 (253라인 + 3개 참조)
- NanoGPT - Karpathy가 만든 약 300라인의 교육용 GPT (283라인 + 3개 참조)
- Gemma-2B - 대부분의 벤치마크에서 강력한 성능을 보이는 구글의 2B 규모의 경량 오픈 모델
 토큰화 / Tokenization (2 skills)
토큰화 / Tokenization (2 skills)
- HuggingFace Tokenizers - Rust 기반, GB당 20초 미만, BPE/WordPiece/Unigram 알고리즘 (486라인 + 4개 참조)
- SentencePiece - 언어 독립적, 초당 5만 문장 처리, T5/ALBERT에서 사용됨 (228라인 + 2개 참조)
 파인튜닝 / Fine-Tuning (4 skills)
파인튜닝 / Fine-Tuning (4 skills)
- Axolotl - 100개 이상의 모델을 지원하는 YAML 기반 파인튜닝 (156라인 + 4개 참조)
- LLaMA-Factory - WebUI 기반 노코드(No-code) 파인튜닝 (78라인 + 5개 참조)
- Unsloth - 2배 더 빠른 QLoRA 파인튜닝 (75라인 + 4개 참조)
- PEFT - LoRA, QLoRA, DoRA 등 25개 이상의 방법론을 포함한 파라미터 효율적 파인튜닝 (431라인 + 2개 참조)
 데이터 처리 / Data Processing (2 skills)
데이터 처리 / Data Processing (2 skills)
- Ray Data - 분산 ML 데이터 처리, 스트리밍 실행, GPU 지원 (318라인 + 2개 참조)
- NeMo Curator - GPU 가속 데이터 큐레이션, 16배 빠른 중복 제거 (375라인 + 2개 참조)
 사후 학습 / Post-Training (4 skills)
사후 학습 / Post-Training (4 skills)
- TRL Fine-Tuning - 트랜스포머 강화학습 (Transformer Reinforcement Learning) (447라인 + 4개 참조)
- GRPO-RL-Training (TRL) - TRL을 활용한 그룹 상대 정책 최적화 (Group Relative Policy Optimization) (569라인, 골드 스탠다드)
- OpenRLHF - Ray와 vLLM을 활용한 전체 RLHF 파이프라인 (241라인 + 4개 참조)
- SimPO - 단순 선호 최적화(Simple Preference Optimization), 참조 모델 불필요 (211라인 + 3개 참조)
 안전성 & 정렬 / Safety & Alignment (3 skills)
안전성 & 정렬 / Safety & Alignment (3 skills)
- Constitutional AI - 원칙을 통한 AI 주도 자가 개선 (282라인)
- LlamaGuard - LLM 입출력을 위한 안전 분류기 (329라인)
- NeMo Guardrails - Colang을 활용한 프로그래밍 가능한 가드레일 (289라인)
 분산 학습 / Distributed Training (5 skills)
분산 학습 / Distributed Training (5 skills)
- Megatron-Core - H100에서 47% MFU로 20억~4620억 파라미터 모델을 학습하는 NVIDIA 프레임워크 (359라인 + 4개 참조)
- DeepSpeed - Microsoft의 ZeRO 최적화 (137라인 + 9개 참조)
- PyTorch FSDP - 완전 샤딩 데이터 병렬 (Fully Sharded Data Parallel) (124라인 + 2개 참조)
- Accelerate - HuggingFace의 4줄 분산 학습 API (324라인 + 3개 참조)
- PyTorch Lightning - Trainer 클래스를 활용한 고수준 학습 프레임워크 (339라인 + 3개 참조)
- Ray Train - 멀티 노드 오케스트레이션 및 하이퍼파라미터 튜닝 (399라인 + 1개 참조)
 최적화 / Optimization (6 skills)
최적화 / Optimization (6 skills)
- Flash Attention - 메모리 효율성을 갖춘 2-4배 빠른 어텐션 (359라인 + 2개 참조)
- bitsandbytes - 50-75% 메모리 절감을 위한 8비트/4비트 양자화 (403라인 + 3개 참조)
- GPTQ - 4비트 사후 학습 양자화, 4배 메모리 절감, 2% 미만 정확도 손실 (443라인 + 3개 참조)
- AWQ - 활성화 인식 가중치 양자화, 정확도 손실을 최소화한 4비트 (310라인 + 2개 참조)
- HQQ - 반이차(Half-Quadratic) 양자화, 보정 데이터 불필요, 멀티 백엔드 (370라인 + 2개 참조)
- GGUF - llama.cpp 양자화 포맷, K-quant 방식, CPU/Metal 추론 (380라인 + 2개 참조)
평가 / Evaluation (1 skill)
- lm-evaluation-harness - 60개 이상의 작업에서 LLM을 벤치마킹하기 위한 EleutherAI의 표준 도구 (482라인 + 4개 참조)
 인프라 / Infrastructure (3 skills)
인프라 / Infrastructure (3 skills)
- Modal - Python 네이티브 API를 사용하는 서버리스 GPU 클라우드, T4-H200 온디맨드 (342라인 + 2개 참조)
- SkyPilot - 스팟 복구 기능을 갖춘 20개 이상 제공업체 간 멀티 클라우드 오케스트레이션 (390라인 + 2개 참조)
- Lambda Labs - H100/A100 예약/온디맨드 GPU 클라우드, 영구 파일 시스템 (390라인 + 2개 참조)
 추론 & 서빙 / Inference & Serving (4 skills)
추론 & 서빙 / Inference & Serving (4 skills)
- vLLM - PagedAttention을 활용한 높은 처리량의 LLM 서빙 (356라인 + 4개 참조, 상용 준비 완료)
- TensorRT-LLM - NVIDIA의 가장 빠른 추론, 초당 2만 4천 토큰, FP8/INT4 양자화 (180라인 + 3개 참조)
- llama.cpp - CPU/Apple Silicon 추론, GGUF 양자화 (251라인 + 3개 참조)
- SGLang - RadixAttention을 활용한 구조적 생성, 에이전트 작업 시 5-10배 빠름 (435라인 + 3개 참조)
 에이전트 / Agents (4 skills)
에이전트 / Agents (4 skills)
- LangChain - 가장 인기 있는 에이전트 프레임워크, 500개 이상의 통합, ReAct 패턴 (658라인 + 3개 참조, 상용 준비 완료)
- LlamaIndex - LLM 앱을 위한 데이터 프레임워크, 300개 이상의 커넥터, RAG 중심 (535라인 + 3개 참조)
- CrewAI - 멀티 에이전트 오케스트레이션, 역할 기반 협업, 자율 워크플로우 (498라인 + 3개 참조)
- AutoGPT - 자율 AI 에이전트 플랫폼, 비주얼 워크플로우 빌더, 지속적 실행 (400라인 + 2개 참조)
 RAG (5 skills)
RAG (5 skills)
- Chroma - 오픈소스 임베딩 데이터베이스, 로컬/클라우드, 별 2만 4천 개 (385라인 + 1개 참조)
- FAISS - 페이스북의 유사도 검색, 10억 규모 스케일, GPU 가속 (295라인)
- Sentence Transformers - 5,000개 이상의 임베딩 모델, 다국어 지원, 별 1만 5천 개 (370라인)
- Pinecone - 관리형 벡터 데이터베이스, 오토스케일링, 100ms 미만 지연 시간 (410라인)
- Qdrant - 고성능 벡터 검색, Rust 기반, 필터링을 포함한 하이브리드 검색 (493라인 + 2개 참조)
 멀티모달 / Multimodal (7 skills)
멀티모달 / Multimodal (7 skills)
- CLIP - OpenAI의 비전-언어 모델, 제로샷 분류, 별 2만 5천 개 (320라인)
- Whisper - 강력한 음성 인식, 99개 언어, 별 7만 3천 개 (395라인)
- LLaVA - 비전-언어 어시스턴트, 이미지 채팅, GPT-4V 수준 (360라인)
- Stable Diffusion - HuggingFace Diffusers, SDXL, ControlNet을 통한 텍스트-이미지 생성 (380라인 + 2개 참조)
- Segment Anything - 포인트/박스를 이용한 제로샷 이미지 분할을 위한 메타의 SAM (500라인 + 2개 참조)
- BLIP-2 - Q-Former를 이용한 비전-언어 사전 학습, 이미지 캡셔닝, VQA (500라인 + 2개 참조)
- AudioCraft - 텍스트-음악 및 텍스트-사운드 생성을 위한 메타의 MusicGen/AudioGen (470라인 + 2개 참조)
프롬프트 엔지니어링 / Prompt Engineering (4 skills)
- DSPy - 최적화 도구를 포함한 선언적 프롬프트 프로그래밍, 스탠포드 NLP, 별 2만 2천 개 (438라인 + 3개 참조)
- Instructor - Pydantic 검증을 포함한 구조화된 LLM 출력, 별 1만 5천 개 (726라인 + 3개 참조)
- Guidance - 정규표현식/문법을 활용한 제약된 생성, 마이크로소프트 리서치, 별 1만 8천 개 (485라인 + 3개 참조)
- Outlines - FSM을 활용한 구조화된 텍스트, 제로 오버헤드, 별 8천 개 (601라인 + 3개 참조)
MLOps (3 skills)
- Weights & Biases - 실험 추적, 스윕(Sweeps), 아티팩트, 모델 레지스트리 (427라인 + 3개 참조)
- MLflow - 모델 레지스트리, 추적, 배포, 오토로깅 (514라인 + 3개 참조)
- TensorBoard - 시각화, 프로파일링, 임베딩, 스칼라/이미지 (538라인 + 3개 참조)
 관측성 / Observability (2 skills)
관측성 / Observability (2 skills)
- LangSmith - AI 앱을 위한 LLM 관측성, 트레이싱, 평가, 모니터링 (422라인 + 2개 참조)
- Phoenix - OpenTelemetry 트레이싱 및 LLM 평가를 포함한 오픈소스 AI 관측성 (380라인 + 2개 참조)
 신규 기법들 / Emerging Techniques (6 skills)
신규 기법들 / Emerging Techniques (6 skills)
- MoE Training - DeepSpeed를 활용한 전문가 혼합(Mixture of Experts) 학습, Mixtral 8x7B, 비용 5배 절감 (515라인 + 3개 참조)
- Model Merging - mergekit을 활용하여 TIES, DARE, SLERP 방식으로 모델 병합 (528라인 + 3개 참조)
- Long Context - RoPE, YaRN, ALiBi를 활용한 컨텍스트 윈도우 확장, 32k-128k 토큰 (624라인 + 3개 참조)
- Speculative Decoding - Medusa, Lookahead를 활용한 1.5-3.6배 빠른 추론 (379라인)
- Knowledge Distillation - MiniLLM을 활용한 모델 압축 (70B→7B), 온도 스케일링 (424라인)
- Model Pruning - Wanda, SparseGPT를 활용한 50% 희소성(Sparsity), 1% 미만의 정확도 손실 (417라인)
품질 표준 (Quality Standards)
이 저장소의 스킬들은 단순히 긁어모은 정보가 아니라 엄격한 기준에 따라 작성되었습니다:
-
공식 문서 기반: 각 스킬은 300KB 이상의 공식 문서를 바탕으로 작성되어 정확성을 보장합니다.
-
실전 문제 해결: GitHub 이슈와 솔루션을 포함하여 실제 개발 환경에서 마주칠 수 있는 엣지 케이스(Edge case)를 다룹니다.
-
언어 감지: 프로그래밍 언어 자동 감지 및 버전 관리 정보를 포함합니다.
활용 사례 (Use Case)
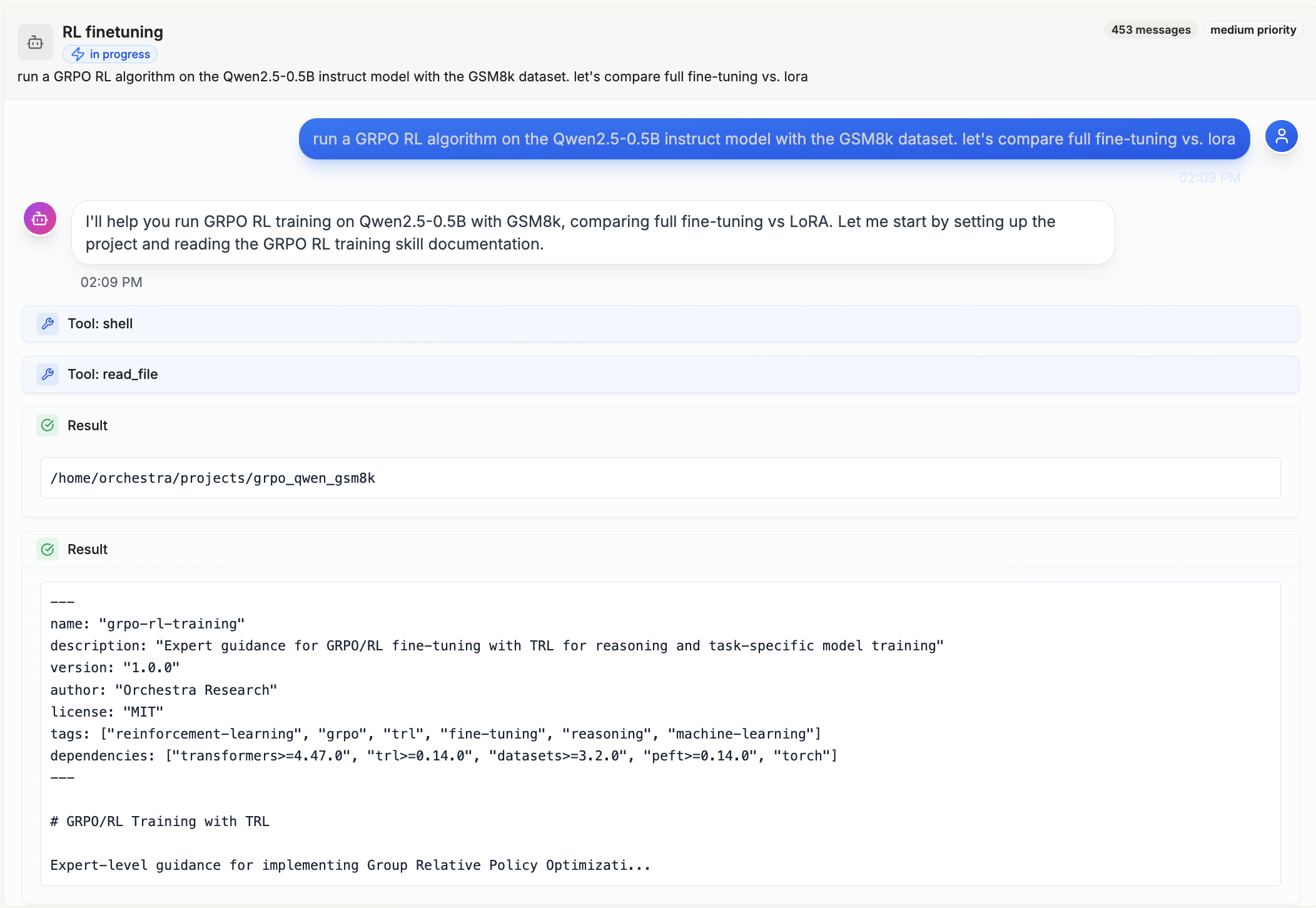
이 프로젝트의 가능성을 증명한 대표적인 사례는 Vibe Fine-tuning입니다. 이 저장소에 소개된 스킬들을 탑재한 에이전트에게 사용자가 자연어로 "LoRA 논문의 실험을 재현해줘"라고 명령을 한 결과, 에이전트는 스스로 코드를 작성하고, GPU 환경(Lambda Labs 등)을 프로비저닝하며, Axolotl을 사용하여 모델을 파인튜닝하고, 결과를 평가했습니다. 즉, 인간의 개입 없이 복잡한 ML 파이프라인을 자율적으로 완수하는 Vibe Fine-tuning이 가능했습니다.
활용 사례와 관련한 상세한 내용은 아래 블로그 및 영상을 참고해주세요:

라이선스
AI-research-SKILLs 저장소의 라이선스는 MIT License를 따르지만, 해당 저장소에 소개된 각 라이브러리 및 도구들은 서로 다른 고유의 라이선스(Apache 2.0, MIT, Community License 등)를 따르고 있습니다. 따라서 사용 전 각 스킬 프로젝트의 라이선스를 반드시 확인해야 합니다. 또한, 저장소이 기여된 스킬은 Orchestra 마켓플레이스와 동기화됩니다.
 AI-research-SKILLs 공식 홈페이지
AI-research-SKILLs 공식 홈페이지
https://github.com/zechenzhangAGI/AI-research-SKILLs
 AI-research-SKILLs 관련 블로그 (Orchestra Research)
AI-research-SKILLs 관련 블로그 (Orchestra Research)
 AI-research-SKILLs 프로젝트 GitHub 저장소
AI-research-SKILLs 프로젝트 GitHub 저장소
https://github.com/zechenzhangAGI/AI-research-SKILLs
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()