- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

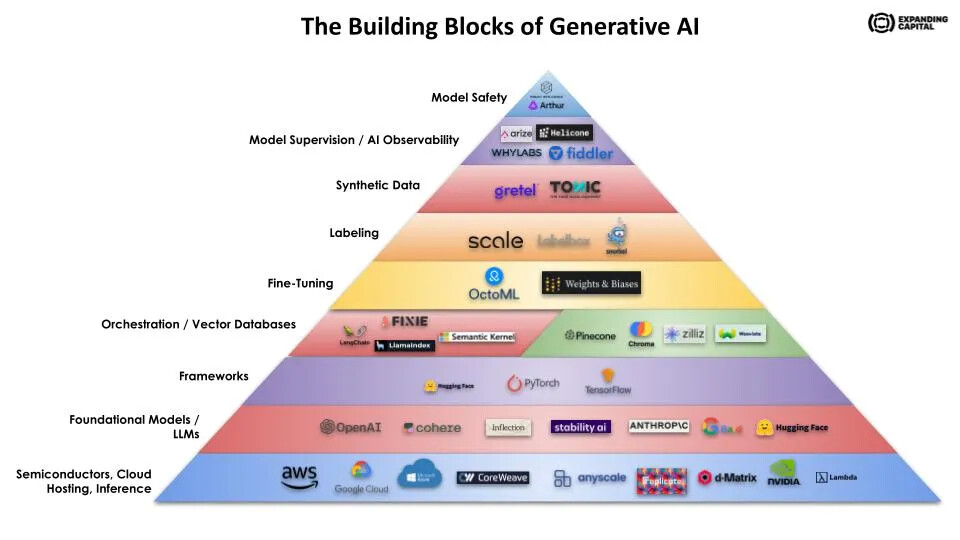
소개
이 블로그 게시물은 생성형 AI의 기반 요소에 대해 설명하고 있습니다. 생성형 AI는 기계 학습의 한 분야로, 새로운 데이터를 생성하거나 기존 데이터를 변형하는 능력을 가진 AI를 말합니다. 이 글은 생성형 AI의 인프라 구조를 이해하는 데 도움이 됩니다.
요약
기반 모델 (Foundation Models)
기반 모델은 AI 인프라의 가장 하위 계층입니다. 이들은 대규모 데이터셋(데이터셋)에서 학습하여 다양한 작업에 적용할 수 있는 범용 AI 모델입니다. GPT-3와 같은 언어 모델은 이 계층의 대표적인 예입니다. 이러한 모델은 다양한 어플리케이션에 사용될 수 있으며, 이를 통해 개발자들은 새로운 서비스와 제품을 만들 수 있습니다.
벡터 데이터베이스 (Vector Databases)
벡터 데이터베이스는 AI 인프라의 다음 계층입니다. 이들은 AI 모델이 생성한 벡터를 저장하고 검색하는 데 사용됩니다. 벡터 데이터베이스는 AI 모델의 출력을 저장하고, 이를 통해 사용자가 쿼리를 실행할 수 있게 합니다. 벡터 데이터베이스는 AI 모델의 출력을 저장하고, 이를 통해 사용자가 쿼리를 실행할 수 있게 합니다.
세부 조정 (Fine-Tuning)
세부 조정은 인프라 스택의 다음 계층입니다. 생성형 AI에서의 세부 조정은 특정 작업이나 데이터셋에서 모델을 추가로 학습시키는 과정을 의미합니다. 이 과정은 모델의 성능을 향상시키고, 해당 작업이나 데이터셋의 독특한 요구 사항에 맞게 모델을 조정합니다.
라벨링 (Labeling)
정확한 데이터 라벨링은 생성형 AI 모델의 성공에 중요합니다. 데이터는 이미지, 텍스트, 오디오 등 다양한 형태를 가질 수 있으며, 라벨은 데이터의 설명 역할을 합니다. 라벨링은 기계 학습 모델에게 필요한 정보를 가르치기 위해 라벨 세트를 제공하는 것이 필요합니다.
합성 데이터 (Synthetic Data)
합성 데이터는 실제 데이터를 모방한 인공적으로 생성된 데이터를 의미합니다. 합성 데이터는 실제 데이터가 사용 불가능하거나 사용할 수 없을 때 주로 사용됩니다.
모델 감독 / AI 관찰성 (Model Supervision / AI Observability)
스택의 다음 계층은 AI 관찰성입니다. 이는 AI 모델의 동작을 모니터링하고 이해하며 설명하는 것에 관한 것입니다. 간단히 말해, AI 모델이 올바르게 작동하고 편향되지 않은, 해를 끼치지 않는 결정을 내리고 있는지를 확인합니다.
모델 안전성 (Model Safety)
스택의 최상위 계층은 모델 안전성입니다. 생성형 AI의 주요 위험 중 하나는 편향된 출력입니다. AI 모델은 학습 데이터에 존재하는 편향을 채택하고 전파하는 경향이 있습니다.
참조
아래는 원문에서 언급된 기업들로, 생성형 AI의 다양한 측면을 다루는 기업들입니다. 이들을 통해 생성형 AI의 다양한 측면을 더 깊게 이해할 수 있습니다.