들어가며 

지난 9월 말 AlphaChip이라고 이름 붙인, 강화학습 기반의 칩 배치 생성 방법에 대한 짧은 추가 논문(Addendum)이 nature에 공개되었습니다. AlphaChip은 지난 2020년 공개된 강화학습(RL) 기반의 칩 설계 및 배치(Chip Design & Placement) 생성 방법에 대한 연구(A graph placement methodology for fast chip design)를 기반으로 하고 있으며, Google의 TPU 설계에 실제로 적용된 것으로 유명합니다. 이번에 추가된 논문(Addendum)에서는 사전학습을 활용한 효율성 증대를 비롯하여 초기 배치와 벤치마크 등에 대한 내용을 다루고 있습니다. 이러한 추가 논문 이해를 위해 먼저 지난 2020년 공개된 논문 내용을 간략히 다루고, 추가된 내용을 살펴보도록 하겠습니다.
AlphaChip의 기반 연구: A graph placement methodology for fast chip design
2020년 Google에서 공개한 연구는 강화학습(Reinforcement Learning) 기법을 칩 설계, 그 중에서도 칩의 물리적 배치(Floorplanning)를 최적화하는데 집중하였습니다. 플로어플래닝(Floorplanning)은 칩의 각 구성 요소(메모리, 컴퓨팅 유닛, 제어 논리 시스템 등)를 물리적 공간에 배치하는 과정입니다. 각 구성 요소는 전기적 신호로 연결되어 있어 배치 방식에 따라 성능, 전력 소모, 발열 등이 크게 달라집니다. 플로어플래닝은 컴퓨터 칩 설계에서 가장 초기 단계 중 하나로, 나중 단계에서 발생할 수 있는 물리적 제약을 미리 고려해야 하는 복잡한 문제입니다.
현대의 칩 설계에서는 수십억 개의 트랜지스터가 사용되며, 이를 최적화하지 못하면 성능 저하 및 비용 증가로 이어집니다. 특히, 전력 소비는 모바일 장치나 데이터 센터 운영에 매우 중요한 요소이며, 이를 줄이는 것이 목표입니다. 플로어플래닝이 잘못되면 칩의 성능과 효율성에 큰 영향을 미칠 수 있습니다. 이를 해결하기 위해 파티셔닝 기반 방법, 확률적 탐색법, 해석적 기법 등과 같은 방법이 주로 사용되고 있으며, 각각은 다음과 같습니다:
- 파티셔닝 기반 방법(partitioning-based methods): 칩을 여러 구역으로 나눈 후 각 구역의 배치를 최적화합니다.
- 확률적 탐색법(stochastic/hill-climbing methods): 무작위로 배치를 변경하면서 최적화를 시도하는 방식입니다.
- 해석적 기법(analytic solvers): 수학적 모델을 사용해 최적화를 시도하지만, 칩이 커질수록 성능이 저하되는 문제점이 있습니다.
하지만 이러한 방법들은 모두 현대 칩의 복잡성을 처리하는 데 한계가 있습니다.
주요 방법론

2020년에 공개한 기반 연구에서는 이러한 칩 플로어플래닝 문제를 수많은 노드와 연결을 가진 칩 구성 요소를 2차원 칩 공간에 배치하는 문제로 보고고, 마코프 결정 과정(MDP, Markov Decision Process)을 도입하여 강화학습을 적용하였습니다. 즉, 전력 소비, 성능(처리 속도), 면적 등을 주요 평가 지표로 삼는 동시에 배선 길이와 혼잡도를 줄이는 것을 목표로 하여 각 구성 요소의 배치를 결정할 때마다, 미래의 상태와 보상이 결정되는 순차적 의사 결정 문제로 변환하여 학습이 가능하도록 합니다. 또한, 그래프 신경망(GNN, Graph Neural Network)을 도입하여 칩의 각 구성요소와 배선을 표현하였습니다. 제안한 주요 방법론을 정리하면 다음과 같습니다:
강화학습을 통한 플로어플래닝 최적화
먼저, 강화학습을 통해 플로어플래닝을 자동화합니다. RL 에이전트는 칩의 구성 요소들을 하나씩 배치하며, 각 배치가 최종적인 성능 지표에 미치는 영향을 학습합니다. 이 과정에서 에이전트는 보상을 받아 더 나은 배치를 찾아가는 방식으로 학습합니다. 이러한 최적화 과정은 일반적인 RL의 상태-행동-보상-상태 전이 과정으로 정의되며, 이러한 과정을 통해 RL 에이전트는 더 나은 정책을 학습하게 됩니다.
이 과정을 거쳐 정책 네트워크는 각 상태에서 가능한 배치들을 확률 분포로 출력하며, 가치 네트워크는 해당 상태의 예상 보상을 예측합니다. 이 두 네트워크는 칩의 구성 요소 간 연결 관계(그래프)를 입력받아, 각 구성 요소가 배치될 최적의 위치를 예측합니다. 네트워크의 입력으로는 노드 특성(너비, 높이, 유형), 엣지 특성(연결 개수), 배치할 매크로 ID, 칩 메타데이터 등이 포함됩니다.
엣지 기반 그래프 신경망(Edge-GNN)
제안된 RL 방법의 핵심은 **엣지 기반 그래프 신경망(Edge-GNN)**입니다. 각 구성 요소(노드)는 그래프의 노드로, 배선(네트)은 엣지로 표현됩니다. Edge-GNN은 칩의 각 구성 요소의 위치를 학습하고, 연결성을 파악해 배치의 품질을 예측하는 데 사용됩니다. 이로 인해 RL 에이전트는 배치 품질을 정확하게 예측하고, 다양한 칩에 대해 일반화할 수 있는 강력한 모델을 학습할 수 있습니다.
RL 에이전트는 Egde-GNN을 통해 상태를 파악합니다. 이러한 상태는 현재까지 배치된 구성 요소와 배치할 구성 요소에 대한 정보, 배선 상태를 포함하고 있습니다. 이후 단계인 행동은 구성 요소를 어느 위치에 배치할지 결정하며, 보상은 최종적으로 배선 길이, 혼잡도, 밀도에 기반하여 주어집니다. 보상 함수는 이 세 가지 요소의 가중 합으로 정의되며, 혼잡도와 밀도는 각 위치에서의 제한을 넘지 않아야 합니다.
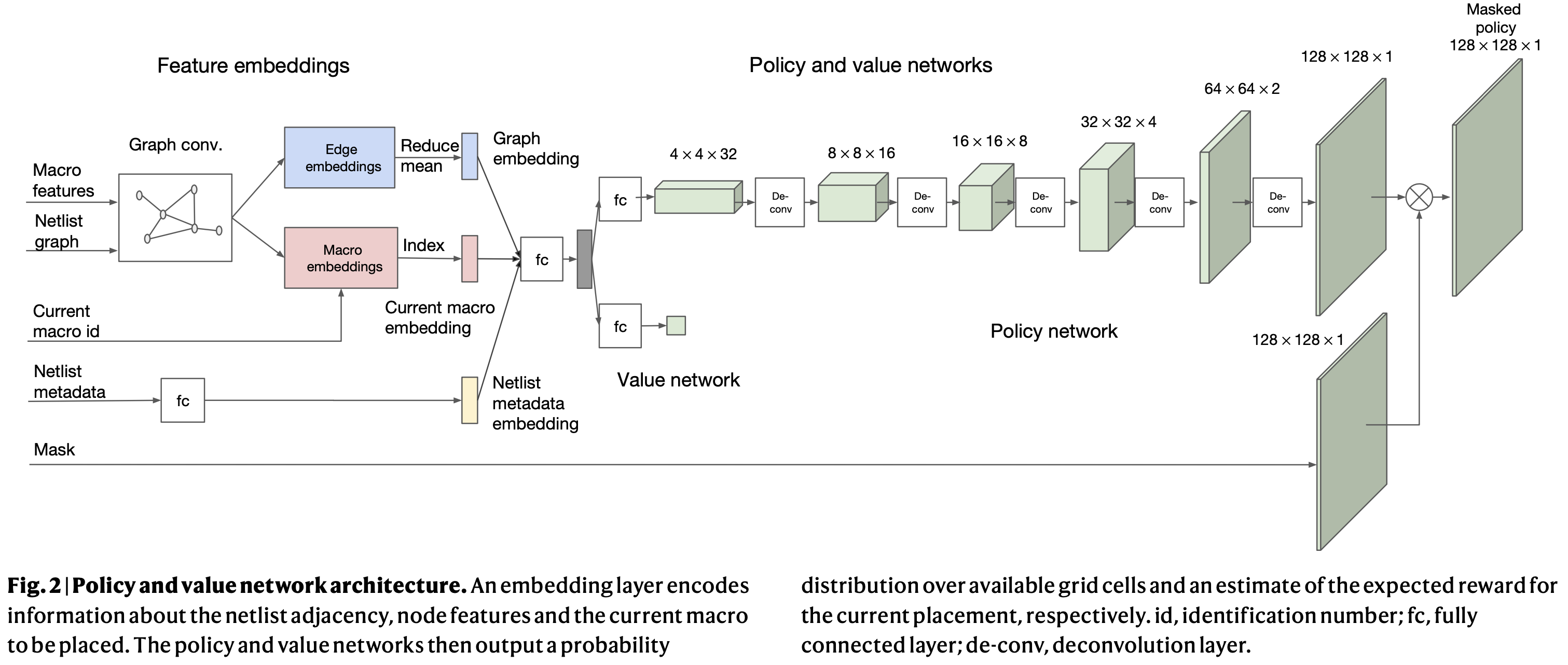
마지막으로 정책 네트워크의 학습을 위해 근접 정책 최적화(PPO: Proximal Policy Optimization) 알고리즘이 사용됩니다. PPO는 기존 정책과 새로 학습된 정책 간의 차이가 너무 크지 않도록 제어하면서 학습을 진행하는 방법으로, 안정적인 성능 향상을 보장합니다.
전이 학습을 통한 네트워크 일반화
또한, 제안된 방법은 다양한 칩 구조에서 학습한 경험을 전이 학습을 통해 새로운 칩에 적용할 수 있습니다. 이는 다양한 종류의 칩 데이터셋에서 학습한 정책 네트워크를 다른 새로운 칩에 적용하여 빠른 시간 내에 고품질의 배치를 생성하는 능력을 제공합니다. 이 방법은 새로운 칩 디자인에서도 학습된 정책을 활용할 수 있어, 전이 학습의 효율성을 극대화합니다.
실험 결과
기반 연구에서는 다양한 칩 블록 데이터셋을 사용하여 RL 정책을 학습하고 평가하였습니다. 실험에 사용된 데이터셋은 구글의 TPU 칩 블록과 오픈 소스 Ariane RISC-V CPU 블록으로 구성되어 있으며, 이들 데이터셋에서의 배치를 평가했습니다.
학습된 RL 정책을 사용하여 칩 블록을 제로샷(Zero-shot) 방식으로 배치하는 실험을 진행한 결과, 미세 조정(fine-tuning) 없이도 높은 품질의 배치를 생성할 수 있음을 확인하였습니다. 특히, 몇 시간의 미세 조정을 거친 후 결과는 더욱 개선되었으며, 이는 전이 학습의 강점을 보여줍니다.

기존 방법인 RePlAce와 비교했을 때, 제안된 방법은 더욱 적은 시간 내에 더 나은 결과를 제공하였습니다. 또한, 수작업으로 이루어진 칩 설계와 비교하더라도 면적, 전력 소모, 배선 길이에서 우수한 성능을 나타냈습니다.
더 읽어보기
 2020년 공개한 강화학습(RL)을 활용한 Chip Floorplanning 방법론에 대한 논문
2020년 공개한 강화학습(RL)을 활용한 Chip Floorplanning 방법론에 대한 논문

https://www.nature.com/articles/s41586-021-03544-w
(Nature를 구독 중이지 않으신 경우, SemanticScholar에서도 전문을 확인하실 수 있습니다)
(Baseline인) RePlAce 논문 (RePlAce: Advancing Solution Quality and Routability Validation in Global Placement)
 RePlAce 관련 GitHub 저장소
RePlAce 관련 GitHub 저장소
https://github.com/The-OpenROAD-Project/RePlAce
추가 연구 소개: AlphaChip
지난 9월 말 Nature에 공개된 추가 연구(Addendum)는 2020년에 소개된 강화 학습(RL) 기반의 칩 배치 생성 방법에 덧붙이는 것으로, AlphaChip으로 이름 붙이고자 합니다. (Today, we give this method a name: AlphaChip.) 이는 실제 공학 문제에 RL을 적용한 첫 사례 중 하나로, AI를 이용한 칩 설계에서 큰 영향을 끼쳤습니다. 지난 2020년의 AlphaChip 연구의 공개 이후 AI 기반 칩 설계에 많은 발전이 있었으나, 일부 해석에서 혼란이 발생해 이번 추가 논문(addendum)에서 각 단계별로 내용을 명확히 정리하고자 합니다.
사전 학습 (Pre-training)
AlphaChip은 사전 학습을 활용하여 더 많은 칩 배치 문제를 해결하면서 성능과 효율성을 높입니다. 사전 학습은 대규모 모델, 예를 들어 Gemini와 ChatGPT와 같은 LLM의 성능을 높이는 데 중요한 요소로 활용되고 있습니다. AlphaChip의 기반 연구에 대한 발표 이후, 저자들은 논문에서 설명한 방법을 완전히 재현하기 위해 소프트웨어 저장소를 오픈소스로 공개했습니다. 외부 연구자들은 이 저장소를 사용하여 다양한 칩 블록에 대해 사전 학습을 진행한 다음, 원래 논문에서 했던 것처럼 사전 학습된 모델을 새로운 블록에 적용할 수 있습니다.
또한, 이번에 공개하는 추가 연구의 일부로 20개의 TPU 블록에 대해 사전 학습된 모델 체크포인트도 함께 공개하고 있습니다. 하지만 더 나은 결과를 얻기 위해서는 개발자가 자체 배포 블록에 대한 사전 학습을 계속하는 것을 권장합니다. 자체 배포 블록에 대한 사전 학습은 GitHub의 오픈소스 저장소(repository)에 공개한 지침 및 도구를 따라 수행할 수 있습니다.
학습 및 컴퓨팅 자원(Computational Resources)
대부분의 머신러닝 모델(특히 RL 에이전트)과 마찬가지로, AlphaChip은 학습하면서 성능이 향상됩니다. 이러한 성능 향상은 수렴(convergence) 이라고 부르는 학습의 정체기(모델이 더 이상 크게 개선되지 않을 때)까지 계속됩니다. 이러한 수렴은 최적의 성능을 보장하는 데 중요하므로, 이러한 과정을 거치지 않으면 성능이 저하될 가능성이 높습니다.
또한, 학습에 사용되는 컴퓨팅 자원이 많을수록 성능이 향상되며, 자원이 줄어들면 같은 성능을 얻기 위해서는 학습 시간이 훨씬 더 길어질 수 있습니다. 이전에 Nature에 공개한 연구에서 살펴본 것처럼, 특정 블록을 미세조정(fine-tuning)할 때 10개의 CPU를 공유하는 GPU 1개와 32개의 RL 환경으로 구성된 16개의 워커(worker)를 사용하였습니다. 이보다 더 적은 컴퓨팅 자원 하에서는 성능이 저하되거나, 동일한 성능(또는 더 나쁜)을 얻기 위해 훨씬 더 오래 실행해야 할 수 있습니다.
초기 배치 (Initial Placement)
AlphaChip의 기반 연구에서는 평가를 수행하기 전, 칩 설계 프로세스의 이전 단계인 물리적 합성(Physical Synthesis)을 통해 얻은 대략적인 초기 배치(approximate initial placement)를 사용하여 hMETIS의 표준 셀 클러스터의 크기 불균형(imbalances in the sizes of standard cell clusters)을 해소하고자 하였습니다. RL 에이전트는 이러한 초기 배치에 접근할 수 없으며, 표준 셀(standard ceslls)을 배치하지 않습니다.
하지만 표준 셀의 초기 배치를 전혀 사용하지 않는 제거 연구(ablation study)를 실행한 결과, 아래 표와 같이 성능 저하가 관찰되지 않았습니다:

특히, 클러스터 재조정 단계(cluster rebalancing step)을 건너뛰는 대신, hMETIS의 클러스터 불균형 매개변수(cluster imbalance paramter)를 가장 낮은 값(UBfactor = 1)으로 설정하여 hMETIS가 보다 균형잡힌 클러스터를 생성하도록 하였습니다. 이러한 전처리 단계는 2022년 중순부터 GitHub 저장소에 오픈소스로 공개되어 있습니다.
벤치마크
AlphaChip의 기반 연구에서는 10nm 미만의 기술 노드를 가진 최신 칩의 TPU 블록에서의 실험 결과를 포함하고 있습니다. 이러한 10nm 미만의 크기는 최신 칩(modern chips)에서는 일반적으로 사용되고 있지만, 많은 학술 논문에서는 45nm 또는 12nm와 같은 상대적으로 오래된 노드 크기를 기준으로 연구를 수행하고 있습니다.
이러한 구형의, 상대적으로 큰 크기의 노드 크기를 갖는 칩은 물리적 설계 관점에서 크게 다릅니다. 예를 들어, 10nm 미만에서는 일반적으로 다중 패터닝(multiple patterning)을 일반적으로 사용하므로 낮은 밀도에서의 라우팅 혼잡 문제가 발생할 수 있습니다.
따라서 구형 기술 노드 크기를 다룰 때는 보상 함수(reward function) 에 대한 변경이 필요할 수 있습니다. 더 나은 상관관계를 갖는 보상 함수 개선을 위한 커뮤니티의 기여를 기대합니다.
기존 연구 논문의 수정
혼란을 줄이기 위해, 다음과 같은 원 논문에 몇 가지 설명과 사소한 수정을 추가하고자 합니다:
-
그림 4의 캡션에서 하이퍼파라미터 설정을 명확히 하고자 합니다:
- "밀도 가중치는 0.1로, 혼잡 가중치는 0으로 설정했습니다." (Density weight was set to 0.1 and congestion weight to 0.)
- 경험적으로 모든 하이퍼파라매터 설정에서 사전 학습이 효과적인 것으로 나타났습니다.
-
방법론(Methods) 섹션의 "표준 셀 클러스터링(Clutering of standard cells)" 부분에 다음 내용을 추가하고자 합니다:
- "hMETIS로 클러스터링한 뒤, 칩 설계 프로세스 이전 단계인 물리적 합성의 초기 배치를 기반으로 휴리스틱하게 클러스터 크기를 재조정합니다." (After clustering with hMETIS, we rebalance cluster sizes using heuristics based on an initial placement from physical synthesis, the previous step in the chip design process)
- 초기 배치 (Initial Placement)에서 살펴봤듯이, 이 단계를 제거하더라도 성능에 미치는 영향은 없는 것으로 보입니다.
-
TPU 블록(TPU blocks)에 대한 설명에서, 사전 학습 및 테스트셋의 매크로 수를 반영하여 다음과 같이 변경합니다:
- "최대 수백개(up to a few hundred)"를 "최대 107개(up to 107)"와 "최대 131개(up to 131)"로.
- 위의 실험과 별개로, AlphaChip은 500 이상의 매크로가 있는 블록에서 상용으로 적용되었습니다.
-
관련 작업에 비선형 최적화의 가중 평균(weighted-average in nonlinear optimization)에 대한 추가 예시로 다음을 추가 인용합니다:
- Hsu, M.-K., Chang, Y.-W. & Balabanov, V. TSV-aware analytical placement for 3D IC designs. In Proc. 48th Annual Design Automation Conference 664–669 (ACM, 2011).
추가로 기반 연구의 저자인 Anna Goldie와 Azalia Mirhoseini는 모두 공동 1저자로, 두 사람의 이름 순서는 동전 던지기(coin flip)로 결정되었음을 명확히 밝혔습니다.
미래 전망: 칩 설계 과정의 AI 혁신
AlphaChip에 대한 기반 연구를 지난 2020년 Nature 게재한 이후, AlphaChip은 Google의 대표적인 AI 가속기인 TPU에 여러 세대에 걸쳐 사용되었습니다. AlphaChip이 TPU의 성능을 개선한 사례를 살펴보면 다음과 같습니다:
- TPU v5e에서 AlphaChip은 인간 전문가보다 10개의 배치 블록과 3.2%의 와이어 길이 감소를 보였습니다.
- TPU v5p에서는 15개의 배치 블록과 4.5%의 와이어 길이 감소를 보였습니다.
- Trilium에서는 25개의 배치 블록과 6.2%의 와이어 길이 감소를 보였습ㅂ니다.
또한, 데이터센터용 CPU인 Axion 및 Google(Alphabet)에서 비공개로 사용 중인 여러 칩에서도 AlphaChip은 뛰어난 성능을 보였습니다. 그 외에도 MediaTek에서는 전력 및 성능, 면적을 개선하기 위해 AlphaChip을 확장하는 연구를 수행했습니다.
AI가 칩 설계 프로세스를 자동화할 미래를 논의하며, 이를 통해 설계 주기가 크게 단축되고 AI, 하드웨어, 소프트웨어의 최적화를 통한 새로운 성능의 한계가 열릴 것으로 기대합니다.
AlphaChip의 추가 연구에 대해 더 읽어보기

https://www.nature.com/articles/s41586-024-08032-5
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()