AnomalyGPT: 산업 이상 탐지를 위한 대형 시각-언어 모델 사용
(AnomalyGPT: Detecting Industrial Anomalies using Large Vision-Language Models)
소개
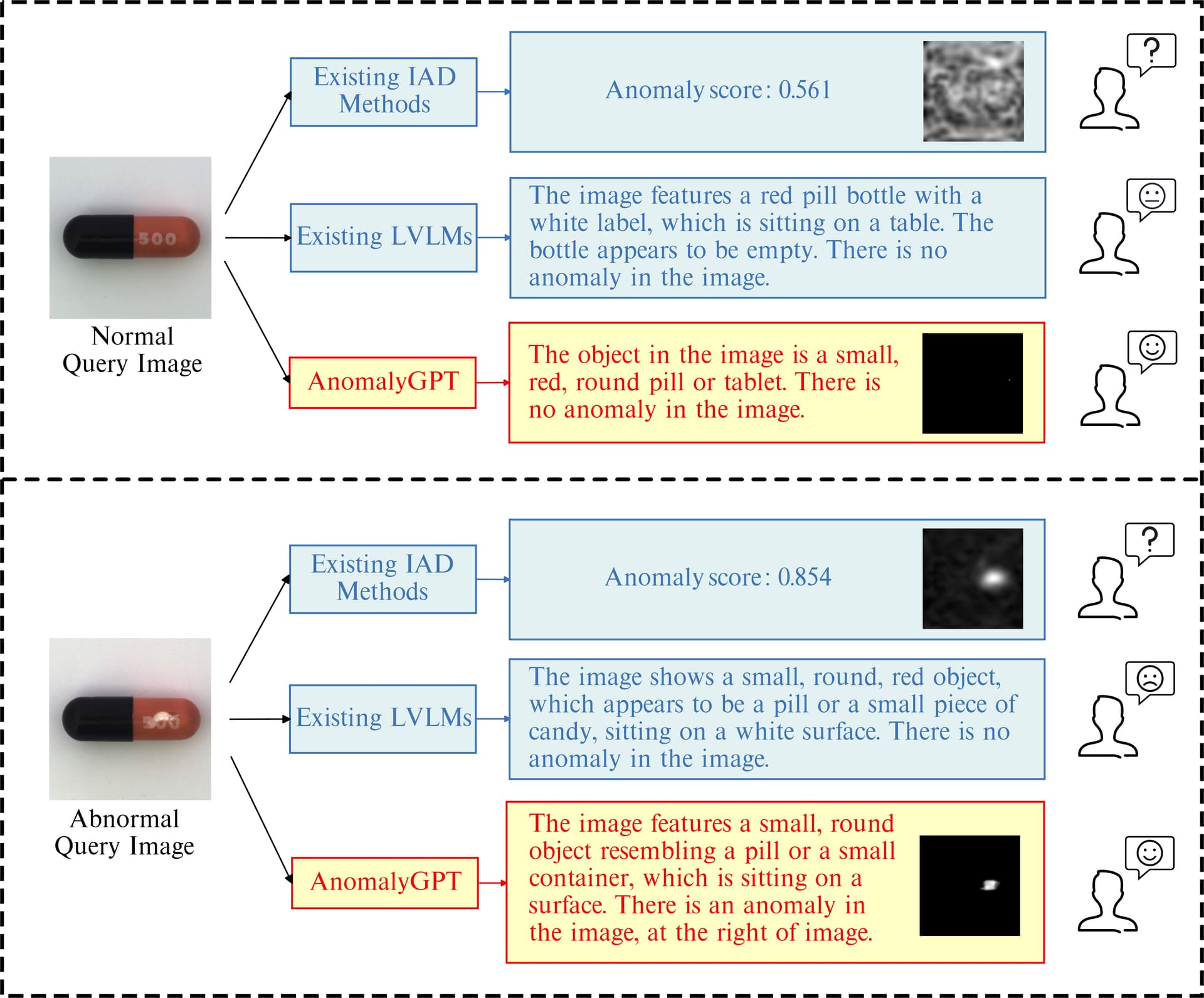
AnomalyGPT는 대형 시각-언어 모델(LVLM; Large Vision-Language Model)의 산업 이상 탐지 (IAD; Industrial Anomaly Detection) 작업에 대한 효과성을 탐구합니다. LVLM은 이미지를 이해하는 능력을 보여주었지만, 특정 도메인 지식이 부족하고 객체 내의 지역화된 세부 사항에 대한 이해가 약하여 IAD 작업에서의 효과성이 제한됩니다.
AnomalyGPT는 이를 해결하기 위해 비정상적인 이미지를 시뮬레이션하고, 각 이미지에 해당하는 텍스트를 생성하여 학습 데이터를 생성하는 방식을 시도하였습니다.
주요 내용
논문 개요 (Abstract)
대형 시각-언어 모델(LVLM)은 이미지를 이해하는데는 탁월한 능력을 보여주고 있지만, 광범위한 학습 데이터셋으로 인해 특정 도메인의 지식이 부족하고, 물체 내의 국소화된 세부 사항에 대한 이해가 부족해 산업 이상 탐지(IAD) 작업에서의 효과성이 제한됩니다. 이 논문에서는 LVLM을 사용하여 IAD 문제를 해결하고, LVLM을 기반으로 한 새로운 IAD 접근법인 AnomalyGPT를 제안합니다. 저자들은 이상한 이미지를 시뮬레이션하여 각 이미지에 대한 텍스트 설명을 생성함으로써 학습 데이터를 생성합니다. 이러한 방식으로 수동 임계값 조정의 필요성을 제거하고, 이상 유무와 이상이 있는 부위의 위치를 직접 평가할 수 있습니다. 또한, 여러 차례의 대화(Multi-turn Chat)을 지원하여, 인상적인 몇 장의 사진들과 대화들만으로도 상황에 맞는 학습 기능을 보여줍니다. 단 하나의 정상 사진으로 MVTec-AD 데이터셋에서 86.1%의 정확도(accuracy), 94.1%의 이미지 수준 AUC, 95.3%의 픽셀 수준의 AUC를 기록하는 최첨단(SotA)의 성능을 달성하였습니다.
AnomalyGPT 모델
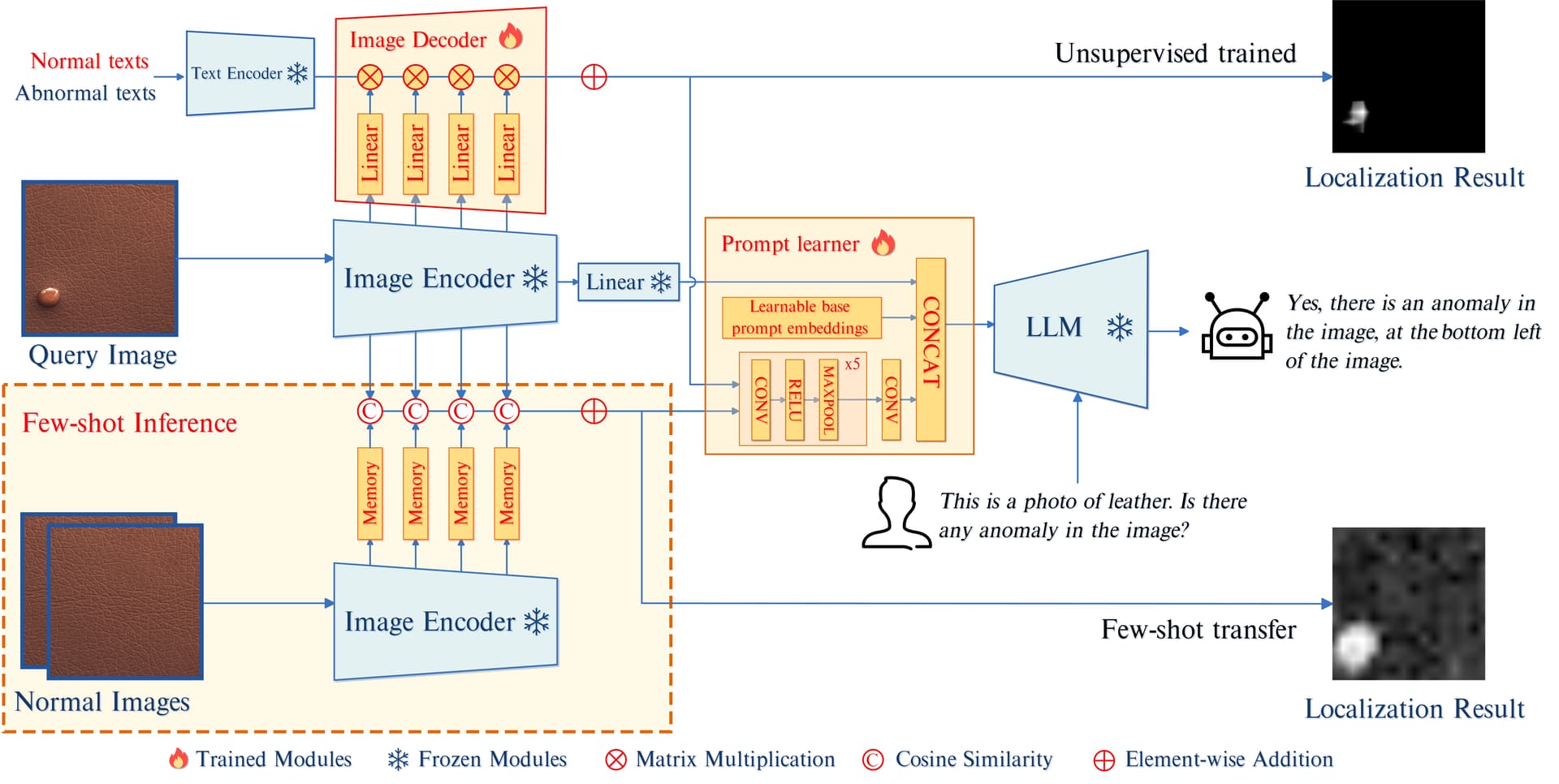
AnomalyGPT는 수동으로 지정된 임계값 없이 산업 이미지에서 이상을 탐지할 수 있는 첫 번째 LVLM 기반 IAD 방법입니다. AnomalyGPT는 이상의 존재와 위치를 나타낼 뿐만 아니라 이미지에 대한 정보도 제공할 수 있습니다. 사전 학습된 이미지 인코더와 대규모 언어 모델(LLM)을 활용하여 시뮬레이션된 이상 징후 데이터를 통해, IAD 이미지와 그에 해당하는 텍스트 설명을 정렬합니다.
경량의 시각적 텍스트 특징 매칭 기반 이미지 디코더를 사용하여 로컬라이제이션 결과를 얻고, 프롬프트 학습기를 설계하여 LLM에 세분화된 의미를 제공하고 프롬프트 임베딩을 사용하여 LVLM을 미세 조정합니다. 또한 이 방법은 정상 샘플이 거의 제공되지 않은 상태에서 이전에 보이지 않던 항목의 이상 징후를 감지할 수 있습니다.
소개 영상
