
AIMv2 연구 소개
Apple에서 지난 1월 공개한 AIM(Auto-regressive Image Model)의 개선된 버전인 AIMv2를 공개했습니다. AIM은 LLM에서 성공적으로 적용한 자기회귀(Auto-regressive) 방식을 Computer Vision 영역에 적용한 모델입니다.
AIMv2는 순수 비전 모델인 AIMv1과 다르게, 이미지와 텍스트를 모두 포함하는 멀티모달 자기회귀(Multimodal Auto-regressive) 학습 프레임워크를 도입한 것이 특징입니다. 이를 통해 이미지와 텍스트 데이터를 함께 학습하여 멀티모달 이해 분야의 작업에서 강력한 성능을 발휘합니다.
먼저, AIMv1에 대해서 간략히 알아보겠습니다:
기존의 AIM(v1) 소개

AIM(Auto-regressive Image Models)은 자연어 처리(NLP) 영역, 특히 대규모 언어 모델(LLM)에서 적용에 성공한 자기회귀(Auto-regressive) 방식을 CV(Computer Vision)에 적용한 모델입니다. 즉, 이미지를 패치(patch) 단위로 나누어, 각 패치를 이전 패치에 기반해 순차적으로 예측하는 모델로, 이를 위해 causal mask(인과적 마스크)를 적용합니다. 학습 시에는 정규화된 픽셀 단위 회귀 손실(MSE, Mean Squared Error)을 사용하여 각 패치에 대한 견고한 표현 학습을 보장합니다.
AIM은 ViT(Vision Transformer)를 기반으로 다음과 같은 변형을 추가하였습니다:
- Causal Masking: 각 패치가 이전 패치에만 의존하도록 설계
- Prefix Attention: 사전 학습 중 사용되며, 다운스트림 작업에서 양방향 attention으로 자연스럽게 전환 가능
- MLP 헤드: 픽셀 수준 예측을 강화하며, 고수준 특징 전이(transferability)를 보존
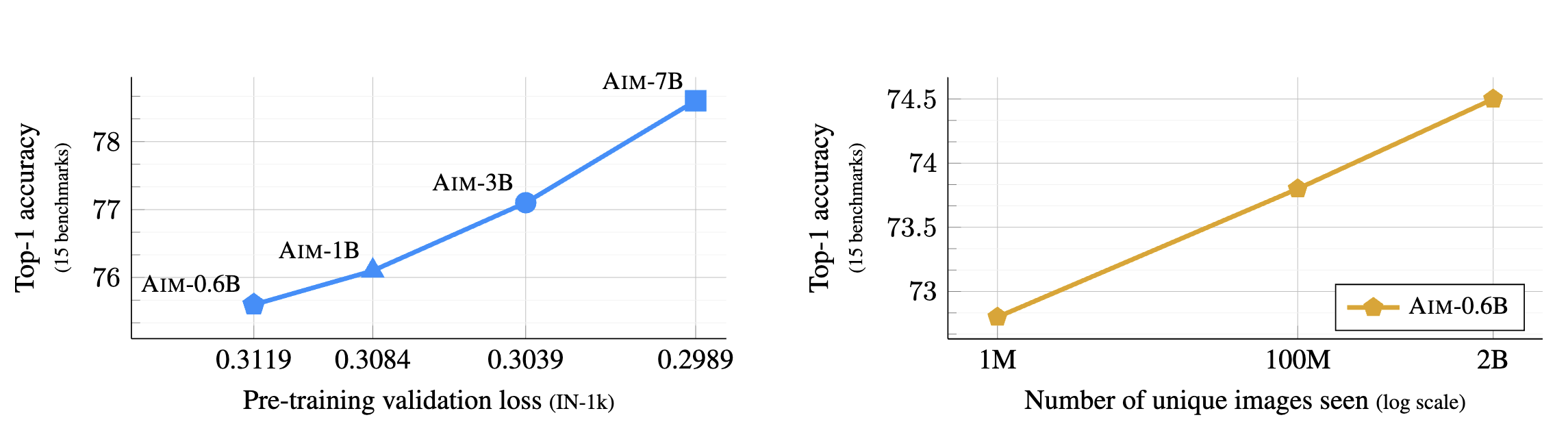
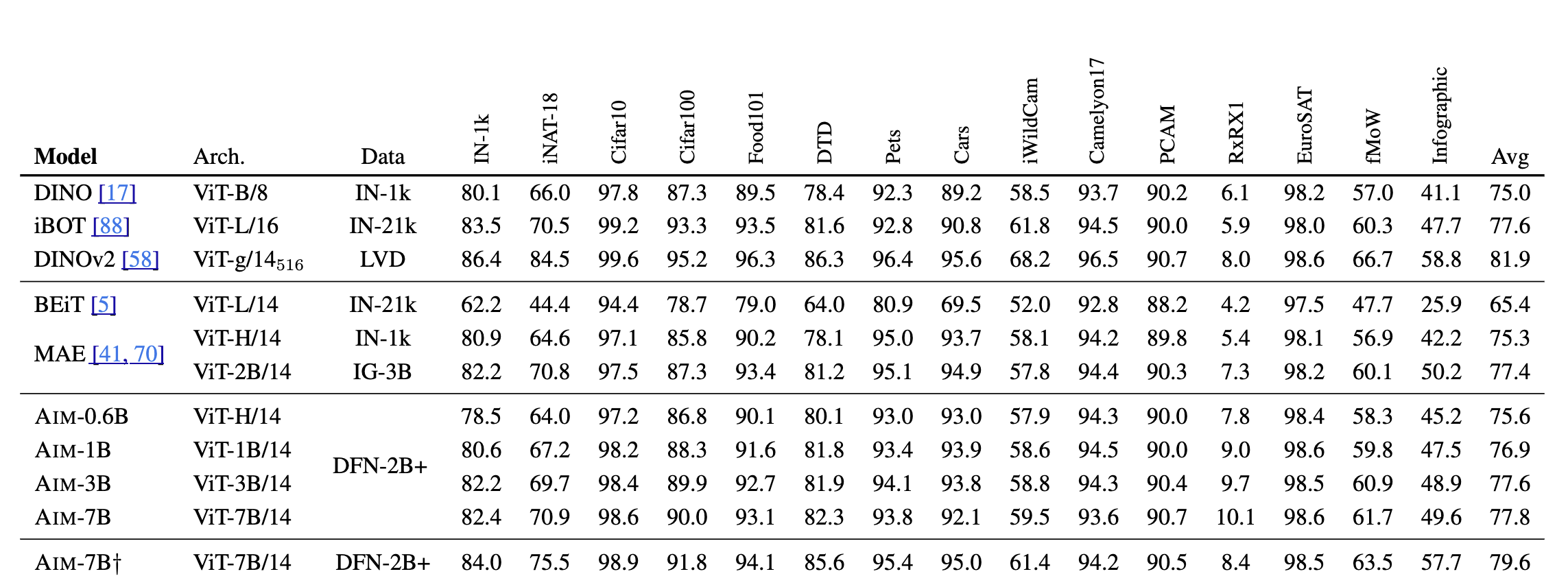
그 결과 AIM은 (1) 모델 파라미터 수와 데이터 크기를 확장할수록 성능이 지속적으로 향상되며 포화(saturation)의 징후가 보이지 않았습니다. 또한, (2) AIM 모델은 동결된 트렁크(frozen trunk)로 15개 비전 벤치마크에서 경쟁력 있는 성능을 보이며, 가장 큰 모델은 ImageNet-1k에서 84.0% 정확도를 기록했습니다.
AIMv2의 연구 소개

AIM에서는 ViT(Vision Transformer) 기반 인코더를 중심으로 설계 및 학습 후, 다운스트림 작업에서는 인코더 가중치를 고정(frozen) 시킨 후 특징을 추출했습니다. 하지만 AIMv2에서는 멀티모달 디코더를 추가하여 이미지 패치와 텍스트 토큰을 자기회귀적으로 생성하도록 하였습니다. 이를 통해 기존의 대조학습(Contrastive Learning) 기반의 CLIP과 같은 모델과 달리, AIMv2는 생성 중심의 접근 방식을 취하고 있습니다.
AIMv2는 Localization, Grounding, Classification 등 여러 다운스트림 작업에서 기존의 대조학습 기반의 모델인 CLIP이나 SigLIP 대비 탁월한 성능을 보입니다. 특히, 89.5%의 ImageNet-1k 정확도를 달성했으며, 시각적 이해와 멀티모달 작업에서 모두 뛰어난 성능을 보이는 것이 특징입니다:
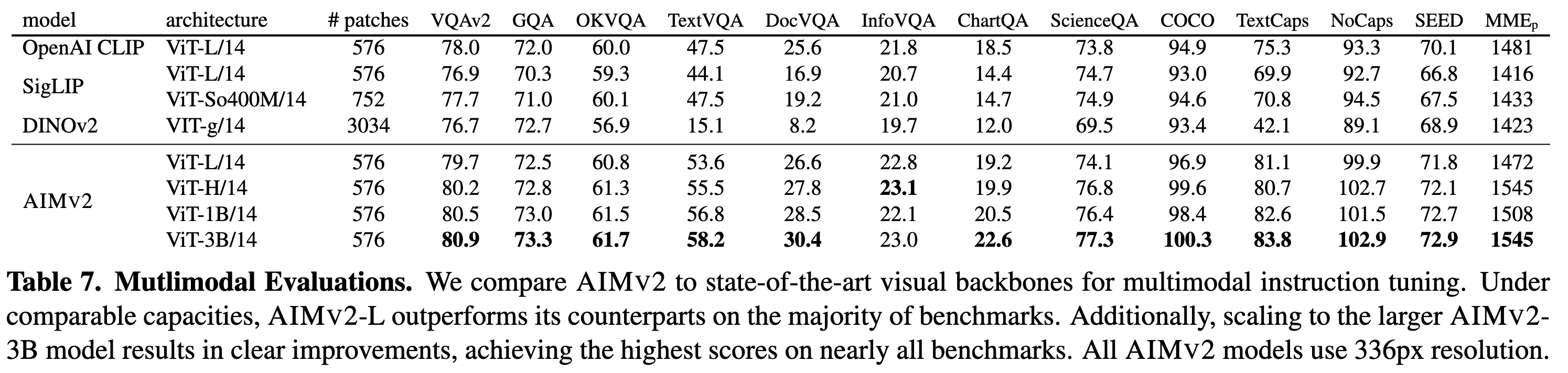
AIMv2와 CLIP, DINOv2와의 비교해보면 다음과 같습니다:
| 모델 | 특징 및 강점 | 단점 |
|---|---|---|
| AIMv2 | 멀티모달 및 이미지 이해에서 높은 성능, 다양한 해상도 지원 | 학습 및 사용을 위해 고사양 필요 |
| CLIP | 텍스트-이미지 연결 작업에서 높은 성능 | 멀티모달 확장성이 제한적 |
| DINOv2 | 객체 탐지에서 우수한 성능 | 멀티모달 성능은 제한적 |
AIMv2 모델 개요
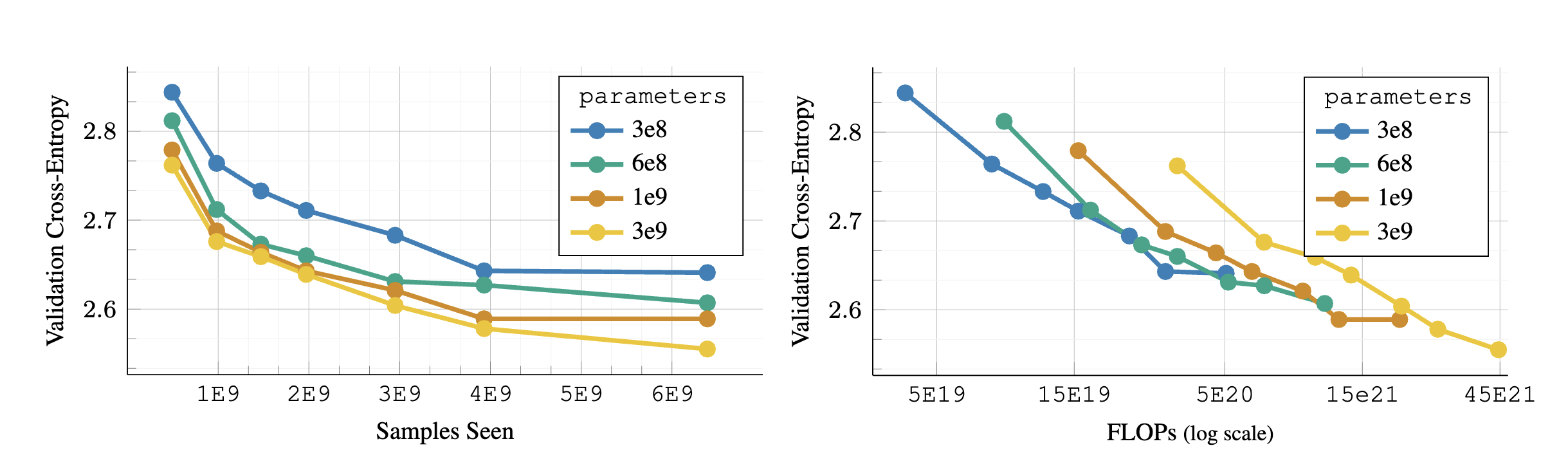
AIMV2 모델은 기존 단일 모달 오토레그레시브 프레임워크를 다중 모달 환경으로 확장하여 이미지와 텍스트를 통합합니다. 이미지 데이터는 패치로 나뉘며, 텍스트 데이터는 서브워드 토큰으로 변환되어 시퀀스로 결합됩니다. 이 과정에서 이미지 토큰과 텍스트 토큰이 상호 참조할 수 있도록 설계되었습니다.
AIMV2의 비전 인코더는 Vision Transformer(ViT) 아키텍처를 채택하였으며, 패치 데이터에 대한 프리픽스 어텐션(prefix attention)을 활용합니다. 멀티모달 디코더는 이미지와 텍스트 데이터를 결합하여 오토레그레시브 방식으로 처리하며, 두 가지 토큰 유형을 동시에 다룰 수 있도록 설계되었습니다.
사전 학습 시에는 대규모 공개 데이터셋(예: COYO)과 고품질 이미지-텍스트 쌍 데이터를 포함하는 비공개 데이터셋을 결합하여 사용하였습니다. 데이터셋의 샘플링 확률은 사전 정의된 비율에 따라 조정되었습니다.
또한, 모델의 사전 학습 성능을 한층 강화하기 위해 고해상도 이미지 데이터(예: 336px 및 448px)를 사용한 추가 학습이 수행되었습니다. 이러한 사후 학습은 객체 탐지 및 분할과 같은 고해상도 작업에 적합한 모델을 만드는 데 초점을 맞췄습니다.
실험 결과 및 분석
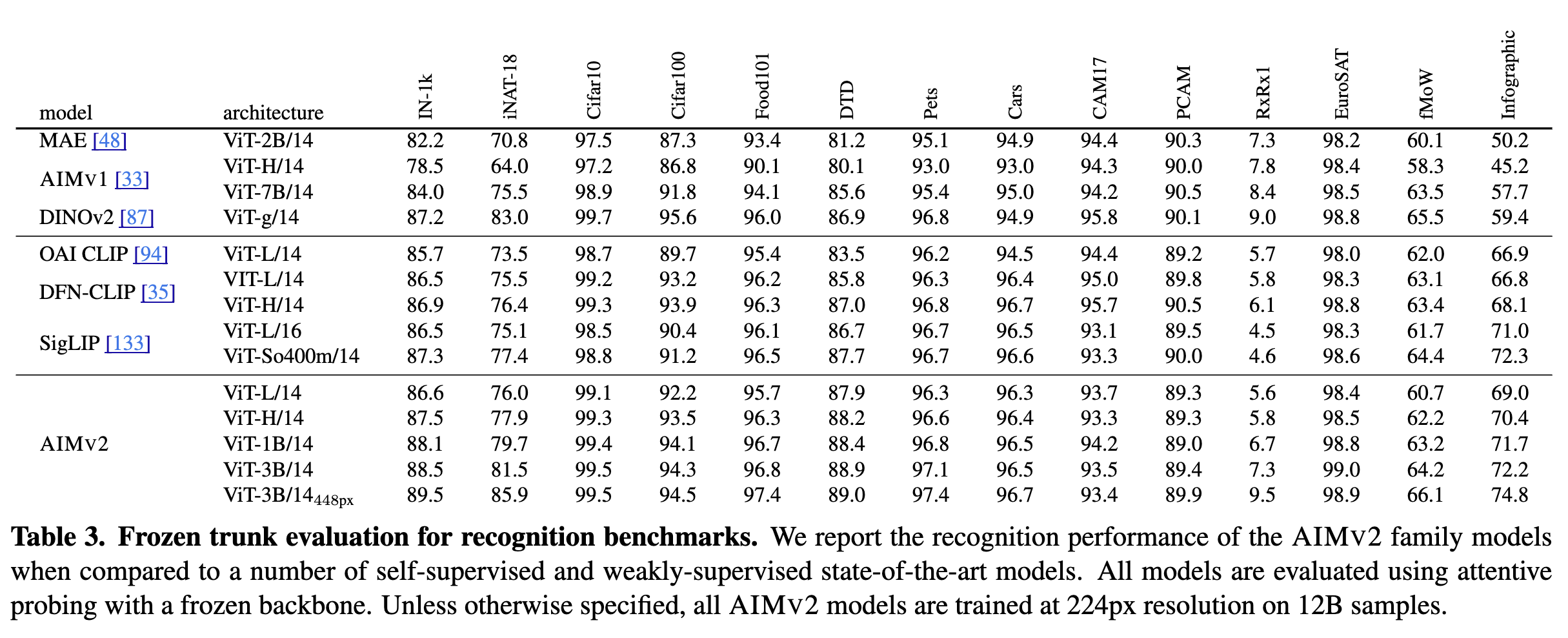
AIMV2는 다양한 이미지 인식 작업에서 높은 성능을 기록하였습니다. 특히, 고정된 트렁크(frozen trunk)로 ImageNet-1k에서 89.5%의 정확도를 달성하였으며, 기존 대조 모델들(CLIP, DINOv2) 대비 우수한 성능을 보였습니다. 또한, 객체 탐지(Object Detection) 및 시각적 참조 표현(Referring Expressions) 작업에서 더 나은 성능을 입증하였습니다.
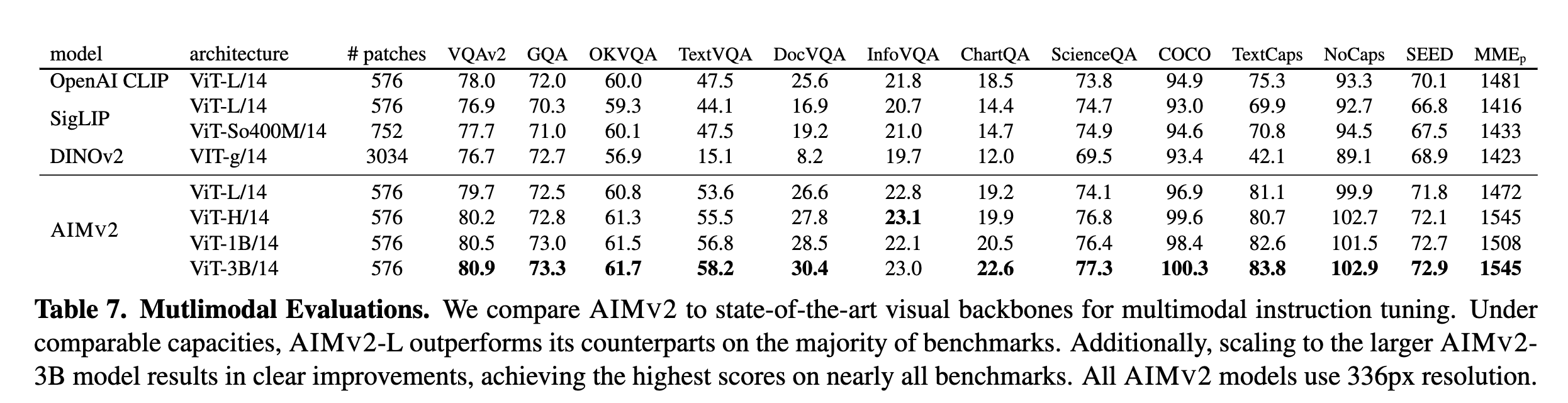
마지막으로 멀티모달 이해(Multimodal Understanding) 분야에서 다양한 질문 응답 및 캡셔닝 작업에서 AIMV2는 기존 대비 우수한 성능을 기록했습니다. 특히, 3B 모델 크기로 확장한 AIMV2는 대부분의 벤치마크에서 최고 성능을 기록하였습니다.
AIMV2는 간단한 설계 덕분에 구현과 확장이 용이합니다. 데이터 및 모델 크기를 확장할 때 성능이 지속적으로 향상되는 것을 관찰했으며, 이는 대규모 데이터셋 및 연산 예산에 적합한 특성을 보여줍니다.
 Apple의 AIMv2 논문: Multimodal Autoregressive Pre-training of Large Vision Encoders
Apple의 AIMv2 논문: Multimodal Autoregressive Pre-training of Large Vision Encoders
Apple의 AIMv1 논문: Scalable Pre-training of Large Autoregressive Image Models
 Apple의 AIMv1 및 AIMv2 GitHub 저장소
Apple의 AIMv1 및 AIMv2 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()