
OpenPipe의 ART 프로젝트 소개
OpenPipe에서 공개한 Agent Reinforcement Trainer(ART)는 LLM 기반 에이전트를 강화 학습으로 훈련할 수 있는 오픈소스 라이브러리입니다. 기존 코드베이스를 거의 변경하지 않고도 강화 학습을 적용할 수 있어, 에이전트의 성능 향상을 원하는 개발자들에게 매우 유용합니다. 현재는 GRPO 알고리즘만 지원하지만, 향후 PPO 등 다른 기법들도 지원할 예정입니다.
OpenPipe의 ART는 LLM 기반 에이전트의 성능을 강화 학습을 통해 향상시키기 위한 오픈소스 라이브러리입니다. 기존의 강화 학습 라이브러리들과 달리, ART는 에이전트 실행을 기존 코드베이스에서 그대로 유지하면서, 강화 학습 루프의 복잡한 부분을 ART 백엔드에서 처리합니다. 이를 통해 개발자는 최소한의 코드 변경으로 강화 학습을 적용할 수 있습니다.
ART는 GRPO(Generalized Reinforcement Policy Optimization) 알고리즘을 활용하여, 에이전트가 자신의 경험을 통해 학습하도록 지원합니다. 또한, vLLM 및 HuggingFace Transformers와 호환되는 다양한 언어 모델을 지원하므로, 다양한 환경에서 활용이 가능합니다.
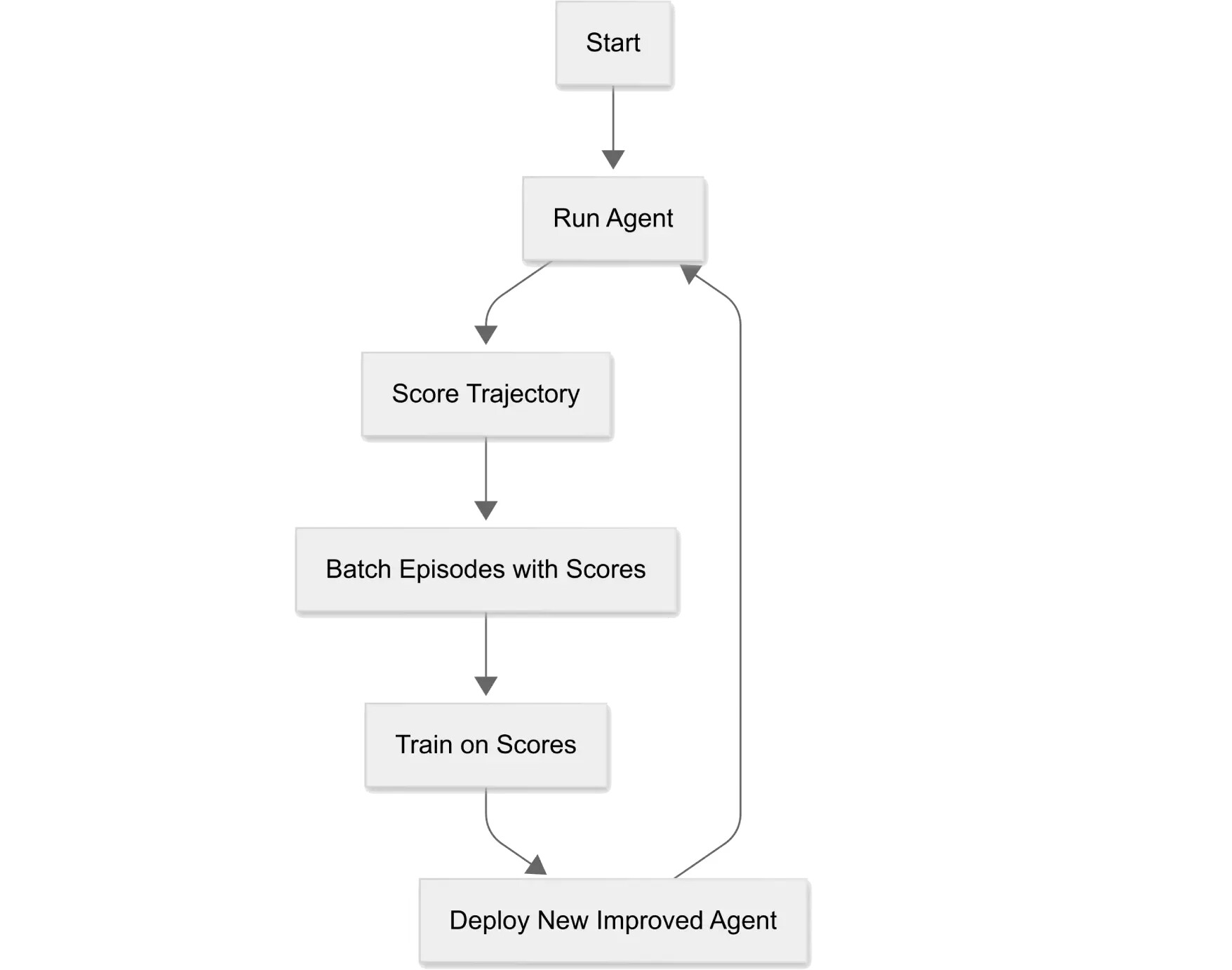
기존의 강화 학습 라이브러리들은 에이전트의 실행과 학습을 모두 개발자가 직접 구현해야 하는 경우가 많았습니다. 이에 비해 ART는 에이전트의 실행은 기존 코드베이스에서 그대로 유지하면서, 학습 루프의 복잡한 부분을 ART 백엔드에서 처리합니다. 이를 통해 개발자는 에이전트의 실행 로직에 집중할 수 있으며, 학습 루프의 구현 부담을 줄일 수 있습니다.
또한, ART는 GRPO 알고리즘을 활용하여, 기존의 PPO(Proximal Policy Optimization)보다 더 일반화된 정책 최적화를 제공합니다. 이를 통해 다양한 환경에서의 학습 성능 향상이 기대됩니다.
ART의 주요 기능
- GRPO 기반 강화 학습: 일반화된 정책 최적화 알고리즘을 활용하여 효율적인 학습 지원
- 기존 코드베이스와의 통합: 에이전트 실행은 기존 코드에서 유지하면서, 학습 루프는 ART 백엔드에서 처리
- 다양한 모델 지원: vLLM 및 HuggingFace Transformers와 호환되는 다양한 언어 모델 지원
- 예제 노트북 제공: 2048, 틱택토 등의 게임을 통한 학습 예제 제공
- SkyPilot 통합: 분산 학습 및 클러스터 환경에서의 실행 지원
사용 방법
ART는 클라이언트와 서버로 구성되어 있습니다. 클라이언트는 기존 코드베이스에서 에이전트의 실행을 담당하며, 서버는 학습 루프를 처리합니다.
- 에이전트 실행: 클라이언트를 통해 에이전트를 실행하고, 실행 결과를 Trajectory로 저장합니다.
- 보상 할당: 각 Trajectory에 대해 보상을 할당합니다.
- 학습 루프 실행: 서버는 수집된 Trajectory를 기반으로 GRPO 알고리즘을 통해 모델을 학습합니다.
- 모델 업데이트: 학습된 모델은 vLLM을 통해 업데이트되며, 이후의 에이전트 실행에 활용됩니다.
자세한 예제는 2048 게임 학습 노트북과 틱택토 게임 학습 노트북을 참고하시기 바랍니다.
ART를 사용한 Agent 강화 예시 노트북
| Agent Task | Example Notebook | Description | Comparative Performance |
|---|---|---|---|
| 2048 | Qwen 2.5 3B learns to play 2048 | benchmarks | |
| Temporal Clue | Qwen 2.5 7B learns to solve Temporal Clue | [Link coming soon] | |
| Tic Tac Toe | Qwen 2.5 3B learns to play Tic Tac Toe | benchmarks |
라이선스
ART(Agent Reinforcement Trainer) 프로젝트는 Apache-2.0 License로 공개 및 배포되고 있습니다. 상업적 사용에 대한 제한은 없습니다.
 ART(Agent Reinforcement Trainer) 프로젝트 소개 블로그
ART(Agent Reinforcement Trainer) 프로젝트 소개 블로그
 ART(Agent Reinforcement Trainer) 프로젝트 GitHub 저장소
ART(Agent Reinforcement Trainer) 프로젝트 GitHub 저장소
https://github.com/OpenPipe/ART
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()