AutoTTS 소개
새로운 보드게임을 처음 배울 때를 떠올려 봅시다. 우리는 보통 고수들이 정리해 둔 정석(定石)을 외우는 것에서 시작합니다. 하지만 진짜 실력은, 수많은 판을 직접 두면서 "여기서는 공격적으로, 저기서는 물러서야 한다"는 감각을 스스로 체득할 때 늘어납니다. 정석은 출발점일 뿐, 최적의 수는 결국 게임 환경 안에서 직접 찾아내는 것입니다.
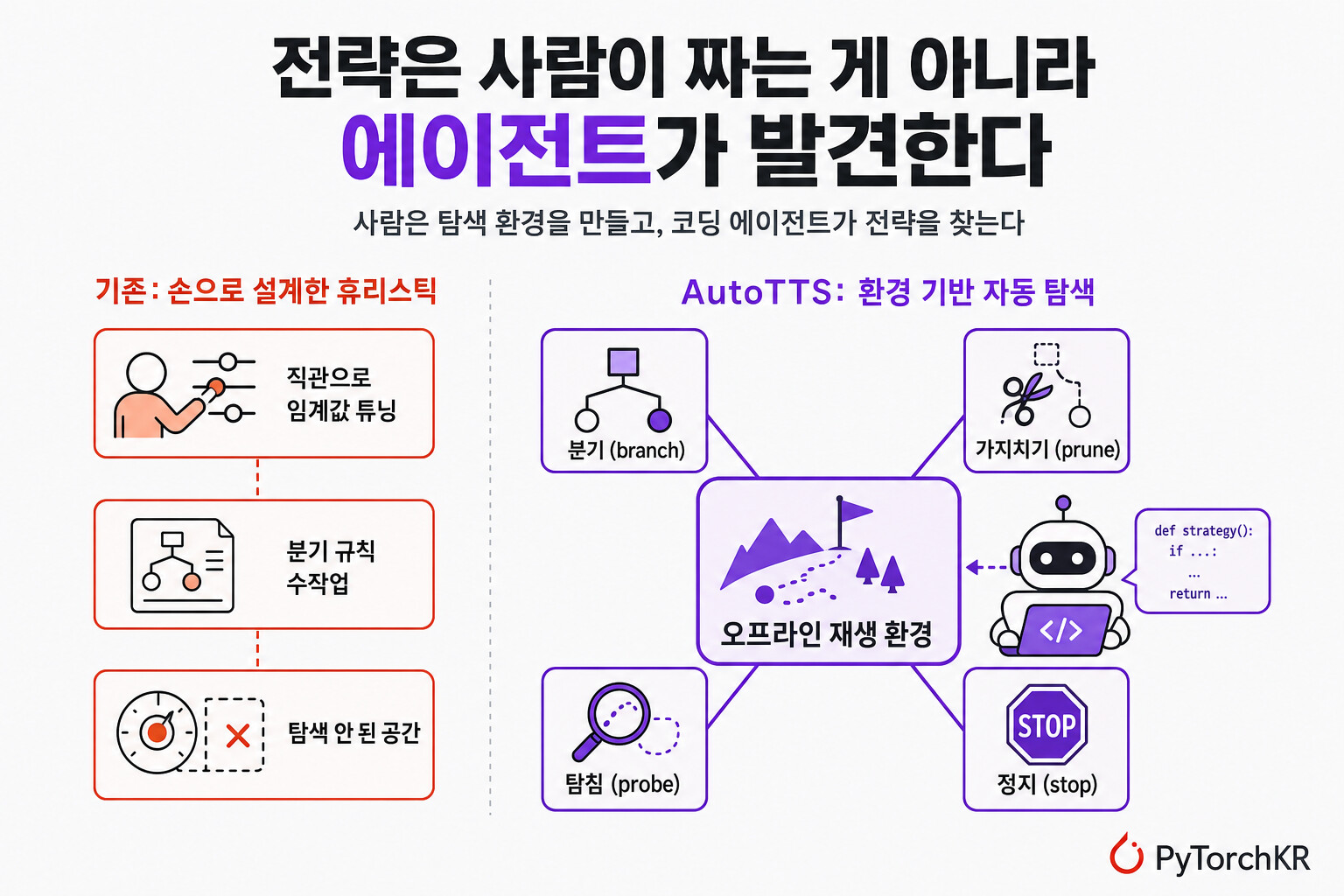
이 논문은 대형 언어 모델(Large Language Model, LLM)의 추론 시점 연산 배분 전략, 즉 Test-Time Scaling(TTS) 을 바로 이 관점에서 다시 봅니다. 지금까지 TTS 전략은 연구자가 직관으로 손수 설계하는 정석에 가까웠습니다. 이 논문은 사람이 전략 자체를 설계하는 대신 전략을 탐색할 수 있는 환경(environment)을 설계하고, 코딩 에이전트가 그 환경 안에서 더 나은 전략을 자동으로 발견하게 만드는 AutoTTS 프레임워크를 제안합니다. UMD, UVA, WUSTL, UNC, Google, Meta 연구진이 공동으로 참여했습니다.
Test-Time Scaling이란 무엇이고, 왜 어려운가
Test-Time Scaling(TTS) 은 모델을 추가로 학습시키지 않고, 추론(inference) 시점에 연산을 더 투입하여 성능을 끌어올리는 방법론입니다. 가장 단순한 형태는 같은 문제에 대해 여러 개의 추론 경로(reasoning trajectory)를 뽑은 뒤 다수결로 답을 정하는 Self-Consistency 입니다. 최근에는 어려운 수학 문제나 코딩 문제에서 이런 추론 시점 연산 확장이 사전 학습 못지않게 중요한 성능 레버로 자리 잡았습니다.
문제는 성능이 단순히 "연산을 얼마나 썼는가"가 아니라 "연산을 어떻게 배분했는가"에 크게 좌우된다는 점입니다. 저자들은 "성능은 사용한 연산의 총량이 아니라 그것을 어떻게 할당하느냐에 달려 있다" 고 지적합니다. 그런데 이 배분 전략은 대부분 사람이 손으로 만든 것입니다. 연구자가 "언제 새 추론 가지를 펼치고(branch), 언제 더 깊이 이어가고(deepen), 언제 중간 답을 확인하고(probe), 언제 가지를 쳐내고(prune), 언제 멈출지(stop)"에 대한 휴리스틱을 직관으로 가설하고, 코드로 구현하고, 임계값을 손으로 튜닝합니다.
여기서 핵심 통찰이 나옵니다. 겉보기에 제각각인 기존 TTS 방법들도, 사실은 어떤 공통된 연산 배분 공간(computation-allocation space) 안에서 사람이 수동으로 지정한 정책으로 해석할 수 있다는 것입니다. 대표적인 예가 너비-깊이 공간(width-depth space) 입니다. 여기서 너비(width)는 몇 개의 추론 가지를 탐색하는지를, 깊이(depth)는 각 가지를 얼마나 멀리까지 전개하는지를 나타냅니다.
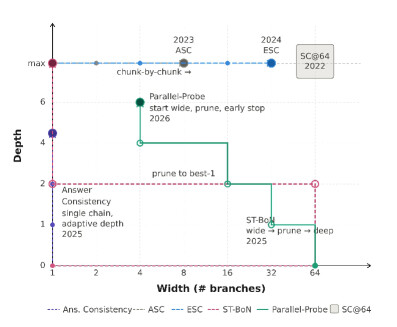
이 관점에서 보면 기존 방법들은 같은 공간을 서로 다른 경로로 지나갑니다.
- SC@64 (Self-Consistency): 64 개의 추론 경로를 한꺼번에 끝까지 뽑는, 너비-깊이 공간의 고정된 최대 예산 코너에 머무는 방식입니다. 강력하지만 모든 문제에 동일한 풀 예산을 쏟아 비효율적입니다.
- ASC, ESC: 최대 깊이에서 너비 축만 적응적으로 조절합니다. 즉 끝까지 생성하되, 답이 충분히 안정되면 경로 샘플링을 일찍 멈춥니다. 깊이를 조절하지는 못합니다.
- Answer Consistency: 반대로 단일 추론 체인에서 깊이 축만 조절합니다.
- Parallel-Probe: 넓게 펼친 뒤 점진적으로 가지를 쳐내면서 깊이를 더해 갑니다.
이렇게 다양한 알고리즘이 하나의 구조화된 제어 공간 안에서 손으로 설계한 특수 사례들이라면, 자연스러운 질문이 떠오릅니다. "이 공간 전체를 사람의 직관이 아니라 자동 탐색으로 뒤져보면 어떨까?" 너비-깊이 공간은 넓고, 사람이 직접 손대지 않은 영역이 훨씬 많기 때문입니다.
발상의 전환: 전략이 아니라 환경을 설계한다
AutoTTS의 핵심 발상은 사람의 역할을 옮기는 것입니다. 기존에는 사람이 분기, 가지치기, 정지 휴리스틱을 직접 만들었다면, AutoTTS에서는 사람이 탐색 환경을 만듭니다. 즉 상태(state), 행동(action), 피드백(feedback), 목표(objective)를 정의해서 제어 공간을 규정하고, 에이전트가 그 공간 안에서 효과적인 배분 정책을 찾아내도록 합니다.
이는 마치 과학자가 모든 실험을 손수 수행하는 대신, 잘 통제된 실험실과 측정 장비를 갖춰 두고 다양한 가설을 빠르게 검증할 수 있게 만드는 것과 비슷합니다. 좋은 실험실(환경)만 갖춰지면, 그 안에서 어떤 전략이 좋은지는 탐색이 알아서 밝혀줍니다.
다만 이 발상을 실제로 작동시키려면 환경 구성이 결정적으로 중요합니다. 저자들은 "AutoTTS의 핵심은 환경 구성에 있다" 고 강조합니다. 탐색 환경은 두 가지 조건을 만족해야 합니다. 첫째, 제어 공간이 다룰 수 있을(tractable) 만큼 정리되어 있어야 하고, 둘째, 탐색을 위한 저렴하고 빈번한 피드백을 줄 수 있어야 합니다. 이 두 조건을 어떻게 충족시키는가가 이 논문의 기술적 핵심입니다.
미리 결과를 살짝 언급하자면, AutoTTS가 발견한 전략은 강력한 수작업 베이스라인들의 정확도-비용 파레토 프론티어(Pareto frontier)를 넘어섰고, 탐색에 쓴 적이 없는 벤치마크와 모델 크기로도 일반화되었습니다. 그러면서 전체 탐색 비용은 단돈 \$39.9 와 160 분에 불과했습니다.
핵심 방법론: 환경 기반 자동 탐색
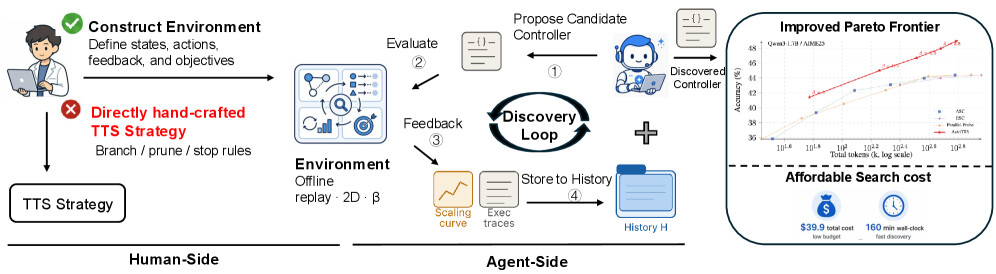
AutoTTS는 너비-깊이 TTS를 컨트롤러 합성(controller synthesis) 문제로 정식화합니다. 각 문제에 대해 컨트롤러는 상태를 관찰하고, 언제 분기/계속/탐침/가지치기/정지할지를 결정하는 코드로 정의된 정책입니다. 이 절에서는 이 탐색을 실제로 가능하게 만드는 세 가지 설계 선택을 차례로 살펴봅니다.
너비-깊이 제어를 위한 상태와 행동 정의
먼저 환경의 인터페이스를 정해야 합니다. 매 결정 단계 t 에서 컨트롤러가 보는 상태는 질문 q, 지금까지 만든 가지의 수 m_t, 현재 활성 가지 집합 I_t, 각 가지의 깊이 \ell_t, 생성된 프리픽스 Z_t, 그리고 지금까지 드러난 탐침 피드백 \Omega_t 로 구성됩니다. 여기서 한 가지의 깊이 \ell_{t,i} 는 그 가지에서 고정 길이의 생성 구간(interval)을 몇 번 거쳤는지를 뜻합니다.
컨트롤러가 취할 수 있는 행동(action)은 다섯 가지입니다.
- BRANCH: 새 추론 가지를 하나 열고 첫 구간까지 전진시킵니다. (너비 확장)
- CONTINUE(i): 가지 i 를 한 구간만큼 더 깊이 이어갑니다. (깊이 확장)
- PROBE(i): 가지 i 를 더 전진시키지 않고, 현재 시점에서 그 가지가 내놓을 중간 답 \omega_{i,\ell} 을 들여다봅니다.
- PRUNE(i): 가지 i 를 활성 집합에서 제거합니다. 단 그동안 쌓인 정보는 그대로 남습니다.
- ANSWER: 추론을 종료하고 집계 규칙(aggregation rule)을 적용해 최종 답을 냅니다.
연산 비용은 구간 단위로 측정합니다. 한 상태의 비용은 모든 가지의 깊이 합 \sum_{i} \ell_{t,i} 에 탐침 비용 \kappa_{\text{probe}}|\Omega_t| 를 더한 값입니다. 탐침이 생성에 비해 사실상 공짜인 설정에서는 \kappa_{\text{probe}}=0 으로 둡니다.
최종 목표는 정확도를 최대화하면서 연산 비용을 통제하는 코드 정의 정책 \pi(\cdot \mid s, \beta) 를 찾는 것입니다. 트레이드오프 파라미터 \gamma 를 두고, 다음과 같이 정답일 때 1 의 보상에서 연산 비용에 비례하는 페널티를 뺀 값을 기대값으로 최대화합니다.
오프라인 재생 환경: LLM 호출 없는 평가
이 탐색에서 가장 큰 걸림돌은 평가 비용입니다. 후보 컨트롤러 하나를 온라인으로 평가하려면, 매 결정마다 토큰 구간 z_{i,k} 를 생성하고 중간 답 \omega_{i,k} 를 확인하기 위해 LLM을 실제로 호출해야 합니다. 탐색 과정에서 수많은 후보를 반복 평가해야 하는데, 매번 LLM을 부르는 것은 비용 면에서 감당하기 어렵습니다.
AutoTTS는 이 문제를 오프라인 재생 환경(offline replay environment) 으로 해결합니다. 핵심 아이디어는 모든 LLM 호출을 탐색 이전 으로 옮겨 두는 것입니다. Parallel-Probe의 데이터 수집 방식을 따라, 각 질문 q 에 대해 베이스 LLM으로부터 N 개의 독립적인 추론 경로를 미리 뽑고, 각 경로를 \Delta 토큰 길이의 고정 구간으로 잘라 둡니다. 이렇게 하면 가지 프리픽스 z_{i,1}, z_{i,2}, \ldots 와 탐침 신호 \omega_{i,1}, \omega_{i,2}, \ldots 가 모두 디스크에 저장됩니다.
이제 컨트롤러의 모든 행동은 LLM을 부르는 대신 이 사전 수집 데이터를 결정론적으로 읽어 옵니다. 예를 들어 가지 i 의 깊이 k 에서 PROBE 를 수행하면, 새로 디코딩하는 것이 아니라 미리 저장해 둔 신호 \omega_{i,k} 를 그냥 꺼내 옵니다. 그 결과 후보 컨트롤러는 추가 LLM 호출 없이 저렴하고 결정론적으로 평가됩니다. 저자들의 표현을 빌리면 탐색 평가 과정의 LLM 호출은 정확히 0 번입니다. 마치 체스 기보를 미리 잔뜩 모아 두고, 새로운 전략을 그 기보 위에서 재생(replay)하며 점수만 빠르게 매기는 것과 같습니다.
탐색 루프: 코드를 고쳐 전략을 진화시키다
환경이 갖춰지면 실제 탐색이 시작됩니다. 저자들은 전체 문제 집합 \mathcal{Q} 를 탐색용 \mathcal{Q}_{\text{search}} 와 평가용 \mathcal{Q}_{\text{eval}} 로 나눕니다. 탐색은 여러 라운드의 루프로 진행됩니다.
매 라운드마다 explorer LLM(이 논문에서는 Claude Code) 이 누적된 히스토리 \mathcal{H} 를 읽습니다. 이 히스토리에는 지금까지 제안된 컨트롤러 구현, 각각의 정확도-비용 결과, 그리고 실행 트레이스가 담겨 있습니다. explorer는 이전 제안들이 무엇을 잘못했는지 분석하고, 정확도는 높이면서 토큰 사용은 줄이는 새 컨트롤러를 직접 코드를 수정해서 제안합니다. 제안된 컨트롤러는 \mathcal{Q}_{\text{search}} 에서 평가되고, 그 결과가 다시 \mathcal{H} 에 덧붙여집니다.
여기서 중요한 점은 이 최적화에 경사 갱신(gradient update)이 전혀 없다는 것입니다. 베이스 모델의 파라미터를 미세조정하는 것이 아니라, 에이전트가 명시적인 컨트롤러 프로그램을 고쳐 가며 재생 기반 피드백을 받고, 더 나은 경험적 트레이드오프를 향해 행동을 옮겨 갑니다. 마치 과학계가 선행 연구의 성공과 실패를 기록으로 남기고, 그것을 읽으며 다음 연구를 설계하는 누적적 과정을 코드 탐색으로 구현한 셈입니다.
Beta 파라미터화: 탐색 공간을 1차원으로 압축
저자들은 예비 실험에서 흥미로운 실패 모드를 발견했습니다. 에이전트는 그냥 두면 하이퍼파라미터를 10 개까지 잔뜩 가진 복잡한 컨트롤러를 제안하는 경향이 있었습니다. 그런데 탐색 라운드는 다섯 번뿐이라, 이 고차원 공간을 헤매다 보면 에이전트는 극단적인 해법으로 붕괴해 버립니다. 예를 들어 지나치게 공격적인 가지치기 임계값처럼, 탐색 집합에서만 토큰 비용을 최소화할 뿐 견고한 배분 전략을 대표하지 못하는 해에 빠지는 것입니다. 일종의 과적합(overfitting)입니다.
이를 막기 위해 저자들은 Beta 파라미터화(beta parameterization) 를 도입합니다. 모든 컨트롤러는 오직 하나의 스칼라 하이퍼파라미터 \beta 만 외부에 노출하고, \beta 로부터 내부의 모든 하이퍼파라미터를 결정론적으로 유도하는 매핑 함수를 구현해야 합니다. 게다가 이 매핑은 단조(monotone) 여야 해서, \beta 가 클수록 토큰 예산도 커지도록 강제됩니다. 이렇게 하면 탐색 공간이 1차원 \beta 스윕(sweep)으로 압축되고, 에이전트가 탐색 집합에만 들어맞는 날카로운 임계값을 발견하는 것을 막아 줍니다. 주목할 점은 이 매핑 함수 자체도 코딩 에이전트가 직접 작성한다는 것입니다.
실행 트레이스 피드백: "왜 실패했는가"를 진단하기
탐색을 효율적으로 만드는 마지막 조각은 피드백의 질입니다. 정확도와 토큰 사용량 같은 스칼라 결과는 컨트롤러가 충분히 좋은지에 대한 거친 신호는 주지만, 왜 실패했는지는 거의 알려주지 않습니다.
저자들은 이 한계를 실행 트레이스(execution trace) 로 보완합니다. 각 라운드에서 여러 \beta 값을 스윕해 얻은 스케일링 곡선을 스칼라 성분으로 기록하고, 여기에 더해 컨트롤러가 재생 환경에서 실제로 수행한 결정 한 단계 한 단계의 궤적 을 함께 저장합니다. 어떤 가지가 확장되었고, 어디서 가지치기가 일어났으며, 언제 정지가 발동했는지가 그대로 드러납니다. 이런 세밀한 행동 증거 덕분에 explorer는 실패 모드를 진단하고, 다음 라운드에서 표적화된 개선을 제안할 수 있습니다. 이는 세밀한 실행 피드백이 하니스 엔지니어링에서 에이전트 기반 발견을 돕는다는 선행 연구의 발견과도 일치합니다.
발견된 컨트롤러: Confidence Momentum Controller (CMC)
그렇다면 AutoTTS는 실제로 어떤 전략을 발견했을까요? 다섯 라운드의 탐색 끝에 나온 최종 컨트롤러는 Confidence Momentum Controller(CMC) 로 명명되었습니다. CMC는 사람이 설계하지 않았지만, 그 동작 원리는 명확하고 해석 가능한 네 가지 메커니즘으로 정리됩니다.
추세 기반 정지(trend-based stopping): 초기 제안들(IBC, SCR, DGCC)은 모두 현재 단계의 완료된 답 풀에서 계산한 "순간적인" 다수결 신뢰도를 정지 신호로 썼습니다. 이는 한 번의 운 좋은 신뢰도 급등에 취약합니다. 우연히 같은 답이 일찍 몇 개 뭉치면, 분포가 안정되기도 전에 정지가 발동되어 버립니다. CMC는 이 순간 신뢰도 게이트를 신뢰도의 지수이동평균(EMA)으로 대체합니다. 정지는 EMA 신뢰도가 충분히 높고(레벨 조건), 동시에 그 추세가 비음수일 때(모멘텀 조건)에만 발동됩니다. 즉 한 라운드의 급등만으로는 멈출 수 없고, EMA가 높으면서도 떨어지지 않고 있어야 합니다.
결합된 너비-깊이 제어(coupled width-depth control): 너비 확장과 깊이 확장이 EMA의 변화량(delta)을 통해 서로 연결됩니다. 신뢰도가 강하게 오르는 중이면 새 가지 생성을 억제하고(곧 정지할 가능성이 높으니), 정체되거나 후퇴하면 새 가지를 펼칩니다. 깊이를 더 파는 것이 증거 품질의 향상으로 이어지는지에 따라 너비 결정이 직접 결합되는, 기존 제안에는 없던 피드백 루프입니다.
정렬 인식 깊이 배분(alignment-aware depth allocation): 가장 최근 답이 현재 풀의 우세 답(pool winner)과 일치하는 가지에는 추가 탐침 단계를 더 줍니다. 떠오르는 합의에 연산을 집중하되, 활성 가지들도 계속 전진시킵니다. 구체적으로는 각 가지가 받은 탐침 횟수를 기준으로 우선순위 큐를 만들어, 완성에 가장 가까운(많이 투자된) 가지부터 우선 서비스합니다.
보수적 가지 포기(conservative branch abandonment): 한 가지는 여러 라운드 동안 지속적으로 우세 답에서 벗어났을 때에만 포기됩니다. 그리고 어떤 경우에도 최소 2 개의 활성 가지는 보존합니다. 단발성 불일치로 성급하게 가지를 버리지 않는 것입니다.
이 네 메커니즘은 모두 코드로 정의된 컨트롤러 로직으로 구현되었고, 수작업 베이스라인과 동일한 재생 환경에서 평가되었습니다. 흥미로운 점은, 이들이 사람이 만든 정석(IBC, SCR, DGCC)의 약점을 한 단계씩 진단하며 진화한 산물이라는 것입니다. CMC는 모든 순간 게이트를 단일 EMA 모멘텀 게이트로 교체하고, 탐침 횟수 기반 우선순위 스케줄링을 새로 도입했습니다.
실험 결과 및 성능 분석
실험 설정
모든 실험은 오프라인 재생 환경에서 수행되었으며, 각 환경은 특정 (모델, 벤치마크) 쌍으로 구성됩니다. 베이스 모델로는 네 가지 크기의 Qwen3 모델($0.6$B, $1.7$B, $4$B, $8$B)을 사용했습니다. Parallel-Probe를 따라 각 (모델, 문제) 쌍마다 온도 0.7 에서 128 개의 추론 경로를 미리 샘플링하고, 탐침 간격은 500 토큰으로 두어 재생 행렬을 만들었습니다. 분산을 줄이기 위해 각 컨트롤러는 128 개 풀에서 부분집합을 무작위로 뽑아 64 번 독립 평가한 뒤 평균을 냈습니다.
탐색에는 AIME24 를 \mathcal{Q}_{\text{search}} 로 사용했고, 네 모델의 AIME24 환경을 합쳐 탐색 환경을 구성했습니다. 탐색 루프는 Claude Code를 에이전트로 하여 다섯 라운드 돌렸습니다. 발견된 컨트롤러는 고정한 뒤, 탐색이나 선택에 한 번도 쓰이지 않은 AIME25 와 HMMT25 환경에서 평가했습니다.
비교 대상 베이스라인은 대표적인 수작업 TTS 방법들입니다. 64 개 경로를 뽑아 다수결하는 SC@64, 임계값 0.95 에서 멈추는 ASC, 슬라이딩 윈도우로 답 안정성을 감지하는 ESC(청크 크기 8), 그리고 가지 간 정보를 활용하는 Parallel-Probe 입니다.
주요 결과
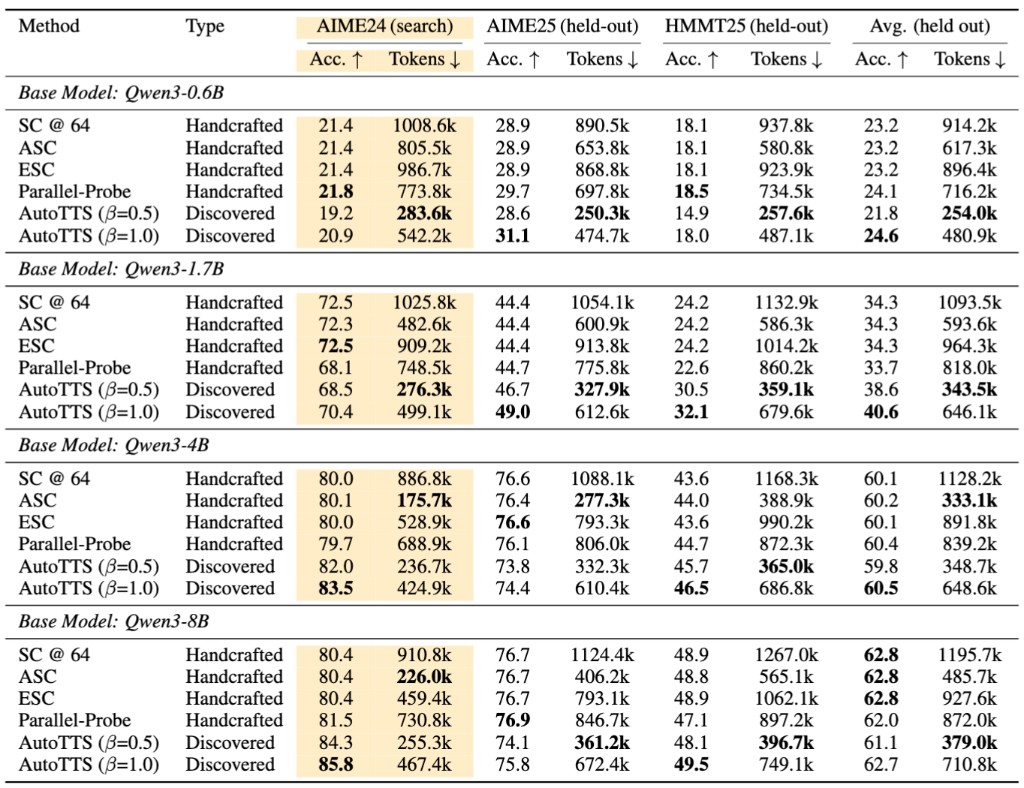
핵심 결과는 두 가지로 요약됩니다. 첫째, 일반화 입니다. AIME24만으로 최적화한 컨트롤러가 held-out 벤치마크인 AIME25와 HMMT25로 전이되어, 네 모델 중 세 모델에서 평균적으로 모든 수작업 베이스라인을 앞섰습니다. 가장 큰 Qwen3-8B에서도 62.7 대 62.8(SC@64)로 사실상 대등했습니다. 탐색에 쓰지 않은 문제 분포로도 전략이 그대로 통한다는 것은, 발견된 로직이 탐색 집합에 과적합된 잔재가 아니라 일반적인 배분 원리를 담고 있음을 시사합니다.
둘째, 정확도-토큰 트레이드오프 입니다. 트레이드오프 파라미터를 \beta=0.5 로 두면, 네 모델 평균 정확도를 SC@64와 거의 동일하게 유지(45.3 대 45.2)하면서 토큰 소비를 약 69.5\% 줄였습니다. 같은 정확도를 약 \frac{1}{3} 의 연산으로 달성한 것입니다. 반대로 \beta=1.0 으로 예산을 키우면, 8 개 비교 셀 중 5 개에서 모든 수작업 베이스라인을 넘는 최고 정확도를 기록했습니다.
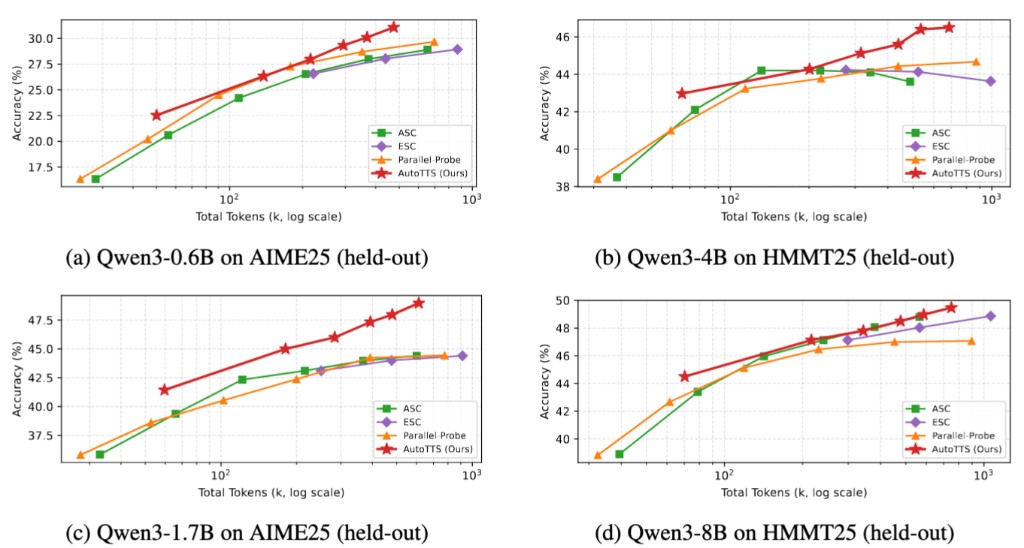
위 스케일링 곡선은 이 트레이드오프를 직관적으로 보여줍니다. 수작업 베이스라인은 샘플링하는 경로 수를 바꿔 예산을 조절하고, 발견된 컨트롤러는 \beta 를 바꿔 조절합니다. 네 설정 모두에서 발견된 컨트롤러의 곡선이 다른 곡선들 위에 위치하며, 더 강한 정확도-효율 프론티어를 그립니다. 게다가 발견된 컨트롤러는 단순히 같은 정확도를 더 싸게 내는 데 그치지 않고, 도달 가능한 최고 성능 자체를 끌어올렸습니다. 이는 컨트롤러가 잡음이 많거나 생산적이지 않은 가지를 더 잘 식별해 낸다는 뜻입니다.
다른 모델 계열과 비수학 과제로의 일반화
발견된 전략이 Qwen 기반 수학 설정에만 들어맞는 것은 아닌지 확인하기 위해, 저자들은 두 가지 표적 일반화 시나리오를 추가로 검증했습니다.
첫 번째는 DeepSeek-R1-Distill-Llama-8B 라는 전혀 다른 계열(Llama 기반, DeepSeek-R1에서 증류)의 모델을 HMMT25에서 평가한 것입니다. \beta=1 일 때 발견된 컨트롤러는 모든 방법 중 최고 정확도를 내면서, 총 토큰을 SC@64의 $985.7$K에서 $533.9$K로 줄였습니다. 더 낮은 예산인 \beta=0.5 변형은 토큰을 $279.0$K까지 더 줄였고, 정확도는 소폭만 떨어졌습니다.
두 번째는 GPQA-Diamond 라는 비수학(non-math) 추론 벤치마크를 Qwen3-1.7B로 평가한 것입니다. 여기서도 \beta=1 과 \beta=0.5 변형 모두 SC@64와 비슷하거나 약간 더 나은 정확도를 내면서 훨씬 적은 토큰을 썼습니다. 특히 \beta=0.5 변형은 토큰을 $510.0$K에서 $151.0$K로 줄였고, 정확도와 토큰 사용 양쪽에서 ASC를 앞섰습니다. 발견된 전략이 다른 모델 계열과 비수학 추론 과제로도 전이된다는 강력한 증거입니다.
Ablation: 무엇이 탐색을 작동하게 했는가
저자들은 두 가지 핵심 설계 선택, 즉 Beta 파라미터화와 히스토리 설계가 정말로 중요한지 ablation으로 검증했습니다. AIME24, AIME25, HMMT25에서 네 모델 평균 점수를 비교했습니다.
Beta 파라미터화를 제거 하면, 컨트롤러가 자유 하이퍼파라미터를 과도하게 갖게 되어 탐색 공간이 커지고 \mathcal{Q}_{\text{search}} 에 쉽게 과적합됩니다. 이 과적합은 탐색 집합에서만 잘 작동하는 지나치게 공격적인 가지치기 및 정지 임계값으로 나타나, held-out 성능이 떨어집니다.
실행 트레이스를 제거 하면 탐색 효율이 크게 나빠집니다. 저자들은 "상세한 실행 트레이스가 컨트롤러 탐색에 필수적" 이라고 결론짓습니다. 트레이스는 어떤 가지가 확장되고 가지치기되는지 같은 중간 결정을 드러내며, 이것이 없으면 explorer는 스칼라 결과만 보고 어둠 속에서 더듬는 셈이 됩니다.
탐색 비용
마지막으로 이 모든 것이 얼마나 저렴한지를 봅시다. 다섯 라운드의 전체 탐색 과정은 단돈 \$39.87 와 160 분이 들었습니다. 오프라인 재생 덕분에 탐색 중 추가 LLM 호출이 없기 때문에, 한 번 환경을 구축해 두면 그 위에서 전략을 발견하는 비용은 미미합니다. 사람이 며칠에 걸쳐 휴리스틱을 가설하고 튜닝하던 작업을, 환경 하나에 40 달러도 안 되는 비용으로 대체한 것입니다.
한계점 및 의의
이 연구의 가장 솔직한 한계는 개념 증명(proof-of-concept)의 범위 입니다. 저자들은 AutoTTS를 너비-깊이 공간이라는 구조화된 제어 공간 위에서 구현했습니다. 그런데 실제 TTS 방법 중에는 트리 탐색(tree search)이나 검증자 기반 정제(verifier-guided refinement)처럼 2차원 너비-깊이 추상으로는 담기 어려운 더 풍부한 구조를 가진 것들도 많습니다. AutoTTS가 이런 더 일반적인 환경으로 확장될 수 있을지는 후속 연구의 몫입니다.
또한 발견 과정 자체가 오프라인 재생 환경의 품질에 의존합니다. 사전 수집한 경로의 수 N, 구간 길이 \Delta, 탐침 신호의 정확도 같은 환경 설계 선택이 탐색이 도달할 수 있는 전략의 상한을 결정합니다. 결국 "사람이 전략 대신 환경을 설계한다"는 것은 설계 부담을 없앤 것이 아니라 더 추상적인 층위로 옮긴 것이며, 좋은 환경을 만드는 것 자체에 여전히 사람의 통찰이 필요합니다.
그럼에도 이 연구가 던지는 메시지는 분명합니다. TTS 연구가 발전하는 방식이 전략 설계(strategy design)에서 환경 설계(environment design)로 옮겨갈 수 있다는 것입니다. 좋은 환경만 주어지면 효과적인 추론 시점 연산 배분 전략은 자동으로 발견될 수 있고, 그 발견은 경사 갱신 없이 코드를 진화시키는 것만으로도 가능합니다. 저자들의 표현대로 "인간의 노력을 투자해야 할 올바른 자리는 전략 설계가 아니라 환경 설계" 입니다. LLM이 LLM의 추론 전략을 직접 개선한다는 이 논문의 부제처럼, AutoTTS는 모델 개선의 한 축이 사람의 손에서 에이전트의 탐색으로 넘어가는 흐름을 보여주는 흥미로운 이정표입니다.
설치 및 사용 방법
AutoTTS의 데이터와 코드는 오픈소스로 공개되어 있습니다. 저장소는 탐색용 재생 저장소(efficient_reasoning_controller/workspace/code_base/environment/)와, 제안자에게 절대 노출되지 않는 held-out 재생 저장소(efficient_reasoning_controller/test_environment/)를 분리해 둡니다. 발견된 CMC 컨트롤러의 전체 소스 코드도 저장소에서 확인할 수 있습니다.
git clone https://github.com/zhengkid/AutoTTS
cd AutoTTS
# 설치 및 재현 방법은 저장소 README의 Install / Reproduction 섹션 참고
 LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling 논문
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling 논문
Test-time scaling 전략을 사람이 손으로 설계하는 대신, 사람은 탐색 환경을 구성하고 코딩 에이전트가 효과적인 연산 배분 전략을 자동으로 발견하게 만드는 환경 기반 프레임워크입니다.
 AutoTTS 프로젝트 홈페이지
AutoTTS 프로젝트 홈페이지
 AutoTTS GitHub 저장소
AutoTTS GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()