
BidirLM 소개: 버려진 GPU 시간을 되살리는 아이디어
오픈소스 생태계에는 이미 수백만 GPU 시간이 투입되어 학습된 Gemma3, Qwen3, Qwen3-VL, Qwen3-ASR 같은 수많은 특화 Causal 디코더 모델이 존재합니다. 그러나 이들은 대부분 생성(generation) 작업에만 활용되고, 검색(retrieval)이나 임베딩처럼 표현(representation)이 핵심인 작업에는 거의 쓰이지 못해왔습니다. 문장/문서 임베딩 시장은 여전히 BERT 계열이나 별도로 재훈련한 특수 인코더가 주도하고 있고, 이 과정에서 이미 존재하는 디코더 모델들의 지식은 거의 재활용되지 못합니다.
BidirLM은 바로 이 격차를 메우기 위해 등장했습니다. Nicolas Boizard, Théo Deschamps-Berger 등이 공개한 이 연구는, 어떤 causal 디코더 LLM이든 강력한 양방향 인코더(Bidirectional Encoder) 로 변환하는 완전한 오픈소스 레시피를 제시합니다. Gemma3와 Qwen3를 대상으로 한 체계적인 ablation을 통해 "어떤 적응 전략이 실제로 효과가 있는가"를 규명하고, 원본 사전학습 데이터 없이도 규모를 키울 수 있는 방법까지 제안했습니다.
여기서 한 걸음 더 나아가, 저자들은 가중치 병합(weight merging) 기법을 활용해 특화된 Causal 모델(비전, 음성 등)의 능력을 텍스트 인코더에 흡수시키는 실험을 진행했고, 그 결과물이 바로 BidirLM-Omni-2.5B입니다. 이렇게 생성한 BidirLM-Omni-2.5B 컴팩트 모델은 텍스트, 이미지, 오디오를 모두 다루면서 기존 옴니모달 및 단일모달 특화 모델들을 벤치마크에서 앞섭니다.
Causal 모델을 양방향으로 만드는 "올바른" 레시피
이러한 시도는 이전부터 있었지만, 지금까지는 정리되지 않고 혼란스러웠습니다. 어떤 연구는 마스킹 단계를 건너뛰고 바로 대조 학습(Contrastive Training)에 돌입하고, 다른 연구는 양방향 어텐션을 켜거나 Causal 마스킹을 그대로 두는 등, 어떤 조합이 최적인지에 대한 합의가 없었습니다.
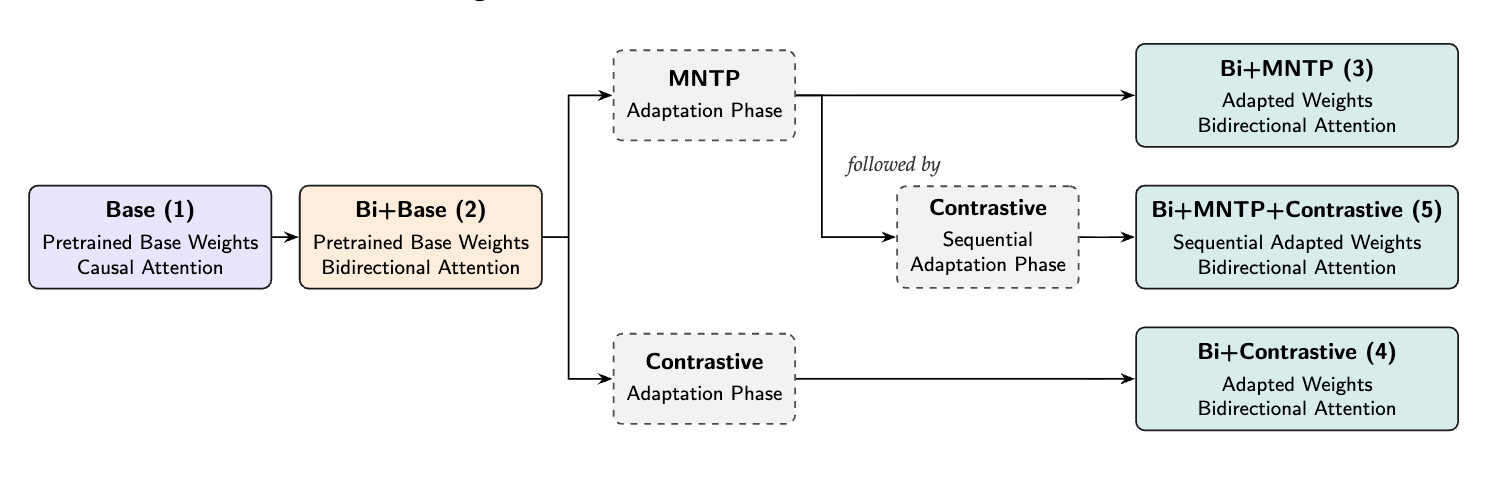
저자들은 Gemma3와 Qwen3 두 계열에서 다섯 가지 적응 변형을 통제된 조건으로 비교했습니다:
- Base (1): 원본 causal 모델
- Bi+Base (2): Base에 양방향 어텐션만 활성화
- Bi+MNTP (3): Bi+Base에 MNTP(Masked Next-Token Prediction) 적응 단계 추가
- Bi+Contrastive (4): Bi+Base에 대조 학습 단계 추가
- Bi+MNTP+Contrastive (5): Bi+Base에 MNTP를 먼저 적용한 뒤 대조 학습 수행
결과는 명확했습니다. 단순히 어텐션 마스크를 causal에서 bidirectional로 뒤집기만 해서는 결과가 들쭉날쭉했습니다. 모델은 양방향 컨텍스트를 사용하는 법 자체를 학습해야 하며, 그 역할을 담당하는 것이 바로 MNTP(Masked Next-Token Prediction) 단계입니다. 이 단계를 거친 뒤 대조 학습을 적용하면 범용 임베딩 품질이 크게 향상됩니다.

핵심 발견은 "최근의 contrastive-only 접근법은 임베딩 성능을 얻는 대신 파인튜닝 품질을 희생한다" 는 것입니다. MNTP 단계를 앞에 붙이면 두 가지를 모두 가져갈 수 있습니다. 이 MNTP → Contrastive 2단계 파이프라인이 모든 BidirLM 모델의 백본 레시피가 됩니다.
원본 데이터 없이 스케일업하기: 파국적 망각과의 싸움
문제는 여기서부터 시작됩니다. 최근 공개된 적응형 인코더들은 대부분 원본 모델을 훈련한 조직(Google, Alibaba 등)에서 나옵니다. 이들은 원본 사전학습 데이터를 보유하고 있어 적응 과정에서 자연스럽게 파국적 망각(Catastrophic Forgetting) 을 방지할 수 있습니다. 하지만 제3자 연구자에게는 그 데이터가 없고, 다른 분포의 데이터로 적응 훈련을 확장하면 모델이 기존에 알던 언어, 코드, 수학 지식을 잃어버립니다.
저자들도 이를 직접 관찰했습니다. 영어 전용 데이터로 MNTP 훈련을 10B에서 30B 토큰으로 확장하자, Gemma는 아랍어 검색에서 7점이 떨어졌고, Qwen은 수학과 코드에서 성능이 후퇴했습니다.

저자들이 찾아낸 해결책은 두 가지 가벼운 전략의 조합입니다:
-
선형 가중치 병합(Linear weight merging): 적응된 모델의 가중치를 원본 베이스 체크포인트와 50/50 비율로 평균냅니다. 두 모델이 가중치 공간에서 매우 가깝기 때문에 (Qwen의 경우 cosine similarity 0.97), 이 보간은 베이스 모델의 분포 커버리지를 회복시키면서도 새로 학습한 양방향 어텐션 패턴을 보존합니다.
-
다중 도메인 데이터 믹스(Multi-Domain Data Mixture): 영어 학습 데이터의 단 20%만 다국어, 수학, 코드 샘플로 교체합니다. 이 작은 비율만으로도 크로스 도메인 지식을 유지할 수 있습니다.
두 전략을 결합한 결과, 다국어 벤치마크에서 +2점, Gemma의 코드 성능에서는 최대 +11점 향상을 얻었습니다. 독점 데이터도, 값비싼 리플레이 버퍼도 필요 없었습니다.
오픈소스 Pareto 프론티어를 새로 그리다
이렇게 찾은 레시피를 Gemma3 1B, Qwen3 1.7B까지 확장하고 1,000만 개의 다중 도메인 샘플로 대조 학습을 추가하여 BidirLM 텍스트 인코더 패밀리를 완성했습니다.

다국어 NLU, 검색, 코드, 수학을 아우르는 augmented XTREME 벤치마크에서 모든 BidirLM 변형이 새로운 성능 프론티어를 달성했습니다. BidirLM-270M은 mmBERT-base를 10% 적은 파라미터로 매치하고, BidirLM-0.6B는 EuroBERT-610m을 1점 이상 앞섭니다. MTEB Multilingual v2에서도 네 가지 크기 구성 중 세 곳에서 오픈소스 Pareto 프론티어를 전진시켰습니다. 독점 모델로부터의 지식 증류도, 다중 실행 평균 트릭도 없이, 순수하게 오픈 데이터에서의 전통적 대조 학습만으로 얻은 결과입니다.
핵심 아이디어: 병합을 통해 전문가를 합성하기
가중치 병합이 망각 완화에 효과적이었다는 사실에서, 저자들은 더 대담한 질문을 던집니다: "같은 기법으로 완전히 다른 특화 모델의 능력을 흡수할 수 있을까?"
Qwen3 생태계만 봐도 Qwen3Guard(안전성), Qwen3-VL(비전-언어), Qwen3-ASR(음성)처럼 수천 GPU 시간이 투입된 특화 모델이 즐비합니다. 이들은 모두 동일한 Qwen3 백본 아키텍처를 공유합니다. 그렇다면 그냥 합쳐버릴 수 있지 않을까요?
도메인 전이: 안전성을 테스트 케이스로
먼저 안전성 모더레이션으로 실험했습니다. Bi+MNTP Qwen3-0.6B 인코더를 Qwen3Guard-Gen-0.6B와 50/50으로 병합한 뒤, 단 500 스텝(단일 GPU 2분) 동안 파인튜닝했습니다.

병합된 모델은 세 가지 안전성 벤치마크(그중 두 개는 훈련 중 본 적이 없는 것)에서 모든 베이스라인을 평균 1점 이상 앞섰습니다. 더 놀라운 점은 20스텝(80개 샘플) 만에 최종 성능의 93%에 도달했다는 것입니다. 병합은 단순히 지식을 전이하는 것을 넘어, 적응 과정을 극적으로 샘플 효율적으로 만듭니다.
모달리티 전이: 비전과 오디오
저자들은 여기서 멈추지 않고 Qwen3-1.7B 인코더를 Qwen3-VL-2B-Instruct와 병합(비전), Qwen3-0.6B 인코더를 Qwen3-ASR-0.6B와 병합(오디오)했습니다.

결과는 더욱 극적이었습니다. 시각-텍스트 추론(visual-textual entailment)에서 병합 모델은 unmerged 베이스라인을 F1 기준 30점 이상 초과했고, 오디오 이해에서는 격차가 19점에 달했습니다. 가장 흥미로운 결과는, 사전에 겹치는 모달리티가 전혀 없어도 병합이 성공했다는 점입니다. 오디오 특화 모델은 음성 인식 목적으로만 훈련되어 텍스트 이해 목표가 전혀 없었지만, 텍스트 인코더와 결합되자 두 모달리티를 모두 이해하는 모델이 만들어졌습니다.
BidirLM-Omni: 하나의 모델, 세 가지 모달리티
모든 것이 결합되는 지점이 BidirLM-Omni입니다. 핵심 통찰은 아키텍처적입니다: Qwen3-VL-2B-Instruct(비전), Qwen3-ASR-1.7B(오디오), 그리고 Bi+MNTP Qwen3-1.7B 텍스트 인코더는 모두 동일한 트랜스포머 백본을 공유합니다. 같은 사전학습된 Qwen3 가중치에서 파생되어 서로 다른 방향으로 특화되었기 때문에, 가중치 공간에서 멀리 떨어지지 않았습니다(비전 모델과 cosine similarity 0.97, 오디오 0.93). Linear mode connectivity에 관한 선행 연구는 공유 체크포인트에서 파인튜닝된 모델들이 loss landscape의 동일한 basin에 머문다는 것을 시사하며, 이것이 가중치를 평균내도 노이즈가 아닌 일관된 결과가 나오는 이유입니다.
병합 레시피
레시피는 두 단계입니다:
먼저 각 모델의 텍스트 백본을 분리하여 모달리티별 프로젝션 헤드를 제거한 뒤, 세 백본을 1/3씩 동일 비율로 선형 병합합니다. 이렇게 모든 특화의 교집합 지점에 있는 통합 백본이 만들어집니다.
다음으로, Qwen3-VL의 비전 헤드와 Qwen3-ASR의 오디오 헤드를 동결 상태로 이 병합 백본에 그대로 부착합니다. 이 헤드들은 이미 자신의 원본 백본 표현 공간으로 모달리티를 투영하도록 학습되어 있어, 재학습 없이도 자연스럽게 연결됩니다.
대조 학습으로 모달리티 정렬
병합된 백본에 헤드를 붙이는 것만으로는 부족합니다. 모델은 여전히 텍스트, 이미지, 오디오가 의미 있게 비교될 수 있는 공유 표현 공간을 학습해야 합니다. 이를 위해 저자들은 Sentence Transformers 프레임워크로 최종 대조 학습 단계를 실행했습니다.
데이터셋은 모달리티별로 균형 잡힌 180만 쌍의 Omni-Contrastive 코퍼스를 사용했습니다:
텍스트-텍스트 65%, 오디오-텍스트 17.5%(Laion-Audio-300M, LibriSpeech), 이미지-텍스트 17.5%(ColPali, NatCap, MSCOCO). in-batch negatives를 사용한 InfoNCE 손실로, 매칭되는 크로스 모달 쌍을 끌어당기고 비매칭 쌍을 밀어냅니다. 병합과 대조 학습을 합쳐 단 250 GPU 시간(MI250X 기준)이 소요되었으며, 각 특화 모델을 처음부터 훈련하는 데 쓰인 수천 시간에 비하면 극히 일부입니다.
옴니모달과 단일모달 모델을 모두 앞서는 결과

BidirLM-Omni는 이전 최고 옴니모달 모델이었던 Nemotron-Omni-3B를 세 모달리티 모두에서 앞섰고, 특히 텍스트(MTEB) +17점, 이미지(MIEB) +5점의 차이를 보이면서도 크기는 거의 절반(2.5B vs 4.8B)에 불과합니다. 더 인상적인 것은 옴니모달 모델뿐 아니라 단일 모달리티 전용 모델들과 비교해도 Pareto 프론티어를 새로 그었다는 점입니다:
- MIEB(이미지 임베딩): SigLIP-400M, CLIP 계열, E5-V 등을 모두 제치고 1위
- MAEB(오디오 임베딩): 5B에 달하는 bimodal 아키텍처들을 앞서며 3위
- MTEB Multilingual v2(텍스트): 63.1점으로 텍스트 전용 BidirLM-1.7B(62.9)와 동등, 두 개의 추가 모달리티를 다루면서도 동급 성능 유지
단일 2.5B 모델이, 추가 250 GPU 시간만으로, 각 분야에 특화된 모델들과 대등하거나 앞서는 성능을 달성했습니다.
왜 이것이 중요한가: 멀티모달 인코더 구축의 새로운 경로
전통적인 멀티모달 인코더 구축 방식은 관심 있는 모달리티 조합마다 모든 것을 처음부터 훈련하는 것이었습니다. 비싸고, 경직되고, 낭비가 큽니다. BidirLM-Omni는 근본적으로 다른 경로를 제시합니다:
- 강력한 적응형 텍스트 인코더로 시작합니다
- Hub에 새로운 특화 causal 모델이 나오면 병합합니다
- 모달리티 헤드를 부착합니다
- 가벼운 대조 학습을 실행합니다. 끝.
새 오디오 모델이 나왔다면 병합, 더 나은 비전 백본이 나왔다면 병합, 바이오메디컬 도메인 변형이 있다면 병합. 파이프라인이 모듈식이고, 점진적이며, 저렴합니다. 이는 오픈소스 생태계에 흩어져 있는 막대한 GPU 시간을 표현 학습 쪽으로 재활용할 수 있다는 실질적 의미를 가집니다.
공개된 모델과 데이터
BidirLM 팀은 모든 것을 오픈소스로 공개했습니다:
- 논문: [2604.02045] BidirLM: From Text to Omnimodal Bidirectional Encoders by Adapting and Composing Causal LLMs
- 모델: BidirLM-270M, BidirLM-0.6B, BidirLM-1B, BidirLM-1.7B, BidirLM-Omni-2.5B
- 데이터: 전체 대조 학습 코퍼스와 Omni-Contrastive 멀티모달 데이터셋
- 체크포인트: 모든 중간 실험 변형
 BidirLM 소개 블로그
BidirLM 소개 블로그
 BidirLM 모델 컬렉션
BidirLM 모델 컬렉션
BidirLM 논문 (arXiv)
BidirLM 학습에 사용한 데이터셋
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()