
Cactus 소개
Cactus는 모바일 및 엣지(Edge) 디바이스 환경에 최적화된 고성능 AI 추론 엔진(Inference Engine)이자, 하드웨어 성능을 극한으로 끌어내기 위한 커널(Kernel) 라이브러리입니다. 클라우드 서버가 아닌 스마트폰, 웨어러블 기기, Raspberry Pi와 같은 저전력 로컬 디바이스에서 대규모 언어 모델(LLM), 시각 언어 모델(VLM), 음성 인식 모델(Whisper) 등을 직접 구동할 수 있도록 설계되었습니다.
최근 AI 모델의 크기가 거대해짐에 따라, 데이터 프라이버시 보호와 서버 비용 절감, 그리고 지연 시간(Latency) 없는 즉각적인 반응을 위해 온디바이스 AI(On-device AI) 에 대한 수요가 폭발적으로 증가하고 있습니다. 그러나 기존의 범용 딥러닝 프레임워크들은 모바일의 제한된 배터리와 메모리 대역폭 환경에서 최적의 성능을 내는 데 한계가 있었습니다. Cactus는 이러한 병목 현상을 해결하기 위해 ARM 아키텍처에 특화된 SIMD 커널과 메모리 복사를 최소화하는 제로 카피(Zero-copy) 연산 그래프를 도입했습니다. 이를 통해 개발자들은 인터넷 연결 없이도 강력한 AI 기능을 자신의 앱에 통합할 수 있습니다.
Cactus의 프로젝트의 핵심 철학은 모바일 퍼스트(Mobile-First) 입니다. 기존의 많은 AI 프레임워크가 데스크탑이나 서버용 GPU를 기준으로 설계된 후 모바일로 경량화(Porting)된 것과 달리, Cactus는 태생부터 모바일 하드웨어(특히 ARM CPU와 NPU)의 특성을 고려하여 설계되었습니다. 개발진은 이를 두고 모바일 하드웨어를 위한 CUDA 또는 **"모바일 환경을 위한 PyTorch/NumPy"**라고 비유합니다. 이는 단순히 모델을 실행하는 것을 넘어, 하드웨어 레벨의 최적화를 통해 에너지 효율성과 처리 속도(Throughput)를 동시에 극대화했음을 의미합니다.
Cactus vs. 기존 모바일 AI 런타임
Cactus는 TFLite(TensorFlow Lite), PyTorch Mobile, Executorch와 같은 기존 모바일 AI 실행 환경들과 비교했을 때, 아키텍처와 효율성 면에서 뚜렷한 차별점을 가집니다.
압도적인 모델 효율성 (Smart Blend & Mixed Precision): 기존 프레임워크가 단일 정밀도(예: FP16 또는 INT8)에 의존하는 경향이 있는 반면, Cactus는 INT4, INT8, FP16 정밀도를 계층별로 혼합(Mixed Precision) 하여 모델 가중치를 저장하고 연산합니다. 이를 통해 ONNX나 TFLite 포맷 대비 모델 파일의 크기를 획기적으로 줄이면서도 정확도(Perplexity) 손실을 최소화했습니다. 실제로 Qwen3-0.6B 모델을 기준으로 할 때, Cactus 포맷은 타 포맷 대비 약 30~60% 더 작은 용량을 차지하여 저장 공간이 부족한 모바일 기기에 유리합니다.
수직 통합형 아키텍처 (Vertical Integration): Cactus는 하드웨어 제어 계층인 커널부터 상위 응용 계층인 엔진까지 수직적으로 통합 설계되었습니다. 범용 프레임워크의 경량화 버전들은 최신 NPU나 DSP의 가속 기능을 100% 활용하지 못하거나 오버헤드가 발생하는 경우가 많습니다. 반면 Cactus는 모바일 전용으로 짜여진 커널을 통해 불필요한 연산을 제거하고 배터리 소모를 줄입니다.
하이브리드 처리 지원 (Cloud Handoff): 순수 로컬 처리만 고집하지 않고, 디바이스의 성능 한계를 넘어서는 작업이 필요할 때를 대비해 Cloud Handoff 기능을 네이티브로 지원합니다. 이는 로컬 처리와 클라우드 처리를 유연하게 전환하여 사용자 경험을 해치지 않도록 돕습니다.
Cactus의 구성 및 주요 특징
┌─────────────────┐
│ Cactus FFI │ ←── OpenAI compatible C API for integration (tools, RAG, cloud handoff)
└─────────────────┘
│
┌─────────────────┐
│ Cactus Engine │ ←── High-level transformer engine (NPU support, INT4/INT8/FP16/MIXED)
└─────────────────┘
│
┌─────────────────┐
│ Cactus Models │ ←── Implements SOTA models using Cactus Graphs
└─────────────────┘
│
┌─────────────────┐
│ Cactus Graph │ ←── Unified zero-copy computation graph (think NumPy for mobile)
└─────────────────┘
│
┌─────────────────┐
│ Cactus Kernels │ ←── Low-level ARM-specific SIMD operations (think CUDA for mobile)
└─────────────────┘
Cactus는 성능과 유연성을 모두 잡기 위해 4계층(Layered) 아키텍처로 구성되어 있습니다. 각 계층은 개발자가 저수준의 하드웨어 제어부터 고수준의 모델 구동까지 폭넓게 활용할 수 있도록 돕습니다.
계층별 아키텍처 (Layered Architecture)
Layer 1: Cactus Kernels (Hardware Level) 은 모바일의 CUDA에 해당하는 최하위 계층입니다. ARM 아키텍처의 NEON 등 SIMD(Single Instruction Multiple Data) 명령어셋을 직접 활용하여 행렬 연산과 같은 고부하 작업을 처리합니다. 이 계층 덕분에 보급형 스마트폰의 CPU에서도 놀라운 연산 속도를 확보할 수 있습니다.
Layer 2: Cactus Graph (Compute Level) 은 모바일의 NumPy를 지향하는 통합 수치 연산 프레임워크입니다. 이 계층의 가장 큰 특징은 **제로 카피(Zero-copy)**입니다. 데이터가 텐서 간에 이동할 때 메모리 복사를 수행하지 않고 포인터나 참조를 통해 처리함으로써, 모바일 기기의 주된 발열 원인인 메모리 대역폭 소모를 최소화합니다.
Layer 3: Cactus Models (Model Level) 는 SOTA(State-of-the-Art) 모델들을 Cactus Graph 코드로 최적화하여 구현한 계층입니다. 여기에서는 단순한 변환이 아니라, 해당 모델이 모바일 NPU에서 가장 잘 돌아가도록 재설계됩니다. Google Gemma 3, Liquid AI LFM2, OpenAI Whisper (음성), Qwen 등 다양한 오픈소스 모델들이 즉시 사용할 수 있도록 최적화되어 있습니다.
Layer 4: Cactus Engine & FFI (Application Level) 는 최상위 응용 계층으로, Cactus Engine과 Cactus FFI을 함께 포함합니다. 먼저 Cactus Engine은 고수준 트랜스포머 엔진으로, 복잡한 양자화(INT4/INT8/FP16) 처리를 자동으로 수행하며 NPU 가속을 관장합니다. 또한, Cactus FFI는 OpenAI 호환 C API를 제공하여, Python, Swift, Kotlin, C++ 등 어떤 언어에서도 마치 REST API를 호출하듯 쉽게 온디바이스 모델을 제어할 수 있게 합니다. 또한 RAG(검색 증강 생성)나 툴 사용(Tool Use) 같은 고급 에이전트 기능도 이 계층에서 처리됩니다.
Cactus 성능 벤치마크 (Performance)
Cactus는 최신 하드웨어에서 인상적인 초당 토큰 처리 속도(Tokens per Second)를 보여줍니다. 이는 단순한 텍스트 생성을 넘어 실시간 대화가 가능한 수준임을 시사합니다. (README 공식 기준)
| 디바이스 (Device) | 칩셋 (Chipset) | 디코딩 속도 (Decode Speed) | 비고 |
|---|---|---|---|
| MacBook Pro | Apple M4 Pro | 170 tokens/s | 데스크탑급 성능 |
| iPhone 17 Pro | A19 Pro (예상) | 126 tokens/s | 모바일 최고 수준 |
| Galaxy S25 Ultra | Snapdragon 8 Elite | 80 tokens/s | 안드로이드 플래그십 |
| Raspberry Pi 5 | Broadcom BCM2712 | 20 tokens/s | 엣지 디바이스 |
단, 위 수치는 Apple Silicon 및 최신 Android 기기의 NPU/DSP 가속을 활용했을 때의 결과이며, 전력 소모를 억제하면서도 높은 처리량을 유지하는 것이 특징입니다.
Cactus 코드 사용 예제 (Usage Examples)
Cactus는 저수준의 그래프 제어가 필요한 경우(C++)와, 빠르게 앱 기능을 구현해야 하는 경우(Python/Swift) 모두를 지원합니다.
C++ API (Graph 레벨 제어)
C++ API는 주로 하드웨어 연산을 직접 제어하거나 커스텀 모델을 구현할 때 사용합니다. 다음은 예시 코드입니다:
#include "cactus.h"
// 1. 그래프 생성 및 입력 텐서 정의 (FP16과 INT8 혼합 사용)
CactusGraph graph;
auto a = graph.input({2, 3}, Precision::FP16);
auto b = graph.input({3, 4}, Precision::INT8);
// 2. 연산 정의: 행렬 곱(MatMul) 및 전치(Transpose)
// Cactus는 이 과정에서 불필요한 메모리 복사를 하지 않습니다.
auto x1 = graph.matmul(a, b, false);
auto x2 = graph.transpose(x1);
auto result = graph.matmul(b, x2, true);
// 3. 데이터 주입 및 실행 (Execution)
graph.set_input(a, a_data, Precision::FP16);
graph.set_input(b, b_data, Precision::INT8);
graph.execute(); // 최적화된 커널을 통해 연산 수행
Python 패키지 (Engine 레벨 제어)
Python 패키지는 주로 Mobile App 등을 개발하는 경우, LLM을 기능으로 활용할 때 사용하는 고수준 인터페이스입니다. OpenAI API와 유사한 구조를 가집니다. 다음은 예시 코드입니다:
from cactus_ffi import cactus_init, cactus_complete, cactus_destroy
# 1. 모델 초기화
# 필요한 가중치 파일을 자동으로 다운로드하고 로드합니다.
model = cactus_init("weights/lfm2-vl-450m")
# 2. 텍스트 생성 (Inference)
# OpenAI Chat 포맷을 그대로 사용할 수 있어 마이그레이션이 쉽습니다.
response = cactus_complete(model, [
{"role": "user", "content": "What is the capital of South Korea?"}
])
print(f"AI Response: {response['content']}")
# 3. 리소스 해제
cactus_destroy(model)
Cactus 성능 벤치마크 (Performance Benchmarks)
Cactus는 최신 모바일 기기에서 놀라운 추론 속도를 보여줍니다. 특히 Cactus Pro 기능을 통해 Apple 기기의 NPU를 활용할 경우, 거의 실시간에 가까운 초저지연 성능을 발휘합니다.
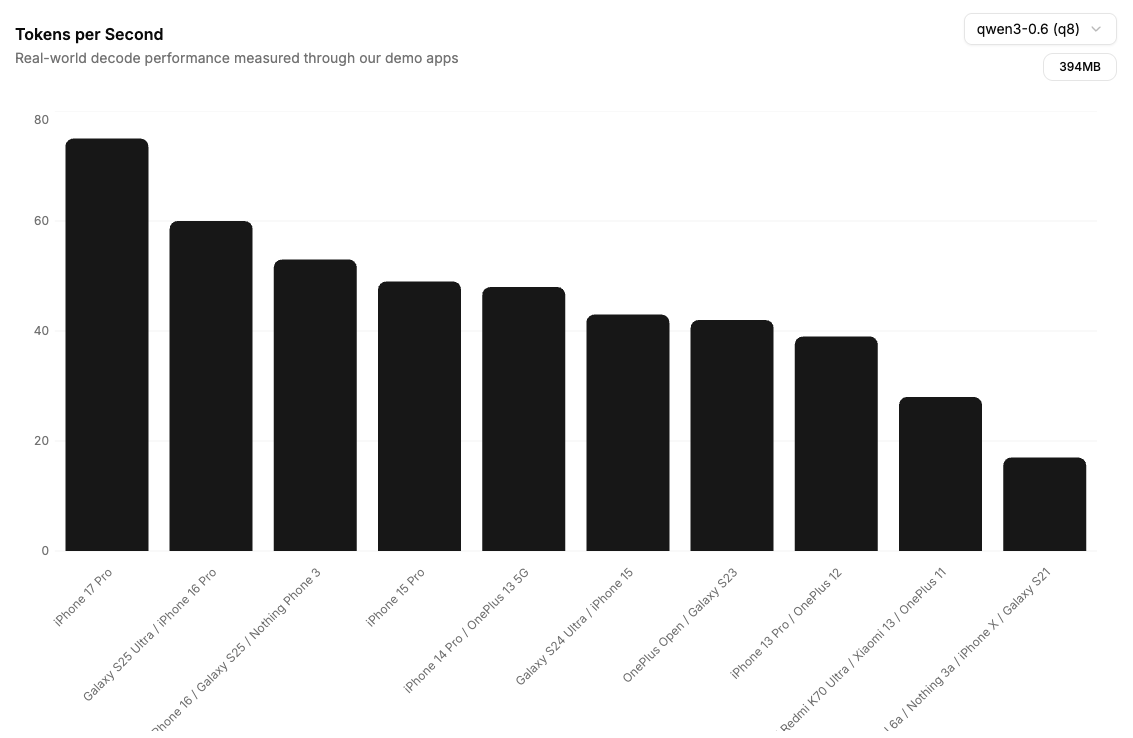
다음은 Decode 기준, 주요 기기별 성능 데이터입니다:
| 디바이스 (Device) | 칩셋 | Decode Speed | 비고 |
|---|---|---|---|
| Mac M4 Pro | M4 Pro | 170 tok/s | 데스크탑급, 초고속 에이전트 작업 가능 |
| iPhone 17 Pro | A19 Pro | 126 tok/s | 모바일 최고 수준, 인간 읽기 속도 상회 |
| iPhone 15 Pro | A17 Pro | 90 tok/s | 구형 기기에서도 안정적인 고성능 |
| Galaxy S25 Ultra | 8 Elite | 80 tok/s | 안드로이드 플래그십 최적화 |
| Nothing 3 | Mid-range | 56 tok/s | 보급형 기기에서도 실사용 가능 수준 |
| Raspberry Pi 5 | BCM2712 | 20 tok/s | 엣지 디바이스/IoT 활용 가능 |
-
VLM (비전 모델) 성능: iPhone 17 Pro 기준, 256x256 이미지를 처리하고 첫 토큰을 생성하는 시간(TTFT)이 불과 0.5초입니다. 이는 실시간 카메라 인식 앱 구현이 가능함을 의미합니다.
-
Cactus Pro: Apple 기기(Mac, iPad, iPhone)에서는 NPU를 적극 활용하여, 긴 컨텍스트 처리는 물론 VLM/STT 작업에서 CPU 부하를 획기적으로 줄입니다.
또한, Cactus는 'Smart Blend' 기술을 통해 모델 사이즈를 극도로 경량화했습니다. 모든 가중치에 INT4, INT8, FP16을 혼합 적용하여 용량 대비 성능을 극대화합니다.
Cactus가 지원하는 주요 모델 및 파일 크기는 다음과 같습니다:
- Google Gemma 3 (270M): 252MB - 초경량 모델, 간단한 챗봇 및 지시 이행에 적합.
- LiquidAI LFM2 (350M): 244MB - Tool 사용 및 임베딩 지원, 온디바이스 에이전트에 최적화.
- OpenAI Whisper (Small): 283MB - 음성 인식(STT) 지원 (Cactus Pro - Apple NPU 가속 지원).
- Qwen 3 (0.6B): 514MB - Tool 사용 및 임베딩 지원, 다국어 처리에 강점.
- LiquidAI LFM2.5-VL (1.6B): 954MB - 1GB 미만의 용량으로 시각(Vision) 처리 및 텍스트 생성을 동시에 수행.
대부분의 모델이 Tool Use(도구 사용) 및 Embedding(임베딩) 기능을 내장하고 있어, RAG(검색 증강 생성) 시스템을 별도 라이브러리 없이 구축할 수 있습니다.
개발자 도구 및 생태계 (SDK & Demos)
Cactus는 다양한 모바일 및 시스템 프로그래밍 환경을 위한 SDK를 제공하여, 개발자가 자신의 앱에 손쉽게 AI 기능을 통합할 수 있도록 지원합니다.
공식 SDK 지원
- Kotlin Multiplatform SDK: Android와 iOS 로직을 공유하는 KMP 프로젝트를 위한 SDK입니다.
- Flutter SDK: 단일 코드베이스로 크로스 플랫폼 앱을 개발하는 Flutter 환경을 지원합니다.
- React Native SDK: JavaScript/TypeScript 기반의 React Native 앱에 고성능 네이티브 모듈로 통합됩니다.
- Swift SDK: iOS/macOS 네이티브 개발을 위한 Swift 패키지입니다.
- Rust SDK: 시스템 레벨 통합이나 고성능 백엔드 로직 구성을 위한 Rust 크레이트(Crate)입니다.
데모 앱 (Demo Apps)
실제 디바이스에서 Cactus의 성능과 속도를 직접 체험해 볼 수 있는 데모 앱이 각 앱 스토어에 공개되어 있습니다. 별도의 설정 없이 모델을 다운로드하고 바로 채팅을 테스트해 볼 수 있습니다.
라이선스
Cactus 프로젝트는 자체적인 라이선스 정책을 따르고 있으며, 이에 따라 개인 프로젝트나 연구 목적, 취미 용도, 비상업적 오픈소스 프로젝트 등에서는 무료로 사용할 수 있습니다.
하지만 기업이 상업적인 제품에 통합하거나 대규모로 배포할 경우 별도의 라이선스 계약이 필요할 수 있습니다. 이 때, 펀딩 및 매출 규모 등에 세부 사항이 존재하므로, 기업에서 사용한 경우 반드시 라이선스 원문을 확인하셔야 합니다.
 Cactus 공식 홈페이지
Cactus 공식 홈페이지
 Cactus 관련 문서/블로그
Cactus 관련 문서/블로그
 Cactus 프로젝트 GitHub 저장소
Cactus 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()