
Chain-of-Draft (CoD) 연구 소개
대규모 언어 모델(LLM, Large Language Model)의 성능을 높이는 방법 중 하나로, 생각의 사슬(CoT, Chain-of-Thought)과 같은 프롬프팅 기법이 사용되고 있습니다. 생각의 사슬(CoT)은 복잡한 추론 문제를 해결하는데 있어, 단계별로 상세한 추론 과정을 제공하는 방식입니다. 하지만 CoT는 추론 과정에서 상당한 연산 자원을 필요로 하며, 결과적으로 장황한 출력을 생성하고 지연 시간을 증가시키는 문제가 있습니다. 반면, 인간은 문제를 해결할 때 긴 설명을 적는 것이 아니라 핵심적인 정보만을 요약한 초안(draft)이나 메모를 작성하는 방식을 선호합니다.
초안의 사슬(CoD, Chain-of-Draft)라는 이름의 연구는 인간과 같이 초안이나 메모를 작성하는 방식의 새로운 프롬프팅 전략을 제안하고 있습니다. 즉, 기존의 CoT 방법보다 더 인간적인 사고와 유사하게 '효율성과 최소주의'를 추구합니다. CoD는 추론 중간에 장황한 설명 대신 핵심 정보만 간결하게 포함하는 방식으로 모델을 유도하여 추론 속도와 연산 비용을 줄이면서도 정확도를 유지할 수 있습니다.
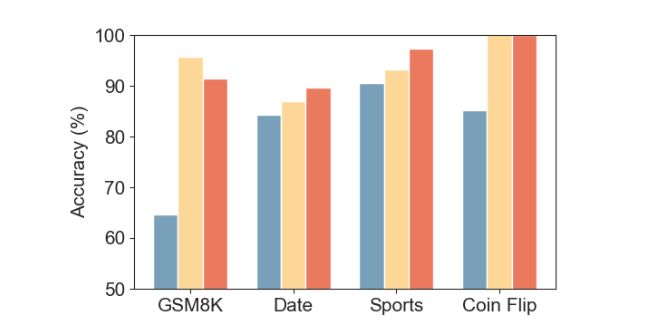
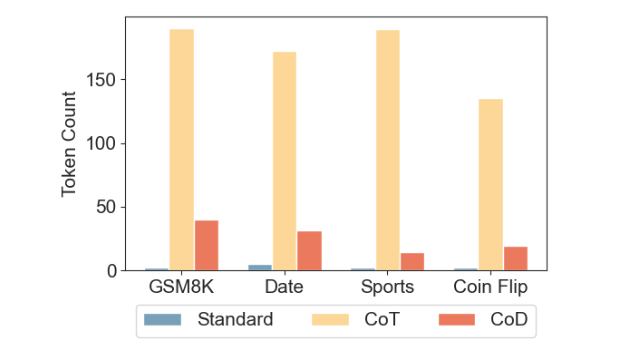
저자들은 CoD의 효과를 검증하기 위해, 수학적 추론(arithmetic reasoning), 상식적 추론(commonsense reasoning), 기호적 추론(symbolic reasoning) 등 다양한 벤치마크에서 실험을 수행하였습니다. 그 결과, CoD는 기존 CoT와 동일하거나 더 높은 정확도를 기록하면서도 토큰 사용량과 지연 시간을 대폭 절감하는 것으로 나타났습니다.
Chain-of-Draft 프롬프팅 기법 소개
CoT(Chain-of-Thought) 기법은 단계별(Step-by-Step)로 추론을 수행하는 방식으로 복잡한 문제 해결에 효과적이라는 점은 이미 입증되었습니다. 하지만, CoT 방식은 추론 과정이 지나치게 장황해지고 토큰 사용량이 많은 단점이 있습니다. 즉, CoT는 문제 해결 과정을 명확하게 보여준다는 장점이 있지만, 현실적으로는 불필요한 추론 과정을 상세히 보여주면서 불필요한 연산이 수행되는 경향이 있습니다.
CoD(Chain-of-Draft) 기법은 인간의 문제 해결방식을 본딴 것이 특징입니다. CoD는 문제 해결 과정에서 불필요한 세부 정보를 모두 작성하는 대신, 핵심 정보만을 요약한 초안(Draft)를 작성하는 기법입니다. 이렇게 하면 중간 과정에서 핵심 정보만을 남겨 불필요한 토큰 출력을 줄이면서도 정확한 결과를 도출할 수 있습니다.
CoD 기법을 이해할 수 있도록, 간단한 산술 문제를 예시로 들어 기본 방식과 CoT, CoD 방식을 비교해보겠습니다:
-
예시 질문(Q): Jason은 20개의 사탕을 가지고 있었다. 그는 Denny에게 몇 개를 주었다. 현재 Jason은 12개의 사탕을 가지고 있다. Jason이 Denny에게 몇 개의 사탕을 주었는가?
Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
-
표준(Standard) 프롬프팅 방식
- 위 예시 질문에 대한 답변은 정확하지만, 추론 과정이 생략되었기 때문에 답변이 도출되는 과정에 대한 설명 가능성(Explainability)가 부족한 단점이 있습니다.
-
CoT(Chain-of-Thought) 프롬프팅 방식
- 위 예시 질문에 대한 답변이 정확하며, 추론 과정 또한 명확합니다. 하지만, 불필요하게 장황한 표현이 많기 때문에 LLM의 토큰 사용량이 증가하는 단점이 있습니다.
-
CoD(Chain-of-Draft) 프롬프팅 방식
- 답변이 정확하며, 핵심적인 수식만 포함하여 충분한 설명력을 유지하고 있습니다. 토큰 사용량을 최소화하면서도 정확성을 보장하는 장점이 있습니다.



CoT와 CoD 기법 비교 실험
CoD 기법의 효과를 검증하기 위해 산술적 추론(arithmetic reasoning), 상식적 추론(commonsense reasoning), 기호적 추론(symbolic reasoning) 등 다양한 벤치마크 데이터를 활용하는 실험을 수행하였습니다. 이를 통해 CoT 기법 대비 CoD 기법이 정확도를 유지하면서도 응답 지연 시간과 토큰 사용량을 줄이는데 효과적인지를 평가하는 것이 주요 목표입니다. 특히, CoT 방식이 기존 베이스라인보다 성능을 크게 향상시킨 사례를 중심으로 CoD의 성능을 분석하였습니다.
산술적 추론 실험에서는 GSM8K 데이터셋을 사용하였으며, 상식적 추론 실험에서는 BIG-bench에서 날짜 이해(date understanding) 및 스포츠 이해(sports understanding) 태스크를 선정하였습니다. 기호적 추론 실험에서는 CoT 논문에서 소개한 동전 던지기(coin flip) 문제를 기반으로 250개의 테스트 샘플을 생성하여 평가를 진행하였습니다.
실험 시에는 다음과 같은 세 가지 프롬프팅 방식을 비교하였습니다:
-
표준(Standard) 프롬프팅 방식: 기존의 few-shot prompting 방식을 사용하여 LLM이 중간 추론 과정 없이 최종 정답만을 출력하도록 유도하는 방식입니다.
-
CoT(Chain-of-Thought) 프롬프팅 방식: 원본 CoT 논문의 few-shot 예제와 동일한 방식을 유지하되, 최종 정답을 #### 기호 이후에 위치하도록 조정하여 보다 안정적인 응답 추출이 가능하도록 하였습니다. CoT 방식은 LLM이 문제를 단계별로 분석하여 논리적인 흐름을 따라 최종 해답을 도출하도록 유도하는 방식으로, 현재까지 가장 효과적인 추론 전략 중 하나로 인정받고 있습니다.
-
CoD(Chain-of-Draft) 프롬프팅 방식: CoT와 유사한 단계별 추론을 수행하되, 각 단계에서 핵심적인 정보만을 남겨 간결한 표현을 유지하도록 유도하는 방식입니다. CoD 방식에서는 각 추론 단계에서 5개 이하의 단어만 사용하도록 요청하였으며, 이를 통해 토큰 사용량을 줄이면서도 정확도를 유지하는 것이 가능한지 평가하였습니다. 이 같은 설정은 강제적인 제한이 아니라 일반적인 가이드라인으로 적용되었으며, few-shot 예제는 저자들이 직접 작성하였습니다.



또한, LLM은 OpenAI의 GPT-4o(gpt-4o-2024-08-06)와 Anthropic의 Claude 3.5 Sonnet(claude-3-5-sonnet-20240620)을 사용하여 비교 평가를 수행하였습니다.
산술적 추론 (Arithmetic Reasoning)
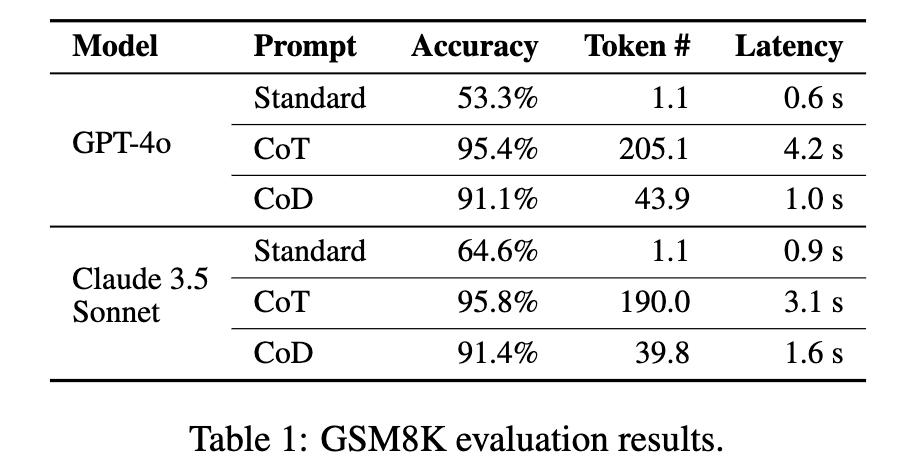
산술적 추론 실험에서는 GSM8K 데이터셋을 사용하여 LLM의 산술 문제 해결 능력을 평가하였습니다. GSM8K는 8,500개의 초등학교 수준 산술 문제로 구성되어 있으며, 덧셈, 뺄셈, 곱셈, 나눗셈, 기하학, 논리적 사고 등이 포함된 대표적인 수학 데이터셋입니다.
실험 결과를 살펴보면, CoT 방식은 높은 정확도를 기록하였으나 응답당 평균 200개 이상의 토큰을 생성하여 연산 비용과 응답 시간이 증가하는 문제가 있었습니다. 반면, CoD 방식은 토큰 사용량을 80% 이상 줄이면서도 91%의 정확도를 유지하였습니다. 특히 GPT-4o에서는 응답 지연 시간이 76.2% 감소하였으며, Claude 3.5에서는 48.4% 감소하여 실용적인 성능 개선 효과를 보였습니다.
상식적 추론 (Commonsense Reasoning)
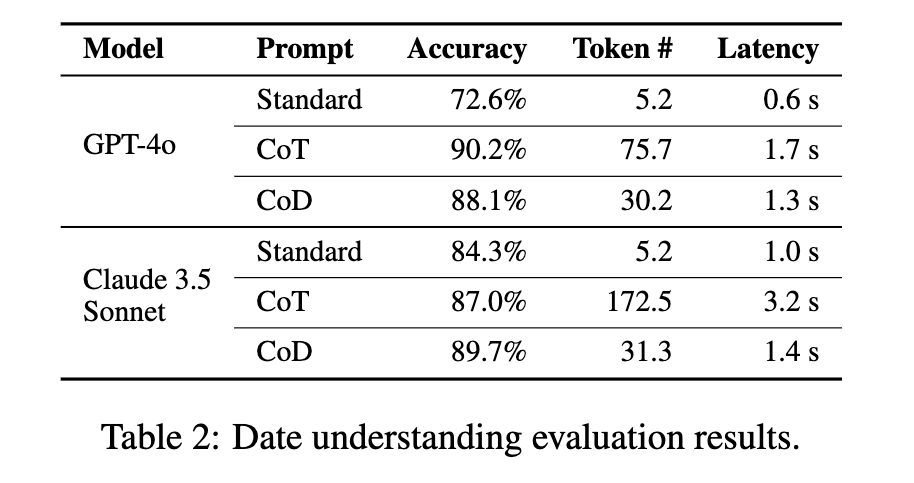
BIG-bench 데이터셋의 날짜 이해(date understanding) 및 스포츠 이해(sports understanding) 태스크를 활용하여 LLM의 상식적 추론(Commonsense Reasoning) 능력을 평가하였습니다. 실험 결과, CoD 방식은 평균적으로 85% 이상의 토큰을 절감하면서도 CoT와 유사하거나 더 높은 정확도를 기록하는 것으로 나타났습니다.
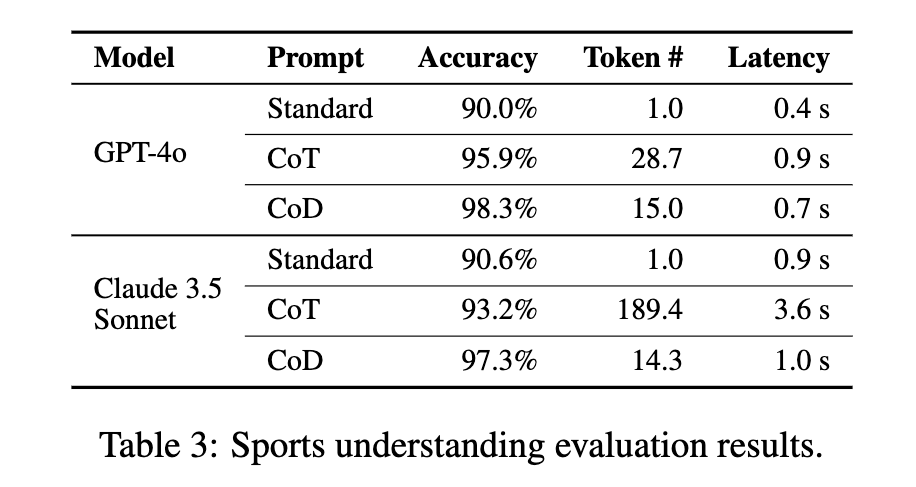
특히, Claude 3.5 Sonnet 모델이 스포츠 이해 태스크에서 CoT를 사용할 경우 응답당 평균 189.4개의 토큰을 사용했으나, CoD 방식에서는 이를 14.3개로 줄이면서도 동일한 정확도를 유지하는 결과를 보였습니다.
기호적 추론 (Symbolic Reasoning)

기호적 추론(Symbolic Reasoning) 태스크로는 동전 던지기(coin flip) 문제를 활용하였습니다. 이 문제에서는 여러 사람이 동전을 뒤집거나 그대로 유지하는 동작을 수행하며, 마지막 상태에서 동전이 앞면인지 뒷면인지 예측해야 합니다.

실험 결과, CoT와 CoD 방식 모두 100%의 정확도를 기록하였지만, CoD는 토큰 사용량을 68%~86%까지 절감하는 효과를 보였습니다.
CoD 기법의 한계 (Limitations of CoD)
CoD 방식이 효과적인 성능 개선을 제공하는 것으로 나타났지만, 몇 가지 한계점도 확인되었습니다:
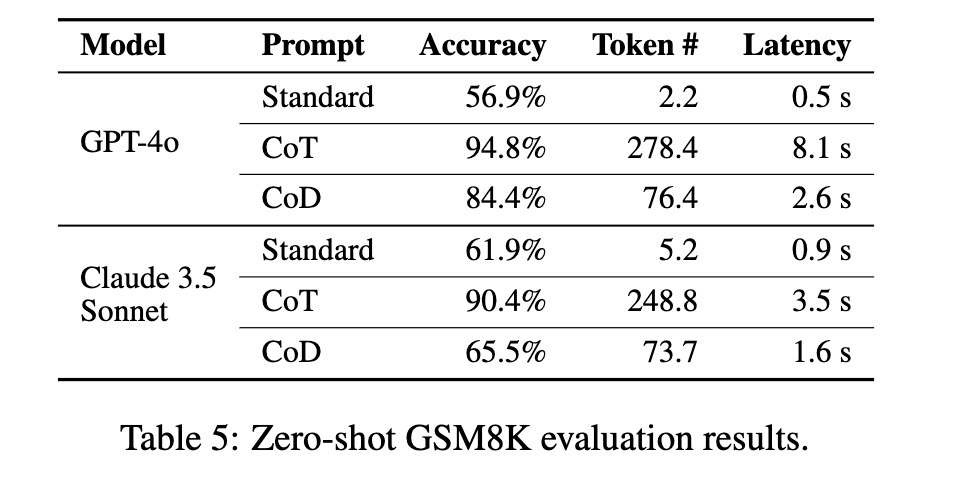
첫 번째로, Few-shot 예제 없이 Zero-shot 설정에서 사용할 경우 성능이 급격히 저하되는 문제가 있었습니다. 이는 CoD 방식이 기존 LLM의 사전 학습 데이터에서 자주 등장하지 않는 방식이기 때문으로 추정됩니다.
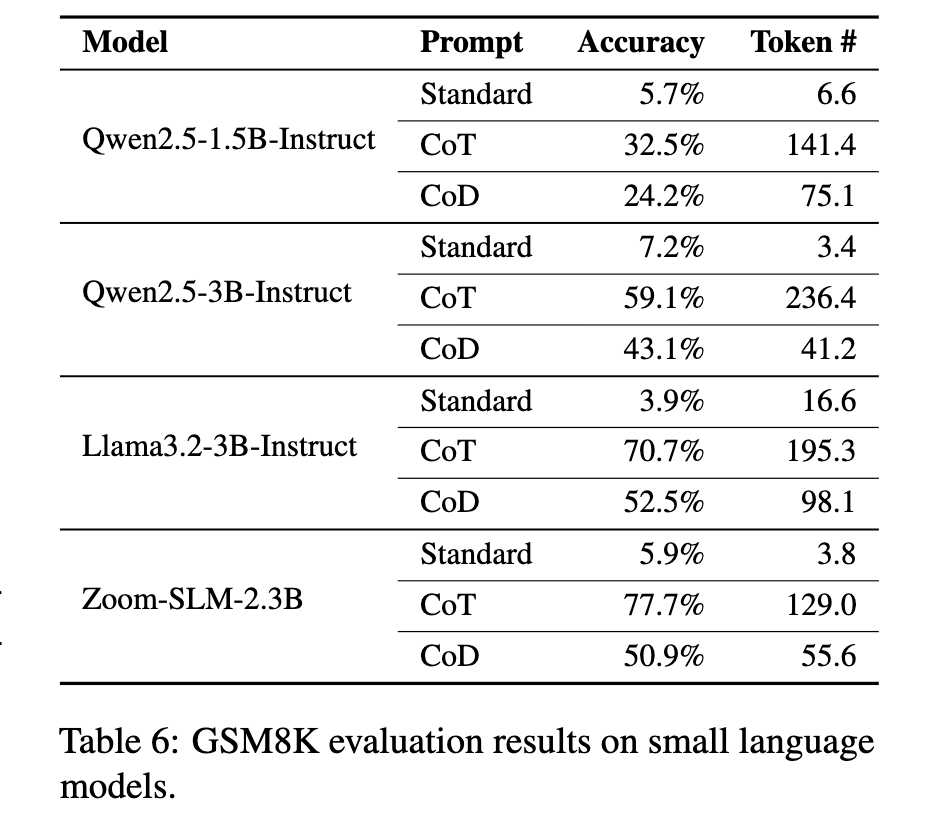
두 번째로, 소형 모델(3B 이하의 파라미터를 가진 LLM)에서 성능이 감소하는 현상이 발견되었습니다. Qwen2.5 1.5B/3B 및 Llama 3 3B 모델에서 CoD를 적용한 결과, CoT 대비 성능이 더 낮아지는 현상이 관찰되었습니다.
결론 및 논의
대규모 언어 모델(LLM)의 추론 능력에 대한 연구는 주로 정확도 향상에 초점을 맞추어 왔으며, 지연 시간(Latency) 문제는 상대적으로 덜 다루어져 왔습니다. 그러나 실시간 응답이 중요한 애플리케이션에서는 높은 품질의 답변을 신속하게 제공하는 것이 필수적이며, 이는 LLM의 실용성을 결정짓는 중요한 요소입니다.
본 연구에서는 CoD(Chain-of-Draft) 프롬프팅을 통해 LLM이 과도한 토큰을 사용하지 않고도 정확한 답변을 도출할 수 있도록 유도하는 방법을 제안하였습니다. 실험 결과, CoD는 기존의 CoT 방식과 유사하거나 더 높은 정확도를 유지하면서도 연산 비용과 응답 지연 시간을 대폭 절감하는 데 성공하였습니다.
향후 연구에서는 CoD 방식과 적응형 병렬 추론(Adaptive Parallel Reasoning)이나 다단계 검증(Multi-pass Validation) 같은 기술을 결합하여 더욱 최적화된 프롬프팅 전략을 개발하는 것이 유용할 것입니다.
 Chain-of-Draft(CoD) 논문, Chain of Draft: Thinking Faster by Writing Less
Chain-of-Draft(CoD) 논문, Chain of Draft: Thinking Faster by Writing Less
 Chain-of-Draft 기법의 코드 및 데이터
Chain-of-Draft 기법의 코드 및 데이터
https://github.com/sileix/chain-of-draft
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()